Teaching Ordinal Patterns to a Computer: Efficient Encoding Algorithms Based on the Lehmer Code


Abstract
1. Introduction
1.1. Efficient but Infeasible?
1.2. Structure of the Article
2. Preliminaries
2.1. Iversonian Brackets
2.2. Ordinal Patterns
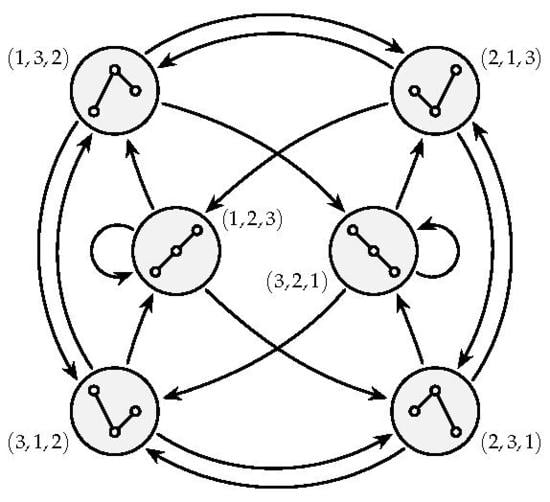
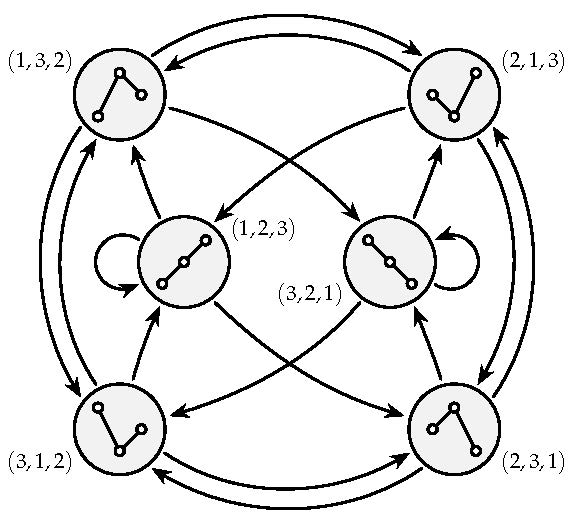
2.3. Ordinal Processes and Markov Chains
3. Ordinal Patterns in the Digital Domain
- While there are distinct ordinal patterns of order m, a block of m bytes can take on different states. Due to for small m, the memory footprint of the above encoding is far from optimal.
- Testing a pair of ordinal patterns for equality requires up to m byte-wise comparisons, which is particularly detrimental to the run-time of operations like sorting and searching.
- Counting distinct pattern occurrences in a sequence of ordinal patterns requires an associative array that provides a map from each possible tuple of ranks to its respective counter variable.
3.1. The Keller–Sinn–Emonds Code
3.2. The Lehmer Code
| Algorithm 1. Given an m-tuple of elements from a totally ordered set X, a distinct numerical representation of its ordinal pattern of order m can be obtained as outlined by the following pseudocode. |
| 1 function encode_pattern 2 input 3 with 4 output 5 n 6 begin 7 8 for to do 9 for to m do 10 11 end 12 13 end 14 return n 15 end. |
4. Encoding Time Series Data
4.1. The Straightforward Approach (Plain Algorithm)
| Algorithm 2. Plain Algorithm. To transform a finite time series of elements from a totally ordered set X into a sequence of non-negative integers , select a pattern order and a time lag , and proceed according to the pseudocode below. The value then uniquely identifies the ordinal pattern of order m, which is extracted from the time series at time index t using the time lag . The function encode_pattern is specified in Algorithm 1. |
| 1 function encode_sequence 2 input 3 m with m 4 with 5 with and 6 output 7 with and 8 begin 9 for to do 10 encode_pattern 11 end 12 end. |
4.2. An Optimised Encoding Strategy (Overlap Algorithm)
| Algorithm 3. Overlap Algorithm. To transform a finite time series of elements into a sequence of non-negative integers representing the ordinal patterns of the time series, select a pattern order and time lag . Then, proceed as follows. |
| 1 function encode_sequence 2 input 3 with and 4 m with m 5 with 6 output 7 with and 8 locals 9 with and 10 begin 11 for all and all 12 13 /* Obtain initial right inversion counts */ 14 for to τ do 15 for to do 16 for to do 17 18 end 19 end 20 end 21 22 /* Extract and encode ordinal patterns */ 23 24 for to do 25 for to do 26 27 28 end 29 /* Increment circular buffer index */ 30 end 31 end. |
4.3. The Unakafova–Keller Approach (Lookup Algorithm)
| Algorithm 4.Lookup Algorithm. To transform a finite time series into a sequence of non-negative integers representing its ordinal patterns, select a pattern order and time lag . In addition, prepare a lookup table according to Equation (21) that matches the encode_pattern function to be used. This can be the sym-function given by Equation (11), the -function of Equation (9), or any other bijective map yielding . Then, proceed as follows. |
