1. Introduction
The problem of reducing (or selecting) the set of attributes (or features) is known for many decades [
1,
2,
3,
4,
5,
6]. It is a central topic in multivariate statistics and data analysis [
7]. It was recognized as a variant of the Set Covering problem in [
3]. The problem of finding a minimal set of features is crucial for the study of medical and bioinformatics data, with tens of thousands of features representing genes [
7]. An analysis of feature selection methods, presented in [
7], included filter, wrapper and embedded methods, based on mathematical optimization, e.g., on linear programming. An algorithm for discretization that removes redundant attributes was presented in [
8,
9,
10]. An example of a MicroArray Logic Analyzer (MALA), where feature selection was based on cluster analysis, was presented in [
11]. An approach to feature selection, based on logic, was presented in [
12]. A lot of attention has been paid to benefits of feature reduction in data mining, machine learning and pattern recognition, see for example, References [
4,
5,
6,
13,
14,
15,
16,
17]. Recently, feature reduction or reducing of the attribute set, combined with discretization of numerical attributes, was discussed in Reference [
13,
15,
16,
18,
19]. In Reference [
18], results of experiments conducted on ten numerical data sets with four different types of reducts were presented. The authors used two classifiers, Support Vector Machine (SVM) [
20] and C4.5 [
21]. In both cases, results of the Friedman test are inconclusive, so benefits of data reduction are not clear. In experiments presented in Reference [
19], genetic algorithms and artificial neural networks were used for a few tasks: discretization, feature reduction and prediction of stock price index. It is difficult to evaluate how feature reduction contributed to final results. In Reference [
13] experimental results on ten numerical data sets, discretized using a system called C-GAME, are reported. C-GAME uses reducts during discretization. The authors claim that C-GAME outperforms five other discretization schemes. Some papers, for example, Reference [
14,
15,
16], discuss reducts combined with discretization. However, no convincing experimental results are included. A related problem, namely how reduction of the attribute set as a side-effect of discretization of numerical attributes changes an error rate, was discussed in Reference [
17].
For symbolic attributes, it was shown [
22] that the quality of rule sets induced from reduced data sets, measured by an error rate evaluated by ten-fold cross validation, is worse than the quality of rule sets induced form the original data sets, with no reduction of the attribute set.
2. Reducts
The set of all cases of the data set is denoted by
U. An example of the data set with numerical attributes is presented in
Table 1. For simplicity, all attributes have repetitive values, though in real-life numerical attribute values are seldom repetitive. In our example
U = {1, 2, 3, 4, 5, 6, 7, 8}. The set of all attributes is denoted by
A. In our example
A = {
Length,
Height,
Width,
Weight}. One of the variables is called a
decision, in
Table 1 it is
Quality.
Let
B be a subset of the set
A of all attributes. The
indiscernibility relation [
23,
24] is defined as follows
where
and
denotes the value of an attribute
for a case
. The relation
is an equivalence relation. An equivalence class of
, containing
, is called a
B-
elementary class and is denoted by
. A family of all sets
, where
, is a partition on
U denoted by
. A union of
B-elementary classes is called
B-
definable. For a decision
d we may define an indiscernibility relation
by analogy. Additionally, {
d}-elementary classes are called
concepts.
A decision d depends on the subset B of the set A of all attributes if and only if . For partitions and on U, if and only if for every there exists such that . For example, for B = {Width, Weight}, = {{1}, {2, 3}, {4}, {5}, {6, 7, 8}}, = {{1, 2, 3}, {4}, {5, 6, 7, 8}} and . Thus d depends on B.
For
Table 1 and for
B = {
Weight},
= {{1, 2, 3}, {4}, {5, 6, 7, 8}}. The concepts {4, 5}, {6, 7, 8} are not
B-definable. For an undefinable set
X we define two definable sets, called
lower and
upper approximations of
X [
23,
24]. The lower approximation of
X is defined as follows
and is denoted by
. The upper approximation of
X is defined as follows
and is denoted by
. For
Table 1 and
B = {Weight},
{6, 7, 8} = ∅ and
{6, 7, 8} = {5, 6, 7, 8}.
