1. Introduction
Usually, in lifetime experiments, due to the restrictions of limited time and cost, accurate product lifetime data cannot be observed so we have censored data. The most common censoring schemes are so-called Type-I and Type-II censoring. In the first one, place N units in a life experiment and terminate the experiment after a predetermined time; for the other, terminate the experiment after the predetermined units number m has failed. Progressive censoring is a generalization of Type-II censoring which permits the units to be randomly removed at various time points instead of the end of the time.
Compared to conventional Type-I and Type-II censoring, progressive censoring, i.e., withdrawal of non-failed items, decreases the accuracy of estimation. However, in certain practical circumstances, experimenters are forced to withdraw items from tests. Thus, the application of the progressive censoring methodology allows profiting from information related to withdrawn items.
When the above methods still fail to meet the time and cost constraints, to further improve efficiency, other censoring schemes are successively filed by researchers. One of the successful attempts is the first failure censoring. In this censoring scheme, units are assigned to n groups in random with k identical units in each group. The lifetime experiment is conducted by testing all groups simultaneously until the first failure is observed in each group.
Since progressive censoring and first-failure censoring can both greatly enhance the efficiency of the lifetime experiment, Ref. [
1] united these two items and developed a novel censoring scheme called the progressive first-failure censoring. In this censoring,
samples are divided into
n disjoint groups in random with
k identical units at the beginning of the life experiment, and the experiment is terminated when the
mth unit fails. When the
ith unit fails, the group containing the
ith is removed together with
randomly selected groups, and when the
mth fails, all the surviving groups are removed. Here,
and
m are set in advance. Note that
(1) When , the progressive first failure censoring can be reduced to the well-known progressive Type-II censoring.
(2) When , this censoring becomes the mentioned first-failure censoring.
(3) When , and , this censoring corresponds to Type-II censoring.
Since it is more efficient than other censoring schemes, many researchers have discussed the study of the progressive first-failure censoring. Ref. [
2] considered both the point and interval estimation of two parameters from a Burr-XII distribution when both of the parameters are unknown; Ref. [
3] dealt with the reliability function of GIED (Generalized inverted exponential distribution) under progressive first-failure censoring; Ref. [
4] established different reliability sampling plans using two criteria from a Lognormal distribution based on the progressive first-failure censoring; Ref. [
5] chose a competing risks data model under progressive first-failure censoring from a Gompertz distribution and estimated the model using Bayesian and non-Bayesian methods; Ref. [
6] considered the lifetime performance index (
) under the progressive first-failure censoring schemes of a Pareto model, solved the problem of the hypothesis testing of
, and gave a lower specification limit.
The Weibull distribution is used in a widespread manner in analyzing lifetime data. Nevertheless, the Weibull distribution possesses a constant, decreasing or increasing failure rate function, its failure rate function cannot be non-monotone, such as unimodal. In practice, if the research shows that the empirical failure rate function is non-monotone, then the Inverse Weibull model is a more suitable choice than the Weibull model. The Inverse Weibull model has a wide variety of applications in pharmacy, economics and chemistry.
The cumulative distribution function and the probability density function of the Inverse Weibull distribution (IWD) are separately written as
and
where
,
is the scale parameter and
is the shape parameter.
