1. Introduction
Bayesian networks (BN) represent, in an efficient and accurate way, the joint probability of a set of random variables [
1]. Dynamic Bayesian networks (DBN) are the dynamic counterpart of BNs and model stochastic processes [
2]. DBNs consist of a prior network, representing the distribution over the initial attributes, and a set of transition networks, representing the transition distribution between attributes over time. They are used in a large variety of applications such as protein sequencing [
3], speech recognition [
4] and clinical forecasting [
5].
The problem of learning a BN given data consists in finding the network that best fits the data. In a score-based approach, a scoring criterion is considered, which measured how well the network fits the data [
6,
7,
8,
9,
10]. In this case, learning a BN reduces to the problem of finding the network that maximizes the score, given the data. Methods for learning DBNs are simple extensions of those considered for BNs [
2]. Not taking into account the acyclicity constraints, it was proved that learning BNs does not have to be NP-hard [
11]. This result can be applied to DBNs, not considering the intra-slice connections, as the resulting unrolled graph, which contains a copy of each attribute in each time slice, is acyclic. Profiting from this result, a polynomial-time algorithm for learning optimal DBN was proposed using the Mutual Information Tests (MIT) [
12]. However, none of these algorithms learns general
mth-order Markov DBNs such that each transition network has inter- and intra-slice connections. More recently, a polynomial-time algorithm was proposed that learns both the inter- and intra-slice connections in a transition network [
13]. The search space considered, however, is restricted to the tree-augmented network structures, resulting in the so-called tDBN.
By looking into lower-bound complexity results for learning BNs, it is known that learning tree-like structures is polynomial [
14]. However, learning 2-polytrees is already NP-hard [
15]. Learning efficiently structures richer than branchings (a.k.a. tree-like structures) has eluded the community, that resorted to use heuristic approaches. Carvalho et al. [
16] suggested to search over graphs consistent with the topological order of an optimal branching. The advantage of this approach is that the search space increased exponentially with respect to branchings, while keeping the learning complexity in polynomial time. Later, the breadth-first search (BFS) order of an optimal branching was also considered [
17], further improving the previous results in terms of search space.
In this paper, we propose a generalization of the tDBN algorithm, considering DBNs such that each transition network is consistent with the order induced by the BFS order of the optimal branching of the tDBN network, that we call bcDBN. Furthermore, we prove that the search space increases exponentially, in the number of attributes, comparing with the tDBN algorithm, while running in polynomial time.
We start by reviewing the basic concepts of Bayesian networks, dynamic Bayesian networks and their learning algorithms. Then, we present the proposed algorithm and the experimental results. The paper concludes with a brief discussion and directions for future work.
2. Bayesian Networks
Let
X denote a discrete random variable that takes values over a finite set
. Furthermore, let
represent an
n-dimensional random vector, where each
takes values in
, and
denotes the probability that
takes the value
. A Bayesian network encodes the joint probability distribution of a set of
n random variables
[
1].
Definition 1 (Bayesian Network).
A n-dimensional Bayesian Network (BN) is a triple , where:
and each random variable takes values in the set , where denotes the k-th value takes.
is a directed acyclic graph (DAG) with nodes in and edges E representing direct dependencies between the nodes.
encodes the parameters of the network G, a.k.a. conditional probability tables (CPT):where denotes the set of parents of in the network G and is the j-th configuration of , among all possible configurations given by , with denoting the total number of parent configurations.
