2.1. Market Model for Trading Probabilities
Consider a situation when we have two possible binary outcomes,
with
. At time
t, the probability of these outcomes is given by
. As a process,
is the conditional expected value of the final outcome:
under the true probability measure
. In particular,
as a process is a martingale under the true probability measure. The true values
are typically unobserved and they are a subject of statistical estimation. Since there can be several competing models for these probabilities, the question is what model is the best among the available alternatives. Let us consider the situation when we have two models that give two probability measures
and
. Thus we have two probability estimates at time
t:
and
of the outcomes
. Obviously,
and
.
Let us limit our analysis to the situation of two outcomes, the generalization to an arbitrary number of the number of outcomes is possible, but the formulas involved become rather complicated which we will address it in subsequent work. Given two different estimates, a natural question is which probability series is better in the sense that it is closer to the true probability. We present an approach to compare these estimators based on the following. When there is any discrepancy between the two estimates and at time t, it introduces a possibility of placing a bet. This bet will have two exposures: that corresponds to the win of the first player if the first selection happens and that corresponds to the win of the first player if the second selection happens. These bet sizes will be added to the existing cumulative exposures from the past , resulting in
The market is a zero sum game, and the second agent will collect the negative value of these: and respectively. We now discuss how to determine the changes in the exposures and the cumulative exposures that would be acceptable for both agents.
An agent can evaluate the current exposures by using some utility function that is increasing and concave. The standard choices are
- Logarithmic Utility:
- Exponential Utility:
,
- Power Utility:
The parameter B is a free parameter and it can be interpreted as a bankroll. In the case of logarithmic utility, the exposures cannot fall below as the evaluation of such a position would be negative infinity, thus bounding the resulting exposures. This is not the case for the exponential utility, where exposures below are evaluated with a finite value, but such positions are still evaluated highly negatively, meaning that exposures below are possible, but unlikely to be realized. Note that logarithmic utility is a limiting case of a power utility when . As it turns out, the choice of power utility does not lead to analytical formulas for the below described trading algorithm, and thus we will give formulas only for the logarithmic and exponential utilities.
The agent with probability estimates
that correspond to probability measure
assigns an evaluation of his positions
as
Similar evaluation of
appears in Kelly [
12] and more recently in Wolfers and Zitzewitz [
14], but these works are limited to the logarithmic utility function and to static positions. Note that the evaluation of the trading positions
,
, is based on a subjective probability measure
. For any given odds of the first selection that corresponds to the inverse of the traded probability
p, an agent can add or subtract some quantity from the existing exposures which will result in a more favorable utility value. This creates a supply/demand function for each agent, which represents a volume that the agent is willing to bet given the available market odds
.
More specifically, if the first agent accepts an additional bet of
units on the first selection at price
p, his exposures will change to
so the changes in the exposures are given by
If the first selection materializes, the first agent is obliged to pay off units that correspond to the bet size N at the odds. If the first selection does not materialize, the agent that accepted the bet will collect the original bet size N. Thus for every probability p that represents the trading price, we can find the corresponding N that maximizes the utility function, thus creating a supply/demand function. The reader should note that the parameter p plays a dual role of representing both the trading price and the probability of the first selection. In the following text, parameter p is used exclusively for the trading price as quoted by the market, while parameters and represent subjective probabilities of the respective agents.
The optimal betting size
N maximizes
This defines the supply function:
Definition 1. A supply function is equal to N that maximizesfor a given utility function U. Given a utility function U, the current exposures and the opinion about the probability , the agent finds an optimal bet size for any quoted price p. This is how we interpret the supply function.
The following theorem assures that the supply function is well defined:
Theorem 1. The supply function is uniquely defined.
