Emotional Speech Recognition Based on the Committee of Classifiers


Abstract
1. Introduction
- This research is carried out on three different types of Polish corpora, which allows the analysis of impact of various type of database on the final result. The classifiers were tested by using mixed sets (corpora-dependent and corpora-independent tests) to verify if acted out database can be used as a training set for application operating in real environment.
- In comparison to similar research where each classifier is trained with the exact same data, in this paper the whole feature set is divided into subsets before classification process. Despite their similarity (e.g., MFCC and BFCC) different models provide varied results on specific feature subsets, affecting the final assessment. Thus, the most effective model may be selected appropriately for a specific subset (in similar research voting is performed on different classifiers working on the same features). This approach significantly increases accuracy of results, in comparison to related works. Presented algorithm was verified using different voting methods.
- It presents a thorough analysis of extensive set of features on the recognition of several emotional classes-groups of features are examined separately as well as a whole collection.
2. Related Works
3. Methods
3.1. Database
3.1.1. MERIP Database
3.1.2. Polish Emotional Speech Database
3.1.3. Polish Spontaneous Speech Database
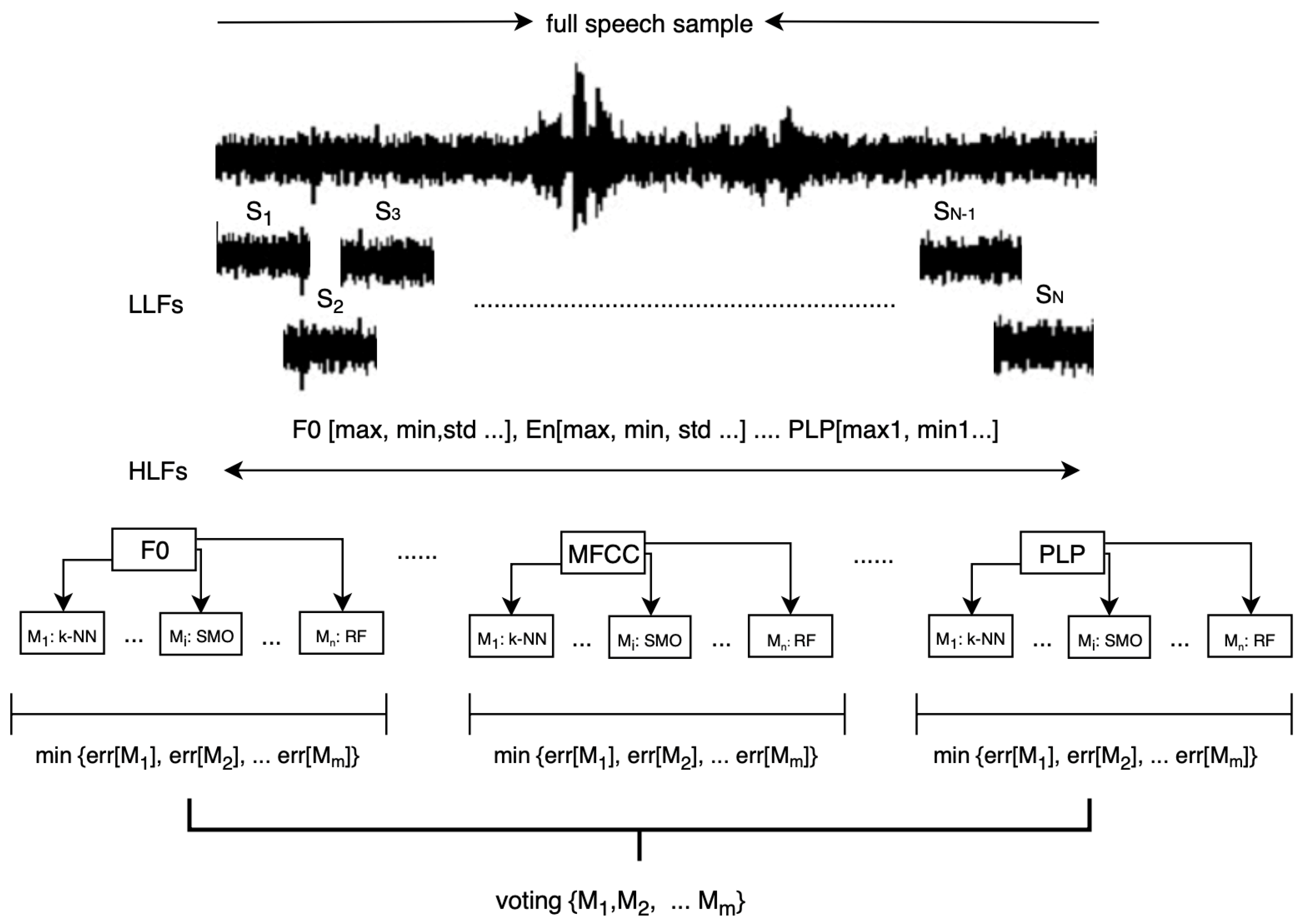
3.2. Extracted Features
3.2.1. Prosodies
3.2.2. Spectrum Characteristics
3.2.3. Features Selection
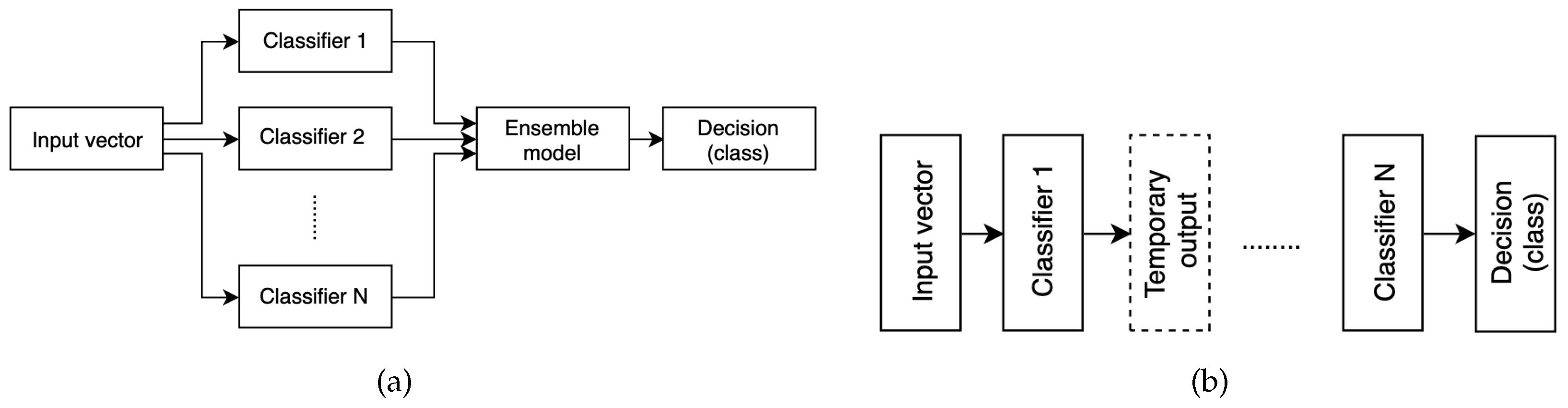
3.3. Classification Model
4. Results and Discussion
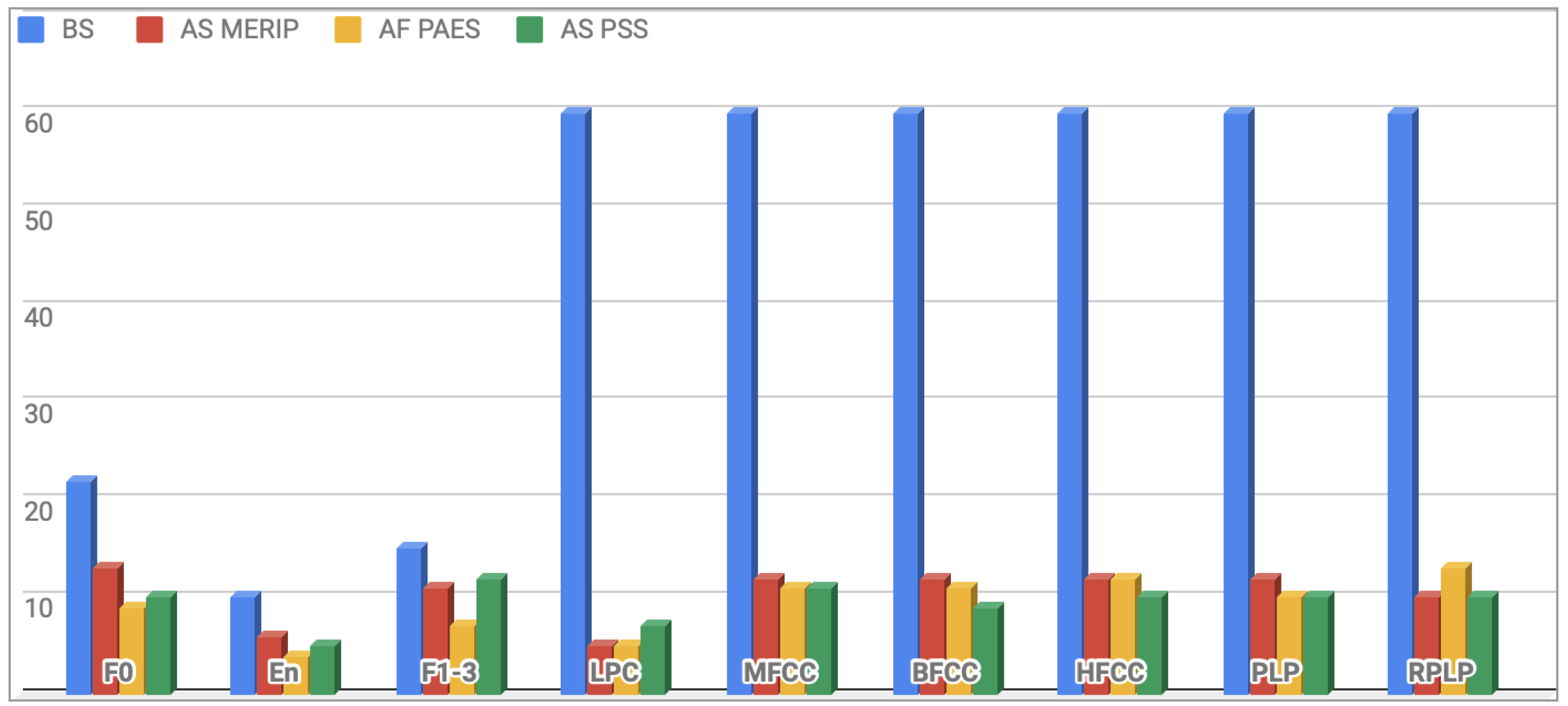
4.1. Efficiency of Features Subsets
4.2. Efficiency of Proposed Algorithm
5. Conclusions
Funding
Conflicts of Interest
Abbreviations
| BFCC | Bark Frequency Cepstral Coefficients |
| CNN | Convolutional Neural Network |
| EC | Ensemble Committee |
| EV | Equal Voting |
| HFCC | Human Factor Cepstral Coefficients |
| HMM | Hidden Markov Models |
| LSTM | Long Short-Term Memory |
| k-NN | k Nearest Neighbours |
| LDA | Linear Discriminant Analysis |
| LMT | Logistic Model Trees |
| MERIP | Multimodal Emotion Recognition in Polish |
| MFCC | Mel Frequency Cepstral Coefficients |
| MLP | Multilayer Perceptron |
| NBTree | Naive Bayes Tree |
| PCA | Principal Component Analysis |
| PESD | Polish Emotional Speech Database, |
| PLP | Perceptual Linear Prediction |
| PSSD | Polish Spontaneous Speech, |
| RC | Random Cometee |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| RPLP | Revised Perceptual Linear Prediction |
| SER | Speech Emotion Recognition |
| SMO | Sequential Minimal Optimization |
| SL | Simple Logistic |
| SVM | Support Vector Machines |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Features |
|---|---|
| MERIP | F0: mean; energy: median, std; F1, F2: mean, median, F2, F3: max, min, F3:std, LPC mean: 2–11; MFCC mean: 1,6, 10, 11,12; MFCC std: 12, MFCC median: 6,11; MFCC min: 1; MFCC max: 7,11; BFCC mean: 1,6,10; BFCC median: 1,6; BFCC min: 1,6; BFCC max: 11; PLP mean: 5–8; PLP median: 6,10,11; PLP std: 3–10, RPLP mean: 1,3,5,9; RPLP median: 3; RPLP std: 5,9–10; |
