A Novel Residual Dense Pyramid Network for Image Dehazing

Abstract
:1. Introduction
- We propose a new end-to-end residual dense pyramid network (RDPN) based on the encoder-decoder architecture, which achieves high performance in image dehazing.
- We propose the residual dense pyramid (RDP) as the basic building module, which not only can effectively boost network performance by improving the information flow via dense connection and the residual learning mechanism, but also can learn structural features at different resolutions from all the layers of the encoder and decoder.
- By using one RDP in the encoder and two RDPs in the decoder, the light-weight RDPN contains much fewer network parameters (only 6% of that used by DCPDN [24]) and is much faster than existing CNN based methods (run time is reduced to 0.021 s).
- To enhance the generalization ability of the RDPN, both indoor and outdoor images are collected to generate a new synthetic dataset for training. The extensive experimental results demonstrate that our light-weight RDPN can achieve competitive results compared to other heavy-weight network models.
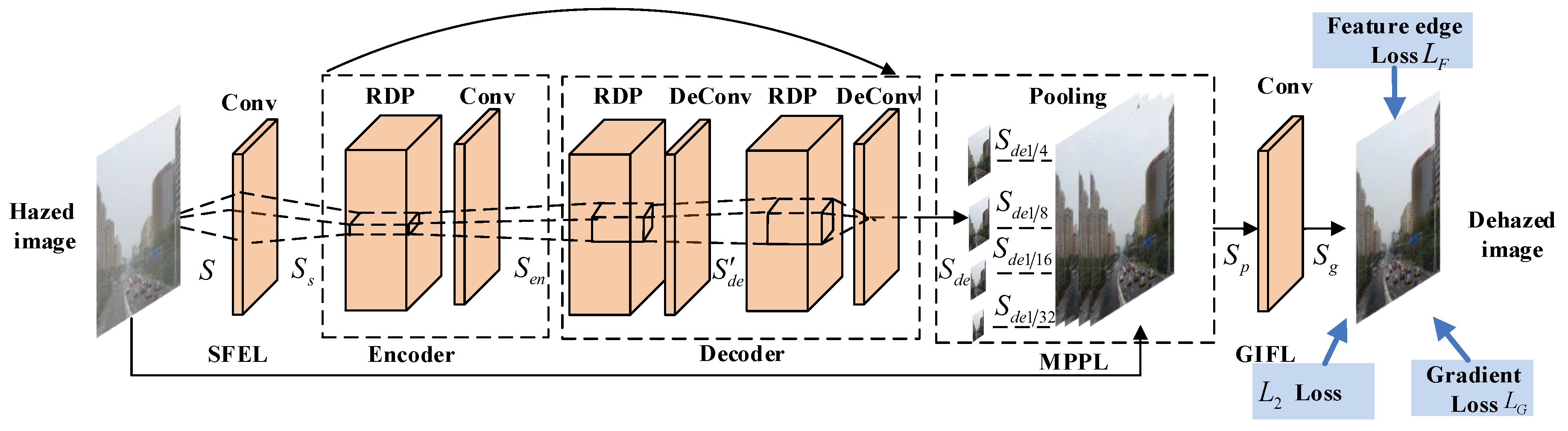
2. Residual Dense Pyramid Network for Image Dehazing
2.1. Network Structure
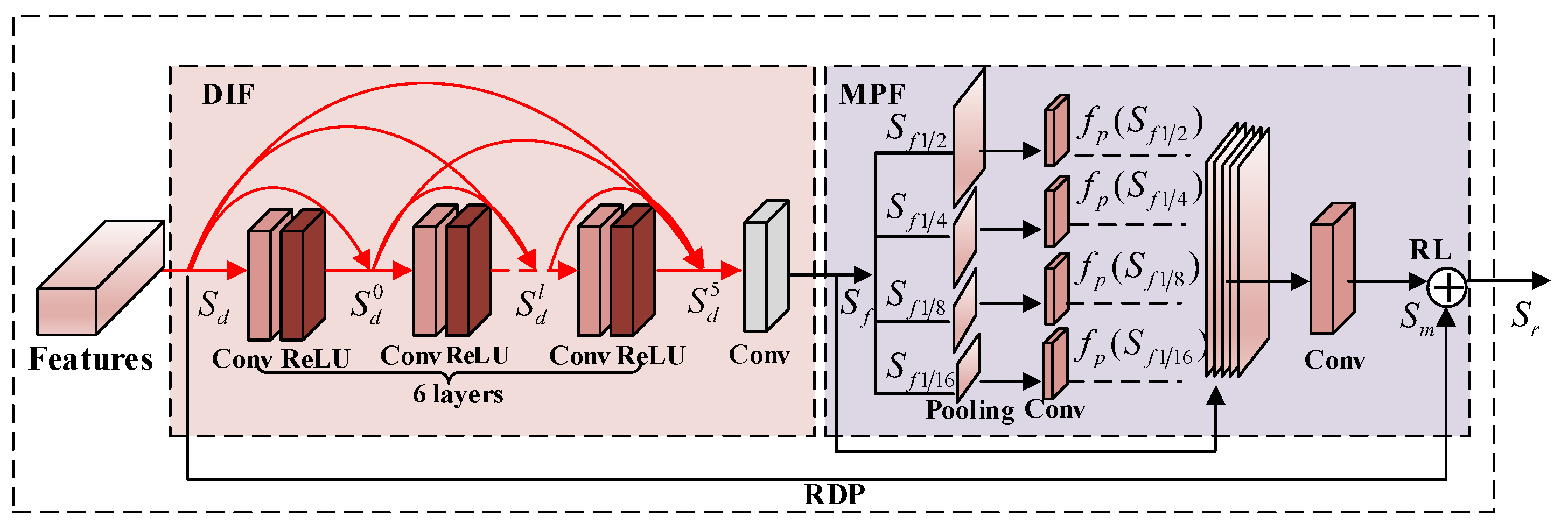
2.2. Residual Dense Pyramid
2.3. Loss Function
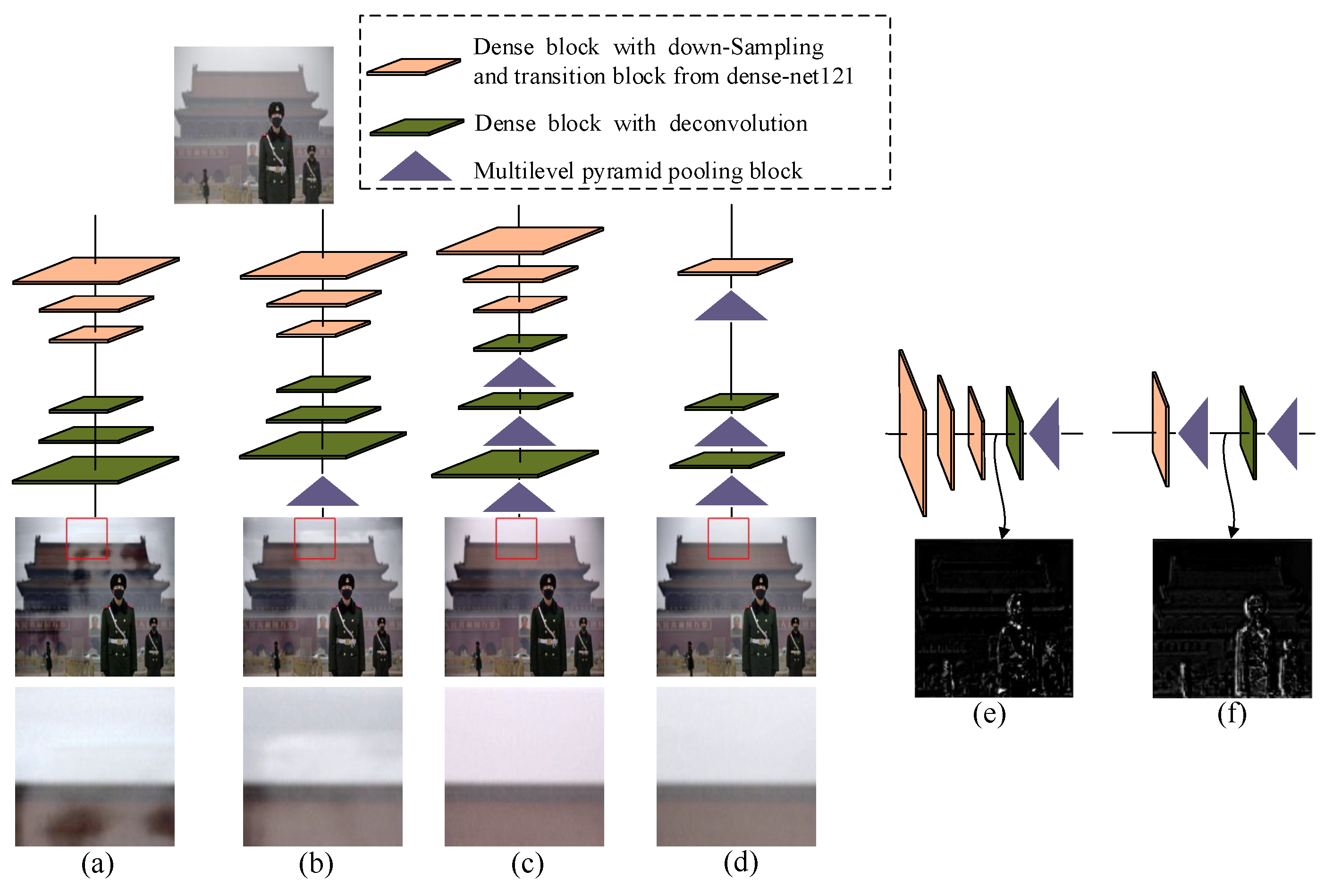
3. Discussions
4. Implementation Details
5. Experimental Results
5.1. Datasets
5.2. Testing on the Synthetic Dataset
Comparison with Existing Dehazing Methods
5.3. Testing on Real Images
5.4. Analysis and Discussion
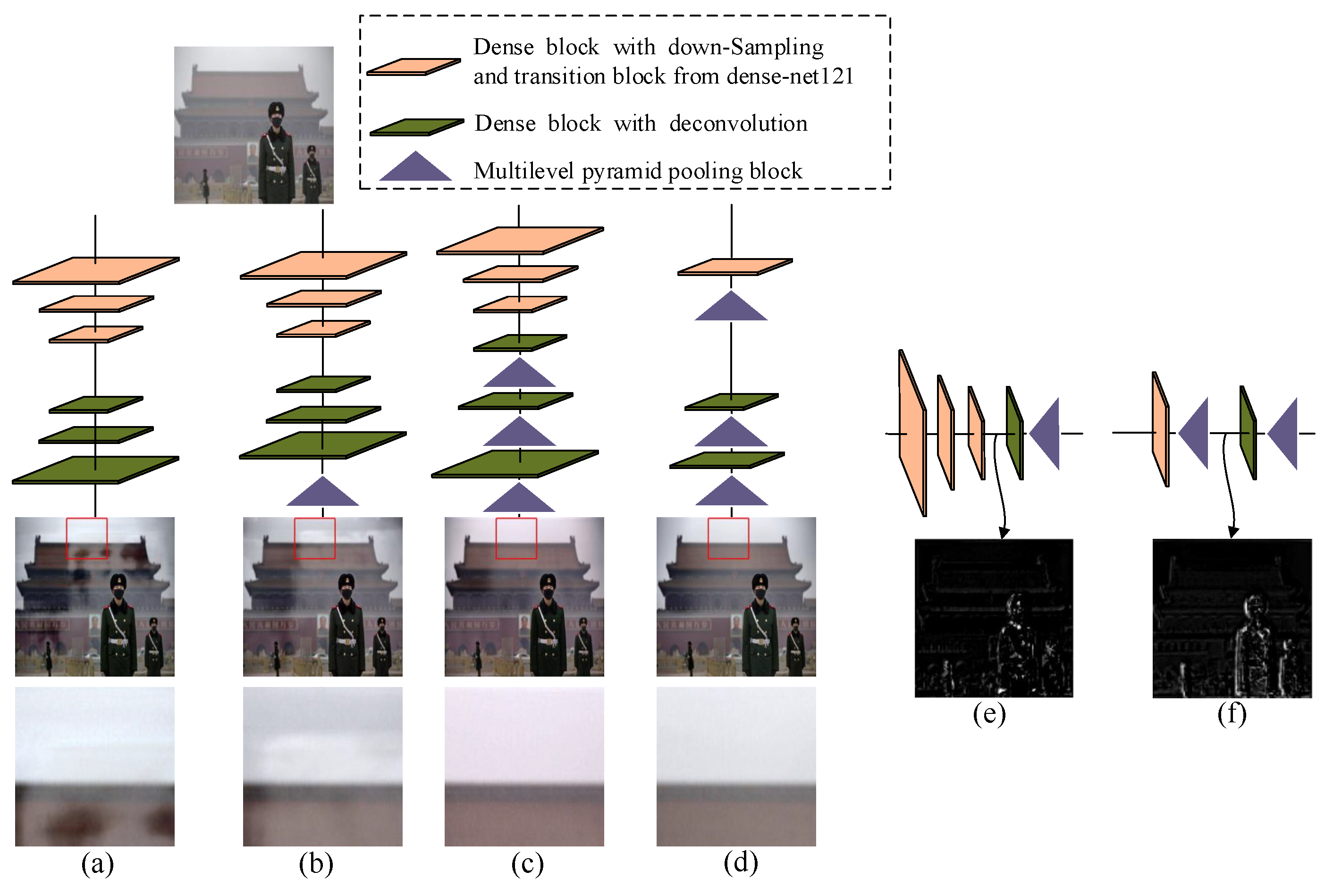
