5.1. Item-Sets and Rules
Using the methods described in
Section 3.2, an experiment was performed to create frequent item-sets and build association rules for these sets. The resulting frequent item-sets are depicted in
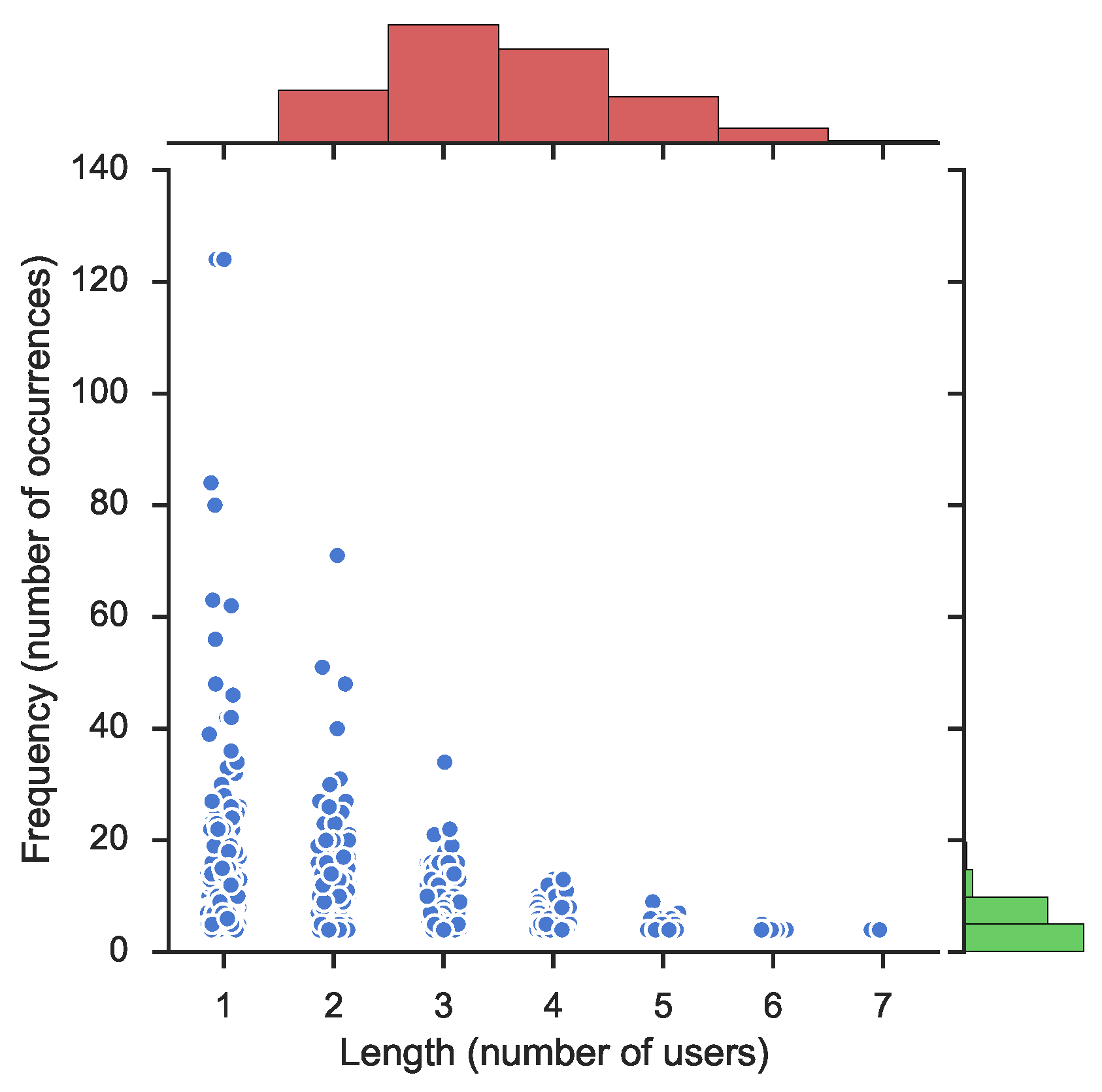
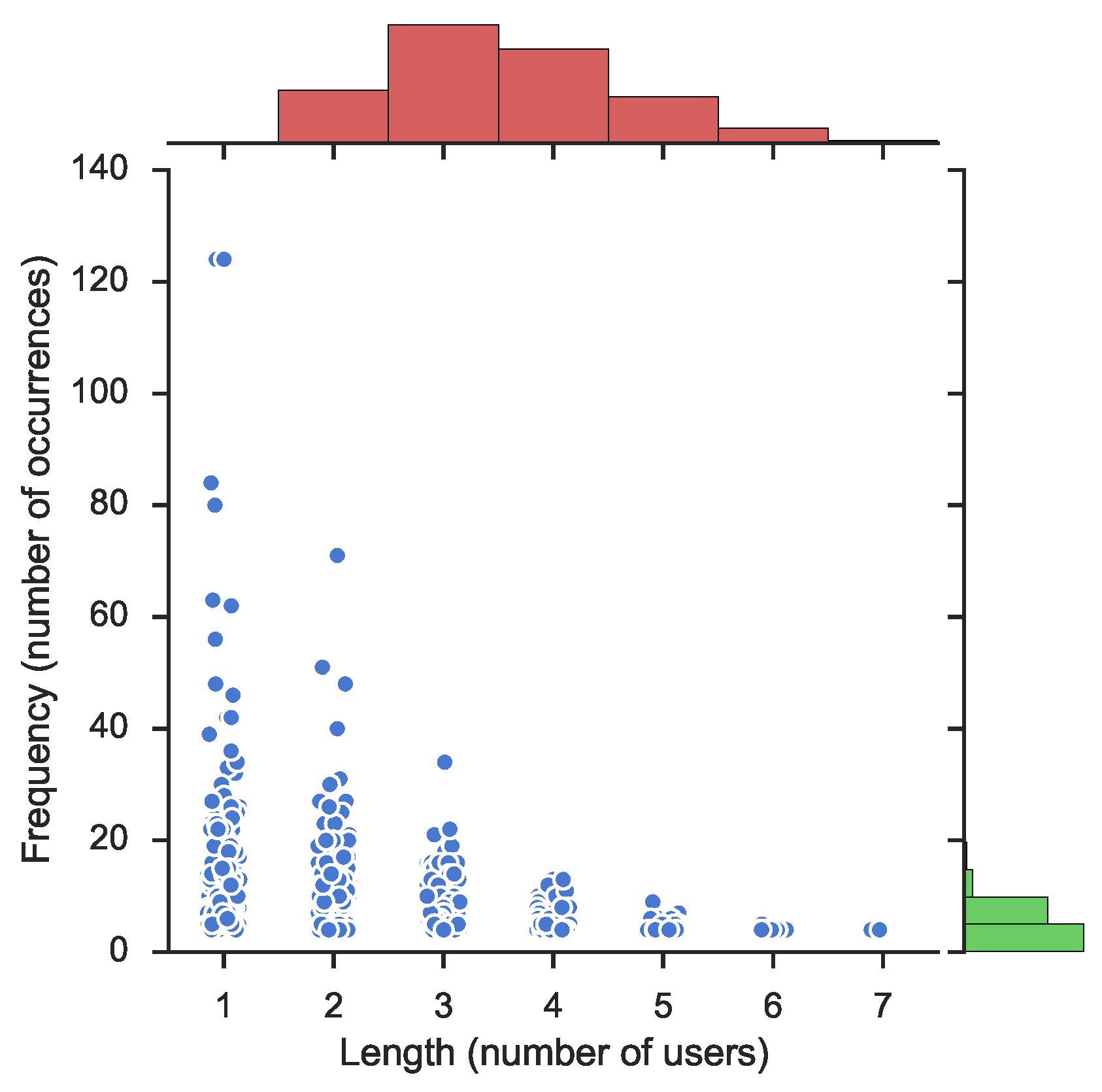
Figure 1 for the page OccupyTogether. This figure illustrates frequency, or the number of occurrences for each item-set, with respect to the length of elements, or the number of collaborating users. The main scatter-plot illustrates how the
frequency decreases when the number of users (
length) increases, a natural feature of frequent item-sets.
Figure 1 also depicts the distribution as histograms. The top histogram, in green, shows the distribution of frequency and, the histogram on the right hand side, in red, shows the distribution of the length of the learned item-sets. The histogram to the right (in green) illustrates a significant density of user collaboration that occurs at a low frequency, between 1 and 10. This is natural as the frequency of user participation decreases for most of the users. Noticeable on the length distribution (in red) is the fact that the density is higher for two and three participating users than for just one. This is because there exist more combinations of users than the number of single users.
Association rules supporting the hypothesis of user participation based on other users’ activities were computed from the calculated frequency item-sets. This resulted in
rules for the page [
39].
Table 2 shows descriptive statistics for all the computed rules. It can be noted that although the confidence median and mean is low, the high level of lift indicates a high dependency of the learned rules,
i.e., the computed rules show that our hypothesis is valid and users tend to follow each other. Since our dataset is big, with many users and many posts, a low support mean and median is expected. Moreover, it is noticeable that users are not active in all posts but more on a subset of them.