A set B is called a reduct if and only if B is the smallest set with . The set {Width, Weight} is the reduct since {Width} = {{1, 4, 5}, {2, 3, 6, 7, 8}} and {Weight} = {{1, 2, 3}, {4}, {5, 6, 7, 8}} , so B is the smallest set with .
An idea of the reduct is important since we may restrict our attention to a subset B and construct a decision tree with the same ability to distinguish all concepts that are distinguishable in the data set with the entire set A of attributes. Note that any algorithm for finding all reducts is of exponential time complexity. In practical applications, we have to use some heuristic approach. In this paper, we suggest two such heuristic approaches, left and right reducts.
A
left reduct is defined by a process of a sequence of attempts to remove one attribute at a time, from right to left and by checking after every attempt whether
, where
B is the current set of attributes. If this condition is true, we remove an attribute. If not, we put it back. For the example presented in
Table 1, we start from an attempt to remove the rightmost attribute, that is,
Weight. The current set
B is {
Length,
Height,
Width},
= {{1}, {2, 3}, {4}, {5}, {6}, {7, 8}}
, so we remove
Weight for good. The next candidate for removal is
Width, the set
B = {
Length,
Height},
= {{1}, {2, 3}, {4}, {5}, {6}, {7, 8}} and
, so we remove
Width as well. The next candidate is
Height, if we remove it,
B = {
Length}
, so {
Length} is the left reduct since it cannot be further reduced.
Similarly, a right reduct is defined by a similar process of a sequence of attempts to remove one attribute at a time, this time from left to right. Again, after every attempt we check whether . It is not difficult to see that the right reduct is the set {Width, Weight}.
For a discretized data set we may compute left and right reducts, create three data sets: with the discretized (non-reduced) data set and with attribute sets restricted to the left and right reducts and then for all three data sets compute an error rate evaluated by C4.5 decision tree generation system using ten-fold cross validation. Our results show again that reduction of data sets causes increase of an error rate.
3. Discretization
For a numerical attribute
a, let
be the smallest value of
a and let
be the largest value of
a. In discretizing of
a we are looking for the numbers
,
, ...,
, called
cutpoints, where
,
,
<
for
l = 0, 1,...,
and
k is a positive integer. As a result of discretization, the domain
of the attribute
a is divided into
k intervals
In this paper we denote such intervals as follows
Discretization is usually conducted not on a single numerical attribute but on many numerical attributes. Discretization methods may be categorized as supervised or decision-driven (concepts are taken into account) or unsupervised. Discretization methods processing all attributes are called global or dynamic, discretization methods processing a single attribute are called local or static.
Let
v be a variable and let
,
, ...,
be values of
v, where
n is a positive integer. Let
S be a subset of
U. Let
be a probability of
in
S, where
i = 1, 2, ..., n. An
entropy is defined as follows
All logarithms in this paper are binary.
Let
a be an attribute, let
,
, ...,
be all values of
a restricted to
S, let
d be a decision and let
,
, ...,
be all values of
d restricted to
S, where
m and
n are positive integers. A conditional entropy
of the decision
d given an attribute
a is defined as follows
where
is the conditional probability of the value
of the decision
d given
;
and
.
As is well-known [
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36], discretization that uses conditional entropy of the decision given attribute is believed to be one of the most successful discretization techniques.
Let
S be a subset of
U, let
a be an attribute and let
q be a cutpoint splitting the set
S into two subsets
and
. The corresponding conditional entropy, denoted by
is defined as follows
where
denotes the cardinality of the set
X. Usually, the cutpoint
q for which
is the smallest is considered to be the best cutpoint.