Proof of Theorem 1. This is a simple consequence of concavity of the utility function
U and the proof can end here. For more details, consider the case when
U has a second derivative:
. Define
The second derivative of
is
so
f is also concave and thus attains a unique maximum. □
The supply function
gives the size of the bet
N on the second selection. This is directly the change of the size of the second selection
:
The change in the first selection
is given by
However, the betting positions can be flipped from
with probabilities
to
with probabilities
. This also flips
for
, meaning they can be directly determined from the same supply function
S, but with flipped positions:
Finding the maximum in Equation (
1) may not lead in general to a simple closed form formula. In particular, a supply function is not closed form for power utilities even for the simplest choices of the coefficient
a. On the other hand, the choice of logarithmic or exponential utility functions leads to convenient formulas. We can take the derivative of Equation (
1) and find where it equals zero, which is equivalent to
For the choice of the logarithmic utility function, we find
Similarly, exponential utility gives:
We are adding the bankroll B as a parameter since the utility functions depend on it. To the best of our knowledge, there are no previous results in the literature that produce analytical formula for a supply function which is a result of utility maximization.
In the later text, we will specify the market behavior of the second agent, leading to an automated procedure of market matching. However, the following result is true regardless of the matching behavior of the second agent. This theorem is analogous to the concept of a proper scoring rule, which means that the true probability estimate cannot be beaten in expectation when compared with any other alternative model. In addition, it does not matter what utility function is used, the true model is expected to generate a profit regardless of the utility used. Thus the exact choice of the utility function is secondary.
Theorem 2 (True probability has a non-negative expectation)
. The exposures of an agent trading with the true probability measure , , satisfy the following inequalities: In particular, for all .
Proof of Theorem 2. This is consequence of a submartingale property of the expected utility and concavity of the utility function. First, note that under the true measure, the process
is a submartingale, meaning
for
. This is by design. The expected utility moves either by trading actions of the trader or by the evolution of the probabilities. The trading action of the agent always improves the value of the utility with respect to its probability measure, which is true even for agents with other probability estimates. However, in contrast to other probability estimates, the evolution of true probabilities has a neutral impact on the expected utility as the probability
