
Reliability Analysis Based on a Jump Diffusion Model with Two Wiener Processes for Cloud Computing with Big Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Research
- ► In the case of a mobile device, the network access devices are frequently used by many types of software installed via the installer software.
- ► By using the installer software, the various types of third-party software are installed via the network.
- ► In the case of open source software, the weakness of reliability and security becomes a significant problem with respect to a computer network.
- ► Cloud computing has a particular maintenance phase, such as the provisioning processes.
- ► Big data as the result of many and complicated data from using the Internet cause system-wide failures because of the complexity of data management.
- ► The various mobile devices are connected via the network to the cloud service.
- ► The data storage areas for cloud computing are reconfigured via the various mobile devices.
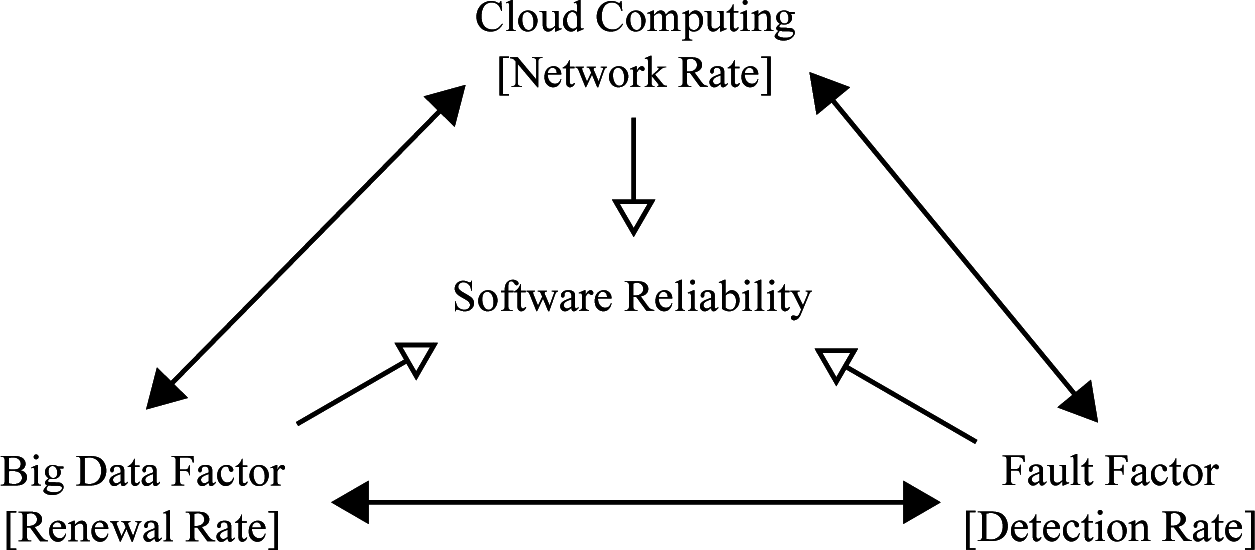
3. Model Description
3.1. Wiener Process Modeling
3.2. Jump-Diffusion Modeling
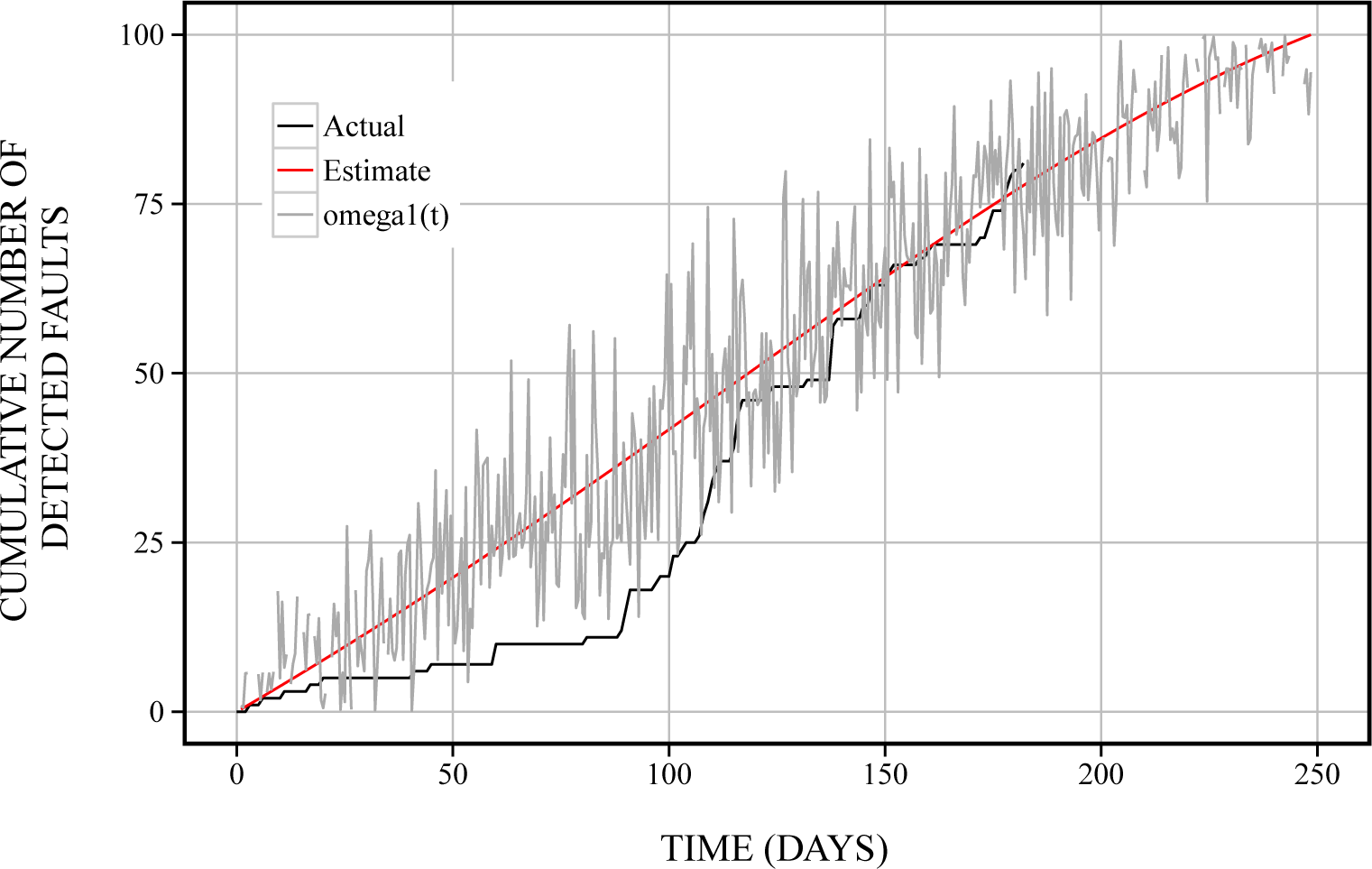
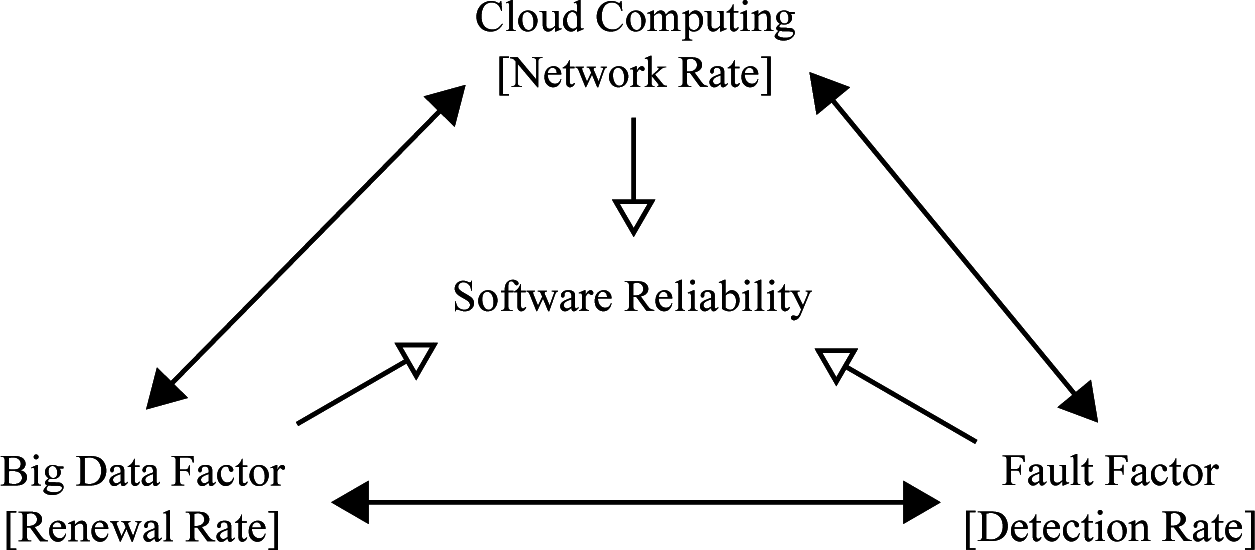
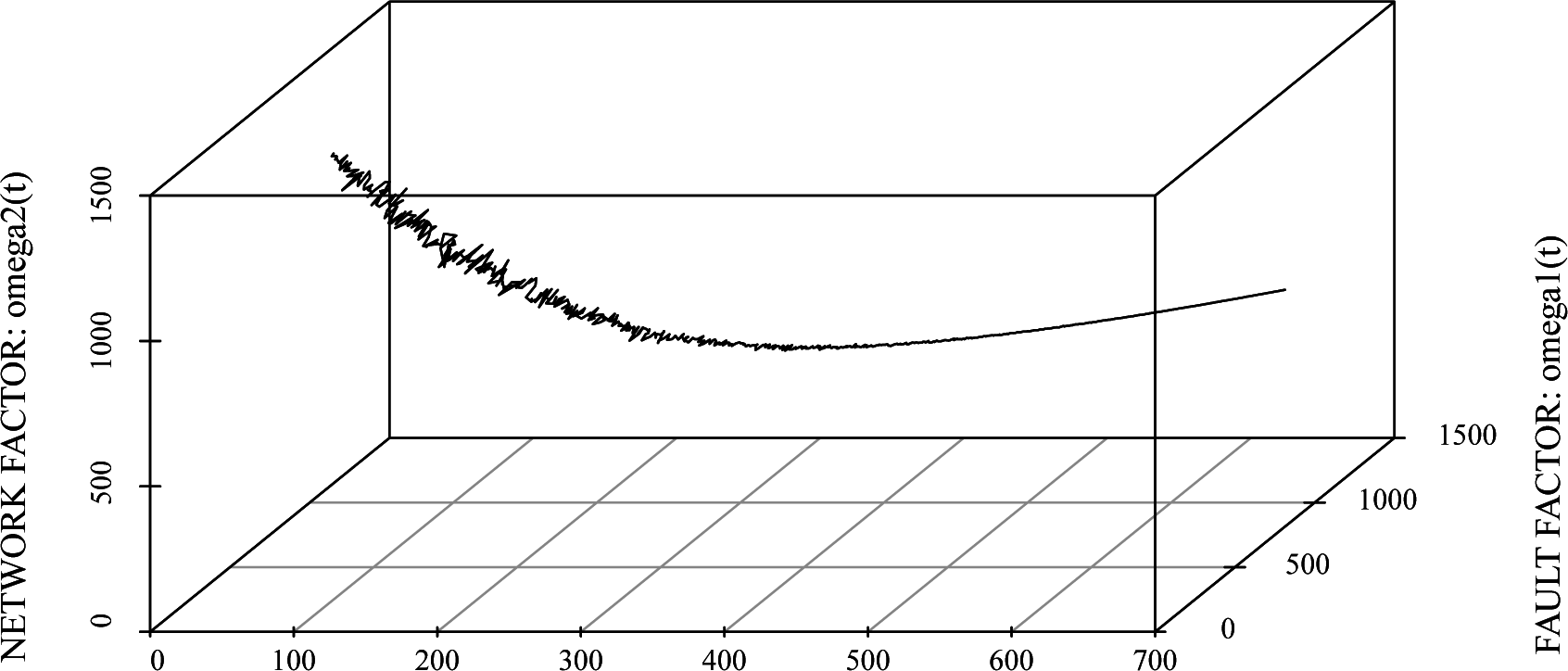
- ► The Brownian motion ω1 represents the results from the failure-occurrence phenomenon.
