1. Introduction
Game theory has enjoyed a close relationship with the topology of dynamical systems from its very beginnings. Nash’s 1950 brilliant proof of the universality of equilibria is based on fixed point theorems—the most sophisticated class of topological theorems of that time, stating that all continuous dynamics have a fixpoint. Recent work in algorithmic game theory has brought these two concepts—Nash equilibria and fixpoints—even closer by establishing that they are in a formal sense computationally equivalent [
1].
The Nash equilibrium is the foremost solution concept in game theory—the standard notion of
outcome of the game. However, natural dynamics do not always converge to a Nash equilibrium, and there are results suggesting that no dynamics can converge to the Nash equilibrium in every game [
2,
3]. It is therefore interesting to ask,
to which object do natural dynamics converge?One way to answer this question is suggested by the fundamental theorem of dynamical systems, the pinnacle of modern dynamical systems theory introduced in the seminal work of Conley [
4] in 1978. The theorem states that, given an arbitrary initial condition, a dynamical system converges to a set of states with a natural recurrence property akin to periodicity, explained next.
Conley’s concept of recurrence—a subtle generalization of cycling and periodicity—is elegant in a way that should appeal to any student of computation, and especially cryptography. Imagine that Alice is trying to simulate the trajectory of a given system on a powerful computer. Every time she computes a single iteration of the dynamical process, there is a rounding error . Furthermore, imagine that inside the machine there is an infinitely powerful demon, Bob who, before the next computational step is taken, rounds the result in arbitrary fashion of his own choosing (but within distance of the actual outcome). If, no matter how high the accuracy of Alice’s computer is, Bob can always fool her into believing that the starting point is periodic, then this point is a chain recurrent point.
Naturally, periodic points are chain recurrent, since Bob does not have to intervene. Therefore, equilibria are also chain recurrent since they are trivially periodic. On the other hand, there exist chain recurrent points that are not periodic. Imagine for example a system that is defined as the product of two points moving at constant angular speed along circles of equal length, but where the ratio of the speed of the two points is an irrational number, e.g., . This system will, after some time, get arbitrarily close to its initial position and a slight bump of the state by Bob would convince Alice that the initial condition is periodic. Thus, chain recurrent points are the natural generalization of periodic points in a world where measurements may have arbitrarily high, but not infinite, accuracy. The surprising implication of the fundamental theorem of dynamical system is that this generalization is not just necessary when arguing about computational systems but also sufficient. It captures all possible limit behaviors of the system.
How does this connect back to game theory? We can apply the fundamental theorem of dynamical systems on the system
that emerges by coupling game
G and learning dynamics
f. (For most of this paper, we take
f to be replicator dynamics [
5], that is, the continuous-time version of Multiplicative Weights Update [
6]). This defines a new solution concept, the set of chain recurrent points of the system, which we denote
or simply
.
Our results.We characterize the set of chain recurrent points for replicator dynamics for two classic and well-studied classes of games, zero-sum games and potential games (as well as variants thereof). For zero-sum games with fully mixed (i.e., interior) Nash equilibria, the set of chain recurrent points of replicator dynamics is equal to the whole state space (i.e., is all (randomized) strategy profiles). For potential games, is minimal coinciding with the set of equilibria/fixed points of the (replicator) dynamics. We discuss how our results are robust as they straightforwardly extend to natural variants of the above games, i.e., affine/network zero-sum games and weighted potential games. Thus, an interesting high level picture emerges. In games with strongly misaligned incentives, tends to be large implying unpredictability of the dynamics, whereas in games with strongly aligned incentives tends to be small implying that learning/adaptation is easier in collaborative environments.
Zero-sum games. In zero-sum games, we show that, if a fully mixed Nash equilibrium exists (like in Matching Pennies), then the set of chain recurrent states is the whole state space (Theorem 6). This seems to fly in the face of the conventional game theoretic wisdom that in a zero-sum game with a unique maxmin/Nash equilibrium, all natural, self-interested dynamics will “solve” the game by converging swiftly to the maxmin. It is well known that convergence is restored if one focuses not on behavior, but on the time-average of the players’ utilities, strategies [
7]; however, time averages are a poor way to capture the actual system behavior.
More generally, in zero-sum games with fully mixed (interior) equilibria replicator dynamics exhibit constants of motion [
5]. Combining this with the fact that replicator dynamics can be shown to preserve “volume”, this implies that almost all initial conditions are (Poincaré) recurrent. That is, almost all initial conditions return arbitrarily close to themselves. Rounding errors can cause the system to jump from one trajectory to a nearby one. No matter how small these jumps are, one can fully migrate from any point of the phase space to any other, rendering the system completely unpredictable in the presence of an arbitrarily small and infrequent perturbation.
(Weighted) potential games. On the contrary, for potential games, it is already well known that replicators (and many other dynamics) converge to equilibria (e.g., [
5,
8]). As the name suggests, natural dynamics for these games have a Lyapunov/potential function that strictly decreases as long as we are not at equilibrium. As we show, unsurprisingly, this remains true for the more expansive class of weighted potential games. One could naturally come to hypothesize that, in such systems, known in dynamical systems theory as
gradient-like, the chain recurrent set must be equal to the set of equilibria. However, this is not the case as one can construct artificial counterexamples where the limit points of each trajectories have a unique equilibrium but the whole statespace is chain recurrent.
