Examining the Limits of Predictability of Human Mobility


Abstract
1. Introduction
1.1. Benchmarking Limits of Mobility Prediction
- Confirm the discrepancy between the upper limit of predictability and prediction accuracy through extensive experimentation using widely contrasting prediction models on contrasting datasets.
- Following the discrepancy confirmation, revisit the assumptions underlying the upper bound computation methodology.
- Scrutinize the assumptions, analyze the reasons contributing to the failure of the methodology.
1.2. Discrepancies and Inconsistencies
1.3. Questioning the Predictability Upper Bound
- Substantiate the observed discrepancy between and . To this end, we build prediction models using seven distinct approaches and conduct a comprehensive accuracy analysis based on three real-world mobility datasets.
- Revisit the assumptions hereafter, which might have lead to this discrepancy.
- (a)
- Human mobility is Markovian and thus possesses a memoryless structure.
- (b)
- The mobility entropy estimating technique achieves an asymptotic convergence.
- (c)
- The predictability upper bound accounts for (all) the long-distance dependencies in a mobility trajectory.
1.4. Roadmap and Main Findings
- We discuss all the relevant concepts used in this work in Section 2 and illustrate how diverse concepts such as entropy, mutual information and predictive information interact with each other in the light of the predictability upper bound.
- In Section 3, we describe the mobility datasets used in this work and confirm the discrepancy between the maximum upper bound of mobility prediction derived by the previous works and the empirical prediction accuracy derived using recurrent-neural network variants. In order to minimize any bias, we construct seven different prediction models and compute the accuracy across three datasets differing with respect to their collection timespans, region, demographics, sampling frequency and several other parameters.
- In Section 4, we audit three underlying assumptions in the currently used methodology for computation.
- (a)
- In Section 4.1, we demonstrate the non-Markovian character of human mobility dynamics contrary to the previously held assumption. Our statistical tests to confirm the nature of human mobility include (i) rank-order distribution, (ii) inter-event and dwell time distribution, and (iii) mutual information decay.
- (b)
- In Section 4.2, we analyze the entropy convergence by comparing entropies derived by using Lempel–Ziv 78 and Lempel–Ziv 77 encoding schemes on mobility trajectories. Based on this result, we show that there does not exist an ideal entropy estimation scheme for mobility trajectories that achieves an asymptotic convergence.