p is a martingale under the true probability measure
. Note that other probability estimates
are not martingales under the true measure
and the evolution of the probabilities does not have a neutral impact on the conditional expected value, meaning other probabilities are not guaranteed to lead to submartingale evolution.
Second, due to the Jensen’s inequality, we have
Combining the two properties, we get
and the inequality stated in the theorem is a result of taking the inverse of the utility function
, which is increasing. In particular, when
, we have
and we find
This finishes the proof. □
Note that while the expected utility process,
, is a submartingale with an increasing expected value, the same is not true for the expected profit,
. Theorem 2 gives lower bounds for the expected profit, but this does not guarantee that the expected profit is non-decreasing in time. An agent maximizing the utility function may prefer a position with a smaller expectation and a smaller variance over a position with a higher expectation and a higher variance. As an illustrative example, consider an agent with a utility function
that corresponds to the logarithmic utility function with a choice of parameter
. Consider the situation when the true probability is
and the agent uses this probability for trading. The supply function is positive for probabilities above 0.5, and negative for probabilities below 0.5 with the intercept at 0.5. Consider a second agent asking for a trade at
. As we discuss in the later text, this trading price would be chosen if the second agent uses the same utility function, but his probabilistic view is
. The supply function gives
, leading to exposures
This leads to a favorable position for the first agent with the expected utility
and the expected profit
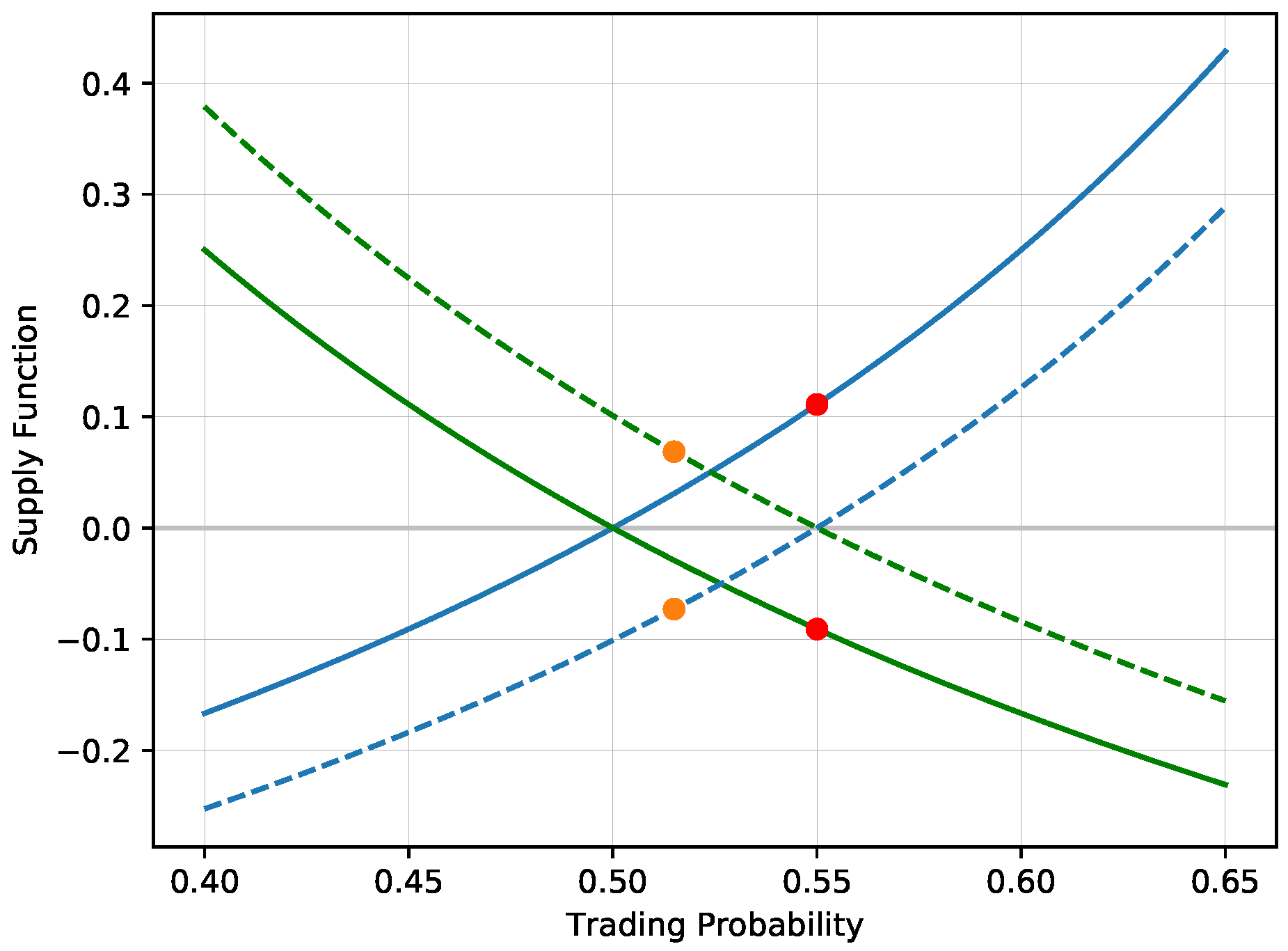
After this trade, the supply function of the first agent shifts down, the supply function is positive for probabilities above 0.55 and negative below 0.55. The first agent accepts additional bets on the first selection only for prices above 0.55. This trade itself is a good illustration of the entire trading procedure. The true probability
corresponds to the situation of a coin toss with odds
. At these odds, the agent is unwilling to trade. However, at odds equal to
, he is willing to accept the bet, creating the exposures
. After this trade, the agent would accept additional bets only above the price 0.55, or equivalently, for odds below 1.8181. Although accepting bet prices in the interval
would further increase his expected profit, it would reduce the expected utility. The first agent would rather reduce his exposure on the first selection at the expense of the expected value. He has already sold the first selection at the higher price of 0.55, so any trade at a buying price below 0.55 would reduce variability of the payoff, which would be reflected in a higher expected utility.
