1. Introduction
The clustering problem is related to the partition of an analyzed set of samples into a settled number of pairwise disjoint classes or clusters, where samples in the same cluster are more similar to each other than those samples of other clusters. Center-based clustering methods group the samples based on some measure of distance from cluster centers. In this context, the center of a cluster can be a medoid or a centroid. A medoid is the most representative point of a cluster, while a centroid is usually calculated as a minimizer of an optimization problem, with a measure of distortion as the objective function. The choice of a proper measure of similarity or dissimilarity (distance) is a key factor in cluster analysis, since the performance of clustering algorithms greatly relies on this choice.
Arguably, the most popular clustering algorithm is
k-means with Lloyd’s heuristic, in which squared Euclidean distance is used to compute the distortion. However, there has been a recent burst of interest in extending classical
k-means algorithm to a larger family of distortion measures. In particular, the use of divergence-based distance functions as a similarity measure has recently gained attention. Research on this topic makes use mainly of two families of divergences, Csiszár
f-divergences and Bregman divergences. Both families include some well-known divergences. For example,
-divergences, which includes the Kullback-Leibler (KL) divergence, is a type of Bregman and Csiszár
f-divergences. In fact,
-divergence is the unique class of divergence sitting at the intersection of the Csiszár
f-divergence and Bregman divergence classes [
1]. Other notable Csiszár
f-divergences are the Hellinger distance and the
-squared distance [
2], whereas the squared Euclidean distance, the Itakura-Saito (IS) divergence and the
-divergence are special cases of Bregman divergences [
3].
Such distance functions do not always satisfy certain properties, such as triangular inequality and distance symmetry, making them an improper metric. Thus, for the development of a clustering strategy, one must consider two kinds of centroids obtained by performing the minimization process either on the left argument or on the right argument of the distance function, yielding the left-sided and right-sided centroids, respectively. Closed formulas for both sided centroids computation have been proposed in the literature for different divergence families.
In [
4], the classical hard
k-means algorithm is generalized to the large family of Bregman divergences. The resulting Bregman
k-means algorithm works for any given Bregman divergence. Since Bregman divergences are not necessarily symmetric, it is necessary to distinguish the two aforementioned sided centroids. It has been shown that the left-centroid is the generalized means of the cluster, also called cluster’s
f-mean, whereas the right centroid is the center of mass of the cluster, independently of the considered Bregman divergence [
5]. For the specific case of
-divergences, closed formulas for the computation of the sided centroids were derived in [
6] for the right-type, and in [
7,
8] for the left-type. Symmetrized centroids have also been derived for clustering histograms in the Bag-of-Words modeling paradigm in [
9]. Total Bregman divergences (TDB), which are invariant to particular transformations on the natural space, have also been used for estimating the center of a set of vectors in [
10] in the context of the shape retrieval problem. Complete formulation of sided centroids in
k-means algorithm with TDB are reported in [
11]. To the best of our knowledge, there is no closed formulation for the computation of centroids for the whole of Csiszár
f-divergence family. One of the works that relates Csiszár
f-divergences and clustering can be found in [
12], in which a generalized version of
f-divergences, called
-divergence is used for clustering in the particular case of KL-divergence. Finally, other classes of distance functions which are not necessarily Bregman or Csiszár
f-divergences have been employed for clustering. For example, a notable recent study can be found in [
13], in which a
k-means algorithm using the
S-divergence is developed for feature coding.
We propose a new center-based clustering algorithm, namely -k-means algorithm, using -divergence family as a measure of distortion. Our motivations to explore the family of -divergences for centroid-based clustering are the great flexibility to obtain a rich collection on particular divergences by just tuning the parameters , and the possibility to yield simple closed formulas for the centroids computation that are of interests for processing several types of data.
-divergences, which were introduced in [
14] as a new dissimilarity measure for positive data, have been proven useful in several applications, such as for example the separation of convolved speech mixtures [
15], to perform the canonical correlation analysis [
16] and noise-robust speech recognition [
17]. This family of divergences are governed by two parameters
and
, and cover many of the divergences previously used for clustering, such as
-divergence,
-divergence and KL-divergence.
This is not the first attempt to take into account the
-divergences in a clustering approach. In [
18], a variation of a k-medoid clustering algorithm is presented based on the
-divergences. The resulting algorithm fixes the value of the
parameter to
, and varies the value of the parameter
in each iteration through the prominence of the cluster. However, the method is completely different to our proposal. The algorithm we propose in this article computes the centroid of the cluster by solving a minimization problem, whereas the algorithm in [
18] obtains the center of the cluster by an exhaustive search optimization technique on the set of the current members of the cluster. Thus, we propose a k-means-type algorithm whereas in [
18] it is presented as a k-medoid-type algorithm.
Finally, some authors have pointed out that k-means clustering can be formulated as a constrained matrix factorization problem [
19,
20]. For instance, in [
19] the authors showed that orthogonal symmetric Non-negative Matrix Factorization (NMF) with the sum of squared error cost function is equivalent to Kernel
k-means clustering. Other variants of NMF, such as Semi-NMF, Convex-NMF, Cluster-NMF and Kernel-NMF are all soft versions of
k-means clustering [
21]. There is also a relationship between NMF based on certain divergences and some clustering approaches. NMF with generalized KL-divergence or
I-divergence is equivalent to Probabilistic Latent Semantic Indexing (PLSI) [
22]. In addition, in [
23] it is established that orthogonal NMF based on Bregman divergence problem is equivalent to Bregman hard clustering derived in [
4].
This paper is organized as follows: we begin with the formal definition and some properties of
-divergences in
Section 2. In
Section 3 we derive the closed-form formula for the sided centroids by using the
-divergence, and generalize the
k-means algorithm to the
-
k-means algorithm. In
Section 4 we demonstrate that the obtained formula for centroid computation match with previous formula for some specific distances and divergences that belong to
-divergence family.
Section 5 presents some experimental clustering results for synthetic and real datasets. Finally,
Section 6 summarizes our main conclusions and provides some suggestions for future research.
2. -Divergences
In this section, we recall the definition and some useful properties of the
-divergences [
14].
