How the Choice of Distance Measure Influences the Detection of Prior-Data Conflict


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Prior-Data Conflict Criteria
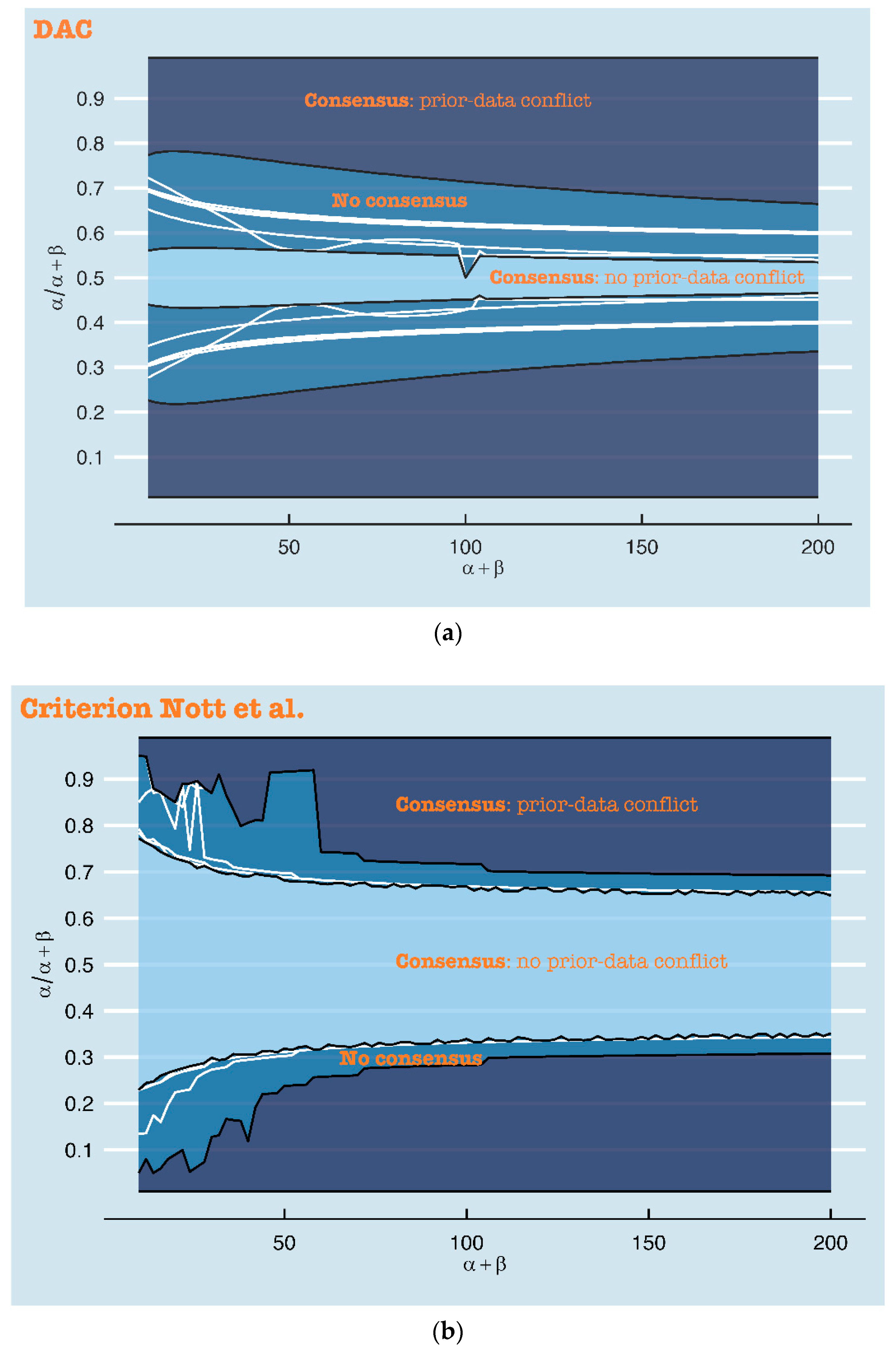
2.1. DAC
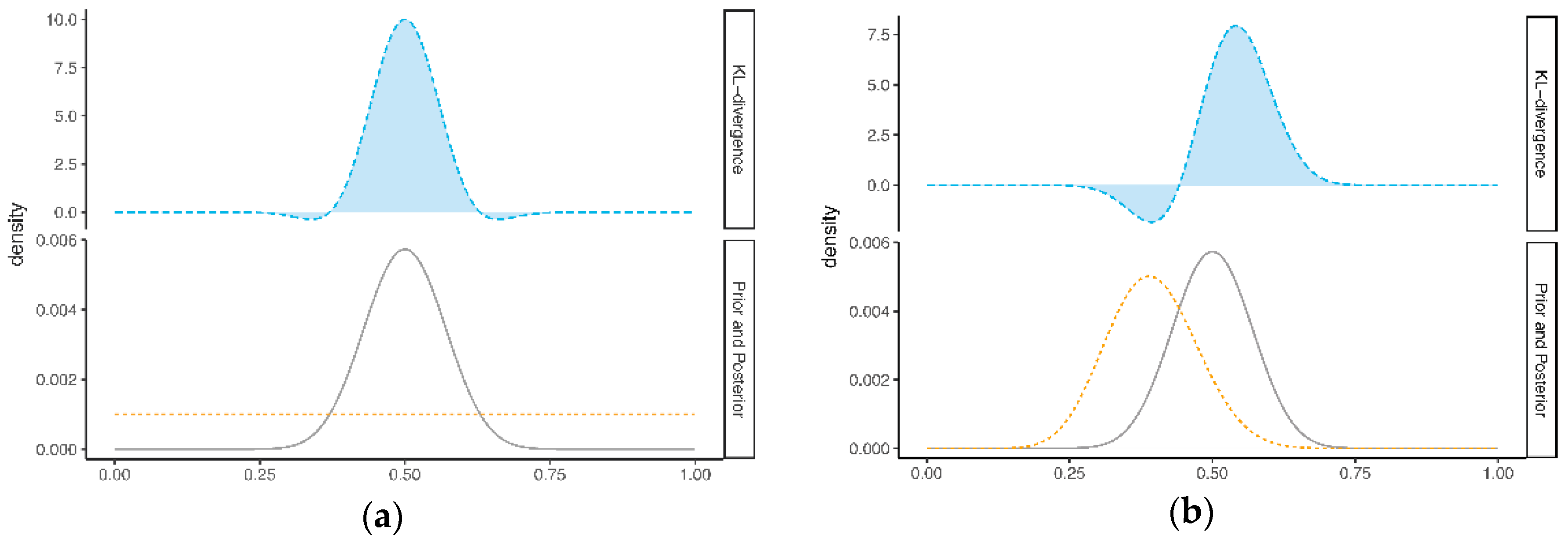
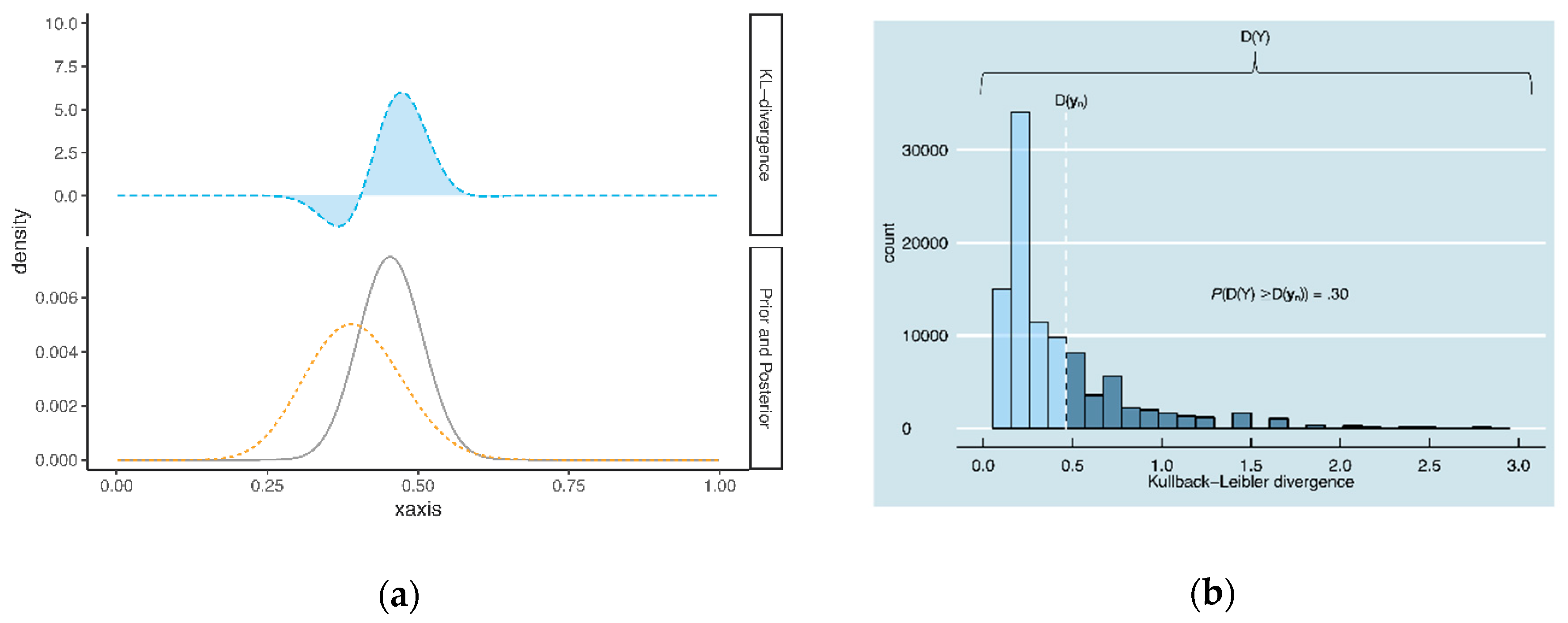
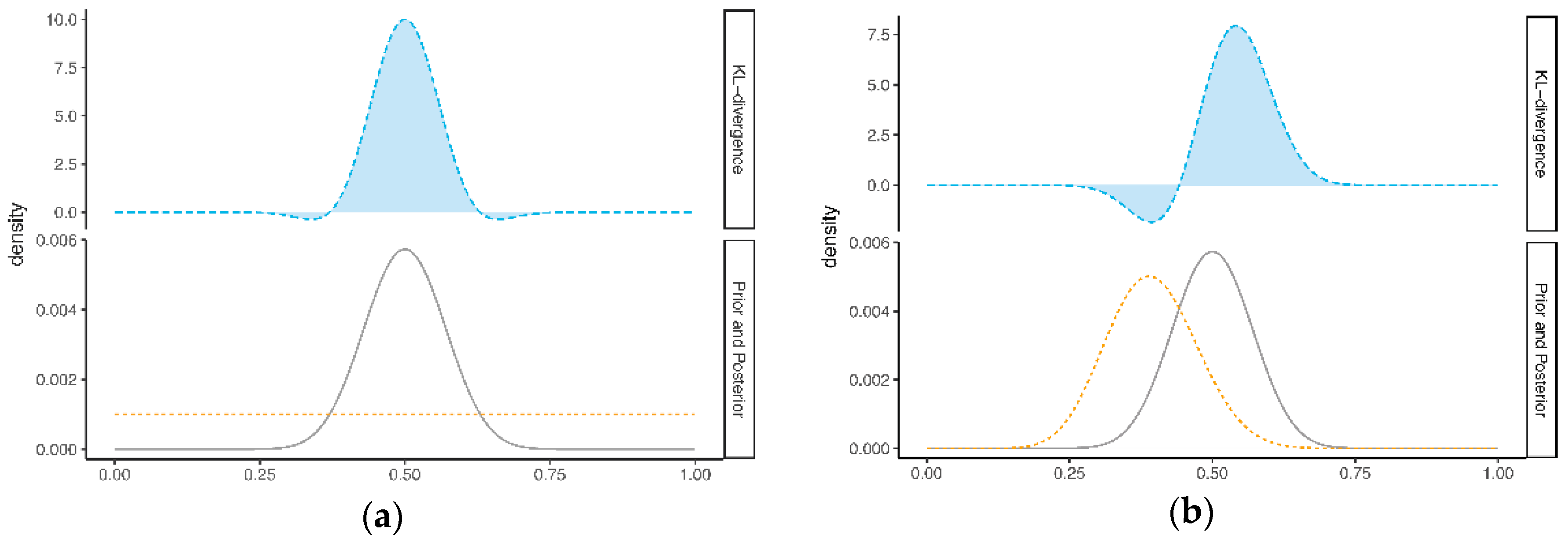
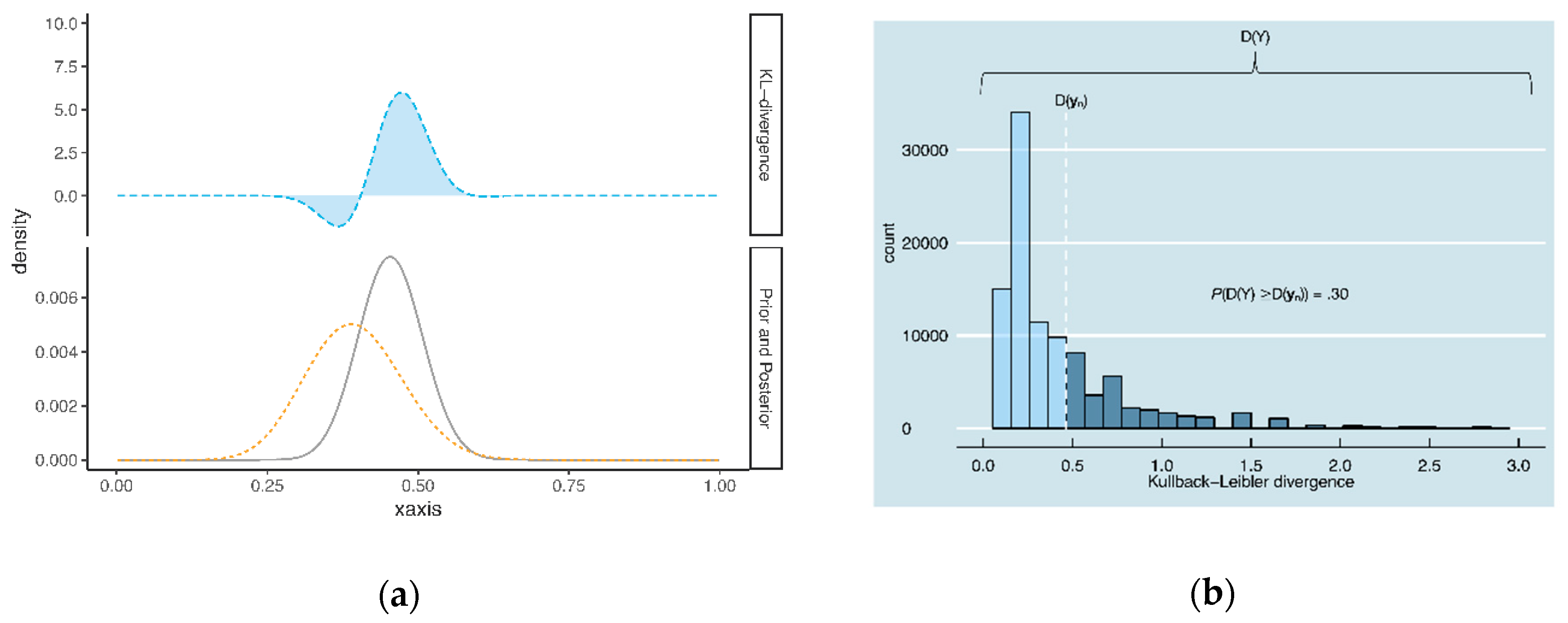
2.1.1. Computation of Prior-Data Conflict
2.1.2. Definition of Prior-Data Conflict
2.1.3. Pros and Cons
2.2. Criterion of Nott et al.
2.2.1. Computation of Prior-Data Conflict
2.2.2. Definition of Prior-Data Conflict
2.2.3. Pros and Cons
3. Simulation Study
3.1. Goal of the Simulation
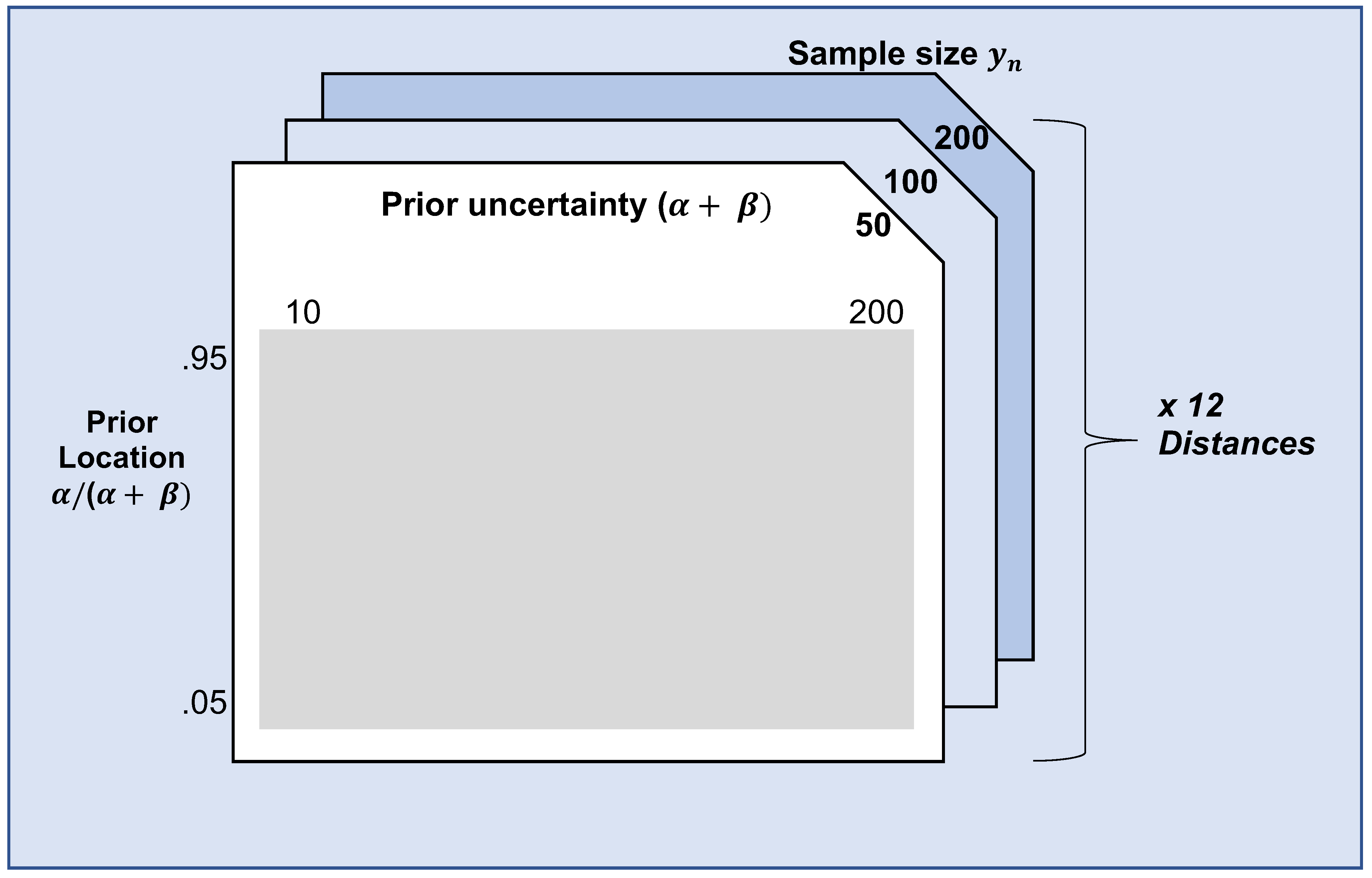
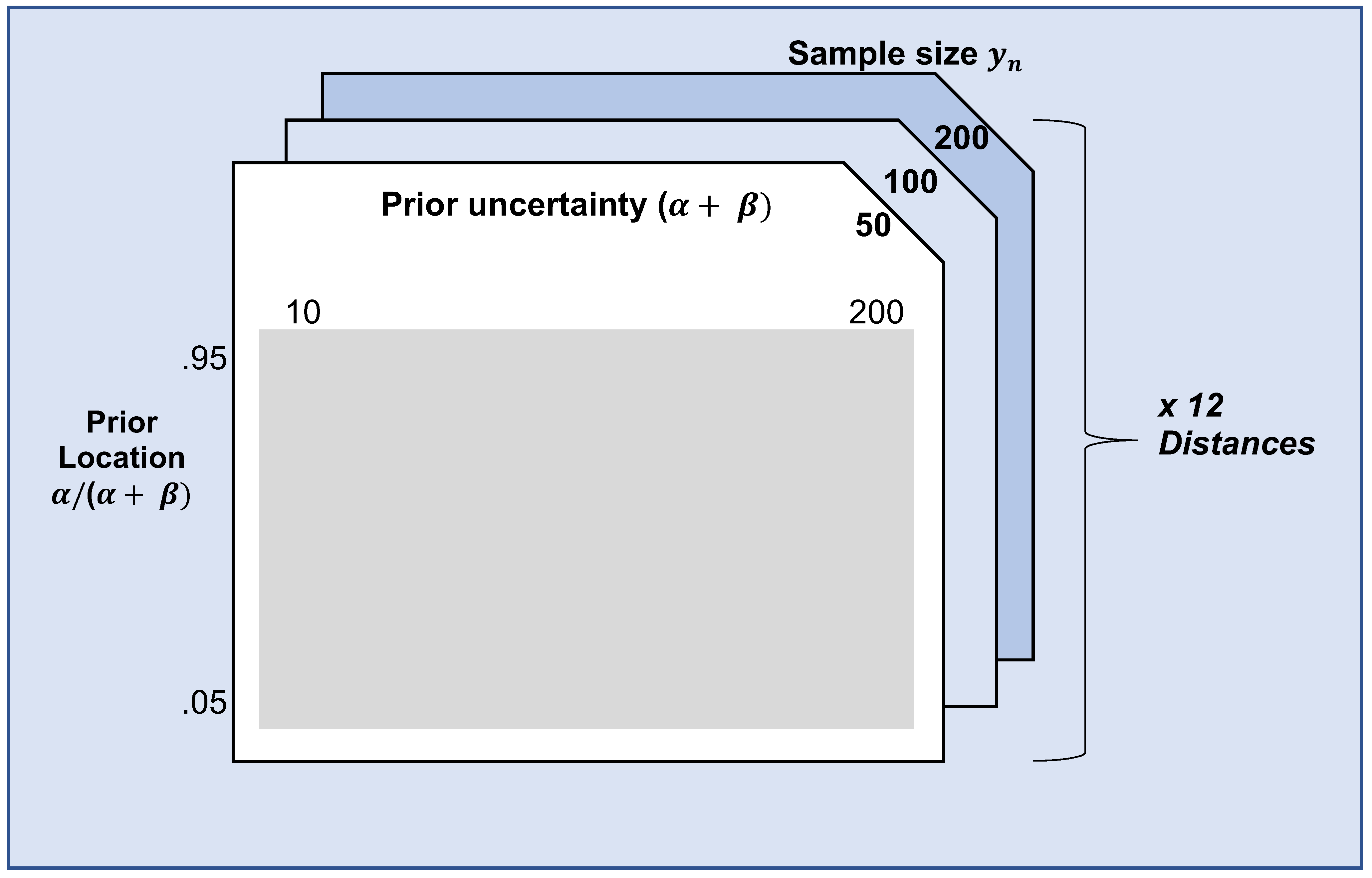
3.2. Simulation Design
3.2.1. Scenario
3.2.2. Steps
3.2.3. Distance Measures
4. Results
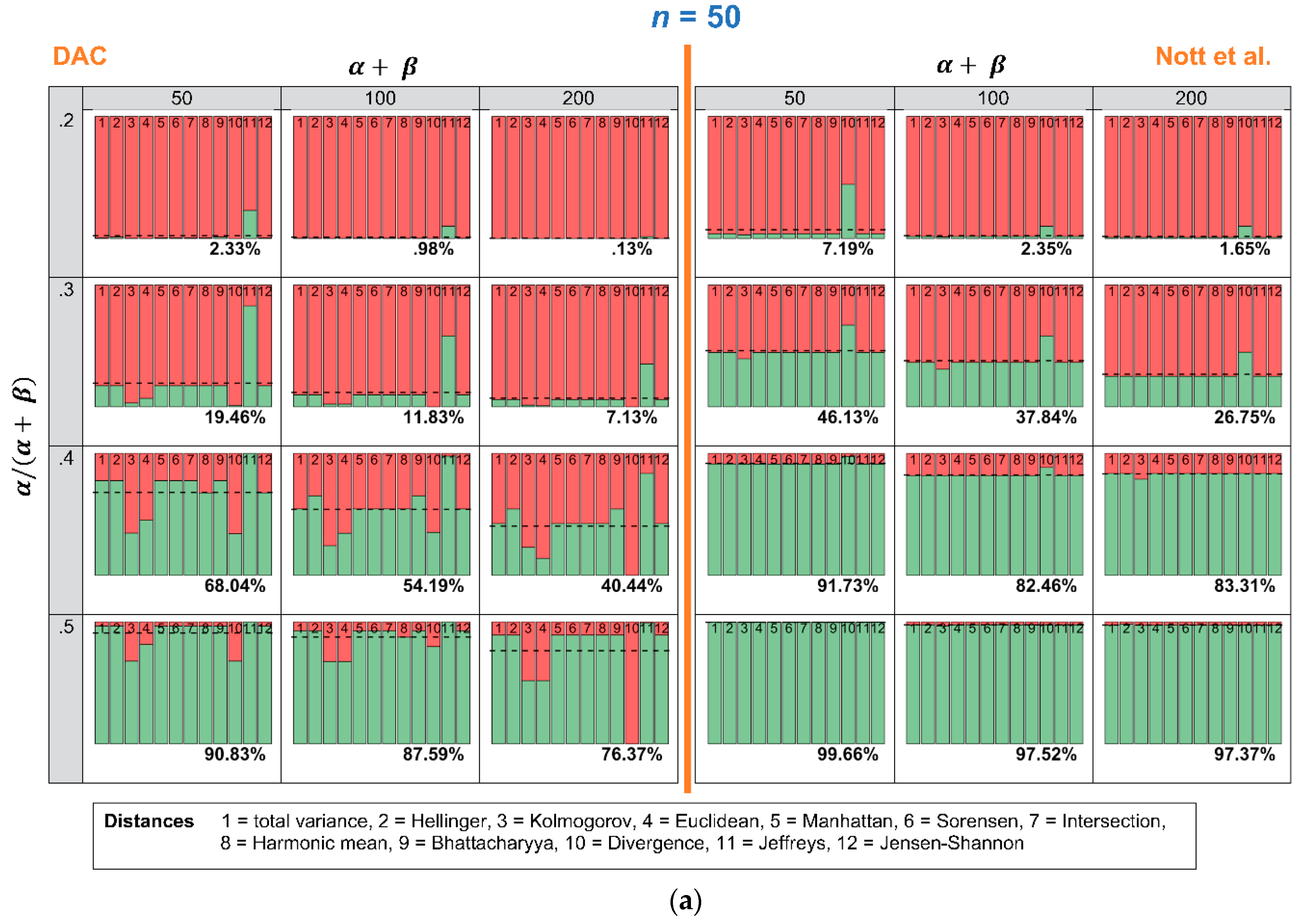
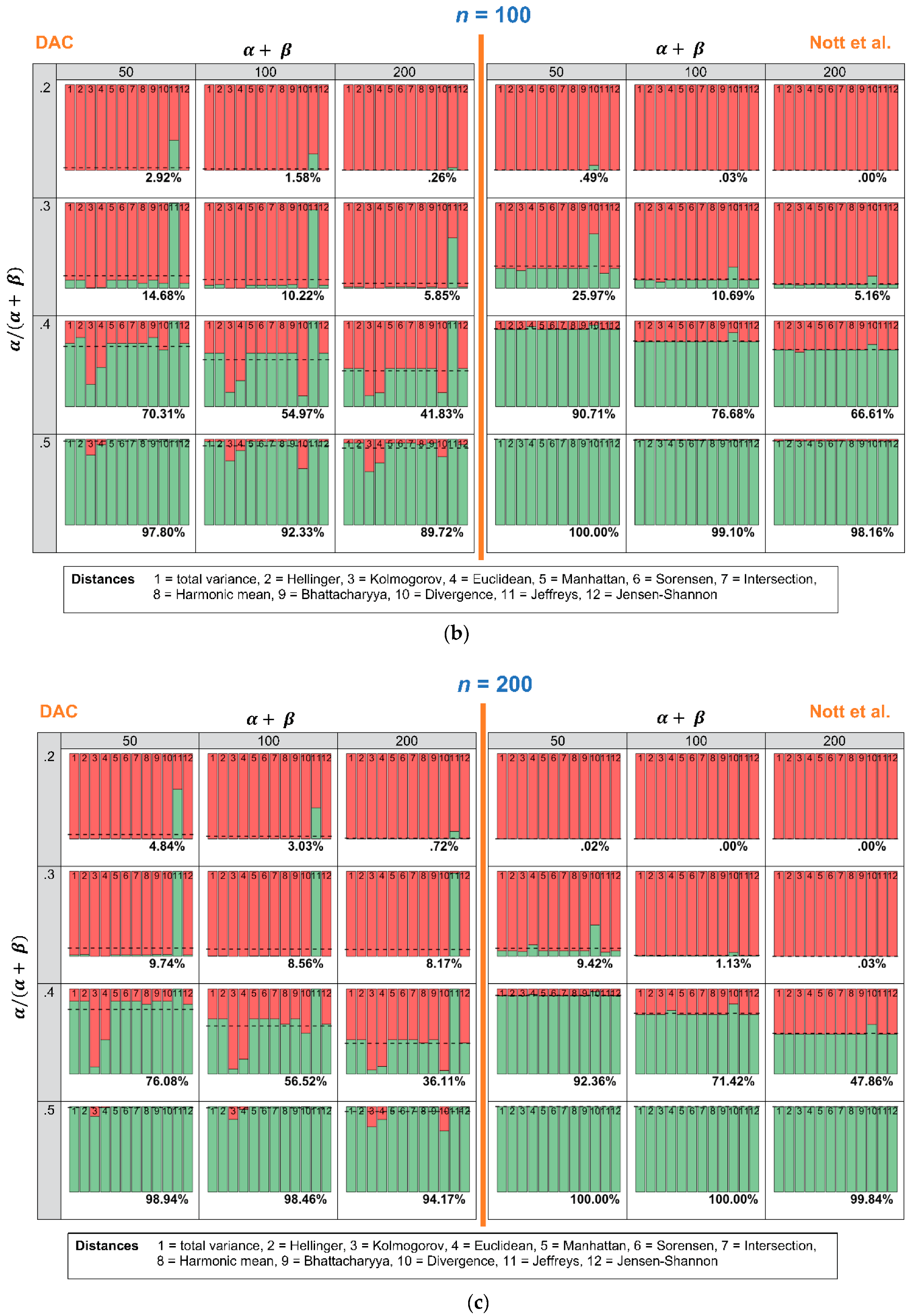