- (c)
- In Section 4.3, we assert that the current methodology used to estimate does not represent an accurate entropy estimate of mobility trajectory. To this end, we demonstrate that the individual elements present in a mobility subsequence derived by the currently used encoding schemes have non-zero dependencies un-accounted for, when deriving the mobility entropy. We validate such a manifestation by computing the pointwise mutual information associated with mobility trajectories which indicate an on average positive pointwise mutual information (PMI).
- In Section 5 we discuss the likely causes behind this discrepancy being overlooked. We also present the potential reasons as to why recurrent neural networks (RNN) extensions exceed the theoretical upper bound and discuss the applicability of the prediction models in different contexts. We conclude the paper in Section 6.
2. Relevant Concepts
2.1. Mobility Modeling
2.2. Markov Processes
2.3. Long-Distance Dependencies
2.4. Recurrent Neural Networks and Extensions
2.5. Mutual Information
2.6. Entropy, Encoding and Compression
2.7. Predictive Information
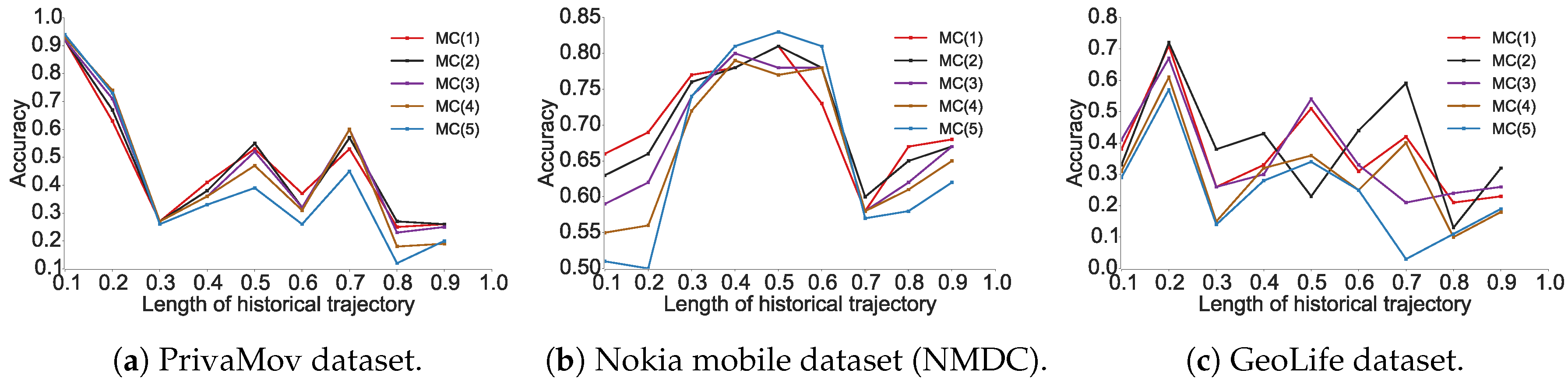
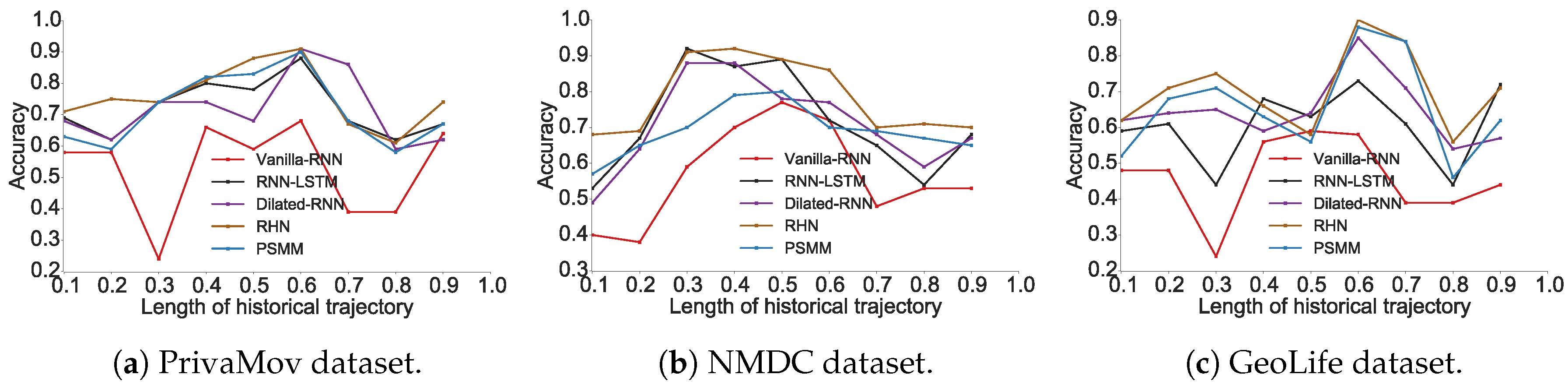
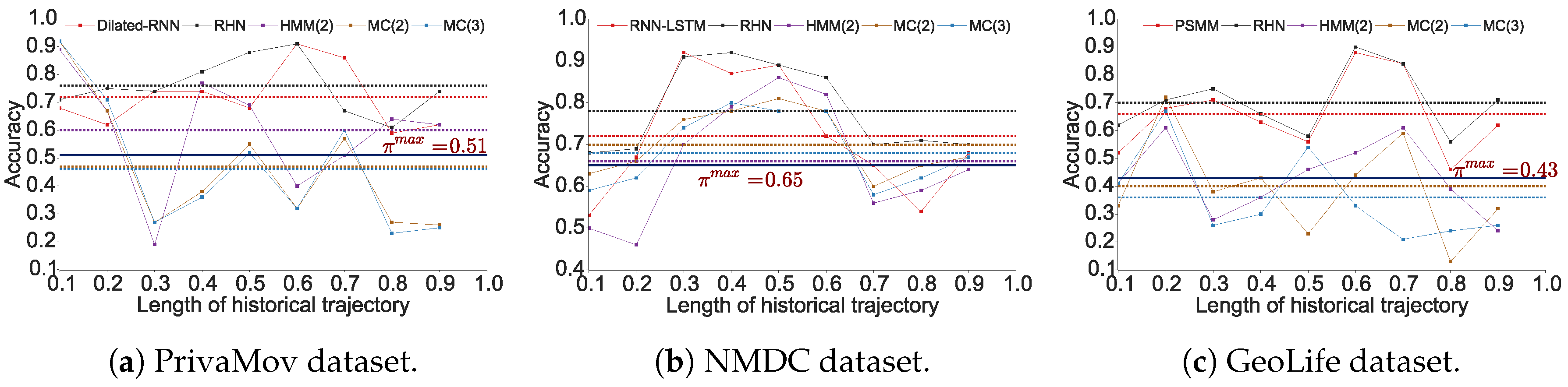
3. Confirming Discrepancy with Real-World Datasets
3.1. Experimental Setup
3.2. Confirming the Predictability Upper Bound Discrepancy
4. Revisiting the Underlying Assumptions
4.1. Questioning the Markovian Nature of Human Mobility
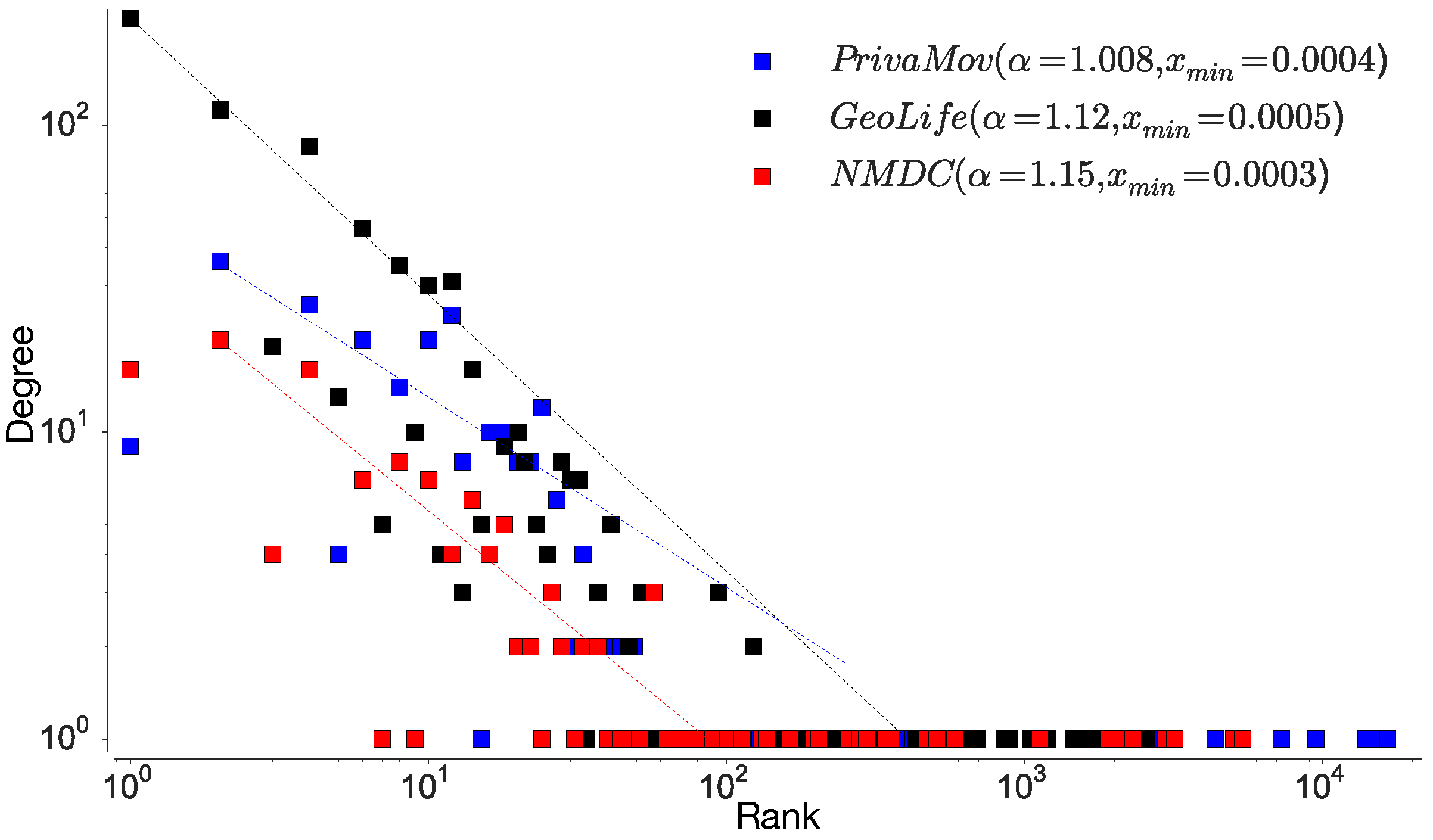
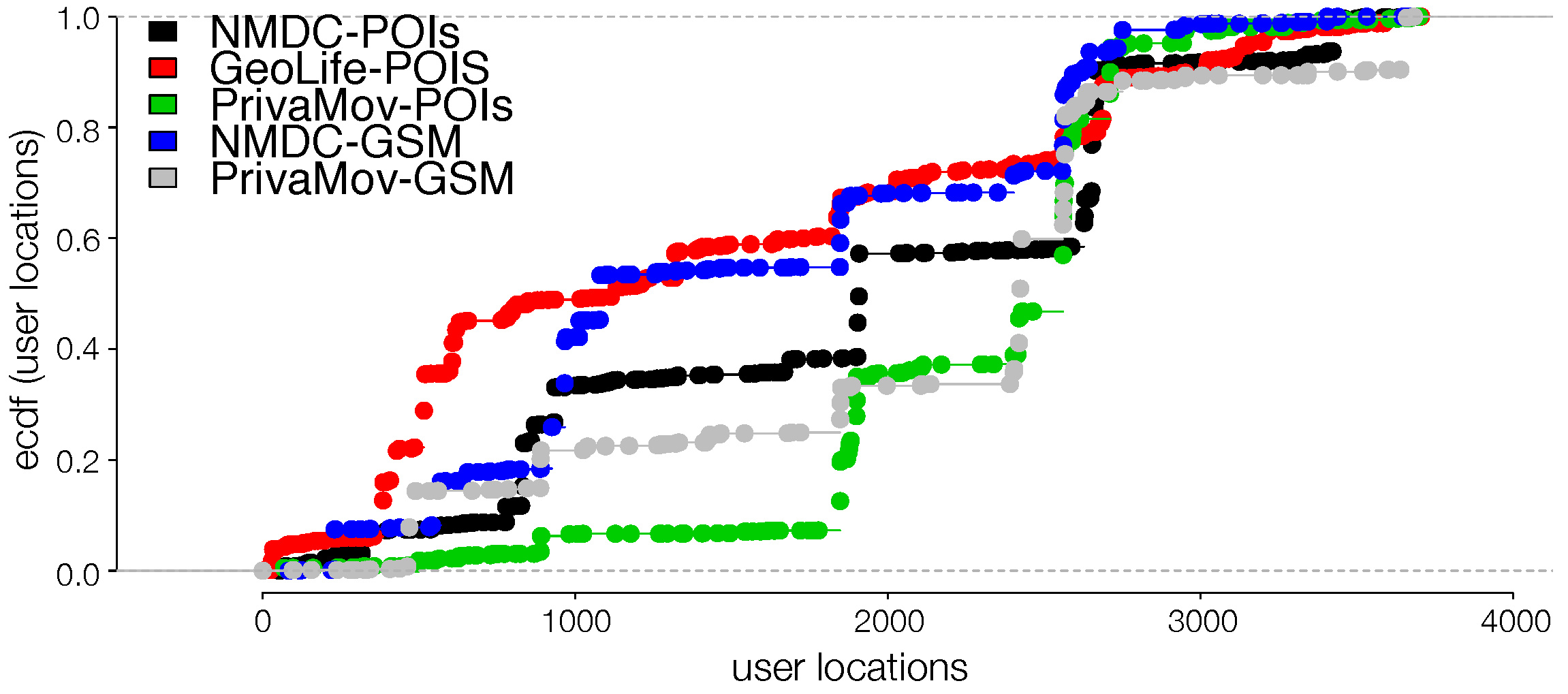
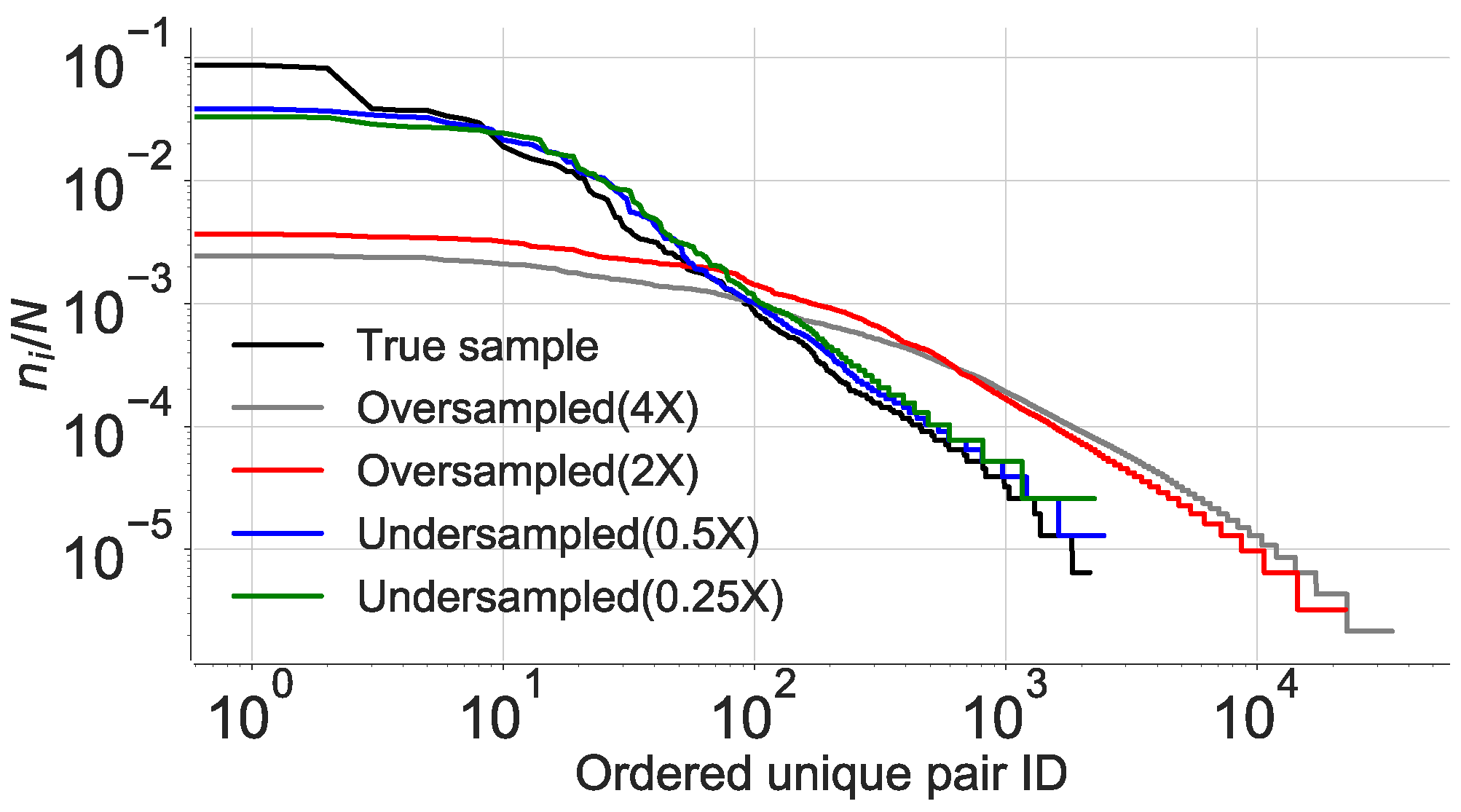
4.1.1. Location Rank-Order Distribution
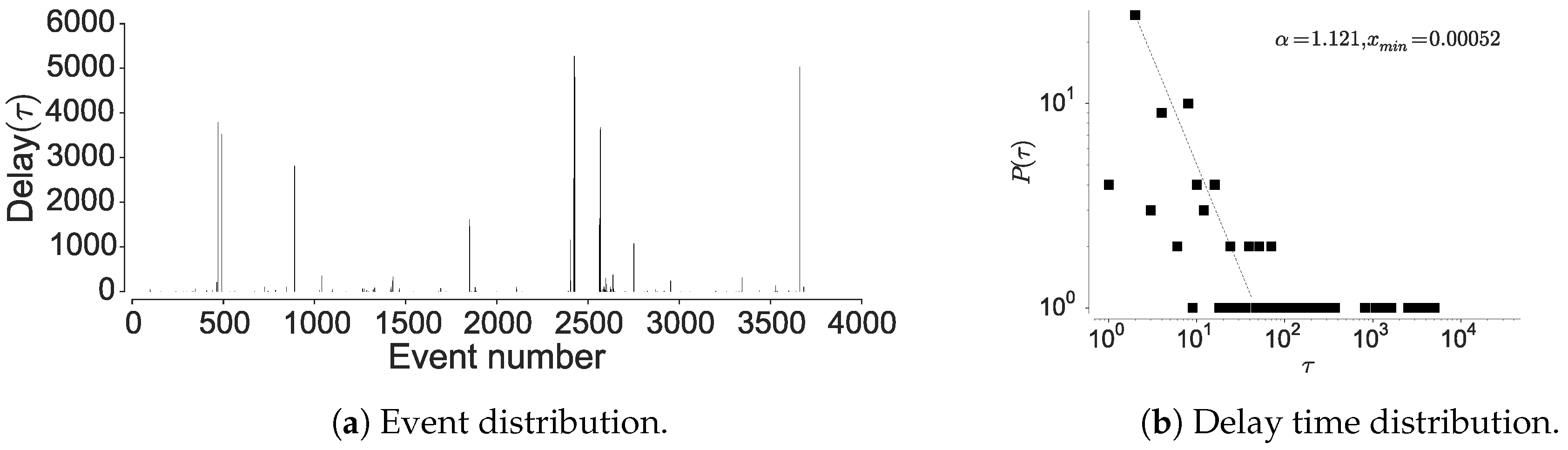
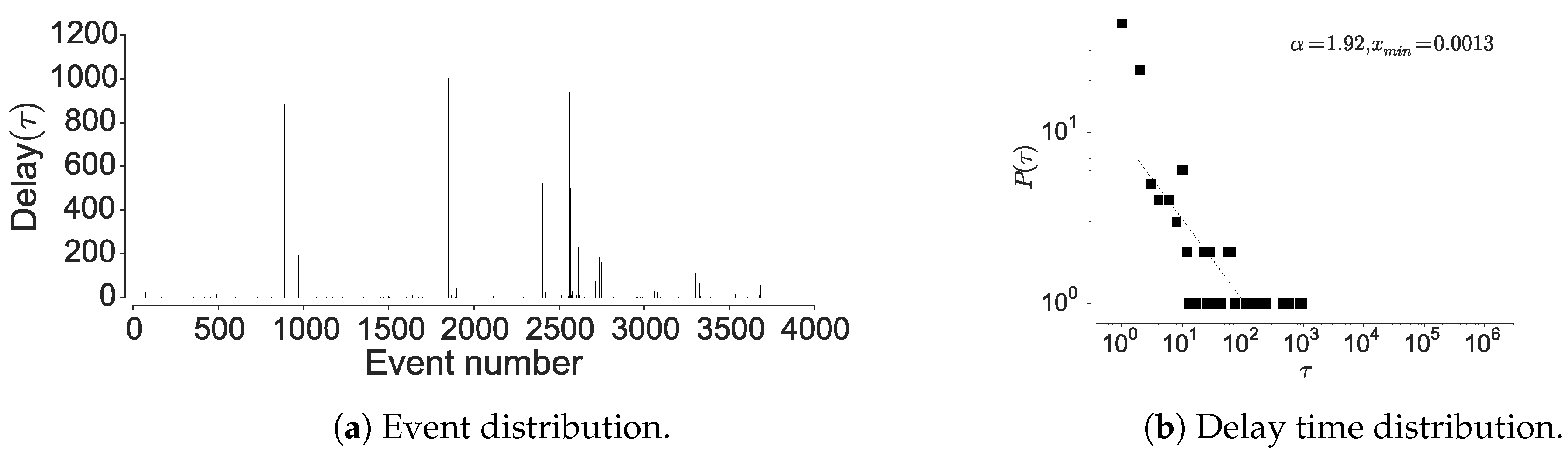
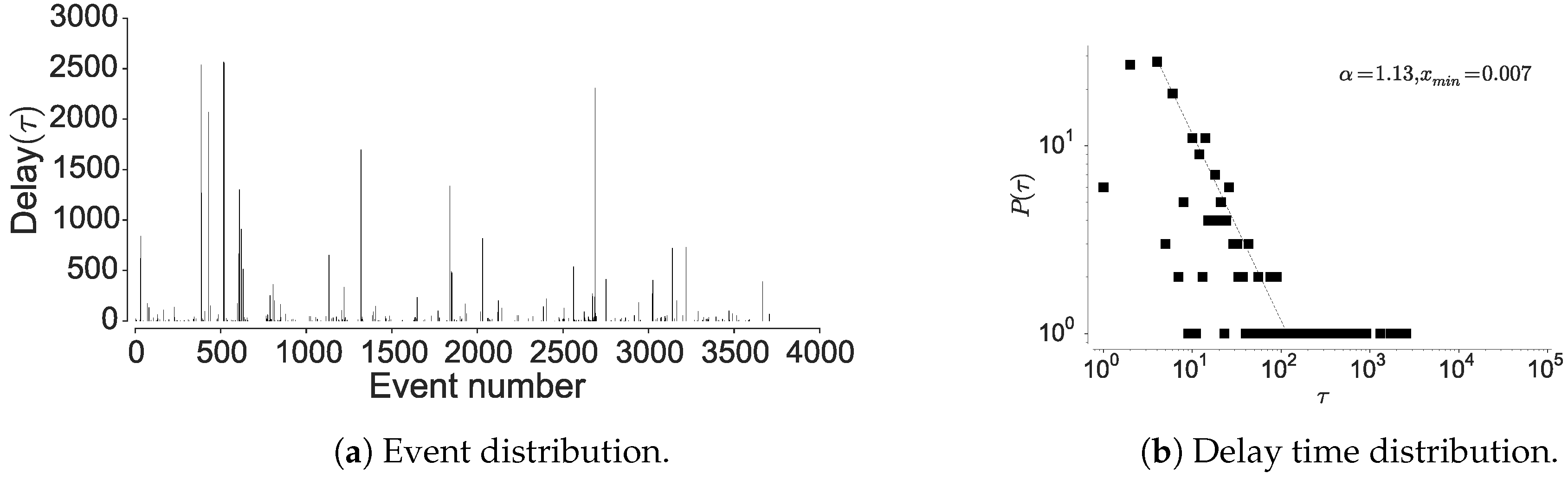
4.1.2. Inter-Event Time Distribution
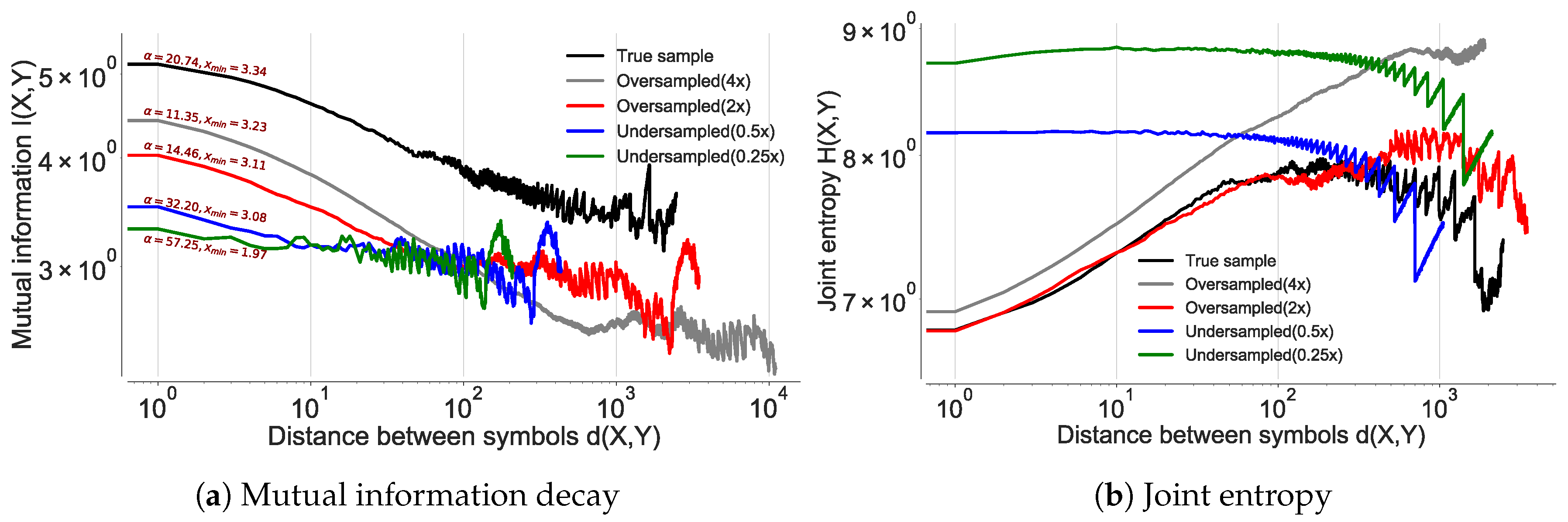
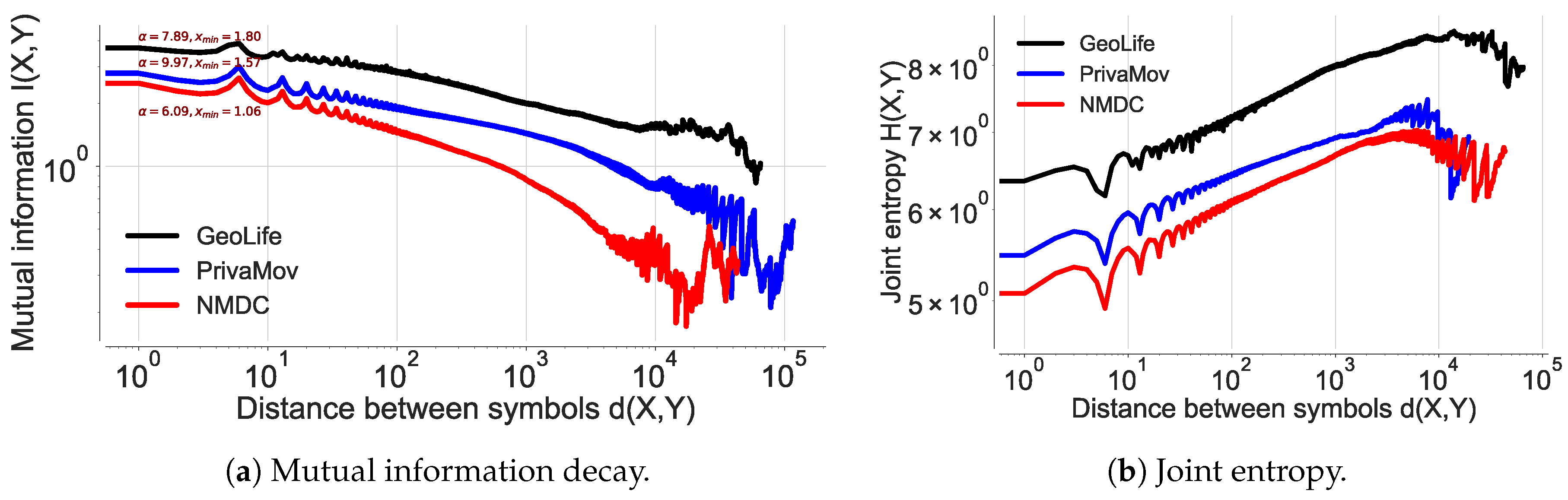
4.1.3. Mutual Information Decay
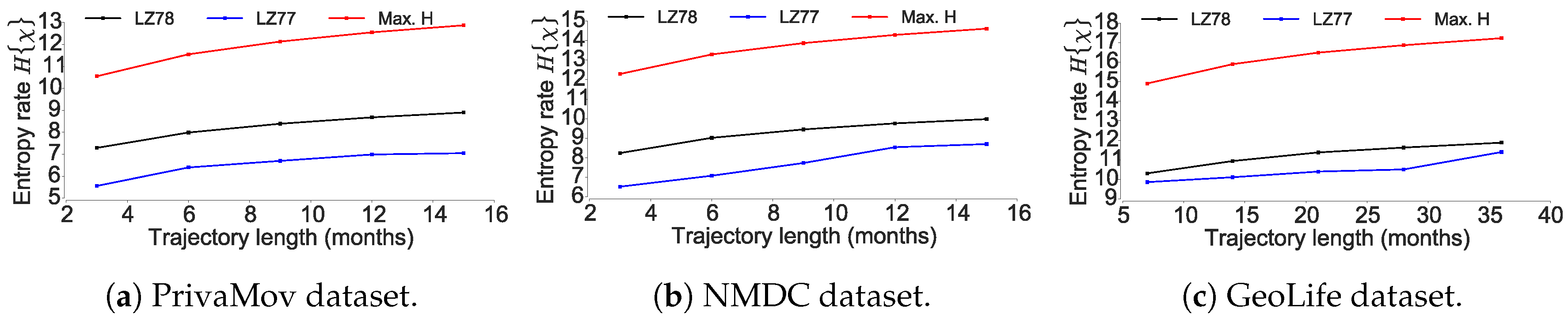
4.2. Questioning the Asymptotic Convergence of the Entropy Estimate
4.3. Questioning as a Relative Entropy Estimate for Human Mobility
5. Discussion
- number of unique locations present in the trajectory,
- length of the trajectory and the size of the dataset,
- number of interacting locations within a long-distance dependency,
- distance between the interacting locations.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Data Availability
References
- Lin, H.W.; Tegmark, M. Critical behavior from deep dynamics: A hidden dimension in natural language. arXiv 2016, arXiv:1606.06737. [Google Scholar]
- Kulkarni, V.; Moro, A.; Garbinato, B. MobiDict: A Mobility Prediction System Leveraging Realtime Location Data Streams. In Proceedings of the 7th ACM SIGSPATIAL International Workshop on GeoStreaming, Burlingame, CA, USA, 31 October–3 November 2016; pp. 8:1–8:10. [Google Scholar] [CrossRef]
