1. Introduction
Multiple sclerosis (MS) is a lifelong condition that always affects the brain and sometimes, but not always, the spinal cord [
1]. It may cause various potential symptoms, including visual problems [
2], spasms [
3], numbness [
4], fatigue [
5], etc. MS is typically diagnosed by the presenting symptoms, together with supporting neuroimaging methods, such as magnetic resonance imaging (MRI) to detect the damaged white matter (WM).
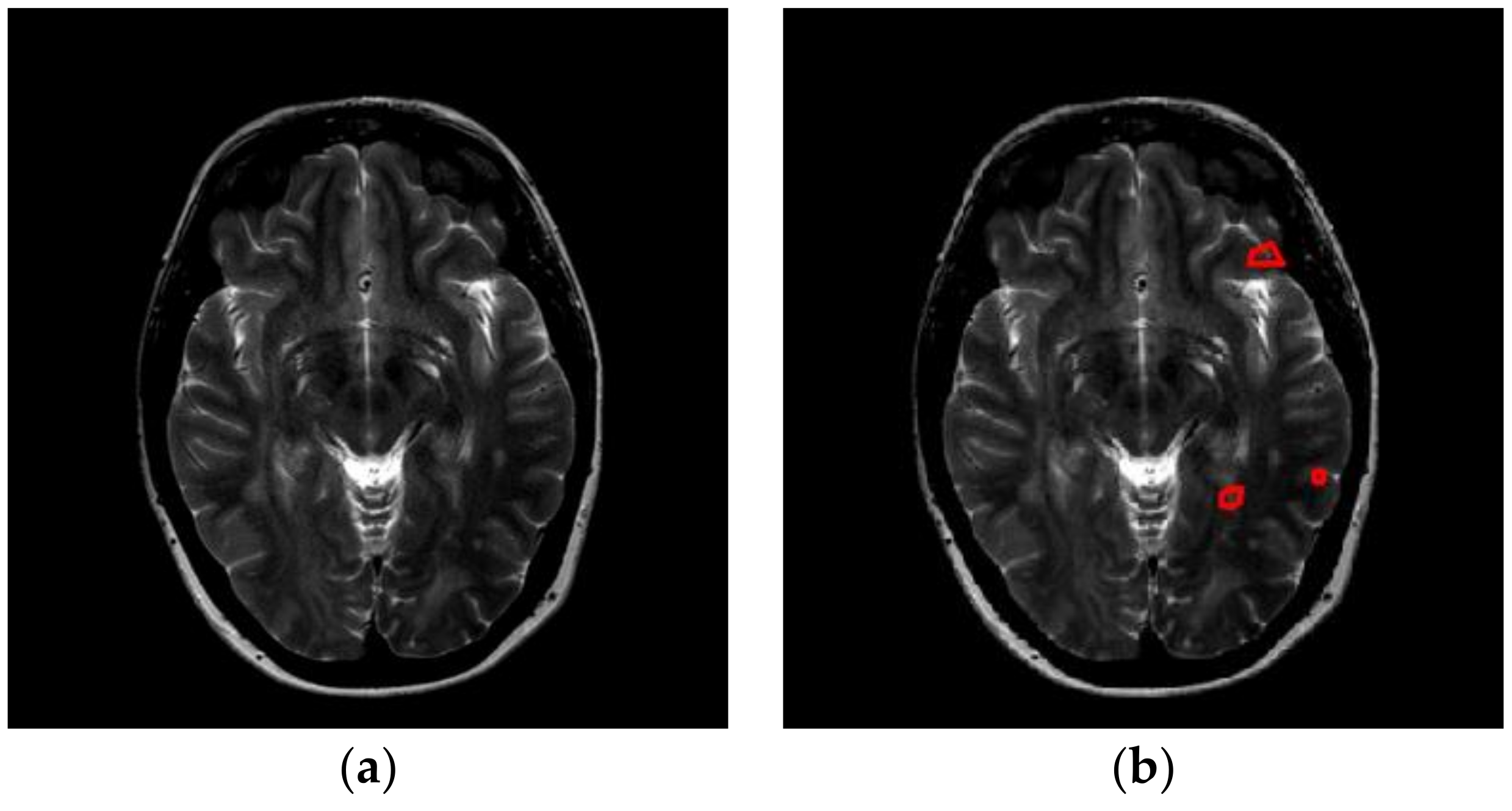
Nevertheless, MS diagnosis is difficult, since it may be confused with other white matter diseases, such as neuromyelitis optica (NMO), acute disseminated encephalomyelitis (ADEM), acute cerebral infarction (ACI), etc. For example, the spinal cord lesions in MS patients are typically oval, peripheral, and asymmetric, but in NMO patients, they are longitudinally extensive and centrally located. The mean number of involved vertebral segments in NMO patients is significantly more than that in MS patients. Furthermore, the number of spinal cord lesions in MS patients is remarkably more than in NMO.
In this study, we carried out a preliminary study that differentiates MS with healthy controls. It is a physically and mentally laborious task for neuro-radiologists to identify MS from healthy brains. As is known, computers perform better than human in terms of machine vision, since the computer machines can identify slight brightness change, and perceive slight structural change [
6,
7]. In the last decade, scholars have proposed many computer-vision based methods to identify MS from healthy brains.
For instances, Ghribi et al. [
8] proposed a segmentation method based on gray-level co-occurrence matrix (GLCM) and gray-level run length (GLRL) methods. Murray et al. [
9] presented a multiscale amplitude-modulation frequency-modulation (MAMSM) method. Nayak et al. [
10] offered a random forest (RF) approach. Lopez and co-workers [
11] employed Haar wavelet transform (HWT) and logistic regression (LR). They found three-level decomposition performed the best.
To identify MS in a more efficient and accurate way, we consider to use a relatively new feature extraction method—fractional Fourier entropy (FRFE) [
12], which combines the fractional Fourier transform (FRFT) and Shannon entropy. The reason why we used FRFE is due to its super-effectiveness for fine-grained classification. Besides, we proposed an idea of FRFE map based on different combination angles. Multilayer perceptron (MLP) was chosen as the classifier because of the universal approximation theory, which states that MLP can approximate to any function in any degree.
In addition, we proposed a modified Jaya algorithm to further train the MLP. Jaya was chosen since it does not need to set the algorithm-specific parameters. In this paper, we proposed two improvements, so this improved Jaya algorithm does not need to set population size and number of hidden neurons.
The following contents are structured as follows:
Section 2 gives the two brain imaging datasets, describes the subjects used, and introduces the inter-scan normalization and cost-sensitive learning.
Section 3 presents the methodology, including the FRFE spectrum map and our proposed Self-adaptive Three-segment-encoding Jaya algorithm.
Section 4 covers the experiments and results. Finally,
Section 5 is devoted to conclusion and future directions.
3. Methodology
3.1. Fractional Fourier Entropy
The fractional Fourier entropy (FRFE) is a relatively new feature extraction method. It combines both the fractional Fourier transform (FRFT) and Shannon entropy. It has successfully been applied to tea category identification [
17], disease detection [
18], hearing loss identification [
19].
Take one-dimensional signal as an example, assume
v(
t) is a one-dimensional signal,
t is the time domain, and
q is the frequency domain. We have the FRFT defined as:
here
Q represents the FRFT result, and
a the angle of FRFT.
is the transform kernel as:
Here represents the imaginary unit, and exp(.) represents the exponential function.
As is familiar to readers that if
a is set the value of a multiple of π, then both “csc” and “cot” operators will diverge to infinity. We can transform Equation (3) via this knowledge as:
where
represents the Dirac delta function, and
c represents an arbitrary integer.
The entropy was then performed over the fractional spectrum
Q, and we obtained the final FRFE result as:
where
F is the FRFE measure.