Definition 1. Given two non-negative data matrices of same dimension and , with entries and , the -divergence is given bywhere It must be pointed out that some specific choices of
parameters simplify the
-divergence into some known divergences or families of divergences, allowing smooth interpolation between many known divergences. In particular, when
the
-divergence takes the form of a Log-Euclidean distance
where
represents the squared Euclidean distance. When
, with
, the
-divergence can also be expressed in terms of a generalized Itakura-Saito distance
with an
-zoom of the arguments
where
denotes the one-to-one transformation that raises each element of the vector
to the power
. When
the
-divergence reduces to the
-divergence,
whereas when
, it reduces to the
-divergence
For
, it is proportional to the Hellinger distance
Also, the AB-divergence reduces to the standard KL-divergence for
and
,
Although
-divergences are not true metrics, they satisfy some interesting properties (see [
14] for details and proofs), such us duality, inversion, and scaling:
(Duality)
(Inversion)
(Scaling)
-divergence is more flexible, powerful, and robust against errors and noise than other divergence families, such as the
-divergence and
-divergence [
14]. The role of the hyperparameters
and
in the robustness property of the
-divergence is described in [
14]. Formally, it has been shown that if we assume that the right argument of the divergence,
is a function of a vector of parameters
, then
In this case, the parameter can be used to control the influence of large or small ratios by the deformed logarithm of order , while the parameter provides some control on the weighting of the ratios by scaling factors .
3. K-means Clustering with -Divergences
One of the most popular and well-studied data analysis methods for clustering is
k-means clustering. Let
X be a random variable that take values in a finite set
.
k-means clustering aims to split
into
k disjoint partitions
, finding a set of centroids
, with
and
. The standard
k-means formulation finds the partition
through the minimization of the sum of the squared Euclidean distances between each sample and its cluster centroid. Formally speaking, for a fixed integer
k, one can define the following squared Euclidean loss function
The most popular optimization method for this minimization problem is Lloyd’s algorithm [
24], which converges to a stable fixed point that corresponds to a local minimum of the loss function. For a given initial partition, Lloyd’s algorithm finds the partition in a two-step iterative process. In the
assignment step, each data is assigned with the cluster whose centroid is closest. In the
update step, the centroids are updated as the arithmetic mean of its assigned points. It is well established that the arithmetic mean is the optimal centroid
for the Euclidean distance
where
refers to the cardinality of th
h-th cluster.
We propose in this paper to generalize the standard
k-means clustering to the
-divergences. As in k-means standard technique, our objective is to find the set of centroids
that minimizes the AB-divergence of points in the set
to their corresponding centroids. In this context, the centroid of a cluster is defined as the optimizer of the minimum average
-divergence. However, since the
-divergences are not symmetrical, one must consider two kinds of centroids obtained by performing the minimization process either on the left argument or on the right argument of the divergences. We shall consider the right-sided centroid,
the optimizer when the minimization process is performed with respect to the right side of the divergence, and the left-sided centroid,
, the optimizer when the minimization is performed with respect to the left
In [
5] it is proven that sided centroids with respect to Bregman divergences coincide with the center of mass for the right-type, and with the center of mass for the gradient point set that is a
f-mean, for the left-type. This implies that the formula for the right-type centroid computation does not depend on the Bregman divergence considered, whereas the formula for the computation of the left-type centroid strongly depends on it. Moreover, the sided centroids for Bregman divergences exhibit different characteristics, and therefore it is necessary to choose between the left and right centroid depending on the application. Contrary to the Bregman divergences case, we can establish a relationship between the sided centroids obtained with
-divergences that unifies the optimization process for the sided centroids in a unique problem.
Lemma 1. Let denote the optimal right-sided centroid defined in Equation (12) for a given parametrization pair . The left-sided centroid for the same parametrization is Proof. Using the duality property of
-divergences, we observe that
□
This last result allows us to formulate the following theorem.
Theorem 1. (Sided -centroids) The right-sided and left-sided -centroid coordinates of a set of point are: The proof is reported in the
Appendix A. Please note that the expression obtained for
in Equation (
16) corresponds to the limit when
evaluated with L’Hôpital’s rule, in the same way as with
in Equation (
17). Closed-form formulas presented in Theorem 1 are essential, since it allows us to develop efficient
k-means algorithms using
-divergences.
Now, we can introduce the following iterative Algorithm 1, known as the -k-means algorithm. As in the traditional k-means algorithm, the algorithm begins with an initial guess of the centroids (usually at random), and then alternates between the assignment and update steps. In the assignment step, each data point is assigned to the closest cluster centroid, measuring the distance through the -divergence. In the updated step, the centroids are computed using the results on Theorem 1. The algorithm is reiterated until convergence is met. In practice, we can control the stopping criterion by taking the difference between the cost function of two successive iterations. If it is less than a prescribed threshold the algorithm will stop. A precise definition of the aforementioned strategy using the right-type centroid is presented in Algorithm 1.
| Algorithm 1-divergence clustering. |
Input: Set , hyperparameters , number of clusters k.
Output: , local minimizer of where , hard partitioning of .
Method:
Initialize with
repeat
(The Assignment Step)
Set
for to n do
where
end for
(The Update Step)
for to k do
end for
until convergence
return |
Obviously, this algorithm can be extended to the left-type centroid in a straightforward manner by just changing the order of the arguments of the -divergence in the assignment step, and using the left-centroid formulas in the update step to obtain the set of centroids and the hard partitioning of data . However, it is easy to check that there is a relationship between the -k-means algorithm for the right-type centroid and for the left-type centroid. For the same initialization, due to the property the duality of the -divergences and the result of Lemma 1 one can get that and . Therefore, the behavior of the left-type -k-means algorithm in the plane is equal to behavior of the right-type reflected in the line .
