1. Introduction
Bayesian inference is a popular approach for solving inverse problems with far-reaching applications, such as parameter estimation and uncertainty quantification (see for example [
1,
2,
3]). In this article, we will focus on a classical Bayesian inference problem of estimating the conditional distribution of hidden parameters of dynamical systems from a given set of noisy observations. In particular, let
be a time-dependent state variable, which implicitly depends on the parameter
through the following initial value problem,
Here, for any fixed
,
f can be either deterministic or stochastic. Our goal is to estimate the conditional distribution of
, given discrete-time noisy observations
, where:
Here,
are the solutions of Equation (
1) for a specific hidden parameter
,
g is the observation function, and
are unbiased noises representing the measurement or model error. Although the proposed approach can also estimate the conditional density of the initial condition
, we will not explore this inference problem in this article.
Given a prior density,
, Bayes’ theorem states that the conditional distribution of the parameter
can be estimated as,
where
denotes the likelihood function of
given the measurements
that depend on a hidden parameter value
through (
2). In most applications, the statistics of the conditional distribution
are the quantity of interest. For example, one can use the mean statistic as a point estimator of
and the higher order moments for uncertainty quantification. To realize this goal, one draws samples of
and estimates these statistics via Monte Carlo averages over these samples. In this application, Markov Chain Monte Carlo (MCMC) is a natural sampling method that plays a central role in the computational statistics behind most Bayesian inference techniques [
4].
In our setup, we assume that for any
, one can simulate:
where
denote solutions to the initial value problem in Equation (
1). If the observation function has the following form,
where
are i.i.d. noises, then one can define the likelihood function of
,
, as a product of the density functions of the noises
,
When the observations are noise-less,
, and the underlying system is an Itô diffusion process with additive or multiplicative noises, one can use the Bayesian imputation to approximate the likelihood function [
5]. In both parametric approaches, it is worth noting that the dependence of the likelihood function on the parameter is implicit through the solutions
. Practically, this implicit dependence is the source of the computational burden in evaluating the likelihood function since it requires solving the dynamical model in (
1) or every proposal in the MCMC chain. In the case when simulating
is computationally feasible, but the likelihood function is intractable, then one can use, e.g., the Approximate Bayesian Computation (ABC) rejection algorithm [
6,
7] for Bayesian inference. Basically, the ABC rejection scheme generates the samples of
by comparing the simulated
to the observed data,
, with an appropriate choice of metric comparison for each proposal
. In general, however, repetitive evaluation of (
4) can be expensive when the dynamics in (
1) is high-dimensional and/or stiff, or when
T is large, or when the function
g is an average of a long time series. Our goal is to address this situation in addition to not knowing the approximate likelihood function.
Broadly speaking, the existing approaches to overcome repetitive evaluation of (
4) require knowledge of an approximate likelihood function such as in (
6). They can be grouped into two classes. The first class consists of methods that improve/accelerate the sampling strategy; for example, the Hamiltonian Monte Carlo [
8], adaptive MCMC [
9], and delay rejection adaptive Metropolis [
10], just to name a few. The second class consists of methods that avoid solving the dynamical model in (
1) when running the MCMC chain by replacing it with a computationally more efficient model on a known parameter domain. This class of approach, also known as
surrogate modeling, includes Gaussian process models [
11], polynomial chaos [
12,
13], and enhanced model error [
14]; for example, the non-intrusive spectral projection [
13] approximate
in (
6) with a polynomial chaos expansion. Another related approach, which also avoids MCMC on top of integrating (
1), is to employ a polynomial expansion on the likelihood function [
15]. This method represents the parametric likelihood function in (
6) with orthonormal basis functions of a Hilbert space weighted by the prior measure. This choice of basis functions makes the computation for the statistics of the posterior density straightforward, and thus, MCMC is not needed.
In this paper, we consider a surrogate modeling approach where a nonparametric likelihood function is constructed using a data-driven spectral expansion. By nonparametric, we mean that our approach does not require any parametric form or assume any distribution as in (
6). Instead, we approximate the likelihood function using the kernel embedding of conditional distribution formulation introduced in [
16,
17]. In our application, we will extend their formulation onto a Hilbert space weighted by the sampling measure of the training dataset as in [
18]. We will rigorously demonstrate that using orthonormal basis functions of this data-driven weighted Hilbert space, the error bound is independent of the variance of the basis functions, which allows us to determine the amount of training data for accurate likelihood function estimations.
