1. Introduction and Preliminaries
The problem of determining the distribution of aggregate losses begins by developing a model for the random variable in whose distribution we are interested. To state the basic problem, we suppose that all random variables involved are defined on a common probability space
A typical aggregate loss is modeled by a random variable like
where
is some positive integer describing the total number of compound losses to be aggregated. For each loss type
we shall suppose that
is an integer-valued random variable modeling the frequency of losses in a given (and fixed) time lapse, and that for each
the random variable
is a positive, continuous random variable, modeling the occurrence of the individual
n-th loss of that type. We shall follow the standard modeling assumption, and suppose that the individual losses are independent among themselves and independent of the corresponding
The standard “constructive direct” problem can be stated to consist of determining the probability density of the total loss S when we know the statistical nature of the and that of the densities of the . This is a “classical” problem that has been studied from many angles already reported in many treatises. When all that we have is empirical data about aggregate losses, and no models at hand, the direct approach may not be applied. In this case, we must recur to numerical procedures to determine the density of a continuous random variable S from an empirical sample The sample could be thought have been obtained by collecting data over a very large number of time lapses or to have been generated by simulating samples from the distributions that make up the building blocks of the model.
And this point of view connects us to a reciprocal related “inverse” problem. Suppose that we have a sample
Besides recovering the density
we want to recover the statistical information about the building blocks entering (
1). That is, we want to know the statistical nature of the
and as much as possible about the statistical nature of the
Since the probability density of a positive random variable can be recovered from its Laplace transform, here we examine how maximum entropy methods invert numerically the Laplace transform. What makes the use of the maximum entropy-based method important is that in most cases of practical interest, the Laplace transform must be estimated numerically. it is important that the inversion method is stable with respect to changes in the available data set and in the presence of errors in the data. This makes the maximum entropy methodology doubly interesting: it is robust and allows for extensions to incorporate errors in the data. We shall examine all these issues below.
Recall that the Laplace transform of (the density of) a continuous random variable
S is defined by
As mentioned above, when this quantity can be obtained from a model of and when it can be inverted, analytically or numerically, we are done. However, not only is it not always possible as in our examples, but in actual practice, what we may have is just empirical data. Thus, we must determine the Laplace transform from it, and then invert the estimated Laplace transform.
To bring in our proposed maxentropic methodology, it is convenient to perform the change of variables
and change problem (
2) into a problem on
consisting of determining a density
g from its fractional moments, i.e., to solve
where
It is at this point that the method of maximum entropy comes in.
We have already introduced enough notation to explain what comes next. The first issue to take care of is how to go from aggregate data such as (
1) to estimate the right-hand side of (
3). This is done in
Section 2,
Section 3 and
Section 4 we shall rapidly review the standard maximum entropy (SME) method. The SME is the stepping stone for the extension to the case in which there are measurement errors (SMEE) and to the method of maximum entropy in the mean (MEM). These extensions are briefly described in the
Appendix A.
In
Section 5 we shall then examine how to relate the variability of the solution to (
2) to the variability in the data, which comes through in the dependence of the
on the sample data, and in
Section 6 we shall explain how the sample dependence of the reconstructed densities affects expected values computed with it. This is a rather important issue, because many quantities of interest depend heavily of the tail behavior of the density and cannot be estimated with a small amount of data in the tail of the distribution, if it exists at all. In the last
Appendix A we add some further mathematical details about this issue.
After that, we shall explain why only a few moments are enough to solve (
3) for
This fact shows the power of the maxentropic procedure compared to the actual analytical inversion of (
2) which requires the knowledge of the behavior of
in the complex
-plane.
In
Section 8 we present some numerical examples. We begin by finding the density of a Poisson compound variable in which the individual losses are log-normal. As there is no closed analytical expression for the Laplace transform of such variables, the example stresses the need for the purely numerical approach. Then we tackle the problem of decompounding at the first level of aggregation.
After that, to illustrate the problem of disaggregation and decompounding, we consider data coming from two compound random variables. The same data will be used to illustrate the sample dependence of the density reconstruction and that of the sample dependence of risk measures (VaR and TVaR). Then, we shall illustrate the sample variability of some risk premia that depend strongly on the tail of the distribution.
2. The Aggregation Problem: From Data to Fractional Moments
In the process of data aggregation problems, there are several layers of aggregation, as implied in (
1). In the first one, we have to form the compounded sums. The passage from the first layer of aggregation to the second involves computing the distribution of a sum of compound random variables. When there is statistical dependence between the variables, we must devise methods to take this into account. For details see [
1,
2].
Let us now explain how to go from the loss data to the fractional moment problem via the Laplace transform. It is well known—see [
3] for examples—that the distribution function of a positive random variable
S can be recovered from its Laplace transform, defined by
Notice that the full distribution of
S includes a point mass at
which corresponds to the possibility of with no losses, which occurs when
Therefore, to relate
to the density of the continuous part of
we must condition the mass at
Notice that
and then
where
We mentioned in the introduction that if we have a statistical model for the blocks of we can compute and from it which is the starting point to compute However, if we cannot compute analytically, which happens when, for example, the individual losses are log-normal, or when we only have observational data, we are forced to estimate from a sample.
Therefore, if we record the losses for a certain number
N of periods, in
M of which we have a sequence like
where
n is the number of risk events during the observation period, and the
are the losses occurring at each event, the total loss during the period is
In the remaining
we observe no losses. Invoking the law of large numbers, we verify that an unbiased estimator of
is
Since the estimator of
is
and it is clear that in this case, after some simple arithmetic, instead of (
5), an estimator of
is given by:
These estimated moments will become the fractional moments that the SME method needs as inputs for the determination of the densities of losses. We also emphasize that it is through these estimated moments that the sample variability of the reconstructed densities comes in.
3. The Decompounding and Disaggregation Problems
We have already mentioned that the problem of decompounding is reciprocal to the problem of compounding. In the latter, we have to find the distribution function of a compound random variable. In the former, we are given aggregate data, and we are interested in the distribution of the individual severities. The reason for that is that the distribution of individual severities might be related to the cause of the losses, and its knowledge might be useful for control or preventive management. When the model of individual severities is known beforehand, the determination of individual severities provides a consistency check.
