All articles published by MDPI are made immediately available worldwide under an open access license. No special
permission is required to reuse all or part of the article published by MDPI, including figures and tables. For
articles published under an open access Creative Common CC BY license, any part of the article may be reused without
permission provided that the original article is clearly cited. For more information, please refer to
https://www.mdpi.com/openaccess.
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature
Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for
future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive
positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world.
Editors select a small number of articles recently published in the journal that they believe will be particularly
interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the
most exciting work published in the various research areas of the journal.
Preserving the utility of published datasets while simultaneously providing provable privacy guarantees is a well-known challenge. On the one hand, context-free privacy solutions, such as differential privacy, provide strong privacy guarantees, but often lead to a significant reduction in utility. On the other hand, context-aware privacy solutions, such as information theoretic privacy, achieve an improved privacy-utility tradeoff, but assume that the data holder has access to dataset statistics. We circumvent these limitations by introducing a novel context-aware privacy framework called generative adversarial privacy (GAP). GAP leverages recent advancements in generative adversarial networks (GANs) to allow the data holder to learn privatization schemes from the dataset itself. Under GAP, learning the privacy mechanism is formulated as a constrained minimax game between two players: a privatizer that sanitizes the dataset in a way that limits the risk of inference attacks on the individuals’ private variables, and an adversary that tries to infer the private variables from the sanitized dataset. To evaluate GAP’s performance, we investigate two simple (yet canonical) statistical dataset models: (a) the binary data model; and (b) the binary Gaussian mixture model. For both models, we derive game-theoretically optimal minimax privacy mechanisms, and show that the privacy mechanisms learned from data (in a generative adversarial fashion) match the theoretically optimal ones. This demonstrates that our framework can be easily applied in practice, even in the absence of dataset statistics.
The explosion of information collection across a variety of electronic platforms is enabling the use of inferential machine learning (ML) and artificial intelligence to guide consumers through a myriad of choices and decisions in their daily lives. In this era of artificial intelligence, data is quickly becoming the most valuable resource [1]. Indeed, large scale datasets provide tremendous utility in helping researchers design state-of-the-art machine learning algorithms that can learn from and make predictions on real life data. Scholars and researchers are increasingly demanding access to larger datasets that allow them to learn more sophisticated models. Unfortunately, more often than not, in addition to containing public information that can be published, large scale datasets also contain private information about participating individuals (see Figure 1). Thus, data collection and curation organizations are reluctant to release such datasets before carefully sanitizing them, especially in light of recent public policies on data sharing [2,3].
To protect the privacy of individuals, datasets are typically anonymized before their release. This is done by stripping off personally identifiable information (e.g., first and last name, social security number, IDs, etc.) [4,5,6]. Anonymization, however, does not provide immunity against correlation and linkage attacks [7,8]. Indeed, several successful attempts to re-identify individuals from anonymized datasets have been reported in the past ten years. For instance, ref. [7] were able to successfully de-anonymize watch histories in the Netflix Prize, a public recommender system competition. In a more recent attack, ref. [9] showed that participants of an anonymized DNA study were identified by linking their DNA data with the publicly available Personal Genome Project dataset. Even more recently, ref. [10] successfully designed re-identification attacks on anonymized fMRI imaging datasets. Other annoymization techniques, such as generalization [11,12,13] and suppression [14,15,16], also cannot prevent an adversary from performing the sensitive linkages or recover private information from published datasets [17].
Addressing the shortcomings of anonymization techniques requires data randomization. In recent years, two randomization-based approaches with provable statistical privacy guarantees have emerged: (a) context-free approaches that assume worst-case dataset statistics and adversaries; (b) context-aware approaches that explicitly model the dataset statistics and adversary’s capabilities.
Context-free privacy. One of the most popular context-free notions of privacy is differential privacy (DP) [18,19,20]. DP, quantified by a leakage parameter (Smaller implies smaller leakage and stronger privacy guarantees), restricts distinguishability between any two “neighboring” datasets from the published data. DP provides strong, context-free theoretical guarantees against worst-case adversaries. However, training machine learning models on randomized data with DP guarantees often leads to a significantly reduced utility and comes with a tremendous hit in sample complexity [21,22,23,24,25,26,27,28,29,30,31,32,33] in the desired leakage regimes. For example, learning population level histograms under local DP suffers from a stupendous increase in sample complexity by a factor proportional to the size of the dictionary [27,29,30].
Context-aware privacy. Context-aware privacy notions have been so far studied by information theorists under the rubric of information theoretic (IT) privacy [34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54]. IT privacy has predominantly been quantified by mutual information (MI) which models how well an adversary, with access to the released data, can refine its belief about the private features of the data. Recently, Issa et al. introduced maximal leakage (MaxL) to quantify leakage to a strong adversary capable of guessing any function of the dataset [55]. They also showed that their adversarial model can be generalized to encompass local DP (wherein the mechanism ensures limited distinction for any pair of entries—a stronger DP notion without a neighborhood constraint [27,56]) [57]. When one restricts the adversary to guessing specific private features (and not all functions of these features), the resulting adversary is a maximum a posteriori (MAP) adversary that has been studied by Asoodeh et al. in [52,53,58,59]. Context-aware data perturbation techniques have also been studied in privacy preserving cloud computing [60,61,62].
Compared to context-free privacy notions, context-aware privacy notions achieve a better privacy-utility tradeoff by incorporating the statistics of the dataset and placing reasonable restrictions on the capabilities of the adversary. However, using information theoretic quantities (such as MI) as privacy metrics requires learning the parameters of the privatization mechanism in a data-driven fashion that involves minimizing an empirical information theoretic loss function. This task is remarkably challenging in practice [63,64,65,66,67].
Generative adversarial privacy. Given the challenges of existing privacy approaches, we take a fundamentally new approach towards enabling private data publishing with guarantees on both privacy and utility. Instead of adopting worst-case, context-free notions of data privacy (such as differential privacy), we introduce a novel context-aware model of privacy that allows the designer to cleverly add noise where it matters. An inherent challenge in taking a context-aware privacy approach is that it requires having access to priors, such as joint distributions of public and private variables. Such information is hardly ever present in practice. To overcome this issue, we take a data-driven approach to context-aware privacy. We leverage recent advancements in generative adversarial networks (GANs) to introduce a unified framework for context-aware privacy called generative adversarial privacy (GAP). Under GAP, the parameters of a generative model, representing the privatization mechanism, are learned from the data itself.
1.1. Our Contributions
We investigate a setting where a data holder would like to publish a dataset in a privacy preserving fashion. Each row in contains both private variables (represented by Y) and public variables (represented by X). The goal of the data holder is to generate in a way such that: (a) is as good of a representation of X as possible; and (b) an adversary cannot use to reliably infer Y. To this end, we present GAP, a unified framework for context-aware privacy that includes existing information-theoretic privacy notions. Our formulation is inspired by GANs [68,69,70] and error probability games [71,72,73,74,75]. It includes two learning blocks: a privatizer, whose task is to output a sanitized version of the public variables (subject to some distortion constraints); and an adversary, whose task is to learn the private variables from the sanitized data. The privatizer and adversary achieve their goals by competing in a constrained minimax, zero-sum game. On the one hand, the privatizer (a conditional generative model) is designed to minimize the adversary’s performance in inferring Y reliably. On the other hand, the adversary (a classifier) seeks to find the best inference strategy that maximizes its performance. This generative adversarial framework is represented in Figure 2.
At the core of GAP is a loss function (We quantify the adversary’s performance via a loss function and the quality of the released data via a distortion function) that captures how well an adversary does in terms of inferring the private variables. Different loss functions lead to different adversarial models. We focus our attention on two types of loss functions: (a) a 0-1 loss that leads to a maximum a posteriori probability (MAP) adversary; and (b) an empirical log-loss that leads to a minimum cross-entropy adversary. Ultimately, our goal is to show that our data-driven approach can provide privacy guarantees against a MAP adversary. However, derivatives of a 0-1 loss function are ill-defined. To overcome this issue, the ML community uses the more analytically tractable log-loss function. We do the same by choosing the log-loss function as the adversary’s loss function in the data-driven framework. We show that it leads to a performance that matches the performance of game-theoretically optimal mechanisms under a MAP adversary. We also show that GAP recovers mutual information privacy when a log-loss function is used (see Section 2.2).
To showcase the power of our context-aware, data-driven framework, we investigate two simple, albeit canonical, statistical dataset models: (a) the binary data model; and (b) the binary Gaussian mixture model. Under the binary data model, both X and Y are binary. Under the binary Gaussian mixture model, Y is binary whereas X is conditionally Gaussian. For both models, we derive and compare the performance of game-theoretically optimal privatization mechanisms with those that are directly learned from data (in a generative adversarial fashion).
For the above-mentioned statistical dataset models, we present two approaches towards designing privacy mechanisms: (i) private-data dependent (PDD) mechanisms, where the privatizer uses both the public and private variables; and (ii) private-data independent (PDI) mechanisms, where the privatizer only uses the public variables. We show that the PDD mechanisms lead to a superior privacy-utility tradeoff.
1.2. Related Work
In practice, a context-free notion of privacy (such as DP) is desirable because it places no restrictions on the dataset statistics or adversary’s strength. This explains why DP has been remarkably successful in the past ten years, and has been deployed in array of systems, including Google’s Chrome browser [76] and Apple’s iOS [77]. Nevertheless, because of its strong context-free nature, DP has suffered from a sequence of impossibility results. These results have made the deployment of DP with a reasonable leakage parameter practically impossible. Indeed, it was recently reported that Apple’s DP implementation suffers from several limitations—most notable of which is Apple’s use of unacceptably large leakage parameters [78].
Context-aware privacy notions can exploit the structure and statistics of the dataset to design mechanisms matched to both the data and adversarial models. In this context, information-theoretic metrics for privacy are naturally well suited. In fact, the adversarial model determines the appropriate information metric: an estimating adversary that minimizes mean square error is captured by -squared measures [40], a belief refining adversary is captured by MI [39], an adversary that can make a hard MAP decision for a specific set of private features is captured by the Arimoto MI of order ∞ [58,59], and an adversary that can guess any function of the private features is captured by the maximal (over all distributions of the dataset for a fixed support) Sibson information of order ∞ [55,57].
Information-theoretic metrics, and in particular MI privacy, allow the use of Fano’s inequality and its variants [79] to bound the rate of learning the private variables for a variety of learning metrics, such as error probability and minimum mean-squared error (MMSE). Despite the strength of MI in providing statistical utility as well as capturing a fairly strong adversary that involves refining beliefs, in the absence of priors on the dataset, using MI as an empirical loss function leads to computationally intractable procedures when learning the optimal parameters of the privatization mechanism from data. Indeed, training algorithms with empirical information theoretic loss functions is a challenging problem that has been explored in specific learning contexts, such as determining randomized encoders for the information bottleneck problem [63] and designing deep auto-encoders using a rate-distortion paradigm [64,65,66]. Even in these specific contexts, variational approaches were taken to minimize/maximize a surrogate function instead of minimizing/maximizing an empirical mutual information loss function directly [80]. In an effort to bridge theory and practice, we present a general data-driven framework to design privacy mechanisms that can capture a range of information-theoretic privacy metrics as loss functions. We will show how our framework leads to very practical (generative adversarial) data-driven formulations that match their corresponding theoretical formulations.
In the context of publishing datasets with privacy and utility guarantees, a number of similar approaches have been recently considered. We briefly review them and clarify how our work is different. In [81], the author presents a data-driven methodology to design filters in a way that allows non-malicious entities to learn some public features from the filtered data, while preventing malicious entities from learning other private features. While this approach is the closest to ours, the privatizer model considered in [81] is quite restrictive: a deterministic, compressive mapping of the input data with differentially private noise added either before or after the mapping. However, differentially private noise often leads to significant reduction in utility since it assumes worst-case dataset statistics. We capture a broader class of randomization-based mechanisms via a generative model which allows the privatizer to tailor the noise to the statistics of the dataset. Another restriction of [81] is the approach considered to trade off utility and privacy: a weighted combination of two functions, one that quantifies the utility of the privatized dataset and another that quantifies the adversary’s performance. Such a Lagrangian formulation is commonly used to regularize machine learning algorithms without having to solve constrained optimization problems. However, this approach suffers from two important drawbacks: (i) it is often the case that the optimal privatization mechanism lies on the boundary of the distortion constraints (this means that the Lagrangian formulation does not make much sense for privacy applications because the Lagrangian objective is invariant/constant with respect to the Lagrange multiplier when the optimal solution lies on the boundary of the constraint); and (ii) the Lagragian formulation (whenever applicable) necessitates an excruciating tuning phase where the privacy designer carefully selects the Lagrange multiplier to get a meaningful privacy-utility tradeoff. Our formulation allows the designer to place a meaningful distortion constraint thereby directly capturing the privacy-utility tradeoff.
