Abstract
Lattices provide useful structure for distributed coding of correlated sources. A common lattice encoder construction is to first round an observed sequence to a ‘fine’ lattice with dither, then produce the result’s modulo to a ‘coarse’ lattice as the encoding. However, such encodings may be jointly-dependent. A class of upper bounds is established on the conditional entropy-rates of such encodings when sources are correlated and Gaussian and the lattices involved are a from an asymptotically-well-behaved sequence. These upper bounds guarantee existence of a joint–compression stage which can increase encoder efficiency. The bounds exploit the property that the amount of possible values for one encoding collapses when conditioned on other sufficiently informative encodings. The bounds are applied to the scenario of communicating through a many-help-one network in the presence of strong correlated Gaussian interferers, and such a joint–compression stage is seen to compensate for some of the inefficiency in certain simple encoder designs.
1. Introduction
Lattice codes are a useful tool for information theoretic analysis of communications networks. Sequences of lattices can be designed to posess certain properties which make them useful for noisy channel coding or source coding in limit with dimension. These properties have been termed ‘good for channel coding’ and ‘good for source coding’ [1]. Sequences posessing both such properties exist, and an arbitrary number of sequences can be nested [2]. One application of ‘good’ sequences of nested lattices is in construction of distributed source codes for Gaussian signals. Well designed codes for such a scenario built off of such lattices enables encoders to produce a more efficient representation of their observations than would be possible without joint code design [3]. Such codes can provide optimal or near-optimal solutions to coding problems [4,5,6]. Despite their demonstrated ability to compress signals well in these cases, literature has identified redundancies across lattice encodings in other contexts [7,8,9,10]. In these cases, further compression of encodings is possible. This paper studies the correlation between lattice encodings of a certain design.
A class of upper bounds on the conditional Shannon entropies between lattice encodings of correlated Gaussian sources is produced by exploiting linear relations between lattice encodings and their underlying signals’ covariances. The key idea behind the analysis is that when the lattice-modulo of one random signal is conditioned on the lattice-modulo of a related signal, the region of feasible points for the first modulo collapses. A sketch of this support reduction is shown in Figure 1. This process is repeated until all information from the conditionals is integrated into the estimate of the support set. The upper bound establishes stronger performance limits for such coding structures since it demonstrates that encoders are able to convey the same encodings at lower messaging rates.
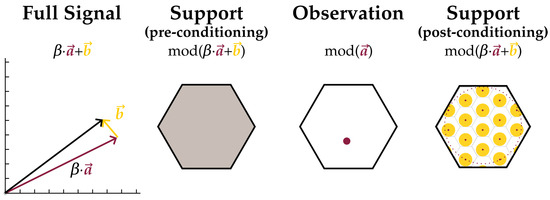
Figure 1.
Collapse of the support of a random signal’s modulo after conditioning on the modulo of a related signal. Modulo is shown to some lattice L with base region B. Consider a signal comprised of two independent random components, and , equaling . A possible outcome is drawn on the far left. Unconditioned, the support for is the entire base region B, shown fully shaded in gray. Once is observed, the component is known up to an additive factor in . If further the powers of and are bounded above, this leaves feasible points for as a subset of those of the unconditioned variable. This subset is shaded yellow on the far right.
1.1. Contributions
The following novel contributions are provided:
- A class of upper bounds on conditional entropy-rates of appropriately designed lattice encoded Gaussian signals.
- An application of the bounds to the problem of point-to-point communication through a many-help-one network in the presence of interference. This strategy takes advantage of a specially designed transmitter codebook’s lattice structure.
- A numerical experiment demonstrating the behavior of these bounds. It is seen that a joint–compression stage can partially alleviate inefficiencies in lattice encoder design.
1.2. Background
The redundancy of lattice-modulo-encoded messages has been noticed before, usually in the context of the following many-help-one problem: many `helpers’ observe correlated Gaussian signals and forward messages to a decoder which is interested in recovering a linear combination of said signals. Towards this end, Wagner in [7] provides an upper and lower bound on conditional entropies such as those here for a case with two lattice encodings. Yang in [8] realized a similar compression scheme for such encodings using further lattice processing on them and presents an insightful `coset planes’ abstraction. It was further noticed by Yang in [9] that improvement towards the many-help-one problem is obtained by splitting helper messages into two parts: one part a coarse quantization of the signal, compressed across helpers via Slepian–Wolf joint–compression (these message parts corresponding to the ‘high bit planes’), and another a lattice-modulo-encoding representing signal details (corresponding to ‘low bit planes’). This paper extends these ideas to a general quantity of helpers, and treats a case where a single component of the observations is known to have lattice structure.
