
Bayesian Hierarchical Scale Mixtures of Log-Normal Models for Inference in Reliability with Stochastic Constraint

Abstract
:1. Introduction
2. The Class of SMLNFT Models
- (i)
- LNFT model:where
- (ii)
- LFT model:where and denote the cdf and density function of a Student- distribution, respectively.
- (iii)
- LCFT model:
- (iv)
- LLFT model:
- (v)
- LSFT model:
3. Two-Stage MaxEnt Prior
3.1. Stochastic Constraint on Reliability Measures
3.2. Two-Stage MaxEnt Prior
4. Bayesian Hierarchical SMLNFT Model
4.1. Bayesian Hierarchical Model
4.2. The Gibbs Sampler
- (1)
- The full conditional distribution of is an univariate normal given by:where
- (2)
- The full conditional distribution of is a truncated normal given by:where
- (3)
- The full conditional distribution of is a Gamma distribution:
- (4)
- The full conditional distributions of s are independent and their densities arewhere is the density of a mixing variable.
4.3. Markov Chain Monte Carlo Method
- note 1:
- With given initial values of , implementation of the Gibbs (or Metropolis-within-Gibbs) sampling algorithm consists of drawing repeatedly from distributions Equation (15) through Equation (18). The R package tmvtnorm and the R package mvtnorm can be used to sample from the conditionals and to calculate for a given from Equation (11).
- note 2:
- In cases using the LNFT model, degenerates at This means that the conditional distribution Equation (18) can be eliminated from the Gibbs sampler by setting for the conditionals of and
- note 3:
- When the LFT model is used for reliability analysis, the last stage of the Bayesian hierarchical model in Equation (13) becomes with Thus, the conditional distribution in Equation (18) yieldswhere denotes an vector whose elements are those of except for Note that the LCFT model is a special case of the LFT model with To allow to be determined within the model, one can specify one more prior stage for the Bayesian hierarchy in Equation (13). As suggested by [19,27], a uniform prior on () can be considered. To limit model complexity, we consider only fixed so that the investigation of different LFT models is possible.
