1. Introduction
Inferring the statistical dependencies between two variables from a few measured samples is a ubiquitous task in many areas of study. Variables are often linked through nonlinear, relations, which contain stochastic components. The standard measure employed to quantify the amount of dependency is the mutual information, defined as the reduction in entropy of one of the variables when conditioning the other variable [
1,
2]. If the states of the joint distribution are well-sampled, the joint probabilities can be estimated by the observed frequencies. Replacing such estimates in the formula for the mutual information yields the so-called “plug-in” estimator of mutual information. However, unless all the states of the joint distribution are sampled extensively, this procedure typically over-estimates the mutual information [
3,
4,
5]. In fact, when the number of samples is of the order of the effective number of joint states, even independent variables tend to appear as correlated.
The search for an estimator of mutual information that remains approximately unbiased even with small data samples is an open field of research [
6,
7,
8,
9,
10,
11]. Here, we focus on discrete variables, and assume it is not possible to overcome the scarceness of samples by grouping states that are close according to some metric. In addition to corrections that only work in the limit of large samples [
12], the state of the art for this problem corresponds to quasi-Bayesian methods that estimate mutual information indirectly through measures of the entropies of the involved variables [
8,
13,
14]. These approaches have the drawback of not being strictly Bayesian, since the linear combination of two or more Bayesian estimates of entropies does not, in general, yield a Bayesian estimator of the combination of entropies [
8]. The concern is not so much to remain within theoretical Bayesian purity, but rather to avoid frameworks that may be unnecessarily biased, or where negative estimates of information may arise.
Here, we propose a new method for estimating mutual information that is valid in the specific case in which there is an asymmetry between the two variables: One variable has a large number of effective states, and the other only a few. Examples of asymmetric problems can be found for instance in neuroscience, when assessing the statistical dependence between the activity of a population of neurons and a few stereotyped behaviors, as “lever to the left” or “lever to the right.” If the neural activity is represented as a collection of binary strings, with zeroes and ones tagging the absence or presence of spikes in small time bins, the set of possible responses is huge, and typically remains severely undersampled in electrophysiological experiments. If the behavioral paradigm is formulated in terms of a binary forced choice, the behavioral response only has two possible states.
In our approach, no hypotheses are made about the probability distribution of the large-entropy variable, but the marginal distribution of the low-entropy variable is assumed to be well sampled. The prior is chosen so as to accurately represent the amount of dispersion of the conditional distribution of the low-entropy variable around its marginal distribution. This prior is motivated in the framework of Bayesian estimation of information, and then tested with selected examples in which the hypotheses implied in the prior are fulfilled in varying degree, from high to low. The examples show that our estimator has very low bias, even in the severely under-sampled regime, where there are few coincidences that is, when any given state of the large-entropy variable has a low probability of being sampled more than once. The key data statistics that determine the estimated information is the inhomogeneity of the distribution of the low-entropy variable in those states of the high-entropy variable where two or more samples are observed. In addition to providing a practical algorithm to estimate mutual information, our approach sheds light on the way in which just a few samples reveal those specific properties of the underlying joint probability distribution that determine the amount of mutual information.
2. Bayesian Approaches to the Estimation of Entropies
We seek a low-bias estimate of the mutual information between two discrete variables. Let
X be a random variable with a large number
of effective states
with probabilities
, and
Y be a variable that varies in a small set
, with
. Given the conditional probabilities
, the marginal and joint probabilities are
and
, respectively. The entropy
is
and can be interpreted as the average number of well-chosen yes/no questions required to guess the sampled value of
Y (when using a logarithm of base two). Since the entropy is a function of the probabilities, and not of the actual values taken by the random variable, here we follow the usual notation in which the expressions
and
are taken to represent the same concept, defined in Equation (
1). The conditional entropy
is the average uncertainty of the variable
Y once
X is known,
The mutual information is the reduction in uncertainty of one variable once we know the other [
2]
Our aim is to estimate
when
Y is well sampled, but
X is severely undersampled, in particular, when the sampled data contain few coincidences in
X. Hence, for most values
x, the number of samples
is too small to estimate the conditional probability
from the frequencies
. The plug-in estimators of entropy, conditional entropy and mutual information are defined as the ones in which all the probabilities appearing in Equations (
1)–(
3) are estimated naïvely by the frequencies obtained in a given sample. In fact, when
, the plug-in estimator typically underestimates
severely [
5], and often leads to an overestimation of
.
One possibility is to estimate
and
using a Bayesian estimator, and then insert the obtained values in Equation (
3) to estimate the mutual information. We now discuss previous approaches to Bayesian estimators for entropy, to later analyze the case of information. For definiteness, we focus on
, but the same logic applies to
, or
.