In the first aggregation level, the total severity is a compound variable, and the Laplace transform technique yields a direct connection between the Laplace transform of all the blocks of the model. The relationship is given by
where
is the generating function of the frequency of losses and
is the Laplace transform of the density of individual losses. Thus, once we know the law of
we can solve
from (
8) and then apply the SME method to obtain
Nice as this might be, it is only partially useful. The reason is that we might not have statistical information about the frequency of losses. A similar problem appears when the total loss has several levels of aggregation. Fortunately, in most cases the model is such that determining the statistical nature of the underlying frequency of events reduces to a problem of disentangling a collection of overlapping linear regressions, a problem which can be solved by a variety of methods. It is here that the material in the next section is essential.
3.1. The Panjer (a,b,0) Class
There is a particular class of frequency models for which determining the distribution of losses can be carried out systematically. Not only that, but also knowing that the frequencies belong to this class makes the disentangling of the frequencies a routine matter.
Please note that the probabilities
of the binomial, geometric, negative binomial, and Poisson distributions satisfy the recursion relation
See [
4] for details.
There and
If we set
we can write the recursion in
Table 1 as
which can be thought of as linear regressions. If we empirically estimate
by
and plot
we can use the plot to obtain the coefficients
and then the parameters of the distributions as specified in
Table 1. Not only that, but also if we have a collection of risks such that their collective frequency can be considered to be a mixture of the frequencies of the collection, we can use the representation provided by the Panjer recursions plus a clustering or classification technique to determine the underlying frequency models. This will be the starting point of the decompounding procedure implemented in the section of numerical results. This procedure is detailed in [
1] and later in [
2]; we direct the reader there for complete details and many references to the subject.
4. The Maxentropic Solution of the Fractional Moment Problem
Above, we explained how to transform the Laplace inversion problem into a fractional moment problem consisting of finding a probability density
on
satisfying the integral constraints:
where the
are estimated as in (
7). At this point two questions come up: first, do the fractional moments determine uniquely the distribution? And then a practical question: how to actually solve (
9).
The answer to the first is resolved in the positive in [
5]: the fractional moments determine uniquely a density
A method to solve the (
9) problem seems to have been originally proposed in [
6] or [
7], and its mathematical subtleties are addressed in [
8]. This method can be extended in several directions. Here we shall consider two possible extensions. One of them, the standard maximum entropy with errors in the data (SMEE), is particularly useful when the sample dependence is strong and can be regarded as additive noise. The other method, that of MEM, is an important alternative maxentropic method, particularly useful when there are convex constraints imposed on it.
In (
9), we set
and
to take care of the natural normalization requirement on
The intuition behind the maxentropic methods is rather simple: The class of probability densities satisfying (
9) is convex. One can pick up a point in that class one by maximizing (or minimizing) a concave (convex) functional (an “entropy”) that achieves a maximum (minimum) in that class. That optimal point is the “maxentropic” solution to the problem. It actually takes a standard computation to see that when the problem has a solution, it is of the type
which depends on the
s through the
s. It is usually customary to write
where
is a
K–dimensional vector. Clearly, the generic form of the normalization factor is given by
With this notation the generic form of the solution looks like
Recall that once
is at hand, the density on the half line is given by
How to determine
, and further details about the SME procedure are presented in the
Appendix A.
We close this section stating a result that plays a role in the forthcoming sections. It takes a standard computation to verify that
5. Variability of the Probability Densities
The results presented next are a variation on the theme of sample dependence in the generalized moment problem studied in [
9] and applied in [
10]. The necessary results are stated without proof and we direct the reader to [
9] for details and proofs.
Denote by
the moments computed as in (
7) and
the exact moments. Denote as well
and
the corresponding minimizers of (
A5) and by
and
the maxentropic densities.
Lemma 1. With the notations just introduced, suppose that the risks observed during M consecutive years are independent of each other.
Then and and therefore
To relate the sample variability of
to the sample variability of the
we start with
and apply the chain rule, to obtain that up to terms of
where
is the inverse matrix of the Jacobian of
evaluated at
Recall that the maxentropic solution to the inverse problem is
in which reference to the sample size
M is made explicit. Consider now:
Lemma 2. With the notations introduced above, up to terms that are using the computation in (14) Here K is the number of moments used to determine the density and
This result relates the deviation of
from its exact value
up to first order in the
Notice if we integrate both sides of (
15) with respect to
x we get 0 on both sides. In addition, if we multiply
and
by
we obtain
Using this, Proposition A1 in the
Appendix A, and Lemma 1, the following is clear.
Proposition 1. With the notations introduced above we have We direct the reader to Appendix 10.3 where
is defined and its properties stated. We can also combine Lemma 1, (
A9) and (
1) to relate the deviations
to the deviations of
from
as described in the following result.
Proposition 2. With the notations introduced above we have Here and are as above.
The proof drops out from the fact that up to terms of order
6. Sample Variability of Expected Values
Before describing the sample variability of expected values, we address an obvious question. Notice that the determination of any risk premium involves the computation of an expected value with respect to a density of losses. For a review of premium calculation procedures see [
11,
12]. It is here where the results described in
Section 5 come in. An obvious issue comes to mind. If we need to compute
for some positive, measurable
and all we have is sample data
why not just compute
? And if we are interested in the sample variability, we might as well just look at the variability of
whose statistical properties are standard procedure, i.e., if we consider the sample values
as a collection of i.i.d. random variables, their confidence intervals, the oscillations about the mean, and the rate of convergence to the mean can be treated using standard statistical tools. However, if we happen to be interested in the computations of quantities such as
in which the value
d may be of the order of the
quantile of
S and
K may be larger, the dependence on the sample becomes harder to handle because we would have to deal with values at the tail of the distribution. Such problems do not appear if we compute expected values with respect to a density whose dependence on the sample can be made explicit.
As with the case of Lemma 1, an appeal to the law of large number yields the simple observation.
The sample variability of expected values, and in particular, for quantities such as (
19), follows from the following generic result which is a direct consequence of Lemma 1.
Lemma 3. Let us denote Let be such that Thenwhere the randomness is carried by the second term on the right-hand side. Clearly, The relevance of this Lemma is that it relates the deviations of the estimated densities from the true density to the deviations of the empirical moments from the true moments. Similar considerations apply to the computation of risk measures lake VaR and TVaR, which depend of the tail of the distribution. A relationship between them is established in [
13]. In
Section 8.6 and
Section 8.7 we present some numerical examples of sample dependence of risk measures and premium prices.
7. Number of Moments Necessary to Determine the Density
Here we address a problem of practical interest: How many values of the Laplace transform parameter
are necessary to determine
This is interesting in itself because the theoretical inversion of a Laplace transform involves an integration in the complex
plane, which in principle requires the knowledge of an extension of
as an analytic function and the location of its singularities in the complex plane. There are inversion methods based on the knowledge of
on the positive half of the real line (see [
3] for an introduction to this subject).