| 1 function encode_sequence 2 input 3 with and 4 m with m 5 with 6 output 7 with and t 8 locals 9 with and i and 10 begin 11 12 13 /* Encode first τ ordinal patterns */ 14 for to τ do 15 16 end 17 18 /* Encode all remaining patterns */ 19 for to do 24 20 21 for to do 22 23 end 25 26 end 27 end. |
5. Implementation and Run-Time Performance
5.1. Theoretical Computational Complexities
5.2. Memory Alignment
5.3. Run-Time Test Environment
5.4. Test Signal Generation
5.5. The Plain Algorithm (Algorithm 2)
5.6. The Overlap Algorithm (Algorithm 3)
- an arbitrary-precision integer representation for the variable ,
- a function that adds a non-negative integer to , and
- a function that multiplies with a non-negative integer
5.7. The Lookup Algorithm (Algorithm 4)
5.8. Sequence Length and Time Lag
6. Conclusions
6.1. Picking the Right Tool for the Job
6.2. Final Remarks
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Zanin, M.; Zunino, L.; Rosso, O.A.; Papo, D. Permutation Entropy and Its Main Biomedical and Econophysics Applications: A Review. Entropy 2012, 14, 1553–1577. [Google Scholar] [CrossRef]
- Amigó, J.M.; Keller, K.; Kurths, J. Recent Progress in Symbolic Dynamics and Permutation Complexity. Eur. Phys. J. Spec. Top. 2013, 222, 241–247. [Google Scholar] [CrossRef][Green Version]
- Amigó, J.M.; Keller, K.; Unakafova, V.A. Ordinal symbolic analysis and its application to biomedical recordings. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2014, 373, 20140091. [Google Scholar] [CrossRef] [PubMed]
- Fadlallah, B.; Chen, B.; Keil, A.; Príncipe, J. Weighted-permutation entropy: A complexity measure for time series incorporating amplitude information. Phys. Rev. E 2013, 87, 022911. [Google Scholar] [CrossRef]
- Li, D.; Li, X.; Liang, Z.; Voss, L.J.; Sleigh, J.W. Multiscale permutation entropy analysis of EEG recordings during sevoflurane anesthesia. J. Neural Eng. 2010, 7, 046010. [Google Scholar] [CrossRef]
- Morabito, F.C.; Labate, D.; La Foresta, F.; Bramanti, A.; Morabito, G.; Palamara, I. Multivariate Multi-Scale Permutation Entropy for Complexity Analysis of Alzheimer’s Disease EEG. Entropy 2012, 14, 1186–1202. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J. Amplitude-aware permutation entropy: Illustration in spike detection and signal segmentation. Comput. Methods Programs Biomed. 2016, 128, 40–51. [Google Scholar] [CrossRef]
- Unakafov, A.M.; Keller, K. Conditional entropy of ordinal patterns. Phys. D Nonlinear Phenom. 2014, 269, 94–102. [Google Scholar] [CrossRef]
- King, J.R.; Sitt, J.D.; Faugeras, F.; Rohaut, B.; El Karoui, I.; Cohen, L.; Naccache, L.; Dehaene, S. Information sharing in the brain indexes consciousness in noncommunicative patients. Curr. Biol. 2013, 23, 1914–1919. [Google Scholar] [CrossRef] [PubMed]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed]
- Staniek, M.; Lehnertz, K. Symbolic Transfer Entropy. Phys. Rev. Lett. 2008, 100, 158101. [Google Scholar] [CrossRef] [PubMed]
- Groth, A. Visualization of coupling in time series by order recurrence plots. Phys. Rev. E 2005, 72, 046220. [Google Scholar] [CrossRef]
- Bandt, C.; Shiha, F. Order patterns in time series. J. Time Ser. Anal. 2007, 28, 646–665. [Google Scholar] [CrossRef]
