1. Introduction
The Renewal process (RP) is a commonly used method for the statistical analysis of the successive inter-arrival times data set observed from a counting process. When the data set is non-trending, independently and identically distributed (iid), RP is a possible approach to modeling the data set. However, if the data follow a monotone trend, the data set can be modeled by a more possible approach than RP, such as the non-homogeneous Poisson process with a monotone intensity function, or a GP.
GP is first introduced as a direct approach to modeling of the inter-arrival times data with the monotone trend by Lam [
1]. Actually, GP is a generalization of the RP with a ratio parameter. However, GP is a more flexible approach than RP for modeling of the successive inter-arrival time data with a trend. Because of this feature, GP has been successfully used as a model in many real-life problems from science, engineering, and health.
Before progressing further, let us recall the following definition of GP given in [
2].
Definition 1. Let be the inter-arrival time the th and ith events of a counting process for . Then, the stochastic process generated by random variables is said to be a geometric process (GP) with parameter a if there exists a real number such thatare iid random variables with the distribution function F, where a is called the ratio parameter of the GP. Clearly, the parameter
a arranges monotonic behavior of the GP. In
Table 1, the monotonic behavior of the GP is given.
In the GP, the assumption on the distribution of
has a special significance because of the fact that the distribution of
and the other random variables
are from the same family of distributions with a different set of parameters. Namely,
s
are distributed independently, but not identically. This is trivial from Definition 1. By considering this property, the expectation and variance of
s are immediately obtained as
where
and
are the expectation and variance of the random variable
respectively. Since the distribution of the random variable
determines the distribution of the other variables, the selection of the distribution of
based on the observed data is quite important to optimal statistical inference [
3,
4]. There are many studies in the literature on the solution to the parameter estimation problem of GP while selecting some special distributions for
. Chan et al. [
5] investigated the parameter estimation problem of GP by assuming that the distribution of random variable
was Gamma. Lam et al. [
6] investigated the statistical inference problem for GP with Log-Normal distribution according to parametric and non-parametric methods. When the distribution of random variable
was the inverse Gaussian, Rayleigh, two-parameter Rayleigh and Lindley, the problems of statistical inference for GP were investigated according to ML and modified moment method by [
7,
8,
9,
10], respectively.
The main objective of this study extensively investigates the solution of parameter estimation problem for GP when the distribution of the first arrival time is Power Lindley. In accordance with this objective, estimators for the parameters of GP with the Power Lindley distribution are obtained according to methods of maximum likelihood (ML), modified moment (MM), modified L-moment (MLM) and modified least-squares (MLS). The method of moments and the least-squares estimators of Power Lindley distribution are available in the literature [
11]. The L-moments estimator of the Power Lindley distribution is obtained with this paper. In addition, the novelty of this paper is that the distribution of first inter-arrival time is assumed to be Power Lindley for GP and the ML and MLM estimators under this assumption are obtained.
The rest of this study is organized as follows:
Section 2 includes the detailed infomation about the Power Lindley Distribution. In
Section 3, the ML, the MLS, the MM and the MLM estimators of the parameters
,
and
are obtained.
Section 4 presents the results of performed Monte Carlo simulations for comparing the performances of the estimators obtained in
Section 3. For illustrative purposes, two examples with real data sets are given in
Section 5.
Section 6 concludes the study.
2. An Overview to Power Lindley Distribution
The Power Lindley distribution was originally introduced by Githany et al. [
11] as an important alternative for modeling of failure times. The distribution has a powerful modeling capability for positive data from different areas, such as reliability, lifetime testing, etc. In addition, for modeling the data sets with various shapes, many different extensions of the Power Lindley distribution have been attempted by researchers under different scenarios [
12,
13,
14,
15,
16,
17,
18,
19,
20].
