Leveraging Shannon Entropy to Validate the Transition between ICD-10 and ICD-11


Abstract
1. Introduction
2. Materials and Methods
2.1. ICD Mapping Framework
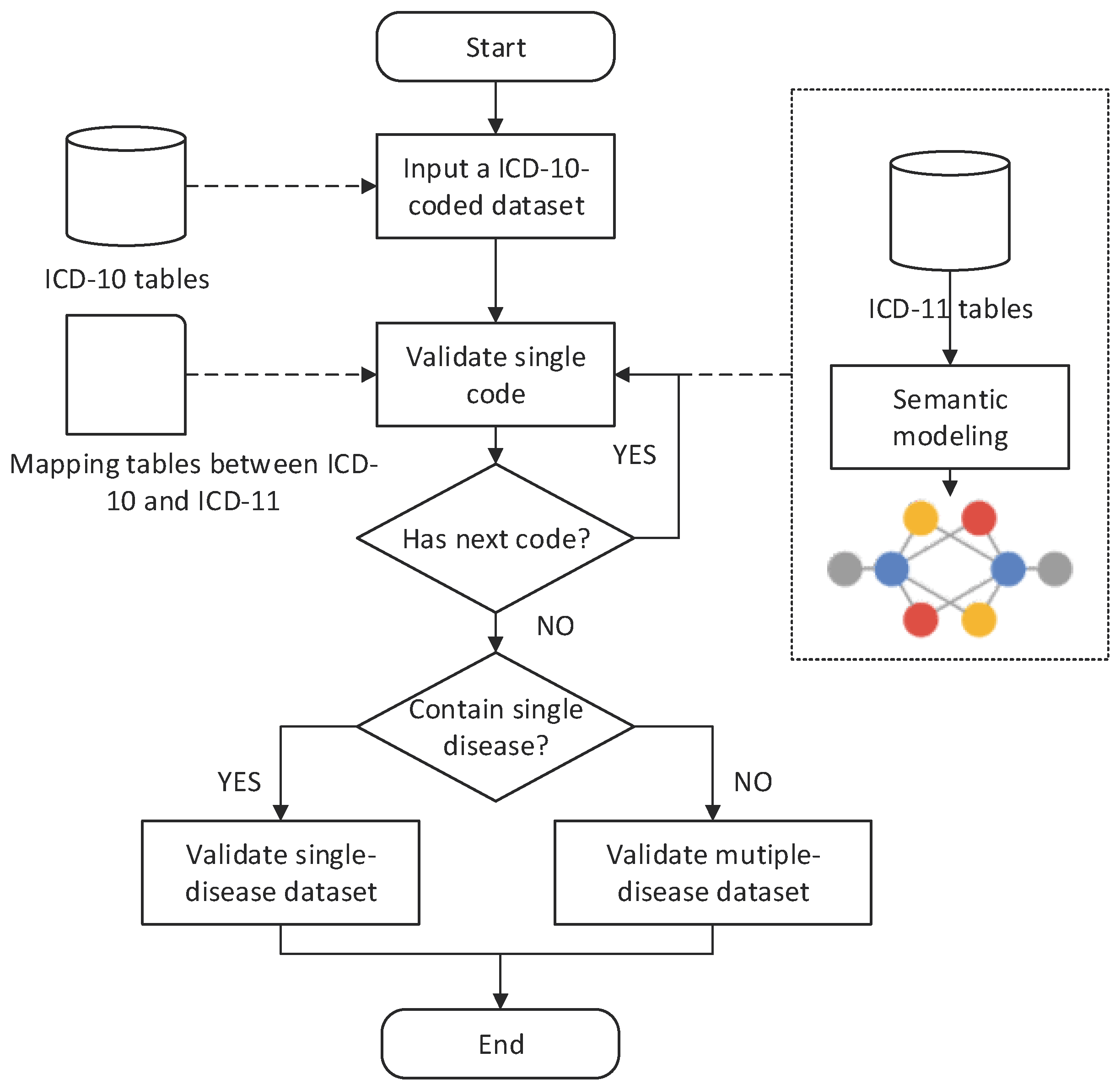
2.2. ICD Validation Methods
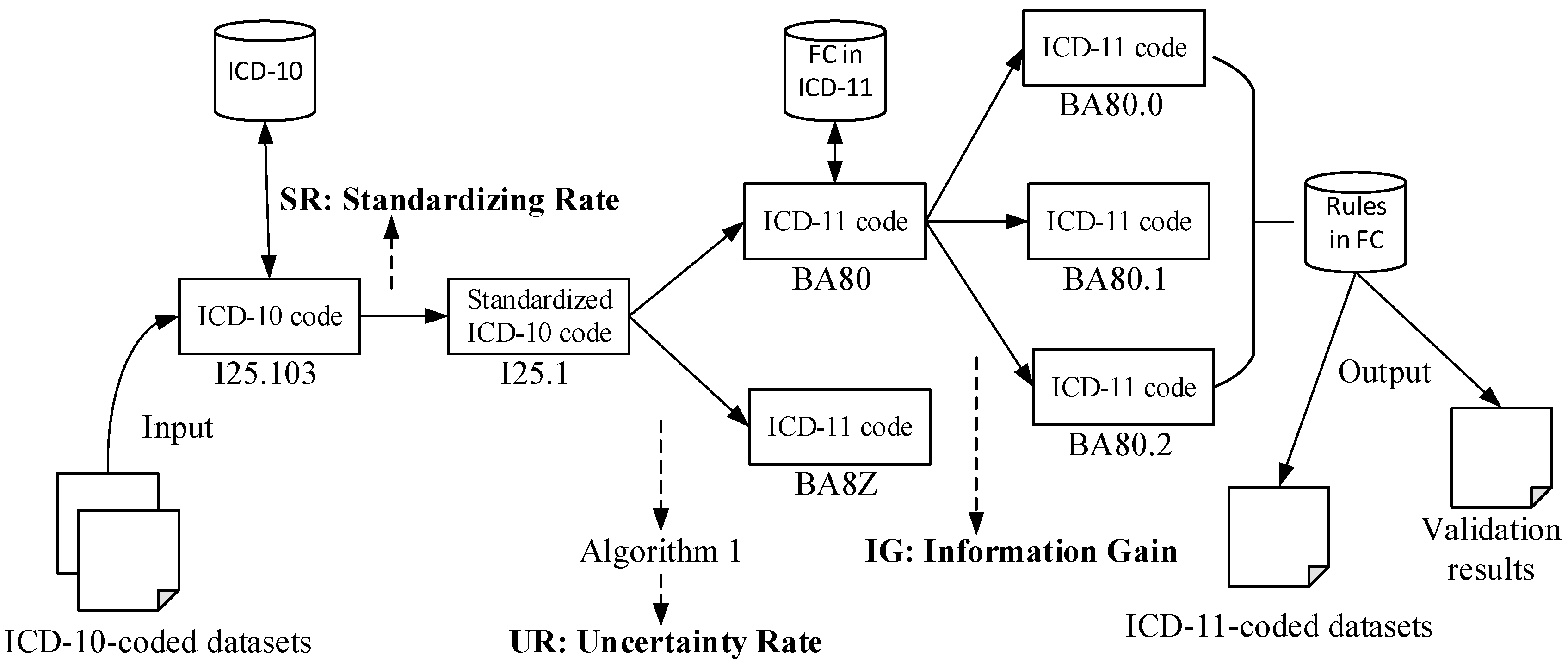
2.2.1. Single-Code Validation (SV)
| Algorithm 1. Multiple-code selection algorithm |