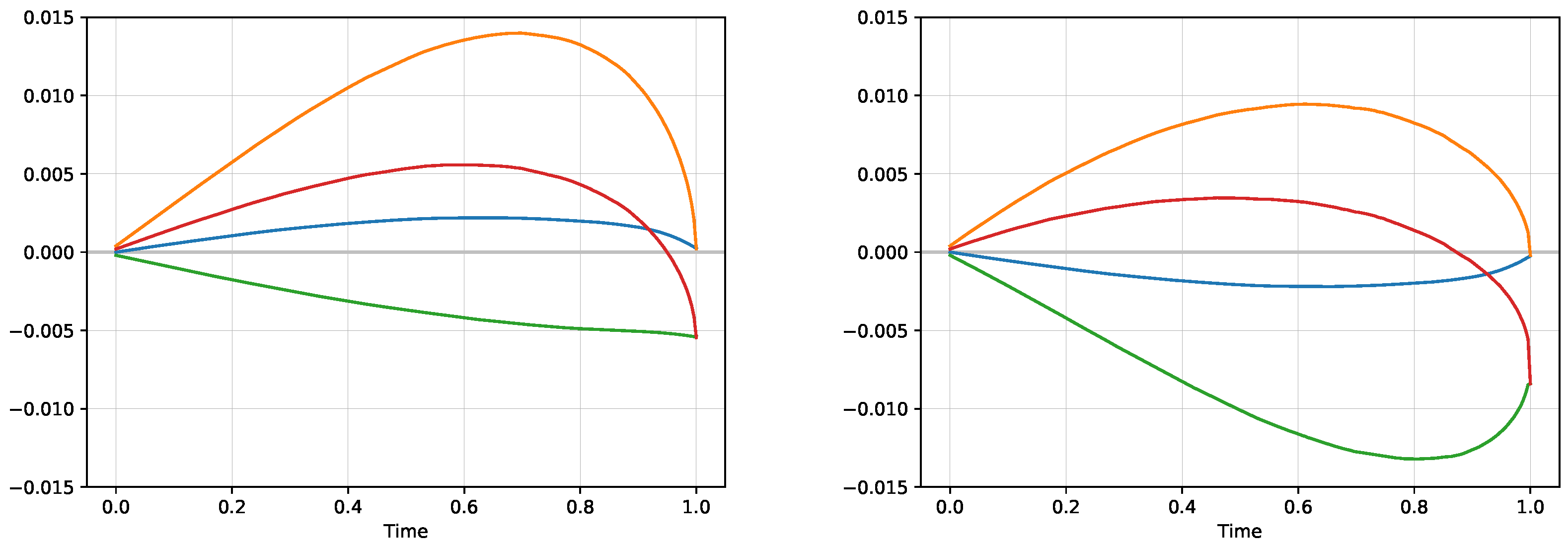
Figure 1 shows the supply/demand functions corresponding to the changes of both exposures
before and after the trade, illustrating the shift of the offered volume.
Consider a follow up trade on a price
. The existing exposures update to
leading to
and
Thus the expected utility has increased, but the expected value has decreased. Theorem 2 gives a lower bound for the expected value. The inverse of the utility function
is given by
which guarantees that the expected value will be in any case at least
B times the expected utility value (set
). When
, the expected profit is higher than the expected utility. While the expected utility is monotonically increasing, the expected profit may decrease as illustrated by the above example.