A BN
B induces a unique joint probability distribution over
given by:
Let
be the number of instances in data set
D of size
N, where variable
takes the value
and the set of parents
takes the configuration
. Denote the number of instances in
D where the set of parents
takes the configuration
by
Observe that,
for
and
.
Intuitively, the graph of a BN can be viewed as a network structure that provides the skeleton for representing the joint probability compactly in a factorized way, and making inferences in the probabilistic graphical model provides the mechanism for gluing all these components back together in a probabilistic coherent manner [
18].
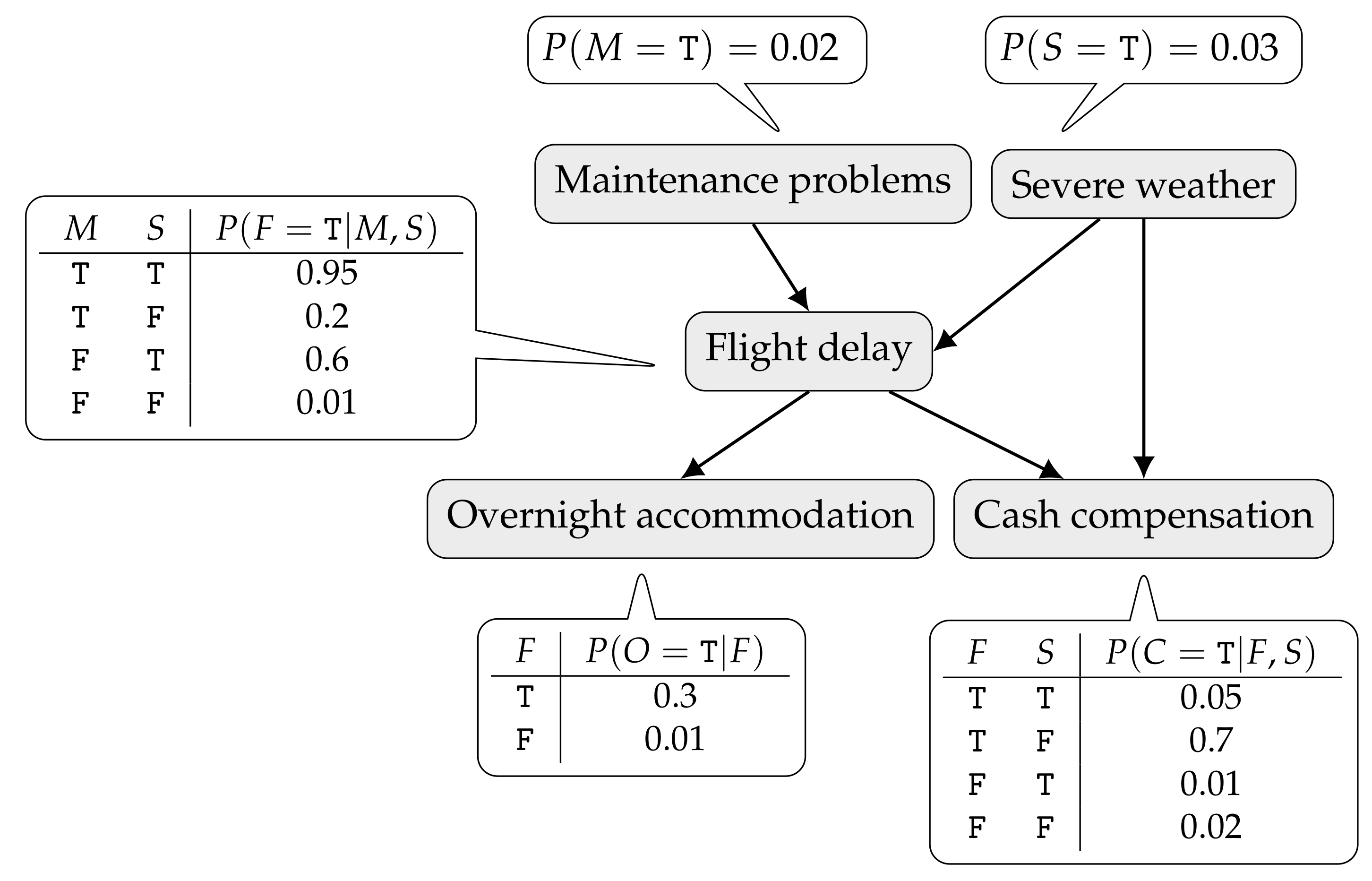
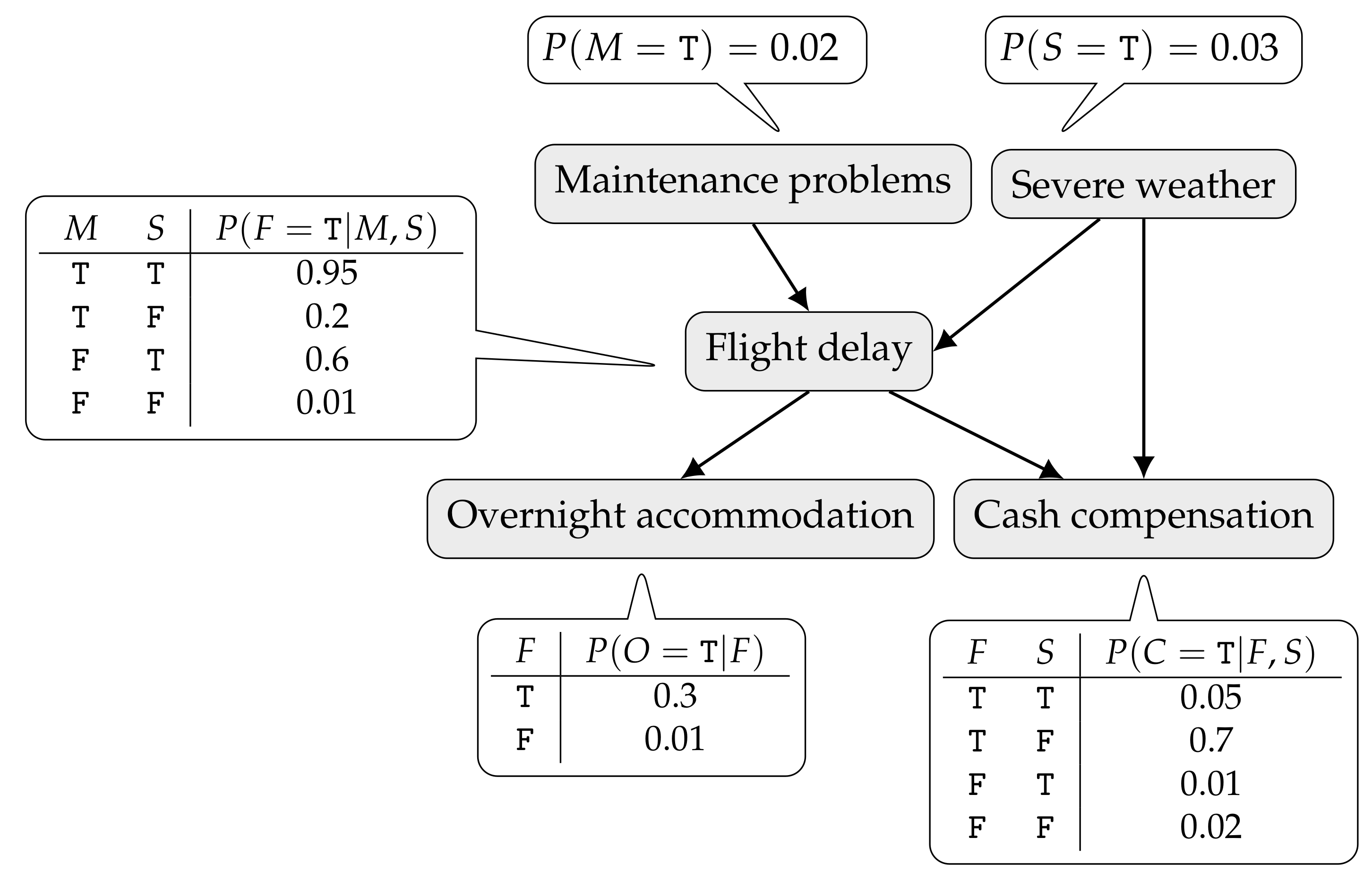
An example of a BN is depicted in
Figure 1. It describes cash compensation and overnight accommodation to air passengers in the event of long flight delays. A flight may be delayed due to aircraft maintenance problems or severe weather (hurricane, blizzard, etc.). Whenever the delay is not caused by an external event to the airline company, a passenger may be entitled to a monetary compensation. Regardless of the cause, if the delay is long enough, the passenger might be offered an overnight accommodation. As a result of the dependences encoded by the graph, the joint probability distribution of the network can be factored as
where only the first letter of a variable name is used:
M—Maintenance problems;
S—Severe weather;
F—Flight delay;
O—Overnight accommodation; and
C—Cash compensation. In this simple example, all variables are Bernoulli (ranging over
T and
F). Inside the callouts only the CPTs for variables taking the value
T are given.
3. Learning Bayesian Networks
Learning a Bayesian network is two-fold: parameter learning and structure learning. When learning the parameters, we assume the underlying graph
G is given, and our goal is to estimate the set of parameters of the network
. When learning the structure, the goal is to find a structure
G, given only the training data. We assume data is complete, i.e., each instance is fully observed, there are no missing values nor hidden variables, and the training set
is given by a set of
N i.i.d. instances. Using general results of the maximum likelihood estimate in a multinomial distribution we get the following estimate for the parameters of a BN
B:
that is denoted by observed frequency estimate (OFE).
In score-based learning, a scoring function
is required to measure how well a BN
B fits the data
D (where
denotes the search space). In this case, the learning procedure can be extremely efficient if the employed score is decomposable. A scoring function
is said to be decomposable if the score can be expressed as a sum of local scores that depends only on each node and its parents, that is, in the form:
Well-known decomposable scores are divided in two classes: Bayesian and information-theoretical. Herein, we focus only on two information-theoretical criteria, namely Log-Likelihood (LL) and Minimum Description Length (MDL) [
19]. Information-theoretical scores are based on the compression achieved to describe the data, given an optimal code induced by a probability distribution encoded by a BN.
This criterion favours complete network structures, and does not generalize well, leading to the overfitting of the model to the training data. The MDL criterion, proposed by Rissanen [
19], imposes that the parameters of the model, ignored in the LL score, must also be accounted. The MDL score for learning BNs is defined by:
where
corresponds to the number of parameters
of the network, given by:
The penalty introduced by MDL creates a trade off between fitness and model complexity, providing a model selection criterion robust to overfitting.
The structure learning reduces to an optimization problem: given a scoring function, a data set, a search space and a search procedure, find the network that maximizes this score. Denote the set of BNs with n random variables by .
Definition 2 (Learning a Bayesian Network).
Given a data and a scoring function ϕ, the problem of learning a Bayesian network is to find a Bayesian network that maximizes the value .
