Abstract
This paper uses a classical approach to feature selection: minimization of a cost function applied on estimated joint distributions. However, in this new formulation, the optimization search space is extended. The original search space is the Boolean lattice of features sets (BLFS), while the extended one is a collection of Boolean lattices of ordered pairs (CBLOP), that is (features, associated value), indexed by the elements of the BLFS. In this approach, we may not only select the features that are most related to a variable Y, but also select the values of the features that most influence the variable or that are most prone to have a specific value of Y. A local formulation of Shannon’s mutual information, which generalizes Shannon’s original definition, is applied on a CBLOP to generate a multiple resolution scale for characterizing variable dependence, the Local Lift Dependence Scale (LLDS). The main contribution of this paper is to define and apply the LLDS to analyse local properties of joint distributions that are neglected by the classical Shannon’s global measure in order to select features. This approach is applied to select features based on the dependence between: i—the performance of students on university entrance exams and on courses of their first semester in the university; ii—the congress representative party and his vote on different matters; iii—the cover type of terrains and several terrain properties.
1. Introduction
The problem of feature selection is equivalent to the problem of nonparametric estimation of a discrete joint distribution from a sample of n pairs , in which is an m-dimensional real or integer vector of features, i.e., measures of phenomenon characteristics, and Y is a natural number, which represents the class of . The problem is to find a subspace of characteristics with dimension that permits to properly estimate , emphasizing one of its important characteristics: for example, that is a good predictor of Y, i.e., for all , the conditional distribution has its mass concentrated around some value .
Formally, let be an m-dimensional feature vector and Y a single variable. Let be a feature vector, whose features are also in , and denote as the set of all feature vectors whose features are also in . In this scenario, we define the classical approach to feature selection, in which the search space is the Boolean lattice of features sets (BLFS), as follows.
Definition 1.
Given a variable Y, a feature vector and a cost function calculated from the estimated joint distribution of and Y, the classical approach to feature selection consists in finding a subset of features such that is minimum.
In light of Definition 1, we note that some families of feature selection algorithms may be considered as classical approaches. In fact, according to the taxonomy of feature selection, as presented in [1] for example, feature selection algorithms may be divided into three families, filters, wrappers and embedded methods, being the last two classical approaches to feature selection. Indeed, in the wrappers methods, the feature selection algorithm exists as a wrapper around a learning machine (or induction algorithm), so that a subset of features is chosen by evaluating its performance on the machine [2]. Furthermore, in the embedded methods, a subset of features is also chosen based on its performance on a learning machine, although the feature selection and the learning machine cannot be separated [3]. Therefore, both wrappers and embedded methods satisfy Definition 1, as the performance on the learning machine may be established by a cost function, so that these methods are special cases of the classical approach to feature selection. For more details about these methods see [1,2,3,4,5,6,7].
Under this approach for feature selection, a classical choice for the cost function is the estimated mean conditional entropy [8] that measures the mean mass concentration of the conditional distribution. Great mass concentration indicates that the chosen features define equivalence classes with almost homogeneous classifications, hence it is a good choice to represent the complete set of features. For a joint distribution estimated by a sample of size n, the curve formed by this cost function applied in a chain of the BLFS has an U shape and is called U-curve. For a small set of features, in the left side of the U-curve, the cost is high for the small amount of features generates large equivalence classes that mix labels, which leads to high entropy. For a large set of features, in the right side of the U-curve, the cost is also high, for severe conditional distribution estimation error leads to high entropy. Therefore, the ideal set of features in this chain is in the U-curve minimum, that is achieved by a set that contains the maximum number of features, whose corresponding distribution estimation is not seriously affected by estimation error. Choosing the best set of features consists of comparing the minimum of all lattice chains. There are some NP-hard algorithms that find the absolute minimum [9,10]. There are also some heuristics that give approximate solutions such as Sequential Forward Selection (SFS) [11], which adds features progressively until it finds a local minimum, and Sequential Forward Floating Selection (SFFS) [11], which, at first, adds features, but after takes some of them out and adds others, trying to improve the first local minimum found.
The main goal of the classical approach is to select the features that are most related to Y according to a metric defined by a cost function. Although useful in many scenarios, this approach may not be suitable in some applications in which it is of interest to select not only the features that are most related to Y, but also the features’ values that most influence Y, or that are most prone to have a specific value y of Y. Therefore, it would be relevant to extend the search space of the classical approach to an extended space that also contemplates the range of the features, so that we may select features and subsets of their range. This extended space is a collection of Boolean lattices of ordered pairs (features, associated values) (CBLOP) indexed by the elements of the BLFS. In other words, for each we have the Boolean lattice that represents the powerset of its range , that is denoted by , and the CBLOP is the collection of these Boolean lattices, i.e., . If are Boolean features, then its CBLOP is as the one in Figure 1. Note that the circle nodes and solid lines form a BLFS, that around each circle node there is an associated Boolean lattice that represents the powerset of , for a , and that the whole tree is a CBLOP (Note that if the features are not Boolean, we also have that is a Boolean lattice for all , so that the search space of the algorithm is always a CBLOP in this framework, regardless of the features’ range).
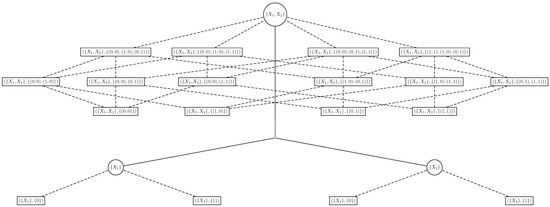
Figure 1.