We seek the Bayesian estimator of the entropy conditional to having sampled the state
a number
of times. We denote the collection of sampled data as a vector
, and the total number of samples
. The Bayesian estimator of the entropy is a function that maps each vector
on a non-negative real number
, in such a way that the posterior expected error is minimized [
15,
16]. In the Bayesian framework, the sampled data
are known, whereas the underlying distribution
originating the data is unknown, and must be inferred. In this framework, the estimator of the entropy is the function
for which
is minimized. The Bayesian nature of this framework is embodied in the fact that the integral weighs all candidate distributions
that could have originated the data with the posterior distribution
, which can be related to the multinomial distribution
by means of Bayes rule. The estimator
can be found by taking the derivative of Equation (
4) with respect to
and equating to zero. The result is [
17]
where the first equation results from the minimization procedure, and the second, from using Bayes rule. As a result, the Bayesian estimator is the expected value of
.
Since
is the multinomial distribution
and since the normalization constant
can be calculated from the integral
the entire gist of the Bayesian approach is to find an adequate prior
to plug into Equations (
5) and (
7). For the sake of analytical tractability,
is often decomposed into a weighted combination of distributions
that can be easily integrated, each tagged by one or a few parameters, here generically called
that vary within a certain domain,
The decomposition requires to introduce a prior
. Hence, the former search for an adequate prior
is now replaced by the search for an adequate prior
. The replacement implies an assumption and also a simplification. The family of priors that can be generated by Equation (
8) does not necessarily encompass the entire space of possible priors. The decomposition relies on the assumption that the remaining family is still rich enough to make good inference about the quantity of interest, in this case, the entropy. The simplification stems from the fact that the search for
is more restricted than the search for
because the space of alternatives is smaller (the dimensionality of
is typically high, whereas the one of
is low). Two popular proposals of Bayesian estimators for entropies are Nemenman–Shafee–Bialek (NSB) [
13] and Pitman–Yor Mixture (PYM) [
14]. In NSB, the functions
are Dirichlet distributions, in which
takes the role of a concentration parameter. In PYM, these functions are Pitman–Yor processes, and
stands for two parameters: one accounting for the concentration, and the other for the so-called discount. In both cases, the Bayesian machinery implies
where
is the weight of each
in the estimation of the expected entropy
When choosing the family of functions
, it is convenient to select them in such a way that the weight
can be solved analytically. However, this is not the only requirement. In order to calculate the integral in
, the prior
also plays a role. The decomposition of Equation (
8) becomes most useful when the arbitrariness in the choice of
is less serious than the arbitrariness in the choice of
. This assumption is justified when
is peaked around a specific
-value, so that, in practice, the shape of
hardly has an effect. In these cases, a narrow range of relevant
-values is selected by the sampled data, and all assumptions about the prior probability outside this range play a minor role. For the choices of the families
proposed by NSB and PYM,
can be calculated analytically, and one can verify that, indeed, a few coincidences in the data suffice for a peak to develop. In both cases, the selected
is one for which
favours a range of
values that are compatible with the measured data (as assessed by
), and also produce non-negligible entropies (Equation (
10)).
When the chosen Bayesian estimates of the entropies are plugged into Equation (
3) to obtain an estimate of the information, each term is dominated by its own preferred
. Since the different entropies are estimated independently, the
values selected by the data to dominate the priors
and
need not be compatible with the ones dominating the priors of the joint or the conditional distributions. As a consequence, the estimation of the mutual information is no longer Bayesian, and can suffer from theoretical issues, as, for example, yield negative estimates [
8].
A first alternative would be to consider an integrable prior containing a single
for the joint probability distribution
, and then replace
H by
I in the equations above, to calculate
. This procedure was tested by Archer et al. [
8], and the results were only good when the collection of
values governing the data were well described by a distribution that was contained in the family of proposed priors
. The authors concluded that mixtures of Dirichlet priors do not provide a flexible enough family of priors for highly-structured joint distributions, at least for the purpose of estimating mutual information.
To make progress, we note that
can be written as
where
and
stand for the
-dimensional vectors
and
, and
represents the Kullback–Leibler divergence. The average divergence between
and
captures a notion of spread. Therefore, the mutual information is sensitive not so much to the value of the probabilities
, but rather, to their degree of scatter around the marginal
. The parameters controlling the prior should hence be selected in order to match the width of the distribution of
values, and not so much each probability. With this intuition in mind, in this paper, we put forward a new prior for the whole ensemble of conditional probabilities
obtained for different
x values. In this prior, the parameter
controls the spread of the conditionals
around the marginal
.
3. A Prior Distribution for the Conditional Entropies
Our approach is valid when the total number of samples
N is at least of the order of magnitude of
, since in this regime, some of the
x states are expected to be sampled more than once [
18,
19]. In addition, the marginal distribution
must be well sampled. This regime is typically achieved when
X has a much larger set of available states than
Y. In this case, the maximum likelihood estimators
of the marginal probabilities
can be assumed to be accurate that is,
In this paper, we put forward a Dirichlet prior distribution centered at
that is,
where
contains the
conditional probabilities
corresponding to different
x values. Large
values select conditional probabilities close to
, while small values imply a large spread that pushes the selection towards the border of the
-simplex.
