1. Introduction
Capturing the “complexity” of an object, for purposes such as classification and object profiling, is one of the most fundamental challenges in science. This is so because one has to either choose a computable measure (e.g., Shannon entropy) that is not invariant to object descriptions and probability distributions [
1] and lacks an
invariance theorem—which forces one to decide on a particular feature shared among several objects of interest—or else estimate values of an uncomputable function in applying a “universal” measure of complexity that is invariant to object description (such as
algorithmic complexity). This latter drawback has led to computable variants and the development of time- and resource-bounded algorithmic complexity/probability that is finitely computable [
2,
3,
4]. A good introduction and list of references is provided in [
5]. Here we study a measure that lies half-way between two universally used measures that enables the action of both at different scales by dividing data into smaller pieces for which the halting problem involved in an uncomputable function can be partially circumvented, in exchange for a huge calculation based on the concept of algorithmic probability. The calculation can, however, be precomputed and hence reused in future applications, thereby constituting a strategy for efficient estimations—bounded by Shannon entropy and by algorithmic (Kolmogorov–Chaitin) complexity—in exchange for a loss of accuracy.
In the past, lossless compression algorithms have dominated the landscape of applications of algorithmic complexity. When researchers have chosen to use lossless compression algorithms for reasonably long strings, the method has proven to be of value (e.g., [
6]). Their successful application has to do with the fact that compressibility is a sufficient test for non-algorithmic randomness (though the converse is not true). However, popular implementations of lossless compression algorithms are based on estimations of
entropy [
7], and are therefore no more closely related to algorithmic complexity than is Shannon entropy by itself. They can only account for statistical regularities and not for algorithmic ones, though accounting for algorithmic regularities ought to be crucial, since these regularities represent the main advantage of using algorithmic complexity.
One of the main difficulties with computable measures of complexity such as Shannon entropy is that they are not robust enough [
1,
8]. For example, they are not invariant to different descriptions of the same object-unlike algorithmic complexity, where the so-called
invariance theorem guarantees the invariance of an object’s algorithmic complexity. This is due to the fact that one can always translate a lossless description into any other lossless description simply with a program of a fixed length, hence in effect just adding a constant. Computability theorists are not much concerned with the relatively negligible differences between evaluations of Kolmogorov complexity which are owed to the use of different descriptive frameworks (e.g., different programming languages), yet these differences are fundamental in applications of algorithmic complexity.
Here we study a Block Decomposition Method (BDM) that is meant to extend the power of the so-called
Coding Theorem Method (CTM). Applications of CTM include image classification [
9] and visual cognition [
10,
11,
12], among many applications in cognitive science. In these applications, other complexity measures, including entropy and lossless compressibility, have been outperformed by CTM. Graph complexity is another subject of active research [
13,
14,
15,
16,
17], the method here presented has made a contribution to this subject proposing robust measures of algorithmic graph complexity [
18,
19].
After introducing the basics of algorithmic complexity, algorithmic probability, Shannon entropy and other entropic measures, and after exploring the limitations and abuse of the use of lossless compression to approximate algorithmic complexity, we introduce CTM, on which BDM heavily relies. After introducing BDM, we thoroughly study its properties and parameter dependency on size, the problem of the boundaries in the decomposition process, we prove theoretical bounds and provide numerical estimations after testing on actual data (graphs) followed by error estimations for the numerical estimations by BDM. We also introduce a normalized version of BDM.
1.1. Algorithmic Complexity
The
Coding Theorem Method was first introduced as a method for dealing with the problem of compressing very short strings, for which no implementation of lossless compression gives reasonable results. CTM exploits the elegant and powerful relationship between the algorithmic frequency of production of a string and its algorithmic complexity [
20].
The
algorithmic complexity [
21,
22]
of a string
s is the length of the shortest program
p that outputs the string
s, when running on a universal (prefix-free, that is, the group of valid programs forms a prefix-free set or no element is a prefix of any other, a property necessary to keep
. For details see [
5,
23].) Turing machine
U.
A technical inconvenience of
K as a function taking
s to be the length of the shortest program that produces
s, is that
K is lower semi-computable. In other words, there is no effective algorithm which takes a string
s as input and produces the integer
as output. This is usually considered a major problem, but the theory of algorithmic randomness [
24] ascribes uncomputability to any universal measure of complexity, that is, a measure that is at least capable of characterizing mathematical randomness [
25]. However, because it is lower semi-computable,
can be approximated from above, or in other words, upper bounds can be found, for example, by finding and exhibiting a small computer program (measured in bits) relative to the length of a bit string.
1.2. Algorithmic Probability
The classical probability of production of a bit string s among all possible bit strings of length n is given by . The concept of algorithmic probability (also known as Levin’s semi-measure) replaces the random production of outputs by the random production of programs that produce an output. The algorithmic probability of a string s is thus a measure that estimates the probability of a random program p producing a string s when run on a universal (prefix-free) Turing machine U.
The algorithmic probability
of a binary string
s is the sum over all the (prefix-free) programs
p for which a universal Turing machine
U running
p outputs
s and halts [
20,
21,
26]. It replaces
n (the length of
s) with
, the length of the program
p that produces
s:
can be considered an approximation to , because the greatest contributor to is the shortest program p that generates s using U. So if s is of low algorithmic complexity, then , and will be considered random if .
The Coding Theorem [
20,
26] further establishes the connection between
and
.
where
c is a fixed constant, independent of
s.
The Coding Theorem implies [
27,
28] that the output frequency distribution of random computer programs to approximate
can be clearly converted into estimations of
using the following rewritten version of Equation (
2):
Among the properties of Algorithmic Probability and
that makes it optimal is that the data does not need to be stationary or ergodic and is universal (stronger than ergodic) in the sense that it will work for any string and can deal with missing and multidimensional data [
29,
30,
31,
32], there is no underfitting or overfitting because the method is parameter free and the data need not to be divided into training and test sets.
1.3. Convergence Rate and the Invariance Theorem
One other fundamental property that provides the theory of algorithmic complexity with the necessary robustness to stand as a universal measure of (random) complexity is the so-called
Invariance theorem [
20,
26], which guarantees the convergence of values despite the use of different reference universal Turing machines (UTMs) or e.g., programming languages.
Invariance theorem [
21,
22,
26]: If
and
are two UTMs and
and
the algorithmic complexity of
s for
and
, there exists a constant
c such that:
where
is independent of
s and can be considered to be the length (in bits) of a translating function between universal Turing machines
and
, or as a compiler between computer programming languages
and
.
In practice, however, the constant involved can be arbitrarily large, and the invariance theorem tells us nothing about the convergence (see
Figure 1). One may perform the calculation of
for a growing sequence
s under
in the expectation that for long
s,
. However, there is no guarantee that this will be the case, and the size of
in general is unknown.
It is a question whether there can be a
natural universal Turing machine
such that
converges faster for
s than for any other universal Turing machine (UTM), or whether specific conditions must be met if
is to generate “
well-behaved” (monotonic) behaviour in
c [
33]. The
invariance theorem guarantees that such optimal “well-behaved” machines
always exist-indeed their existence is implicit in the very sense of the theorem (meaning any universal machine can be optimal in the sense of the theorem)—but it tells nothing about the rate of convergence or about transitional behaviour (see
Figure 1 for illustration).
The longer the string, the less important
c is (i.e., the choice of programming language or UTM). However, in practice
c can be arbitrarily large, thus having a great impact, particularly on short strings, and never revealing at which point one starts approaching a stable
K or when one is diverging before finally monotonically converging, as is seen in the different possible behaviours illustrated in the sketches in
Figure 1.
The invariance theorem tells us that it is impossible to guarantee convergence but it does not imply that one cannot study the behaviour of such a constant for different reference universal Turing machines nor that K cannot be approximated from above.
2. The Use and Misuse of Lossless Compression
Notice that the same problem affects compression algorithms as they are widely used to approximate K. They are not exempt from the same constant problem. Lossless compression is also subject to the constant involved in the invariance theorem, because there is no reason to choose one compression algorithm over another.
Lossless compression algorithms have traditionally been used to approximate the Kolmogorov complexity of an object (e.g., a string) because they can provide upper bounds to K and compression is sufficient test for non-randomness. In a similar fashion, our approximations are upper bounds based on finding a small Turing machine producing a string. Data compression can be viewed as a function that maps data onto other data using the same units or alphabet (if the translation is into different units or a larger or smaller alphabet, then the process is called an encoding).
Compression is successful if the resulting data are shorter than the original data plus the decompression instructions needed to fully reconstruct said original data. For a compression algorithm to be lossless, there must be a reverse mapping from compressed data to the original data. That is to say, the compression method must encapsulate a bijection between “plain” and “compressed” data, because the original data and the compressed data should be in the same units. By a simple counting argument, lossless data compression algorithms cannot guarantee compression for all input data sets, because there will be some inputs that do not get smaller when processed by the compression algorithm, and for any lossless data compression algorithm that makes at least one file smaller, there will be at least one file that it makes larger. Strings of data of length N or shorter are clearly a strict superset of the sequences of length or shorter. It follows therefore that there are more data strings of length N or shorter than there are data strings of length or shorter. In addition, it follows from the pigeonhole principle that it is not possible to map every sequence of length N or shorter to a unique sequence of length or shorter. Therefore there is no single algorithm that reduces the size of all data.
One of the more time consuming steps of implementations of, for example, LZ77 compression (one of the most popular) is the search for the longest string match. Most lossless compression implementations are based on the LZ (Lempev-Ziv) algorithm. The classical LZ77 and LZ78 algorithms enact a greedy parsing of the input data. That is, at each step, they take the longest dictionary phrase which is a prefix of the currently unparsed string suffix. LZ algorithms are said to be “universal” because, assuming unbounded memory (arbitrary sliding window length), they asymptotically approximate the (infinite) entropy rate of the generating source [
34]. Not only does lossless compression fail to provide any estimation of the algorithmic complexity of small objects [
33,
35,
36], it is also not more closely related to algorithmic complexity than Shannon entropy by itself [
7], being only capable of exploiting statistical regularities (if the observer has no other method to update/infer the probability distribution) [
8].
The greatest limitation of popular lossless compression algorithms, in the light of algorithmic complexity, is that their implementations only exploit statistical regularities (repetitions up to the size of the sliding window length). Thus in effect no general lossless compression algorithm does better than provide the Shannon entropy rate (c.f.
Section 2.1) of the objects it compresses. It is then obvious that an exploration of other possible methods for approximating
K is not only desirable but needed, especially methods that can, at least, in principle, and more crucially in practice, detect algorithmic features in data that statistical approaches such as Entropy and to some extent compression would miss.
2.1. Building on Block Entropy
The entropy
H of a discrete random variable
s with possible values
and probability distribution
is defined as:
In the case of for some i, the value of the corresponding summand 0 log is taken to be 0.
It is natural to ask how random a string appears when blocks of finite length are considered.
For example, the string is periodic, but for the smallest granularity (1 bit) or 1-symbol block, the sequence has maximal entropy, because the number of 0 s and 1 s is the same assuming a uniform probability distribution for all strings of the same finite length. Only for longer blocks of length 2 bits can the string be found to be regular, identifying the smallest entropy value for which the granularity is at its minimum.
When dealing with a given string
s, assumed to originate from a stationary stochastic source with known probability density for each symbol, the following function
gives what is variously denominated as block entropy and is Shannon entropy over blocks (or subsequences of
s) of length
l. That is,
where
is the set resulting of decomposing
s in substrings or blocks of size
l and
is the probability of obtaining the combination of
n symbols corresponding to the block
b. For infinite strings assumed to originate from a stationary source, the
entropy rate of
s can be defined as the limit
where
indicates we are considering all the generated strings of length
l. For a fixed string we can think on the normalized block entropy value where
l better captures the periodicity of
s.
Entropy was originally conceived by Shannon as a measure of information transmitted over an stochastic communication channel with known alphabets and it establishes hard limits to maximum lossless compression rates. For instance, the Shannon coding (and Shannon–Fano) sorts the symbols of an alphabet according to their probabilities, assigning smaller binary self-delimited sequences to symbols that appear more frequently. Such methods form the base of many, if not most, commonly used compression algorithms.
Given its utility in data compression, entropy is often used as a measure of the information contained in a finite string . Let’s consider the natural distribution, the uniform distribution that makes the least number of assumptions but does consider every possibility equally likely and is thus uniform. Suggested by the set of symbols in s and the string length the natural distribution of s is the distribution defined by , where is the number of times the object x occurs in s (at least one to be considered), and the respective entropy function . If we consider blocks of size and the string , where n is the length of the string, then s can be compressed in a considerably smaller number of bits than a statistically random sequence of the same length and, correspondingly, has a lower value. However, entropy with the natural distribution suggested by the object, or any other computable distribution, is a computable function therefore is an imperfect approximation to algorithmic complexity.
The best possible version of a measure based on entropy can be reached by partitioning an object into blocks of increasing size (up to half the length of the object) in order for Shannon entropy to capture any periodic statistical regularity.
Figure 2 illustrates the way in which such a measure operates on 3 different strings.
However, no matter how sophisticated a version or variation of an Entropic measure will characterize certain algorithmic aspects of data that are not random but will appear to have maximal entropy if no knowledge about the source is known. In
Figure 3 depicted is how algorithmic probability/complexity can find such patterns and ultimately characterize any, including statistical ones, thereby offering a generalization and complementary improvement to the application of Entropy alone.
BDM builds on block entropy’s decomposition approach using algorithmic complexity methods to obtain and combine its building blocks. The result is a complexity measure that, as shown in
Section 4.3, approaches
K in the best case and behaves like entropy in the worst case (see
Section 7.1), outperforming
in various scenarios. First we introduce the algorithm that conforms the building blocks of BDM, which are local estimations of algorithmic complexity. Specific examples of objects that not even Block entropy can characterize are found in
Section 6 showing how our methods are a significant improvement over any measure based on entropy and traditional statistics.
For example, the following two strings were assigned near maximal complexity but they were found to have low algorithmic complexity by CTM/BDM given that we were able to find not only a small Turing machine that reproduces them but also many Turing machines producing them on halting thereby, by the Coding theorem, of low algorithmic complexity: 001010110101, 001101011010 (and their negations and reversions). These strings display nothing particularly special and they look in some sense typically random, yet this is what we were expecting, to find strings that would appear random but are actually not algorithmic random. This means that these strings would have been assigned higher randomness by Entropy and popular lossless compression algorithms but are assigned lower randomness when using our methods thus thus providing a real advantage over those other methods that can only exploit statistical regularities.
3. The Coding Theorem Method (CTM)
A computationally expensive procedure that is nevertheless closely related to algorithmic complexity involves approximating the algorithmic complexity of an object by running every possible program, from the shortest to the longest, and counting the number of times that a program produces every string object. The length of the computer program will be an upper bound of the algorithmic complexity of the object, following the Coding theorem (Equation (
3)), and a (potentially) compressed version of the data itself (the shortest program found) for a given computer language or “reference” UTM. This guarantees discovery of the shortest program in the given language or reference UTM but entails an exhaustive search over the set of countable infinite computer programs that can be written in such a language. A program of length
n has asymptotic probability close to 1 of halting in time
[
37], making this procedure exponentially expensive, even assuming that all programs halt or that programs are assumed never to halt after a specified time, with those that do not being discarded.
As shown in [
33,
35], an exhaustive search can be carried out for a small-enough number of computer programs (more specifically, Turing machines) for which the halting problem is known, thanks to the Busy Beaver problem [
38]. This problem consists in finding the Turing machine of fixed size (states and symbols) that runs longer than any other machine of the same size. Values are known for Turing machines with 2 symbols and up to 4 states that can be used to stop a resource-bounded exploration, that is, by discarding any machine taking more steps than the Busy Beaver values. For longer strings we also proceed with an informed runtime cut-off, below the theoretical
optimal runtime that guarantees an asymptotic drop of non-halting machines [
37] but above any value to capture most strings up to any degree of accuracy as performed in [
39].
The so called
Coding Theorem Method (or simply CTM) [
33,
35] is a bottom-up approach to algorithmic complexity and, unlike common implementations of lossless compression algorithms, the main motivation of CTM is to find algorithmic features in data rather than just statistical regularities that are beyond the range of application of Shannon entropy and popular lossless compression algorithms [
7].