Example of multi-resolution tree for feature selection. The circle nodes and solid lines form a BLFS. The rectangular nodes and dashed lines around each circle node form a Boolean lattice. The whole tree is a CBLOP.
A downside of this extension is that the sample size needed to perform feature selection at the extended space is greater than the one needed at the associated BLFS, what demands more refined optimal and sub-optimal algorithms in order to select features and subsets of their range. Nevertheless, the extended space brings advances to the state-of-art in feature selection, as it expands the method to a new variety of applications. As an example of such applications, we may cite market segmentation. Suppose it is of interest to segment a market according to the products that each market share is most prone to buy. Denote Y as a discrete variable that represents the products sold by a company, i.e., is the probability of an individual of the market buying the product sold by the company, and as the socio-economic and demographic characteristics of the people that compose the market. In this framework, it is not enough to select the characteristics (features) that are most related to Y: we need to select, for each product (value of Y), the characteristics and their values (the profile of the people) that are prone to buy a given product, so that feature selection must be performed on a CBLOP instead of a BLFS.
We call the approach to feature selection in which the search space is a CBLOP multi-resolution, for we may choose the features based on a global cost function calculated for each (low resolution); or choose the features and a subset of their range based on a local cost function calculated for each and (medium resolution); or choose the features and a point of their range based on a local cost function calculated for each and (high resolution). Formally, the multi-resolution approach to feature selection may be defined as follows.
Definition 2.
Given a variable Y, a feature vector and cost functions , calculated from the estimated joint distribution of and Y, the multi-resolution approach to feature selection consists in finding a subset of features and a such that is minimum.
The cost functions considered in this paper measure the local dependence between of length and Y restricted to the subset , i.e., for . More specifically, our cost functions are based on the Local Lift Dependence Scale, a scale for measuring variable dependence in multiple resolutions. In this scale we may measure variable dependence globally and locally. On the one hand, global dependence is measured by a coefficient, that summarizes it. On the other hand, local dependence is measured for each subset , again by a coefficient. Therefore, if the cardinality of is N, we have dependence coefficients: one global and local, each one measuring the influence of in Y restricted to a subset of . Furthermore, the Local Lift Dependence Scale also provides a propensity measure for each point of the joint range of and Y. Note that the dependence is indeed measured in multiple resolutions: globally, for each subset of and pointwise.
Thus, in this paper, we extend the classical approach to feature selection in order to select not only the features, but also their values that are most related to Y in some sense. In order to do so, we extend the search space of the feature selection algorithm from the BLFS to the CBLOP and use cost functions based on the Local Lift Dependence Scale, which is an extension of Shannon’s mutual information. The feature selection algorithms proposed in this paper are applied to a dataset consisting of student performances on a university’s entrance exam and on undergraduate courses in order to select exam’s subjects, and the performances on them, that are most related to undergraduate courses, considering student performance on both. The method is also applied to two datasets publicly available at the UCI Machine Learning Repository [12], namely, the Congressional Voting Records and Covertype datasets. We first present the main concepts related to the Local Lift Dependence Scale. Then, we propose feature selection algorithms based on the Local Lift Dependence Scale and apply them to solve real problems.
2. Local Lift Dependence Scale
The Local Lift Dependence Scale (LLDS) is a scale for measuring the dependence between a random variable Y and a random vector (also called feature vector) in multiple resolutions. Although consisting of well known mathematical objects, there does not seem to exist any literature that thoroughly defines and study the properties of the LLDS, even though it is highly used in marketing [13] and data mining [14] (Chapter 10), for example. Therefore, we present an unprecedented characterization of the LLDS, despite the fact that much of it is known in the theory.
The LLDS analyses the raw dependence between the variables, as it does not make any assumption about its kind, nor restrict itself to the study of a specific kind of dependence, e.g., linear dependence. Among LLDS dependence coefficients, there are three measures of dependence, one global and two local, but with different resolutions, that assess variable dependence on multiple levels. The global measure and one of the local are based on well known dependence measures, namely, the Mutual Information and the Kullback-Leibler Divergence. In the following paragraphs we present the main concepts of the LLDS and discuss how they can be applied to the classical and multi-resolution approaches to feature selection. The main concepts are presented for discrete random variables and Y defined on , with range , although, with simple adaptations, i.e., by interchanging probability functions with probability density functions, the continuous case follows from it.
The Mutual Information (MI), proposed by [15], is a classical dependence quantifier that measures the mass concentration of a joint probability function. As more concentrated the joint probability probability function is, the more dependent the random variables are and greater is their MI. In fact, the MI is a numerical index defined as
in which , and for all . An useful property of the MI is that it may be expressed as
in which is the Entropy of Y and is the Conditional Entropy (CE) of Y given . The form of the MI in (1) is useful because, if we fix Y, and consider features , we may determine which one of them is the most dependent with Y by observing only the CE of Y given each one, as the feature that maximizes the MI is the one that minimizes the CE. In this paper, we consider the normalized MI that is given by
when . We have that , that if, and only if, and Y are independent and that if, and only if, there exists a function such that , i.e., Y is a function of . The , MI and CE are equivalent global and general measures of dependence, that summarize to an index a variety of dependence kinds that are expressed by mass concentration.
