Guessing with Distributed Encoders



Abstract
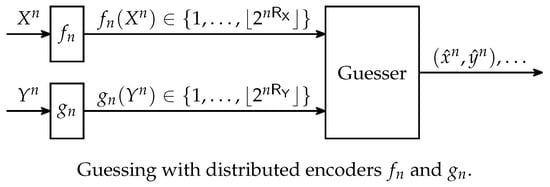
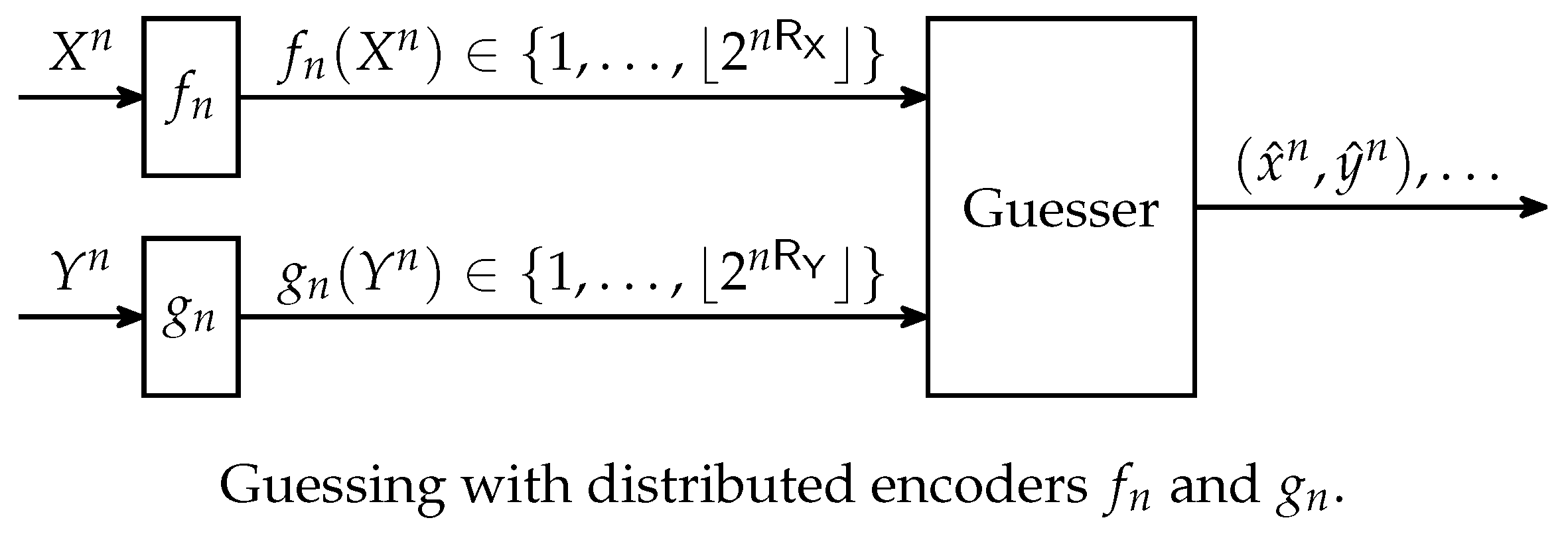
:
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Related Work
3. Preliminaries
4. Converse
5. Achievability
Author Contributions
Funding
Conflicts of Interest
References
- Massey, J.L. Guessing and entropy. In Proceedings of the 1994 IEEE International Symposium on Information Theory (ISIT), Trondheim, Norway, 27 June–1 July 1994; p. 204. [Google Scholar] [CrossRef]
- Arıkan, E. An inequality on guessing and its application to sequential decoding. IEEE Trans. Inf. Theory 1996, 42, 99–105. [Google Scholar] [CrossRef]
- Sason, I.; Verdú, S. Improved bounds on lossless source coding and guessing moments via Rényi measures. IEEE Trans. Inf. Theory 2018, 64, 4323–4346. [Google Scholar] [CrossRef]
- Bracher, A.; Hof, E.; Lapidoth, A. Guessing attacks on distributed-storage systems. arXiv, 2017; arXiv:1701.01981v1. [Google Scholar]
- Graczyk, R.; Lapidoth, A. Variations on the guessing problem. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 231–235. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2006; ISBN 978-0-471-24195-9. [Google Scholar]
- Fehr, S.; Berens, S. On the conditional Rényi entropy. IEEE Trans. Inf. Theory 2014, 60, 6801–6810. [Google Scholar] [CrossRef]
- Csiszár, I. Generalized cutoff rates and Rényi’s information measures. IEEE Trans. Inf. Theory 1995, 41, 26–34. [Google Scholar] [CrossRef]
- Bracher, A.; Lapidoth, A.; Pfister, C. Distributed task encoding. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 1993–1997. [Google Scholar] [CrossRef]
- Lapidoth, A.; Pfister, C. Two measures of dependence. In Proceedings of the 2016 IEEE International Conference on the Science of Electrical Engineering (ICSEE), Eilat, Israel, 16–18 November 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Rosenthal, H.P. On the subspaces of Lp (p > 2) spanned by sequences of independent random variables. Isr. J. Math. 1970, 8, 273–303. [Google Scholar] [CrossRef]
- Boztaş, S. Comments on “An inequality on guessing and its application to sequential decoding”. IEEE Trans. Inf. Theory 1997, 43, 2062–2063. [Google Scholar] [CrossRef]
- Hanawal, M.K.; Sundaresan, R. Guessing revisited: A large deviations approach. IEEE Trans. Inf. Theory 2011, 57, 70–78. [Google Scholar] [CrossRef]
- Christiansen, M.M.; Duffy, K.R. Guesswork, large deviations, and Shannon entropy. IEEE Trans. Inf. Theory 2013, 59, 796–802. [Google Scholar] [CrossRef]
