Abstract
This paper considers a special class of wiretap networks with a single source node and K sink nodes. The source message is encoded into a binary digital sequence of length N, divided into K subsequences, and sent to the K sink nodes respectively through noiseless channels. The legitimate receivers are able to obtain subsequences from arbitrary sink nodes. Meanwhile, there exist eavesdroppers who are able to observe subsequences from arbitrary sink nodes, where . The goal is to let the receivers be able to recover the source message with a vanishing decoding error probability, and keep the eavesdroppers ignorant about the source message. It is clear that the communication model is an extension of wiretap channel II. Secrecy capacity with respect to the strong secrecy criterion is established. In the proof of the direct part, a codebook is generated by a randomized scheme and partitioned by Csiszár’s almost independent coloring scheme. Unlike the linear network coding schemes, our coding scheme is working on the binary field and hence independent of the scale of the network.
1. Introduction
Network coding is a novel technique that allows the intermediate node to make a combination of its received messages before sending out to the network, instead of the store-forward method [1], and it has been shown to offer large advantages in throughput, power consumption, and security in wireline and wireless networks. Field size and adaption to varying topologies are two of the key issues in network coding, since field size affects the complexity of encoding and decoding processes, and the code construction is related to the knowledge of network topology. Li et al. [2] proved that linear network coding was able to achieve the multicast capacity as the field size was sufficiently large. Later, random linear network coding (RLNC) [3] was proposed for the unknown or changing topology to achieve the multicast capacity asymptotically in field size and network size, in which nodes independently and randomly select coding kernels. Since then, network coding has attracted a substantial amount of research attention.
In practical communication networks, transmission is often under wiretapping attacks. A general communication model of wiretap network is specified by a quintuple , where
- is a directed graph of the network topology, where and are sets of nodes and edges, respectively;
- α is the unique source node in the graph;
- is the set of user nodes. Each user node is fully accessed by a legal user who is required to recover the source message without error or with a vanishing decoding error probability;
- is a collection of subsets of . Each member in may be fully accessed by an eavesdropper;
- specifies the capacities of edges in .
Feldman et al [6] proved that the problem of making a linear network code secure was equivalent to the problem of finding a linear code with certain generalized distance properties, and they also showed that the required field size for secure network coding could be much smaller if they gave up a small amount of overall capacity. Namely, sending random symbols and message symbols, then a random linear transformation would be secure with high probability as long as , which allowed a trade-off between capacity and field size.
Furthermore, a new level of information theoretic security was defined as weakly secure network coding [7], in which adversaries were unable to obtain any “meaningful” information about the source messages. The weak security requirements could also be satisfied when the number of independent messages available to the adversary was less than the multicast capacity. Ho et al. [8] considered the related problem of network coding in the presence of a Byzantine attacker that could modify data sent from a node the the network.
The idea of wiretap network came from a wiretap channel of type II, which was firstly studied by Ozarow and Wyner [9]. The transmitter sent a message to the legitimate receiver via a binary noiseless channel. An eavesdropper could observe a subset of received data from the receiver with a certain size. It was assumed that the eavesdropper could always choose the best observing subset of received digital bits to minimize the equivocation over sent data. Wiretap channel II can be regarded as a special case of wiretap network with , , and , and (see Figure 1).
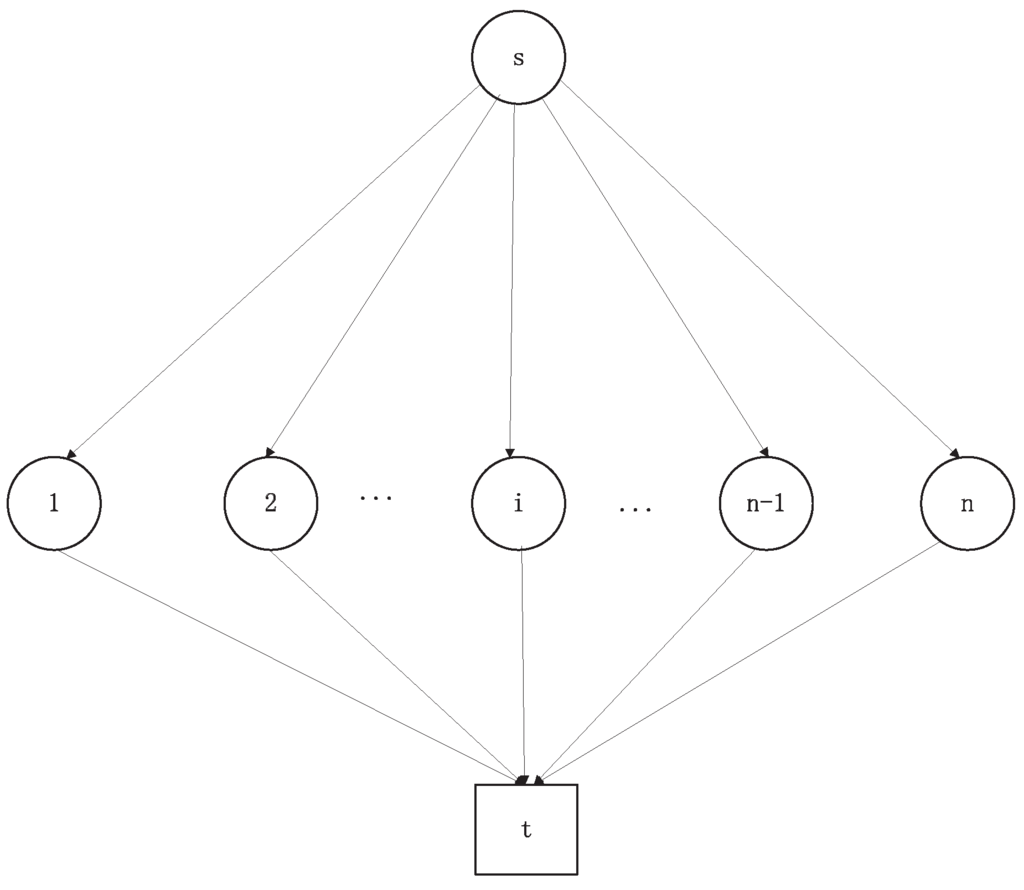
Figure 1.
