
Distant Supervision for Relation Extraction with Ranking-Based Methods †



Abstract
:1. Introduction
- We are the first to make use of the group-level information to select effective training data.
- Three ranking-based methods and the ensemble are proposed and validated as effective.
- We achieve state-of-the-art results both on the average and optimal performance.
- We analyze why the data selection methods are beneficial through examples and statistical figures.
2. Related Work
2.1. Distant Supervision for Relation Extraction
2.2. Noise Reduction for Distant Supervision
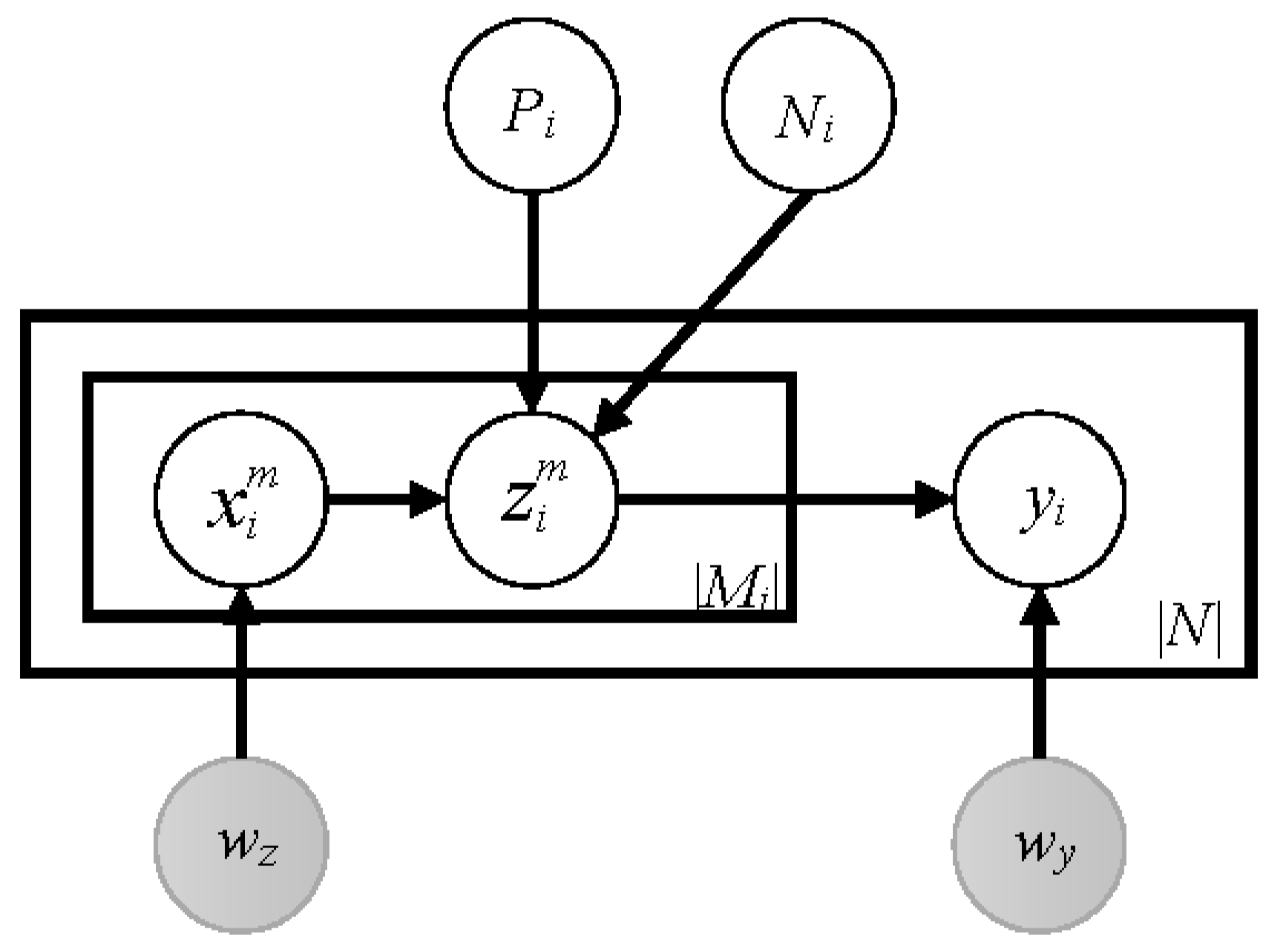
3. Methods
3.1. MIML-Sort
| Algorithm 1 MIML-Sort Training |
| Input: training bags {xi}, positive/negative label sets {Pi/Ni}, label set Ɍ, proportion parameter θ |
| Output: instance-level and group-level classifiers wz and wy |
| 1: foreach in each bag xi: |
| 2: ←each r in Pi |
| 3: end for |
| 4: foreach iteration t in T: |
| 5: foreach bag xi: |
| 6: foreach in each bag xi: |
| 7: |
| 8: end for |
| 9: end for |
| 10: foreach bag xi: |
| 11: |
| 12: foreach r in Ɍ: |
| 13: |
| 14: end for |
| 15: end for |
| 16: |
| 17: |
| 18: foreach r in Ɍ: |
| 19: |
| 20: end for |
