1. Introduction
The energy consumption of an analogue-to-digital converter (ADC) (measured in Joules/sample) grows exponentially with its resolution (in bits/sample) [
1,
2].When the available power is limited, for example, for mobile devices with limited battery capacity, or for wireless receivers that operate on limited energy harvested from ambient sources [
3], the receiver circuitry may be constrained to operate with low resolution ADCs. The presence of a low-resolution ADC, in particular a one-bit ADC at the receiver, alters the channel characteristics significantly. Such a constraint not only limits the fundamental bounds on the achievable rate, but it also changes the nature of the communication and modulation schemes approaching these bounds. For example, in a real additive white Gaussian noise (AWGN) channel under an average power constraint on the input, if the receiver is equipped with a
K-bin (i.e.,
-bit) ADC front end, it is shown in [
4] that the capacity-achieving input distribution is discrete with at most
mass points. This is in contrast with the optimality of the Gaussian input distribution when the receiver has infinite resolution.
Especially with the adoption of massive multiple-input multiple-output (MIMO) receivers and the millimetre wave (mmWave) technology enabling communication over large bandwidths, communication systems with limited-resolution receiver front ends are becoming of practical importance. Accordingly, there has been a growing research interest in understanding both the fundamental information theoretic limits and the design of practical communication protocols for systems with finite-resolution ADC front ends. In [
5], the authors showed that for a Rayleigh fading channel with a one-bit ADC and perfect channel state information at the receiver (CSIR), quadrature phase shift keying (QPSK) modulation is capacity-achieving. In case of no CSIR, [
6] showed that QPSK modulation is optimal when the signal-to-noise ratio (SNR) is above a certain threshold, which depends on the coherence time of the channel, while for SNRs below this threshold, on-off QPSK achieves the capacity. For the point-to-point multiple-input multiple-output (MIMO) channel with a one-bit ADC front end at each receive antenna and perfect CSIR, [
7] showed that QPSK is optimal at very low SNRs, while with perfect channel state information at the transmitter (CSIT), upper and lower bounds on the capacity are provided in [
8].
To the best of our knowledge, the existing literature on communications with low-resolution ADCs focuses exclusively on point-to-point systems. Our goal in this paper is to understand the impact of low-resolution ADCs on the capacity region of a multiple access channel (MAC). In particular, we consider a two-transmitter Gaussian MAC with a one-bit quantizer at the receiver. The inputs to the channel are subject to average power constraints. We show that any point on the boundary of the capacity region is achieved by discrete input distributions. Based on the slope of the tangent line to the capacity region at a boundary point, we propose upper bounds on the cardinality of the support of these distributions. Finally, based on numerical analysis for the sum capacity, it is observed that we cannot obtain a sum rate higher than is achieved by time division with power control.
The paper is organized as follows.
Section 2 introduces the system model. In
Section 3, the capacity region of a general two-transmitter memoryless MAC under input average power constraints is investigated. The main result of the paper is presented in
Section 3, and a detailed proof is given in
Section 4. The proof has two parts: (1) it is shown that the support of the optimal distributions is bounded by contradiction; and (2) we make use of this boundedness to prove the finiteness of the optimal support by using Dubins’ theorem [
9].
Section 5 analyses the sum capacity, and finally,
Section 6 concludes the paper.
Notations: Random variables are denoted by capital letters, while their realizations with lower case letters. denotes the cumulative distribution function (CDF) of random variable X. The conditional probability mass function (pmf) will be written as . For integers , we have . For , denotes the binary entropy function. The unit-step function is denoted by .