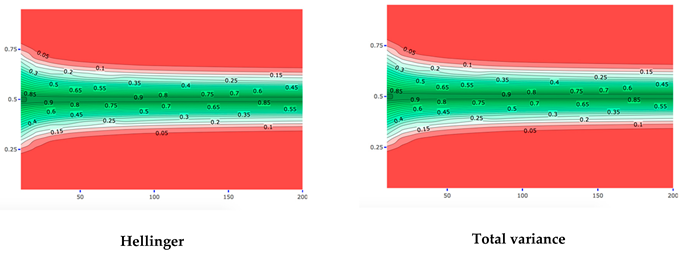
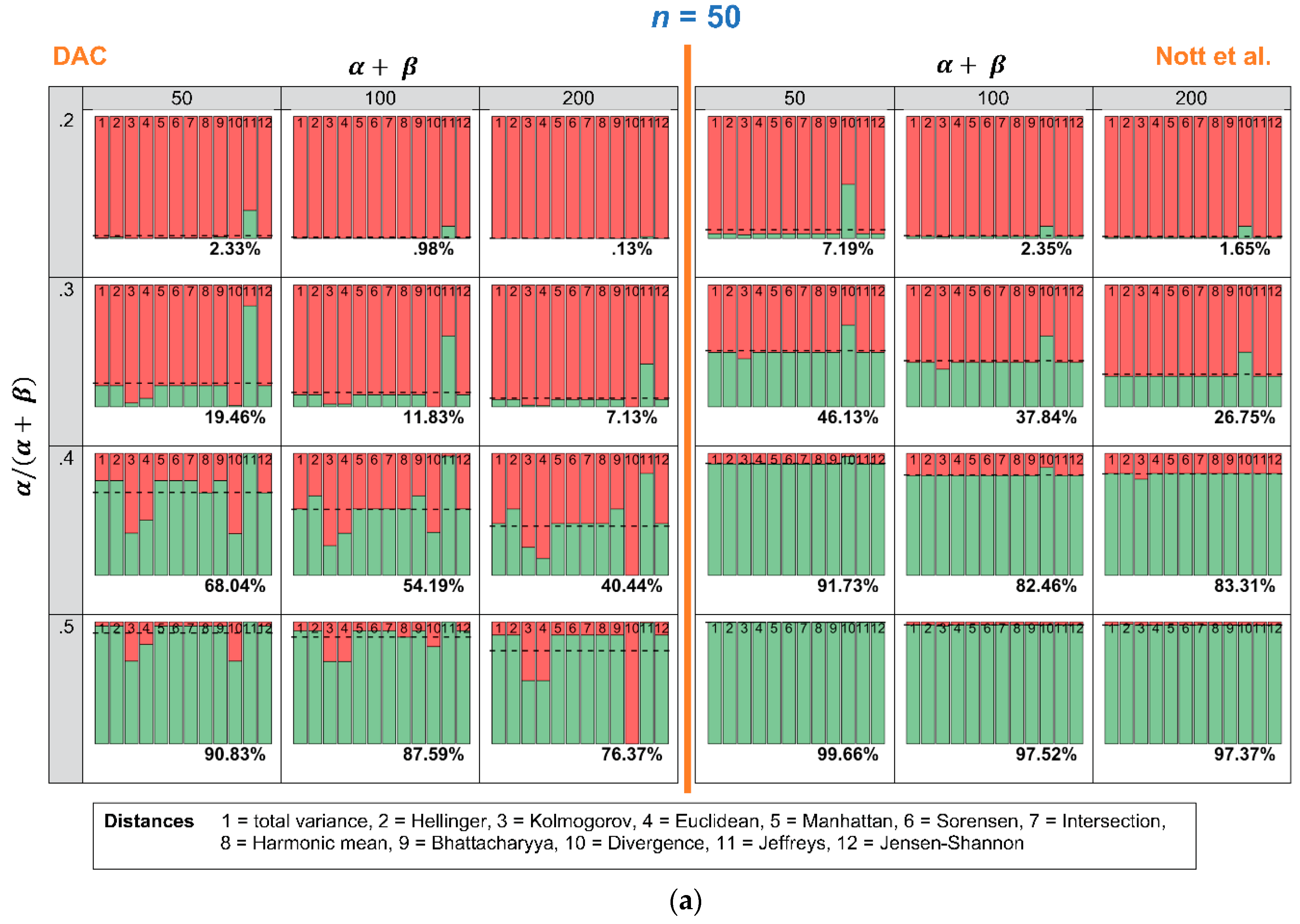
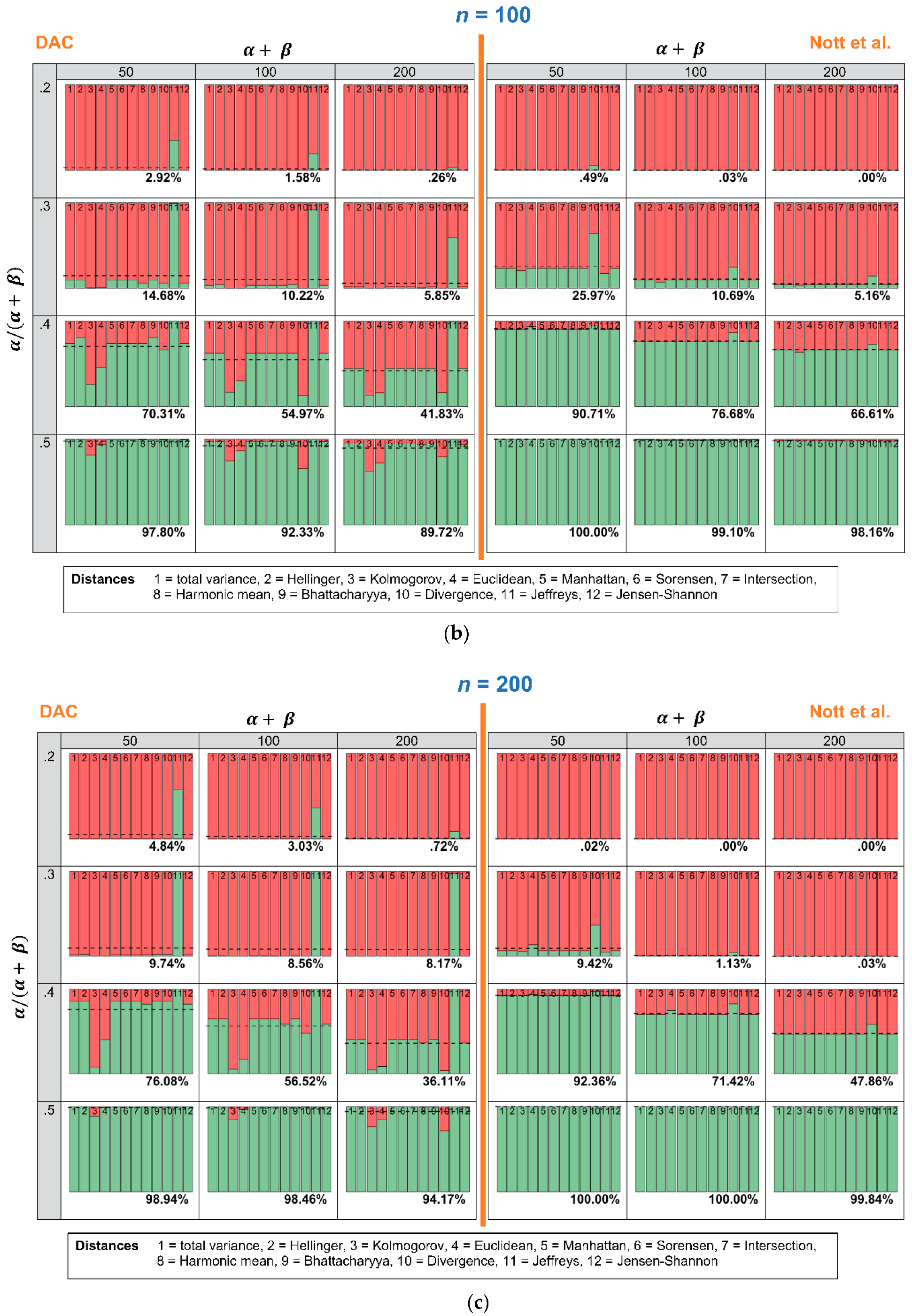
4.1. Robustness in Relation to the Choice of Distance Measure: Specific Sample and Varying Expert Priors
4.2. Robustness in Relation to the Choice of Distance Measure: Specific Expert Prior and Varying Samples
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. DAC- and p-Values Separately for Each of the Twelve Distance Measures, for Fixed Sample and Varying Expert Priors
DAC

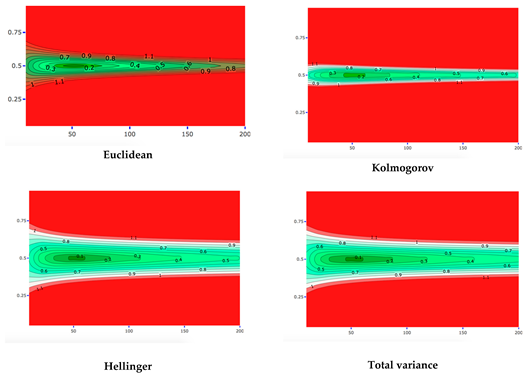
Criterion Nott et al.
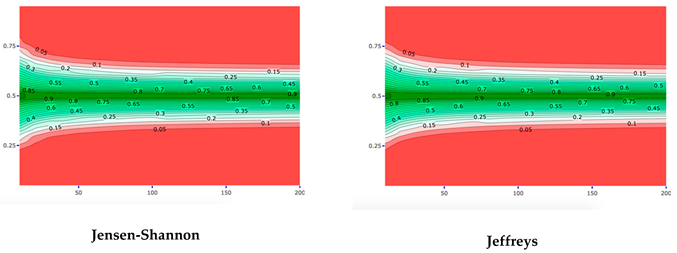
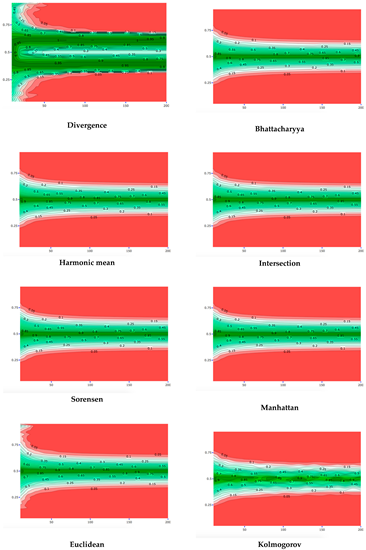
References
- O’Hagan, A.; Buck, C.E.; Daneshkhah, A.; Eiser, J.R.; Garthwaite, P.H.; Jenkinson, D.J.; Oakley, J.E.; Rakow, T. Uncertain Judgements: Eliciting Experts’ Probabilities, 3rd ed.; John Wiley & Sons: London, UK, 2006. [Google Scholar]