On the other hand, we may define a LLDS local and general measure of dependence that expands the global dependence measured by the MI into local indexes, enabling a local interpretation of variable dependence. As the MI is an index that measures variable dependence by measuring the mass concentration incurred in one variable by the observation of another, it may only give evidences about the existence of a dependence, but cannot assert what kind of dependence is being observed. Therefore, it is relevant to break down the MI by region, so that it can be interpreted in an useful manner and the kind of dependence outlined by it may be identified. The Lift Function (LF) is responsible for this break down, as it may be expressed as
in which . When there is no doubt about which variables the LF refers to, it is denoted simply by . Note that the LF is the exponential of the pontual mutual information (see [16,17] for example for more details).
The MI is the expectation on of the LF logarithm, so that the LF presents locally the mass concentration measured by the MI. As the LF may be written as the ratio between the conditional probability of Y given and the marginal probability of Y, the main interest in its behaviour is in determining for which points and for which . If then the fact of being equal to increases the probability of Y being equal to y, as the conditional probability is greater than the marginal one. Therefore, we say that event lifts event or that instances with profile are prone to be of class y. In the same way, if , we say that event inhibits event , for . If , then the random variables are independent. Note that the LF is symmetric: lifts if, and only if, lifts . Therefore, the LF may be interpreted as lifting Y or Y lifting . From now on, we interpret it as lifting Y, even though it could be the other way around.
An important property of the LF is that it cannot be greater than one nor lesser than one for all points . Indeed, if , then what implies the absurd for . With an analogous argument we see that cannot be lesser than one for all . Therefore, if there are LF values greater than one, then there must be values lesser than one, what makes it clear that the values of the LF are dependent and that the lift is a pointwise characteristic of the joint probability function and not a global property of it. Thus, the study of the LF behaviour gives the full view of the dependence between the variables, without restricting it to a specific kind nor making assumptions about it.
Although the LF presents a wide picture of variable dependence, it may present it in a too high resolution, making it complex to interpret. Therefore, instead of measuring dependence for each point in the range , we may measure it for a window . The dependence between and Y in the window W, i.e., for , may be measured by the coefficient defined as
when and , in which is the Kullback-Leibler divergence [18], is the cross-entropy [19] and means the cross-entropy between the conditional distribution of Y given and the marginal distribution of Y. The coefficient (3) compares the conditional probability of Y given , , with the marginal probability of Y, so that as greater the coefficient, as distant the conditional probability is from the marginal one and, therefore, greater is the influence of the event in Y. Note that, analogously to the MI, we may write
in which means the Entropy of the conditional distribution of Y given , and we have that , that if, and only if, , and that if, and only if, there exists a function such that . Observe that the coefficient of a window is also a local dependence quantifier, although its resolution is lower than that of the LF if the cardinality of W is greater than one. Also note that the coefficient (3) is a generalization of (2) to all subsets (windows) of , as is a window and that the numerator of equals . It is important to outline that we may complete the LLDS with coefficients that are given by normalized, with and , that measure the dependence between and Y for . However, we do not use coefficients of this type in this paper for in our case the variable Y and its range are always fixed. Note that if the cardinality of is one then so that the scale is indeed complete.
The three dependence coefficients presented, when analysed collectively, measure variable dependence in all kinds of resolutions: since the low resolution of the MI, through the middle resolutions of the windows W, until the high resolution of the LF. Indeed, the coefficients and the LF define a dependence scale in , that we call LLDS, that gives a dependence measure for each subset . This scale may be useful for various purposes and we outline some of them in the following paragraphs.
Potential applications of the Local Lift Dependence Scale
The LLDS, more specifically the LF, is relevant in frameworks in which we want to choose a set of elements, e.g, people, in order to apply some kind of treatment to them, obtaining some kind of response Y, and are interested in maximizing the number of elements with a given response . In this scenario, given the features , the LF provides the set of elements that must be chosen, that is the set whose elements have profile such that is greatest. Formally, we must choose elements whose profile is
Indeed, if we choose n elements randomly from our population, we expect that of them will have the desired response. However, if we choose n elements from the population of all elements with profile , then we expect that of them will have the desired response, what is more elements when comparing with the whole population sampling framework. Observe that this framework is the exact opposite of the classification problem. In the classification problem, we want to classify an instance given its profile into a class , that may be, for example, the class y such that is maximum. On the other hand, in this framework, we are interested in, given a , finding the profile such that is maximum. In the applications section we further discuss the differences between this framework and the classification problem, and how the LLDS may be applied to both.
Furthermore, the coefficient is relevant in scenarios in which we want to understand the influence of in Y by region, i.e., for each subset of . As an example of such framework, consider an image in the grayscale, in which represents the pixels of the image and Y is the random variable whose distribution is the distribution of the colors in the picture, i.e., in which is the number of pixels whose color is and n is the total number of pixels in the image. If we define the distribution of properly for all , we may calculate , in order to determine the regions that are a representation of the whole picture, i.e., whose color distribution is the same of the whole image, and the regions W whose color distribution differs from that of the whole image. The coefficient may be useful for identifying textures and recognizing patterns in images.
Lastly, the LLDS may be used for feature selection, when we are not only interested in selecting the features that are most related to Y, but also want to determine the features whose levels most influence Y. In the same manner, we may want to select the features whose level maximizes L, for a given , so that we may sample from the population of elements with profile in order to maximize the number of elements of class y. Feature selection based on the LLDS is a special case of the classical and multi-resolution approaches to feature selection as presented next.
3. Feature Selection Algorithms based on the Local Lift Dependence Scale
In this section we present the characteristics of feature selection algorithms based on the LLDS. We first outline the special case of the classical approach to feature selection that is based on the LLDS, and then propose multi-resolution feature selection algorithms that are also based on the LLDS.