CTM is rooted in the relation [
33,
35] provided by algorithmic probability between frequency of production of a string from a random program and its algorithmic complexity as described by Equation (
3). Essentially it uses the fact that the more frequent a string is, the lower Kolmogorov complexity it has; and strings of lower frequency have higher Kolmogorov complexity. The advantage of using algorithmic probability to approximate
K by application of the Coding Theorem 3 is that
produces reasonable approximations to
K based on an average frequency of production, which retrieves values even for small objects.
Let
denote the set of all Turing machines with
t states and
k symbols using the Busy Beaver formalism [
38], and let
T be a Turing machine in
with empty input. Then the empirical output distribution
for a sequence
s produced by some
gives an estimation of the
algorithmic probability of
s,
defined by:
For small values
t and
k,
is computable for values of the Busy Beaver problem that are known. The Busy Beaver problem [
38] is the problem of finding the
t-state,
k-symbol Turing machine which writes a maximum number of non-blank symbols before halting, starting from an empty tape, or the Turing machine that performs a maximum number of steps before halting, having started on an initially blank tape. For
and
, for example, the Busy Beaver machine has maximum runtime
[
40], from which one can deduce that if a Turing machine with 4 states and 2 symbols running on a blank tape hasn’t halted after 107 steps, then it will never halt. This is how
D was initially calculated by using known Busy Beaver values. However, because of the undecidability of the Halting problem, the Busy Beaver problem is only computable for small
values [
38]. Nevertheless, one can continue approximating
D for a greater number of states (and colours), proceeding by sampling, as described in [
33,
35], with an informed runtime based on both theoretical and numerical results.
Notice that , and is thus said to be a semi-measure, just as is.
Now we can introduce a measure of complexity that is heavily reliant on algorithmic probability , as follows:
Let
be the space of all
t-state
k-symbol Turing machines,
and
the function assigned to every finite binary string
s. Then:
where
b is the number of symbols in the alphabet (traditionally 2 for binary objects, which we will take as understood hereafter).
That is, the more frequently a string is produced the lower its Kolmogorov complexity, with the converse also being true.
Table 1 shows the rule spaces of Turing machines that were explored, from which empirical algorithmic probability distributions were sampled and estimated.
We will designate as base string, base matrix, or base tensor the objects of size l for which CTM values were calculated such that the full set of objects have CTM evaluations. In other words, the base object is the maximum granularity of application of CTM.
Table 1 provides figures relating to the number of base objects calculated.
Validations of CTM undertaken before show the correspondence between CTM values and the exact number of instructions used by Turing machines when running to calculate CTM [
41] (
Figure 1 and
Table 1) to produce each string, i.e., direct
K complexity values for this model of computation (as opposed to CTM using algorithmic probability and the Coding theorem) under the chosen model of computation [
38]. The correspondence in values found between the directly calculated
K and CTM by way of frequency production was near perfect.
Results in [
9] support the agreements in correlation using different rule spaces of Turing machines and different computing models altogether (cellular automata). In the same paper it is provided a first comparison to lossless compression. The sections “Agreement in probability” and “Agreement in rank” in [
9] provide further material comparing rule space (5,2) to the rule space (4,3) previously calculated in [
35,
36]. The section “Robustness” in [
33] provides evidence relating to the behaviour of the
invariance theorem constant for a standard model of Turing machines [
38].
4. The Block Decomposition Method (BDM)
Because finding the program that reproduces a large object is computationally very expensive and ultimately uncomputable, one can aim at finding short programs that reproduce small fragments of the original object, parts that together compose the larger object. In addition, this is what the BDM does.
BDM is divided into two parts. On the one hand, approximations to K are performed by CTM which values can then be used and applied in by exchanging time for memory in the population of a precomputed look-up table for small strings, which would diminish its precision as a function of object size (string length) unless a new iteration of CTM is precomputed again. On the other hand, BDM decomposes the original data into fragments for which CTM provides an estimation and then puts the values together based on classical information theory.
BDM is thus a hybrid complexity measure that combines Shannon Entropy in the long range but provides local estimations of algorithmic complexity. It is meant to improve the properties of Shannon Entropy that in practice are reduced to finding statistical regularities and to extend the power of CTM. It consists in decomposing objects into smaller pieces for which algorithmic complexity approximations have been numerically estimated using CTM, then reconstructing an approximation of the Kolmogorov complexity for the larger object by adding the complexity of the individual components of the object, according to the rules of information theory. For example, if s is an object and is a repetition of s ten times smaller, upper bounds can be achieved by approximating rather than , because we know that repetitions have a very low Kolmogorov complexity, given that one can describe repetitions with a short algorithm.
Here we introduce and study the properties of this
Block Decomposition Method based on a method advanced in [
33,
35] that takes advantage of the powerful relationship established by algorithmic probability between the frequency of a string produced by a random program running on a (
prefix-free) UTM and the string’s Kolmogorov complexity. The chief advantage of this method is that it deals with small objects with ease, and it has shown stability in the face of changes of formalism, producing reasonable Kolmogorov complexity approximations. BDM must be combined with CTM if it is to scale up properly and behave optimally for upper bounded estimations of
K. BDM + CTM is universal in the sense that it is guaranteed to converge to
K due to the invariance theorem, and as we will prove later, if CTM no longer runs, then BDM alone approximates the Shannon entropy of a finite object.
Like compression algorithms, BDM is subject to a trade-off. Compression algorithms deal with the trade-off of compression power and compression/decompression speed.
4.1. l-Overlapping String Block Decomposition
Let us fix values for
t and
k and let
be the frequency distribution constructed from running all the Turing machines with
n states and
k symbols. Following Equation (
5), we have it that—
is an approximation of
K (denoted by
). We define the BDM of a string or finite sequence
s as follows,
where
is the multiplicity of
and
the subsequence
i after decomposition of
s into subsequences
, each of length
l, with a possible remainder sequence
if
is not a multiple of the decomposition length
l.
The parameter m goes from 1 to the maximum string length produced by CTM, where means no overlapping inducing a partition of the decomposition of s, m is thus an overlapping parameter when for which we will investigate its impact on BDM (in general, the smaller m a greater overestimation of BDM).
The parameter m is needed because of the remainder. If is not a multiple of the decomposition length l then the option is to either ignore the remainder in the calculation of BDM or define a sliding window with overlapping .
The choice of t and k for CTM in BDM depend only on the available resources for running CTM, which involves running the entire space of Turing machines with t symbols and k states.
BDM approximates
K in the following way: if
is the minimum program that generates each base string
, then
and we can define an unique program
q that runs each
, obtaining all the building blocks. How many times each block is present in
s can be given in
bits. Therefore, BDM is the sum of the information needed to describe the decomposition of
s in base strings. How close is this sum to
K is explored in
Section 4.3.
The definition of BDM is interesting because one can plug in other algorithmic distributions, even computable ones, approximating some measure of algorithmic complexity even if it is not the one defined by Kolmogorov–Chaitin such as, for example, the one defined by Calude et al. [
23] based on finite-state automata. BDM thus allows the combination of measures of classical information theory and algorithmic complexity.
For example, for binary strings we can use
and
to produce the empirical output distribution
of all machines with 2 symbols and 2 states by which all strings of size
are produced, except two (one string and its complement). However, we assign them values
where
e is different from zero because the missing strings were not generated in
and therefore have a greater algorithmic random complexity than any other string produced in
of the same length. Then, for
and
,
decomposes
of length
into the following subsequences:
with 010101010101 having multiplicity 4 and 101010101010 multiplicity 3.
We then get the CTM values for these sequences:
To calculate BDM, we then take the sum of the CTM values plus the sum of the
of the multiplicities, with
because the string alphabet is 2, the same as the number of symbols in the set of Turing machines producing the strings. Thus:
4.2. 2- and w-Dimensional Complexity
To ask after the likelihood of an array, we can consider a 2-dimensional Turing machine. The Block Decomposition Method can then be extended to objects beyond the unidimensionality of strings, e.g., arrays representing bitmaps such as images, or graphs (by way of their adjacency matrices). We would first need CTM values for 2- and w-dimensional objects that we call base objects (e.g., base strings or base matrices).
A popular example of a 2-dimensional tape Turing machine is Langton’s ant [
42]. Another way to see this approach is to take the BDM as a way of deploying all possible 2-dimensional deterministic Turing machines of a small size in order to reconstruct the adjacency matrix of a graph from scratch (or smaller pieces that fully reconstruct it). Then, as with the
Coding theorem method (above), the algorithmic complexity of the adjacency matrix of the graph can be estimated via the frequency with which it is produced from running random programs on the (prefix-free) 2-dimensional Turing machine. More specifically,
where the set
is composed of the pairs
,
r is an element of the decomposition of
X (as specified by a
partition , where
is a submatrix of
X) in different sub-arrays of size up to
(where
w is the dimension of the object) that we call
base matrix (because
values were obtained for them) and
n is the multiplicity of each component.
is a computable approximation from below to the algorithmic information complexity of
r,
, as obtained by applying the coding theorem method to
w-dimensional Turing machines. In other words,
is the set of
base objects.
Because string block decomposition is a special case of matrix block decomposition, and square matrix block decomposition is a special case of w-block decomposition for objects of w dimensions, let us describe the way in which BDM deals with boundaries on square matrices, for which we can assume CTM values are known, and that we call base strings or base matrices.
Figure 4 shows that the number of permutations is a function of the complexity of the original object, with the number of permutations growing in proportion to the original object’s entropy—because the number of different resulting blocks determines the number of different
n objects to distribute among the size of the original object (e.g., 3 among 3 in
Figure 4 (top) or only 2 different
blocks in
Figure 4 (bottom)). This means that the non-overlapping version of BDM is not invariant vis-à-vis the variation of the entropy of the object, on account of which it has a different impact on the error introduced in the estimation of the algorithmic complexity of the object. Thus, non-overlapping objects of low complexity will have little impact, but with random objects non-overlapping increases inaccuracy. Overlapping decomposition solves this particular permutation issue by decreasing the number of possible permutations, in order to avoid trivial assignment of the same BDM values. However, overlapping has the undesired effect of systematically overestimating values of algorithmic complexity by counting almost every object of size
n,
times, hence overestimating at a rate of about
for high complexity objects of which the block multiplicity will be low, and by
for low complexity objects.
Applications to graph theory [
18], image classification [
10] and human behavioural complexity have been produced in the last few years [
11,
12].
4.3. BDM Upper and Lower Absolute Bounds
In what follows we show the hybrid nature of the measure. We do this by setting lower and upper bounds to BDM in terms of the algorithmic complexity , the partition size and the approximation error of , such that these bounds are tighter in direct relation to smaller partitions and more accurate approximations of K. These bounds are independent of the partition strategy defined by .
Proposition 1. Let be the function defined in Equation (8) and let X be an array of dimension w. Then and , where A is a set composed of all possible ways of accommodating the elements of in an array of dimension w, and ϵ is the sum of errors for the approximation over all the sub-arrays used. Proof. Let and , be the sequences of programs for the reference prefix-free UTM U such that, for each , we have , , and . Let be a positive constant such that ; this is the error for each sub-array. Let be the sum of all the errors.
For the first inequality we can construct a program , whose description only depends on w, such that, given a description of the set and an index l, it enumerates all the ways of accommodating the elements in the set and returns the array corresponding to the position given by l.
Please note that
,
and all
’s are of the order of
. Therefore
and
which gives us the inequality.
Now, let
be the smallest program that generates
X. For the second inequality we can describe a program
which, given a description of
X and the index
j, constructs the set
and returns
, i.e.,
. Please note that each
is of the order of
. Therefore, for each
j we have
and
. Finally, by adding all the terms over the
j’s we find the second inequality:
☐
Corollary 1. If the partition defined by is small, that is, if is close to 1, then .
Proof. Given the inequalities presented in Proposition 1, we have it that
and
which at the limit leads to
and
. From [
33], we can say that the error rate
ϵ is small, and that by the invariance theorem it will converge towards a constant value. ☐
5. Dealing with Object Boundaries
Because partitioning an object—a string, array or tensor—leads to boundary leftovers not multiple of the partition length, the only two options to take into consideration such boundaries in the estimation of the algorithmic complexity of the entire object is to either estimate the complexity of the leftovers or to define a sliding window allowing overlapping in order to include the leftovers in some of the block partitions. The former implies mixing object dimensions that may be incompatible (e.g., CTM complexity based on 1-dimensional TMs versus CTM based on higher dimensional TMs). Here we explore these strategies to deal with the object boundaries. Here we introduce a strategy for partition minimization and base object size maximization that we will illustrate for 2-dimensionality. The strategies are intended to overcome under- or over-fitting complexity estimations that are due to conventions, not just technical limitations (due to, e.g., uncomputability and intractability).
Notice that some of the explorations in this section may give the wrong impression to use and introduce ad-hoc methods to deal with the object boundaries. However, this is not the case. What we will do in this section is to explore all possible ways we could conceive in which we can estimate K according to BDM taking into considerations the boundaries that may require special treatment when they are not of multiple size to the partition length from the decomposition of the data after BDM. Moreover, we show that in all cases, the results are robust because the errors found are convergent and can thus be corrected, so any possible apparently ad-hoc condition has little to no implications in the calculation of BDM in the limit and only very limited at the beginning.
5.1. Recursive BDM
In
Section 4.3, we have shown that using smaller partitions for
yields more accurate approximations to the algorithmic complexity
K. However, the computational costs for calculating
are high. We have compiled an exhaustive database for square matrices of size up to
. Therefore it is in our best interest to find a method to minimize the partition of a given matrix into squares of size up to
for a given
l.
The strategy consists in taking the biggest base matrix multiple of on one corner and dividing it into adjacent square submatrices of the given size. Then we group the remaining cells into 2 submatrices and apply the same procedure, but now for . We continue dividing into submatrices of size .
Let
X be a matrix of size
with
. Let’s denote by
the set of quadrants on a matrix and by
the set of vectors of quadrants of dimension
l. We define a function
, where
, as follows:
where
is the largest set of adjacent submatrices of size
that can be clustered in the corner corresponding to the quadrant
,
is the submatrix composed of all the adjacent rightmost cells that could not fit on
and are not part of the leftmost cells,
is an analogue for the leftmost cells and
is the submatrix composed of the cells belonging to the rightmost and leftmost cells. We call the last three submatrices
residual matrices.
By symmetry, the number of matrices generated by the function is invariant with respect to any vector of quadrants . However, the final BDM value can (and will) vary according to the partition chosen. Nevertheless, with this strategy we can evaluate all the possible BDM values for a given partition size and choose the partition that yields the minimum value, the maximum value, or compute the average for all possible partitions.
The partition strategy described can easily be generalized and applied to strings (1 dimension) and tensors (objects of n-dimensions).
5.2. Periodic Boundary Conditions
One way to avoid having remaining matrices (from strings to tensors) of different sizes is to embed a matrix in a topological torus (see
Figure 5) such that no more object borders are found. Then let
X be a square matrix of arbitrary size
m. We screen the matrix
X for all possible combinations to minimize the number of partitions maximizing block size. We then take the combination of smallest BDM for fixed
base matrix size
d and we repeat for
until we have added all the components of the decomposed
X. This procedure, will, however, overestimate the complexity values of all objects (in unequal fashion along the complexity spectra) but will remain bounded, as we will show in
Section 7.
Without loss of generality the strategy can be applied to strings (1 dimension) and tensors (any larger number of dimensions, e.g., greater than 2), the former embedded in a cylinder while tensors can be embedded in
n-dimensional tori (see
Figure 5).
6. BDM versus Shannon Entropy
Let us address the task of quantifying how many strings with maximum entropy rate are actually algorithmically compressible, i.e., have low algorithmic complexity. That is, how many strings are actually algorithmically (as opposed to simply statistically) compressible but are not compressed by lossless compression algorithms, which are statistical (entropy rate) estimators [
7]. We know that most strings have both maximal entropy (most strings look equally statistically disordered, a fact that constitutes the foundation of thermodynamics) and maximal algorithmic complexity (according to a pigeonhole argument, most binary strings cannot be matched to shorter computer programs as these are also binary strings). However, the gap between those with maximal entropy and low algorithmic randomness diverges and is infinite at the limit (for an unbounded string sequence). That is, there is an infinite number of sequences that have maximal entropy but low algorithmic complexity.
The promise of BDM is that, unlike compression, it does identify some cases of strings with maximum entropy that actually have low algorithmic complexity.