| 21: end for |
3.2. Sorting by Conformance of Group-Level Labels
3.3. Sorting by Precision of Labels
3.4. Sorting by Ranking of Group-Level Labels
- Rl—the number of labels that has a higher predicted score than label l within a group.
- Ll—the ranking loss for a certain label l in a group which is related to Rl.
3.5. Sorting by Ensemble
4. Experiments and Analysis
4.1. Dataset
4.2. Implementation
4.2.1. Implementation Details
4.2.2. Baseline Methods
4.3. Evaluation Metrics
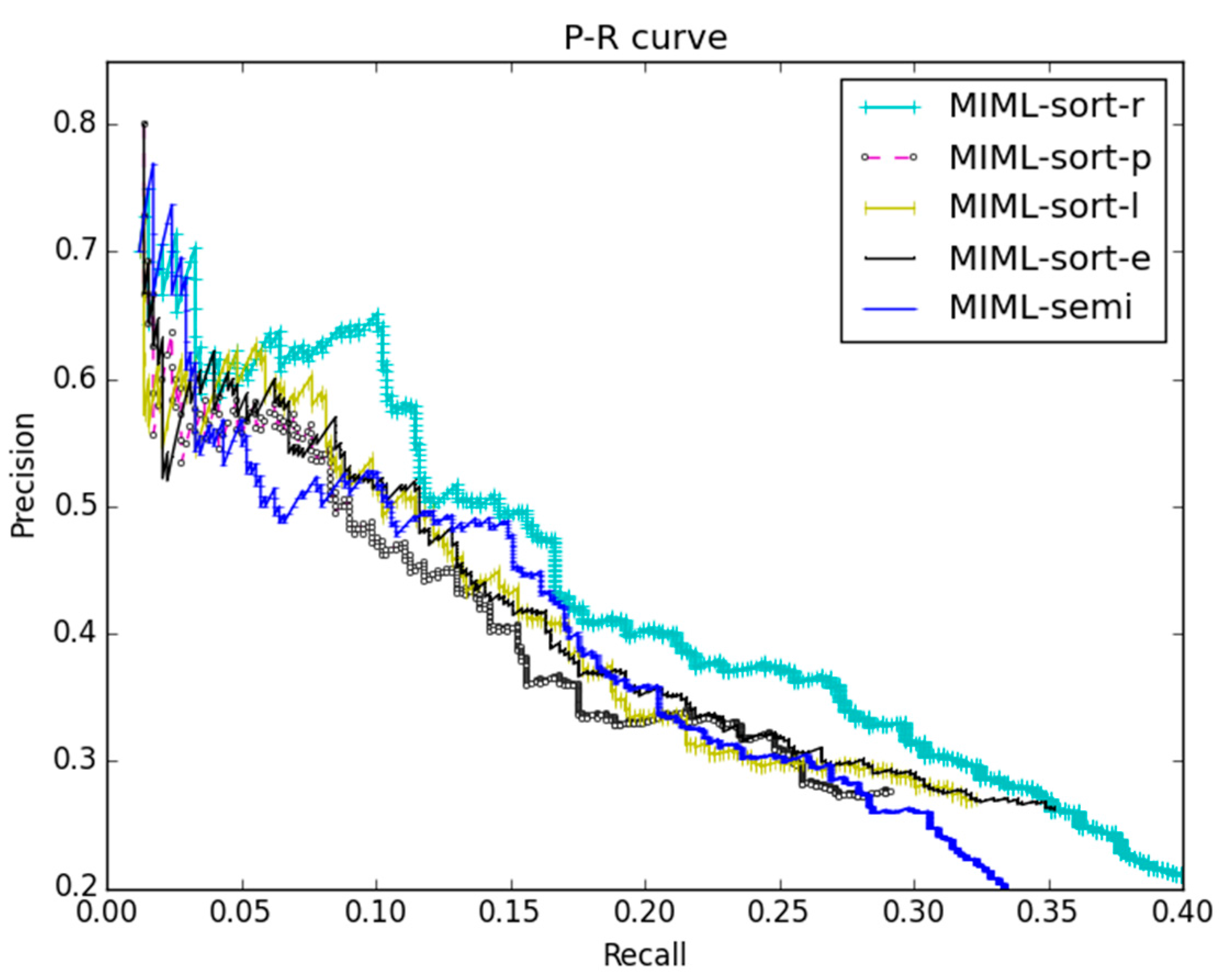
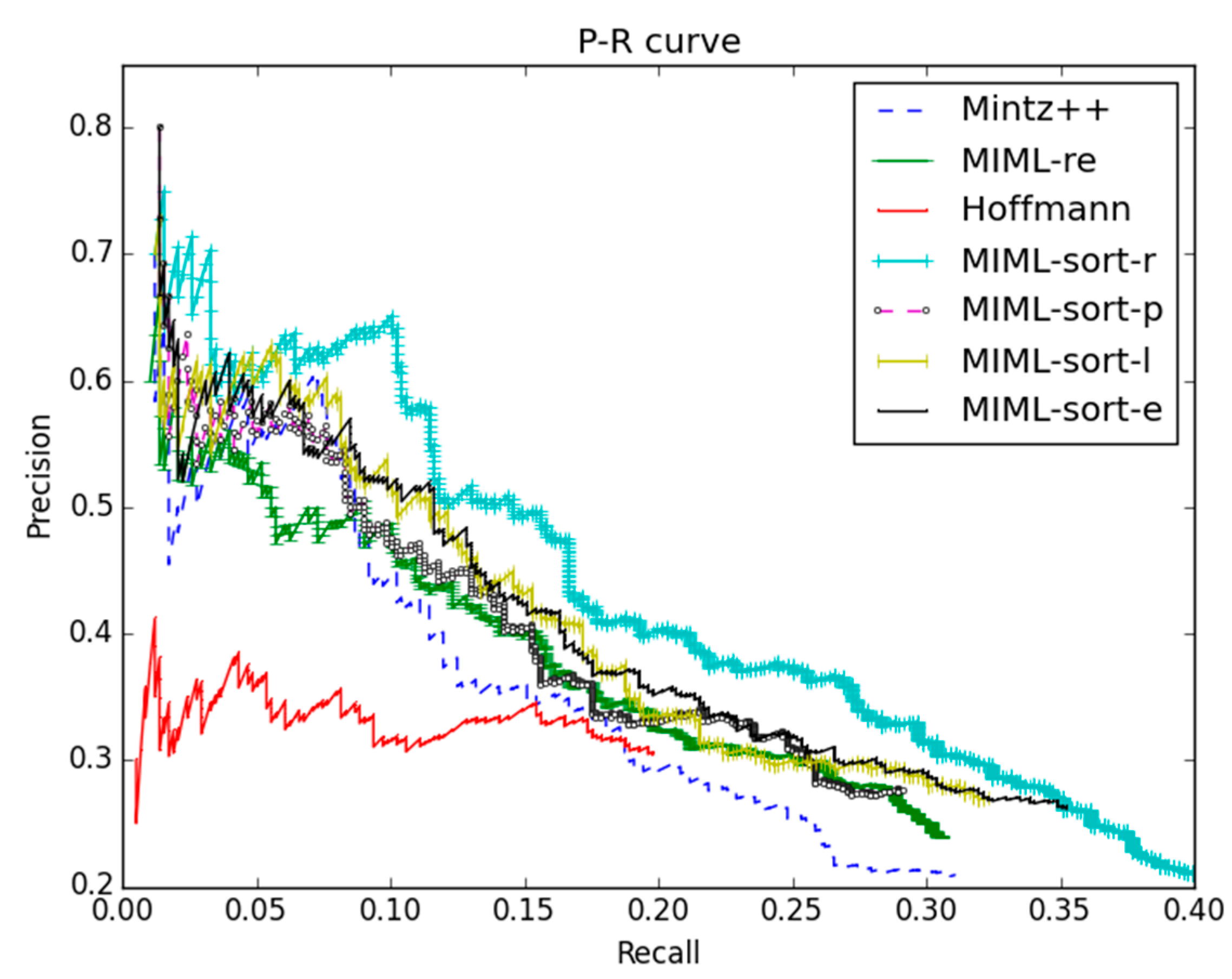
- P/R curve
- Precision, Recall, Final F1
- Max F1 & Avg F1
4.4. Results
4.4.1. Compared with MIML-Semi
4.4.2. Compared with Other Baselines
5. Discussion and Future Work
5.1. Analysis of the Removed Groups
5.2. Parameter Settings
5.3. Analysis on Relation Types
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Miller, S.; Fox, H.; Ramshaw, L.; Weischedel, R. A Novel Use of Statistical Parsing to Extract Information from Text. In Proceedings of the 1st North American Chapter of the Association for Computational Linguistics Conference (NAACL), San Diego, CA, USA, 29 April 2000; pp. 226–233.