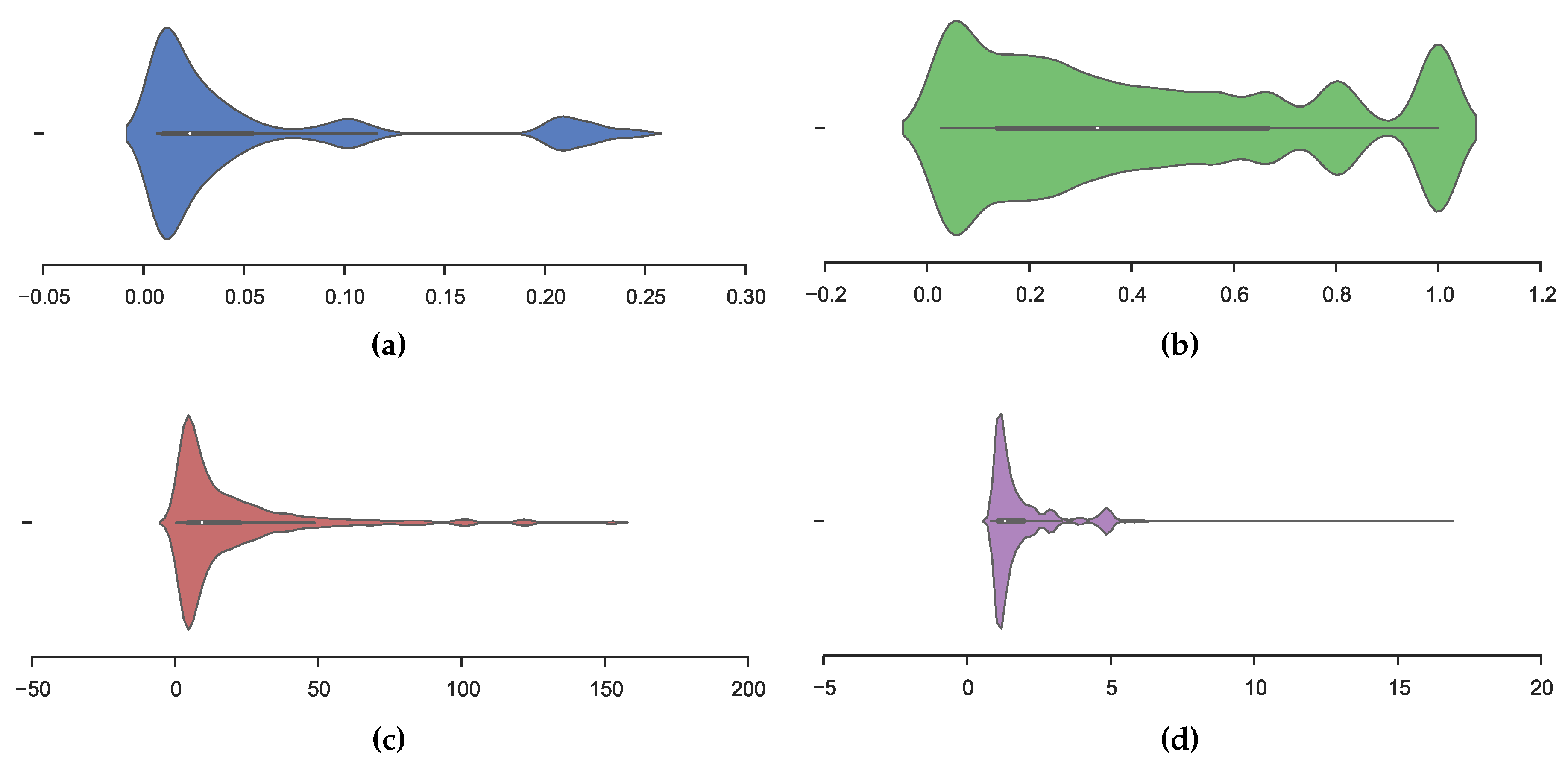
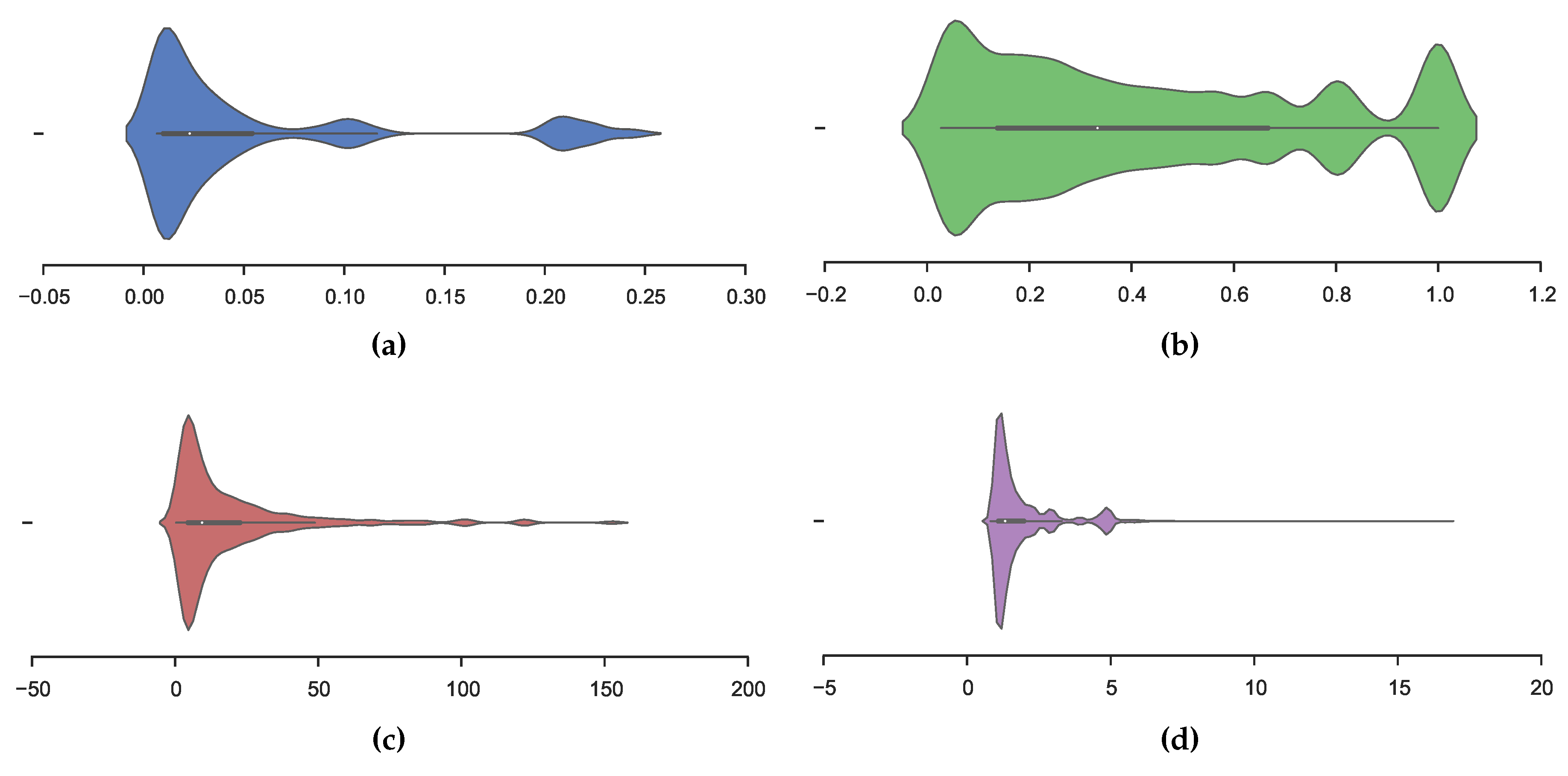
Figure 2 depicts the distribution, Confidence, Lift, Conviction and Frequency respectively in our learned model. The figures are violin-plots, which illustrate the kernel density (shown as height and depth) in addition to normal box-plots with outer quartiles as thin lines, inner quartiles as bold lines and the mean as a white dot.
Figure 2a shows a dense distribution of support at
and, interestingly, a higher density at
. The confidence distribution is illustrated in
Figure 2b, in which we obtained a dense distribution around
,
i.e., there are a significant number of learned rules with high confidence, thus, the rule is accurate.
Figure 2c shows that the lift measure has a heavy tail distribution. In addition,
Figure 2d illustrates a distribution of conviction to be concentrated between zero and five.
Table 3 presents learned rules in three sections. Each section is sorted firstly, by Confidence, Lift and Conviction, respectively, and secondly by the number of supporting users. The rule
should be interpreted as user 429 together with user 578 influencing the participation of user 19. Notably, when sorting by confidence and lift, the conviction is infinite (this is due to the confidence of
) which is shown in how conviction is calculated in Equation (
4). All of the rules in
Table 3 have high confidence and show high dependency (via the lift metric),
i.e., the top five rules sorted by either Confidence, Lift or Conviction are relevant for predicting user participation.
The rule,
presented in
Table 3 with a confidence of
and a lift of
, strongly indicates that the left-hand-side user set influences the right-hand-side user set,
i.e., when the left-hand-side user set is active on a post, the right-hand-side user set also will be active. A confidence of
means that
of the posts where the left-hand-side user set is active, the right-hand-side user set also will be active. A lift value of
, in this specific rule, shows that the right-hand-side user set is dependent on the left.