3.2. FRFE Map
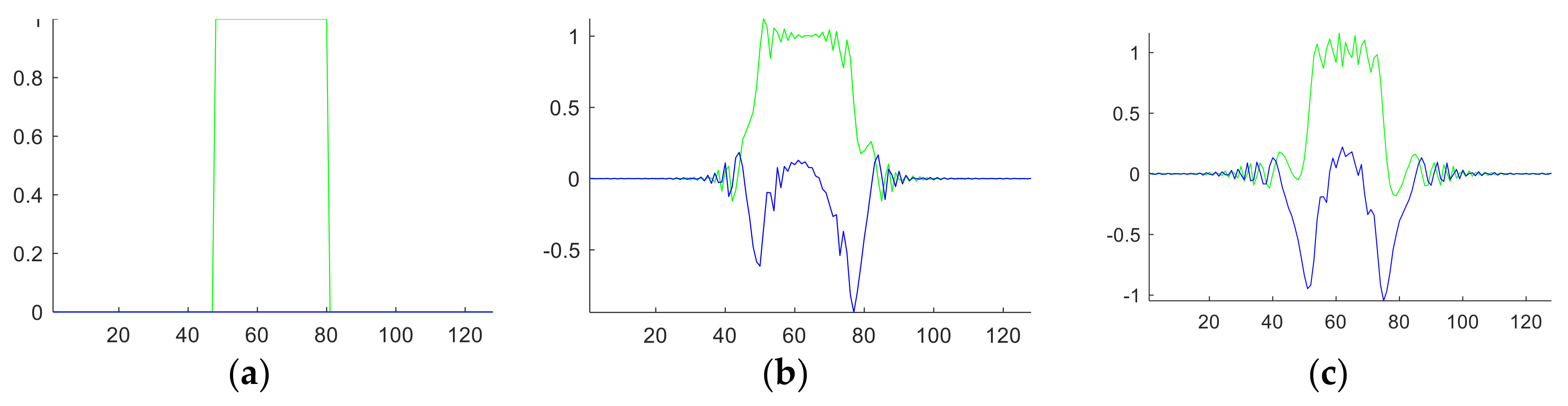
For one-dimensional signal, the angle value is scalar. For example, suppose we have a rectangular function
o(
t) defined as:
The FRFT results
Qa(
q) with
a of from 0 to 1 with increase of 0.1 are shown in
Figure 3. In this figure, the green line represents the real part, and the blue line represents the imaginary part of the FRFT results.
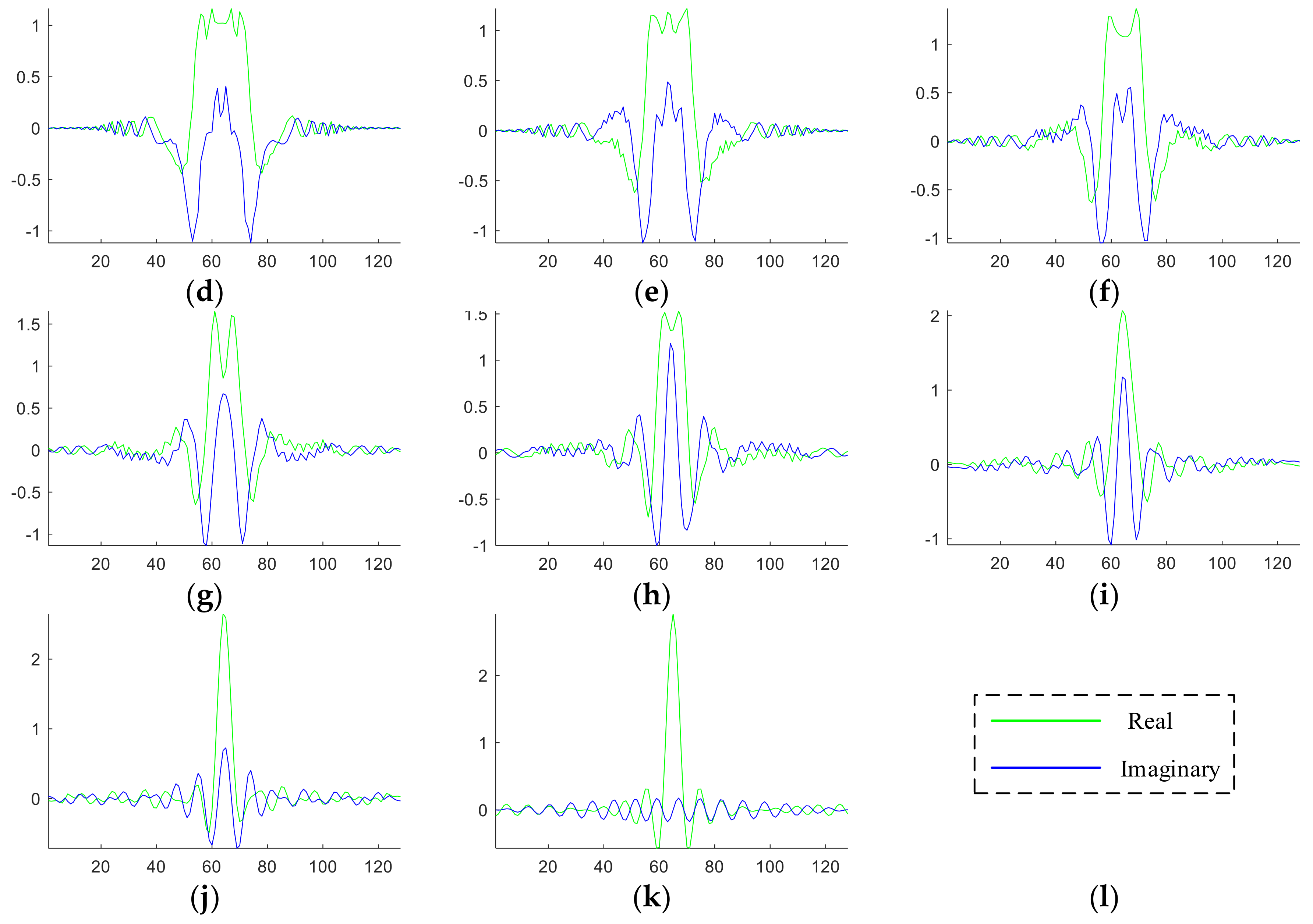
When the signal comes to the 2D situation, the angle
a is now a two-element vector
a = (
a1,
a2). This angle vector served as rotation angle for a 2D image when performing 2D-FRFT. To balance the computation complexity and classification accuracy, we finally selected a grid map as shown in
Figure 4. Here we chose 36 vector-angles. For each dimension, the value varies from 0 to 1 with increase of 0.2, and hence we have six values for one dimension. After combination, we have altogether 36 vector-angles, viz., (0, 0), (0, 0.2), …, (0, 1), (0.2, 0), (0.2, 0.2), …, (0.2, 1), …, (1, 0), (1, 0.2), …, (1, 1). The pseudo-codes of 2D-FRFE were presented in Algorithm 1.
| Algorithm 1. Pseudocode of 2D FRFE |
 |
3.3. Multilayer Perceptron
A multilayer perceptron (MLP) is a type of two-layer feedforward neural network mapping input training to target labels [
20]. The accuracy of MLP can be guaranteed by universal approximation theorem. MLP is a kind of shallow network. The reason why we do not use deep neural network is Occam’s razor [
21]. Another reason is our dataset is comparatively smaller than those million-image datasets used in deep learning. The small number of images may impair the convergence of deep neural network.