Most recently, a joint–compression scheme for lattice encodings called ‘Generalized Compute Compress and Forward’ was introduced in [10], towards coding for a multi-user additive white Gaussian noise channel where a decoder seeks to recover all user’s messages and is informed by helpers. The scheme in [10] makes use of concepts from [9]. In the scheme each lattice message is split into a combination of multiple components, each component from a different coset plane. Design of which coset planes are used yields different performance results. Section 3 in the present work follows along the same lines, although for a network with one user and where many interferers without codebook structure are also present.
Throughout the paper, terminology and basic lattice theory results are taken from [1]. The lattice encoders studied are built from an ensemble of nested lattices, all both ‘good for quantization’ (Rogers-good) and ‘good for coding’ (Poltyrev-good). Such a construction is provided in [2]. An algorithm from [3] is also used which takes as an argument the structure of some lattice modulo encodings and returns linear combinations of the underlying signals recoverable by a certain type of processing on such encodings. This algorithm is listed here as Stages* and is shown in Appendix A.
1.3. Outline
The main theorem providing upper bounds on conditional entropies of lattice messages, along with an overview of its proof is stated in Section 2. The theorem is slightly strengthened for an application to the problem of communicating over a many-help-one network in Section 3. A numerical analysis of the bounds is given in Section 3.2. A conclusion and discussion on the bound’s remaining inefficiencies is given in Section 4. A table of notation is provided in Table 1. A key for the interpretation of significant named variables is given in Table 2.

Table 1.
Symbols and notation.
Table 2.
Description of variables.
2. Main Results
The main results are as follows:
Theorem 1.
For covariance , take to be n independent draws from the joint-distribution Take rates and any . If n is large enough, an ensemble of nested lattices (with base regions ) from [2] (Theorem 1) can be designed so that the following holds. First fix independent dithers . These dithers have Also fix and lattice modulo encodings .
Now for any , number , basis fix variables:
Then the conditional entropy-rate is bounded:
Bounds of this form hold simultaneously for any subset and reordering of message indices .
Proof for Theorem 1 is given in Appendix B. The proof is built from [3] (Theorem 1), its associated algorithm (listed here in Appendix A) and two lemmas which provide useful decompositions of the involved random variables.
Lemma 1.
Take variables as in the statement of Theorem 1. Then, the ensemble of lattices described can include an ‘auxiliary lattice’ with base region , nesting ratio so that
where are functions of , and with high probability
In addition,
Lemma 2.
Take variables as in the statement of Theorem 1. Then, the ensemble of lattices described can include ‘auxiliary lattices’ with base regions , nesting ratios so that, for any linear combination Y of , vector , matrix and , then
where are functions of , β is some scalar estimation coefficient, and with high probability
In addition, , .
Proofs for Lemmas 1, 2 are given in Appendix B. These lemmas do not strictly require that the sources be multivariate normal. This technical generalization is relevant in the application to the communication strategy in Section 3. Broadly, the proof of Theorem 1 goes as follows.
- Choose some Apply Lemma 1 to . Call a ‘residual.’
- Choose some Apply Lemma 2 to the residual to break the residual up into the sum of a lattice part due to and a new residual, whatever is left over.
- Repeat the previous step until the residual vanishes (up to times). Notice that this process has given several different ways of writing ; by stopping at any amount of steps, is the modulo sum of several lattice components and a residual.
- Design the lattice ensemble for the encoders such that the log-volume contributed to the support of by each component can be estimated. The discrete parts will each contribute log-volume and residuals log-volume
- Recognize the entropy of is no greater than the log-volume of its support. Choose the lowest support log-volume estimate of those just found.
Notice that each lemma application involves choice of some integer parameters. Choices which yield the strongest bound are unknown. Possible schemes for these decisions are the subroutines Alpha0(·), Alpha(·), listed in Appendix A. As implemented, Alpha0(·) chooses and the integer linear combination which leaves the least residual. As implemented, chooses the integer linear combination for which is closest to being recoverable from current knowledge at each lemma application. It produces the combination for which the entropy of the unknown part of is minimized. This may be a suboptimal choice since, while such combinations are close to recoverable, they may not be very pertinent to a description of . Nonetheless, it is still a good enough rule to produce nontrivial entropy bounds, as seen in Section 3.2.