3.1. Classical Feature Selection Algorithm
Let Y and be random variables. We call the random variables in features and note that , the set of all feature vectors whose features are also in , may be seen as a BLFS, in which each vector represents a subset of features. In this scheme, feature selection is given by the minimization, in the BLFS, of a cost function applied on the estimated joint probability of a feature vector and Y. In fact, the subset of features selected by this approach is given by
in which is a cost function. The estimated error of a predictor as presented in [20] (Chapter 2), for example, is a classical cost function. Another classical cost function is the CE as defined in (1). A pseudo-code for such algorithm is presented in Algorithm 1. Algorithm 1 is naive, performs an exhaustive search on the BLFS and is known to be NP-hard [21]. However, some other algorithms may be applied to find a sub-optimal solution to this problem, as sequential selection algorithms and floating search methods [22,23,24,25,26,27]. Also, the search space may be restricted to a subspace of . Nevertheless, there are algorithms, as the branch-and-bound [28] and the u-curve [9,10,29], that does not perform an exhaustive search, but ensure that the selected subset of features is optimal.
| Algorithm 1 Select that minimizes . |
| Ensure: Ensure:
|
As an example of the classical approach to feature selection, suppose that , in which and are Boolean features. Then, the search space may be represented by a tree, i.e., a BLFS, as the one displayed in Figure 1, considering only the circle nodes and solid lines. Algorithm 1 may be performed by walking through this tree seeking the minimum of .
3.2. Multi-resolution Feature Selection based on the Local Lift Dependence Scale
Feature selection based on the LLDS may be performed in three distinct resolutions. As a low resolution approach, we may select the features that are most globally related to Y, that are given by
Note that, in this resolution, the feature selection approach is the classical one, with in (2) as the cost function, i.e., Algorithm 1 may be applied to determine (4) taking as . The use of the MI as a cost function in classical feature selection algorithms is quite common in the literature (see [30,31,32] for example) and is not original of this paper. The search space of (4) may be restricted, sub-optimal algorithms may be applied or the discretization of the continuous features may be performed jointly, so that the subset selected in (4) is not always the subset of all features. In the applications section we show how the continuous features may be discretized jointly.
Increasing the resolution, we may be interested in finding not the features most related to Y, but the features levels that most influence Y. In this approach the selected features and their levels are
A pseudo-code for this feature selection approach is presented in Algorithm 2. Note that the space in which the exhaustive search is conducted in Algorithm 2, i.e., the CBLOP, is even greater than the one in Algorithm 1. However, optimal algorithms that do not exhaustively search the space, and sub-optimal algorithms, may also be applied in this scenario, saving some computational time. Note that this approach is not suitable for the case in which the features in are continuous, as , , is uncountable, although the continuous features may be discretized. Furthermore, as is further discussed in the applications section, this algorithm is subjected to overfitting if the sample size is not relatively great (as is the majority of statistical models and feature selection algorithms), so that it may be needed to restrict its search space to a subset of the CBLOP.
| Algorithm 2 Select and that maximizes . |
| Ensure: Ensure: Ensure:
|
Finally, as a higher resolution approach, we may fix an and then look for the features levels that maximize the LF at the point y. Formally, the selected features and levels are given by
A pseudo-code to perform (6) is presented in Algorithm 3, that is analogous to Algorithm 2. Note that the search space of Algorithm 3 is greater than that of Algorithm 1 and smaller than that of Algorithm 2. Nevertheless, it has the same general characteristics of Algorithm 2: optimal algorithms that do not search all the space, and sub-optimal algorithms, may be applied; it cannot be applied to continuous features; and it is subjected to overfitting.
| Algorithm 3 Select and that maximizes L for some fixed . |
| Ensure: Ensure: Ensure: Ensure:
|
As an example of a multi-resolution approach to feature selection based on the LLDS, suppose again that are Boolean features. Then, for all the proposed resolutions, the selection of the features and their levels, i.e., Algorithms 1, 2 and 3, may be performed by walking through the tree (CBLOP) in Figure 1. Indeed, we may calculate the global at the circle nodes, the on all windows W at the rectangular nodes and the LF at the leaves, where we may determine its maximum for a fixed value . Therefore, we call a tree as the one in Figure 1 a multi-resolution tree for feature selection, where we may apply feature selection algorithms for all the resolutions of the LLDS, i.e., Algorithms 1, 2 and 3.
4. Applications
The multi-resolution approach proposed in the previous sections is now applied to three different datasets. First, we apply it to the performances dataset, that consists of student performances on entrance exams and undergraduate courses. Then, we apply the algorithms to two UCI Machine Learning Repository datasets: the Congressional Voting Records and Covertype datasets [12].
4.1. Performances dataset
A recurrent issue in universities all over the world is the framework of their recruitment process, i.e., the manner of selecting their undergraduate students. In Brazilian universities, for example, the recruitment of undergraduate students is solely based on their performance on exams that cover high school subjects, called vestibulares, so that knowing which subjects are most related to the performance on undergraduate courses is a matter of great importance to universities admission offices, as it is important to optimize the recruitment process in order to select the students that are most likely to succeed. Therefore, in this scenario, the algorithm presented in the previous sections may be an useful tool in determining the entrance exam subjects, and the performances on them, that are most related to the performance on undergraduate courses, so that students may be selected based on their performance on these subjects.