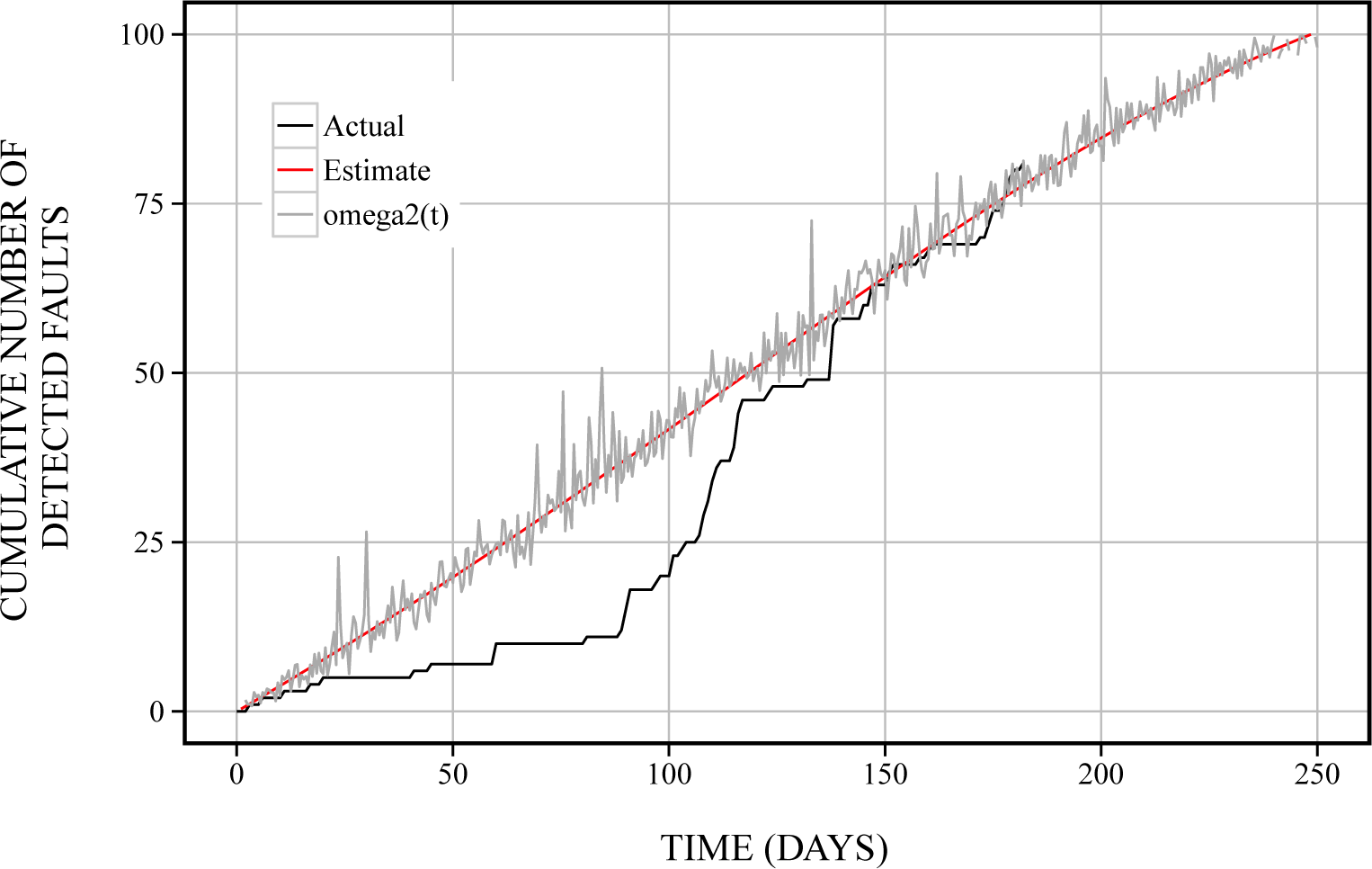
- ► The Brownian motion ω2 represents the results from cloud computing having the unique characteristics of provisioning processes, the change of the number of log-in users, etc.
- ► The jump term means the indirect effects as a result of the many and complicated data from using the Internet, causing the system-wide failures because of the complexity of data management, i.e., the system failures of DataNodeand NameNodein terms of Hadoop and NoSQLin order to manage big data, etc.
4. Parameter Estimation
4.1. Method of Maximum-Likelihood
4.2. Estimation of the Jump Diffusion Parameters
- Step 1: The initial individuals are randomly generated. Furthermore, the set of initial individuals is converted to the binary digit.
- Step 2: Two parental individuals are selected, and new individuals are produced by the crossover recombination.
- Step 3: The value of fitness is calculated from the evaluated value of each individual. The following value of fitness as the error between the estimated and the actual values is defined in this paper:where Mj(i) is the number of detected faults at operation time i in the proposed jump diffusion model and yi the number of actual detected faults. Furthermore, θ means the set of parameters γ, μ, and τ.
- Step 4: Step 2 and Step 3 are continued until reaching a specific size.
5. Optimal Maintenance Problem
- c1: the fixing cost per fault during the operation,
- c2: the maintenance cost per unit time during the operation,
- c3: the maintenance cost per fault after the maintenance.