Considering rules where at least two separate users affect another user with a confidence of ⩾ 95%, we can reduce the
rules to 4959 rules, which have a median lift of
and a median support of
. In other words, we have close to 5000 rules that strongly indicate that users are affected by each other when it comes to participating in online social networks. From learned rules, we can also identify influential users, or the users that exists on the left side of multiple rules as presented in
Section 5.3.
The learned rules of the complete dataset are presented in
Table 4, after filtering out rules with
Confidence ⩾ 95%.
5.2. Verification of Learned Rules
To test how well association rule learning works for predicting user participation, a split, learn and test pattern have been used. For the page in question, we sort all comments based on creation time and use the first 80% for learning and the last 20% of the posts for testing. The learning part is performed as described in
Section 3.2, and the testing part is carried out as follows: for each post with comments in the testing set, the active users are considered by finding rules that affect the users with respect to temporal order. Say that user
D is commenting on a post (in the testing set), and there exists a rule saying that
affect user
D, this rule will only be considered to be valid if all of
have made at least one comment each before
D makes a comment. Of the 787 intersecting users between the learning and test sets, it is possible to predict 113 (14.36 %) users, making use of 5310 (9.63 %) of the original 55,166 rules.
To calculate
accuracy and
precision of learned rules, we have defined
true/false positive/negatives as follows: A
true positive is a rule that predicts user activeness, and the user is active. A
false positive is when a rule predicts user activeness, but the user is not active. A
true negative is when no user is active, and there is no rule. A
false negative is when a user is active, but there is no rule. An example of all four classes are shown in
Table 5.