- Kuhnert, P.M.; Martin, T.G.; Griffiths, S.P. A guide to eliciting and using expert knowledge in Bayesian ecological models. Ecol. Lett. 2010, 13, 900–914. [Google Scholar] [CrossRef] [PubMed]
- O’Leary, R.; Low Choy, S.; Murray, J.V.; Kynn, M.; Denham, R.; Martin, T.G.; Mengersen, K. Comparison of three expert elicitation methods for logistic regression on predicting the presence of the threatened brush-tailed rock-wallaby Petrogale penicillata. Environmetrics 2009, 20, 379–398. [Google Scholar] [CrossRef]
- Martin, T.G.; Burgman, M.A.; Fidler, F.; Kuhnert, P.M.; Low-Choy, S.; McBride, M.; Mengersen, K. Eliciting expert knowledge in conservation science. Conserv. Biol. 2011, 26, 29–38. [Google Scholar] [CrossRef] [PubMed]
- Zondervan-Zwijnenburg, M.; Van De Schoot-Hubeek, W.; Lek, K.; Hoijtink, H.; Van De Schoot, R. Application and evaluation of an expert judgment elicitation procedure for correlations. Front. Psychol. 2017, 8, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Lek, K.M.; Van De Schoot, R. Development and evaluation of a digital expert elicitation method aimed at fostering elementary school teachers’ diagnostic competence. Front. Educ. 2018, 3, 1–14. [Google Scholar] [CrossRef]
- Bousquet, N. Diagnostics of prior-data agreement in applied Bayesian analysis. J. Appl. Stat. 2008, 35, 1011–1029. [Google Scholar] [CrossRef]
- Evans, M.; Moshonov, H. Checking for prior-data conflict. Bayesian Anal. 2006, 1, 893–914. [Google Scholar] [CrossRef]
- Veen, D.; Stoel, D.; Schalken, N.; Mulder, K.; Van De Schoot, R. Using the data agreement criterion to rank experts’ beliefs. Entropy 2018, 20, 592. [Google Scholar] [CrossRef]
- Nott, D.J.; Xueou, W.; Evans, M.; Englert, B.-G. Checking for prior-data conflict using prior to posterior divergences. arXiv 2016, arXiv:1611.00113. [Google Scholar]