- Keller, K.; Sinn, M.; Emonds, J. Time Series From the Ordinal Viewpoint. Stochastics Dyn. 2007, 7, 247–272. [Google Scholar] [CrossRef]
- Amigó, J.M. Permutation Complexity in Dynamical Systems; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Cao, Y.; Tung, W.w.; Gao, J.B.; Protopopescu, V.A.; Hively, L.M. Detecting dynamical changes in time series using the permutation entropy. Phys. Rev. E 2004, 70, 046217. [Google Scholar] [CrossRef]
- Frank, B.; Pompe, B.; Schneider, U.; Hoyer, D. Permutation entropy improves fetal behavioural state classification based on heart rate analysis from biomagnetic recordings in near term fetuses. Med. Biol. Eng. Comput. 2006, 44, 179. [Google Scholar] [CrossRef]
- Unakafova, V.A.; Keller, K. Efficiently Measuring Complexity on the Basis of Real-World Data. Entropy 2013, 15, 4392–4415. [Google Scholar] [CrossRef]
- Zunino, L.; Olivares, F.; Scholkmann, F.; Rosso, O.A. Permutation entropy based time series analysis: Equalities in the input signal can lead to false conclusions. Phys. Lett. A 2017, 381, 1883–1892. [Google Scholar] [CrossRef]
- Dickten, H.; Lehnertz, K. Identifying delayed directional couplings with symbolic transfer entropy. Phys. Rev. E 2014, 90, 062706. [Google Scholar] [CrossRef] [PubMed]
- Unakafov, A.M.; Keller, K. Change-Point Detection Using the Conditional Entropy of Ordinal Patterns. Entropy 2018, 20, 709. [Google Scholar] [CrossRef]
- Kaiser, A.; Schreiber, T. Information transfer in continuous processes. Phys. D Nonlinear Phenom. 2002, 166, 43–62. [Google Scholar] [CrossRef]
- Staniek, M.; Lehnertz, K. Parameter selection for permutation entropy measurements. Int. J. Bifurc. Chaos 2007, 17, 3729–3733. [Google Scholar] [CrossRef]
- Amigó, J.M.; Kocarev, L.; Szczepanski, J. Order patterns and chaos. Phys. Lett. A 2006, 355, 27–31. [Google Scholar] [CrossRef]
- Amigó, J.M.; Zambrano, S.; Sanjuán, M.A.F. True and false forbidden patterns in deterministic and random dynamics. Europhys. Lett. 2007, 79, 50001. [Google Scholar] [CrossRef]
- Riedl, M.; Müller, A.; Wessel, N. Practical considerations of permutation entropy. Eur. Phys. J. Spec. Top. 2013, 222, 249–262. [Google Scholar] [CrossRef]
- Iverson, K.E. A Programming Language; Wiley: New York, NY, USA, 1962. [Google Scholar]
- Knuth, D.E. Two Notes on Notation. Am. Math. Mon. 1992, 99, 403. [Google Scholar] [CrossRef]
- Laisant, C.A. Sur la numération factorielle, application aux permutations. Bull. la Société Mathématique Fr. 1888, 16, 176–183. [Google Scholar] [CrossRef]
- Lehmer, D.H. Teaching combinatorial tricks to a computer. Proceedings of Symposia in Applied Mathematics; Bellman, R., Hall, M., Jr., Eds.; American Mathematical Society: Providence, RI, USA, 1960; Volume 10, pp. 179–193. [Google Scholar]
- Eaton, J.W. GNU Octave and reproducible research. J. Process Control 2012, 22, 1433–1438. [Google Scholar] [CrossRef]
- Oliphant, T.E. Python for Scientific Computing. Comput. Sci. Eng. 2007, 9, 10–20. [Google Scholar] [CrossRef]
- IEEE 754-1985: IEEE Standard for Binary Floating-Point Arithmetic; IEEE Computer Society: New York, NY, USA, 1985.
- IEEE 754-2008: IEEE Standard for Floating-Point Arithmetic; IEEE Computer Society: New York, NY, USA, 2008.