2. System Model and Preliminaries
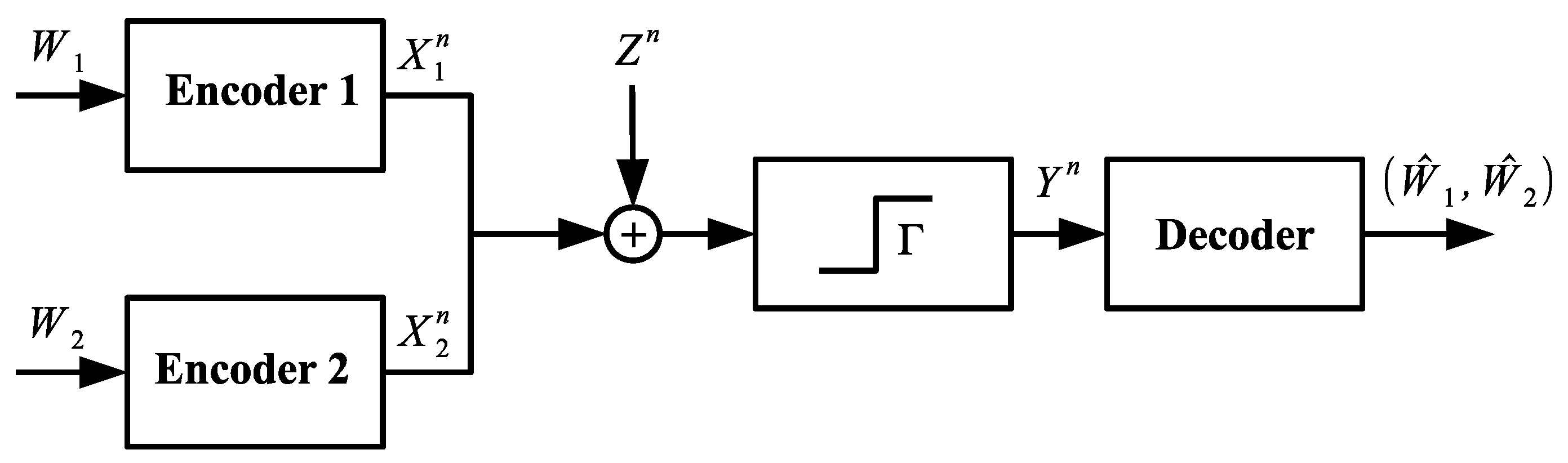
We consider a two-transmitter memoryless Gaussian MAC (as shown in
Figure 1) with a one-bit quantizer
at the receiver front end. Transmitter
encodes its message
into a codeword
and transmits it over the shared channel. The signal received by the decoder is given by:
where
is an independent and identically distributed (i.i.d.) Gaussian noise process, also independent of the channel inputs
and
with
.
represents the one-bit ADC operation given by:
This channel can be modelled by the triplet
, where
(
) and
(
), respectively, are the alphabets of the inputs and the output. The conditional pmf of the channel output
Y conditioned on the channel inputs
and
(i.e.,
) is characterized by:
where
.
We consider a two-transmitter stationary and memoryless MAC model
, where
,
,
is given in (
1).
A
code for this channel consists of (as in [
10]):
two message sets and ,
two encoders, where encoder assigns a codeword to each message , and
a decoder that assigns estimates or an error message to each received sequence .
The stationary property means that the channel does not change over time, while the memoryless property indicates that for any message pair .
We assume that the message pair
is uniformly distributed over
. The average probability of error is defined as:
Average power constraints are imposed on the channel inputs as:
where
denotes the
i-th element of the codeword
.
A rate pair
is said to be achievable for this channel if there exists a sequence of
codes satisfying the average power constraints (
3), such that
. The capacity region
of this channel is the closure of the set of achievable rate pairs
.
4. Proof of Theorem 1
In order to show that the boundary points of the capacity region are achieved, it is sufficient to show that the capacity region is a closed set, i.e., it includes all of its limit points.
Let
be a set with
and
be defined as:
which is the set of all CDFs on the triplet
, where
U is drawn from
, and the Markov chain
and the corresponding average power constraints hold.
In
Appendix B, it is proven that
is a compact set. Since a continuous mapping preserves compactness, the capacity region is compact. Since the capacity region is a subset of
, it is closed and bounded (note that a subset of
is compact if and only if it is closed and bounded [
11]). Therefore, any point
P on the boundary of the capacity region is achieved by a distribution denoted by
.
Since the capacity region is a convex space, it can be characterized by its supporting hyperplanes. In other words, any point on the boundary of the capacity region, denoted by
, can be written as:
for some
. Here, we have excluded the cases
and
, where the channel is not a two-transmitter MAC any longer, and boils down to a point-to-point channel, whose capacity is already known.
Any rate pair
must lie within a pentagon defined by (
4) for some
that satisfies the power constraints. Therefore, due to the structure of the pentagon, the problem of finding the boundary points is equivalent to the following maximization problem.
where on the right-hand side (RHS) of (
7), the maximizations are over all
that satisfy the power constraints. It is obvious that when
, the two lines in (
7) are the same, which results in the sum capacity.
For any product of distributions
and the channel in (
1), let
be defined as:
With this definition, (
7) can be rewritten as:
where the second maximization is over distributions of the form
, such that:
Proposition 2. For a given and any , is a concave, continuous and weakly differentiable function of . In the statement of this proposition, and could be interchanged.
Proposition 3. Let be two arbitrary non-negative real numbers. For the following problem:the optimal inputs and , which are not unique in general, have the following properties, - (i)
The support sets of and are bounded subsets of .
