Appendix A
A.1. Upper Bound of Possible Entropy of an SRV by Induction
A.1.1. Base Case
The base case is that it is true that
, which is proven for
in
Section 4.1.
A.1.2. Induction Step
We will prove that the base case induces .
An must be chosen which satisfies:
Here, the negative maximization term arises from applying the base case. We emphasize that this upper bound relation must be true for all choices of orderings
of all
labels (since the labeling is arbitrary and due to the desired property in
Section 3.3). Therefore,
must satisfy all
simultaneous instances of the above inequality, one for each possible ordering. Any
that satisfies the “most constraining” inequality, i.e., where the r.h.s. is minimal, necessarily also satisfies all
inequalities. The r.h.s. is minimized for any ordering where the
with overall maximum
is part of the subset
. In other words, for the inequality with minimal r.h.s. it is true that, due to considering all possible reorderings,
Substituting this above we find indeed that
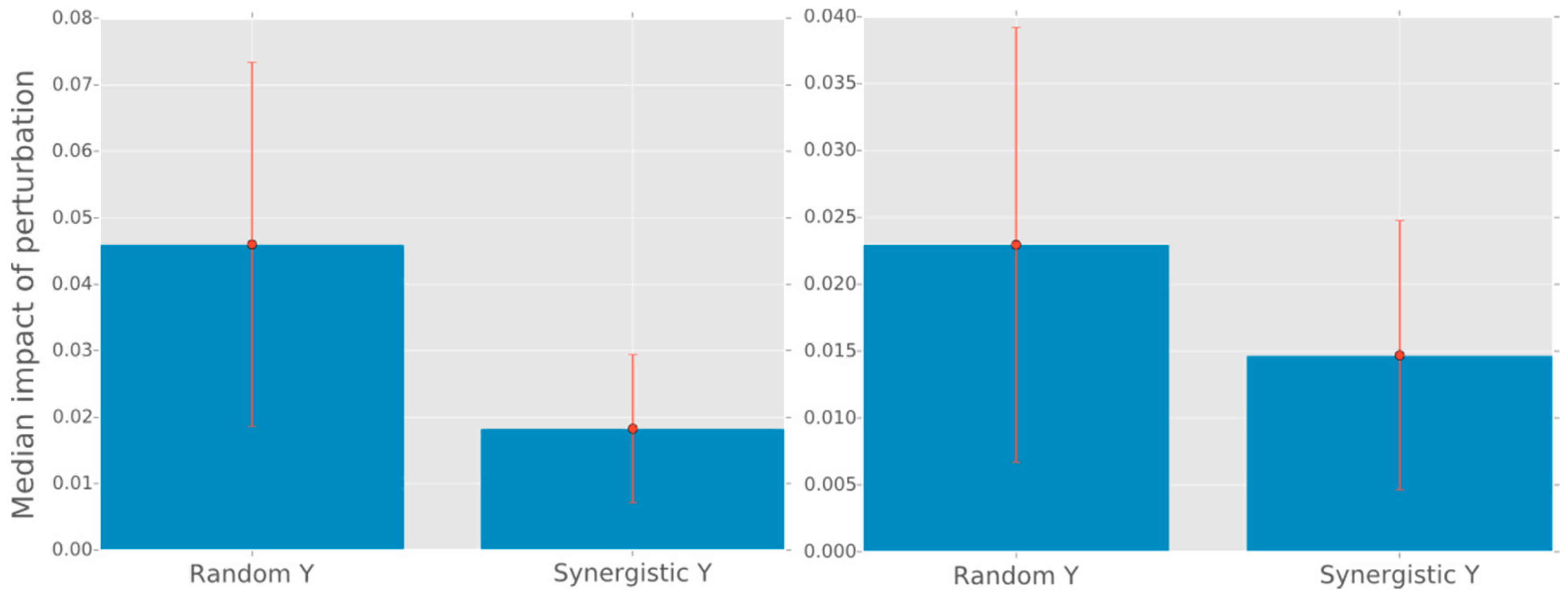
A.2. Does Not “Overcount” Any Synergistic Information
All synergistic information that any
can store about
is encoded by the set of SRVs
which is informationally equivalent to
, i.e., they have equal entropy and zero conditional entropy. Therefore
should be an upper bound on
since otherwise some synergistic information must have been doubly counted. In this section we derive that
. In
Appendix A.2.1 we use the same derivation to demonstrate that a positive difference
is undesirable at least in some cases.