- note 4:
- The conditional distribution Equation (18) for LSFT model isa truncated gamma whose support is
- note 5:
- note 6:
- The convergence of an MCMC algorithm is an important issue for the correct estimation of the posterior distribution of interest. See [30] for an example of multiple convergence diagnosis and output analysis. When the Markov chain is converged, Rao–Blackwellization yields good estimates of and
- note 7:
- As measures of model comparison among SMLNFT models, a deviance information criterion (DIC) can be used. This measure can be calculated based on extensions of the MCMC method. See [31] and references therein for a review and comparisons of such extensions.
5. Numerical Illustrations
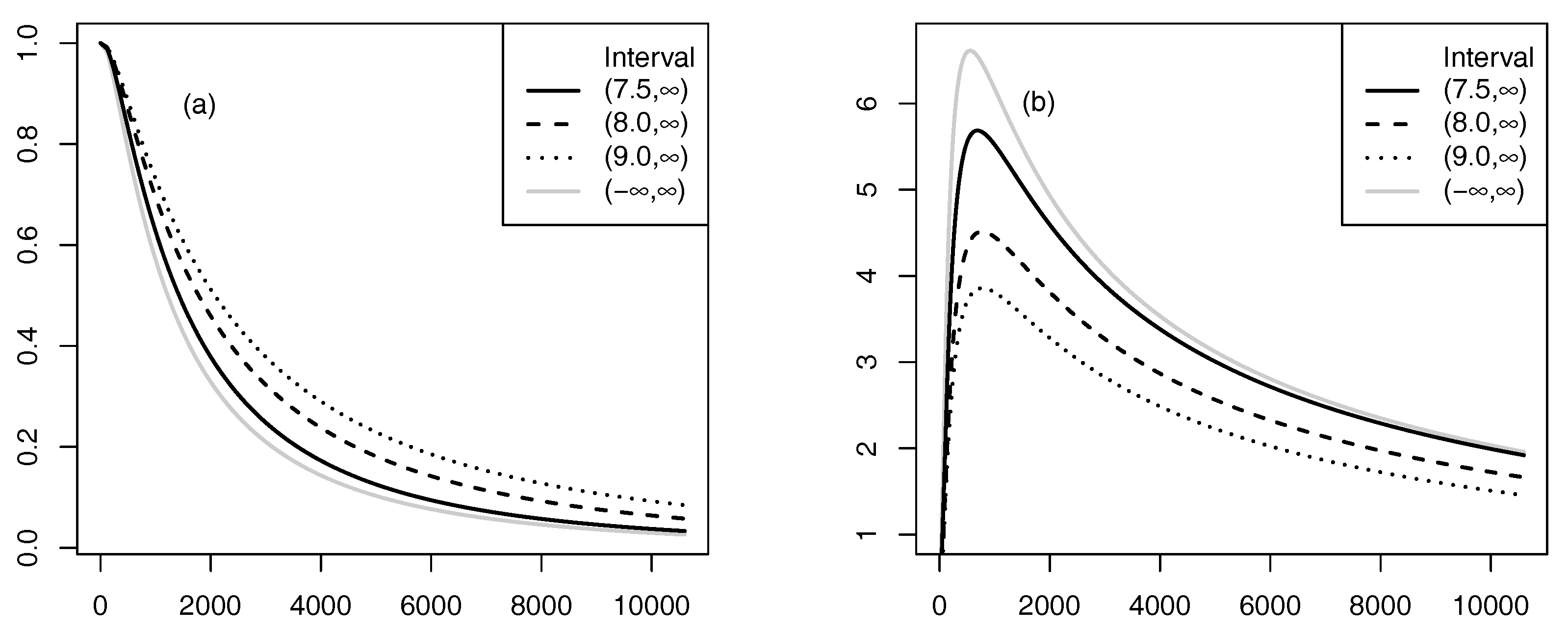
5.1. Equipment Failure Data Example
5.2. Artificial Data Example
6. Conclusions
Acknowledgments
Conflicts of Interest
References
- Stefanescu, C.; Turnbull, B.W. Multivariate frailty models for exchangeable survival data with covariates. Technometrics 2006, 48, 411–417. [Google Scholar] [CrossRef]
- Kavam, P.H.; Pena, E.A. Estimating load-sharing properties in a dynamic reliability system. J. Am. Stat. Assoc. 2005, 100, 262–272. [Google Scholar] [CrossRef]
- Sun, J. The Statistical Analysis of Interval-Censored Failure Time Data; Spring: New York, NY, USA, 2002. [Google Scholar]
- Yue, S. The bivariate lognormal distribution for describing joint statistical properties of multivariate storm event. Environmetrics 2002, 13, 811–819. [Google Scholar] [CrossRef]
- Yerel, S.; Konuk, A. Bivariate lognormal distribution model of cutoff grade impurities: A case study of magnesitr ore deposit. Sci. Res. Essay 2009, 4, 1500–1504. [Google Scholar]
- Lee, C.-F.; Finnerty, J.; Lee, J.; Lee, A.C.; Wort, D. Security Analysis, Portpolio Management, and Financial Derivatives; World Scientific Publishing Company: Singapore, 2012. [Google Scholar]
- Halliwell, L.J. The lognormal random multivariate. In Casualty Actuarial Society E-Forum; Spring, 2015; Available online: www.casact.org/pubs/forrum/15spforum/Halliwell.pdf (accessed on 13 June 2017).
