1. Introduction
Wired or wireless communication channels are under multipath fading as well as impulsive noise from various sources [
1,
2]. The impulsive noise can cause large instantaneous errors and system failure so that enhanced signal processing algorithms for coping with such obstacles are needed. Most algorithms are designed based on the mean squared error (
MSE) criterion, but it often fails in impulsive noise environments [
3].One of the cost functions based on information theoretic learning (ITL), minimum error entropy (
MEE) has been developed by Erdogmus [
4]. As a nonlinear version of
MEE, the decision feedback
MEE (
DF-MEE) algorithm has been known to yield superior performance under severe channel distortions and impulsive noise environments [
5]. It also has been shown for shallow underwater communication channels that the
DF-MEE algorithm has not only robustness against impulsive noise and severe multipath fading but can also be more improved by some modification of the kernel size [
6].
One of the problems of the
MEE algorithm is its heavy computational complexity caused by the computation of double summations for the gradient estimation of
MEE algorithm at each iteration time. In the work conducted by [
7], a computation reducing method by the recursive gradient estimation of the
DF-MEE has been proposed for practical implementation. Though those practical difficulties have been removed through the recursive method, theoretic analysis in depth on its optimum solutions and their behavior has not been carried out yet for further enhancement of the algorithm.
In this paper, based on the analysis of behavior of optimum weight and some factors on mitigation of influence from large errors due to impulsive noise, we propose to employ a time-varying step size through normalization by the input power that is recursively estimated for effectiveness in computational complexity. The performance comparison with
MEE will be discussed and experimented through simulation in equalization as well as in system identification problems with impulsive noise that can be encountered in experiments investigating physical phenomenon [
8].
2. MSE Criterion and Related Algorithms
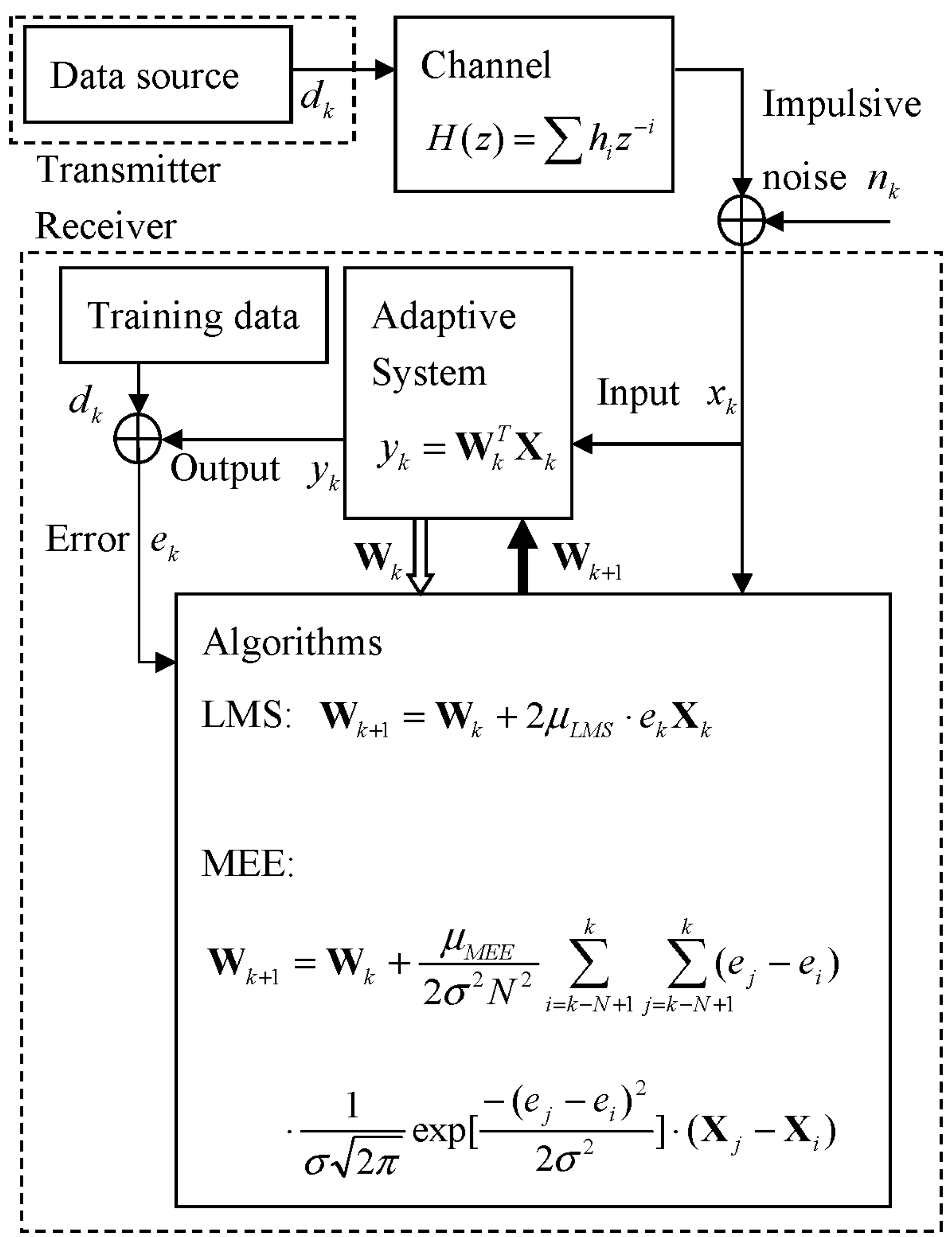
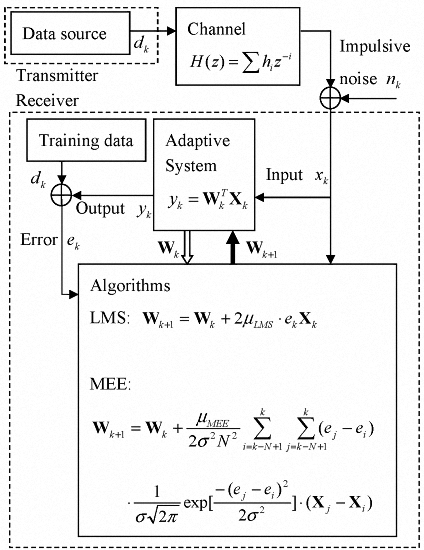
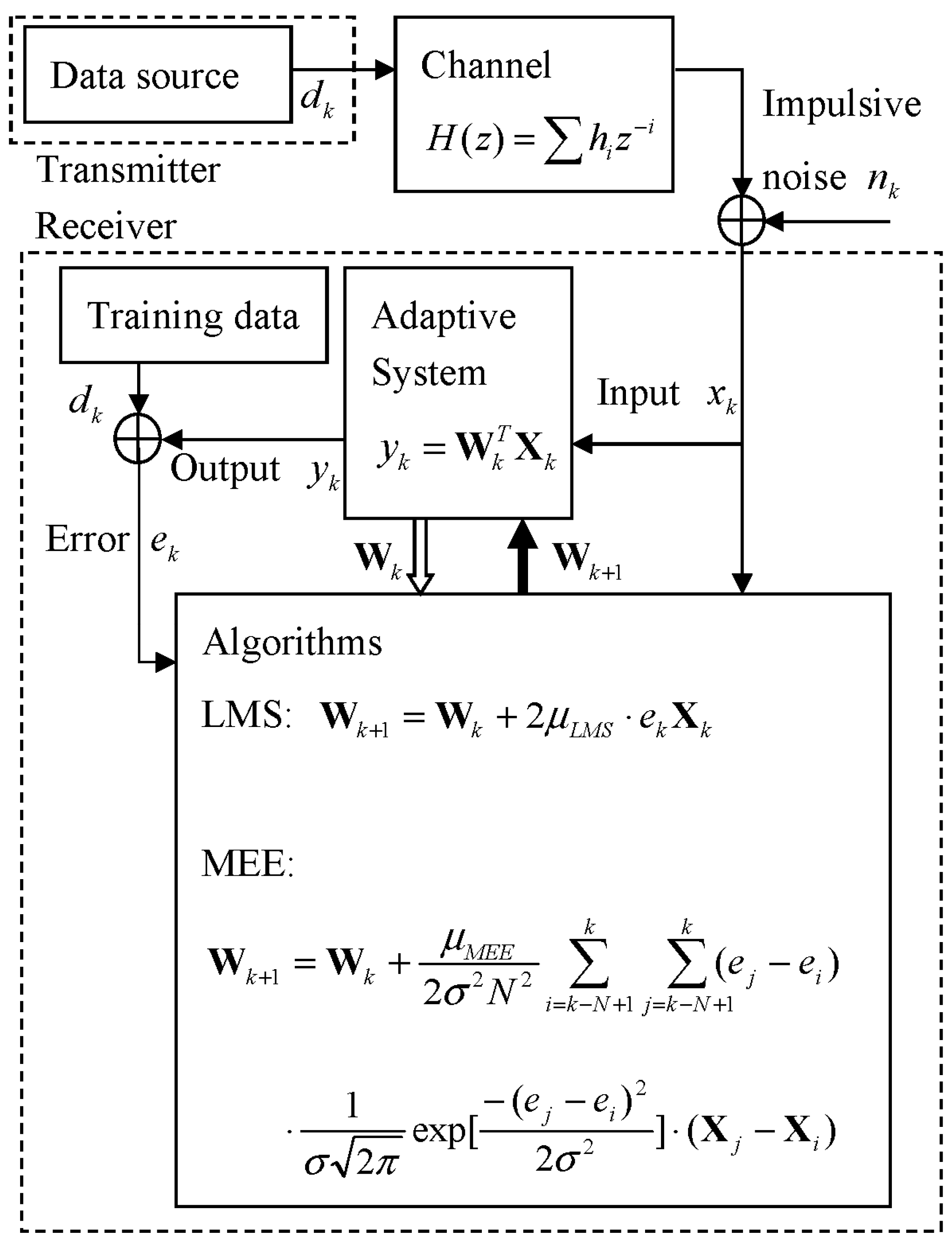
The overall communication system model for this work is described in
Figure 1. The transmitter sends a symbol
at time k through the multipath channel described in z-transform,
, and then impulsive noise
is added to the channel output to become the received signal
so that the adaptive system input
contains noise
and intersymbol interference (ISI) caused by the channel’s multipath [
9].