Here we start with the proof that in case consists of two OSRVs, taken as base case for a proof by induction. Then we also work out the case so that the reader can see how the derivation extends for increasing . Then we provide the proof by induction in .
Let consist of an arbitrary number of OSRVs. Let denote the first OSRVs for . Let be defined using instead of , i.e., only the first terms in the sum in Equation (5).
For we use the property by construction of :
For we similarly use the independence properties and :
Essentially, the proof for each proceeds by rewriting each conditional mutual information term as a mutual information term and four added entropy terms (third equality above) of which two cancel out ( above) and the remaining two terms summed together are non-negative ( above). Thus, by induction:
Thus we find that it is not possible for our proposed to exceed the mutual information . This suggests that does not “overcount” any synergistic information.
A.2.1. Also Includes Non-Synergistic Information
In the derivation of the previous section we observe that, conversely, can exceed and we will now proceed to show that this is undesirable at least in some cases.
The positive difference
must arise from one of the non-negative terms in square brackets in all derivations above. Suppose that
and therefore has zero information with any individual OSRV by definition. That is,
does not correlate with any possible synergistic relation (SRV) about
. In our view,
should thus be said to store zero synergistic information about
. However, even though
by construction, this does not necessarily imply
, among others, and therefore any term in square brackets above can still be positive. In other words, it is possible for
to “cooperate” or have synergy with one or more OSRVs to have non-zero mutual information about another OSRV. A concrete example of this is given in
Section 4.3. This would lead to a non-zero synergistic information if quantified by
, which is undesirable in our view. In contrast, our proposed definition for
in Equation (5) purposely ignores this “synergy-of-synergies” and in fact will always yield
in case
, which is desirable in our view and proved in
Section 3.5.
A.3. Synergy Measure Correctly Handles Synergy-of-Synergies among SRVs
By “correctly handled” we mean that synergistic information is neither overcounted nor undercounted. We already start by the conjecture that “non-synergistic” redundancy among a pair of SRVs does not lead to under or overcounting synergistic information. That is, suppose that
, which we consider “non-synergistic” mutual information. If
correlates with one or neither SRV then the optimal ordering is trivial. If it correlates with both then any ordering will do, assuming that their respective “parallel” parts (see
Section 2.1.1) are informationally equivalent and it does not matter which one is retained in
. The respective orthogonal parts are retained in any case. Therefore we now proceed to handle the case where there is synergy among SRVs.
First we illustrate the apparent problem which we handle in this section. Suppose that and further suppose that while . In other words, by this construction the pair synergistically makes fully redundant, and no non-synergistic redundancy among the SRVs exists. Finally, let . At first sight it appears possible that happens to be constructed using an ordering such that appears after and . This is unwanted because then will not be part of the used to compute , i.e., the term disappears from the sum, which potentially leads to the contribution of to the synergistic information being ignored.
In this Appendix we show that the contribution is always counted towards by construction, and that the only possibility for the individual term to disappear is if its synergistic information is already accounted for.
First we interpret each such (synergistic) mutual information from a set of SRVs to another, single SRV as a (
to
) hyperedge in a hypergraph. In the above example, there would be a hyperedge from the pair
to
. Let the weight of this hyperedge be equal to the mutual information. In the
Appendix A.3.1 below we prove that in this setting, one hyperedge from
n − 1 SRVs to one SRV implies a hyperedge from all other possible
n − 1 subsets to the remaining SRV, at the same weight. That is, the hypergraph for
forms a fully connected “clique” of three hyperedges.
In this setting, finding a “correct” ordering translates to letting appear before all have appeared in case there is a hyperedge and . This translates to traversing a path of steps through the hyperedges in reverse order, each time choosing one SRV from the ancestor set that is not already previously chosen, such that for each SRV either (i) not all ancestor SRVs were chosen, or (ii) it has zero mutual information with . In other words, in case there is an such that then any ordering with as last element will suffice. Only if correlates with all SRVs then one of the SRVs will be (partially) discarded by the order maximization process in . This is desirable because otherwise could exceed or even . Intuitively, if correlates with SRVs then it automatically correlates with the th SRV as well, due to the redundancy among the SRVs. Counting this synergistic information would be overcounting this redundancy, leading to the violation of the boundedness by mutual information.
