
Stimuli-Magnitude-Adaptive Sample Selection for Data-Driven Haptic Modeling


Abstract
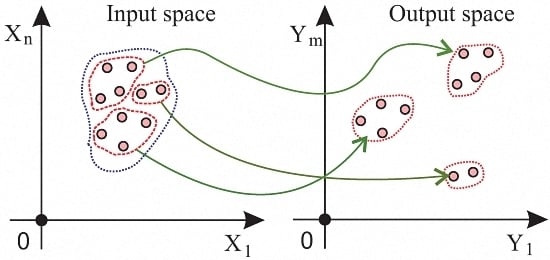
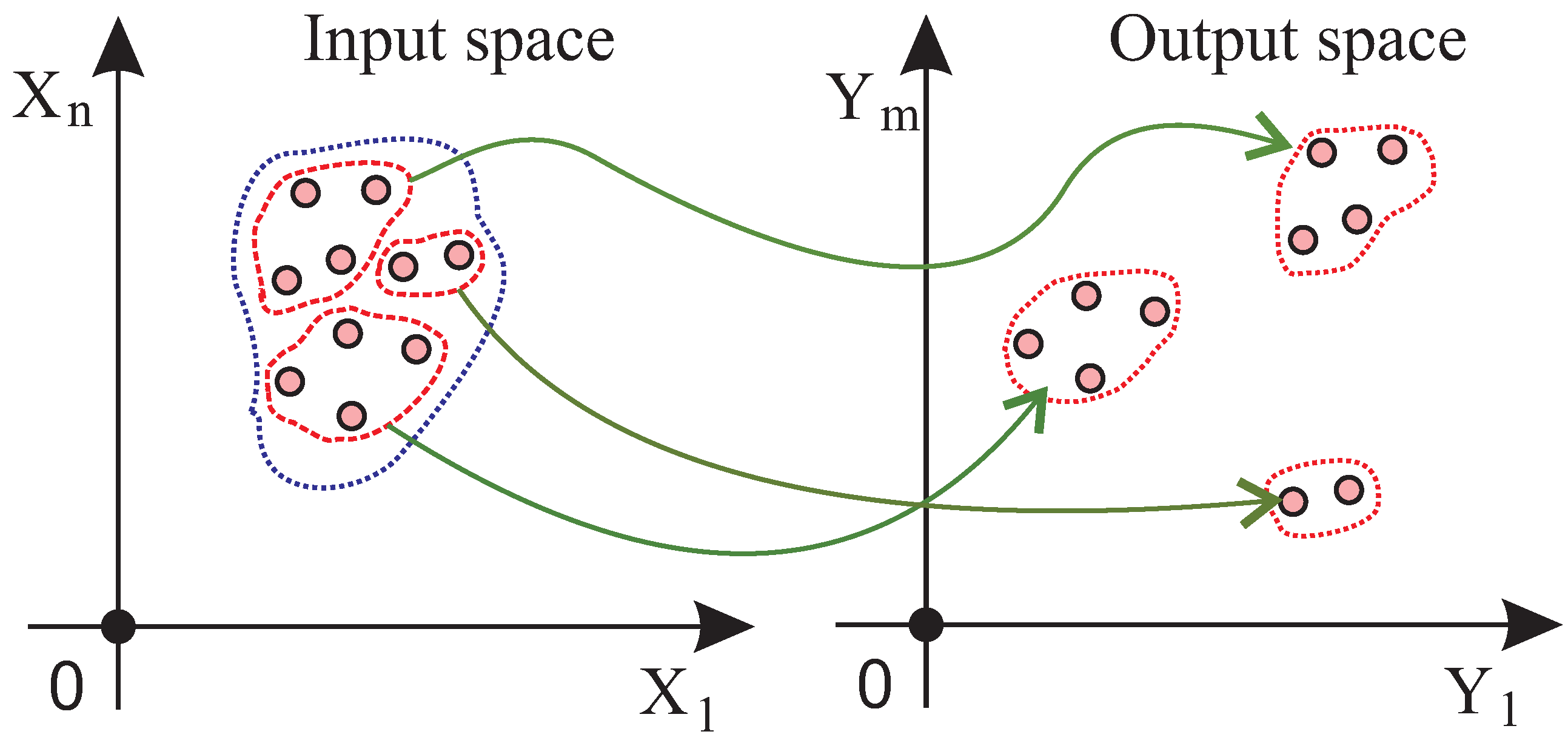
:
1. Introduction
- -
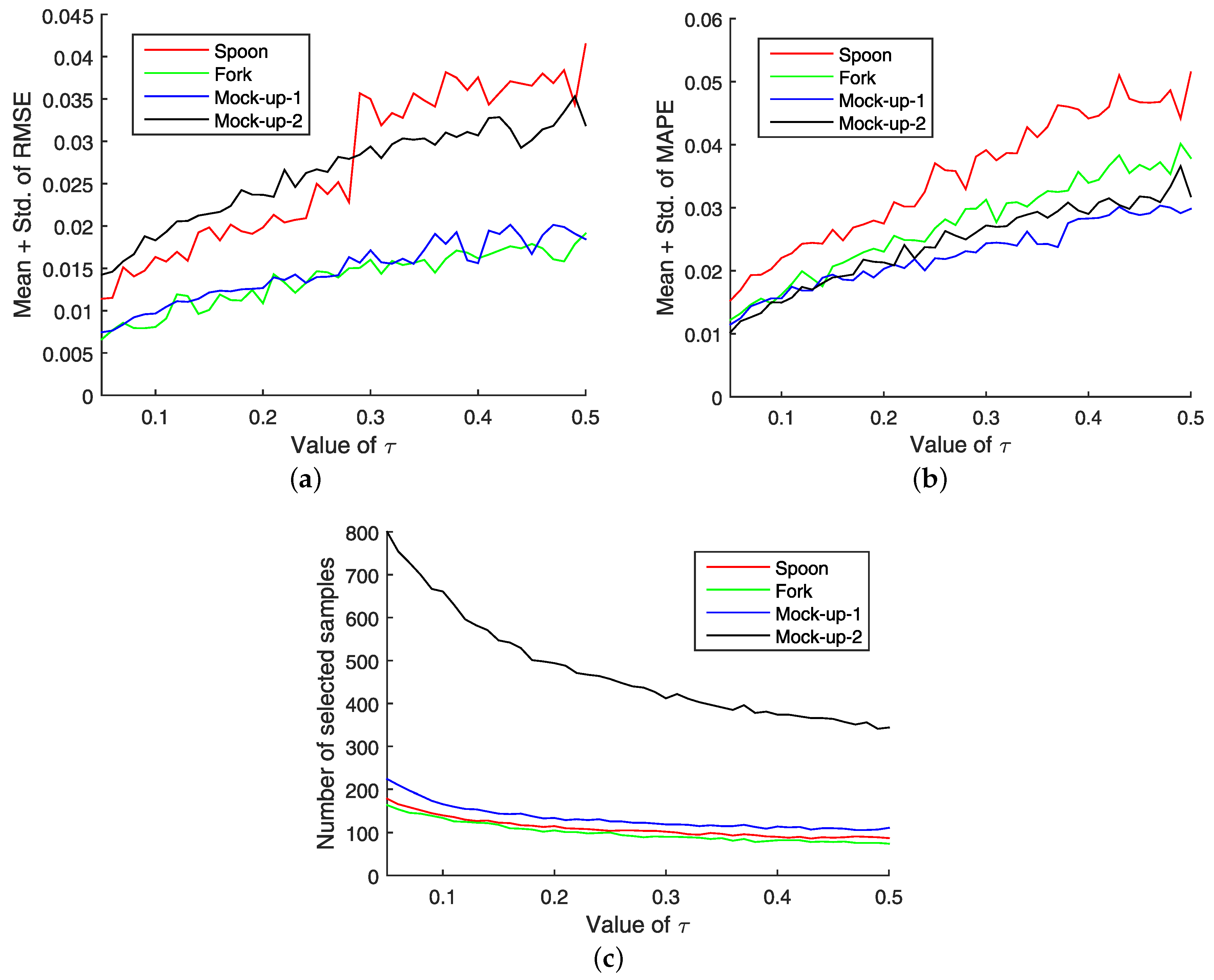
- SMASS selects a high number of representative points when the reference stimulus is low, while it selects a low number of points when the reference stimulus is high, which fits well to the human perception characteristic: stimuli difference in small magnitude is more prone to be detected than that in large magnitudes, e.g., humans can detect the difference between 0.3 N and 0.5 N but cannot do it between 30.3 N and 30.5 N (see Section 5 for more details).