5.4.1. Different RDP Number
5.4.2. Analysis of the RDP Structure
5.4.3. Different RDP Placement
5.4.4. Effectiveness of SFEL
5.4.5. The Impact of Regulation Coefficients in the Loss Function
5.4.6. Run Time and Number of Network Parameters
5.4.7. Limitations
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hržić, F.; Štajduhar, I.; Tschauner, S.; Sorantin, E.; Lerga, J. Local-Entropy Based Approach for X-Ray Image Segmentation and Fracture Detection. Entropy 2019, 21, 338. [Google Scholar] [CrossRef]
- Mandić, I.; Peić, H.; Lerga, J.; Štajduhar, I. Denoising of X-ray images using the adaptive algorithm based on the LPA-RICI algorithm. J. Imaging 2018, 4, 34. [Google Scholar] [CrossRef]
- Yin, S.; Qian, Y.; Gong, M. Unsupervised hierarchical image segmentation through fuzzy entropy maximization. Pattern Recognit. 2017, 68, 245–259. [Google Scholar] [CrossRef]
- Wang, M.; Mai, J.; Liang, Y.; Cai, R.; Fu, T.Z.; Zhang, Z. A component-driven distributed framework for real-time video dehazing. Multimed. Tools Appl. 2018, 77, 11259–11276. [Google Scholar] [CrossRef]
- Ren, W.; Zhang, J.; Xu, X.; Ma, L.; Cao, X.; Meng, G.; Liu, W. Deep video dehazing with semantic segmentation. IEEE Trans. Image Process. 2018, 28, 1895–1908. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Liu, Q.; Gao, X.; He, L.; Lu, W. Single image dehazing with depth-aware non-local total variation regularization. IEEE Trans. Image Process. 2018, 27, 5178–5191. [Google Scholar] [CrossRef] [PubMed]
- Bhattacharya, S.; Gupta, S.; Venkatesh, K. Dehazing of color image using stochastic enhancement. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2251–2255. [Google Scholar]