- Collins, M.; Duffy, N. Convolution Kernels for Natural Language. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 3–8 December 2001; pp. 625–632.
- Zelenko, D.; Aone, C.; Richardella, A. Kernel Methods for Relation Extraction. J. Mach. Learn. Res. 2003, 3, 1083–1106. [Google Scholar]
- Kambhatla, N. Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL), Barcelona, Spain, 21–26 July 2004.
- Culotta, A.; Sorensen, J. Dependency Tree Kernels for Relation Extraction. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL), Barcelona, Spain, 21–26 July 2004.
- Bunescu, R.C.; Mooney, R.J. A Shortest Path Dependency Kernel for Relation Extraction. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing (HLT/EMNLP), Vancouver, BC, Canada, 6–8 October 2005; pp. 724–731.
- Zhao, S.; Grishman, R. Extracting Relations with Integrated Information Using Kernel Methods. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL), Ann Harbor, MI, USA, 25–30 June 2005; pp. 419–426.
- Zhou, G.; Su, J.; Zhang, J.; Zhang, M. Exploring Various Knowledge in Relation Extraction. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics (ACL), Ann Harbor, MI, USA, 25–30 June 2005; pp. 427–434.
- Bach, N.; Badaskar, S. A Review of Relation Extraction. Available online: orb.essex.ac.uk/CE/CE807/Readings/A-survey-on-Relation-Extraction.pdf (accessed on 20 May 2016).
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant Supervision for Relation Extraction without Labeled Data. In Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 1003–1011.
- Riedel, S.; Yao, L.; McCallum, A. Modeling Relations and Their Mentions without Labeled Text. In Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases, Barcelona, Spain, 20–24 September 2010; pp. 148–163.
- Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; Weld, D.S. Knowledge Based Weak Supervision for Information Extraction of Overlapping Relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL), Portland, OR, USA, 19–24 June 2011; pp. 541–550.
- Surdeanu, M.; Tibshirani, J.; Nallapati, R.; Manning, C.D. Multi-Instance Multi-Label Learning for Relation Extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP), Jeju Island, Korea, 12–14 July 2012; pp. 455–465.
- Min, B.; Grishman, R.; Wan, L.; Wang, C.; Gondek, D. Distant Supervision for Relation Extraction with an Incomplete Knowledge Base. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Atlanta, GA, USA, 9–15 June 2013; pp. 777–782.