Theorem 2 is a key result for model comparison. The expected profit for the model with true probabilities is positive against any other alternative model. This result does not depend on the choice of the utility function, all that is needed here is that the utility function is increasing and concave. It also does not depend on the potential trading strategy of the second agent. In particular, the above described betting strategy with true probabilities is expected to generate a positive profit against the rest of the market even with multiple actors in the market.
2.2. Market Matching for Two Models
If we have two models to compare, the question is how to set the market matching algorithm for both agents representing the two alternative probabilistic views. While the results of the previous sections are valid regardless of the actions of the remaining market actors, this section focuses on a trading algorithm for two agents, where the trading price and the volume is acceptable for both sides. Let us assume that the second agent is also maximizing a utility function, but since he uses a different set of probabilities, the valuation of his exposures is different. The exposures of the second agent are as he is on a negative side of the trade. Thus both agents have a supply/demand function based on how much they are willing to bet, and it is natural to set the bet size N where the two functions intersect at the equilibrium. As discussed in the previous text, the trading behavior of the second agent is irrelevant for the profitability of an agent that uses true probabilities. For sake of symmetry, it makes sense that both agents use the same utility function. The supply function for the second agent must be taken with a negative sign as he is filling a negative position .
A general approach to a matching algorithm requires one to determine the trading price and the trading volume where the two supply and demand functions for the two agents intersect. The trading price
solves
which is a point on the
x-axis where the supply of the first agent with probabilistic view
and exposures
and
matches the negative supply of the second agent with probabilistic view
and exposures
and
. Similarly, the exact volume
N to trade is given by the supply function itself
Since we do not have a supply function for an arbitrary utility function, we will limit ourselves to the situations of the logarithmic and exponential utility functions. It does not matter for the statistical comparison of different probability models as the true model will always outperform any other model regardless of the choice of the utility function. The trading price for the logarithmic utility function is given by
with the corresponding volume
Note that the initial values when
simplify to
meaning that the trading price is at the arithmetic average of the two probability estimates and the corresponding exposures are
This corresponds to the model comparison of two static models where we have only one reading, and where one can use the traditional scoring function.
The trading price for the exponential utility function is given by
and the volume is
In contrast to the logarithmic utility, the trading price for the exponential utility model does not depend on the existing exposures . The trading price is a scaled geometric average of the two probability estimates.
Remark 1 (Relationship to statistical divergence)
. The resulting expected profit from the above described matching algorithm based on utility maximization can be used as a definition of statistical divergence D between two probability measures and aswhere the is the true measure based on Theorem 2. Moreover, the only way that the expected profit is exactly zero is when there is no trade, meaning that the two probabilistic measures much be identical , which is a condition required for statistical divergence. The important generalization is that this divergence is defined for time evolving probabilities. For instance, consider two probabilistic measures , and a logarithmic matching algorithm with in a static case. We have seen that the resulting exposures () areso the expected profit under the true measure is given byfor functionThis is a type of f-divergence. The divergence which is a result of maximization of the exponential utility function is not an f-divergence. However, the exponential utility plays a role in the Kullback-Leibler divergence. The Kullback-Leibler divergence can be viewed as a bet with resulting exposures After such a trade, both agents would keep zero exponential utility with asand This means that in a static setting, the exposures from the Kullback-Leibler leave both agents ambivalent with a situation of no trade. Since the expected exponential utility function has an approximately parabolic shape, the maximum is achieved close to the midpoints of the two zeroes, namely at and . In particular, the initial exposure satisfieswhich is true with a remarkable precision. One can define a statistical divergence in a dynamic setting by adding the trading positions from the divergence in a static setting. For the case of Kullback-Leibler divergence, we can define This is a natural construction, which moreover guarantees that the process is non-decreasing under the true measure. This is a simple consequence of a divergence property as at each time t. However, this construction ignores the information flow in time as any long lasting discrepancy is added repeatedly. As a consequence, methods based on utility maximization that properly reflect the information flow in time turn out to be superior as we illustrate in the final section.