With the input
and weight
of the tapped delay line (TDL) equalizer, the output
and the error
become
With the current weight , a set of error samples and a set of input samples, the adaptive algorithms designed according to their own criteria such as MSE or MEE produce updated weight with which the adaptive system makes the next output .
Taking statistical average
to the error power
, the
MSE criterion is defined as
. For practical reasons, instantaneous error power
can be used and the
LMS (least mean square) algorithm has been developed based on minimization of
[
9].The minimization of
can be carried out by the steepest descent method utilizing the gradient of
as
With Equation (4) and the step size
, the well-known
LMS algorithm is presented as
By letting the gradient
be zero, we have the optimum condition of the
LMS as
Taking statistical average
to Equation (6) leads us to the optimum condition of the
MSE criterion as
Inserting (3) into (6), we get the optimum weight of the
LMS algorithm,
as
The optimum weight in (8)might be expected to get wildly shaky in impulsive noise situations since it has no protection measures from such impulses existing in the input vector .
When the effect of fluctuations in the input power levels is considered, the fact that the step size
of the
LMS algorithm should be inversely proportional to the power of the input signal
leads to the normalized
LMS algorithm (
NLMS) where its step size is normalized by the squared norm of the input vector
, that is,
[
9]. One of the principal characteristics of the
NLMS algorithm is that the parameter
is dimensionless, whereas
has the dimensioning of inverse power as mentioned above. Therefore, we may view that the
NLMS algorithm has an input power-dependent adaptation step size, so that the effect of fluctuations in the power levels of the input signal is compensated at the adaptation level. When we assume that in the steady state
and
are independent, the input vector
can be viewed as being normalized by its squared norm
in the
NLMS algorithm as
.
Unlike the
LMS or
NLMS, the
MEE algorithm based on the error entropy criterion is known for its robustness against impulsive noise [
6]. In the following section, the
MEE algorithm will be analyzed with respect to its weight behavior under impulsive noise environments.
3. MEE Algorithm and Magnitude Controlled Input Entropy
The MSE criterion is effective under the assumptions of linearity and Gaussianity since it uses only second order statistics of the error signal. When the noise is impulsive, a criterion considering all the higher order statistics of the error signal would be more appropriate.
Error entropy as a scalar quantity provides a measure of the average information contained in a given error distribution. With
N samples (sample size
N) of error samples
the distribution function of error,
can be constructed based on Kernel density estimation as in Equation (9) [
10].
Since the Shannon’s entropy in [
9] is hard to estimate and to minimize due to the integral of the logarithm of a given distribution function, Renyi’s quadratic error entropy
has been effectively used in ITL methods as described in (10).
When error entropy
in (10) is minimized, the error distribution
of an adaptive system is contracted and all higher order moments are minimized [
4].
Inserting (9) into (10) leads to the following
that can be interpreted as interactions among pairs of error samples where error samples act as physical particles.
Since the Gaussian kernel
is always positive and is an exponential decay function with the distance square, the Gaussian kernel may be considered to create a potential field. The sum of all pairs of interactions in the argument of log [.] in (11) is called information potential
[
4].
Then, minimization of error entropy is equivalent to maximization of
. For the maximization of
, the gradient of (12) becomes
At the optimum state (
), we have
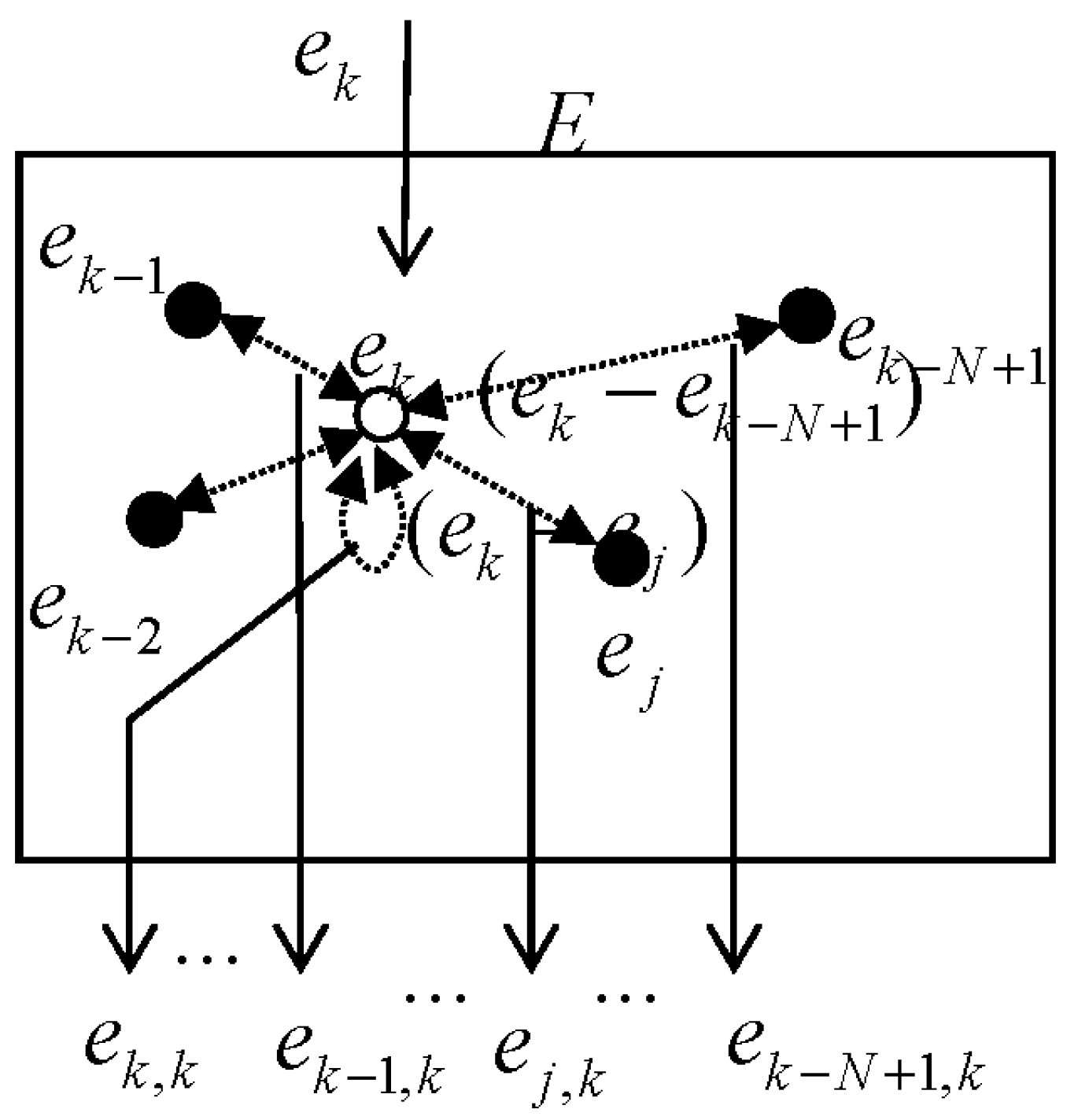
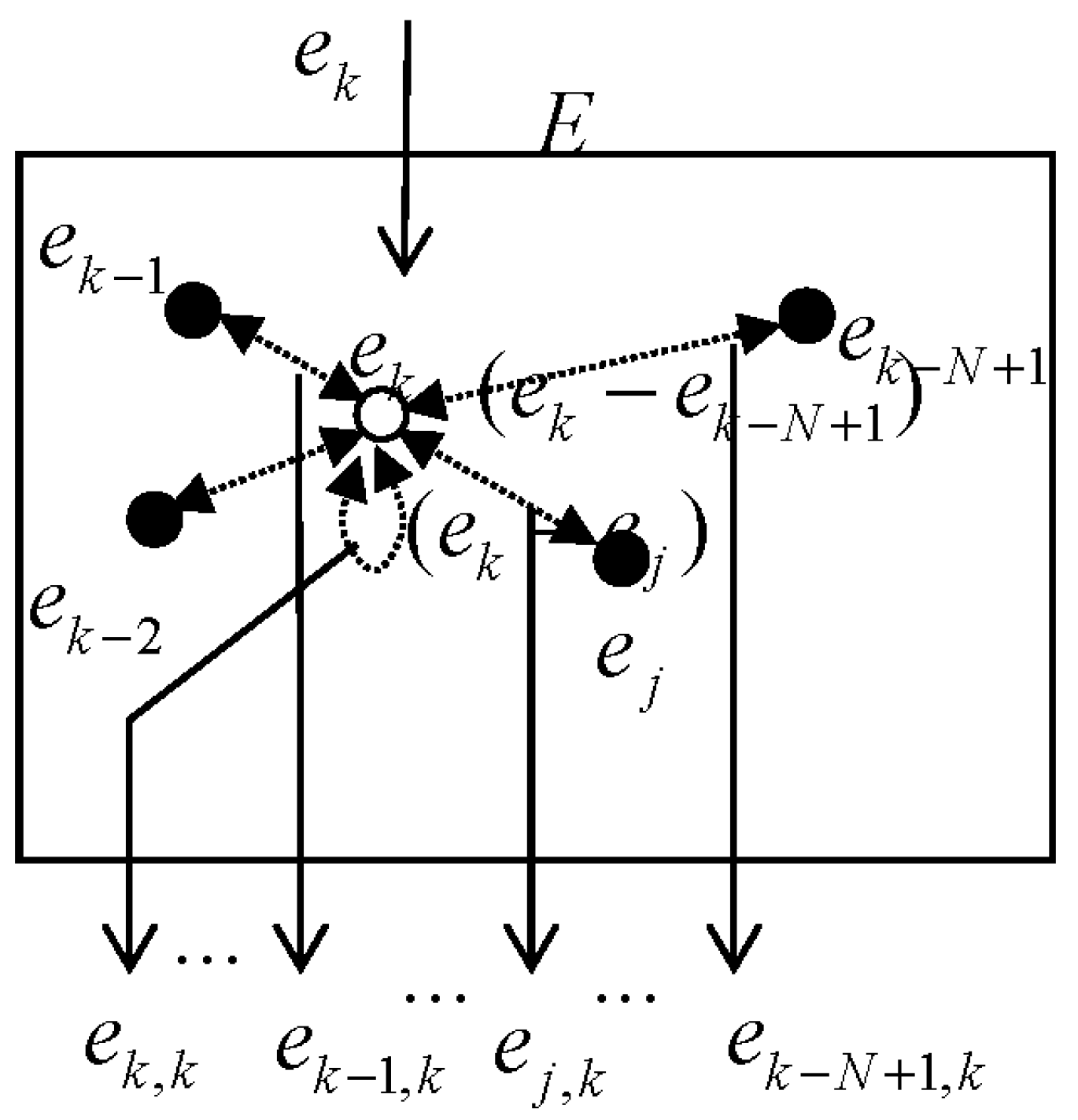
Since the term
implies how far the current error
is located from each error sample
, we may define the error pair
as
which is generated from the error space
at each iteration time as in
Figure 2. The term
can be considered to contain information of the extent of spread of error samples. Considering that entropy is a measure of how evenly energy is distributed or the range of positions of components of a system, we will refer to this information as error entropy (
EE) in this paper for convenience.