- Ritter, A.; Zettlemoyer, L.; Etzioni, O. Modeling Missing Data in Distant Supervision for Information Extraction. Trans. Assoc. Comput. Linguist. 2013, 1, 367–378. [Google Scholar]
- Craven, M.; Kumlien, J. Constructing Biological Knowledge Bases by Extracting Information from Text Sources. In Proceedings of the 7th International Conference on Intelligent Systems for Molecular Biology (ISMB), Heidelberg, Germany, 6–10 August 1999; pp. 77–86.
- Bunescu, R.C.; Mooney, R.J. Learning to Extract Relations from the Web Using Minimal Supervision. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics (ACL), Prague, Czech, 23–30 June 2007; pp. 576–583.
- Bellare, K.; McCallum, A. Learning Extractors from Unlabeled Text Using Relevant Databases. Available online: http://www.aaai.org/Papers/Workshops/2007/WS-07-14/WS07-14-002.pdf (accessed on 20 May 2016).
- Wu, F.; Weld, D. Autonomously Semantifying Wikipedia. In Proceedings of the 16th International Conference on Information and Knowledge Management (CIKM), Lisbon, Portugal, 6–10 November 2007; pp. 41–50.
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the 26th Advances in Neural Information Processing Systems (NIPS), South Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2787–2795.
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; pp. 1112–1119.
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187.
- Fan, M.; Zhao, D.; Zhou, Q.; Liu, Z.; Zheng, T.F.; Chang, E.Y. Distant Supervision for Relation Extraction with Matrix Completion. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (ACL), Baltimore, MD, USA, 22–27 June 2014; pp. 839–849.
- Angeli, G.; Tibshirani, J.; Wu, J.Y.; Manning, C.D. Combining Distant and Partial Supervision for Relation Extraction. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1556–1567.
- Nagesh, A.; Haffari, G.; Ramakrishna, G. Noisy-or Based Model for Relation Extraction Using Distant Supervision. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1937–1941.
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762.
- Intxaurrondo, A.; Surdeanu, M.; de Lacalle, O.L.; Agirre, E. Removing Noisy Mentions for Distant Supervision. Proces. Leng. Nat. 2013, 51, 41–48. [Google Scholar]
- Xu, W.; Hoffmann, R.; Zhao, L.; Grishman, R. Filling Knowledge Base Gaps for Distant Supervision of Relation Extraction. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL), Sofia, Bulgaria, 4–9 August 2013; pp. 665–670.
- Takamatsu, S.; Sato, I.; Nakagawa, H. Reducing Wrong Labels in Distant Supervision for Relation Extraction. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (ACL), Jeju Island, Korea, 8–14 July 2012; pp. 721–729.
- Xiang, Y.; Zhang, Y.; Wang, X.; Qin, Y.; Han, W. Bias Modeling for Distantly Supervised Relation Extraction. Math. Probl. Eng. 2015, 2015, 969053. [Google Scholar] [CrossRef]
- Xiang, Y.; Wang, X.; Zhang, Y.; Qin, Y.; Fan, S. Distant Supervision for Relation Extraction via Group Selection. In Proceedings of the 22nd International Conference on Neural Information Processing (ICONIP), Istanbul, Turkey, 9–12 November 2015; pp. 250–258.
- Usunier, N.; Buffoni, D.; Gallinari, P. Ranking with Ordered Weighted Pairwise Classification. In Proceedings of the 26th International Conference on Machine Learning (ICML), Montreal, QC, Canada, 14–18 June 2009; pp. 1057–1064.
- Weston, J.; Bengio, S.; Usunier, N. Wsabie: Scaling up to Large Vocabulary Image Annotation. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence (IJCAI), Barcelona, Spain, 16–22 July 2011; pp. 2764–2770.
- Huang, S.; Gao, W.; Zhou, Z.H. Fast Multi-Instance Multi-Label Learning. In Proceedings of the 2014 AAAI Conference on Artificial Intelligence (AAAI), Hilton, QC, Canada, 27–31 July 2014; pp. 1868–1874.