| PESD | F0: min, upper quartile, variation rate, rising-ranege max; energy: min; F1-F2: mean; F3: median; F3: min; LPC mean: 2,3,7,8,11; LPC median: 2,7,8; LPC max: 7; MFCC mean: 3,4,6,7,12; MFCC std: 1,4,5,9; MFCC median: 4,6,8–11; MFCC min: 1,3–5; MFCC max: 4; BFCC mean: 1,4; BFCC median: 5–8; BFCC min: 4,6; BFCC max: 5–7; PLP max: 1; PLP min: 1–3,4,10; PLP std: 4–7,10; RPLP mean: 1,4,7,9; RPLP median: 4–7; RPLP std: 1,4; |
| PSSD | F0: mean, kurtosis; energy: median, std; F1:mean, median; F3: min, std; LPC mean: 5–7,10,11; MFCC mean: 1,3,9–11; MFCC std: 11,12, MFCC median: 1,7; MFCC min: 7; MFCC max: 1; BFCC mean: 1–4,10; BFCC median: 2,6,9; BFCC min: 1,5–8; BFCC max: 1–3; PLP mean: 5,6,10,12; PLP std: 3,7,10; PLP min: 1; PLP max: 8,9; RPLP mean: 1,3,5,9; RPLP median: 3; RPLP std: 5,9–10; |
| MERIP | PESD | PSSD | |
|---|---|---|---|
| F0 | mean F0, median F0, std F0, max F0, range F0, upper quartile F0, lower quartile F0, interquartile range F0, skewness F0, kurtosis F0, F0, rising-slope max F0, falling-slope max F0; | mean F0, median F0, max F0, upper quartile F0, lower quartile F0, interquartile range F0, kurtosis F0, rising-range min F0, falling-range min F0; | mean F0, median F0, max F0, min F0, rane F0, upper quartile F0, lower quartile F0, interquartile range F0, skewness F0, falling-range max F0; |
| F1-F3 | mean: F1, F3; max: F1, F3; median: F1, F2, F3, min: F1, F3; standard deviation F1, F3 | mean: F1, F3; median: F2, F3, min: F1; standard deviation F1, F3; | mean: F1, F2, F3; max: F1, F3; median: F1, F2, min: F1, F3; standard deviation F1, F2, F3 |
| Energy | max, min, median, std, range, mean | max, min, median, std | max, min, median, std, range |
| LPC | LPC mean: 2, 4–6,12 | LPC mean: 5,7–11 | LPC mean: 2–10 |
| MFCC | MFCC: 1,3,6 -mean MFCC: 2,4,6 -median MFCC: 5,10 -std MFCC: 3,10 -max MFCC: 2,12 -min | MFCC: 1,3,9 -mean MFCC: 1 -median MFCC: 3,5,12,14 -std MFCC: 1,12 -max MFCC: 14 -min | MFCC: 2,6,7 -mean MFCC: 2 -median MFCC: 1,3,7 -std MFCC: 1,4 -max MFCC: 1,4 -min |
| BFCC | BFCC: 2,7,8 -mean BFCC: 7 - std BFCC: 1,2,3,11 -median BFCC: 1,4 -max BFCC: 2,5 -min | BFCC: 3,9 -mean BFCC: 4,10 -std BFCC: 2,3,5,7, -median BFCC: 1 -max BFCC: 2,3 -min | BFCC: 8 -mean BFCC: 1,2 -std BFCC: 2,6,12 -median BFCC: 1,2 -max BFCC: 4 -min |
| HFCC | HFCC: 1,2 -mean HFCC: 1,2,4,6 -std HFCC: 2,4 median HFCC: 1,7,10 -max HFCC: 5,6 -min | HFCC: 1,2,4 -mean HFCC: 1,3,4 -std HFCC: 1,4 median HFCC: 2,3 -max HFCC: 1,2 -min | HFCC: 3,5 -mean HFCC: 2,5,7 -std HFCC: 2,4 -max HFCC: 1,4,7 -min |
| PLP | PLP: 3,5 -mean PLP: 2,3,6 -median PLP: 7,10 -std PLP: 1,4,7 -max PLP: 1,4 -min | PLP: 1,5,9 -mean PLP: 4,6 -median PLP: 3,7 -std PLP: 1,2 -max PLP: 6 -min | PLP: 1 -mean PLP: 8,10 -median PLP: 1,4,6 -std PLP: 1,5 -max PLP: 1,9 -min |
| RPLP | RPLP: 1,2,3 -mean RPLP: 5,6,8 -median RPLP: 2 -std RPLP: 9–11 -max | RPLP: 1,12 -mean RPLP: 3–5 -median RPLP: 2,7 -std RPLP: 1–3,6, -max RPLP: 2,4 -min | RPLP: 2,3 -mean RPLP: 1 -median RPLP: 2,3 -std RPLP: 1,3,8 -max RPLP: 1,4 -min |
References