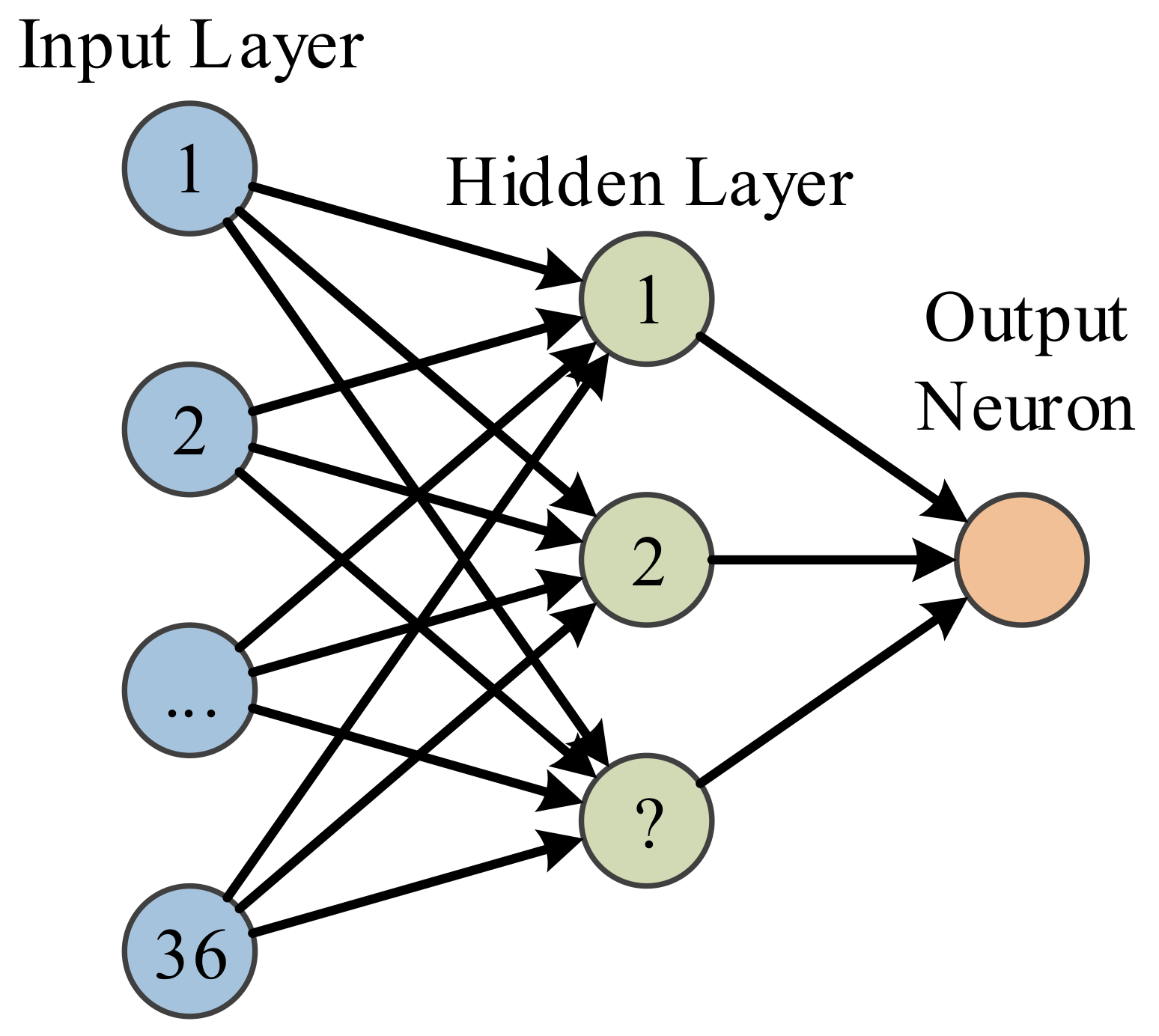
MLP with structure shown in
Figure 5 just shows this is a two-layer feedforward neural network, the output neuron is not a layer since it is not associated with weights. The input layer has 36 neurons linked to the 36 features extracted by FRFE. The number of hidden layer is a parameter to be optimized. The one output neuron shall output value either 1 or 0, indicating MS or healthy brain.
3.4. Jaya Algorithm
Current training methods of MLP include back propagation gradient descent and its variants. The gradient descent may be trapped into local minimum and saddle points. Hence, bioinspired methods were developed to train MLP, such as genetic algorithm [
22], particle swarm optimization (PSO) [
23], dynamic PSO (dPSO) [
24], and biogeography-based optimization [
25]. Nevertheless, those algorithms suffer from a main problem: how to set the hyperparameters of the algorithms themselves?
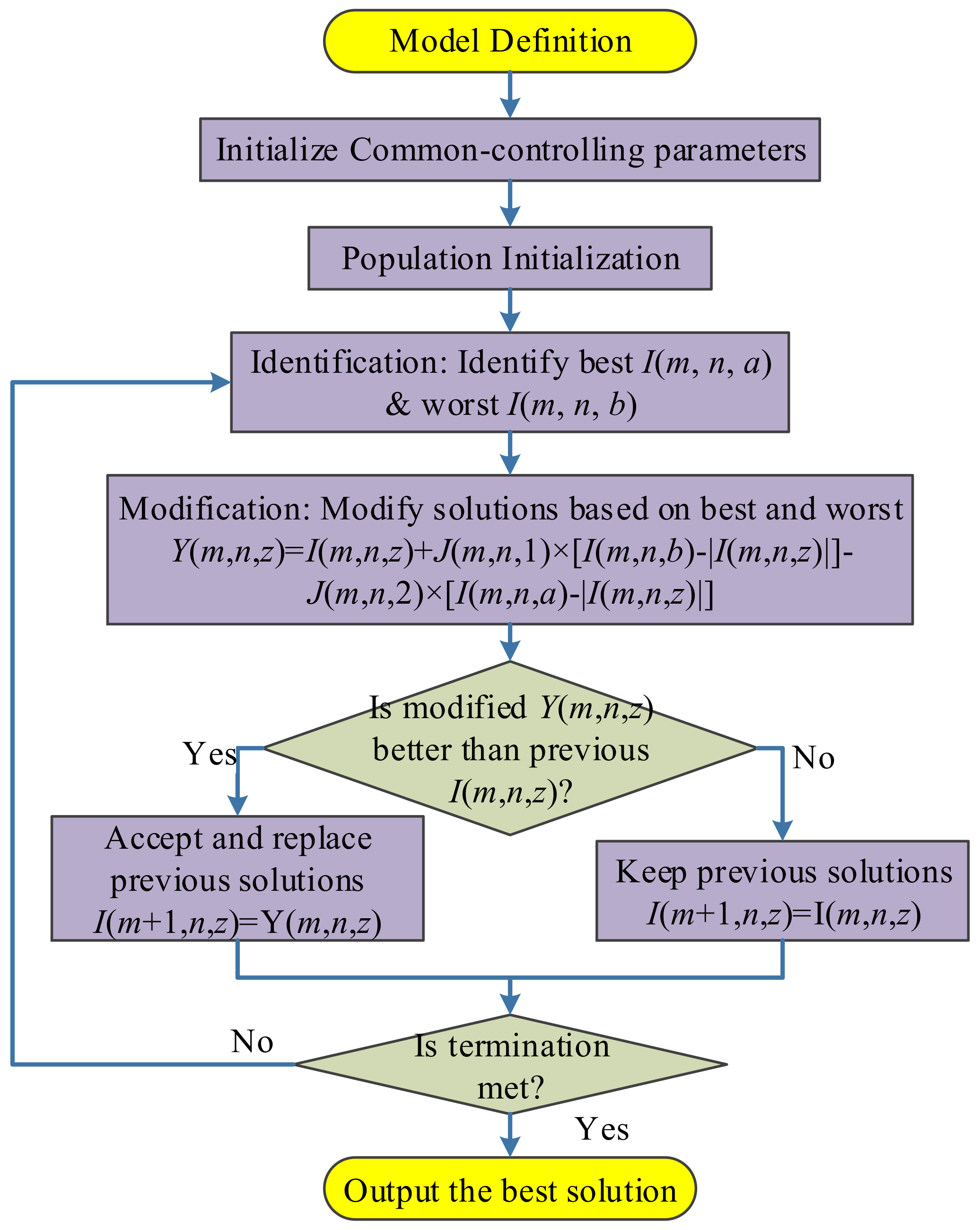
Jaya algorithm is a new optimization method proposed by Rao [
26]. It divides all the hyperparameters into two types: algorithm specific parameter (ACP) and common controlling parameter (CCP). The success of Jaya lies in it only needs to set the values of CCP (the size of population and, the maximum iteration), and does not need to set the values of ASP [
27]. The flowchart of Jaya was depicted in
Figure 6.
Let us suppose
m,
n,
z be the index of iteration, variable, and candidate. Suppose
J(
m,
n, 1) and
J(
m,
n, 2) are two random positive numbers in the range of [0, 1]. Assume
I(
m,
n,
z) represents the
n-th variable of
z-th solution candidate at
m-th step. Suppose
a and
b denotes the index of worst and best candidate within the population, respectively:
Hence, I(m, n, a) and I(m, n, b) denotes the worst and best value of n-th variable at m-th iteration.
We can define the modified solution at each step
Y(
m,
n,
z) as:
The 2nd term “
J(
m,
n, 1)
× [
I(
m,
n,
b) − |
I(
m,
n,
z)|]” in Equation (9) represents that the candidate needs to move closer to the best one. In contrast, the 3rd term “−
J(
m,
n, 2)
× [
I(
m,
n,
a) − |
I(
m,
n,
z)|]” in Equation (9) represents that the candidate needs to move away from the worst candidate, noting the “−” symbol before
J(
m,
n, 2).