Here, we only remark that the maximum entropy method needs a few points to work (for us 8 values were enough). The explanation of why this seems to be so goes as follows. Let us denote by
the maxentropic density estimated from
M moments. It is easy to see from (
A8) and (
13) that
In addition, from the inequality stated in Proposition A1 we have
Thus, if a density with the given sequence of moments exits, and has finite entropy, the sequence
is bounded below and the previous inequality assets that the densities converge (to the true density). In addition, usually, for 4 moments the sequence of entropies tends to stabilize. See [
14] for more on this.
8. Numerical Examples
Below we present some numerical examples of the different problems that can be solved with maximum entropy-based methodology. We begin by considering a first level of aggregation and disaggregation process that is the problem of determining the distribution of a compound random variable form numerical data, and then how to go from the numerical data to fit a model for the frequency of compounding and the distribution of the individual severities. Next, we do the same for the case in which we need to aggregate or disaggregate several compound variables. In these examples we do the density reconstruction using the SME and the SMEE methods. When the data is obtained from a sample, we expect the SMEE to outperform the SME.
In each case, we carry out the corresponding reconstruction error estimation. After examining these examples, we consider the issue of sample variability and its effect, not only in the density reconstruction process, but in the estimation of quantities of interest, like risk measures (VaR and TVaR) or risk premia, among others.
All the code, with the examples used in this article can be obtained from [
15]. The results presented there may change due to convergence of the algorithm, choice of seeds, etc.
8.1. The Sample Generation Process
We consider first a total severity at the first level of aggregation consisting of compounding individual log-normal severities with a Poisson frequency. The parameters to use are for the Poisson distribution and and for the log-normal distribution.
After that we shall consider a second level of aggregation, consisting of a sum of two compound variables, in which the first () is the one we just finished describing, and the second () is a Poisson (with ) compound sum of individual severities described by a Gamma with shape parameter and scale parameter
In these examples we consider losses of an order of magnitude of and to avoid numerical overflow or underflow, we scale down these values, and ,at the end, we scale back the reconstructed density to its original units. We do this for all the examples described here. Here, we work with three different sample sizes of 100, 500, and 2000.
The sample of size 500 will be used for validation purposes. We shall use the densities obtained from the samples of sizes 100 and 2000 to see how well they fit the data of the sample of size 500.
Error Measurement
To finish the preamble, we mention that to measure the discrepancy between the estimated density and the histogram, we used the Mean Absolute Error (MAE) and the Root Mean Squared Error (RMSE). These are computed as follows
A nice feature of these error measures is that they compare the estimated distribution function
and the cumulative distribution function
at the sample data only. See [
16] for further details.
8.2. Density Reconstruction
As a first example, we consider the determination of the density of a loss at the first level of aggregation. We consider the Poisson compound sum of log-normal random variables described above. To stress the point once more, this density was chosen for two reasons. First its analytic form is known, therefore it serves as reference to compare the densities obtained by the maximum entropy method at the decompounding stage. Second, its Laplace transform cannot be computed analytically, and we must resort to simulated data.
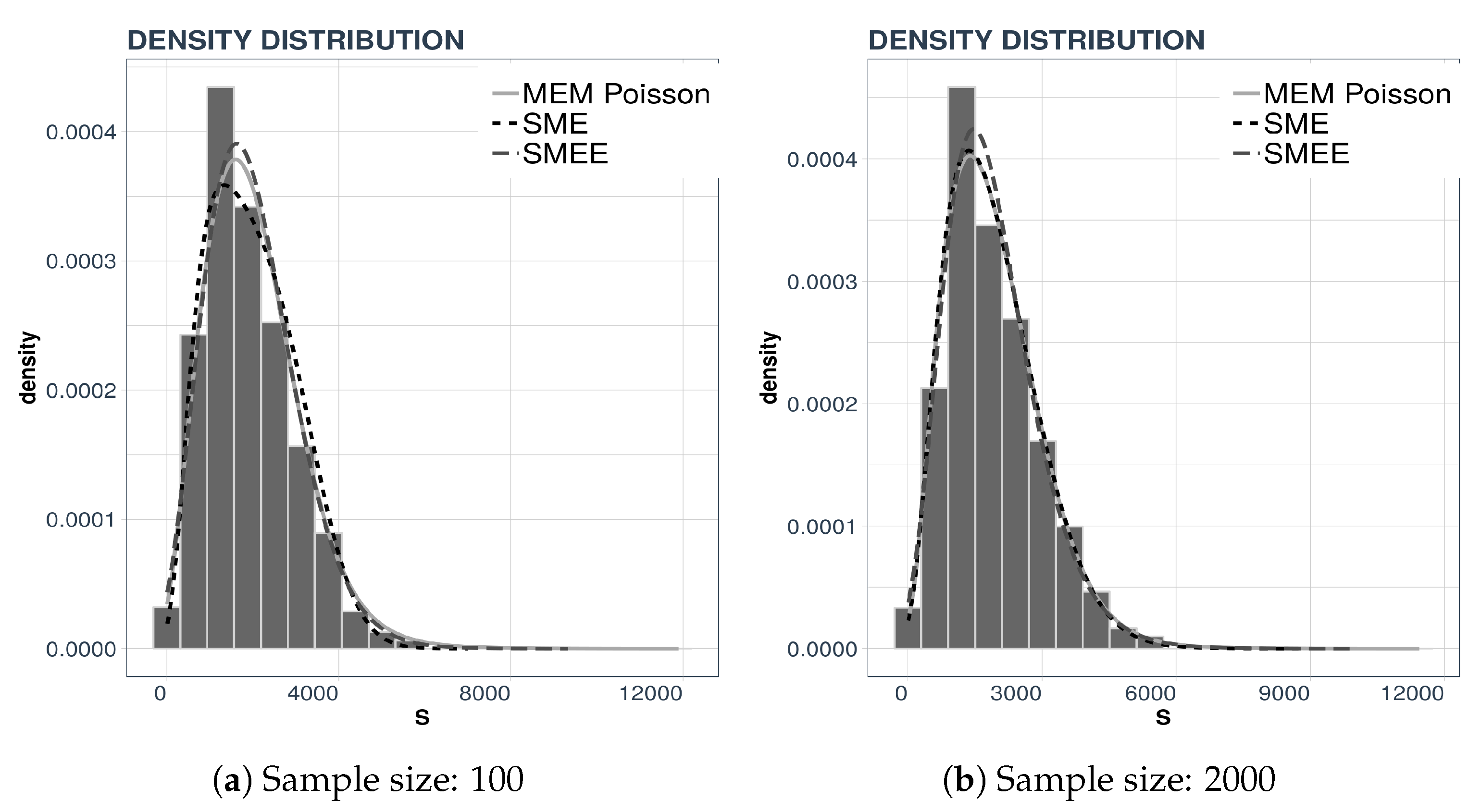
For the example we consider two data sets, consisting of either 100 or 2000 data points and perform a density reconstruction with the three maxentropic techniques: SME, SMEE, and MEM. The results are displayed in
Figure 1 along with the corresponding data histograms.
