
Nonlinear Stochastic Control and Information Theoretic Dualities: Connections, Interdependencies and Thermodynamic Interpretations

Abstract
:1. Introduction
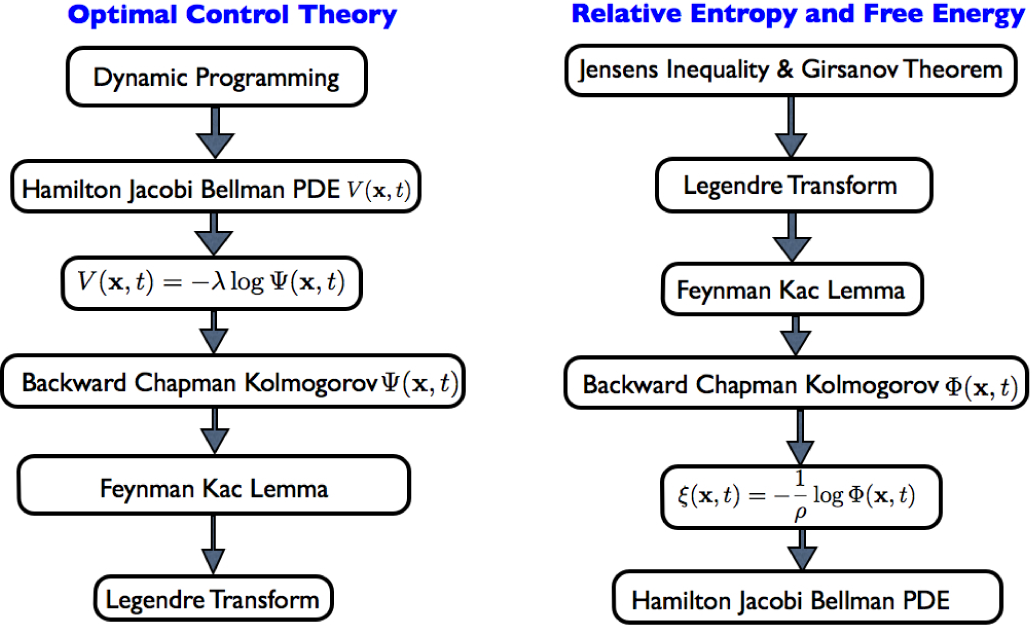
- The PI and KL control framework can be derived using the relative entropy-free energy relationship, and therefore, there are direct connections of the LSOC framework to previous work in control theory. These connections were recently shown in [11]. From the epistemological stand point, the aforementioned connections provide a deeper understanding of optimality principles and identify the conditions under which these optimality principles emerge from information theoretic postulates. Essentially, there are alternative views/methodological approaches of looking into nonlinear stochastic optimal control that are illustrated in Figure 1.
- The derivation of nonlinear stochastic optimal control using the free energy and relative entropy relationship does not rely on the Bellman principle. In other words, one can derive the Hamilton–Jacobi–Bellman (HJB) equation without using dynamic programming. When the form of the optimal control policy has to be found, then the connection with stochastic optimal control based on dynamic programming is necessary. In this paper, we generalize the connection between free energy-relative entropy dualities and stochastic optimal control to systems that are non-affine in controls. The analysis leverages the generalized version of the Feynman–Kac lemma and identifies the necessary and sufficient conditions under which the aforementioned connections are valid. This generalization creates future research directions towards the development of optimal control algorithms for stochastic systems nonlinear in the state and control. In addition, it shows that there is a deeper relation between the Legendre transformation and stochastic control that goes beyond the class of control affine systems.
- While typically in stochastic optimal control theory, the cost function is pre-specified, this is not the case when the stochastic optimal control framework is derived using the free energy-relative entropy relationship. In the latter case, the form of the cost function related to control effort emerges from the structure of the underlying stochastic dynamics. This observation indicates that there are strong interdependencies between cost functions and dynamics and that the choice of the control cost function is not arbitrary. Another way to understand the importance of the aforementioned interdependencies is that, while in the traditional approach, the cost function is imposed to the problem, in the information theoretic view of stochastic optimal control, the cost function partially emerges from the formulation of the problem (see Figure 1).