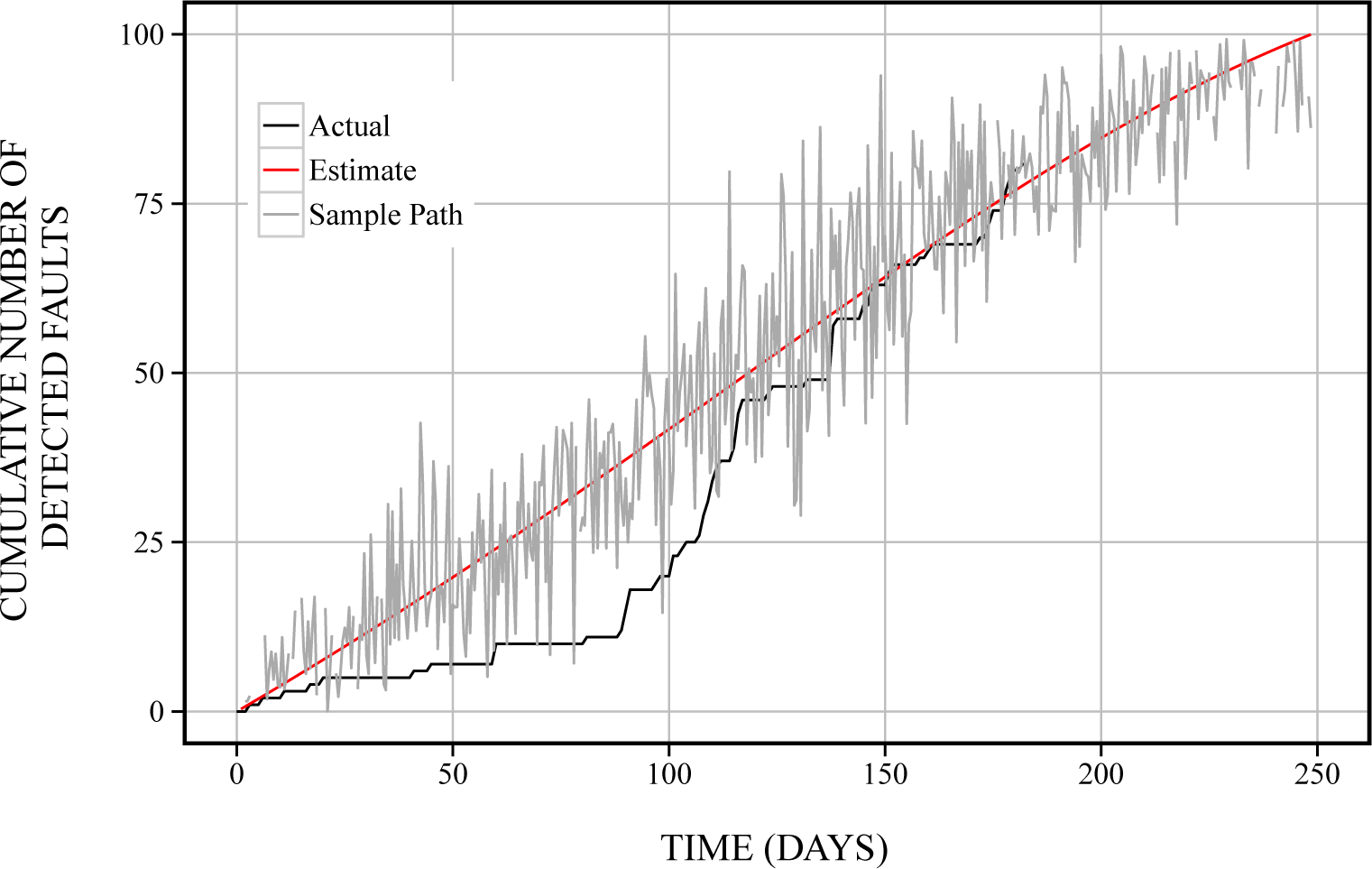
6. Numerical Examples
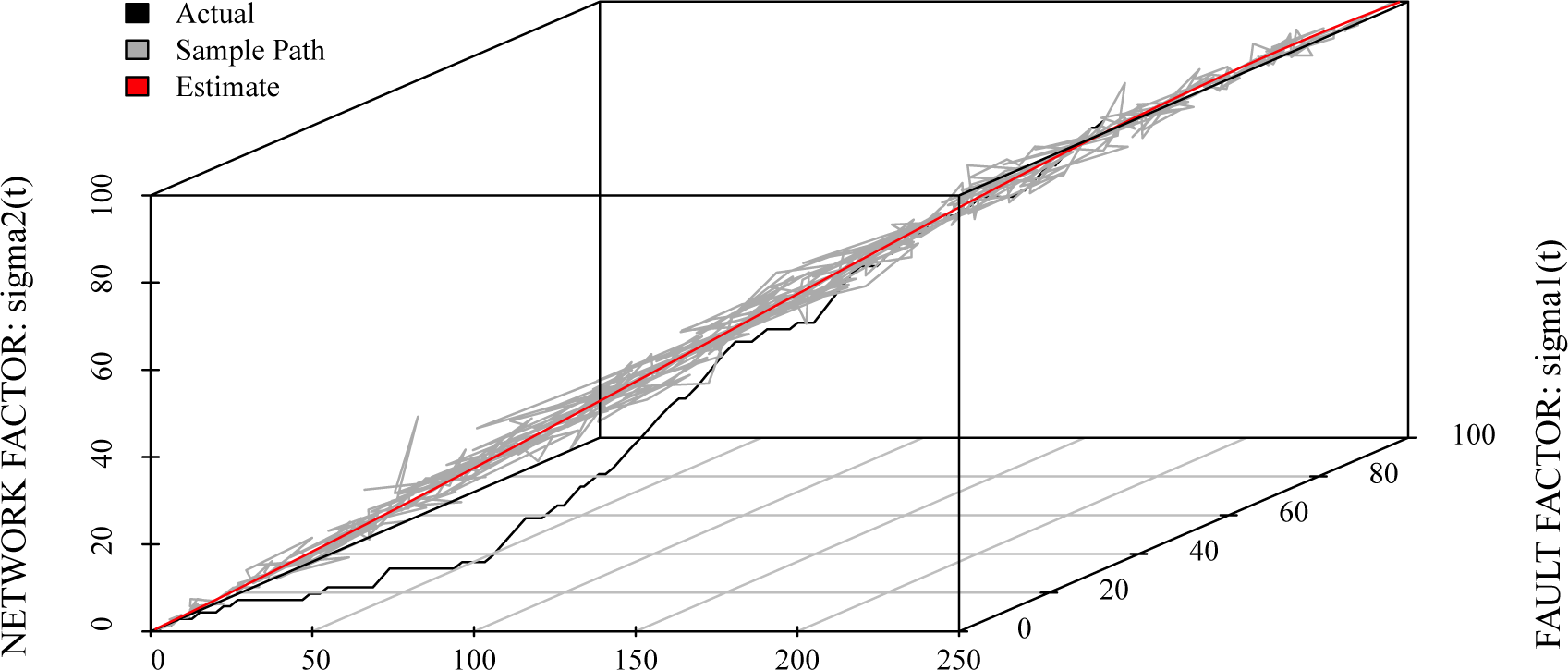
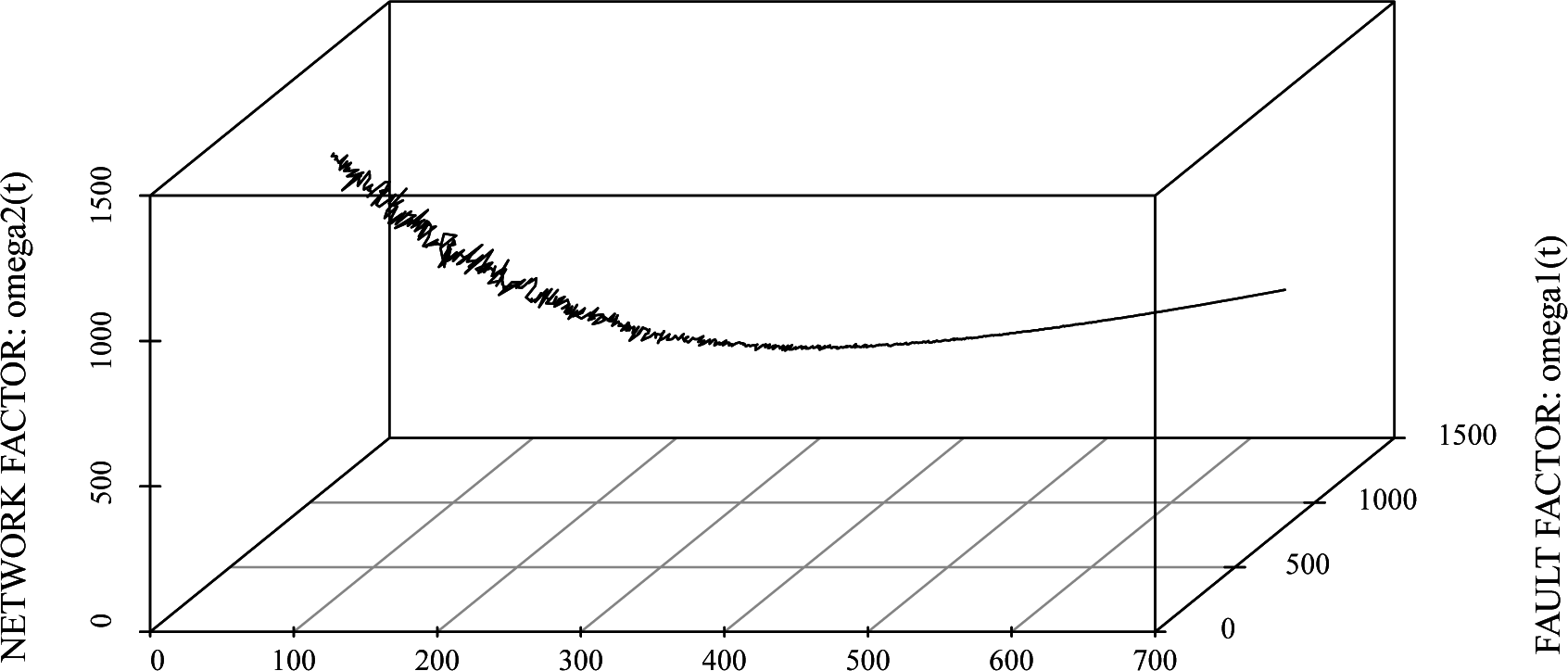
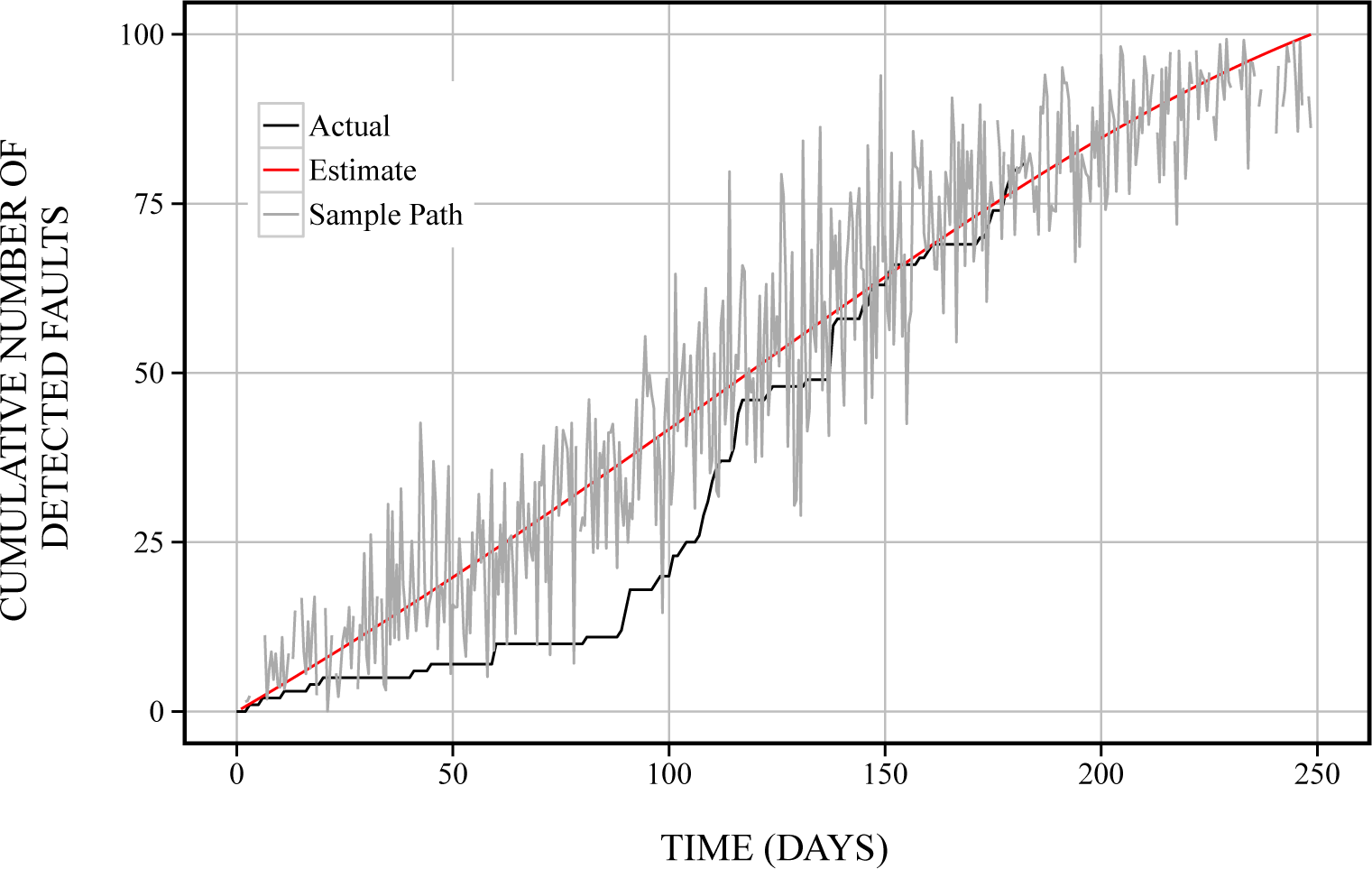