- Weinke, A. Frailty Models in Survival Analysis; Chapman and Hall: Baco Raton, FL, USA, 2010. [Google Scholar]
- De Alba, E. Claims reserving when there iare negative values in the runoff triangle: Bayesian analysis using the three-parameter log-normal distribution. N. Am. Axtuarial J. 2006, 10, 28–38. [Google Scholar]
- Yue, S. The bivariate lognormal distribution to model a multivariate flood episode. Hydrol. Process. 2000, 14, 2575–2588. [Google Scholar] [CrossRef]
- Elshqeirat, B.; Soh, S.; Rai, S.; Lazarescu, M. Dynamic programming for minimal cost topology with reliability constraint. J. Adv. Comput. Netw. 2013, 1, 286–290. [Google Scholar] [CrossRef]
- Lin, Y.-K. Reliability evaluation for an information network with node failure under cost constraint. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2007, 37, 180–188. [Google Scholar] [CrossRef]
- Koide, T.; Shinmori, S.; Ishii, H. Topological optimization with a network reliability constraint. Discret. Appl. Math. 2001, 115, 135–149. [Google Scholar] [CrossRef]
- Cercignani, C. The Boltzman Equation and Its Applications; Springer: Berlin, Germany, 1988. [Google Scholar]
- Leonard, T.; Hsu, J.S.J. Bayesian Methods: An Analysis for Statisticians and Interdisciplinary Researchers; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- O’Hagan, A.; Leonard, T. Bayes estimation subject to uncertainty about parameter constraints. Biometrika 1976, 63, 201–203. [Google Scholar] [CrossRef]
- Lachos, V.H.; Labra, F.V.; Bolfarine, H.; Ghosh, P. Multivariate measurement error models based on scale mixtures of the skew-normal distribution. Statistics 2010, 44, 541–556. [Google Scholar] [CrossRef]
- Lindsey, J.K. Statistical Analysis of Stochastic Process in Time; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Chen, M.H.; Dey, D.K. Bayesian modeling of correlated binary responses via scale mixture of multivariate normal link functions. Sankhya´ Indian J. Stat. 1998, 60, 322–343. [Google Scholar]
- Gago-Benitez, A.; Fernádo-Madrigal, J.-A.; Cruz-Martin, A. Log-logistic modeling of sensory flow delays in networked telerobots. IEEE Sens. J. 2013, 13, 2294–2953. [Google Scholar] [CrossRef]