Figure 6 and
Figure A1 show that indeed BDM assigns lower complexity to more strings than entropy, as expected. Unlike entropy, and implementations of lossless compression algorithms, BDM recognizes some strings that have no statistical regularities but have algorithmic content that makes them algorithmically compressible.
Examples of strings with lower randomness than that assigned by entropy and Block entropy are 101010010101 (and its complement) or the Thue-Morse sequence 011010011001… (or its complement) obtained by starting with 0 and successively appending the Boolean complement [
43], the first with low CTM
and the Thue-Morse with CTM
(the max CTM value in the subset is
for the last string in this table). The Morse sequence is uniformly recurrent without being periodic, not even eventually periodic, so will remain with high entropy and Block entropy.
CTM and BDM as functions of the object’s size (and therefore the size of the Turing machine rule space that has to be explored) have the following time complexity:
CTM is uncomputable but for decidable cases runs in time.
Non-overlapping string BDM and LD runs in linear time and polynomial time for d-dimensional objects.
Overlapping BDM runs in time with m the overlapping offset.
Full overlapping with runs in polynomial time as a function of the number of overlapping elements n.
Smooth BDM runs in linear time.
Mutual Information BDM runs in time for strings and d exponential for dimension d.
So how does this translate into real profiling power of recursive strings and sequences that are of low algorithmic complexity but appear random to classical information theory?
Figure 6, and
Figure A1 in the
Appendix A provide real examples showing how BDM can outperform the best versions of Shannon entropy.
Figure 6 shows the randomness estimation of 2 known low algorithmic complexity objects and CTM to BDM transitions of the mathematical constant
and the Thue-Morse sequence both of which numerical estimations by CTM assign lower randomness than the suggested by both entropy and its best version Block entropy. It is expected to find that CTM does much better at characterizing the low algorithmic randomness of a sequence like the Thue-Morse sequence (beyond the fact that it is not Borel normal [
43]) given that every part of the sequence is algorithmically obtained from another part of the sequence (by logical negation or the substitution system 0→01, 1→10 starting from 0) while the digits of
have been shown to be independent (at least in powers of 2) from each other [
44] and only algorithmic in the way they are produced from any of the many known generating formulas.
One of the most recent found formula producing any digits of any segment of the mathematical constant
(in base
, is given by a very short symbolic summation [
44]:
To produce such a string of 80 ASCII characters (less than 1K bits) has a probability of
or
to be produced by chance typing “random formulae”, where
f is a multiplying factor quantifying the number other formulas of fixed (small) size that can also produce
and for which there are many known since the works of Vieta, Leibniz, Wallis, Euler, Ramanujan, and others. In theory, classical probability is exponentially divergent from the much higher algorithmic probability
that is the classical probability to produce an initial segment of
(in binary) of length
n. A good source of formulae producing digits of
can be found at e.g., the Online Encyclopedia of Integer Sequences (OEIS) (
https://oeis.org/A000796) listing more than 50 references and at Wolfram MathWorld listing around a hundred (
http://mathworld.wolfram.com/PiFormulas.html).
Unlike classical probability, algorithmic probability quantifies the production likelihood of the object (
Figure 6, and
Figure A1 in the
Appendix A) by indirect algorithmic/recursive means rather than by direct production (the typical analogy is writing on a computer equipped with a language compiler program versus writing on a typewriter).
To the authors knowledge, no other numerical method is known to suggest low algorithmic randomness of statistical random-looking constants such as
and the Thue-Morse sequence (
Figure 6, and
Figure A1 in the
Appendix A) from an observer perspective with no access to prior information, probability distributions or knowledge about the nature of the source (i.e., a priori deterministic).
There are two sides of BDM. On the one hand, it is based on a non-computable function but once approximations are computed we build a lookup table of values which makes BDM computable. Lossless compression is also computable but it is taken as able to make estimations of an uncomputable function like K because they can provide upper bounds and estimate K from above just as we do with CTM (and thus BDM) by exhibiting a short Turing machine capable of reproducing the data/string.
Table 2, summarizes the range of application, with CTM and BDM preeminent in that they can more efficiently deal with short, medium and long sequences and other objects such as graphs, images, networks and higher dimensionality objects.
7. Error Estimations
One can estimate the error in different calculations of BDM, regardless of the error estimations of CTM (quantified in [
33,
35]), in order to calculate their departure and deviation both from granular entropy and algorithmic complexity, for which we know lower and upper bounds. For example, a maximum upper bound for binary strings is the length of the strings themselves. This is because no string can have an algorithmic complexity greater than its length, simply because the shortest computer program (in bits) to produce the string may be the string itself.
In the calculation of BDM, when an object’s size is not a multiple of the base object of size d, boundaries of size will be produced, and there are various ways of dealing with them to arrive at a more accurate calculation of an object that is not a multiple of the base. First we will estimate the error introduced by ignoring the boundaries or dealing with them in various ways, and then we will offer alternatives to take into consideration in the final estimation of their complexity.
If a matrix X of size is not a multiple of the base matrix of size , it can be divided into a set of decomposed blocks of size , and R, L, T and B residual matrices on the right, left, top and bottom boundaries of M, all of smaller size than d.
Then boundaries R, L, T and B can be dealt with in the following way:
Trimming boundary condition:
R,
L,
T and
B are ignored, then
, with the undesired effect of general underestimation for objects not multiples of
d. The error introduced (see
Figure 7) is bounded between 0 (for matrices divisible by
d) and
, where
k is the size of
X. The error is thus convergent (
grows much faster than
) and can therefore be corrected, and is negligible as a function of array size as shown in
Figure 7.
Cyclic boundary condition (
Figure 5 bottom): The matrix is mapped onto the surface of a torus such that there are no more boundaries and the application of the overlapping BDM version takes into consideration every part of the object. This will produce an over-estimation of the complexity of the object but will for the most part respect the ranking order of estimations if the same overlapping values are used with maximum overestimation
, where
is the maximum CTM value among all base matrices
b in
X after the decomposition of
X.
Full overlapping recursive decomposition: X is decomposed into base matrices of size by traversing X with a sliding square block of size d. This will produce a polynomial overestimation in the size of the object of up to , but if consistently applied it will for the most part preserve ranking.
Adding low complexity rows and columns (we call this “add col”): If a matrix of interest is not multiple the base matrices, we add rows and columns until completion to the next multiple of the base matrix, then we correct the final result by substracting the borders that were artificially added.
The BDM error rate (see
Figure 8) is the discrepancy of the sum of the complexity of the missed borders, which is an additive value of, at most, polynomial growth. The error is not even for a different complexity. For a tensor of
d dimensions, with all 1 s as entries, the error is bounded by
for objects with low algorithmic randomness and by
for objects with high algorithmic randomness.
Ultimately there is no optimal strategy for making the error disappear, but in some cases the error can be better estimated and corrected
Figure 8 and all cases are convergent
Figure 9, hence asymptotically negligible, and in all cases complexity ranking is preserved and under- and over-estimations bounded.
7.1. BDM Worse-Case Convergence towards Shannon Entropy
Let
be a partition of
X defined as in the previous sections for a fixed
d. Then the Shannon entropy of
X for the partition
is given by:
where
and the array
is taken as a symbol itself. The following proposition establishes the asymptotic relationship between
and
.
Proposition 2. Let M be a 2-dimensional matrix and a partition strategy with elements of maximum size . Then: Proof. First we note that
and, given that the set of matrices of size
is finite and so is the maximum value for
, there exists a constant
such that
. Therefore:
Now, let’s recall that the sum of
’s is bounded by
. Therefore there exists
such that
☐
Now, is important to note that the previous proof sets the limit in terms of the constant , which minimum value is defined in terms of matrices for which the value has been computed. The smaller this number is, the tighter is the bound set by Proposition 2. Therefore, in the worst case, this is when has been computed for a comparatively small number of matrices, or the larger base matrix have small algorithmic complexity, the behavior of is similar to entropy. In the best case, when is updated by any means, BDM approximates algorithmic complexity (Corollary 1).
Furthermore, we can think on as a measure of the deficit in information incurred by both, entropy and BDM, in terms of each other. Entropy is missing the number of base objects needed in order to get an approximation of the compression length of M, while BDM is missing the position of each base symbol. In addition, giving more information to both measures wont necessarily yield a better approximation to K.
8. Normalized BDM
A normalized version of BDM is useful for applications in which a maximal value of complexity is known or desired for comparison purposes. The chief advantage of a normalized measure is that it enables a comparison among objects of different sizes, without allowing size to dominate the measure. This will be useful in comparing arrays and objects of different sizes. First, for a square array of size
, we define:
where
is the set of binary matrices of size
. For any
n,
returns the minimum value of Equation (
10) for square matrices of size
n, so it is the minimum BDM value for matrices with
n nodes. It corresponds to an adjacency matrix composed of repetitions of the least complex
square. It is the all-1 or all-0 entries matrix, because
and
are the least complex square base matrices (hence the most compressible) of size
d.
Secondly, for the maximum complexity, Equation (
10) returns the highest value when the result of dividing the adjacency matrix into the
base matrices contains the highest possible number of different matrices (to increase the sum of the right terms in Equation (
10)) and the repetitions (if necessary) are homogeneously distributed along those squares (to increase the sum of the left terms in Equation (
10)) which should be the most complex ones in
. For
, we define a function
that verifies:
The value
indicates the number of occurrences of
in the decomposition into
squares of the most complex square array of size
. Condition Equation (
11) establishes that the total number of component squares is
. Condition Equation (
12) reduces the square repetitions as much as possible, so as to increase the number of differently composed squares as far as possible and distribute them homogeneously. Finally, Equation (
13) ensures that the most complex squares are the best represented. Then, we define:
Finally, the normalized BDM value of an array X is as follows:
Given an square matrix
X of size
n,
is defined as
This way we take the complexity of an array
X to have a normalized value which is not dependent on the size of
X but rather on the relative complexity of
X with respect to other arrays of the same size.
Figure 10, provides an example of high complexity for illustration purposes. The use of
in the normalization is relevant. Please note that the growth of
is linear with
n, and the growth of
exponential. This means that for high complexity matrices, the result of normalizing by using just
would be similar to
. However, it would not work for low complexity arrays, as when the complexity of
X is close to the minimum, the value of
drops exponentially with
n. For example, the normalized complexity of an empty array (all 0s) would drop exponentially in size. To avoid this, Equation (
14) considers not only the maximum but also the minimum.
Notice the heuristic character of
. It is designed to ensure a quick computation of
, and the distribution of complexities of squares of size
in
ensures that
is actually the maximum complexity of a square matrix of size
n, but for other distributions it could work in a different way. For example, condition (
12) assumes that the complexities of the elements in
are similar. This is the case for
in
, but it may not be true for other distributions. However, at any rate it offers a way of comparing the complexities of different arrays independent of their size.
9. CTM to BDM Transition
How BDM scales CTM remains a question, as does the rate at which BDM loses the algorithmic estimations provided by CTM. Also unknown is what the transition between CTM and CTM + BDM looks like, especially in the face of applications involving objects of medium size between the range of application of CTM (e.g., 10 to 20 bit strings) and larger objects (e.g., longer sequences in the hundreds of bits).
We perform a Spearman correlation analysis to test the strength of a monotonic relationship between CTM values and BDM values with various block sizes and block overlap configurations in all 12 bit strings. We also test the strength of this relationship with CTM on Shannon entropy and compression length.
Figure 11 shows the agreement between BDM and CTM for strings for which we have exact CTM values, against which BDM was tested. The results indicate an agreement between CTM and BDM in a variety of configurations, thereby justifying BDM as an extension of the range of application of CTM to longer strings (and to longer objects in general).
In the set of all 12 bit strings, the correlation is maximal when block size = 11 and overlap = 10 (b11o10,
); Shannon entropy has
with BDM when strings are divided in blocks of size = 1 and overlap = 0 (b1o0,
), as is expected from what is described in
Section 7.1.
The Spearman rank test performed on the first 4096 binary strings has
p-values
, while the Spearman rank test on the 2048 strings with CTM below the median has
p-values
. Finally, the Spearman rank test on the 2048 strings with CTM value above the median has
p-values
, in all cases except those corresponding to b4o1, b4o0, and b3o0, where
and 0.045 ≤
p-value
. The lower
coefficients in above median CTM strings indicates that there is a greater difficulty in estimating the algorithmic complexity of highly irregular strings through either BDM, entropy, or compression length than in detecting their regularity.
Figure 11 shows that for block size >6 the Spearman
of BDM is always higher than the correlation of CTM with either Shannon entropy or compression length. Some block configurations of size <6 (e.g., b2o1) also have higher
than both Shannon entropy and compression.
While BDM approximates the descriptive power of CTM and extends it over a larger range, we prove in
Section 4.3 that BDM approximates Shannon entropy if base objects are no longer generated with CTM, but if CTM approximates algorithmic complexity, then BDM does.
9.1. Smooth BDM (and “Add Col”)
As an alternative method for increasing accuracy while decreasing computational cost, is the use of a weighted function as penalization parameter in BDM. Let the base matrix size be . We first partition the matrix into sub matrices of the matrix base size . If the matrix size is not divisible by 4 we (1) use a smooth BDM with full overlap boundary condition (we call this method simply “smooth” BDM) or (2) add an artificial low complexity boundary to “complete” the matrix to the next multiple of 4 and apply “smooth” (we call this approach “add col” in future sections).
When using the BDM full overlap boundary condition, we screen the entire matrix by moving a sliding square of size 4 × 4 over it (as it is done for “recursive BDM”). When adding artificial low complexity boundaries we only calculate non overlapping sub-matrices of size because the expanded matrix of interest is of multiple of 4. These artificial low complexity boundary are columns and rows of one symbols (zeroes or ones). We then correct the final result by subtracting the information added to the boundaries from .
To prevent the undesired introduction of false patterns in the “completion” process (add col), we use the minimum BDM of the extended matrix for both cases (column and rows of zeroes and ones denoted by and respectively).
In both cases, to distinguish the occurrence of rare and thus highly complex patterns, we assign weights to each base matrix based on the probability of seeing each pattern, denoted by , where i is the index of the base matrix. We thereby effectively “smooth” the transition to decide matrix similarity, unlike the previous versions of BDM which counts multiplicity of equal matrices. Thus the main difference introduced in the “smooth” version of BDM is the penalization by base matrix (statistical) similarity rather than only perfect base matrix match.
To simplify notation, in what follows let us denote the adjacency matrix
of a matrix
M simply as
M. The
smooth version of BDM is then calculated as follows:
9.2. Weighted Smooth BDM with Mutual Information
The Smooth BDM version assigns a weight to each base matrix depending on its statistical likelihood, which is equivalent to assigning a weight based on the entropy of the base matrix over the distribution of all base matrices of . An equivalent version that is computationally more expensive is the use of classical mutual information. This is arrived at by measuring the statistical similarity between base matrices precomputed by mutual information.
Mutual information is a measure of the statistical dependence of a random variable
X on a random variable
Y in the joint distribution of
X and
Y relative to the joint distribution of
X and
Y under an assumption of independence. If
, then
X and
Y are statistically independent, but if the knowledge of
X fully determines
Y,
, then
X and
Y are not independent. Because
is symmetric
; if
, then knowing all about
Y also implies knowing all about
X. In one of its multiple versions MI of
X and
Y can be defined as:
where
is the Shannon entropy of
X and
the conditional Shannon entropy of
X given
Y.
In this way, statistically similar base matrices are not counted as requiring 2 completely different computer programs, one for each base matrix, but rather a slightly modified computer program producing 2 similar matrices accounting mostly for one and for the statistical difference of the other. More precisely, BDM can be defined by:
where MIBDM is defined by:
and where
is a weight for each CTM value of each base matrix such that
j is the index of the matrix that maximizes
(or maximizes statistical similarity) over the distribution of all the base matrices such that
for all
,
.
However, this approach requires comparisons between all base matrices r with indexes and .
Notice that because
is symmetric, then
, but the min in Equation (
19) is because we look for the minimum CTM value (i.e., the length of the shortest program) for the 2 cases in which one base matrix is the one helping define the statistical similarities of the other and vice versa.
10. Testing BDM and Boundary Condition Strategies
A test for both CTM and BDM can be carried out using objects that have different representations or may look very different but are in fact algorithmically related. First we will prove some theorems relating to the algorithmic complexity of dual and cospectral graphs and then we will perform numerical experiments to see if CTM and BDM perform as theoretically expected.