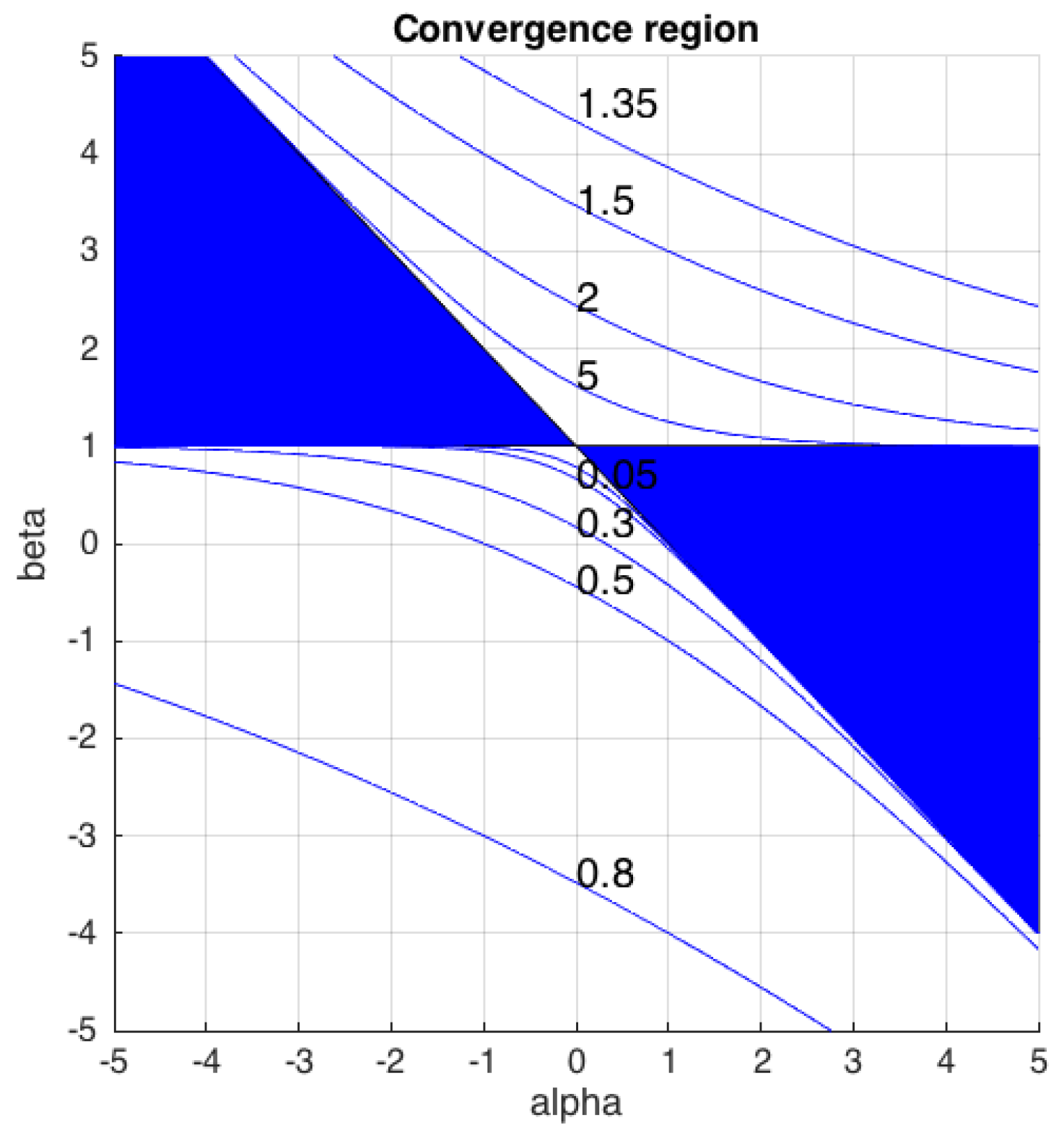
Conditions for the Convergence of Algorithm
Looking for the conditions ensuring the existence of an optimal set of centroids that achieves the minimum of the clustering loss function based on the
-divergence, it is necessary to take into account that
-divergences are not necessarily convex in the second argument. In particular, the conditions required for convexity depends on the value of
and
as follows [
14]
where
is a
deformed exponential
Figure 1 shows an analysis of the convergence region of the
-
k-means algorithm. The region filled in blue represents the convex cone delimited by the lines
and
, in which the
-divergence is always convex with respect to the second argument. Therefore, the proposed algorithm converges to a local minimum within this cone, independently of the values of the data to be analyzed. However, Equation (
18) shows that the convexity of the divergence with respect to
holds outside the convex cone when the ratios
are bounded by the function
. Therefore, theoretically, the convergence region of the proposed algorithm is greater than the convex cone, and its borders depend on the values that the arguments of the divergence could take. In particular, the maximum and the minimum values of the ratios
determine the upper and the lower boundaries, respectively. Blue lines in
Figure 1 represent the boundaries of the convergence region in the
plane for some values of the function
. In practice, for relatively small errors between
and
, Algorithm 1 is guaranteed to converge to a local minimum in a wide range of (
) values.
4. Relations with Known Centroid-Based Algorithms
The obtained formulas for sided centroid computation match the previous expressions obtained for various specific divergences and distances. In fact, the above novel algorithm unifies many existing algorithms for k-means. For example, apart from the most popular squared Euclidean distance, the algorithm includes those k-means algorithms based on -divergences and -divergences, as well as the particular cases KL-divergence and IS-divergence.
We shall start with the squared Euclidean distance that can be obtained from the
-divergence for
. By substituting these
and
values on the sided centroids of Equations (
16) and (
17), we directly obtain that both centroids are the arithmetic mean (
11)
Another interesting case of study is the
-divergence that can be obtained from the
-divergences for the parametrization
. As mentioned before, there are closed formulas for the computation of sided centroids for the
k-means with
-divergences [
7,
9]. However, to compare the formulas, it is necessary to take into account that there are two equivalent ways to define the
-divergence family. In particular, some authors employ a slightly different notation that depends on the parameter
[
3], which is related to the parameter
as follows
The
-divergence parametrized by
takes the following form
Closed formulas for sided centroids employing this notation are:
Substituting Equation (
21) in Equation (4), it is easy to check that
. Also, substituting Equation (
21) in Equations (
23) and (
24) we obtain
One widely employed distance in clustering tasks is the KL-divergence, obtained either for
from the
-divergence, or
from the
-divergence. In this specific case, the left-sided and right-sided centroids are computed as geometric mean and arithmetic mean respectively [
5]. It must be noticed that it is enough to consider
in Equations (
23) and (
24) to obtain the same formulas for centroid’s computation than those reported in [
5]
Finally, another divergence frequently used in the spectral analysis of speech signals [
25] is the IS-divergence. This divergence was first proposed in the context of vector quantization in [
26], and can be expressed by the
-divergence, the Bregman divergence and the
-divergence for
. As all the Bregman divergences, the right-sided centroid is computed as the arithmetic mean, but in this case, the left-sided centroid corresponds to the harmonic mean [
5]. Again, applying
in Equations (
23) and (
24), we get the same results than in [
5]
5. Experimental Results and Discussion
We have evaluated the proposed
-
k-means algorithm on various data types with experiments on both synthetic and real datasets. The first experiment studies the behavior of the algorithm on four different synthetic datasets, whose density is known, whereas the second experiment considers the task of audio genre classification using two different sets of descriptors. The third experiment analyzes the performance of the algorithm in two datasets from the UCI Machine Learning Repository [
27]: Iris and Wine. It is expected that the behavior of the algorithm strongly depends on the choice of the tuning parameters and on the type of the data. Given the huge flexibility of the
-divergence framework, we must restrict the experiment to some particular cases. Therefore, in our simulations we have varied
and
within the range
and
with steps of
. In each simulation we run 10 replicates from different randomly selected starting points and determined the partition with the lowest total sum of distances over all replicates. The resulting clusters have been evaluated in terms of accuracy degree (ACC) measured as the number of correctly assigned data points divided by the total number of data. Let us denote
the ground truth label,
the clustering assignment produced by the algorithm and
the optimal one-to-one mapping function that permutes clustering labels to match the ground truth labels by using the Hungarian algorithm [
28]. The ACC is defined as
where
if
and
otherwise.