For the moment, for simplicity, we work with a prior
defined on the conditional probabilities
, and make no effort to model the prior probability of
. In practice, we estimate the values of
with the maximum likelihood estimator
. Since
X is assumed to be severely undersampled, this is a poor procedure to estimate
. Still, the effect on the mutual information turns out to be negligible, since the only role of
in Equation (
11) is to weigh each of the Kullback–Leibler divergences appearing in the average. If
is large, each
-value appears in several terms of the sum, rendering the individual value of the accompanying
irrelevant, only the sum of all those with the same
matters. In
Section 6, we tackle the full problem of making Bayesian inference both in
and
.
The choice of prior of Equation (
13) is inspired in three facts. First,
captures the spread of
around
, as implied by the Kullback–Leibler divergence in Equation (
13). Admittedly, this divergence is not exactly the one governing the mutual information (Equation (
11)), since
and
are swapped. Yet, it is still a measure of spread. The exchange, as well as the denominator in Equation (
13), were introduced for the sake of the second fact, namely, analytical tractability. The third fact regards the emergence of a single relevant
when the sampled data begin to register coincidences. If we follow the Bayesian rationale of the previous section, now replacing the entropy by the mutual information, we can again define a weight
for the parameter
where
can be obtained analytically, and is a well behaved function of its arguments, whereas
For each
x, the vector
varies in a
-dimensional simplex. For
we take the multinomial
The important point here is that the ratio of the Gamma functions of Equation (
14) develops a peak in
as soon as the collected data register a few coincidences in
x. Hence, with few samples, the prior proposed in Equation (
13) renders the choice of
inconsequential.
Assuming that the marginal probability of
Y is well-sampled, the entropy
is well approximated by the plug-in estimator
. For each
, the expected posterior information can be calculated analytically,
where
is the digamma function. A code implementing the estimate of Equation (
16) is publicly available in the site mentioned in the
Supplementary Material below.
When the system is well sampled,
, so the effect of
becomes negligible, the digamma functions tend to logarithms, and the frequencies match the probabilities. In this limit, Equation (
16) coincides with the plug-in estimator, which is consistent [
20]. As a consequence, our estimator is also consistent. The rest of the paper focuses on the case in which the marginal probability of
X is severely undersampled.
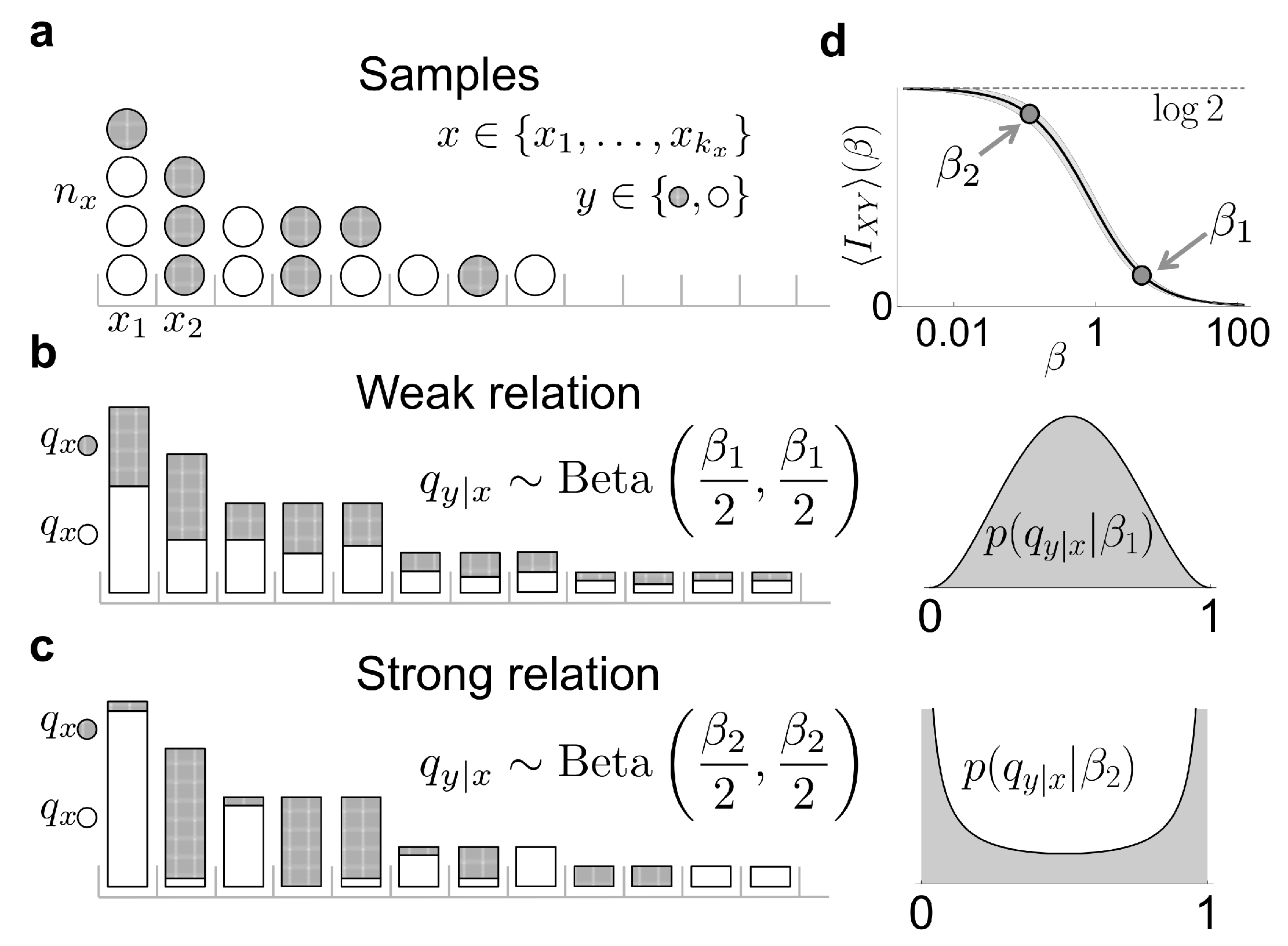
4. A Closer Look on the Case of a Symmetric and Binary -Variable
In this section, we analyze the case of a binary
Y-variable, which, for simplicity, is assumed to be symmetric that is,
, such that
nats. In this case, the Dirichlet prior in each factor of Equation (
13) becomes a Beta distribution
and
. Large values of
mostly select conditional probabilities
close to
. If all conditional probabilities are similar, and similar to the marginal, the mutual information is low, since the probability of sampling a specific
y value hardly depends on
x. Instead, small values of
produce conditional probabilities
around the borders (
or
). In this case,
is strongly dependent on
x (see
Figure 1b), so the mutual information is large. The expected prior mutual information
can be calculated using the analytical approach developed by [