For the page OccupyTogether, an accuracy of
, precision of
, and recall of
was calculated, with a testing time of 9175 s. This result is quite low since all learned rules are being considered. To portray a more realistic view of user influence, the rules were limited to only consider rules with confidence
and rules affecting a single user. Rules affecting more than one user are already covered by the rules affecting a single user, reducing the number of learned rules from 46,170 to 4469 and the execution time down to 890 s. Showing an accuracy of
, precision of
, and recall of
. The testing was also performed on the rest of the pages and the results are reported in
Table 6. The recall is low because there are many
false negatives (calculated with TP/(TP+FN)). The relatively high accuracy is then achieved with a relatively high number of
true negatives used in (TN+TP)/(TP+FP+TN+FN). In general, the unfiltered rules show a lower accuracy, precision, and recall compared to the filtered rules. Furthermore, the complexity of the rule set is reduced by filtering the rules, indicating the beneficial use of rule filtering. The rules set was on average reduced by approximately
. A less complex rules set could be easier to test and also to understand.
5.3. Identifying and Verifying Influential Users Using Social Network Analysis
The state-of-the-art method for identifying influential users is social networks analysis (SNA), using the methods Page Rank Centrality [
3] or Degree Centrality [
40] for ranking users. It is of interest to see how well influential users identified using association rule learning (ARL) match the state-of-the-art techniques. Therefore, we have conducted an SNA of our pages as follows: for each page, we have created social networks in such a way that two users are linked together if they commented on the same post: next, for all social networks, Page Rank [
3] and Degree [
40] measures have been calculated; and, based on those measures, two ordered (descending) user lists were created, one for each of them.
