1. Introduction
The formation of product quality runs through the whole process of product development, from product design and machining to assembly. Improving performance of products and reducing the failure of them has always been the common pursuit of academia and industry. However, due to the random fluctuation of the process factors, deviations in quality characteristics occur, and variations in quality characteristics lead to defects as time goes on, which may cause product failure. As we all know, the failure of products may be a destructive blow to the company’s production and operation. Therefore, it is crucial to identify the failure modes that may exist on products. Hence, the possible effect of any failure mode shall be analyzed, so as to prevent it from happening and reduce its losses. However, with an increasing complexity of current products, a number of products are always composed of several subsystems [
1,
2] and interaction between each subsystem in order to carry out system function [
3]. Moreover, for complex products, the components in the subsystem have many quality characteristics, which are coupled to each other, and different coupling modes make the failure modes in products diverse. In addition, products are affected by various external factors in the design, development and production process. In the Internet of Things (IoT), many devices are connected together by outside resources [
4]. If a device fails, the Internet of Things devices may not function properly at the network layer. These make the identification and importance ranking of failure modes in products more and more difficult.
One of the main identification and importance ranking methods of failure modes is the failure mode, effects and criticality analysis (FMECA). FMECA is a reliability analysis method which discovers the potential failure modes in a system, so as to evaluate the effects on system performance [
5]. The method consists of two parts: failure mode effect analysis (FMEA) and criticality analysis (CA). On the basis of the CEI EN 60812 standard [
6], FMEA is a systematic procedure for the analysis of a system to identify potential failure modes, and their causes and effects on system performance. On the other hand, Criticality Analysis plans and focuses the maintenance activities according to a set of priorities by giving failures with the highest risk the highest priority [
7]. Carrying out a typical FMECA, a complex product can be considered as a system, and the system is divided into several subsystems based on the fundamental principle of functional independence. Then, the subsystem is divided into component level, layer by layer, until the level of single component. FMECA starts from the indenture lowest level (single component) and continues analyzing the upper hierarchical level. According to the importance of the failure modes, FMECA assigns different priorities for taking countermeasures. The higher the importance of the failure mode is, the higher its priority. In the traditional FMECA, importance of each failure mode is ranked based on the risk priority number (RPN), which is derived by the product of three risk factors: occurrence (
O), severity (
S) and detection (
D) [
8]. Therefore, FMECA is a good way to simplify and solve complex product reliability and continuously improve product performance. It has also been widely applied in a range of fields, such as machine tool [
9], healthcare field [
8], wind industry [
10] and nuclear industry [
11]. However, the classical RPN formula has highlighted many drawbacks in analyzing practical problems [
12,
13]. Further, FMECA ignores the association and influence between failure modes, and their causes and effects, and fails to fully exploit failure information. Obviously, as mentioned above, due to its functional coupling, complex structure and numerous parts, classical FCECA is difficult to solve the importance ranking of failure modes in complex products. Therefore, the failure coupling information between products, components and parts must be fully mined to analyze the failure mode more accurately.
Thus, this paper introduces the complex network theory that defines failure modes, and their causes and effects as nodes. The logical relationship between failure cause and failure mode are defined as the edge, and the weight of the edge is represented by the square root of occurrence (O) multiplied by detection (D). Analogously, the relation between failure mode and failure effect is denoted as edge, and the weight of the edge is represented by severity (S). Then a weighted graph is established. Furthermore, the entropy centrality approach is applied to identify influential nodes. Finally, a real-world case is presented to illustrate and verify the proposed method.
The contributions of this paper can be summarized as follows.
(1) Complex network theory is introduced into FMECA, and a weighted graph is established to analyze the influence relation between failure modes, and their causes and effects.
(2) Entropy centrality is used to identify the vital nodes of a weighted graph, and the weight of the network is mutative; moreover, the number of nodes in the network is also changing.
The remaining sections of the paper are organized as follows.
Section 2 reviews the literature on FMECA improvement and identifying influential nodes.
Section 3 includes details of the proposed approach and gives a summary of the method.
Section 4 contains details about a real-world case to illustrate and verify the proposed method. We conclude our work in
Section 5.
2. Literature Review
This article is mainly related to two streams of literature. The first one is the literature on FMECA improvement. The traditional FMECA uses Risk Priority Number (RPN), which given by the multiplication of the risk parameters
O,
S,
D of a failure to quantify the risk of failure modes [
6,
14].
In Equation (1),
O defines the probability of a failure mode will come out,
S indicates the degree of failure mode effect system,
D implies the probability of failure mode has been identified before the system is affected, and each risk factor generally takes a discrete value in the range [
1,
10].
Despite its wide use, the classical RPN has many shortcomings, which have been highlighted countless times, such as the presence of gaps in the range of admissible values and the high sensitivity to small changes [
7,
15,
16,
17].
Several authors proposed some methods to deal with the restriction of RPN. Braband adopts the sum of the three parameters to improve RPN assessment, which is called IPRN [
18]. An exponential RPN (ERPN) was proposed by Chang et al. to reduce the number of duplicates RPNs [
19]. To make the ERPN better, Akbarzade Khorshidi et al. came up with URPN [
20]. Both ERPN and URPN well-solved the trouble of duplicates RPNs and of relative importance among
O,
S and
D. Carmignani suggested the use of a fourth parameter in the RPN calculation [
21]. The profitability based on costs and possible profits after minimizing losses due to failure is taken into consideration. Except the above optimization of RPN, most of the work is mainly focused on fuzzy logic, for the classical FMECA ignores some real situations. Hence, fuzzy FMECA methods are employed to express the uncertainty [
22,
23]. The approach needs a large amount of proper expertise and experience. Thus, the use of evidence theory [
24] is presented to manage the uncertainty and support to characterize this type of evaluation.
Rathore et al. [
25] discussed how a selection with hesitant fuzzy information is a multi-criteria decision-making problem. The multi-criteria decision method (MCDM) is also frequently used to support FMECA. Braglia [
26] proposed the Analytic Hierarchy Process (AHP), which uses the classical risk parameters
O,
S and
D along with the expected cost due to failure as a standard to compare the potential causes of failures. Braglia et al. [
27] also adopted the fuzzy technique for order preference by similarity to ideal solution (FTOPSIS) method to prioritize the potential risks of failure modes in criticality analysis. A combined FTOPSIS and fuzzy-AHP [
28] approach to FMECA is proposed by Kutlu and Ekmekçioğlu [
29]. Based on FTOPSIS and AHP, a decision support tool is proposed by Carpitella et al. to perform a reliability analysis with relation to a subsystem, in which the consensus obtained by modeling the different decision-making capabilities of each expert is not taken into account in the process of judging from the experts. Liu et al. provided an algorithm to cope with the group decision making characterized by the large number of participators in distributed groups and based on conflict assessments and majority opinions [
8].
The second related stream of research is on complex network theory. Complex network theory is an effective method to analyze system complexity, and it has been widely applied to many fields, such as social networks, and biological networks [
30,
31]. It is crucial to identify the most influential nodes in complex networks for optimizing the network structure and accelerating information dissemination. In network analysis, measuring centrality is one of the important ways to identify the most influential spreaders. Degree centrality (DC) [
32] is a basics measure, and the importance of one node is measured by the number of its neighbors. Global measures such as betweenness centrality (BC) [
33] and closeness centrality (CC) [
34] can identify node influences in the global scope. Kitsak [
35] proposed a new centrality measure called “k-shell decomposition”. This measure, which determines the centrality of nodes based on their locations in the network, considers nodes topographically located in the core of the network as influential nodes. Katz [
36] introduced a measure of centrality known as Katz centrality, which computed influence by taking into account the number of walks between a pair of nodes. Stephenson and Zelen [
37] defined the information centrality using the “information” contained in all possible paths between pairs of points. Ahmad Zareie et al. [
38] have taken advantage of an entropy-based approach to detect the spreading capability of nodes in networks on the basis of their topological information.
3. Proposed Method
3.1. Preliminaries
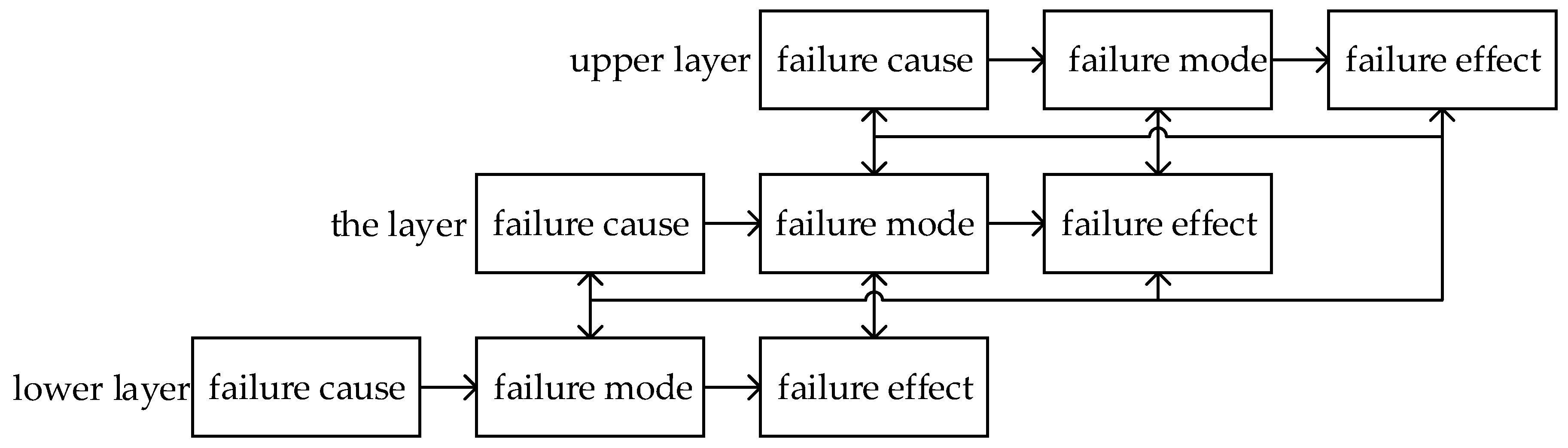
The FMECA worksheet contains a wealth of product failure information, but it can only meet the needs of simple information retrieval. The information mining of failure modes, and their causes and effects are the descriptions of quality features of products from multi-level, which can be transformed between different levels.