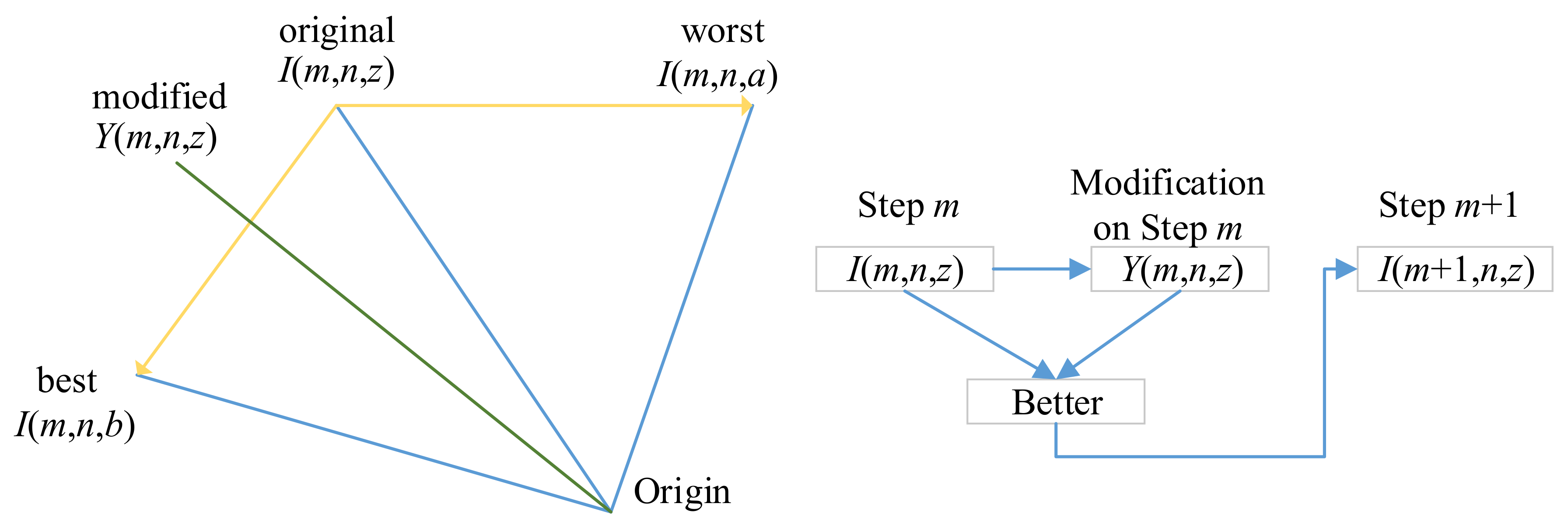
Figure 7 shows an example that the best solution
I(
m,
n,
b) will push
I(
m,
n,
z) towards down-left direction, and the worst solution
I(
m,
n,
a) pushes towards left.
In a word, the algorithm tries to get closer to success,
I(
m,
n,
b), and avoid failure,
I(
m,
n,
a). Hence, the algorithm attempts to select the best solution, and hence it is dubbed as Jaya (A Sanskrit word meaning victory). Rao [
26] tested Jaya algorithm on 24 constrained benchmark functions in the Congress on Evolutionary Computation (CEC 2006). The comparison algorithms include homomorphous mapping, genetic algorithm, differential evolution, artificial bee colony, biogeography-based optimization, multi-membered evolution strategy, particle swarm optimization, and adaptive segregational constraint handling evolutionary algorithm. Their results showed Jaya secured first rank for the “best” and “mean” solutions in Friedman’s rank test for all 24 constrained benchmark problems.
The updated candidate at iteration (
m + 1) can be written as:
where
represents the fitness function.
Equation (10) indicates that
I(
m + 1,
n,
z) is assigned with
Y(
m,
n,
z) if the modified candidate
Y(
m,
n,
z) is better in terms of fitness than
I(
m,
n,
z), otherwise it is assigned with
I(
m,
n,
z) [
28]. The Jaya algorithm loops until the termination criterion is met. We set the termination criterion to either the algorithm reaches maximum iteration epoch, or the error does not reduce for five epochs.
3.5. Two Improvements
To further improve the performance of Jaya, and to fit to our problem, we presented an improved Jaya algorithm based on two points: (i) We use self-adaptive to automatic determine the size of population, and thus we only decide the maximum iteration number; (ii) We embed the three-segment-encoding strategy to optimize both weights, biases, and the number of hidden neurons in the MLP.
In the first improvement, suppose the number of design variable is
l, the self-adaptive mechanism [
29] initialize the population size
S as:
Afterwards, the population size is dynamically adjusted following the formula
where
r is random variable with value between [−0.5, 0.5].
Now the population size is automatically determined without user intervention. If the new population size is larger than older one (Sm+1 > Sm), then all the existing population will go to the next population, and the optimal solution in current population are assigned to the remaining (Sm+1 − Sm) solutions. If the size of new population is smaller than older one (Sm+1 < Sm), then only the best Sm+1 solutions are transferred to the next population. No changes will happen if current population size is equal to next population size (Sm+1 = Sm).
In extreme conditions, if the number of next population decreases even less than the number of design variables (l), we need to increase it to l, viz., if Sm+1 < l, then Sm+1 = l. The term self-adaptive refers to the automatic selection of the population size.
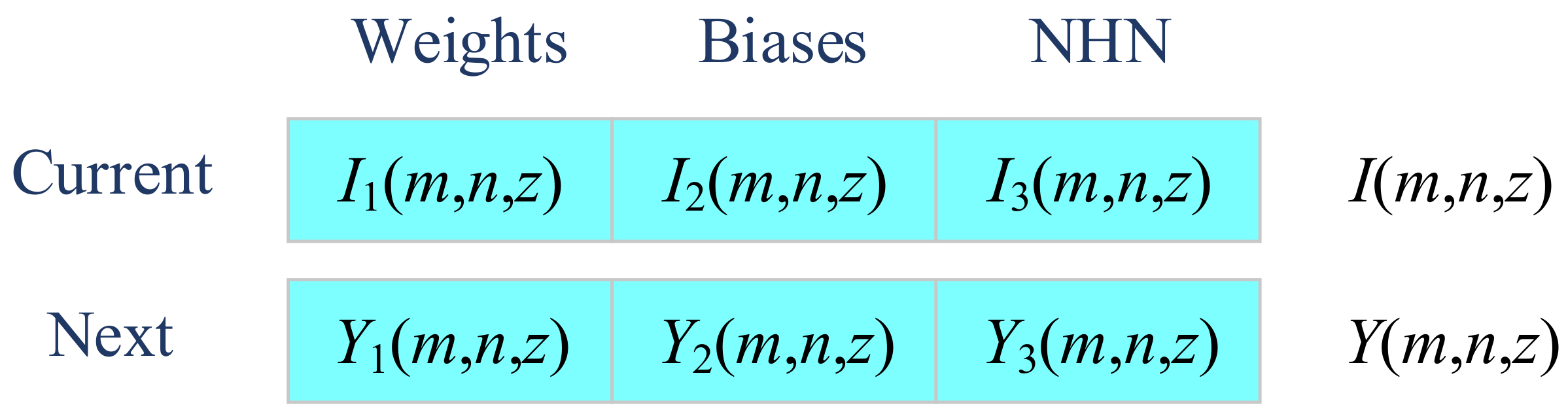
The second improvement is to embed a three-segment-encoding strategy [
30], which optimizes the weights (Segment 1), biases (Segment 2), and number of hidden neurons (Segment 3) simultaneously. Using this method, solution
I(
m,
n,
z) is now comprised of three segments as:
where
I1(),
I2(), and
I3() represents extract the first part, second part, and third part of the solution candidate representation.
I1(
m,
n,
z) encodes the weights,
I2(
m,
n,
z) encodes the biases, and
I3(
m,
n,
z) encodes the number of hidden neurons (NHN). Similarly, the modified solution is defined as:
where
Y1(),
Y2(), and
Y3() encodes the weights, biases, and NHN of next iteration.