Treating wiretap channel II as a special case of wiretap network.
Note that since both the coding schemes developed in [5] and [6] rely on a Galois field with sufficiently large size, neither of them work on the classic wiretap channel of type II, where the symbol of each transmission is binary.
In this paper, we study a special class of wiretap network with a single source node and K sink nodes (considered as distributed servers or disk blocks), which is depicted in Figure 2. In this network model, the legitimate users are able to connect to any sink nodes. On the other hand, there exist eavesdroppers who are able observe digital sequences from arbitrary sink nodes. We propose a randomized secure network coding scheme, ensuring that every legitimate user is able to recover the source message with an arbitrarily small average decoding error probability while every eavesdropper has vanishing information about the source message. The coding scheme in this paper works over the binary field (alphabet), which indicates the complexity of the scheme does not increase accordingly with the scale of the network. Moreover, the coding scheme in this paper can work on the classic wiretap channel II readily, indicating that communication model in this paper includes wiretap channel II as a special case. Differences among the coding schemes in [5,6] and this paper are summarized in Table 1.
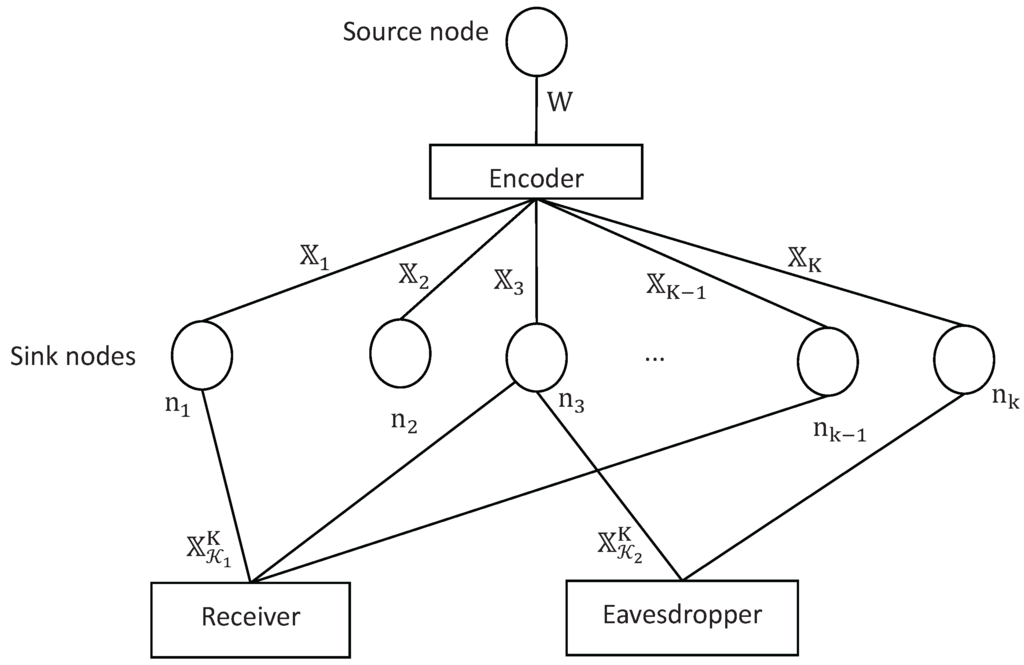
Figure 2.
Communication model of wiretap network in this paper with K sink nodes.

Table 1.
Comparison of different coding schemes. represents the averaged decoding error probability (cf. Equation (2)). Δ represents the quantity of information about source message exposed to the eavesdroppers (cf. Equation (3)). is the secrecy capacity (cf. Definition 5) and ϵ and τ are arbitrarily positive real values.
The coding scheme in this paper comes from that of arbitrarily varying channels (AVCs). In fact, the network defined in this paper can be readily regarded as a special class arbitrarily varying wiretap channels (AVWCs) with constrained state sequences. The difference is that the receivers know the channel state sequences in our case, and hence just one single codebook is enough to assure the reliable transmission (see Remark 8 for details). The partitioning scheme is based on Csiszár’s almost independent coloring scheme [10], which has been recently used to solve the security problem of wiretap channel II with the noisy main channel [11]. Some results on the secrecy capacity of AVWCs can be found in [12,13,14].
Designing a coding scheme with a small field size is critical in some practical engineering problems. As an example, consider the situation where the transmitter needs to send a big file to the receiver through the Internet. To achieve this, the big file is divided into many data frames. Since the size of each data frame is less than 1500 bytes according to the TCP (Transmission Control Protocol) or UDP (User Datagram Protocol) protocols, the number of data frames will be quite large when the size of the file is huge. Packet loss is quite a common problem in network communication. When some data frames get lost, a common method is to require the transmitter to send the lost data frames again. Now, supposing that we plan to deal with the problem of frame loss via the coding scheme, each sink node in Figure 2 can be regarded as a data frame divided from the big file with being the total number of the data frames. Since the size of each data frame is constrained, it cannot represent arbitrarily a large Galois field. Consequently, the number of K cannot be arbitrarily large when the coding schemes in [5,6] are applied, indicating that the size of the big file is constrained. However, if our coding scheme is used, the size of the big file can be arbitrary.
Another application of this model is for splitting and sharing secrete information among authorized persons. In this scenario, a group of n persons is allowed to reconstruct the secrete information correctly, while any groups with less participants can not read the split message. Please refer to [15] and references therein.
The remainder of this paper is organized as follows: the notations and problem statements are introduced in Section 2 and the main result is presented in Section 3. Furthermore, the direct and converse proofs are given in Section 4 and Section 5, respectively. Section 6 explains the coding scheme in Section 4 via two simple examples. Section 7 gives the discussions on the field size, and Section 8 concludes this paper.
2. Notations and Problem Statements
Throughout the paper, is the set of positive integers and for any .