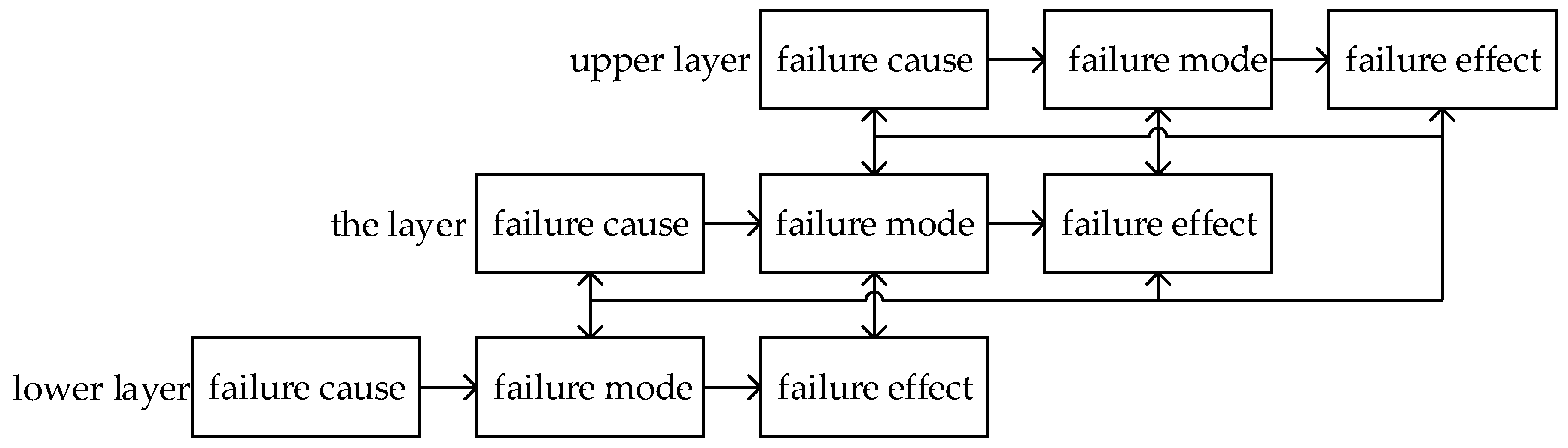
FMECA denotes that the cause of failure is failure mode in the lower layer, and the effect of failure is failure mode in the upper layer. The transformation and logical relation between failure modes, and their causes and effects, are shown in
Figure 1.
Where failure cause leads to failure mode break out, failure mode has three different effects on the product function, which are the local influence on the layer, the high-level impact on the upper adjacent layer, and the final impact on the initial indenture level. We introduce a complex network to describe the coupling relations between failure modes, and their causes and effects. Based on
Figure 1, we consider failure mode, and their causes and effects as nodes. Moreover, the logical relations between failure modes, and their causes and effects, are mapped as edges, for each edge may have different impact on other nodes, and we set weighted value to represent the difference.
3.2. The Construction of Weighted Network
According FMECA, we should first determine the indenture levels dependent on the functional relationship or composition characteristics of products. Generally, it can be divided into three layers, which are initial indenture level, other indenture level and lowest indenture level. Suppose that n and m are the numbers of failure modes, and their causes and effects and indenture levels, respectively, then the failure set and indenture level set are written as
and
. For any two nodes, the coupling relation between
and
is denoted as
. So the coupling set is represented as
. If there exists node
i and node
j directly connected with edge
, then
, otherwise
. In addition, the set of weighted values is denoted as
, which indicates the force of a node on other nodes. In traditional FMECA, occurrence (
O) and detection (
D) have a certain overlap in the information. Generally speaking, it is easily to be detected for the failure mode if the probability of occurrence is large. Therefore, in order to eliminate the redundancy of information, according to the meaning of failure modes, and their causes and effects, combined with the influence relations between them,
is represented as the weight of failure cause to failure mode in this paper, and