| Input: an ICD-10 entity c10, a list of ICD-11 entities {c11(i)|1≤i≤M} Output: entropy of the process UR, optimal ICD-11 code c11* Let pro ← {pi|1≤i≤M} and M ← the number of ICD-11 code candidates for each c11(i) in {c11} do end for for each c11 in {c11} do end for return , |
2.2.2. Single-Disease Dataset Validation (SDV)
2.2.3. Multiple-Disease Dataset Validation (MDV)
3. Results
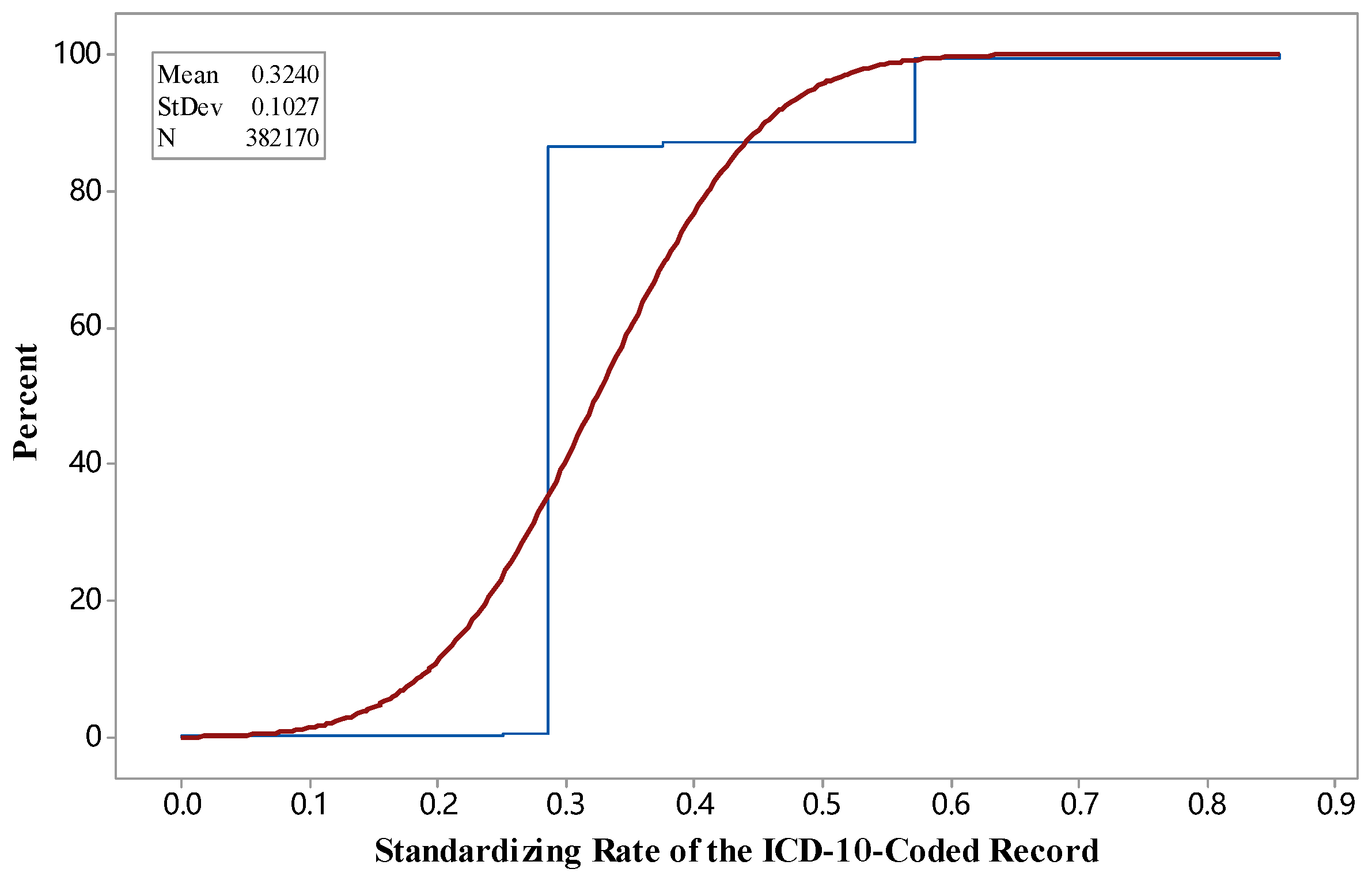
3.1. SR during Standardization
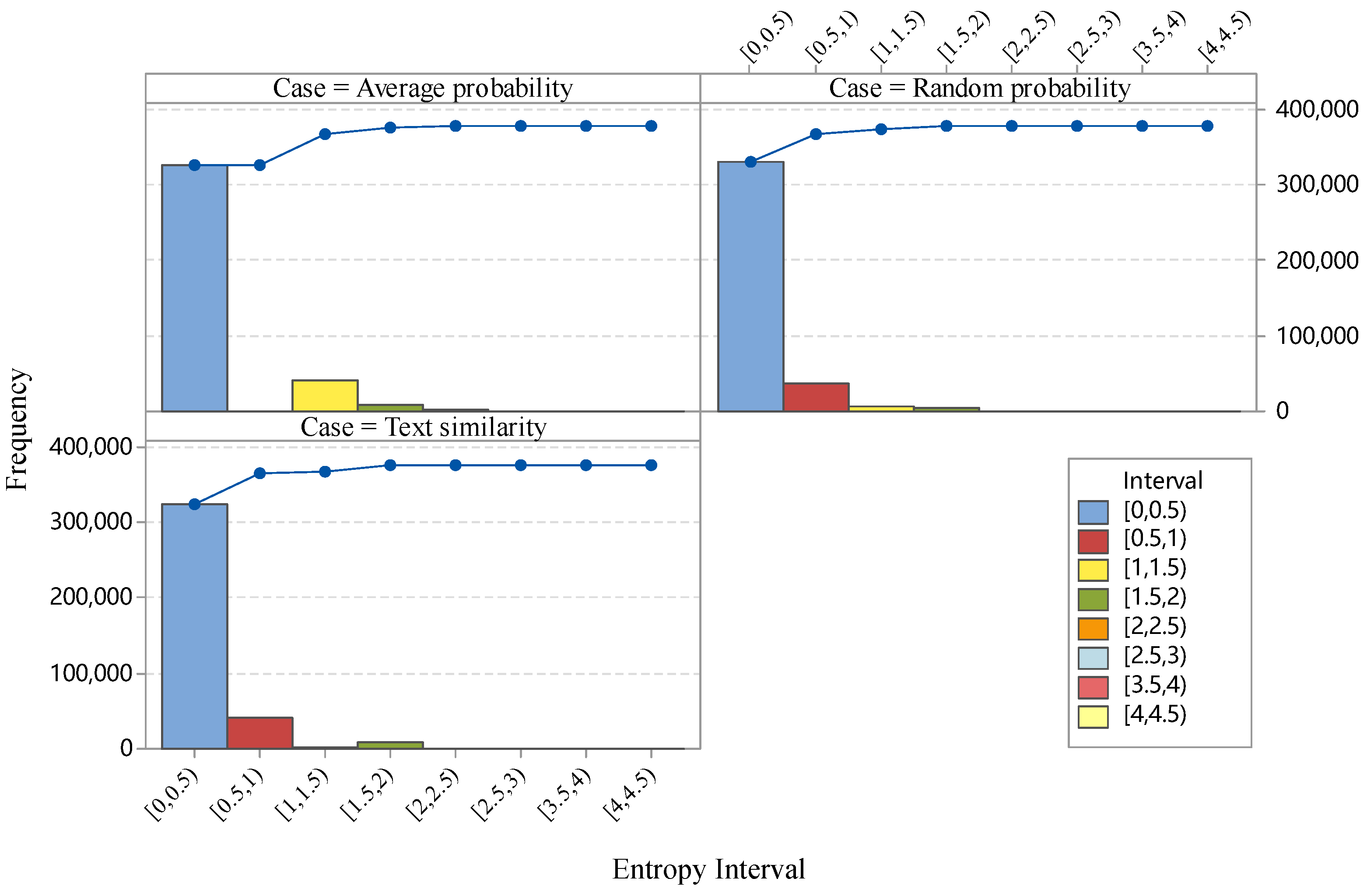
3.2. UR during Validation
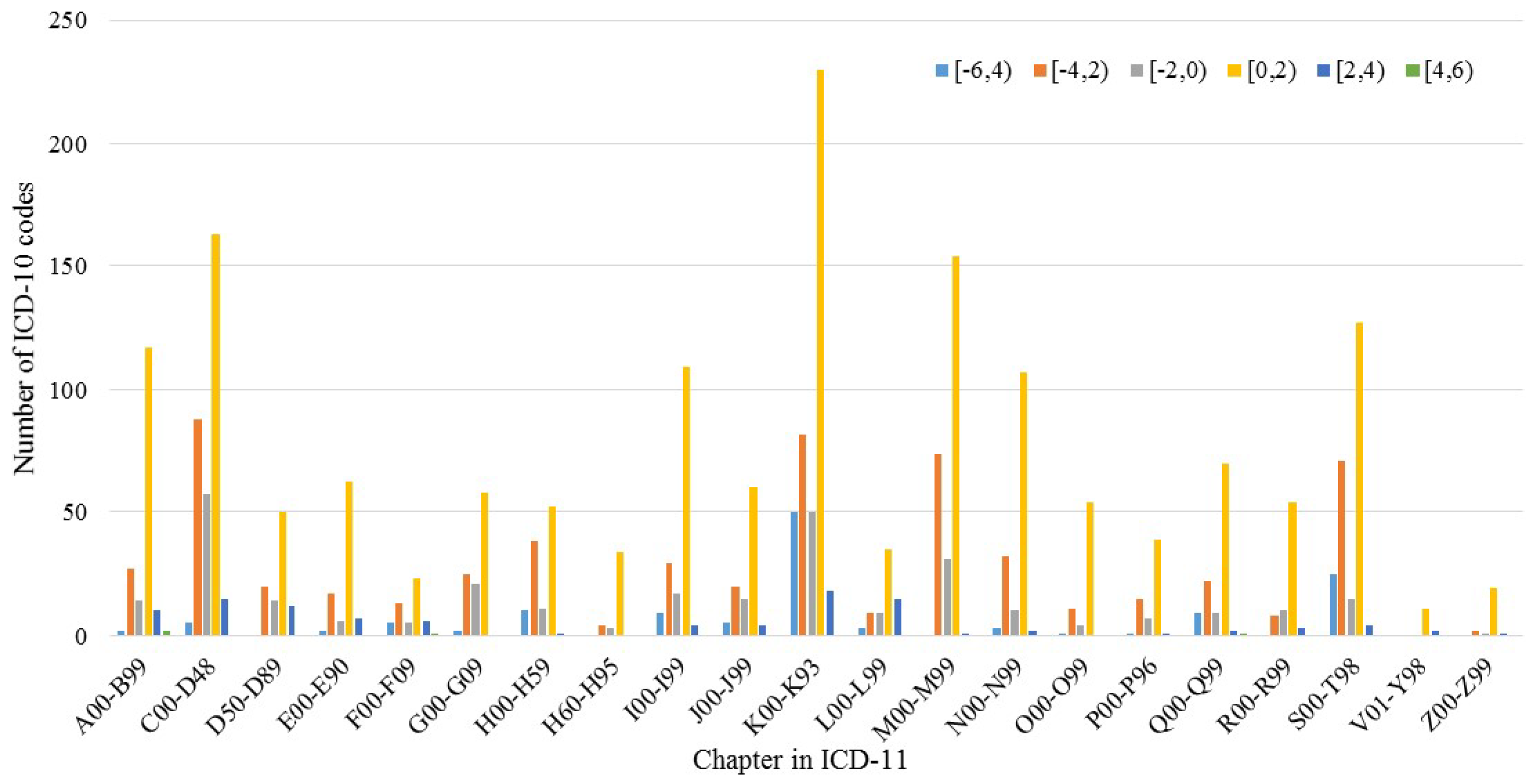
3.3. IG during Mapping
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- ICD-11 Home Page. Available online: https://icd.who.int (accessed on 16 July 2018).
- Southern, D.A.; Hall, M.; White, D.E.; Romano, P.S.; Sundararajan, V.; Droesler, S.E.; Pincus, H.A.; Ghali, W.A. Opportunities and challenges for quality and safety applications in ICD-11: An international survey of users of coded health data. Int. J. Qual. Health Care 2016, 28, 129–135. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, J.M.; Schulz, S.; Rector, A.; Spackman, K.; Millar, J.; Campbell, J.; Ustün, B.; Chute, C.G.; Solbrig, H.; Della Mea, V.; et al. ICD-11 and SNOMED CT Common Ontology: Circulatory system. Stud. Health Technol. Inform. 2014, 205, 1043–1047. [Google Scholar] [PubMed]
- WHO Released New ICD-11. Available online: http://iogt.org/news/2018/06/20/who-released-new-icd11 (accessed on 15 July 2018).