- Noroozi, F.; Kaminska, D.; Corneanu, C.; Sapinski, T.; Escalera, S.; Anbarjafari, G. Survey on emotional body gesture recognition. IEEE Trans. Affect. Comput. 2018. [Google Scholar] [CrossRef]
- Ślot, K.; Cichosz, J.; Bronakowski, L. Emotion recognition with poincare mapping of voiced-speech segments of utterances. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 16–20 June 2019; pp. 886–895. [Google Scholar]
- McDuff, D.; Kaliouby, R.; Senechal, T.; Amr, M.; Cohn, J.; Picard, R. Affectiva-mit facial expression dataset (am-fed): Naturalistic and spontaneous facial expressions collected. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 881–888. [Google Scholar]
- Ofodile, I.; Helmi, A.; Clapés, A.; Avots, E.; Peensoo, K.M.; Valdma, S.M.; Valdmann, A.; Valtna-Lukner, H.; Omelkov, S.; Escalera, S.; et al. Action Recognition Using Single-Pixel Time-of-Flight Detection. Entropy 2019, 21, 414. [Google Scholar] [CrossRef]
- Shaburov, V.; Monastyrshyn, Y. Emotion Recognition in Video Conferencing. U.S. Patent 9,576,190, 2018. [Google Scholar]
- Datta, A.; Shah, M.; Lobo, N.D.V. Person-on-person violence detection in video data. In Object Recognition Supported by User Interaction for Service Robots; IEEE: Quebec, QC, Canada, 2002; Volume 1, pp. 433–438. [Google Scholar]
- Kaliouby, R.; Robinson, P. Mind Reading Machines Automated Inference of Cognitive Mental States from Video. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, The Hague, The Netherlands, 10–13 October 2004; pp. 682–688. [Google Scholar]
- Ofodile, I.; Kulkarni, K.; Corneanu, C.A.; Escalera, S.; Baro, X.; Hyniewska, S.; Allik, J.; Anbarjafari, G. Automatic Recognition of Deceptive Facial Expressions of Emotion. arXiv 2017, arXiv:1707.04061. [Google Scholar]
- Ekman, P.; Wallace, F. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologist Press: Washington, DC, USA, 1978. [Google Scholar]
- Silva, P.; Madurapperuma, A.; Marasinghe, A.; Osano, M. A Multi-Agent Based Interactive System Towards Childs Emotion Performances Quantified Through Affective Body Gestures. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 1236–1239. [Google Scholar]
- Noroozi, F.; Kamińska, D.; Sapiński, T.; Anbarjafari, G. Supervised Vocal-Based Emotion Recognition Using Multiclass Support Vector Machine, Random Forests, and Adaboost. J. Audio Eng. Soc. 2017, 65, 562–572. [Google Scholar] [CrossRef]
- Noroozi, F.; Kamińska, D.; Sapiński, T.; Anbarjafari, G. Vocal-based emotion recognition using random forests and decision tree. Int. J. Speech Technol. 2017, 9, 239–246. [Google Scholar] [CrossRef]
- Kleinsmith, A.; Bianchi-Berthouze, N. Affective Body Expression Perception and Recognition: A Survey. IEEE Trans. Affect. Comput. 2013, 4, 15–33. [Google Scholar] [CrossRef]
- Karg, M.; Samadani, A.A.; Gorbet, R.; Kuhnlenz, K.; Hoey, J.; Kulic, D. Body Movements for Affective Expression: A Survey of Automatic Recognition and Generation. IEEE Trans. Affect. Comput. 2013, 4, 341–359. [Google Scholar] [CrossRef]
- Garay, N.; Cearreta, I.; López, J.; Fajardo, I. Assistive Technology and Affective Mediation. Interdiscip. J. Humans Ict Environ. 2006, 2, 55–83. [Google Scholar] [CrossRef]