is used to weight the influence of that failure mode on failure effect. So we represent the FMECA model as the following.
where,
(
) denote the nodes set, edges set and weights set, respectively. Particularly,
is represented by
or
. Based on the logical relationships at different levels of products in
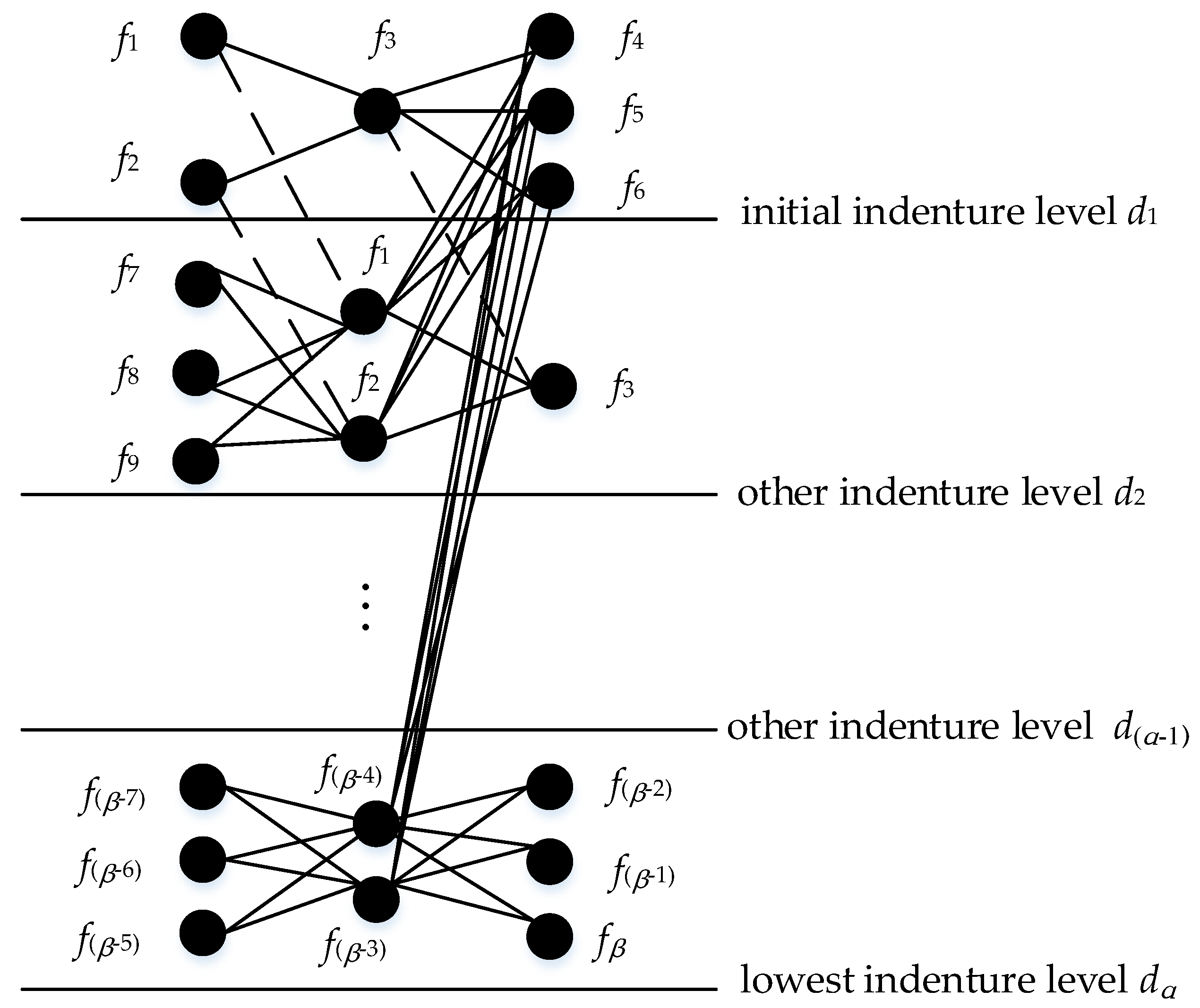
Figure 1, we propose a complex network structure diagram as shown in
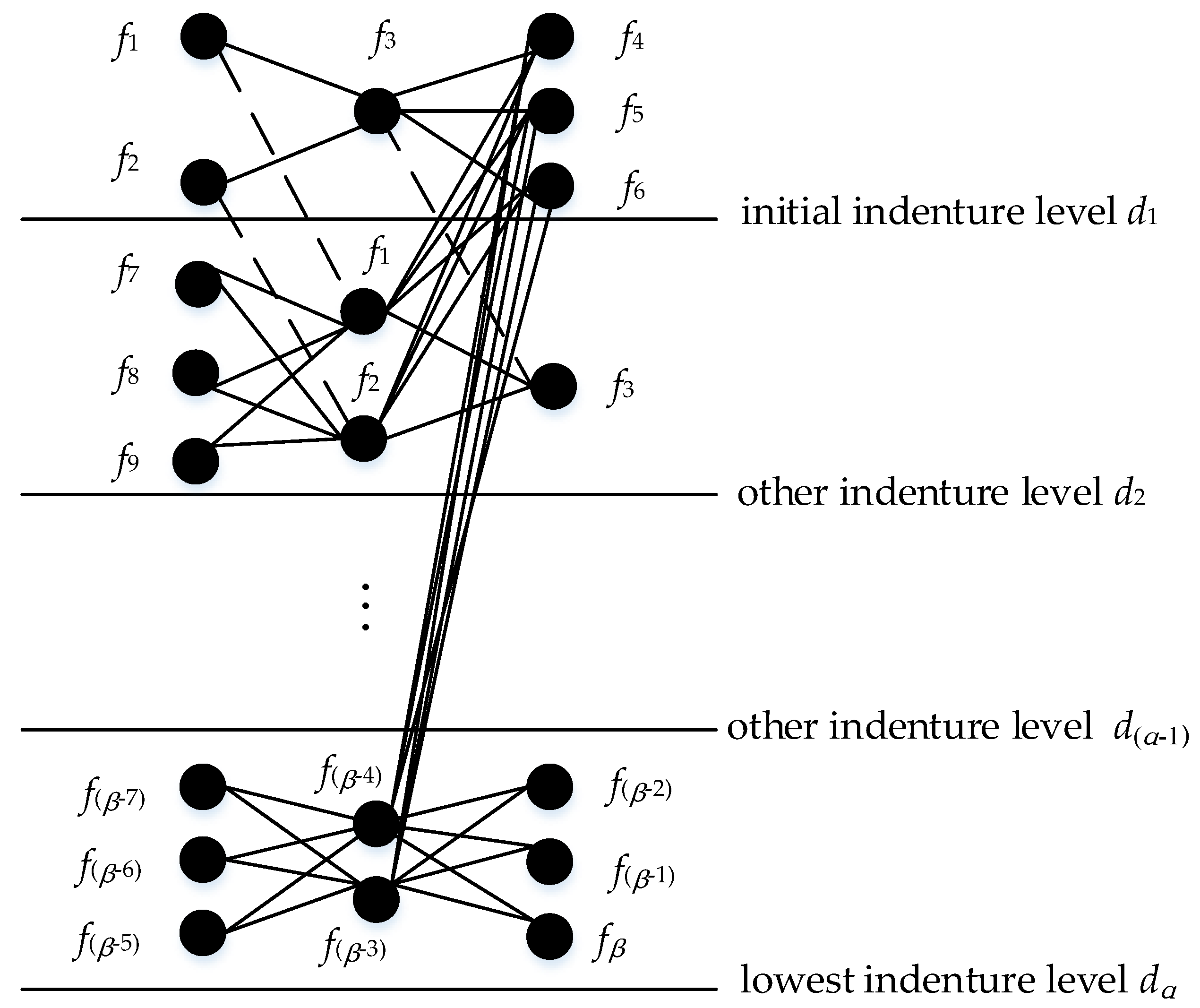
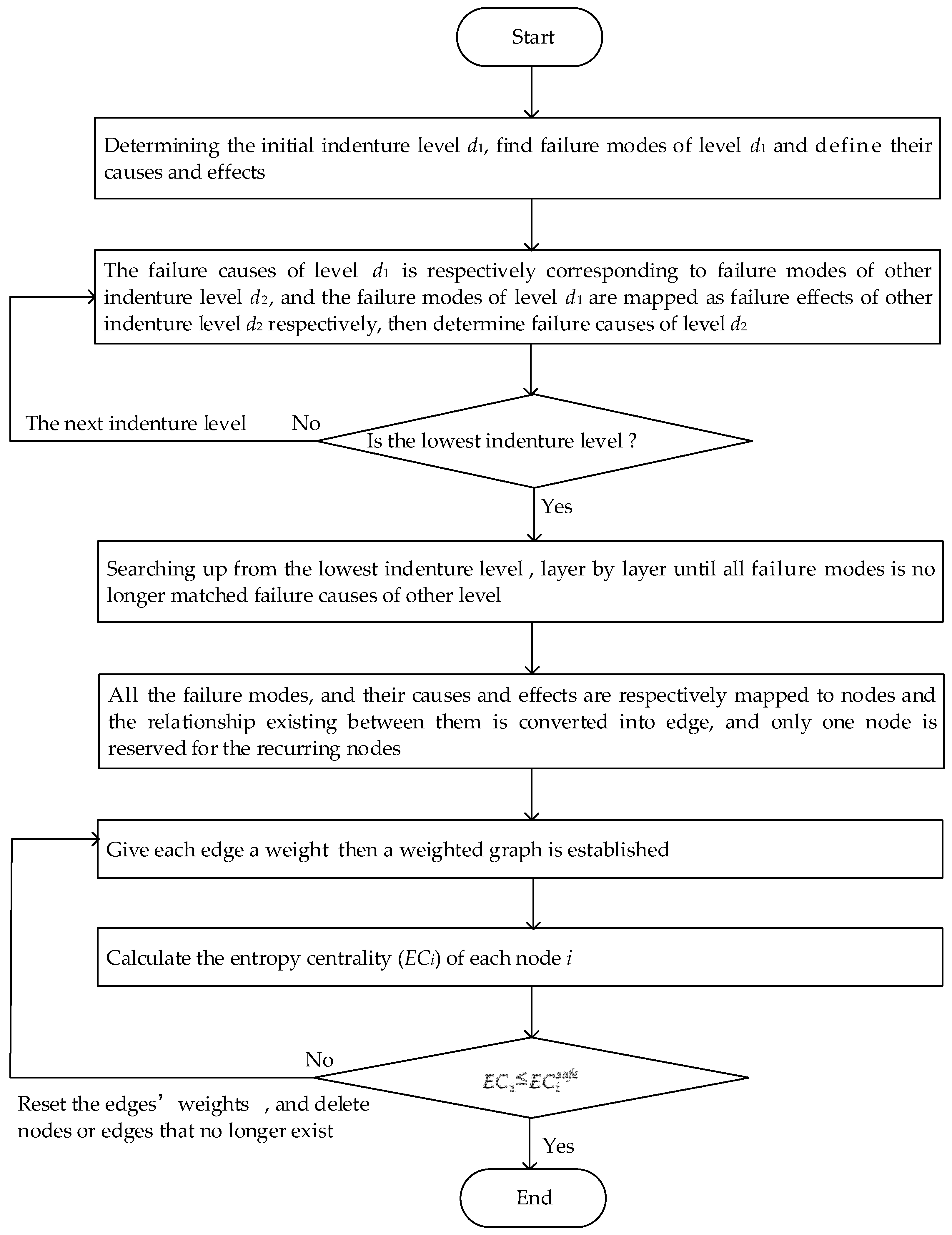
Figure 2. The steps to determine the entire structure diagram are as follows:
Step 1: According to the quality control needs of products, determine the initial indenture level , find failure modes of level and determine their causes and effects.
Step 2: The failure causes of initial the indenture level is respectively corresponding to the failure modes of the other indenture level , and the failure modes of are mapped as the failure effects of the other indenture level , respectively; furthermore, determine failure causes of level .
Step 3: In the same way, continue to search for failure modes and their causes and effects of the next level, until all of them are searched; denote this level as the lowest indenture level .
Step 4: Searching up from the lowest indenture level , layer by layer until all fault modes are no longer matched to the failure causes of the other level.
Step 5: Finally, all the failure modes and their causes and effects are respectively mapped to nodes, and the relationship existing between them is converted into an edge, and only one node is reserved for the recurring nodes. Accordingly, a structure diagram of FMECA is established as shown in
Figure 2.
In
Figure 2, {
} is represented to failure modes, and their causes and effects set. The black solid line is used to describe the direct coupling relation and the dash line indicates that failure modes, and their causes and effects, correspond to each other in different levels; each black solid line is given a weight
.
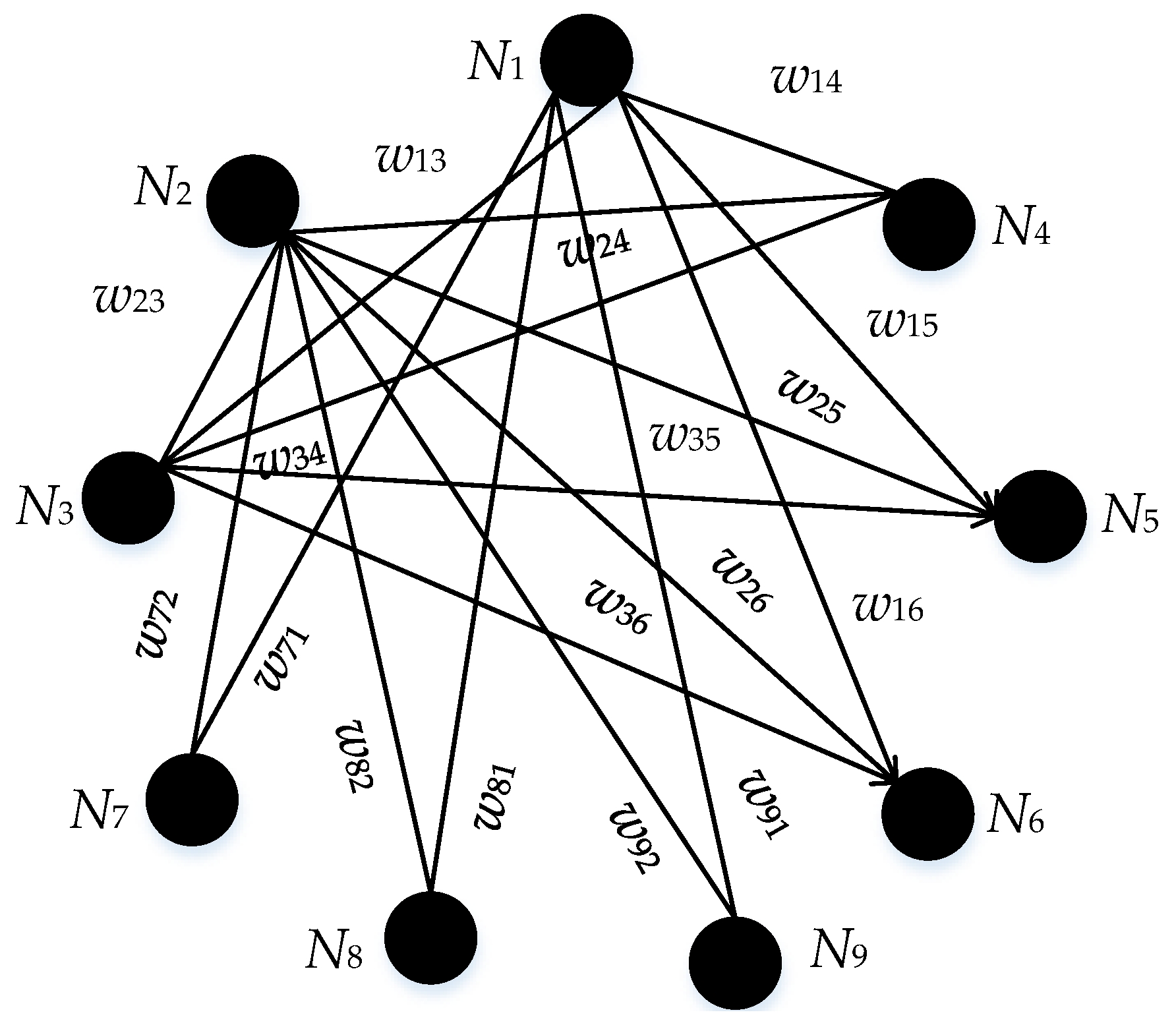
Assume that there are only the initial indenture level
and the lowest indenture level
in
Figure 2. Then an example of a weighted network is set up in
Figure 3.