- (ii)
and are discrete distributions that have at most and points of increase, respectively, where:
Proof of Proposition 3. We start with the proof of the first claim. Assume that
, and
is given. Consider the following optimization problem:
Note that
, since for any
, from (
8),
From Proposition 2,
is a continuous, concave function of
. Furthermore, the set of all CDFs with bounded second moment (here,
) is convex and compact. The compactness follows from Appendix I in [
12], where the only difference is in using Chebyshev’s inequality instead of Markov’s inequality. Therefore, the supremum in (
10) is achieved by a distribution
. Since for any
with
, we have
, the Lagrangian theorem and the Karush–Kuhn–Tucker conditions state that there exists a
such that:
Furthermore, the supremum in (
11) is achieved by
, and:
Lemma 1. The Lagrangian multiplier is non-zero. From (12), this is equivalent to having , i.e., the first user transmits with its maximum allowable power (note that this is for , as used in Appendix D). Proof of Lemma 1. In what follows, we prove that a zero Lagrangian multiplier is not possible. Having a zero Lagrangian multiplier means the power constraint is inactive. In other words, if
, (
10) and (
11) imply that:
We prove that (
13) does not hold by showing that its left-hand side (LHS) is strictly less than one, while its RHS equals one. The details are provided in
Appendix D. ☐
(
) can be written as:
where we have defined:
and:
is nothing but the pmf of
Y with the emphasis that it has been induced by
and
. Likewise,
is the conditional pmf
when
is drawn according to
. From (
14),
can be considered as the density of
over
when
is given.
can be interpreted in a similar way.
Note that (
11) is an unconstrained optimization problem over the set of all CDFs. Since
is linear and weakly differentiable in
, the objective function in (
11) is concave and weakly differentiable. Hence, a necessary condition for the optimality of
is:
Furthermore, (18) can be verified to be equivalent to:
The justifications of (18)–(20) are provided in
Appendix E.
In what follows, we prove that in order to satisfy (20), must have a bounded support by showing that the LHS of (20) goes to with . The following lemma is useful in the sequel for taking the limit processes inside the integrals.
Lemma 2. Let and be two independent random variables satisfying and , respectively (). Considering the conditional pmf in (1), the following inequalities hold. Note that
where (24) is due to the Lebesgue dominated convergence theorem [
11] and (21), which permit the interchange of the limit and the integral; (25) is due to the following:
since
goes to zero when
and
is bounded away from zero by (A34) ; (26) is obtained from (A34) in
Appendix F. Furthermore,
where (27) is due to the Lebesgue dominated convergence theorem along with (23) and (A39) in
Appendix F; (28) is from (22) and the convexity of
in
t when
(see
Appendix G).
Therefore, from (26) and (28),
Using a similar approach, we can also obtain:
From (29) and (30) and the fact that
(see Lemma 1), the LHS of (19) goes to
when
. Since any point of increase of
must satisfy (19) with equality and
, it is proven that
has a bounded support. Hence, from now on, we assume
for some
(note that
and
are determined by the choice of
).
Similarly, for a given
, the optimization problem:
boils down to the following necessary condition:
for the optimality of
. However, there are two main differences between (32) and (20). First is the difference between
and
. Second is the fact that we do not claim
to be nonzero, since the approach used in Lemma 1 cannot be readily applied to
. Nonetheless, the boundedness of the support of
can be proven by inspecting the behaviour of the LHS of (32) when
.
In what follows, i.e., from (33)–(38), we prove that the support of
is bounded by showing that (32) does not hold when
is above a certain threshold. The first term on the LHS of (32) is
. From (17) and (21), it can be easily verified that:
From (33), if
, the LHS of (32) goes to
with
, which proves that
is bounded.
For the possible case of , in order to show that (32) does not hold when is above a certain threshold, we rely on the boundedness of , i.e., . Then, we prove that approaches its limit in (33) from below. In other words, there is a real number K such that when , and when . This establishes the boundedness of . In what follows, we only show the former, i.e., when . The latter, i.e., , follows similarly, and it is omitted for the sake of brevity.