- We illustrate connections between stochastic control and the maximum entropy principle. The analysis relies on the generalized Boltzmann, Gibbs and Shannon entropy [16]. We show that the stochastic control framework is recovered as the maximization of the generalized Boltzmann, Gibbs and Shannon entropy subject to energy and probability measure normalization constraints.
- For the class of stochastic systems that are affine in control and noise, there are cost function formulations that cannot be represented within the information theoretic approach. Thus, although the information theoretic formulation of stochastic optimal control provides a general framework, there are cases in which the a priori specification of the cost function and the use of dynamic programming provide more flexibility.
- Besides the analysis on the connections between different formulations of stochastic optimal control theory, we also present iterative algorithms designed for stochastic systems and demonstrate some examples.
2. Fundamental Relationship between Free Energy and Relative Entropy
3. The Legendre Transformation and Stochastic Optimal Control
3.1. Application to Nonlinear Stochastic Dynamics with Affine Stochastic Disturbances
- The Helmholtz free energy satisfies the HJB PDE for the case of systems that are non-affine in controls and affine in stochastic disturbances. This observation has direct consequences to the development of algorithms that can compute the value function for a stochastic optimal control problem with forward sampling of SDEs. While this connection was known within the LSOC framework for dynamics affine in controls and noise, it is the first time that this connection has been derived for general classes of stochastic systems with dynamics nonlinear in state and control and affine only in noise.
- The optimal measure dℚ∗ for the stochastic control problem with state and control cost as specified in Equation (23) is given by Equation (7). Note that this is the probability measure that corresponds to trajectories generated under the optimal control policy u∗(x, t). A fundamental question at this point is related to how this optimal control can be numerically computed, such that dℚ = dℚ∗. The difficulty arises from the fact that for the case of dynamic systems that are nonlinear in controls and cost functions that are non quadratic, there is no explicit form for the optimal control policy u∗(x, t). This difficulty could be addressed by an a priori specification of the structure of the optimal control policy u(x, t) and then optimization of this structure, such that for any state x and time t, the optimal probability measure dℚ∗ = dℚ∗(x, t) is reached.
3.2. Application to Nonlinear Stochastic Dynamics with Affine Controls and Disturbances
4. Thermodynamic Interpretations and Connections to the Maximum Entropy Principle
- Substitution of the optimal measure dℚ∗ in Lagrangian (37) results in:Moreover, given a certain performance level c, the Lagrange multiplier λ can be found by using the equation:
- The term corresponds to the Helmholtz free energy, since:Therefore, for the case stochastic dynamics affine in control and noise, the term function and satisfies the HJB equation.
- Initially, we considered as a singed measure. However, given the optimal measure ℚ∗ and the form of the Lagrange multiplier µ, the signed measure is positive, and therefore, it is a measure. To show this, one can use the Legendre transformation between free energy and relative entropy.