Similarly, the term
indicates the distance between the current input vector
and another input vector
in the input vector space. Therefore, with the following definition, we can say that
contains the information of the extent of spread of input vectors, that is, input entropy (
IE). Likewise, we will refer to
as an
IE vector in this paper.
Then, with the
EE sample
and
IE vector
Equation (14) can be rewritten as
If we consider the sample-averaged operation
in (16) can be replaced with the statistical average
or vice versa for practical reasons, the comparison between (16) and the optimum condition of the
MSE criterion
in (7) provides insight that
of the
MSE criterion can correspond to
EE sample
, and
of
MSE criterion can be related to
as a kind of modified input entropy vector. We also see that the term
in (16) implies that the magnitude of
is controlled by
. At the occurrence of a strong impulse in
,
can be located far away from
so that the
EE sample
has a very large value. Then, the Gaussian function output
becomes a very small value since its exponential is a decay function of
. In turn, the value of the
IE vector
is reduced by the multiplication of
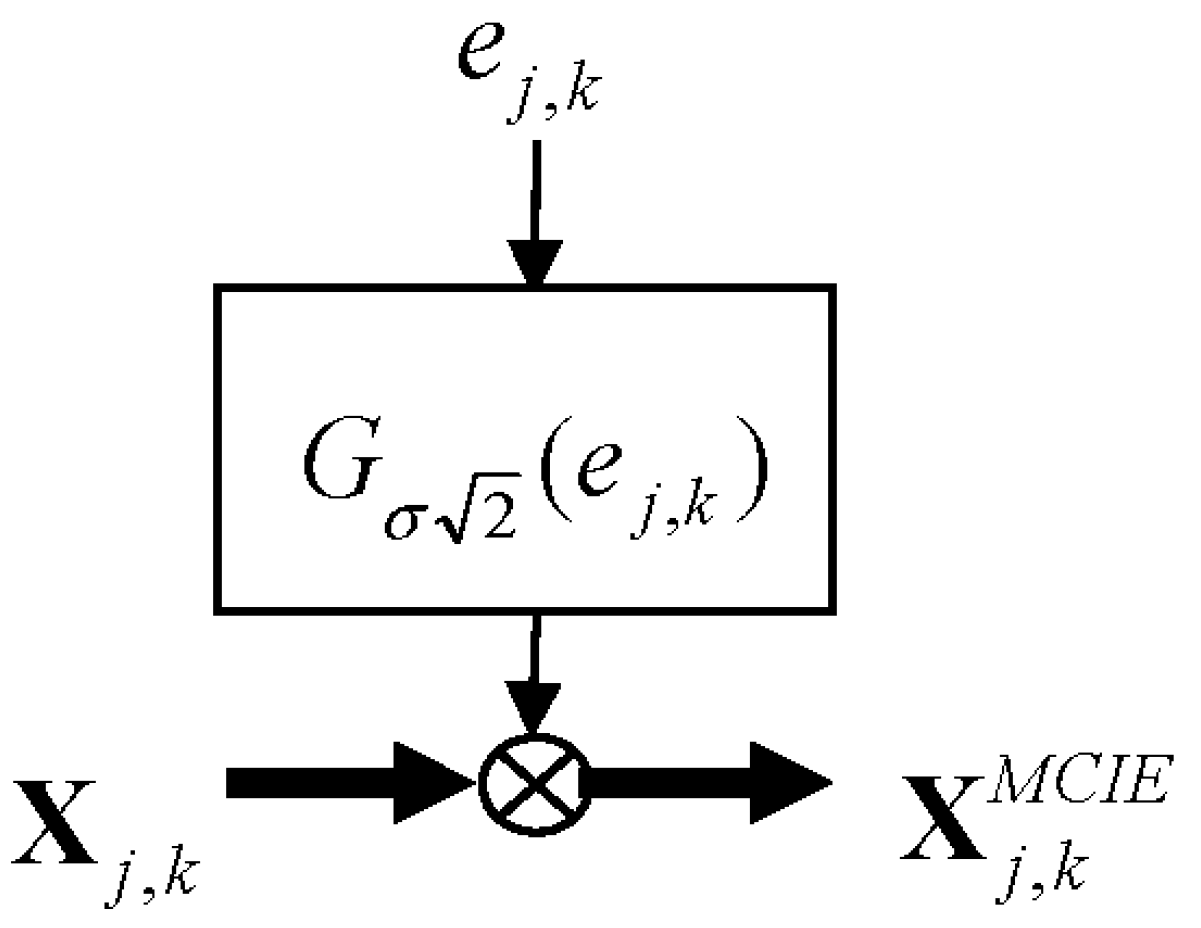
. In this regard, it is appropriate that the term
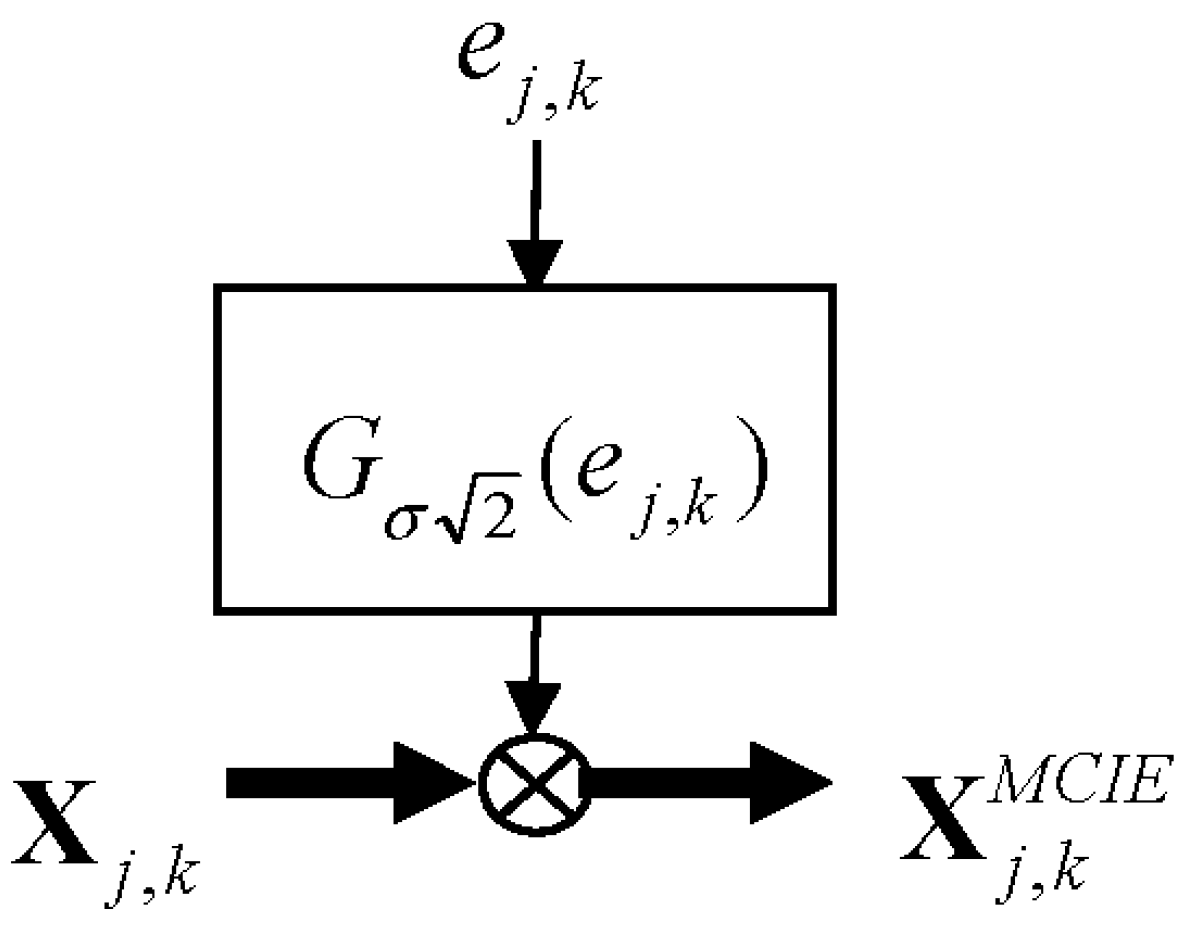
in (16)is interpreted as a magnitude-controlled version of ... Defining
as a magnitude controlled input entropy (
MCIE) in (17), this process can be described as in
Figure 3.
