1. Introduction
In time series analysis, the autoregressive (AR) model, also called the linear prediction model, has received considerable attention, with a host of results on fitting AR models, AR model prediction performance, and decision-making using time series analysis based on AR models [
1,
2,
3]. The linear prediction or AR model also plays a major role in many digital signal processing applications, such as linear prediction modeling of speech signals [
4,
5,
6], geophysical exploration [
7,
8], electrocardiogram (ECG) classification [
9], and electroencephalogram (EEG) classification [
10,
11]. We take a new look at AR modeling and analysis and these applications using a quantity from the field of information theory as defined by Shannon.
In his landmark 1948 paper [
12], Shannon defined what he called the
derived quantity of entropy power (also called entropy rate power) to be the power in a Gaussian white noise limited to the same band as the original ensemble and having the same entropy. He then used the entropy power in bounding the capacity of certain channels and for specifying a lower bound on the rate distortion function of a source. Entropy rate power appears to be as fundamental a concept in Shannon Information Theory as mutual information (then called average mutual information [
13]); however, unlike mutual information and many other quantities in Shannon theory, entropy rate power is not a well-studied, widely employed concept, particularly in signal processing.
We examine entropy rate power from several different perspectives that reveal new possibilities, and we define a new quantity, the log ratio of entropy powers, that serves as a new tool in the information theoretic study of a sequence of signal processing operations. In particular, we use the log ratio of entropy powers to study the change in differential entropy and the change in mutual information as the predictor order is increased for autoregressive processes. We also demonstrate the use of the log ratio of entropy powers for the analysis of speech waveform coders and the analysis of code-excited linear predictive coding of speech. Specifically, for speech waveform coding the overall reduction in mean squared prediction error can be interpreted using the log ratio of entropy powers as the performance gain in terms of bits/sample provided by the predictor. This insight is entirely new. For the analysis of code-excited linear predictive speech coding, the log ratio of entropy powers allows us to decompose the mutual information between the input speech being coded and the reconstructed speech into a sum of mutual informations and conditional mutual informations corresponding to the information provided by each of the components of the code-excited speech codec. This allows us to characterize the contributions of each component in terms of the mutual information with respect to the input speech. This is an entirely new way of analyzing the performance of code-excited linear predictive coding and potentially offers new design approaches for this dominant speech coding structure.
Additionally, we consider the applications of the AR model in geophysical exploration [
7,
8], electrocardiogram (ECG) classification [
9], and electroencephalogram (EEG) classification [
10,
11] and setup how the log ratio of entropy powers can provide new insights and results for these fields. For each of these applications, the interpretation of change in mean squared prediction error for different predictor orders in terms of changes in differential entropy and changes in mutual information open up new analysis and classification paradigms. Separately, Gibson and Mahadevan [
14] have used the log ratio of entropy powers to derive and extend the interpretation of the log likelihood spectral distance measure from signal processing.
We begin by defining the concept of entropy power and entropy rate power in
Section 2 and there summarize the well known results for entropy power in terms of the power spectral density of a Gaussian process.
Section 3 presents the autoregressive model and power spectral density and the Levinson-Durbin recursion for the solution of the Toeplitz set of equations that occurs when solving for the AR or linear prediction coefficients of an asymptotically wide-sense stationary AR process as delineated in [
6,
15,
16]. The equivalence of the entropy power and the minimum mean squared one step ahead prediction error for Gaussian AR sequences and relevant bounds on the minimum mean squared prediction error for non-Gaussian processes are discussed in
Section 4.
The fundamental new quantity, the log ratio of entropy powers, is developed in
Section 5, where it is shown that the key results hold when the entropy power is replaced by the variance for Laplacian and Gaussian processes and where the relationship of the log ratio of entropy powers to changes in differential entropy and mutual information is presented as a signal progresses through a series of linear predictors when the model order is incremented. Also in this section, the log ratio of entropy powers for maximum entropy spectral estimates and for decompositions in terms of orthogonal deterministic and nondeterministic processes are examined.
Examples are presented in
Section 6 illustrating the use of the log ratio of entropy powers for the linear prediction analysis of several speech frames as the predictor order is increased. Applications to speech waveform coding and to speech coding using code-excited linear prediction are given in
Section 7. Other possible applications to AR modeling in geophysical exploration [
7,
8], ECG classification [
9], and EEG classification [
10,
11] are outlined in
Section 8. Conclusions and suggestions for future applications are provided in
Section 9.
2. Entropy Power/Entropy Rate Power
In his landmark 1948 paper [
12], Shannon defined the entropy power (also called entropy rate power) to be the power in a Gaussian white noise limited to the same band as the original ensemble and having the same entropy. He then used the entropy power in bounding the capacity of certain channels and for specifying a lower bound on the rate distortion function of a source. We develop the basic definitions and relationships concerning entropy power in this section for use later in the paper.
Given a random variable
X with probability density function
, we can write the differential entropy
where
X has the variance
=
. Since the Gaussian distribution has the maximum differential entropy of any distribution with mean zero and variance
[
17],
from which we obtain
where
Q was defined by Shannon to be the
entropy power associated with the differential entropy of the original random variable
X [
12]. In addition to defining entropy power, this equation shows that the entropy power is the
minimum variance that can be associated with the not-necessarily Gaussian differential entropy
.
Please note that Equation (
3) allows us to calculate the entropy power associated with any given entropy. For example, if the random variable
X is Laplacian [
18] with parameter
, then
and we can substitute this into Equation (
3) and solve for the entropy power
. Since the variance of the Laplacian distribution is
, we see that
, as expected from Equation (
3). This emphasizes the fact that the entropy power is not limited to Gaussian processes. This simple result is useful since speech signals as well as the linear prediction error for speech are often modeled by Laplacian distributions.
For an
n-vector
with probability density
, and covariance matrix
, we have that
from which we can construct the vector version of the entropy power as
We can write a conditional version of Equation (
3) as
We will have the occasion to study pairs of random vectors
and
where we use the vector
to form the best estimate of
. If
is the covariance matrix of the minimum mean squared error estimate of
given
, then we have
and from which we can get an expression for the conditional entropy power,
,
So,
is upper bounded by the determinant of the conditional error covariance matrix,
. We have equality in Equations (
2)–(
8) if the corresponding random variables or random vectors are Gaussian.