- Goldberg, D. What every computer scientist should know about floating-point arithmetic. ACM Comput. Surv. 1991, 23, 5–48. [Google Scholar] [CrossRef]
- Marsaglia, G. Xorshift RNGs. J. Stat. Softw. 2003, 8, 1–6. [Google Scholar] [CrossRef]
- Berger, S.; Schneider, G.; Kochs, E.F.; Jordan, D. Permutation Entropy: Too Complex a Measure for EEG Time Series? Entropy 2017, 19, 692. [Google Scholar] [CrossRef]
- St. Denis, T.; Rose, G. BigNum Math: Implementing Cryptographic Multiple Precision Arithmetic; Syngress Publishing: Rockland, MA, USA, 2006. [Google Scholar]
- Brent, R.P.; Zimmermann, P. Modern Computer Arithmetic; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ranks | Inversions | Code | Ranks | Inversions | Code | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | n | ||||||||||||||
| 1 | 2 | 3 | 4 | 0 | 0 | 0 | 0 | 3 | 1 | 2 | 4 | 2 | 0 | 0 | 12 |
| 1 | 2 | 4 | 3 | 0 | 0 | 1 | 1 | 3 | 1 | 4 | 2 | 2 | 0 | 1 | 13 |
| 1 | 3 | 2 | 4 | 0 | 1 | 0 | 2 | 3 | 2 | 1 | 4 | 2 | 1 | 0 | 14 |
| 1 | 3 | 4 | 2 | 0 | 1 | 1 | 3 | 3 | 2 | 4 | 1 | 2 | 1 | 1 | 15 |
| 1 | 4 | 2 | 3 | 0 | 2 | 0 | 4 | 3 | 4 | 1 | 2 | 2 | 2 | 0 | 16 |
| 1 | 4 | 3 | 2 | 0 | 2 | 1 | 5 | 3 | 4 | 2 | 1 | 2 | 2 | 1 | 17 |
| 2 | 1 | 3 | 4 | 1 | 0 | 0 | 6 | 4 | 1 | 2 | 3 | 3 | 0 | 0 | 18 |
| 2 | 1 | 4 | 3 | 1 | 0 | 1 | 7 | 4 | 1 | 3 | 2 | 3 | 0 | 1 | 19 |
| 2 | 3 | 1 | 4 | 1 | 1 | 0 | 8 | 4 | 2 | 1 | 3 | 3 | 1 | 0 | 20 |
| 2 | 3 | 4 | 1 | 1 | 1 | 1 | 9 | 4 | 2 | 3 | 1 | 3 | 1 | 1 | 21 |
| 2 | 4 | 1 | 3 | 1 | 2 | 0 | 10 | 4 | 3 | 1 | 2 | 3 | 2 | 0 | 22 |
| 2 | 4 | 3 | 1 | 1 | 2 | 1 | 11 | 4 | 3 | 2 | 1 | 3 | 2 | 1 | 23 |
| Algorithm | Add | Multiply | Compare | Increment | Assign | Modulo | Total |
|---|---|---|---|---|---|---|---|
| plain | 0 | ||||||
| overlap | m | 1 | |||||
| lookup [21] | 0 |
| Data Type | Significant Bits | Maximum Order |
|---|---|---|
| m | ||
| uint8 | 8 | 5 |
| uint16 | 16 | 8 |
| uint32 | 32 | 12 |
| uint64 | 64 | 20 |
| binary32 (single) | 24 | 10 |
| binary64 (double) | 53 | 18 |
| Order | Computation Time () | |||
|---|---|---|---|---|
| m | GNU Octave | NumPy/Python | Matlab | C |
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 | ||||
| 7 | ||||
| 8 | ||||
| 9 | ||||
| Order | Computation Time () | ||||||
|---|---|---|---|---|---|---|---|
| m | GNU Octave | NumPy/Python | Matlab | C | |||
| loops | vectors | loops | vectors | loops | vectors | loops | |
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| 6 | |||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berger, S.; Kravtsiv, A.; Schneider, G.; Jordan, D. Teaching Ordinal Patterns to a Computer: Efficient Encoding Algorithms Based on the Lehmer Code. Entropy 2019, 21, 1023. https://doi.org/10.3390/e21101023
Berger S, Kravtsiv A, Schneider G, Jordan D. Teaching Ordinal Patterns to a Computer: Efficient Encoding Algorithms Based on the Lehmer Code. Entropy. 2019; 21(10):1023. https://doi.org/10.3390/e21101023
Chicago/Turabian StyleBerger, Sebastian, Andrii Kravtsiv, Gerhard Schneider, and Denis Jordan. 2019. "Teaching Ordinal Patterns to a Computer: Efficient Encoding Algorithms Based on the Lehmer Code" Entropy 21, no. 10: 1023. https://doi.org/10.3390/e21101023
APA StyleBerger, S., Kravtsiv, A., Schneider, G., & Jordan, D. (2019). Teaching Ordinal Patterns to a Computer: Efficient Encoding Algorithms Based on the Lehmer Code. Entropy, 21(10), 1023. https://doi.org/10.3390/e21101023