A dual graph of a planar graph G is a graph that has a vertex corresponding to each face of G, and an edge joining two neighbouring faces for each edge in G. If is a dual graph of G, then , making the calculation of the Kolmogorov complexity of graphs and their dual graphs interesting—because of the correlation between Kolmogorov complexity and , which should be the same for . One should also expect the estimated complexity values of graphs to be the same as those of their dual graphs, because the description length of the dual graph generating program is .
Cospectral graphs, also called isospectral graphs, are graphs that share the same graph spectrum. The set of graph eigenvalues of the adjacency matrix is called the spectrum of the graph G. This cospectrality test for complexity estimations is interesting because two non-isomorphic graphs can share the same spectrum.
We have demonstrated that isomorphic graphs have similar complexity as a function of graph automorphism group size [
18]. We have also provided definitions for the algorithmic complexity of labelled and unlabelled graphs based on the automorphism group [
19]. In the
Appendix we prove several theorems and corollaries establishing the theoretical expectation that dual and cospectral graphs have similar algorithmic complexity values, and so we have a theoretical expectation of numerical tests with BDM to compare with.
Compression lengths and BDM values in
Table 3 and
Figure A2 (
Appendix A) are obtained from the adjacency matrices of 113 dual graphs and 193 cospectral graphs from
Mathematica’s
GraphData[] repository. Graphs and their dual graphs were found by BDM to have estimated algorithmic complexities close to each other. While entropy and entropy rate do not perform well in any test compared to the other measures, compression retrieves similar values for cospectral graphs as compared to BDM, but it is outperformed by BDM on the duality test. The best BDM version for duals was different from that for cospectrals. For the duality test, the smooth, fully overlapping version of BDM outperforms all others, but for cospectrality, overlapping recursive BDM outperforms all others. In [
18], we showed that BDM behaves in agreement with the theory with respect to the algorithmic complexity of graphs and the size of the automorphism group to which they belong. This is because the algorithmic complexity
of
G is effectively a tight upper bound on
.
11. Conclusions
We have introduced a well-grounded, theoretically sound and robust measure of complexity that beautifully connects 2 of the main branches of information theory, classical and algorithmic. We have shown that the methods are scalable in various ways, including native n-dimensional variations of the same measure. The properties and numerical experiments are in alignment with theoretical expectations and represent the only truly different alternative and more accurate measure of algorithmic complexity currently available. We have also shown that BDM is computationally efficient, hence complementing the effective use of lossless compression algorithms for calculation of upper bounds of Kolmogorov complexity.
There are thus three methods available today for approximating K (two of which have been advanced by us, one being completely novel: BDM; and one that was known but had never been calculated before: CTM). Here they are described by their range of application:
CTM deals with all bit strings of length 1–12 (and for some 20–30 bits).
BDM deals with 12 bits to hundreds of bits (with a cumulative error that grows by the length of the strings—if not applied in conjunction with CTM). The worst case occurs when substrings share information content with other decomposed substrings and BDM just keeps adding their K values individually.
CTM + BDM (deals with any string length but it is computationally extremely expensive)
Lossless compression deals with no less than 100 bits and is unstable up to about 1 K bits.
While CTM cannot produce estimations of longer bitstrings, estimating the algorithmic complexity of even bitstrings can be key to many problems. Think of the challenge posed by a puzzle of 1000 pieces, if you were able to put together only 12 local pieces at a time, you would be able to put all the puzzle together even without ever looking at the whole piece and thus not even requiring to see possible non-local long-range algorithmic patterns.
Because BDM locally estimates algorithmic complexity via algorithmic probability based on CTM, it is slightly more independent of object description than computable measures such as Shannon entropy, though in the “worst case” it behaves like Shannon entropy. We have also shown that the various flavours of BDM are extremely robust, both by calculating theoretical errors on tensors and by numerical investigation, establishing that any BDM version is fit for use in most cases. Hence the most basic and efficient one can be used without much concern as to the possible alternative methods that could have been used in its calculation, as we have exhaustively and systematically tested most, if not all, of them.
Author Contributions
Conceptualization, H.Z., N.A.K., and F.S.-T.; Methodology, H.Z., N.A.K., F.S.-T., A.R.-T., and S.H.-O.; Software, H.Z., N.A.K., A.R.-T., F.S.-T., and S.H.-O.; Validation, H.Z., N.A.K., A.R.-T., F.S.-T., and S.H.-O.; Formal Analysis, H.Z., N.A.K., F.S.-T., S.H.-O.; Investigation, H.Z., N.A.K., F.S.-T., A.R.-T., S.H.-O.; Resources, H.Z., N.A.K., F.S.-T., J.T.; Data Curation, H.Z., N.A.K., F.S.-T., S.H.-O.; Writing—Original Draft Preparation, H.Z., N.A.K., A.R.-T., F.S.-T., S.H.O.; Writing—Review & Editing, H.Z., N.A.K., S.H.O., A.R.-T., F.S.-T.; Visualization, H.Z., N.A.K., A.R.-T., F.S.-T., S.H.-O.; Supervision, H.Z., N.A.K., J.T.; Project Administration, H.Z., N.A.K., J.T.; Funding Acquisition, H.Z., J.T.
Funding
This research was funded by Swedish Research Council (Vetenskapsrådet) grant number [2015-05299].
Conflicts of Interest
The authors declare no conflict of interest. The founding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| BDM | Block Decomposition Method |
| CTM | Coding Theorem Method |
| TM | Turing machine |
| K | Kolmogorov complexity |
Appendix A. Entropy and Block Entropy v CTM
Figure A1.
The randomness of the digits of
as measured by Shannon entropy, Block entropy and CTM. Strengthening the claim made in
Figure 6, and
Figure A1 in the
Appendix A, here we show the trend of average movement of Entropy and Block Entropy towards 1 and CTM’s average remaining the same but variance slightly reduced. The stronger the colour the more digits into consideration. The direction of Block entropy is the clearest, first from a sample of 100 segments of length 12 bits from the first 1000 decimal digits of
converted to binary (light orange) followed by a second run of 1000 segments of length 12 bits from the first 1 million decimal digits of
. When running CTM over longer period of time, the invariance theorem guarantees convergence to 0.
Figure A1.
The randomness of the digits of
as measured by Shannon entropy, Block entropy and CTM. Strengthening the claim made in
Figure 6, and
Figure A1 in the
Appendix A, here we show the trend of average movement of Entropy and Block Entropy towards 1 and CTM’s average remaining the same but variance slightly reduced. The stronger the colour the more digits into consideration. The direction of Block entropy is the clearest, first from a sample of 100 segments of length 12 bits from the first 1000 decimal digits of
converted to binary (light orange) followed by a second run of 1000 segments of length 12 bits from the first 1 million decimal digits of
. When running CTM over longer period of time, the invariance theorem guarantees convergence to 0.
Appendix A.1. Duality and Cospectral Graph Proofs and Test Complement
Theorem A1. Let be the dual graph of G. Then .
Proof. Let p denote the finite program that, for any graph G, replaces every edge in G by a vertex and every vertex in G by an edge. The resulting graph produced by p is then (uniqueness), which implies that because we did not assume that p was the shortest program. Thus, or up to a constant factor. ☐
Let be the algorithmic complexity of the automorphism group of the graph G (i.e., all possible relabellings that preserve graph isomorphism), that is, the length of the shortest program that generates all the graphs in .
Theorem A2. Let be an isomorphic graph of G. Then for all , where is the automorphism group of G.
The idea is that if there is a significantly shorter program for generating G compared to a program p generating , we can use to generate via G and a relatively short program c that tries, e.g., all permutations, and checks for isomorphism. Let’s assume that there exists a program such that , i.e., the difference is not bounded by any constant, and that . We can replace p by to generate such that , where c is a constant independent of that represents the size of the shortest program that generates , given any G. Then we have it that , which is contrary to the assumption.
Corollary A1. for any .
Proof. Let
be in
such that
. There exists (An algorithm (so far known to be in class
NP) that produces all relabellings—the simplest one is brute force permutation—and can verify graph isomorphism in time class
P [
18]).) a computer program
p that produces
for all
G. With this program we can construct
from any graph
and
from
and the corresponding label
n. Therefore
and
. ☐
Theorem A3. If G and are cospectral graphs, then , i.e., up to a constant and small logarithmic term.
Proof. The strategy is similar: by brute force permutation one can produce all possible adjacency matrices after row and column permutation. Let be the algorithmic complexity of G and be the spectrum of G. Let p be the program that permutes all rows and columns and tests for cospectrality, and its program length. Let . Then where n is the size of G that indicates the index of the right column and row permutation that preserves among all graphs of size n. ☐
Table A1.
List of strings with high entropy and high Block entropy but low algorithmic randomness detected and sorted from lowest to greatest values by CTM.
Table A1.
List of strings with high entropy and high Block entropy but low algorithmic randomness detected and sorted from lowest to greatest values by CTM.
| 101010010101 | 010101101010 | 101111000010 | 010000111101 | 111111000000 |
| 000000111111 | 100101011010 | 011010100101 | 101100110010 | 010011001101 |
| 111100000011 | 110000001111 | 001111110000 | 000011111100 | 111110100000 |
| 000001011111 | 111101000001 | 111100000101 | 101000001111 | 100000101111 |
| 011111010000 | 010111110000 | 000011111010 | 000010111110 | 110111000100 |
| 001000111011 | 110111000001 | 100000111011 | 011111000100 | 001000111110 |
| 110100010011 | 110010001011 | 001101110100 | 001011101100 | 111110000010 |
| 101111100000 | 010000011111 | 000001111101 | 100000111110 | 011111000001 |
| 110101000011 | 110000101011 | 001111010100 | 001010111100 | 111100101000 |
| 111010110000 | 000101001111 | 000011010111 | 111100110000 | 000011001111 |
| 110000111010 | 101000111100 | 010111000011 | 001111000101 | 111100001010 |
| 101011110000 | 010100001111 | 000011110101 | 111011000010 | 101111001000 |
| 010000110111 | 000100111101 | 111000001011 | 110100000111 | 110011100010 |
| 101110001100 | 100011001110 | 011100110001 | 010001110011 | 001100011101 |
| 001011111000 | 000111110100 | 111010000011 | 110000010111 | 001111101000 |
| 000101111100 | 110011010001 | 100010110011 | 011101001100 | 001100101110 |
| 110101001100 | 110011010100 | 001100101011 | 001010110011 | 111000110010 |
| 110010100011 | 110001010011 | 101100111000 | 010011000111 | 001110101100 |
| 001101011100 | 000111001101 | 101100001110 | 100011110010 | 011100001101 |
| 010011110001 | 111000100011 | 110001000111 | 001110111000 | 000111011100 |
| 110000011101 | 101110000011 | 010001111100 | 001111100010 | 111101010000 |
| 000010101111 | 111010001100 | 110011101000 | 001100010111 | 000101110011 |
| 111000101100 | 110010111000 | 001101000111 | 000111010011 | 111011001000 |
| 000100110111 | | | | |
Figure A2.
Scatterplots comparing the various BDM versions tested on dual and cospectral graphs that theoretically have the same algorithmic complexity up to a (small) constant. x-axis values for each top row plot are sorted by BDM for one of the dual and for the cospectral graph series. Bottom rows: on top of each corresponding scatterplot are the Spearman values.
Figure A2.
Scatterplots comparing the various BDM versions tested on dual and cospectral graphs that theoretically have the same algorithmic complexity up to a (small) constant. x-axis values for each top row plot are sorted by BDM for one of the dual and for the cospectral graph series. Bottom rows: on top of each corresponding scatterplot are the Spearman values.
Figure A3.
Scatterplots comparing other measures against the best BDM performance. x-axis values for each top row plot are sorted by BDM for one of the dual and for the cospectral graph series. Bottom rows: on top of each corresponding scatterplot are the Spearman values.
Figure A3.
Scatterplots comparing other measures against the best BDM performance. x-axis values for each top row plot are sorted by BDM for one of the dual and for the cospectral graph series. Bottom rows: on top of each corresponding scatterplot are the Spearman values.
Appendix A.2. The Online Algorithmic Complexity Calculator and Language Implementations
We are releasing actual implementations of BDM in,
C++,
Pascal,
Perl,
Python,
Mathematica and
Matlab.
Table A2 provides an overview of the various implementations. We are also releasing the data generated by CTM which BDM requires to run. This consists in the Kolmogorov complexity evaluations of all strings up to length 11 (12 with the completion of a single one and its complement) as well as for some longer ones, and of all the square arrays of length up to 4 × 4 as calculated by the canonical 2-dimensional Turing machine model (replacing the unidimensional tape with Rado’s 2-dimensional model). The data is also released with a program (a Wolfram Language “Demonstration”) available on-line at the Wolfram’s Demonstrations Project website [
47].
Table A2.
Computer programs in different languages implementing various BDM versions. We have shown that all implementations agree with each other in various degrees, with the only differences having to do with under- or over-estimated values and time complexity and scalability properties. They are extremely robust, thereby establishing that the use of the most basic versions (1D n-o, 2D n-o) are justified in most cases. “WL” stands for Wolfram Language, the language behind e.g., the
Mathematica platform, “Online” for the online calculator, “Cyc” for Cyclic, “Norm” stands for normalized, “Rec” for recursive, “Smo” for “Smooth”, “N-o” for Nonoverlapping and “addcol” for the method that adds rows and columns of lowest complexity to the borders up to the base string/array/tensor size. If not stated then it supports overlapping. All programs are available at
https://www.algorithmicdynamics.net/software.html.
Table A2.
Computer programs in different languages implementing various BDM versions. We have shown that all implementations agree with each other in various degrees, with the only differences having to do with under- or over-estimated values and time complexity and scalability properties. They are extremely robust, thereby establishing that the use of the most basic versions (1D n-o, 2D n-o) are justified in most cases. “WL” stands for Wolfram Language, the language behind e.g., the
Mathematica platform, “Online” for the online calculator, “Cyc” for Cyclic, “Norm” stands for normalized, “Rec” for recursive, “Smo” for “Smooth”, “N-o” for Nonoverlapping and “addcol” for the method that adds rows and columns of lowest complexity to the borders up to the base string/array/tensor size. If not stated then it supports overlapping. All programs are available at
https://www.algorithmicdynamics.net/software.html.