The recruitment of students to the University of São Paulo is based on an entrance exam that consists of an essay and questions of eight subjects: Mathematics, Physics, Chemistry, Biology, History, Geography, English and Portuguese. The selection of students is entirely based on this exam, although the weights of the subjects differ from one course to another. In the exact sciences courses, as Mathematics, Statistics, Physics, Computer Science and Engineering, for example, the subjects with greater weights are Portuguese, Mathematics and Physics, as those are the subjects that are qualitatively most related to what is taught at these courses. Although weights are given to each subject in a systematic manner, it is not known what subjects are indeed most related to the performance on undergraduate courses. Therefore, it would be of interest to measure the relation between the performance on exam subjects and undergraduate courses and, in order to do so, we apply the algorithms proposed on the previous sections.
The dataset to be considered consists of 8,353 students that enrolled in 28 courses of the University of São Paulo between 2011 and 2016. The courses are those of its Institute of Mathematics and Statistics, Institute of Physics and Polytechnic School, and are in general Mathematics, Computer Science, Statistics, Physics and Engineering courses. The variable of interest (Y) is the weighted mean grade of the students on the courses they attended in their first year at the university (the weights being the courses credits), and is a number between zero and ten. The features, that are denoted , are the performances on each one of the eight entrance exam subjects, that are numbers between zero and one, and the performance on the essay, that is a number between zero and one hundred.
In order to apply the proposed algorithm to the data at hand, it is necessary to conveniently discretize the variables and, to do so, we take into account an important characteristic of the data: the scale of the performances. The scale of the performances, both on the entrance exam and the undergraduate courses, depends on the course and the year. Indeed, the performance on the entrance exam of students of competitive courses is better, as only the students with high performance are able to enrol in these courses. In the same way, the performances differ from one year to another, as the entrance exam is not the same every year and the teachers of the first year courses also change from one year to another, what causes the scale of the grades to change. Therefore, we discretize all variables by tertiles inside each year and course, i.e., we take the tertiles considering only the students of a given course and year. Furthermore, we do not discretize each variable by itself, but rather discretize the variables jointly, by a method based on distance tertiles, as follows.
Suppose that at a step of the algorithm we want to measure the relation between Y and the features . In order to do so, we discretize Y by its tertiles inside each course and year, e.g., a student is in the third tertile if he is on the top one third students of his class according to the weighted mean grade, and discretize the performance on jointly, i.e., by discretizing the distance between the performance of each student on these subjects and zero by its tertiles. Indeed, students whose performance is close to zero have low joint performance on the subjects , while those whose performance is far from zero have high joint performance on the subjects . Therefore, we take the distance between each performance and zero, and then discretize it inside each course and year, e.g., a student is at the first tertile if he is on the bottom students of his class according to his joint performance on the subjects . The Mahalanobis distance [33] is used, as it takes into account the variance and covariance of the performance on the subjects .
As an example, suppose that we want to measure the relation between the performances on Mathematics and Physics and the weighted mean grade of students that enrolled in the Statistics undergraduate course in 2011 and 2012. In order to do so, we discretize the weighted mean grade by year and the performance on Mathematics and Physics by the Mahalanobis distance between it and zero, also by year, as is displayed in Figure 2. Observe that each year has its own ellipses that partition the performance on Mathematics and Physics in three and the tertile of a student depends on the ellipses of his year. The process used in Figure 2 is extended to the case in which there are more than two subjects and one course. When there is only one subject, the performance is discretized in the usual manner inside each course and year. The LF between the weighted mean grade and the joint performance on Mathematics and Physics is presented in Table 1. From this table we may search for the maximum lift or calculate the coefficient for its windows. In this example, we have , in which .
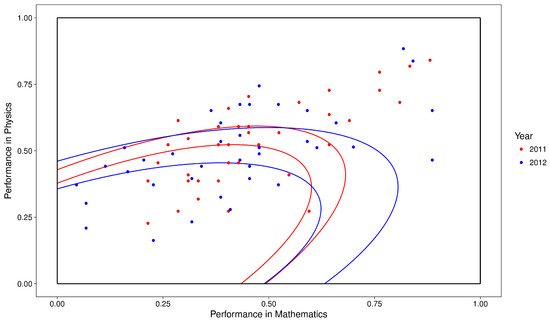
Figure 2.
Discretization of the joint performance on Mathematics and Physics of Statistics students that enrolled at the University of São Paulo in 2011 and 2012 by the tertiles of the Mahalanobis distance inside each year.

Table 1.
The Lift Function between the weighted mean grade, discretized by year, and the joint performance on Mathematics and Physics, discretized by the Mahalanobis distance inside each year, of Statistics students that enrolled at the University of São Paulo in 2011 and 2012. The numbers in parentheses represent the quantity of students in each category.
The proposed algorithm is applied to the discretized variables using three cost functions. First, we use the coefficient on the window that represents the whole range of the features in order to determine what are the subjects (features) that are most related to the weighted mean grade, i.e., the features (4). Then, we apply the algorithm using as cost function the coefficient for all windows in order to determine the subjects performances (features and window) that are most related to the weighted mean grade, i.e., the subjects and performances (5). Finally, we determine what are the subjects and their performance that most lift the weighted mean grade third tertile, i.e., the subjects and performances (6) with .
The subjects that are most related to the weighted mean grade, according to the proposed discretization process and the coefficient (2), are and , in which . The LF between the weighted mean grade and is presented in Table 2. The features are the ones that are in general most related to the weighted mean grade, i.e., are the output of the classical feature selection algorithm that employs the inverse of the global coefficient as cost function (Algorithm 1). Therefore, the recruitment of students could be optimized by taking into account only the subjects .
Table 2.