Figure 8 shows the illustration of three-segment encoding.
The modification rule does not follow Equation (9). The new modification rule is three-folds as described in following three equations. A caveat is
K and
T are two random positive numbers, similar to variable
J:
Considering both improvements, we name our method as Self-adaptive Three-segment-encoded Jaya (ST-Jaya). In the experiments, we shall compare this proposed ST-Jaya with state-of-the-art approaches.
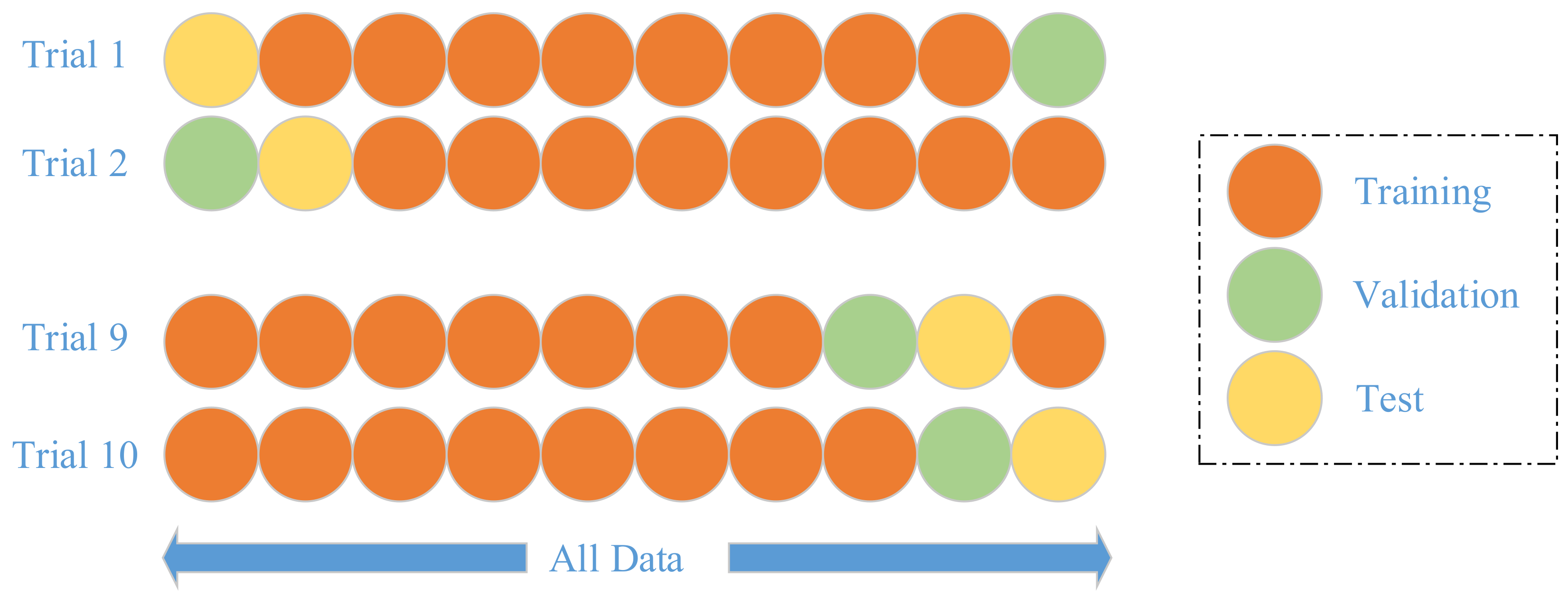
3.6. Implementation
We do not segment the whole dataset into training and test set, since our dataset is already quite small. Instead, we employ a
k-fold cross validation method [
31], where
k equals to 10 following conventions.
k-fold cross validation is a strict model validation approach available in statistics textbooks. In
k-th trial, the (
k − 1)-th fold is used as validation,
k-th fold as test, other folds are used as training set, as shown in
Figure 9. Hence, the training, validation, and test folds in each trial are always independent.
The training iterates until the accuracy over validation set increases for five continuous epochs. Hence, the training set is used for learning the weights, biases, and NHN. The validation set is used for learning the maximum iteration number. The test set is used for reporting unbiased error.
3.7. Evaluation
Finally, our method was implemented in this 10-fold cross validation and cost-sensitivity learning way. Suppose
f represents the number of folds,
t the time of runs. We can deduce the ideal confusion matrix
E of one time 10-fold cross validation:
We repeated it ten times and performed a 10 × 10-fold cross validation in realistic. Therefore, the confusion matrix is:
Suppose the positive class is multiple sclerosis (MS), and the false class is healthy control (HC). Then TP is MS correctly identified as MS, TN is HC correctly identified as HC, FN is MS falsely diagnosed as HC, FP is HC falsely diagnosed as MS. We define the sensitivity (Sen), specificity (Spc), and accuracy (Acc) on the basis of the realistic confusion matrix by following three formulae as:
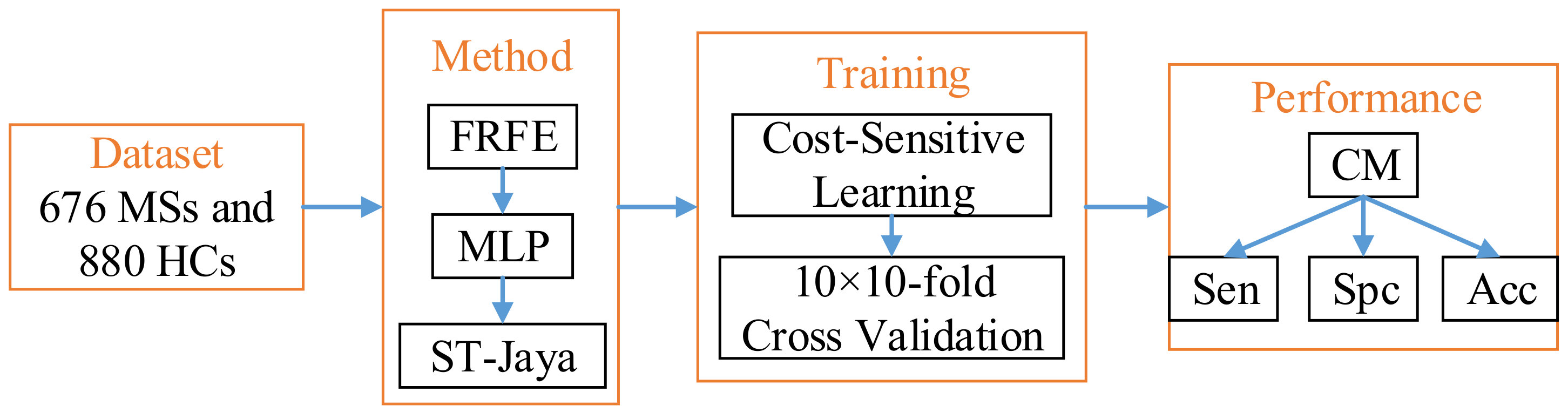
We shall report the mean and standard deviation of above three measure indicators. Finally, the diagram of proposed method was drawn in
Figure 10.