Here is a counterexample that is due to Conley [
4]. Imagine a continuous dynamical system on the unit square, where all points on the boundary are equilibria and all other trajectories flow straight downwards. This is a gradient-like system since the height
y is always strictly decreasing unless we are at an equilibrium. Nevertheless, by allowing hops of size
, for any
, we can return from every point to itself. Starting from any
, we move downwards along the flow, and when we get close enough to the boundary, we hop to the point
. Afterwards, we use these hops to traverse the boundary until we reach point
, and then one last hop to
places us on a trajectory that will revisit our starting point. Hence, once again, the whole state space is chain recurrent despite the fact that the system has a Lyapunov function. The situation is reminiscent of the game of snakes and ladders. The interior states correspond to snakes that move you downwards, whereas the boundary and the
perturbations work as ladders that you can traverse upwards. Unlike the game of snakes and ladders, however, there is no ending state in this game and you can keep going in circles indefinitely.
In the case of (weighted) potential games, we show that such contrived counterexamples cannot arise (Theorem 8). The key component to this proof is to establish that the set of values of the potential function over all system equilibria is of zero measure. We prove this by using tools from analysis (Sard’s theorem). Thus, we establish that, as we decrease the size of allowable perturbations, eventually these perturbations do not suffice for any new recurrent states to emerge and thus the set of equilibria and chain recurrent points of replicator dynamics coincide.
2. Related Work
Studying dynamics in game theoretic settings is an area of research that is effectively as old as game theory itself. Nevertheless, already from its very beginnings with the work of Brown and Robinson [
9,
10] on dynamics in zero-sum games, the study of dynamics in game theory played a second fiddle to the main tune of Nash equilibria. The role of dynamics in game theory has predominantly been viewed as a way to provide validation and computational tools for equilibria.
At the same time, starting with Shapley [
11], there has been an ever increasing trickle of counterexamples to the dominant Nash equilibrium paradigm that has been building up to a steady stream within the algorithmic game theory community ([
12,
13,
14,
15,
16,
17,
18]). Several analogous results are well known within evolutionary game theory [
5,
19]. Replicator dynamics [
20] is known to be a good model of stochastic learning behavior under frequent play and slow movement creating a formal bridge between these non-equilibrium results. These observations do not fit the current theoretical paradigm.
Recent intractability results in terms of computing equilibria [
1,
21] have provided an alternate, more formal tone to this growing discontent with the Nash solution concept, however, the key part is still missing. We need a general theory that fully encompasses all these special cases.
The definition of chain recurrent sets as well as a reference to the fundamental theorem of dynamical systems have been actually introduced in what is currently the definitive textbook reference of evolutionary game theory [
19]; however, the treatment is rather cursory, limited to abridged definitions and references to the dynamical systems literature. No intuition is built and no specific examples are discussed.
One recent paper [
3] is quite related to the issues examined here. In this work, Benaïm, Hofbauer, and Sorin establish stability properties for chain recurrence sets in general dynamical systems. Applications to game theory are discussed. It is shown that there exist games where chain recurrent sets for learning dynamics can be more inclusive than Nash. However, no explicit characterization for these sets is established and all fully mixed (i.e., interior) initial conditions actually converge to Nash. Connections between chain recurrence sets in potential games and equilibria are discussed without formal proofs. Our results provide complete characterizations of chain recurrent sets and reflect the realized behavior given generic initial states. We believe that chain recurrent sets is a central object of interest whose properties need to be carefully analyzed and we set up a series of analytical goals along these lines in the future work section.
Follow-up work: In follow-up work to our conference version paper [
22], Mertikopoulos, Piliouras and Papadimitriou [
18] showed how to generalize the proofs of recurrent behavior for replicator dynamics in (network) zero-sum games by Piliouras and Shamma [
23] to more general dynamics, i.e., the class of continuous time variants of follow the regularized leader (FTRL) dynamics. Bailey and Piliouras [
24] studied the discrete-time version of FTRL dynamics in (network) zero-sum games (including Multiplicative Weights Update) and showed how they diverge away from equilibrium and towards the boundary. Piliouras and Schulman [
25] show how to prove periodicity for replicator dynamics in the cases of non-bilinear zero-sum games. Specifically, they consider games that arise from the competition between two teams of agents where all the members in the team have identical interests but where the two teams have opposing interests (play a constant sum game). Periodicity for replicator dynamics has also been established for triangle-network zero-sum games [
26]. Recurrence arguments for zero-sum games can also be adapted in the case of dynamically evolving games [
27]. FTRL dynamics can be adapted so that they converge in bilinear [
28] (or even more general non-convex-concave [
29]) saddle problems. Such algorithms can be used for training algorithms for generative adversarial neural networks (GANs). Finally, Balduzzi et al. show how to explicitly “correct” the cycles observed in dynamics of zero-sum games by leveraging connections to Hamiltonian dynamics and use these insights to design different algorithms for training GANs [
30].
3. Preliminaries
3.1. Game Theory
We denote an n-agent game as . Each agent chooses a strategy from its set of available strategies . Given a strategy profile , the payoff to each agent i is defined via its utility function . Every potential game has a potential function , such that at any strategy profile s and for each possible deviation of agent i from strategy to : . A weighted potential game has a potential function , such that at any strategy profile s and for each possible deviation of agent i from strategy to : for some agent specific . Wlog we can assume for all agents i, by scaling as needed. Naturally, the definitions of strategy and utility can be extended in the usual multilinear fashion to allow for randomized strategies. In that case, we usually overload notation in the following manner: if is a mixed strategy for each agent i, then we denote by the expected utility of agent i, . We denote by the probability that agent i assigns to strategy in (mixed) strategy profile x. To simplify notation, sometimes instead of we merely write .