An example that demonstrates this phenomenon is given by consisting of three i.i.d. binary variables. It has four pairwise-independent MSRVs, namely the three pairwise XOR functions and one nested “XOR-of-XOR” function (verified numerically). However, one pairwise XOR is synergistically fully redundant given the two other pairwise XORs, so the entropy , which equals . Taking e.g., yields indeed 3 bits of synergistic information according to our proposed definition of , correctly discarding the synergistic redundancy among the four SRVs. However, if the synergistically redundant SRV would not be discarded from the sum then we would find 4 bits of synergistic information in about , which is counterintuitive because it exceeds , , and . Intuitively, the fact that correlates with two pairwise XORs necessarily implies that it also correlates with the third pairwise XOR, so this redundant correlation should not be counted.
A.3.1. Synergy among SRVs Forms a Clique
Given is a particular set of SRVs in arbitrary order. Suppose that the set is fully synergistic about , i.e., and we first assume that . This assumption is dropped in the subsection below. The question is: are then also synergistic about , and about ? We will now prove that in fact they are indeed synergistic at exactly the same amount, i.e., . The following proof is thus for the case of two variables being synergistic about a third, but trivially generalizes to variables (in case the condition is also generalized for variables).
First we find that the given condition leads to known quantities for two conditional mutual information terms:
Then we use this to derive a different combination (the third combination is derived similarly):
In conclusion, we find that if a set of SRVs synergistically stores mutual information about at amount , then all subsets of SRVs of will store exactly the same synergistic information about the respective remaining SRV. If each such synergistic mutual information from a set of SRVs to another SRV is considered as a directed ( to ) hyperedge in a hypergraph, then the resulting hypergraph of SRVs will have a clique in .
A.3.2. Generalize to Partial Synergy among SRVs
Above we assumed . Now we remove this constraint and thus let all mutual informations of (or in general) to be arbitrary. We then proceed as above, first:
Then:
We see that again is obtained for the mutual information among variables, but a correction term appears to account for a difference in the mutual information quantities among variables.
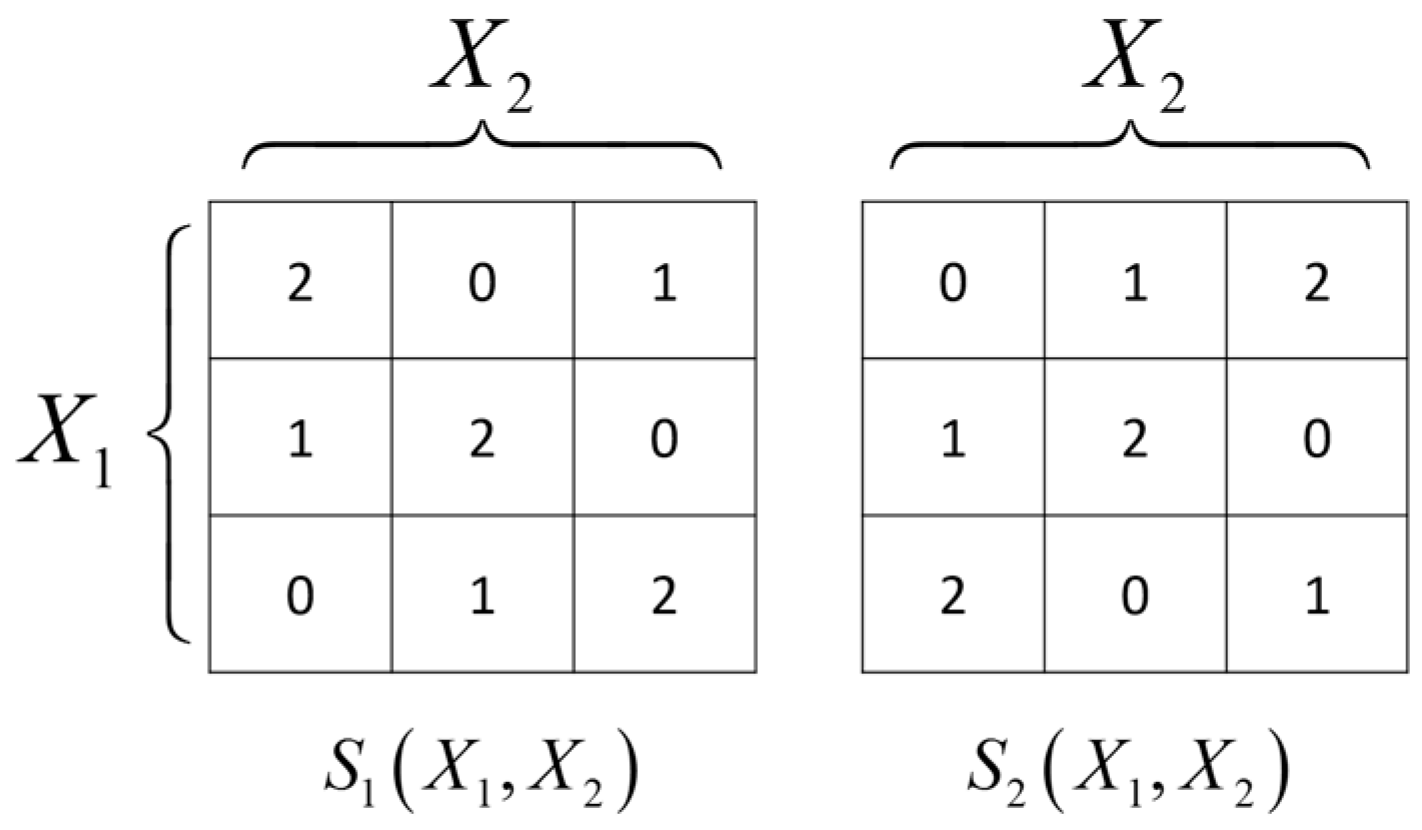
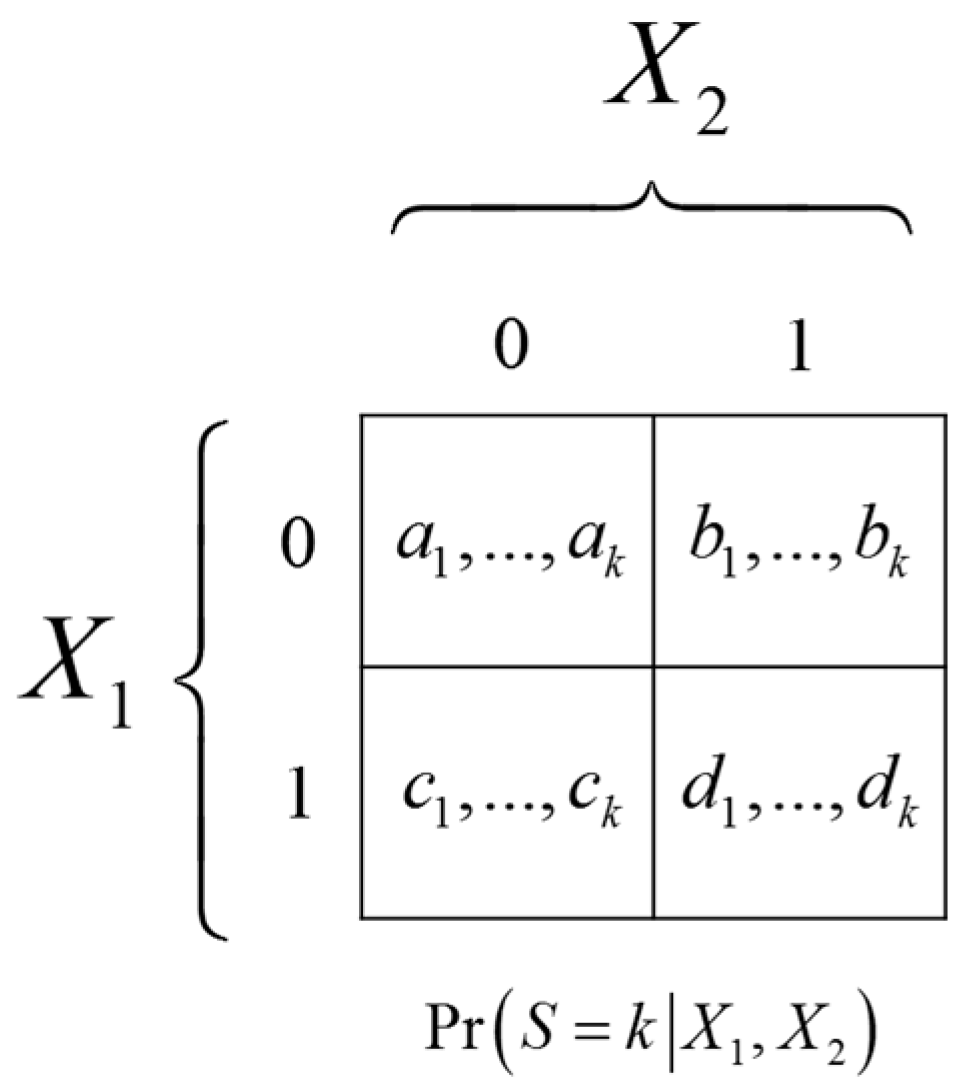