Often our interest is in investigating the properties of stationary random processes. Thus, if we let
X be a stationary continuous-valued random process with samples
=
, then the differential entropy rate of the process
X is [
19]
We assume that this limit exists in our developments and we drop the overbar notation and use h = . Using the entropy rate in the definition of entropy power yields the nomenclature entropy rate power.
Within the context of calculating and bounding the rate distortion function of a a discrete-time stationary random process, Kolmogorov [
20] and Pinsker [
21] derived an expression for the entropy rate power in terms of its power spectral density.
If we now consider a discrete-time stationary Gaussian process with correlation function
=
, the periodic discrete-time power spectral density is defined by
for
. We know that an
n-dimensional Gaussian density with correlation matrix
has the differential entropy
=
. Then, the entropy rate power
Q can be found from [
22,
23]
which yields [
22,
23]
as the entropy rate power.
Later we develop a closely related result for any distribution using the definition of entropy power.
3. Autoregressive Models
An AR process is given by
where the autoregressive parameters
, are called the linear prediction coefficients for speech processing applications, and
is the excitation sequence. For purposes of linear prediction speech analysis, we generally do not need to make an assumption on the distribution of the excitation. However, it is often assumed that the prediction error for speech is Laplacianly distributed [
6,
18,
24].
In general time series analysis, the excitation is often chosen to be some i.i.d. sequence, the distribution of which is unspecified. The AR model in Equation (
13) is a one-sided process and depends on the initial conditions, which we will assume to be zero, and therefore is not wide sense stationary (WSS). As a result, the power spectral density of the AR process is not accurately represented by Equation (
10). Fortunately, an important result due to Gray [
15], provides the necessary power spectral density expression for AR processes.
3.1. The Power Spectral Density
For the AR model in Equation (
13), the correlation function
=
depends on
j and therefore is not WSS. However, the AR model can be shown to be asymptotically WSS under suitable conditions [
15,
25,
26,
27]. Leaving the details to the references, for asymptotically WSS AR processes with coefficients
, the asymptotic power spectral density is given by
where
with
the variance of the AR process input sequence and
.
is the power spectral density of the AR process that we use in the remainder of the paper.
3.2. The Levinson-Durbin Recursion
In linear prediction for speech analysis and coding, the linear prediction model is used to capture the spectral envelope. For a given windowed frame of
L input speech samples, where the windowing sets all samples outside the window to zero, it is necessary to calculate the linear prediction coefficients. This is done by choosing the coefficients to minimize the sum of the squared prediction errors over the frame; that is, choose the coefficients to minimize
[
4,
5,
6]. Taking the partial derivatives with respect to each of the coefficients,
,
, yields the set of linear simultaneous equations
for
, where
with
. In matrix notation this becomes
where
R is an
m by
m Toeplitz matrix of the autocorrelation terms in Equation (
17),
, and
is a column vector of the autocorrelation terms
.
An efficient method to solve the set of linear simultaneous equations in Equation (
18) is due to Durbin [
28] and is given by [
4,
5,
6,
16]:
Let
then compute
for
. Then we compute the linear prediction coefficients as
and
We next calculate
and then go to Equation (
20) and continue until
, the desired predictor order.
The quantity
is the mean squared prediction error (MSPE) for the
nth order predictor, which is also given by the expression
and is nonincreasing with increasing predictor order so we have that
In many problems, such as speech coding applications, the predictor order m is chosen based on a combination of predictor accuracy over a wide set of speech data and a desired bit rate allocation to the set of coefficients.
However, for speech analysis, one can monitor the MSPE and set the predictor order to the value where further decreases in
are small. For applications to seismic exploration [
7], electrocardiogram (ECG) classification [
9], and electroencephalogram (EEG) classification [
10,
11], the AR model order may be fixed to a preselected value, determined via the Durbin recursion according to an acceptable MSPE, or investigated and adjusted for each experimental application. We discuss each explicitly in
Section 8.
Later we use the sequence of mean squared prediction errors in Equation (
25) to infer the change in mutual information as the predictor order is increased, but to justify this approach, first we must develop the key concepts and expressions relating entropy power and minimum mean squared prediction error, which we do in the next section.
4. Minimum MSPE and AR Models
Perhaps surprisingly, the right side of Equation (
12) plays a major role in time series analysis beyond entropy power and the Gaussian assumption. More specifically, using
in Equation (
12) we obtain the minimum mean squared one-step prediction error (MSPE) for autoregressive (AR) processes, even if they are not Gaussian [
2,
3,
22]! That is, the mean squared prediction error, sometimes called the innovation variance [
3], is given by
where we have used the notation from
Section 3 for the minimum mean squared prediction error. This result does not require the AR process to be Gaussian.
Furthermore, the fact that Equation (
26) is the minimum mean squared one-step prediction error for AR processes, even non-Gaussian processes, proves useful for upper bounding the entropy power for autoregressive processes using the estimation counterpart to Fano’s Inequality [
17]
In our notation Equation (
27) becomes
where
S is the signal being predicted,
is the
nth order linear predictor, and
is the differential entropy of the prediction error
.
Notice that in increasing the order of an AR model, we have Equation (
25), that is, the MSPE is nonincreasing with increasing model order, which then implies that
holds for the sequence of entropy powers. Equation (
29) follows since the iteration in Equations (
19)–(
25) builds the minimum mean squared error predictor as the predictor order is increased from 1 to
m. According to Choi and Cover [
29], the minimal order Gauss-Markov process that satisfies the given covariance constraints is the maximum entropy process, which implies that it is the minimum mean squared error process satisfying the constraints. Since we know that the entropy rate power
satisfies Equation (
28), Equation (
29) follows.
As a setup for applications to be discussed later, note that these observations imply the following. If the AR or linear prediction coefficients and the correlation functions are known, it is straightforward to find the minimum MSPE [
6,
30] using Equation (
24). Furthermore, if we fit an AR model to a time series, we can find the minimum MSPE from the
generated by the recursion in
Section 3 and hence upper bound the entropy rate power that corresponds to that model.
If the time series is in fact AR, we can iteratively increase the model order, calculate the AR or linear prediction coefficients for the iterated model order which yields the best fit, and for that model, we can calculate the minimum MSPE and thus an upper bound to the entropy rate power. If the time series is not AR, then we can find the best approximation and its corresponding minimum MSPE, which is again an upper bound on the entropy power for that best fit model.