3.2. Replicator Dynamics
The replicator equation [
31,
32] is described by:
where
is the proportion of type
i in the population,
is the vector of the distribution of types in the population,
is the fitness of type
i, and
is the average population fitness. The state vector
p can also be interpreted as a randomized strategy. Replicator dynamics enjoy connections to classic models of ecological growth (e.g., Lotka–Volterra equations [
5]), as well as discrete time dynamics, e.g., Multiplicative Weights Update algorithm (MWU) [
6,
8,
33].
Remark 1. In the context of game theory will be replaced with , i.e., the probability that agent i plays strategy at time t.
Replicator dynamics as the “fluid limit” of MWU. The connection to Multiplicative Weight Updates (MWU) [
6] is of particular interest and hence it is worth reviewing briefly here. MWU is an online learning dynamics where the decision maker keeps updating a weight vector which can be thought informally as reflecting the agent’s confidence that the corresponding actions will perform well in the future. In every time period, the weights are updated multiplicatively (as the name suggests)
. In the next time period, the agent chooses each action with probability proportional to its weight. As long as the learning rate
is a small constant (or even better decreasing with time, e.g., at a rate
), then it is well known that MWU has good performance guarantees in online (or even adversarial) environments, i.e., low regret [
34]. When all agents in a game apply MWU with learning parameter
(MWU(
)), this defines a deterministic map from the space of weights (or after normalization from the space of probability distributions over actions) to the space of probability distributions over actions. If we define this map from the space of mixed strategy profiles to itself as
then the replicator vector field corresponds to the coefficient of the first order term in the Taylor expansion of
f as a function of
. In other words, the replicator vector field is equal to
, a first order “smooth” approximation of the expected motion of the discrete time map MWU(
). This argument was first exploited in [
8] to study MWU dynamics in potential games.
Both replicator and MWU have strong connections to entropy. They can be interpreted as solutions to a softmax problem where the agent chooses the (mixed) strategy that maximizes his expected payoff (if each action was assigned value equal to its accumulated payoff) minus the (negative) entropy of the strategy. The (negative) entropy of the distribution is employed as a convex regularizer encouraging the algorithm to pick more “mixed” strategies. These connections are discussed in more detail in the following papers [
18,
35].
3.3. Topology of Dynamical Systems
In an effort to make our work as standalone as possible, we provide an introduction to some key concepts in topology of dynamical systems. The presentation follows along the lines of [
36], the standard text in evolutionary game theory, which itself borrows material from the classic book by Bhatia and Szegö [
37]. The exposition on chain recurrence follows from [
38].
Definition 1. A flow on a topological space X is a continuous function such that
- (i)
is a homeomorphism for each .
- (ii)
for all and all .
The second property is known as the group property of the flows. The topological space X is called the phase (or state) space of the flow.
Definition 2. Let X be a set. A map (or discrete dynamical system) is a function .
Typically, we write for and denote a flow by , where the group property appears as for all and . Sometimes, depending on context, we use the notation to also signify the map for a fixed real number t. The map is useful to relate the behavior of a flow to the behavior of a map.
Definition 3. If is a flow on a topological space X, then the function defines the time-one map of .
Since our state space is compact and the replicator vector field is Lipschitz-continuous, we can present the unique solution of our ordinary differential equation by a flow , where X denotes the set of all mixed strategy profiles. Fixing starting point defines a function of time which captures the trajectory (orbit, solution path) of the system with the given starting point. This corresponds to the graph of , i.e., the set .
If the starting point x does not correspond to an equilibrium, then we wish to capture the asymptotic behavior of the system (informally the limit of when t goes to infinity). Typically, however, such functions do not exhibit a unique limit point so instead we study the set of limits of all possible convergent subsequences. Formally, given a dynamical system with flow and a starting point , we call point an -limit point of the orbit through x if there exists a sequence such that Alternatively, the -limit set can be defined as:
Definition 4. We say a point is a recurrent point if there exists a sequence such that , i.e., if .
We denote the boundary of a set X as bd(X) and the interior of S as . In the case of replicator dynamics where the state space X corresponds to a product of agent (mixed) strategies, we will denote by the projection of the state on the simplex of mixed strategies of agent i. In our replicator system, we embed our state space with the standard topology and the Euclidean distance metric.
3.3.1. Liouville’s Formula
Liouville’s formula can be applied to any system of autonomous differential equations with a continuously differentiable vector field on an open domain of . The divergence of at is defined as the trace of the corresponding Jacobian at x, i.e., . Since divergence is a continuous function, we can compute its integral over measurable sets . Given any such set A, let be the image of A under map at time t. is measurable and its volume is . Liouville’s formula states that the time derivative of the volume exists and is equal to the integral of the divergence over :
A vector field is called divergence free if its divergence is zero everywhere. Liouville’s formula trivially implies that volume is preserved in such flows.
3.3.2. Poincaré’s Recurrence Theorem
Poincaré [
39] proved that in certain systems almost all trajectories return arbitrarily close to their initial position infinitely often. Specifically, if a flow preserves volume and has only bounded orbits, then for each open set there exist orbits that intersect the set infinitely often.