Random variables, sample values and alphabets (sets) are denoted by capital letters, lower case letters and calligraphic letters, respectively. A similar convention is applied to random vectors and their sample values. For example, represents a random N-vector (), and is a specific vector of in . is the Nth Cartesian power of .
Let “?” be a “dummy” letter. For any index set and finite alphabet not containing the “dummy” letter “?”, denote
For any given random vector and index set ,
- is a “projection” of onto with for , and otherwise;
- is a subvector of .
Example 1.
Supposing that , the index set and the random vector , we have and .
Proposition 1.
For any N-random vector and index set , it holds that
Proof.
Let g be a mapping from to such that
for every . One can easily verify that g is an one-to-one mapping. Furthermore,
for every , implying that and share the same distribution. This completes the proof of the proposition. ☐
The communication model of wiretap network with K sink nodes, depicted in Figure 2, consists of four parts, namely encoder, network, receiver and eavesdropper. The formal definitions of those parts are introduced in Definitions 1–4, respectively. The definition of achievable transmission rate is given in Definition 5.
Definition 1.
(Encoder) The source message W is uniformly distributed on the message set . The (stochastic) encoder is specified by a matrix of conditional probability for and , indicating the probability that the message w is encoded into the digital sequence , where is binary.
Definition 2.
(Network) Suppose that the source message W is encoded into . The encoder firstly divides into K parts, denoted by with
for all , where is an integer without loss of generality. Then, those sequences are transmitted to the sink nodes , respectively, through K noiseless channels. Therefore, the digital sequence received by the sink node is for every . Let
The sequence can then be rewritten as .
Definition 3.
(Receiver) Let be a constant real number with being an integer. The receiver is able to access digital sequences from arbitrary sink nodes. Let
be the collection of subsets of sink nodes possibly selected by the receiver. The whole digital sequence obtained by the receiver may be any random sequence from where with . It is clear that is distributed on . Denoting by
the decoder is a mapping . If it is known that the receiver has access to the sink nodes, whose indices lie in , the estimation of the source message is then denoted by , and the average decoding error probability is . However, since the sink nodes accessed by the receiver are actually unknown, the average decoding error is defined as
Remark 1.
Denoting , it follows that for every . Consequently, setting
yields for every .
Remark 2.
The communication model can also be regarded as a wiretap network with legitimate receivers, each of whom has access to a certain set of sink nodes in . Equation (2) represents the maximal value of the average decoding error probabilities of all those legitimate receivers.
Definition 4.
(Eavesdropper) Let be a constant real number with being an integer. The eavesdropper is able to access digital sequences of arbitrary sink nodes. Let
be the collection of subsets of sink nodes possibly selected by the eavesdropper. The whole digital sequence obtained by the eavesdropper may be any random sequence from where with . The quantity of source information exposed to the eavesdropper is then denoted by
Remark 3.
Similar to Remark 1, denoting and
it follows that for every .
Remark 4.
The communication model can also be regarded as a wiretap network with eavesdroppers, each of whom has access to a certain set of sink nodes in . Equation (3) represents the maximal quantity of exposed source information to those eavesdroppers.
Example 2.
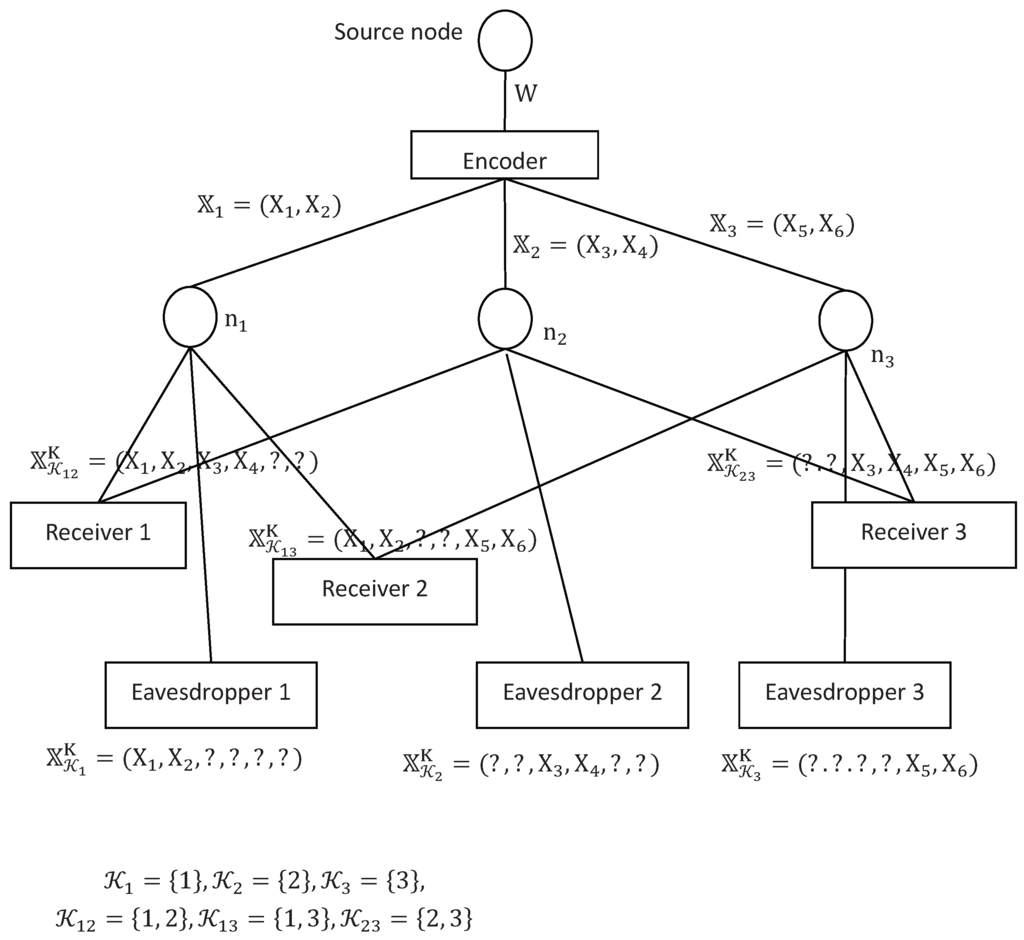
To have a clearer idea on the notations defined in this section, a special example of wiretap network is given in Figure 3 with
This can be treated as a network with three receivers and three eavesdroppers. In this case, we have
with
and
Figure 3.