- Petzold, J.; Bagci, F.; Trumler, W.; Ungerer, T. Global and local state context prediction. In Artificial Intelligence in Mobile Systems; Springer: San Diego, CA, USA, 2003. [Google Scholar]
- Cuttone, A.; Lehmann, S.; González, M.C. Understanding predictability and exploration in human mobility. EPJ Data Sci. 2018, 7, 2. [Google Scholar] [CrossRef]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed]
- Bandi, F.M.; Perron, B.; Tamoni, A.; Tebaldi, C. The scale of predictability. J. Econom. 2019, 208, 120–140. [Google Scholar] [CrossRef]
- Qin, S.M.; Verkasalo, H.; Mohtaschemi, M.; Hartonen, T.; Alava, M. Patterns, entropy, and predictability of human mobility and life. PLoS ONE 2012, 7, e51353. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef]
- Prelov, V.V.; van der Meulen, E.C. Mutual information, variation, and Fano’s inequality. Probl. Inf. Transm. 2008, 44, 185–197. [Google Scholar] [CrossRef]
- Gambs, S.; Killijian, M.O.; del Prado Cortez, M.N. Next place prediction using mobility markov chains. In Proceedings of the First Workshop on Measurement, Privacy, and Mobility, Bern, Switzerland, 10 April 2012. Article No. 3. [Google Scholar]
- Lu, X.; Wetter, E.; Bharti, N.; Tatem, A.J.; Bengtsson, L. Approaching the limit of predictability in human mobility. Sci. Rep. 2013, 3, 2923. [Google Scholar] [CrossRef]
- Smith, G.; Wieser, R.; Goulding, J.; Barrack, D. A refined limit on the predictability of human mobility. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communications (PerCom), Budapest, Hungary, 24–28 March 2014; pp. 88–94. [Google Scholar]
- Zheng, Y.; Xie, X.; Ma, W.Y. Geolife: A collaborative social networking service among user, location and trajectory. IEEE Data Eng. Bull. 2010, 33, 32–39. [Google Scholar]
- Stopczynski, A.; Sekara, V.; Sapiezynski, P.; Cuttone, A.; Madsen, M.M.; Larsen, J.E.; Lehmann, S. Measuring large-scale social networks with high resolution. PLoS ONE 2014, 9, e95978. [Google Scholar] [CrossRef]
- Barabasi, A.L. The origin of bursts and heavy tails in human dynamics. Nature 2005, 435, 207. [Google Scholar] [CrossRef]
- Bialek, W.; Tishby, N. Predictive information. arXiv 1999, arXiv:cond-mat/9902341. [Google Scholar]
- Ikanovic, E.L.; Mollgaard, A. An alternative approach to the limits of predictability in human mobility. EPJ Data Sci. 2017, 6, 12. [Google Scholar] [CrossRef]
- Zhao, Z.D.; Cai, S.M.; Lu, Y. Non-Markovian character in human mobility: Online and offline. Chaos 2015, 25, 063106. [Google Scholar] [CrossRef]
- Newman, M.E. Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 2005, 46, 323–351. [Google Scholar] [CrossRef]