Theorem 1 ([
39,
40])
. Let be a finite measure space and let be a measure-preserving transformation. Then, for any , the set of those points x of E such that for all has zero measure. That is, almost every point of E returns to E. In fact, almost every point returns infinitely often. Namely, If we take X to be a separable metric space as well as a finite measure space, then we can conclude that almost every point is recurrent. Cover X by countably many balls of radius , and apply the previous theorem to each ball. We conclude that almost every point of X returns to within an of itself. Since is arbitrary, we conclude that almost every point of X is recurrent.
Corollary 1. Let be a separable metric space as well as a finite measure space and let be a measure-preserving transformation. Then, almost every point of X is recurrent.
3.3.3. Homeomorphisms and Conjugacy of Flows
A function
f between two topological spaces is called a
homeomorphism if it has the following properties:
f is a bijection,
f is continuous, and
f has a continuous inverse. A function
f between two topological spaces is called a
diffeomorphism if it has the following properties:
f is a bijection,
f is continuously differentiable, and
f has a continuously differentiable inverse. Two flows
and
are conjugate if there exists a homeomorphism
such that for each
and
:
Furthermore, two flows
and
are
diffeomorhpic if there exists a diffeomorphism
such that for each
and
. If two flows are diffeomorphic, then their vector fields are related by the derivative of the conjugacy. That is, we get precisely the same result that we would have obtained if we simply transformed the coordinates in their differential equations [
41].
3.4. The Fundamental Theorem of Dynamical Systems
In order to characterize chain recurrent sets of replicator dynamics in games, we will exploit some tools and theorems developed about chain recurrence in more general dynamical systems. The standard formulation of the fundamental theorem of dynamical systems is built on the following set of definitions, based primarily on the work of Conley [
4].
Definition 5. Let be a flow on a metric space . Given , , and , an -chain from x to y with respect to and d is a pair of finite sequences in X and in , denoted together by such thatfor . Definition 6. Let be a flow on a metric space . The forward chain limit set of with respect to and d is the set Definition 7. Let be a flow on a metric space . Two points are chain equivalent with respect to and d if and .
Definition 8. Let be a flow on a metric space . A point is chain recurrent with respect to and d if x is chain equivalent to itself. The set of all chain recurrent points of , denoted , is the chain recurrent set of .
One key definition is the notion of a complete Lyapunov function. The game theoretic analogue of this idea is the notion of a potential function in potential games. In a potential game, as long as we are not at an equilibrium, the potential is strictly decreasing guiding the dynamics towards the standard game theoretic solution concept, i.e., equilibria. The notion of a complete Lyapunov function switches the target solution concept from equilibria to chain recurrent points. More formally:
Definition 9. Let be a flow on a metric space X. A complete Lyapunov function for is a continuous function such that
- (i)
is a strictly decreasing function of t for all ,
- (ii)
for all the points x, y are chain equivalent with respect to if and only if ,
- (iii)
is nowhere dense.
The powerful implication of the fundamental theorem of dynamical systems is that complete Lyapunov functions always exist. In game theoretic terms, every game is a “potential” game, if only we change our solution concept from equilibria to chain recurrent sets.
Theorem 2 ([
4])
. Every flow on a compact metric space has a complete Lyapunov function. 3.5. Chain Components
Definition 12. The relation ∼ defined by if and only if x is chain equivalent to y is an equivalence relation on the chain recurrent set of a flow on a metric space. An equivalence class of the chain equivalence relation for is a chain component of .
One key insight of Conley was the discovery of this formal and intuitive connection between equivalence classes and connectedness.
Theorem 4 ([
4,
38])
. The chain components of a flow on a compact metric space are the connected components of the chain recurrent set of the flow. This interplay between chain transitivity and connectedness motivates the reference to the equivalence classes of the chain equivalence relation as chain components. Furthermore, chains components are dynamically irreducible, i.e., they cannot be partitioned more finely in a way that respects the system dynamics. To make this notion precise, we need the notion of chain transitivity introduced by Conley [
4].
Definition 13. Let be a flow on a metric space X. A set is chain transitive with respect to if A is a nonempty closed invariant set with respect to such that for each , and there exists an -chain from x to y.
Theorem 5 ([
38])
. Every chain component of a flow on a compact metric space is closed, connected, and invariant with respect of the flow. Moreover,Every chain component of a flow on a metric space is chain transitive with respect to the flow.
Every chain transitive set with respect to a flow on a metric space is a subset of a unique chain component of the flow.
If A and B are chain transitive with respect to a flow on a metric space, and C is the unique chain component containing A, then .
4. Chain Recurrent Sets for Zero-Sum Games
Zero-sum games are amongst the most well studied class of games within game theory. Equilibria here are classically considered to completely “solve” the setting. This is due to the fact that the equilibrium prediction is essentially unique, Nash computation is tractable, and many natural classes of learning dynamics are known to “converge weakly” to the set of Nash equilibria.
The notion of weak convergence encodes that the time average of the dynamics converge to the equilibrium set. However, this linguistic overloading of the notion of convergence is unnatural and arguably can lead to a misleading sense of certainty about the complexity that learning dynamics may exhibit in this setting. For example, would it be meaningful to state that the moon “converges weakly” to the earth instead of stating that e.g., the moon follows a trajectory that has earth at its center?