- Sundaresan, R. Guessing based on length functions. In Proceedings of the 2007 IEEE International Symposium on Information Theory (ISIT), Nice, France, 24–29 June 2007; pp. 716–719. [Google Scholar] [CrossRef]
- Sason, I. Tight bounds on the Rényi entropy via majorization with applications to guessing and compression. Entropy 2018, 20, 896. [Google Scholar] [CrossRef]
- Sundaresan, R. Guessing under source uncertainty. IEEE Trans. Inf. Theory 2007, 53, 269–287. [Google Scholar] [CrossRef]
- Arıkan, E.; Merhav, N. Guessing subject to distortion. IEEE Trans. Inf. Theory 1998, 44, 1041–1056. [Google Scholar] [CrossRef]
- Bunte, C.; Lapidoth, A. On the listsize capacity with feedback. IEEE Trans. Inf. Theory 2014, 60, 6733–6748. [Google Scholar] [CrossRef]
- Gallager, R.G. Information Theory and Reliable Communication; John Wiley & Sons: Hoboken, NJ, USA, 1968; ISBN 0-471-29048-3. [Google Scholar]
- Arıkan, E.; Merhav, N. Joint source-channel coding and guessing with application to sequential decoding. IEEE Trans. Inf. Theory 1998, 44, 1756–1769. [Google Scholar] [CrossRef]
- Bunte, C.; Lapidoth, A. Encoding tasks and Rényi entropy. IEEE Trans. Inf. Theory 2014, 60, 5065–5076. [Google Scholar] [CrossRef]
- Rényi, A. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 20 June–30 July 1960; Volume 1, pp. 547–561. [Google Scholar]
- Arimoto, S. Information measures and capacity of order α for discrete memoryless channels. In Topics in Information Theory; Csiszár, I., Elias, P., Eds.; North-Holland Publishing Company: Amsterdam, The Netherlands, 1977; pp. 41–52. ISBN 0-7204-0699-4. [Google Scholar]
- Sason, I.; Verdú, S. Arimoto–Rényi conditional entropy and Bayesian M-Ary hypothesis testing. IEEE Trans. Inf. Theory 2018, 64, 4–25. [Google Scholar] [CrossRef]


© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bracher, A.; Lapidoth, A.; Pfister, C. Guessing with Distributed Encoders. Entropy 2019, 21, 298. https://doi.org/10.3390/e21030298
Bracher A, Lapidoth A, Pfister C. Guessing with Distributed Encoders. Entropy. 2019; 21(3):298. https://doi.org/10.3390/e21030298
Chicago/Turabian StyleBracher, Annina, Amos Lapidoth, and Christoph Pfister. 2019. "Guessing with Distributed Encoders" Entropy 21, no. 3: 298. https://doi.org/10.3390/e21030298
APA StyleBracher, A., Lapidoth, A., & Pfister, C. (2019). Guessing with Distributed Encoders. Entropy, 21(3), 298. https://doi.org/10.3390/e21030298