- Tang, K.; Yang, J.; Wang, J. Investigating haze-relevant features in a learning framework for image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2995–3000. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed]
- Fattal, R. Dehazing using color-lines. ACM Trans. Graph. (TOG) 2014, 34, 13. [Google Scholar] [CrossRef]
- Yu, T.; Song, K.; Miao, P.; Yang, G.; Yang, H.; Chen, C. Nighttime Single Image Dehazing via Pixel-Wise Alpha Blending. IEEE Access 2019, 7, 114619–114630. [Google Scholar] [CrossRef]
- Galdran, A. Image dehazing by artificial multiple-exposure image fusion. Signal Process. 2018, 149, 135–147. [Google Scholar] [CrossRef]
- Hernandez-Beltran, J.E.; Diaz-Ramirez, V.H.; Trujillo, L.; Legrand, P. Design of estimators for restoration of images degraded by haze using genetic programming. Swarm Evol. Comput. 2019, 44, 49–63. [Google Scholar] [CrossRef]
- Valeriano, L.C.; Thomas, J.B.; Benoit, A. Deep learning for dehazing: Comparison and analysis. In Proceedings of the 2018 Colour and Visual Computing Symposium (CVCS), Gjøvik, Norway, 19–20 September 2018; pp. 1–6. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Dudhane, A.; Murala, S. C2MSNet: A Novel Approach for Single Image Haze Removal. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1397–1404. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Qu, Y.; Chen, Y.; Huang, J.; Xie, Y. Enhanced Pix2pix Dehazing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 8160–8168. [Google Scholar]