Computationally, assuming that the observations lie on (or close to) a Riemannian manifold
embedded in
with sampling density
, we apply the diffusion maps algorithm [
19,
20] to approximate orthonormal basis functions
using the training dataset. Subsequently, a nonparametric likelihood function is represented as a weighted sum of these data-driven basis functions, where the coefficients are precomputed using the kernel embedding formulation. In this fashion, our approach respects the geometry of the data manifold. Using this nonparametric likelihood function, we then generate the MCMC chain for estimating the conditional distribution of hidden parameters. For the present work, our aim is to demonstrate that one can obtain accurate and robust parameter estimation by implementing a simple Bayesian inference algorithm, the Metropolis scheme, with the data-driven nonparametric likelihood function. We should also point out that the present method is computationally feasible on low-dimensional parameter space, like any other surrogate modeling approach. Possible ways to overcome this dimensionality issue will be discussed.
This paper is organized as follows: In
Section 2, we review the formulation of the reproducing kernel Hilbert space to estimate conditional density functions. In
Section 3, we discuss the error estimate of the likelihood function approximation. In
Section 4, we discuss the construction of the analytic basis functions for the Euclidean data manifold, as well as the data-driven basis functions with the diffusion maps algorithm for data that lie on embedded Riemannian geometry. In
Section 5, we provide numerical results with parameter estimation application on instructive examples. In one of the examples where the dynamical model is low-dimensional and the observation is in the form of (
5), we compare the proposed approach with the direct MCMC and non-intrusive spectral projection method (both schemes use likelihood of the form (
6)). In addition, we will also demonstrate the robustness of the proposed approach on an example where
g is a statistical average of a long-time trajectory (in which the likelihood is intractable) and the dynamical model has relatively high-dimensional chaotic dynamics such that repetitive evaluation of (
4) is numerically expensive. In
Section 6, we conclude this paper with a short summary. We accompany this paper with Appendices for treating large amount of data and more numerical results.
2. Conditional Density Estimation via Reproducing Kernel Weighted Hilbert Spaces
Let , where is a smooth manifold with intrinsic dimension . In practice, we measure the observations in the ambient coordinates and denote their components as . For the parameter space, has a Euclidean structure with components, , so is assumed to be either an m-dimensional hyperrectangle or . For training, we are given M number of training parameters . For each training parameter , we generate a discrete time series of length N for noisy observation data for and . Here, the sub-index i and the sub-index j of correspond to the observation data for the training parameter . Our goal for training is to learn the conditional density from the training dataset and for arbitrary and within the range of .
The construction of the conditional density
is based on a machine learning tool known as the kernel embedding of the conditional distribution formulation introduced in [
16,
17]. In their formulation, the representation of conditional distributions is an element of a Reproducing Kernel Hilbert Space (RKHS).
Recently, the representation using a Reproducing Kernel Weighted Hilbert Space (RKWHS) was introduced in [
18]. That is, let
be the orthonormal basis of
, where they are eigenbasis of an integral operator,
that is,
.
In the case where
is compact and
is Hilbert–Schmidt, the kernel can be written as,
which converges in
. Define the feature map
as,
Therefore, any
can be represented as
, where
and provided that
. If we define
, we can write the kernel in (
8) as
. Throughout this manuscript, we denote the RKHS
generating the feature map
in (
9) as the space of square integrable functions with a reproducing property,
induced by the basis of
. While this definition deceptively suggests that
is similar to
, we should also point out that the RKHS requires that the Dirac functional
defined as
be continuous. Since
contains a class of functions, it is not an RKHS and
. See, e.g., Chapter 4 of [
21] for more details. Using the same definition, we denote
as the RKHS induced by orthonormal basis of
of functions of the parameter
.
In this work, we will represent conditional density functions using the RKWHS induced by the data, where the bases will be constructed using the diffusion maps algorithm. The outcome of the training is an estimate of the conditional density, , for arbitrary and within the range of .
2.1. Review of Nonparametric RKWHS Representation of Conditional Density Functions
We first review the RKWHS representation of conditional density functions deduced in [
18]. Let
be the orthonormal basis functions of
, where
contains the domain of the training data
, and the weight function
is defined with respect to the volume form inherited by
from the ambient space
. Let
be the orthonormal basis functions in the parameter
space, where the training parameters are
, with weight function
. For finite modes,
, and
, a nonparametric RKWHS representation of the conditional density can be written as follows [
18]:
where
denotes an estimate of the conditional density
, and the expansion coefficients are defined as:
Here, the matrix
is
, and the matrix
is
, whose components can be approximated by Monte Carlo averages [
18]:
where the expectations
are taken with respect to the sampling densities of the training dataset
and
. The equation for the expansion coefficients in Equation (
11) is based on the theory of kernel embedding of the conditional distribution [
16,
17,
18]. See [
18] for the detailed proof of Equations (
11)–(13). Note that for RKWHS representation, the weight functions
q and
can be different from the sampling densities of the training dataset
and
, respectively. This generalizes the representation in [
18], which sets the weights
q and
to be the sampling densities of the training dataset
and
, respectively. If the assumption of
is not satisfied, then
can be singular. In such a case, one can follow the suggestion in [
16,
17] to regularize the linear regression in (
11) by replacing
with
, where
is an empirically-chosen parameter and
denotes an identity matrix of size
.