Let
X be a Power Lindley distributed random variable with the parameters
and
. From now on, a Power Lindley distributed random variable
X will be indicated as
for brevity. The probability density function (pdf) of the random variable
X is
and the corresponding cumulative distribution function (cdf) is
where
and
are the positive and real-valued scale parameter and shape parameter of the distribution, respectively. Essentially, the Power Lindley distribution is a two-component mixture distribution with mixing ratio
in which the first component is a Weibull distribution with parameters
and
and the second component is a generalized Gamma distribution with parameter 2,
and
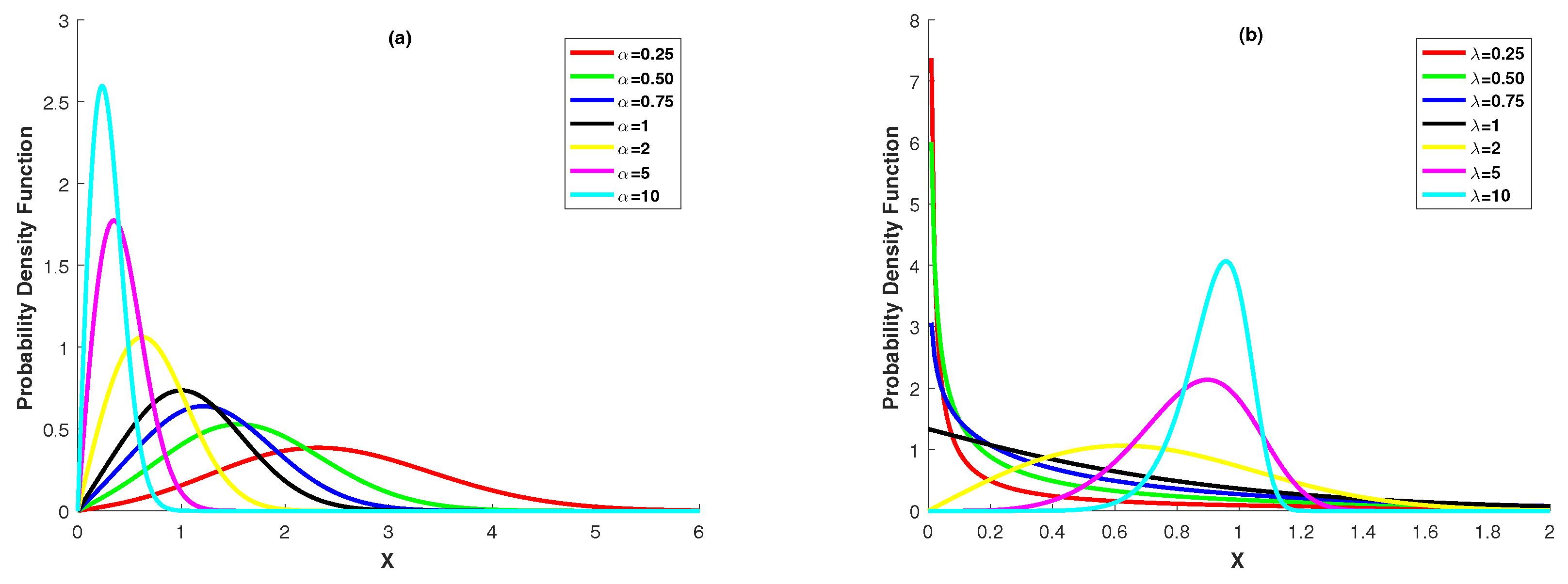
. The Power Lindley distribution is a quite important alternative to standard distribution families for analyzing of lifetime data, since its distribution function, survival function and hazard function are expressed in explicit form. The Power Lindley distribution also has uni-mode and belongs to the exponential family. To clearly show the shape of the distribution, we present
Figure 1.
Figure 1a,b show the behavior of the pdf of Power Lindley distribution at the different values of the parameters
and
.
Some basic measures of the Power Lindley distribution are tabulated in
Table 2.
Advanced readers can refer to [
11] for more information on the Power Lindley distribution.
2.1. Shannon and Rényi Entropy of the Power Lindley Distribution
The entropy is a measure of variation or uncertainty of a random variable. In this subsection, we investigate the Shannon and Rényi entropy, which are the two most popular entropies for Power Lindley distribution. The Shannon entropy (SE) of a random variable
X with pdf
f is defined as, see [
21],
Then, by using the pdf (
4), the SE of the Power Lindley distribution is found as
where
is the digamma function [
22]. The Rényi entropy of a random variable with pdf
f is defined as
By using the pdf (
4), Rényi entropy of the Power Lindley distribution is obtained as follows:
Applying the power expansion formula and gamma function to Equation (
9),
is obtained as
5. Illustrative Examples
Practical applications of the parameter estimation with developed procedures in
Section 3 are illustrated in this section with two data sets called Aircraft data set and Coal mining disaster data set.