4. Experiments, Results, and Discussions
4.1. FRFE Map
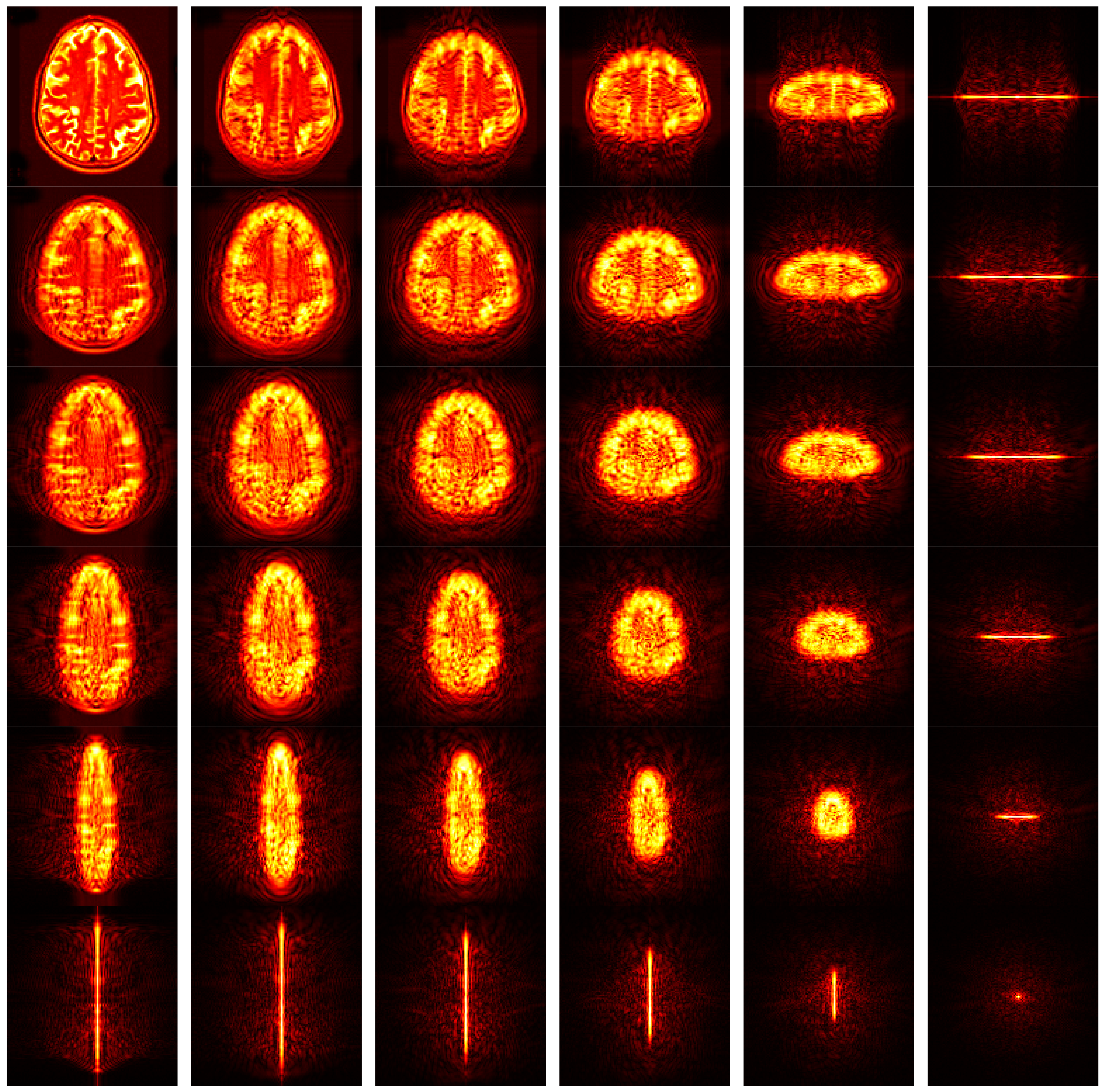
Figure 11 shows the FRFT map. The original brain image was shown in the top left corner, where the angle is (0, 0), corresponding to original spatial-domain image. From left to right, the first angle increases from 0 to 1 with increase of 0.2. From top to bottom, the second angle increases in similar way. The bottom right corner is associated with the FRFT map with angle of (1, 1).
Hence, the most prominent advantage of FRFT compared to other feature extraction methods, is it provides a continuous spectrum-like feature maps. Then, the entropy will further extract important information from those 36 spectrum maps. In all, we obtained a 36-element feature vector after this step.
Note that FRFE is still a hand-crafted feature, which has already been used for fine-grained classification, such as pathological brain detection [
12], tea category identification [
17], hearing loss identification [
19], etc. Nevertheless, Riabchenko et al. [
32] stated that they found superiority of the learned deep features to the engineered (viz., hand-crafted features), which suggests us to develop AI-based techniques to let the algorithm “learn” more efficient features than FRFE.
4.2. Statistical Analysis
The sensitivity, specificity, and accuracy results of 10 × 10-fold cross validation with cost-sensitive learning were shown in
Table 2. The mean and standard deviation were listed in the caption. The final average result was Sen = 97.40 ± 0.60%, Spc = 97.39 ± 0.65%, Acc = 97.39 ± 0.59%. In the table R represents run, and F fold. We can observe the sensitivity is almost equivalent to the specificity, which indicates the success of our cost-sensitive learning technique.
4.3. ST-Jaya versus Plain Jaya
We compared the proposed ST-Jaya versus plain Jaya. We tested nine different settings of plain Jaya, in which two hyper-parameters need to be set beforehand (population size
S, and number of hidden neurons NHN). The settings were listed in
Table 3.
The Setting 2 achieved the best results among all nine settings. The statistical results of Setting 2 were listed in
Table 4. It obtained a sensitivity of 97.03 ± 0.95%, a specificity of 97.05 ± 0.95%, and an accuracy of 97.04 ± 0.90%. Due to page limit, we only give the results other than the details of other eight settings, as shown in
Table 5.
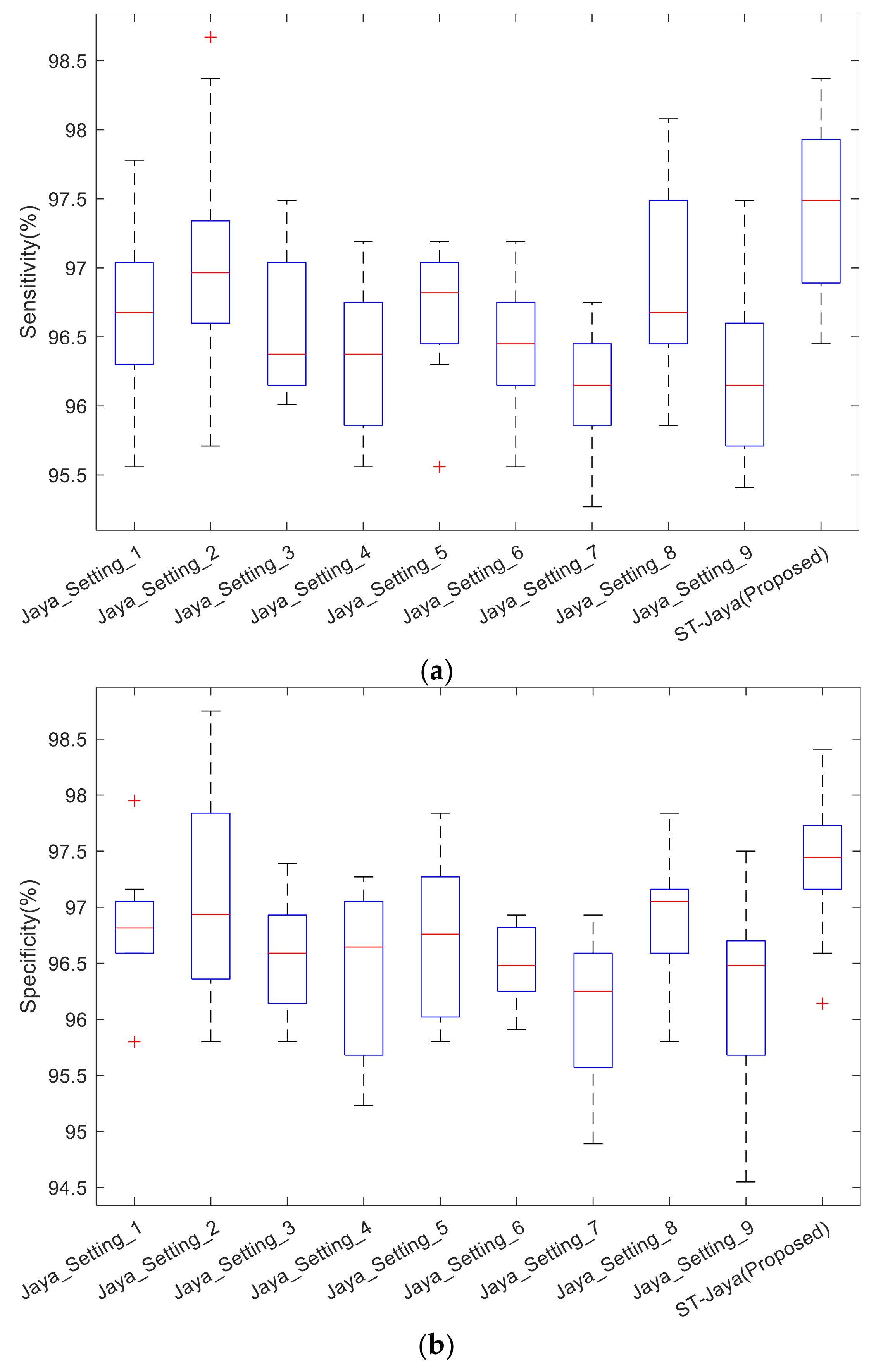
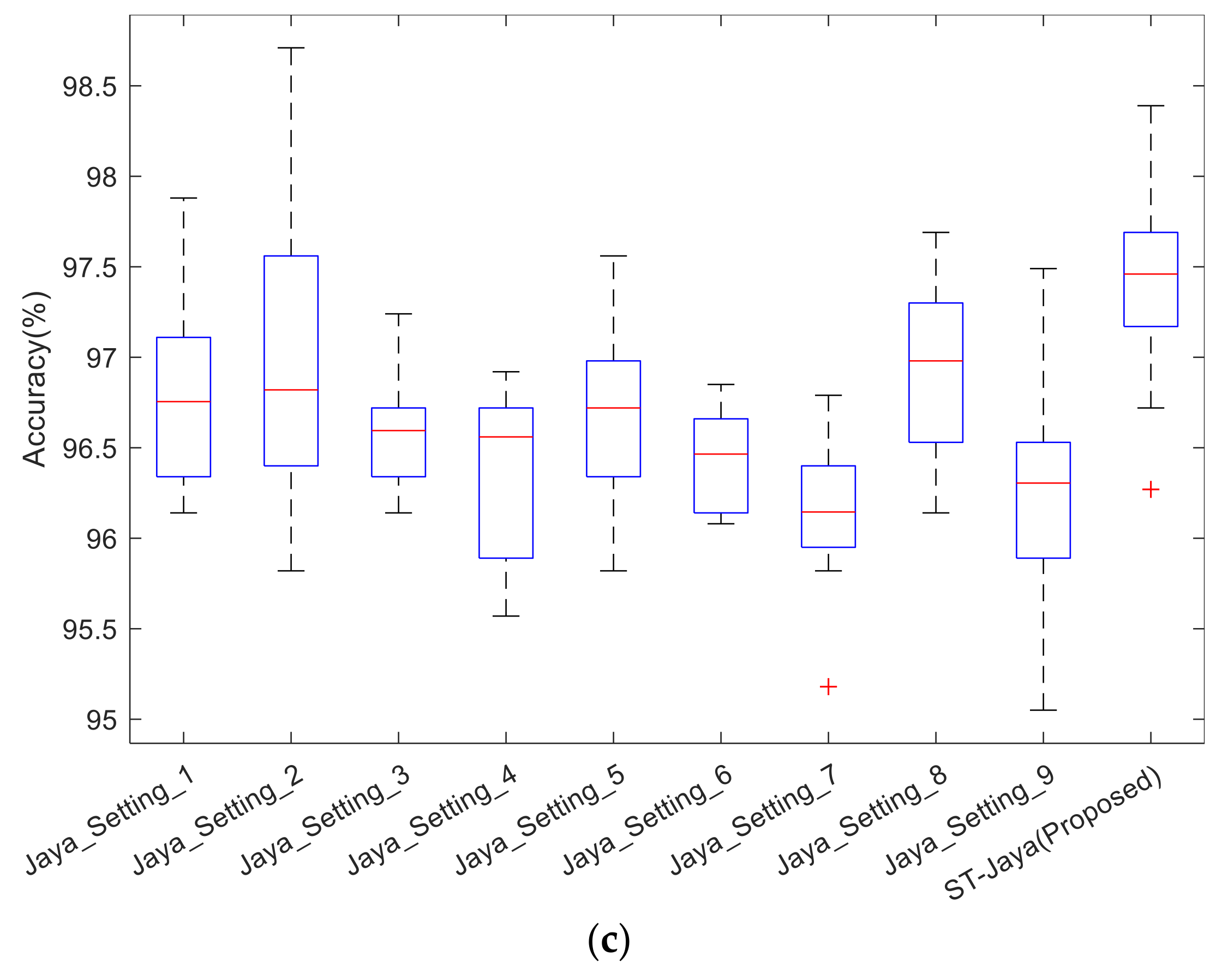
The boxplot was shown in
Figure 12. Note that the central red line is median, not mean as shown in