5. Log Ratio of Entropy Powers
We can use the definition of the entropy power in Equation (
3) to express the logarithm of the ratio of two entropy powers in terms of their respective differential entropies as
We are interested in studying the change in the differential entropy brought on by different signal processing operations by investigating the log ratio of entropy powers. However, in order to calculate the entropy power, we need an expression for the differential entropy! So, why do we need the entropy power?
First, entropy power may be easy to calculate in some instances, as we show later. Second, the accurate computation of the differential entropy can be quite difficult and requires considerable care [
31]. Generally, the approach is to estimate the probability density function (pdf) and then use the resulting estimate of the pdf in Equation (
1) and numerically evaluate the integral.
Depending on the method used to estimate the probability density, the operation requires selecting bin widths, a window, or a suitable kernel [
31], all of which must be done iteratively to determine when the estimate is sufficiently accurate. The mutual information is another quantity of interest, as we shall see, and the estimate of mutual information also requires multiple steps and approximations [
32,
33]. These statements are particularly true when the signals are not i.i.d. and have unknown correlation.
In the following we consider special cases where Equation (
30) holds with equality when the entropy powers are replaced by the corresponding variances. We then provide justification for using the signal variance rather than entropy power in other situations. The Gaussian and Laplacian distributions often appear in studies of speech processing and other signal processing applications, so we show that substituting the variances for entropy powers for these distributions satisfies Equation (
30) exactly.
5.1. Gaussian Distributions
For two i.i.d. Gaussian distributions with zero mean and variances
and
, we have directly that
and
, so
which satisfies Equation (
30) exactly. Of course, since the Gaussian distribution is the basis for the definition of entropy power, this result is not surprising.
5.2. Laplacian Distributions
For two i.i.d. Laplacian distributions with parameters
and
[
18], their corresponding entropy powers
and
, respectively, so we form
so the Laplacian distribution also satisfies Equation (
30) exactly. We thus conclude that we can substitute the variance, or for zero mean Laplacian distributions, the mean squared value for the entropy power in Equation (
30) and the result is the difference in differential entropies.
For speech processes, the prediction residual or prediction error often is modeled as being i.i.d. Laplacian based on speech data histograms [
6,
24] or simply assumed to be Gaussian for convenience [
27]. As a consequence, this implies that for speech processing applications, we can use the variances of mean squared errors instead of the entropy powers without penalty, thus avoiding the calculation of the differential entropies from limited data.
Interestingly, it can be shown that the Logistic distribution [
18] also satisfies Equation (
30) exactly. The author has not been able to identify a broad model class for which Equation (
30) is satisfied exactly.
5.3. Increasing Predictor Order
We can use Equation (
30) in terms of the entropy powers for increasing AR model orders in the signal processing iterations as
If we add and subtract
to the right hand side of Equation (
33), we then obtain an expression in terms of the difference in mutual information between the two stages as
From the series of inequalities on the entropy power in Equation (
29), we know that both expressions in Equations (
33) and (
34) are greater than or equal to zero. It is important to note that Equations (
33) and (
34) are not based on a Gaussian assumption for the underlying processes. For these expressions, the entropy power
Q is calculated from the differential entropy of the signal being analyzed.
Even though the results in Equations (
33) and (
34) are not based on a Gaussian assumption, we know from the definition of entropy power that they hold exactly for i.i.d. Gaussian processes. Of course, because of the example in
Section 5.2, we also know that these equations hold exactly for i.i.d. Laplacian processes as well. Explicitly, for two i.i.d. Laplacian distributions with parameters
and
, their corresponding entropy powers
and
, respectively, so we form
so when the prediction error sequence at time instants
and
n satisfy, or are assumed to satisfy, the Laplacian distribution, Equation (
30) is satisfied exactly. Similarly, if we add and subtract the differential entropy of the original Laplacian sequence being predicted, then Equation (
34) is satisfied exactly as well. We thus conclude that we can substitute the error variance, or for zero mean Laplacian distributions, the mean squared value for the entropy power and obtain the desired relationships from the log ratio of entropy powers.
This increase in mutual information between the input and the predicted sequence also implies changes in the relationship between the prediction error sequence
and the input
X. In fact, since we know from Equation (
33) that
, then we have that
. From this, we form
which says that the differential entropy of the prediction error is nonincreasing with increasing prediction order. This result is consistent with the minimum mean squared prediction error (MMSPE) and entropy power results in Equations (
25) and (
29), and with the fact that the minimum mean squared error (MMSE) is nonincreasing with predictor order in statistical minimum mean squared error prediction [
2,
3], particularly for AR processes.
So, using the log ratio of entropy powers, what we have is a new interpretation of the improvement in mean squared prediction error in terms of a decrease in the differential entropy of the prediction error expressed in terms of bits. The results in terms of mutual information and differential entropy are exact for i.i.d. Gaussian and Laplacian prediction errors, but it would greatly simplify our investigations if we could infer the change in differential entropy and mutual information without checking the distributions of the data, calculating the differential entropies and/or the mutual information, and the entropy powers.
More specifically, it would be very helpful if we could substitute the mean squared prediction errors for the entropy powers in Equations (
33) and (
34) in general.
5.4. Maximum Entropy Spectral Estimate
As shown in [
29], we know that the entropy of any finite length segment of a random process with a specified covariance structure is bounded above by the entropy of the minimal order Gaussian AR process that satisfies the given covariance constraints. Thus, one way to achieve the goal of using the minimum mean squared prediction error in Equations (
33) and (
34) for the entropy power is to assume that the linear predictor coefficients from
Section 3 are the results of the given autocorrelation constraints for a maximum entropy spectrum estimate.
Since the maximum entropy spectrum is the minimal order Gauss-Markov process satisfying the given covariance constraints, the minimum mean squared prediction errors equal the entropy powers and therefore can be used in Equations (
33) and (
34) [
29], thus avoiding the need to calculate the entropy power directly using Equation (
3).
Following [
29], by assuming the maximum entropy estimate of the spectral density, we are not assuming that the higher order,
, covariance terms in Equation (
10) are equal to zero but that they satisfy
for
. However, for our development, this fact is unimportant.
5.5. Orthogonal Decompositions and Whitened Prediction Errors
We can also motivate using the minimum mean squared prediction error for the entropy power in Equations (
33) and (
34) by considering the series of AR predictors obtained in
Section 3 as
n progresses from 1 to
m as a series of orthogonal decompositions into deterministic and nondeterministic processes [
2,
3,
34], producing a whitened prediction error at each stage. Of course, this idea is not far-fetched because it is intuitive that the goal of the linear predictor for each
n is to obtain the whitest prediction error possible [
27].