- Chung, J.; Ahn, S.; Bengio, Y. Hierarchical multiscale recurrent neural networks. arXiv 2016, arXiv:1609.01704. [Google Scholar]
- Somaa, F.; Adjih, C.; Korbi, I.E.; Saidane, L.A. A Bayesian model for mobility prediction in wireless sensor networks. In Proceedings of the 2016 International Conference on Performance Evaluation and Modeling in Wired and Wireless Networks (PEMWN), Paris, France, 22–25 November 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Bapierre, H.; Groh, G.; Theiner, S. A variable order markov model approach for mobility prediction. In Proceedings of the Pervasive Computing, San Francisco, CA, USA, 12–15 June 2011; pp. 8–16. [Google Scholar]
- Chomsky, N. On certain formal properties of grammars. Inf. Control 1959, 2, 137–167. [Google Scholar] [CrossRef]
- Hauser, M.D.; Chomsky, N.; Fitch, W.T. The faculty of language: What is it, who has it, and how did it evolve? Science 2002, 298, 1569–1579. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.Y.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the INTERSPEECH, Makuhari, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Sutskever, I.; Martens, J.; Hinton, G.E. Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 1017–1024. [Google Scholar]
- Salehinejad, H.; Sankar, S.; Barfett, J.; Colak, E.; Valaee, S. Recent advances in recurrent neural networks. arXiv 2017, arXiv:1801.01078. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zilly, J.G.; Srivastava, R.K.; Koutník, J.; Schmidhuber, J. Recurrent Highway Networks. In Proceedings of the ICML, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Merity, S.; Xiong, C.; Bradbury, J.; Socher, R. Pointer Sentinel Mixture Models. CoRR 2016. [Google Scholar]
- Grossberg, S. Recurrent neural networks. Scholarpedia 2013, 8, 1888. [Google Scholar] [CrossRef]
- Chang, S.; Zhang, Y.; Han, W.; Yu, M.; Guo, X.; Tan, W.; Cui, X.; Witbrock, M.J.; Hasegawa-Johnson, M.A.; Huang, T.S. Dilated Recurrent Neural Networks. In Proceedings of the NIPS, Vancouver, BC, Canada, 4–9 December 2017. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mobile Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Vegetabile, B.; Molet, J.; Baram, T.Z.; Stern, H. Estimating the Entropy Rate of Finite Markov Chains with Application to Behavior Studies. arXiv 2017, arXiv:1711.03962. [Google Scholar] [CrossRef]
- Kontoyiannis, I.; Algoet, P.H.; Suhov, Y.M.; Wyner, A.J. Nonparametric entropy estimation for stationary processes and random fields, with applications to English text. IEEE Trans. Inf. Theory 1998, 44, 1319–1327. [Google Scholar] [CrossRef]
- Shields, P.C. Universal redundancy rates do not exist. IEEE Trans. Inf. Theory 1993, 39, 520–524. [Google Scholar] [CrossRef]