The space of all Bayesian networks with
n nodes has a superexponential number of structures,
. Learning general Bayesian networks is a NP-hard problem [
20,
21,
22]. However, if we restrict the search space
to tree-like structures [
14,
23] or to networks with bounded in-degree and a known ordering over the variables [
24], it is possible to obtain a global optimal solution for this problem. Polynomial-time algorithms to learn BNs with underlying consistent
k-graphs (C
kG) [
16] and breadth-first search consistent
k-graphs (BC
kG) [
17] network structures were proposed. The sets of C
kG and BC
kG graphs are exponentially larger, in the number of variables, when compared with branchings [
16,
17].
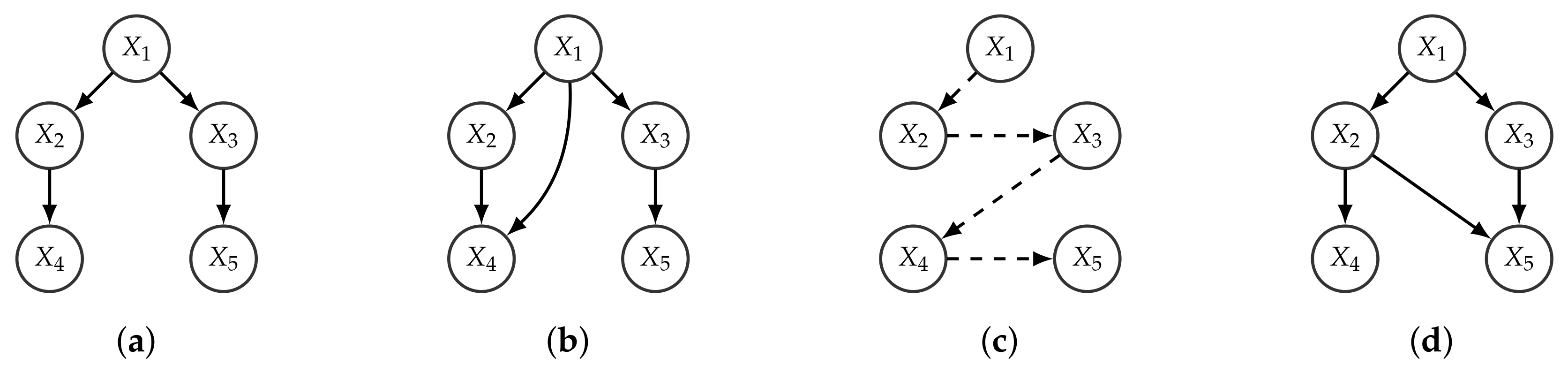
Definition 3 (
k-graph).
A k-graph is a graph where each node has in-degree at most k.
Definition 4 (Consistent
k-graph).
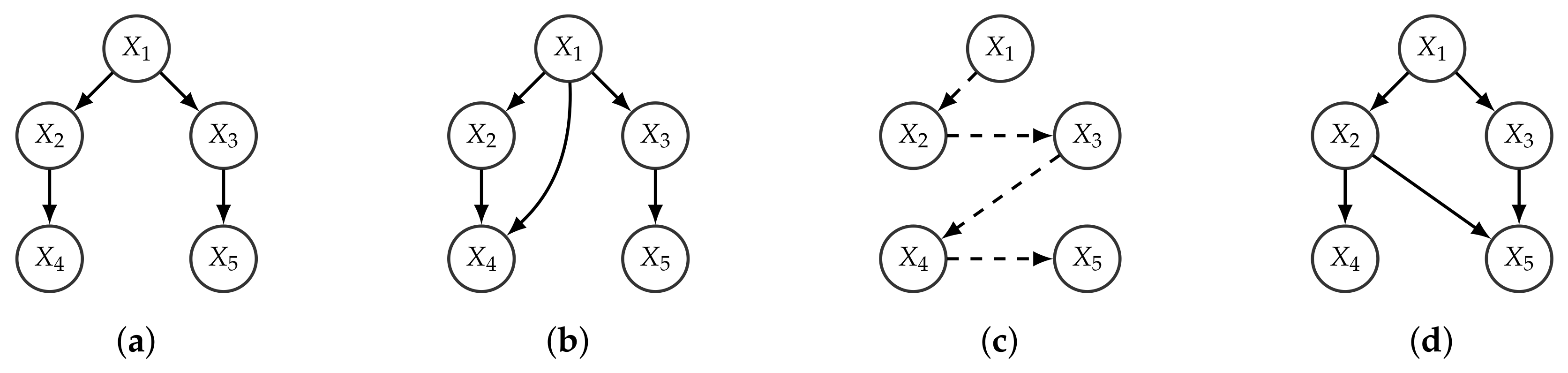
Given a branching R over a set of nodes V, a graph is said to be a consistent k-graph (CkG) w.r.t. R if it is a k-graph and for any edge in E from to the node is in the path from the root of R to .
Definition 5 (BFS-consistent
k-graph).
Given a branching R over a set of nodes V, a graph is said to be a BFS-consistent k-graph (BCkG) w.r.t. R if it is a k-graph and for any edge in E from to the node is visited in breadth-first search (BFS) of R before .
Observe that the order induced by the optimal branching might be partial, while its BFS order is always total (and refines it). Given a BFS-consistent
k-graph, there can only exist an edge from
to
if
is less than or as deep as
in
R. We assume that if
and
and
are at the same level, then the BFS over
R reaches
before
. An example is given in
Figure 2.
4. Dynamic Bayesian Networks
Dynamic Bayesian networks (DBN) model the stochastic evolution of a set of random variables over time [
2]. Consider the discretization of time in time slices given by the set
. Let
be a random vector that denotes the value of the set of attributes at time
t. Furthermore, let
denote the set of random variables
for the interval
. Consider a set of individuals
measured over
T sequential instants of time. The set of observations is represented as
, where
is a single observation of
n attributes, measured at time
t and referring to individual
h.
In the setting of DBNs the goal is to define a probability joint distribution over all possible trajectories, i.e., possible values for each attribute and instant t, . Let denote the joint probability distribution over the trajectory of the process from to . The space of possible trajectories is very large, therefore in order to define a tractable problem it is necessary to make assumptions and simplifications.
Observations are viewed as i.i.d. samples of a sequence of probability distributions
. For all individuals
, and a fixed time
t, the probability distribution is considered constant, i.e.,
. Using the chain rule the joint probability over
is given by:
Definition 6 (
mth-Order Markov assumption).
A stochastic process over satisfies the mth-order Markov assumption if, for all In this case m is called the Markov lag of the process.
If all conditional probabilities in Equation (
7) are invariant to shifts in time, that is, are the same for all
, then the stochastic process is called a stationary
mth-order Markov process.
Definition 7 (First-order Markov DBN).
A non-stationary first-order Markov DBN consists of:
A prior network , which specifies a distribution over the initial states .
A set of transition networks over the variables , representing the state transition probabilities, for .
We denote by the subgraph of with nodes , that contains only the intra-slice dependencies. The transition network has the additional constraint that edges between slices (inter-slice connections) must flow forward in time. Observe that in the case of a first-order DBN a transition network encodes the inter-slice dependencies (from time transitions ) and intra-slice dependencies (in the time slice ).