- Hoijtink, H.; van de Schoot, R. Testing small variance priors using prior-posterior predictive p values. Psychol. Methods 2018, 23, 561–569. [Google Scholar] [CrossRef] [PubMed]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 1, 79–86. [Google Scholar] [CrossRef]
- Deza, M.M.; Deza, E. Encyclopedia of Distances; Springer: Berlin, Germany, 2009. [Google Scholar]
- Bernardo, J.M. Reference posterior distributions for Bayesian inference. J. Royal Stat. Soc. B Methodol. 1979, 41, 113–147. [Google Scholar] [CrossRef]
- Berger, J.O.; Bernardo, J.M.; Sun, D. The formal definition of reference priors. Ann. Stat. 2009, 37, 905–938. [Google Scholar] [CrossRef]
- Box, G. Sampling and Bayes’ inference in scientific modelling and robustness. J. Royal Stat. Soc. A 1980, 143, 383–430. [Google Scholar] [CrossRef]
- Evans, M.; Jang, G.-H. A limit result for the prior predictive applied to checking for prior-data conflict. Stat. Probab. Lett. 2011, 81, 1034–1038. [Google Scholar] [CrossRef]
- Evans, M.; Moshonov, H. Checking for prior-data conflict with hierarchically specified priors. In Bayesian Statistics and its Applications; Upadhyay, A., Singh, U., Dey, D., Eds.; Anamaya Publishers: New Delhi, India, 2007; pp. 145–159. [Google Scholar]
- Cox, D.R.; Hinkley, D.V. Theoretical Statistics; Chapman and Hall: London, UK, 1974. [Google Scholar]
- Jang, G.-H. Invariant procedures for model checking, checking for prior-data conflict and Bayesian inference. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2010. [Google Scholar]
- Evans, M. Measuring Statistical Evidence Using Relative Belief; Taylor & Francis: Didcot, UK, 2015. [Google Scholar]
- Bernardo, J.M.; Smith, A.F.M. Bayesian Theory; Wiley Series in Probability and Statistics; John Wiley & Sons Ltd.: New York, NY, USA, 2000; Paperback. [Google Scholar]