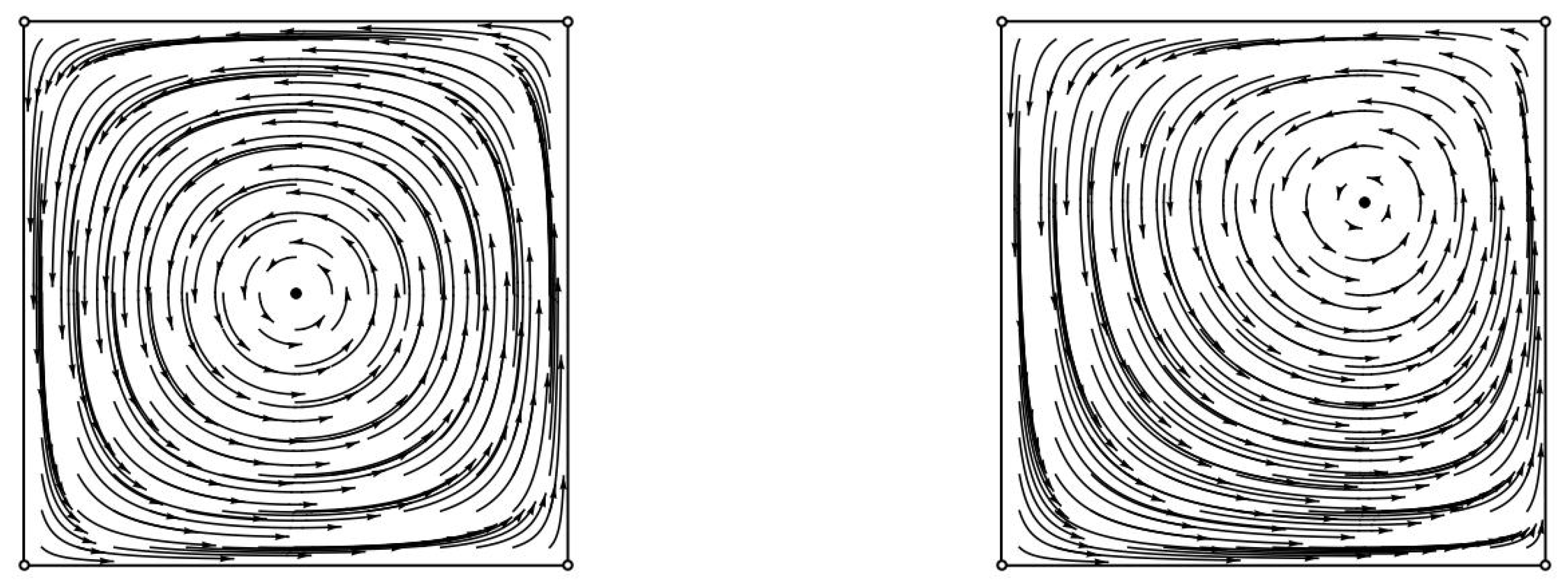
The complexity and unpredictability of the actual behavior of dynamics becomes apparent when we characterize the set of chain recurrent points even for the simplest zero-sum games, Matching Pennies. Despite the uniqueness and symmetry of the Nash equilibrium, it is shown to not capture fully the actual dynamics. The set of chain recurrent points is the whole strategy space. This means that, in the presence of arbitrary small noise, replicator dynamics can become completely unpredictable. Even in an idealized implementation without noise, there exist absolutely no initial conditions that converge to a Nash equilibrium. This result extends to all zero-sum games that have at least one interior Nash equilibrium, i.e., a mixed strategy Nash equilibrium where both agents play all of their strategies with positive probability.
To argue this, we will use two lemmas. The first lemma, which follows from previous work [
5,
23], argues that the Kullback–Leibler divergence (KL-divergence) from the evolving state to the Nash equilibrium is constant for all trajectories. The second lemma, which is a strengthening of arguments from [
23], argues that in the case of zero-sum games with fully mixed equilibria almost all states are recurrent (see also
Figure 1 and
Figure 2). Their proofs can be found in the
Appendix B.
Lemma 1 ([
5,
23])
. Let φ denote the flow of replicator dynamics when applied to a zero sum game with a fully mixed Nash equilibrium . Given any (interior) starting point then the sum of the KL-divergences between each agent’s mixed Nash equilibrium and his evolving strategy is time invariant. Equivalently, for all t. Lemma 2. Let φ denote the flow of replicator dynamics when applied to a zero sum game with a fully mixed Nash equilibrium. Then, all but a zero-measure set of its initial conditions are recurrent.
The main theorem of this section is the following:
Theorem 6. Let φ denote the flow of replicator dynamics when applied to a zero sum game with a fully mixed Nash equilibrium. Then, the set of chain recurrent points is the whole state space. Its unique chain component is the whole state space.
Proof. By Lemma 2, all but a zero measure set of initial conditions are recurrent (and hence trivially chain-recurrent). By Theorem 5, all chain components and thus the chain recurrent set are closed. By taking closure over the set of all recurrent points, we have that all points in the state space must be chain recurrent. By Theorem 4, since the chain components of a flow on a compact metric space are the connected components of its chain recurrent set, the whole state space is the unique chain component. ☐
It is easy to generalize the above proofs in the case where the two-agent game is a weighted zero-sum game, i.e., in the case where
for some
, where
are the payoff matrices of the two agents. In this case, the weighted sum of the KL-divergences remains constant and the rest of the proof holds as long as the game has a fully mixed Nash equilibrium. In fact, the proof generalizes even in the case where we have a network polymatrix game, where each agent corresponds to a node on a undirected graph and each edge correspond to a zero-sum game. In this case, the sum of the KL divergences of all agents remains constant and the rest of the proof holds as is. See also [
18,
23].