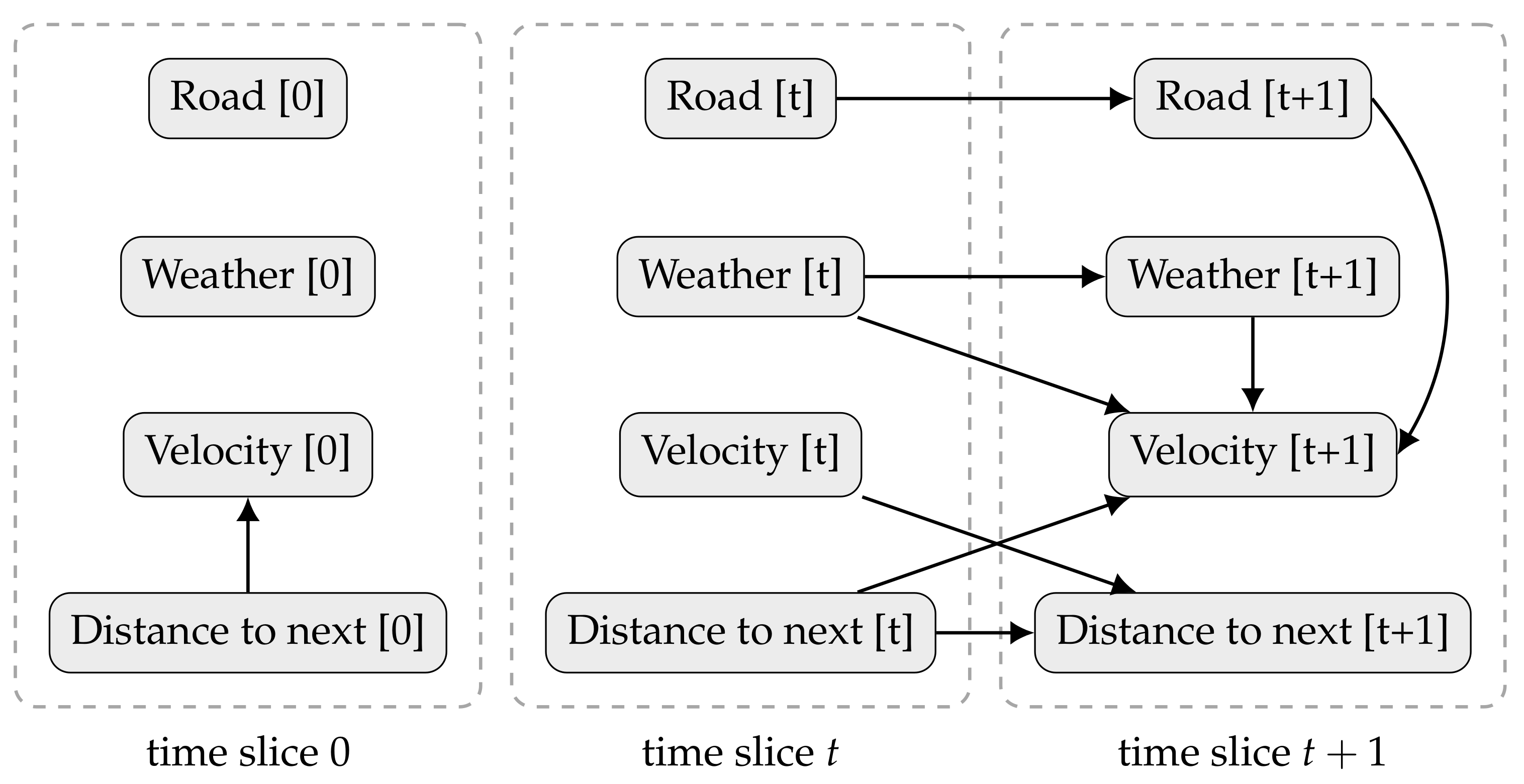
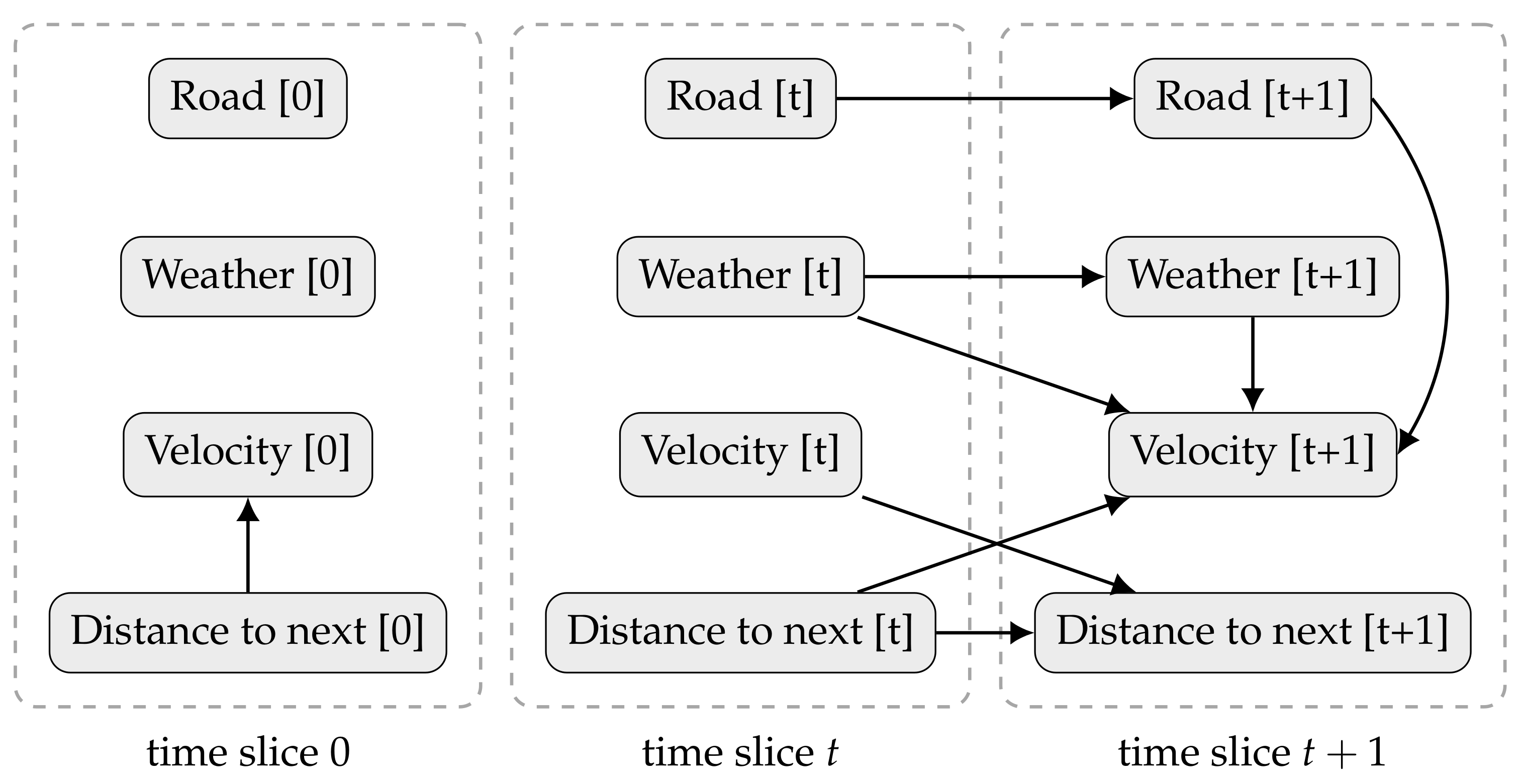
Figure 3 shows an example of a DBN, aiming to infer a driver behaviour. The model describes the state of a car, including its velocity and distance to the following vehicle, as well as, the weather and the type of road (highway, arterial, local road, etc.). In the beginning, the speed depends only if there is a car nearby. After that, the velocity depends on: (i) the previous weather (the road might be icy because it snowed last night); (ii) the current weather (it might be raining now); (iii) how close the car was from another (if it gets too close the driver might need to break); and (iv) the current type of road (with different velocity limits). The current distance to the following car depends on the previous car velocity and on the previous distance to the next vehicle.