A.4. SRVs of Two Independent Binary Variables are Always XOR Gates
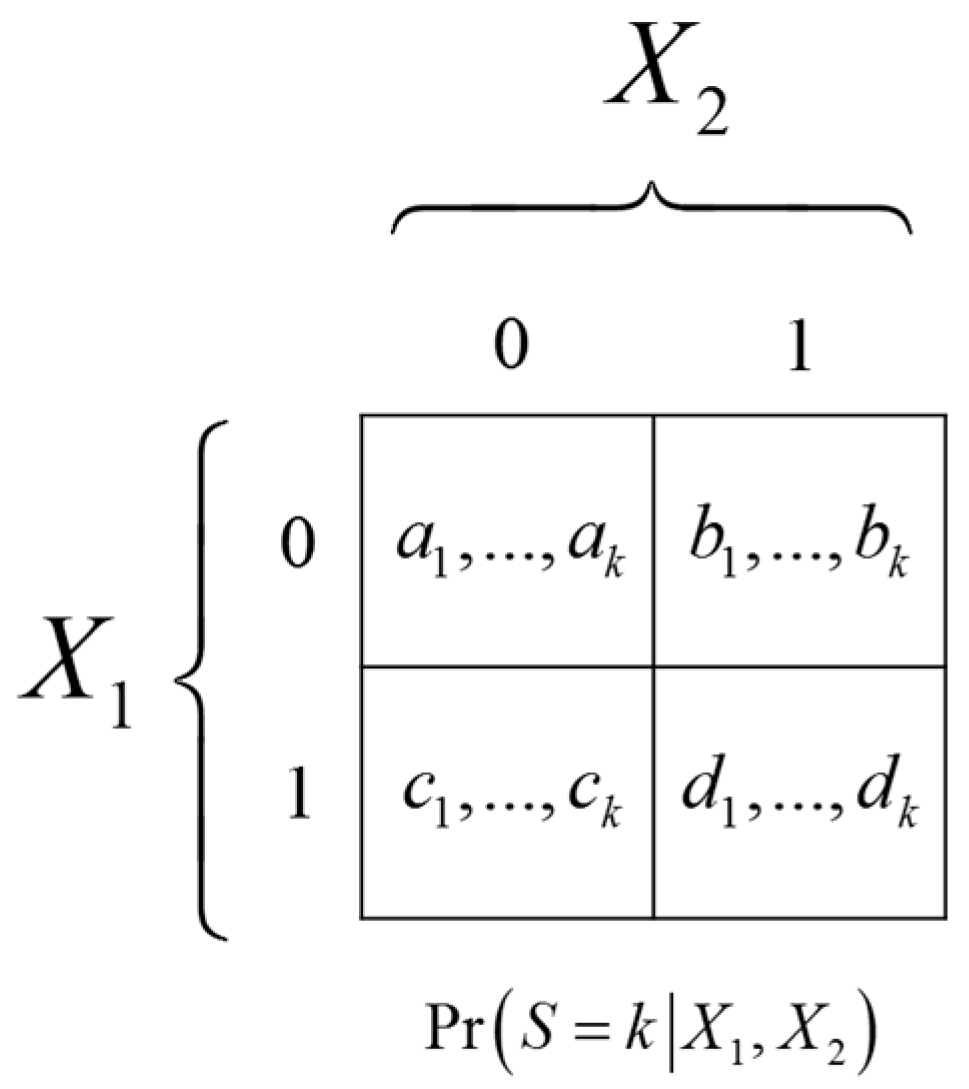
Let
and
. Let
S be a
k-valued SRV of
. The conditional probability
is illustrated in
Figure 6.
For to satisfy the conditions for being an SRV in Equation (2) the conditional probabilities must satisfy the following constraints. Firstly, it must be true that which implies , and similarly , leading to:
Secondly, in order to ensure that it must be true that , meaning that the four -vectors cannot be all equal:
The first set of constraints implies that the diagonal probability vectors must be equal, which can be seen by summing the two equalities:
The second constraint then requires that the non-diagonal probability vectors must be unequal, i.e.:
The mutual information equals the entropy computed from the average of the four probability vectors minus the average entropy computed of one of the probability vectors. First let us define the shorthand:
Then the mutual information equals:
Let and . Due to the equality of diagonal probability vectors the above simplifies to:
In words, the mutual information that any SRV stores about two independent bits is equal to the mutual information with the XOR of the bits, . Intuitively, one could therefore think of as the result of the following sequence of (stochastic) mappings: .