- Gelder, B.D. Why Bodies? Twelve Reasons for Including Bodily Expressions in Affective Neuroscience. Hilosophical Trans. R. Soc. Biol. Sci. 2009, 364, 3475–3484. [Google Scholar] [CrossRef]
- Darwin, C. The Expression of the Emotions in Man and Animals; John Murray: London, UK, 1872. [Google Scholar]
- Izdebski, K. Emotion in the Human Voice, Volume I Fundations; Plural Publishing: San Diego, CA, USA, 2008. [Google Scholar]
- Kamińska, D.; Sapiński, T. Polish emotional speech recognition based on the committee of classifiers. Przegląd Elektrotechniczny 2017, 93, 101–106. [Google Scholar] [CrossRef]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Ozcinar, C.; Avots, E.; Anbarjafari, G. Multimodal Database of Emotional Speech, Video and Gestures. In Proceedings of the International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 153–163. [Google Scholar]
- Kaminska, D.; Sapinski, T.; Pelikant, A. Polish Emotional Natural Speech Database. In Proceedings of the Conference: Signal Processing Symposium 2015, Debe, Poland, 10–12 June 2015. [Google Scholar]
- Liu, Z.T.; Wu, M.; Cao, W.H.; Mao, J.W.; Xu, J.P.; Tan, G.Z. Speech emotion recognition based on feature selection and extreme learning machine decision tree. Neurocomputing 2018, 273, 271–280. [Google Scholar] [CrossRef]
- Mannepalli, K.; Sastry, P.N.; Suman, M. Analysis of Emotion Recognition System for Telugu Using Prosodic and Formant Features. In Speech and Language Processing for Human-Machine Communications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 137–144. [Google Scholar]
- Nancy, A.M.; Kumar, G.S.; Doshi, P.; Shaw, S. Audio Based Emotion Recognition Using Mel Frequency Cepstral Coefficient and Support Vector Machine. J. Comput. Theor. Nanosci. 2018, 15, 2255–2258. [Google Scholar] [CrossRef]
- Zamil, A.A.A.; Hasan, S.; Baki, S.M.J.; Adam, J.M.; Zaman, I. Emotion Detection from Speech Signals using Voting Mechanism on Classified Frames. In Proceedings of the 2019 International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST), Dhaka, Bangladesh, 10–12 January 2019; pp. 281–285. [Google Scholar]
- Anagnostopoulos, C.N.; Iliou, T.; Giannoukos, I. Features and classifiers for emotion recognition from speech: A survey from 2000 to 2011. Artif. Intell. Rev. 2015, 43, 155–177. [Google Scholar] [CrossRef]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Fewzee, P.; Karray, F. Dimensionality Reduction for Emotional Speech Recognition. In Proceedings of the 2012 ASE/IEEE International Confer-ence on Social Computing and 2012 ASE/IEEE International Conference on Privacy, Security, Risk and Trust, Amsterdam, The Netherlands, 3–5 September 2012; pp. 532–537. [Google Scholar]
- Arruti, A.; Cearreta, I.; Álvarez, A.; Lazkano, E.; Sierra, B. Feature Selection for Speech Emotion Recognition in Spanish and Basque: On the Use of Machine Learning to Improve Human-Computer Interaction. PLoS ONE 2014, 9, e108975. [Google Scholar] [CrossRef] [PubMed]