- -
- SMASS processes multivariate output as a whole, unlike most other algorithms that work with uni-dimensional projections of multivariate output data (one at a time). This significantly increases the training efficiency when there are multiple dimensions in output.
- -
- The computation speed of the proposed algorithm is very high due to its simplicity and the use of the binary partitioning approach.
- -
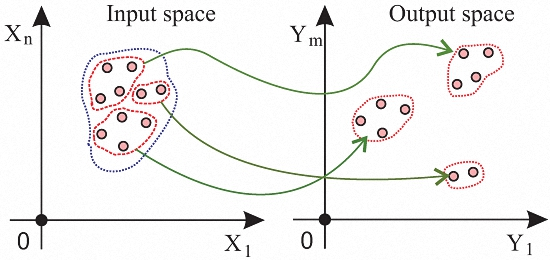
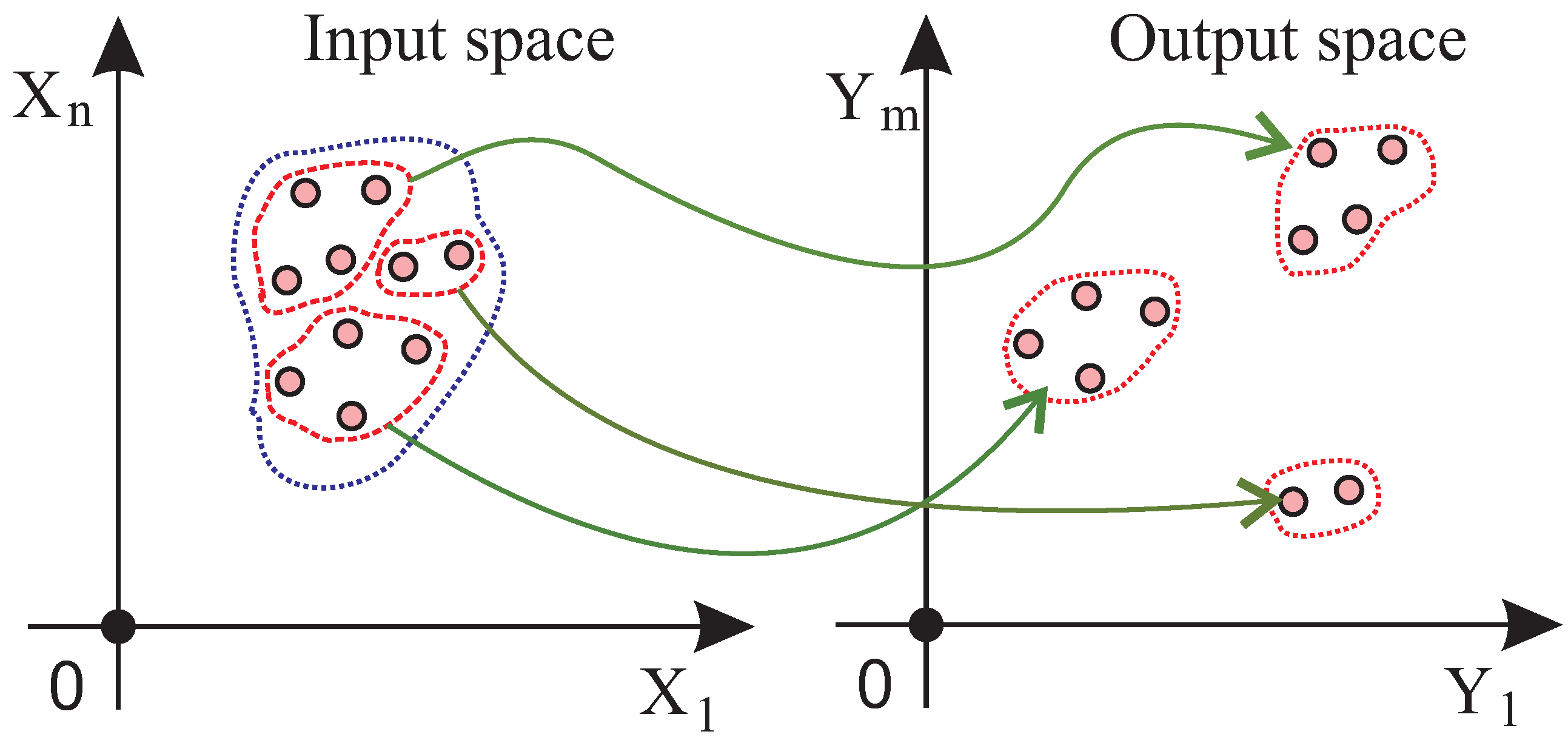
- Unlike previous approaches, both the input and output and their relationship are used for the selection of representative samples. This allows an appropriate sample selection in the case when closely clustered input points are mapped to sparsely distributed output points, and vice versa. Previous approaches that only see input or output would fail to capture the relationship in such cases.