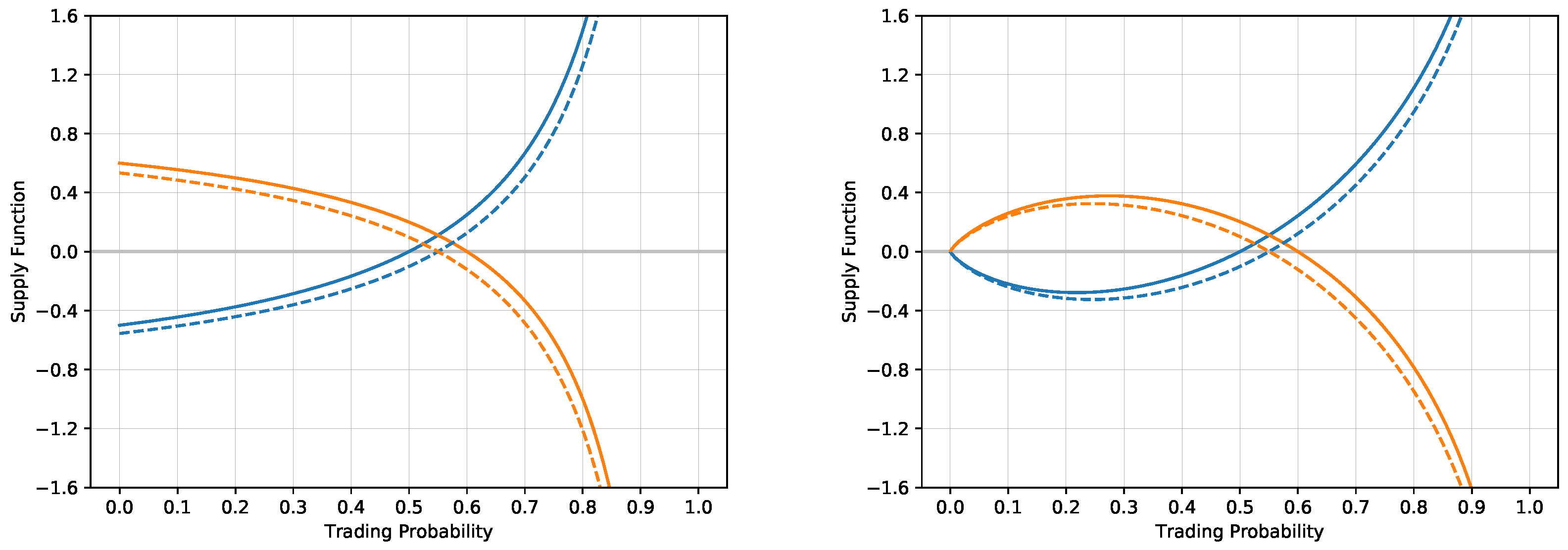
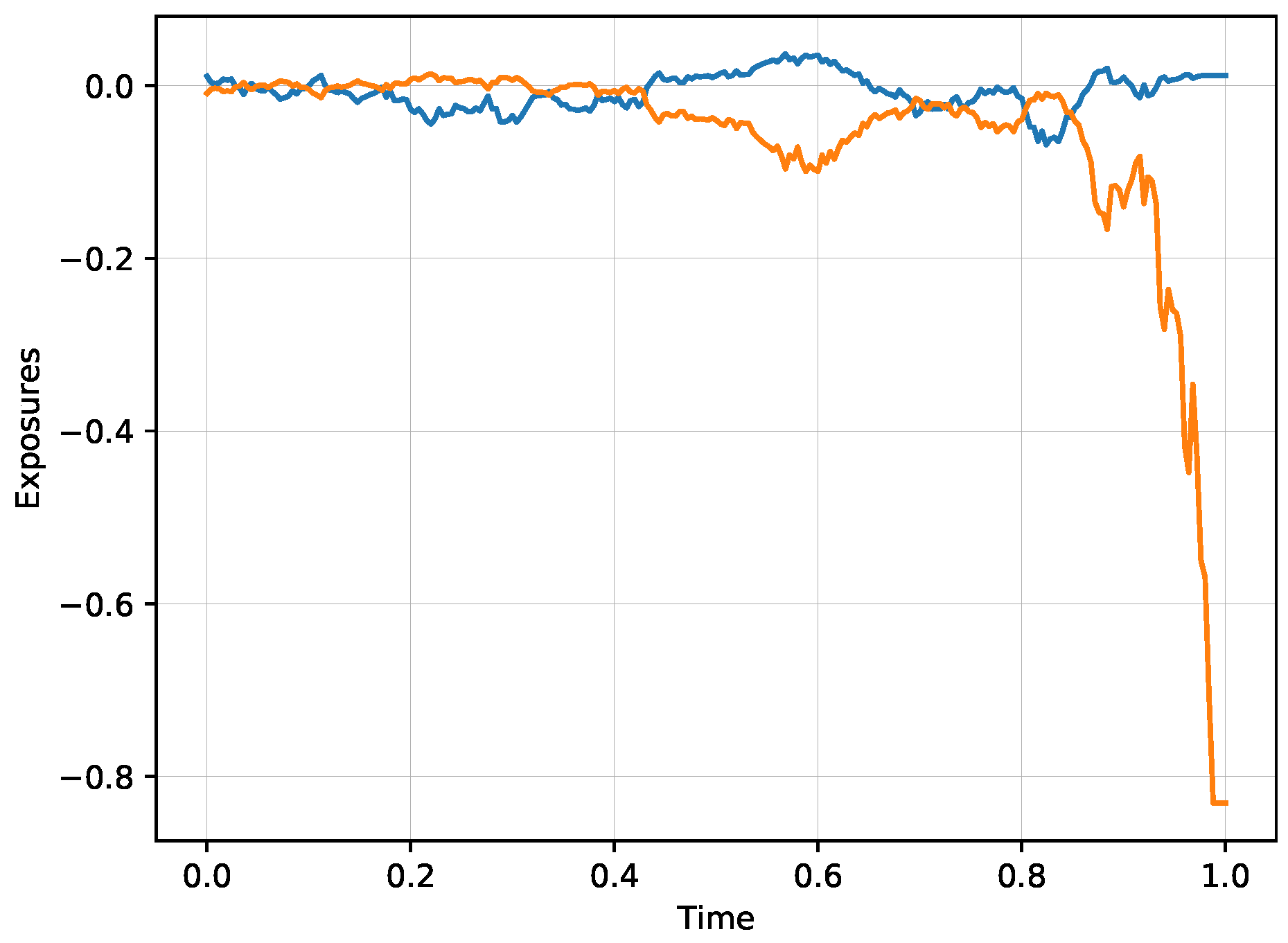
Figure 2 illustrates the situation when the two agents trade two probability estimates, one with
and one with
with zero exposures
for both situations of the logarithmic and exponential utility functions. Both agents produce the supply/demand functions. In the situation of the logarithmic utility, the supply/demand functions intersect at the trading price
with the corresponding volume
The exponential utility gives slightly different results, the trading price is at