Conceptually, this is equivalent to assuming that for each
n, the process is exactly an
order AR process. Under these assumptions, we would have a series of minimum mean squared prediction errors expressible as [
2,
3]
, where
is the power spectral density of the corresponding
order AR process, which holds even if the AR processes are non-Gaussian. Since the mean squared prediction error
is exactly the entropy power if the series of
order AR processes are Gaussian (by definition of entropy power), it is natural to use the minimum mean squared prediction error for the entropy power under these conditions.
In summary, based on (a) the fact that Equation (
30) is satisfied exactly for i.i.d. Gaussian and Laplacian random variables, as can be seen from Equations (
31) and (
32), respectively; (b) the fact that the maximum entropy spectral estimate for the given correlation constraints is a Gaussian AR process; and (c) the fact that the linear predictors that yield the best whitened prediction errors for each order produce a minimum mean squared prediction error that satisfies Equation (
38), which is the expression for the entropy power for a Gaussian AR process, we proceed in the following to replace the entropy power in key equations, such as Equations (
33) and (
34) with the minimum mean squared prediction error.
To reiterate, the purpose of using the minimum mean squared prediction error, which is readily available, is to eliminate the need to numerically calculate/estimate the histogram of the data and then use the histogram to form the entropy power from Equation (
3). This is a substantial simplification that is very useful in practice and also is a process that eliminates the histogram estimation step, which as discussed earlier in this section, is in itself fraught with sources of inaccuracies.
Examples and applications of the log ratio of entropy powers are developed in the following sections.
6. Experimental Examples
To illustrate the utility of the expression in Equation (
34), we consider four frames of narrowband voiced speech. For each frame, we list the MMSPE as the predictor order is incremented up to order
and also list the corresponding change in mutual information as calculated from Equation (
34) as the model order is increased, but where we use
, as in Equations (
24) and (
25) in place of
.
To categorize the differences in the speech frames we investigate, we use a common indicator of predictor performance, the Signal-to-Prediction Error (SPER) in dB [
35], also called the Prediction Gain [
6], defined as
where
is the average energy in the utterance and
is the minimum mean squared prediction error achieved by a
order predictor. The SPER can be calculated for any predictor order but we choose
, a common choice in narrowband speech codecs and the predictor order that, on average, captures most of the possible reduction in mean squared prediction error without including long term pitch prediction.