- Tudorache, T.; Nyulas, C.I.; Noy, N.F.; Musen, M.A. Using semantic web in ICD-11: Three years down the road. Lect. Notes Comp. Sci. 2018, 8219, 195–211. [Google Scholar]
- Boerma, T.; Harrison, J.; Jakob, R.; Mathers, C.; Schmider, A.; Weber, S. Revising the ICD: Explaining the WHO approach. Lancet 2016, 388, 2476. [Google Scholar] [CrossRef]
- Sofia, D.A.; Chris, F.; Shana, P.; Suarez-Almazor, M.E. Validation of ICD-9-CM codes for identification of acetaminophen-related emergency department visits in a large pediatric hospital. BMC Health Serv. Res. 2013, 13, 72. [Google Scholar]
- Rey, G.; Bounebache, D.; Rondet, C. Causes of deaths data, linkages and big data perspectives. J. Forensic Leg. Med. 2016, 57, 37–40. [Google Scholar] [CrossRef] [PubMed]
- Seare, J.; Yang, J.; Yu, S.; Zarotsky, V. Building a bridge: ICD-9-CM to ICD-10-CM mapping challenges and solutions. Val. Health 2014, 17, A187. [Google Scholar] [CrossRef]
- Plznyak, V.; Reed, G.M.; Medina-Mora, M.E. Aligning the ICD-11 classification of disorders due to substance use with global service needs. Epidemiol. Psychiatr. Sci. 2017, 27, 212–218. [Google Scholar] [CrossRef] [PubMed]
- ICD-11 Reference Guide. Available online: https://icd.who.int/browse11/content/refguide.ICD11_en/html/index.html (accessed on 16 July 2018).
- Tu, S.W.; Bodenreider, O.; Çelik, C.; Chute, C.G.; Heard, S.; Jakob, R.; Jiang, G.; Kim, S.; Miller, E.; Musen, M.A.; et al. A content model for the ICD-11 revision. Available online: https://www.researchgate.net/publication/267792997_A_Content_Model_for_the_ICD-11_Revision (accessed on 2 October 2018).
- Jiang, G.; Pathak, J.; Chute, C.G. Formalizing ICD coding rules using Formal Concept Analysis. J. Biomed. Inform. 2009, 42, 504–517. [Google Scholar] [CrossRef] [PubMed]
- Fung, K.W.; Richesson, R.; Smerek, M. Preparing for the ICD-10-CM transition: Automated methods for translating ICD codes in clinical phenotype definitions. eGEMs 2016, 4, 1211. [Google Scholar] [CrossRef] [PubMed]
- Brocco, S.; Vercellino, P.; Goldoni, C.A.; Alba, N.; Gatti, M.G.; Agostini, D.; Autelitano, M.; Califano, A.; Deriu, F.; Rigoni, G.; et al. “Bridge coding” ICD-9, ICD-10 and effects on mortality statistics. Epidemiol. Prev. 2010, 34, 109–119. [Google Scholar] [PubMed]
- Shannon, C.E. A mathematical theory of communication. Bell Sys. Techn. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Utter, G.H.; Cox, G.L.; Atolagbe, O.O.; Owens, P.L.; Romano, P.S. Conversion of the agency for healthcare research and quality’s quality indicators from ICD-9-CM to ICD-10-CM/PCS: The process, results, and implications for users. Health Serv. Res. 2018, 53, 3704–3727. [Google Scholar] [CrossRef] [PubMed]
- Startsev, N.; Dimov, P.; Grosche, B.; Tretyakov, F.; Schüz, J.; Akleyev, A. Methods for ensuring high quality of coding of cause of death. the mortality register to follow southern Urals populations exposed to radiation. Methods Inf. Med. 2015, 54, 359–363. [Google Scholar] [PubMed]
- Simard, M.; Sirois, C.; Candas, B. Validation of the combined comorbidity index of Charlson and Elixhauser to predict 30-day mortality across ICD-9 and ICD-10. Med. Care 2018, 56, 441–447. [Google Scholar] [CrossRef] [PubMed]
- Boyd, A.D.; Li, J.J.; Kenost, C.; Joese, B.; Yang, Y.M.; Kalagidis, O.A.; Zenku, I.; Saner, D.; Bahroos, N.; Lussier, Y.A. Metrics and tools for consistent cohort discovery and financial analyses post-transition to ICD-10-CM. J. Am. Med. Inform. Assoc. 2015, 22, 730–737. [Google Scholar] [CrossRef] [PubMed]