- Wyner, A.D.; Ziv, J. Some asymptotic properties of the entropy of a stationary ergodic data source with applications to data compression. IEEE Trans. Inf. Theory 1989, 35, 1250–1258. [Google Scholar] [CrossRef]
- Grassberger, P. Estimating the information content of symbol sequences and efficient codes. IEEE Trans. Inf. Theory 1989, 35, 669–675. [Google Scholar] [CrossRef]
- Grassberger, P. Entropy estimates from insufficient samplings. arXiv 2003, arXiv:physics/0307138. [Google Scholar]
- Shannon, C.E. Prediction and entropy of printed English. Bell Labs Tech. J. 1951, 30, 50–64. [Google Scholar] [CrossRef]
- Hilberg, W. Der bekannte Grenzwert der redundanzfreien Information in Texten-eine Fehlinterpretation der Shannonschen Experimente? Frequenz 1990, 44, 243–248. [Google Scholar] [CrossRef]
- Geyik, S.C.; Bulut, E.; Szymanski, B.K. PCFG based synthetic mobility trace generation. In Proceedings of the 2010 IEEE Global Telecommunications Conference (GLOBECOM 2010), Miami, FL, USA, 6–10 December 2010; pp. 1–5. [Google Scholar]
- Mokhtar, S.B.; Boutet, A.; Bouzouina, L.; Bonnel, P.; Brette, O.; Brunie, L.; Cunche, M.; D’Alu, S.; Primault, V.; Raveneau, P.; et al. PRIVA’MOV: Analysing Human Mobility Through Multi-Sensor Datasets. In Proceedings of the NetMob 2017, Milan, Italy, 5–7 April 2017. [Google Scholar]
- Laurila, J.K.; Gatica-Perez, D.; Aad, I.; Bornet, O.; Do, T.M.T.; Dousse, O.; Eberle, J.; Miettinen, M. The mobile data challenge: Big data for mobile computing research. In Proceedings of the Pervasive Computing, Newcastle, UK, 18–22 June 2012. number EPFL-CONF-192489. [Google Scholar]
- Gerchinovitz, S.; Ménard, P.; Stoltz, G. Fano’s inequality for random variables. arXiv 2017, arXiv:1702.05985. [Google Scholar]
- Yan, X.Y.; Han, X.P.; Wang, B.H.; Zhou, T. Diversity of individual mobility patterns and emergence of aggregated scaling laws. Sci. Rep. 2013, 3, 2678. [Google Scholar] [CrossRef]
- Kulkarni, V.; Moro, A.; Chapuis, B.; Garbinato, B. Extracting Hotspots Without A-priori by Enabling Signal Processing over Geospatial Data. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; pp. 79:1–79:4. [Google Scholar] [CrossRef]
- Si, H.; Wang, Y.; Yuan, J.; Shan, X. Mobility prediction in cellular network using hidden markov model. In Proceedings of the 2010 7th IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2010; pp. 1–5. [Google Scholar]
- Idiap. NMDC Dataset. 2012. Available online: https://www.idiap.ch/dataset/mdc/download (accessed on 26 July 2018).
- Inria. PrivaMOv Dataset. 2012. Available online: https://projet.liris.cnrs.fr/privamov/project/ (accessed on 26 July 2018).
- Microsoft. GeoLife Dataset. 2012. Available online: https://www.microsoft.com/en-us/download/ (accessed on 26 July 2018).