In [82], the authors focus on inferences in mobile sensing applications by presenting an algorithmic approach to preserving utility and privacy. Their approach relies on using auto-encoders to determine the relevant feature space to add noise to, eliminating the need to add noise to the original data (which can be very high dimensional). Thus, the data is compressed via a deep auto-encoder which extracts the necessary features to enable learning of select public features. After extracting those low dimensional features, differentially private noise is added to all the features and the original signal is reconstructed. It is worthwhile to note that the autoencoder parameters are carefully selected not just to minimize the loss between the original and reconstructed signal but also to maximize the performance of a linear classifier that attempts to learn the public features from the reconstructed signal. This novel approach leverages deep auto-encoders to incorporate a notion of context-aware privacy and achieve a better privacy-utility tradeoff while using DP to enforce privacy. However, fundamentally, DP will still incur an insurmountable utility cost. Our approach follows similar steps but replaces differential privacy (a context free notion) with a more meaningful context-aware notion of privacy.
In [83], the authors consider linear adversarial models and linear privatizers. Specifically, they ensure privacy by adding noise in directions that are orthogonal to the public features in the hope that the “spaces” of the public and private features are orthogonal (or nearly orthogonal). Ideally, if the public and private features are statistically orthogonal, the privatizer can add noise in directions along which private features are concentrated. This allows the privatizer to achieve full privacy without sacrificing utility. This work, though interesting, provides no rigorous quantification of privacy and only investigates a restrictive class of linear adversaries and privatizers.
Our work is also closely related to adversarial neural cryptography [84] and learning censored representations [85], in which adversarial learning is used to learn how to protect communications by encryption or hide/remove sensitive information. Similar to these problems, our model includes a minimax formulation and uses adversarial neural networks to learn privatization schemes. However, in [85], the authors use non-generative auto-encoders to remove sensitive information, which do not have an obvious generative interpretation. Instead, we use a GANs-like approach to learn privatization schemes that prevent an adversary from inferring the private features. Furthermore, we go beyond these works by studying a game-theoretic setting with constrained optimization and comparing the performance of the privatization schemes learned in an adversarial fashion with the game-theoretically optimal ones.
Finally, in [32], the authors take an approach similar to ours in considering an adversarial formulation to share images between consumers and data curators. Their framework is not precisely a GANs-like one but more analogous to [81] in that it takes a specific learning function for the attacker (adversary), which in turn is the loss function for the obfuscator (privatizer) and considers a Lagrangian formulation for the utility-privacy tradeoff that the obfuscator computes.
We use conditional generative models to represent privatization schemes. Generative models have recently received a lot of attention in the machine learning community [68,69,70,86,87]. Ultimately, deep generative models hold the promise of discovering and efficiently internalizing the statistics of the target signal to be generated. State-of-the-art generative models are trained in an adversarial fashion [68,70]: the generated signal is fed into a discriminator which attempts to distinguish whether the data is real (i.e., sampled from the true underlying distribution) or synthetic (i.e., generated from a low dimensional noise sequence). Training generative models in an adversarial fashion has proven to be successful in computer vision and enabled several exciting applications. Analogous to how the generator is trained in GANs, we train the privatizer in an adversarial fashion by making it compete with an attacker.
1.3. Outline
The remainder of our paper is organized as follows. We formally present our GAP model in Section 2. We also show how, as a special case, it can recover several information theoretic notions of privacy. We then study a simple (but canonical) binary dataset model in Section 3. In particular, we present theoretically optimal PDD and PDI privatization schemes, and show how these schemes can be learned from data using a generative adversarial network. In Section 4, we investigate binary Gaussian mixture dataset models, and provide a variety of privatization schemes. We comment on their theoretical performance and show how their parameters can be learned from data in a generative adversarial fashion. Our proofs are deferred to Appendix A, Appendix B and Appendix C. We conclude our paper in Section 5 with a few remarks and interesting extensions.
2. Generative Adversarial Privacy Model
We consider a dataset which contains both public and private variables for n individuals (see Figure 1). We represent the public variables by a random variable , and the private variables (which are typically correlated with the public variables) by a random variable . Each dataset entry contains a pair of public and private variables denoted by . Instances of X and Y are denoted by x and y, respectively. We assume that each entry pair is distributed according to , and is independent from other entry pairs in the dataset. Since the dataset entries are independent of each other, we restrict our attention to memoryless mechanisms: privacy mechanisms that are applied on each data entry separately. Formally, we define the privacy mechanism as a randomized mapping given by
We consider two different types of privatization schemes: (a) private data dependent (PDD) schemes; and (b) private data independent (PDI) schemes. A privatization mechanism is PDD if its output is dependent on both Y and X. It is PDI if its output only depends on X. PDD mechanisms are naturally superior to PDI mechanisms. We show, in Section 3 and Section 4, that there is a sizeable gap in performance between these two approaches.
In our proposed GAP framework, the privatizer is pitted against an adversary. We model the interactions between the privatizer and the adversary as a non-cooperative game. For a fixed g, the goal of the adversary is to reliably infer Y from using a strategy h. For a fixed adversarial strategy h, the goal of the privatizer is to design g in a way that minimizes the adversary’s capability of inferring the private variable from the perturbed data. The optimal privacy mechanism is obtained as an equilibrium point at which both the privatizer and the adversary can not improve their strategies by unilaterally deviating from the equilibrium point.
2.1. Formulation
Given the output of a privacy mechanism , we define to be the adversary’s inference of the private variable Y from . To quantify the effect of adversarial inference, for a given public-private pair , we model the loss of the adversary as
Therefore, the expected loss of the adversary with respect to (w.r.t.) X and Y is defined to be
where the expectation is taken over and the randomness in g and h.
Intuitively, the privatizer would like to minimize the adversary’s ability to learn Y reliably from the published data. This can be trivially done by releasing an independent of X. However, such an approach provides no utility for data analysts who want to learn non-private variables from . To overcome this issue, we capture the loss incurred by privatizing the original data via a distortion function , which measures how far the original data is from the privatized data . Thus, the average distortion under is , where the expectation is taken over and the randomness in g.
On the one hand, the data holder would like to find a privacy mechanism g that is both privacy preserving (in the sense that it is difficult for the adversary to learn Y from ) and utility preserving (in the sense that it does not distort the original data too much). On the other hand, for a fixed choice of privacy mechanism g, the adversary would like to find a (potentially randomized) function h that minimizes its expected loss, which is equivalent to maximizing the negative of the expected loss. To achieve these two opposing goals, we model the problem as a constrained minimax game between the privatizer and the adversary:
where the constant determines the allowable distortion for the privatizer and the expectation is taken over and the randomness in g and h.
2.2. GAP under Various Loss Functions
The above formulation places no restrictions on the adversary. Indeed, different loss functions and decision rules lead to different adversarial models. In what follows, we will discuss a variety of loss functions under hard and soft decision rules, and show how our GAP framework can recover several popular information theoretic privacy notions.
Hard Decision Rules. When the adversary adopts a hard decision rule, is an estimate of Y. Under this setting, we can choose in a variety of ways. For instance, if Y is continuous, the adversary can attempt to minimize the difference between the estimated and true private variable values. This can be achieved by considering a squared loss function
which is known as the loss. In this case, one can verify that the adversary’s optimal decision rule is , which is the conditional mean of Y given . Furthermore, under the adversary’s optimal decision rule, the minimax problem in (2) simplifies to
subject to the distortion constraint. Here is the resulting minimum mean square error (MMSE) under . Thus, under the loss, GAP provides privacy guarantees against an MMSE adversary. On the other hand, when Y is discrete (e.g., age, gender, political affiliation, etc.), the adversary can attempt to maximize its classification accuracy. This is achieved by considering a 0-1 loss function [88] given by
In this case, one can verify that the adversary’s optimal decision rule is the maximum a posteriori probability (MAP) decision rule: , with ties broken uniformly at random. Moreover, under the MAP decision rule, the minimax problem in (2) reduces to
subject to the distortion constraint. Thus, under a 0-1 loss function, the GAP formulation provides privacy guarantees against a MAP adversary.
Soft Decision Rules. Instead of a hard decision rule, we can also consider a broader class of soft decision rules where is a distribution over ; i.e., for . In this context, we can analyze the performance under a log-loss
In this case, the objective of the adversary simplifies to
and that the maximization is attained at . Therefore, the optimal adversarial decision rule is determined by the true conditional distribution , which we assume is known to the data holder in the game-theoretic setting. Thus, under the log-loss function, the minimax optimization problem in (2) reduces to
subject to the distortion constraint. Thus, under the log-loss in (6), GAP is equivalent to using MI as the privacy metric [38].
The 0-1 loss captures a strong guessing adversary; in contrast, log-loss or information-loss models a belief refining adversary. Next, we consider a more general -loss function [89] that allows continuous interpolation between these extremes via
for any . As shown in [89], for very large (), this loss approaches that of the 0-1 (MAP) adversary. As decreases, the convexity of the loss function encourages the estimator to be probabilistic, as it increasingly rewards correct inferences of lesser and lesser likely outcomes (in contrast to a hard decision rule by a MAP adversary of the most likely outcome) conditioned on the revealed data. As , (7) yields the logarithmic loss, and the optimal belief is simply the posterior belief. Denoting as the Arimoto conditional entropy of order , one can verify that [89]
which is achieved by a ‘-tilted’ conditional distribution [89]
Under this choice of a decision rule, the objective of the minimax optimization in (2) reduces to
where is the Arimoto mutual information and is the Rényi entropy. Note that as , we recover the classical MI privacy setting and when , we recover the 0-1 loss.
2.3. Data-Driven GAP
So far, we have focused on a setting where the data holder has access to . When is known, the data holder can simply solve the constrained minimax optimization problem in (2) (theoretical version of GAP) to obtain a privatization mechanism that would perform best against a chosen type of adversary. In the absence of , we propose a data-driven version of GAP that allows the data holder to learn privatization mechanisms directly from a dataset of the form . Under the data-driven version of GAP, we represent the privacy mechanism via a conditional generative model parameterized by . This generative model takes as inputs and outputs . In the training phase, the data holder learns the optimal parameters by competing against a computational adversary: a classifier modeled by a neural network parameterized by . After convergence, we evaluate the performance of the learned by computing the maximal probability of inferring Y under the MAP adversary studied in the theoretical version of GAP.
We note that in theory, the functions h and g can (in general) be arbitrary; i.e., they can capture all possible learning algorithms. However, in practice, we need to restrict them to a rich hypothesis class. Figure 3 shows an example of the GAP model in which the privatizer and adversary are modeled as multi-layer “randomized” neural networks. For a fixed h and g, we quantify the adversary’s empirical loss using a continuous and differentiable function
where is the ith row of and is the adversary loss in the data-driven context. The optimal parameters for the privatizer and adversary are the solution to
where the expectation is taken over the dataset and the randomness in g.
In keeping with the now common practice in machine learning, in the data-driven approach for GAP, one can use the empirical log-loss function [90,91] given by (9) with
which leads to a minimum cross-entropy adversary. As a result, the empirical loss of the adversary is quantified by the cross-entropy
An alternative loss that can be readily used in this setting is the -loss introduced in Section 2.2. In the data-driven context, the -loss can be written as
for any constant . As discussed in Section 2.2, the -loss captures a variety of adversarial models and recovers both the log-loss (when ) and 0-1 loss (when ). Futhermore, (12) suggests that -leakage can be used as a surrogate (and smoother) loss function for the 0-1 loss (when is relatively large).
The minimax optimization problem in (10) is a two-player non-cooperative game between the privatizer and the adversary. The strategies of the privatizer and adversary are given by and , respectively. Each player chooses the strategy that optimizes its objective function w.r.t. what its opponent does. In particular, the privatizer must expect that if it chooses , the adversary will choose a that maximizes the negative of its own loss function based on the choice of the privatizer. The optimal privacy mechanism is given by the equilibrium of the privatizer-adversary game.