3. Lattice-Based Strategy for Communication via Decentralized Processing
Consider a scenario where a decoder seeks to decode a message from a single-antenna broadcaster in an additive white Gaussian noise (AWGN). The decoder does not observe a signal directly but instead is provided information by a collection of distributed observers (‘helpers’) which forward it digital information, each observer-to-decoder link supporting a different communications rate. This network is depicted in Figure 2. A block diagram is shown in Figure 3. This is the problem of a single-antenna transmitter communicating to a decoder informed out-of-band by a network of helpers in the presence of additive white Gaussian noise and interference.
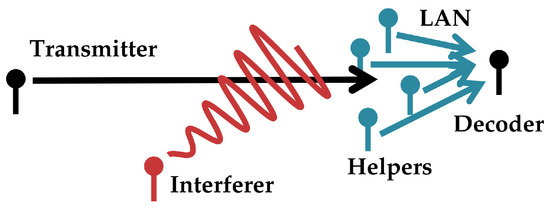
Figure 2.
High level overview of the communications scenario in Section 3. A transmitter seeks to communicate digital information to a decoder through a Gaussian channel in the presence of Gaussian interference (one interferer drawn). The decoder is informed of the transmitter’s signal through helpers which pass it digital information through an out-of-band local area network (LAN).
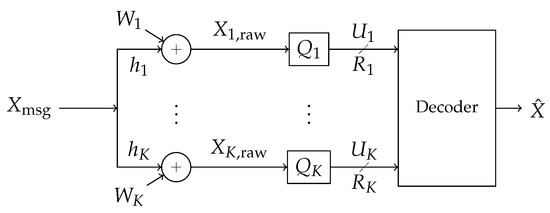
Figure 3.
Block diagram of the communications scenario. A signal from a codebook is broadcast through an additive white Gaussian noise (AWGN) channel in the presence of independent Gaussian interference, creating correlated additive noise . The signal is observed at K receivers labeled . The k-th reciver observes and processes its observation into a rate- message . The messages are forwarded losslessly over a local area side channel to a decoder which attempts to recover the message.
Note that this problem is different from the problem of distributed source coding of a linear function [3,7,8,9,11]. In contrast to the source coding problem, the signal being preserved by the many-help-one network in the present case has a codebook structure. This structure can be exploited to improve the source-to-decoder communications rate. This problem has been studied [12,13], but the best achievable rate is still unknown. In this section, we present a strategy that takes advantage of this codebook structure.
The core of the strategy is to apply a slight modification of Theorem 1 to the network. The transmitter modulates its communications message using a nested lattice codebook such as one in [4]. The helpers employ lattice encoders such as those from Theorem 1, and then perform Slepian–Wolf distributed lossless compression [14] (Theorem 10.3) on their encodings to further reduce their rate. Because the codeword appears as a component of all the helper’s observations, the bound on the message’s joint entropy obtained from Theorem 1 can be strengthened, allowing one to use a more aggressive compression stage.
3.1. Description of the Communication Scheme
It is well known that a nested lattice codebook with dither achieves Shannon information capacity in a point-to-point AWGN channel with a power-constrained transmitter [4]. One interesting aspect of the point-to-point communications scheme described in [4] is that decoding of the noisy signal is done in modulo space. We will see in this section how lattice encodings like those in Theorem 1 can be used to provide such a decoder enough information to recover a communications message.
Without loss of generality, assume that the transmitter is limited to have average transmission power 1. The scheme’s codebook is designed from nested lattices with base regions . is chosen to be good for coding and good for quantization. The messaging rate of this codebook is determined by the nesting ratio of in :
Lattices can be designed with nesting ratios such that any rate above zero can be formed. Taking a message and choosing a dither of which the decoder is informed, then the codeword associated with M takes the form:
We now describe observations of such a signal by helpers in the presence of AWGN interferers. For covariance , take
to be n independent draws from the joint-distribution In addition, take a random vector as described at the beginning of Section 3.1 and a vector and define . Now, the k-th helper observes the vector:
Form an observations vector:
and finally form a cumulative time-averaged covariance matrix as
If helpers are informed of message dither , then they are informed of the codebook for and its lattice structure. Using lattice encoders such as those described in Theorem 1, this codebook information can be used to strengthen the upper bound on conditional entropies between the messages.
Theorem 2.