- Kim, H.J. A best linear threshold classification with scale mixture of skew normal populations. Comput. Stat. 2015, 30, 1–28. [Google Scholar] [CrossRef]
- Steiger, J. When constraints interact: A caution about reference variables, identification constraints, and scale dependencies in structural equation modeling. Psychol. Methods 2002, 7, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Lopes, H.F.; West, M. Bayesian model assessment in factor analysis. Stat. Sin. 2004, 14, 41–67. [Google Scholar]
- Loken, E. Identification constraints and inference in factor models. Struct. Equ. Model. 2005, 12, 232–244. [Google Scholar] [CrossRef]
- Gupta, S.D. A note on some inequalities for multivariate distribution. Bull. Calcutta Stat. Assoc. 1969, 18, 179–180. [Google Scholar] [CrossRef]
- Kim, H.J. A two-stage maximum entropy prior of location parameter with a stochastic multivariate interval constraint and its properties. Entropy 2016, 18, 1–20. [Google Scholar] [CrossRef]
- Sisson, S. Trans-dimensional Markov chains: A decade of progress and future perspectives. J. Am. Stat. Assoc. 2005, 100, 1077–1089. [Google Scholar] [CrossRef]
- Koop, G; Poirier, D.J.; Tobias, J.L. Bayesian Econometric Methods; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Chib, S.; Greenberg, E. Understanding the Metropolis-Hastings algorithm. Am. Stat. 1995, 49, 327–335. [Google Scholar] [CrossRef]
- Heidelberger, P.; Welch, P. Simulation run length control in the presence of an initial transient. Oper. Res. 1992, 31, 1109–1144. [Google Scholar] [CrossRef]
- Ntzoufras, I. Bayesian Modeling Using WinBUGS; Wiley: New York, NY, USA, 2009. [Google Scholar]
- Dagpunar, J.S. Simulation and Monte Carlo; Wiley: New York, NY, USA, 2007. [Google Scholar]
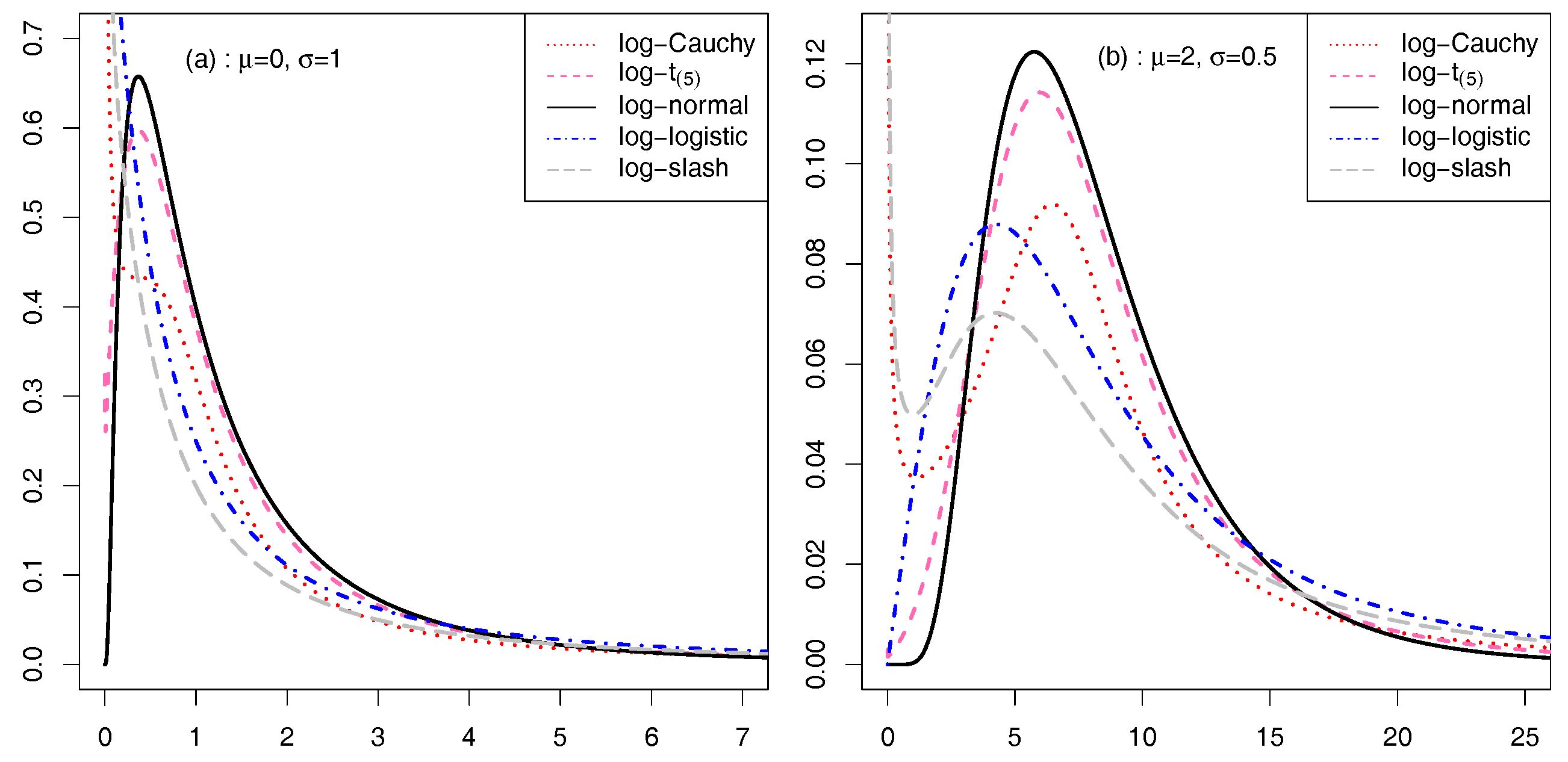


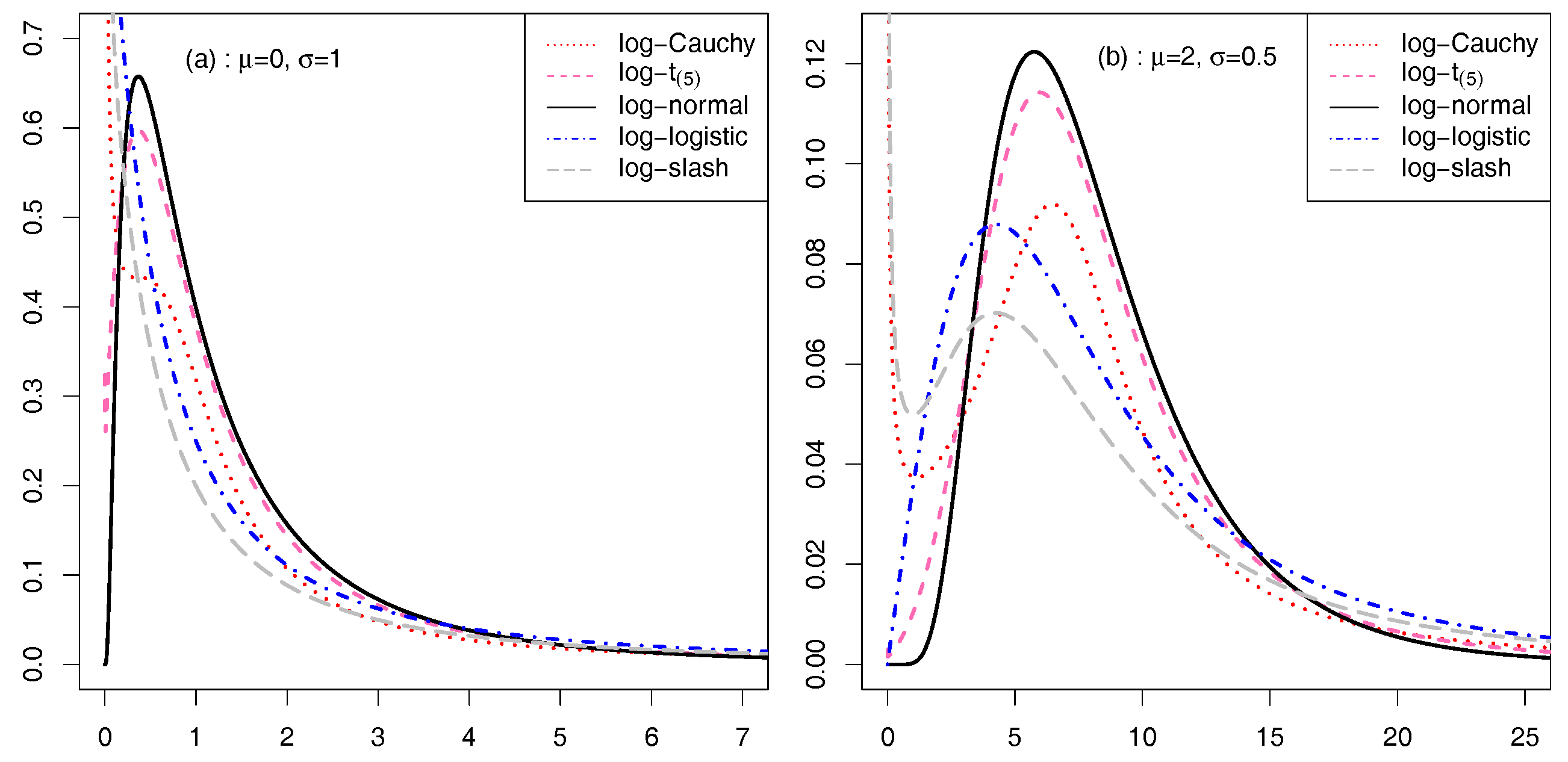{kind=link}
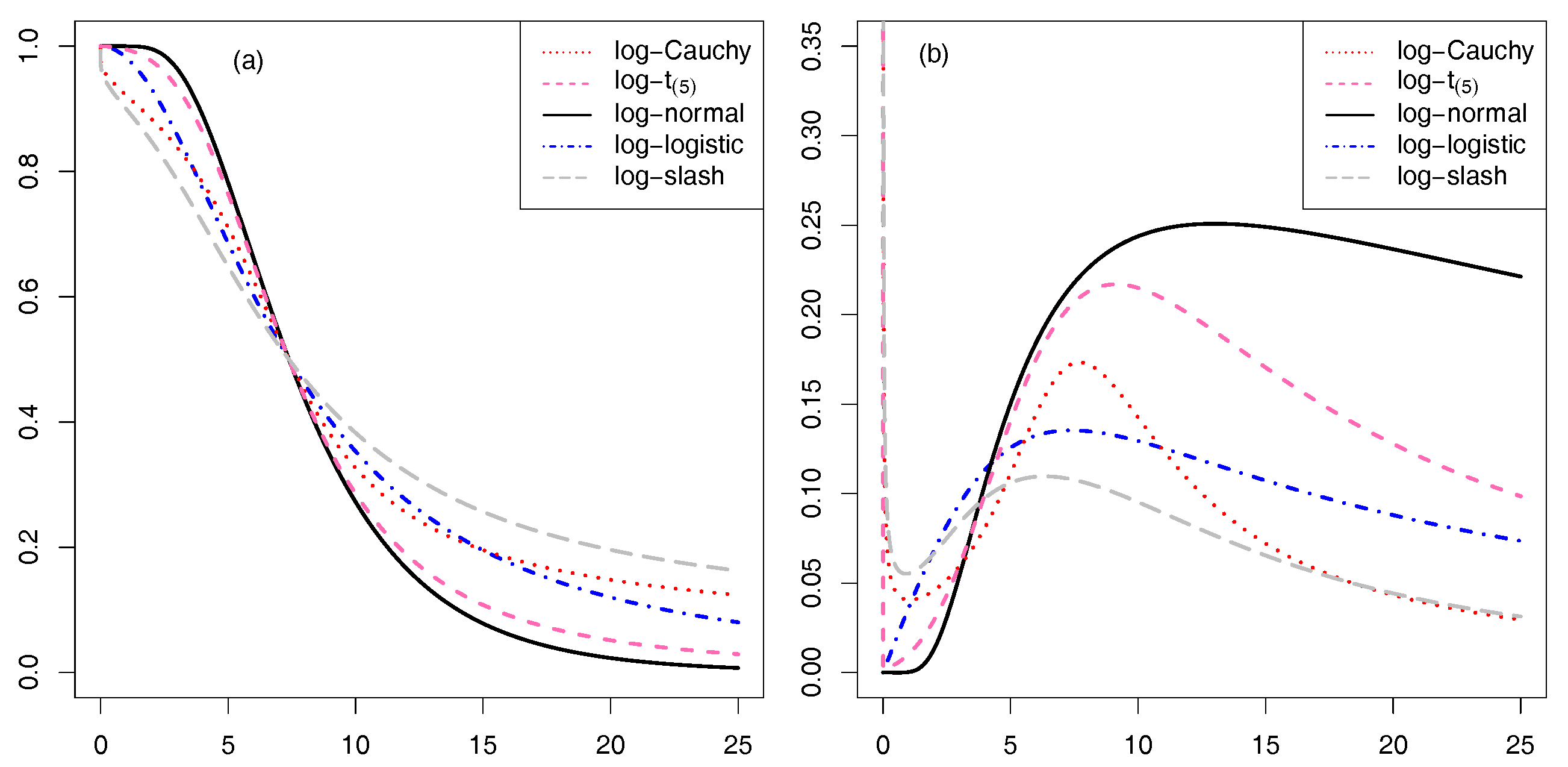
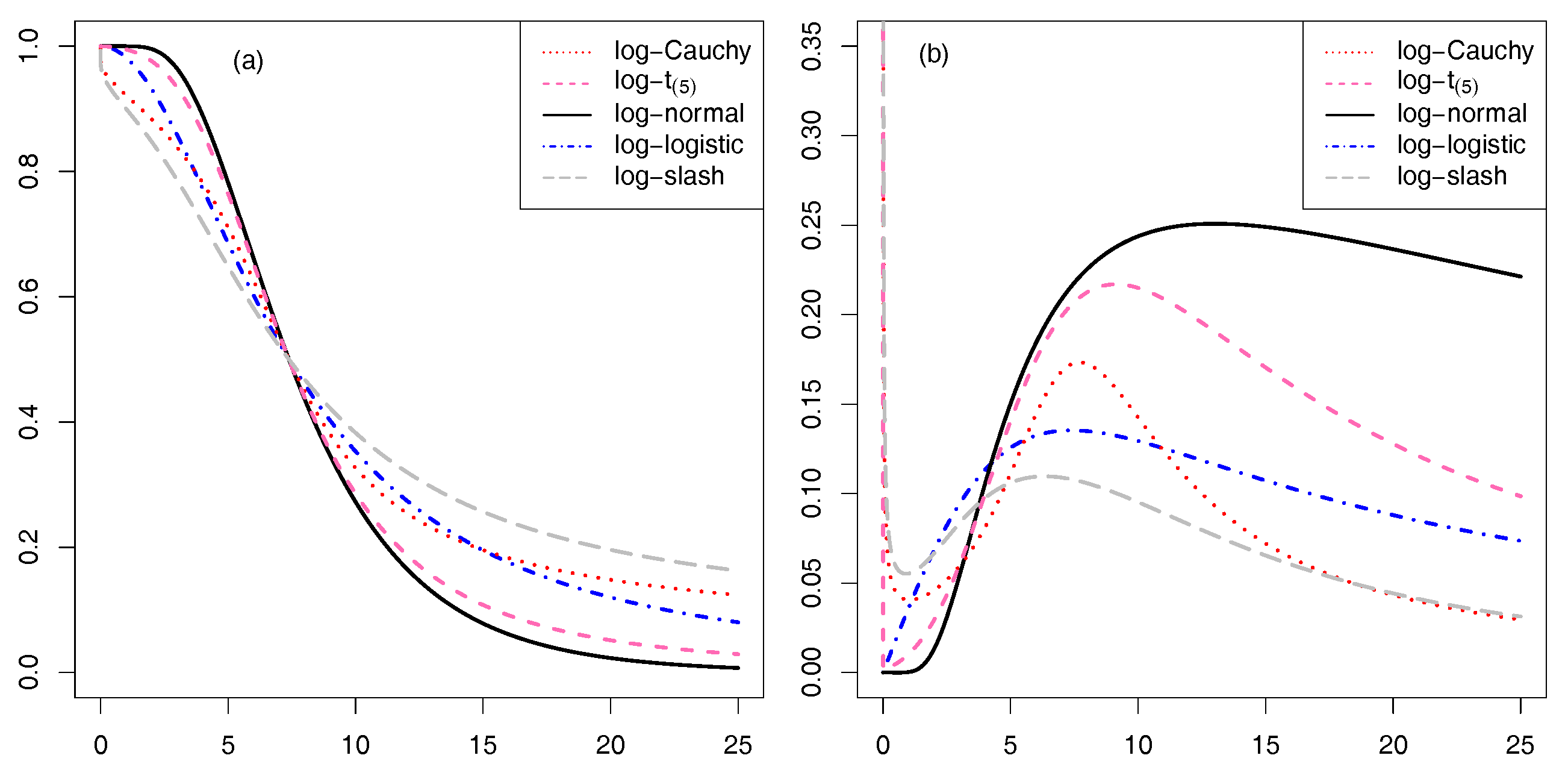{kind=link}
{kind=link}
| Variable | Mean | S.D. | S–W (p-Value) | K–S (p-Value) |
|---|---|---|---|---|
| Y | 2201.488 | 2519.174 | 0.732 (<0.01) | 0.231 (<0.01) |
| X | 7.143 | 1.088 | 0.982 (0.760) | 0.064 (>0.150) |
| Parameter | S.D. | 2.5% | 97.5% | MC Error | |||||