- Han, W.; Zhang, Z.; Deng, J.; Wöllmer, M.; Weninger, F.; Schuller, B. Towards Distributed Recognition of Emotion From Speech. In Proceedings of the 5th International Symposium on Communications, Control and Signal Processing, Rome, Italy, 2–4 May 2012. [Google Scholar]
- Ke, X.; Zhu, Y.; Wen, L.; Zhang, W. Speech Emotion Recognition Based on SVM and ANN. Int. J. Mach. Learn. Comput. 2018, 8, 198–202. [Google Scholar] [CrossRef]
- Avots, E.; Sapiński, T.; Bachmann, M.; Kamińska, D. Audiovisual emotion recognition in wild. Mach. Vis. Appl. 2018, 30, 975–985. [Google Scholar] [CrossRef]
- Sun, L.; Fu, S.; Wang, F. Decision tree SVM model with Fisher feature selection for speech emotion recognition. Eurasip J. Audio Speech Music. Process. 2019, 2019, 2. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar]
- Zhao, J.; Mao, X.; Chen, L. Learning deep features to recognise speech emotion using merged deep CNN. IET Signal Process. 2018, 12, 713–721. [Google Scholar] [CrossRef]
- Han, K.; Yu, D.; Tashev, I. Speech emotion recognition using deep neural network and extreme learning machine. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Hajarolasvadi, N.; Demirel, H. 3D CNN-Based Speech Emotion Recognition Using K-Means Clustering and Spectrograms. Entropy 2019, 21, 479. [Google Scholar] [CrossRef]
- Swain, M.; Routray, A.; Kabisatpathy, P. Databases, features and classifiers for speech emotion recognition: A review. Int. J. Speech Technol. 2018, 21, 93–120. [Google Scholar] [CrossRef]
- Swain, M.; Sahoo, S.; Routray, A.; Kabisatpathy, P.; Kundu, J.N. Study of feature combination using HMM and SVM for multilingual Odiya speech emotion recognition. Int. J. Speech Technol. 2015, 18, 387–393. [Google Scholar] [CrossRef]
- Rathor, S.; Jadon, R. Acoustic domain classification and recognition through ensemble based multilevel classification. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 3617–3627. [Google Scholar] [CrossRef]
- Wu, C.H.; Liang, W.B.; Cheng, K.C.; Lin, J.C. Hierarchical modeling of temporal course in emotional expression for speech emotion recognition. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 810–814. [Google Scholar]
- Shih, P.Y.; Chen, C.P.; Wu, C.H. Speech emotion recognition with ensemble learning methods. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2756–2760. [Google Scholar]
- Pao, T.L.; Chien, C.S.; Chen, Y.T.; Yeh, J.H.; Cheng, Y.M.; Liao, W.Y. Combination of multiple classifiers for improving emotion recognition in Mandarin speech. In Proceedings of the Third International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP 2007), Kaohsiung, Taiwan, 26–28 November 2007; Volume 1, pp. 35–38. [Google Scholar]
- Morrison, D.; Wang, R.; De Silva, L.C. Ensemble methods for spoken emotion recognition in call-centres. Speech Commun. 2007, 49, 98–112. [Google Scholar] [CrossRef]
- Zantout, R.; Klaylat, S.; Hamandi, L.; Osman, Z. Ensemble Models for Enhancement of an Arabic Speech Emotion Recognition System. In Proceedings of the Future of Information and Communication Conference, San Francisco, CA, USA, 14–15 March 2019; pp. 174–187. [Google Scholar]