An example of wiretap network II with three sink nodes.
Definition 5.
(Achievablility) A non-negative real number R is said to be achievable, if for any there exists an integer such that for any , one can construct a pair of encoder and decoder of length N satisfying
and
The capacity of the communication model described in Figure 2 is denoted by .
Remark 5.
When regarding the communication model depicted in Figure 2 as a wiretap network with multiple legitimate receivers and multiple eavesdroppers, Equations (5) and (6) require that every legitimate receiver is able to decode the source message with a vanishing average decoding error probability, and the quantity of information about the source message exposed to every eavesdropper is vanishing.
3. The Main Result
Theorem 1.
The capacity of the communication model of wiretap network described in Figure 2 is .
The problem of wiretap network was firstly studied by Cai and Yeung in [5]. They constructed a linear network coding scheme over the wiretap network such that the legitimate receivers were able to decode the source message with exactly no decoding error while the eavesdroppers had absolutely no information on the source message. However, the coding scheme should work on a Galois field whose size was related to the scale of the network. When the number of nodes in the network increased, the size of the Galois field should have been larger accordingly, which made the encoding process much more complicated. On the other hand, the coding scheme introduced in this paper is unrelated to the scale of the network. Therefore, it turns out to be simpler than the coding scheme in [5] when the scale of the network is quite huge.
Moreover, the coding scheme in this paper is designed with a binary alphabet. Therefore, this scheme can be readily applied to the classic wiretap channel II, indicating that the communication model in this paper includes wiretap channel II as a special case. See Section 7 for details.
4. Direct Half of Theorem 1
This section gives the proof of the direct half of Theorem 1, i.e., it is achievable for every . More precisely, we need to prove that for any and any sufficiently large N, there exists a pair of encoder and decoder satisfying
and
On account of Remarks 1 and 3, it follows that
and
Therefore, instead of constructing encoder and decoder pair satisfying Equations (7)–(9), this section would prove the existence of the encoder and decoder pair satisfying Equation (7),
and
The main idea of the proof goes as follows. Let the codebook C be randomly generated, such that the size of the codebook is about . Then, partition the codebook C into about subcodes, each of which is related to a unique source message. Since the receiver is able to obtain a -subsequence of the transmitted codeword, which is probably distinct from those corresponding subsequences of other codewords, the receiver is able to decode the source message with a vanishing average decoding error probability. On the other hand, receiving a -subsequence of the transmitted codeword, the eavesdropper concludes that the transmitted codeword comes from a collection of about codewords. If those codewords are uniformly distributed on every subcode, the eavesdropper is unable to have any information on the source message.
The proof is organized as follows. Section 4.1 firstly gives the coding scheme achieving the capacity. Then, Section 4.2 establishes that, using the scheme of generating codebook randomly, we can obtain the codebook satisfying Equation (10) with probability when . Finally, Section 4.3 shows that when N is sufficiently large, there exists a desired “good” partition on every random generated sample codebook such that Equation (14) holds. Equation (11) is an immediate consequence of (14) and Remark 6. Equation (7) is obtained directly from (13). Therefore, the direct half of Theorem 1 is totally established.
4.1. Code Construction
Codebook generation. Let be the ordered set of i.i.d. random vectors with mass function for all and , where
Codebook partition. Suppose that is a specific sample value of randomly generated codewords. Let be a random variable uniformly distributed on and be the random sequence uniformly distributed on . Set and partition into
subsets with equal cardinality, i.e., . Let be the index of subcode containing , i.e., . We need to find a partition of the codebook satisfying
The partition satisfying Inequality (14) is called a “good” partition. It will be proved in Section 4.3 that there exists desired “good” partition on every given sample codebook when the block length N is sufficiently large.
Encoder. Suppose that a desired partition on a specific codebook is given. When the source message W is to be transmitted, the encoder uniformly randomly chooses a codeword from the subcode and emits it to the network.
Remark 6.
For a given codebook and a desired partition applied on it, denote by the output of the encoder, when the source message W is transmitted. It is clear that and share the same joint distribution.
Decoder. Suppose that a desired partition on a deterministic codebook is given. Receiving digital sequence from the sink nodes, the decoder tries to find the minimal number of such that , and decodes as the estimation of the transmitted source message, where is the index of subcode containing , i.e., , and
4.2. Proof of Inequality (10)
This subsection establishes that using the coding scheme introduced in Section 4.1, one can generate a codebook satisfying Equation (10) with probability when the block length .
Let be a fixed codebook applied by the encoder. For any and , denote
and
Then, it follows from the decoding scheme introduced in Section 4.1 that
Therefore, Equation (5) is finally established by the following lemma, whose proof is given in Appendix A.
Lemma 1.
Let be the codebook randomly generated via the scheme introduced in Section 4.1. It holds that
where
Remark 7.
Remark 8.
The idea of generating codebook randomly comes from the random code for AVCs, which was firstly established by Blackwell et al. [16] and further developed by Ahlswede and Wolfowitz [17] (see also Lemma 12.10 in [18]). The coding scheme for AVCs is based on the following results. Let be a random codebook with being smaller than the capacity. If the decoding scheme of maximal mutual information (MMI) is applied by the decoder, it follows that the expected average decoding error probability under each state sequence is , when N is sufficiently large. To make the random coding scheme work, for each transmission, we need a separate channel sharing the exact sample value of the random codebook, which is called the common randomness (CR). However, that would occupy a large amount of bandwidth. To solve this problem, Ahlswede developed an elimination technique [19] and claimed that it sufficed to let the random codebook C be uniformly selected from a collection of deterministic codebooks. Moreover, if the capacity of an AVC was positive, the encoder could send the index of selected codebook before each transmission, and no extra CR was needed.