In each panel we present three curves. In the left panel,
Figure 1a we present the density reconstructed by the three maxentropic methods using 100 data points, whereas in the right panel,
Figure 1b, we present the reconstruction from 2000 data points. Consider
Table 2—there, one can see that the standard maxentropic reconstruction with errors in the data yields the best fit.
Two important quantities for risk management and regulatory capital determination are the VaR and the TVaR. These can be readily computed once the density (or cumulative distribution functions) are at hand. In
Table 3 below, we list these quantities for the distribution obtained by the three methods.
A Validation Procedure
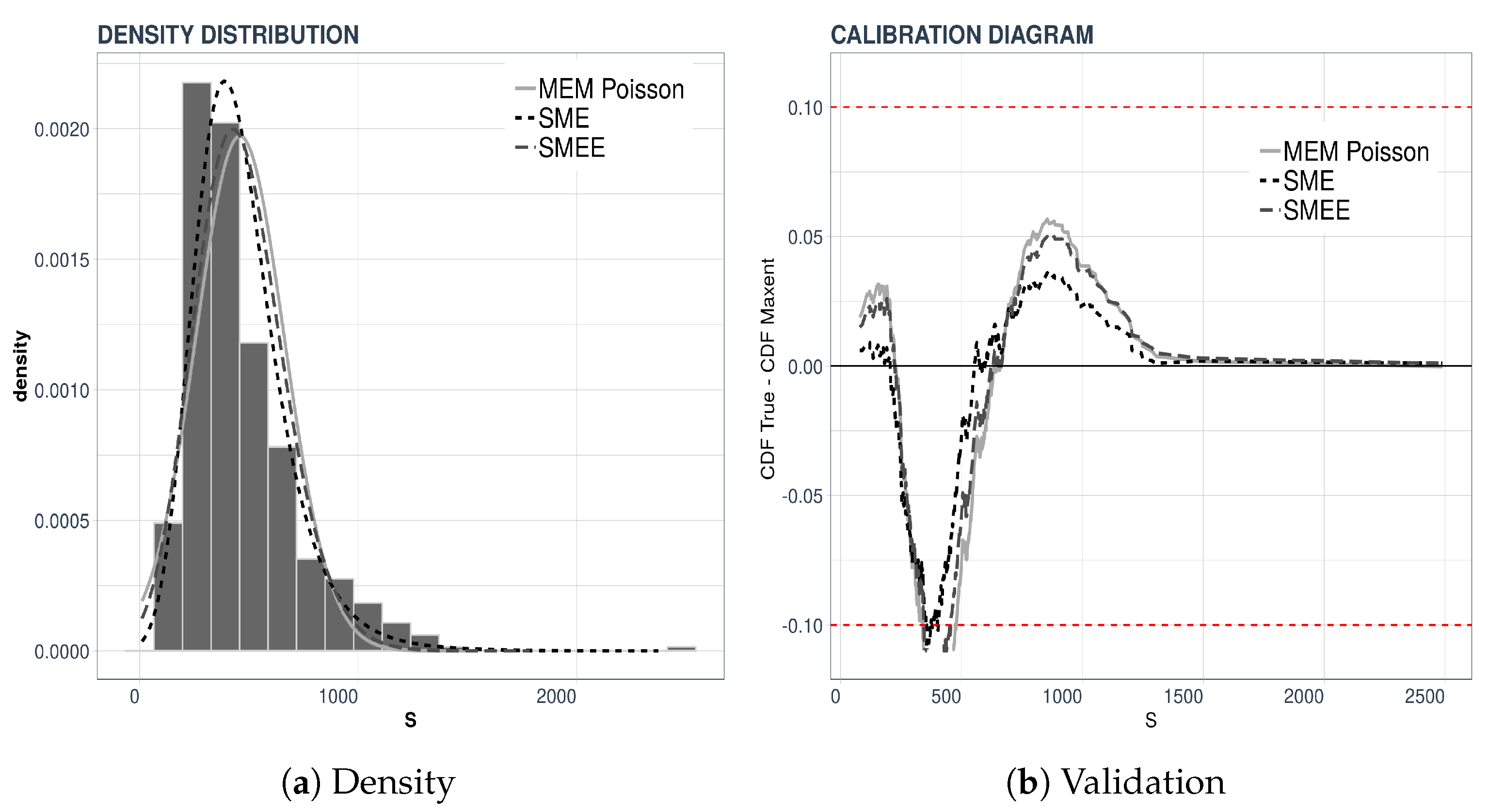
We carry out a validation procedure proposed in [
17] under the name “Calibration Diagram”. The validation consists of a visual comparison of plots. In our case, the cumulative empirical distribution of a data set of 500 is the test distribution. We then compare it to the cumulative densities obtained from 100 or 2000 data points by plotting the difference
where
is the cumulative distribution function of
S obtained by the maxentropic methodology from either 100 or 2000 data points. This test tells us how well the densities from large or small data sets predict or fit data sets of a different size.
The results of the validation procedure are displayed in
Figure 2. In the left-hand panel, the maxentropic densities were obtained from the sample of size 100 and those on the right from the full sample of size 2000, and, as said, the empirical distribution is that of a sample of size 500. Clearly, the larger difference between the distributions occurs in the central region of the range of the variable.
8.3. Decompounding at the First Level of Aggregation
Here we shall consider an implementation of the theme described in
Section 3. We already noted that the Laplace transform of a compound sum of positive random variables can be written as
where
is the Laplace transform of the individual severity. We know how to compute
from a sample, and if we can solve the last equation for
we can then apply the maxentropic machinery to obtain the density of the individual severity.