- Trivedi, K.S. Probability & Statistics with Reliability, Queuing and Computer Science Applications; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Clauset, A.; Shalizi, C.R.; Newman, M.E. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Virkar, Y.; Clauset, A. Power-law distributions in binned empirical data. Ann. Appl. Stat. 2014, 8, 89–119. [Google Scholar] [CrossRef]
- Lin, H.W.; Tegmark, M. Critical Behavior in Physics and Probabilistic Formal Languages. Entropy 2017, 19, 299. [Google Scholar] [CrossRef]
- Gu, L. Moving kriging interpolation and element-free Galerkin method. Int. J. Numer. Methods Eng. 2003, 56, 1–11. [Google Scholar] [CrossRef]
- Pérez-Cruz, F. Kullback-Leibler divergence estimation of continuous distributions. In Proceedings of the 2008 IEEE International Symposium on Information Theory, Toronto, ON, Canada, 6–11 July 2008; pp. 1666–1670. [Google Scholar]
- Google. S2 Geometry. 2017. Available online: https://s2geometry.io/ (accessed on 25 July 2018).
- Khandelwal, U.; He, H.; Qi, P.; Jurafsky, D. Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use Context. arXiv 2018, arXiv:1805.04623. [Google Scholar]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef]
- Schürmann, T. Scaling behaviour of entropy estimates. J. Phys. A Math. Gen. 2002, 35, 1589. [Google Scholar] [CrossRef]
- Storer, J.A. Data Compression: Methods and Theory; Computer Science Press, Inc.: New York, NY, USA, 1987. [Google Scholar]
- Lesne, A.; Blanc, J.L.; Pezard, L. Entropy estimation of very short symbolic sequences. Phys. Rev. E 2009, 79, 046208. [Google Scholar] [CrossRef] [PubMed]
- Arimoto, S. Information-theoretical considerations on estimation problems. Inf. Control 1971, 19, 181–194. [Google Scholar] [CrossRef]
- Mahalunkar, A.; Kelleher, J.D. Using Regular Languages to Explore the Representational Capacity of Recurrent Neural Architectures. arXiv 2018, arXiv:1808.05128. [Google Scholar]
- A.M.(silentknight). Mutual Information. 2018. Available online: https://github.com/silentknight/Long-Distance-Dependencies (accessed on 7 March 2019).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors (year) | () | Prediction Model | Dataset Duration | Dataset Type | |
|---|---|---|---|---|---|
| Song et al. [5] (2010) | 93% (3–4 km) | – | – | 3 months | CDR |
| Lu et al. [11] (2013) | 88% (3–4 km) | 91% | Markov (first-order) | five months | CDR |
| Smith et al. [12] (2014) | 93.05–94.7% (350 m, 5 min) 81.45–85.57% (100 m, 5 min) 74.23–78.20% (350 m, 60 min) | – | – | 36 months | GPS |
| Ikanovic and Mollgaard [17] (2017) | 95.5 ± 1.8% (1.7 km) 71.1% (25 m) | 88.3 ± 3.8% 75.8% | Markov (first-order) | 36 months (same as previous) | GPS |
| Extension | Architecture | Features |
|---|---|---|