In fact, the network model in this paper can be regarded as a special case of AVCs with state sequences known at the receiver, if we ignore the participation of eavesdroppers. The capacity of the current network model is obviously positive since each receiver has access to at least one noiseless channel. Therefore, the coding scheme for AVCs works on the current network with no need of extra CR. Nevertheless, we should point out that the communication model of AVCs with state sequences known at the receiver is essentially different from the classic AVCs. In the former model, the decoder knows exactly the probability distribution of the channel input, and this would reduce the degree of difficulty on the coding scheme. In particular, it is proved in Appendix A that a single deterministic codebook is sufficient for the current network model.
4.3. Proof of the Existence of “Good” Partition for Every Given Sample Codebook
This subsection proves the existence of “good” partition satisfying Equation (14) for every codebook generated via the scheme in Section 4.1, when N is sufficiently large. The result in this subsection can establish Equation (9) immediately on account of Remark 6. Notations in Section 4.1 will continue to be used in this Subsection.
The main result of this subsection is given in the following lemma.
Lemma 2.
For any generated sample codebook of length N satisfying
there exists a partition on it such that
for all .
Remark 9.
Proof of Lemma 2..
The main idea of the proof is firstly pointed out here. For any , to satisfy , we need . On account of the following obvious equality
it suffices to construct a partition satisfying for almost all the . In the following proof, we will construct a collection of subsets of , namely Equation (21), and prove that there exists a partition on such that for all . Then is proved on account of Equation (23).
The proof, based on Csiszár’s almost independent coloring scheme, is divided into the following three steps. Step 1 constructs a mapping satisfying Equations (27) and (28) with the help of Lemma 2. Step 2 establishes Equation (29) from (28). Step 3 constructs a “good” partition satisfying Equation (14) from the mapping f with the help of Lemma 4.
Proof of Step 1.
The following lemma plays an important role in the proof of step 1.
Lemma 3.
(Lemma 3.1 in [20]) Let be a set of distributions on . If there exist
and , such that
holds for all , then for any positive integer,
there exists a function , such that
holds for all .
To apply Lemma 3, the main task is to construct the parameter . In our proof, each element P in is a conditional probability distribution of for a given for and . The set is defined as
where
The useful properties of are given in the following proposition.
Proposition 2.
For any , and , it follows that
and
The proof of Proposition 2 will be given later in this subsection. With the help of , the parameters introduced in Lemma 3 are introduced as
where
and
The verification that parameters given in Formula (24) satisfy the requirements of Equations (18)–(20) is given in Appendix B.
Remark 10.
Since for every , where , it follows that
Remark 11.
The proof of Step 1 is completed.
Proof of Step 2.
Proof of Step 3.
The proof depends on the following lemma.
Lemma 4.
For any given codebook , if the function satisfies Equation (27), there exists a partition on such that
- 1.
- for all ,
- 2.
- ,
The proof of Lemma 4 is discussed in Appendix C. In fact, Equation (27) indicates that the random variable is almost uniformly distributed on . This implies the cardinalities of the sets are quite close. Therefore, a desired partition with the same cardinality can be constructed through slight adjustments.
From Lemma 4 and Equation (29),
for all , where M and ε are given by Equations (13) and (24), respectively. This completes the proof of Step 3.
The proof of Lemma 2 is completed. ☐
Proof of Proposition 2.
5. Converse Half of Theorem 1
This section proves that every achievable rate R should be no greater than , which is the converse half of Theorem 1. The proof is based on the standard technique.
Let be a pair of encoder-decoder satisfying
and
Deduced from Equation (31), it follows that
where as and the last inequality follows from Fano’s inequality. Combing Equation (35) and the equation above, we have
Since, clearly, is a function of , we have
Recalling Proposition 1, the equation above is further bounded by
where (a) follows from the chain rule; (b) follows because is binary and (c) follows because
Substituting Equation (37) into (36), we arrive at
The desired inequality is finally proved by letting ϵ and hence .
6. Examples
This section gives two simple examples, showing how the coding scheme introduced in Section 4.1 works.
Example 3.
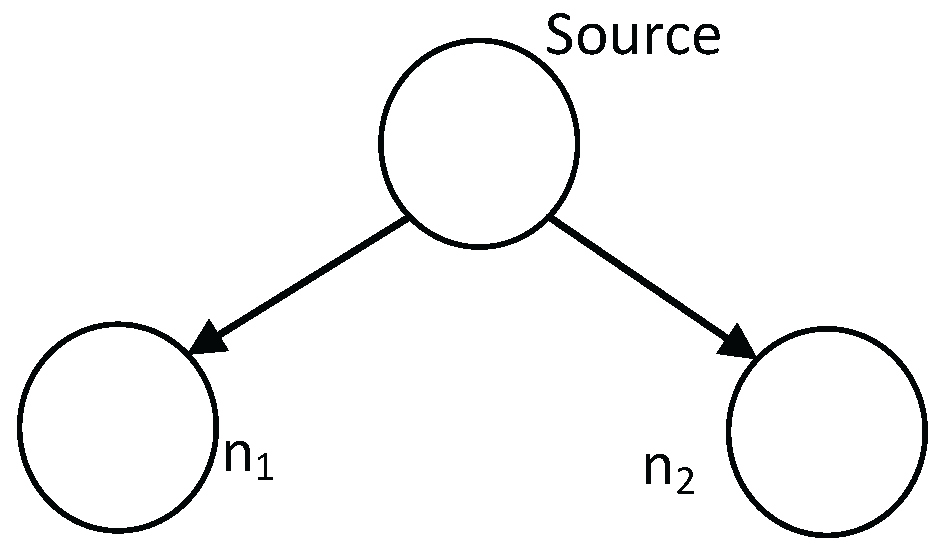
Let , and . We obtain a network with two sink nodes depicted in Figure 4. In this network, the legitimate receivers are able to access both of the sink nodes, while the eavesdroppers are able to access only one sink node. It is easy to construct a code satisfying , and . The coding scheme goes as the following.
- Codebook generation and partition. Let the codebook be partitioned as and .