Incidentally, it is worth mentioning that the conditional density in (
10) and (
11) is represented as a regression in infinite-dimensional spaces with basis functions
and
. The expression (
10) is a nonparametric representation in the sense that we do not assume any particular distribution for the density function
. In this representation, only training dataset
and
with appropriate basis functions are used to specify the coefficients
and the densities
. In
Section 4, we will demonstrate how to construct the appropriate basis completely from the training data, motivated by the theoretical result in
Section 3 below.
2.2. Simplification of the Expansion Coefficients (11)
If the weight function
is the sampling density of the training parameters
, the matrix
in (13) can be simplified to a
identity matrix,
where
is the Kronecker delta function. Here, the second equality follows from the weight
being the sampling density, and the third equality follows from the orthonormality of
with respect to the weight function
. Then, the expansion coefficients
in (
11) can be simplified to,
with the
matrix
still given by (
12). In this work, we always take the weight function
to be the sampling density of the training parameters
for the simplification of the expansion coefficients
in (
15). This assumption is not too restrictive since the training parameters are specified by the users.
Finally, the formula in (
10) combined with the expansion coefficients
in (
15) and the matrix
in (
12) forms an RKWHS representation of the conditional density
for arbitrary
and
. Numerically, the training outcome is the matrix
in (
12), and then, the conditional density
can be represented by (
10) with coefficients (
15) using the basis functions
and
. From above, one can see that two important questions naturally arise as a consequence of the usage of RKWHS representation: first, whether the representation
in (
10) is valid in estimating the conditional density
; second, how to construct the orthonormal basis functions
and
. We will address these two important questions in the next two sections.
6. Conclusions
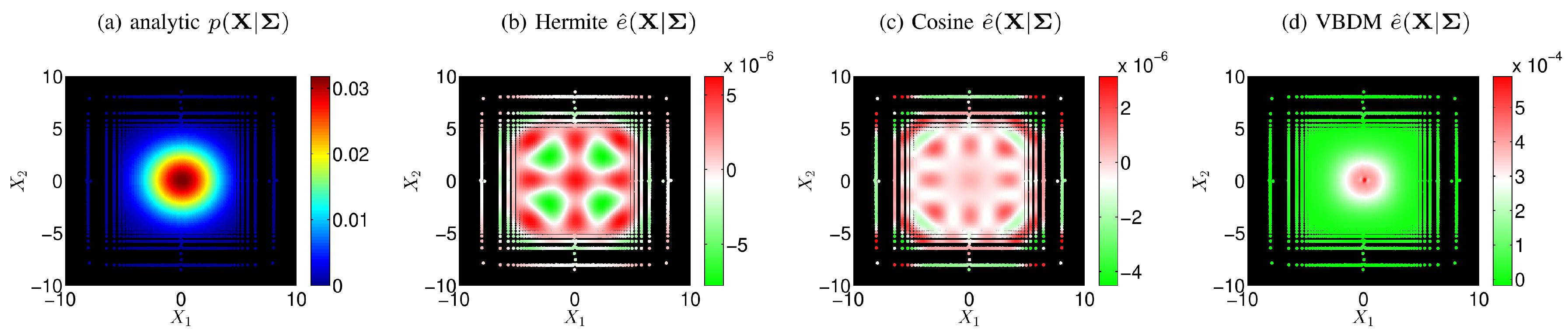
We have developed a framework of a parameter estimation approach where MCMC was employed with a nonparametric likelihood function. Our approach approximated the likelihood function using the kernel embedding of conditional distribution formulation based on RKWHS. By analyzing the error estimation in Theorem 1, we have verified the validity of our RKWHS representation of the conditional density as long as induced by the basis in and Var is finite. Furthermore, the analysis suggests that if the weight q is chosen to be the sampling density of the data, the Var is always finite. This justifies the use of Variable Bandwidth Diffusion Maps (VBDM) for estimating the data-driven basis functions of the Hilbert space weighted by the sampling density on the data manifold.