5. Bellman Principle of Optimality
6. Kullback–Leibler Control in Discrete Formulations
6.1. Connections to Continuous Time
7. Algorithms
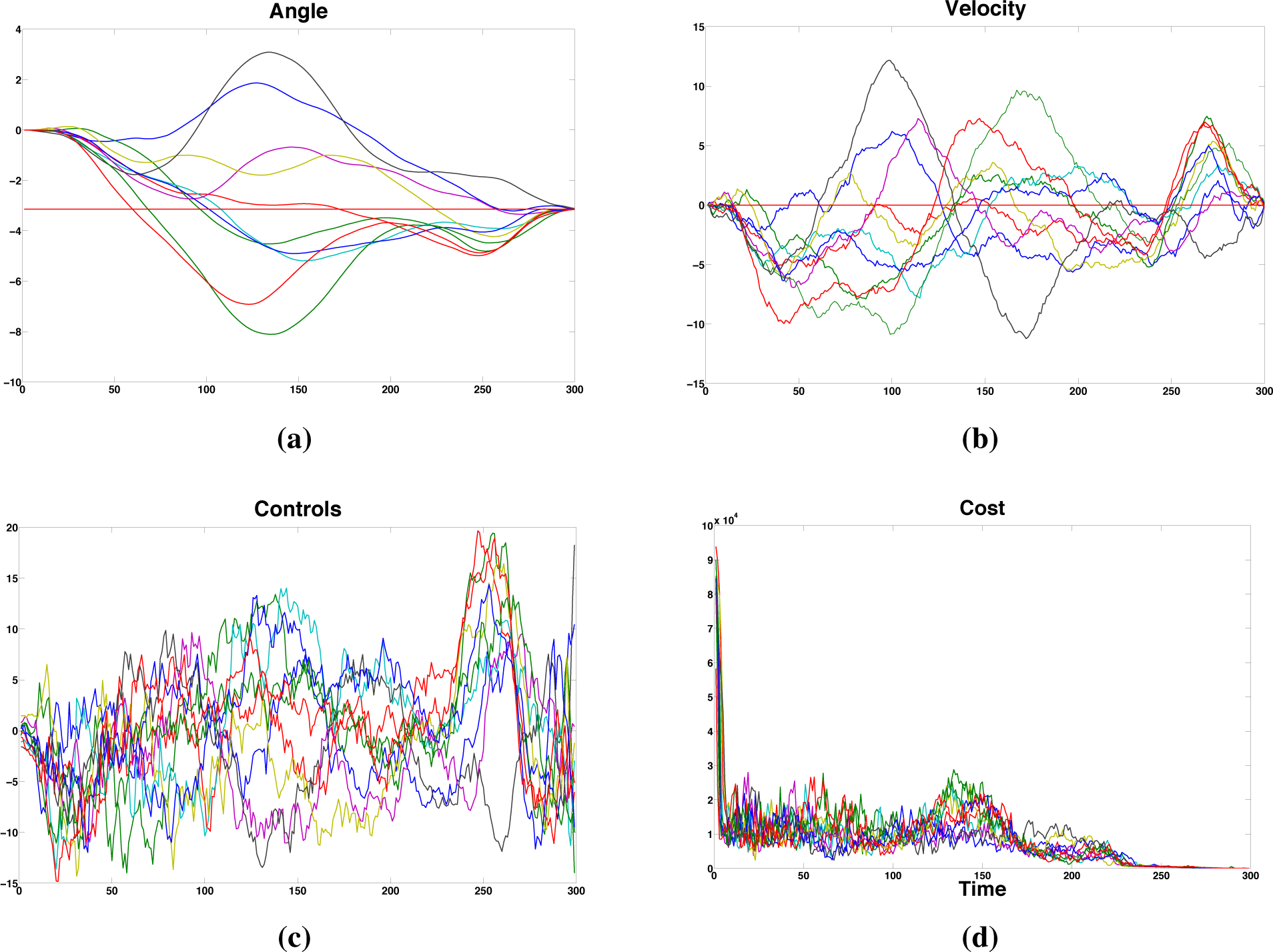
7.1. Open Loop Formulations and Application to an Inverted Pendulum

{kind=link}
{kind=link}
{kind=link}
{kind=link}
 |
 |
8. Discussion
Conflicts of Interest
References
- Kappen, H.J. An introduction to stochastic control theory, path integrals and reinforcement learning. In Cooperative Behavior in Neural Systems; Marro, J., Garrido, P.L., Torres, J.J., Eds.; American Institute of Physics: College Park, MD, USA, 2007; Volume 887, pp. 149–181. [Google Scholar]
- Kappen, H.J. Path integrals and symmetry breaking for optimal control theory. J. Stat. Mech. Theory Exp. 2005, 11, P11011. [Google Scholar]
- Theodorou, E.; Buchli, J.; Schaal, S. A Generalized Path Integral Approach to Reinforcement Learning. J. Mach. Learn. Res. 2010, 3137–3181. [Google Scholar]
- Todorov, E. Efficient computation of optimal actions. Proc. Natl. Acad. Sci. USA 2009, 106, 11478–11483. [Google Scholar]
- Todorov, E. Linearly-solvable markov decision problems. In Advances in Neural Information Processing Systems 19; Scholkopf, B., Platt, J., Hoffman, T., Eds.; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Pan, Y.; Theodorou, E. Nonparametric infinite horizon Kullback-Leibler stochastic control, Proceedings of the 2014 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL), Orlando, USA, 9–12 December 2014; pp. 1–8.