As shown in
Figure 3,
and {
} is one-to-one correspondence. The values of weights, denoted as
, are listed in
Table 1.
3.3. Information Entropy and Algorithm
Information entropy is widely used in information science and statistical physics to describe the order of information distribution [
39]. If X is a set of possible events
,
, …,
, and
is the probability of
, the entropy of X can be calculated as:
where,
,
= 1. On the one hand, when the values of
n are equal, if the probabilities
have uniform distribution, then the higher the entropy value will be. Additionally, as the value of
n increases, so does the entropy value. Therefore, employing entropy can be useful for the detection of nodes with high-degree, more uniform neighbors.
Dehmer suggested introducing a tuple (
) of non-negatives in order to form a probability distribution
which is described as follows [
40].
In Equation (4),
represents the
ith non-negative integer. Therefore, the Equation (4) can be written as
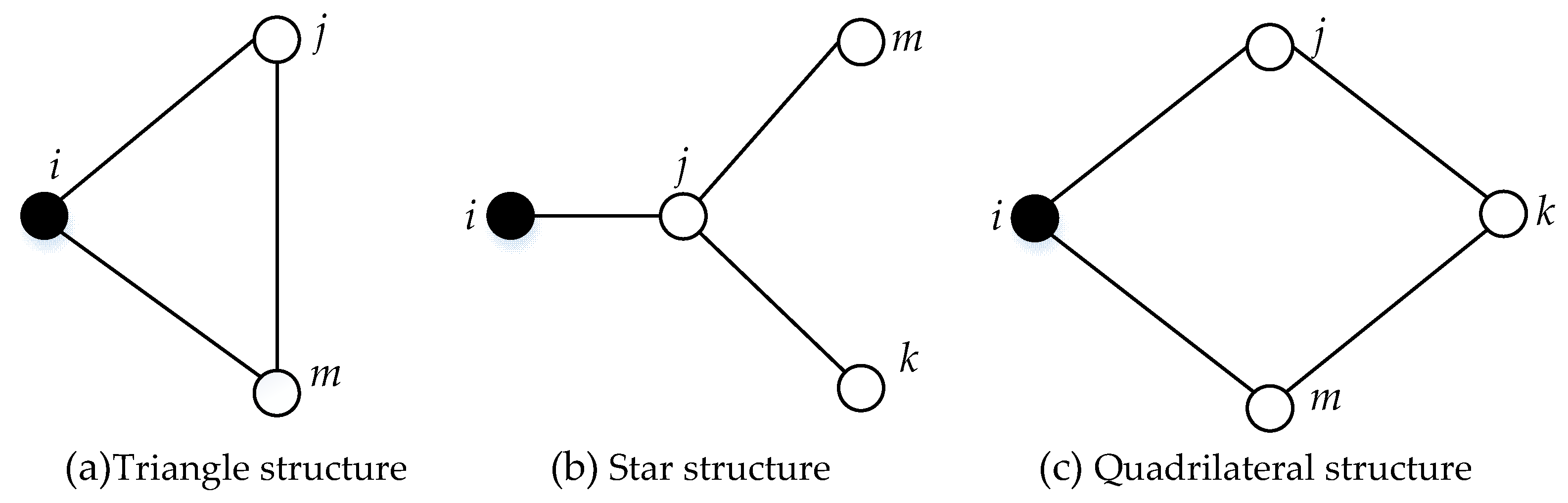
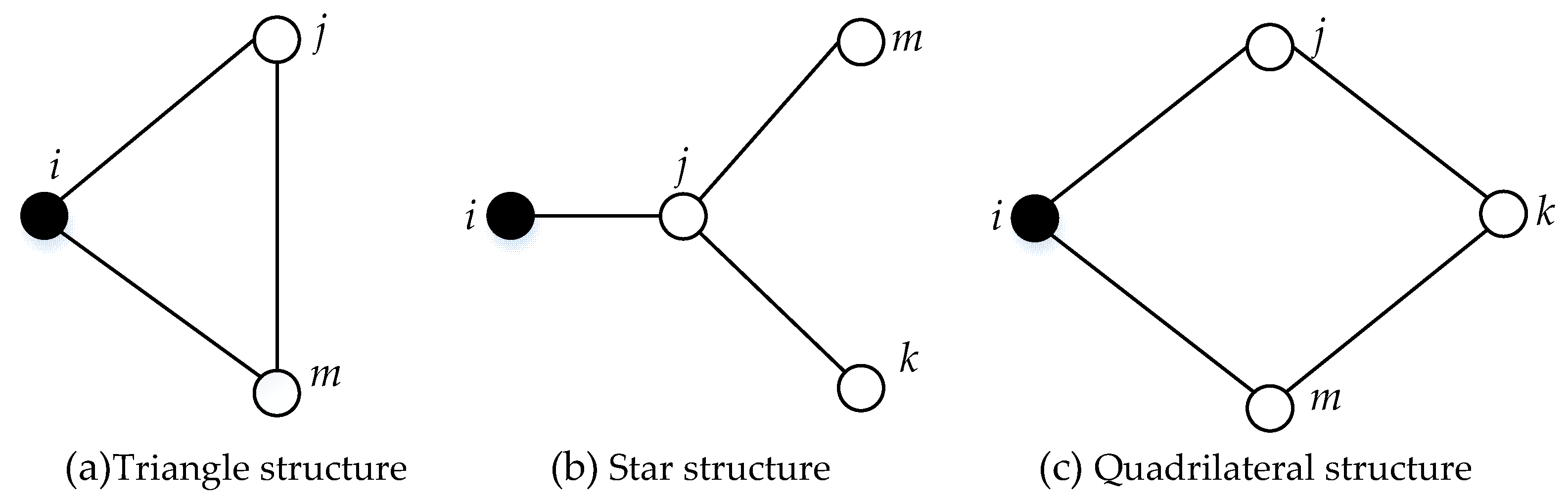
In addition, we find that a neighborhood network of FMECA usually concludes three argument structures, which are showed in
Figure 4.
Particularly, in a complex network for FMECA, there is a direct connection between fault cause and fault mode, and fault mode link to fault effect as well. Moreover, a correspondence between different indenture level makes a number of vertices directly linked together; the second order or above neighbor node in the network is quite rare. Based on the above analysis, although research has shown that the entropy centrality should have higher precision if considering the influence of the second order or above neighbor node, this paper calculates entropy centrality and only considers the first neighbor node.
In this paper, we take advantages of both topological structure and information entropy, where the local power of a given vertex includes not only structural entropy but also interaction frequency entropy [
41]. The structural entropy evaluates the influence or strength of a given node based on the topographic properties of the sub-graph. Similarly, the interaction frequency entropy, which takes advantage of information contained in the weights of edges that rest between nodes and nodes, depicts the propagation effectiveness of a given node.
Additionally, the degree of node
i is represented as
, and expresses the influence on the neighbor nodes,
where,
which denotes the node
i has a direct link to the neighbor node
j. In addition, we denote
M is the number of first order neighbors of node
i. Thus, we obtain the tuple (
), and define it as follows.
Based on the above definition, we obtain that the structural entropy centrality of node
i is denoted by
:
In addition, the weight of edges plays a role in estimating the interaction frequency, we denote
as the interaction frequency entropy of node
i, and it is defined as:
where
denotes the weight of the edge and
M indicates the number of first order neighbors of node
i. Combining
with
, denoted as
, which equals the summation of the structural entropy and frequency entropy, multiplied by two parameters, respectively, so the
is computed through the following equation:
where
and
stand for the weight coefficients, respectively, and
3.4. A Summary of Method
We present a novel method for supporting FMECA that introduces complex theory into FMECA, and failure modes, and their causes and effects are denoted as nodes, while the edges represent nodes connected to the other nodes. In addition, the edge between failure cause and failure mode is weighted as
, and the link for that failure mode with failure effect is denoted as S. By mining topological structure in complex networks, and making use of information contained in the weighted links, we finally get an improved RPN indicator, which is
, and it is named as ECRPN, and means a way to evaluate RPN by entropy centrality. Moreover, the weight of each edge will change as long as any indicator of the
O,
S,
D changes. Besides, with the improvement of social management and technology, when people discover there is no longer any influence relation on certain failure modes, and their causes and effects, or some failure modes, and their causes and effects no longer affect the product quality, some corresponding vertices or edges will also disappear. Therefore, the weighted graph which we established is dynamic. Further, values for
and
are purposely set as
and
, respectively. Peng et al. [
42] have demonstrated that entropy-based centrality outperformances the classic degree-based centralities and path-based centralities under the conditions of this particular set of parameters. Thus, the Equation (10) is denoted as:
where,
M is the number of node
i’s neighbors. Furthermore, a specific safe threshold is set to screen for nodes with high risk, and the safe threshold is 70% of the maximum value of the entropy centrality of each node. It is represented as the Equation (12).