Table 5. The bottom and top edges indicate the 25th and 75th percentile. Outliers were marked individually using “+” mark. We observed from those boxplots that plain Jaya with any of nine different settings did not perform better than proposed ST-Jaya, which validated the superiority of proposed ST-Jaya to plain Jaya.
The success of ST-Jaya may attribute to the two factors: One is the self-adaptive strategy that avoid the users to set the value of population size, and the other is the three-segment-encoding strategy help the users to determine the number of hidden neuron automatically.
Except self-adaptive and three-segment-coding, there are other advanced strategies that may help bioinspired algorithms. Those strategies include adding chaotic [
33] and/or fuzzy operators, opposition-based learning, manipulating topologic positions of population candidates, hybridization of other bioinspired algorithms. Those strategies may improve the convergence speed and the robustness of proposed ST-Jaya algorithm.
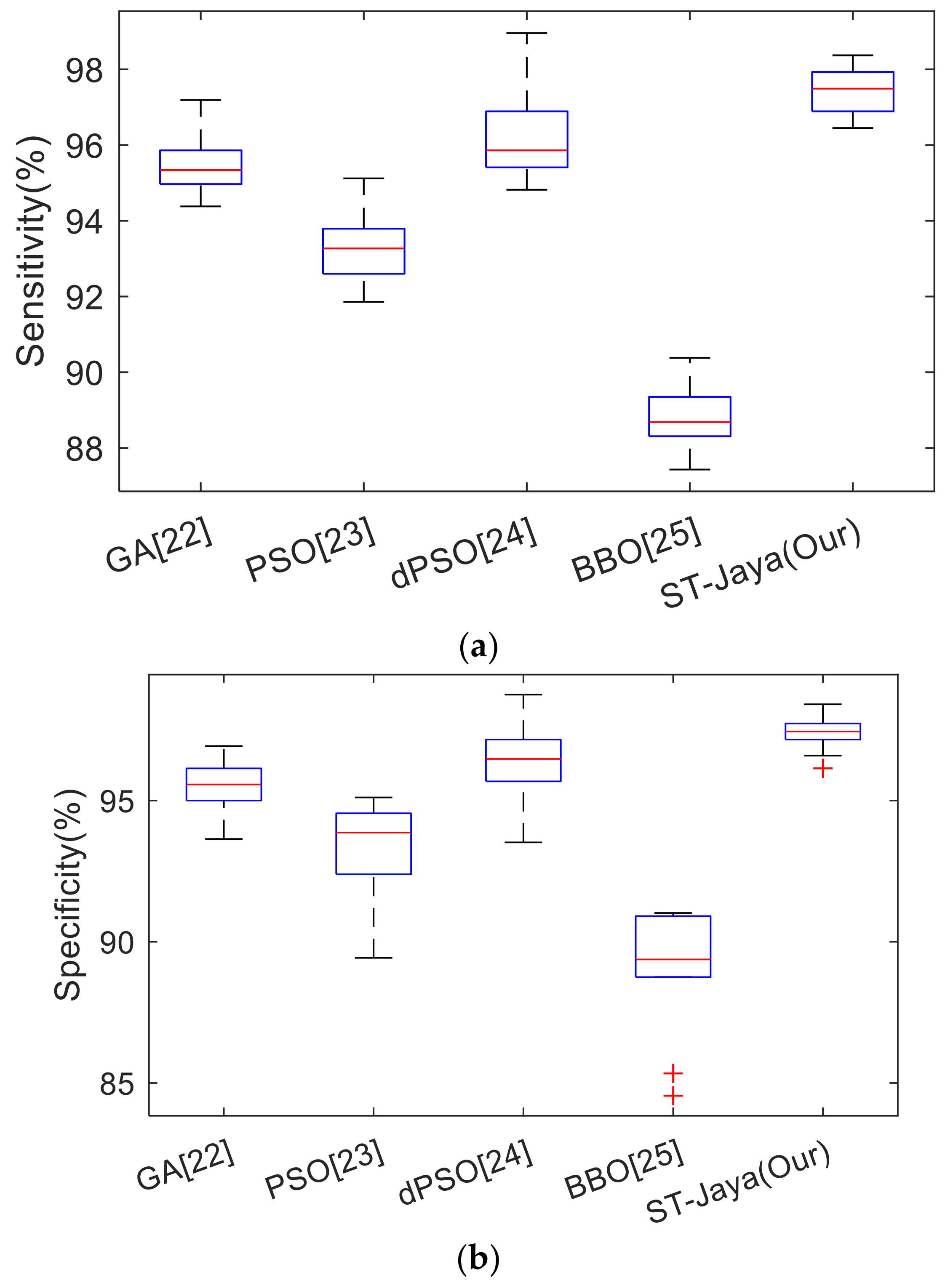
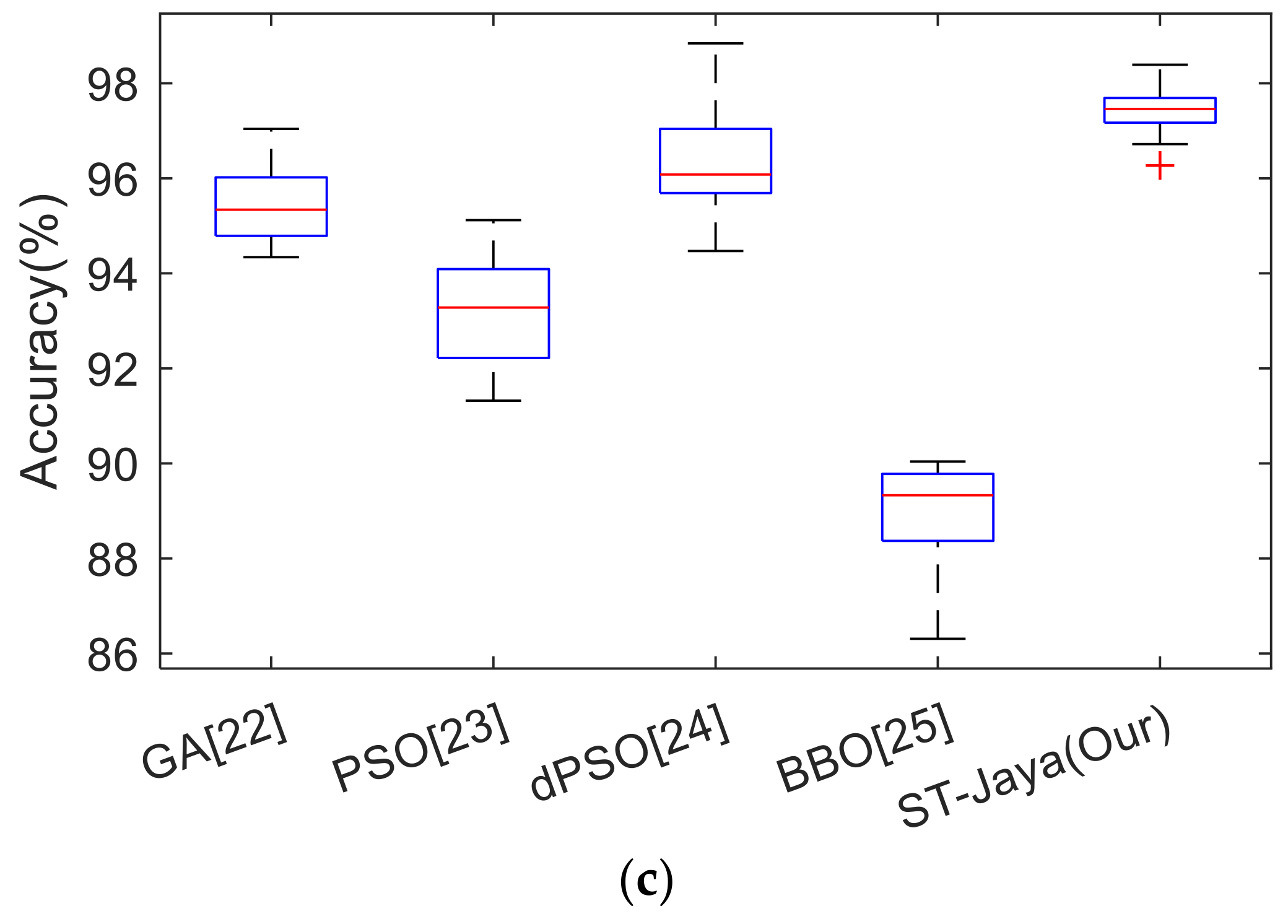
4.4. Comparison to Other Bioinspired Algorithms
In this experiment, we shall compare the proposed ST-Jaya with state-of-the-art bio-inspired algorithms, including GA [
22], PSO [
23], dynamic PSO (dPSO) [
24], and BBO [
25]. Their full names can be found in
Section 3.4. The optimal hyper-parameters of those four comparison basis methods were obtained by grid-search algorithm. The comparison results were listed in
Table 6, and the corresponding boxplots were shown in
Figure 13.
Next, we compared proposed ST-Jaya with those above four bioinspired methods: GA [
22], PSO [
23], dynamic PSO (dPSO) [
24], and BBO [
25] in terms of computation time. The 10 × 10-fold cross validation meant each algorithm ran 100 times. The average computation time of all methods are shown in
Table 7.
The results in
Table 7 indicated that GA [
22] cost 25.54 ± 4.39 s, PSO [
23] cost 16.08 ± 2.61 s, dPSO [
24] cost 15.59 ± 3.17 s, BBO [
25] cost 18.82 ± 3.80 s, while our proposed ST-Jaya cost the least time of only 13.77 ± 3.53 s. Hence, proposed ST-Jaya has a faster training speed than those four state-of-the-art approaches in training MLP.
Due to page limit, we only compared our proposed ST-Jaya with four bioinspired approaches. At present, there are numerous new bioinspired methods, such as gray wolf optimization, multi-verse optimizer, etc. Nevertheless, PSO is a classic and powerful swarm-intelligence method, and hence we included it as one of comparison algorithms. In our future studies, we shall extract the advantages of those latest algorithm, and try to improve the optimization performance of our proposed algorithm.