- Sultana, S.; Shahnaz, C. A non-hierarchical approach of speech emotion recognition based on enhanced wavelet coefficients and K-means clustering. In Proceedings of the 2014 International Conference on Informatics, Electronics & Vision (ICIEV), Dhaka, Bangladesh, 23–24 May 2014; pp. 1–5. [Google Scholar]
- Trabelsi, I.; Ayed, D.B.; Ellouze, N. Evaluation of influence of arousal-valence primitives on speech emotion recognition. Int. Arab J. Inf. Technol. 2018, 15, 756–762. [Google Scholar]
- Xiao, Z.; Dellandrea, E.; Dou, W.; Chen, L. Automatic hierarchical classification of emotional speech. In Proceedings of the Ninth IEEE International Symposium on Multimedia Workshops (ISMW 2007), Beijing, China, 10–12 December 2007; pp. 291–296. [Google Scholar]
- Shaqra, F.A.; Duwairi, R.; Al-Ayyoub, M. Recognizing Emotion from Speech Based on Age and Gender Using Hierarchical Models. Procedia Comput. Sci. 2019, 151, 37–44. [Google Scholar] [CrossRef]
- Xiao, Z.; Dellandréa, E.; Chen, L.; Dou, W. Recognition of emotions in speech by a hierarchical approach. In Proceedings of the 2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, The Netherlands, 10–12 September 2009; pp. 1–8. [Google Scholar]
- You, M.; Chen, C.; Bu, J.; Liu, J.; Tao, J. A hierarchical framework for speech emotion recognition. In Proceedings of the 2006 IEEE International Symposium on Industrial Electronics, Montreal, QC, Canada, 9–13 July 2006; Volume 1, pp. 515–519. [Google Scholar]
- Engberg, I.S.; Hansen, A.V. Documentation of the Danish Emotional Speech Database (DES); Internal AAU Report; Center for Person Kommunikation: Aalborg, Denmark, 1996; p. 22. [Google Scholar]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124. [Google Scholar] [CrossRef]
- Plutchik, R. The nature of emotions: Human emotions have deep evolutionary roots, a fact that may explain their complexity and provide tools for clinical practice. Am. Sci. 2001, 89, 344–350. [Google Scholar] [CrossRef]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar]
- Rao, K.S.; Koolagudi, S.G.; Vempada, R.R. Emotion recognition from speech using global and local prosodic features. Int. J. Speech Technol. 2013, 16, 143–160. [Google Scholar] [CrossRef]
- Zieliński, T. Cyfrowe Przetwarzanie Sygnałów; Wydawnictwa Komunikacji i a̧czności: Warsaw, Poland, 2013. [Google Scholar]
- Skowronski, M.; Harris, J. Increased mfcc filter bandwidth for noise-robust phoneme recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002; pp. 801–804. [Google Scholar]
- Kumar, P.; Biswas, A.; Mishra, A.; Chandra, M. Spoken Language Identification Using Hybrid Feature Extraction Methods. J. Telecommun. 2010, 1, 11–15. [Google Scholar]
- Hermansky, H. Perceptual Linear Predictive (PLP) Analysis of Speech. J. Acoust. Soc. Am. 1989, 87, 1738–1752. [Google Scholar] [CrossRef] [PubMed]
- O’Shaughnessy, D. Linear predictive coding. IEEE Potentials 1988, 7, 29–32. [Google Scholar] [CrossRef]
- Mermelstein, P. Determination of the vocal-tract shape from measured formant frequencies. J. Acoust. Soc. Am. 1967, 41, 1283–1294. [Google Scholar] [CrossRef] [PubMed]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Available online: https://www.cs.waikato.ac.nz/~mhall/thesis.pdf (accessed on 20 September 1999).