| Lang | 1D n-o | 1D 2D n-o | 2D Rec | 2D Cyc | 2D Smo | 2D Norm | 1-D LD | Addcol |
|---|
| Online | ✓ | ✓ | ✓ | × | × | × | × | × |
| WL | ✓ | ✓ | ✓ | ✓ | ✓ | × | ✓ | × |
| R | ✓ | ✓ | ✓ | ✓ | × | × | × | × |
| Matlab | ✓ | × | ✓ | ✓ | × | ✓ | × | ✓ |
| Haskell | ✓ | ✓ | ✓ | ✓ | × | × | × | × |
| Perl | × | × | ✓ | × | × | × | × | × |
| Python | × | × | ✓ | × | × | × | × | × |
| Pascal | × | × | ✓ | × | × | × | × | × |
| C++ | × | × | ✓ | × | × | × | × | × |
References
- Zenil, H.; Kiani, N.A.; Tegnér, J. Low-algorithmic-complexity entropy-deceiving graphs. Phys. Rev. E 2017, 96, 012308. [Google Scholar] [CrossRef] [PubMed]
- Daley, R.P. An Example of Information and Computation Trade-Off. J. ACM 1973, 20, 687–695. [Google Scholar] [CrossRef]
- Levin, L.A. Universal sequential search problems. Probl. Inf. Transm. 1973, 9, 265–266. [Google Scholar]
- Schmidhuber, J. The Speed Prior: A New Simplicity Measure Yielding Near-Optimal Computable Predictions. In Proceedings of the 15th Annual Conference on Computational Learning Theory (COLT 2002), Sydney, Australia, 8–10 July 2002; Kivinen, J., Sloan, R.H., Eds.; Springer: Berlin, Germany, 2002; pp. 216–228. [Google Scholar]
- Li, M.; Vitányi, P. An Introduction to Kolmogorov Complexity and Its Applications, 3rd. ed.; Springer: Heidelberg, Germany, 2009. [Google Scholar]
- Cilibrasi, R.; Vitányi, P.M. Clustering by compression. IEEE Trans. Inf. Theory 2005, 51, 1523–1545. [Google Scholar] [CrossRef]
- Zenil, H.; Badillo, L.; Hernández-Orozco, S.; Hernández-Quiroz, F. Coding-theorem Like Behaviour and Emergence of the Universal Distribution from Resource-bounded Algorithmic Probability. Int. J. Parallel Emerg. Distrib. Syst. 2018, 1–20. [Google Scholar] [CrossRef]
- Zenil, H. Algorithmic Data Analytics, Small Data Matters and Correlation versus Causation. In Berechenbarkeit der Welt? Philosophie und Wissenschaft im Zeitalter von Big Data (Computability of the World? Philosophy and Science in the Age of Big Data); Ott, M., Pietsch, W., Wernecke, J., Eds.; Springer: Berlin, Germany, 2017; pp. 453–475. [Google Scholar]
- Zenil, H.; Soler-Toscano, F.; Delahaye, J.P.; Gauvrit, N. Two-dimensional Kolmogorov complexity and an empirical validation of the Coding Theorem Method by compressibility. PeerJ Comput. Sci. 2015, 1, e23. [Google Scholar] [CrossRef]
- Gauvrit, N.; Soler-Toscano, F.; Zenil, H. Natural scene statistics mediate the perception of image complexity. Vis. Cognit. 2014, 22, 1084–1091. [Google Scholar] [CrossRef]
- Gauvrit, N.; Singmann, H.; Soler-Toscano, F.; Zenil, H. Algorithmic complexity for psychology: A user-friendly implementation of the coding theorem method. Behav. Res. Methods 2016, 48, 314–329. [Google Scholar] [CrossRef] [PubMed]
- Kempe, V.; Gauvrit, N.; Forsyth, D. Structure emerges faster during cultural transmission in children than in adults. Cognition 2015, 136, 247–254. [Google Scholar] [CrossRef] [PubMed]
- Emmert-Streib, F.; Dehmer, M. Exploring statistical and population aspects of network complexity. PLoS ONE 2012, 7, e34523. [Google Scholar] [CrossRef] [PubMed]
- Dehmer, M.M. A novel method for measuring the structural information content of networks. Cybern. Syst. 2008, 39, 825–842. [Google Scholar] [CrossRef]
- Dehmer, M.M.; Barbarini, N.N.; Varmuza, K.K.; Graber, A.A. Novel topological descriptors for analyzing biological networks. BMC Struct. Biol. 2010, 10, 18. [Google Scholar] [CrossRef] [PubMed]
- Mowshowitz, A.; Dehmer, M.M. Entropy and the complexity of graphs revisited. Entropy 2012, 14, 559–570. [Google Scholar] [CrossRef]
- Holzinger, A.; Ofner, B.; Stocker, C.; Valdez, A.C.; Schaar, A.K.; Ziefle, M.; Dehmer, M. On graph entropy measures for knowledge discovery from publication network data. In International Conference on Availability, Reliability, and Security; Springer: Berlin/Heidelberg, Germany, 2013; pp. 354–362. [Google Scholar]
- Zenil, H.; Soler-Toscano, F.; Dingle, K.; Louis, A. Correlation of Automorphism Group Size and Topological Properties with Program-size Complexity Evaluations of Graphs and Complex Networks. Physica A 2014, 404, 341–358. [Google Scholar] [CrossRef]
- Zenil, H.; Kiani, N.A.; Tegnér, J. Methods of information theory and algorithmic complexity for network biology. In Seminars in Cell & Developmental Biology; Academic Press: Cambridge, MA, USA, 2016; Volume 51, pp. 32–43. [Google Scholar]
- Levin, L.A. Laws of information conservation (nongrowth) and aspects of the foundation of probability theory. Probl. Pereda. Inf. 1974, 10, 30–35. [Google Scholar]
- Chaitin, G.J. On the length of programs for computing finite binary sequences. J. ACM 1966, 13, 547–569. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Three approaches to the quantitative definition of information. Probl. Inf. Transm. 1965, 1, 1–7. [Google Scholar] [CrossRef]
- Calude, C.S.; Salomaa, K.; Roblot, T.K. Finite state complexity. Theor. Comput. Sci. 2011, 412, 5668–5677. [Google Scholar] [CrossRef]
- Downey, R.G.; Hirschfeldt, D.R. Algorithmic Randomness and Complexity; Springer: Berlin, Germany, 2010. [Google Scholar]
- Martin-Löf, P. The definition of random sequences. Inf. Control 1966, 9, 602–619. [Google Scholar] [CrossRef]
- Solomonoff, R.J. A formal theory of inductive inference. Part I. Inf. Control 1964, 7, 1–22. [Google Scholar] [CrossRef]
- Calude, C.S. Information and Randomness: An Algorithmic Perspective; Springer: Berlin, Germany, 2002. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Kirchherr, W.; Li, M.; Vitányi, P. The Miraculous Universal Distribution. Math. Intell. 1997, 19, 7–15. [Google Scholar] [CrossRef]
- Solomonoff, R.J. Complexity–Based Induction Systems: Comparisons and Convergence Theorems. IEEE Trans. Inf. Theory 1978, 24, 422–432. [Google Scholar] [CrossRef]
- Solomonoff, R.J. The Application of Algorithmic Probability to Problems in Artificial Intelligence. In Uncertainty in Artificial Intelligence; Kanal, L.N., Lemmer, J.F., Eds.; Elsevier: New York, NY, USA, 1986; pp. 473–491. [Google Scholar]
- Solomonoff, R.J. A System for Incremental Learning Based on Algorithmic Probability. In Proceedings of the Sixth Israeli Conference on Artificial Intelligence, Computer Vision and Pattern Recognition, Tel Aviv, Israel, 26–27 December 1989; pp. 515–527. [Google Scholar]
- Soler-Toscano, F.; Zenil, H.; Delahaye, J.P.; Gauvrit, N. Calculating Kolmogorov complexity from the output frequency distributions of small Turing machines. PloS ONE 2014, 9, e96223. [Google Scholar] [CrossRef] [PubMed]
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef]
- Delahaye, J.P.; Zenil, H. Numerical Evaluation of the Complexity of Short Strings: A Glance Into the Innermost Structure of Algorithmic Randomness. Appl. Math. Comput. 2012, 219, 63–77. [Google Scholar] [CrossRef]
- Zenil, H. Une Approche Expérimentalea la Théorie Algorithmique de la Complexité. Ph.D. Thesis, Université de Paris, Paris, France, 2013. (In French). [Google Scholar]
- Calude, C.S.; Stay, M.A. Most programs stop quickly or never halt. Adv. Appl. Math. 2008, 40, 295–308. [Google Scholar] [CrossRef]
- Rado, T. On non-computable functions. Bell Syst. Tech. J. 1962, 41, 877–884. [Google Scholar] [CrossRef]
- Zenil, H. From Computer Runtimes to the Length of Proofs: With an Algorithmic Probabilistic Application to Waiting Times in Automatic Theorem Proving. In Computation, Physics and Beyond International Workshop on Theoretical Computer Science; Dinneen, M.J., Khousainov, B., Nies, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 223–240. [Google Scholar]
- Brady, A.H. The determination of the value of Rado’s noncomputable function Σ(k) for four-state Turing machines. Math. Comput. 1983, 40, 647–665. [Google Scholar]
- Soler-Toscano, F.; Zenil, H.; Delahaye, J.P.; Gauvrit, N. Correspondence and Independence of Numerical Evaluations of Algorithmic Information Measures. Computability 2013, 2, 125–140. [Google Scholar]
- Langton, C.G. Studying artificial life with cellular automata. Physica D 1986, 22, 120–149. [Google Scholar] [CrossRef]
- Morse, M.; Hedlund, G.A. Unending Chess, Symbolic Dynamics, and a Problem in Semigroups. Duke Math. J. 1944, 11, 1–7. [Google Scholar] [CrossRef]
- Bailey, D.H.; Borwein, P.B.; Plouffe, S. On the Rapid Computation of Various Polylogarithmic Constants. Math. Comput. 1997, 66, 903–913. [Google Scholar] [CrossRef]
- Gauvrit, N.; Singmann, H.; Soler-Toscano, F.; Zenil, H. Acss: Algorithmic Complexity for Short Strings, Package at the Comprehensive R Archive Network. Available online: https://cran.r-project.org/web/packages/acss/ (accessed on 13 June 2018).
- Rueda-Toicen, A.; Singmann, H. The Online Algorithmic Complexity Calculator, R Shiny Code Repository. Available online: https://github.com/andandandand/OACC (accessed on 13 June 2018).
- Soler-Toscano, F.; Zenil, H. Kolmogorov Complexity of 3 × 3 and 4 × 4 Squares, on the Wolfram Demonstrations Project. Available online: http://demonstrations.wolfram.com/KolmogorovComplexityOf33And44Squares/ (accessed on 13 June 2018).
Figure 1.
Hypothetical behaviour of (non-)regular convergence rates of the constant involved in the invariance theorem. The invariance theorem guarantees that complexity values for a string s measured by different reference UTMs and will only diverge by a constant c (the length between and ) independent of s yet it does not tell how fast or in what way the convergence may happen particularly at the beginning. The invariance theorem only tells us that at the limit the curve will converge to a small and constant value c, but it tells us nothing about the rate of convergence or about transitional behaviour.
Figure 1.
Hypothetical behaviour of (non-)regular convergence rates of the constant involved in the invariance theorem. The invariance theorem guarantees that complexity values for a string s measured by different reference UTMs and will only diverge by a constant c (the length between and ) independent of s yet it does not tell how fast or in what way the convergence may happen particularly at the beginning. The invariance theorem only tells us that at the limit the curve will converge to a small and constant value c, but it tells us nothing about the rate of convergence or about transitional behaviour.
Figure 2.
The best version of Shannon entropy can be rewritten as a function of variable block length where the minimum value best captures the (possible) periodicity of a string here illustrated with three strings of length 12, regular, periodic and random-looking. Because blocks larger than would result in only one block and therefore entropy equal to 0, the largest possible block is . The normalized version (bottom) divides the entropy value for that block size by the largest possible number of blocks for that size and alphabet (here binary).
Figure 2.
The best version of Shannon entropy can be rewritten as a function of variable block length where the minimum value best captures the (possible) periodicity of a string here illustrated with three strings of length 12, regular, periodic and random-looking. Because blocks larger than would result in only one block and therefore entropy equal to 0, the largest possible block is . The normalized version (bottom) divides the entropy value for that block size by the largest possible number of blocks for that size and alphabet (here binary).
Figure 3.
(A) Observed data, a sequence of successive positive natural numbers. (B) The transition table of the Turing machine found by running all possible small Turing machines. (C) The same transition table in visual form. (D) The space-time evolution of the Turing machine for starting from an empty tape. (E) Space-time evolution of the Turing machine implementing a binary counter, taking as halting criterion the leftmost position of the original Turing machine head as depicted in C (states are arrows). (E) This small computer program that our CTM and BDM methods find (c.f. next Section) mean that the sequence in A is not algorithmic random as the program represents a succinct generative causal model (and thus not random) for any arbitrary length that otherwise would have been assigned a maximal randomness with Shannon Entropy among all strings of the same length (in the face of no other knowledge about the source) despite its highly algorithmic non-random structured nature. Entropy alone—only equipped to spot statistical regularities when there is no access to probability distributions—cannot find this kind of generative models demonstrating the low randomness of an algorithmic sequence. (F) This illustrates how algorithmic complexity and entropy may diverge in practice.
Figure 3.
(A) Observed data, a sequence of successive positive natural numbers. (B) The transition table of the Turing machine found by running all possible small Turing machines. (C) The same transition table in visual form. (D) The space-time evolution of the Turing machine for starting from an empty tape. (E) Space-time evolution of the Turing machine implementing a binary counter, taking as halting criterion the leftmost position of the original Turing machine head as depicted in C (states are arrows). (E) This small computer program that our CTM and BDM methods find (c.f. next Section) mean that the sequence in A is not algorithmic random as the program represents a succinct generative causal model (and thus not random) for any arbitrary length that otherwise would have been assigned a maximal randomness with Shannon Entropy among all strings of the same length (in the face of no other knowledge about the source) despite its highly algorithmic non-random structured nature. Entropy alone—only equipped to spot statistical regularities when there is no access to probability distributions—cannot find this kind of generative models demonstrating the low randomness of an algorithmic sequence. (F) This illustrates how algorithmic complexity and entropy may diverge in practice.

Figure 4.
Non-overlapping BDM calculations are invariant to block permutations (reshuffling base strings and matrices), even when these permutations may have different complexities due to the reorganization of the blocks that can produce statistical or algorithmic patterns. For example, starting from a string of size 24 (top) or an array of size (bottom), with decomposition length for strings and decomposition block size for the array, all 6 permutations for the string and all 6 permutations for the array have the same BDM value regardless of the shuffling procedure.
Figure 4.
Non-overlapping BDM calculations are invariant to block permutations (reshuffling base strings and matrices), even when these permutations may have different complexities due to the reorganization of the blocks that can produce statistical or algorithmic patterns. For example, starting from a string of size 24 (top) or an array of size (bottom), with decomposition length for strings and decomposition block size for the array, all 6 permutations for the string and all 6 permutations for the array have the same BDM value regardless of the shuffling procedure.
Figure 5.
One way to deal with the decomposition of n-dimensional tensors is to embed them in an n-dimensional torus ( in the case of the one depicted here), making the borders cyclic or periodic by joining the borders of the object. Depicted here are three examples of graph canonical adjacency matrices embedded in a 2-dimensional torus that preserves the object complexity on the surface, a complete graph, a cycle graph and an Erdös-Rényi graph with edge density 0.5, all of size 20 nodes and free of self-loops. Avoiding borders has the desired effect of producing no residual matrices after the block decomposition with overlapping.
Figure 5.
One way to deal with the decomposition of n-dimensional tensors is to embed them in an n-dimensional torus ( in the case of the one depicted here), making the borders cyclic or periodic by joining the borders of the object. Depicted here are three examples of graph canonical adjacency matrices embedded in a 2-dimensional torus that preserves the object complexity on the surface, a complete graph, a cycle graph and an Erdös-Rényi graph with edge density 0.5, all of size 20 nodes and free of self-loops. Avoiding borders has the desired effect of producing no residual matrices after the block decomposition with overlapping.
Figure 6.
(
A) Telling
and the Thue-Morse sequence apart from truly (algorithmic) random sequences. CTM assigns significantly lower randomness (
B,
D–
F) to known low algorithmic complexity objects. (
B) If absolute Borel normal (as strongly suspected and statistically demonstrated to any confidence degree),
’s entropy and block entropy asymptotically approximate 1 while, by the invariance theorem of algorithmic complexity, CTM asymptotically approximates 0. Smooth transitions between CTM and BDM are also shown (
C,
D) as a function of string complexity. Other smooth transition functions of BDM are explored and introduced in
Section 9.1.
Figure 6.
(
A) Telling
and the Thue-Morse sequence apart from truly (algorithmic) random sequences. CTM assigns significantly lower randomness (
B,
D–
F) to known low algorithmic complexity objects. (
B) If absolute Borel normal (as strongly suspected and statistically demonstrated to any confidence degree),
’s entropy and block entropy asymptotically approximate 1 while, by the invariance theorem of algorithmic complexity, CTM asymptotically approximates 0. Smooth transitions between CTM and BDM are also shown (
C,
D) as a function of string complexity. Other smooth transition functions of BDM are explored and introduced in
Section 9.1.
Figure 7.
Strings that are assigned lower randomness than that estimated by entropy.
Top left: Comparison between values of entropy, compression (
Compress[]) and BDM over a sample of 100 strings of length 10,000 generated from a binary random variable following a Bernoulli distribution and normalized by maximal complexity values. Entropy follows a Bernoulli distribution and, unlike compression that follows entropy, BDM values produce clear convex-shaped gaps on each side assigning lower complexity to some strings compared to both entropy and compression.
Top right: The results confirmed using a popular lossless compression algorithm BZip2 (and also confirmed, even if not reported, with LZMA) on 100 random strings of 100 bits each (BZip2 is slower than Compress but achieves greater compression).