A corollary of this result is that the deterministic XOR function is an MSRV of two independent bits since this maximizes due to the data-processing inequality condition.
To be more precise and as an aside, the MSRV would technically also have to include all additional stochastic variables (“noise sources”) which are used in any SRVs, in order for to make all SRVs redundant and thus satisfy Equation (3). For instance, for to make, e.g., redundant it would also have to store the outcome of the independent random probability as a stochastic variable, meaning that the combined variable must actually be the MSRV, and so forth for the uncountably many SRVs in . However we assume that these noise sources like are independent of the inputs and outputs . Therefore in the mutual information terms in calculating the synergistic information in Equation (5) they do not contribute anything, meaning that we may ignore them in writing down MSRVs.
A.5. Independence of the Two Decomposed Parts
From the first constraint it follows that:
Here we used the shorthand . From the resulting combined with the second constraint it follows that and must be independent, namely:
A.6. Impossibility of Decomposition for Binary Variables
Consider as stochastic binary variables. The orthogonal decomposition imposes constraints on and which cannot always be satisfied perfectly for the binary case, as we show next. We use the following model for and :
In particular, we will show that cannot be computed from without storing information about , violating the orthogonality condition. Being supposedly independent from , we encode by its dependence on fully encoded by two parameters as:
Intuitively, in the case of binary variables, cannot store information about without also indirectly storing information about . A possible explanation is that the binary case has an insufficient number of degrees of freedom for this.
To satisfy the condition it must be true that and therefore that , among others. Let us find the conditions for this equality:
The conditions for satisfying this equality are either or . The first condition describes the trivial case where is independent from . The second condition is less trivial but severely constrains the relations that can have with . In fact it constrains the mutual information to exactly zero regardless of and , as we show next. Using the shorthand ,
Using the substitution and after some algebra steps it can be verified that indeed simplifies to zero.
Extending the parameters to also depend on would certainly be possible and add degrees of freedom, however this can only create a non-zero conditional mutual information, . As soon as is calculated then these extra parameters will be summed out into certain parameters, which we demonstrated will lead to zero mutual information under the orthogonality constraint.
This result demonstrates that a class of correlated binary variables and exists for which perfect orthogonal decomposition is impossible. Choices for binary and for which decomposition is indeed possible do exist, such as the trivial independent case. Exactly how numerous such cases are is currently unknown, especially when the number of possible states per variable is increased.
A.7. Wyner’s Common Variable Satisfies Orthogonal Decomposition if
Wyner’s common variable is defined as a non-trivial minimization procedure, namely
where
means that the minimization considers only random variables
which make
and
independent, i.e.,
. Wyner showed that in general
[
15]. Here we show that for cases where the equality condition is actually reached,
satisfies all three orthogonal decomposition conditions which do not involve also
. Wyner leaves
undefined and therefore his work cannot satisfy those conditions, but this shows at least one potential method of computing
.
The two starting conditions are:
From the second condition it follows that:
Similarly:
Then from the first condition we can derive:
from which follows:
Firstly this implies the “non-spuriousness” condition on the last line. Then from combining Equations (A12) and (A13) with either Equation (A10) or Equation (A11) we find, respectively,
These are the “parallel” and “parsimony” conditions, concluding the proof.
A.8. Use-Case of Estimating Synergy Using the Provided Code
Our code can be run using any Python interface. As an example, suppose that a particular probability distribution is given of two “input” stochastic variables, each having three possible values. We generate a random probability distribution as follows:
from jointpdf import JointProbabilityMatrix
# randomly generated joint probability mass function p(A,B)
# of 2 discrete stochastic variables, each having 3 possible values
p_AB = JointProbabilityMatrix(2,3)
We add a fully redundant (fully correlated) output variable as follows:
# append a third variable C which is deterministically computed from A and B, i.e., such that I(A,B:C)=H(C)
p_AB.append_redundant_variables(1)
p_ABC = p_AB # rename for clarity
Finally we compute the synergistic information
with the following command:
# compute the information synergy that C contains about A and B
p_ABC.synergistic_information([2], [0,1])
With the
jointpdf package it is also easy to marginalize stochastic variables out of a joint distribution, add variables using various constraints, compute various information-theoretic quantities, and estimate distributions from data samples. It is implemented for discrete variables only. More details can be found on its website (
https://bitbucket.org/rquax/jointpdf).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}