We need how to halt discretization. Commonly, we halt discretization when we may distinguish the same cases in the discretized data set as in in the original data set with numerical attributes. In this paper discretization is halted when the
level of consistency [
26], defined as follows
and denoted by
, is equal to 1. For
Table 1,
= {{1}, {2, 3}, {4}, {5}, {6}, {7, 8}}, so
=
X for any concept
X from
. On the other hand, for
B = {
Weight},
4. Equal Frequency per Interval and Equal Interval Width
Both discretization methods, Equal Frequency per Interval and Equal Interval Width, are frequently used in discretization and both are known to be efficient [
25]. In local versions of these methods, only a single numerical attribute is discretized at a time [
31]. The user provides a parameter denoted by
k. This parameter is equal to a requested number of intervals. In the Equal Frequency per Interval method, the domain of a numerical attribute is divided into
k intervals with approximately equal number of cases. In the Equal Interval Width method, the domain of a numerical attribute is divided into
k intervals with approximately equal width.
In this paper we present a supervised and global version of both methods, based on entropy [
26]. Using this idea, we start from discretizing all numerical attributes assuming
k = 2. Then the level of consistency is computed for the data set with discretized attributes. If the level of consistency is sufficient, discretization ends. If not, we select the worst attribute for additional discretization. The measure of quality of the discretized attribute, denoted by
and called the
average block entropy, is defined as follows
A discretized attribute with the largest value of
is the worst attribute. This attribute is further discretized into
intervals. The process is continued by recursion. The time computational complexity, in the worst case, is
, where
m is the number of cases and
n is the number of attributes. This method is illustrated by applying the Equal Frequency per Interval method for the data set from