- Encoder. The source message W is uniformly distributed on the message set in this example. To transmit W, a random key K, which is uniformly distributed on and independent of W, is firstly generated. Then, the encoder emits a codeword into the network. Figure 5 shows the digital bits emitted into the sink nodes with respect to different values of W and K.
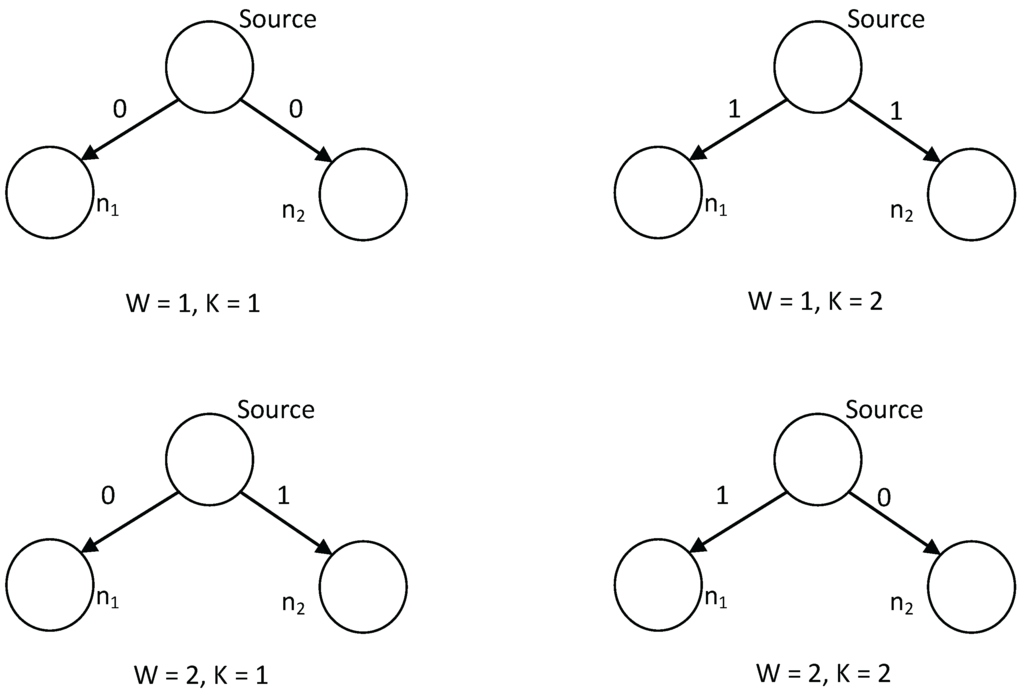 Figure 5. Coding scheme for wiretap network with two sink nodes.
Figure 5. Coding scheme for wiretap network with two sink nodes.
Figure 4.
Wiretap network with two sink nodes.
Example 4.
Let , and . We obtain a network with three sink nodes, which is similar to that depicted in Example 2 (see also Figure 3). The only difference is that the block length in this example. Therefore, we have
Suppose that the digital sequence emitted to the network is . The digital sequences received by Receiver 1, Receiver 2 and Receiver 3 are denoted by , and , respectively. The digital sequences received by Eavesdropper 1, Eavesdropper 2 and Eavesdropper 3 are denoted by , and , respectively.
It can be verified by enumerating all the possible coding schems that constructing a code satisfying , and is impossible for this example. A coding scheme, achieving that
is given as the following. The codebook is defined and partitioned as and . The encoding scheme is similar to that introduced in Example 3, and hence omitted. The decoding scheme and the calculation of and Δ are detailed below.
Decoding scheme and calculation of .
This part calculates the average decoding error probability of all the three receivers.
- Receiver 1. The received digital sequences of Receiver 1 with different values of W and K are given in the following table.
The best decoding scheme is to decode sequence ’’ as , and decode the other sequences as . The decoding error probability of Receiver 1 is .W and K Received Sequence W = 1, K = 1 00? W = 1, K = 2 00? W = 2, K = 1 01? W = 2, K = 2 10? - Receiver 2. The received digital sequences of Receiver 2 with different values of W and K are given in the following table.
One of the best decoding schemes is to decode sequence ’’ as , and decode the other sequences as . In this case, a decoding error would occur when and . Therefore, the average decoding error probability of Receiver 2 is .W and K Received Sequence W = 1, K = 1 0?0 W = 1, K = 2 0?1 W = 2, K = 1 0?0 W = 2, K = 2 1?0 - Receiver 3. Similar to Receiver 2, the average decoding error probability of Receiver 3 is .
Calculation of Δ.
This part calculates the amount of the source information exposed to the eavesdroppers. We only take Eavesdropper 1 as an example for the sake of simplicity. The received digital sequences with respect to different values of W and K are given in the following table.
| W and K | Received Sequence |
| W = 1, K = 1 | 0?? |
| W = 1, K = 2 | 0?? |
| W = 2, K = 1 | 0?? |
| W = 2, K = 2 | 1?? |
According to the table above, it follows that
This indicates that
Moreover, it can be obtained similarly that
Therefore, we conclude that
Remark 12.
One may find that the eavesdroppers can also decode the source message with the average decoding error probability in Example 4. This indicates that the eavesdroppers have the same decoding ability as Receiver 1 and Receiver 2. The coding scheme is not a desired one. In fact, a sufficiently large block length N is necessary to design a desired coding scheme. The examples in this section do not focus on the construction of optimal coding scheme. They just show the encoding and decoding processes when the codebook is given.
7. Discussions on Field Size
In [5], Cai and Yeung have constructed an admissible linear block code over a more general wiretap network with intermediate nodes. However, the construction was working on with q being sufficiently large. Applying coding scheme in [5] to the wiretap network of this paper, we get the following linear network encoder and decoder:
- The source message W is uniformly distributed on the message set of size M;
- The stochastic encoder is a matrix of conditional probability for and , indicating the probability that the message w is encoded into the digital sequence , where is actually the . Supposing that the source message W is encoded into , the encoder emits the random symbol to the sink node ;
- For every , the decoder is a mapping from to , where (see Definition 3);
- The decoding error probability is defined asand the quantity of source information exposed to the eavesdroppers is defined as
Remark 13.