14,
17],
The prior information is a slowly-varying function of the order of magnitude of
, namely of
. Therefore, if a uniform prior in information is desired, it suffices to choose a prior on
such that
,
When
, the expected posterior information (Equation (
16)) becomes
The marginal likelihood of the data given
is also analytically tractable. The likelihood is binomial for each
x, so
The posterior for can be obtained by adding a prior , as . The role of the prior becomes relevant when the number of coincidences is too low for the posterior to develop a peak (see below).
In order to gain intuition about the statistical dependence between variables with few samples, we here highlight the specific aspects of the data that influence the estimator of Equation (
20). Grouping together the terms of Equation (
21) that are equal, the marginal likelihood can be rewritten in terms of the multiplicities
that is, the number of states
x with specific occurrences
or
,
where
The posterior for
is independent from states
x with just a single count, as
. Only states
x with coincidences matter. In order to see how the sampled data favor a particular
, we search for the
-value (denoted as
) that maximizes
in the particular case where at most two samples coincide on the same
x, obtaining
Denoting the fraction of 2-count states that have one count for each
y-value as
, Equation (
24) implies that the likelihood
is maximized at
If the y-values are independent of x, we expect . This case corresponds to a large and, consequently, to little information. On the other side, for small , the parameter is also small and the information grows. Moreover, the width of is also modulated by . When the information is large, the peak around is narrow. Low information values, instead, require more evidence, and they come about with more uncertainty around .
In Equation (
24), the data only intervene through
and
, which characterize the degree of asymmetry of the
y-values throughout the different
x-states. This asymmetry, hence, constitutes a sufficient statistics for
. If a prior
is included, the
that maximizes the posterior
may shift, but the effect becomes negligible as the number of coincidences grows.
We now discuss the role of the selected
in the estimation of information, Equation (
20), focusing on the conditional entropy
. First, in terms of the multiplicities, the conditional entropy can be rewritten as
where
is the fraction of the
N samples that fall in states
x with
r counts, and
is the fraction of all states
x with
counts, of which
n correspond to one
y-value (whichever) and
for the other. Finally,
is the estimation of the entropy of a binary variable after
samples,
A priori,
, as in
Figure 1d. Surprisingly, from the property
, it turns out that
(in fact,
). Hence, if only a single count breaks the symmetry between the two
y-values, there is no effect on the conditional entropy. This is a reasonable result, since a single extra count is no evidence of an imbalance between the underlying conditional probabilities, it is just the natural consequence of comparing the counts falling on an even number of states (2) when taking an odd number of samples. Expanding the first terms for the conditional entropy,
In the severely under-sampled regime, these first terms are the most important ones. Moreover, when evaluating these terms in
(Equation (
25)), the conditional entropy simplifies into
Typically, takes most of the weight, so the estimation is close to the prior evaluated at the -value that maximizes the marginal likelihood (or the posterior).