5.1. Clustering on Synthetic Datasets
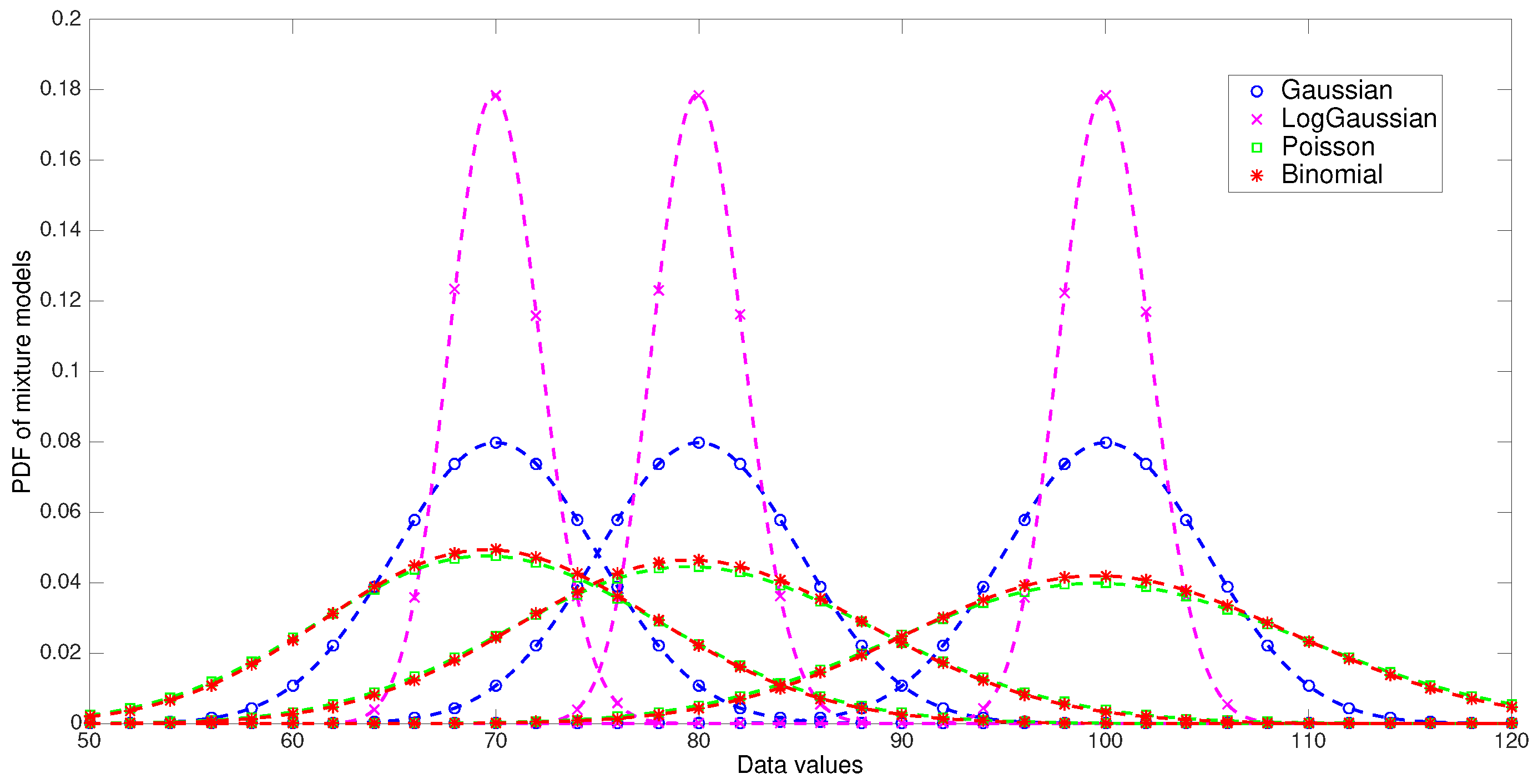
In this experiment we have generated four 1-dimensional datasets of 3000 samples each, based on mixture models of Gaussian, Log-Gaussian, Poisson, and Binomial distributions, respectively. The datasets have three components of 1000 samples each with means equals to 70, 80, and 100, respectively. The standard deviation of the Gaussian and Log-Gaussian densities was set to 5, and the number of trials of the binomial distribution was set to 1000. According this, the variance of the four models are approximately the same. The density functions of the generative models are depicted in
Figure 2.
The choice of these density functions is not arbitrary. Gaussian, Poisson, and Binomial distributions are class members of the exponential family of distributions, and in [
4] it is well stablished that for every exponential family distribution, it exists a corresponding generalized distance measure. For instance, normal distributions are associated with Euclidean distance, the exponential distribution with IS-divergence and Binomial distribution with KL-divergence. Additionally, Tweedie distributions, which are a particular type of exponential family, are tied to
-divergences [
29,
30]. Tweedie distributions include Poisson distribution which has been connected to
-divergence with
, that is the KL-divergence. Thus, we expect to obtain satisfactory clustering results for some specific divergences in each dataset analyzed.