5. Chain Recurrent Sets for Weighted Potential Games
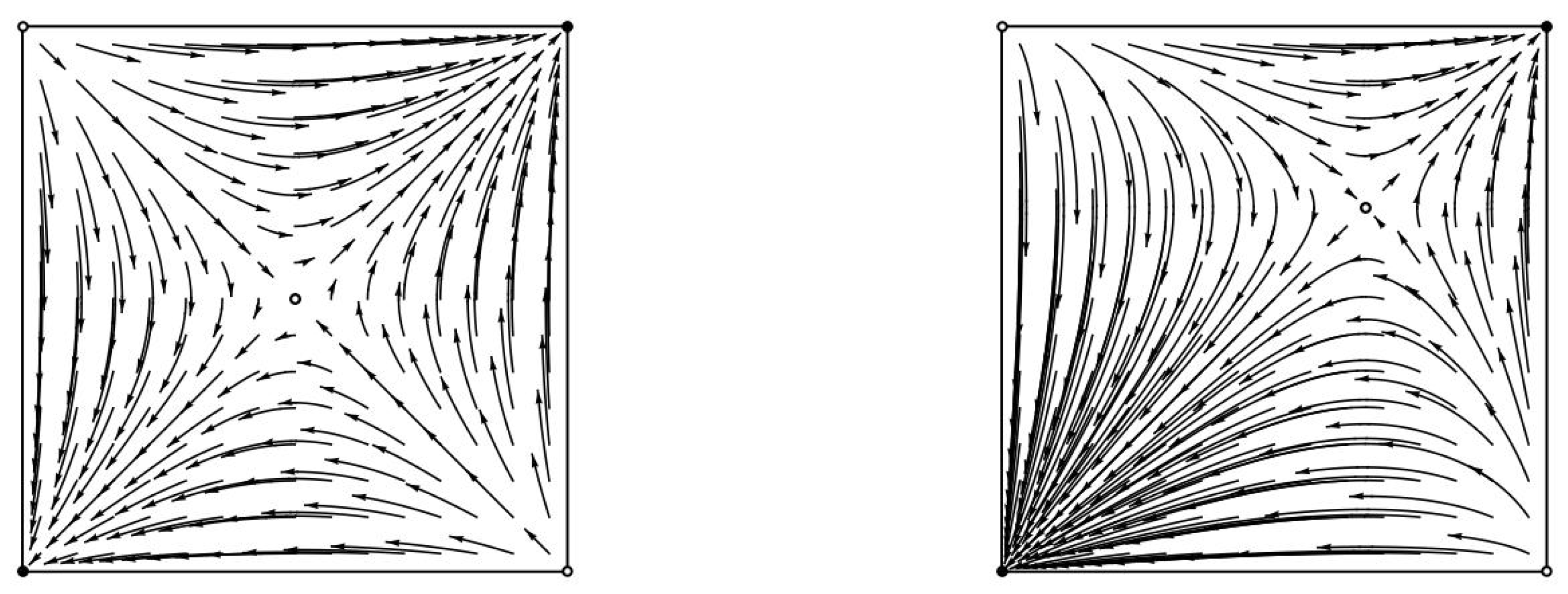
We show that under replicator dynamics the chain recurrent sets for any (weighted) potential games coincides with the set of system equilibria. The set of chain recurrent points of gradient-like systems can be rather complicated and Conley [
4] constructs a specific example of a gradient-like system with a set of equilibria of zero measure where the set of chain recurrent points is the whole state space. Nevertheless, we establish that such contrived examples do not arise in (weighted) potential games. For the proof of this characterization, we will apply the following theorem due to Hurley that we have already discussed in the preliminaries:
Theorem 7 ([
42])
. The chain recurrent set of a continuous (semi)flow on an arbitrary metric space is the same as the chain recurrent set of its time-one map. Theorem 8. Let φ denote the flow of replicator dynamics when applied to a weighted potential game. Then, the set of chain recurrent points coincides with its set of equilibria. The chain components of the flow are exactly the connected components of the set of equilibria.
Proof. Replicator dynamics defines a gradient-like system, where the (expected) value of the potential function always increases unless we are at a fixed point. Specifically, it is well known that in any potential game the utility of any agent at a state
s,
can be expressed as a summation of the potential
and a dummy term
that depends on the strategies of all of the other
agents other than
i. Similarly, by the definition of the weighted potential game for any possible deviation of agent
i from strategy
to
:
and hence for each
and any two possible strategies
of agent
i, we have that
. Hence, these differences are independent of the choice of strategy of agent
i and can be expressed as
, a function of the choices of all other agents. We can now express
and similarly
for mixed strategy profiles. Furthermore, we have that since
, we have that for each
. Therefore, we have that:
where
expresses the replicator vector field. This suffices to argue convergence to equilibria for weighted potential games (expanding an analogous construction in [
8] for congestion/potential games). We will furthermore use this argument to establish that the set of potential values attained at equilibrium points, i.e.,
is of measure zero.