When dealing with few samples, it is important to have not just a good estimate of the mutual information, but also a confidence interval. Even a small information may be relevant, if the evidence attests that it is strictly above zero. The theory developed here also allows us to estimate the posterior variance of the mutual information, as shown in
Appendix A. The variance (Equation (
A4)) is shown to be inversely proportional to the number of states
, thereby implying that our method benefits from a large number of available states
X, even if undersampled.
If an estimator, such as ours, is guaranteed to provide a non-negative estimate for all possible sets of sampled data, it cannot be free of bias, not at least if the samples are generated by an independent distribution (
), for which the true information vanishes. In
Appendix B, we show that, in this specific case, the bias decreases with the square root of the number of coincidences. This number may be large, even in the severely undersampled regime, if
. If the distribution
is approximately uniform, the number of coincidences is proportional to the square of the total number of samples, so the bias is inversely proportional to
N.
5. Testing the Estimator
We now analyze the performance of our estimator in three examples where the number of samples
N is below or in the order of the effective size of the system
. In this regime, most observed
x-states have very few samples. In each example, we define the probabilities
and
with three different criteria, giving rise to collections of probabilities that can be described with varying success by the prior proposed in this paper, Equation (
17). Once the probabilities are defined, the true value
of the mutual information can be calculated, and compared to the one estimated by our method in 50 different sets of samples
of the measured data. We present the estimate obtained with
from Equation (
20) evaluated in the
that maximizes the marginal likelihood
. We did not observe any improvement when integrating over the whole posterior
with the prior
of Equation (
19), except when
or
were of order 1. This fact implies the existence of a well-defined peak in the marginal likelihood.
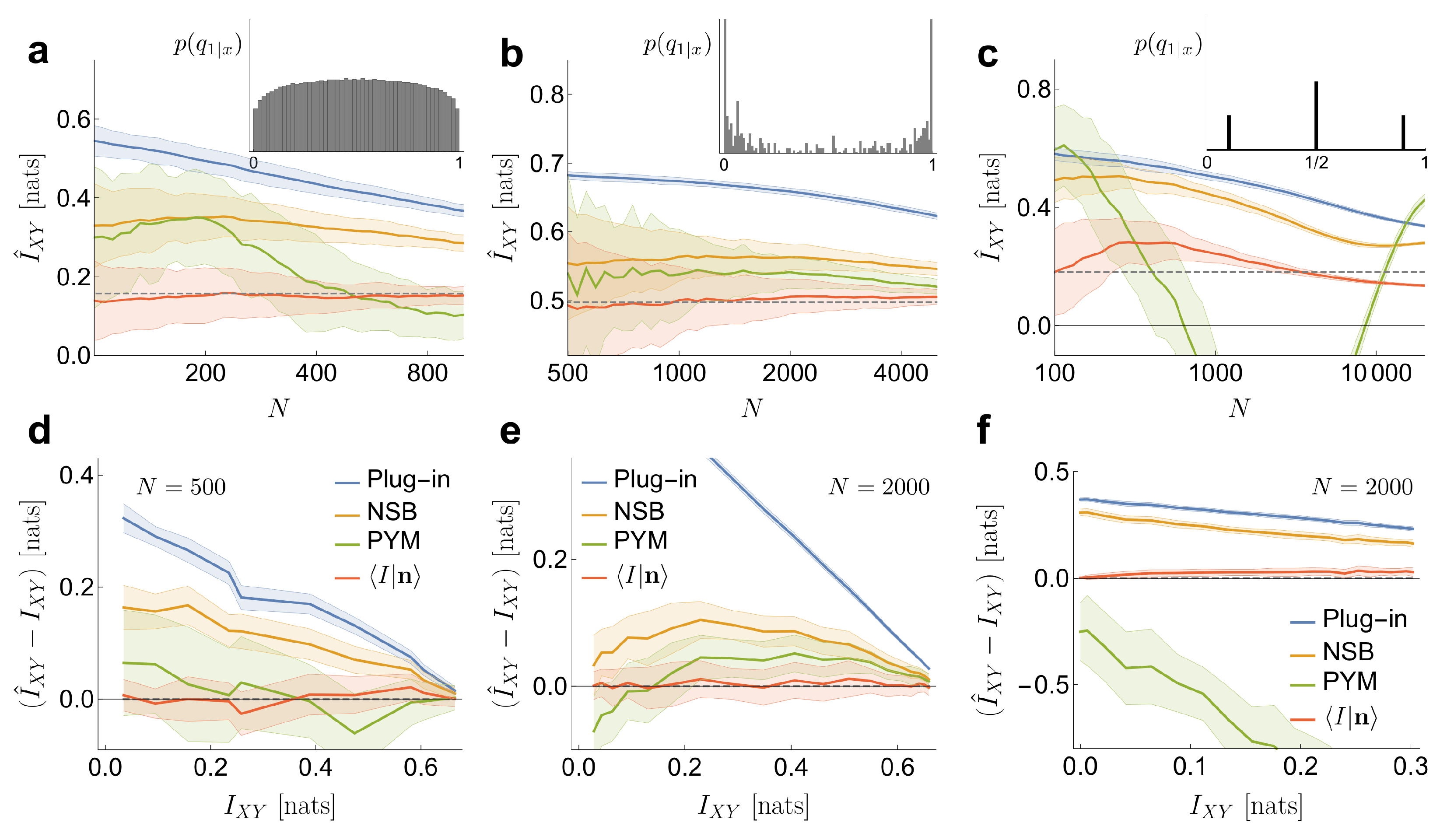
In
Figure 2, the performance of our estimator is compared with that of three other methods widely employed in the literature: Plug in, NSB and PYM. In addition, two other estimators were evaluated, but not shown in the figure to avoid cramming: the one of reference [
21], which is a particularly convenient case of the Schuermann family of estimators [
22], and the one of reference [
23], extensively used in ecology. Their estimates fell between the plug-in estimator and NSB in the first case, and between NSB and PYM in the second case.
In the first example (
Figure 2a,d), the probabilities
are obtained by sampling a Pitman–Yor distribution with concentration parameter
and tail parameter
(as described in [
14]). These values correspond to a Pitman–Yor prior with a heavy tail. The conditional probabilities
