2.1. Distinguishability
At a minimum, computation requires two things: logical tokens of computations (i.e., things that are operated on and that change) and rules that dictate the dynamics of how tokens evolve. The proposed axioms meet these requirements by defining the tokens of computation in the first and its possible dynamics by the second.
Any intelligent process is attempting to solve a problem. Whatever the problem, it corresponds to what is called its computational issue. An intelligent process wants to solve its problem by formally resolving its issue through its processing.
A practical example is that of finding one’s car keys for the drive to work in the morning. The issue is: “Where are my keys?” They are lost! Resolving this issue requires searching every room in the house to hopefully resolve the problem by finding them. A smart search strategy would be to first search the most likely rooms where the keys could be (e.g., entryway, bedroom, kitchen). This will, on average, reduce search time and minimize the energy required to solve this problem.
As will be shown, one can quantify intelligence as an exact number specifiable in units of bits per decision by way of analogy to the bandwidth of digital communication systems [
2]. It is the rate given in units of bits per second of the capacity of a system to resolve its computational issue. The faster a system can solve its problem, the higher its intelligence.
Consider the following two axioms:
A1 is discussed first. It captures how a system can distinguish its environment and what subjectively comprises information and control.
Consider a system that can observe X and make decisions Y. Uppercase italicized letters denote logical questions. By asking X, the system can acquire information from and about its environment. By making decisions Y, it can control it.
Consider a simple single-cell organism, a protozoan. Some protozoa have the ability to sense light and to “see”. They can also propel themselves in water using their cilia [
3]. Consider such a species living in a pond and that it likes to eat algae and other material found near the pond surface. Water near the surface is preferentially illuminated by the sun and tends to provide a richer source of nutrients that the protozoa like to consume.
Imagine protozoa in the pond being perturbed by internal currents that randomly reorient them over time. Moreover, there will be times when a protozoan is oriented such that its forward optical sensor will point in the direction of the brighter pond surface. It may or may not sense light as dictated by its detection threshold and its depth in the pond. The organism’s ability to sense light corresponds to the subjective question X. Possible answers to X must correspond to a binary internal state of the organism placed into one state or another by its environment.
Upon a positive detection, the protozoan may or may not activate its cilia to propel itself forward and toward the surface of the pond where it can successfully feed. Call this decision Y. It again is an internal state set of the organism with it representing one of two possible binary decisions. However, in this case, it is the organism, not the environment, that decides this state.
The only energy-efficient survival strategy for the protozoan is for it to move toward light when it sees it. However, there are three other possible strategies that can be delineated: (1) never activate its cilia when light is detected; (2) activate its cilia when it does not sense light; or (3) never activate its cilia under any circumstances. None of these support survival. Therefore, in some regards, one can say that this simple creature behaves intelligently in how it converts information into action. It could not flourish otherwise.
Now associate the physical protozoan system with a computational issue denoted A to survive. To sense light, A asks the question X ≡ “Do I sense light?” The induced response within A is that this question is either answered “yes” or “nothing” (i.e., no response from its threshold detector). To move, A can be thought of answering a question Y ≡ “Should I activate my cilia?” by either doing so or not through the activation of an internal state.
In general, a subjective inquiry
X allows a system
A to actively acquire information from its environment. Answers are determined by the specific question posed and by the environment. However, the ability to pose
X is defined totally within the system
A itself. Most fundamentally, it is how
A distinguishes its environment from an information perspective. Similarly, answering
Y allows
A to make subjective decisions as to how it wants to behave in its environment. It is the way
A subjectively distinguishes the possible ways it can control its environment through its subjective decisions. Note that philosophically a question represents a way that a system establishes boundaries of its subjective reality. The world is as we apportion our subjective experience into discrete experiential quanta. The philosopher Clarence Irving Lewis [
4] first used the term “qualia” to capture this idea.
The notion of distinguishability underlies the subjective acquisition of information by an intelligent system and its use to make decisions. If one could formalize the notion of questions in this manner, it would allow for a powerful computing paradigm by providing a formal way of considering what it means to ask and answer questions within the subjective frame of a system.
Cox [
5], as inspired by Cohen [
6], showed that Boolean algebra as currently known is incomplete. In fact, exactly half is missing. Cox formulated a joint Boolean algebra of assertions and questions that captures the elementary dynamics of the physical exchange of information and control of a system with its environment.
Conventional Boolean algebra is an algebra of propositions. “This ball is red!” Conversely, Cox [
5] proposes two mutually defining quantities he calls assertions and questions. “An assertion is defined by the questions it answers. A question is defined by the assertions that answer it.” These definitions result in two complete and complementary Boolean algebras, each with its respective logical measures of probability and entropy. Assertions, questions, probability, and entropy all have physical manifestations and are intrinsic to all dynamical system processes including intelligent ones.
That is, logical propositions in fact assert answers or states of nature like “The ball is red!” Every logical expression in conventional logic has a dual question, e.g., “Is the ball red?” Action potentials can be thought of as computational tokens in brains that answer questions posed by the dendrites of neurons or answered by their output axons. Likewise, photons are assertions that answer the question posed by an optical detector.
As a trivial example, consider a card-guessing game where one player desires to know the card held by another. Lower-case italicized letters denote logical assertions such as a and b. The first player resolves this issue by asking the second player questions like S ≡ “What is the suit of the card?” or C ≡ “What is the color of the card?” These questions are defined by the assertions that answer them, where S ≡ {h, c, d, s} and C ≡ {r, b} to make explicit the fact that questions are defined by the assertions that answer them. Of course h ≡ “Heart!”, c ≡ “Club!”, d ≡ “Diamond!”, and s ≡ “Spade!”, whereas r ≡ “Red!” and b ≡ “Black!”.
The common question is denoted by the symbol “∨” with S ∨ C = C an example of usage. This is the disjunction of two questions and asks what both question asks. The information common to suite S and color C is the color of the card C. Intelligent systems are interested in X ∨ Y, the information X common to the decisions Y to be made. In the case of the protozoan system, X ∨ Y is all the organism is interested in because this drives its survival. Disjunction is a powerful and simple construct for quantifying the concept of actionable information.
The joint question S ∧ C = S provides the information given by asking both questions S and C. This is the conjunction of two questions and in this case is the suit of the card question S = S ∧ C.
Regarding disjunction [
5], the question
S ∨
C ≡ {
h,
c,
d,
s,
r,
b}. Moreover, any assertion that implies an assertion that defines a question also defines that question. In this case,
h →
r,
d →
r,
c →
b, and
s →
b, and so
S ∨
C ≡ {
r,
b} ≡
C. Regarding conjunction [
5],
S ∧
C ≡ {
h ∧
r,
h ∧
b,
c ∧
r,
c ∧
b,
d ∧
r,
d ∧
b,
s ∧
r,
s ∧
b}. Assertions like
h ∧
b and so on where suites and colors are absurd and can be eliminated leaving
S ∧
C ≡ {
h ∧
r,
c ∧
b,
d ∧
r,
s ∧
b}. But for instance
h ∧
r →
h and so
S ∧
C ≡ {
h,
c,
d,
s} ≡
S.
In the case of the card-guessing game, a special logical relationship exists between
C and
S called strict logical implication [
7], whereby “
S implies
C” or
S →
C. Either condition
S ∨
C =
C or
S ∧
C =
S is necessary and sufficient for strict implication to hold. The implication of one question by another means that if
S is answered, then so is
C. In the case of the protozoan system, it desires the condition
Y →
X so that it properly activates its cilia when it sees light.