The Lift Function between the weighted mean grade and the joint performance on . The numbers in parentheses represent the quantity of students in each category.
Applying Algorithms 2 and 3 we obtain the same result, that the performance, i.e., window, that is most related to the weighted mean grade and that most lifts the third tertile of the weighted mean grade is the third tertile in Mathematics, for which and L, in which M = Mathematics. The LF between the weighted mean grade and the performance on Mathematics is presented in Table 3.
Table 3.
The Lift Function between the weighted mean grade and the performance on Mathematics. The numbers in parentheses represent the quantity of students in each category.
The output of the algorithms provides relevant information to the admission office of the University. Indeed, it is now known that the subjects that are most related to the performance on the undergraduate courses are Mathematics, Physics, Chemistry, Biology and Portuguese. Furthermore, in order to optimize the number of students that will succeed in the undergraduate courses, the office must select those that have high performance on Mathematics, as it lifts by more than 50% the probability of the student having also a high performance on the undergraduate course, i.e., students with high performance on Mathematics are prone to have high performance on the undergraduate course. Although the subjects that are most related to the performance on the courses are obtained from the classical feature selection algorithm, only the LLDS outlines what is the performance on the entrance exam that is most related to the success on the undergraduate course, that is high performance on Mathematics. Therefore, feature selection algorithms based on the LLDS provide more information than the classical feature selection algorithm, as they have a greater resolution and take into account the local relation between the variables.
4.2. Congressional Voting Records dataset
The Congressional Voting Records dataset consists of 435 instances of 16 Boolean features and a Boolean variable that indicates the party of the instance (democrat or republican). The features indicate how the instance voted (yes or no) in the year of 1984 about each one of 16 matters, that are displayed in Table 4. Algorithm 3 is applied to this dataset in order to determine what are the voting profiles that are most prone to be that of a republican and that of a democrat.
Table 4.
Features of the Congressional Voting Records dataset.
As the number of instances is relatively small, we perform Algorithm 3 under a restriction that avoids overfitting. Indeed, if we apply the algorithm without the restriction, then the chosen profiles are those in which all the instances are of the same party. If there is only a couple of instances with some profile, and all of them are of the same party, then this profile is chosen as a prone one for the party. However, we do not know if the profile is really prone, i.e., everybody with it is in fact of the same party, or if the fact of everybody with this profile being of the same party is just a sample deviation. In other words, without the restriction, the estimation error of the LF is too great as some profiles have low frequency in the sample and the feature selection algorithm overfits.
Therefore, we restrict the search space to the profiles with a relative frequency in the sample of at least . In other words, we select the profiles
for , in which , is estimated by the relative frequency of the profile. The selected profiles, their LF value and the sample size considered are presented in Table 5. At each iteration of the algorithm, only the instances that have no missing data in the features being considered are taken into account when calculating the LF, so that the sample size of each iteration is not the same.
Table 5.
Selected profiles obtained applying Algorithm 3 to the Congressional Voting Records dataset with the restriction that only the profiles with relative frequency greater than are considered. The instances with missing data were excluded at each iteration of the algorithm, i.e., L is calculated using only the instances that have all the observations on the features .
The profiles with maximum LF lifts by 94% the probability of democrat and by around 165% the probability of republican. This difference in the lift is due to the fact that there are more democrats than republicans, so that the probability of democrat is greater and, therefore, cannot be lifted as much as the probability of republican can. The profiles in Table 5 present a wide view of the voting profile of democrats and republicans, what allows an understanding of what differentiates a democrat from a republican regarding their vote.
This application to the Congressional Voting Records dataset shed light on two interesting properties of the LLDS approach to feature selection in its higher resolution. First, this approach is indeed local, as we are not interested in selecting the features that best classify the representatives accordingly to their party, but rather the voting profiles that are most prone to be that of a democrat or republican. Secondly, the problem treated here is the opposite of the classification problem. Indeed, in the classification problem, we are interested in classifying a representative according to his party, given his voting profile. On the other hand, the problem treated here is the exact opposite: given a party, we want to know what are the profiles of the representatives that are most prone to be of that party. In other words, in the classification problem we want to determine the party given the voting profile, while on the LLDS problem we want to determine the voting profile given the party.
4.3. Covertype dataset
The Covertype dataset consists of 581,012 instances (terrains) of 54 features (10 continuous and 44 discrete) and a variable that indicates the cover type of the terrain (7 types). We apply Algorithms 1, 2 and 3 to select features among the continuous ones that are displayed in Table 6. The features are discretized in the same way they were in the performances dataset: by taking sample quantiles of the Mahalanobis distance between the features and zero. However, we now consider the quantiles and as cutting points, i.e., quintiles, instead of tertiles.
Table 6.
Features of the Covertype dataset that are considered in this application.
Applying Algorithm 1 we select the features , with a coefficient and the LF in Table 7. We see that being in the first quintile of the selected features lifts classes 3, 4, 5 and 6; being in the second quintile lifts classes 2 and 5; being in the third quintile lifts class 2; being in the fourth quintile lifts class 1; and being in the fifth quintile lifts classes 1 and 7. From Table 7 we may interpret the relation between the selected features and the cover type. For example, we see that terrains with cover types 3, 4, 5 and 6 tend to have low joint values in the selected features, while terrains with cover 7 tend to have great joint values in them. This example shows how the proposed approach allows not only to select the features, but also understand why these features were selected, i.e., what is the relation between them and the cover type, by analysing the local dependence between the variables.
Table 7.