| Vanilla-RNN [34] | • no cell state/gating mechanism • recurrent connections | • faster and stable training • simple architecture |
| RNN-LSTM [31] | • similar connections as Vanilla-RNN • diff. cell state with gating mechanism | • actively maintain self-connecting loops • prevents memory degradation |
| Dilated-RNN [35] | • similar cell structure as LSTM • dilated skip connections | • increased parallelism in the computation • improves long-term memorization capabilities |
| RHN [32] | • diff. cell design • long credit assignment paths | • handles short-term patterns • reduces data-dependent parameters for LDD memorization |
| PSMM [33] | • diff. gating function, shortcut connections • variable dimensionality hidden state | • improves handling of rare symbols • allows for better long-distance gradients |
| Datasets | Num. Users | Duration (months) | Avg. Trajectory Length | Distinct Locations | Avg. Spatio-Temporal Granularity | ||
|---|---|---|---|---|---|---|---|
| PrivaMov | 100 | 15 | 1,560,000 | 2651 | 246 m 24 s | 6.63 | 0.5049 |
| NMDC | 191 | 24 | 685,510 | 2087 | 1874 m 1304 s | 5.08 | 0.6522 |
| GeoLife | 182 | 36 | 8,227,800 | 3892 | 7.5 m 5 s | 7.77 | 0.4319 |
| RNN Variant | Hidden-Layer Size | Unroll Steps | Learning Rate | Activation Function | Optimizer | Dropout Rate |
|---|---|---|---|---|---|---|
| Vanilla-RNN | 100 | 25 | 0.1 | tanh | Adam | 0.2 |
| RNN-LSTM | 100 | 50 | 1.0 × | ReLU | Adam | 0.2 |
| Dilated-RNN | 100 | 32 | 1.0 × | ReLU | Adam | 0.2 |
| RHN | 100 | 50 | 1.0 × | ReLU | Adam | 0.2 |
| PSMM | 100 | 50 | 1.0 × | ReLU | Adam | 0.2 |
| Datasets | ||||||
|---|---|---|---|---|---|---|
| PrivaMov | 0.50 | 0.47 | 0.46 | 0.60 | 0.76 | 0.72 (Dilated-RNN) |
| NMDC | 0.65 | 0.70 | 0.68 | 0.66 | 0.78 | 0.72 (RNN-LSTM) |
| GeoLife | 0.43 | 0.40 | 0.36 | 0.43 | 0.70 | 0.66 (PSMM) |
| Name | Density | |
|---|---|---|
| Power law with cutoff | ||
| Exponential | ||
| Stretched exponential | ||
| Log-normal | ||
| Rank Order | Power Law p | Log-Normal | Exponential | Stretched Exp. | Power Law + Cutoff | Support for Power-Law | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| LR | p | LR | p | LR | p | LR | p | |||
| Privamov | 0.00 | −12.72 | 0.00 | −30.12 | 0.00 | −11.42 | 0.00 | −113.1 | 0.00 | with Cutoff |
| NMDC | 0.00 | −11.28 | 0.00 | −27.23 | 0.00 | −13.95 | 0.00 | −320 | 0.00 | with Cutoff |
| Geolife | 0.006 | −17.04 | 0.00 | −19.21 | 0.00 | −18.21 | 0.08 | −560.78 | 0.00 | with Cutoff |
| MSE | ||||
|---|---|---|---|---|
| Measure | Log-Normal | Exponential | Stretched Exp. | Power Law + Cutoff |
| NMDC-POIs | 0.04501 | 0.05648 | 0.02348 | 0.00616 |
| GeoLife-POIs | 0.00324 | 0.07306 | 0.00378 | 0.00087 |
| PrivaMov-POIs | 0.05824 | 0.09386 | 0.00739 | 0.00114 |
| NMDC-GSM | 0.25584 | 0.00224 | 0.00584 | 0.07268 |