- RStudio Team. RStudio: Integrated Development for R. RStudio Inc.: Boston, MA, USA, 2016. Available online: http://www.rstudio.com (accessed on 9 April 2019).
- Drost, H.-G. Package ‘Philentropy’, Similarity and Distance Quantification between Probability Functions. Available online: https://github.com/HajkD/philentropy (accessed on 9 April 2019).
- Ruckdeschel, P.; Kohl, M.; Stabla, T.; Camphausen, F. S4 Classes for Distributions. R News 2006, 6, 2–6. Available online: https://CRAN.R-project.org/doc/Rnews/ (accessed on 9 April 2019).
- Ali, S.M.; Silvey, S.D. A general class of coefficients of divergence of one distribution from another. J. Royal Stat. Soc. Ser. B 1966, 28, 131–142. [Google Scholar] [CrossRef]
- Liese, F.; Vajda, I. On divergences and informations in statistics and information theory. IEEE Trans. Inf. Theory 2006, 52, 4394–4412. [Google Scholar] [CrossRef]
- Cha, S.-H. Comprehensive survey on distance/similarity measures between probability density functions. Int. J. Math. Model. Methods Appl. Sci. 2007, 1, 300–307. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lek, K.; Van De Schoot, R. How the Choice of Distance Measure Influences the Detection of Prior-Data Conflict. Entropy 2019, 21, 446. https://doi.org/10.3390/e21050446
Lek K, Van De Schoot R. How the Choice of Distance Measure Influences the Detection of Prior-Data Conflict. Entropy. 2019; 21(5):446. https://doi.org/10.3390/e21050446
Chicago/Turabian StyleLek, Kimberley, and Rens Van De Schoot. 2019. "How the Choice of Distance Measure Influences the Detection of Prior-Data Conflict" Entropy 21, no. 5: 446. https://doi.org/10.3390/e21050446
APA StyleLek, K., & Van De Schoot, R. (2019). How the Choice of Distance Measure Influences the Detection of Prior-Data Conflict. Entropy, 21(5), 446. https://doi.org/10.3390/e21050446