Bottom left: The
gap between near-maximal entropy and low algorithmic complexity grows and is consistent along different string lengths, here from 8 to 12 bits. This gap is the one exploited by BDM and carried out over longer strings, which gives it the algorithmic edge against entropy and compression.
Bottom right: When strings are sorted by CTM, one notices that BZip2 collapses most strings to minimal compressibility. Over all
possible binary strings of length 12, entropy only produces 6 different entropy values, but CTM is much more fine-grained, and this is extended to the longer strings by BDM, which succeeds in identifying strings of lower algorithmic complexity that have near-maximal entropy and therefore no statistical regularities. Examples of such strings are in
Section 6.
Figure 7.
Strings that are assigned lower randomness than that estimated by entropy.
Top left: Comparison between values of entropy, compression (
Compress[]) and BDM over a sample of 100 strings of length 10,000 generated from a binary random variable following a Bernoulli distribution and normalized by maximal complexity values. Entropy follows a Bernoulli distribution and, unlike compression that follows entropy, BDM values produce clear convex-shaped gaps on each side assigning lower complexity to some strings compared to both entropy and compression.
Top right: The results confirmed using a popular lossless compression algorithm BZip2 (and also confirmed, even if not reported, with LZMA) on 100 random strings of 100 bits each (BZip2 is slower than Compress but achieves greater compression).
Bottom left: The
gap between near-maximal entropy and low algorithmic complexity grows and is consistent along different string lengths, here from 8 to 12 bits. This gap is the one exploited by BDM and carried out over longer strings, which gives it the algorithmic edge against entropy and compression.
Bottom right: When strings are sorted by CTM, one notices that BZip2 collapses most strings to minimal compressibility. Over all
possible binary strings of length 12, entropy only produces 6 different entropy values, but CTM is much more fine-grained, and this is extended to the longer strings by BDM, which succeeds in identifying strings of lower algorithmic complexity that have near-maximal entropy and therefore no statistical regularities. Examples of such strings are in
Section 6.

Figure 8.
Error rate for 2-dimensional arrays. With no loss of generalization, the error rate for n-dimensional tensors is convergent and thus negligible, even for the discontinuities disregarded in this plot which are introduced by some BDM versions, such as non-overlapping blocks and discontinuities related to trimming the boundary condition.
Figure 8.