The Lift Function between the cover type of the terrain and the features Elevation, Horizontal distance to hydrology and Horizontal distance to fire points discretized by the sample quintiles of the Mahalanobis distance to zero. The numbers in parentheses represent the sample size of each category.
Applying Algorithm 2 to this dataset we obtain the windows displayed in Table 8. We see that the window that seems to most influence the cover type is the first and fifth quintile of the features Elevation and Horizontal distance to hydrology. Indeed, all the top ten windows contain those two features, and either their first or fifth quintile. As we can see in Table 7, the influence of the fifth quintile of , the top window, is given by the fact that no terrain of the types 3, 4, 5 and 6 is in this quintile. Note that, again, our approach allows a better interpretation of the selected features by the analysis of the local dependence between the features and the cover type.
Table 8.
Features selected applying Algorithm 2 to the Covertype dataset.
Finally, applying Algorithm 3 we choose the profiles displayed in Table 9 for . We see, for example, that the profile most prone to be of type 1 is and of type 3 is . Note that it does not mean that most of the terrains with these profiles are of type 1 and 3, but rather that the probability of a terrain with these profiles being of types 1 and 3, respectively, is 87% and 396% greater than the probability of a terrain for which we do not know the profile. Therefore, we see again the difference between the LLDS approach and the classification problem. In the LLDS approach, given a profile, we are interested in determining the type of which the conditional probability given the profile is greater than the marginal probability, while in the classification problem, given a profile, we are interested in determining the type for which the conditional probability given the profile is the greatest.
Table 9.
Profiles selected applying Algorithm 3 to the Covertype dataset for .
As an example, suppose the joint distribution that generated the LF of Table 7 and the profile Quintile 1. We have that the maximum conditional probability given this profile is the probability of type 2 (), while the maximum lift is that of type 4, although its conditional probability is only . However, the conditional probability of type 4 given the profile, even though absolutely small, is relatively great: it is 5 times the marginal probability . Therefore, on the one hand, if there is a new terrain whose profile is , we classify it as being of type 2. On the other hand, if we want to sample terrains from a population and are interested in maximizing the number of terrains of type 4, we may sample from the population with profile instead of the whole population, expecting to sample four times more terrains of type 4.
5. Final Remarks
The feature selection algorithms based on the LLDS extend the classical approach to feature selection to a higher resolution one, as they take into account the local dependence between the features and the variable of interest. Indeed, classical feature selection may be performed by walking through a tree in which each node is a vector of features, i.e., a BLFS, while feature selection based on the LLDS is established by walking through an extended tree, i.e., a CBLOP, in which inside each node there is another tree, that represents the windows of the features, as displayed in the example in Figure 1. Therefore, feature selection based on the LLDS increases the reach of feature selection algorithms to a new variety of applications.
The LLDS may treat a problem that is the opposite of that of classification, i.e., when we are interested in, given a class y, finding the profile of which we may sample from its population in order to maximize the number of instances of class y. Indeed, in the classification problem we want to do the exact opposite: classify a instance with known profile into a class of Y. Therefore, although LLDS tools may also be applied to the classification problem (as they are in the literature), they are of great importance in problems that we may call the reverse engineering of the classification one. Thus, our approach broadens the application of feature selection algorithms to a new set o problems by the extension of their search spaces from BLFs to CBLOPs.
The algorithms proposed in this paper may be optimized in order to not walk through the entire CBLOP, as its size increases exponentially with the number of features, so that the algorithm may not be computable for a great number of features. Moreover, the algorithms may be subjected to overfitting if the sample size is relatively small, so that their search space may be restricted. The methods of [1,2,3,4,5,6,7,9,10,22,23,24,25,26,27,28,29], for example, may be adapted to the multi-resolution algorithms in order to optimize them. Furthermore, the properties of the coefficients and the LF must be studied in a theoretical framework, in order to establish their variances, sample distributions and develop statistical methods to estimate and test hypothesis about them.
The LLDS adapts classical measures, such as the MI and the Kullback-Leibler Divergence, into coherent dependence coefficients that assess the dependence between random variables in multiple resolutions, presenting a wide view of it. As it does not make any assumption about the dependence kind, the LLDS measures the raw dependence between the variables and, therefore, may be relevant for numerous purposes, being feature selection just one of them. We believe that the algorithms proposed in this paper, and the LLDS in general, bring advances to the state-of-art in dependence measuring and feature selection, and may be useful in various frameworks.
Supplementary Materials
The following are available online at http://www.mdpi.com/1099-4300/20/2/97/s1: an R [34] package called localift that performs the algorithms proposed by this paper; an R object that contains the results of the algorithms used to analyse the performances dataset; and an R code that apply the algorithms to the Congressional Voting Records and Covertype datasets.
Acknowledgments
We would like to thank Antonio Carlos Hernandes who kindly provided the performances dataset used in the application section. The Covertype dataset is Copyrighted 1998 by Jock A. Blackard and Colorado State University.