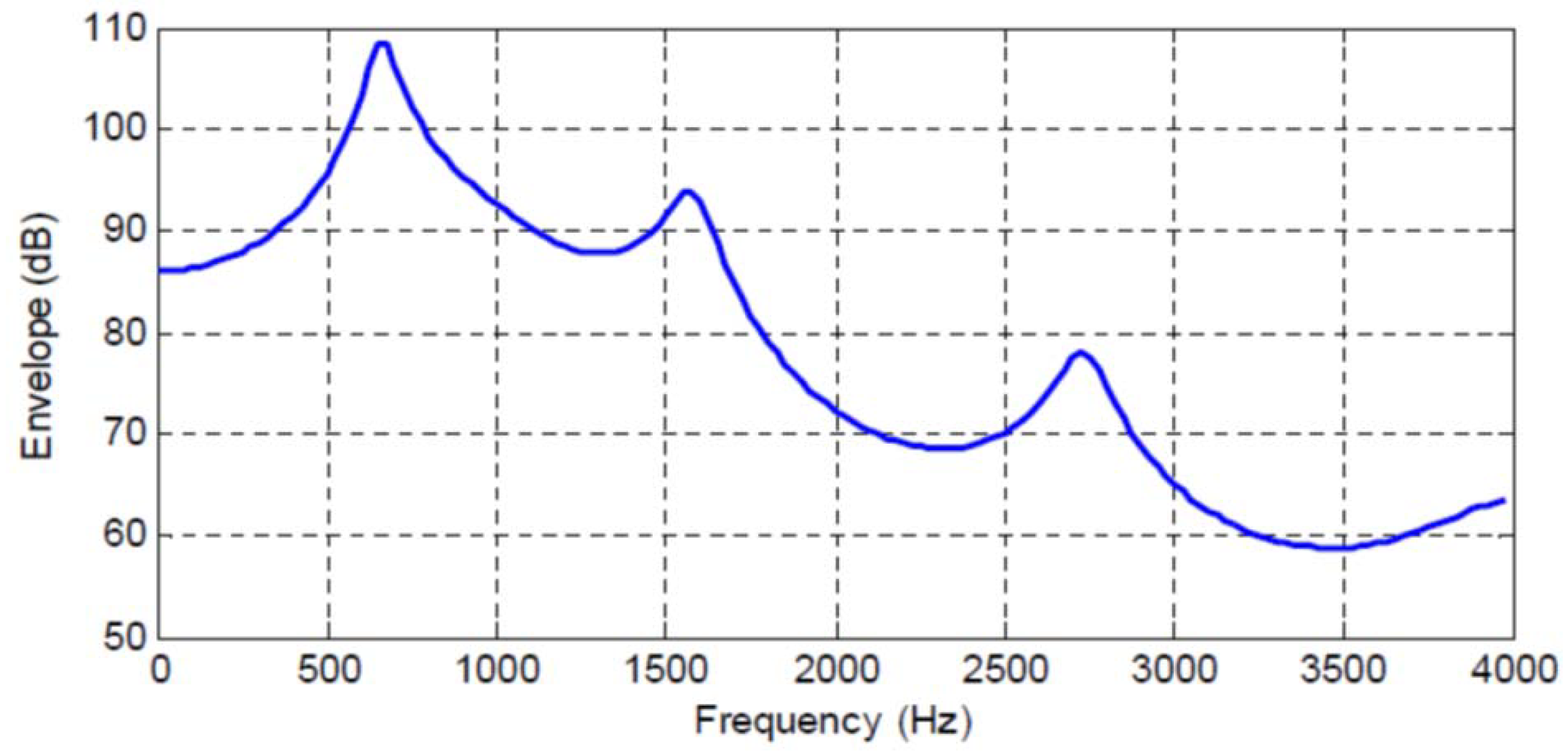
Figure 1,
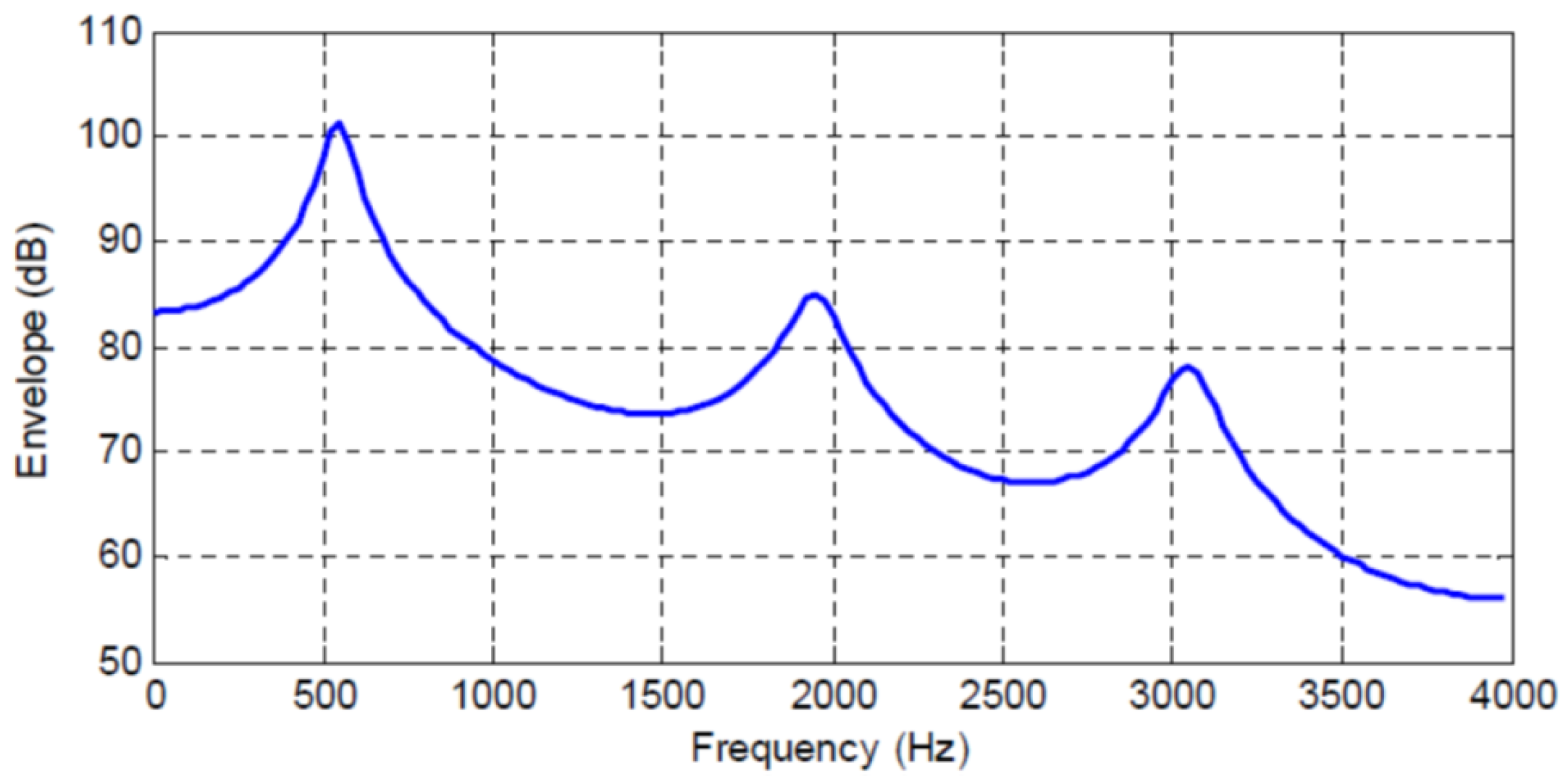
Figure 2,
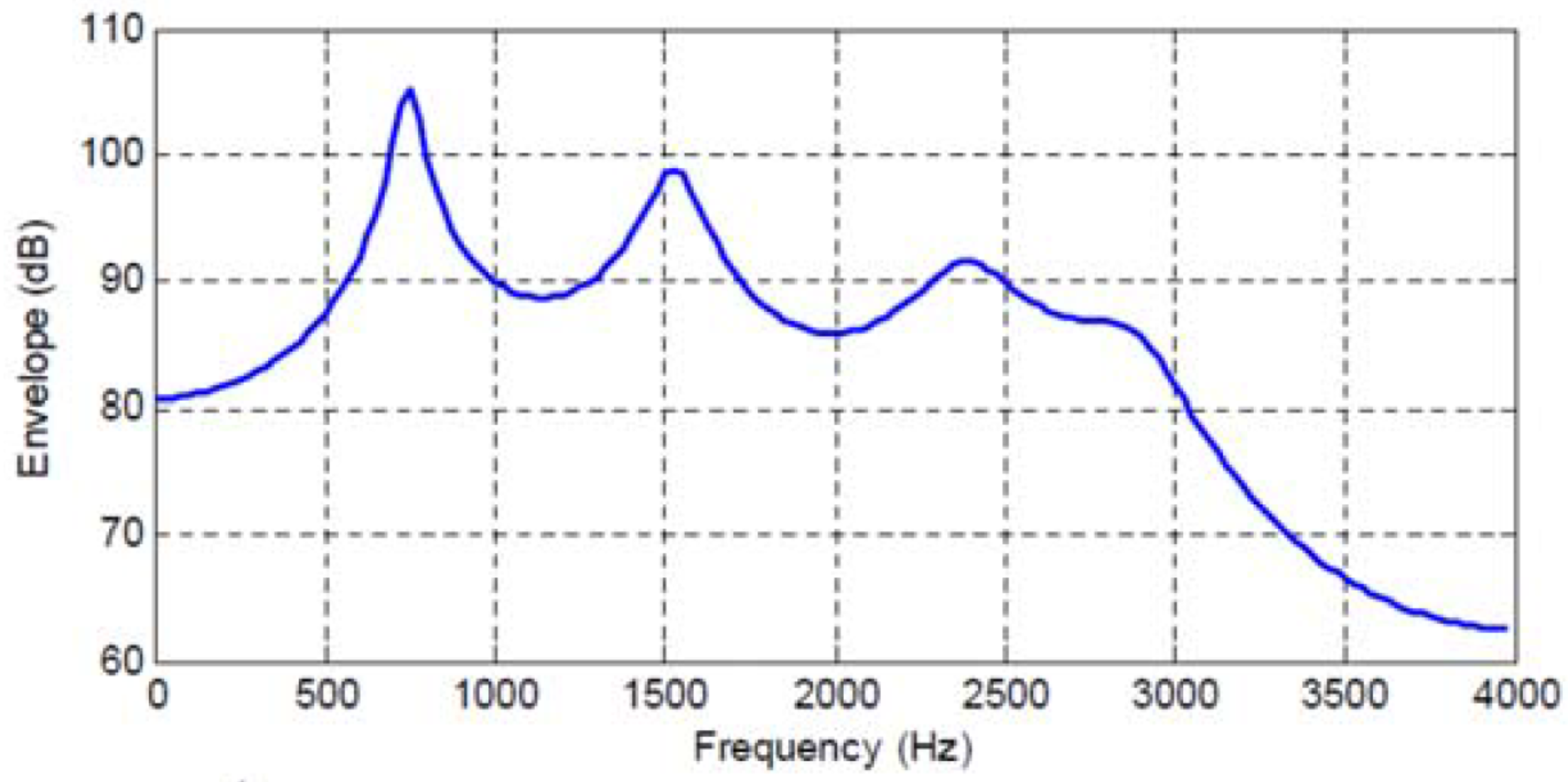
Figure 3 and
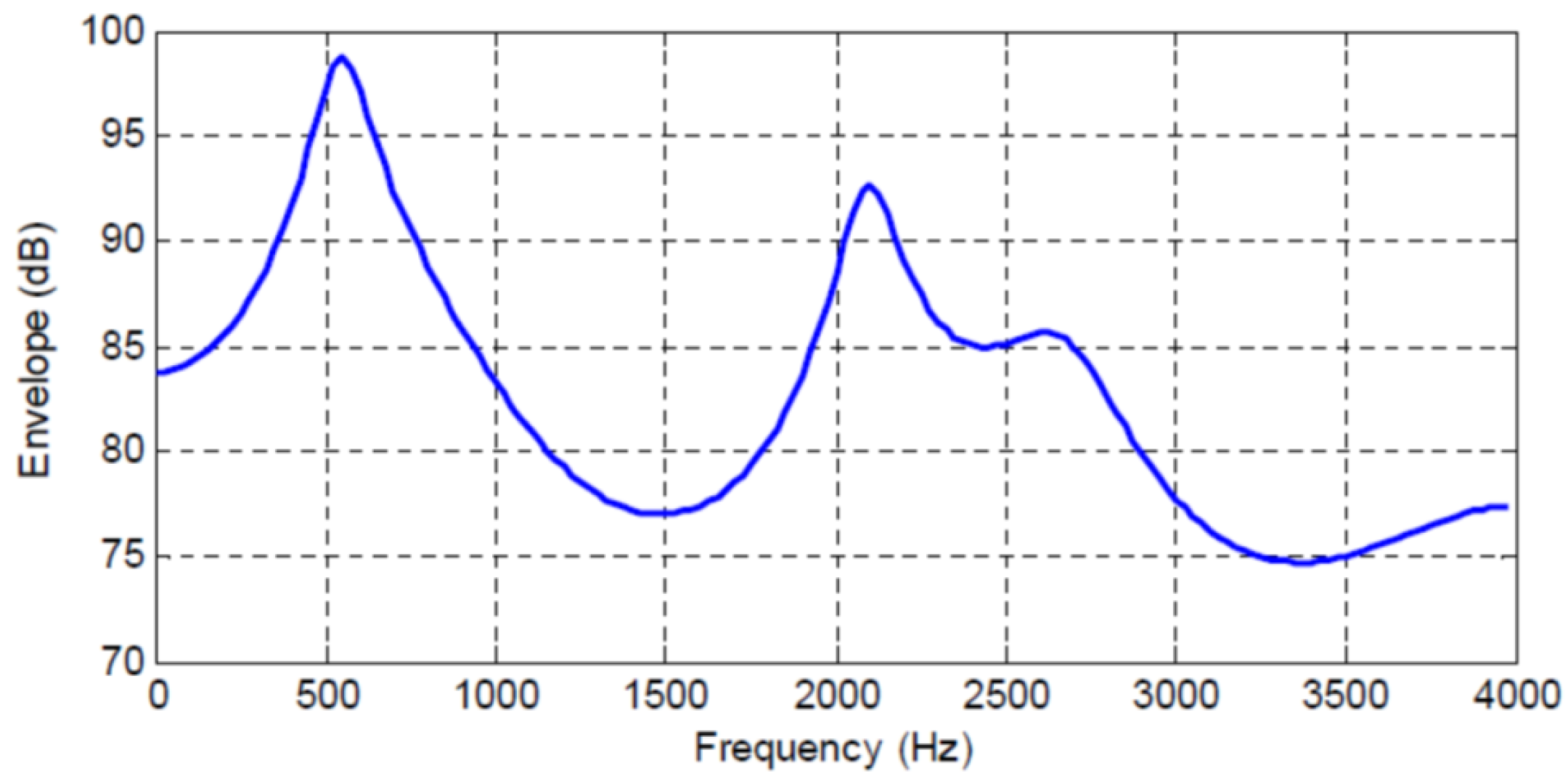
Figure 4 show the spectral envelopes calculated using an
order AR model for four different speech frames. Correspondingly,
Table 1,
Table 2 and
Table 3 list the
as the predictor order is increased from
up to
in increments of one for the speech frames in
Figure 1,
Figure 2 and
Figure 3. We do not include a table or Frame 87 since the MMSPE is only reduced from
to
. The third column in the tables labeled as
is obtained from Equation (
34) but with the entropy power for each
N replaced by the
so we have
In this equation and the tables, we interpret the mutual information when as equal to zero since in that case .
We are approximating the entropy power
by
at each stage, since the latter is much simpler to calculate. While this can be argued to be equivalent to assuming that the speech signal is Gaussian, thus leading to Equations (
27) and (
28) being satisfied with equality, we are not arguing that speech signals have a Gaussian distribution. Our goal instead is to characterize the incremental change in mean squared prediction error for AR processes in terms of gains in mutual information. The results are interesting and potentially highly useful in many applications.