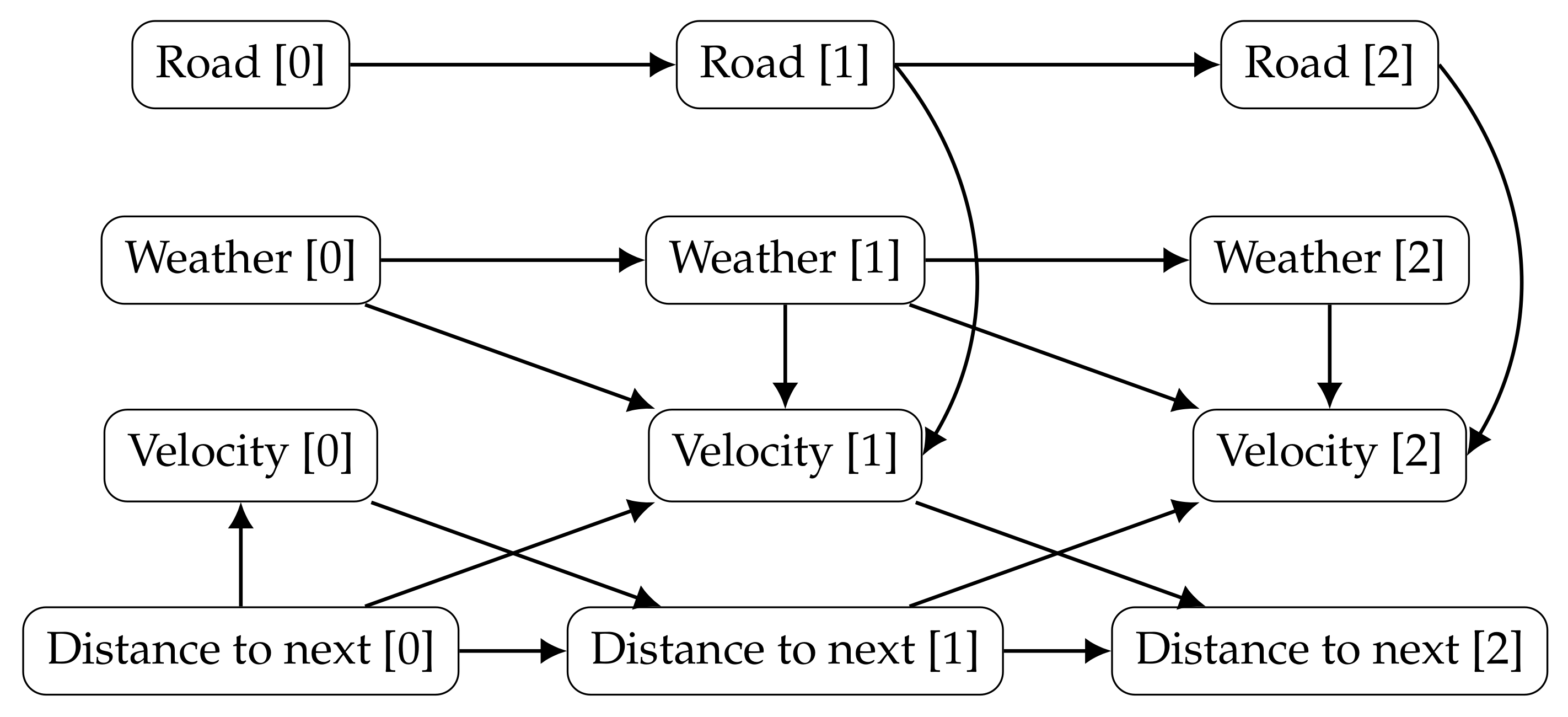
Figure 4 joins the prior and transition networks and extends the unrolled DBN to a third time slice.
Learning DBNs, considering no hidden variables or missing values, i.e., considering a fully observable process, reduces simply to applying the methods described for BNs for each transition of time [
25]. Several algorithms for learning DBNs are concerned with identifying inter-slice connections only, disregarding intra-slice dependencies or assuming they are given by some prior network and kept fixed over time [
11,
12,
26]. Recently, a polynomial-time algorithm was proposed that learns both the inter and intra-slice connections in a transition network [
13]. However, the search space is restricted to tree-augmented network structures (tDBN), i.e., acyclic networks such that each attribute has one parent from the same time slice, but can have at most
p parents from the previous time slices.
Definition 8 (Tree-augmented DBN).
A dynamic Bayesian network is called tree-augmented (tDBN) if for each transition network each attribute has exactly one parent in the time slice , except the root, and at most p parents from the preceding time slices .
5. Learning Consistent Dynamic Bayesian Networks
We introduce a polynomial-time algorithm for learning DBNs such that: the intra-slice network has in-degree at most k and is consistent with the BFS order of the tDBN; the inter-slice network has in-degree of at most p. The main idea of this approach is to add dependencies that were lost due to the tree-augmented restriction of the tDBN and, furthermore, remove irrelevant ones that might be present because a connected graph was imposed. Moreover, we also consider the BFS order of the intra-slice network as an heuristic for a causality order between variables. We make this concept rigorous with the following definition.
Definition 9 (BFS-consistent
k-graph DBN).
A dynamic Bayesian network is called BFS-consistent k-graph (bcDBN) if for each intra-slice network , with , the following holds:
is a k-graph, i.e., each node has in-degree at most k;
Given an optimal branching over the set of nodes , for every edge in from to , the node is visited in the BFS of before .
Moreover, each node has at most p parents from previous time slices.
Before we present the learning algorithm, we need to introduce some notation, namely, the concept of ancestors of a node.
Definition 10 (Ancestors of a node).
The ancestors of a node in time slice , denoted by , are the set of nodes in slice connecting the root of the BFS of an optimal branching and .
We will now describe briefly the proposed algorithm for learning a transition network of a
mth-order bcDBN. Let
be the set of subsets of
of cardinality less than or equal to
p. For each node
, the optimal set of past parents (
) and maximum score (
) is found,
where
is the local contribution of
for the overall score
and
is the subset of observations concerning the time transition
. For each possible edge in
,
, the optimal set of past parents and maximum score (
) is determined,
We note that the set
that maximizes Equations (
8) and (
9) needs not to be the same. The one in Equation (
8) refers to the best set of
p parents from past time slices, and the one in Equation (
9) concerns the best set of
p parents from the past time slices when
is also a parent of
.