The failure rate function is
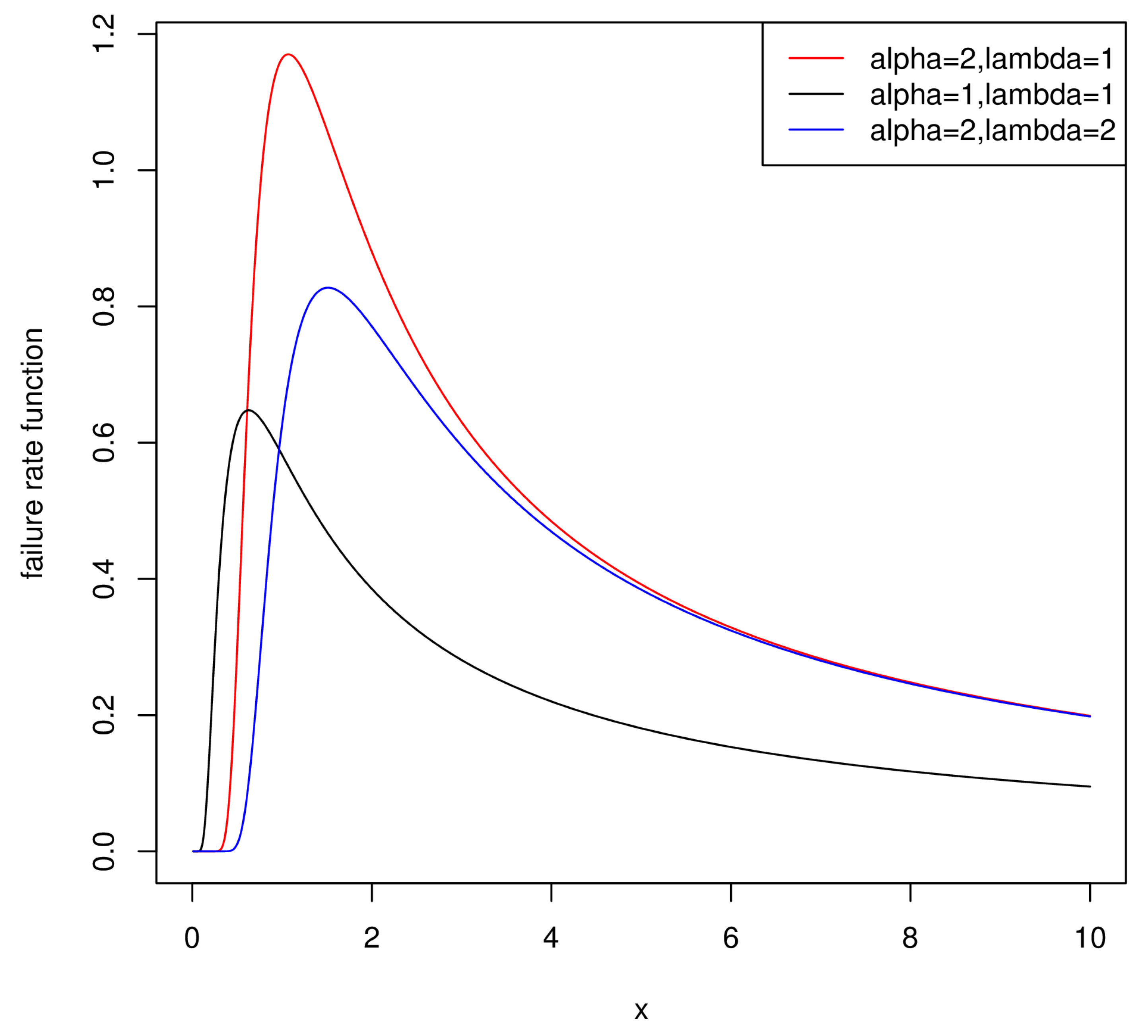
One of the most important properties of the IWD is that its failure rate function can be unimodal.
Figure 1 also evidently supports this conclusion, and we can observe that the distribution whose failure rate function is unimodal is more flexible in application.
Many researchers have studied the Inverse Weibull distribution. Ref. [
7] invesigated the Bayesian inference and successfully predicted the IWD for the type-II censoring scheme; Ref. [
8] not only considered the Baysian estimation but also the generalized Bayesian estimation for the IWD parameters; Ref. [
9] used three classical methods to estimate the parameters from IWD; Ref. [
10] estimated the unknown parameters from IWD under the progressive type-I interval censoring and chose the optimal censoring schemes; Ref. [
11] adopted two methods to get bias corrections of unknown parameters using maximum likelihood method of the IWD.
Entropy is a quantitive measure of the uncertainty of each probability distribution. For the random variable X, of the probability density distribution
, the Shannon entropy, recorded as
, is written as:
Many studies about entropy can be found in the literature. Ref. [
12] proposed an indirect method using a decomposition to simplify the entropy’s calculation under the progressive Type-II censoring; Ref. [
13] estimated the entropy for several exponential distributions and extended the results to other circumstances; Ref. [
14] estimated the Shannon entropy of a Rayleigh model under doubly generalized Type-II hydrid censoring, and compared the performance by two criteria.
The Shannon entropy of the IWD is given by:
where
is a Euler constant.
In this paper, we discuss the maximum likelihood and Bayesian estimation of the paramaters and entropy of IWD under progressive first-failure censoring. As far as we know, this topic is very new and few researchers study it. However, it needs in-depth research and innovation. The rest of this paper is elaborated as follows:
In
Section 2, we derive the maximum likelihood estimation of entropy and parameters. In
Section 3, we present the asymptotic intervals for the entropy and parameters. In
Section 4, we work out the Bayesian estimation of entropy and parameters using Lindley and Importance Sampling methods. In
Section 5, a simulation study is organized to compare different estimators. In
Section 6, we analyze a real data set to explain the previous conclusions. Finally, in
Section 7, a conclusion is presented.