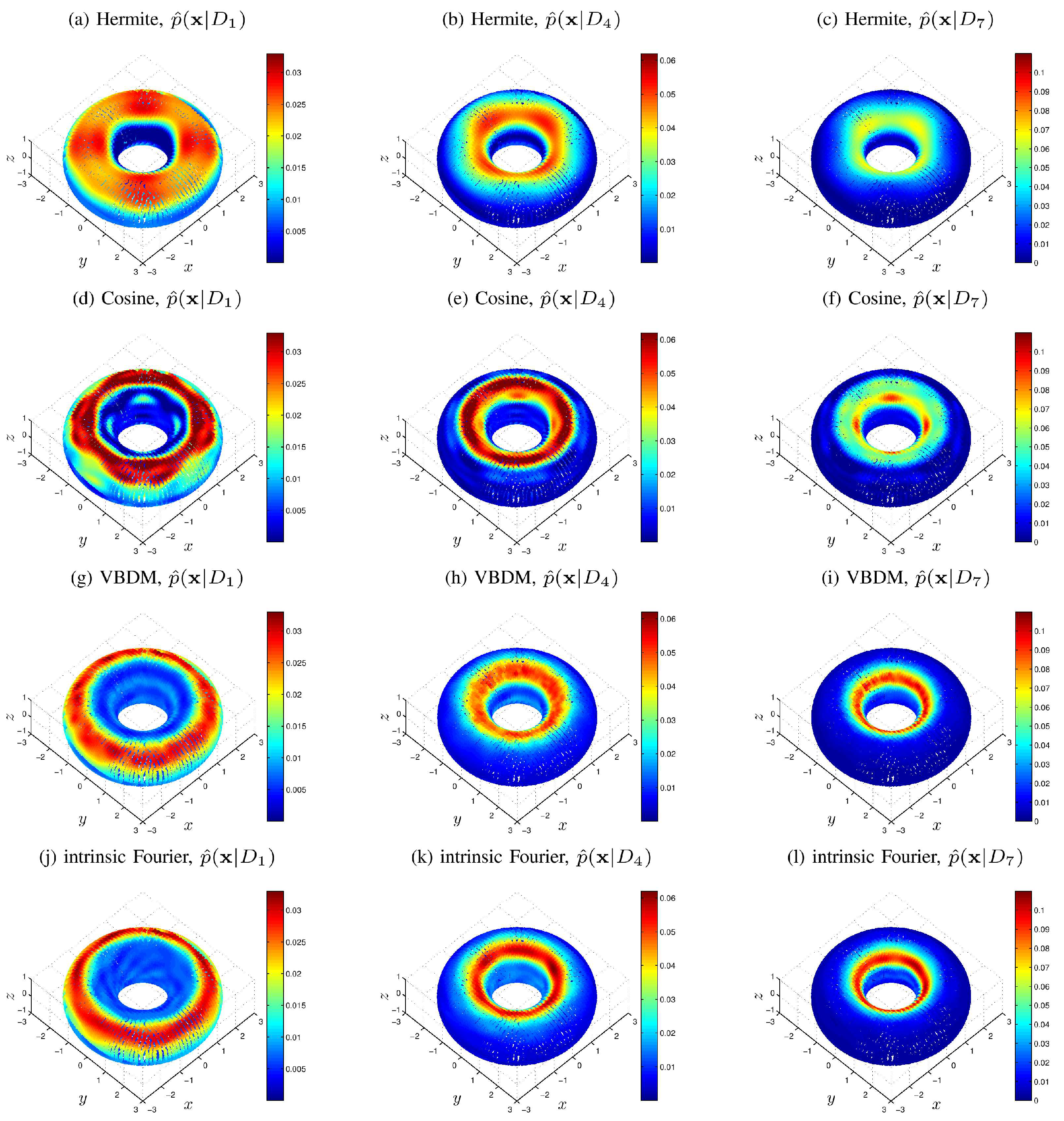
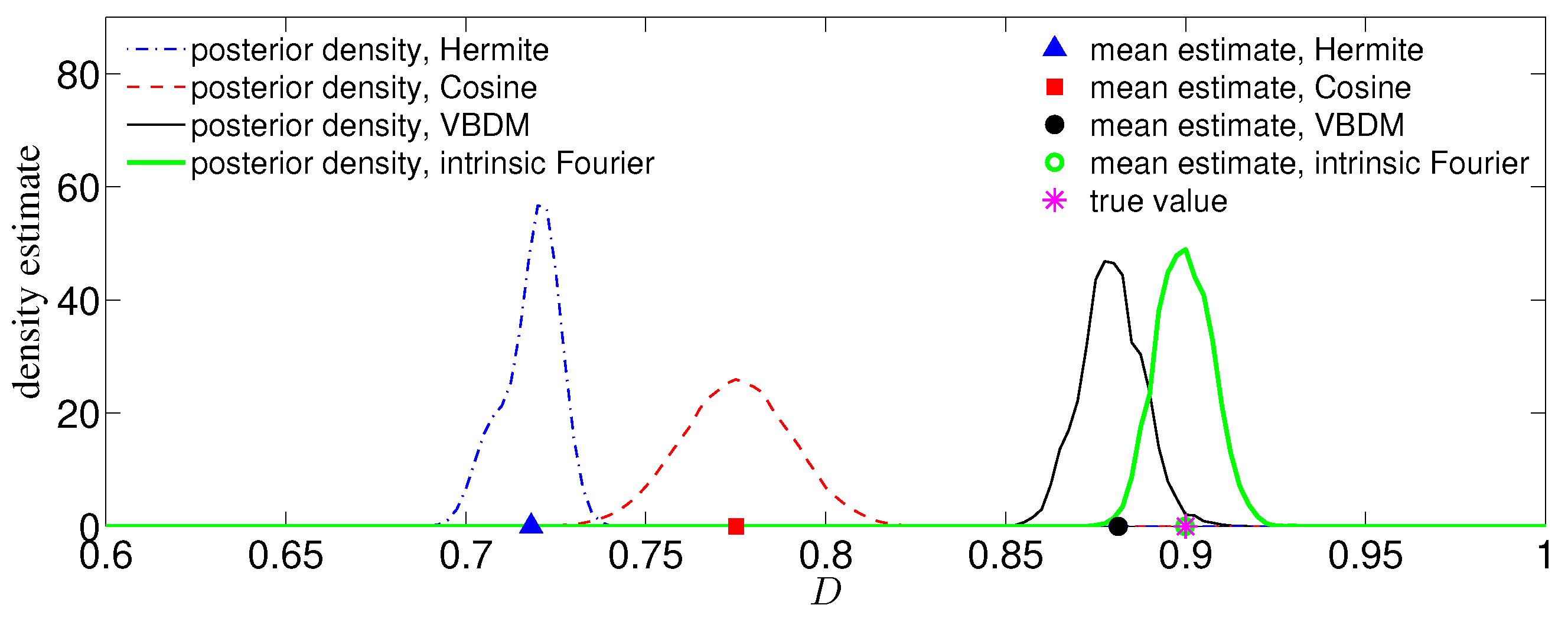
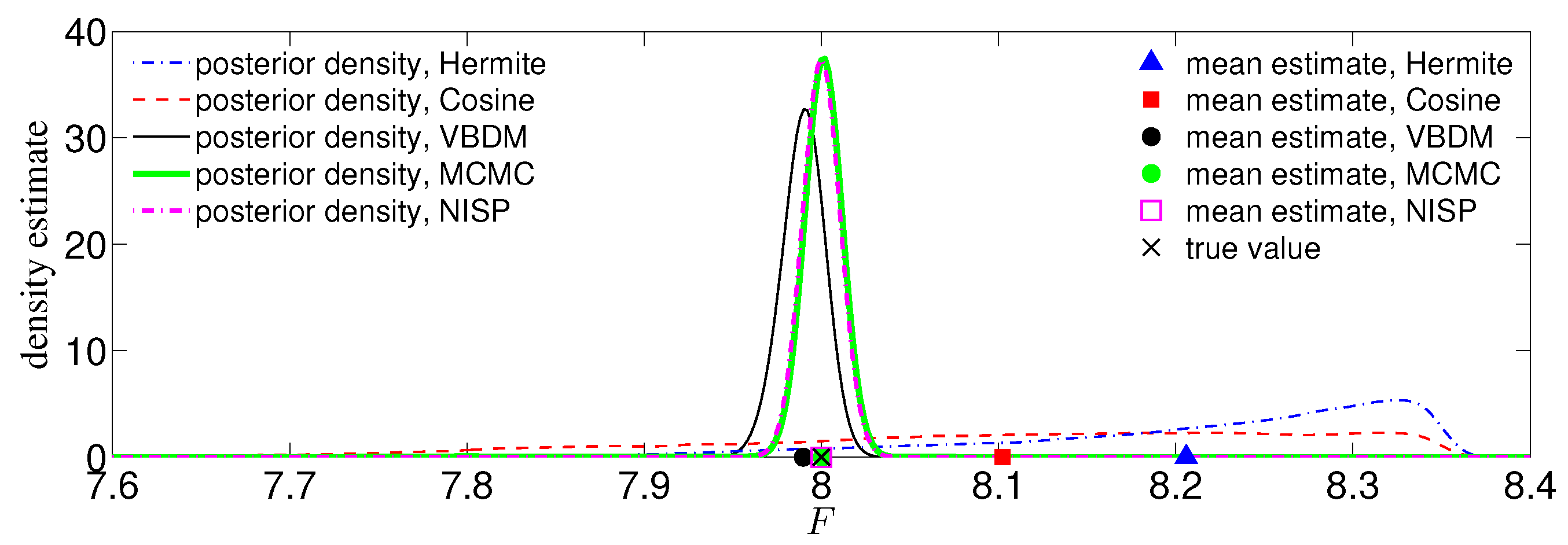
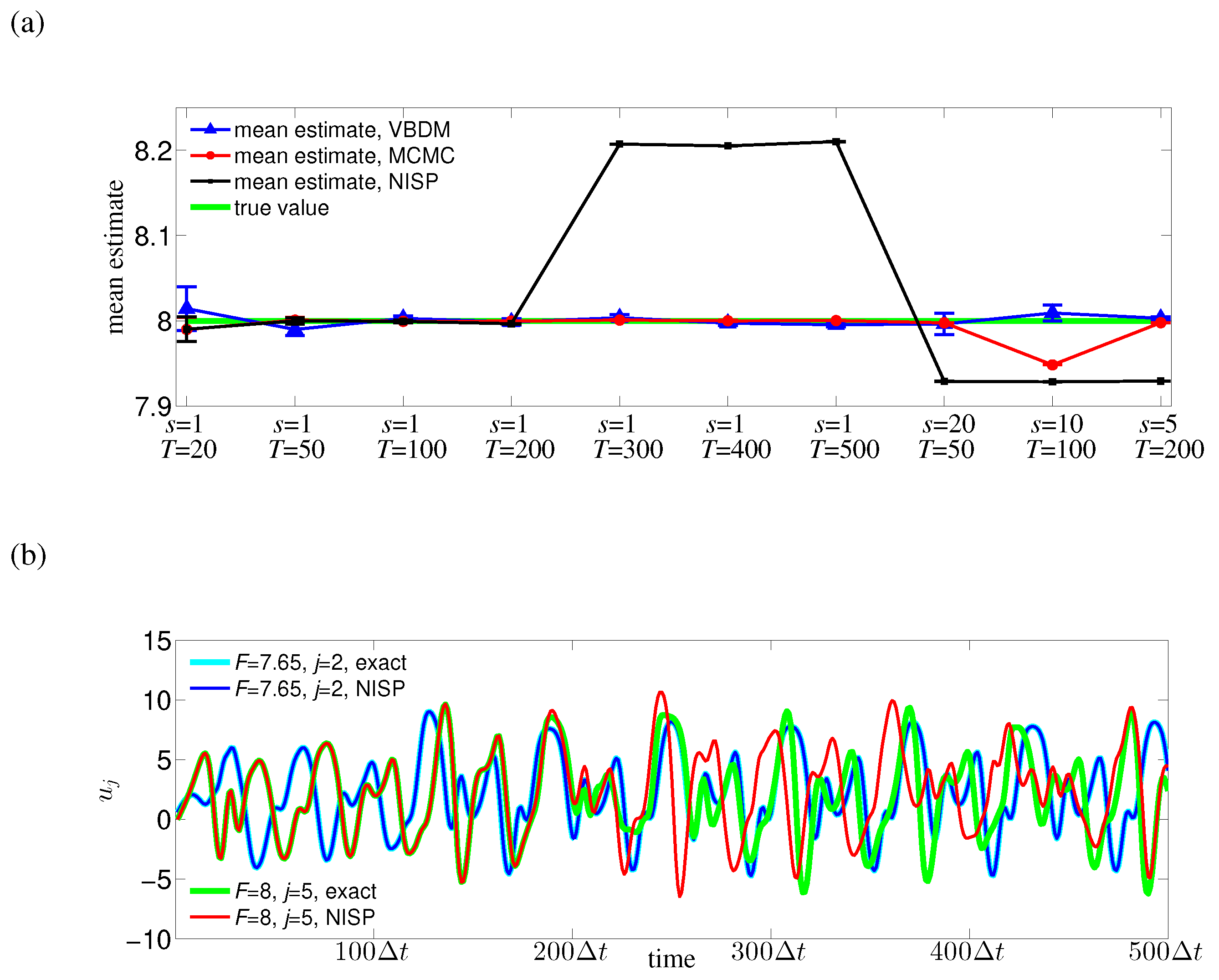
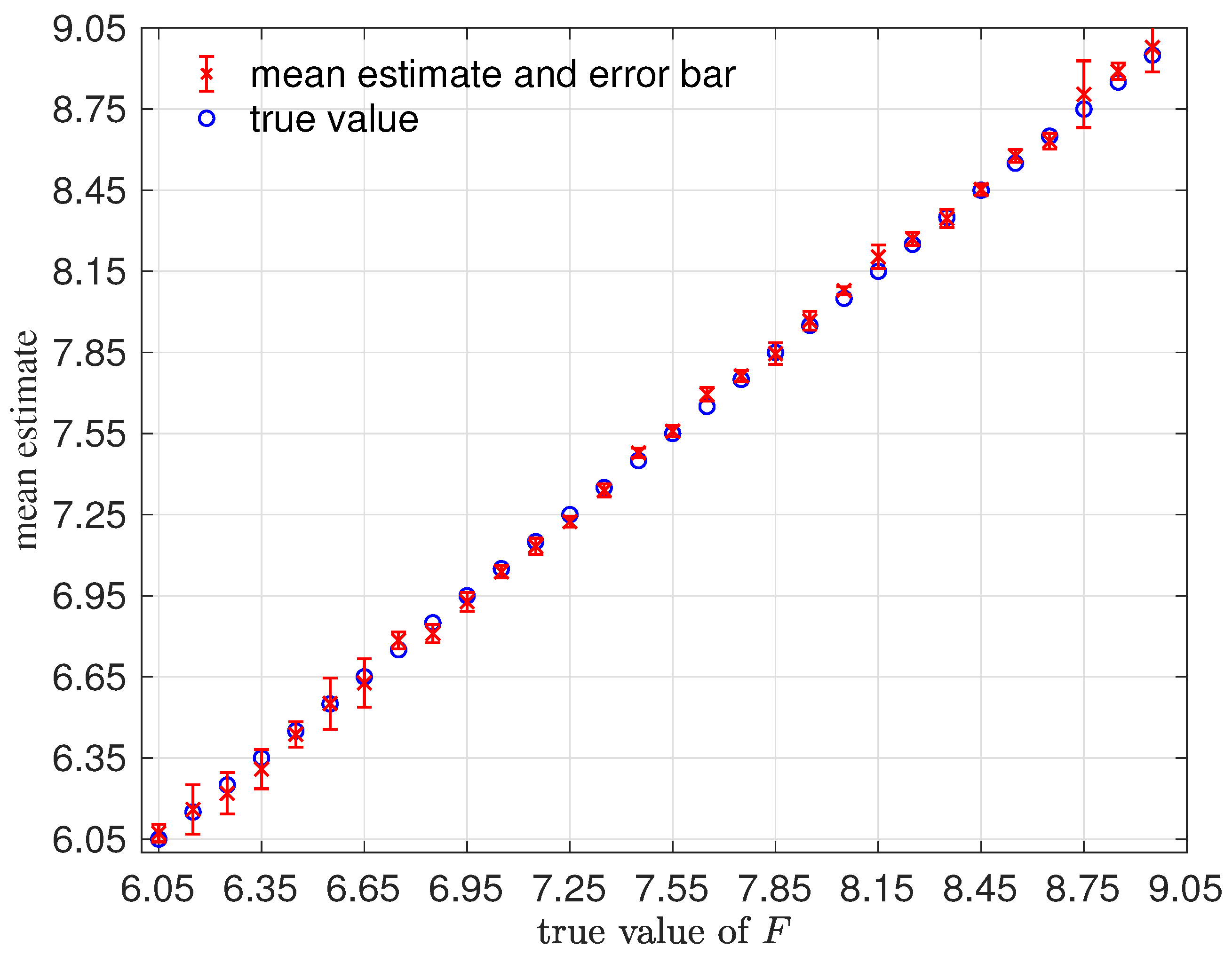
We have demonstrated the proposed approach with four numerical examples. In the first example, where the dimension of the data manifold was exactly the dimension of the ambient space, , the RKHS representation with VBDM basis yielded a parameter estimate as accurate as using other analytic basis representation. However, in the examples where the dimension of the data manifold was strictly less than the dimension of the ambient space, , only VBDM representation could provide more accurate estimation of the true parameter value. We also found that VBDM representation produced mean estimates that were robustly accurate (with accuracies that were comparable to the direct MCMC) on various observation configurations where the NISP was not accurate. This numerical comparison was based on using only eight model evaluations, which can be done in parallel for both VBDM and NISP, whereas the direct MCMC involved 4000 sequential model evaluations. Finally, we demonstrated robust accurate parameter estimation on an example where the analytic likelihood function was intractable and computationally demanding, even if it became available. Most importantly, this result was based on training on a wide parameter domain that included different chaotic dynamical behaviors.
From our numerical experiments, we conclude that the proposed nonparametric representation was advantageous in any of these configurations: (1) when the parametric likelihood function was not known, such as in Example IV; (2) when the observation time stamp was long (such as in Example II or for large in Example III and Example IV). Ultimately, the only real advantage of this method (as a surrogate model) was when the direct MCMC or ABC, which require sequential model evaluation, was computationally not feasible.