are defined by sampling a symmetric Beta distribution
, as in Equation (
17). In
Figure 2a, we use
. Once the joint probability
is defined, 50 sets of samples
are generated. The effective size of the system is
. We compare our estimator to the plug-in estimator (Plug-in), NSB and PYM when applied to
and
(all methods coincide in the estimation of
). Our estimator has a low bias, even when the number of samples per effective state is as low as
. The variance is larger than in the Plug-in estimator, comparable to NSB and smaller than PYM. All the other methods (Plug-in, NSB and to a lesser extend PYM) overestimate the mutual information. In
Figure 2d, the performance of the estimators is also tested for different values of the exact mutual information
, which we explore by varying
. For each
, the conditional probabilities
are sampled once. Each vector
contains
samples, and
is sampled 50 times. Our estimates have very low bias, even as the mutual information goes to zero —namely, for independent variables.
Secondly, we analyze an example where the statistical relation between
X and
Y is remarkably intricate (example inspired by [
25]), which underscores the fact that making inference about the mutual information does not require inferences on the joint probability distribution. The variable
x is a binary vector of dimension 12. Each component represents the presence or absence of one of a maximum of 12 delta functions equally spaced on the surface of a sphere. There are
possible
x vectors, and they are governed by a uniform prior probability:
. The conditional probabilities are generated in such a way that they be invariant under rotations of the sphere that is,
, where
R is a rotation. Using a spherical harmonic representation [
24], the frequency components
of the spherical spectrum are obtained, where
is the combination of deltas. The conditional probabilities
are defined as a sigmoid function of
. The offset of the sigmoid is chosen such that
, and the gain such that
nats. In this example, and, unlike the Dirichlet prior implied by our estimator,
has some level of roughness (inset in
Figure 2b), due to peaks coming from the invariant classes in
. Hence, the example does not truly fit into the hypothesis of our method. With these settings, the effective size of the system is
. Our estimator has little bias (
Figure 2b,e), even with
samples per effective state. In this regime, around
of the samples fall on
x states that occur only once (
),
on states that occur twice and
on states with three counts, or maybe four. As mentioned above, in such cases, the value of
is very similar to the one that would be obtained by evaluating the prior information
of (Equation (
18)) at the
that maximizes the marginal likelihood
, which in turn is mainly determined by
. In
Figure 2e, the estimator is tested with a fixed number of samples
for different values of the mutual information, which we explore by varying the gain of the sigmoid. The bias of the estimate is small in the entire range of mutual informations.