In the examples, we use two criteria, the mean-squared error (MSE*) [
28] for the fitted values and the maximum percentage error (MPE), which are defined in [
25], for comparing the stochastic processes GP and RP. The MSE* and MPE are described as follows:
MSE* =
MPE =
where
is calculated by
and
and
. Then, in order to compare the relative performances of the RP and four GPs with the ML, the MLS, the MM and the MLM estimators, the plot of
and
against
can be used.
Example 1. Aircraft data.
The aircraft dataset consists of 30 observations that deal with the air-conditioning system failure times of a Boeing 720 aircraft (aircraft number 7912). The aircraft dataset was originally studied by Proschan [
29]. The successive failure times in aircraft dataset are 23, 261, 87, 7, 120, 14, 62, 47, 225, 71, 246, 21, 42, 20, 5, 12, 120, 11, 3, 14, 71, 11, 14, 11, 16, 90, 1, 16, 52, 95.
We first investigate the underlying distribution of the set of data. To test whether the underlying distribution of the data
is the Power Lindley, the following procedures can be used. From Definition 1, we know that the
and the
s follow the Power Lindley. We can write immediately as
by taking the logarithm of
. Note that
s follow the Log-Power Lindley distribution. Therefore, a linear regression model
can be defined, where
and
. If the exponential errors are Power Lindley distributed, then the underlying distribution of the set of data is Power Lindley. The error term
in Equation (
39) can be estimated by
where
. Thus, consistency of the exponentiated errors to Power Lindley distribution can be tested by using a goodness of fit test such as Kolmogorov–Smirnov (K-S). The parameter estimates of the exponentiated errors are
and
and also the value of the K-S test is 0.1225 and the corresponding
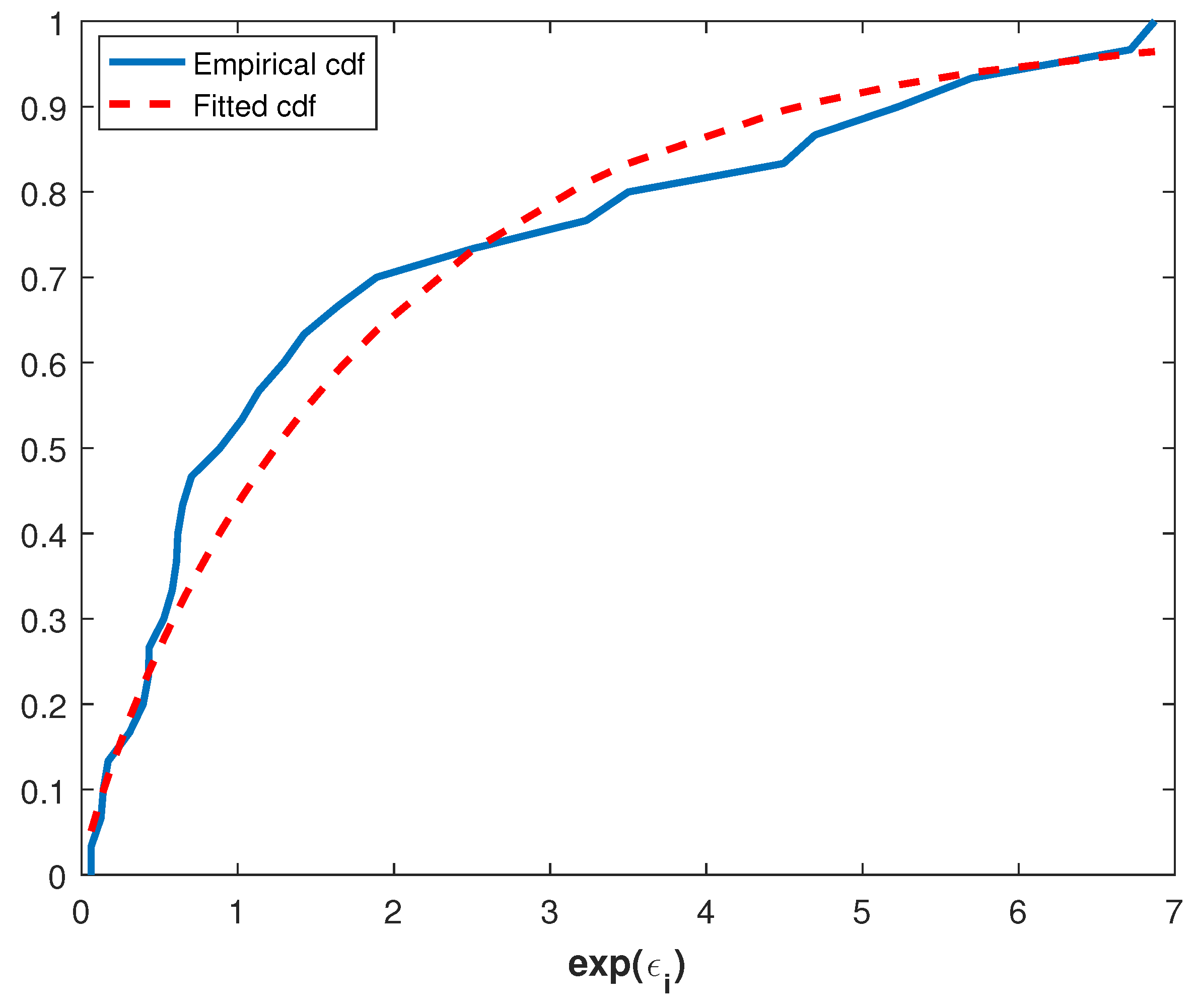
p-value is 0.7134. Therefore, it can be said that the underlying distribution of this data set is Power Lindley. This can also be seen from
Figure 2, which illustrates the plots of the empirical and the fitted cdf.