In the context of the channel description given in Section 3.1, entropy bounds identical to those from Theorem 1 hold for its described observer encodings. The bounds also hold re-defining:
defining the rest of the variables in the theorem as stated. The bounds also hold instead re-defining:
vectors a basis where all vectors but one have 0 as their -th component and taking
and taking the rest of the variables in the theorem as stated over range
A sketch for Theorem 2 is provided in Appendix C. The theorem’s statement can be broadly understood in terms of the proof of Theorem 1. After a number of steps s in the support analysis for Theorem 1, the codebook component can be partially decoded yielding tighter estimation of that component’s contribution to the support of . The variables are parameters for this partial decoding. Lattice modulo messages such as those described in Theorem 2 can be recombined in a useful way:
Lemma 3.
For and vectors , , then lattice modulo encodings from Theorem 2 can be processed into:
where is some constant:
and the noise term has the following properties:
- is with high probability in the base cell of any lattice good for coding semi norm-ergodic noise up to power.
Lemma 3 is demonstrated in Appendix D. Notice that Equation (1) is precisely the form of signal processed by the communications decoder described in [4]. The following result summarizes the performance of this communications strategy.
Corollary 1.
Fix a codebook rate As long as helper-to-decoder messaging rates satisfy all the following criteria:
each being any entropy-rate bound obtained from Theorem 2, then the following communications rate from source to decoder is achievable, taking from their definitions in Lemma 3:
Proof for Corollary 1 is given in Appendix E, and evaluation of the achieved communications rates for certain lattice code designs is shown in Section 3.2.
3.2. Numerical Results
The achievable rate given in Corollary 1 depends on the design of the lattice encoding scheme at the helpers. Identification of the best such lattice encoders for such a system is closely tied to a receivers’ covariance structure [3]. For this reason and for the purpose of evaluating the effect of joint compression stage, we restrict our attention to a particular channel structure and lattice encoder design.
The line-of-sight configuration shown in Figure 4 is considered. It yields helper observations with the following covariance structure, labeling interferer signals in Figure 4 from top to bottom as and indexing helpers from top to bottom:
where are signal, interferer powers, respectively. Choice of this channel is arbitrary but provides an instance where the decoder would not be able to recover the signal of interest if it observed directly without the provided helper messages.
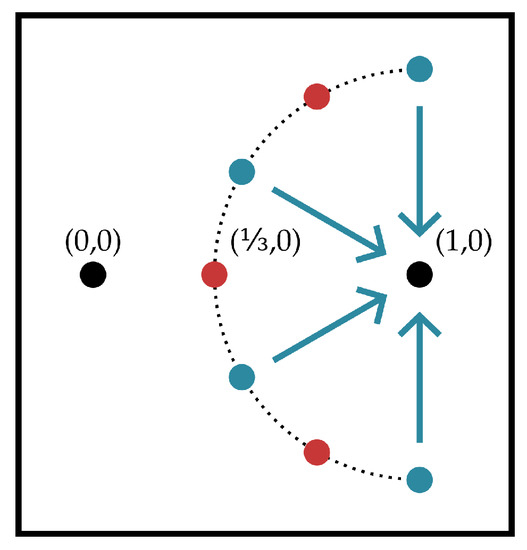
Figure 4.
The line-of-sight channel considered. A black transmit node at seeks to communicate with a black decoder node at . Three red ‘interferer’ nodes broadcast an independent Gaussian signal, each interferer has its own signal. The decoder does not observe any signal directly but is forwarded messages from four blue ‘helper’ nodes which observe signals through a line-of-sight additive-white-Gaussian noise channel. The interferers and helpers are oriented alternatingly and equispaced about a radius- semicircle towards the encoder with center .
3.2.1. Communications Schemes
First, we describe a class of lattice encoders the four helpers could employ:
- Fix some . If helper in the channel from Figure 4 observes , then it encodes a normalized version of the signal:
- Fix equal lattice encoding rates per helper , and take lattice encoders as described in Theorem 1. Note that these rates may be distinct from the helper-to-base rates if post-processing of the encodings is involved.