Furthermore, with the choice of these distributions we want to verify the relation between the convergence region of the algorithm and the extreme values of the different datasets. For example, Poisson and Binomial datasets have similar extreme values and therefore the theoretical convergence region of the algorithm in both cases should be similar. On the contrary, the convergence region for the Log-Gaussian dataset is theoretically more extensive than the convergence regions of the other three datasets considered. In fact, for each cluster it seems probable that the ratio approaches to unit, so that the convergence region covers the whole plane.
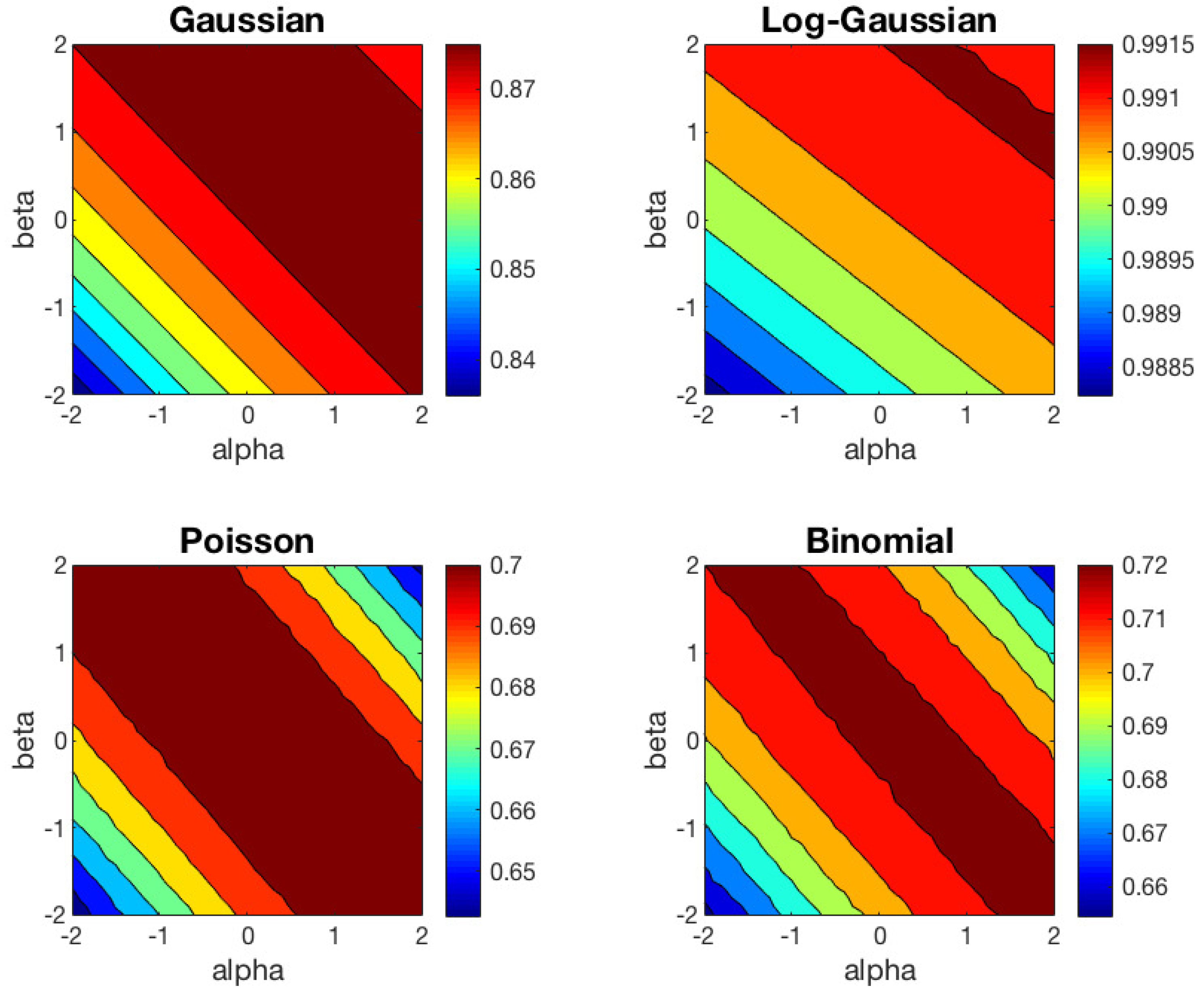
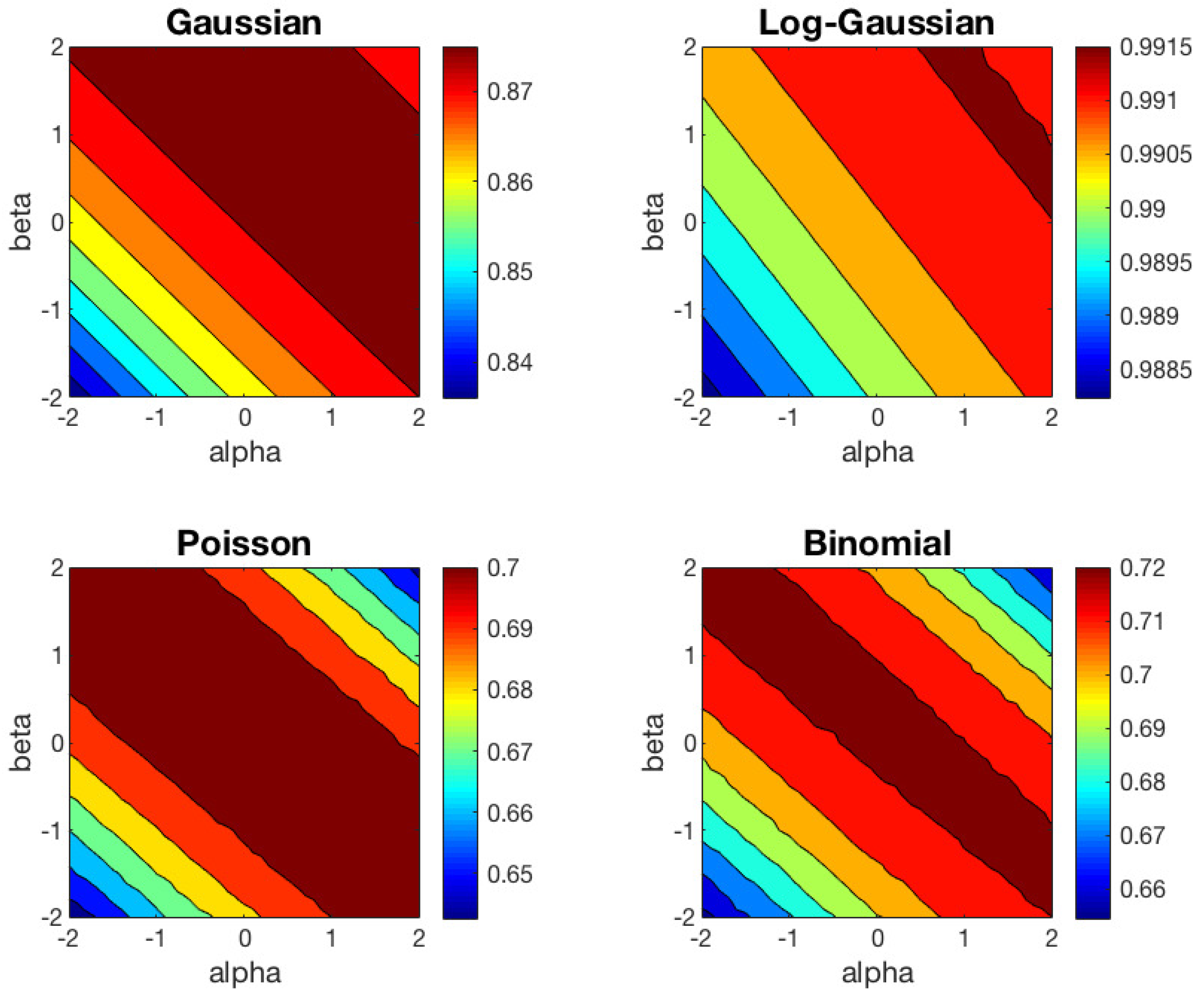
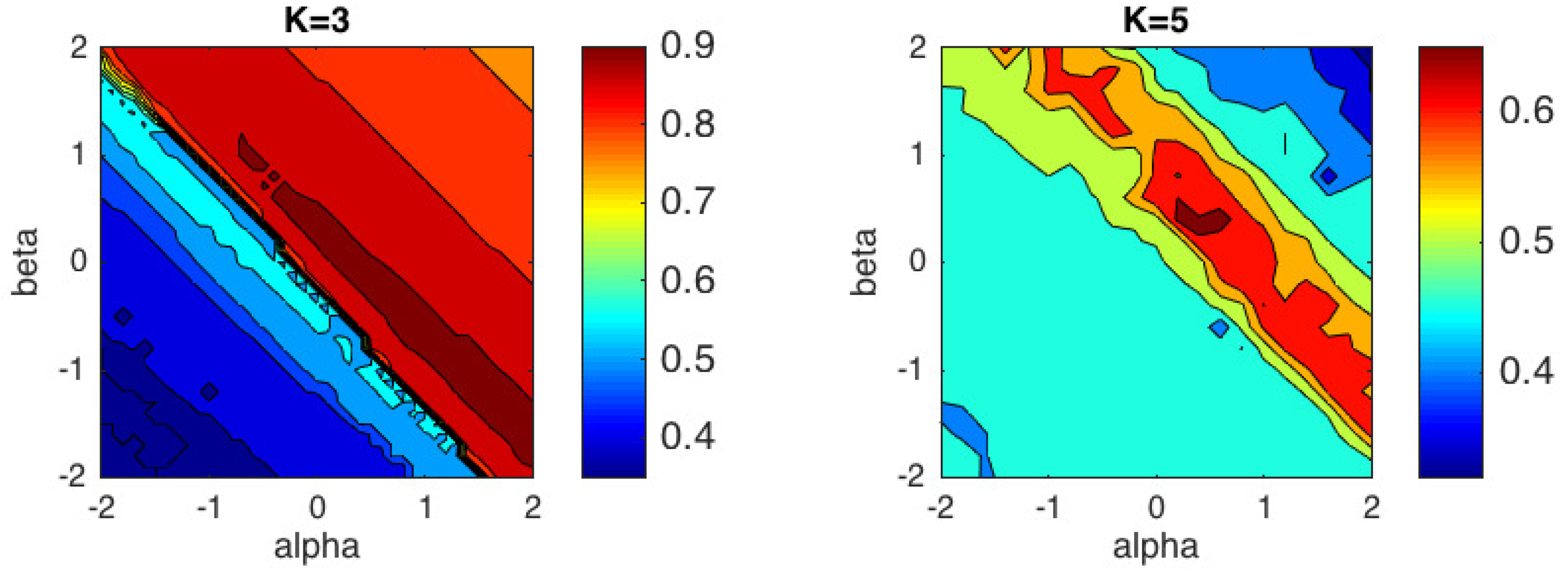
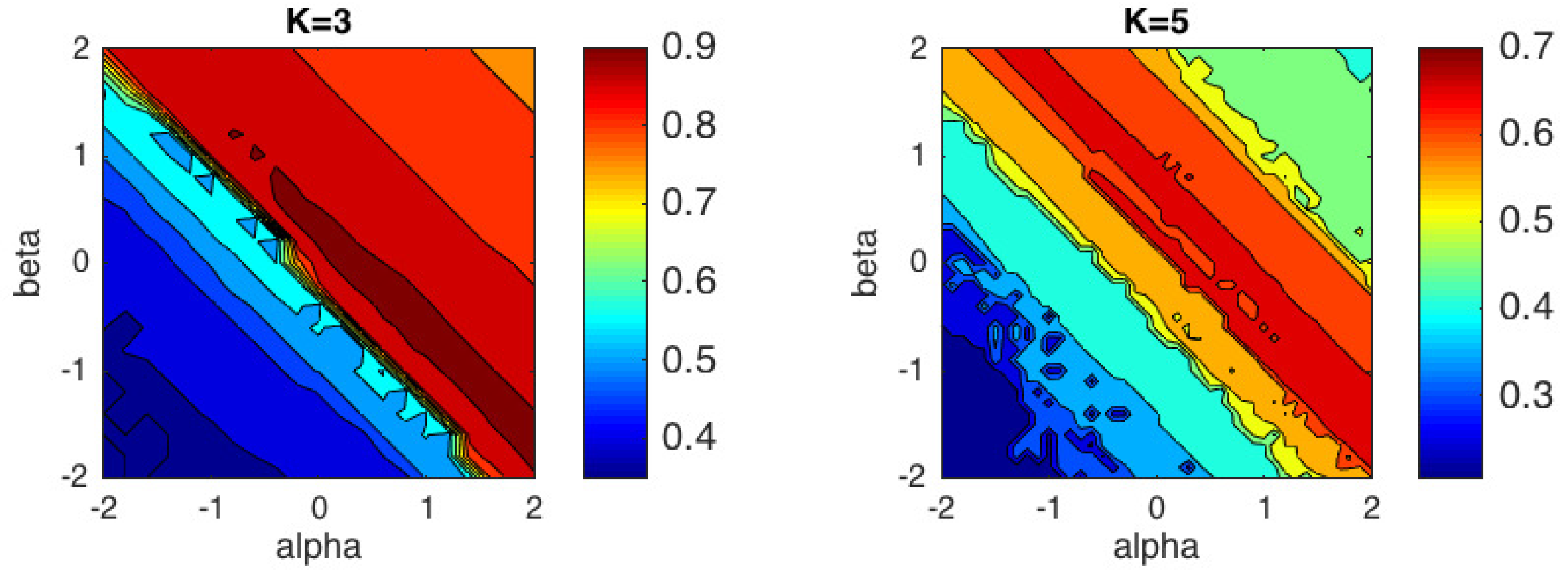
We have repeated the clustering experiment based on 1000 different random datasets, but preserving the same random initialization to run the left and right-type
-
k-means algorithm in each trial. The contour plots of the average ACC results of
-
k-means for the right and left cases are shown in
Figure 3 and
Figure 4, respectively. In these contour plots, the areas between isolines are filled with constant colors. In
Table 1, we show the mean and standard deviation of ACC over 1000 trials obtained for some representative values of the
pair for the right-type algorithm. We have omitted the values for the left-type since they can be easily inferred from the right-type solutions.
These results can be interpreted from different points of view. First, as we predicted in
Section 3, one can check that the behavior of the left-type algorithm is equal to the behavior of the right-type reflected in the line
. Second, we observe that the Euclidean distance (
) is well suited to Gaussian dataset, and KL-divergence (
) to Poisson and Binomial datasets, as expected. For the Log-Gaussian dataset, the
-
k-means algorithm behaves practically in the same way in the whole (
) region studied. This can be interpreted as the algorithm converges in the whole
plane studied, as we had foreseen. Furthermore, for the Gaussian dataset, we observe that the performance of the algorithm begins to decrease significantly for (
) values below the line