In practice, we can learn the equilibrium of the game using an iterative algorithm presented in Algorithm 1. We first maximize the negative of the adversary’s loss function in the inner loop to compute the parameters of h for a fixed g. Then, we minimize the privatizer’s loss function, which is modeled as the negative of the adversary’s loss function, to compute the parameters of g for a fixed h. To avoid over-fitting and ensure convergence, we alternate between training the adversary for k epochs and training the privatizer for one epoch. This results in the adversary moving towards its optimal solution for small perturbations of the privatizer [70].
Input: dataset , distortion parameter D, iteration number T Output: Optimal privatizer parameter procedureAlernate Minimax() Initialize and fordo Random minibatch of M datapoints drawn from full dataset Generate via Update the parameter for the adversary
Compute the descent direction , where
subject to Perform line search along and update
Exit if solution converged return
To incorporate the distortion constraint into the learning algorithm, we use the penalty method [92] and augmented Lagrangian method [93] to replace the constrained optimization problem by a series of unconstrained problems whose solutions asymptotically converge to the solution of the constrained problem. Under the penalty method, the unconstrained optimization problem is formed by adding a penalty to the objective function. The added penalty consists of a penalty parameter multiplied by a measure of violation of the constraint. The measure of violation is non-zero when the constraint is violated and is zero if the constraint is not violated. Therefore, in Algorithm 1, the constrained optimization problem of the privatizer can be approximated by a series of unconstrained optimization problems with the loss function
where is a penalty coefficient which increases with the number of iterations t. For convex optimization problems, the solution to the series of unconstrained problems will eventually converge to the solution of the original constrained problem [92].
The augmented Lagrangian method is another approach to enforce equality constraints by penalizing the objective function whenever the constraints are not satisfied. Different from the penalty method, the augmented Lagrangian method combines the use of a Lagrange multiplier and a quadratic penalty term. Note that this method is designed for equality constraints. Therefore, we introduce a slack variable to convert the inequality distortion constraint into an equality constraint. Using the augmented Lagrangian method, the constrained optimization problem of the privatizer can be replaced by a series of unconstrained problems with the loss function given by
where is a penalty coefficient which increases with the number of iterations t and is updated according to the rule . For convex optimization problems, the solution to the series of unconstrained problems formulated by the augmented Lagrangian method also converges to the solution of the original constrained problem [93].
2.4. Our Focus
Our GAP framework is very general and can be used to capture many notions of privacy via various decision rules and loss funcitons. In the rest of this paper, we investigate GAP under 0-1 loss for two simple dataset models: (a) the binary data model (Section 3); and (b) the binary Gaussian mixture model (Section 4). Under the binary data model, both X and Y are binary. Under the binary Gaussian mixture model, Y is binary whereas X is conditionally Gaussian. We use these results to validate that the data-driven version of GAP can discover “theoretically optimal” privatization schemes.
In the data-driven approach of GAP, since ) is typically unknown in practice and our objective is to learn privatization schemes directly from data, we have to consider the empirical (data-driven) version of (5). Such an approach immediately hits a roadblock because taking derivatives of a 0-1 loss function w.r.t. the parameters of h and g is ill-defined. To circumvent this issue, similar to the common practice in the ML literature, we use the empirical log-loss (see Equation (11)) as the loss function for the adversary. We derive game-theoretically optimal mechanisms for the 0-1 loss function, and use them as a benchmark against which we compare the performance of the data-driven GAP mechanisms.
3. Binary Data Model
In this section, we study a setting where both the public and private variables are binary valued random variables. Let denote the joint probability of where . To prevent an adversary from correctly inferring the private variable Y from the public variable X, the privatizer applies a randomized mechanism on X to generate the privatized data . Since both the original and privatized public variables are binary, the distortion between x and can be quantified by the Hamming distortion; i.e., if and if . Thus, the expected distortion is given by .
3.1. Theoretical Approach for Binary Data Model
The adversary’s objective is to correctly guess Y from . We consider a MAP adversary who has access to the joint distribution of and the privacy mechanism. The privatizer’s goal is to privatize X in a way that minimizes the adversary’s probability of correctly inferring Y from subject to the distortion constraint. We first focus on private-data dependent (PDD) privacy mechanisms that depend on both Y and X. We later consider private-data independent (PDI) privacy mechanisms that only depend on X.
3.1.1. PDD Privacy Mechanism
Let denote a PDD mechanism. Since X, Y, and are binary random variables, the mechanism can be represented by the conditional distribution that maps the public and private variable pair to an output given by
Thus, the marginal distribution of is given by
If , the adversary’s inference accuracy for guessing is
and the inference accuracy for guessing is
Let . For , the MAP adversary’s inference accuracy is given by
Similarly, if , the MAP adversary’s inference accuracy is given by
where
As a result, for a fixed privacy mechanism , the MAP adversary’s inference accuracy can be written as
Thus, the optimal PDD privacy mechanism is determined by solving
Notice that the above constrained optimization problem is a four dimensional optimization problem parameterized by and D. Interestingly, we can formulate (20) as a linear program (LP) given by
where and are two slack variables representing the maxima in (17) and (18), respectively. The optimal mechanism can be obtained by numerically solving (21) using any off-the-shelf LP solver.
3.1.2. PDI Privacy Mechanism
In the previous section, we considered PDD privacy mechanisms. Although we were able to formulate the problem as a linear program with four variables, determining a closed form solution for such a highly parameterized problem is not analytically tractable. Thus, we now consider the simple (yet meaningful) class of PDI privacy mechanisms. Under PDI privacy mechanisms, the Markov chain holds. As a result, can be written as
where the second equality is due to the conditional independence property of the Markov chain .
For the PDI mechanisms, the privacy mechanism can be represented by the conditional distribution . To make the problem more tractable, we focus on a slightly simpler setting in which , where is a random variable independent of X and follows a Bernoulli distribution with parameter q. In this setting, the joint distribution of can be computed as
Let in which and . The joint distribution of is given by
Using the above joint probabilities, for a fixed , we can write the MAP adversary’s inference accuracy as
Therefore, the optimal PDI privacy mechanism is given by the solution to
where the distortion in (30) is given by . By (29), can be considered as a sum of two functions, where each function is a maximum of two linear functions. Therefore, it is convex in and for different values of and D.
Theorem1.
For fixed and D, there exists infinitely many PDI privacy mechanisms that achieve the optimal privacy-utility tradeoff. If , any privacy mechanism that satisfies is optimal. If , the optimal PDI privacy mechanism is given as follows:
If , the optimal privacy mechanism is given by . The adversary’s accuracy of correctly guessing the private variable is
Otherwise, the optimal privacy mechanism is given by and the adversary’s accuracy of correctly guessing the private variable is
Proof sketch: The proof of Theorem 1 is provided in Appendix A. We briefly sketch the proof details here. For the special case , the solution is trivial since the private variable Y is independent of the public variable X. Thus, the optimal solution is given by any , that satisfies the distortion constraint . For , we separate the optimization problem in (30) into four subproblems based on the decision of the adversary. We then compute the optimal privacy mechanism of the privatizer in each subproblem. Summarizing the optimal solutions to the subproblems for different values of and D yields Theorem 1.
3.2. Data-driven Approach for Binary Data Model
In practice, the joint distribution of is often unknown to the data holder. Instead, the data holder has access to a dataset , which is used to learn a good privatization mechanism in a generative adversarial fashion. In the training phase, the data holder learns the parameters of the conditional generative model (representing the privatization scheme) by competing against a computational adversary represented by a neural network. The details of both neural networks are provided later in this section. When convergence is reached, we evaluate the performance of the learned privatization scheme by computing the accuracy of inferring Y under a strong MAP adversary that: (a) has access to the joint distribution of ; (b) has knowledge of the learned privacy mechanism; and (c) can compute the MAP rule. Ultimately, the data holder’s hope is to learn a privatization scheme that matches the one obtained under the game-theoretic framework, where both the adversary and privatizer are assumed to have access to . To evaluate our data-driven approach, we compare the mechanisms learned in an adversarial fashion on with the game-theoretically optimal ones.
Since the private variable Y is binary, we use the empirical log-loss function for the adversary (see Equation (11)). For a fixed , the adversary learns the optimal by maximizing given in Equation (11). For a fixed , the privatizer learns the optimal by minimizing subject to the distortion constraint (see Equation (10)). Since both X and Y are binary variables, we can use the privatizer parameter to represent the privacy mechanism directly. For the adversary, we define , where and . Thus, given a privatized public variable input , the output belief of the adversary guessing can be written as .
For PDD privacy mechanisms, we have . Given the fact that both and are binary, we use two simple neural networks to model the privatizer and the adversary. As shown in Figure 4, the privatizer is modeled as a single-layer neural network parameterized by , while the adversary is modeled as a two-layer neural network classifier. From the perspective of the privatizer, the belief of an adversary guessing conditioned on the input is given by
where
Furthermore, the expected distortion is given by
Similar to the PDD case, we can also compute the belief of guessing conditional on the input for the PDI schemes. Observe that in the PDI case, . Therefore, we have
Under PDI schemes, the expected distortion is given by
Thus, we can use Algorithm 1 proposed in Section 2.3 to learn the optimal PDD and PDI privacy mechanisms from the dataset.
3.3. Illustration of Results
We now evaluate our proposed GAP framework using synthetic datasets. We focus on the setting in which , where is a random variable independent of X and follows a Bernoulli distribution with parameter q. We generate two synthetic datasets with equal to and , respectively. Each synthetic dataset used in this experiment contains training samples and 2000 test samples. We use Tensorflow [94] to train both the privatizer and the adversary using Adam optimizer with a learning rate of and a minibatch size of 200. The distortion constraint is enforced by the penalty method provided in (13).
Figure 5a illustrates the performance of both optimal PDD and PDI privacy mechanisms against a strong theoretical MAP adversary when . It can be seen that the inference accuracy of the MAP adversary reduces as the distortion increases for both optimal PDD and PDI privacy mechanisms. As one would expect, the PDD privacy mechanism achieves a lower inference accuracy for the adversary, i.e., better privacy, than the PDI mechanism. Furthermore, when the distortion is higher than some threshold, the inference accuracy of the MAP adversary saturates regardless of the distortion. This is due to the fact that the correlation between the private variable and the privatized public variable cannot be further reduced once the distortion is larger than the saturation threshold. Therefore, increasing distortion will not further reduce the accuracy of the MAP adversary. We also observe that the privacy mechanism obtained via the data-driven approach performs very well when pitted against the MAP adversary (maximum accuracy difference around compared to the theoretical approach). In other words, for the binary data model, the data-driven version of GAP can yield privacy mechanisms that perform as well as the mechanisms computed under the theoretical version of GAP, which assumes that the privatizer has access to the underlying distribution of the dataset.
Figure 5b shows the performance of both optimal PDD and PDI privacy mechanisms against the MAP adversary for . Similar to the equal prior case, we observe that both PDD and PDI privacy mechanisms reduce the accuracy of the MAP adversary as the distortion increases and saturate when the distortion goes above a certain threshold. It can be seen that the saturation thresholds for both PDD and PDI privacy mechanisms in Figure 5b are lower than the “equal prior” case plotted in Figure 5a. The reason is that when , the correlation between Y and X is weaker than the “equal prior” case. Therefore, it requires less distortion to achieve the same privacy. We also observe that the performance of the GAP mechanism obtained via the data-driven approach is comparable to the mechanism computed via the theoretical approach.
The performance of the GAP mechanism obtained using the log-loss function (i.e., MI privacy) is plotted in Figure 5c,d. Similar to the MAP adversary case, as the distortion increases, the mutual information between the private variable and the privatized public variable achieved by the optimal PDD and PDI mechanisms decreases as long as the distortion is below some threshold. When the distortion goes above the threshold, the optimal privacy mechanism is able to make the private variable and the privatized public variable independent regardless of the distortion. Furthermore, the values of the saturation thresholds are very close to what we observe in Figure 5a,b.
4. Binary Gaussian Mixture Model
Thus far, we have studied a simple binary dataset model. In many real datasets, the sample space of variables often takes more than just two possible values. It is well known that the Gaussian distribution is a flexible approximate for many distributions [95]. Therefore, in this section, we study a setting where and X is a Gaussian random variable whose mean and variance are dependent on Y. Without loss of generality, let and . Thus, and .