A complete directed graph is built such that each edge
has the following weight,
that is, the gain in the network score of adding
as a parent of
. Generally
, as the edge
may account for the contribution from the inter-slice parents and, in general, inter-slice parents of
and
are not the same. Therefore, Edmond’s algorithm is applied to obtain a maximum branching for the intra-slice network [
27]. In order to obtain a total order, the BFS order of the output maximum branching is determined and the set of candidate ancestors
is computed. For node
, the optimal set of past parents
and intra-slice parents, denoted by
, are obtained in a one-step procedure by finding
where
is the set of all subsets of
of cardinality less than or equal to
k. Note that, if
is the root,
, so the set of intra-slice parents
of
is always empty.
The pseudo-code of the proposed algorithm is given in Algorithm 1. As parameters, the algorithm needs: a dataset D, a Markov lag m, a decomposable scoring function , a maximum number of inter-slice parents p and a maximum number of intra-slice parents k.
| Algorithm 1 Learning optimal mth-order Markov bcDBN |
- 1:
for each transition do - 2:
Build a complete directed graph in . - 3:
Weight all edges of the graph with as in Equation ( 10) (Algorithm 2). - 4:
Apply Edmond’s algorithm to the intra-slice network, to obtain an optimal branching. - 5:
Build the BFS order of the output optimal branching. - 6:
for all nodes do - 7:
Compute the set of parents of as in Equation ( 11) (Algorithm 3). - 8:
end for - 9:
end for - 10:
Collect the transition networks to obtain the optimal bcDBN structure.
|
The algorithm starts by building the complete directed graph in Step 2, after which the graph is weighted according to Equation (
10); this procedure is described in detail in Algorithm 2. The Edmonds’ algorithm is then applied to the intra-slice network, resulting from that an optimal branching (Step 4). The BFS order of this branching is computed (Step 5) and the final transition network is redefined to be consistent with it. This is done by computing the parents of
given by Equation (
11) (Steps 6–7), further detailed in Algorithm 3.
Theorem 1. Algorithm 1 finds an optimal mth-order Markov bcDBN, given a decomposable scoring function ϕ, a set of n random variables, a maximum intra-slice network in-degree of k and a maximum inter-slice network in-degree of p.
Proof. Let B be the optimal bcDBN and be the DBN output of Algorithm 1. Consider without loss of generality the time transition . The proof follows by contradiction, assuming that the score of is lower than B. The contradiction found is the following: the optimal branching algorithm applied to the intra-slice graph, Step 4 of Algorithm 1, outputs an optimal branching; moreover, all sets of parents with cardinality of at most k consistent with the BFS order of the optimal branching and all sets of parents from the previous time slices with cardinality of at most p are checked in the for-loop at Step 6. Therefore, the optimal set of parents is found for each node. Finally, note that the selected graph is acyclic since: (i) in the intra-slice network the graph is consistent with a total order (so no cycle can occur); and (ii) in the inter-slice network there are only dependencies from previous time slices to the present one (and not on the other way). ☐
| Algorithm 2 Compute all the weights |
- 1:
for all nodes do - 2:
Let . - 3:
for do - 4:
if then - 5:
Let . - 6:
end if - 7:
end for - 8:
for all nodes do - 9:
Let . - 10:
for do - 11:
if then - 12:
Let . - 13:
end if - 14:
end for - 15:
end for - 16:
Let . - 17:
end for
|
| Algorithm 3 Compute the set of parents of |
- 1:
Let . - 2:
for do - 3:
for do - 4:
if then - 5:
Let max = . - 6:
Let the parents of be . - 7:
end if - 8:
end for - 9:
end for
|
Theorem 2. Algorithm 1 takes timegiven a decomposable scoring function ϕ, a Markov lag m, a set of n random variables, a bounded in-degree of each intra-slice transition network of k, a bounded in-degree of each inter-slice transition network of p and a set of observations of N individuals over T time steps. Proof. For each time transition
, in order to compute all weights
(Algorithm 2), it is necessary to iterate over all the edges, that takes time
. The number of subsets of parents from the preceding time slices with at most
p elements is given by:
Calculating the score of each parent set (Step 11 of Algorithm 2), considering that the maximum number of states a variable may take is r, and that each variable has at most parents (p from the past and 1 in ), the number of possible configurations is given by . The score of each configuration is computed over the set of observations , therefore taking . Applying Edmond’s optimal branching algorithm to the intra-slice network and computing its BFS order, in Steps 4 and 5, takes time. Hence, Steps 1–5 take time . Step 6 iterates over all nodes in time slice , therefore iterates times. In Algorithm 3, Step 7, the number of subsets with at most p elements from the past and k elements from the present is upper bounded by . Computing the score of each configuration takes time complexity of . Therefore Steps 6–9 take time complexity of . Algorithm 1 ranges over all time transitions, hence, takes time , . ☐
Theorem 3. There are at least non-tDBN transition networks in the set of bcDBN structures, where n is the number of variables, T is the number of time steps considered, m is the Markov lag and k is the maximum intra-slice in-degree considered.
Proof. Consider without loss of generality the time transition
and the optimal branching in
,
. Let
be the total order induced by the BFS over
. For any two nodes
and
, with
, we say that node
is lower than
if
. The
i-th node of
has precisely
lower nodes. When
, there are at least
subsets of
V with at most
k lower nodes. When
, only
subsets of
V with at most
k lower nodes exist. Therefore, there are at least
BFS-consistent
k-graphs.
Let
be the root of
and
its child node. Let ∅ denote the empty set.
and ∅ are the only possible ancestors of
. If ∅ is the optimal one, then the resultant graph will not be a tree-augmented network. Therefore there are at least
non-tree-augmented graphs in the set of BFS-consistent
k-graphs.
There are transition networks, hence, there are at least non-tDBN network structures in the set of bcDBN network structures. ☐
6. Experimental Results
We assess the merits of the proposed algorithm comparing it with one state-of-the-art DBN learning algorithm, tDBN [
13]. Our algorithm was implemented in Java using an object-oriented paradigm and was released under a free software license (
https://margaridanarsousa.github.io/learn_cDBN/). The experiments were run on an Intel
® Core™ i5-3320M CPU @ 2.60GHz×4 machine.