Assertions can also strictly imply one another. An assertion a implying another is denoted by a → b. This means that if b answers a question, then so does a. The assertion a may contain information extraneous to answering the reference question. For example, s ≡ “He is my son!” implies b ≡ “He is a boy!” regarding the gender question G ≡ “Is your child a girl or boy?” Upon hearing “He is my son!” the person posing question G will strip away the extraneous information about “son” and only hear “boy” given the inquiry G ≡ {b, g}.
In probability theory, the probability of
c given
a is denoted by
p(
c|
a). Formally, probability is the measure or degree [
8] to which one assertion
a implies another
c or
a →
c. The introduction of notation
p(
c|
a) = (
a →
c) denotes this. By way of symmetry, one can ask if there is a similar measure for the degree of implication of one question by another, and indeed there is. Cox [
5] introduces the notation
b(
B|
A) as the bearing of one question
B on answering another
A, which is represented by the notation
b(
B|
A) = (
B →
A). Formally, bearing
b is just entropy [
5]. The protozoan, for instance, wants to maximize (
X ∨
Y →
A) =
b(
X ∨
Y|
A), where
A is formally its computational issue to survive. In the card-guessing problem,
b(
S ∨
C|
A) =
b(
C|
A) and
b(
S ∧
C|
A) =
b(
S|
A). The first provides one bit of information, and the second provides two bits.
The complement of a question ~B asks what B does not ask relative to resolving an issue A. Therefore, ~B ∧ B asks everything. Similarly for assertions, ~b asserts what b does not, and this is the active information perspective assumed. In this case, ~b ∨ b tells everything and is always asserted.
It is easy to map back and forth between logical expressions involving bearing and equivalent information-theoretic expressions. This mapping is summarized in
Table 1.
The remainder of this paper emphasizes the use of the notations I(X; Y), H(X), and H(Y) instead of b(X ∨ Y|A), b(X|A), and b(Y|A), respectively. However, keep in mind that any particular intelligent process has a reference frame A to which the corresponding information-theoretic expressions refer. For example, H(X) is sometimes called “self-information”. Conversely, b(X|A) measures the amount of information to be expected by posing the question X to resolve an issue A. In the card-guessing game, C and S are posed relative to the broader issue A ≡ {c1, c2, …, c52} of which card ci in a deck of 52 cards is being held by the other player.
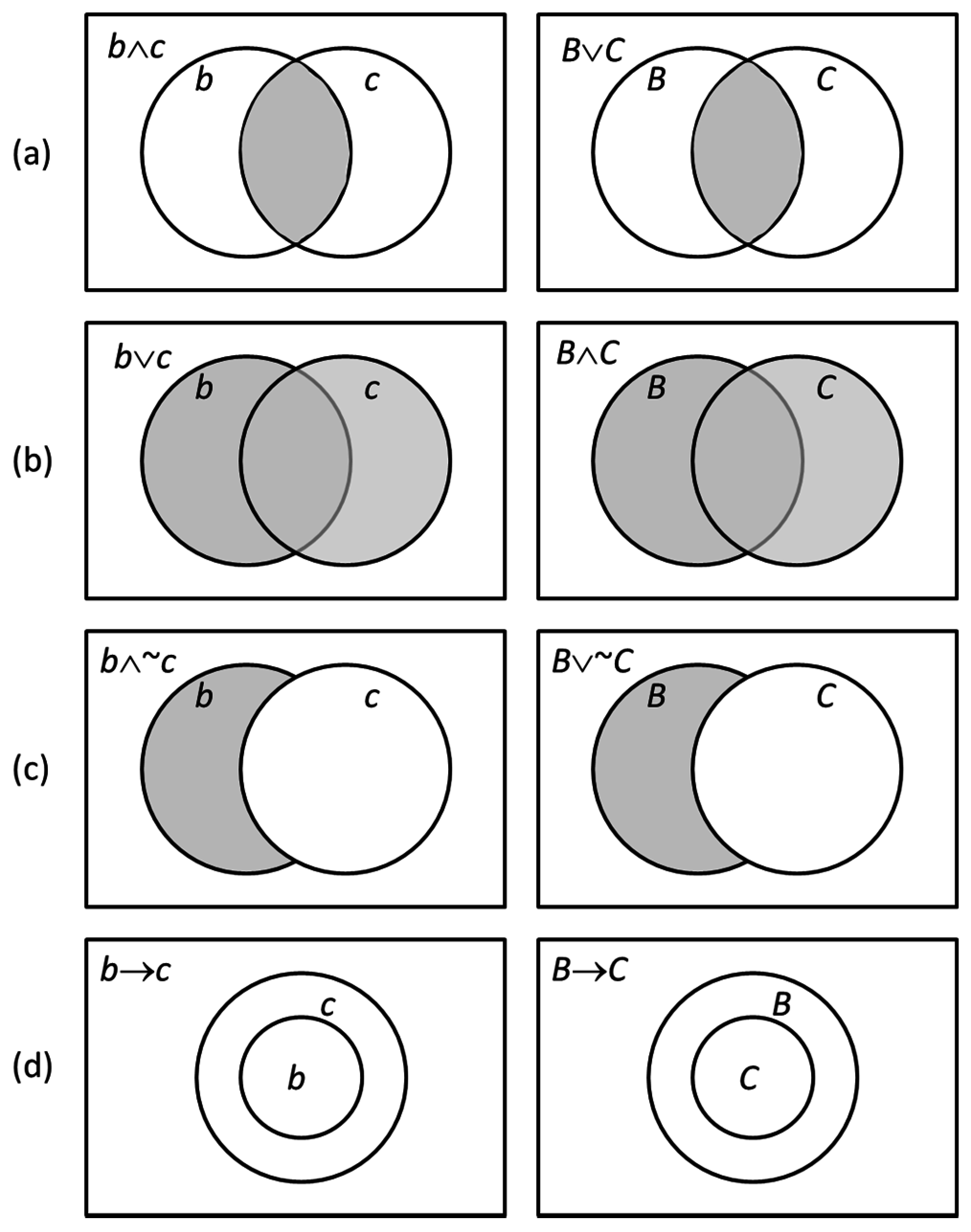
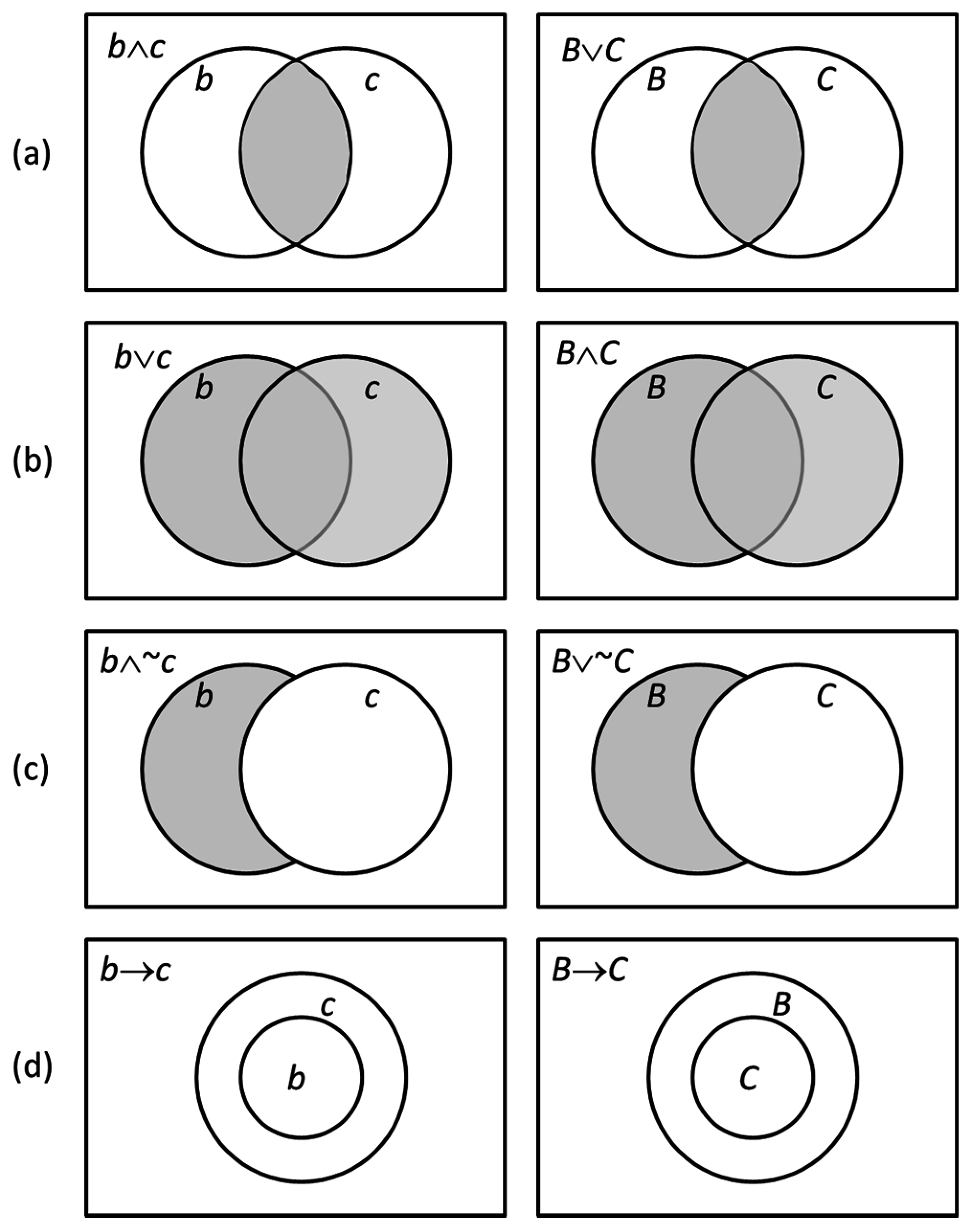
Venn diagrams [