- Ji, H.; Grishman, R.; Dang, H.T.; Griffitt, K.; Ellis, J. Overview of the TAC 2010 Knowledge Base Population Track. In Proceedings of the Third Text Analysis Conference (TAC 2010), Gaithersburg, MD, USA, 15–16 November 2010.
- Ji, H.; Grishman, R.; Dang, H.T. Overview of the TAC 2011 Knowledge Base Population Track. In Proceedings of the Forth Text Analytics Conference (TAC 2011), Gaithersburg, MD, USA, 14–15 November 2011.

{kind=link}
{kind=link}
{kind=link}
| <Obama, US> | |
|---|---|
| Relations from KB | president_of <Obama, US> born_in <Obama, US> |
| DS annotated sentences | S1. Obama is the 44th President of US. S2. Born in Honolulu, Hawaii, US, Obama is a graduate of Columbia University and Harvard Law School. S3. Obama talks up US recovery and urges Republicans to back higher wages. |
| Precision | Recall | Final F1 | Max F1 | Avg F1 | Parameters | |
|---|---|---|---|---|---|---|
| Hoffmann | 30.65 1 | 19.79 | 23.97 | 24.05 | 15.40 | - |
| Mintz++ | 26.24 | 24.83 | 24.97 | 25.51 | 21.61 | - |
| MIML-re | 30.56 | 24.68 | 27.30 | 28.25 | 22.75 | T 2 = 8 |
| MIML-semi | 13.38 | 42.88 | 20.39 | 28.28 | 23.27 | T = 8 |
| MIML-sort-l | 27.00 | 32.29 | 29.41 | 29.55 | 23.33 | T = 6, θ = 98% |
| MIML-sort-p | 27.50 | 29.17 | 28.31 | 28.33 | 22.05 | T = 8, θ = 99% |
| MIML-sort-r | 20.95 | 39.93 | 27.48 | 31.29 | 26.87 | T = 2, θ = 98% |
| MIML-sort-e | 26.09 | 35.24 | 29.98 | 30.32 | 24.34 | T = 7, θ = 98% |
| S = 1 (%) | S = 2 (%) | S = 3 (%) | S = 4 (%) | S ≥ 5 (%) | |
|---|---|---|---|---|---|
| MIML-sort-l | 46.10 | 25.99 | 11.94 | 6.73 | 9.24 |
| (sum) | (46.10) | (72.09) | (84.03) | (90.76) | (100) |
| MIML-sort-p | 94.63 | 4.54 | 0.65 | 0.11 | ≈0 |
| (sum) | (94.63) | (99.16) | (99.81) | (99.92) | (100) |
| MIML-sort-r | 75.53 | 12.48 | 5.07 | 2.44 | 4.48 |
| (sum) | (75.53) | (88.01) | (93.08) | (95.52) | (100) |
| MIML-sort-e | 86.32 | 11.32 | 1.48 | 0.50 | 0.38 |
| (sum) | (86.32) | (97.64) | (99.11) | (99.62) | (100) |
| S = 1 (%) | S = 2 (%) | S = 3 (%) | S = 4 (%) | S ≥ 5 (%) | |
|---|---|---|---|---|---|
| Percentage | 73.15 | 12.69 | 5.66 | 2.85 | 6.25 |
| (sum) | (73.15) | (85.84) | (90.91) | (93.76) | (100) |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, Y.; Chen, Q.; Wang, X.; Qin, Y. Distant Supervision for Relation Extraction with Ranking-Based Methods. Entropy 2016, 18, 204. https://doi.org/10.3390/e18060204
Xiang Y, Chen Q, Wang X, Qin Y. Distant Supervision for Relation Extraction with Ranking-Based Methods. Entropy. 2016; 18(6):204. https://doi.org/10.3390/e18060204
Chicago/Turabian StyleXiang, Yang, Qingcai Chen, Xiaolong Wang, and Yang Qin. 2016. "Distant Supervision for Relation Extraction with Ranking-Based Methods" Entropy 18, no. 6: 204. https://doi.org/10.3390/e18060204
APA StyleXiang, Y., Chen, Q., Wang, X., & Qin, Y. (2016). Distant Supervision for Relation Extraction with Ranking-Based Methods. Entropy, 18(6), 204. https://doi.org/10.3390/e18060204