2. Related Works
Sample Selection in Haptics
3. Stimuli-Magnitude-Adaptive Sample Selection Algorithm
3.1. Problem Definition and Approach
3.2. Algorithm
 |
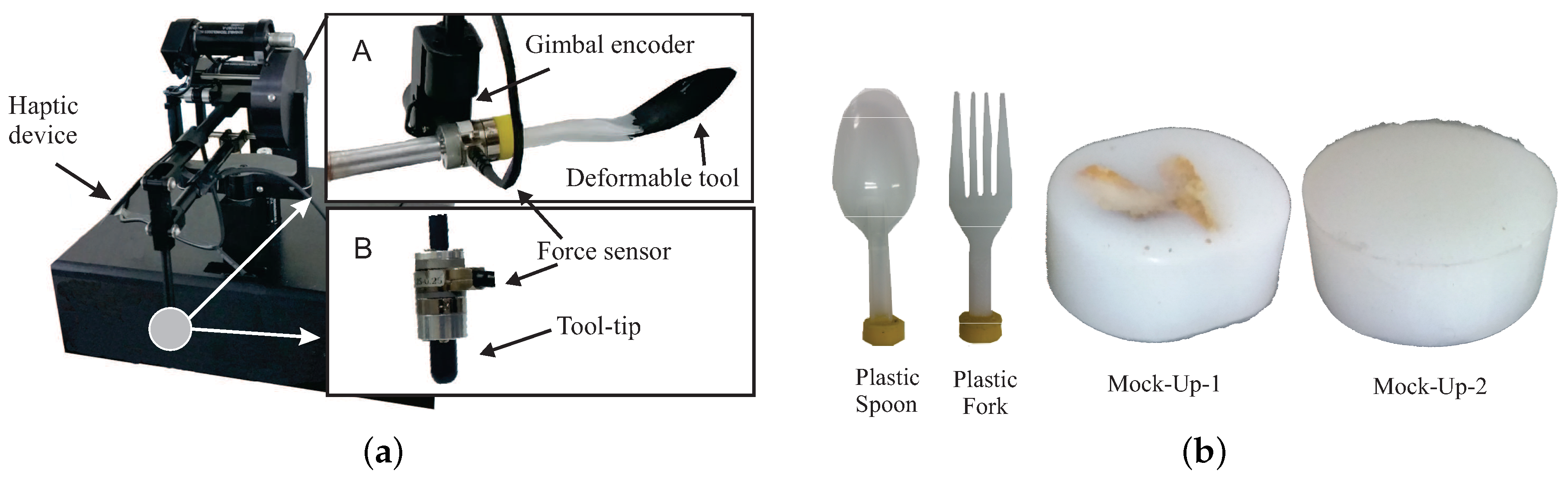
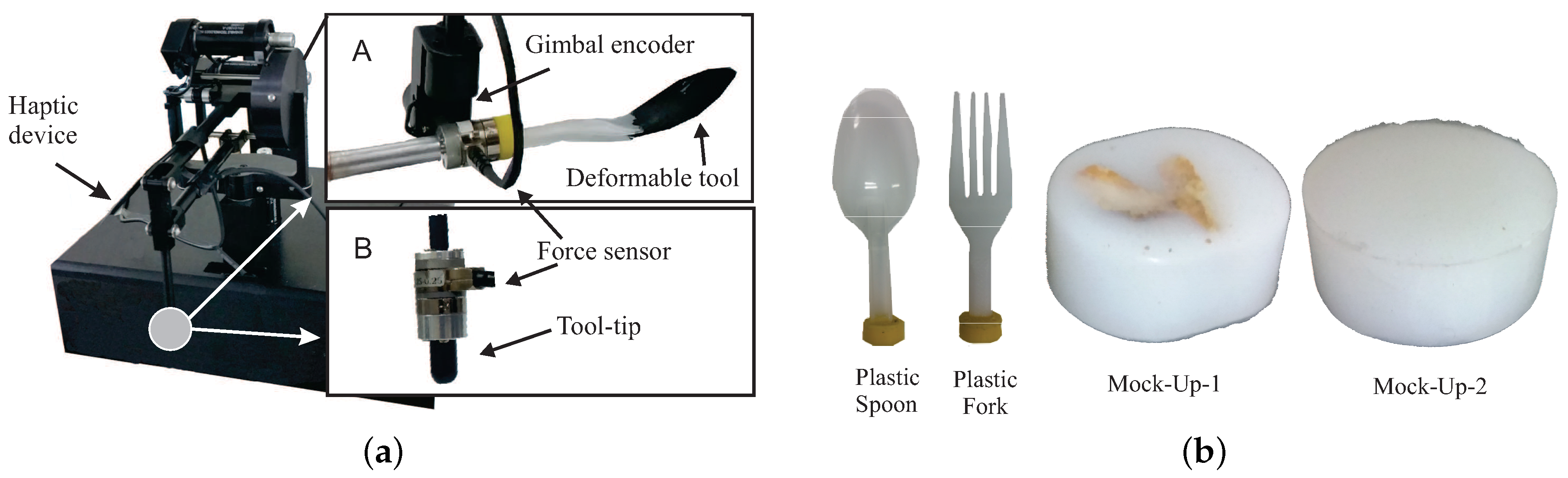
4. Dataset Collection and Recording Setup
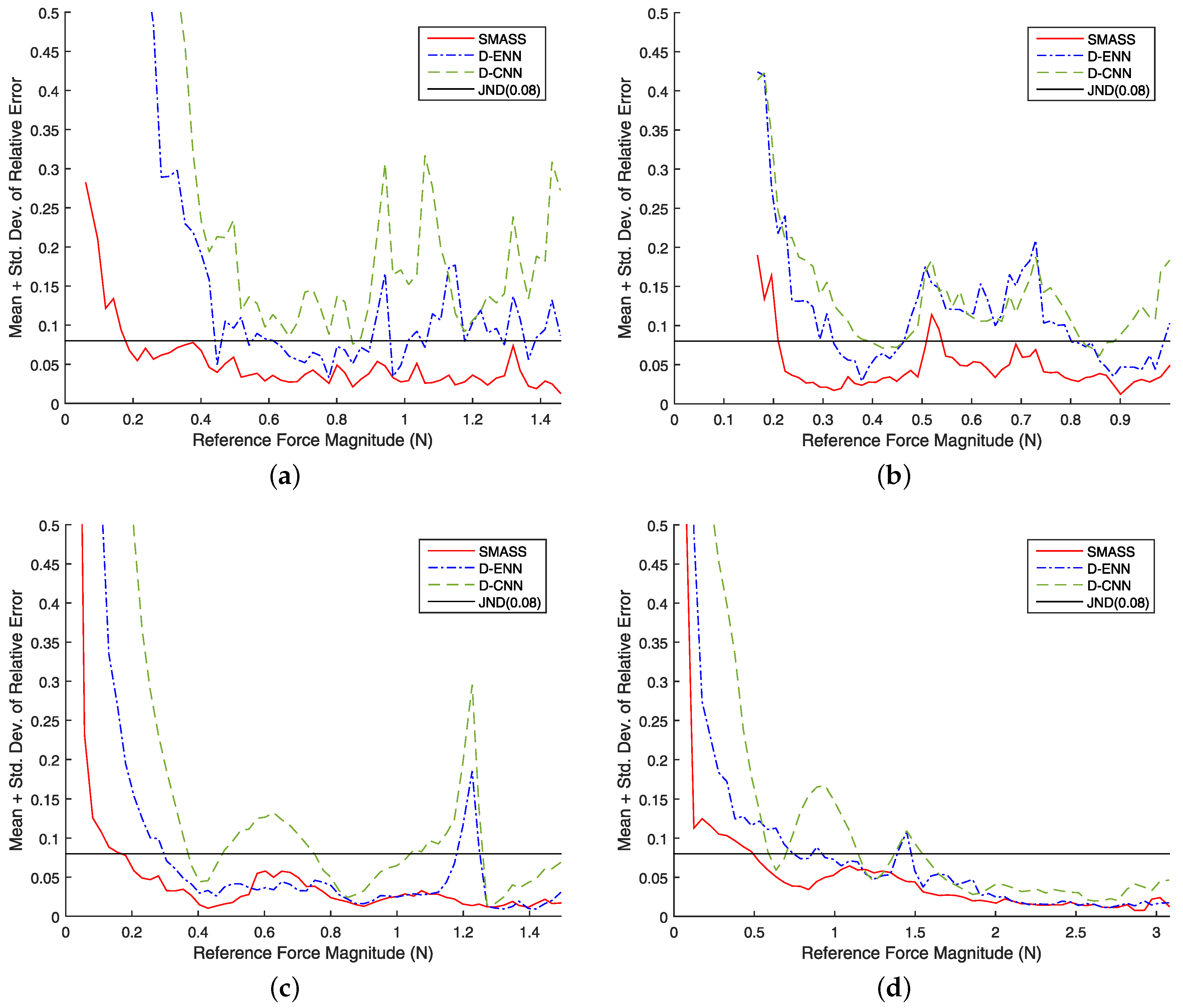
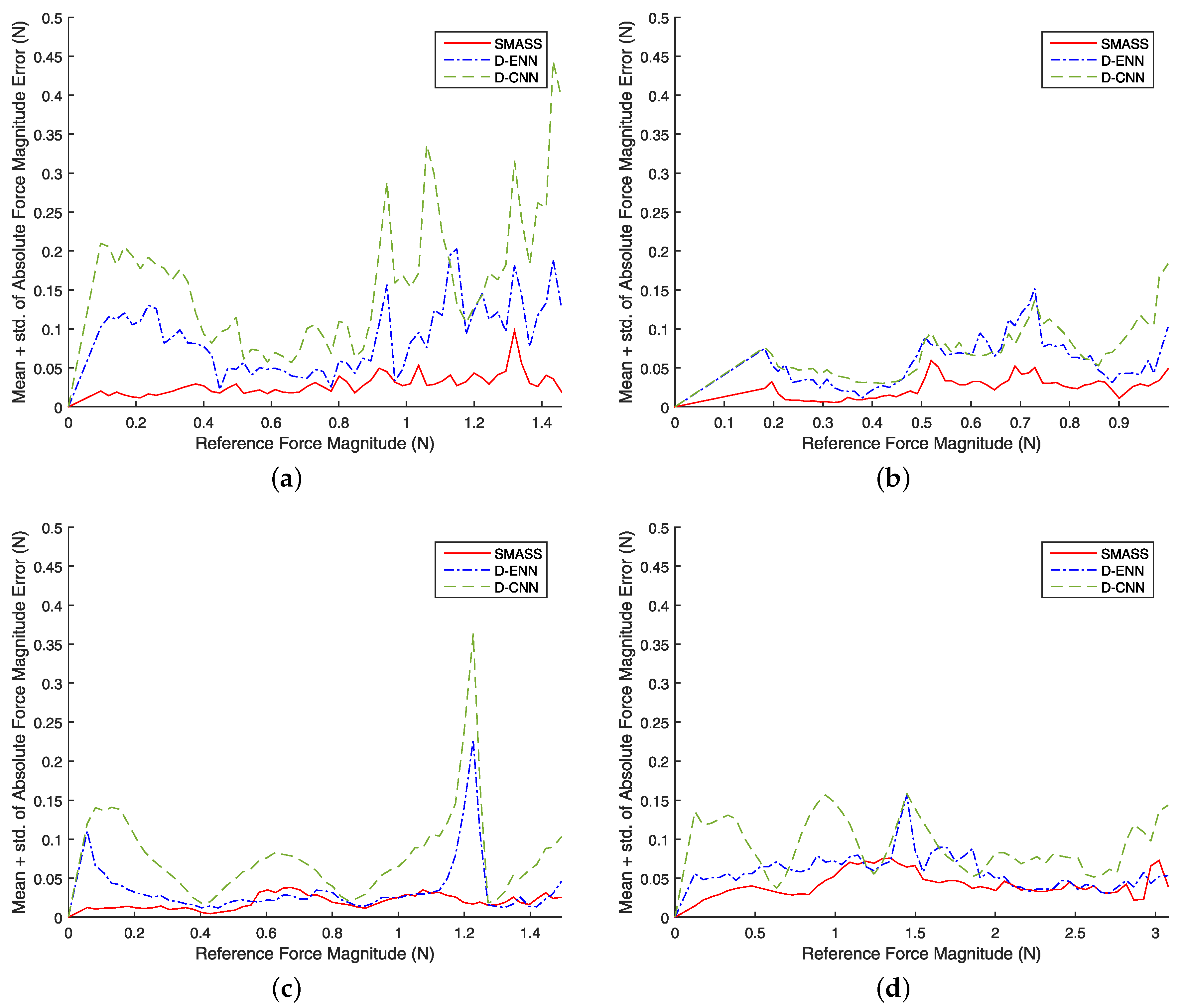
5. Experimental Evaluation
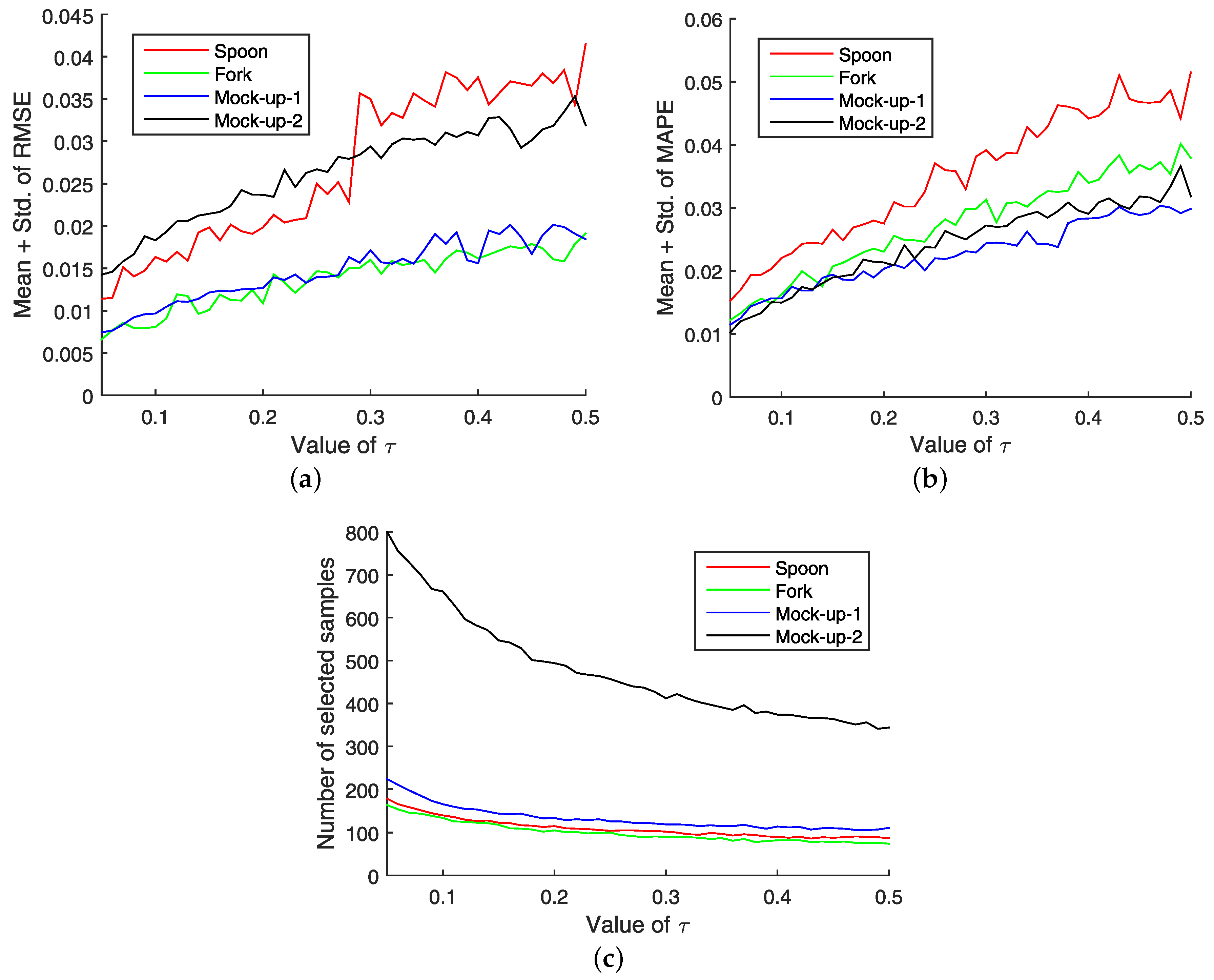
5.1. Parameter Selection
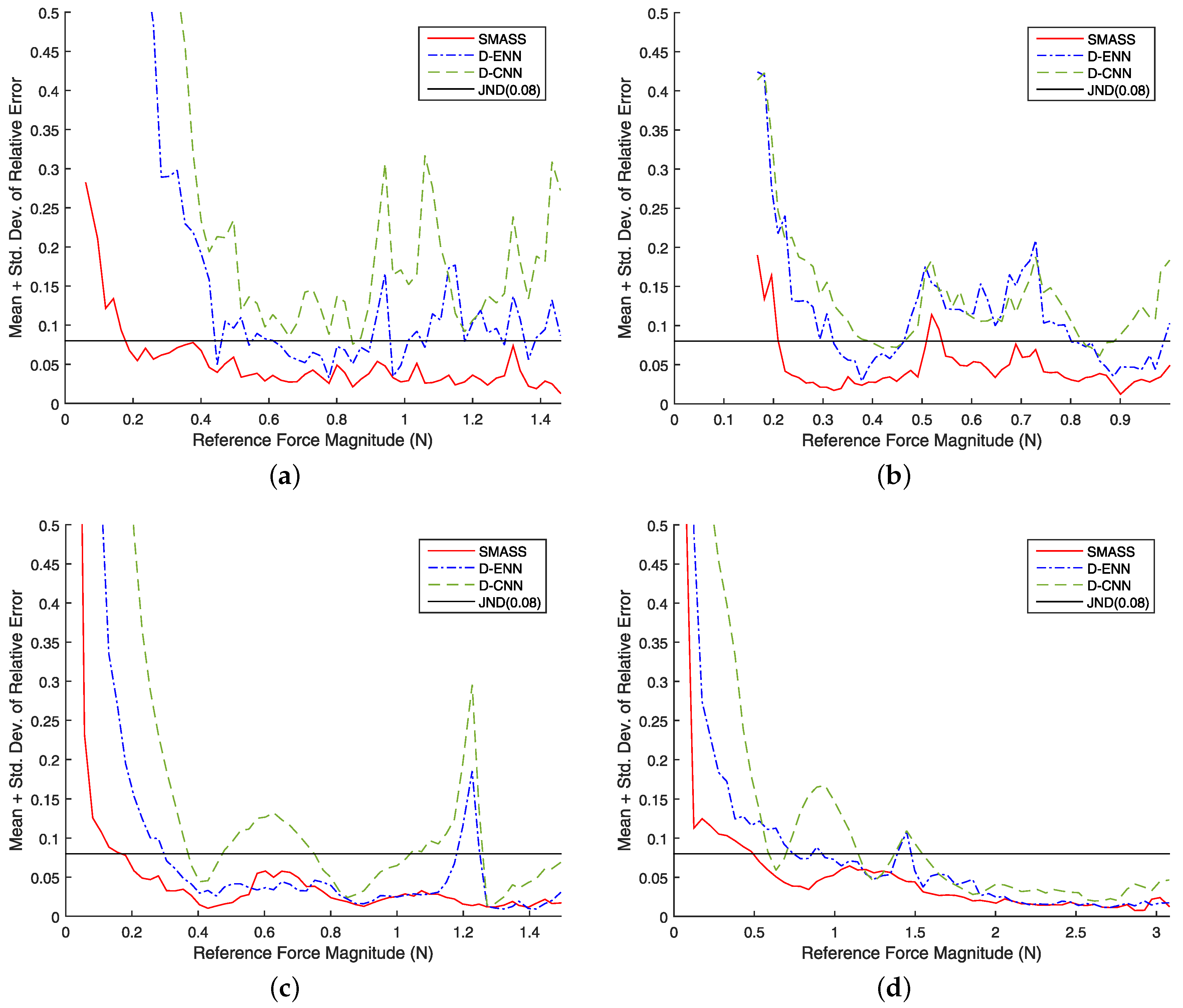
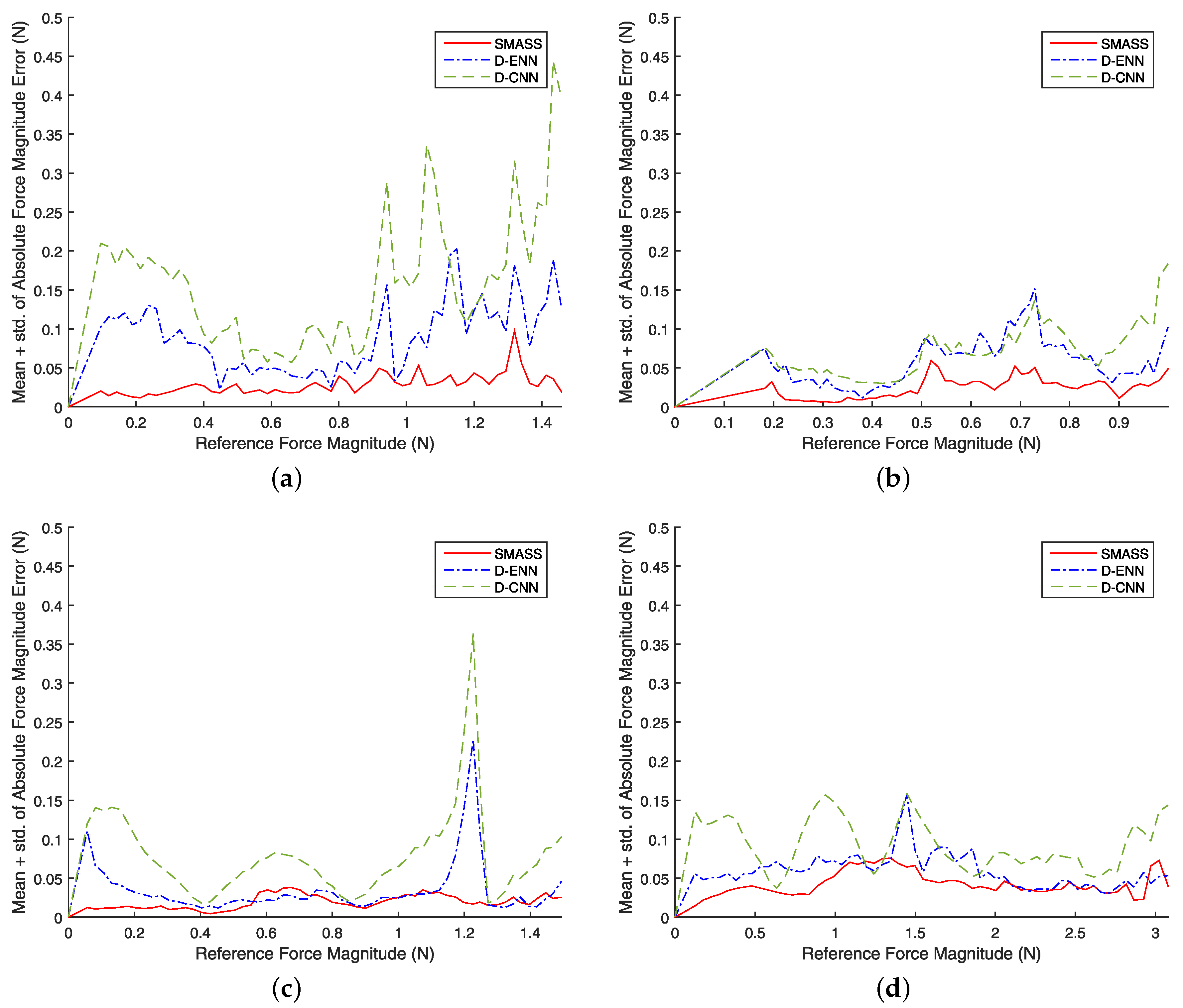
5.2. Results
6. Discussion