9] provide a convenient way of graphically capturing strict logical implication of assertions and questions. If
b →
c, then a smaller circle labeled
a will reside somewhere inside a larger circle labeled
c such as depicted in
Figure 1d. If
B →
C, then a larger circle
B contains a smaller circle labeled
C again as depicted in
Figure 1d right bottom. This depicts that the information request of
B is greater than
C and includes that of
C. The latter diagrams are formally called
I-diagrams [
10], whereas those for assertions are conventional Venn diagrams.
Figure 1 illustrates dual Venn and
I-diagrams for several cases of interest. The transformation between each column is accomplished using the reflection operator [
11] where, for instance,
,
, and
. The conversion rules [
5] are that assertions and questions are interchanged, as are conjunction “∧” and disjunction “∨”. The complementation operator is preserved.
The
I-diagram in
Figure 1d is of particular interest. Suppose that an intelligent process asks
X =
C and decides
Y =
B. As will be shown, the condition
Y →
X means that “control authority” of the system exceeds its informational uncertainty. This implies
b(
X ∨
Y|
A) =
b(
X|
A), meaning that the available information is adequate to provide for perfect control.
As an example, consider the shell game played at least as far back as ancient Greece [
12]. In this game, one player using sleight of hand quickly moves three nut shells around one another. One of these shells contains a pea. The objective of the second player is to guess which shell contains the pea. In this game, suppose that the second player has the information
X ≡ {
x1,
x2,
x3}. If this player has good visual acuity, he may be able to follow and track the moving shells. In general, this is not the case. The second player then makes the decision
Y ≡ {
y1,
y2,
y3}. Because of inadequate information, the second player cannot make perfect decisions. If, however, the second player had the option of making additional choices following wrong ones, he would be guaranteed the ability to win the game given
Y →
X. This increase in control authority is required to overcome informational uncertainty.
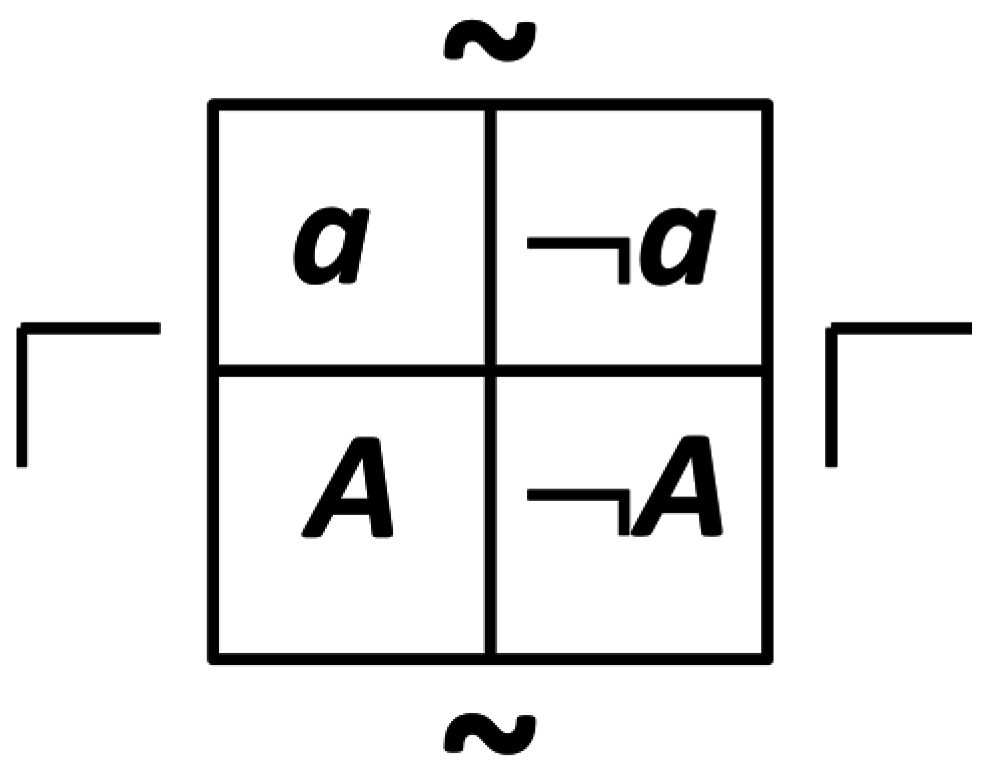
Consider a physical example of a question and assertion consisting of a photon detector with quantum efficiency η. If a photon hits the detector, it is detected with probability η. The detector corresponds to a question D ≡ “Is a photon present?” Photons correspond to assertions. If one can instead physically build a “photon absent” detector, it would be denoted by ¬D and have the property that it would only respond if no photon is detected.