The four speech frames being considered have quite different SPER values, specifically
= 16, 11.85, 7.74 and 5 dB, and thus constitute an interesting cross section of speech segments to be analyzed; however, although different, the average
of these four frames is about 10 dB, which is the usual
or prediction gain that is shown for average speech data and
in the literature [
6,
24]. The first significant observation is that now we can map an increase in predictor order to an increase in the mutual information between the input sequence and the
order predicted value, which is an entirely different interpretation and a new indicator of predictor quality.
In particular, we see that the
order predictors corresponding to the spectral envelopes in
Figure 1,
Figure 2,
Figure 3 and
Figure 4 increase the mutual information between the input segment and predicted signal by 2.647, 1.968, 1.29, and 0.83 bits/sample, respectively. We also see the incremental change in mutual information as the predictor order is indexed up from 1 to
N. This characterization opens up new analysis and research directions by extending the MSE to an information measure.
Along these lines of analysis, note that in
Table 1 when the predictor order is increased from
to
, the mean squared error changes by 0.311 − 0.066 = 0.245, which as shown in the table corresponds to an increase in mutual information between the original input and the predicted value of 1.11 bits/letter. While the normalized change in mean squared error is noticeable, the increase in mutual information is more than 1 bit! For the same table, we see that in increasing the predictor order from
to
the mean squared error changes by 0.0587 − 0.0385 = 0.0202, a seemingly very small change, but from
Table 1 we see that the corresponding increase in mutual information is 0.304 bits/letter. Thus, the change in mutual information captures more clearly an improvement perhaps not as evident in the change in mean squared error. This behavior is also evident in the other tables.
For example, in
Table 2 when the predictor order is increased from
to
the mean squared error changes by 0.096 while the increase in mutual information is 0.339 bits/letter and similarly as the predictor order is increased from
to
the mean squared error changes by 0.0258 while the increase in mutual information is 0.226 bits/letter. We can see other such occurrences in
Table 3 when the predictor order is increased from
to
, the mean squared error changes by 0.1365 while the increase in mutual informaton is 0.36 bits/letter, and as the predictor order is increased from
to
, the mean squared error changes by 0.0277 while the increase in mutual information is 0.104 bits/letter. It is therefore clear, that the log ratio of entropy powers provides significantly different, but complementary, insights to the observed changes in mean squared prediction error.
For some applications, such as speech waveform coding, the interpretation is direct in terms of the decrease in average number of bits/sample required for transmitting or storing the waveform, as developed in
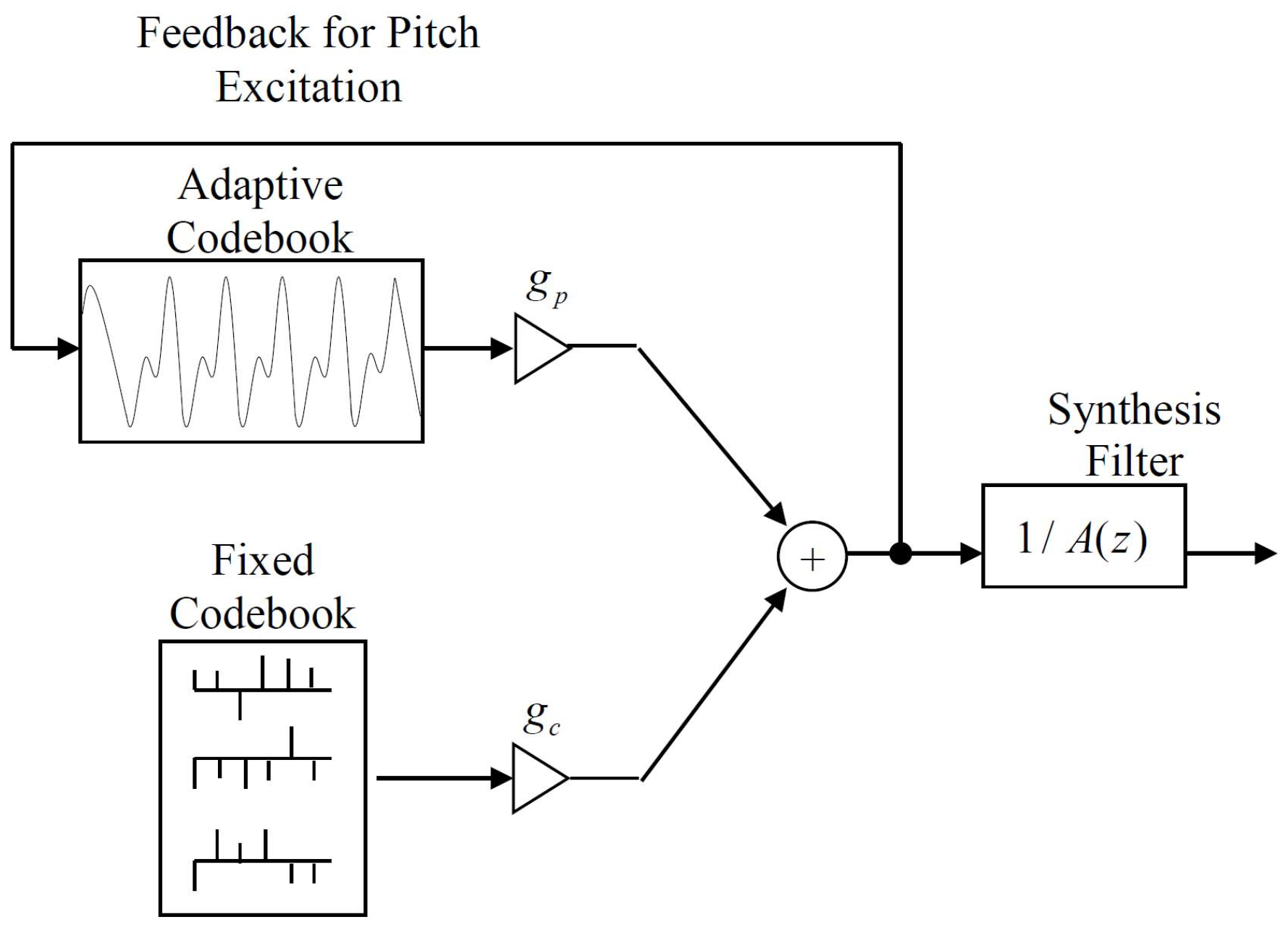
Section 7.1. More generally, the incorporation of an information measure into analyses of seismic, speech, EEG, and ECG signals offers a new way forward for researchers modeling these signals for analysis, detection, and classification. The change in mutual information as the linear predictor order is adjusted can also provide a new interpretation and categoration of the codebooks used in code-excited linear predictive speech coding, which is discussed in
Section 7.2. In any event, these results suggest an interesting new, and previously unexplored way for researchers to classify the contributions of AR predictors and linear prediction in their applications.