and the resulting volume is
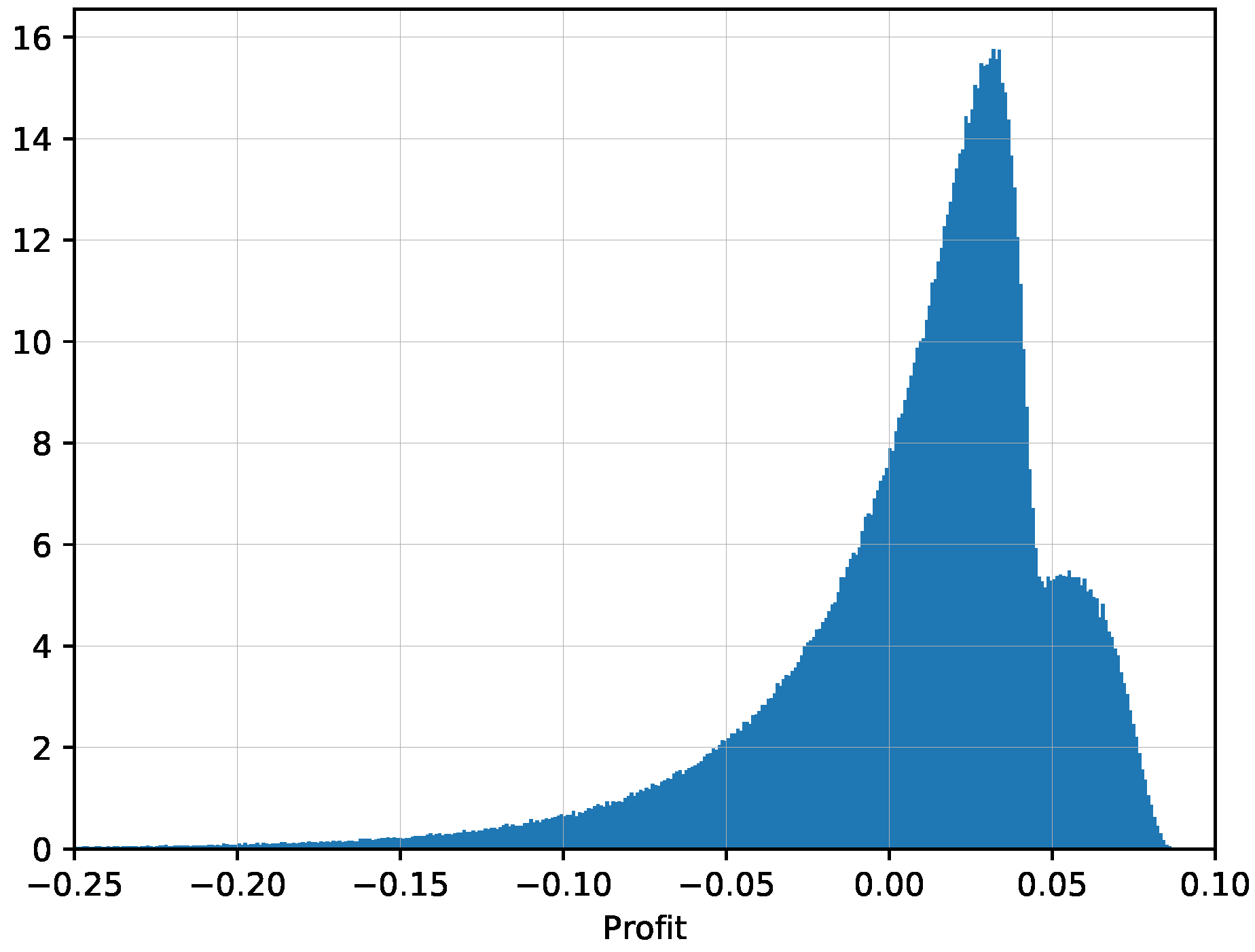
For the comparison statistics, all we need to check is whether the profit statistic,
is statistically positive. This is the exposure corresponding to the winning side, which is observed only after observing the ultimate outcome in one comparison. If we have
n scenarios that are independent and identically distributed, the ratio
will converge to a standard normal distribution
according to the Central Limit Theorem. Since the standard deviation of
is typically not observed, we can introduce
and the test statistic
has
t-distribution with
degrees of freedom. In particular, we can test the hypothesis that
, giving the statistical significance to the comparison of two alternative models. The absolute magnitude of
is not important as different utilities may scale this value up or down, but rather the statistical significance depends on its ratio with the corresponding standard deviation.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}