. For the Poisson and Binomial datasets, the region in which the algorithm achieves good results are very similar, although the optimal values of
and
within this region are different for each type of distribution. Finally, we would like to highlight that the regions with good performance for Poisson and Binomial datasets are narrower than the region obtained for the Gaussian dataset.
5.2. Musical Genre Clustering
In this experiment we have classified music audio according to the genre of the track. The goal of this experiment is to investigate the optimal divergence for different feature vectors by performing clustering experiments using different () pairs. Moreover, we have considered two levels of complexity building datasets with and genres. The tracks were extracted from the Music Information Retrieval Evaluation eXchange (MIREX) database for US Pop Music Genre Classification that considers a total of 10 genres. Each genre contains 100 tracks of 30-sec duration and the tracks are all 22,050 Hz Mono 16-bit audio files in .wav format. The first built dataset is composed of the genres classical, metal and pop from the MIREX dataset, while the second built dataset adds to the three previous genres country and disco. Therefore, the first dataset is composed of 300 tracks whereas the second dataset is composed of 500 tracks.
Relevant descriptors that could sufficiently discriminate the audio genre were extracted from the audio tracks. Two sets of positive features were analyzed: Discrete-Fourier-Transform-based (DFT-based) descriptors and acoustic spectro-temporal features. The feature extraction process for the computation of the DFT-based descriptors was composed of the following stages [
18]. First, the audio segment was divided into
L overlapping frames of size 2048 points, with
overlap between contiguous sections. For each audio track the number of segments obtained was
. Then, we performed the DFT of each segment using the Fast-Fourier Transform (FFT) algorithm with Hamming-windowing. After that, we calculated the arithmetic average in each frequency bin considering the absolute values of the complex DFT-vectors, and finally we normalized the average DFT by the sum of the DFT average coefficients. The length of the DFT-based descriptors was 1025.