We already saw in
Section 3 that when the frequency of losses is in the Panjer
class, there is a systematic way to obtain the model for the loss frequency. This was carried out in [
1,
2], so let us not repeat it here. According to the Panjer plot, the distribution seems to be Poisson. Even though this can be double-tested compared its mean and its variance, we use the following indirect approach to find the correct value of
Therefore, let us suppose that the frequency model is Poisson, and solve for
in (
8) to obtain
where
ℓ now stands for the unknown parameter of the Poisson distribution (which for the sake of comparison, we know to be
). The quest for the best
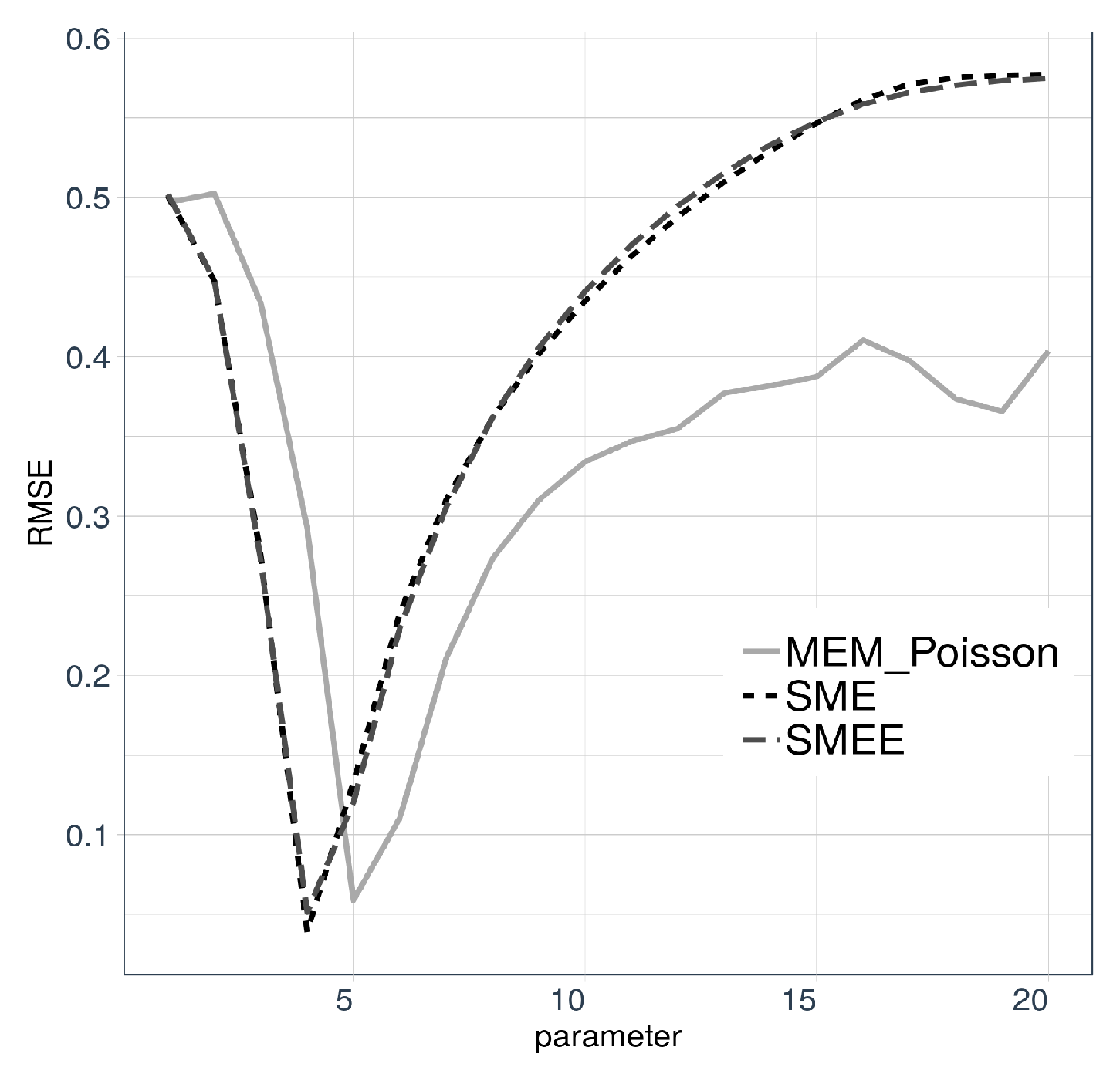
ℓ goes as follows. Fix
ℓ and use maxentropic procedures to obtain
For each version of the maxentropic density, we compute the RMSE reconstruction error for each
ℓ and eventually settle for the value of
ℓ that yields a smaller reconstruction error. The results are displayed in
Figure 3. For the SME and SMEE-based methods, the optimal Poisson parameter happened to be
whereas for the reconstruction using MEM, it happened to be
Once the value of
ℓ is determined, we move on to the determination of the probability density of the individual severities. In
Figure 4 we display the densities of the individual severities for the two sample sizes that we considered.
The left-hand panel of
Figure 4a displays the reconstructions of the density of the individual severities when the Laplace transform of the total loss was computed from 2000 data points, whereas the right-hand panel,
Figure 4b, displays the result of a validation test like the one explained above. This time we compared the densities obtained from 500 and 2000 data points.
Next we list the reconstruction errors in
Table 4. As above, we use the MAE and RMSE as discrepancy error between the reconstructed densities, and the true density, which in our case happens to be known. This test cannot be performed in practice when all that is available to us is the aggregate data.
8.4. Decompounding and Disaggregating Risk Sources
When there are several sources of risk, to determine the possible distributions of individual losses becomes a truly hard problem. To begin with, the analysis requires an initial step consisting of disentangling the possible underlying frequencies of events. For this we must estimate how many sources of risk are present in the data and which are their corresponding frequency of events. After this comes the determination of the distributions of individual severities. It turns out the best we can do here is to recover an appropriate weighted mixture of the individual loss densities. This step is essentially the same as that developed above for the single risk source case. We direct the reader to [
2] for further details and more elaborate examples.
There are several methodologies that can be used to determine the number of sources present in the data, such as AIC, AIC3, BIC, ICL-BIC, and Negentropy, all discussed in [
2]. The essential assumption is that the frequencies of events are in the Panjer
class. This transforms the problem into a problem consisting of disentangling a collection of linear regressions.