- Dudhane, A.; Singh Aulakh, H.; Murala, S. RI-GAN: An End-To-End Network for Single Image Haze Removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated fusion network for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3253–3261. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 22 April 2019; pp. 7314–7323. [Google Scholar]
- Zhang, H.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3194–3203. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Multi-scale single image dehazing using perceptual pyramid deep network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 902–911. [Google Scholar]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 22 April 2019; pp. 3937–3946. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A Simple Pooling-Based Design for Real-Time Salient Object Detection. arXiv 2019, arXiv:1904.09569, 3917–3926. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 4700–4708. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef] [PubMed]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the ECCV’12 Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Layer Type | Kernel | Filter | Stride | Pad |
|---|---|---|---|---|---|
| SFEL | 1 convolution | 1 × 1 | 32 | 2 | 0 |
| Encoder | RDP 1 convolution | / 1 × 1 | 32 64 | / 2 | / 0 |
| Decoder | RDP 1 deconvolution RDP 1 deconvolution | / 3 × 3 / 3 × 3 | 64 32 64 16 | / 2 / 2 | / 1 / 1 |
| MPPL | 4 poolings 4 up-samplings 4 convolutions | 4 × 4, 8 × 8, 16 × 16, 32 × 32 / 1 × 1 | 16 / 1 | 4,8,16,32 / 1 | 0 / 0 |
| GIFL | 1 convolution | 3 × 3 | 3 | 1 | 1 |
| Name | Layer Type | Kernel | Filter | Stride | Pad |
|---|---|---|---|---|---|