Figure 5 shows the performance of the proposed algorithm and
Table 2 resumes the results for some specific distances and divergences that belong to the
-divergences family. The best performance for
, ACC =
, was obtained for the pair
, which is quite close to the
-divergence. For
, the best performance, ACC =
was obtained for
that is also close to an
-divergence, and in particular to the Hellinger distance.
The acoustics descriptors were composed of temporal features and spectral features. The temporal features extracted were Beat-Per-Minute (BPM) [
31], and mean and standard deviation of: Zero-Crossing Rate (ZCR), energy and entropy. The spectral descriptors used were mean and standard deviation of: Spectral Centroid, Spectral Entropy, Spectral Flux, Spectral Flux Centroid, and Spectral Roll-off. The MATLAB Audio Analysis Library [
32] was employed for the calculation of all the features except the BPM. The total feature vector consisted on 17 elements.
Figure 6 shows simulation results for the acoustic descriptors for the right-type
-
k-means algorithm. The best performance for
, with ACC =
, was obtained for the pair
, which is quite close to the Log-Gaussian distance, while for
, the highest value, ACC =
was obtained for
, which is quite close to IS-divergence. In general, the graph reveals that the region with best performance for this feature vector is close to the generalized IS-divergence, obtained from the
-divergence for the values
.
Table 3 summarizes the results for some specific divergences and distances obtained with
-divergences.
It can be clearly seen from
Figure 5 and
Figure 6 that the region where the performance is satisfactory is enclosed between the lines
and
for the two tested feature vectors. These two lines correspond to the generalized IS-divergence and the
-divergence, respectively. However, a theoretical explanation for this fact is not trivial. As reported in
Section 2, the hyperparameters (
) can control influence of individual ratios
in the centroid computation (see Equation
9). In particular, for
the smaller values of the ratio are down-weighted with respect to the larger ones, whereas for
, the larger ratios are down-weighted with respect to the smaller ones. Simultaneously, those ratios are weighted by scaling factors
.