We have created a similar list for the most influential users from association rule learning. Most influential users are defined as the top-k users from the left side of the rules, with a confidence level of greater than 95 %, that affect other users to comment on posts. In the most influential users list, users are ranked based on how often they appear on the left side of the rule, e.g., if user A has appeared three times in all rules and users and D have appeared one, five and four times, respectively, and the list will look as follows: .
Finally, we compared the most influential users identified from association rule learning with top users according to the degree and Page Rank. Comparison between association rule learning, Degree and Page Rank are considered the top 1 %, 5 %, 10 %, 25 %, 50 %, 75 %, and 100 % of the most influential users identified by association rule learning, respectively. The comparison was made as an intersection of two sets created from two lists. For example, if the top four users are for Degree and for association rule learning, the intersection of those two sets will be and the size of that set is three, and, in this case, the similarity is 75 %.
The example of the SNA analysis for one of the pages [
39] is presented in
Table 7. The table shows that for the top 209 users on the page OccupyTogether (the 50 % most influential users from association rule learning), there is a similarity of 95 % between the users ranked by Page Rank and Degree. When considering users ranked from association rule learning, there is a similarity of 51 % compared to Degree and 53 % compared to Page Rank.
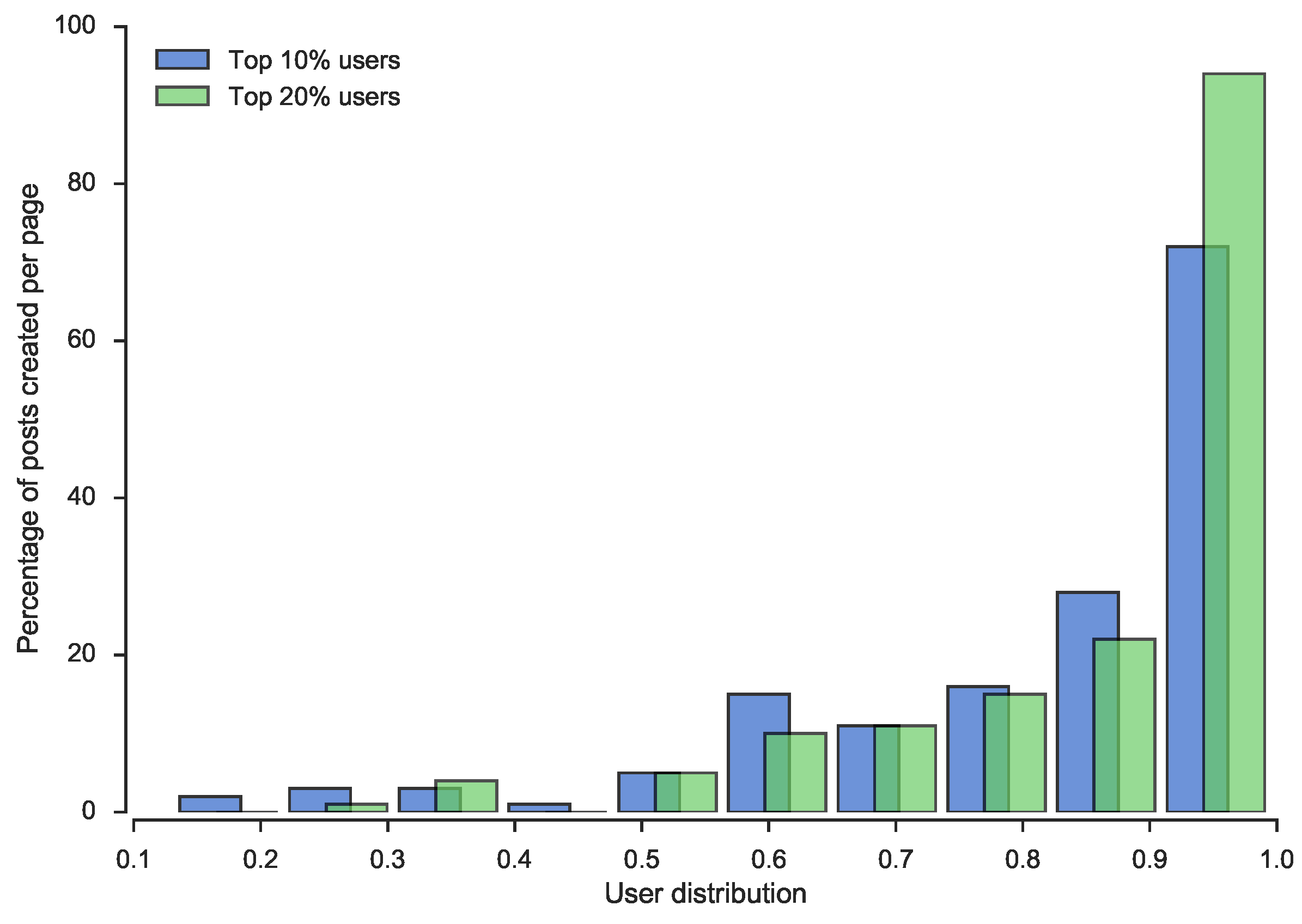
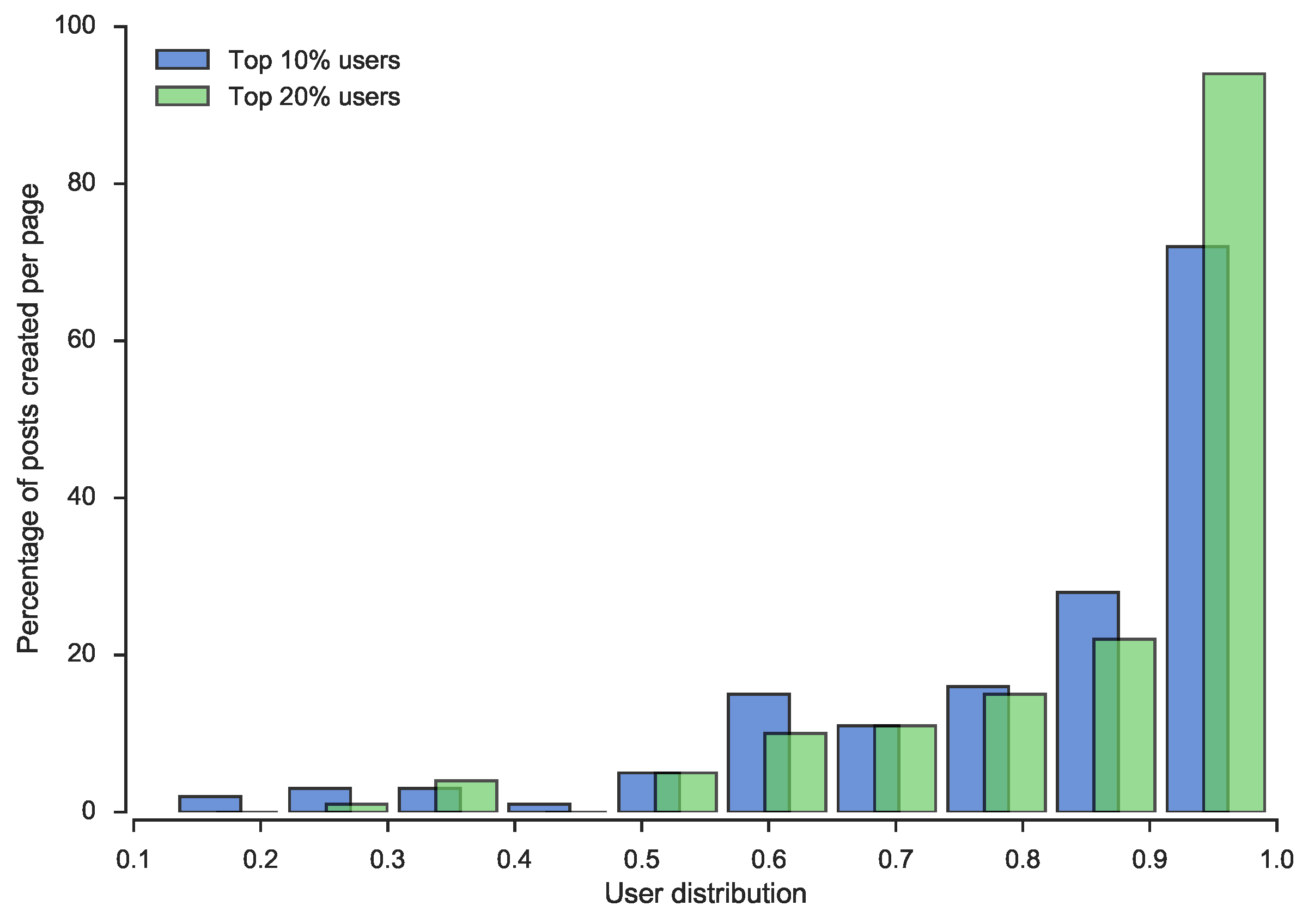
From the SNA analysis, we detected yet another interesting insight into users’ behavior in social media pages. We noticed that 10 % of users with the highest value of degree measure, created an average of 82.64 % posts, and an additional 10 % of the most important users add only four more percentage points of posts,
i.e., 20 % of users with the highest value of the degree measure, create 86.84 % posts on average. In
Figure 3, the distribution of that phenomena is depicted for all pages.