In an element expression,
With
, the
MEE algorithm becomes
The optimum condition in (16) can be rewritten as
We may observe that the MEE algorithm in (20) is very similar to (7) in the aspect of the error and input terms. One different part is that the MEE algorithm consists of summations of error entropy samples and input entropy vectors, while the LMS just has an error sample and an input vector.
On the other hand, it can be noticed that MCIE can keep the algorithm stable even at the occurrences of large error entropy that occurs mostly when the input is contaminated by impulse noise. The summation process over can also mitigate the influence of impulses, but it does not contribute much to deterring the influence of large errors since even an impulse can dominate the averaging (summation) operation.
4. Recursive Power Estimation of MCIE
The fixed step size of the MEE algorithm may make the MEE require an understanding of the statistics of the input entropy prior to the adaptive filtering operation. This makes it hard in practice to choose an appropriate step size that controls its learning speed and stability.
Like the approach of the normalized
LMS that solves this kind of problem through normalization by the summed power of the current input samples as in [
9,
11], we propose heuristically to normalize the step size by the summed power of the current
MCIE element in (18) as
Considering the fact that impulses can defeat the average operation as explained in
Section 3, we can notice that the denominator may become large in an incident with impulsive noise; in turn,
becomes a very small value, so that it may induce a very slow convergence. To avoid this kind of situation, we may adopt a sliding window as
However, this approach places a heavier computational complexity on the
MEE algorithm. For reducing the burdensome computations, we need to track the power recursively using a single-pole low-pass filter, i.e.,
where
β controls the bandwidth and time constant of the system whose transfer function
with its input
is given by
Then, the resulting algorithm that we will refer to in this paper as normalized
MEE (
NMEE) becomes
On the other hand, the
NLMS in (19) has been developed based on the principle of minimum disturbance that states the tap weight change of an adaptive filter from one iteration to the next, that is, the squared Euclidean norm (
SEN) of the change in the tap-weight vector,
should be minimal [
9]. From that perspective, the effectiveness of the proposed
NMEE algorithm can be analyzed based on the disturbance,
SEN, at around the optimum state as
For the existing
MEE algorithm of (19),
For the proposed
NMEE algorithm,
Comparison of
in (27) and
in (29) leads to
This result indicates that the proposed method is more suitable for the conventional MEE when the MCIE power is greater than , which means when a smaller is demanded, such as when the input signal is contaminated with strong impulsive noise. On the other hand, it can be noticed that when the input signal is not large so that a bigger can be employed for faster convergence, the proposed method may not be guaranteed to be better than the fixed step size MEE algorithm.
On the other hand, we know there are a lot of step size selection methods for gradient-based algorithms, and we need to verify that this approach is the right one for the MEE problems. Considering that the proposed step size selection method is motivated and designed by the concept of the input power normalization as in the NLMS algorithm, it may be reasonable to investigate whether the input power normalization is effective in the MEE algorithm under impulsive noise.