Similar to the binary data model, we study two privatization schemes: (a) private-data independent (PDI) schemes (where ); and (b) private-data dependent (PDD) schemes (where ). In order to have a tractable model for the privatizer, we assume is realized by adding an affine function of an independently generated random noise to the public variable X. The affine function enables controlling both the mean and variance of the privatized data. In particular, we consider , in which N is a one dimensional random variable and are constant parameters. The goal of the privatizer is to sanitze the public data X subject to the distortion constraint .
4.1. Theoretical Approach for Binary Gaussian Mixture Model
We now investigate the theoretical approach under which both the privatizer and the adversary have access to . To make the problem more tractable, let us consider a slightly simpler setting in which . We will relax this assumption later when we take a data-driven approach. We further assume that N is a standard Gaussian random variable. One might, rightfully, question our choice of focusing on adding (potentially Y-dependent) Gaussian noise. Though other distributions can be considered, our approach is motivated by the following two reasons:
(a)
Even though it is known that adding Gaussian noise is not the worst case noise adding mechanism for non-Gaussian X [72], identifying the optimal noise distribution is mathematically intractable. Thus, for tractability and ease of analysis, we choose Gaussian noise.
(b)
Adding Gaussian noise to each data entry preserves the conditional Gaussianity of the released dataset.
In what follows, we will analyze a variety of PDI and PDD mechanisms.
We consider a PDI noise adding privatization scheme which adds an affine function of the standard Gaussian noise to the public variable. Since the privacy mechanism is PDI, we have , where and are constant parameters and . Using the classical Gaussian hypothesis testing analysis [96], it is straightforward to verify that the optimal inference accuracy (i.e., probability of detection) of the MAP adversary is given by
where and . Moreover, since , the distortion constraint is equivalent to .
Theorem2.
For a PDI Gaussian noise adding privatization scheme given by , with and , the optimal parameters are given by
Let . For this optimal scheme, the accuracy of the MAP adversary is
The proof of Theorem 2 is provided in Appendix B. We observe that the PDI Gaussian noise adding privatization scheme which minimizes the inference accuracy of the MAP adversary with distortion upper-bounded by D is to add a zero-mean Gaussian noise with variance D.
For PDD privatization schemes, we first consider a simple case in which . Without loss of generality, we assume that both and are non-negative. The privatized data is given by . This is a PDD mechanism since depends on both X and Y. Intuitively, this mechanism privatizes the data by shifting the two Gaussian distributions (under and ) closer to each other. Under this mechanism, it is easy to show that the adversary’s MAP probability of inferring the private variable Y from is given by in (37) with . Observe that since , we have . Thus, the distortion constraint implies .
Theorem3.
For a PDD privatization scheme given by , , the optimal parameters are given by
For this optimal scheme, the accuracy of the MAP adversary is given by (37) with
The proof of Theorem 3 is provided in Appendix C. When , we have , which implies that the optimal privacy mechanism for this particular case is to shift the two Gaussian distributions closer to each other equally by regardless of the variance . When , the Gaussian distribution with a lower prior probability, in this case, , gets shifted times more than .
Next, we consider a slightly more complicated case in which . Thus, the privacy mechanism is given by , where . Intuitively, this mechanism privatizes the data by shifting the two Gaussian distributions (under and ) closer to each other and add another Gaussian noise scaled by a constant . In this case, the MAP probability of inferring the private variable Y from is given by (37) with . Furthermore, the distortion constraint is equivalent to .
Theorem4.
For a PDD privatization scheme given by with , the optimal parameters are given by the solution to
Using this optimal scheme, the accuracy of the MAP adversary is given by (37) with .
Proof.
Similar to the proofs of Theorem 2 and 3, we can compute the derivative of w.r.t. . It is easy to verify that is monotonically increasing with . Therefore, the optimal mechanism is given by the solution to (41). Substituting the optimal parameters into (37) yields the MAP probability of inferring the private variable Y from . ☐
Remark: Note that the objective function in (41) only depends on and . We define . Thus, the above objective function can be written as
It is straightforward to verify that the determinant of the Hessian of (42) is always non-positive. Therefore, the above optimization problem is non-convex in and .
Finally, we consider the PDD Gaussian noise adding privatization scheme given by , where . This PDD mechanism is the most general one in the Gaussian noise adding setting and includes the two previous mechanisms. The objective of the privatizer is to minimize the adversary’s probability of correctly inferring Y from subject to the distortion constraint given by . As we have discussed in the remark after Theorem 4, the problem becomes non-convex even for the simpler case in which . In order to obtain the optimal parameters for this case, we first show that the optimal privacy mechanism lies on the boundary of the distortion constraint.
Proposition1.
For the privacy mechanism given by , the optimal parameters satisfy .
Proof.
We prove the above statement by contradiction. Assume that the optimal parameters satisfy . Let , where is chosen so that . Since the inference accuracy is monotonically decreasing with , the resultant inference accuracy can only be lower for replacing with . This contradicts with the assumption that . Using the same type of analysis, we can show that any parameter that deviates from is suboptimal. ☐
Let and . Since the optimal parameters of the privatizer lie on the boundary of the distortion constraint, we have . This implies lies on the boundary of an ellipse parametrized by and D. Thus, we have and , where . Therefore, the optimal parameters satisfy
This implies lie on the boundary of two circles parametrized by and . Thus, we can write as
where . The optimal parameters can be computed by a grid search in the cube parametrized by that minimizes the accuracy of the MAP adversary. In the following section, we will use this general PDD Gaussian noise adding privatization scheme in our data-driven simulations and compare the performance of the privacy mechanisms obtained by both theoretical and data-driven approaches.
4.2. Data-driven Approach for Binary Gaussian Mixture Model
To illustrate our data-driven GAP approach, we assume the privatizer only has access to the dataset but does not know the joint distribution of . Finding the optimal privacy mechanism becomes a learning problem. In the training phase, we use the empirical log-loss function provided in (11) for the adversary. Thus, for a fixed privatizer parameter , the adversary learns the optimal parameter that maximizes . On the other hand, the optimal parameter for the privacy mechanism is obtained by solving (10). After convergence, we use the learned data-driven GAP mechanism to compute the accuracy of inferring the private variable under a strong MAP adversary. We evaluate our data-driven approach by comparing the mechanisms learned in an adversarial fashion on with the game-theoretically optimal ones in which both the adversary and privatizer are assumed to have access to .
We consider the PDD Gaussian noise adding privacy mechanism given by . Similar to the binary setting, we use two neural networks to model the privatizer and the adversary. As shown in Figure 6, the privatizer is modeled by a two-layer neural network with parameters . The adversary, whose goal is to infer Y from privatized data , is modeled by a three-layer neural network classifier with leaky ReLU activations. The random noise is drawn from a standard Gaussian distribution .
In order to enforce the distortion constraint, we use the augmented Lagrangian method to penalize the learning objective when the constraint is not satisfied. In the binary Gaussian mixture model setting, the augmented Lagrangian method uses two parameters, namely and to approximate the constrained optimization problem by a series of unconstrained problems. Intuitively, a large value of enforces the distortion constraint to be binding, whereas is an estimate of the Lagrangian multiplier. To obtain the optimal solution of the constrained optimization problem, we solve a series of unconstrained problems given by (14).
4.3. Illustration of Results
We use synthetic datasets to evaluate our proposed GAP framework. We consider four synthetic datasets shown in Table 1. Each synthetic dataset used in this experiment contains 20,000 training samples and 2000 test samples. We use Tensorflow to train both the privatizer and the adversary using Adam optimizer with a learning rate of and a minibatch size of 200.
Figure 7a,b illustrate the performance of the optimal PDD Gaussian noise adding mechanisms against the strong theoretical MAP adversary when and , respectively. It can be seen that the optimal mechanisms obtained by both theoretical and data-driven approaches reduce the inference accuracy of the MAP adversary as the distortion increases. Similar to the binary data model, we observe that the accuracy of the adversary saturates when the distortion crosses some threshold. Moreover, it is worth pointing out that for the binary Gaussian mixture setting, we also observe that the privacy mechanism obtained through the data-driven approach performs very well when pitted against the MAP adversary (maximum accuracy difference around compared with theoretical approach). In other words, for the binary Gaussian mixture model, the data-driven approach for GAP can generate privacy mechanisms that are comparable, in terms of performance, to the theoretical approach, which assumes the privatizer has access to the underlying distribution of the data.
Figure 8, Figure 9, Figure 10, Figure 11, Figure 12 and Figure 13 show the privatization schemes for different datasets. The intuition of this Gaussian noise adding mechanism is to shift distributions of and closer and scale the variances to preserve privacy. When and , the privatizer shifts and scales the two distributions almost equally. Furthermore, the resultant and have very similar distributions. We also observe that if , the public variable whose corresponding private variable has a lower prior probability gets shifted more. It is also worth mentioning that when , the public variable with a lower variance gets scaled more.
The optimal privacy mechanisms obtained via the data-driven approach under different datasets are presented in Table 2, Table 3, Table 4 and Table 5. In each table, D is the maximum allowable distortion. , , , and are the parameters of the privatizer neural network. These learned parameters dictate the statistical model of the privatizer, which is used to sanitize the dataset. We use to denote the inference accuracy of the adversary using a test dataset and to denote the converged cross-entropy of the adversary. The column titled represents the average distortion that results from sanitizing the test dataset via the learned privatization scheme. is the MAP adversary’s inference accuracy under the learned privatization scheme, assuming that the adversary: (a) has access to the joint distribution of ; (b) has knowledge of the learned privatization scheme; and (c) can compute the MAP rule. is the “lowest” inference accuracy we get if the privatizer had access to the joint distribution of , and used this information to compute the parameters of the privatization scheme based on the approach provided at the end of Section 4.1.2.
5. Concluding Remarks
We have presented a unified framework for context-aware privacy called generative adversarial privacy (GAP). GAP allows the data holder to learn the privatization mechanism directly from the dataset (to be published) without requiring access to the dataset statistics. Under GAP, finding the optimal privacy mechanism is formulated as a game between two players: a privatizer and an adversary. An iterative minimax algorithm is proposed to obtain the optimal mechanism under the GAP framework.
To evaluate the performance of the proposed GAP model, we have focused on two types of datasets: (i) binary data model; and (ii) binary Gaussian mixture model. For both cases, the optimal GAP mechanisms are learned using an empirical log-loss function. For each type of dataset, both private-data dependent and private-data independent mechanisms are studied. These results are cross-validated against the privacy guarantees obtained by computing the game-theoretically optimal mechanism under a strong MAP adversary. In the MAP adversary setting, we have shown that for the binary data model, the optimal GAP mechanism is obtained by solving a linear program. For the binary Gaussian mixture model, the optimal additive Gaussian noise privatization scheme is determined. Simulations with synthetic datasets for both types (i) and (ii) show that the privacy mechanisms learned via the GAP framework perform as well as the mechanisms obtained from theoretical computation.
Binary and Gaussian models are canonical models with a wide range of applications. However, moving next, we would like to consider more sophisticated dataset models that can capture real life signals (such as time series data and images). The generative models we have considered in this paper were tailored to the statistics of the datasets. In the future, we would like to experiment with the idea of using a deep generative model to automatically generate the sanitized data. Another straightforward extension to our work is to use the GAP framework to obtain data-driven mutual information privacy mechanisms. Finally, it would be interesting to investigate adversarial loss functions that allow us to move from weak to strong adversaries.
Acknowledgments
L. Sankar and C. Huang are supported in part by the National Science Foundation under Grant No. CAREER Award CCF-1350914. R. Rajagopal, P. Kairouz and X. Chen are supported in part by the NSF CAREER Award ECCS-1554178, NSF CPS Award #1545043 and DOE SunShot Office Solar Program Award Number 31003.
Author Contributions
The problem studied here was conceived by P. Kairouz, L. Sankar and R. Rajagopal. The theoretical analysis were performed by C. Huang, P. Kairouz and L. Sankar; the data analysis and simulations were performed by X. Chen, C. Huang, P. Kairouz and R. Rajagopal. C. Huang, P. Kairouz and L. Sankar wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 1
Proof.