- Friedman, A. Stochastic Differential Equations And Applications; Academic Press: Waltham, MA, USA, 1975. [Google Scholar]
- Karatzas, I.; Shreve, S.E. Brownian Motion and Stochastic Calculus (Graduate Texts in Mathematics), 2 ed; Springer: Berlin/Heidelberg, Germany, 1991. [Google Scholar]
- Øksendal, B.K. Stochastic differential equations: An Introduction with Applications, 6 ed; Springer: Berlin, Germany, 2003. [Google Scholar]
- Horowitz, M.B.; Damle, A.; Burdick, J.W. Linear Hamilton Jacobi Bellman Equations in High Dimensions. 2014 arXiv:1404.1089.
- Theodorou, E.; Todorov, E. Relative entropy and free energy dualities: Connections to Path Integral and KL control, Proceedings of 51st IEEE Conference on Decision and Control, Maui, HI, USA, 10–13 December 2012; pp. 1466–1473.
- Fleming, W. Exit probabilities and optimal stochastic control. Appl. Math. Optim. 1971, 9, 329–346. [Google Scholar]
- Dai Pra, P.; Meneghini, L.; Runggaldier, W. Connections between stochastic control and dynamic games. Math. Control Signals Syst. (MCSS) 1996, 9, 303–326. [Google Scholar]
- Mitter, S.K.; Newton, N.J. A Variational Approach to Nonlinear Estimation. SIAM J. Control Optim. 2003, 42, 1813–1833. [Google Scholar]
- Fleming, W.H.; Soner, H.M. Controlled Markov Processes and Viscosity Solutions, 2 ed; Springer: New York, NY, USA, 2006. [Google Scholar]
- Wehrl, A. The many facets of entropy. Rep. Math. Phys. 1991, 30, 119–129. [Google Scholar]
- Yang, J.; Kushner, J.H. A monte carlo method for sensitivity analysis and parametric optimization of nonlinear stochastic systems. SIAM J. Control Optim. 1991, 29, 1216–1249. [Google Scholar]
- Fleming, W.H.; Soner, H.M. Controlled Markov Processes and Viscosity Solutions, 1 ed; Springer: New York, NY, USA, 1993. [Google Scholar]
- Stengel, R.F. Optimal Control and Estimation; Dover Publications: New York, NY, USA, 1994. [Google Scholar]
- Leadbetter, R.; Cambanis, S.; Pipiras, P. Basic Course in Measure and Probabilty; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Kappen, H.J. Linear theory for control of nonlinear stochastic systems. Phys. Rev. Lett. 2005, 95, 200201. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Theodorou, E.A. Nonlinear Stochastic Control and Information Theoretic Dualities: Connections, Interdependencies and Thermodynamic Interpretations. Entropy 2015, 17, 3352-3375. https://doi.org/10.3390/e17053352
Theodorou EA. Nonlinear Stochastic Control and Information Theoretic Dualities: Connections, Interdependencies and Thermodynamic Interpretations. Entropy. 2015; 17(5):3352-3375. https://doi.org/10.3390/e17053352
Chicago/Turabian StyleTheodorou, Evangelos A. 2015. "Nonlinear Stochastic Control and Information Theoretic Dualities: Connections, Interdependencies and Thermodynamic Interpretations" Entropy 17, no. 5: 3352-3375. https://doi.org/10.3390/e17053352
APA StyleTheodorou, E. A. (2015). Nonlinear Stochastic Control and Information Theoretic Dualities: Connections, Interdependencies and Thermodynamic Interpretations. Entropy, 17(5), 3352-3375. https://doi.org/10.3390/e17053352