When we employ the squared norm of the input vector
, that is,
in the
MEE algorithm (we will refer to this as
NMEE2 for convenience), the squared Euclidean norm becomes
Assuming the error entropy
and
MCIE are independent in the steady sate, (33) becomes
The
SEN in (29) adopting the squared norm of the
MCIE instead of
can be rewritten as
Comparing the two
SENs, (34) and (35), the
MCIE in
is normalized by
MCIE power
, whereas the
MCIE in
is normalized by the simply summed input power
. This indicates that
might vary to some degree since the denominator
containing impulsive noise can fluctuate from small values to large values due to strong impulses dominating the sum operation. From this analysis, the fact that the
MCIE in
is normalized by
MCIE power
that uses the output of the magnitude controller cutting the outliers from strong impulses leads us to the argument that our proposed method is appropriate for impulsive noise situations. This will be tested in
Section 5. As observed in (30), when the input signal is not in strong impulsive noise environments, the proposed method may not be better than the existing
MEE algorithm.
The effectiveness of the proposed NMEE algorithm under strong impulsive noise will be investigated in the following section.
5. Results and Discussion
The simulation for observations of the optimum weight behavior of
MEE algorithm is carried out in equalization of the multipath channel of
[
12]. The transmitted symbol
sent at time k is randomly chosen from the symbol set
(
). The impulsive noise
in (1) consists of the background white Gaussian noise (BWGN) and impulses (IM) with variance
and
, respectively. The impulses are generated according to a Poisson process with its incident rate
ε [
10]. The distribution
of the impulses is
The BWGN with = 0.001 is added throughout the whole time to the channel output. The impulses are generated with variance = 50. The TDL equalizer has 11 tap weights . For the parameters for the MEE algorithm, the sample size N, the kernel size σ and convergence parameter are 20, 0.7 and 0.01, respectively. The step size for the LMS algorithm is 0.001. All parameter values are selected when they produce the lowest minimum MSE in this simulation.
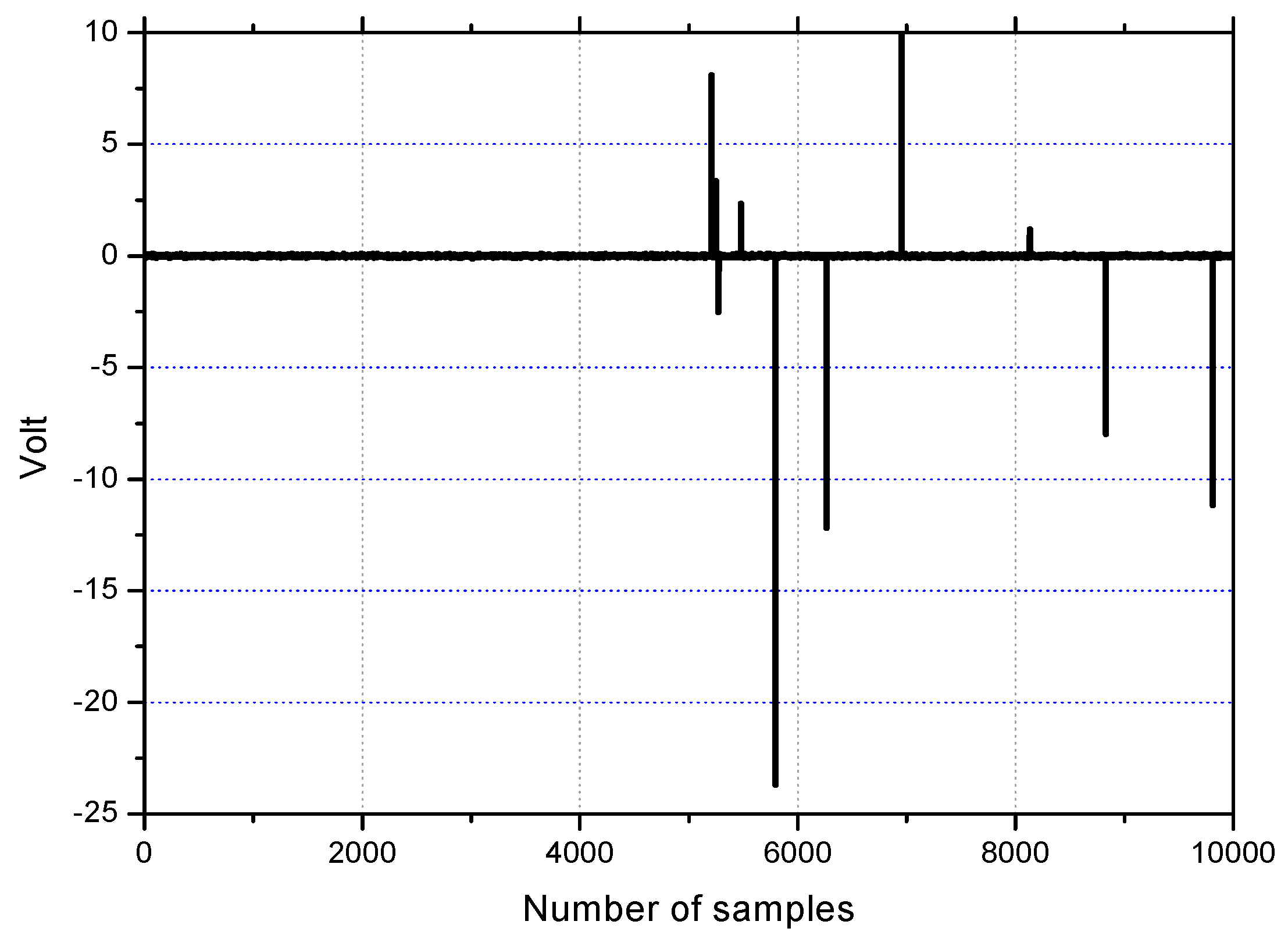
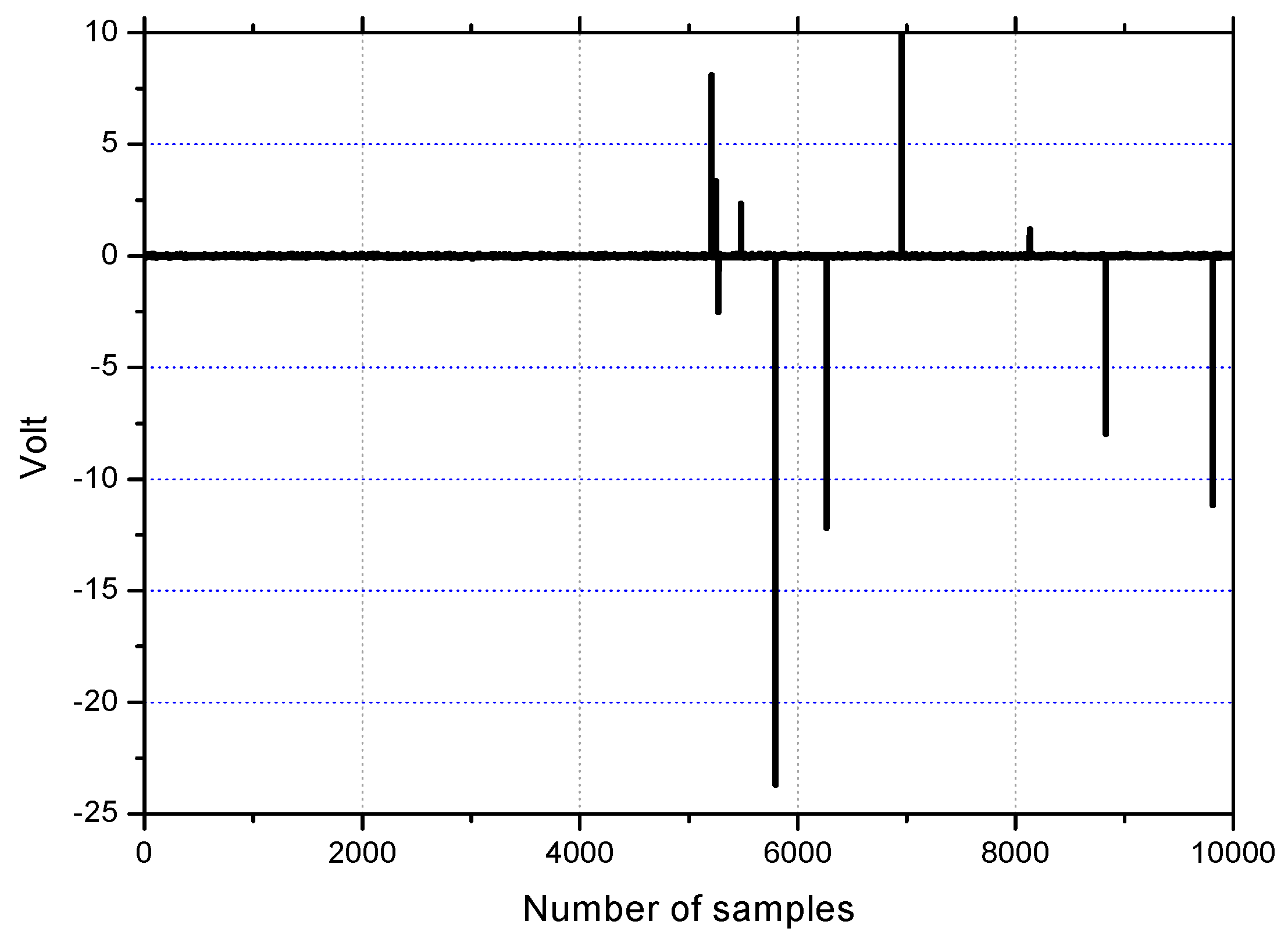
Firstly, the weight traces will be investigated through simulation in order to verify the property of robustness against impulsive noise. The impulses are generated with
ε = 0.01 for clear observation of the weight behavior. The impulse noise as depicted in
Figure 4 is applied to the channel output in the steady state, that is, after convergence.
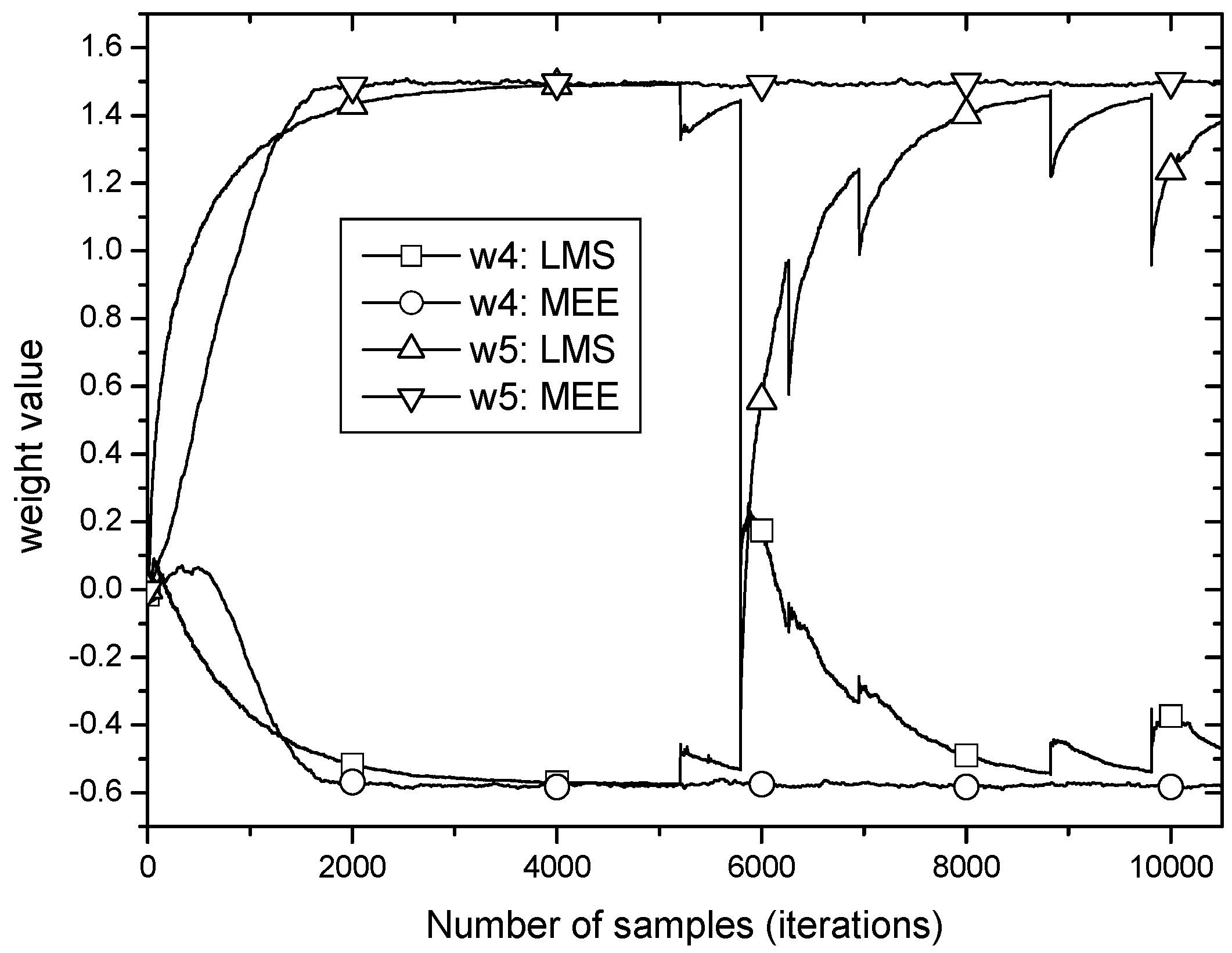
Figure 5 shows the learning curves of weight
and
(only two weights are chosen due to the page limitation). At around 5000 samples, both reach their optima completely, and then they undergo the impulsive noise like that in
Figure 4. In
Figure 5, it is observed that
MEE and
LMS have the same steady state weight values and each weight trace of
MEE in the steady state shows no fluctuations remaining undisturbed under the strong impulses. This is obviously in contrast to the case of the
LMS algorithm where traces of
and
have sharp perturbations at impulse occurrences and remain perturbed for a long time though gradually dying.
We can notice that the optimum weight of MEE has averaging operations and MCIE in (23) has some differences when the weight update Equation (8) is compared. Since the average operations can easily be defeated even by just one strong impulse, we can figure out that the dominant role of robustness against impulsive noise is the MCIE.