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Hook, J.; Noroozi, F.; Toygar, O.; Anbarjafari, G. Automatic speech based emotion recognition using paralinguistics features. Bull. Pol. Acad. Sci. Tech. Sci. 2019, 67, 479–488. [Google Scholar]
- Yüncü, E.; Hacihabiboglu, H.; Bozsahin, C. Automatic speech emotion recognition using auditory models with binary decision tree and svm. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 773–778. [Google Scholar]
- Kamińska, D.; Sapiński, T.; Anbarjafari, G. Efficiency of chosen speech descriptors in relation to emotion recognition. EURASIP J. Audio Speech Music. Process. 2017, 2017, 3. [Google Scholar] [CrossRef]





| Database | No. of Samples/Per Emotion | Female/Male | Type | No. of Emotions |
|---|---|---|---|---|
| MERIP | 560/unsp | 8/8 | acted | 7: Ne, Sa, Su, Fe, Di, An, Ha |
| PESD | 240/40 | 4/4 | acted | 6: Ha, Bo, Fe, An, Sa, Ne |
| PSSD | 748/80 | nd/nd | natural | 8: Ha, Sa, An, Fe, Di, Su, An, Ne |
| k-NN | MLP | SL | SMO | Bagging | RC | j48 | LMT | NBTree | RF | |
|---|---|---|---|---|---|---|---|---|---|---|
| F0 | 34,02 | 32,39 | 34,75 | 34,75 | 34,75 | 34,75 | 30,26 | 33,33 | 26,47 | 37,35 |
| En | 30,91 | 29,03 | 26,93 | 25,99 | 33,49 | 28,57 | 26,22 | 31,62 | 29,03 | 28,1 |
| F1-F3 | 36,06 | 35,36 | 39,11 | 36,06 | 34,43 | 33,02 | 29,03 | 40,04 | 33,26 | 33,3 |
| LPC | 42,39 | 45,2 | 44,73 | 41,22 | 39,11 | 42,39 | 32,55 | 44,26 | 34,43 | 45,9 |
| MFCC | 59,33 | 57,37 | 51,52 | 53,63 | 50,58 | 54,1 | 44,73 | 51,05 | 44,96 | 51,3 |
| BFCC | 57,21 | 58,39 | 52,69 | 54,56 | 51,05 | 53,63 | 45,19 | 57,61 | 46,37 | 56,9 |
| HFCC | 39,11 | 33,02 | 37 | 37 | 35,12 | 39,81 | 33,72 | 37,23 | 37 | 42,86 |
| PLP | 56,44 | 49,18 | 43,09 | 40,75 | 47,3 | 54,1 | 44,26 | 53,16 | 41,69 | 54,8 |
| RPLP | 55,5 | 43,09 | 39,11 | 43,32 | 50,11 | 52,46 | 46,37 | 47,54 | 40,28 | 56,9 |
| k-NN | MLP | SL | SMO | Bagging | RC | j48 | LMT | NBTree | RF | |
|---|---|---|---|---|---|---|---|---|---|---|
| F0 | 33,76 | 34,18 | 38,82 | 34,18 | 30,8 | 32,91 | 30,8 | 37,55 | 32,49 | 40,08 |
| En | 35,02 | 34,17 | 34,17 | 29,95 | 37,97 | 32,06 | 29,95 | 37,55 | 35,86 | 33,75 |
| F1-F3 | 38,82 | 36,71 | 34,18 | 36,29 | 38,4 | 37,55 | 37,97 | 34,17 | 32,91 | 39,24 |
| LPC | 38,82 | 32,06 | 38,37 | 37,55 | 32,49 | 33,75 | 32,07 | 38,96 | 31,22 | 31,22 |
| MFCC | 38,82 | 58,22 | 51,89 | 57,38 | 45,99 | 49,36 | 41,77 | 51,89 | 39,24 | 54,43 |
| BFCC | 54 | 61,6 | 49,37 | 59,49 | 42,19 | 49,36 | 41,35 | 48,1 | 43,46 | 55,69 |
| HFCC | 55,27 | 51,05 | 56,19 | 56,96 | 47,26 | 50,21 | 42,62 | 55,27 | 41,77 | 52,74 |
| PLP | 57,74 | 53,58 | 56,96 | 49,36 | 47,68 | 54,85 | 44,72 | 55,69 | 43,04 | 56,11 |
| RPLP | 54,43 | 60,34 | 54,43 | 53,59 | 48,95 | 47,26 | 42,19 | 53,16 | 41,77 | 56,96 |