8. Other Possible Applications
Of course, AR models play a large role in many applications, including ECG classification [
9], EEG classification [
10,
11], and geophysical exploration [
7,
8]. We have not conducted experiments using our log ratio of entropy powers approach to these problems, but, in the following subsections, we outline in some detail possible approaches to a few of these applications. The applications described are chosen such that each application uses the AR model in different ways. Sufficient details are provided such that researchers skilled in these several areas should be able to follow the descriptions to implement their particular application.
8.1. ECG Classification
Reference [
9] describes a method for electorcardiogram (ECG) classification and detection based on AR models of the QRS complex in an ECG signal. The overall method consists of multiple signal processing steps, beginning with preprocessing to remove artifacts from respiratory modulation and baseline drift, then filter bank methods to identify QRS peaks, followed by AR modeling of one or two beats of the ECG signal available from the pre-processing step, and finally clustering to arrive at a classification or patient identification.
The classification task is to determine whether an ECG shows a normal heart rhythm, an arrhythmia, or a ventricular arrhythmia. The patient identification task is to recognize a patient from a recorded ECG. The AR modeling step is the central component of the method, and the authors state that having an accurate AR model order is crucial to the success of both tasks and that using the prediction error power in addition to the predictor coefficients significantly improves the patient identification task. Of course, both the prediction error power and the model order are intimately intertwined, since the former is an output of the latter.
The authors in [
9] determine the model order from the observation of a “knee” in the modeling error power curve as the model order is increased. In their work, they use orders of 2–4, which do, in fact, yield a small MSPE for the one example specifically presented. We suggest that the log ratio of entropy powers as the model order is increased as presented in
Section 5.3 of the current paper can serve as an additional indicator of a suitable AR model order through Equations (
33) and (
34) with the entropy powers replaced by MSPE as in Equation (
40).
Specifically, from the examples in
Section 6, we have seen that the log ratio of entropy powers can be interpreted as a possibly more sensitive indicator of the match produced as the model order is increased in comparison to the straightforward MSPE. Since for the patient identification task, the prediction error power improved recognition performance, folding in the change in mutual information as from Equation (
40) may supply a further improvement in performance.
8.2. EEG Classification
Autoregressive models have been used in a variety of EEG signal processing applications. One such application is the classification of an EEG to determine if a patient has sufficient anethesia for deep surgery [
10]. The approach in [
10] is to develop
order AR models, denoted as
from EEG signals taken from other patients that are labeled as being in some state (inadequate anethesia, sufficient anethesia), which are then used as templates representing the different states of anethesia. The challenge is that while the template EEGs are labeled as being in one of two classes, the interpatient variability is high, so a statistical comparison of the input EEG is needed to see which template it is closest to.
To accomplish this, the input EEG is passed through the prediction error filters formed from all of the order AR models, with the output of each filter producing a prediction error that is the result of predicting the input EEG with the AR coefficients determined from each labeled template. Each template covariance matrix and its’ corresponding MMSPE are fed to a Gaussian assumption Karhunen-Loeve Nearest Neighbor (KL-NN) rule to select the correct classification.
In [
10,
11] the order of all of the
models are set at some fixed
N, and it is possible that the change in mutual information as indicated by the log ratio of entropy powers could be used to aid in the selection of the appropriate model order. However, as an alternative application, we suggest here that the log ratio of entropy power between the EEG being tested and each of the template
models might be a good classification rule.
What we propose is to use the prediction errors at the output of each prediction filter as in reference [
10] and determine the MMSPE for each, then form the log ratio of entropy powers to compare each of these to the MMSPE for each template, and then use these quantities in a NN algorithm. Notationally, let the MMSPE for each template
be
,
, where
is the EEG used to develop template
m, and let the MMSPE when predicting the input EEG with each
be
, where
Y denotes the input EEG signal. By the definition of the optimality of the templates in being matched to their particular
EEG signal, we know that
for
.
We can thus form the log ratio of entropy powers as
which we know is greater than or equal to zero. A mutual information expression for the log ratio of entropy powers does not appear to be possible for this problem setup. The quantity in Equation (
48),
, can then be used directly in a NN calculation as in [
10].
8.3. Geophysical Exploration
There is a very long history of autoregressive or linear prediction models in geophysical signal processing and exploration [
7,
8,
41,
42] for use in developing an understanding of the subsurface crustal layer interfaces. In those applications, the predictor order
N may be chosen to be (1) some previously determined length, or (2) the predictor order where the normalized mean squared error meets some prior-selected threshold or shows only slight further increases.
From
Table 1,
Table 2 and
Table 3, we see the normalized MMSPE as the predictor order is increased from
to
. Observing these values, it would appear that choosing a preset value for the predictor order in this range would not produce reliable results, except perhaps if
N were chosen to be large. Additionally, selecting a predetermined threshold for the MMSPE to select the predictor order also appears to be difficult. However, selecting the predictor order where the normalized mean squared prediction error shows only slight further increases as
N is incremented appears workable. Of course, quantifying “only slight further increases” can be a challenge.
As discussed in detail toward the end of
Section 6, the mutual information or the log ratio of entopy powers provides an alternative indicator of the new “information” being obtained as the predictor order is incremented. Reiterating a few of those points, we see that in
Table 1 when the predictor order is increased from
to
the mean squared error changes by 0.0202, an apparently small change, but the corresponding increase in mutual information is 0.304 bits/letter. Similarly, in
Table 2 when the predictor order is increased from
to
the mean squared error changes by 0.0258, less than three hundredths of the normalized energy, while the increase in mutual information is 0.226 bits/letter. Additionally, from
Table 3 when the predictor order is increased from
to
, the mean squared error changes by 0.0277, a relatively small value, while the increase in mutual information is 0.104 bits/letter.
Therefore, for the geophysical application of the AR model, the log ratio of entropy powers or change in mutual information provides a perhaps more sensitive indicator of the appropriate model order and certainly a new intuitive interpretation of changes in mean squared prediction error as the model order is increased.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}