5. Simulation Results
We will use the Monte Carlo simulation method to analyze the behavior of different estimators obtained by the above sections based on the expected value (EV) and mean squared error (MSE). The progressive first-failure censored samples are produced from different censoring schemes of
and various parameter values from the IWD by using the algorithm originally proposed by [
17].
In general, we let
,
, and correspondingly the entropy is 1.172676. We use the ‘optim’ command in the R software (version 3.6.1, Lucent Technologies, Mary Hill, NJ, USA) to get the approximate MLEs of
,
, and entropy presented in
Table 1. The Bayesian estimates under both asymmetric and symmetric loss functions are precisely computed by the Lindley method and Importance Samplings. For the Bayes estimation, we assign the value of hyperparameters as
for
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7 and
for
Table 8 and
Table 9. Under the LLF, we let
and
. Under the GELF, we choose
and
. We derive
asymmetric intervals of parameters using the MLEs and log-transformed MLEs and
HPD intervals. Pay attention that, for simplicity, the censoring schemes are presented by abbreviations such as
represents
and
represents
.
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6,
Table 8 present the Bayes estimation of
,
, and entropy using the Lindley method. The Bayes estimation based on Importance Samplings is shown in
Table 7 and
Table 9. In
Table 10, the interval estimation of entropy is presented.
As a whole, the EVs and MSEs of parameters and entropy all significantly decrease as the sample size
n increases. In
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9, set
m and
n invariant, the EVs and MSEs of parameters and entropy both decrease as the group size
k increases. Furthermore, set
k and
n invariant, the EVs and MSEs of parameters and entropy both decrease as
m increases. Bayesian estimates with
perform more precise than
, which is so-called non-informative. Using MLE and Bayes estimation based on the Lindley method is better than the Importance Sampling procedure. Bayes estimation using the Lindley method is a little bit more precise than the MLE. For LLF, choosing
seems to be better than
. For GELF,
competes as well as
. In
Table 7 and
Table 9, we observe that the few censoring schemes such as
and
do not compete well.
In
Table 10, the average length (AL) narrows down as the sample size
n increases. Moreover, HPD intervals are more precise than confidence intervals based on AL. For confidence intervals, using log-transformed MLEs performs much better than MLEs. In almost all circumstances, the coverage probability (CP) of entropy derived here achieve their specified confidence intervals.
6. Real Data Analysis
We will analyze a real data set and apply the approaches put forward in the sections above. The data set was analyzed by [
7,
18]. The data show the surviving days of guinea pig injected with vairous species of tubercle bacilli. The quantity of regimen is the logarithmic of the quantity of bacillary units in 0.5 mL of the challenging solution. The sample size is 72 which are listed below: 12, 15, 22, 24, 24, 32, 32, 33, 34, 38, 38, 43, 44, 48, 52, 53, 54, 54, 55, 56, 57, 58, 58, 59, 60, 60, 60, 60, 61, 62, 63, 65, 65, 67, 68, 70, 70, 72, 73, 75, 76, 76, 81, 83, 84, 85, 87, 91, 95, 96, 98, 99, 109, 110, 121, 127, 129, 131, 143, 146, 146, 175, 175, 211, 233, 258, 258, 263, 297, 341, 341, 376 (unit: days).
Before analyzing the data, we want to test if the IWD matches the complete data well. To begin with, from [
7], we conclude that the failure rate function of this data are unimodal, so it is scientific and reasonable to analyze the data using IWD. Then, we choose various approaches to analyze the goodness of fit of IWD using the MLE. We compute the
and Kolmogorov–Smirnov (K–S) statistics with its associated
p-value represented in
Table 11. According to the
p-value, the IWD fits the complete data well.
Now, we can consider the censoring data to illustrate the previous approaches. To generate the first-failure censored sample, we randomly sort the given data into
groups with
identical units in each group, and we can get the first-failure censored sample: 12, 15, 22, 24, 32, 32, 33, 34, 38, 38, 43, 44, 48, 52, 54, 55, 56, 58, 58, 60, 60, 61, 63, 65, 65, 68, 70, 70, 73, 76, 84, 91, 109, 110, 129, 143. Then, we produce samples using three diffrent progressive first-failure censoring which are
,
and
from the above sample with
. The results are organized in
Table 12.
In
Table 13, for MLE, we calculate the EVs, MSEs, and confidence intervals of the parameters and entropy; for Bayes estimation, we obtain the EVs, MSEs, and HPD intervals of entropy and two parameters. The estimates of
,
, and entropy using the MLE and the Importance Sampling method are relatively close.




{kind=link}