Remark 14.
The coding scheme constructed above is called linear, because the encoder can be interpreted as a generating matrix from . Please refer to [5] for more details.
The following theorem is actually a direct consequence of Theorem 3 in [5].
Theorem 2.
Suppose that the wiretap network depicted in Figure 2 with K sink nodes is given. Let be a alphabet of size q such that
with and for fixed (cf. Definitions 1 and 3). Then, there exists a pair of linear block encoder and decoder working on the alphabet such that
where and are given by Equations (38) and (39), respectively.
Theorem 2 asserts that the capacity is able to be achieved absolutely with exactly no decoding error and no exposed source information, if the alphabet is sufficiently large. However, it is well known that the alphabets of most channels are binary. To make the theorem work on the binary channels, it is necessary to map the elements in on to binary digital sequences, which produces the following corollary.
Corollary 1.
Proof.
Set . The stochastic encoder E is defined as
for every and , where is given by Equation (1) for and the range is the subset of . The decoder ϕ is defined as
for every and . One can easily verify that the pair of encoder and decoder constructed above satisfies Equation (42). The proof is completed. ☐
Remark 15.
Corollary 1 requires the block length N should satisfy that
indicating N is an approximately quadratic function of K, where the second inequality follows from (40) and the third inequality follows from Lemma 2.3 in [18].
Remark 16.
Remark 15 claims that the block length N is an approximately quadratic function of K if the linear network coding scheme introduced in [5] is applied over the wiretap network and one needs to emit about digital bits onto each edge. Remark 16 asserts that by sacrificing a small portion of transmission rate, the length of digital bits emitted on each edge can be decreased to , if the coding scheme in [6] is applied. Nevertheless, when the number K of sink nodes is large, both of the encoding processes turn out to be quite complicated. To have a comparison between the coding scheme in this paper and those in [5,6], the following corollary claims that by sacrificing a tiny portion of transmission rate, it is possible to construct a pair of encoder and decoder with a vanishing average decoding error probability and vanishing exposed source information to the eavesdroppers such that only one digital bit is transmitted onto each edge when the number K of sink nodes is sufficiently large.
Corollary 2.
For any given and , if the block length N satisfies
and
one can construct a pair of encoder and decoder formulated by Definitions 1 and 3 (with binary alphabet), such that
Proof.
Remark 17.
When and , the wiretap network depicted in Figure 2 is equivalent to the wiretap channel II [9] of N times of transmission. Each edge in the network is related to one time of transmission in wiretap channel II. See Figure 1. Therefore, the coding scheme introduced in this paper also works for the communication model of wiretap channel II. However, it is clear that the coding schemes introduced in [5,6], which depend on the size of alphabet, do not work for wiretap channel II.
After the discussion above, it has been known that the major advantage of the coding scheme in this paper is that there exists a pair of encoder and decoder such that the source message is transmitted to the legitimate receivers with exactly one time of transmission, when the number K of sink nodes is sufficiently large. More precisely, denoting by the minimal value of N satisfying Equations (44)–(47), when and ϵ are given, the number sink nodes K should be at least to implement the one-time transmission. The values of versus and is given by Figure 6. The figure shows that when , the value of is totally determined by the value of . As a concrete example, the data points marked in Figure 6 are those with and they lie on the identical horizontal line and hence share the same value of .
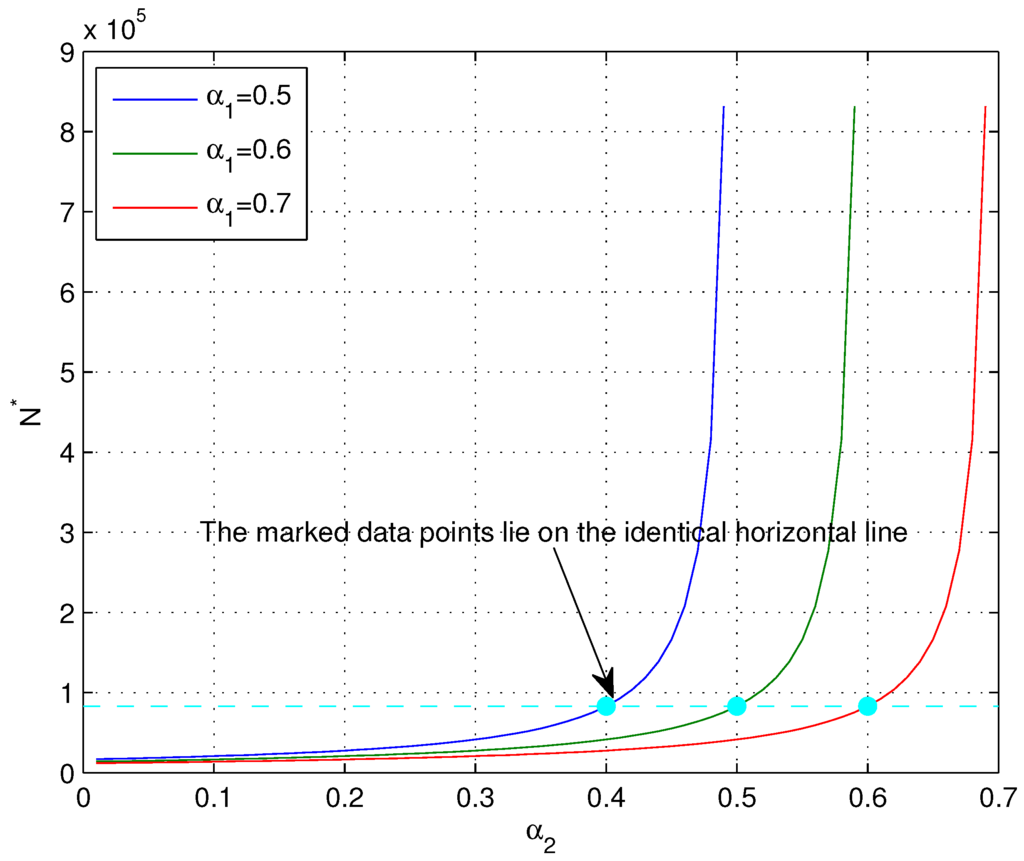
Figure 6.