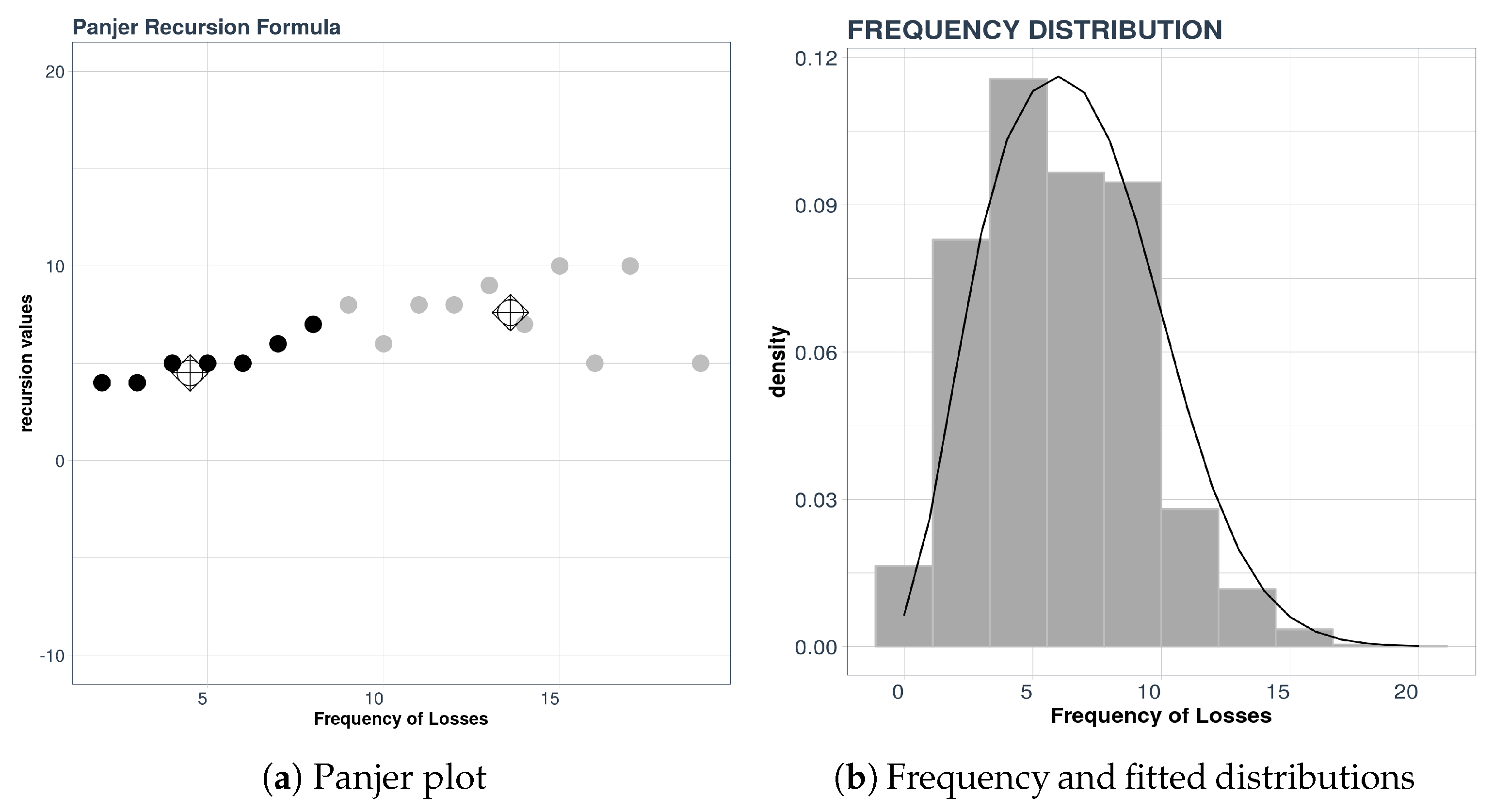
For the example considered here, consisting of the aggregate data described above, we will use the Panjer plot technique combined with a k-means clustering procedure. In
Figure 5, we see the distribution of the frequencies (which is a mixture of distributions) and the result of applying the Panjer recursion formula and k-means.
In
Figure 5a we see that there appears to be two groups of points with zero slope; one group is centered around the value 4 and the other group is centered around the value 8 on the vertical axis. These two values represent the parameters of the distribution, which is the Poisson distribution as indicated in
Table 1 of
Section 3.1.
To test the quality of the results we compared frequency data with the density of the mixture determined by our procedure. The result is displayed in
Figure 5b. The analysis is completed using other measures of statistical error. For details about this, consult [
2], for example.
Once we have the parameters of the mixture of frequencies, we apply the decompounding procedure. Regretfully, the nature of the problem is such that the best one can do is to obtain an “equivalent” individual loss density which is a mixture of the true densities, or in other words, the random variable modeling the aggregate loss is a mixture of the random variables modeling the aggregate losses. The formal result in the case at hand is:
where
and
are the probability densities of the individual severities that are unknown. As this is usually the case, by the use of the maxentropic methodology we can decompound the aggregate losses as before to obtain the distribution of the individual severities that produces the observed aggregate loss.
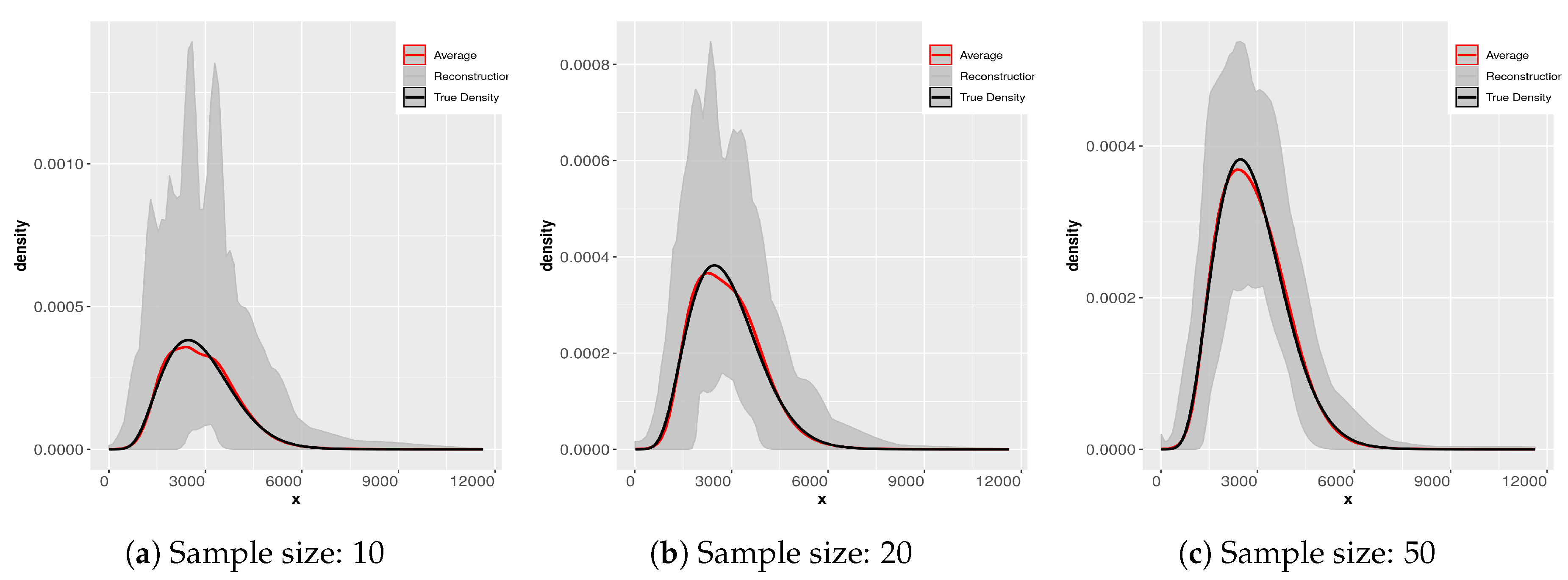
8.5. Sample Size Dependence of the Reconstructed Densities
To examine the sample size dependence of the densities obtained by the maxentropic method, we consider sample sizes of 10, 20, 50, 200, 500, and 1000 of a total loss resulting from aggregating to compound losses that is
. We supposed as well that the two compound losses
and
are independent. In [
18] we go through various elaborate schemes of coupling to analyze the aggregation issue.