| DIF | 6 convolutions 1 convolution | 3 × 3 1 × 1 | 32 / 64 32 / 64 | 1 1 | 1 0 |
| MPF | 4 poolings 4 up-samplings 4 convolutions 1 convolution | 2 × 2, 4 × 4, 8 × 8, 16 × 16 / 1 × 1 1 × 1 | 32 / 64 / 1 32 / 64 | 2,4,8,16 / 1 1 | 0 / 0 0 |
| RL | summation | / | 32 / 64 | / | / |
| DCP [6] | NLP [7] | CAP [11] | AODN [19] | Dehazenet [17] | DCPDN [24] | Ours | |
|---|---|---|---|---|---|---|---|
| Indoor testing dataset | 13.97/0.8842 | 17.44/0.7959 | 18.04/0.8567 | 17.83/0.8842 | 20.19/0.8773 | 29.22/0.9560 | 29.29/0.9747 |
| Outdoor testing dataset | 13.59/0.8664 | 16.59/0.7736 | 16.01/0.7696 | 18.54/0.852 | 22.30/0.9159 | 28.12/0.9416 | 28.59/0.9752 |
| GPE [15] | PWAB [13] | AMEF | GFN [22] | GridDN [23] | EPDN [20] | RIGAN [21] | Ours |
|---|---|---|---|---|---|---|---|
| 11.97/0.6301 | 15.96/0.7415 | 16.01/0.7573 | 22.30/0.8800 | 32.16/0.9836 | 25.06/0.9232 | 18.61/0.8179 | 19.66/0.8972 |
| GPE [15] | PWAB [13] | AMEF [14] | GFN [22] | GridDN [23] | EPDN [20] | Ours |
|---|---|---|---|---|---|---|
| 15.91/0.7297 | 12.33/0.6759 | 17.62/0.8201 | 21.55/0.8444 | 30.86/0.9819 | 22.57/0.8630 | 26.82/0.9598 |
| RDPN, (C = 6, G = 32) | RDPN (D = 1) | RDPN (D = 1) | |||||
|---|---|---|---|---|---|---|---|
| D = 1 | D = 2 | D = 3 | C = 5 | C = 7 | G = 16 | G = 64 | |
| Indoor testing dataset | 29.29/0.9747 | 28.69/0.9675 | 29.09/0.9713 | 29.02/0.9710 | 28.84/0.9708 | 29.05/0.9721 | 29.11/0.9729 |
| outdoor testing dataset | 28.59/0.9752 | 28.28/0.9710 | 28.42/0.9729 | 28.57/0.9733 | 28.30/0.9725 | 28.35/0.9723 | 28.41/0.9739 |
| Model | Indoor Testing Dataset | Outdoor Testing Dataset |
|---|---|---|
| RDPN | 29.29/0.9747 | 28.59/0.9752 |