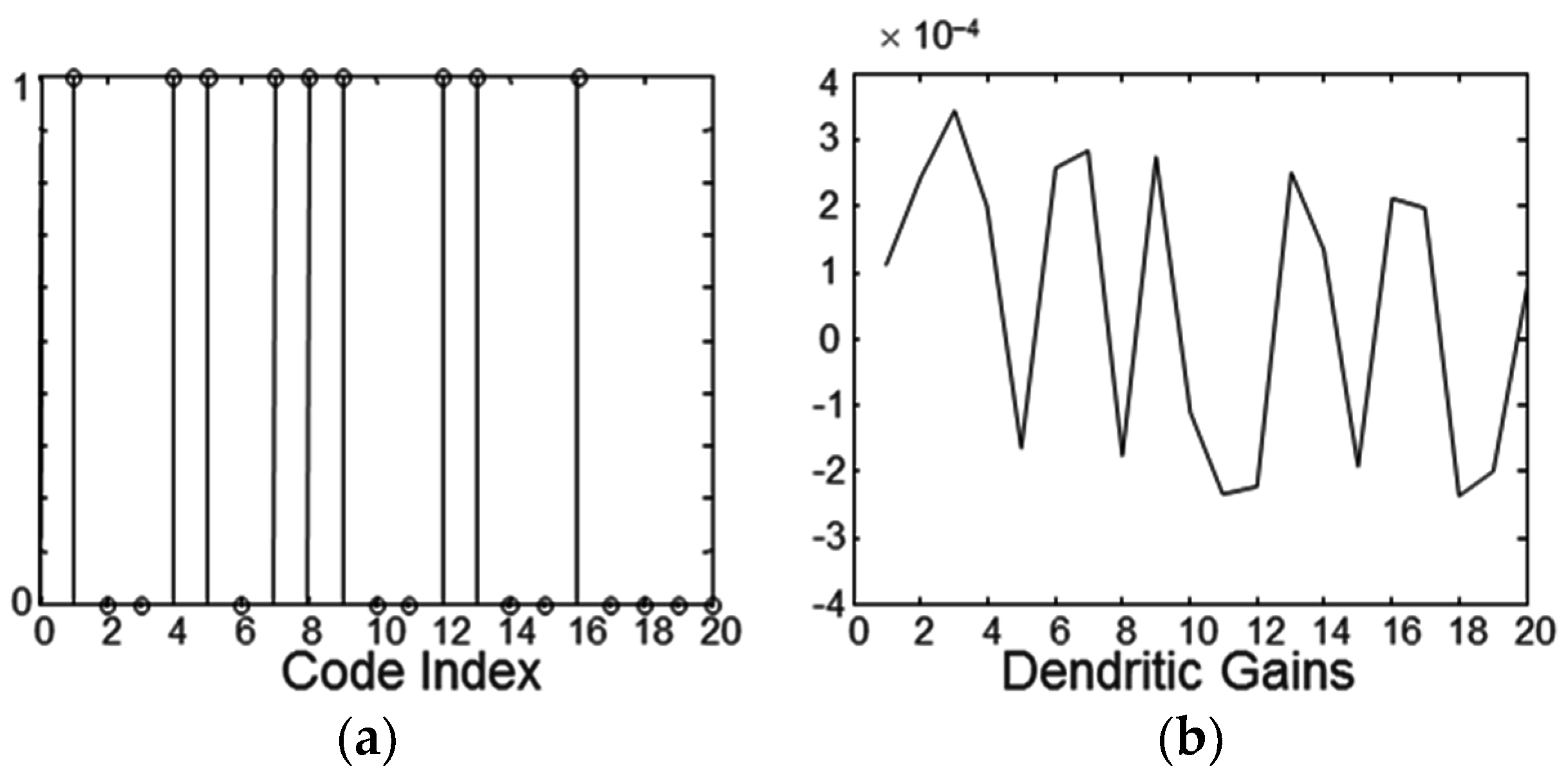
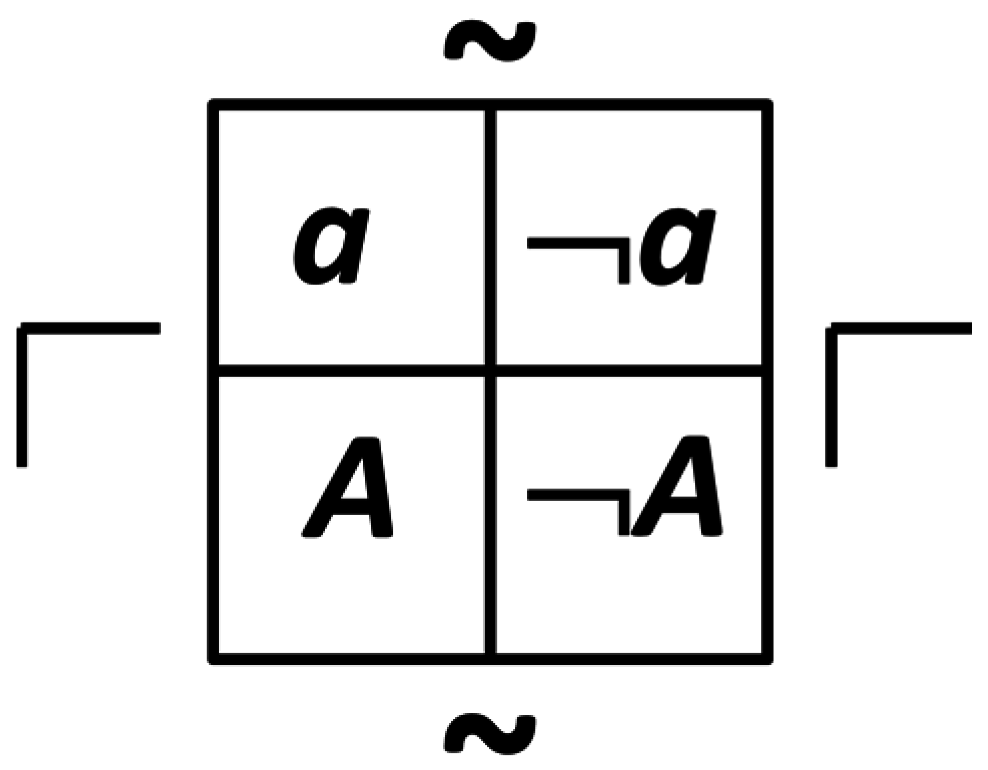
Photon detectors, photons, dendrites, and axons and action potentials are examples of binary questions. They can be graphically described in a diagram called a dyadic, as shown in
Figure 2 for
Q ≡ {
a, ¬
a}. The complementation operator allows the transformation of assertion states, whereas the reflection operator transforms between corresponding assertions and questions.
Cohen [
6] described the importance of having a formal means of logically manipulating questions by way of analogy with conventional logic. Clearly, he had some anticipation of Cox’s work [
5] as reflected by his statement in Reference [
6]: “In order to be able to ask the question ‘What is a question?’, one must already know the answer”.
2.3. Communication Systems
Consider a process that reconstructs the past. A communication system does this because its only purpose is to reconstruct information transmitted through a channel. It tries to reconstruct at the present a symbol transmitted to it in the past by a source with a time delay specific to the channel being used. The system must be synchronized such that the receiver will know when the source transmits a symbol and when it should expect to receive it. The symbol itself is not directly received; instead, a modulated signal is inserted into the channel by the source. This signal, while propagating within the channel, is subject to information loss relative to the receiver caused by possible attenuation, channel distortion effects, and noise.
Suppose that the communication system has an input alphabet given by x1, x2, …, xn. The receiver asks the question X ≡ “What symbol was transmitted by the course?” Formally, X ≡ {x1, x2, …, xn}. As the receiver awaits reception, it possesses uncertainty H(X) regarding what was sent. The entropy H(X) is dictated by the alphabet of the communication and the relative probabilities the receiver assigns to each symbol it deems possible to have been sent. The key item of note in this perspective is that the uncertainty H(X) is defined relative to the receiver because the source knows perfectly well what it is transmitting, whereas the receiver does not.
The source, having selected a symbol to send, will modulate and expend energy to transmit it through the communication channel to a receiver. While propagating through the channel, the energy of the signal will be passively dissipated to the environment. At the same time, the signal will be affected by channel noise and distortion effects. These effects combine to reduce the ability of the receiver to perfectly reconstruct codes sent to it in the past.