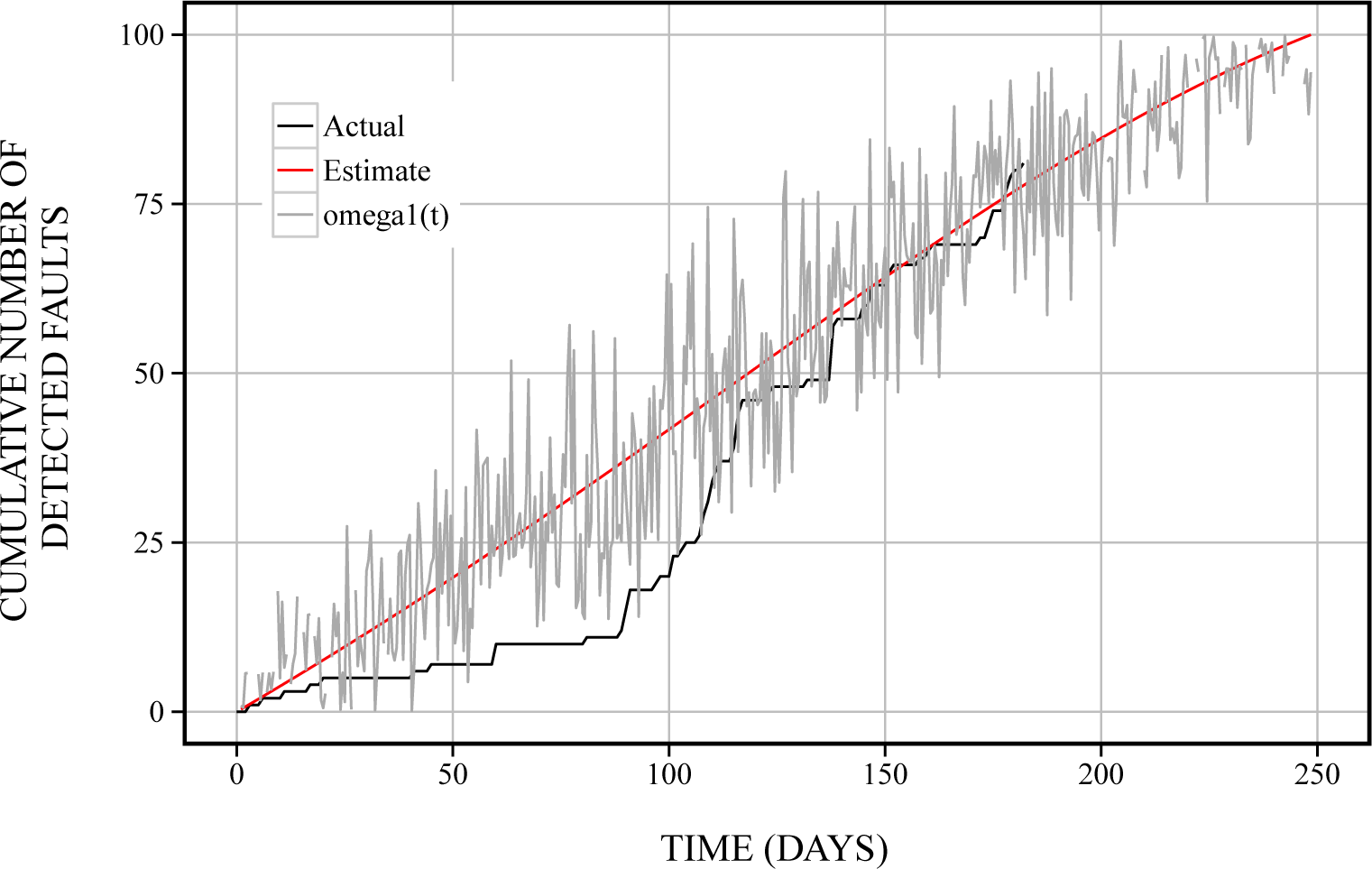
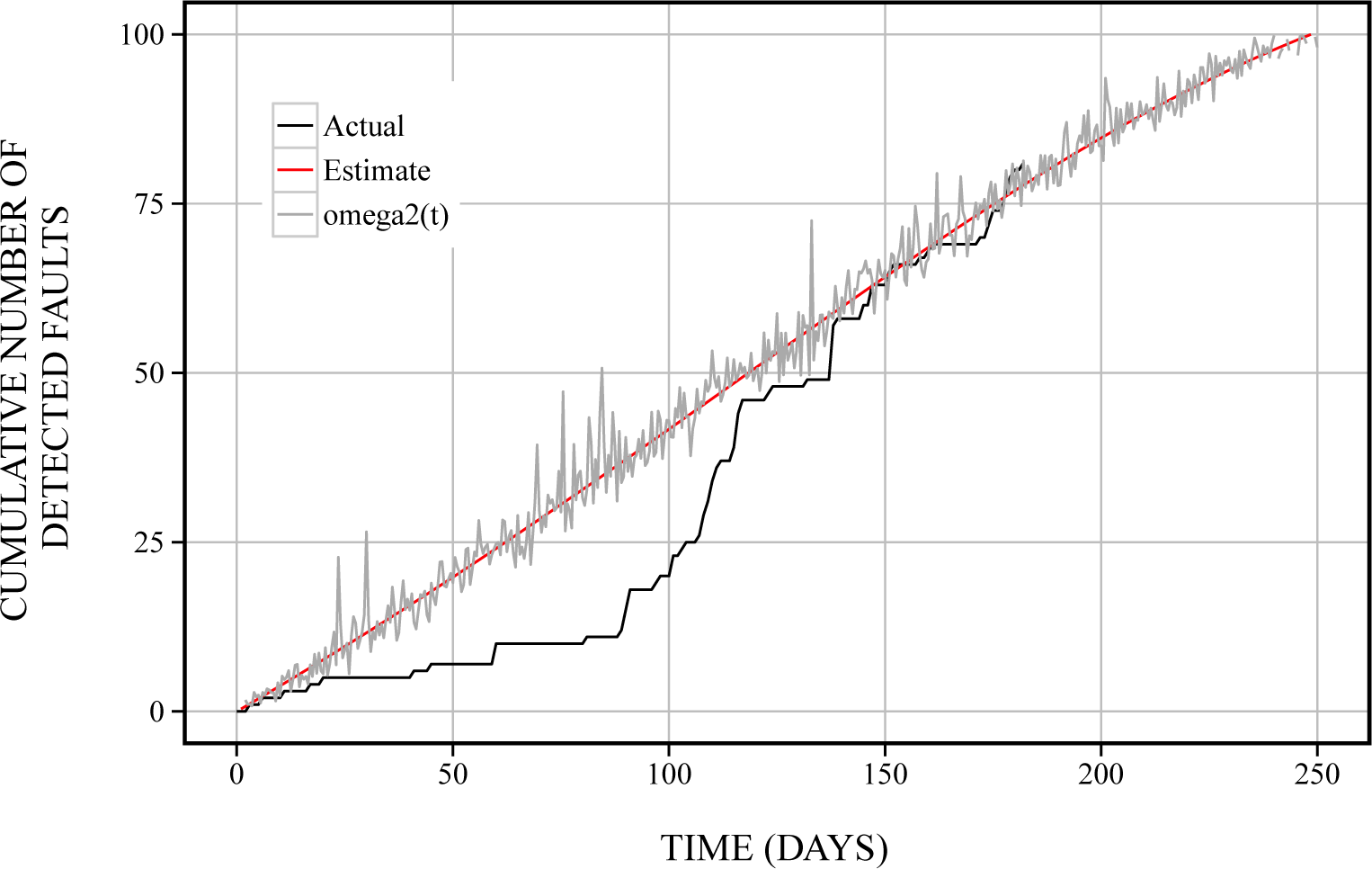
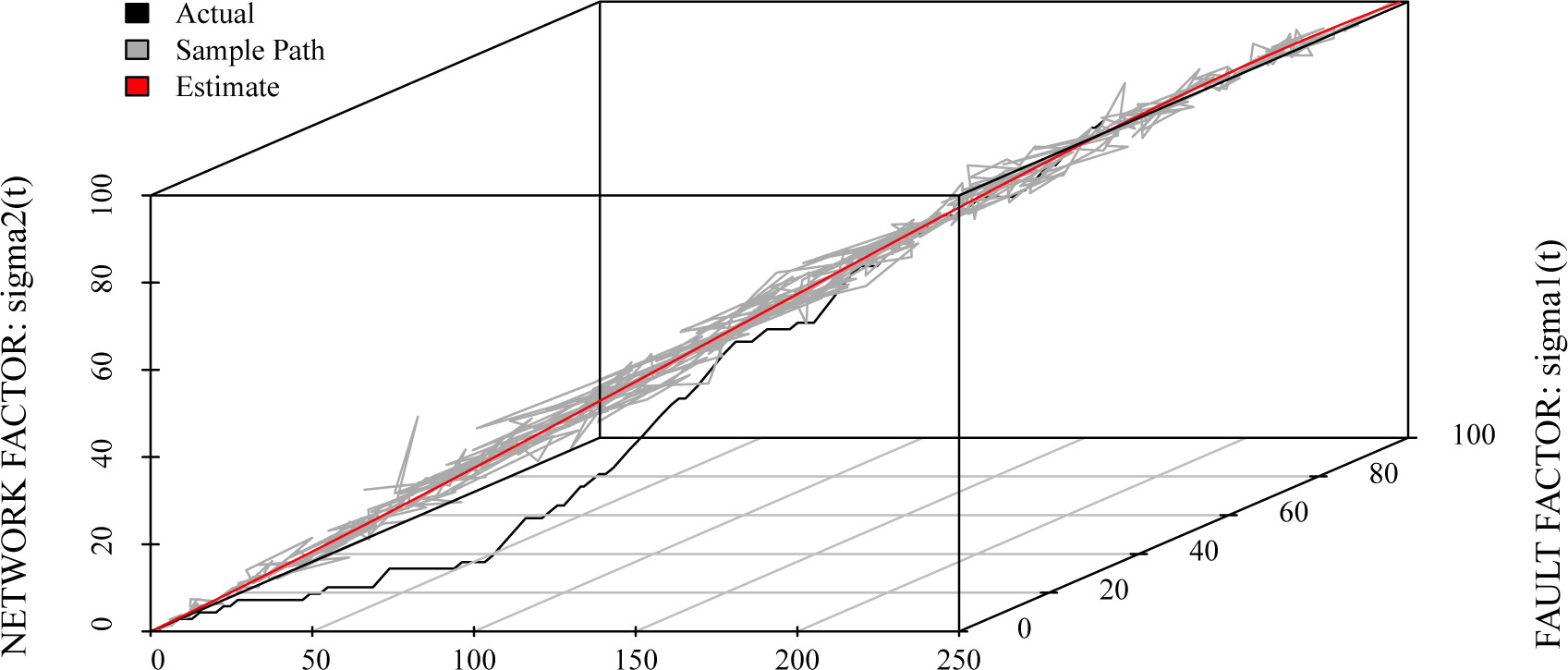
6.1. Reliability Assessment
6.2. Optimal Maintenance Time
7. Concluding Remarks
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Open Handset Alliance, Android. Available online: http://www.android.com/ accessed on 25 June 2015.
- Andersen, E. BUSYBOX. Available online: http://www.busybox.net/ accessed on 25 June 2015.
- Firefox, O.S. Marketplace, Android–Partners–mozilla.org, Mozilla Foundation. Available online: http://www.mozilla.org/firefoxos/ accessed on 25 June 2015.