Author Contributions
Diego Marcondes wrote the paper and analysed the data of the application section. All authors substantially contributed to the theoretical content of the paper. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| BLFS | Boolean lattice of feature sets |
| CBLOP | Collection of Boolean lattices of ordered pairs |
| CE | Conditional Entropy |
| LF | Lift Function |
| LLDS | Local Lift Dependence Scale |
| MI | Mutual Information |
| SFFS | Sequential Forward Floating Selection |
| SFS | Sequential Forward Selection |
References
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Lal, T.; Chapelle, O.; Weston, J.; Elisseeff, A. Embedded methods. In Feature Extraction. Studies in Fuzziness and Soft Computing; Guyon, I., Nikravesh, M., Gunn, S., Zadeh, L.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 207, pp. 137–165. [Google Scholar]
- John, G.H.; Kohavi, R.; Pfleger, K. Irrelevant features and the subset selection problem. In Proceedings of the Eleventh International Conference on International Conference on Machine Learning, New Brunswick, NJ, USA, 10–13 July 1994; pp. 121–129. [Google Scholar]
- Hall, M.A. Correlation-based Feature Selection for Discrete and Numeric Class Machine Learning. In Proceedings of the Seventeenth International Conference on Machine Learning, Stanford, CA, USA, 29 June 29–2 July 2000; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2000; pp. 359–366. [Google Scholar]
- Das, S. Filters, Wrappers and a Boosting-Based Hybrid for Feature Selection. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 74–81. [Google Scholar]
- Yu, L.; Liu, H. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 856–863. [Google Scholar]
- Martins, D.C.; Cesar, R.M.; Barrera, J. W-operator window design by minimization of mean conditional entropy. Pattern Anal. Appl. 2006, 9, 139–153. [Google Scholar] [CrossRef]
- Ris, M.; Barrera, J.; Martins, D.C. U-curve: A branch-and-bound optimization algorithm for U-shaped cost functions on Boolean lattices applied to the feature selection problem. Pattern Recognit. 2010, 43, 557–568. [Google Scholar] [CrossRef]
- Atashpaz-Gargari, E.; Reis, M.S.; Braga-Neto, U.M.; Barrera, J.; Dougherty, E.R. A fast Branch-and-Bound algorithm for U-curve feature selection. Pattern Recognit. 2018, 73, 172–188. [Google Scholar] [CrossRef]
- Mitra, P.; Murthy, C.; Pal, S.K. Unsupervised feature selection using feature similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 301–312. [Google Scholar] [CrossRef]
- Lichman, M. UCI Machine Learning Repository, 2013. Available online: http://archive.ics.uci.edu/ml/index.php (accessed on 26 January 2018).
- Coppock, D.S. Why Lift? Data Modelling and Mining. 2002. Available online: https://www.information-management.com/news/why-lift (accessed on 26 January 2018).
- Tufféry, S.; Riesco, R. Data Mining and Statistics for Decision Making; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Urbana, IL, USA, 1949; Volume 29. [Google Scholar]
- Bouma, G. Normalized (Pointwise) Mutual Information in Collocation Extraction. 2009. Available online: https://svn.spraakdata.gu.se/repos/gerlof/pub/www/Docs/npmi-pfd.pdf (accessed on 26 January 2018).
- Role, F.; Nadif, M. Handling the Impact of Low Frequency Events on Co-occurrence based Measures of Word Similarity. In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval, Paris, France, 26–29 October 2011; pp. 226–231. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Deng, L.Y. The Cross-Entropy Method: A Unified Approach to Combinatorial Optimization, Monte-Carlo Simulation, and Machine Learning; Taylor & Francis: Boca Raton, FL, USA, 2006. [Google Scholar]
- Neto, U.M.B.; Dougherty, E.R. Error Estimation for Pattern Recognition; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar]
- Amaldi, E.; Kann, V. On the approximability of minimizing nonzero variables or unsatisfied relations in linear systems. Theor. Comput. Sci. 1998, 209, 237–260. [Google Scholar] [CrossRef]
- Marill, T.; Green, D. On the effectiveness of receptors in recognition systems. IEEE Trans. Inf. Theory 1963, 9, 11–17. [Google Scholar] [CrossRef]
- Whitney, A.W. A direct method of nonparametric measurement selection. IEEE Trans. Inf. Theory 1971, 100, 1100–1103. [Google Scholar] [CrossRef]
- Pudil, P.; Novovičová, J.; Kittler, J. Floating search methods in feature selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Somol, P.; Pudil, P.; Novovičová, J.; Paclık, P. Adaptive floating search methods in feature selection. Pattern Recognit. Lett. 1999, 20, 1157–1163. [Google Scholar] [CrossRef]
- Somol, P.; Novovičová, J.; Pudil, P. Flexible-hybrid sequential floating search in statistical feature selection. Structural, Syntactic, and Statistical Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2006; pp. 632–639. [Google Scholar]
- Nakariyakul, S.; Casasent, D.P. An improvement on floating search algorithms for feature subset selection. Pattern Recognit. 2009, 42, 1932–1940. [Google Scholar] [CrossRef]
- Narendra, P.M.; Fukunaga, K. A branch and bound algorithm for feature subset selection. IEEE Trans. Comput. 1977, 9, 917–922. [Google Scholar] [CrossRef]
- Ris, M.S. Minimization of Decomposable in U-Shaped Curves Functions Defined on Poset Chains—Algorithms and Applications. Ph.D. Thesis, Institute of Mathematics and Statistics, University of Sao Paulo, Sao Paulo, Brazil, 2012. (In Portuguese). [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Śmieja, M.; Warszycki, D. Average information content maximization—A new approach for fingerprint hybridization and reduction. PLoS ONE 2016, 11, e0146666. [Google Scholar] [CrossRef] [PubMed]
- Kwak, N.; Choi, C.H. Input feature selection by mutual information based on Parzen window. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1667–1671. [Google Scholar] [CrossRef]
- Mahalanobis, P.C. On the generalized distance in statistics. Proc. Natl. Inst. Sci. (Calcutta) 1936, 2, 49–55. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2016. [Google Scholar]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).