If , X is independent of Y. The optimal solution is given by any that satisfies the distortion constraint () since X and Y are already independent. If , since each maximum in (30) can only be one of the two values (i.e., the inference accuracy of guessing or ), the objective function of the privatizer is determined by the relationship between and . Therefore, the optimization problem in (30) can be decomposed into the following four subproblems:
Subproblem 1: and , which implies and . As a result, the objective of the privatizer is given by . Thus, the optimization problem in (30) can be written as
If , i.e., , we have and . The privatizer must maximize to reduce the adversary’s probability of correctly inferring the private variable. Thus, if , the optimal value is given by ; the corresponding optimal solution is given by . Otherwise, the problem is infeasible.
If , i.e., , we have and . In this case, the privatizer has to minimize . Thus, if , the optimal value is given by ; the corresponding optimal solution is . Otherwise, the optimal value is and the corresponding optimal solution is given by .
Subproblem 2: and , which implies and . Thus, the objective of the privatizer is given by . Therefore, the optimization problem in (30) can be written as
If , i.e., , we have and . The privatizer needs to minimize to reduce the adversary’s probability of correctly inferring the private variable. Thus, if , the optimal value is given by ; the corresponding optimal solution is . Otherwise, the optimal value is and the corresponding optimal solution is given by .
If , i.e., , we have and . In this case, the privatizer needs to maximize . Thus, if , the optimal value is given by ; the corresponding optimal solution is given by . Otherwise, the problem is infeasible.
Subproblem 3: and , we have and . Under this scenario, the objective function in (30) is given by . Thus, the privatizer solves
If , i.e., , the problem becomes infeasible for . For , if , the problem is also infeasible; if , the optimal value is given by and the corresponding optimal solution is ; otherwise, the optimal value is and the corresponding optimal solution is given by .
If , i.e., , the problem is infeasible for . For , if , the problem is also infeasible; if , the optimal value is given by and the corresponding optimal solution is ; otherwise, the optimal value is and the corresponding optimal solution is given by .
Subproblem 4: and , which implies and . Thus, the optimization problem in (30) is given by
If , i.e., , the problem becomes infeasible for . For , if , the problem is also infeasible; if , the optimal value is given by and the corresponding optimal solution is ; otherwise, the optimal value is and the corresponding optimal solution is given by .
If , i.e., , the problem becomes infeasible for . For , if , the problem is also infeasible; if , the optimal value is given by and the corresponding optimal solution is ; otherwise, the optimal value is and the corresponding optimal solution is given by .
Summarizing the analysis above yields Theorem 1. ☐
Appendix B. Proof of Theorem 2
Proof.
Let us consider , where and . Given the MAP adversary’s optimal inference accuracy in (37), the objective of the privatizer is to
Define . The gradient of w.r.t. is given by
Note that
Therefore, the second term in (A7) is 0. Furthermore, the first term in (A7) is always positive. Thus, is monotonically increasing in . As a result, the optimization problem in (A5) is equivalent to
Therefore, the optimal solution is given by and . Substituting the optimal solution back into (37) yields the MAP probability of correctly inferring the private variable Y from . ☐
Appendix C. Proof of Theorem 3
Proof.
Let us consider , where and are both non-negative. Given the MAP adversary’s optimal inference accuracy , the objective of the privatizer is to
Recall that is monotonically increasing in . As a result, the optimization problem in (A10) is equivalent to
Note that the above optimization problem is convex. Therefore, using the KKT conditions, we obtain the optimal solution
Substituting the above optimal solution into yields the MAP probability of correctly inferring the private variable Y from . ☐
References
Economist, T. The World’s Most Valuable Resource Is No Longer Oil, but Data; The Economist: New York, NY, USA, 2017. [Google Scholar]
National Science and Technology Council Networking and Information Technology Research and Development Program. National Privacy Research Strategy; Technical Report; Executive Office of the President of the United States: Washington, DC, USA, 2016.
EUGDPR. The EU General Data Protection Regulation (GDPR). Available online: http://www.eugdpr.org/ (accessed on 22 November 2017).
Samarati, P.; Sweeney, L. Protecting Privacy When Disclosing Information: k-Anonymity and Its Enforcement through Generalization and Suppression; Technical Report; SRI International: Menlo Park, CA, USA, 1998. [Google Scholar]
Sweeney, L. k-Anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst.2002, 10, 557–570. [Google Scholar] [CrossRef]
Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy beyond k-anonymity and l-diversity. In Proceedings of the IEEE 23rd International Conference on Data Engineering, ICDE 2007, Istanbul, Turkey, 11–15 April 2007; pp. 106–115. [Google Scholar]
Narayanan, A.; Shmatikov, V. Robust de-anonymization of large sparse datasets. In Proceedings of the IEEE Symposium on Security and Privacy (SP 2008), Oakland, CA, USA, 18–21 May 2008; pp. 111–125. [Google Scholar]
Harmanci, A.; Gerstein, M. Quantification of private information leakage from phenotype-genotype data: Linking attacks. Nat. Methods2016, 13, 251–256. [Google Scholar] [CrossRef] [PubMed]
Sweeney, L.; Abu, A.; Winn, J. Identifying Participants in the Personal Genome Project by Name (A Re-identification Experiment). arXiv, 2013; arXiv:1304.7605. [Google Scholar]
LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Incognito: Efficient full-domain k-anonymity. In Proceedings of the 2005 ACM SIGMOD international conference on Management of data, Baltimore, MD, USA, 13–17 June 2005; pp. 49–60. [Google Scholar]
Bayardo, R.J.; Agrawal, R. Data privacy through optimal k-anonymization. In Proceedings of the 21st International Conference on Data Engineering (ICDE 2005), Tokyo, Japan, 5–8 April 2005; pp. 217–228. [Google Scholar]
Fung, B.C.; Wang, K.; Philip, S.Y. Anonymizing classification data for privacy preservation. IEEE Trans. Knowl. Data Eng.2007, 19, 711–725. [Google Scholar] [CrossRef]
Iyengar, V.S. Transforming data to satisfy privacy constraints. In Proceedings of the eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–25 July 2002; pp. 279–288. [Google Scholar]
Samarati, P. Protecting respondents identities in microdata release. IEEE Trans. Knowl. Data Eng.2001, 13, 1010–1027. [Google Scholar] [CrossRef]
Wang, K.; Fung, B.C.; Philip, S.Y. Handicapping attacker’s confidence: An alternative to k-anonymization. Knowl. Inf. Syst.2007, 11, 345–368. [Google Scholar] [CrossRef]
Fung, B.; Wang, K.; Chen, R.; Yu, P.S. Privacy-preserving data publishing: A survey of recent developments. ACM Comput. Surv. (CSUR)2010, 42, 14. [Google Scholar] [CrossRef]
Dwork, C. Differential privacy. In Proceedings of the 33rd International Colloquium (ICALP 2006), Venice, Italy, 10–14 July 2006. [Google Scholar]
Dwork, C. Differential privacy: A survey of results. In Theory and Applications of Models of Computation: Lecture Notes in Computer Science; Springer: New York, NY, USA, 2008. [Google Scholar]
Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci.2014, 9, 211–407. [Google Scholar] [CrossRef]
Fienberg, S.E.; Rinaldo, A.; Yang, X. Differential Privacy and the Risk-Utility Tradeoff for Multi-dimensional Contingency Tables. In Proceedings of the Privacy in Statistical Databases: UNESCO Chair in Data Privacy, International Conference, PSD 2010, Corfu, Greece, 22–24 September 2010; Domingo-Ferrer, J., Magkos, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 187–199. [Google Scholar]
Uhlerop, C.; Slavković, A.; Fienberg, S.E. Privacy-preserving data sharing for genome-wide association studies. J. Priv. Confid.2013, 5, 137. [Google Scholar] [PubMed]
Yu, F.; Fienberg, S.E.; Slavković, A.B.; Uhler, C. Scalable privacy-preserving data sharing methodology for genome-wide association studies. J. Biomed. Inform.2014, 50, 133–141. [Google Scholar] [CrossRef] [PubMed]
Karwa, V.; Slavković, A. Inference using noisy degrees: Differentially private β-model and synthetic graphs. Ann. Stat.2016, 44, 87–112. [Google Scholar] [CrossRef]
Duchi, J.; Wainwright, M.J.; Jordan, M.I. Local privacy and minimax bounds: Sharp rates for probability estimation. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 5–10 December 2013; pp. 1529–1537. [Google Scholar]
Duchi, J.C.; Jordan, M.I.; Wainwright, M.J. Local privacy and statistical minimax rates. In Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science (FOCS), Berkeley, CA, USA, 26–29 October 2013; pp. 429–438. [Google Scholar]
Duchi, J.; Wainwright, M.; Jordan, M. Minimax optimal procedures for locally private estimation. arXiv, 2016; arXiv:1604.02390. [Google Scholar]
Kairouz, P.; Oh, S.; Viswanath, P. Extremal Mechanisms for Local Differential Privacy. J. Mach. Learn. Res.2016, 17, 492–542. [Google Scholar]
Kairouz, P.; Bonawitz, K.; Ramage, D. Discrete Distribution Estimation Under Local Privacy. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2436–2444. [Google Scholar]
Ye, M.; Barg, A. Optimal schemes for discrete distribution estimation under local differential privacy. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 759–763. [Google Scholar]
Raval, N.; Machanavajjhala, A.; Cox, L.P. Protecting Visual Secrets using Adversarial Nets. In Proceedings of the CVPR Workshop, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
Hayes, J.; Melis, L.; Danezis, G.; De Cristofaro, E. LOGAN: Evaluating Privacy Leakage of Generative Models Using Generative Adversarial Networks. arXiv, 2017; arXiv:cs.CR/1705.07663. [Google Scholar]
Yamamoto, H. A source coding problem for sources with additional outputs to keep secret from the receiver or wiretappers. IEEE Trans. Inf. Theory1983, 29, 918–923. [Google Scholar] [CrossRef]
Rebollo-Monedero, D.; Forne, J.; Domingo-Ferrer, J. From t-Closeness-Like Privacy to Postrandomization via Information Theory. IEEE Trans. Knowl. Data Eng.2010, 22, 1623–1636. [Google Scholar] [CrossRef]
Varodayan, D.; Khisti, A. Smart meter privacy using a rechargeable battery: Minimizing the rate of information leakage. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1932–1935. [Google Scholar]
Sankar, L.; Kar, S.K.; Tandon, R.; Poor, H.V. Competitive Privacy in the Smart Grid: An Information-theoretic Approach. In Proceedings of the Smart Grid Communications, Brussels, Belgium, 17–22 October 2011. [Google Scholar]