| Features: | k-NN | MLP | SL | SMO | Bagging | RC | j48 | LMT | NBTree | RF |
|---|---|---|---|---|---|---|---|---|---|---|
| F0 | 48,86 | 48,57 | 50,28 | 48,01 | 51,42 | 49,14 | 41,76 | 51,13 | 42,04 | 53,69 |
| En | 55,39 | 52,84 | 45,45 | 42,61 | 57,95 | 50 | 50,85 | 55,11 | 51,7 | 55,96 |
| F1-F3 | 53,97 | 52,56 | 57,95 | 59,94 | 54,26 | 53,41 | 50,28 | 57,67 | 45,45 | 58,52 |
| LPC | 65,9 | 70,73 | 67,89 | 66,19 | 61,93 | 66,19 | 63,92 | 67,89 | 57,38 | 68,18 |
| MFCC | 76,7 | 76,98 | 71,85 | 76,13 | 64,2 | 73,57 | 63,35 | 71,87 | 64,2 | 80,68 |
| BFCC | 76,32 | 72,29 | 77,55 | 77,55 | 69,66 | 71,36 | 62,85 | 77,7 | 63,46 | 79,87 |
| HFCC | 72,29 | 69,97 | 72,91 | 71,82 | 74,67 | 71,39 | 61,76 | 72,91 | 60,22 | 74,61 |
| PLP | 76,42 | 74,14 | 71,59 | 71,02 | 67,89 | 74,43 | 65,34 | 71,59 | 67,05 | 74,43 |
| RPLP | 72,29 | 69,45 | 68,11 | 69,67 | 66,09 | 71,21 | 55,72 | 68,11 | 54,48 | 74,45 |
| k-NN | MLP | SL | SMO | Bagging | RC | j48 | LMT | NBTree | RF | |
|---|---|---|---|---|---|---|---|---|---|---|
| MERIP | 60,99 | 66,9 | 60,75 | 61,22 | 48,22 | 56,26 | 49,4 | 60,28 | 43,97 | 59,1 |
| PESD | 66,83 | 62,82 | 59,4 | 57,27 | 59,15 | 57 | 41,88 | 60,25 | 47,86 | 65,55 |
| PSSD | 78,97 | 83,52 | 80,96 | 83,23 | 74,43 | 77,84 | 65,9 | 80,68 | 69,03 | 81,53 |
| EV | ||||
|---|---|---|---|---|
| MERIP | 60,99 | 66.43 | 67.61 | 69,38 |
| PESD | 64,58 | 76,25 | 72,39 | 74,58 |
| PSSD | 83,52 | 84,94 | 85,22 | 86,14 |
| Database | Reference | Method | Accuracy |
|---|---|---|---|
| PESD | [65] | SVM | 75,42 |
| PESD | [66] | Binary Tree/SVM | 56,25 |
| PESD | [19] | EC (k-NN) | 70,9 |
| PSSD | [19] | EC (k-NN) | 84,7 |
| PSSD | [67] | k-NN/SVM | 83,95 |
| Training | Testing | k-NN | MLP | SL | Bagging | RC | RF | EV | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MERIP | PSSD | 31,94 | 29,94 | 32,84 | 30,67 | 29,03 | 30,12 | 31,65 | 32,91 | 33,02 | 33,26 |
| PESD | PSSD | 29,47 | 28,2 | 32,73 | 32 | 38,52 | 34,72 | 35,02 | 38,4 | 38,82 | 39,24 |
| MERIP + PESD | PSSD | 37,97 | 42,89 | 32,07 | 32,07 | 34,6 | 45,99 | 44,3 | 47,68 | 48,57 | 47,72 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kamińska, D. Emotional Speech Recognition Based on the Committee of Classifiers. Entropy 2019, 21, 920. https://doi.org/10.3390/e21100920
Kamińska D. Emotional Speech Recognition Based on the Committee of Classifiers. Entropy. 2019; 21(10):920. https://doi.org/10.3390/e21100920
Chicago/Turabian StyleKamińska, Dorota. 2019. "Emotional Speech Recognition Based on the Committee of Classifiers" Entropy 21, no. 10: 920. https://doi.org/10.3390/e21100920
APA StyleKamińska, D. (2019). Emotional Speech Recognition Based on the Committee of Classifiers. Entropy, 21(10), 920. https://doi.org/10.3390/e21100920