Depending on the physical proximity of the source and the receiver as measured through the channel, the receiver will measure or otherwise acquire the signal observed at its end of the channel. The receiver necessarily must include an algorithm that will demodulate this signal and then compute a single number that guides its selection of a symbol from its alphabet of hypothetical symbols it thinks could be sent to it by the source in the past. This serves to reduce its entropy H(X).
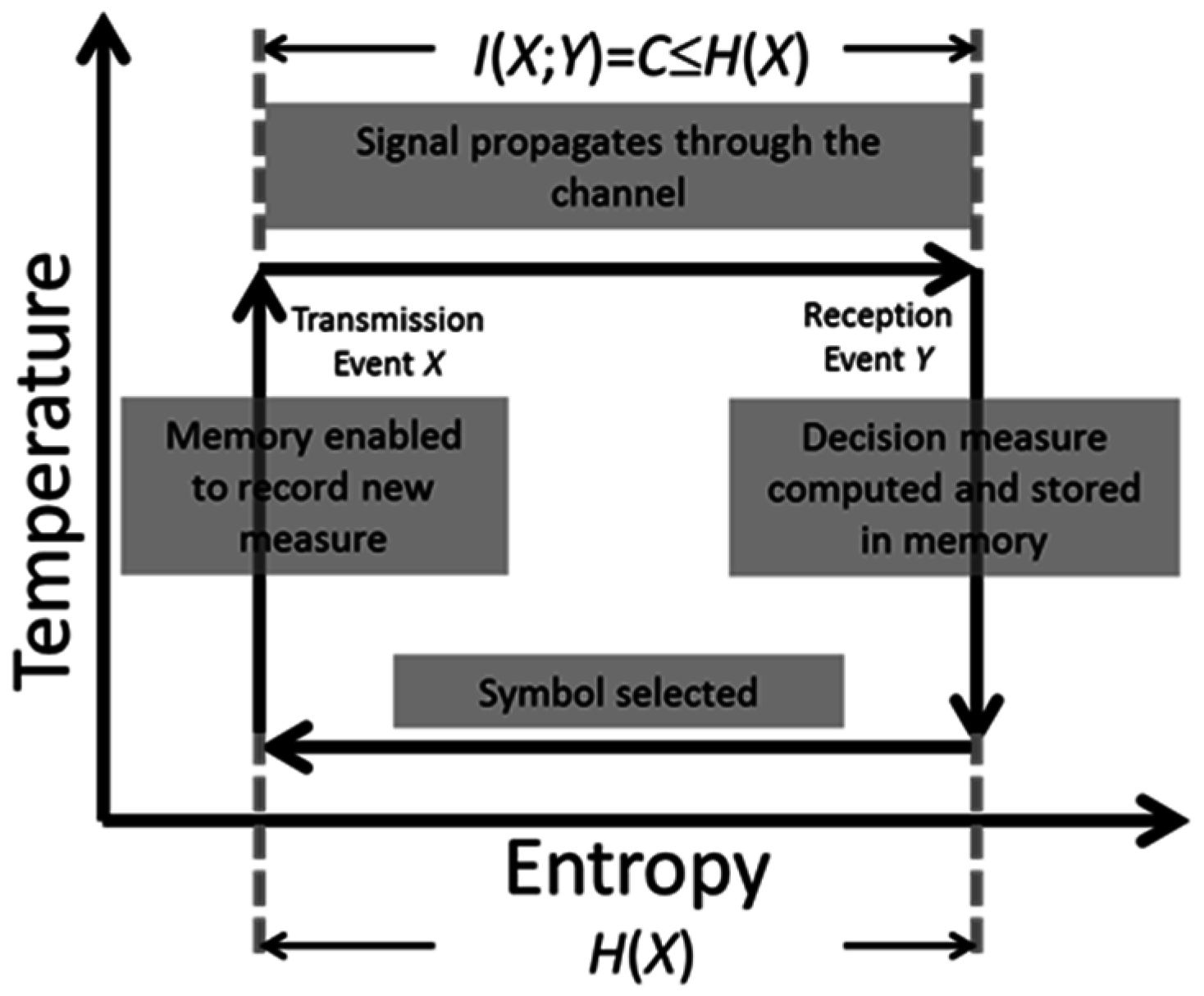
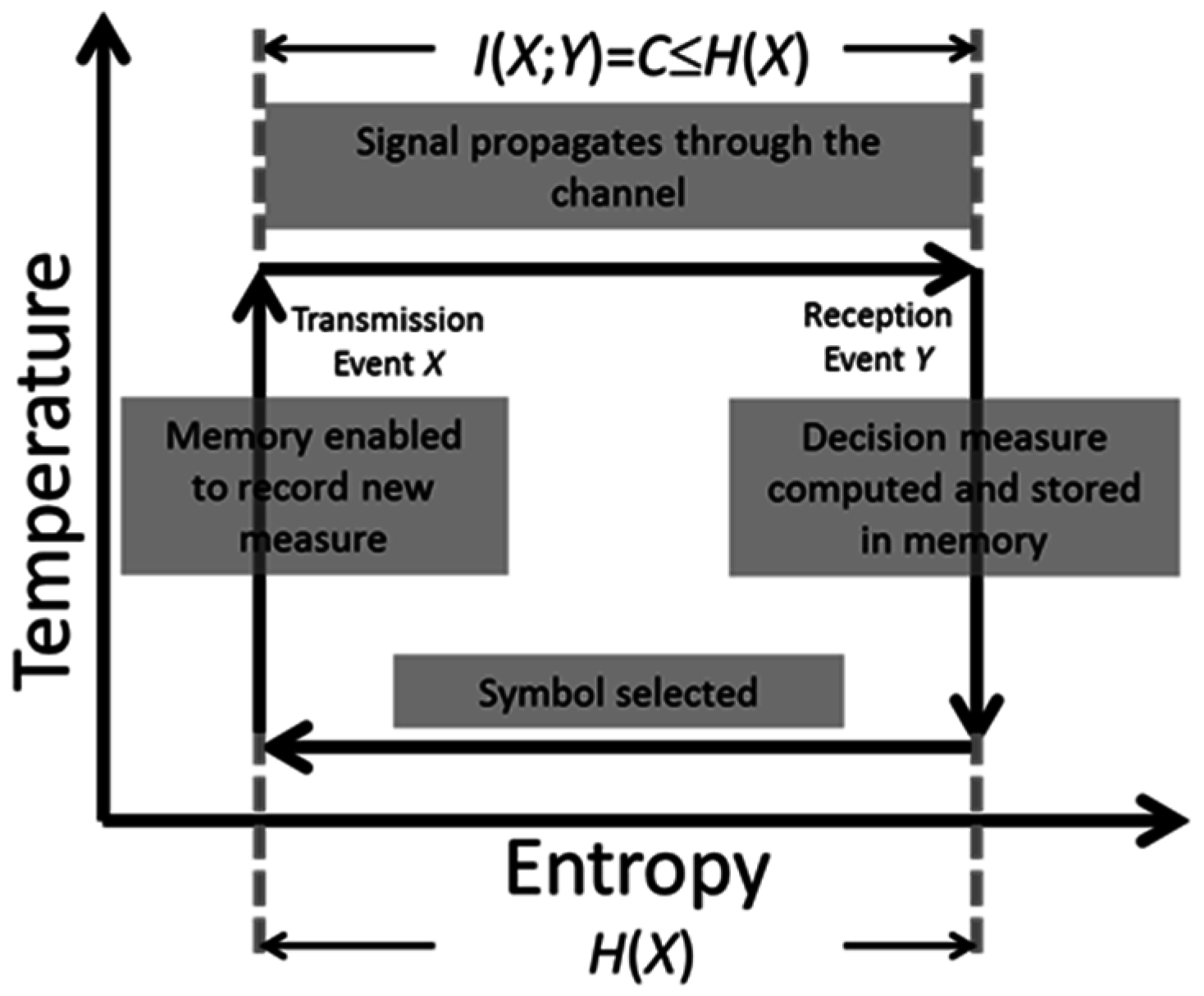
This number must causally exist prior to the receiver’s choice. Hence, this number must be stored in some type of memory and be causally available when this decision is made. Once this specification is made by the receiver, the utility of the acquired and stored information is consumed. Once exhausted, the entropy of the receiver is restored to its original value H(X). This restoration occurs at the receiver.