In the third place, we consider an example where the conditional probabilities are generated from a distribution that is poorly approximated by a Dirichlet prior. The conditional probabilities are sampled from three Dirac deltas, as
, with
. The delta placed in
could be approximated by a Dirichlet prior with a large
, while the other two deltas could be approximated by a small
, but there is no single value of
that can approximate all three deltas at the same time. The
x states are generated as Bernoulli (
) binary vectors of dimension
, while the conditional probabilities
depend on the parity of the sum of the components of the vector
x. When the sum is even, we assign
, and when it is odd, we assign
or
, both options with equal probability. Although in this case our method has some degree of bias, it still preserves a good performance in relation to the other approaches (see
Figure 2c,f). The marginal likelihood
contains a single peak in an intermediate value of
, coinciding with none of the deltas in
, but still capturing the right value of the mutual information. As in the previous examples, we also test the performance of the estimator for different values of the mutual information, varying in this case the value of
(with
). Our method performs acceptably for all values of mutual information. The other methods, instead, are challenged more severely, probably because a large fraction of the
x states have a very low probability, and are therefore difficult to sample. Those states, however, provide a crucial contribution to the relative weight of each of the three values of
. PYM, in particular, sometimes produces a negative estimate for
, even on average.
Finally, we check numerically the accuracy of the analytically predicted mean posterior information (Equation (
20)) and variance (Equation (
A4)) in the severely under-sampled regime. The test is performed in a different spirit than the numerical evaluations of
Figure 2. There, averages were taken for multiple samples of the vector
, from a fixed choice of the probabilities
and
. The averages of Equations (
20) and (
A4), however, must be interpreted in the Bayesian sense. The square brackets in
and
represent averages taken for a fixed data sample
, and unknown underlying probability distributions
and
. We generate many such distributions with
(a Dirichlet Process with concentration parameter
) and
. A total of 13,500 distributions
are produced, with
sampled from Equation (
19), and three equiprobable values of
. For each of these distributions, we generate five (5) sets of just
samples, thereby constructing a list of
13,500 cases, each case characterized by specific values of
and
. Following the Bayesian rationale, we partition this list in classes, each class containing all the cases that end up in the same set of multiplicities
—for example,
. For each of the 100 most occurring sets of multiplicities (which together cover
of all the cases), we calculate the mean and the standard deviation of the mutual information
of the corresponding class, and compare them with our predicted estimates
and
, using the prior
from Equation (
19).
Figure 3 shows a good match between the numerical (
y-axis) and analytical (
x-axis) averages that define the mean information (panel
a) and the standard deviation (
b). The small departures from the diagonal stem from the fact that the analytical average contains all the possible
and
, even if some of them are highly improbable for one given set of multiplicities. The numerical average, instead, includes the subset of the 13,500 explored cases that produced the tested multiplicity. All the depicted subsets contained many cases, but, still, they remained unavoidably below the infinity covered by the theoretical result.
We have also tested cases where Y takes more than two values, and where the marginal distribution is not uniform, observing similar performance of our estimator.
6. A Prior Distribution for the Large Entropy Variable
The prior considered so far did not model the probability
of the large-entropy variable
X. Throughout the calculation, the probabilities
were approximated by the maximum likelihood estimator
. Here, we justify such procedure by demonstrating that proper Bayesian inference on
hardly modifies the estimation of the mutual information. To that end, we replace the prior of Equation (
13) by another prior that depends on both
and
.
The simplest hypothesis is to assume that the prior
factorizes as
, implying that the marginal probabilities
are independent of the conditional probabilities
. We propose
, so that the marginal probabilities
are drawn from a Dirichlet Process with concentration parameter
, associated with the total number of pseudo-counts. After integrating in
and in
, the mean posterior mutual information for fixed hyper-parameters
and
is
Before including the prior
, in the severely undersampled regime, the mean posterior information was approximately equal to the prior information evaluated in the best
(Equation (
16)). The new calculation (Equation (
30)) contains the prior information explicitly, weighted by
, that is, the ratio between the number of pseudo-counts from the prior and the total number of counts. Thereby, the role of the non-observed (but still inferred) states is established.
The independence assumed between
and
implies that
The inference over
coincides with the one of PYM with the tail parameter as
[
14], since
where
is the number of states
x with at least one sample. With few coincidences in
x,
develops a peak around a single
-value that represents the number of effective states. Compared to the present Bayesian approach, maximum likelihood underestimates the number of effective states (or entropy) in
x. Since the expected variance of the mutual information decreases with the square root of the number of effective states, the Bayesian variance is reduced with respect to the one of the Plug-in estimator.
7. Discussion
In this work, we propose a novel estimator for mutual information of discrete variables
X and
Y, which is adequate when
X has a much larger number of effective states than
Y. If this condition does not hold, the performance of the estimator breaks down. We inspire our proposal in the Bayesian framework, in which the core issue can be boiled down to finding an adequate prior. The more the prior is dictated by the data, the less we need to assume from outside. Equation (
11) implies that the mutual information
is the spread of the conditional probabilities of one of the variables (for example,
, but the same holds for
) around the corresponding marginal (
or
, respectively). This observation inspires the choice of our prior (Equation (
13)), which is designed to capture the same idea, and, in addition, to be analytically tractable. We choose to work with a hyper-parameter
that regulates the scatter of
around
, and not the scatter of
around
because the asymmetry in the number of available states of the two variables makes the
of the first option (and not the second) strongly modulated by the data, by the emergence of a peak in
.