|---|---|---|---|---|---|---|---|---|---|
| 7.141 | 7.182 | 7.261 | 7.553 | 0.155 | 6.964 | 7.569 | 0.002 | ||
| 1.181 | 1.185 | 1.196 | 1.327 | 0.295 | 0.812 | 1.930 | 0.004 | ||
| 0.308 | 0.698 | 0.865 | 1.000 | - | - | - | - | ||
| 7.141 | 7.202 | 7.364 | 8.029 | 0.157 | 7.067 | 7.684 | 0.002 | ||
| 1.181 | 1.188 | 1.228 | 1.941 | 0.313 | 0.823 | 2.036 | 0.004 | ||
| 0.158 | 0.660 | 0.834 | 1.000 | - | - | - | - | ||
| 7.141 | 7.255 | 7.637 | 9.035 | 0.187 | 7.306 | 8.041 | 0.002 | ||
| 1.181 | 1.198 | 1.408 | 4.734 | 0.401 | 0.901 | 2.450 | 0.005 | ||
| 0.023 | 0.610 | 0.780 | 1.000 | - | - | - | - |
| Model | Parameter | Mean | S.D. | MC Error | 2.5% | Median | 97.5% | DIC |
|---|---|---|---|---|---|---|---|---|
| LNFT | 2.043 | 0.147 | <0.001 | 1.755 | 2.043 | 2.332 | 861.602 | |
| 4.329 | 0.438 | 0.002 | 3.554 | 4.300 | 5.274 | - | ||
| LCFT | 1.948 | 0.043 | <0.001 | 1.863 | 1.948 | 2.035 | 463.242 | |
| 0.146 | 0.026 | <0.001 | 0.101 | 0.146 | 0.204 | - | ||
| LFT | 1.948 | 0.043 | <0.001 | 1.862 | 1.948 | 2.033 | 394.339 | |
| 0.289 | 0.036 | <0.001 | 0.225 | 0.286 | 0.365 | - | ||