As described above, the three different approaches were used to detect the most influential users. The intersection between the different user lists were then calculated to evaluate how much each method differs from the others. To detect whether any statistical significant difference exists, Friedman’s test was used with the Nemenyi
post hoc test. Friedman’s test is a non-parametric statistical test that ranks the methods over datasets [
41]. When a normal distribution cannot be assumed and several datasets are used, Friedman’s test has been suggested as preferable when comparing algorithms [
42]. The Nemenyi
post hoc test evaluates between which intersections a significant difference exists. The means and standard deviation for the intersections of several posts are presented in
Table 8. A low standard deviation indicates that the expected value,
i.e., the intersection between two sets, is close to the mean. However, there might still exist results which are not close to the mean, e.g., as seen in
Table 7.
The average shows that, regardless of the size of the intersection,
Page Rank ∩ Degree has more users in common than the other intersections, while Page Rank and Degree, considered state-of-the-art, have a high amount of users in common (see
Page Rank ∩ Degree in
Table 8), the rule based learner has fewer users in common with both the Page Rank (
Page Rank ∩ ARL) method and the Degree method (
Page Rank ∩ Degree).
Friedman’s test shows that there are some significant differences between the intersects,
,
,
. The Nemenyi test result (see
Table 9) demonstrates that the
Page Rank ∩ Degree set performs significantly better than the