Table 1.
Table 2 presents the discretized data set for the data set from
Table 1. It is not difficult to see that the level of consistency for
Table 2 is 1.
For the data set presented in
Table 2, both left and right reducts are equal to each other and equal to {Height
, Width
, Weight
}.
Table 3 presents the data set from
Table 1 discretized by the Global Equal Interval Width discretization method. Again, the level of consistency for
Table 3 is equal to 1. Additionally, for the data set from
Table 3, both reducts, left and right, are also equal to each other and equal to {Length
, Width
}.
5. Experiments
We conducted experiments on 13 numerical data sets, presented in
Table 4. All of these data sets may be accessed in
Machine Learning Repository, University of California, Irvine, except for
bankruptcy. The
bankruptcy data set was described in Reference [
37].
The main objective of our research is to compare the quality of decision trees generated by C4.5 directly from discretized data sets and from data sets based on reducts, in terms of an error rate and tree complexity. Data sets were discretized by the Global Equal Frequency per Interval and Global Equal Interval Width methods with the level of complexity equal to 1. For each numerical data set three data sets were considered:
an original (non-reduced) discretized data set,
a data set based on the left reduct of the original discretized data set and
a data set based on right reduct of the original discretized data set.
The discretized data sets were inputted to the C4.5 decision tree generating system [
21]. In our experiments, the error rate was computed using an internal mechanism of the ten-fold cross validation of C4.5.
Additionally, an internal discretization mechanism of C4.5 was excluded in experiments for left and right reducts since in this case data sets were discretized by the global discretization methods, so C4.5 considered all attributes as symbolic.
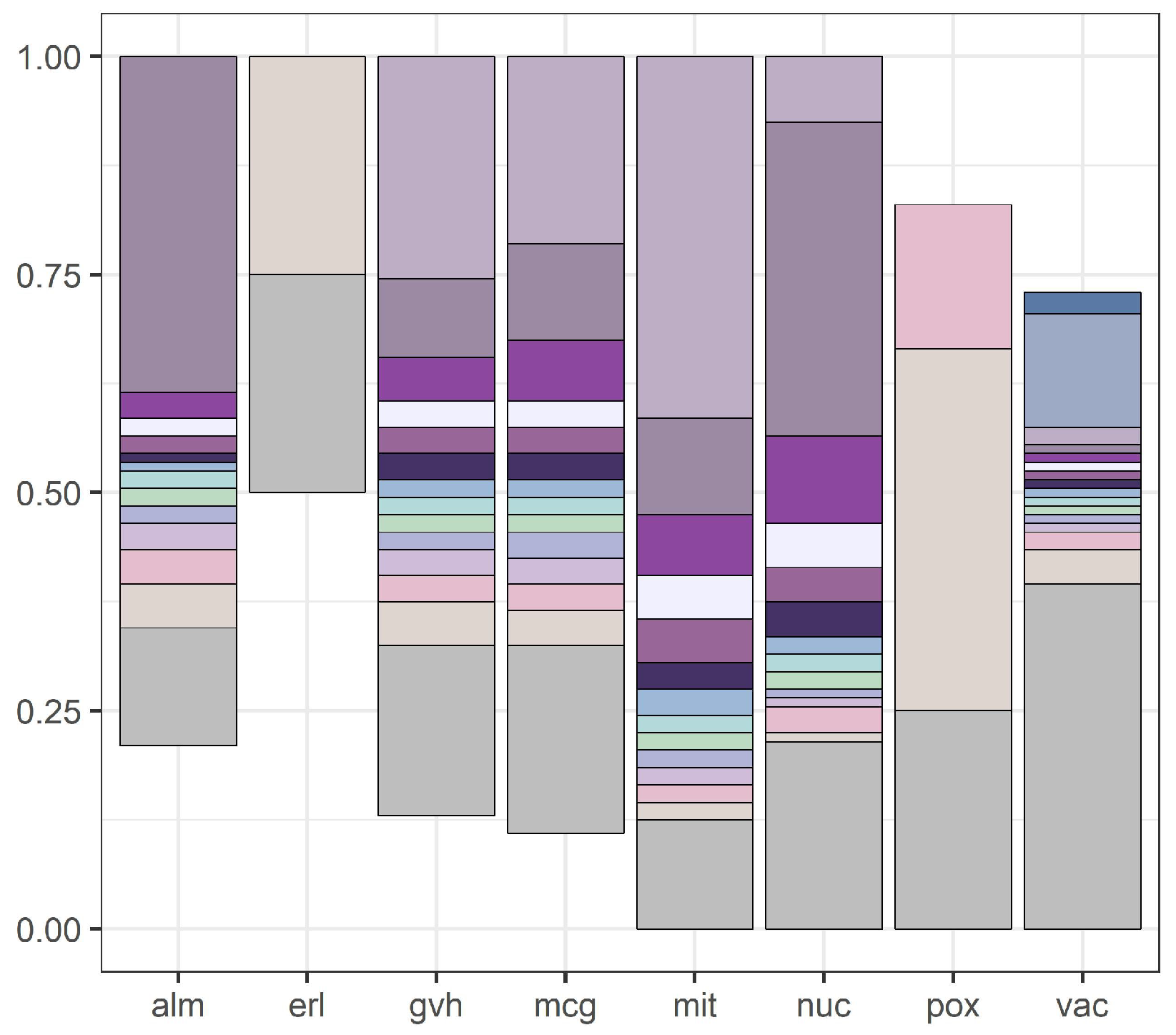
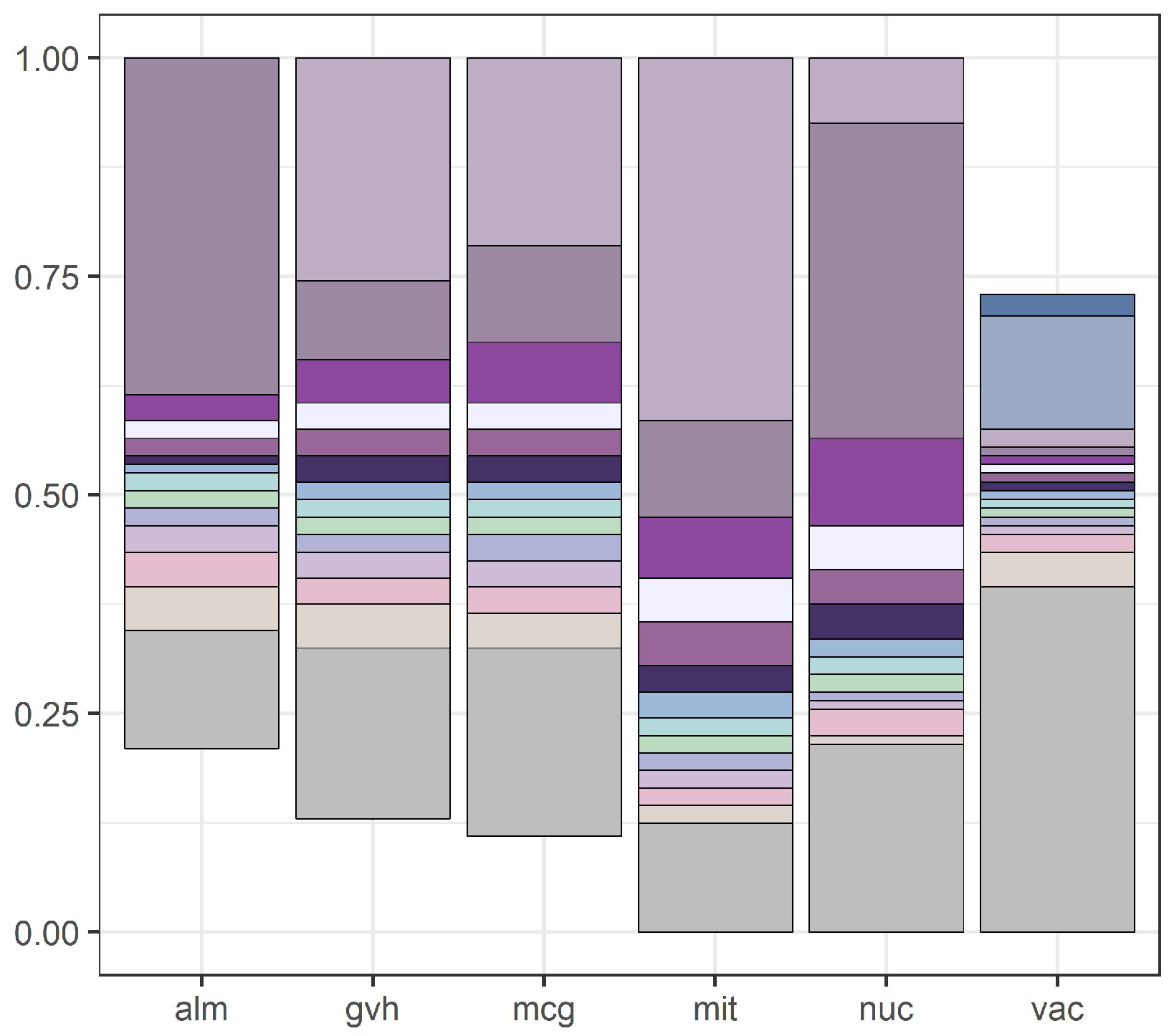
We illustrate our results with
Figure 1 and