Secondly, the effectiveness of the proposed
NMEE algorithm (25) designed with the
MCIE is investigated through the learning performance comparison with the original
MEE algorithm in (19) under the same impulsive noise with
= 50 and
ε = 0.03 as in the work [
5] in which the impulsive noise is used in all time. The
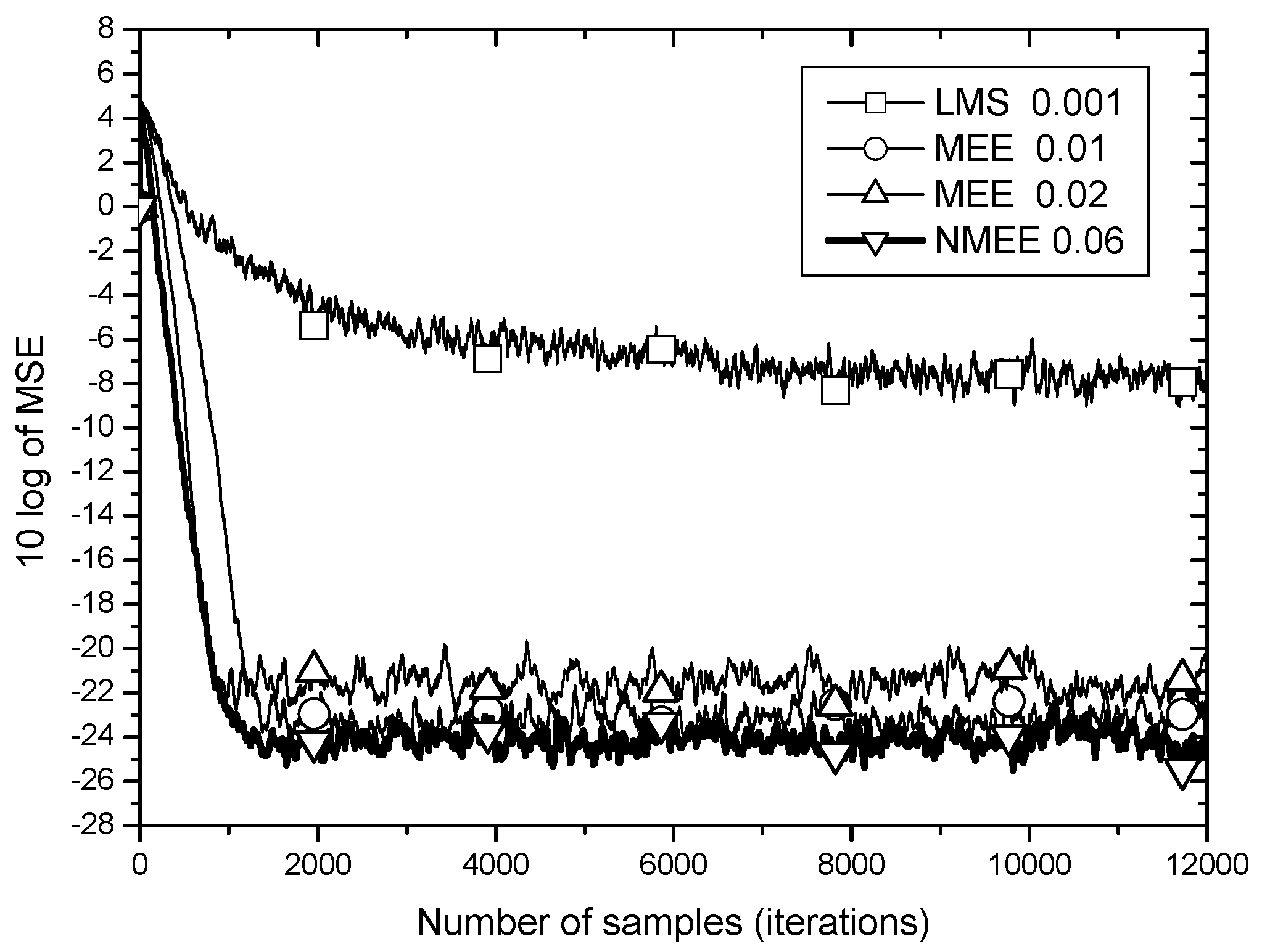
MSE learning results are shown in
Figure 6.
The
LMS algorithm converges very slow and stays at about −8 dB of
MSE in the steady state. This result can be explained from the expression of
in (8) having no measures to protect it from fluctuations from impulsive noise as discussed in
Section 3. On the other hand, the
MEE algorithm rigged with the magnitude controller for
IE converges in about 1000 samples even under the strong impulsive noise. This result supports the analysis that the
MCIE keeps the algorithm (19) and its steady state weight undisturbed by large error values that may be induced from excessive noise such as impulses.
As for the performance comparison between
MEE and
NMEE in
Figure 6,
NMEE shows lower minimum
MSE and faster convergence speed simultaneously. The difference of convergence speed is about 500 samples and that of minimum
MSE is around 1 dB. When compared to the condition of the same convergence speed, the difference in minimum
MSE is shown to be about 3 dB. This amount of performance gap indicates that the proposed method of tracking the power of
MCIE recursively and using it in normalization of the step size is significantly effective in the aspect of performance as well as computational complexity.
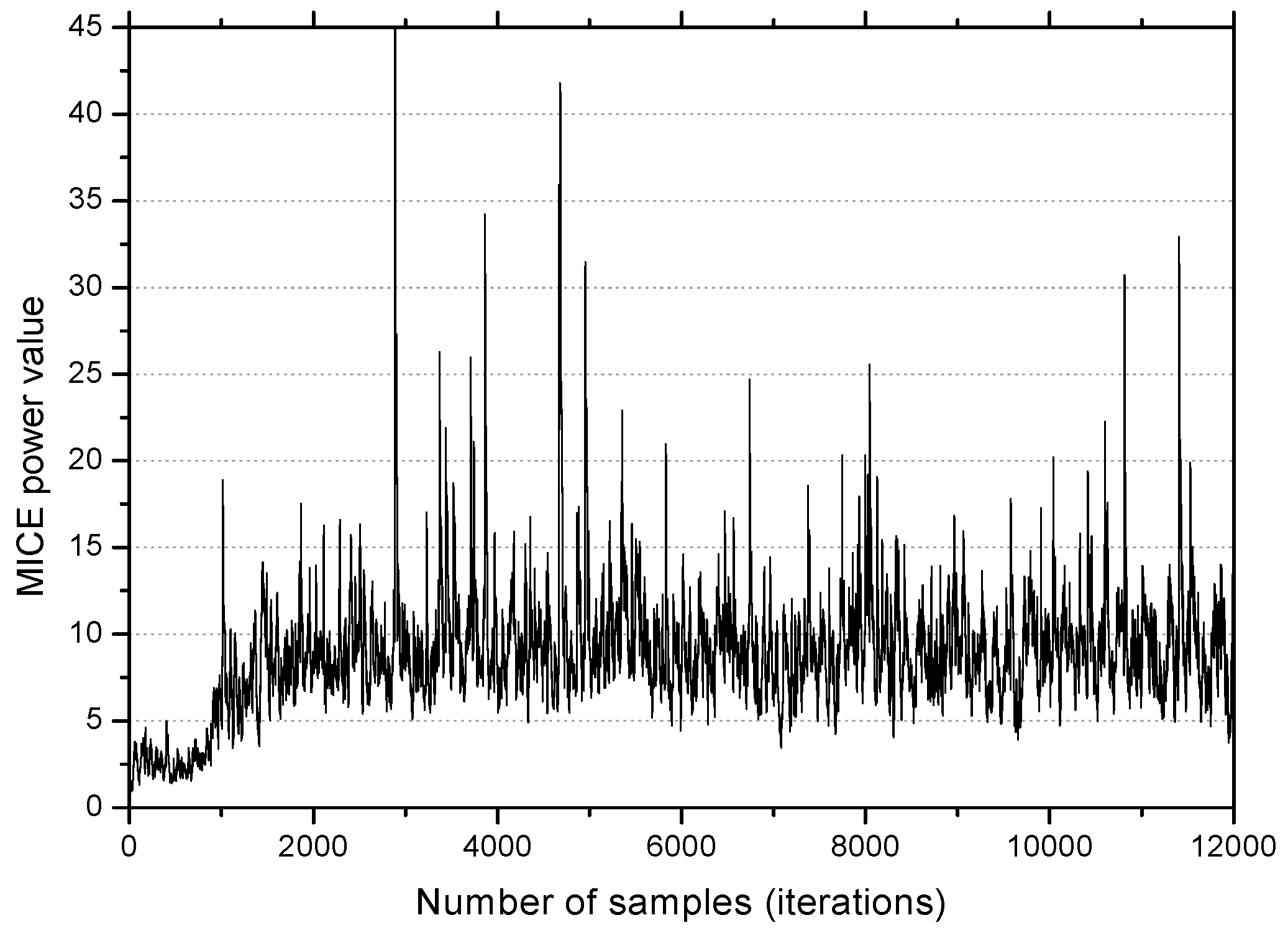
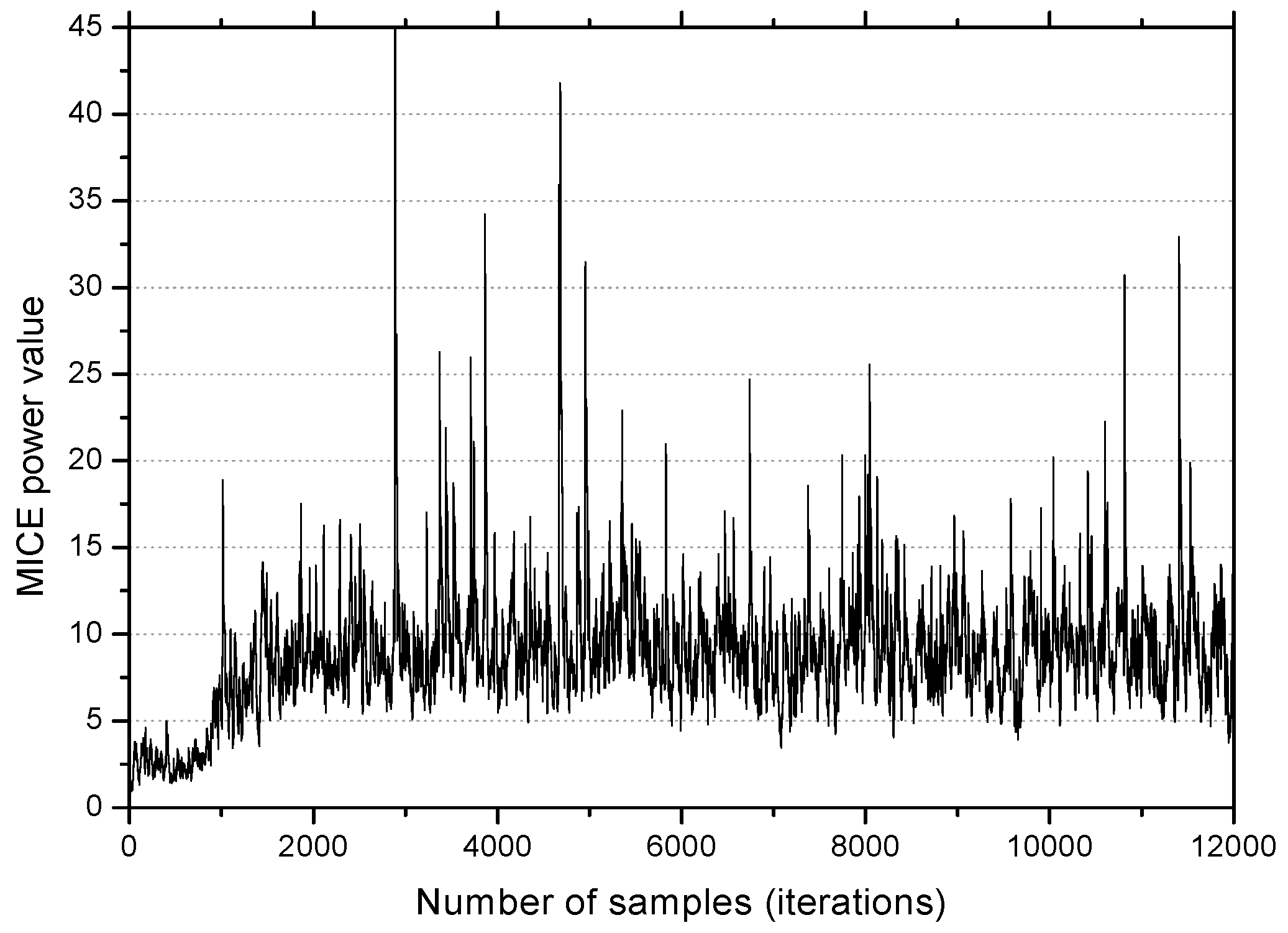
In
Figure 7, the
MCIE power becomes large as the
MEE algorithm converges, and after convergence, the trace shows large variations, mostly above 6. The condition
in this simulation implies that when
NMEE is employed, the value
μ according to (32) must be greater than
for better performance. The fact that this is exactly in accordance with the choice
described in
Figure 6 justifies the effectiveness of the proposed method by simulation.