By rewriting
, we have:
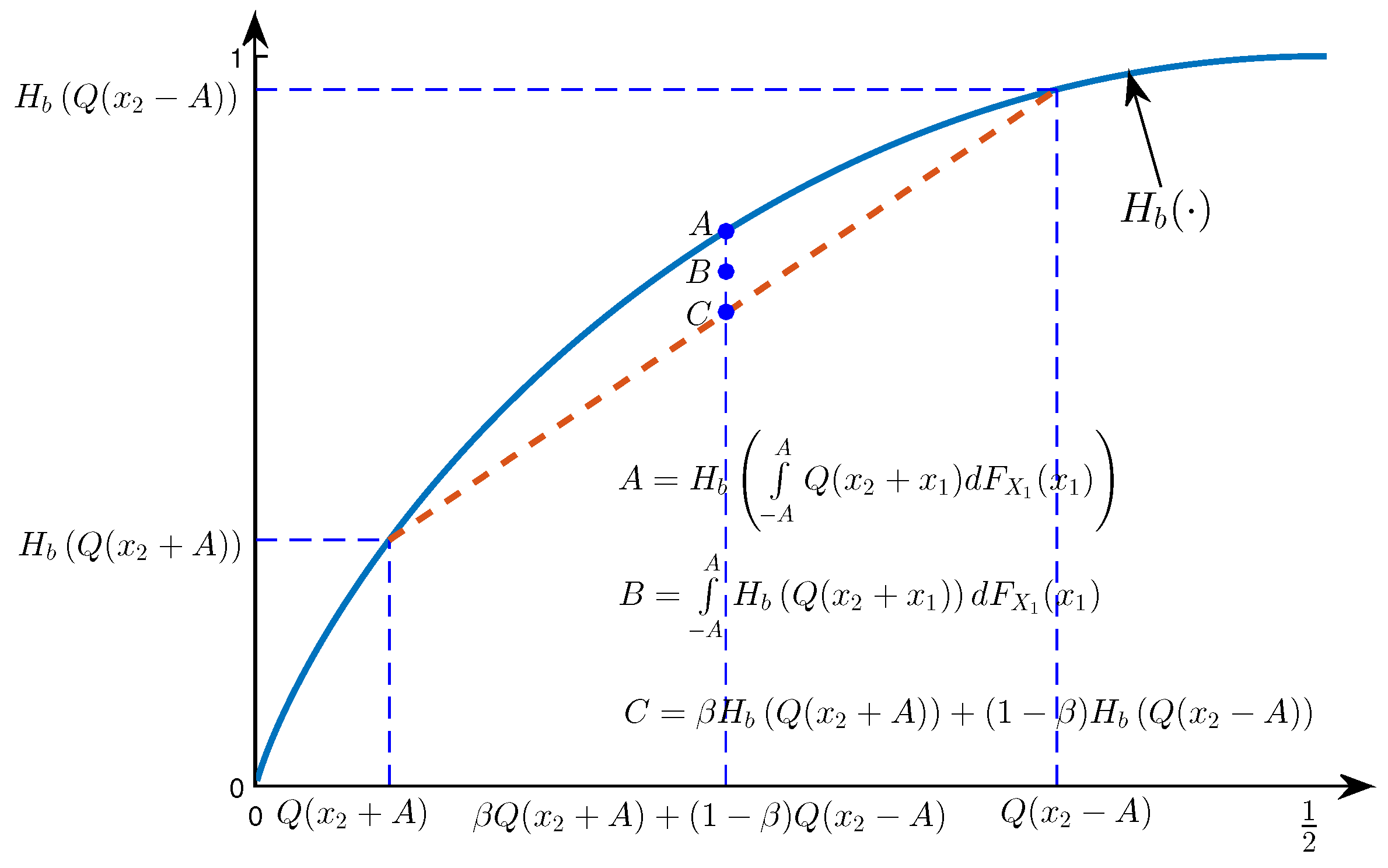
It is obvious that the first term on the RHS of (34) approaches from below when , since . It is also obvious that the remaining terms go to zero when . Hence, it is sufficient to show that they approach zero from below, which is proven by using the following lemma.
Lemma 3. Let be distributed on according to . We have: From (35), we can write:
where
(due to the concavity of
), and
when
(due to (35)). Furthermore, from the fact that
, we have:
where
and
when
. From (36)–(37), the second and the third line of (34) become:
Since and as , there exists a real number K such that when . Therefore, the second and the third line of (34) approach zero from below, which proves that the support of is bounded away from . As mentioned before, a similar argument holds when . This proves that has a bounded support.
Remark 1. We remark here that the order of showing the boundedness of the supports is important. First, for a given (not necessarily bounded), it is proven that is bounded. Then, for a given bounded , it is shown that is also bounded. Hence, the boundedness of the supports of the optimal input distributions is proven by contradiction. The order is reversed when , and it follows the same steps as in the case of . Therefore, it is omitted.