| LSFT | 1.992 | 0.118 | <0.001 | 1.761 | 1.992 | 2.227 | 867.325 | |
| 0.557 | 0.098 | <0.001 | 0.389 | 0.548 | 0.776 | - | ||
| LLFT | 2.025 | 0.132 | <0.001 | 1.767 | 2.025 | 2.282 | 842.847 | |
| 1.363 | 0.176 | <0.001 | 1.056 | 1.350 | 1.745 | - |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.-J. Bayesian Hierarchical Scale Mixtures of Log-Normal Models for Inference in Reliability with Stochastic Constraint. Entropy 2017, 19, 274. https://doi.org/10.3390/e19060274
Kim H-J. Bayesian Hierarchical Scale Mixtures of Log-Normal Models for Inference in Reliability with Stochastic Constraint. Entropy. 2017; 19(6):274. https://doi.org/10.3390/e19060274
Chicago/Turabian StyleKim, Hea-Jung. 2017. "Bayesian Hierarchical Scale Mixtures of Log-Normal Models for Inference in Reliability with Stochastic Constraint" Entropy 19, no. 6: 274. https://doi.org/10.3390/e19060274
APA StyleKim, H.-J. (2017). Bayesian Hierarchical Scale Mixtures of Log-Normal Models for Inference in Reliability with Stochastic Constraint. Entropy, 19(6), 274. https://doi.org/10.3390/e19060274