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lin, M.C.; Otaduy, M. Haptic Rendering: Foundations, Algorithms, and Applications; CRC Press: Boca Raton, FL, USA, 2008; Chapter 15; pp. 311–331. [Google Scholar]
- Lebiedź, J.; Skokowski, J.; Flisikowski, P. Modeling of human tissue for medical purposes. Development 2012, 27, 43–48. [Google Scholar]
- Maule, M.; Maciel, A.; Nedel, L. Efficient Collision Detection and Physics-based Deformation for Haptic Simulation with Local Spherical Hash. In Proceedings of the 23rd SIBGRAPI Conference on Graphics, Patterns and Images, Gramado, Brazil, 30 August–3 September 2010; pp. 9–16.
- Vaughan, N.; Dubey, V.N.; Wee, M.Y.; Isaacs, R. Haptic feedback from human tissues of various stiffness and homogeneity. Adv. Robot. Res. 2015, 1, 215–237. [Google Scholar]
- Laycock, S.D.; Day, A. Incorporating haptic feedback for the simulation of a deformable tool in a rigid scene. Comput. Graph. 2005, 29, 341–351. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Y.; Esen, H. Modeling of deformable objects in haptic rendering system for virtual reality. In Proceedings of the International Conference on Mechatronics and Automation, Changchun, China, 9–12 August 2009; pp. 90–94.
- Susa, I.; Takehana, Y.; Balandra, A.; Mitake, H.; Hasegawa, S. Haptic rendering based on finite element simulation of vibration. In Proceedings of the 2014 IEEE Haptics Symposium, Houston, TX, USA, 23–26 February 2014; pp. 123–128.
- Höver, R.; Harders, M.; Székely, G. Data-driven haptic rendering of visco-elastic effects. In Proceedings of the Symposium on Haptic interfaces for virtual environment and teleoperator systems, Reno, NV, USA, 13–14 March 2008; pp. 201–208.
- Yim, S.; Jeon, S.; Choi, S. Data-driven haptic modeling and rendering of deformable objects including sliding friction. In Proceedings of the World Haptics Conference (WHC), Chicago, IL, USA, 22–25 June 2015; pp. 305–312.