Communications schemes involving lattice encoders of this form are compared in Figure 5 over an ensemble of choices for lattice encoder rates r and scales Achieved transmitter-to-decoder communication rate versus sum-rate from helpers to decoder are plotted. The following quantities are plotted:
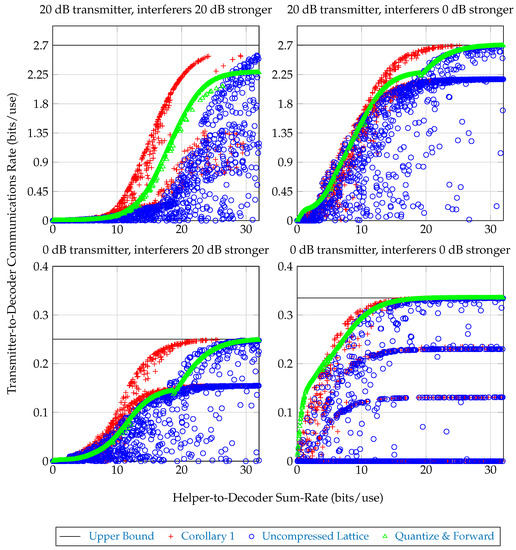
Figure 5.
Communications rate versus helper-sum-rate for 1000 randomly chosen encoding schemes as described in Section 3.2.1 in the line-of-sight channel from Figure 4, Equation (4). In each subplot, the transmitter broadcasts with power such that the average SNR seen across helpers is the given ‘transmitter’ dB figure. Each interferer broadcasts its own signal with its power the given ‘interferer’ dB stronger than the transmitter’s power. Notice that, although the uncompressed lattice scheme is often outperformed by plain Quantize & Forward for the same helper message rates, adding a properly configured compression stage can more than make up for the sum-rate difference. In certain regimes, even the compressed lattice scheme performs worse or practically the same as Quantize & Forward, indicating the given lattice encoder design is weak; uncompressed lattice encoders can be configured to implement the Quantize & Forward scheme.
- Upper Bound: An upper bound on the achievable transmitter-to-decoder communications rate, corresponding to helpers which forward with infinite rate. This bound is given by the formula .
- Corollary 1 The achievable communications rate from Corollary 1, where each helper computes the lattice encoding described above, then employs a joint–compression stage to reduce its messaging rate. The sum-helpers-to-decoder rate for this scheme is given by Equation (2), taking The achieved messaging rate is given by the right-hand-side of Equation (3).
- Uncompressed Lattice: The achievable communications rate from Corollary 1, with each helper forwarding to the decoder its entire lattice encoding without joint–compression. The sum-helpers-to-decoder rate for this scheme is since in this scheme each helper forwards to the base at rate . The achieved messaging rate is given by the right-hand-side of Equation (3).
- Quantize & Forward: An achievable communications rate where helper-to-decoder rates are chosen so that and each helper forwards a rate-distortion-optimal quantization of its observation to the decoder. The decoder processes these quantizations into an estimate of and decodes. This is discussed in more detail in [13]. The sum-helpers-to-decoder rate for this scheme is . The achieved messaging rate is , where .
Performance of these strategies for different broadcaster powers is shown in Figure 5. It is seen that, although the lattice encoder designs are poor, the joint–compression stage partially compensates for this, and with joint compression the scheme outperforms the plain ‘Quantize & Forward’ scheme. Notice that none of the strategies produce convex rate regions, indicating that time-sharing can be used to achieve better rates in some regimes.
In all figures shown, the gap between achieved rates from the joint–compression bound given from Theorem 1 and Theorem 2 (the latter being an improvement) were often nonzero but too small to noticeably change the graphs in Figure 5. For this reason only, achievable rates for the strategy from Corollary 1 are plotted. The gain from involving codebook knowledge in lattice encoding compression is either insignificant for the tested scenario, or choices in computing the upper bounds are too poor to reveal its performance gains. Sub-optimality of the algorithm implementations here are all summarized and discussed in Section 4.
4. Conclusions
A class of upper bounds on the joint entropy of lattice-modulo encodings of correlated Gaussian signals was presented in Theorem 1. Proof of these bounds involves reducing the problem to the entropy of one lattice message, say, conditioned on the rest, . The upper bound for this reduced case involves an iterative construction where in each step a suitable integer vector is chosen. Choice of vectors in these steps determines the order in which the observed lattice-modulo components are integrated into an estimate of ’s support. Different choice of vectors at each step yields a different bound, and the strongest sequence of choices is unknown. For numerical results in Section 3.2, a certain suboptimal was used although there is no guarantee that this choice is optimal.