| PrivaMov-GSM | 0.03655 | 0.00895 | 0.00098 | 0.00783 |
| K-S Test | ||||
| NMDC-POIs | 0.65843 | 0.75615 | 0.07456 | 0.00825 |
| GeoLife-POIs | 0.63288 | 0.93644 | 0.04289 | 0.00046 |
| PrivaMov-POIs | 0.96752 | 0.69748 | 0.27896 | 0.00116 |
| NMDC-GSM | 0.56825 | 0.00987 | 0.00967 | 0.04568 |
| PrivaMov-GSM | 0.85621 | 0.00567 | 0.00165 | 0.00927 |
| Inter-Event Times | Power Law p | Log-Normal | Exponential | Stretched Exp. | Power Law + Cutoff | Support for Power-Law | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| LR | p | LR | p | LR | p | LR | p | |||
| Privamov | 0.12 | −1.13 | 0.28 | 5.69 | 0.00 | 0.09 | 0.00 | −0.34 | 0.74 | with Cutoff |
| NMDC | 0.08 | −0.11 | 0.02 | 2.98 | 0.00 | 3.78 | 0.54 | −2.87 | 0.31 | weak |
| Geolife | 0.86 | −7.76 | 0.00 | −20.43 | 0.00 | 17.87 | 0.08 | −0.30 | 0.59 | good |
| Sampling Rate | Power Law p | Power Law + Cutoff | Log-Normal | Exponential | Stretched Exp. | Support for Power Law | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| LR | p | LR | p | LR | p | LR | p | |||
| 1X | 0.51 | 5.43 | 0.19 | 0.278 | 0.47 | 9.89 | 0.96 | 4.32 | 0.12 | good |
| 2X | 0.06 | 0.00 | 0.07 | −1.25 | 0.08 | 2.89 | 0.11 | 10.08 | 0.00 | with Cutoff |
| 4X | 0.46 | −0.065 | 0.67 | −0.072 | 0.87 | 1.89 | 0.87 | 1.78 | 0.07 | moderate |
| 0.5X | 0.00 | 0.00 | 0.00 | −5.54 | 0.01 | 8.66 | 0.38 | 11.88 | 0.00 | with Cutoff |
| 0.25X | 0.00 | 0.00 | 0.02 | −1.78 | 0.03 | 9.94 | 0.04 | 13.56 | 0.00 | with Cutoff |
| Dataset | Power Law p | Power Law + Cutoff | Log-Normal | Exponential | Stretched Exp. | Support for Power Law | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| LR | p | LR | p | LR | p | LR | p | |||
| Privamov | 0.43 | 3.25 | 0.69 | 1.78 | 0.28 | 6.28 | 0.83 | 4.89 | 0.34 | good |
| NMDC | 0.27 | 1.82 | 0.11 | −0.27 | 0.10 | 2.47 | 0.65 | 2.21 | 0.16 | moderate |
| Geolife | 0.51 | 5.43 | 0.19 | 0.278 | 0.47 | 9.89 | 0.96 | 4.32 | 0.12 | good |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kulkarni, V.; Mahalunkar, A.; Garbinato, B.; Kelleher, J.D. Examining the Limits of Predictability of Human Mobility. Entropy 2019, 21, 432. https://doi.org/10.3390/e21040432
Kulkarni V, Mahalunkar A, Garbinato B, Kelleher JD. Examining the Limits of Predictability of Human Mobility. Entropy. 2019; 21(4):432. https://doi.org/10.3390/e21040432
Chicago/Turabian StyleKulkarni, Vaibhav, Abhijit Mahalunkar, Benoit Garbinato, and John D. Kelleher. 2019. "Examining the Limits of Predictability of Human Mobility" Entropy 21, no. 4: 432. https://doi.org/10.3390/e21040432
APA StyleKulkarni, V., Mahalunkar, A., Garbinato, B., & Kelleher, J. D. (2019). Examining the Limits of Predictability of Human Mobility. Entropy, 21(4), 432. https://doi.org/10.3390/e21040432