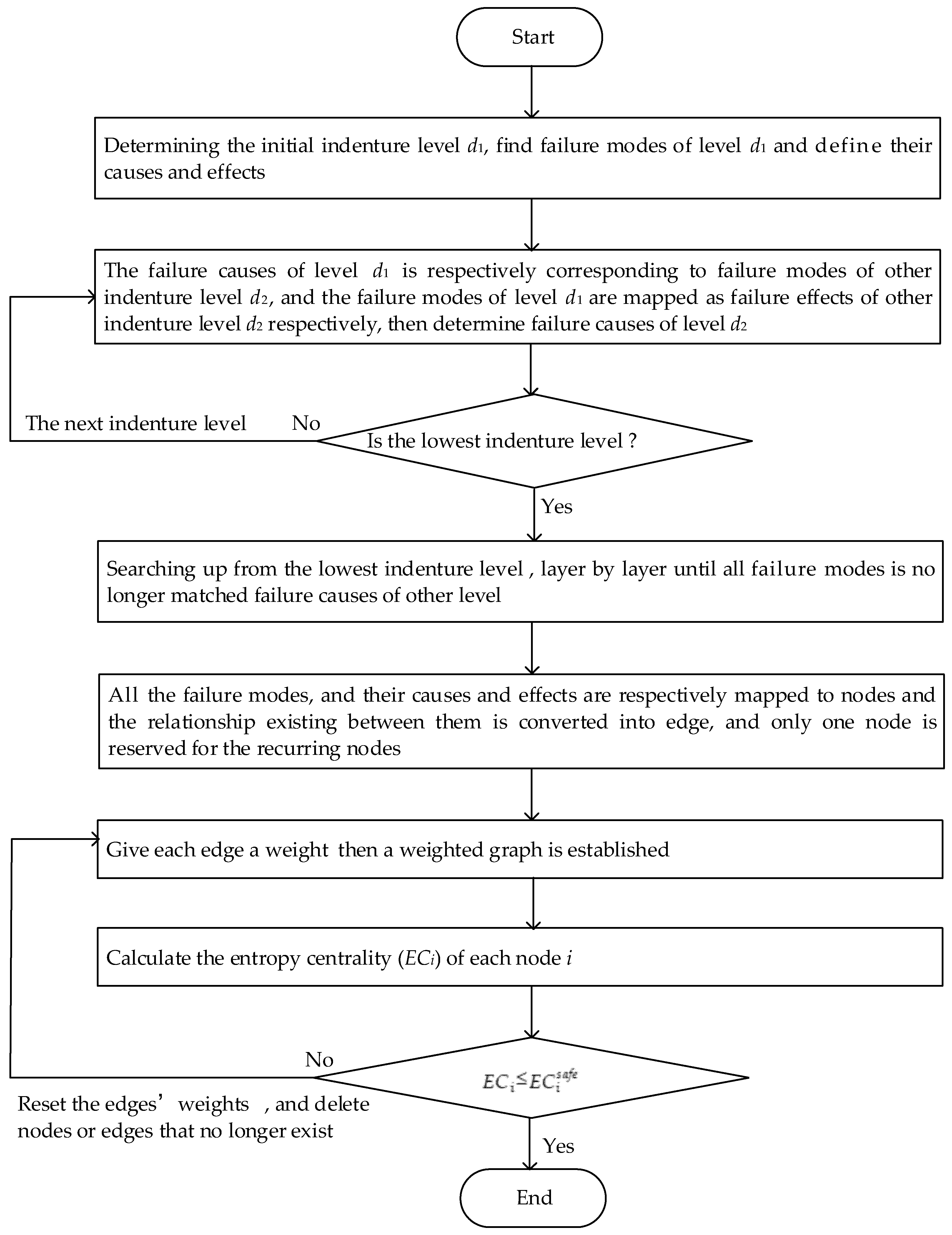
According to the above description, the flow of the whole method we proposed is shown in
Figure 5.
4. Case Study
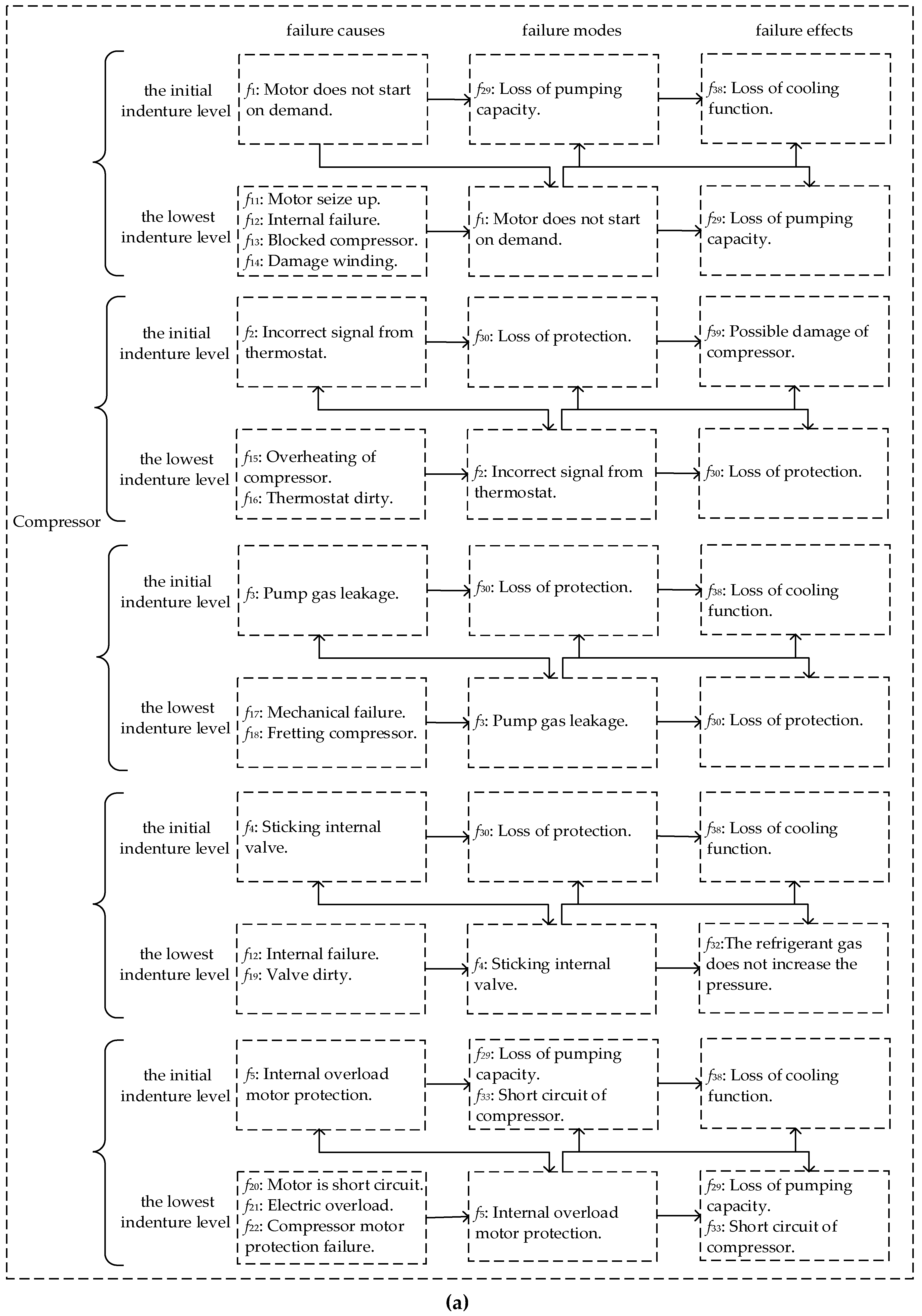
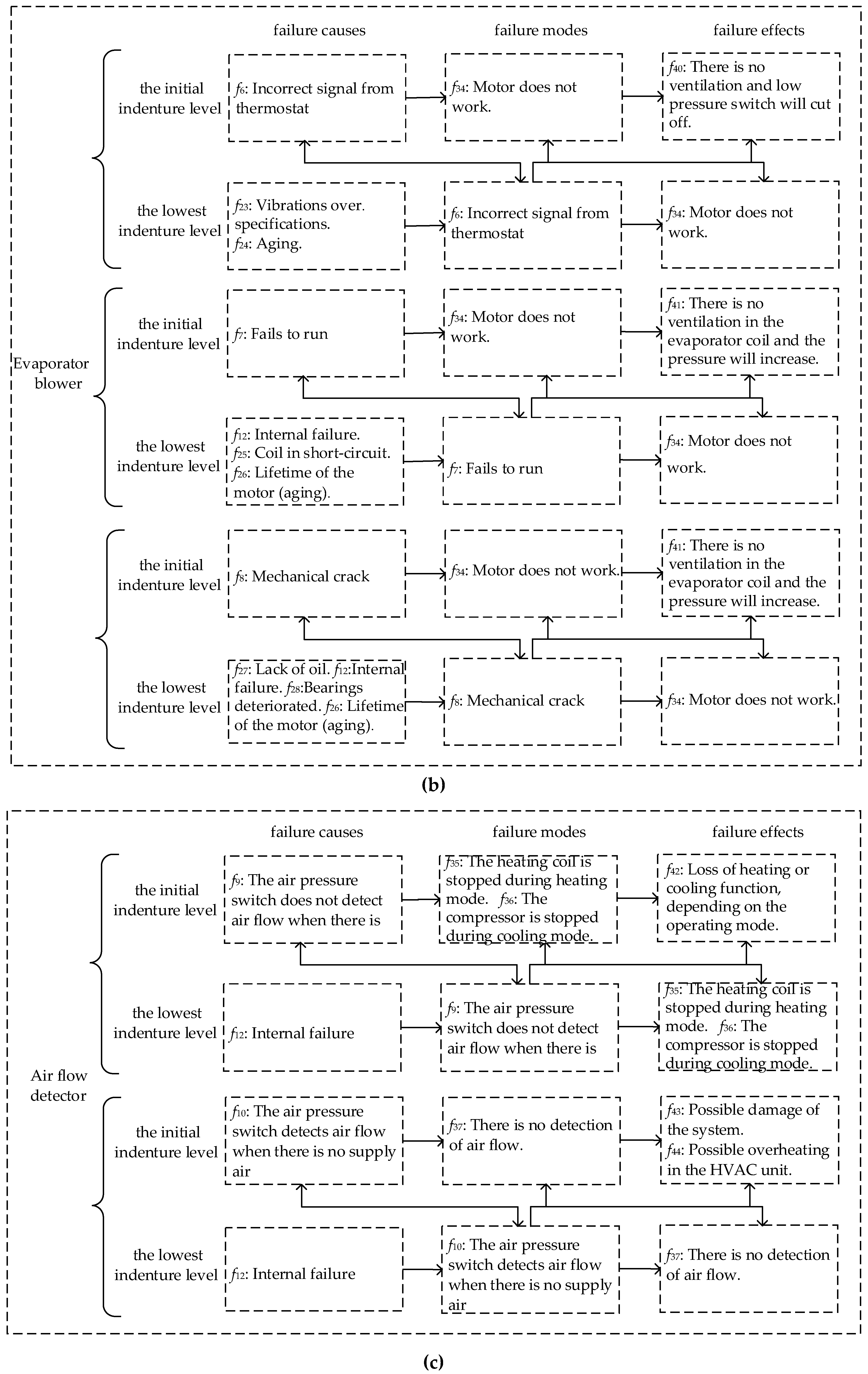
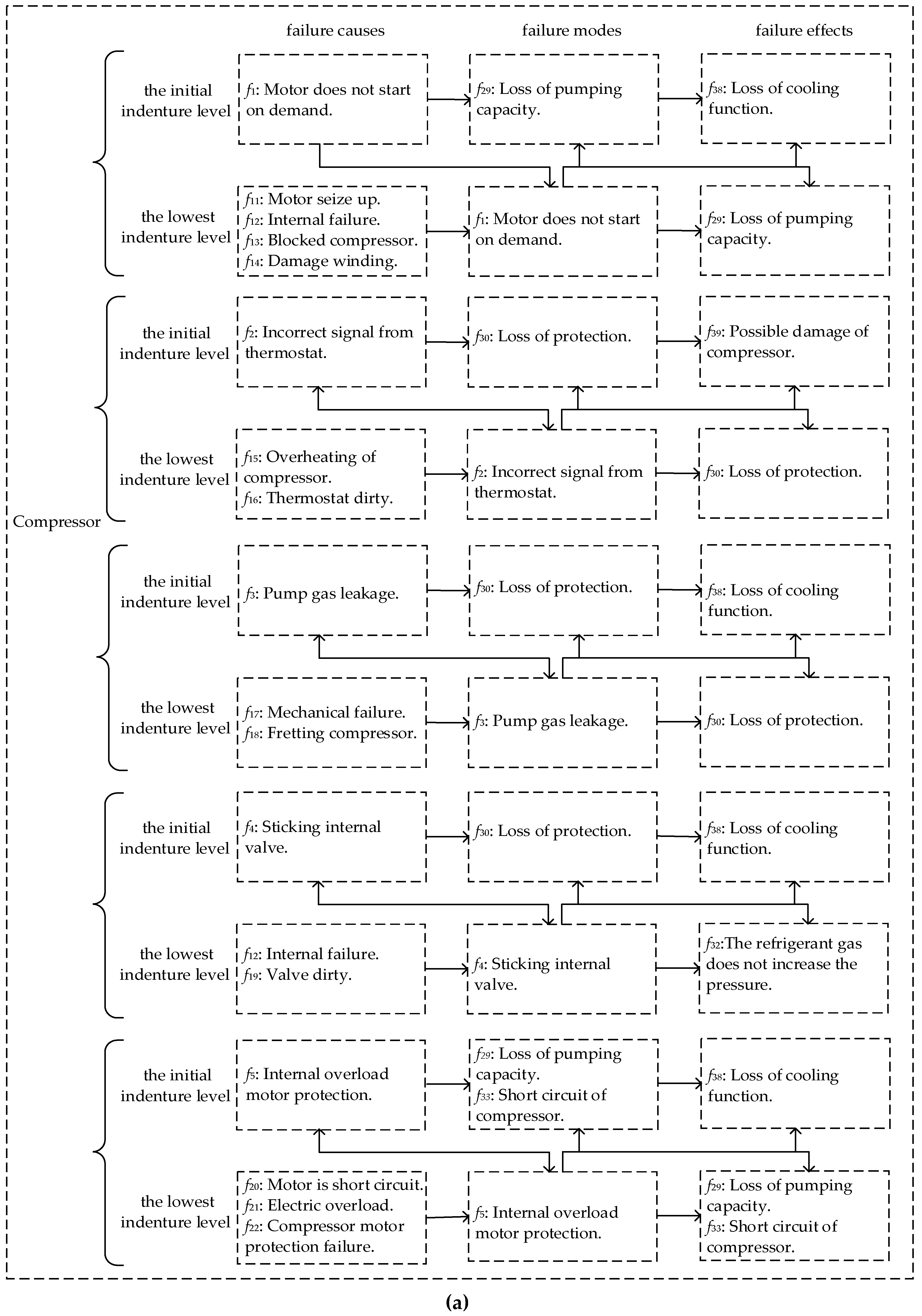
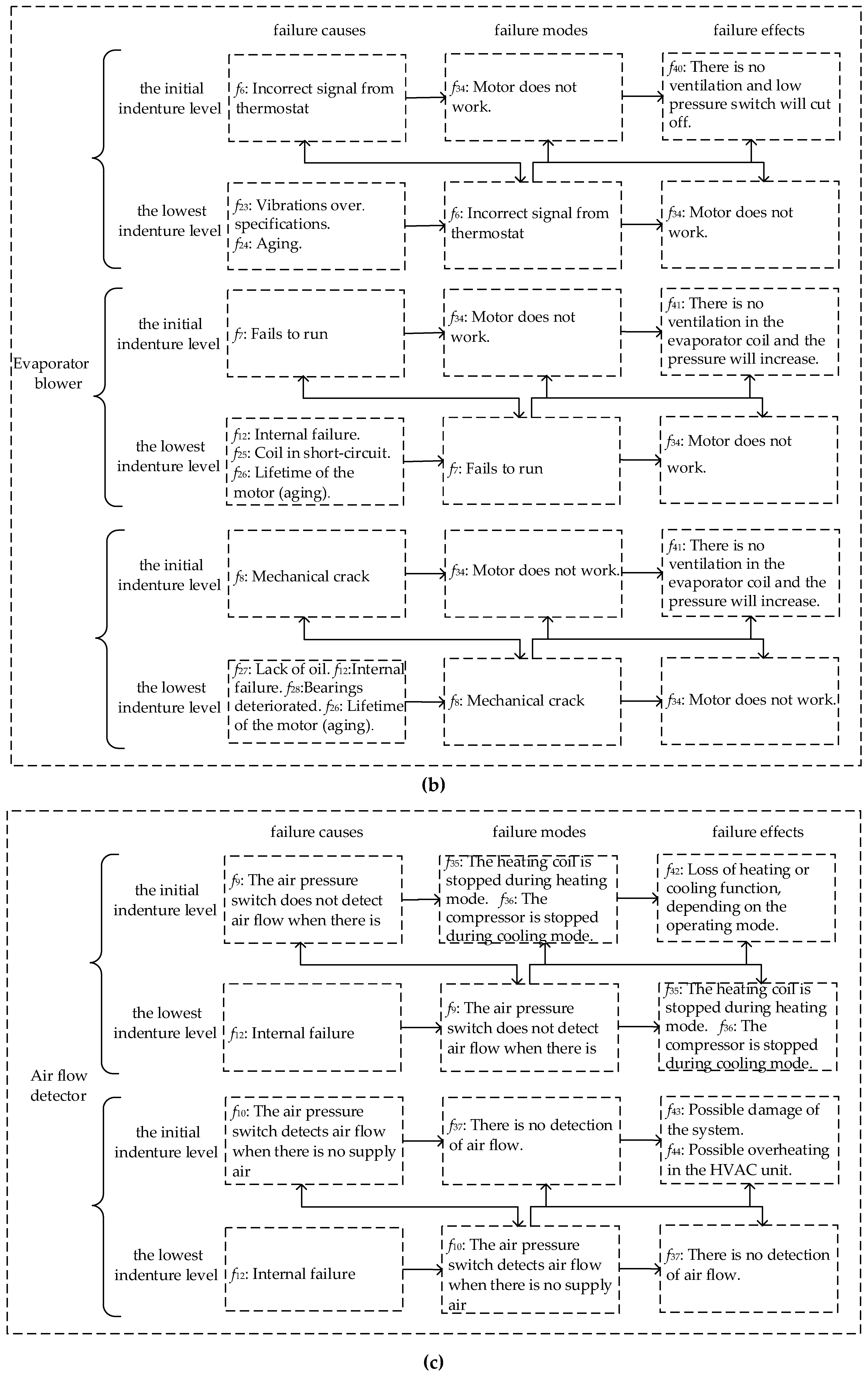
A real-world case about the Heating, Ventilation and Air Conditioning (HVAC) system was analyzed by FMECA, which came from Ciani et al.’s study [
7]. Ciani et al. focused on some of the most critical components that make up the HVAC: compressor, evaporator blower and air flow detector. According to the actual situation, the