- Hover, R.; Kósa, G.; Székely, G.; Harders, M. Data-driven haptic rendering-from viscous fluids to visco-elastic solids. IEEE Trans. Haptics 2009, 2, 15–27. [Google Scholar] [CrossRef]
- Jeon, S.; Metzger, J.C.; Choi, S.; Harders, M. Extensions to haptic augmented reality: Modulating friction and weight. In Proceedings of the World Haptics Conference (WHC), Istanbul, Turkey, 21–24 June 2011; pp. 227–232.
- Okamura, A.M.; Webster, R.J., III; Nolin, J.T.; Johnson, K.; Jafry, H. The haptic scissors: Cutting in virtual environments. In Proceedings of the IEEE International Conference on Robotics and Automation, Taipei, Taiwan, 14–19 September 2003; Volume 1, pp. 828–833.
- Holzinger, A.; Nischelwitzer, A.K. People with motor and mobility impairment: Innovative multimodal interfaces to wheelchairs. In Computers Helping People with Special Needs; Springer: Berlin/Heidelberg, Germany, 2006; pp. 989–991. [Google Scholar]
- Höver, R.; Luca, M.D.; Harders, M. User-based evaluation of data-driven haptic rendering. ACM Trans. Appl. Percept. 2010, 8. [Google Scholar] [CrossRef]
- Höver, R.; Di Luca, M.; Székely, G.; Harders, M. Computationally efficient techniques for data-driven haptic rendering. In Proceedings of the Third Joint EuroHaptics Conference, 2009 and Symposium on Haptic Interfaces for Virtual Environment and Teleoperator Systems, Salt Lake City, UT, USA, 18–20 March 2009; pp. 39–44.
- Arnaiz-González, Á.; Blachnik, M.; Kordos, M.; García-Osorio, C. Fusion of instance selection methods in regression tasks. Inf. Fusion 2016, 30, 69–79. [Google Scholar] [CrossRef]
- Fuchs, H.; Kedem, Z.M.; Naylor, B.F. On visible surface generation by a priori tree structures. In ACM SIGGRAPH Computer Graphics; ACM: New York, NY, USA, 1980; Volume 14, pp. 124–133. [Google Scholar]
- Elhamifar, E.; Sapiro, G.; Vidal, R. See all by looking at a few: Sparse modeling for finding representative objects. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Zurich, Switzerland, 6–12 September 2012; pp. 1600–1607.
- Elhamifar, E.; Sapiro, G.; Sastry, S. Dissimilarity-Based Sparse Subset Selection. IEEE Trans. Pattern Anal. Mach. Intell. 2014. [Google Scholar] [CrossRef] [PubMed]
- Gong, B.; Chao, W.L.; Grauman, K.; Sha, F. Diverse sequential subset selection for supervised video summarization. In Proceedings of Advances in Neural Information Processing Systems 27 (NIPS 2014), Montréal, QC, Canada, 8–13 December 2014; pp. 2069–2077.
- Tsai, C.F.; Chen, Z.Y.; Ke, S.W. Evolutionary instance selection for text classification. J. Syst. Softw. 2014, 90, 104–113. [Google Scholar] [CrossRef]
- Lin, H.; Bilmes, J.; Xie, S. Graph-based submodular selection for extractive summarization. In Proceedings of the IEEE Workshop on Automatic Speech Recognition & Understanding, Merano/Meran, Italy, 13–17 December 2009; pp. 381–386.
- Martínez-Ballesteros, M.; Bacardit, J.; Troncoso, A.; Riquelme, J.C. Enhancing the scalability of a genetic algorithm to discover quantitative association rules in large-scale datasets. Integr. Comput. Aided Eng. 2015, 22, 21–39. [Google Scholar]
- Hu, Y.H.; Lin, W.C.; Tsai, C.F.; Ke, S.W.; Chen, C.W. An efficient data preprocessing approach for large scale medical data mining. Technol. Health Care 2015, 23, 153–160. [Google Scholar] [PubMed]
- Garcia-Pedrajas, N.; de Haro-Garcia, A.; Perez-Rodriguez, J. A scalable approach to simultaneous evolutionary instance and feature selection. Inf. Sci. 2013, 228, 150–174. [Google Scholar] [CrossRef]
- Lin, W.C.; Tsai, C.F.; Ke, S.W.; Hung, C.W.; Eberle, W. Learning to detect representative data for large scale instance selection. J. Syst. Softw. 2015, 106, 1–8. [Google Scholar] [CrossRef]
- Nikolaidis, K.; Mu, T.; Goulermas, J.Y. Prototype reduction based on direct weighted pruning. Pattern Recognit. Lett. 2014, 36, 22–28. [Google Scholar] [CrossRef]
- Triguero, I.; Derrac, J.; Garcia, S.; Herrera, F. A taxonomy and experimental study on prototype generation for nearest neighbor classification. IEEE Trans. Syst. Man Cyber. Part C Appl. Rev. 2012, 42, 86–100. [Google Scholar] [CrossRef]
- Garcia, S.; Derrac, J.; Cano, J.R.; Herrera, F. Prototype selection for nearest neighbor classification: Taxonomy and empirical study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 417–435. [Google Scholar] [CrossRef] [PubMed]
- Jankowski, N.; Grochowski, M. Comparison of instances seletion algorithms i. algorithms survey. In Artificial Intelligence and Soft Computing-ICAISC 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 598–603. [Google Scholar]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef]
- Tolvi, J. Genetic algorithms for outlier detection and variable selection in linear regression models. Soft Comput. 2004, 8, 527–533. [Google Scholar] [CrossRef]
- Antonelli, M.; Ducange, P.; Marcelloni, F. Genetic training instance selection in multiobjective evolutionary fuzzy systems: A coevolutionary approach. IEEE Trans. Fuzzy Syst. 2012, 20, 276–290. [Google Scholar] [CrossRef]
- Kordos, M.; Blachnik, M. Instance selection with neural networks for regression problems. In Artificial Neural Networks and Machine Learning—ICANN 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 263–270. [Google Scholar]
- Kordos, M.; Białka, S.; Blachnik, M. Instance selection in logical rule extraction for regression problems. In Artificial Intelligence and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 167–175. [Google Scholar]
- Wilson, D.L. Asymptotic properties of nearest neighbor rules using edited data. IEEE Trans. Syst. Man Cyber. 1972, 2, 408–421. [Google Scholar] [CrossRef]
- Hart, P. The condensed nearest neighbor rule. IEEE Trans. Inf. Theory 1968, 14, 515–516. [Google Scholar] [CrossRef]
- Chang, C.L. Finding prototypes for nearest neighbor classifiers. IEEE Trans. Comput. 1974, 100, 1179–1184. [Google Scholar] [CrossRef]
- Marchiori, E. Class conditional nearest neighbor for large margin instance selection. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 364–370. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Fdez, I.; Mucientes, M.; Bugarin, A. An instance selection algorithm for regression and its application in variance reduction. In Proceedings of the 2013 IEEE International Conference on Fuzzy Systems (FUZZ), Hyderabad, India, 7–10 July 2013; pp. 1–8.