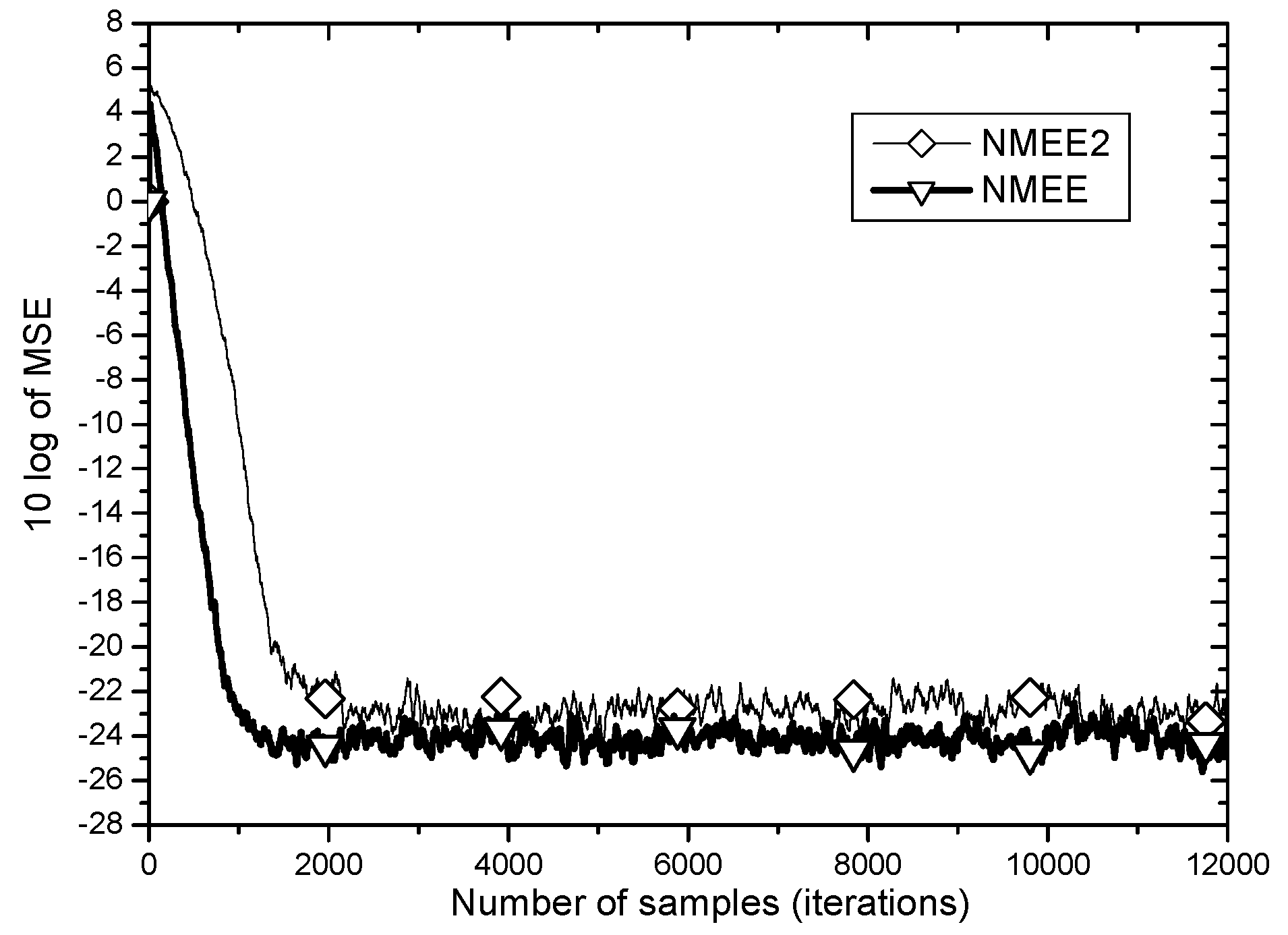
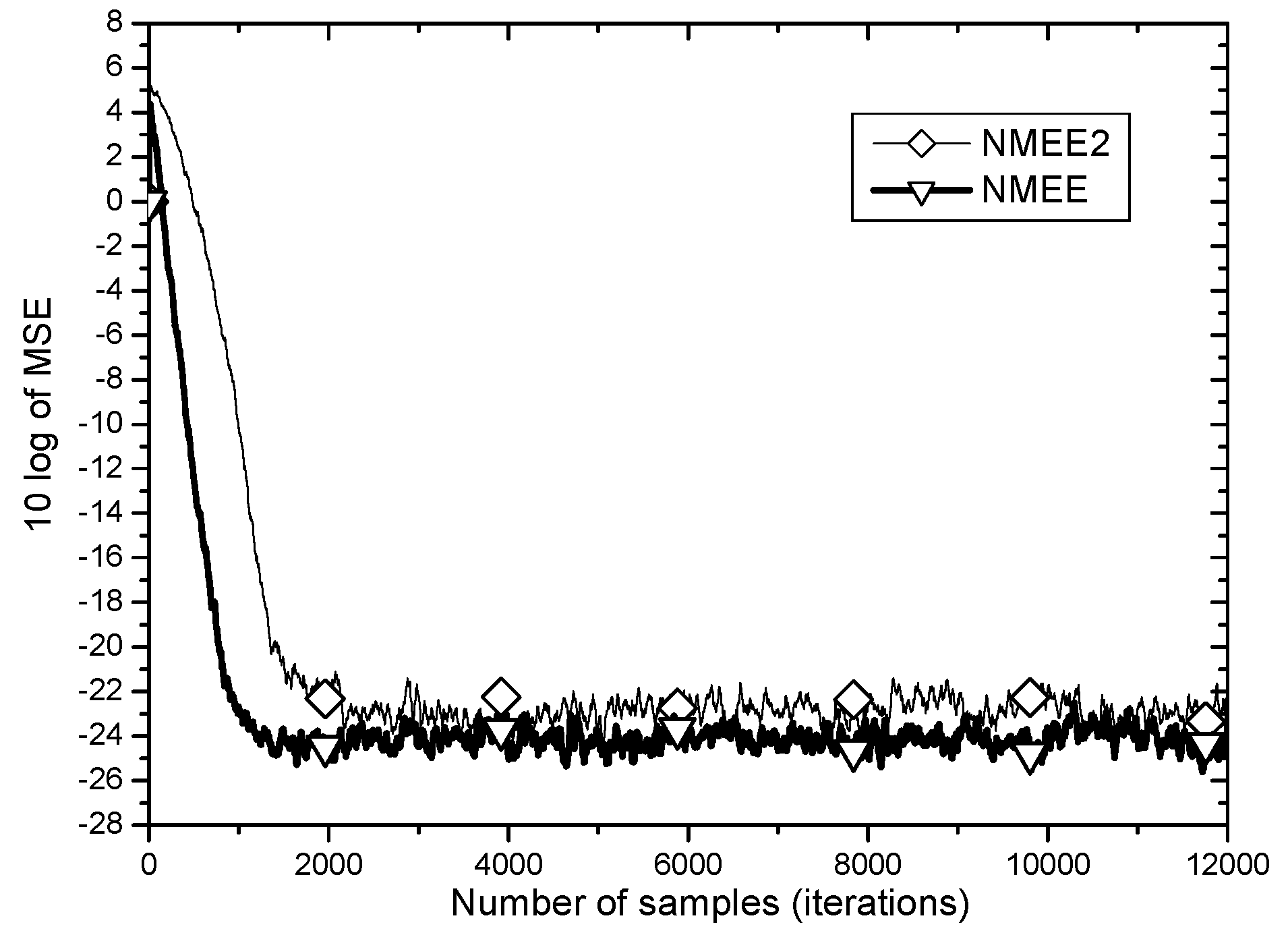
In the same simulation environment, the
MSE learning curves for two input power normalization approaches,
NMEE and
NMEE2 are compared in
Figure 8.