Values of versus and with and .
8. Conclusions
This paper constructs a secure coding scheme for a special class of network with one single source node and K sink nodes, and determines its strong secrecy capacity. Unlike the linear network coding schemes developed in [5,6], which rely on Galois fields with sufficiently large sizes, the coding scheme introduced in this paper is working on the binary alphabet and hence can be readily applied to the classic wiretap channel II.
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable suggestions to improve this paper. This work was supported in part by the National Natural Science Foundation of China under Grants 61271222, 61271174 and 61301178, the National Basic Research Program of China under Grant 2013CB338004 and the Innovation Program of Shanghai Municipal Education Commission under Grant 14ZZ017.
Author Contributions
Dan He proposed the network model and provided the proofs of the coding theorem. Wangmei Guo researched in the background of the network model, and provided the examples and results on field size. The authors wrote this paper together and provided equal contribution. Both authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof of Lemma 1.
Let be the codebook randomly generated via the scheme introduced in Section 4.1. For any sample codebook and , denote
Then, for any , it follows that
Denoting for , the equation above further indicates that
for . Therefore, for any , it follows that
where the first inequality follows from Equation (A1). Repeating the inference above, we have
On account of the Chernoff bound and Equation (A2), we have
for every . Consequently,
The proof is completed. ☐
Appendix B Verification of the Rationality of Parameters in Equation (24)
This appendix proves the parameters introduced in Formula (24) satisfy the requirements of (18)–(20) when N is sufficiently large.
Proof of (19). Notice that for . Therefore,
which is Equation (19) for . Equation (19) for with is established directly by Equation (22).
Proof of (20). Formula (24) gives
if , where the first inequality follows because (cf. Remark 10) and
The verification is completed.
Appendix C
Proof of Lemma 4.
For any , denote by . Then, Equation (27) yields
Setting , it follows that
Let be a partition on with equal cardinality satisfying if , and otherwise. Denoting by the index of subcode containing , i.e., , one can obtain that
for every m out of . Consequently,
On account of Fano’s inequality, the formula above yields
☐
References
- Alshwede, R.; Cai, N.; Li, S.Y.R.; Yeung, R.W. Network information flow. IEEE Trans. Inf. Theory 2000, 46, 1204–1216. [Google Scholar] [CrossRef]
- Li, S.Y.R.; Yeung, R.W.; Cai, N. Linear network coding. IEEE Trans. Inf. Theory 2003, 49, 371–381. [Google Scholar] [CrossRef]
- Ho, T.; Médard, M.; Koetter, R.; Karger, D.R.; Effros, M.; Shi, J.; Leong, B. A random linear network coding approach to multicast. IEEE Trans. Inf. Theory 2006, 52, 4413–4430. [Google Scholar] [CrossRef]
- Cai, N.; Yeung, R.W. Secure network coding. In Proceedings of the 2002 IEEE International Symposium on Information Theory, Lausanne, Switzerland, 30 June–5 July 2002.
- Cai, N.; Yeung, R.W. Secure network coding on a wiretap network. IEEE Trans. Inf. Theory 2011, 57, 424–435. [Google Scholar]
- Feldman, J.; Malkin, T.; Stein, C.; Servedio, R.A. On the capacity of secure network coding. In Proceedings of the 42nd Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 29 September–1 October 2004.
- Bhattad, K.; Narayanan, K.R. Weakly secure network coding. In Proceedings of the First Workshop on Network Coding, Theory, and Applications, Riva del Garda, Italy, 7 April 2005.
- Ho, T.; Leong, B.; Koetter, R.; Médard, M.; Effros, M.; Karger, D.R. Byzantine modification detection in multicast networks using randomized network coding. In Proceedings of the IEEE International Symposium on Information Theory, Chicago, IL, USA, 27 June–2 July 2004.
- Ozarow, L.H.; Wyner, A.D. Wire-tap channel II. AT&T Bell Lab. Tech. J. 1984, 63, 2135–2157. [Google Scholar]
- Csiszár, I. Almost independence and secrecy capacity. Prob. Inf. Transm. 1996, 32, 40–47. [Google Scholar]
- He, D.; Luo, Y.; Cai, N. Strong secrecy capacity of the wiretap channel II with DMC main channel. In Proceedings of the IEEE International Symposium on Information Theory, Barcelona, Spain, 10–15 July 2016.
- MolavianJazi, E.; Bloch, M.; Laneman, J.N. Arbitrary jamming can preclude secure communication. In Proceedings of the 47th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 30 September–2 October 2009; pp. 1069–1075.
- Bjelaković, I.; Boche, H.; Sommerfeld, J. Capacity results for arbitrarily varying wiretap channel. In Information Theory, Combinatorics, and Search Theory; Springer: Berlin, Germany, 2013; Volume 7777, pp. 123–144. [Google Scholar]
- Boche, H.; Schaefer, R.F. Capacity results and super-activation for wiretap channels with active wiretappers. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1482–1496. [Google Scholar] [CrossRef]
- Ogiela, M.R.; Ogiela, U. Linguistic approach to crypotographic data sharing. In Proceedings of the 2008 Second International Conference on Future Generation Communication and Networking, Hainan Island, China, 13–15 December 2008.
- Blackwell, D.; Breiman, L.; Thomasian, A.J. The capacities of certain channel classes under random coding. Ann. Math. Stat. 1960, 31, 558–567. [Google Scholar] [CrossRef]
- Ahlswede, R.; Wolfowitz, J. Correlated decoding for channels with arbitrarily varying channel probability functions. Inf. Control 1969, 14, 457–473. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Ahlswede, R. Elimination of correlation in random codes for arbitrarily varying channels. Probab. Theory Relat. Fields 1978, 44, 159–175. [Google Scholar] [CrossRef]
- Ahlswede, R.; Csiszár, I. Common randomness in information theory and cryptography—Part II: CR capacity. IEEE Trans. Inf. Theory 1998, 44, 225–240. [Google Scholar] [CrossRef]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).