component is regarded as the lowest indenture level. In addition, based on the difference of product hardware, the system is regarded as the initial indenture level. Hence, we can divide the system into two indenture levels, where the HVAC system is the initial indenture level
, and the components are the lowest indenture level
. All the failure modes, and their causes and effects, are shown in
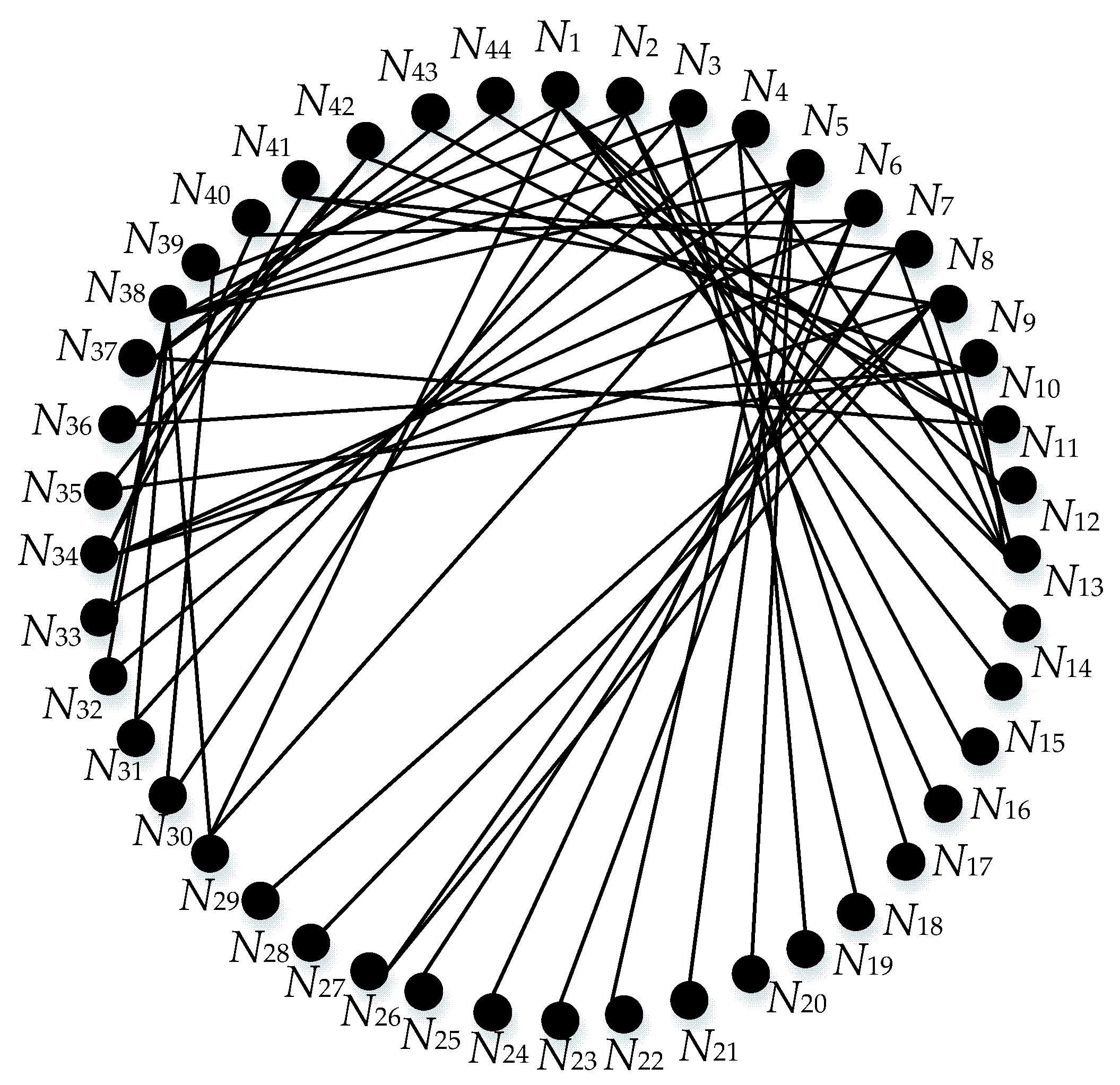
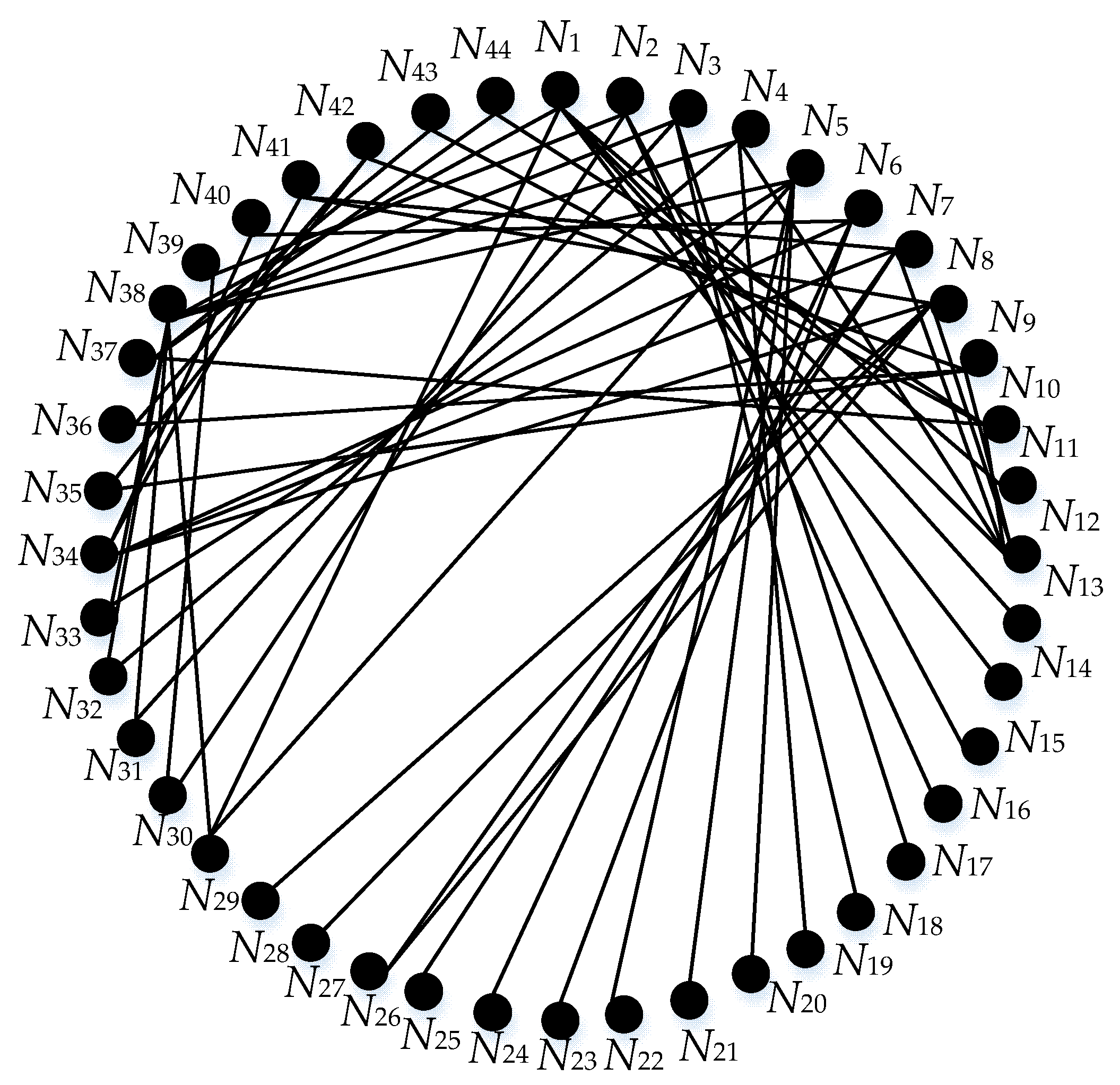
Appendix A Figure A1, based on the method we proposed, and the weighted graph is shown in
Figure 6.
Moreover, the weight between nodes and the nodes’ degrees are included in
Appendix A Table A1. Further, we take the node 1 as an example to describe the calculating process of the proposed algorithm. On the basis of Equation (8), if 10 is the base of the logarithmic function, then the structural entropy of node 1 is computed as follows:
Furthermore, following Equation (9), the interaction frequency entropy is expressed as follows:
And according to the Equation (10), we finally obtain the improved RPN indicator, represented by
, which is stated as follows:
As discussed above, based on the entropy centrality approach, the power of each node and the corresponding results are recorded in
Table 2.