As observed in
Figure 8, the input power normalization approach for variable step size selection for the
MEE algorithm shows different
MSE performances according to which signal power is normalized. When
NMEE is employed where the magnitude controls input entropy,
MCIE is used for power normalization, the
MSE learning performance yields better steady state
MSE of above 2 dB and faster convergence speed by about 1000 samples than when
NMEE2 is adopted, in which the squared norm of the unprocessed input
is used for normalization. As discussed in
Section 4, under strong impulsive noise, the power of
MCIE can be the right choice for step size normalization for better performance.
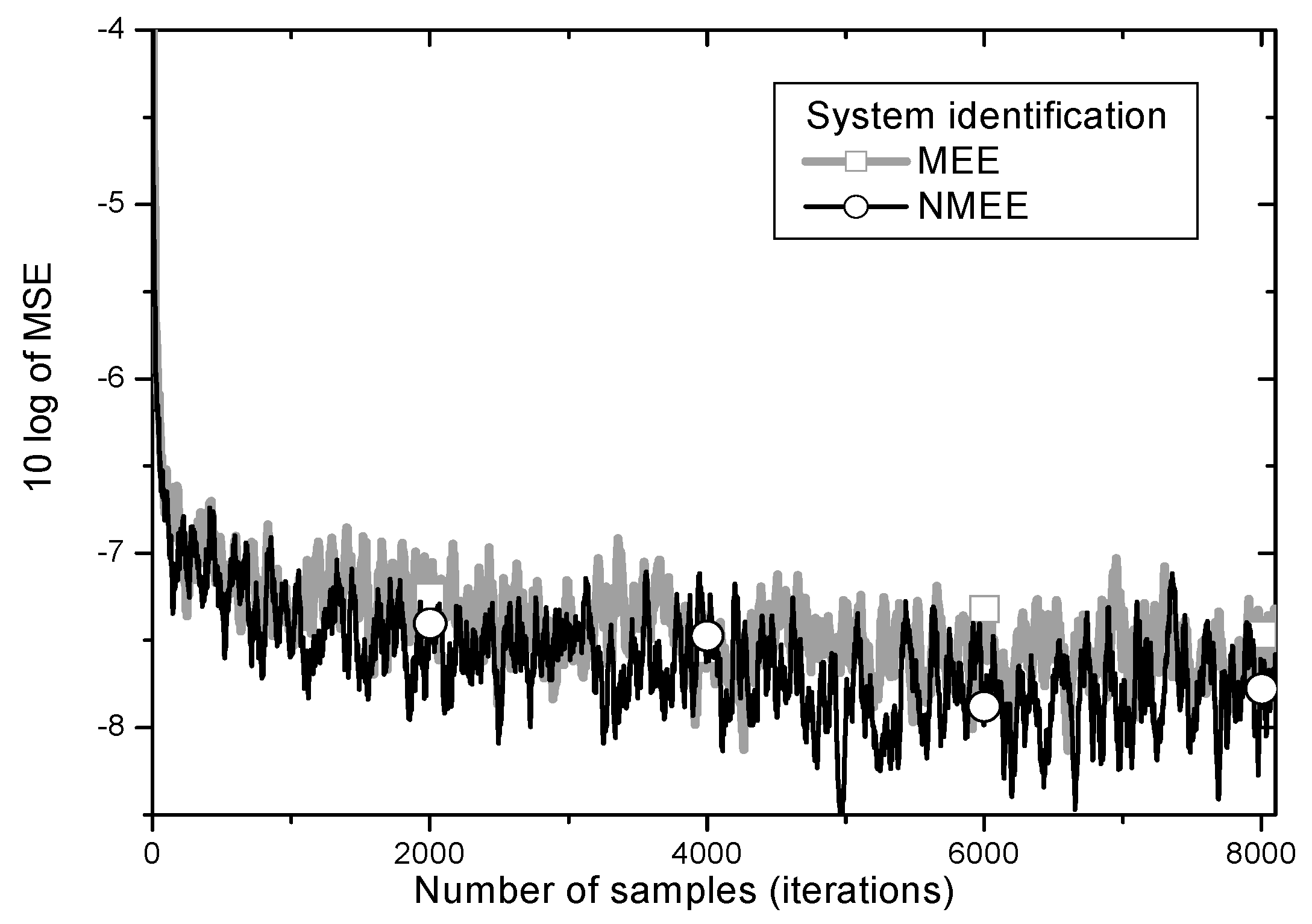
In system identification applications of adaptive filtering as appeared in the work [
8], the desired signal is derived by passing the white Gaussian input through the unknown system. The unknown system in this simulation is of length 9. The impulse response of the unknown system is chosen to follow a triangular wave form that is symmetric with respect to the central tap point [
9,
13]. The TDL filter has 9 tap weights. The input signal is a white Gaussian process with zero mean and unit variance. The same impulsive noise used in
Figure 6, uncorrelated with the input, is added to the output of the unknown system.
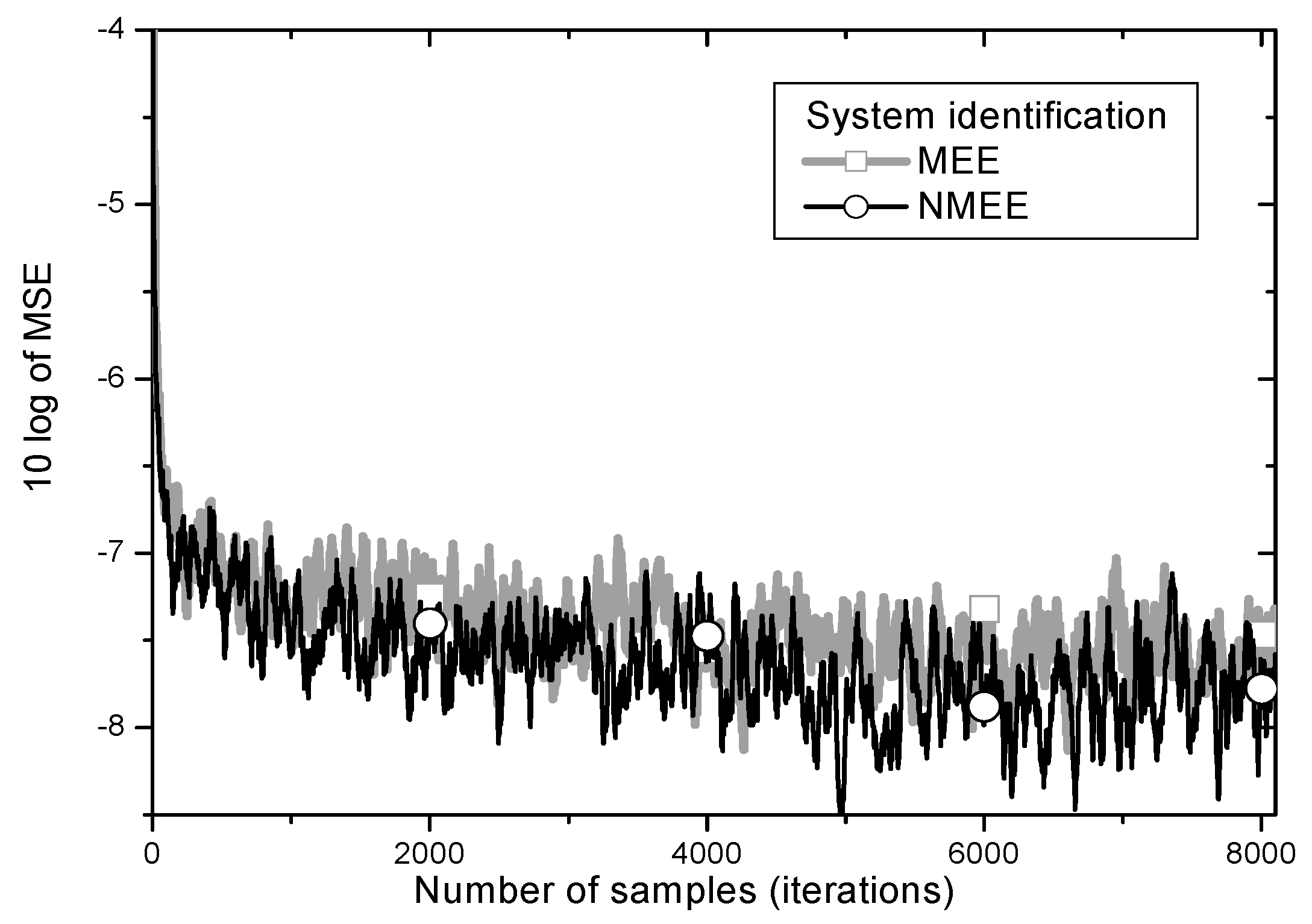
MSE learning curves are depicted in
Figure 9.
One can observe from
Figure 8 that the proposed
NMEE achieves lower steady-state
MSE than the conventional
MEE algorithm in the system identification problems as well.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}