- Quan, H.; Moskal, L.; Forster, A.J. International variation in the definition of “main condition” in ICD-coded health data. Int. J. Qual. Health Care 2014, 26, 511–515. [Google Scholar] [CrossRef] [PubMed]
- Sundararajan, V.; Romano, P.S.; Quan, H.; Burnand, B.; Drösler, S.E.; Pincus, H.A.; Ghali, W.A. Capturing diagnosis-timing in ICD-coded hospital data: Recommendations from the WHO ICD-11 topic advisory group on quality and safety. Int. J. Qual. Health Care 2015, 27, 328–333. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Lu, H.; Li, L. Automatic ICD-10 coding algorithm using an improved longest common subsequence based on semantic similarity. PLoS ONE 2017, 12, e0173410. [Google Scholar] [CrossRef] [PubMed]
- Chako, S.J.; Danziger, R.; Boyd, A. Identifying clinically inaccurate conversions from ICD-9 to ICD-10 in cardiology clinical practice. Circulation 2014, 130, A11693. [Google Scholar]
- Farkas, R.; Szarvas, G. Automatic construction of rule-based ICD-9-CM coding systems. BMC Bioinformatics 2008, 9, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Liu, B. A normalized Levenshtein distance metric. IEEE Trans. Pattern Ana. Mach. Intell. 2007, 29, 1091–1095. [Google Scholar]
- Cartagena, F.P.; Schaeffer, M.; Rifai, D.; Doroshenko, V.; Goldberg, H.S. Leveraging the NLM map from SNOMED CT to ICD-10-CM to facilitate adoption of ICD-10-CM. J. Am. Med. Inform. Assoc. 2015, 22, 659–670. [Google Scholar] [CrossRef] [PubMed]
- Nadkarni, P.M.; Darer, J.A. Migrating existing clinical content from ICD-9 to SNOMED. J. Am. Med. Inform. Assoc. 2010, 17, 602–607. [Google Scholar] [CrossRef] [PubMed]
- Khokhar, B.; Jette, N.; Metcalfe, A.; Cunningham, C.T.; Quan, H.; Kaplan, G.G.; Butalia, S.; Rabi, D. Systematic review of validated case definitions for diabetes in ICD-9-coded and ICD-10-coded data in adult populations. BMJ Open 2016, 6, e009952. [Google Scholar] [CrossRef] [PubMed]
- Chui, K.; Alhalabi, W.; Pang, S.; Pablos, P.O.; Liu, R.W.; Zhao, M. Disease diagnosis in smart healthcare: innovation, technologies and applications. Sustainability 2017, 9, 1209. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interval of Information Gain | Frequency | Percentage (%) | Number of ICD-10 Codes |
|---|---|---|---|
| [−12, −10) | 86 | 0.00 | 2 |
| [−10, −8) | 0 | 0.00 | / |
| [−8, −6) | 0 | 0.00 | / |
| [−6, −4) | 63,256 | 0.17 | 107 |
| [−4, −2) | 101,378 | 0.27 | 523 |
| [−2, 0) | 50,695 | 0.13 | 264 |
| [0, 2) | 156,884 | 0.42 | 1405 |
| [2, 4) | 5277 | 0.01 | 92 |
| [4, 6) | 12 | 0.00 | 4 |
| [6, 8) | 1 | 0.00 | 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Zhang, R.; Zhu, X. Leveraging Shannon Entropy to Validate the Transition between ICD-10 and ICD-11. Entropy 2018, 20, 769. https://doi.org/10.3390/e20100769
Chen D, Zhang R, Zhu X. Leveraging Shannon Entropy to Validate the Transition between ICD-10 and ICD-11. Entropy. 2018; 20(10):769. https://doi.org/10.3390/e20100769
Chicago/Turabian StyleChen, Donghua, Runtong Zhang, and Xiaomin Zhu. 2018. "Leveraging Shannon Entropy to Validate the Transition between ICD-10 and ICD-11" Entropy 20, no. 10: 769. https://doi.org/10.3390/e20100769
APA StyleChen, D., Zhang, R., & Zhu, X. (2018). Leveraging Shannon Entropy to Validate the Transition between ICD-10 and ICD-11. Entropy, 20(10), 769. https://doi.org/10.3390/e20100769