Calmon, F.P.; Fawaz, N. Privacy against statistical inference. In Proceedings of the 2012 50th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 1–5 October 2012; pp. 1401–1408. [Google Scholar]
Calmon, F.P.; Varia, M.; Médard, M.; Christiansen, M.M.; Duffy, K.R.; Tessaro, S. Bounds on inference. In Proceedings of the 51st Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 2–4 October 2013; pp. 567–574. [Google Scholar]
Salamatian, S.; Zhang, A.; Calmon, F.P.; Bhamidipati, S.; Fawaz, N.; Kveton, B.; Oliveira, P.; Taft, N. Managing Your Private and Public Data: Bringing Down Inference Attacks Against Your Privacy. IEEE J. Sel. Top. Signal Process.2015, 9, 1240–1255. [Google Scholar] [CrossRef]
Liao, J.; Sankar, L.; Tan, V.F.; du Pin Calmon, F. Hypothesis testing in the high privacy regime. In Proceedings of the 54th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 28–30 September 2016. [Google Scholar]
Calmon, F.P.; Varia, M.; Médard, M. On Information-Theoretic Metrics for Symmetric-Key Encryption and Privacy. In Proceedings of the 52nd Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 1–3 October 2014. [Google Scholar]
Asoodeh, S.; Alajaji, F.; Linder, T. Notes on information-theoretic privacy. In Proceedings of the 2014 52nd Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 1–3 October 2014; pp. 1272–1278. [Google Scholar]
Calmon, F.P.; Makhdoumi, A.; Médard, M. Fundamental Limits of Perfect Privacy. In Proceedings of the International Symposium on Information Theory, Hong Kong, China, 14–19 June 2015. [Google Scholar]
Basciftci, Y.O.; Wang, Y.; Ishwar, P. On privacy-utility tradeoffs for constrained data release mechanisms. In Proceedings of the 2016 Information Theory and Applications Workshop (ITA), La Jolla, VA, USA, 1–5 February 2016; pp. 1–6. [Google Scholar]
Kalantari, K.; Kosut, O.; Sankar, L. On the fine asymptotics of information theoretic privacy. In Proceedings of the 2016 54th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 27–30 September 2016; pp. 532–539. [Google Scholar]
Kalantari, K.; Sankar, L.; Kosut, O. On information-theoretic privacy with general distortion cost functions. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2865–2869. [Google Scholar]
Kalantari, K.; Kosut, O.; Sankar, L. Information-Theoretic Privacy with General Distortion Constraints. arXiv, 2017; arXiv:1708.05468. [Google Scholar]
Asoodeh, S.; Alajaji, F.; Linder, T. On maximal correlation, mutual information and data privacy. In Proceedings of the 2015 IEEE 14th Canadian Workshop on Information Theory (CWIT), St. John’s, NL, Canada, 6–9 July 2015; pp. 27–31. [Google Scholar]
Asoodeh, S.; Diaz, M.; Alajaji, F.; Linder, T. Information extraction under privacy constraints. Information2016, 7, 15. [Google Scholar] [CrossRef]
Asoodeh, S.; Alajaji, F.; Linder, T. Privacy-aware MMSE estimation. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 1989–1993. [Google Scholar]
Moraffah, B.; Sankar, L. Privacy-Guaranteed Two-Agent Interactions Using Information-Theoretic Mechanisms. IEEE Trans. Inf. Forensics Secur.2017, 12, 2168–2183. [Google Scholar] [CrossRef]
Issa, I.; Kamath, S.; Wagner, A.B. An operational measure of information leakage. In Proceedings of the 2016 Annual Conference on Information Science and Systems, CISS 2016, Princeton, NJ, USA, 16–18 March 2016; pp. 234–239. [Google Scholar]
Warner, S.L. Randomized response: A survey technique for eliminating evasive answer bias. J. Am. Stat. Assoc.1965, 60, 63–69. [Google Scholar] [CrossRef] [PubMed]
Issa, I.; Wagner, A.B. Operational definitions for some common information leakage metrics. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 769–773. [Google Scholar]
Asoodeh, S.; Diaz, M.; Alajaji, F.; Linder, T. Estimation Efficiency Under Privacy Constraints. arXiv, 2017; arXiv:1707.02409. [Google Scholar]
Asoodeh, S.; Diaz, M.; Alajaji, F.; Linder, T. Privacy-aware guessing efficiency. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 754–758. [Google Scholar]
Kerschbaum, F. Frequency-hiding order-preserving encryption. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 656–667. [Google Scholar]
Dong, B.; Wang, W.; Yang, J. Secure Data Outsourcing with Adversarial Data Dependency Constraints. In Proceedings of the 2016 IEEE 2nd International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), New York, NY, USA, 9–10 April 2016; pp. 73–78. [Google Scholar]
Dong, B.; Liu, R.; Wang, W.H. Prada: Privacy-preserving data-deduplication-as-a-service. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 1559–1568. [Google Scholar]
Alemi, A.; Fischer, I.; Dillon, J.; Murphy, K. Deep Variational Information Bottleneck. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
Zhang, Y.; Ozay, M.; Sun, Z.; Okatani, T. Information Potential Auto-Encoders. arXiv, 2017; arXiv:1706.04635. [Google Scholar]
Theis, L.; Shi, W.; Cunningham, A.; Huszár, F. Lossy Image Compression with Compressive Autoencoders. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
Moon, K.R.; Sricharan, K.; Hero, A.O. Ensemble estimation of mutual information. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 3030–3034. [Google Scholar]
Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv, 2014; arXiv:1411.1784. [Google Scholar]
Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
Morris, J. On single-sample robust detection of known signals with additive unknown-mean amplitude-bounded random interference. IEEE Trans. Inf. Theory1980, 26, 199–209. [Google Scholar] [CrossRef]
Shamai, S.; Verdú, S. Worst-case power-constrained noise for binary-input channels. IEEE Trans. Inf. Theory1992, 38, 1494–1511. [Google Scholar] [CrossRef]
Morris, J. On single-sample robust detection of known signals with additive unknown-mean amplitude-bounded random interference—II: The randomized decision rule solution (Corresp.). IEEE Trans. Inf. Theory1981, 27, 132–136. [Google Scholar] [CrossRef]
Morris, J.M.; Dennis, N.E. A random-threshold decision rule for known signals with additive amplitude-bounded nonstationary random interference. IEEE Trans. Commun.1990, 38, 160–164. [Google Scholar] [CrossRef]
Erlingsson, Ú.; Pihur, V.; Korolova, A. Rappor: Randomized aggregatable privacy-preserving ordinal response. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 1054–1067. [Google Scholar]
Tang, J.; Korolova, A.; Bai, X.; Wang, X.; Wang, X. Privacy Loss in Apple’s Implementation of Differential Privacy on MacOS 10.12. arXiv, 2017; arXiv:1709.02753. [Google Scholar]
Verdú, S. α-mutual information. In Proceedings of the 2015 Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 1–6 February 2015. [Google Scholar]
Sugiyama, M.; Borgwardt, K.M. Measuring statistical dependence via the mutual information dimension. DIM2013, 10, 1. [Google Scholar]
Hamm, J. Minimax Filter: Learning to Preserve Privacy from Inference Attacks. arXiv, 2016; arXiv:1610.03577. [Google Scholar]
Liu, C.; Chakraborty, S.; Mittal, P. DEEProtect: Enabling Inference-based Access Control on Mobile Sensing Applications. arXiv, 2017; arXiv:1702.06159. [Google Scholar]
Xu, K.; Cao, T.; Shah, S.; Maung, C.; Schweitzer, H. Cleaning the Null Space: A Privacy Mechanism for Predictors. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
Abadi, M.; Andersen, D.G. Learning to protect communications with adversarial neural cryptography. arXiv, 2016; arXiv:1610.06918. [Google Scholar]
Edwards, H.; Storkey, A. Censoring representations with an adversary. arXiv, 2015; arXiv:1511.05897. [Google Scholar]
Smolensky, P. Information Processing in Dynamical Systems: Foundations of Harmony Theory; Technical Report; Colorado University at Boulder Department of Computer Science: Boulder, CO, USA, 1986. [Google Scholar]
Nguyen, T.; Sanner, S. Algorithms for direct 0-1 loss optimization in binary classification. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1085–1093. [Google Scholar]
Zhang, G.P. Neural networks for classification: A survey. IEEE Trans. Syst. Man Cybern. Part C2000, 30, 451–462. [Google Scholar] [CrossRef]
Tang, Y. Deep learning using linear support vector machines. arXiv, 2013; arXiv:1306.0239. [Google Scholar]
Lillo, W.E.; Loh, M.H.; Hui, S.; Zak, S.H. On solving constrained optimization problems with neural networks: A penalty method approach. IEEE Trans. Neural Netw.1993, 4, 931–940. [Google Scholar] [CrossRef] [PubMed]
Eckstein, J.; Yao, W. Augmented Lagrangian and alternating direction methods for convex optimization: A tutorial and some illustrative computational results. RUTCOR Res. Rep.2012, 32, 1–34. [Google Scholar]
Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv, 2016; arXiv:1603.04467. [Google Scholar]
Weisstein, E.W. Normal Distribution; Wolfram Research Inc.: Champaign, IL, USA, 2002. [Google Scholar]
Van Trees, H.L. Detection, Estimation, and Modulation Theory; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
Figure 1.
An example privacy preserving mechanism for smart meter data.
Figure 1.
An example privacy preserving mechanism for smart meter data.
Figure 2.
Generative Adversarial Privacy.
Figure 2.
Generative Adversarial Privacy.
Figure 3.
A multi-layer neural network model for the privatizer and adversary.
Figure 3.
A multi-layer neural network model for the privatizer and adversary.
Figure 4.
Neural network structure of the privatizer and adversary for binary data model.
Figure 4.
Neural network structure of the privatizer and adversary for binary data model.
Figure 5.
Privacy-distortion tradeoff for binary data model. (a) Performance of privacy mechanisms against MAP adversary for ; (b) Performance of privacy mechanisms against MAP adversary for ; (c) Performance of privacy mechanisms under MI privacy metric for ; (d) Performance of privacy mechanisms under MI privacy metric for .
Figure 5.
Privacy-distortion tradeoff for binary data model. (a) Performance of privacy mechanisms against MAP adversary for ; (b) Performance of privacy mechanisms against MAP adversary for ; (c) Performance of privacy mechanisms under MI privacy metric for ; (d) Performance of privacy mechanisms under MI privacy metric for .
Figure 6.
Neural network structure of the privatizer and adversary for binary Gaussian mixture model.
Figure 6.
Neural network structure of the privatizer and adversary for binary Gaussian mixture model.
Figure 7.
Privacy-distortion tradeoff for binary Gaussian mixture model. (a) Performance of PDD mechanisms against MAP adversary for ; (b) Performance of PDD mechanisms against MAP adversary for .
Figure 7.
Privacy-distortion tradeoff for binary Gaussian mixture model. (a) Performance of PDD mechanisms against MAP adversary for ; (b) Performance of PDD mechanisms against MAP adversary for .
