Figure 2.
Figure 1 presents discretization intervals for
yeast data set, where discretization was conducted by the internal discretization mechanism of C4.5.
Figure 2 presents discretization intervals for the same data set with discretization conducted by the global version of the Equal Frequency per Interval method (right reducts and left reducts were identical).
Results of our experiments are presented in
Table 5,
Table 6,
Table 7 and
Table 8. These results were analyzed by the Friedman rank sum test with multiple comparisons, with 5% level of significance. For data sets discretized by the Global Equal Frequency per Interval method, the Friedman test shows that there are significant differences between the three types of data sets: the non-reduced discretized data sets and data sets based on left and right reducts. In most cases, the original, non-reduced data sets are associated with the smallest error rates than both left and right reducts. However, the test of multiple comparisons shows that the differences are not statistically significant.
For data sets discretized by the Global Equal Interval Width method results are more conclusive. There are statistically significant differences between non-reduced discretized data sets and data sets based on left and right reducts. Moreover, an error rate for the non-reduced discretized data sets is significantly smaller than for both types of data sets, based on left and right reducts. As expected, the difference between left and right reducts is not significant.
For both discretization methods and all types of data sets (non-reduced, based on left and right reducts) the difference in complexity of generated decision trees, measured by tree size and depth, is not significant.
Table 8 shows the size of left and right reducts created from data sets discretized by the Global versions of Equal Frequency per Interval and Equal Interval Width methods. For some data sets, for example, for
bupa, both left and right reducts are identical with the original attribute set.





{kind=link}
{kind=link}