Although our proposal is inspired in previous Bayesian studies, the procedure described here is not strictly Bayesian, since our prior (Equation (
13)) requires the knowledge of
, which depends on the sampled data. However, in the limit in which
is well sampled, this is a pardonable crime, since
is defined by a negligible fraction of the measured data. Still, Bayesian purists should employ a two-step procedure to define their priors. First, they should perform Bayesian inference on the center of the Dirichlet distribution of Equation (
13) by maximizing
, and then replace
in Equation (
13) by the inferred
. For all practical purposes, however, if the conditions of validity of our method hold, both procedures lead to the same result.
By confining the set or possible priors
to those generated by Equation (
13), we relinquish all aspiration to model the prior of, say,
, in terms of the observed frequencies at
. In fact, the preferred
-value is totally blind to the specific
x-value of each sampled datum. Only the
number of
x-values containing different counts of each
y-value matters. Hence, the estimation of mutual information is performed without attempting to infer the specific way the variables
X and
Y are related, a property named
equitability [
26], and that is shared also by other methods [
8,
13,
14]. Although this fact may be seen as a disadvantage, deriving a functional relation between the variables can actually bias the inference on mutual information [
26]. Moreover, fitting a relation is unreasonable in the severe under-sampled regime, in which not all
x-states are observed, most sampled
x-states contain a single count, and few
x-states contain more than two counts—at least without a strong assumption about the probability space. In fact, if the space of probabilities of the involved variables has some known structure or smoothness condition, other approaches that estimate information by fitting the relation first may perform well [
9,
10,
11]. Part of the approach developed here could be extended to continuous variables or spaces with a determined metric. This extension is left for future work.
In the explored examples, our estimator had a small bias, even in the severely under-sampled regime, and it outperformed other estimators discussed in the literature. More importantly, the second and third examples of
Section 5 showed that it even worked when the collection of true conditional probabilities
was not contained in the family of priors generated by
. In these cases, the success of the method relies on the peaked nature of the posterior distribution
. Even if the selected
provides a poor description of the actual collection of probabilities, the dominant
captures the right value of mutual information. This is the sheer instantiation of the equitability property discussed above.
When the number of samples
N is much larger than the total number of available states
, our estimator of mutual information tends to the plug-in estimator, which is known to be consistent [
20]. Consequently, our estimator is also consistent. By construction,
is equal to the mutual information averaged over all distributions
and
compatible with the measured data, each weighted by its posterior probability. As such, it can never produce a negative result, which is a desirable property. The down side is that the estimator must be positively biased, at least, when the true information vanishes. The derivation in
Appendix B shows that, when the number of samples
, this bias is inversely proportional to the square root of the number of pairwise coincidences or, when
is fairly uniform, to the inverse of the total number of samples. Moreover, the factor of proportionality is significantly smaller than the one obtained in the bound of the bias of other frequentist estimators [
3,
27]. If the number of samples
N grows even further, the bias tends to zero, since the bias of all consistent estimators vanishes asymptotically [
28].
Our method provides also a transparent way to identify the statistics that matter, out of all the measured data. Quite naturally, the
x-states that have not been sampled provide no evidence in shaping
, as indicated by Equation (
14), and only shift the posterior information towards the prior (Equation (
30)). More interestingly, the
x-states with just a single count are also irrelevant, both in shaping
and in modifying the posterior information away from the prior. These states are unable to provide evidence about the existence of either flat or skewed conditional probabilities
. Only the states
x that have been sampled at least twice contribute to the formation of a peak in
, and in deviating the posterior information away from the prior.
Our method can also be extended to generalizations of mutual information designed to characterize the degree of interdependence of more than two variables [
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41], as long as all but one of the variables are extensively sampled. The applicability of the method to these measures will be the object of future work, once a certain degree of consensus has been reached regarding their meaning and range of applicability.
Several fields can benefit from the application of our estimator of mutual information. Examples can be found in neuroscience, when studying whether neural activity (a variable with many possible states) correlates with a few selected stimuli or behavioral responses [
12,
42,
43], or in genomics, to understand associations between genes (large-entropy variable) and a few specific phenotypes [
44]. The method can also shed light on the development of rate-distortion methods to be employed in situations in which only a few samples are available. In particular, it can be applied within the information bottleneck framework [
45,
46], aimed at extracting a maximally compressed representation of an input variable, but still preserving those features that are relevant for the prediction of an output variable. The possibility of detecting statistical dependencies with only few samples is of key importance, not just for analyzing data sets, but also to understand how living organisms quickly infer dependencies in their environments and adapt accordingly [
47].


{kind=link}
{kind=link}
{kind=link}