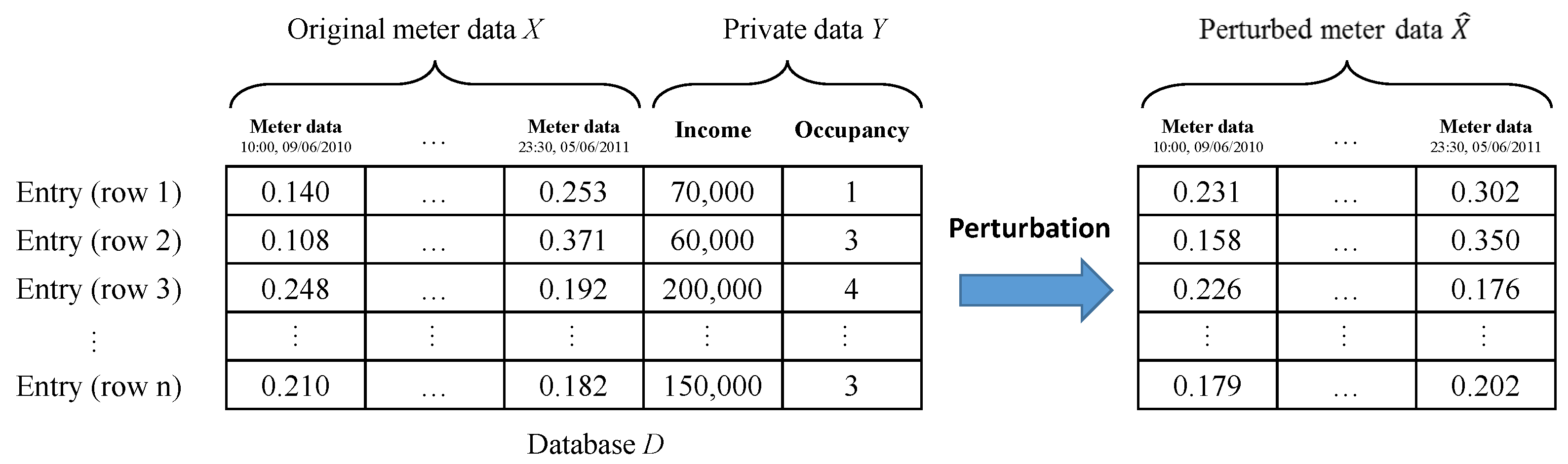{kind=link}
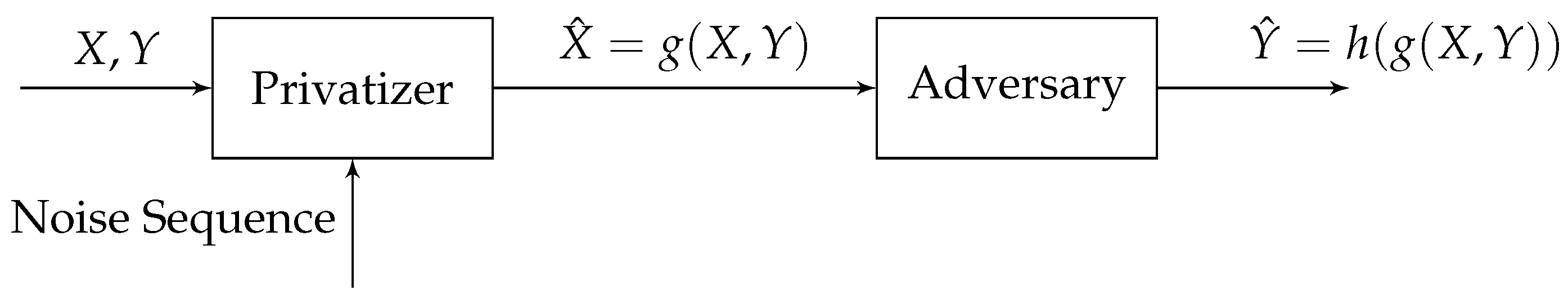{kind=link}
{kind=link}
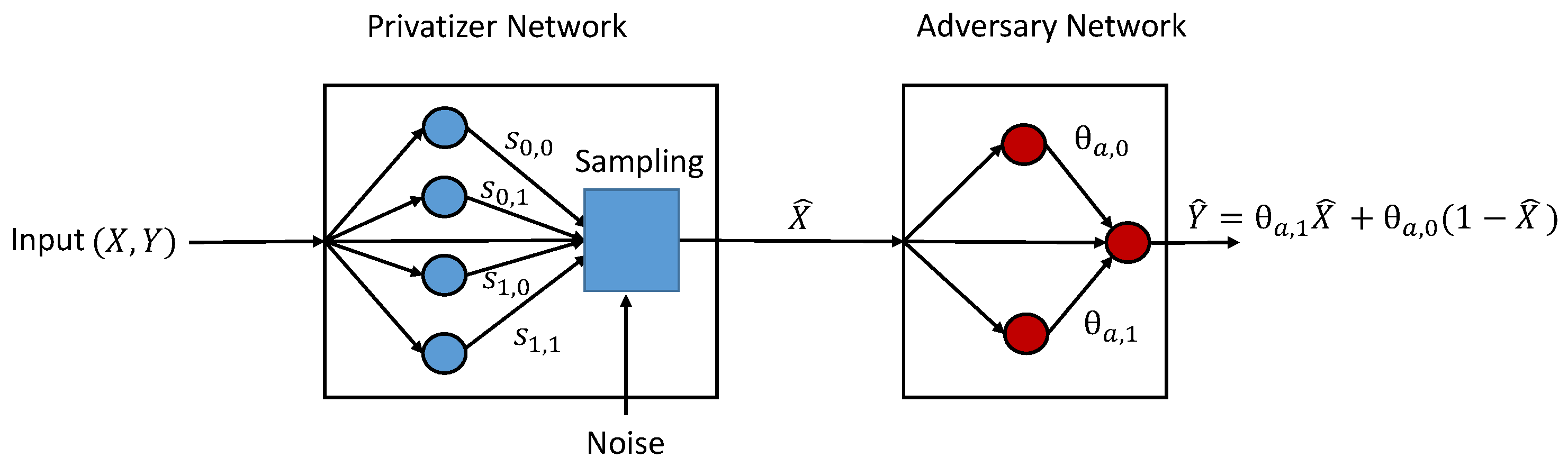{kind=link}
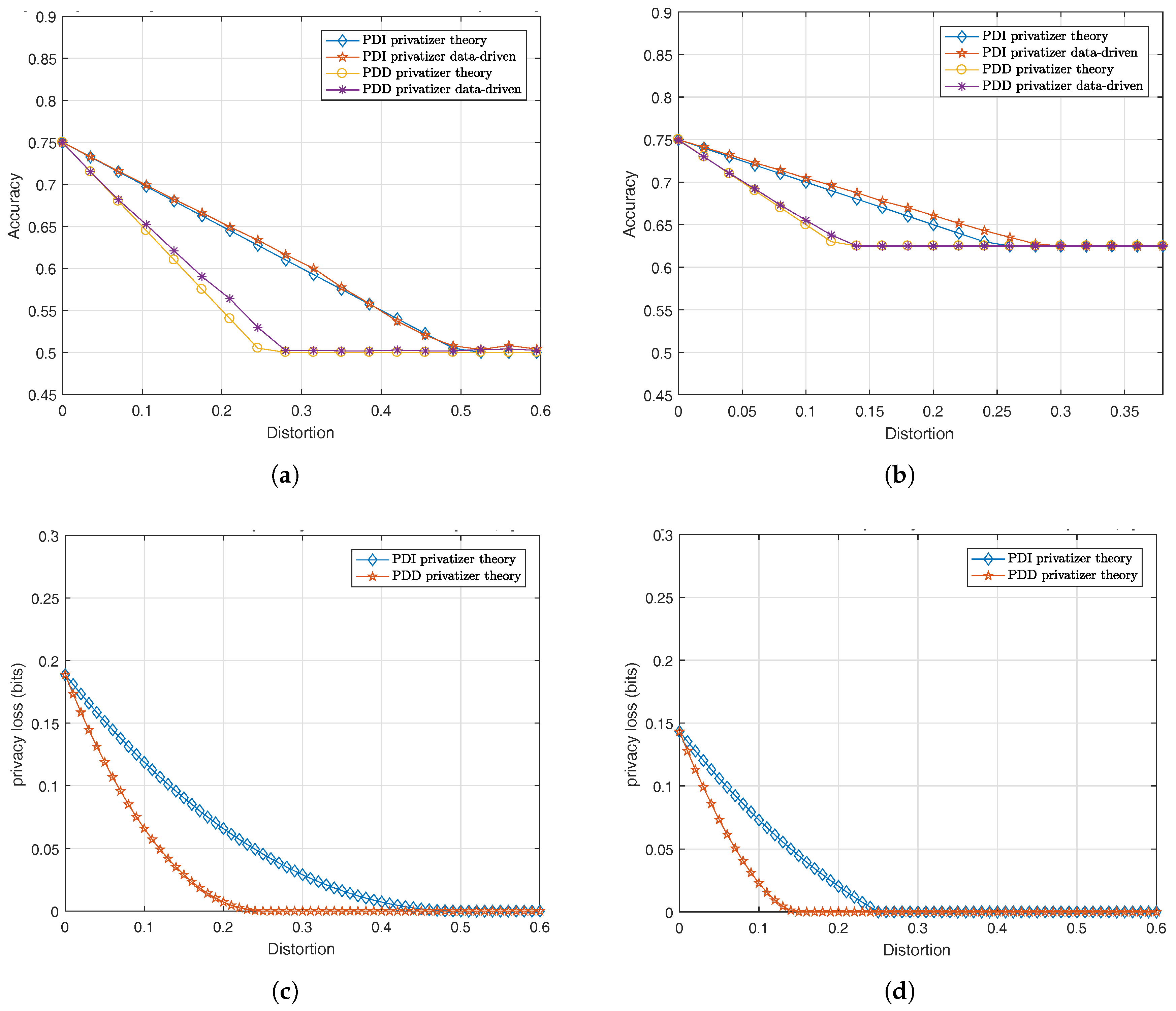{kind=link}
{kind=link}
{kind=link}