When a GP with the Power Lindley distribution is used for modeling of this dataset, the ML, the MLS, the MM and the MLM estimates of the parameters
and
and also MSE* and MPE values are tabulated in
Table 3.
As it can be seen from
Table 7, the ML estimates have the smallest MSE * values consistent with the simulation experiments. The estimator having the smallest MPE is the MM, but estimators of the ML and the MLM are very close to the MM.
Now, we check the model optimality. In order to select an optimal model to a data set, Akaike information criterion (AIC) and maximized log-likelihood (L) value are commonly used methods. For deciding an optimal model among the Power Lindley and its alternatives (Log-Normal, Gamma and inverse Gaussian) for this data set, we compute the -L and AIC values. The -L and AIC values for the models are given in
Table 8.
The results given in
Table 8 show that the Power Lindley distribution is an optimal model for the aircraft dataset with smaller AIC and -L values. In
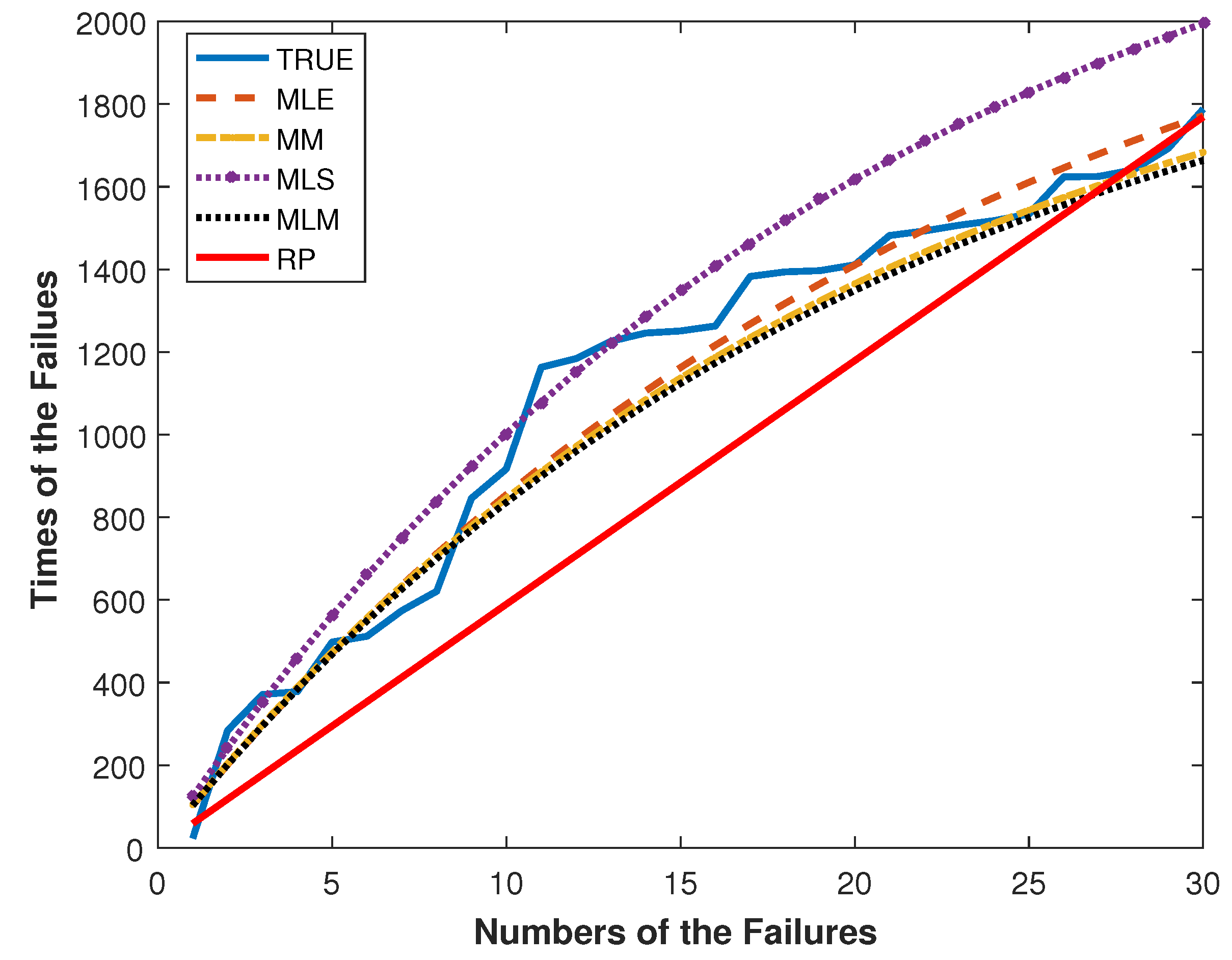
Figure 3, the failure times for the aircraft data and their fitted times are plotted.
The modeling performances of the RP and GP with the ML, the MLS, the MM and the MLM estimators can be easily compared by
Figure 3. By
Figure 3, the GP with the ML, the MLS, the MM and the MLM estimators outperform the RP. This result is compatible with
Table 7.
Example 2. Coal mining disaster data.
This example is from [
30] on the intervals in days between successive disasters in Great Britain from 1851 to 1962. The coal mining disaster data set, which includes 190 successive intervals, was used as an illustrative example for GP by [