The upper bounds were applied to the problem of communicating through a many-help-one network, and these bounds were evaluated for a rendition of the problem using lattice codes of simple structure. The bounds in Theorem 1 can be strengthened in this scenario by integrating codebook knowledge. This strengthening is described in Theorem 2.
In spite of the suboptimal lattice encoder designs analyzed, it was seen in Section 3.2 that jointly-compressed lattice encoders are able to significantly outperform more basic schemes in the presence of heavy interference, even when the joint compression stage uses the weaker entropy bounds from Theorem 1. In the numerical experiments tried, the strengthening in Theorem 2 was not seen to significantly improve compression. Whether this is typically true or just an artifact of poor design of the joint-compression stage is unknown. In either case, the simpler joint-compression strategy without codebook knowledge was seen to improve performance.
The most immediate forwards steps to the presented results is in characterization of the search problems posed by Theorems 1, 2. Although not discussed, corner-points of joint compression described here are implementable using further lattice processing on the encodings and their dithers . Such a process might mimic the compression procedure described in [10]. Tightness arguments from this work may also apply to the present less structured channel.
Finally, according to the transmission method in [10], the achievable rate in Corollary 1 may be improvable by breaking the transmitter’s message M up into a sum of multiple components, each from a finer lattice. Joint–compression for such a transmission could integrate codebook information from each message component separately, allowing for more degrees of freedom in the compression stage’s design, possibly improving the achievable rate. This is an extension of the argument in Appendix D. These improvements are out of this paper’s scope but provide meaningful paths forward.
Author Contributions
C.C. performed formal analysis. The scheme was conceptualized by C.C. and D.W.B. Work was supervised by D.W.B.
Funding
This research was funded by the Raytheon project “Simultaneous Signaling, Sensing, and Radar Operations under Constrained Hardware”.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Subroutines
Here, we provide a list of subroutines involved in a statement of the results:
- Stages*(·) is a slight modification of an algorithm from [3], reproduced here in Algorithm 1. The original algorithm characterizes the integral combinations which are recoverable with high probability from lattice messages and dithers , excluding those with zero power. The exclusion is due to the algorithm’s use of as just defined. Such linear combinations never arose in the context of [3], although it provides justification for them being recoverable; in the paper, the algorithm’s argument is always full-rank. This is not true in the present context. The version here includes these zero-power subspaces by including a call to before returning.
- , ‘Shortest Lattice Vector Coordinates’ returns the nonzero integer vector which minimizes the norm of while , or the zero vector if no such vector exists. can be implemented using a lattice enumeration algorithm like one in [15] together with the LLL algorithm to convert a set of spanning lattice vectors into a basis [16].
- LatticeKernel(B,A), for returns the integer matrix whose columns span the collection of all where while . In other words, it returns a basis for the integer lattice in whose components are orthogonal to the lattice . This can be implemented using an algorithm for finding ‘simultaneous integer relations’ as described in [17].
- is an “Integer Convex Quadratic Minimizer.” It provides a solution for the NP-hard problem: “Minimize over with integer components.” Although finding the optimal solution is exponentially difficult in input size, algorithms are tractable for low dimension. [18] (Algorithm 5, Figure 2).
- CVarComponents returns certain variables involved in computingwhen has covariance . Write some matrices in block form:Then, taking one can check that:
- CVar computes the conditional covariance matrix of conditioned on for . This is given by the formula:
- in Algorithm 2 implements a strategy for choosing in Theorems 1, 2.
- in Algorithm 3 implements a strategy for choosing in theorems 1, 2.
| Algorithm 1 Compute recoverable linear combinations from modulos of lattice encodings with covariance . |
|
| Algorithm 2 Strategy for choosing for Theorems 1, 2 |
|
| Algorithm 3 Strategy for picking for Theorems 1, 2. |
|
Appendix B. Proof of Lemmas 1, 2, Theorem 1
Proof.
(Lemma 1)
Take . Then, by modulo’s distributive property so that . Compute:
Now:
By [3] (Theorem 1), can be recovered by processing , hence can also be recovered. Choose so that the claim holds applying modulo’s distributive property. □
Proof.
(Lemma 2)
Take . Take and . Choose .
Include good-for-coding auxillary lattices with the prescribed scales in the lattice ensemble from Theorem 1. With high probability since is good for coding semi norm-ergodic noise of power [2] and applying [19] (Appendix V) to , yields the result. □
Proof.
(Theorem 1)
Appendix B.1. Upper Bound for Singleton S
Take a nested lattice construction from [20] (Theorem 1), involving the following sets:
- Coarse and fine encoding lattices (base regions ) with each k has designed with nesting ratio .