- Yamada, S. Software Reliability Modeling: Fundamentals and Applications; Springer: Tokyo, Japan and Heidelberg, Germany, 2013. [Google Scholar]
- Lyu, M.R. Handbook of Software Reliability Engineering; Mcgraw-Hill: New York, NY, USA, 1996. [Google Scholar]
- Musa, J.D.; Iannino, A.; Okumoto, K. Software Reliability: Measurement, Prediction, Application; McGraw-Hill: New York, NY, USA, 1987. [Google Scholar]
- Kapur, P.K.; Pham, H.; Gupta, A.; Jha, P.C. Software Reliability Assessment with OR Applications; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Li, X.; Li, Y.F.; Xie, M.; Ng, S.H. Reliability analysis and optimal version-updating for open source software. J. Inf. Softw. Technol. 2011, 53, 929–936. [Google Scholar]
- Ullah, N.; Morisio, M.; Vetro, A. A comparative analysis of software reliability growth models using defects data of closed and open source software, Proceedings of the 35thIEEE Software. Engineering Workshop, Heraclion, Greece, 12–13 October 2012; pp. 187–192.
- Cotroneo, D.; Grottke, M.; Natella, R.; Pietrantuono, R.; Trivedi, K.S. Fault triggers in open-source software: An experience report, Proceedings of the 24th IEEE International Symposium on Software Reliability Engineering, Pasadena, CA, USA, 4–7 November 2013; pp. 178–187.
- Park, J.; Yu, H.C.; Lee, E.Y. Resource allocation techniques based on availability and movement reliability for mobile cloud computing. In Distributed Computing and Internet Technology; Ramanujam, R., Ramaswamy, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 263–264. [Google Scholar]
- Suo, H.; Liu, Z.; Wan, J.; Zhou, K. Security and privacy in mobile cloud computing, Proceedings of the 9th International Wireless Communications and Mobile Computing Conference, Cagliari, Italy, 1–5 July 2013; pp. 655–659.
- Khalifa, A.; Eltoweissy, M. Collaborative autonomic resource management system for mobile cloud computing, Proceedings of the Fourth International Conference on Cloud Computing, GRIDs, and Virtualization, Valencia, Spain, 27 May–1 June 2013; pp. 115–121.
- Gabner, R.; Schwefel, H.P.; Hummel, K.A.; Haring, G. Optimal model-based policies for component migration of mobile cloud services, Proceedings of the 10th IEEE International Symposium on Network Computing and Applications, Cambridge, MA, USA, 25–27 August 2011; pp. 195–202.
- Park, N. Secure data access control scheme using type-based re-encryption in cloud environment. In Semantic Methods for Knowledge Management and Communication; Springer: Berlin/Heidelberg, Germany, 2011; pp. 319–327. [Google Scholar]
- Yang, B.; Tan, F.; Dai, Y.S. Performance evaluation of cloud service considering fault recovery. J. Supercomput. 2013, 65, 426–444. [Google Scholar]
- Iosup, A.; Ostermann, S.; Yigitbasi, M.N.; Prodan, R. Fahringer, T; Epema, D.H.J. Performance analysis of cloud computing services for many-tasks scientific computing. IEEE Trans. Parallel Distrib. Syst. 2011, 22, 931–945. [Google Scholar]
- Tamura, Y.; Miyahara, H.; Yamada, S. Reliability analysis based on jump diffusion models for an open source cloud computing, Proceedings of the IEEE International Conference on Industrial Engineering and Engineering Management, Hong Kong Convention and Exhibition Centre, Hong Kong, China, 10–13 December 2012; pp. 752–756.
- Tamura, Y.; Yamada, S. Reliability analysis methods for an embedded open source software. In Mechatronic Systems, Simulation, Modelling and Control; Milella, A., Di Paola, D., Cicirelli, G., Eds.; IN-TECH: Vienna, Austria, 2010; pp. 239–254. [Google Scholar]
- Yamada, S.; Fujiwara, T. Testing-domain dependent software reliability growth models and their comparisons of goodness-of-fit. Int. J. Reliab. Qual. Saf. Eng. 2001, 8, 205–218. [Google Scholar]
- Arnold, L. Stochastic Differential Equations-Theory and Applications; Wiley: New York, NY, USA, 1974. [Google Scholar]
- Wong, E. Stochastic Processes in Information and Systems; McGraw-Hill: New York, NY, USA, 1971. [Google Scholar]
- Yamada, S.; Kimura, M.; Tanaka, H.; Osaki, S. Software reliability measurement and assessment with stochastic differential equations. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 1994, E77–A, 109–116. [Google Scholar]
- Mikosch, T. Elementary Stochastic Calculus with Finance in View; World Scientific: Singapore, Singapore, 1998. [Google Scholar]
- Merton, R.C. Option pricing when underlying stock returns are discontinous. J. Financ. Econ. 1976, 3, 125–144. [Google Scholar]
- Honoré, P. Pitfalls in estimating jump-diffusion models. 1998. Available online: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=61998 accessed on 25 June 2015.
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Yamada, S.; Osaki, S. Cost-reliability optimal software release policies for software systems. IEEE Trans. Reliab 1985, R-34, 422–424. [Google Scholar]
- Yamada, S.; Osaki, S. Optimal software release policies with simultaneous cost and reliability requirements. Eur. J. Oper. Res. 1987, 31, 46–51. [Google Scholar]
- The OpenStack project, OpenStack. Available online: http://www.openstack.org/ accessed on 25 June 2015.
© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tamura, Y.; Yamada, S. Reliability Analysis Based on a Jump Diffusion Model with Two Wiener Processes for Cloud Computing with Big Data. Entropy 2015, 17, 4533-4546. https://doi.org/10.3390/e17074533
Tamura Y, Yamada S. Reliability Analysis Based on a Jump Diffusion Model with Two Wiener Processes for Cloud Computing with Big Data. Entropy. 2015; 17(7):4533-4546. https://doi.org/10.3390/e17074533
Chicago/Turabian StyleTamura, Yoshinobu, and Shigeru Yamada. 2015. "Reliability Analysis Based on a Jump Diffusion Model with Two Wiener Processes for Cloud Computing with Big Data" Entropy 17, no. 7: 4533-4546. https://doi.org/10.3390/e17074533
APA StyleTamura, Y., & Yamada, S. (2015). Reliability Analysis Based on a Jump Diffusion Model with Two Wiener Processes for Cloud Computing with Big Data. Entropy, 17(7), 4533-4546. https://doi.org/10.3390/e17074533