| RDPN using RDP w/o R | 28.78/0.9642 | 27.89/0.9701 |
| RDPN using DRP | 29.10/0.9732 | 28.32/0.9720 |
| RN | 28.84/0.9251 | 27.15/0.9111 |
| RN w/o MPPL | 27.96/0.9133 | 27.01/0.9087 |
| RDPN-Decoder | 28.97/0.9697 | 27.77/0.9712 |
| RDPN w/o SFEL | 23.04/0.9274 | 25.50/0.9568 |
| Setting | Indoor Testing Dataset | Outdoor Testing Dataset |
|---|---|---|
| λ = 2, β = 0.8 | 29.29/0.9747 | 28.59/0.9752 |
| λ = 0.8, β = 2 | 29.22/0.9745 | 28.54/0.9749 |
| λ = 1, β = 1 | 29.26/0.9746 | 28.55/0.9750 |
| PIDN [20] | PWAB [13] | AMEF [14] | GPE [15] | AODN [19] | DCPDN [24] | Ours | |
|---|---|---|---|---|---|---|---|
| Platform | PyTorch | MATLAB | MATLAB | Python | PyTorch | Python | PyTorch |
| Run time | 0.115 | 0.46 | 1.67 | 2.46 | 0.002 | 0.056 | 0.021 |
| Parameters | 172,044 | / | / | / | 1761 | 12,446,386 | 1,534,799 |
| accuracy | 26.93 | 12.33 | 17.62 | 15.91 | 20.29 | 19.93 | 26.82 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, S.; Wang, Y.; Yang, Y.-H. A Novel Residual Dense Pyramid Network for Image Dehazing. Entropy 2019, 21, 1123. https://doi.org/10.3390/e21111123
Yin S, Wang Y, Yang Y-H. A Novel Residual Dense Pyramid Network for Image Dehazing. Entropy. 2019; 21(11):1123. https://doi.org/10.3390/e21111123
Chicago/Turabian StyleYin, Shibai, Yibin Wang, and Yee-Hong Yang. 2019. "A Novel Residual Dense Pyramid Network for Image Dehazing" Entropy 21, no. 11: 1123. https://doi.org/10.3390/e21111123
APA StyleYin, S., Wang, Y., & Yang, Y.-H. (2019). A Novel Residual Dense Pyramid Network for Image Dehazing. Entropy, 21(11), 1123. https://doi.org/10.3390/e21111123