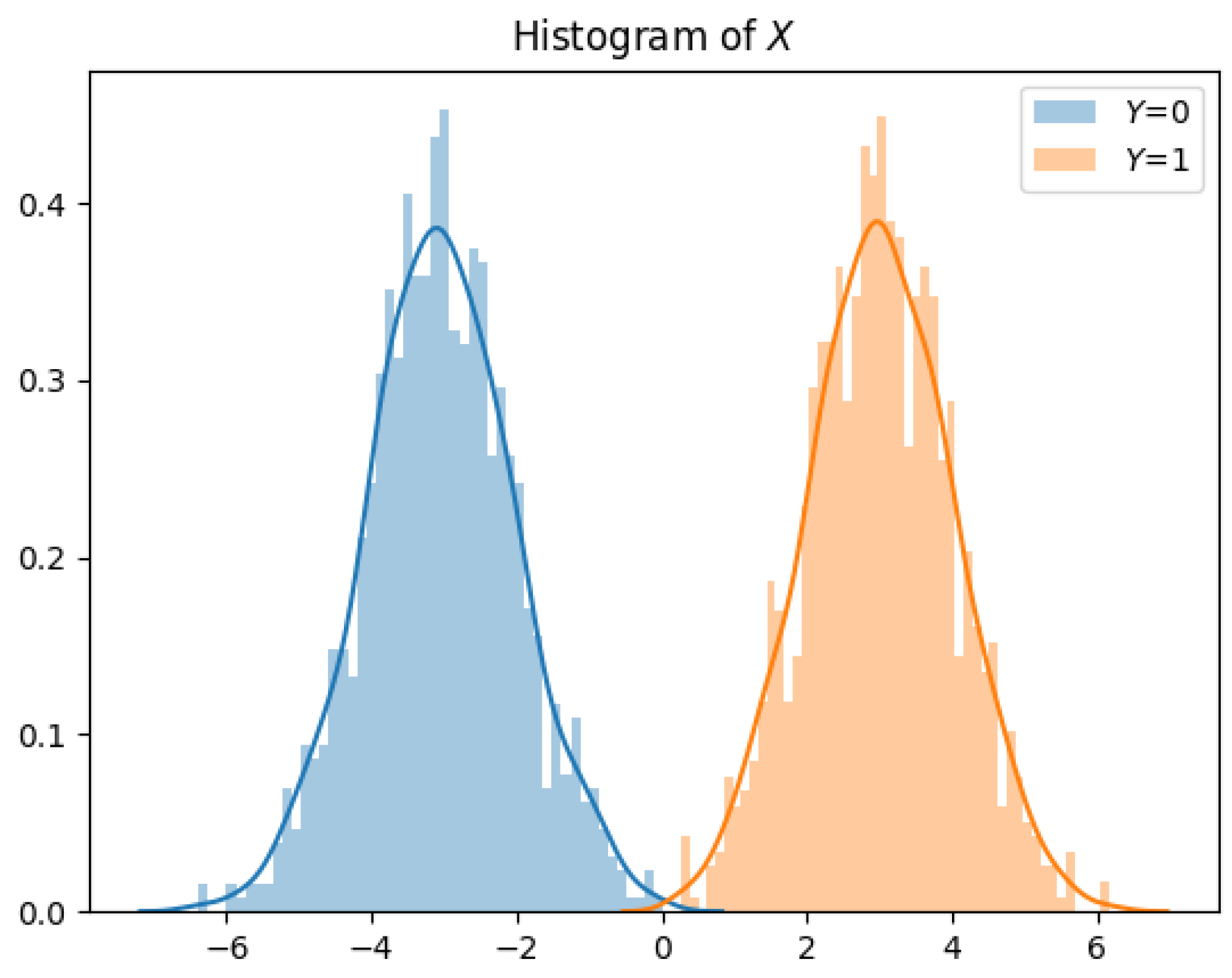{kind=link}
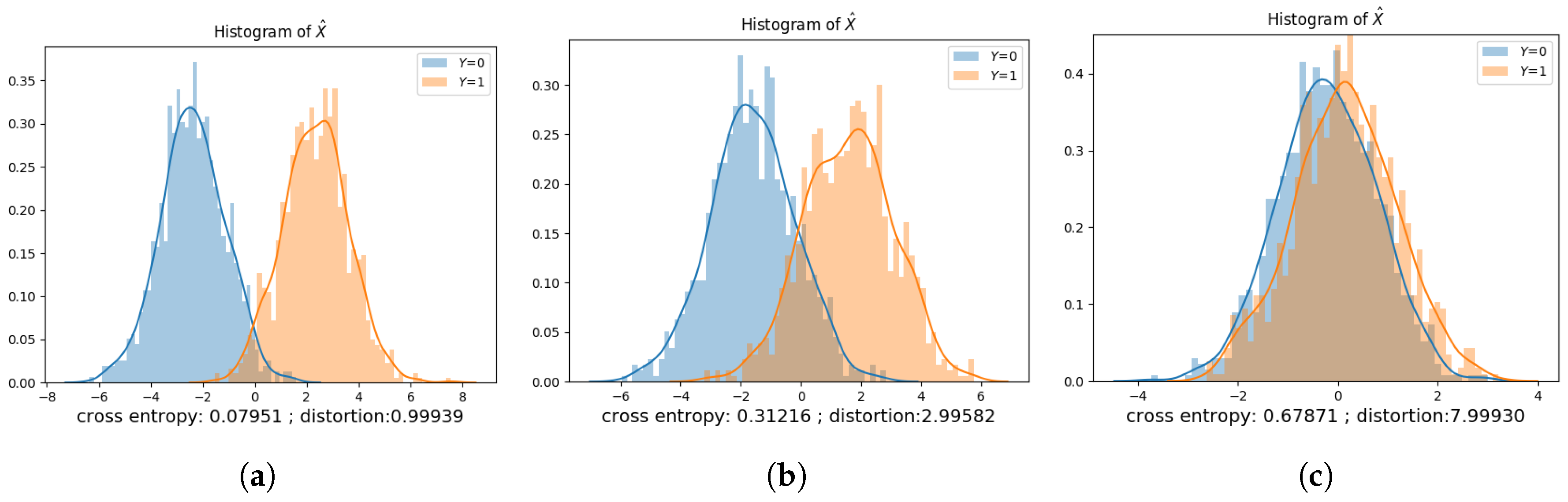{kind=link}
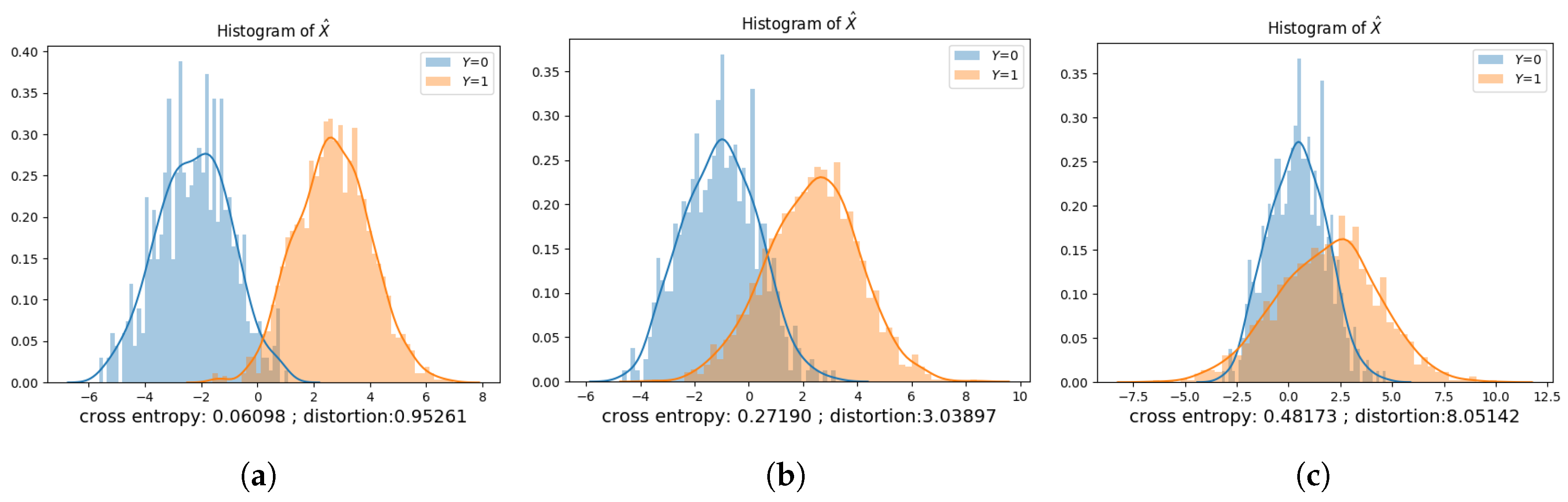{kind=link}
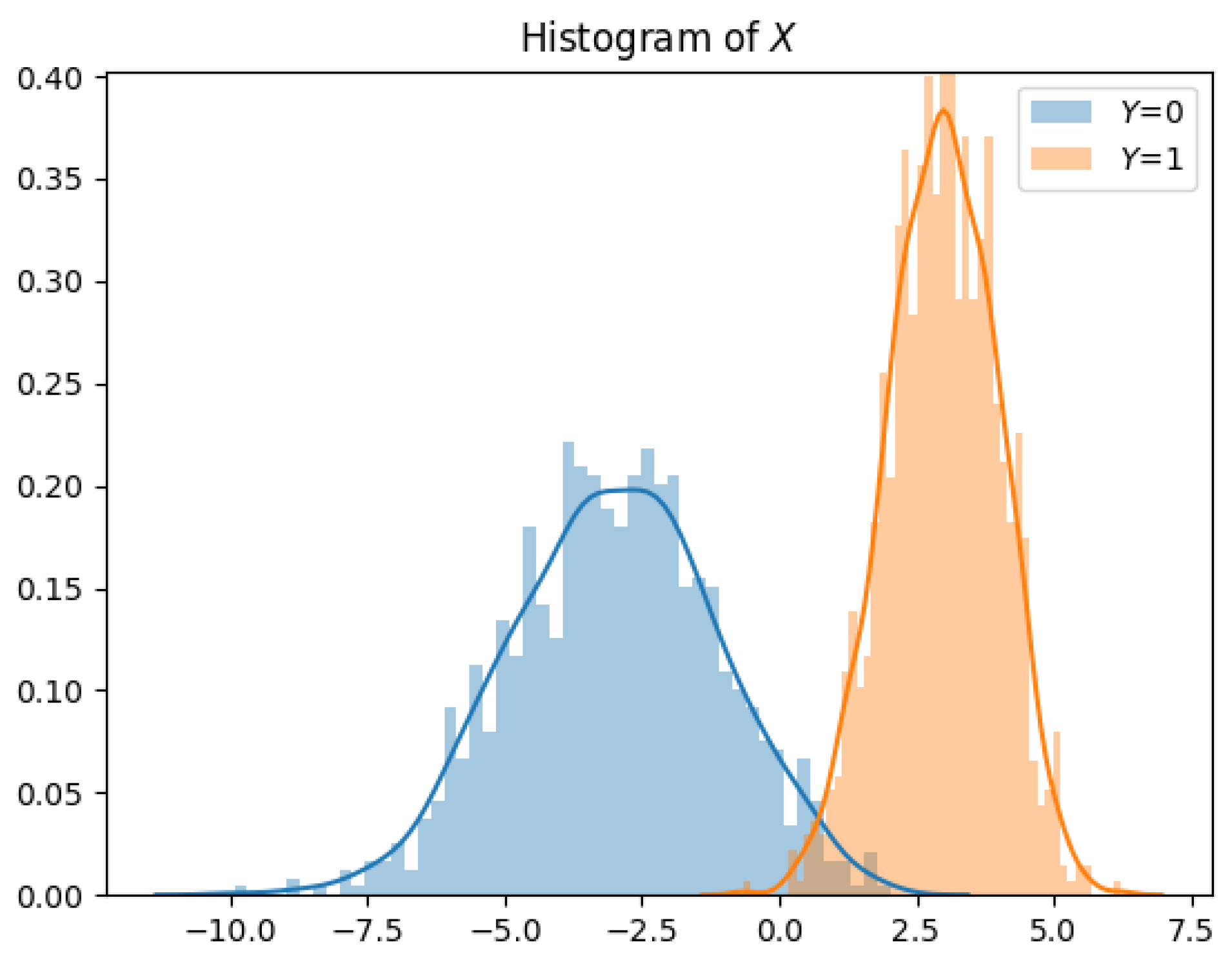{kind=link}
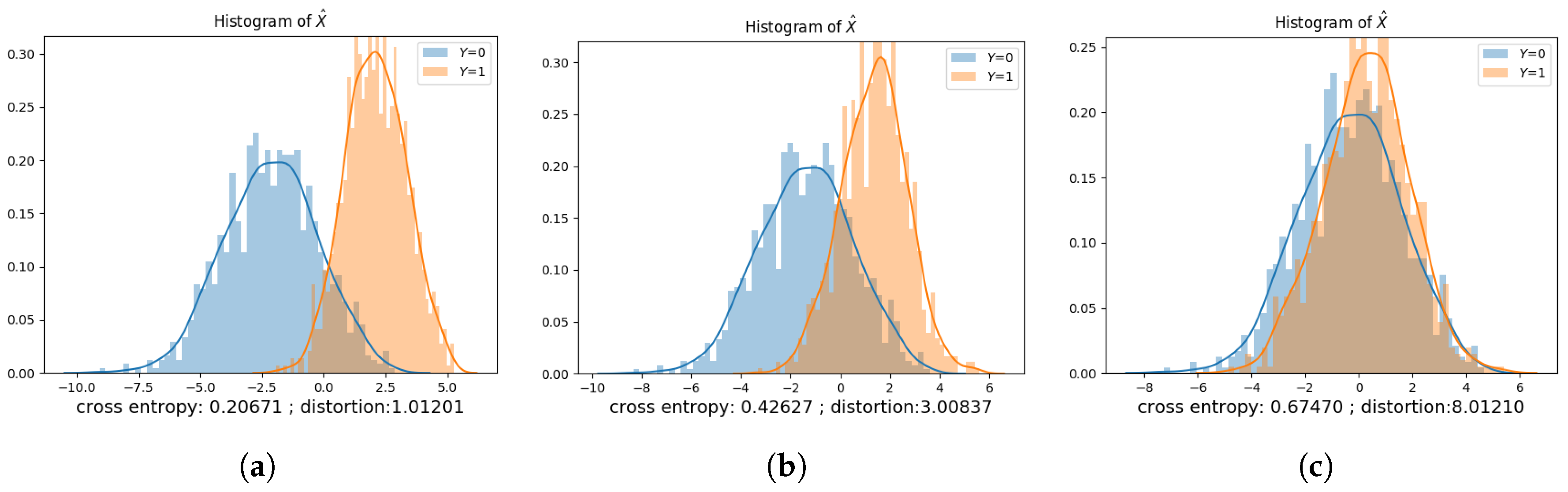{kind=link}
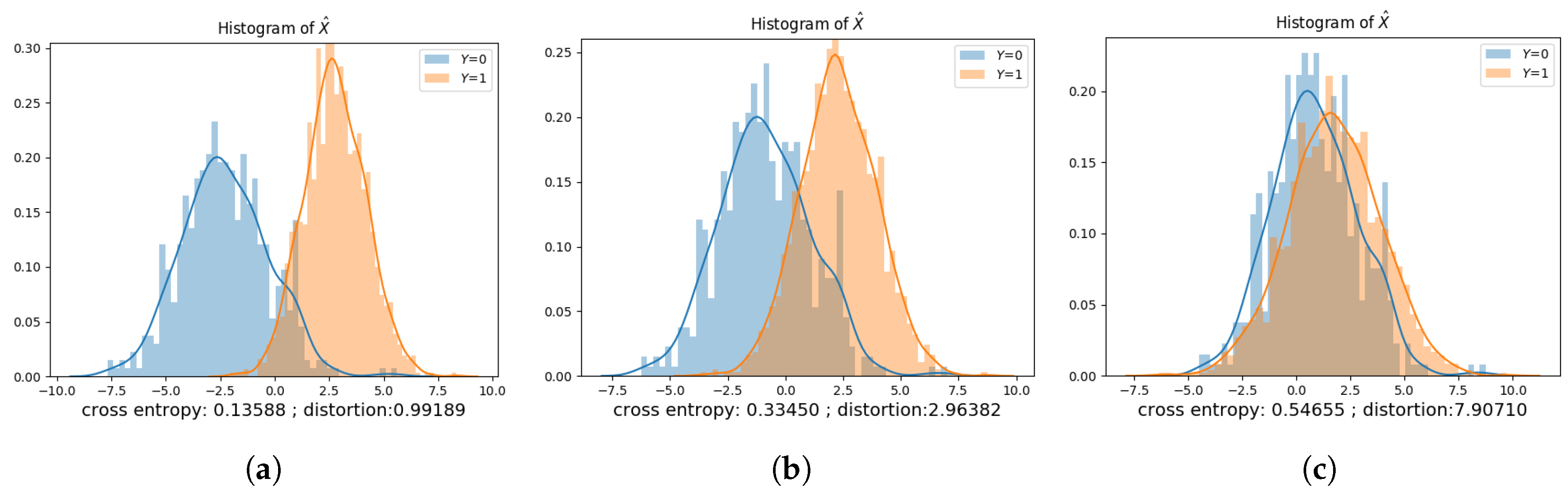{kind=link}