Degree ∩ ARL set at a confidence level of both
and
.
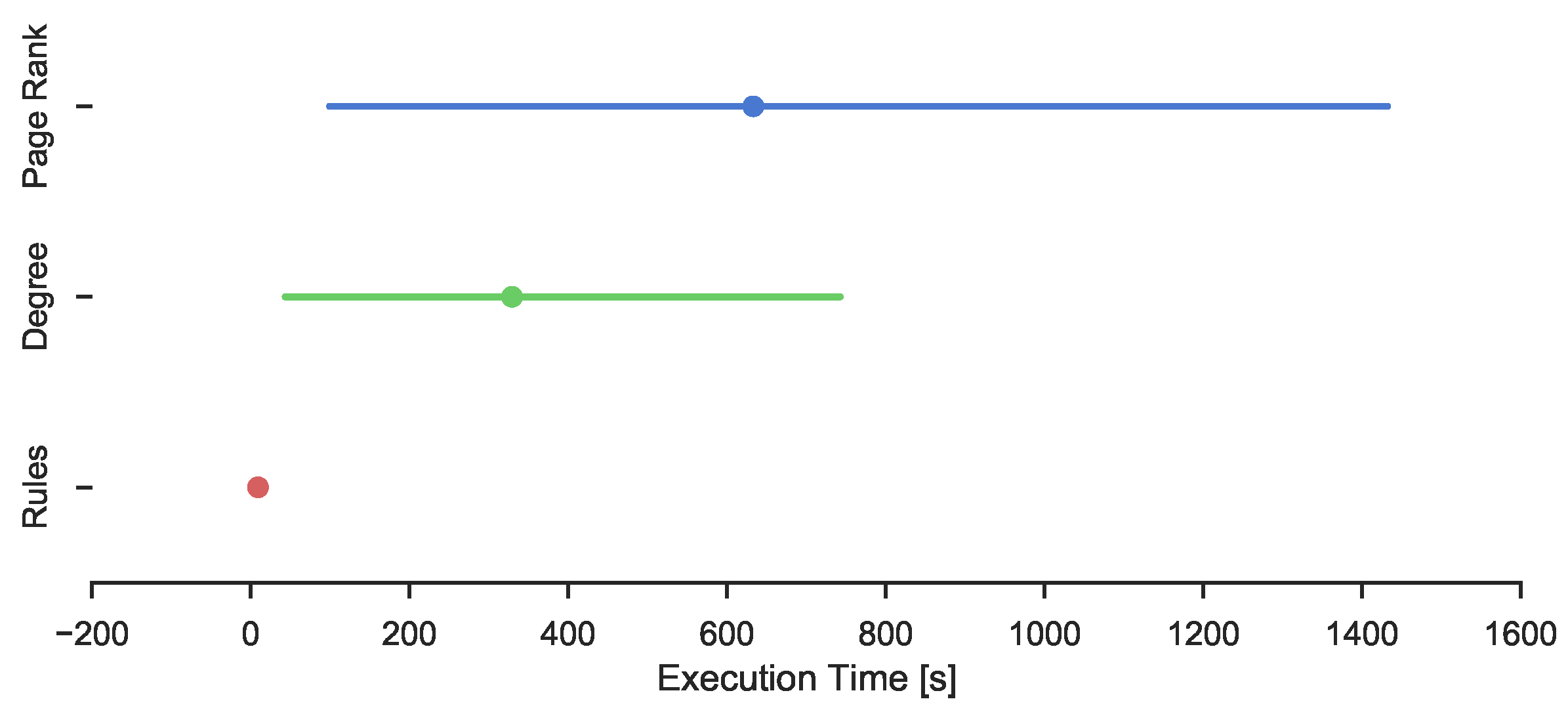
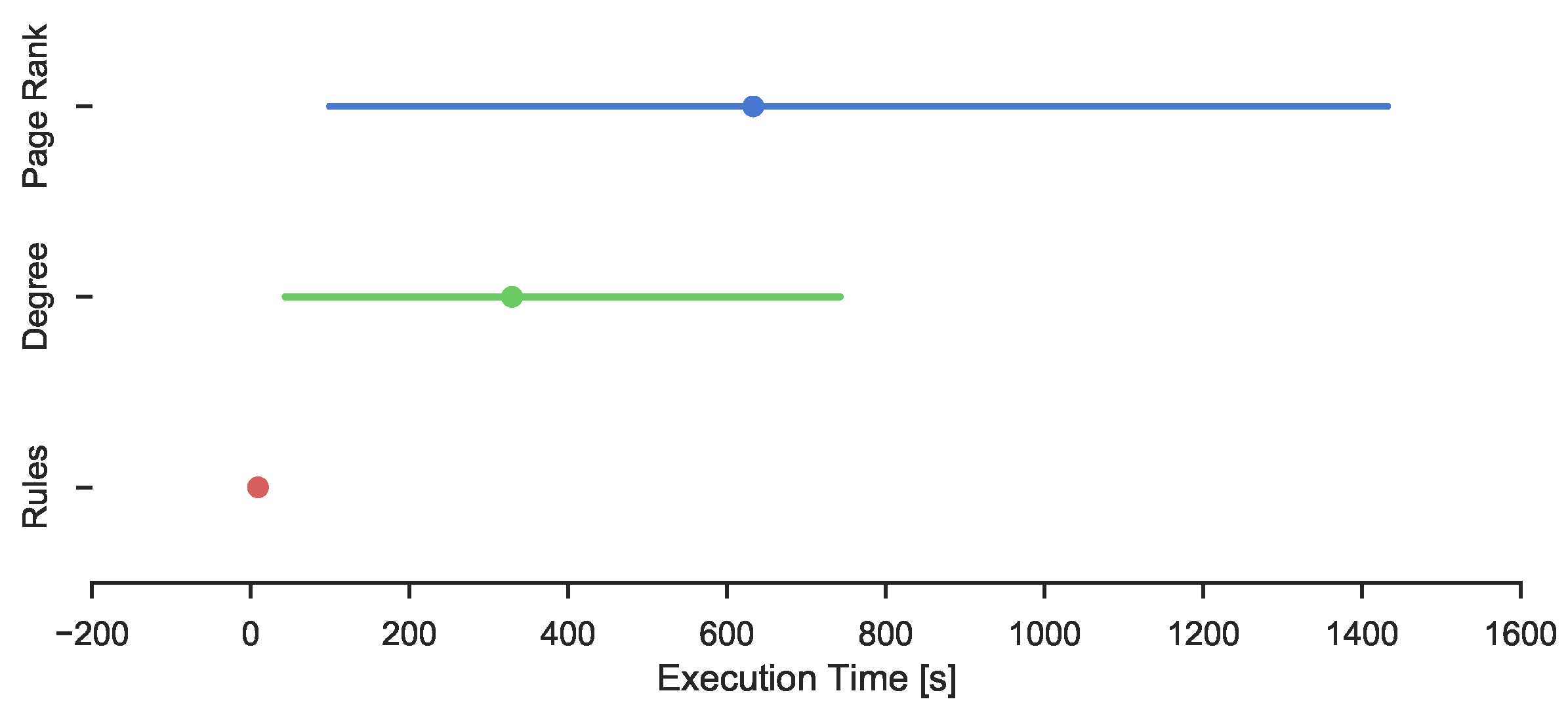
The three different methods were investigated to identify influential users. The amount of time needed to identify influential users differs between the methods. This is shown in
Table 10. Rule based learning is suggested to be the fastest method, and Page Rank the slowest. This might be explained by Page Rank being a global measure compared to the Degree, which is a local measure. The execution time of the different methods with the confidence intervals are also presented in
Figure 4, where intuitively it would seem that the rule based learner has a significantly lower execution time than the other methods.
Whether there is any statistical significant difference is evaluated using a Kruskal–Wallis test followed by a pair-wise Wilcoxon
post hoc test [
41]. The Kruskal–Wallis test is used to see if there is a significant difference between any of the methods, and the
post hoc test is used to detect between which methods the differences exist. The Kruskal–Wallis test detected a significant difference between the methods (
,
,
p < 0.05). The Wilcoxon
post hoc tests showed a significant difference between Rule based and Degree (
p < 0.05,
). No other statistical significant differences were found. While there exists a large difference in mean, there is no detectable significant difference between the Association Rule based method and Page Rank(
,
). This might be due to the high standard deviation.





{kind=link}
{kind=link}
{kind=link}
{kind=link}