Once this occurs, two other actions take place. First, the receiver formulates a new inquiry as to its expectation of the next received code. This formulation can occur instantaneously once a current received code is selected and serves to restore
H(
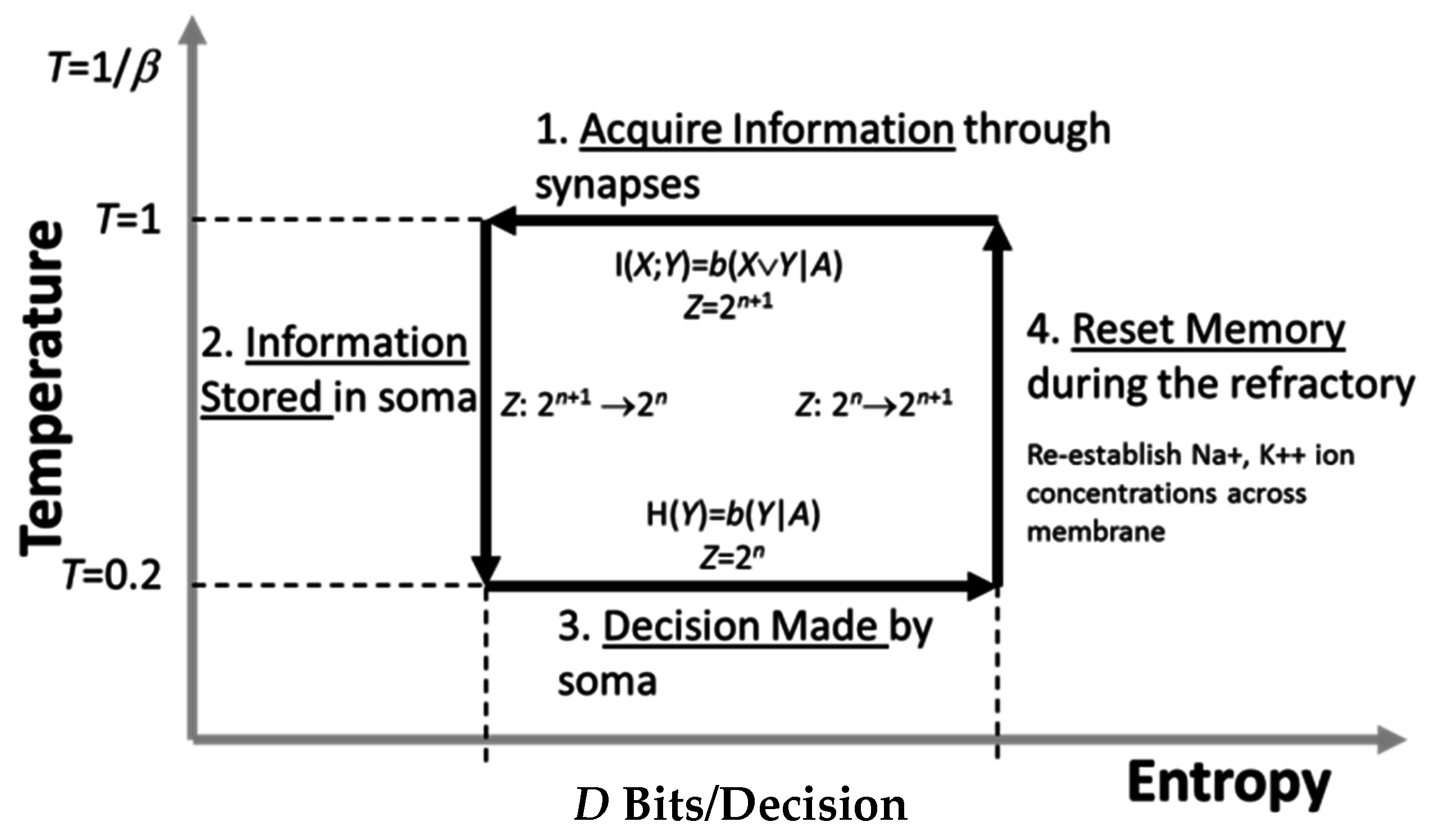
X). Secondly, the memory of the receiver must be ready to record the next measurement to be used in selection of the successive symbol. All of these computational elements are captured by a Carnot cycle depicted on a temperature-entropy plane, as shown in
Figure 3.
As shown in
Figure 1, if the channel capacity
C equals the source entropy
H(
X), the receiver can perfectly reconstruct the past. Otherwise, there will be transmission errors.
There are many implications of adopting a process-oriented perspective of information theory, although not all are covered in this paper. However, assuming the perspective that communication processes can be treated thermodynamically has engineering utility as to what should be explored further.
2.4. Intelligent Systems
Intelligent processes attempt to control their future. They operate in a complementary manner to the communication process previously described. However, their operation is in many ways more intuitive.
Communication processes are exothermic in that energy and information are lost during signal propagation through the channel. The area of the Carnot cycle in
Figure 3 given by Δ
TΔ
H equals the energy dissipated [
16]. To overcome this, symbols have to be successively reconstructed through re-amplification and then retransmission. This requires energy. As an example, one need only think of undersea fiber-optic channels with repeaters that periodically re-amplify and retransmit codes. This process requires an energy source to ensure continued error-free transmission of signals across oceans.