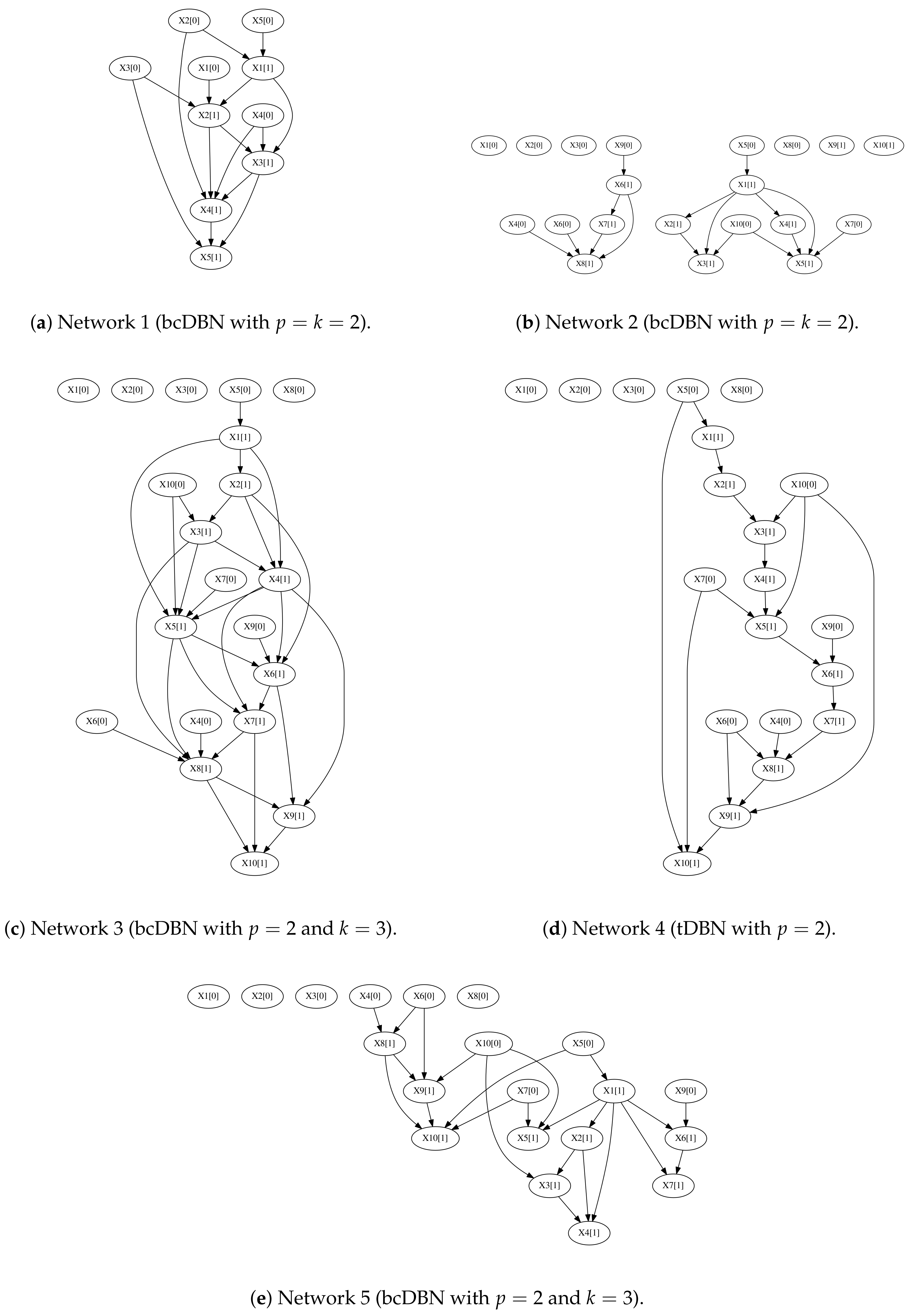
We analyze the performance of the proposed algorithm for synthetic data generated from stationary first-order Markov bcDBNs. Five bcDBN structures were determined, parameters were generated arbitrarily, and observations were sampled from the networks, for a given number of observations N. The parameters p and k were taken to be the maximum in-degree of the inter and intra-slice network, respectively, of the transition network considered.
In detail, the five first-order Markov stationary transition networks considered were:
one intra-slice complete bcDBN network with
and at most
parents from the previous time slice (
Figure 5a);
one incomplete bcDBN network, such that each node in
has a random number of inter-slice (
) and intra-slice (
) parents between 0 and
(
Figure 5b);
two incomplete intra-slice bcDBN network (
) such that each node has at most
parents from the previous time slice (
Figure 5c,e);
one tDBN (
), such that each node has at most
parents from the previous time slice (
Figure 5d).
The tDBN and bcDBN algorithms were applied to the resultant data sets, and the ability to learn and recover the original network structure was measured. We compared the original and recovered networks using the precision, recall and
metrics:
where
are the true positive edges,
are the false positive edges and
are the false negative edges.
The results are depicted in
Table 1 and the presented values are annotated with a
confidence interval, over five trials. The tDBN+LL and tDBN+MDL denote, respectively, the tDBN learning algorithm with LL and MDL criteria. Similarly, the bcDBN+LL and bcDBN+MDL denote, respectively, the bcDBN learning algorithm with LL and MDL scoring functions.
Considering Network 1, the tDBN recovers a significantly lower number of edges, giving raise to lower recalls and similar precisions, when comparing with bcDBN for LL and MDL. The bcDBN+LL and bcDBN+MDL have similar performances. For , bcDBN+LL and bcDBN+MDL are able to recover in average of the total number of edges.
For Networks 2 and 5, considering incomplete networks, the tDBN has again lower recalls and similar precisions than bcDBN. However, in this case, the bcDBN+MDL clearly outperforms bcDBN+LL for all number of instances N considered.
Moreover, in Network 5, taking a maximum intra-slice in-degree , bcDBN only recovers of the total number of edges, for . These results suggest that a considerable number of observations are necessary to fully reconstruct the complex BFS-consistent k-structures.
Curiously, the bcDBN+MDL algorithm has better results considering a complete tree-augmented initial structure (Network 4), with higher precision scores and similar recall, comparing with tDBN+MDL.
For both algorithms, in general, the LL gives raise to better results, when considering a complete network structure and a lower number of instances, whereas taking an incomplete network structure and a higher number of instances, the MDL outperforms LL. The complexity penalization term of MDL prevents the algorithms of choosing false positive edges and gives raise to higher precision scores. The LL selects more complex structures, such that each node has exactly parents.