While the theoretical and numerical results were encouraging as a proof the concept for using the VBDM representation in many other parameter estimation applications, there were still practical limitations that need to be overcome. As in the other surrogate modeling approaches, one needs to have knowledge of the feasible domain for the parameters. Even when the parameter domain is given and wide, it is practically not feasible to generate training dataset by evaluating the model on the specified training grid points on this domain when the dimension of the parameter space is large (e.g., order 10), even if the Smolyak sparse grid is used. One possible way to simultaneously overcome these two issues is to use “crude” methods, such as ensemble Kalman filtering or smoothing, to obtain the training parameters. We refer to such a method as “crude” since the parameter estimation with ensemble Kalman filtering is sensitive to the initial conditions, especially when the persistent model is used as the dynamical model for the parameters [
23]. However, with such crude methods, we can at least obtain a set of parameters that reflect the observational data, instead of specifying training parameters uniformly or in a random fashion, which can lead to unphysical training parameters. Another issue that arises in the VBDM representation is the expensive computational cost when the amount of data
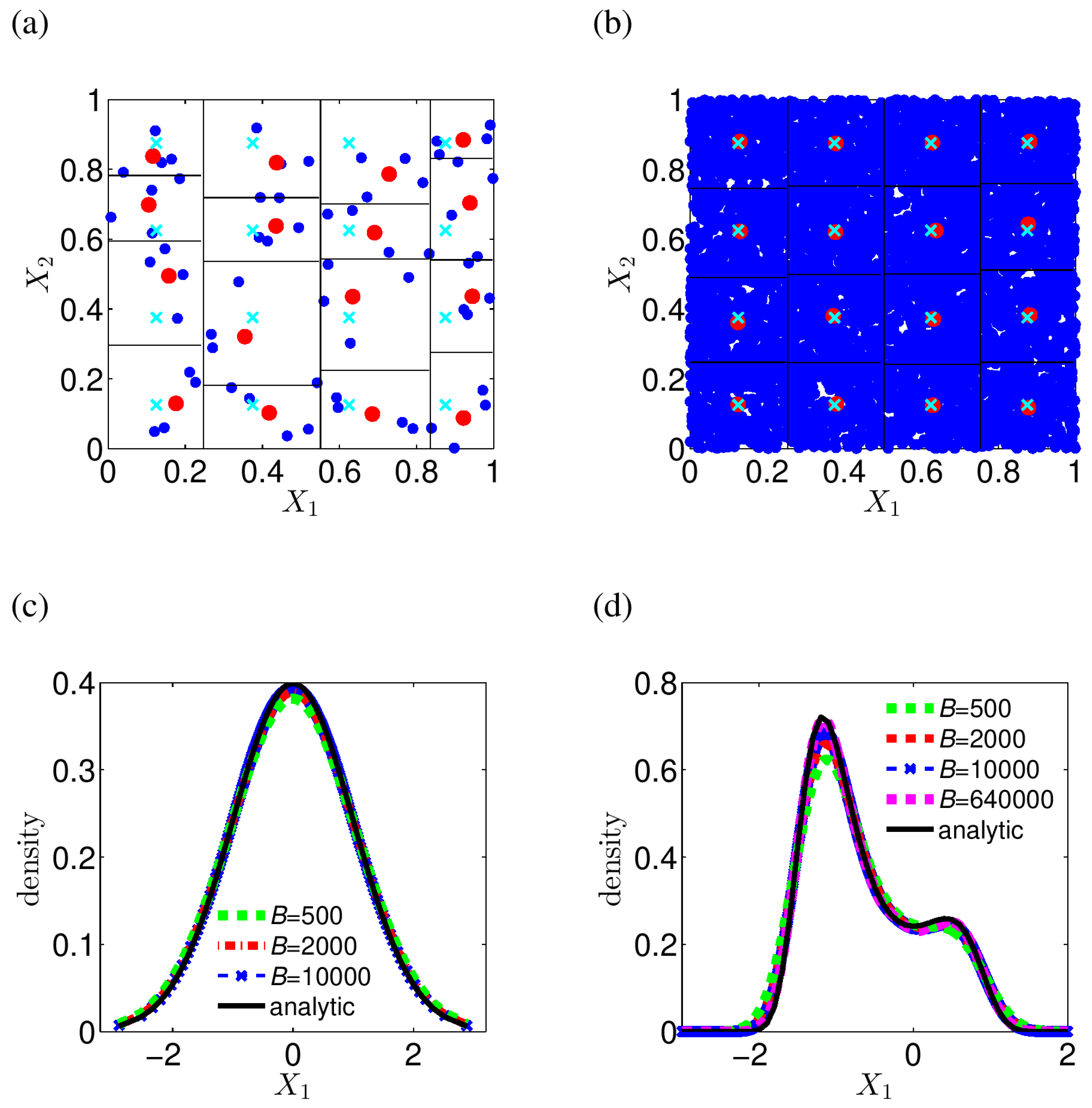
is large. When the dimension of the observations is low (as in the examples in this paper), the data reduction technique described in
Appendix A is sufficient. For larger dimensional problems, a more sophisticated data reduction is needed. Alternatively, one can explore representations using other orthonormal data-driven basis, such as the QR factorized basis functions as a less expensive alternative to the eigenbasis [
27].


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