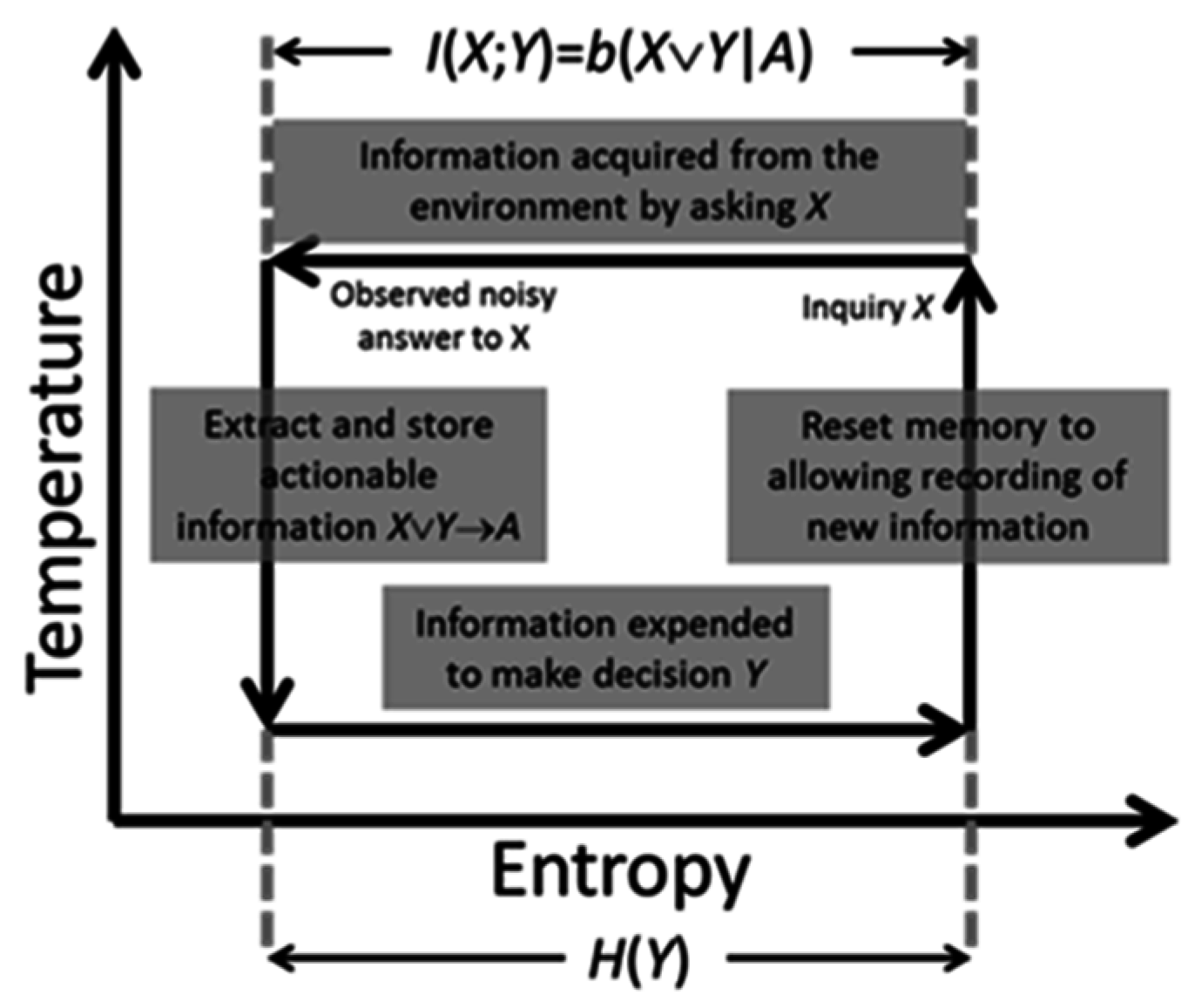
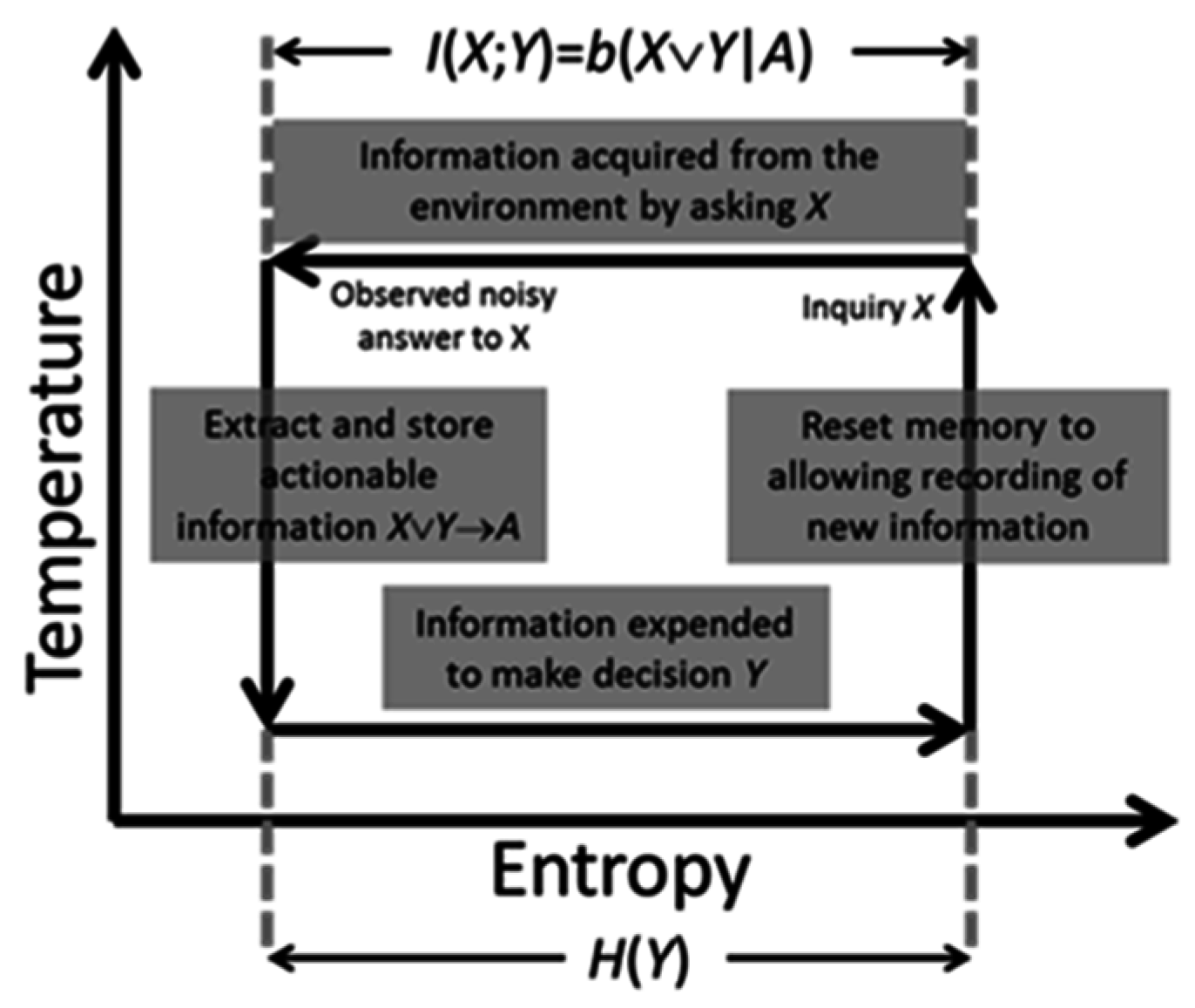
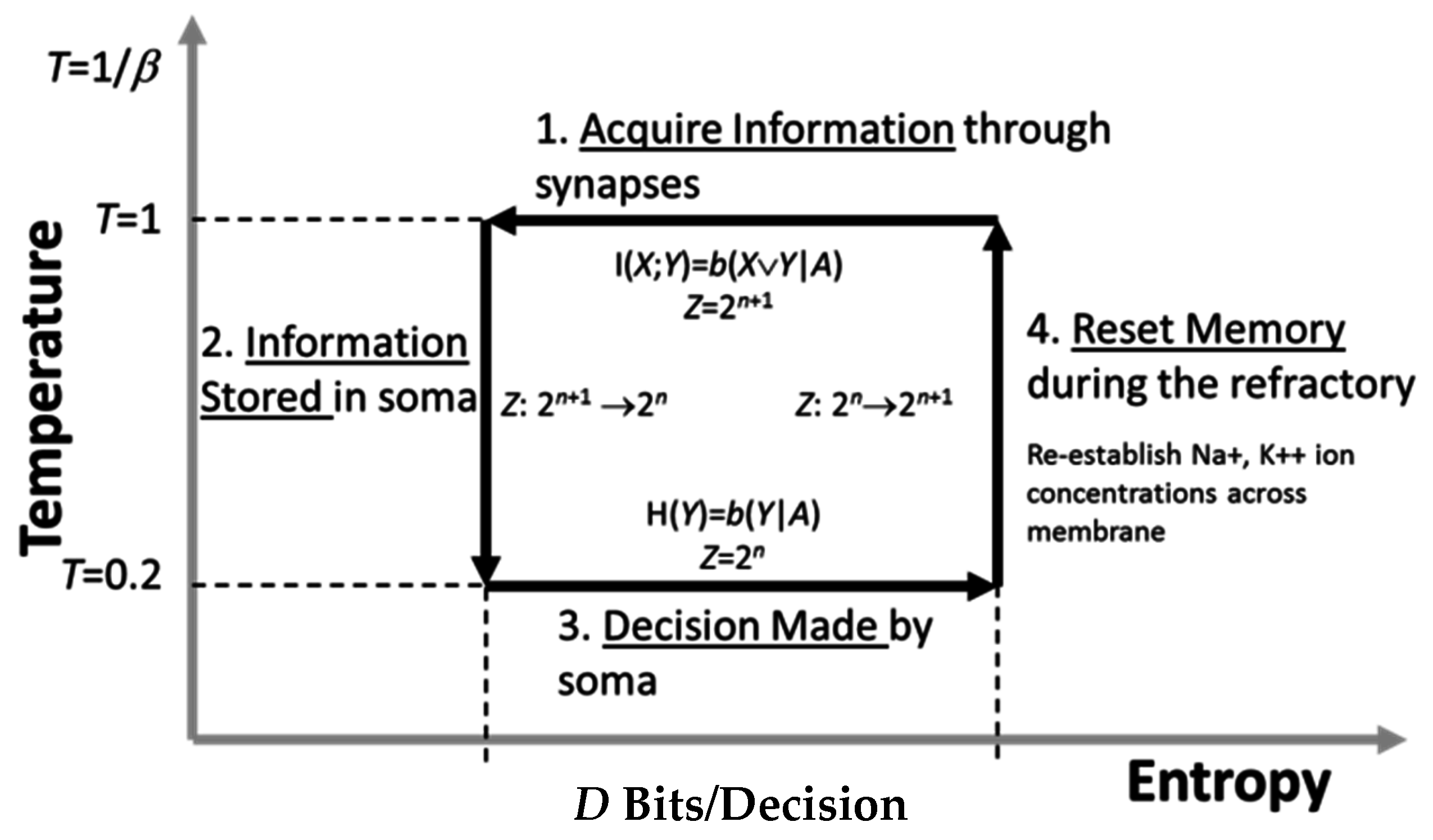
Conversely, intelligent processes require energy to work and compute. They are endothermic. Hence, they must operate in a thermodynamically inverse manner to communicate processes and therefore can be thought to operate as depicted in
Figure 4.
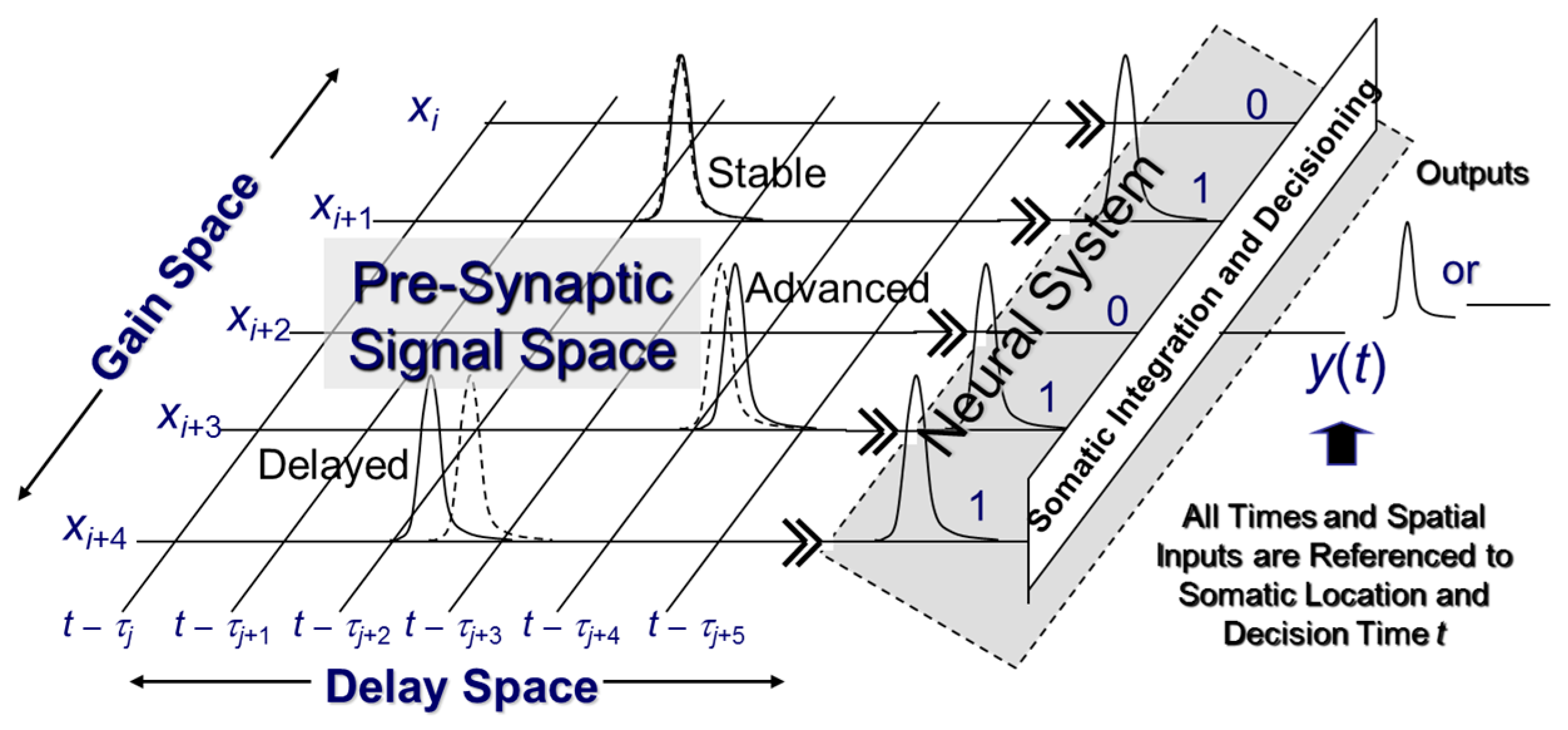
Figure 4 also describes the computational phases comprising a single process cycle within an intelligent process. First, the system poses a question
X to its environment. Information is acquired at a constant “high” temperature. This means that the information in the acquisition channel is subject to measurement noise just like that in a communication channel.
The information in X common to the decision Y is logically given by X ∨ Y. This is formally the actionable information the system possesses relevant to making its decision Y. It takes the form of a single numeric quantity derived from measured data. This mirrors the subjective measure computed by the receiver of a communication system. Once computed, and also as in a communication system, it is stored in memory and the system transitions to a lower temperature. Physically, this means that the actionable information is a fixed numeric quantity stored within the system where it is no longer subject to noise.
The process of storing information is analogous to a physical system undergoing a phase transition because of a reduction in temperature. That, in turn, implies a reduction in the number of thermodynamic microstates that the system can reach. This, for instance, occurs when a liquid transitions into a solid.
Once actionable information is available to the intelligent system, it can then use the information to make decisions. Doing so exhausts this information, and system entropy increases to its original value. This, in turn, will drive the system to acquire new information in the next process cycle.
In its final phase, the intelligent system must physically prepare itself for the next cycle by ensuring it can record new actionable information. As consistent per Landauer’s Principle [
17] and the observations made by Bennett [
18], this requires energy. More specifically, energy is required by the system to reset its memory, thereby allowing it to record new information. Landauer and Bennett state that this energy is used for memory erasure; however, this is not the perspective taken here. Instead, this energy is required for the system to transition back to its initial higher temperature state where it can then record new information. Information erasure is consequential.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}