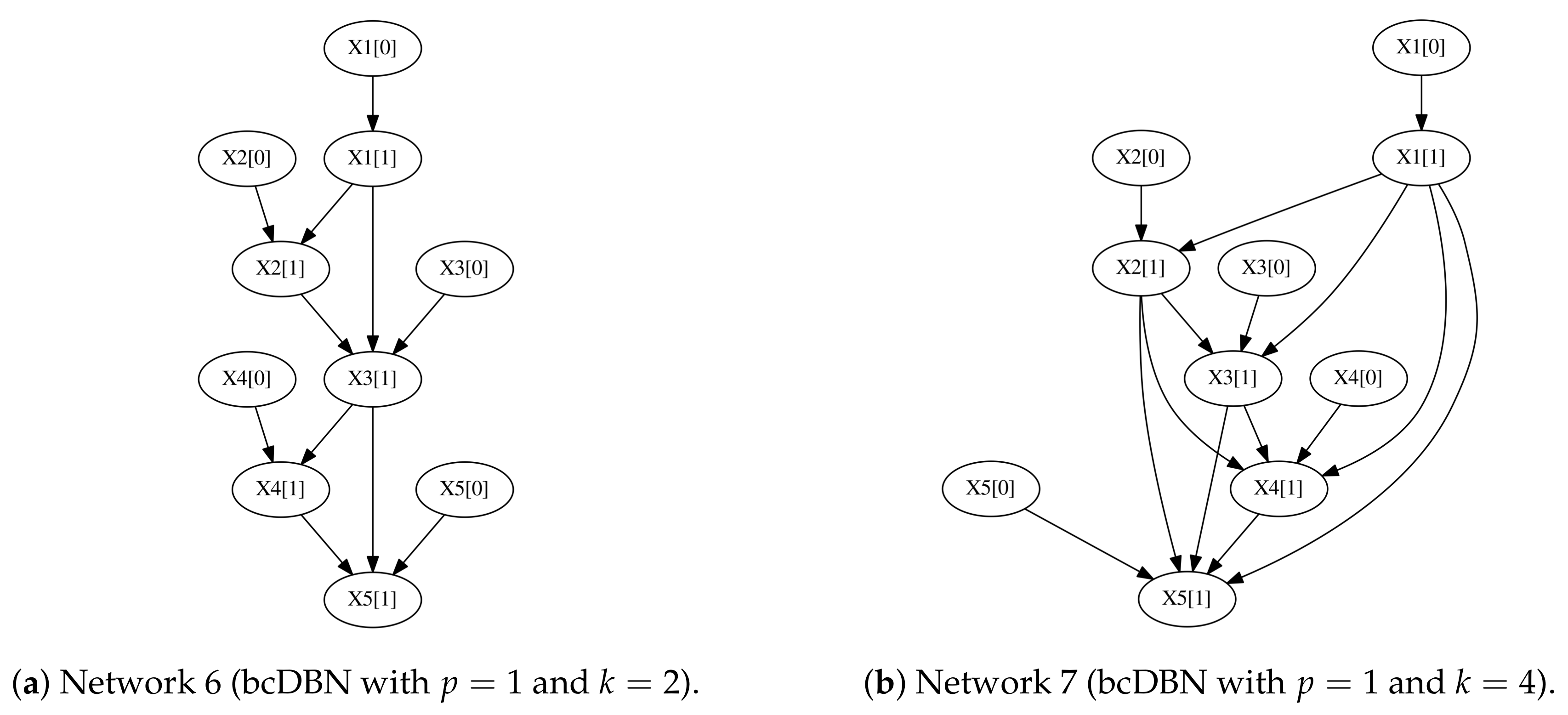
We stress that in all settings considered both algorithms improve their performance when increasing the number of observations
N. In order to understand the number of instances
N needed to fully recover the initial transition network, we designed two new experiments where five samples where generated from the first-order Markov transition networks depicted in
Figure 6.
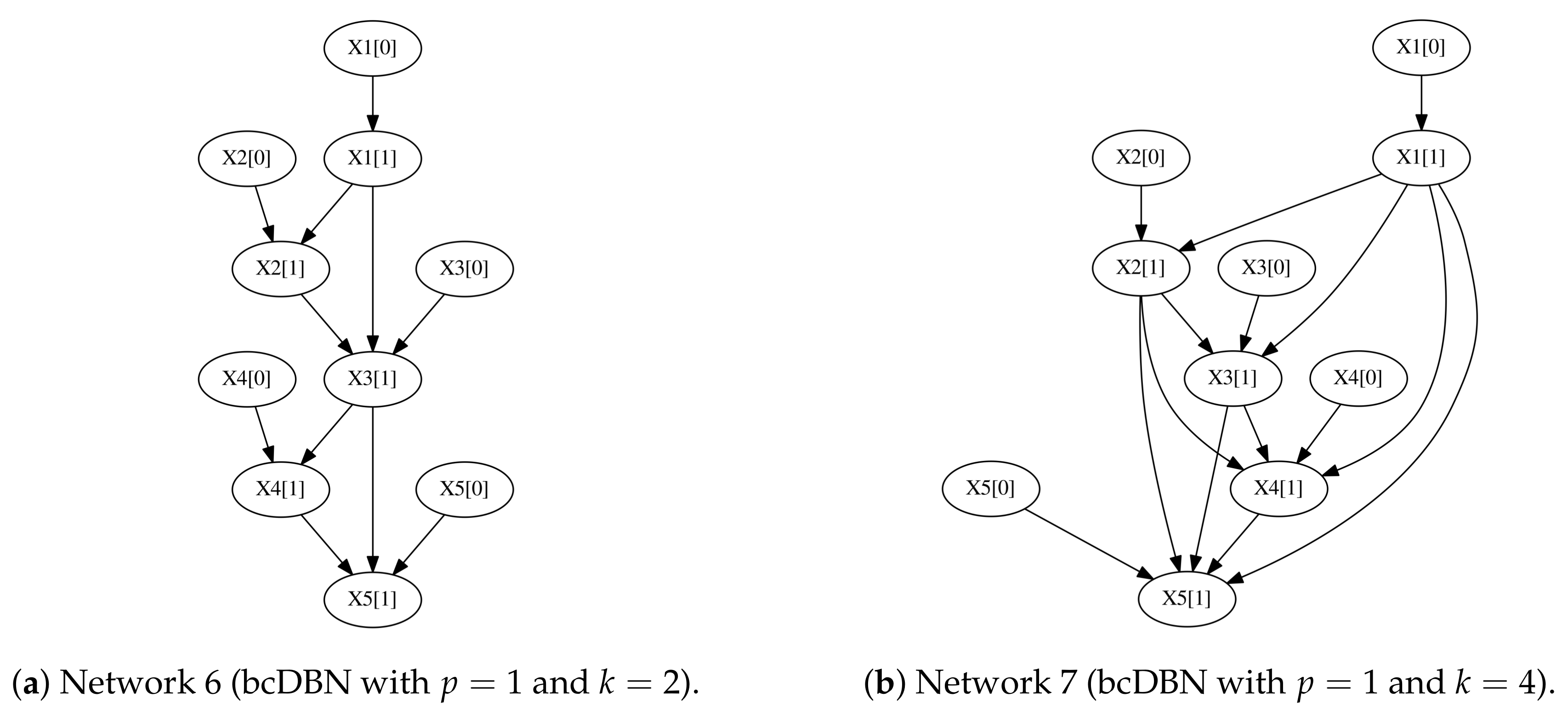
The number of observations needed for the bcDBN+MDL to recover the aforementioned networks are
(
Figure 6a) and
(
Figure 6b), with a
confidence interval, where the five trials were done for each network. When increasing
k, the number of necessary observations to totally recover the initial structure increases significantly.
When considering more complex BFS-consistent k-structures, the bcDBN algorithm achieved consistently significantly higher measures than tDBN. As expected, bcDBN+LL obtained better results for complete structures, whereas bcDBN+MDL achieved better results for incomplete structures.
7. Conclusions
The bcDBN learning algorithm has polynomial-time complexity with respect to the number of attributes and can be applied to stationary and non-stationary Markov processes. The proposed algorithm increases the search space exponentially, in the number of attributes, comparing with the state-of-the-art tDBN algorithm. When considering more complex structures, the bcDBN is a good alternative to the tDBN. Although a higher number of observations are necessary to fully recover the transition network structure, bcDBN is able to recover a significantly larger number of dependencies and surpasses, in all experiments, the tDBN algorithm in terms of -measure.
A possible line of future research is to consider hidden variables and incorporate a structural Expectation-Maximization procedure in order to generalize hidden Markov models. Another possible path to follow is to consider mixtures of bcDBNs, both for classification and clustering.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}