We next prove the second claim in Proposition 3. We assume that
, and a bounded
is given. We already know that for a given bounded
,
has a bounded support denoted by
. Therefore,
where
denotes the set of all probability distributions on the Borel sets of
. Let
denote the probability of the event
, induced by
and the given
. Furthermore, let
denote the second moment of
under
. The set:
is the intersection of
with two hyperplanes (note that
is convex and compact). We can write:
Note that having
, the objective function in (41) becomes:
Since the linear part is continuous and
is compact (The continuity of the linear part follows similarly the continuity arguments in
Appendix C. Note that this compactness is due to the closedness of the intersecting hyperplanes in
, since a closed subset of a compact set is compact [
11]. The hyperplanes are closed due to the continuity of
and
(see (A16)).), the objective function in (41) attains its maximum at an extreme point of
, which, by Dubins’ theorem, is a convex combination of at most three extreme points of
. Since the extreme points of
are the CDFs having only one point of increase in
, we conclude that given any bounded
,
has at most three mass points.
Now, assume that an arbitrary
is given with at most three mass points denoted by
. It is already known that the support of
is bounded, which is denoted by
. Let
denote the set of all probability distributions on the Borel sets of
. The set:
is the intersection of
with four hyperplanes. Note that here, since we know
, the optimal input attains its maximum power of
. In a similar way,
and having
, the objective function in (44) becomes:
Therefore, given any
with at most three points of increase,
has at most five mass points.
When
, the second term on the RHS of (45) disappears, which means that
could be replaced by:
where
is the probability of the event
, which is induced by
and the given
. Since the number of intersecting hyperplanes has been reduced to two, it is concluded that
has at most three points of increase. ☐
Remark 2. Note that, the order of showing the discreteness of the support sets is also important. First, for a given bounded (not necessarily discrete), it is proven that is discrete with at most three mass points. Then, for a given discrete with at most three mass points, it is shown that is also discrete with at most five mass points when and at most three mass points when . When , the order is reversed, and it follows the same steps as in the case of . Therefore, it is omitted.
Remark 3. If are assumed finite initially, similar results can be obtained by using the iterative optimization in the previous proof and the approach in Chapter 4, Corollary 3 of [13]. 5. Sum Rate Analysis
In this section, we propose a lower bound on the sum capacity of a MAC in the presence of a one-bit ADC front end at the receiver, which we conjecture to be tight. The sum capacity is given by:
where the supremum is over
(
), such that
. We obtain a lower bound for the above by considering only those input distributions that are zero-mean per any realization of the auxiliary random variable
U, i.e.,
. Let
and
be two arbitrary non-negative real numbers. We have:
where in (47),
,
; (48) follows from [
4] for the point-to-point channel. Therefore, when
we can write:
where (49) is due to the fact that
is a convex function of
, and (50) follows from
.
The upper bound in (50) can be achieved by time division with power control as follows. Let
and
. Furthermore, let
, where
is the unit step function, and:
With this choice of
, the upper bound in (50) is achieved. Therefore,
A numerical evaluation of (46) is carried out as follows (the codes that are used for the numerical simulations are available at
https://www.dropbox.com/sh/ndxkjt6h5a0yktu/AAAmfHkuPxe8rMNV1KzFVRgNa?dl=0). Although
is upper bounded by
(
), the value of
(
) has no upper bound and could be any non-negative real number. However, in our numerical analysis, we further restrict our attention to the case
Obviously, as this upper bound tends to infinity, the approximation becomes more accurate (This further bounding of the conditional second moments is justified by the fact that the sum capacity is not greater than one, which is due to the one-bit quantization at the receiver. As a result,
increases at most sublinearly with
, while
needs to decrease at least linearly to satisfy the average power constraints. Hence, the product
decreases with
when
is above a threshold.). Each of the intervals
and
are divided into 201 points uniformly, which results in the discrete intervals
and
, respectively. Afterwards, for any pair
, the following is carried out for input distributions with at most three mass points.
The results are stored in a matrix accordingly. In the above optimization, the MATLAB function fmincon is used with three different initial values, and the maximum of these three experiments is chosen. Then, the problem boils down to finding proper gains, i.e., the mass probabilities of U, that maximize and satisfy the average power constraints . This is done via a linear program, which can be efficiently solved by the linprog function in MATLAB. Several cases were considered, such as , , etc. In all these cases, the numerical evaluation of (46) leads to the same value as the lower bound in (51). Since the problem is not convex, it is not known whether the numerical results are the global optimum solutions; hence, we leave it as a conjecture that the sum capacity can be achieved by time division with power control.


{kind=link}
{kind=link}