Error rate for 2-dimensional arrays. With no loss of generalization, the error rate for n-dimensional tensors is convergent and thus negligible, even for the discontinuities disregarded in this plot which are introduced by some BDM versions, such as non-overlapping blocks and discontinuities related to trimming the boundary condition.
Figure 9.
Box plot showing the error introduced by BDM quantified by CTM. The sigmoid appearance comes from the fact that we actually have exact values for CTM up to bitstrings of length 12 and so for but the slope of the curve gives an indication of the errors when assuming that BDM has only access to for versus actual . This means that the error grows linearly as a function of CTM and of the string length, and the accuracy degrades smoothly and slowly towards entropy if CTM is not updated.
Figure 9.
Box plot showing the error introduced by BDM quantified by CTM. The sigmoid appearance comes from the fact that we actually have exact values for CTM up to bitstrings of length 12 and so for but the slope of the curve gives an indication of the errors when assuming that BDM has only access to for versus actual . This means that the error grows linearly as a function of CTM and of the string length, and the accuracy degrades smoothly and slowly towards entropy if CTM is not updated.
Figure 10.
NBDM assigns maximum value 1 to any base matrix with highest CTM or any matrix constructed out of base matrices. In this case, the 4 base matrices on the left are those with the highest CTM in the space of all base matrices of the same size, while the matrix to the left is assigned the highest value because it is built out of the maximum complexity base matrices.
Figure 10.
NBDM assigns maximum value 1 to any base matrix with highest CTM or any matrix constructed out of base matrices. In this case, the 4 base matrices on the left are those with the highest CTM in the space of all base matrices of the same size, while the matrix to the left is assigned the highest value because it is built out of the maximum complexity base matrices.
Figure 11.
Spearman correlation coefficients (
) between CTM and BDM of all possible block sizes and overlap lengths for 12 bit strings, compared with the correlation between CTM and Shannon entropy, and the correlation between CTM and compression length (shown at the rightmost edge of the plot) in blue.
coefficients for the 2048 strings below and above the median CTM value are shown in green and orange, respectively. BDM block size and overlap increases to the left. Compression length was obtained using
Mathematica’s
Compress[] function. All values were normalized as described in
Section 8.
Figure 11.
Spearman correlation coefficients (
) between CTM and BDM of all possible block sizes and overlap lengths for 12 bit strings, compared with the correlation between CTM and Shannon entropy, and the correlation between CTM and compression length (shown at the rightmost edge of the plot) in blue.