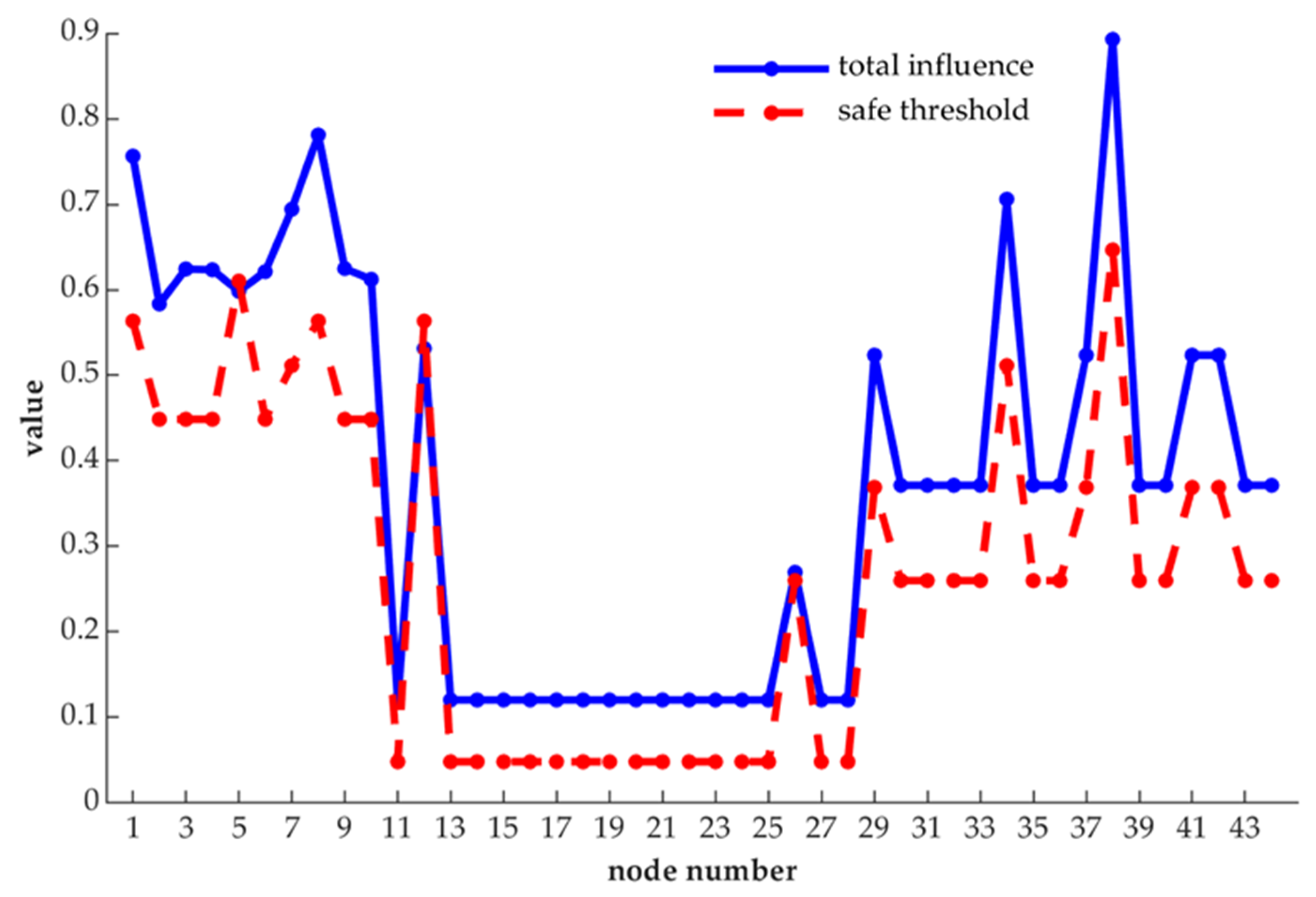
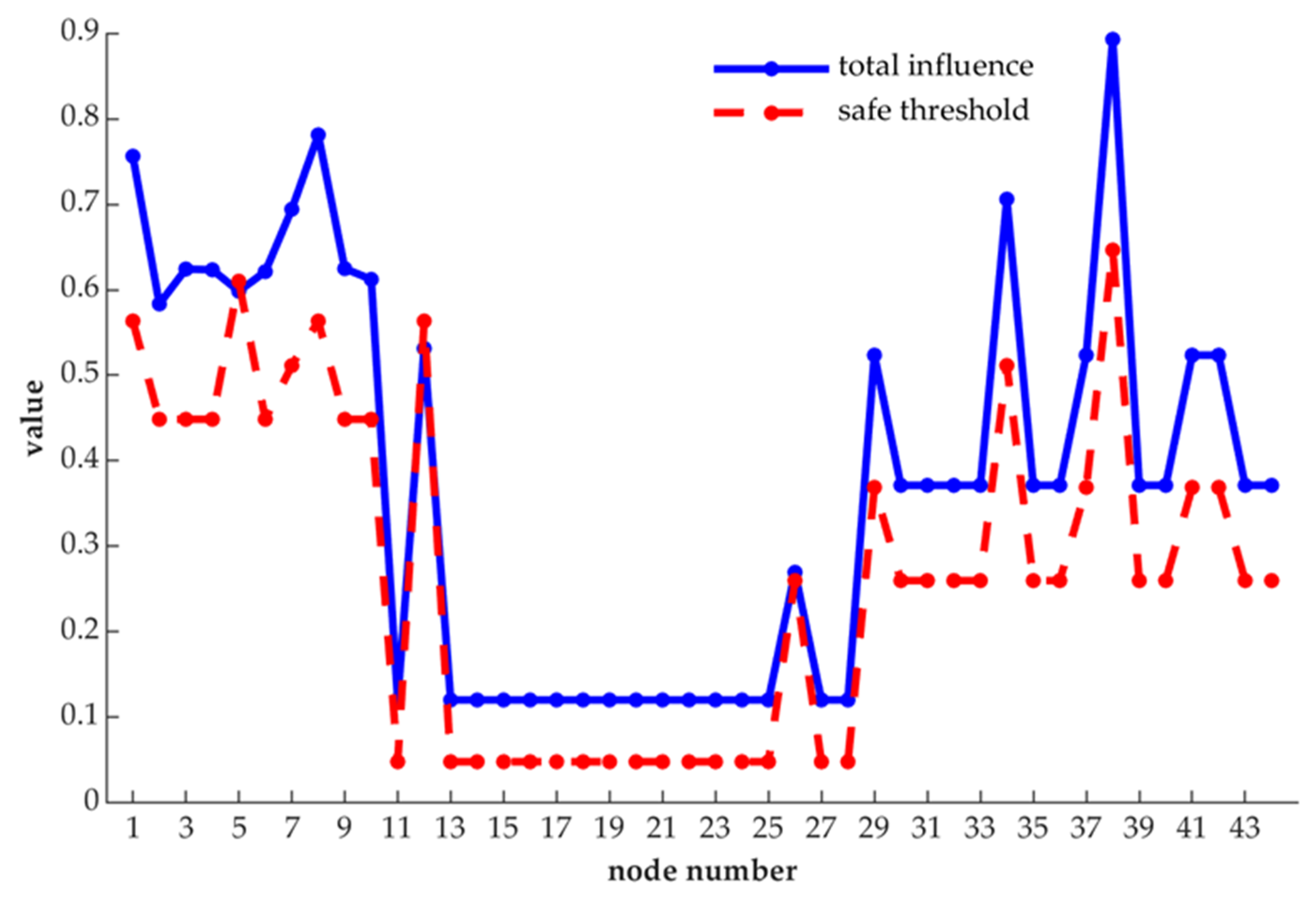
Further, the results obtained from the analysis of our proposed method are compared with each node’s safe threshold, and we present the result in
Figure 7.
In addition, we compare the results with traditional RPN method and alternative RPNs method, the difference is shown in
Table 3.
As shown in
Figure 7, in the whole network, node 1, node 8, node 34 and node 38 are obviously more important than other nodes, for their changes can have a greater impact on the nature of the network, and they can affect more nodes, too. Besides, excepting node 5 and node 12, the remaining nodes have entropy centrality values that exceed their safe threshold. Therefore, these nodes whose entropy centrality values are more than the safe thresholds should be taken as control measures.
Moreover, in
Table 3, it is shown that node 7 has the highest risk priority number based on the traditional RPN method, but it is not among the four most important nodes, it is ranked fifth place. Although node 1 and node 8 are ranked third and fourth floor with the classical RPN method, but their neighbor nodes are all 6, and the neighbor nodes of node 7 are 5, and lastly node 1 and node 8 are more influential than node 7 in the weighted network. On the one hand, nodes 1 and 8 have more neighbor nodes than node 7, which indicates that nodes 1 and 8 have more functional coupling relationships with other nodes. Through functional coupling, components compressor and evaporator blower complete certain specified actions, respectively. On the other hand, the parameters
O and
D overlap in information,
O and
D of node 1 are 8 and 7, respectively,
O and
D of node 7 are 9 and 6, and
O and
D of node 8 are 8 and 5, respectively. If traditional FMECA is used, the results for nodes 1, 7 and 8 are 56, 54 and 40, respectively. The parameters S of nodes 1, 7 and 8 are 6, 8 and 8, respectively. By combining the results of filtering the information of parameters
O and
D, and the size of parameter
S, obviously, the results of ECRPN are more scientific. Moreover, for HVAC systems, more than half of the failures are caused by electrical reasons, while nearly 20% of failures are mechanical faults, and a small part is caused by pipelines and switches, and about 85% of electrical failures are caused by motors which do not start on demand, and considering the effect caused by the failure, and the difficulty of detecting failure, the actual situation shows that the ranking of ECRPN is closer to the actual situation.
5. Conclusions and Discussion
This paper proposed a novel approach of introducing complex network theory into FMECA. The approach starts from the need to transform traditional FMECA into a weighted complex network. So initially we determined indenture levels that depended on the functional relationship or composition characteristics of products. Then, we use traditional FMECA to identify all failure modes, the causes and effects of each mode of the system. Next, we defined failure modes, and their causes and effects as nodes, and the logical relation of nodes are denoted as edges, where the edge between failure cause and failure mode is weighted as , and the link of that failure mode with failure effect is denoted as S. Then a weighted graph is established. Furthermore, the entropy centrality approach is applied to rank influential nodes. Finally, a real-world case is presented to illustrate and verify the proposed method. The results show that considering the logical relationship between the failure modes, and their causes and effects, it does have an impact on the failure mode ranking.
In this study, we use the entropy centrality method to estimate the influential nodes of the weighted graph we proposed, obviously, perfect algorithms do not exist without any limitations or assumptions. Thus, as for future work, we expect to carry out further work on improving entropy-based centrality. Moreover, the work presented in this article does not consider the difference among the local influence on the layer, the high-level impact on the upper adjacent layer, and the final impact on the initial indenture level. The magnitude of these three effects is represented by the weight S, which may not match the real-world situation. In addition, this method is based on complex networks to mine the relation between failure information. It may not be applicable to systems with insufficient failure information. Thus, our proposed method could be enhanced in the future, making it more applicable.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}