7,
10,
24].
For this data set, the value of K-S test is 0.0396 and the corresponding
p-value is 0.9148. Thus, the Power Lindley distribution is an appropriate model for the coal mining disaster data. This is also supported by the following Q-Q plot,
Figure 4, which is constructed by plotting the ordered exponential errors
against the quantiles of the
because the data points fall approximately on the straight line in
Figure 4.
For the coal mining disaster data set, the estimates of the parameters
a,
and
are given in
Table 9.
Moreover, calculated AIC and L values for the coal mining disaster data set with the different models are tabulated in
Table 10.
We can say that the Power Lindley distribution is an optimal model for this data set since it has minimum AIC and -L values. Under the assumption that the underlying distribution of the data is Power Lindley, we present
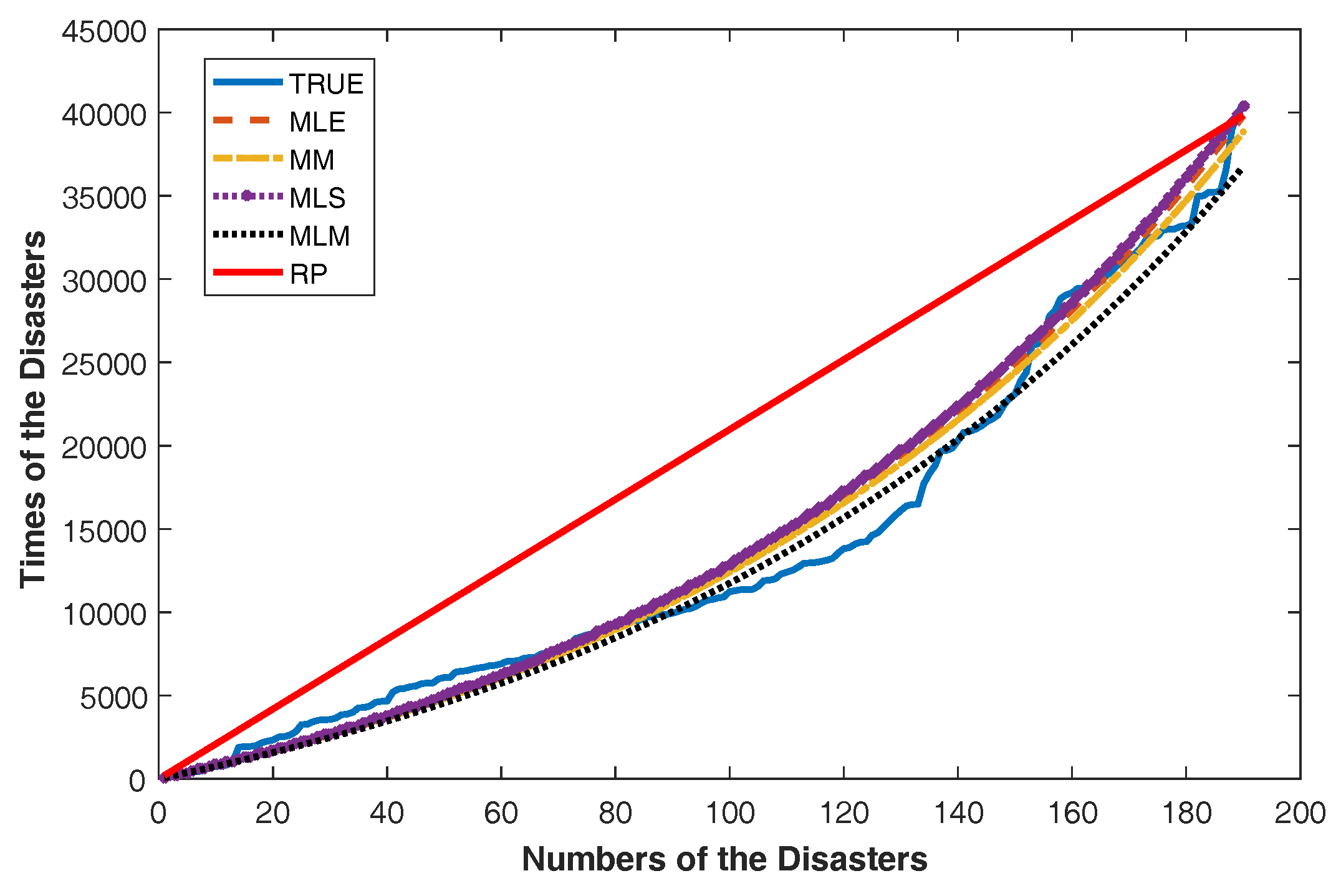
Figure 5 for comparing the modeling performance of the RP and the GP with four estimators obtained in the previous section.
Figure 5 plots
and
versus the number of disasters
.
As can be seen in
Figure 5, the GP with the ML, the MLS, the MM and the MLM estimators more fairly follow real values than the RP. It can also be seen from
Table 9 that the MSE* and MPE values of GP models are much smaller than RP. Thus, according to
Figure 5 and
Table 9, it is concluded that the GP provides the better data fit than RP.
6. Conclusions