coefficients for the 2048 strings below and above the median CTM value are shown in green and orange, respectively. BDM block size and overlap increases to the left. Compression length was obtained using
Mathematica’s
Compress[] function. All values were normalized as described in
Section 8.
Table 1.
Calculated empirical distributions from rulespace . Letter codes: F full space, S sample, reduced enumeration. Time is given in seconds (s), hours (h) and days (d).
Table 1.
Calculated empirical distributions from rulespace . Letter codes: F full space, S sample, reduced enumeration. Time is given in seconds (s), hours (h) and days (d).
| (t,k) | Calculation | Number of Machines | Time |
|---|
| (2,2) | F (6 steps) | | 0.01 s |
| (3,2) | F (21) | | 8 s |
| (4,2) | F (107) | | 4 h |
| (4,2) | (1500) | | 252 d |
| (4,4) | S (2000) | | 62 d |
| (4,5) | S (2000) | | 44 d |
| (4,6) | S (2000) | | 41 d |
| (4,9) | S (4000) | | 75 d |
| (4,10) | S (4000) | | 87 d |
| (5,2) | F (500) | | 450 d |
| (5,2) | (2000) | | 1970 d |
Table 2.
Summary of ranges of application and scalability of CTM and all versions of BDM. d stands for the dimension of the object.
Table 2.
Summary of ranges of application and scalability of CTM and all versions of BDM. d stands for the dimension of the object.
| | Short Strings bits | Long Strings bits | Scalability |
|---|
| Lossless compression | × | ✓ | n |
| Coding Theorem Method (CTM) | ✓ | × | to ∞ |
| Non-overlapping BDM | ✓ | ✓ | n |
| Full-overlapping Recursive BDM | ✓ | ✓ | |
| Full-overlapping Smooth BDM | ✓ | ✓ | |
| Smooth add col BDM | ✓ | ✓ | n |
Table 3.
Spearman values of various BDM versions tested on dual and cospectral graphs that theoretically have the same algorithmic complexity up to a (small) constant.
Table 3.
Spearman values of various BDM versions tested on dual and cospectral graphs that theoretically have the same algorithmic complexity up to a (small) constant.
| | Non-Overlapping BDM | Fully Overlapping Recursive BDM | Smooth Fully Overlapping BDM | Smooth Add Row or Column BDM |
|---|
| Duality test | 0.874 | 0.783 | 0.935 | 0.931 |
| Cospectrality test | 0.943 | 0.933 | 0.9305 | 0.931 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



 ,
, 

{kind=link}
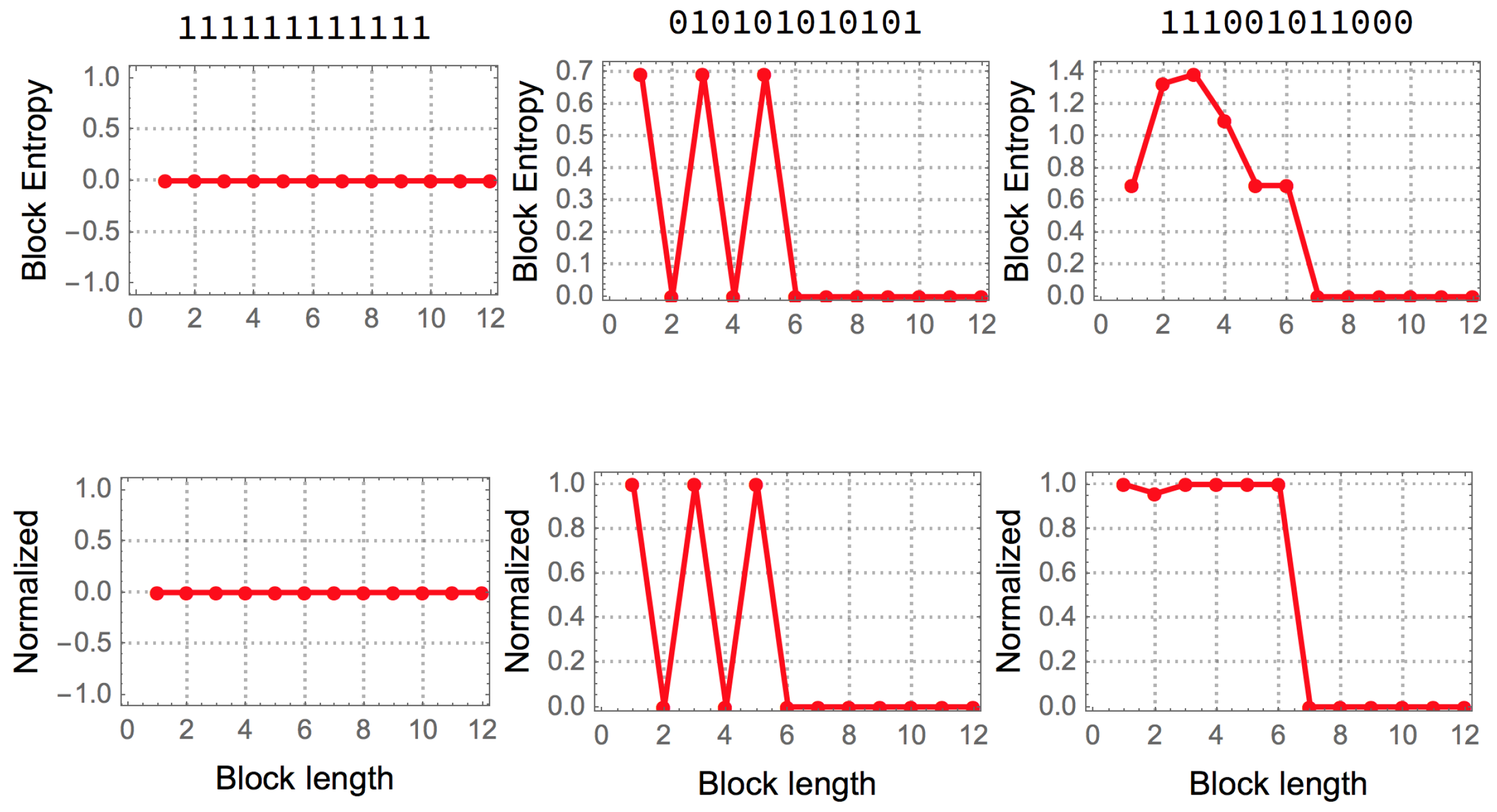{kind=link}
{kind=link}
{kind=link}
{kind=link}
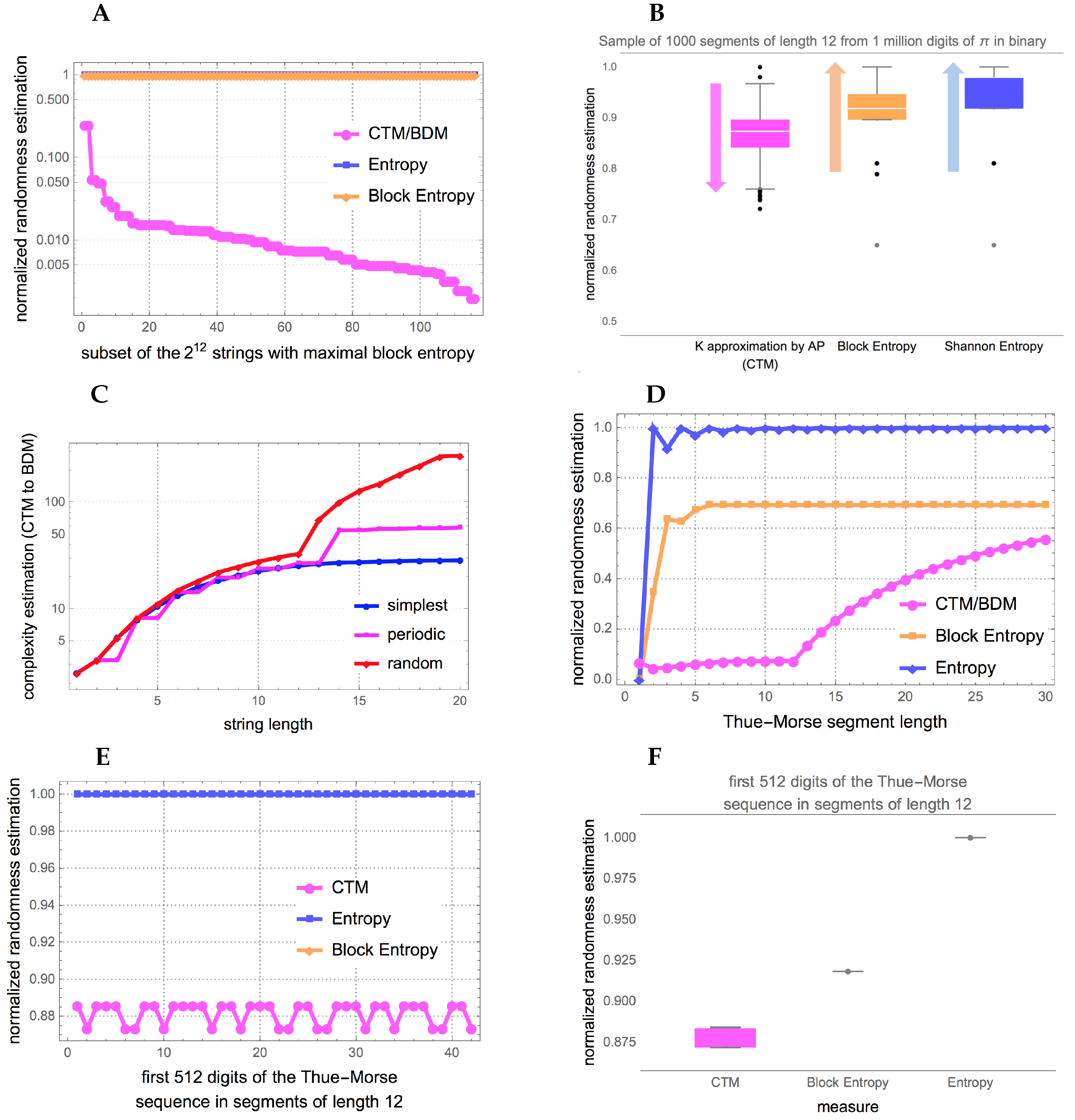{kind=link}
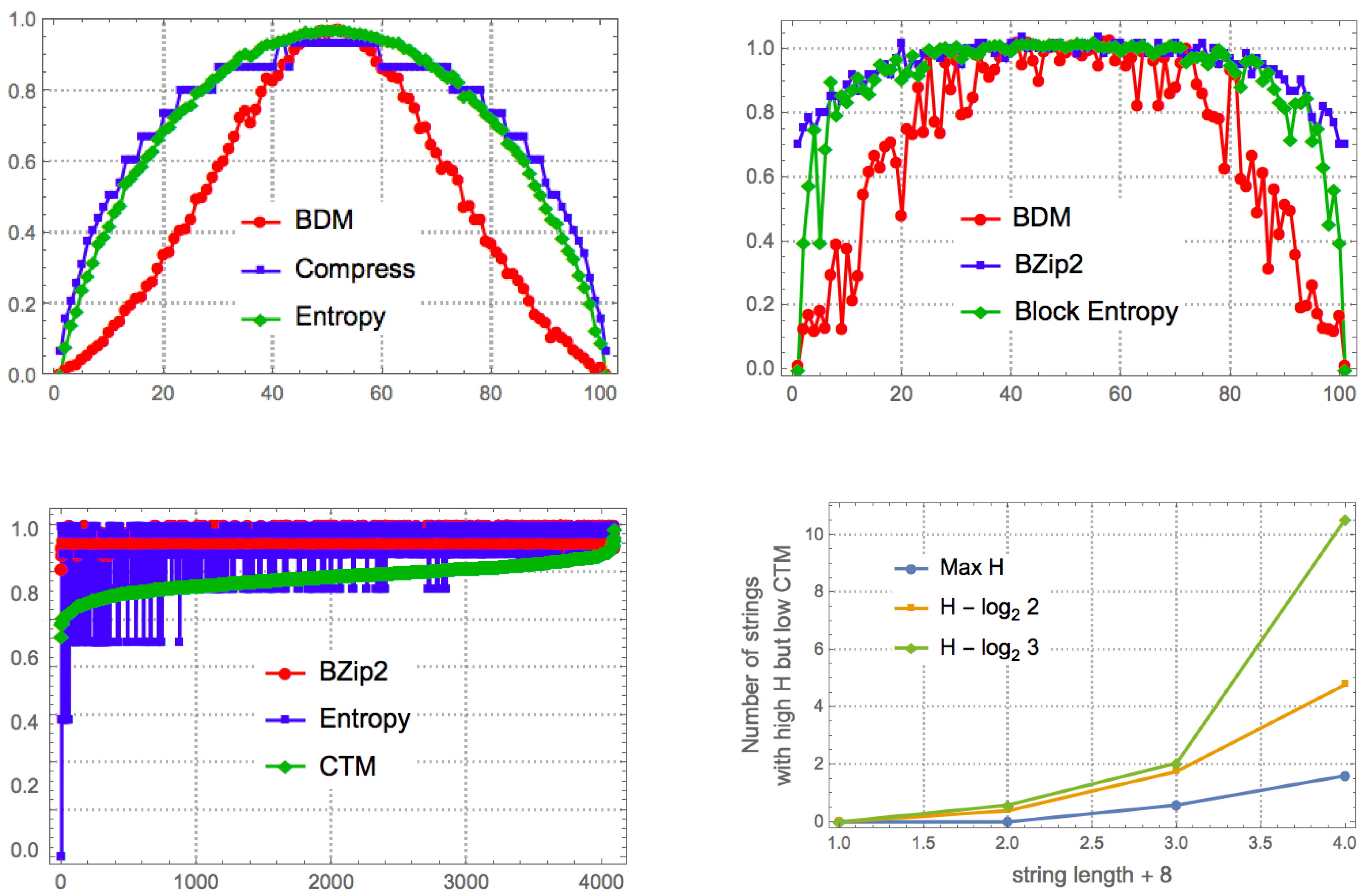{kind=link}
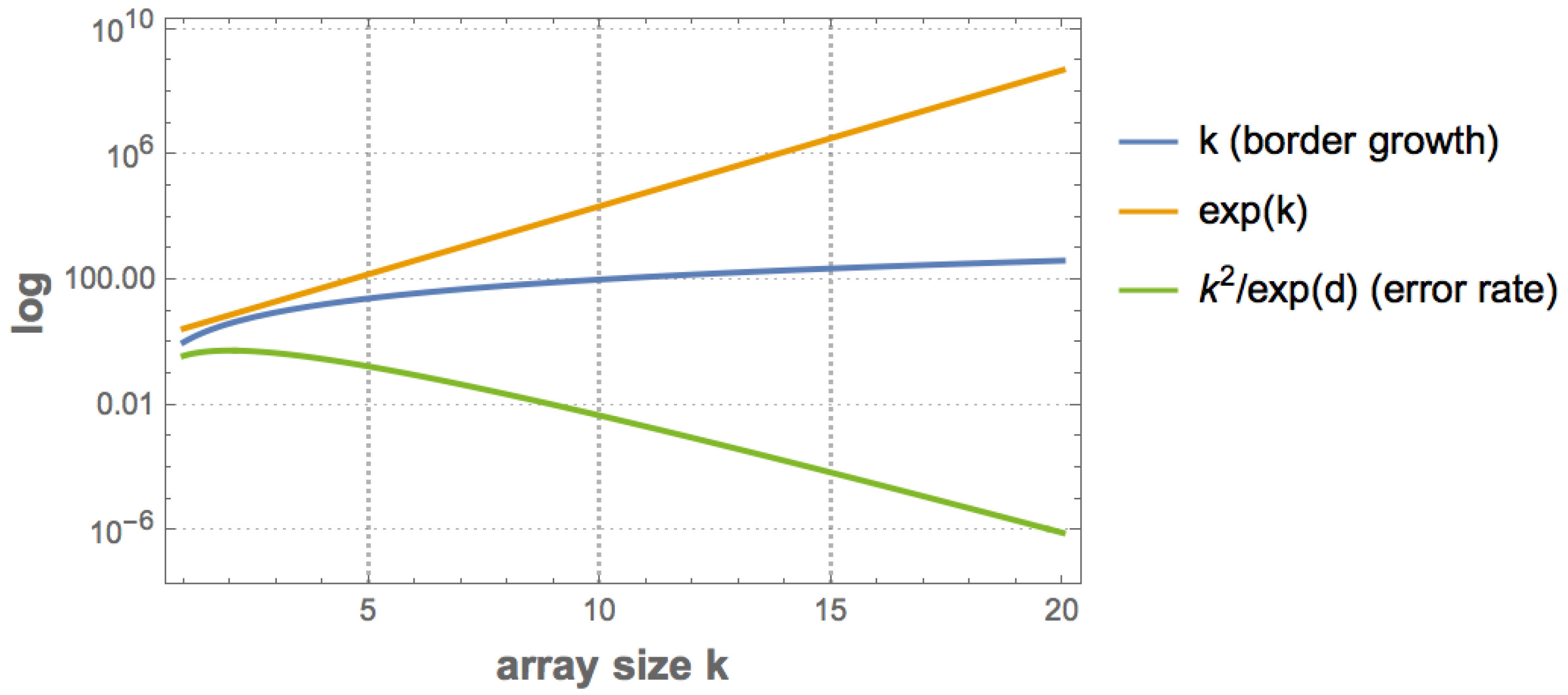{kind=link}
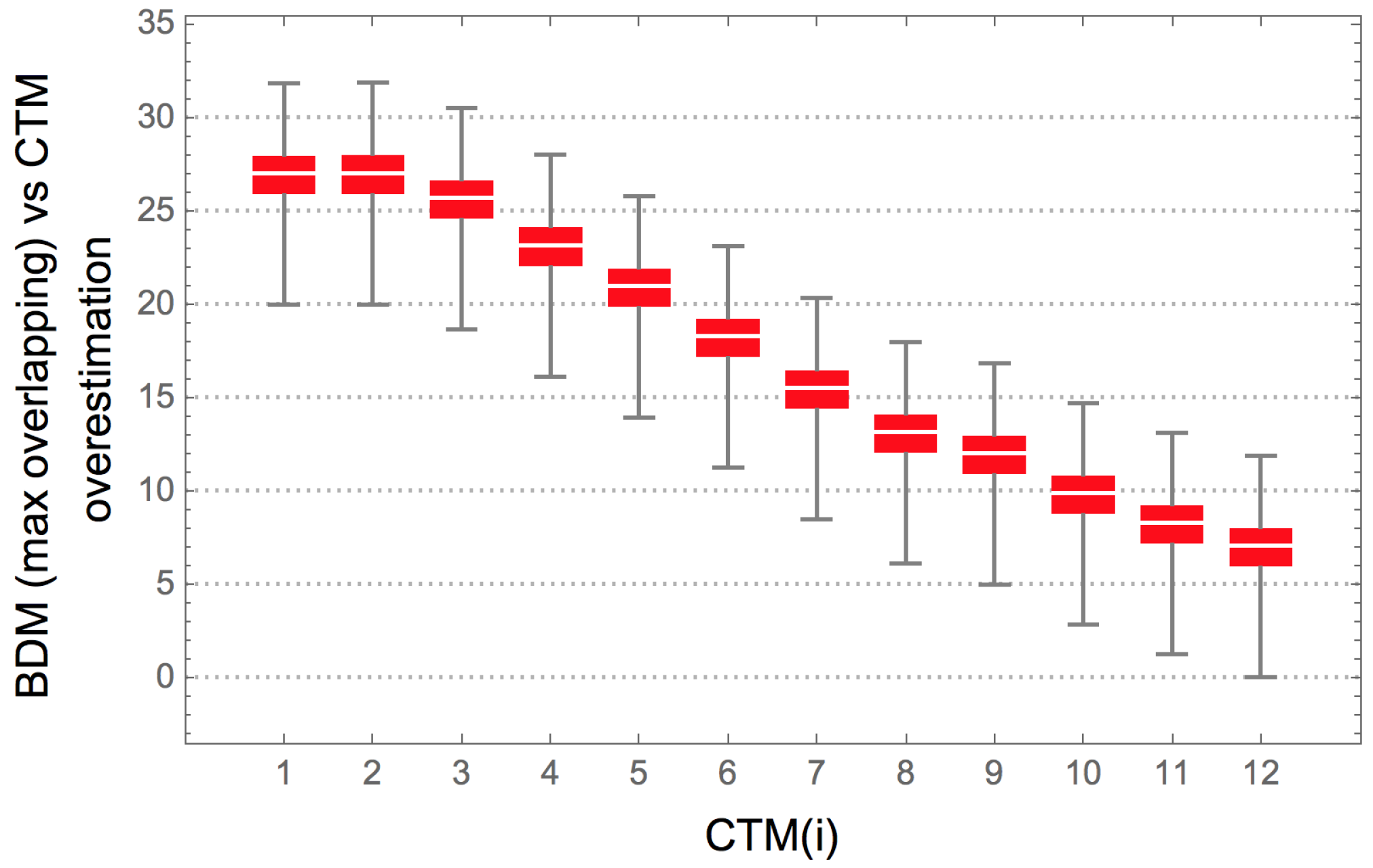{kind=link}
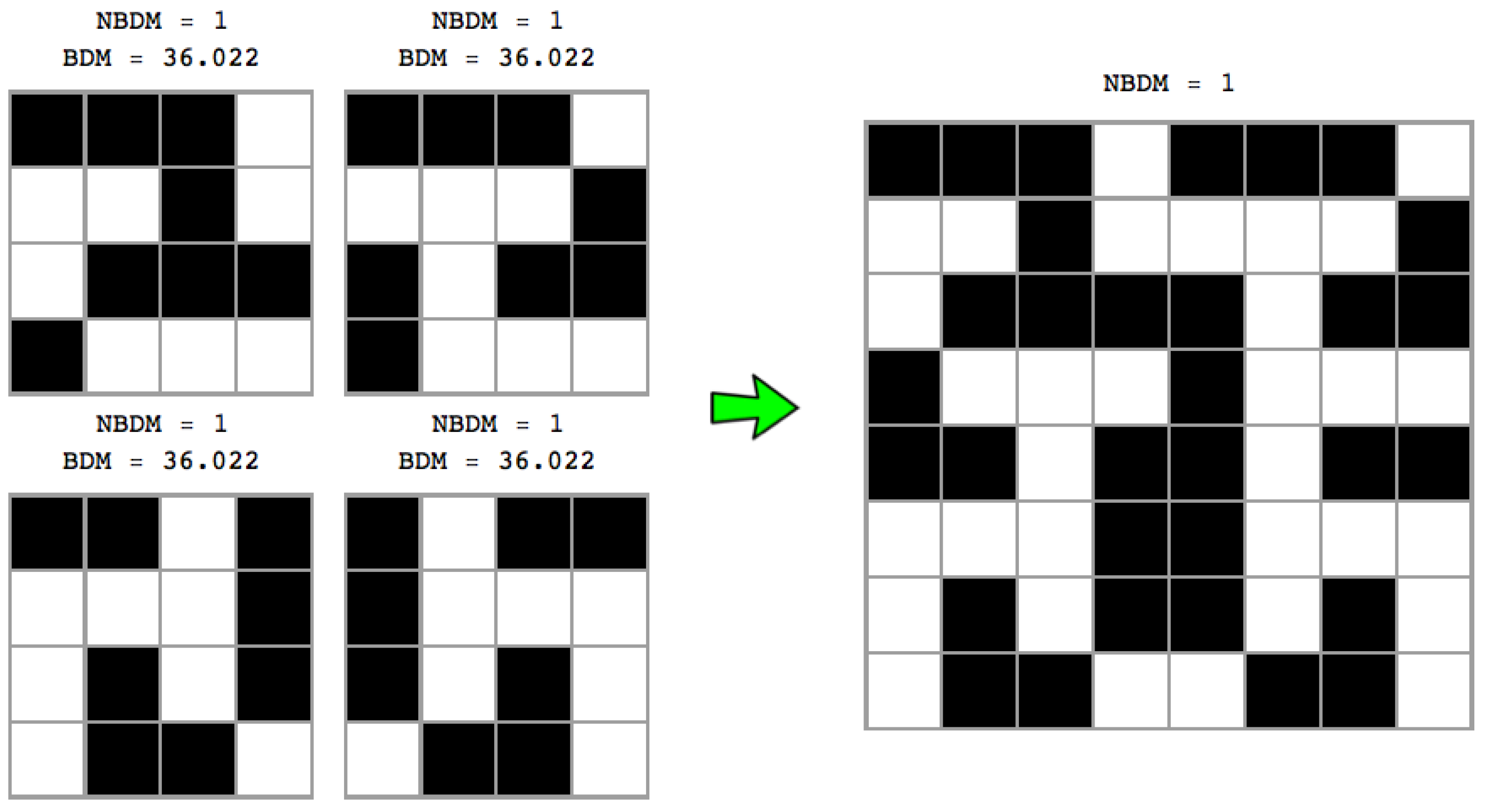{kind=link}
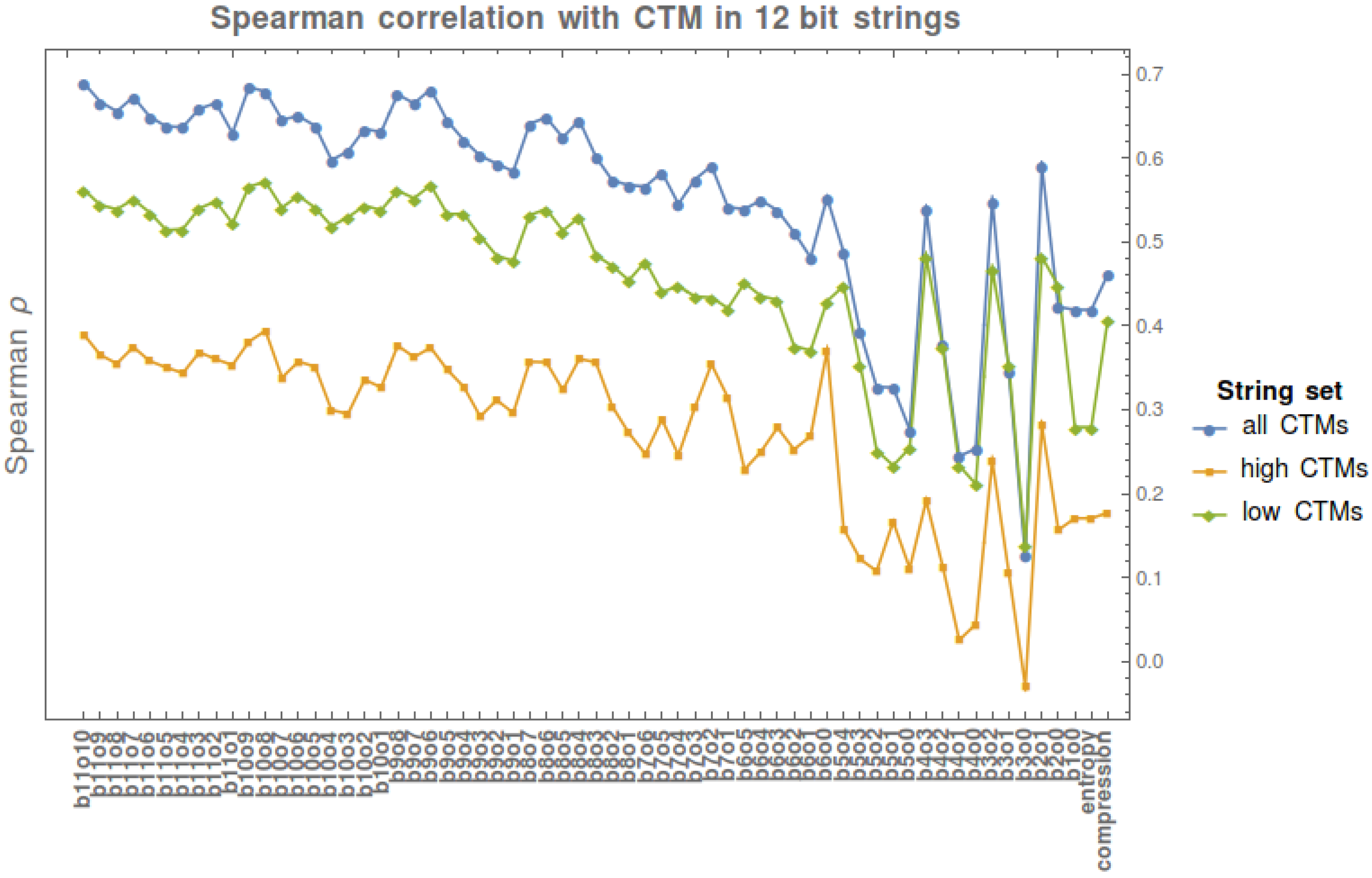{kind=link}
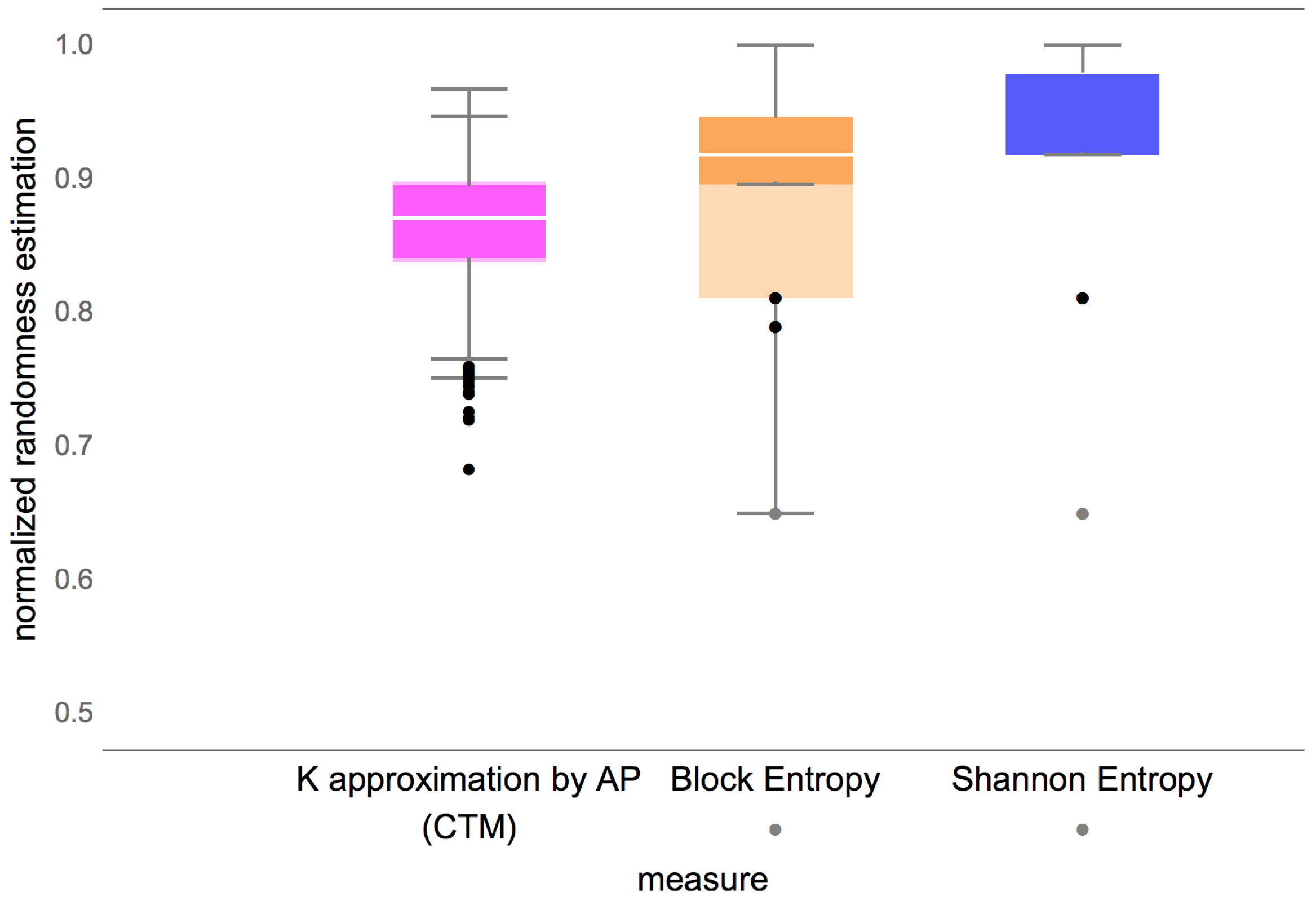{kind=link}
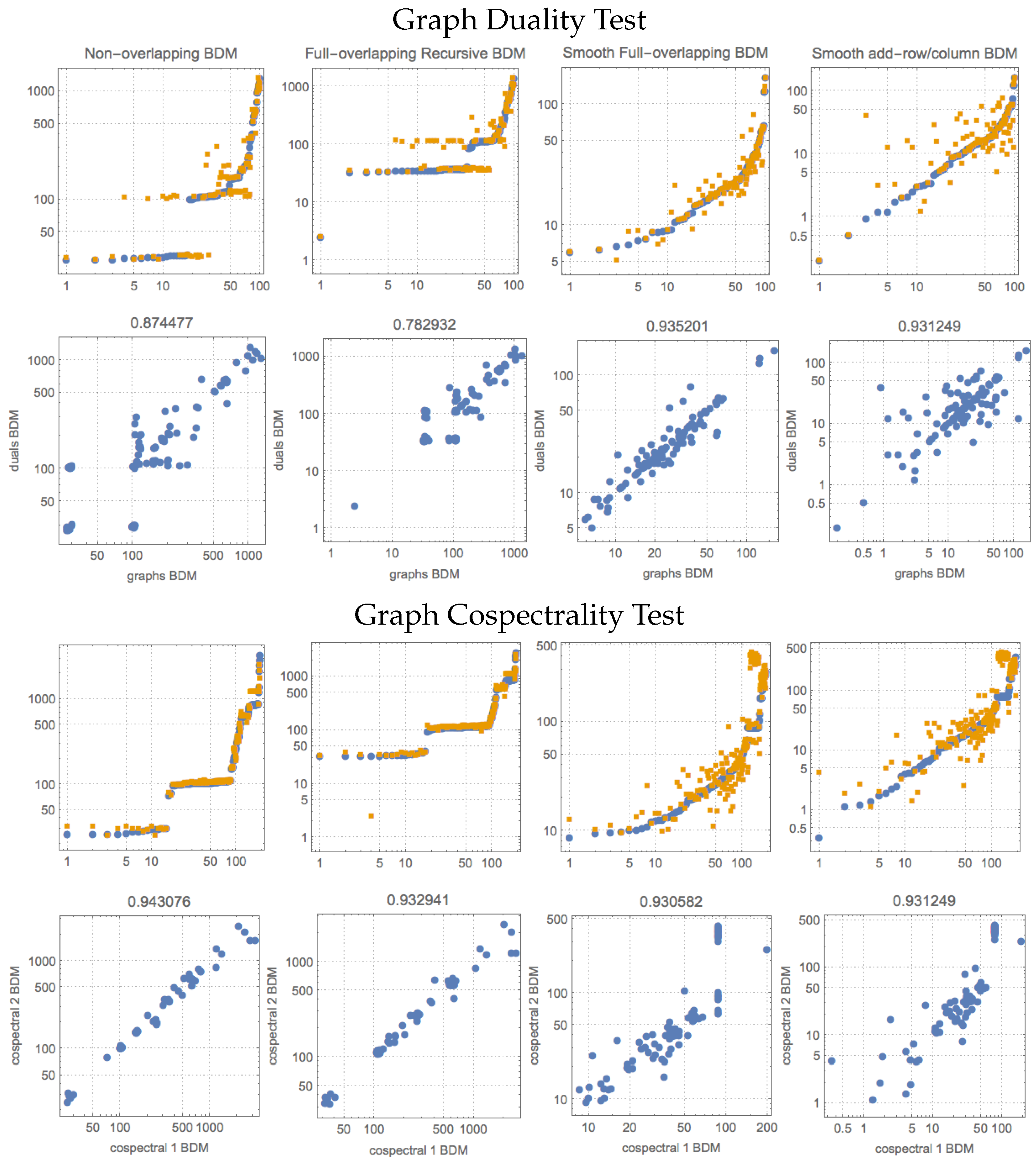{kind=link}
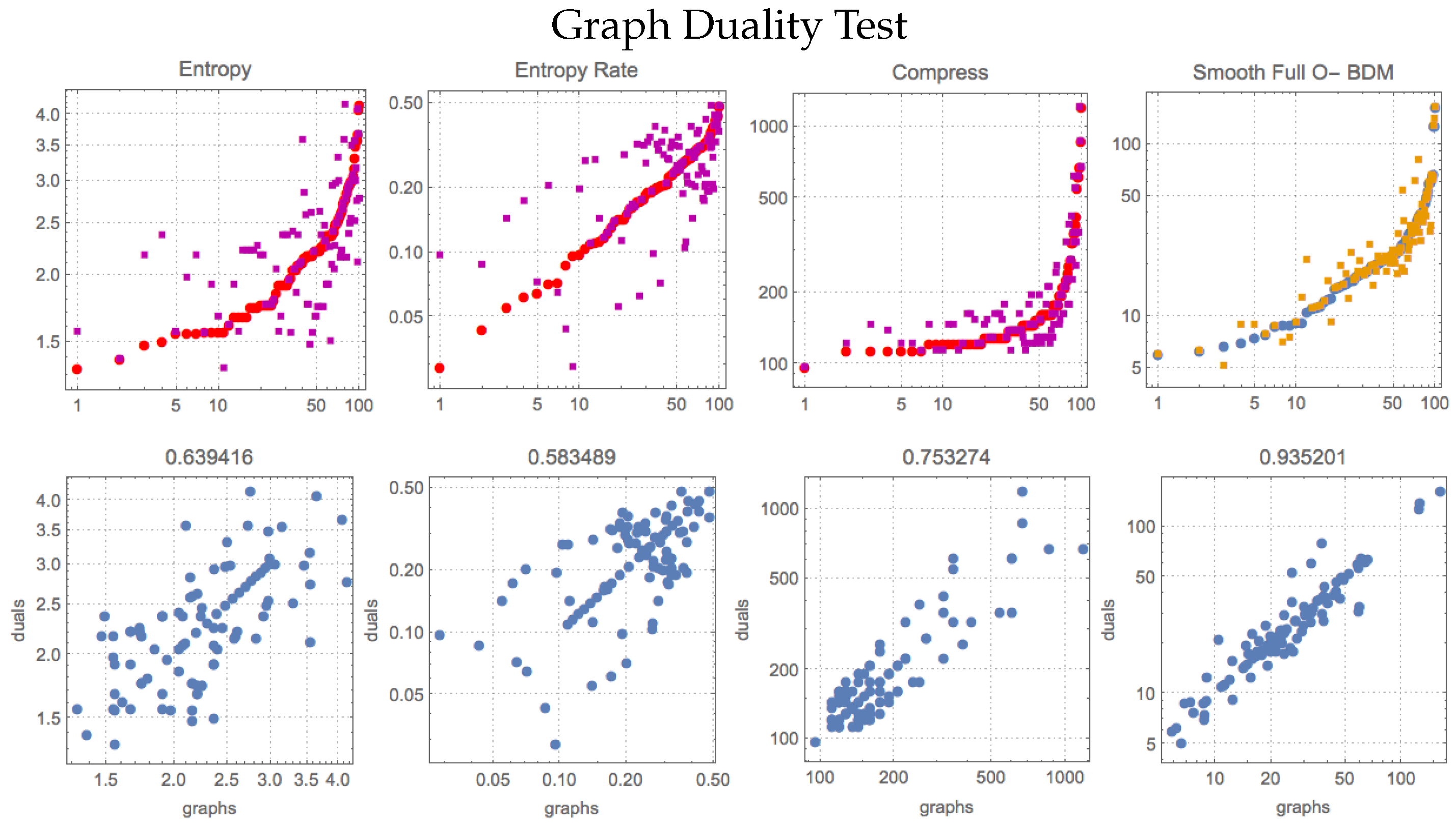{kind=link}
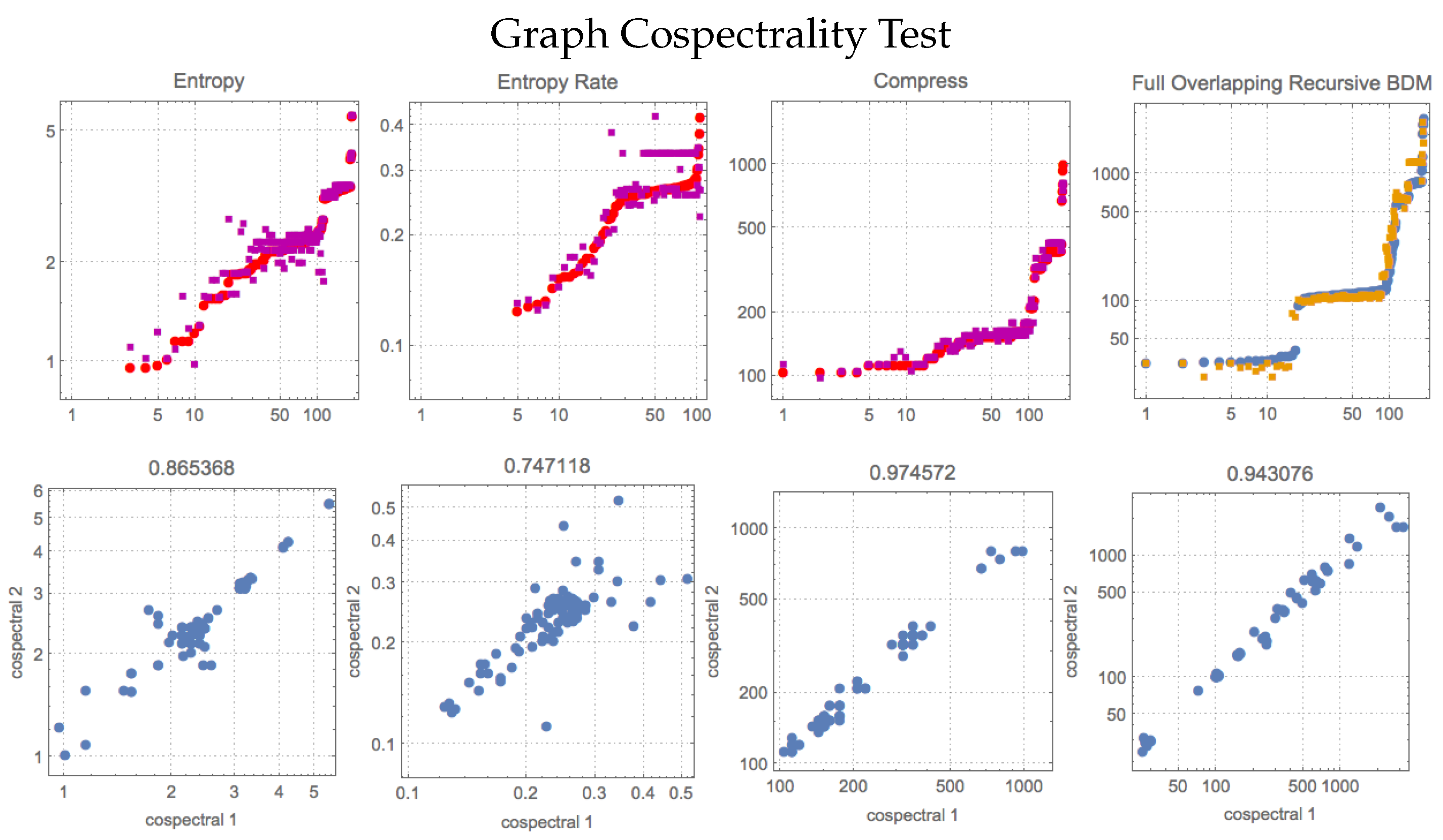{kind=link}
{kind=link}