- Discrete part auxiliary lattices (base regions ) with each having nesting ratio .
- Initial residual part auxiliary lattice (base region ) with , nesting ratio
- Residual part auxiliary lattices (base regions ) with each , having nesting ratio .
The specified nesting ratios for the auxiliary lattices, will be specified later.
Initialization
Apply Lemma 1 to , and label the resulting variables In addition, define Now,
so the support of is contained within:
Support Reduction
Iterate over steps . For step s, condition on any event of the form , of which there are no more than choices due to the nesting ratio for in . Take By [3] (Theorem 1), is recoverable by processing .
Now, apply Lemma 2 to , and label the resulting variables Now,
so the support of is contained within:
Count Points in Estimated Supports
By design, there are no more than possible choices for Each has no more than points. Then,
Bound Simultaneity
An argument is given in Section B.1 for an upper bound on the singleton case. The argument uses a Zamir-good nested lattice construction with a finite amount of nesting criteria, and conditions on a finite amount of high-probability events. Then, the argument holds for all cases of this form simultaneously by using a Zamir-good nested lattice construction satisfying all of each case’s nesting criteria and conditioning on all of each case’s high-probability events.
The entropy for the general case can be rewritten using the chain rule:
Appendix C. Sketch of Theorem 2 for Upper Bound on Entropy-Rates of Decentralized Processing Messages
Proof.
(Sketch) Proceed identically as in the proof of Theorem 1 in Appendix B up until either Section B.1 Initialization if definition for was changed, or repetition s where in Section B.1 Support Reduction if definition for changed. In this portion, perform the following analysis instead. Compute:
The additive terms in Equation (A1) are independent of one another, and the terms besides M have observed power . Choose the nesting ratio for in as
Then, with high probability since is good for coding semi norm-ergodic noise below power [2] and applying [19] (Appendix V) to the derivation in Equation (A1),
where is computable by processing and
Rearranging Equation (A2),
Now, define:
By construction, is the components in uncorrelated with :
Proceed as in proof of Theorem 1. □
Appendix D. Proof of Lemma 3 for Recombination of Decentralized Processing Lattice Modulos
Proof.
By [3] (Theorem 1), a processing of with high probability outputs
One can assume the nested lattices for the message transmitter, , are part of the lattice ensemble from Theorem 1, in particular ones finer than the main coarse lattice so that and:
With this structure, then, for any , the encodings can be processed to produce (using lattice modulo’s distributive and subgroup properties)
where, in Equation (1), and is the conglomerate of noise terms independent of that are left over.
For channels with additive Gaussian noise, is a mixture of Gaussians and independent components uniform over good-for-quantization lattice base regions, so will probably, for long enough blocklength, land inside the base of any coarse enough good-for-coding lattice [19] (Appendix V). □
Appendix E. Proof of Corollary 1 for Achievability of the Decentralized Processing Rate
Proof.
Fix any from their definitions in Lemma 3 and any . Choose a communications rate satisfying the criterion in the statement. Form an ensemble of lattices such as those described in Theorem 2, with nesting ratio for in as for and if . This design means
Have the transmitter encode its message M into a modulation as described at the beginning of Section 3.1 using a dither of which all helpers and the decoder are informed. Have each k-th helper, , process its observation vector into a lattice modulo encoding as described in Theorem 2 using a dither of which the decoder is informed.
By Theorem 2, there exists a Slepian–Wolf binning scheme such that each k-th helper can process its message into a compression with , and where a decoder can with high probability process the ensemble of compressions along with dither side information into . Employ this binning scheme at each of the receivers, and have them each forward their compressions to the decoder.
Have the decoder decompress into . By the previous statement, with high probability, Use the processing obtained from Lemma 3 on , with high probability producing a signal:
Decoding
Decoding proceeds similar to [4]. At the decoder, compute:
Recall that the fine codebook lattice has been designed to be good for coding and so that the coarse codebook lattice has a nesting ratio within it as . This means that is good for coding semi norm-ergodic noise with power less than .