In our experiments, one can observe that in the region with best performance the value of seems to be constant and close to unity for the DFT-based descriptors, and to zero for the acoustic descriptors. This cause that the multiplicative weighting factor does not really affect the estimation of the centroid coordinates for the DFT-based descriptors, whereas the large values in the centroid coordinates are slightly down-weighted compared to the smaller values for the acoustic descriptors. Additionally, we observe that for , the performance of the algorithm deteriorates drastically for the two sets of descriptors analyzed, probably due to the inversion of the arguments of the -divergence. It is easy to see that for , the inversion property of the -divergence causes small values of the data to be strongly enhanced.
It is worth mentioning here that the values of the hyperparameters that provide the best classification could not be generalized to other classification problems. For other classification tasks, it is preferable to carry out a search on the plane to obtain the best performance.
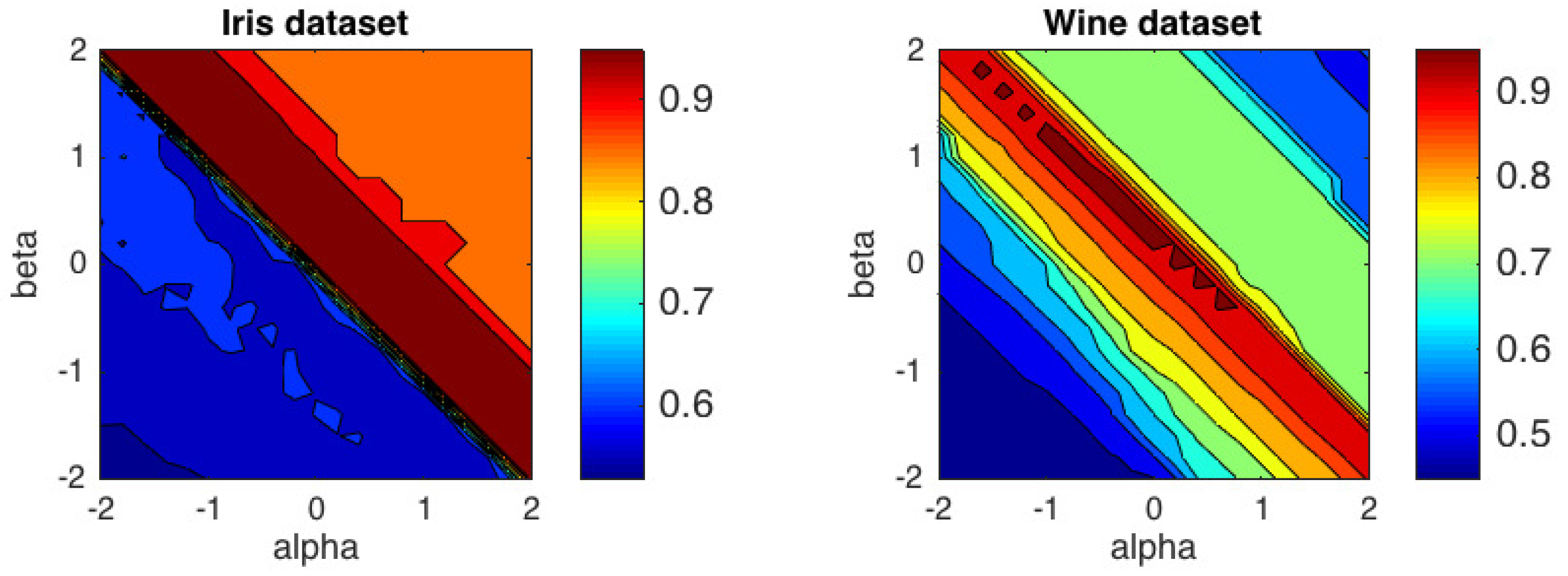
5.3. Clustering Analysis in UCI Repository
We have conducted experiment over two popular datasets from the UCI repository: Iris and Wine. The Iris dataset consist of three species of iris, 50 specimens in each. The features are measurements in centimeters of the length and the width of the sepals and petals. Wine dataset comprises results of chemical analyses of the content of wine grown in the same region but derived from three different cultivars. The dataset has 13 features and 178 instances. In this experiment we have varied
and
within the range
and
with steps of 0.2.
Figure 7 shows the contour plots of the average accuracy obtained over 50 trials with random initializations. The best performance for Iris dataset, with ACC =
, was obtained in the
region delimited by the generalized IS-divergence and the
-divergence. For Wine dataset, the highest value, ACC =
was obtained for
, which is quite close to the generalized IS-divergence. In this case, the
-divergence did not get good results. Average ACC levels for some specific distances and divergences are presented in
Table 4. It is important to emphasize that the Euclidean distance is not included in the distances and divergences with better results in the two datasets analyzed.
6. Conclusions
In this article, we have derived a centroid-based hard clustering algorithm that involves the family of -divergences which are governed by two parameters and have many desirable properties useful for clustering tasks. First, -divergences admit closed-form expressions for the computation of the two sided—left or right—centroids, something relevant from the point of view of the implementation of the clustering algorithm. Second, the proposed algorithm, called -k-means, unifies many existing implementations of k-means obtained with a rich collection of particular divergences that belong to the large family of -divergences. In fact, we have demonstrated that our formulas for sided centroids coincide with other formulas previously developed for some specific cases of the -divergences, such us -divergences, IS-divergence, and KL-divergence. Finally, the convergence of the algorithm is theoretically assured for a wide region in the () plane. Although the boundaries of the region of convergence depends on the ratio between the extreme values of the data, in practice, the algorithm seems to work properly outside of that theoretical region.
One of the important and still-open problems is how to tune the parameters () depending on the distribution of the available dataset and noise or outliers. Our experiments with synthetic datasets have allowed us to verify that the optimal values of the parameters and are related to the distribution of the data to be clustered. With this relationship, we can restrict the search range of the and values to some -divergences close to other well-known divergences, such us KL-divergence or -divergences. The derivation of a precise formula for the choice of the parameters and is beyond the scope of this work.
Finally, it would be very interesting to study the relationship between the proposed
-
k-means algorithm and the multiplicative NMF algorithm based on the
-divergence developed in [
14].












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}