In
Figure 6 and
Figure 7 we display the results of applying the SME methodology to 200 samples of each different sample size. Notice that the scale in the ordinate axis in all the plots is not the same. The subsamples were obtained from the original sample of size 2000. The gray-colored cloud is generated by simultaneously plotting all the densities for each sample size in a light gray line. The black line is that of the “true” density and the dashed line is the average of the 200 reconstructions. Notice as well that the average essentially coincides with the “true” density (reconstructed from the sample of size 2000). What changes from panel to panel is the variability of the reconstructions. Clearly for small sample sizes the variability is greater. We direct the reader to [
9,
10] for further analysis of this problem.
This exercise is useful for several reasons, when we do not have any information about the underlying process of the compound losses (i.e., about the statistical nature of the frequency and/or that of the individual severities), to try to fit a parametric distribution can be problematic. If the available sample is too small, we can have problems estimating the body and the tail of the distribution correctly, especially in the case of heavy tailed distributions. We display the result of the maxentropic procedure for different sample sizes to gain intuition about the quality of the results.
Since the maxentropic procedure yields a curve, we can examine how the reconstructed densities fit the body and the tail in the full range of values of the variable. It is also clear that the average of the reconstructions approximates the true density, so if you have enough data, resampling can help to improve the results of the methodology.
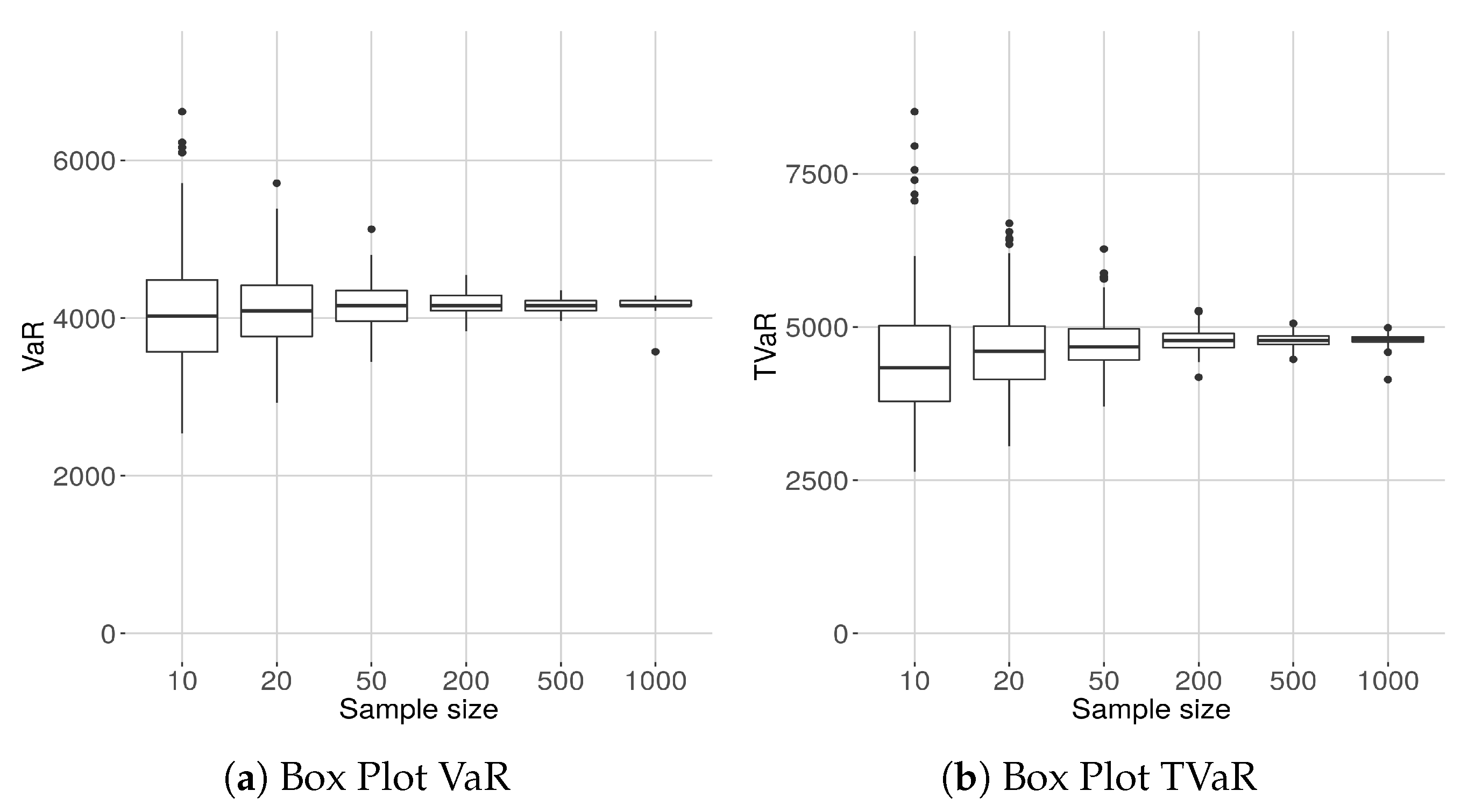
8.6. The Sample Size Variability of VaR and TVaR
In
Figure 8 we show the box plots of the estimated of VaR and TVaR for different sample sizes. The VaR and the TVaR are estimated from the densities plotted in
Figure 7.