4.5. Comparison to Latest MS Identification Approaches
In this experiment, we compared the proposed MS identification method, FRFE + MLP + ST-Jaya, with state-of-the-art approaches, including GLCM-GLRL [
8], MAMSM [
9], RF [
10], and HWT + LR [
11]. Strict statistical analysis, i.e., the 10 × 10-fold cross validation was implemented. The mean and standard deviation values of sensitivities, specificities and accuracies of each algorithm, were reported in
Table 8.
The results in
Table 8 showed the worst algorithm was HWT + LR [
11] with values less than 90%. All the other algorithms achieve performances greater than 90%. The second worst algorithm was MAMSM [
9], which obtained a sensitivity of 93.24 ± 0.93%, a specificity of 93.15 ± 1.94%, and an accuracy of 93.19 ± 1.22%. The reason is the amplitude-modulation and frequency-modulation are originally designed for communication [
34]. The algorithm with average performance was GLCM-GLRL [
8], which combined gray-level cooccurrence matrix and gray-level run-length matrix. The second-best algorithm was the RF [
10]. This method used random forest approach that is an ensemble learning method. The best algorithm was the proposed FRFE + MLP + ST-Jaya, and its success lie in the efficiency of FRFE map and the improvements of standard Jaya algorithm.
As a high-level view, our method shows handcrafted image features may give better performance than biomarkers in terms of classification performance. Besides, these handcrafted image features are accurate and reproducible. In the future, handcrafted features may be replaced by learned features by artificial intelligence techniques such as deep learning, which was a core technique in AlphaGo.
5. Conclusions and Future Direction
In this study, we proposed a method based on fractional Fourier entropy map, multilayer perceptron, and Jaya algorithm with two improvements. Our FRFE + MLP + ST-Jaya method achieved a promising result in identifying multiple sclerosis methods. The proposed parameter-free ST-Jaya has a faster MLP-training speed than other four state-of-the-art methods.
In the future, we may test other features that may help to extract more efficient MS-related characteristics, particularly wavelet-related [
35] and entropy-related features [
36]. Another research direction is to use deep learning technologies to this MS detection problem.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}