In this paper, we have discussed the parameter estimation problem for GP by assuming that distribution of the first inter-arrival time is Power Lindley with parameters and . In the paper, the parameter estimation problem has been solved from two points of view as the parametric (ML) and nonparametric (MLS, MM and MLM). Parametric estimators, ML, of the parameters A, ALF and LAM are also asymptotically normally distributed. However, more work should be done in order to say something about the asymptotic properties of nonparametric estimators MLS, MM and MLM. In addition, this is usually not an easy task because an analytical form of these estimators cannot be written.
Numerical study results have shown that the ML estimators outperform the MLS, MLM and MLS estimators with smaller bias and MSE measures. In addition, it has been observed that both bias and MSE values of all estimators decrease when the sample size increases. Hence, in light of numerical studies, it can be concluded that all of the estimators are asymptotically unbiased and consistent.
In the illustrative examples presented to demonstrate the data modeling performance of GP with the obtained estimators, the GP with Power Lindley distribution gives a better data fit than the RP in both examples. In addition, according to AIC and -L values, it can be said that modeling both the aircraft dataset and the coal mining disaster dataset using a GP with Power Lindley distribution is more appropriate than a GP with Gamma, log-normal or inverse Gaussian distribution. Therefore, it can be said that a GP with Power Lindley distribution is a quite important alternative to a GP with famous distributions such as Gamma, Log-normal or inverse Gaussian in modeling the successive inter-arrival times.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}