We will argue this by showing that
can be expressed as the finite union of zero measure sets. By the above derivation, we have that the potential is strictly decreasing unless we are at a system equilibrium. Equation (
1) implies that in the places where the potential does not increase, i.e., at equilibria, we have that for all agents
i if
, then
. However, this immediately implies that
. Any equilibrium either corresponds to a pure state, in which cases the union of their potential values is trivially of zero measure or its corresponds to a mixed state where one or more agents is randomizing. In order to account for the possibility of continuums of equilibria, we will use Sard’s theorem that implies that the set of critical values (that is, the image of the set of critical points of a smooth function from one Euclidean space to another) is a null set, i.e., it has Lebesgue measure 0. We define an arbitrary fixed ordering over the strategy set of each agent. Given any mixed system equilibrium
x, the expected value of the potential
can be written as a multi-variate polynomial over all strategy variables
played with strictly positive probability. Since the
’s represent probabilities, we can replace the lexicographically smaller variable
as one minus the summation of all other variables in the support of the current mixed strategy of agent
i. Now, however, all partial derivatives of this polynomial at the equilibrium are equal to zero. Hence, each equilibrium can be expressed as a critical point of a smooth function from some space
to
and hence its image (i.e., its set of potential values) is a zero measure subset of
. It is clear that the set of polynomials needed to capture all equilibria depends only on the choice of strategies for each agent that are played with positive probability and hence although they are exponential many they are finite. Putting everything together the set of potential values attained at equilibria is of zero measure.
Naturally, however, the complement of equilibrium values, which we denote , is dense in the set . Indeed, if is not dense in then there exists a point such that and at the same time y is not an accumulation point of . This implies that there exists a neighborhood of y that contains no points of . We reach contradiction since is of zero measure.
Next, we will use the fact that the complement of equilibrium values of the potential is dense in the set
,
to establish that the chain recurrent points of the time one map
of the flow coincide with the set of equilibria. As we stated above, Hurley [
42] has shown that the chain recurrent points of the flow coincide with those of its time one map and hence the theorem follows.
We have that for all x, with equality if and only if we are at equilibrium. Suppose that we choose a regular value r of the potential, i.e., a value that does not correspond to a fixed point. Let us consider the sets , and . Note that is closed while is open (in the topology defined by the set of strategy profiles) and contained in . If , then . This means that . However, since , the time one map of the flow is a homeomorphism, the fact that is closed yields that .
Any chain recurrent point whose forward orbits meets
is furthermore contained in
[
4,
42]. Let
q be a non-equilibrium point; then, we have that
. However, due to the fact that the images of the potential values of non-equilibrium points are dense in
, we can choose such a value
r such that
. Then
but
and thus
. Therefore,
q cannot be a chain recurrent point of
. As such, it cannot be a chain recurrent point for the replicator flow as well. The theorem follows immediately since all equilibria are trivially chain recurrent points.
Finally, by Theorem 4, since the chain components of a flow on a compact metric space are the connected components of its chain recurrent set and for weighted potential games the chain recurrent set is the set of equilibria, the chain components of the flow are exactly the connected components of the set of equilibria. ☐
6. Discussion and Open Questions
Nash equilibrium is the standard solution concept of game theory. It provides a behavioral model that is applicable to any game. Nevertheless, Nash equilibria are not without criticism. They are hard to compute in practice even in simple games [
43], they are rarely chosen when they are not Pareto efficient [
44], and they rarely agree with the behavior of learning/evolutionary dynamics [
45].
In this paper, we shift the focus away from Nash equilibria and on to the dynamics themselves. However, instead of focusing on the fixed points of the dynamics (which would lead back to Nash equilibria and related notions), we focused on their chain recurrent points. This is a natural relaxation of periodic points that is justified as a solution concept via Conley’s fundamental theorem of dynamical systems [
4].
We analyzed two simple and evocative examples, namely zero-sum games with fully mixed equilibria and weighted potential games under replicator dynamics, the most well known evolutionary dynamics. Interestingly, even in simple games, the set of chain recurrence points gives radically different predictions than Nash equilibria. In games with strongly misaligned incentives (e.g., Matching Pennies), this set tends to be large implying unpredictability of the dynamics, whereas in games with strongly aligned incentives it tends to be small implying that learning/adaptation is fundamentally easier in collaborative environments. Naturally, there is much that needs to be done, and below we sample a few research goals that are immediate, important, and each open ended in its own way.