- Arnaiz-González, Á.; Díez-Pastor, J.F.; Rodríguez, J.J.; García-Osorio, C.I. Instance selection for regression by discretization. Expert Syst. Appl. 2016, 54, 340–350. [Google Scholar] [CrossRef]
- Li, B.; Chen, Y.W.; Chen, Y.Q. The nearest neighbor algorithm of local probability centers. IEEE Trans. Syst. Man Cyber. Part B Cyber. 2008, 38, 141–154. [Google Scholar] [CrossRef] [PubMed]
- Li, I.; Wu, J.L. A New Nearest Neighbor Classification Algorithm Based on Local Probability Centers. Math. Probl. Eng. 2014, 2014. [Google Scholar] [CrossRef]
- Wen, G.; Jiang, L. Relative Local Mean Classifier with Optimized Decision Rule. In Proceedings of the 2011 Seventh International Conference on Computational Intelligence and Security (CIS), Surat, India, 21–25 May 2011; pp. 477–481.
- Mitani, Y.; Hamamoto, Y. A local mean-based nonparametric classifier. Pattern Recognit. Lett. 2006, 27, 1151–1159. [Google Scholar] [CrossRef]
- Sun, Y.; Wen, G. Cognitive gravitation model-based relative transformation for classification. Soft Comput. 2016. [Google Scholar] [CrossRef]
- Sun, X.; Chan, P.K. An Analysis of Instance Selection for Neural Networks to Improve Training Speed. In Proceedings of the 2014 13th International Conference on Machine Learning and Applications (ICMLA), Detroit, MI, USA, 3–5 December 2014; pp. 288–293.
- Mao, C.; Hu, B.; Wang, M.; Moore, P. Learning from neighborhood for classification with local distribution characteristics. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8.
- Sianov, A.; Harders, M. Data-driven haptics: Addressing inhomogeneities and computational formulation. In Proceedings of the World Haptics Conference (WHC), Daejeon, Korea, 14–17 April 2013; pp. 301–306.
- Iske, A.; Levesley, J. Multilevel scattered data approximation by adaptive domain decomposition. Numer. Algorithms 2005, 39, 187–198. [Google Scholar] [CrossRef]
- Pettinger, D.; Di Fatta, G. Space partitioning for scalable k-means. In Proceedings of the 2010 Ninth International Conference on Machine Learning and Applications (ICMLA), Washington, DC, USA, 12–14 December 2010; pp. 319–324.
- SMASS Dataset. Available online: http://dx.doi.org/10.5281/zenodo.53938 (accessed on 6 June 2016).
- Zadeh, M.H.; Wang, D.; Kubica, E. Perception-based lossy haptic compression considerations for velocity-based interactions. Multimed. Syst. 2008, 13, 275–282. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 7–9 January 2007; pp. 1027–1035.
- Wright, S.J.; Nowak, R.D.; Figueiredo, M.A. Sparse reconstruction by separable approximation. IEEE Trans. Signal Process. 2009, 57, 2479–2493. [Google Scholar] [CrossRef]
- Jones, L.A. Matching forces: Constant errors and differential thresholds. Perception 1989, 18, 681–687. [Google Scholar] [CrossRef] [PubMed]
- Pang, X.D.; Tan, H.Z.; Durlach, N.I. Manual discrimination of force using active finger motion. Percept. Psychophys. 1991, 49, 531–540. [Google Scholar] [CrossRef] [PubMed]
- Weber, E.H. EH Weber: The Sense of Touch; Academic Press: Cambridge, MA, USA, 1978. [Google Scholar]
- Holzinger, A. Interactive machine learning for health informatics: when do we need the human-in-the-loop? Brain Inform. 2016, 3, 119–131. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D-ENN | D-CNN | SMASS | |||||||
|---|---|---|---|---|---|---|---|---|---|
| k | |||||||||
| Spoon | 114 ± 12 | 116 ± 18 | 107 ± 11 | 112 | 106 ± 2 | 110 ± 1 | 105 ± 3 | 107 | 111 ± 2 |
| Fork | 110 ± 3 | 121 ± 7 | 113 ± 8 | 114 | 100 ± 4 | 113 ± 2 | 101 ± 2 | 104 | 100 ± 2 |
| Mock-up-1 | 134 ± 12 | 136 ± 8 | 133 ± 7 | 134 | 134 ± 1 | 136 ± 3 | 127 ± 4 | 132 | 131 ± 3 |
| Mock-up-2 | 480 ± 34 | 493 ± 19 | 471 ± 26 | 481 | 483 ± 9 | 489 ± 11 | 479 ± 9 | 483 | 476 ± 6 |
| D-ENN | D-CNN | SMASS | |||||||
|---|---|---|---|---|---|---|---|---|---|
| MAPE | RMSE | t (s) | MAPE | RMSE | t (s) | MAPE | RMSE | t (s) | |
| Spoon | 0.1203 | 0.0615 | 171.43 | 0.2766 | 0.1217 | 95.73 | 0.0322 | 0.0215 | 1.7465 |
| Fork | 0.0649 | 0.0302 | 127.13 | 0.0760 | 0.0386 | 83.65 | 0.0261 | 0.0132 | 1.4912 |
| Mock-up-1 | 0.1068 | 0.0529 | 561.56 | 0.1695 | 0.0935 | 204.53 | 0.0212 | 0.0148 | 1.7960 |
| Mock-up-2 | 0.0834 | 0.0353 | 2767.5 | 0.1607 | 0.0596 | 538.15 | 0.0238 | 0.0258 | 7.7340 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulali, A.; Hassan, W.; Jeon, S. Stimuli-Magnitude-Adaptive Sample Selection for Data-Driven Haptic Modeling. Entropy 2016, 18, 222. https://doi.org/10.3390/e18060222
Abdulali A, Hassan W, Jeon S. Stimuli-Magnitude-Adaptive Sample Selection for Data-Driven Haptic Modeling. Entropy. 2016; 18(6):222. https://doi.org/10.3390/e18060222
Chicago/Turabian StyleAbdulali, Arsen, Waseem Hassan, and Seokhee Jeon. 2016. "Stimuli-Magnitude-Adaptive Sample Selection for Data-Driven Haptic Modeling" Entropy 18, no. 6: 222. https://doi.org/10.3390/e18060222
APA StyleAbdulali, A., Hassan, W., & Jeon, S. (2016). Stimuli-Magnitude-Adaptive Sample Selection for Data-Driven Haptic Modeling. Entropy, 18(6), 222. https://doi.org/10.3390/e18060222