Notice , where the first independence is by the crypto lemma [1]. This is to say that additive terms other than M in Equation (A3) are noise with power
Furthermore, by [19] (Appendix V) on the noise, then it is probably in the base region of any lattice good for coding semi norm-ergodic noise with power less than Equation (A4). Then, with high probability if
or, rearranging,
The limit of the right side of Equation (A5) equals Equation (3). □
References
- Zamir, R. Lattice Coding for Signals and Networks: A Structured Coding Approach to Quantization, Modulation, and Multiuser Information Theory; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Ordentlich, O.; Erez, U. A simple proof for the existence of “good” pairs of nested lattices. IEEE Trans. Inf. Theory 2016, 62, 4439–4453. [Google Scholar] [CrossRef]
- Chapman, C.; Kinsinger, M.; Agaskar, A.; Bliss, D.W. Distributed Recovery of a Gaussian Source in Interference with Successive Lattice Processing. Entropy 2019, 21, 845. [Google Scholar] [CrossRef]
- Erez, U.; Zamir, R. Achieving log(1+SNR) on the AWGN Channel With Lattice Encoding and Decoding. IEEE Trans. Inf. Theory 2004, 50, 1. [Google Scholar] [CrossRef]
- Ordentlich, O.; Erez, U.; Nazer, B. Successive integer-forcing and its sum-rate optimality. In Proceedings of the 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–4 October 2013; pp. 282–292. [Google Scholar]
- Ordentlich, O.; Erez, U. Precoded integer-forcing universally achieves the MIMO capacity to within a constant gap. IEEE Trans. Inf. Theory 2014, 61, 323–340. [Google Scholar] [CrossRef]
- Wagner, A.B. On Distributed Compression of Linear Functions. IEEE Trans. Inf. Theory 2011, 57, 79–94. [Google Scholar] [CrossRef]
- Yang, Y.; Xiong, Z. An improved lattice-based scheme for lossy distributed compression of linear functions. In Proceedings of the 2011 Information Theory and Applications Workshop, La Jolla, CA, USA, 6–11 Feburuary 2011. [Google Scholar]
- Yang, Y.; Xiong, Z. Distributed compression of linear functions: Partial sum-rate tightness and gap to optimal sum-rate. IEEE Trans. Inf. Theory 2014, 60, 2835–2855. [Google Scholar] [CrossRef]
- Cheng, H.; Yuan, X.; Tan, Y. Generalized compute-compress-and-forward. IEEE Trans. Inf. Theory 2018, 65, 462–481. [Google Scholar] [CrossRef]
- Saurabha, T.; Viswanath, P.; Wagner, A.B. The Gaussian Many-help-one Distributed Source Coding Problem. IEEE Trans. Inf. Theory 2009, 56, 564–581. [Google Scholar]
- Sanderovich, A.; Shamai, S.; Steinberg, Y.; Kramer, G. Communication via Decentralized Processing. IEEE Trans. Inf. Theory 2008, 54, 3008–3023. [Google Scholar] [CrossRef]
- Chapman, C.D.; Mittelmann, H.; Margetts, A.R.; Bliss, D.W. A Decentralized Receiver in Gaussian Interference. Entropy 2018, 20, 269. [Google Scholar] [CrossRef]
- El Gamal, A.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Schnorr, C.P.; Euchner, M. Lattice Basis Reduction: Improved Practical Algorithms and Solving Subset Sum Problems. Math. Program. 1994, 66, 181–199. [Google Scholar] [CrossRef]
- Buchmann, J.; Pohst, M. Computing a Lattice Basis from a System of Generating Vectors. In Proceedings of the European Conference on Computer Algebra, Leipzig, Germany, 2–5 June 1987; pp. 54–63. [Google Scholar]
- Hastad, J.; Just, B.; Lagarias, J.C.; Schnorr, C.P. Polynomial time algorithms for finding integer relations among real numbers. SIAM J. Comput. 1989, 18, 859–881. [Google Scholar] [CrossRef]
- Ghasemmehdi, A.; Agrell, E. Faster recursions in sphere decoding. IEEE Trans. Inf. Theory 2011, 57, 3530–3536. [Google Scholar] [CrossRef]
- Krithivasan, D.; Pradhan, S.S. Lattices for Distributed Source Coding: Jointly Gaussian Sources and Reconstruction of a Linear Function. In International Symposium on Applied Algebra, Algebraic Algorithms, and Error-Correcting Codes; Springer: Berlin/Heidelberg, Germany, 2007; pp. 178–187. [Google Scholar]
- Erez, U.; Litsyn, S.; Zamir, R. Lattices Which are Good for (Almost) Everything. IEEE Trans. Inf. Theory 2005, 51, 3401–3416. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).