The results are intuitive, but worth keeping in mind, especially for risk-measurement purposes.
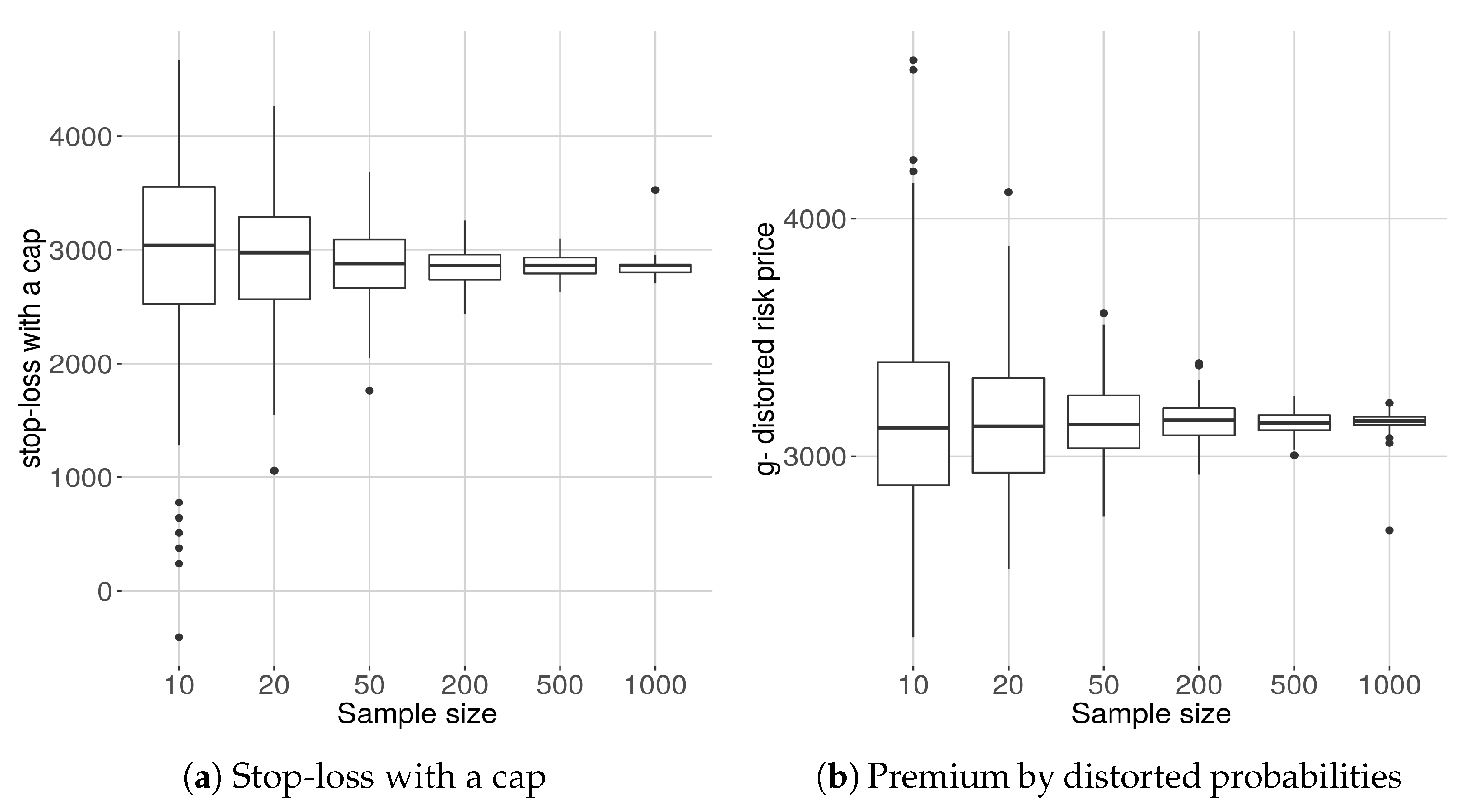
8.7. Sample Dependence of Risk Prices
In this section, we consider the computation of two risk prices that depend heavily on the knowledge of behavior of the density at the extreme tail of the distribution. Here we examine how the size of the sample data affects the computation of the premia. In each of the examples, we consider 200 subsamples of samples of sizes For each we compute each of the expected values and display the results as box plots.
Here denotes the maxentropic density obtained from a sample of size We mention that similar results are obtained using SME or MEM.
8.7.1. Stop-Loss with a Cap
We consider first the sample dependence of a risk a pricing procedure used in the insurance industry for the purpose of reinsurance policy pricing. For each of the 200 samples of size
N we compute (
19), that is
using the maxentropic density using SME, and plot the results in a box plot diagram. For the computations, we used
and
at the 90% level of confidence. Here
denotes the maxentropic density obtained from a sample of size
We mention that similar results are obtained using SME or MEM.
8.7.2. A g–Distorted Premium Price
For this example, we considered
as the distortion function. To obtain the risk price
we must apply (
21), that is, we must compute
Of course, the computations were carried out numerically and as upper limit of integration we considered 1.5× (upper limit of sample). In
Figure 9 we display the box plots of the premia computed using the maxentropic distribution with the Laplace transform computed from samples of different sizes. Even though the result agrees with our intuition, it is nevertheless important to have a quantitative idea of the range of variability of the possible values.
9. Concluding Remarks
Clearly, besides supposing that loses can be described as compound random variables, and that the individual losses are continuous, we have not made any other modeling assumptions. In other words, the methodology based on the maximum entropy method provides us with a truly model-free, non-parametric, and robust technique to obtain loss densities.
When the amount of data is moderately large, combining it with a resampling procedure, we can obtain quite trustworthy estimates of the loss densities, risk measures, and risk premia, or any other quantity expressed as expected value with respect the loss density. This last detail is especially important when the quantities if interest depend strongly on the tail of the density that is of values of the loss that may not be observed in the data.
As a matter of fact, as the last two examples show, even with reasonably large samples, there can be outliers present in the computation of risk measures and risk prices. This is an important detail for risk analysts to keep in mind.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}