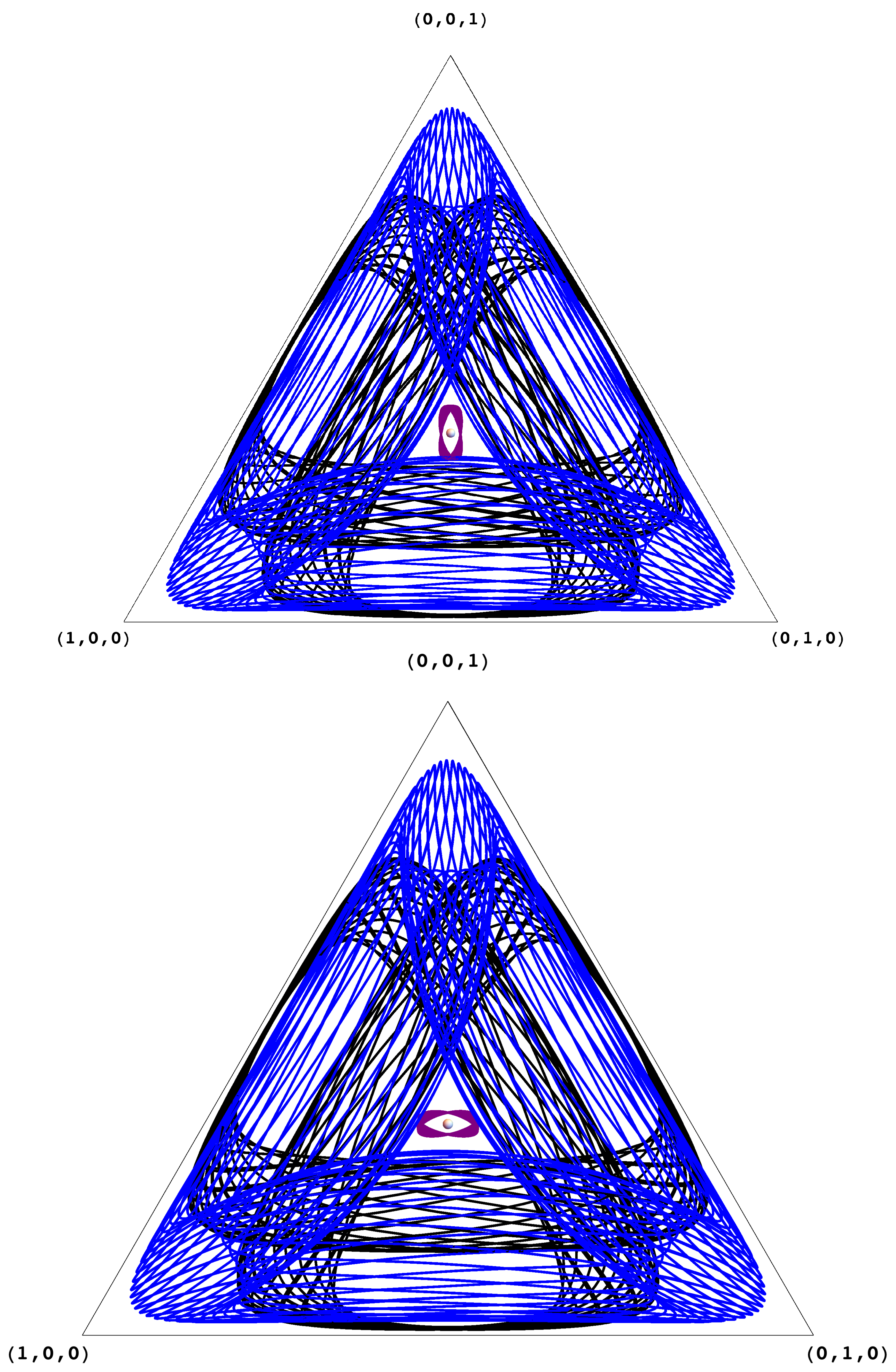
The structure of the Chain Recurrent Set (CRS) and the Chain Components (CCs). A game may have many chain components (for example, the coordination games in
Figure 3 has five). It is not hard to see that the chain components can be arranged as vertices of a directed acyclic graph, where directed edges signify possible transitions after an infinitesimal jump; for the coordination games in
Figure 3, this directed acyclic graph (DAG) has two sinks (the pure Nash equilibria), two sources (the other two pure profiles), and a node of degree 4 (the mixed Nash equilibrium). Identifying this DAG is tantamount to analyzing the game, the generalization of finding its Nash equilibria. Understanding this fundamental structure in games of interest is an important challenge.
Price of Anarchy through Chain Recurrence. We can define a natural distribution over the sink chain components (CCs) of a game, namely, assign to each sink CC the probability that a trajectory started at a (say, uniformly) random point of the state space will end up, perhaps after infinitesimal jumps, at the CC. This distribution, together with the CC’s expected utility, yield a new and productive definition of the average price of anarchy in a game, as well as a methodology for calculating it (see, for example, [
46]).
Inside a Chain Component. Equilibria and limit cycles are the simplest forms of a chain components, in the sense that no “jumps” are necessary for going from one state in the component to another. In Matching Pennies, in contrast, many -jumps are needed to reach the Nash equilibrium, starting from a pure strategy profile. What is the possible range of this form of complexity of a CC?
Complexity. There are several intriguing complexity questions posed by this concept. What is the complexity of determining, given a game and two strategy profiles, whether they belong to the same chain component (CC)? What is the complexity of finding a point in a sink CC? What is the speed of convergence to a CC?
Multiplicative Weights Update and Discrete-time Dynamics through Chain Components. We have explicitly discussed the connection between replicator dynamics and MWU. At the same time, it has recently been shown that for large step-sizes
MWU(
) can behave chaotically even in two agent two strategy coordination/potential games [
17]. Is it possible to understand this chaotic behavior through the lens of CCs? Moreover, can we understand and predict the bifurcation from the convergent behavior of replicator dynamics (i.e., MWU(
) with
) to the chaotic behavior of MWU(
) with large step-size
?
Information Geometry, Social Welfare and the Fundamental Theorem of Dynamical Systems. In the case of zero-sum games, each point of a given replicator trajectory lies at a fixed KL-divergence from the Nash equilibrium. Similar KL-divergence invariant properties also apply in the case of (network) coordination games [
46]. It is not known whether any (information theoretic) invariant properties applies, e.g., to a general two person game for replicator dynamics. The fundamental theorem of dynamical systems shows the existence of a complete Lyapunov function that is invariant on the chain recurrence set (and hence on each chain component) but strictly decreases outside this set. Can we express this function for the replicator flow in a general two-person game as a combination of information theoretic properties (e.g., KL-divergences) and game theoretic properties (e.g., the sum of utilities of all agents)?


{kind=link}
{kind=link}
{kind=link}


