
On Nonlinear Complexity and Shannon’s Entropy of Finite Length Random Sequences



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
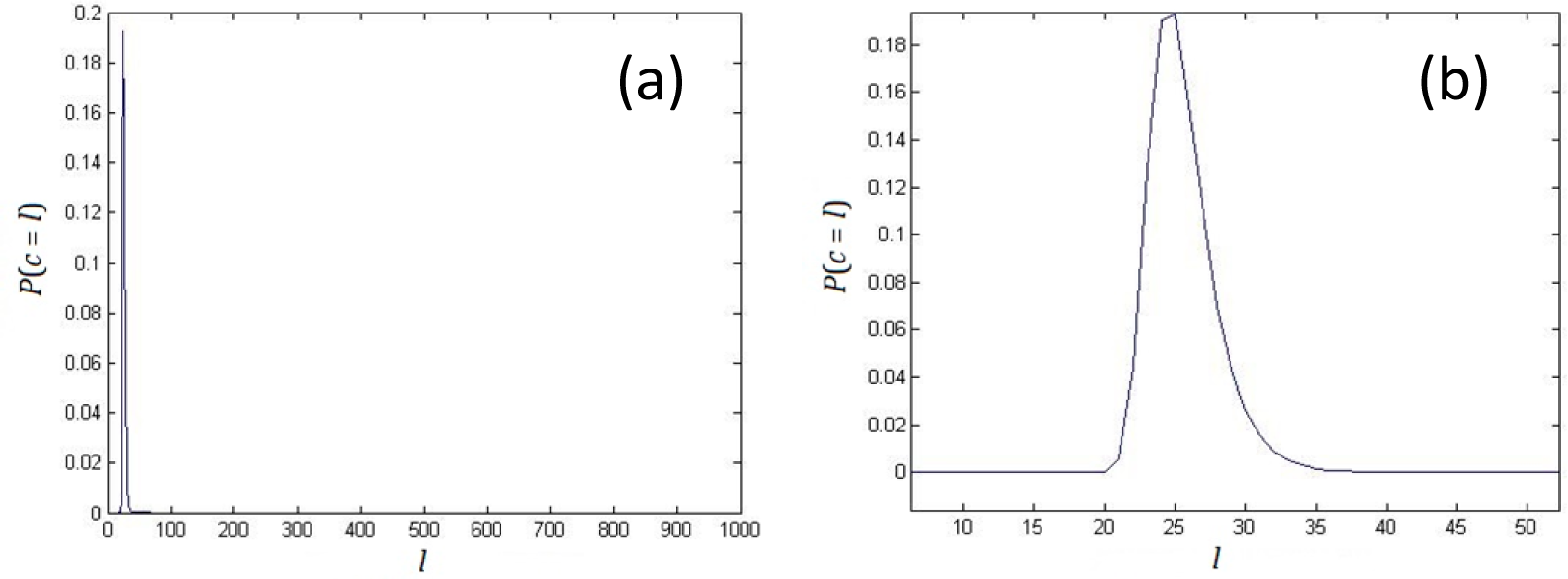
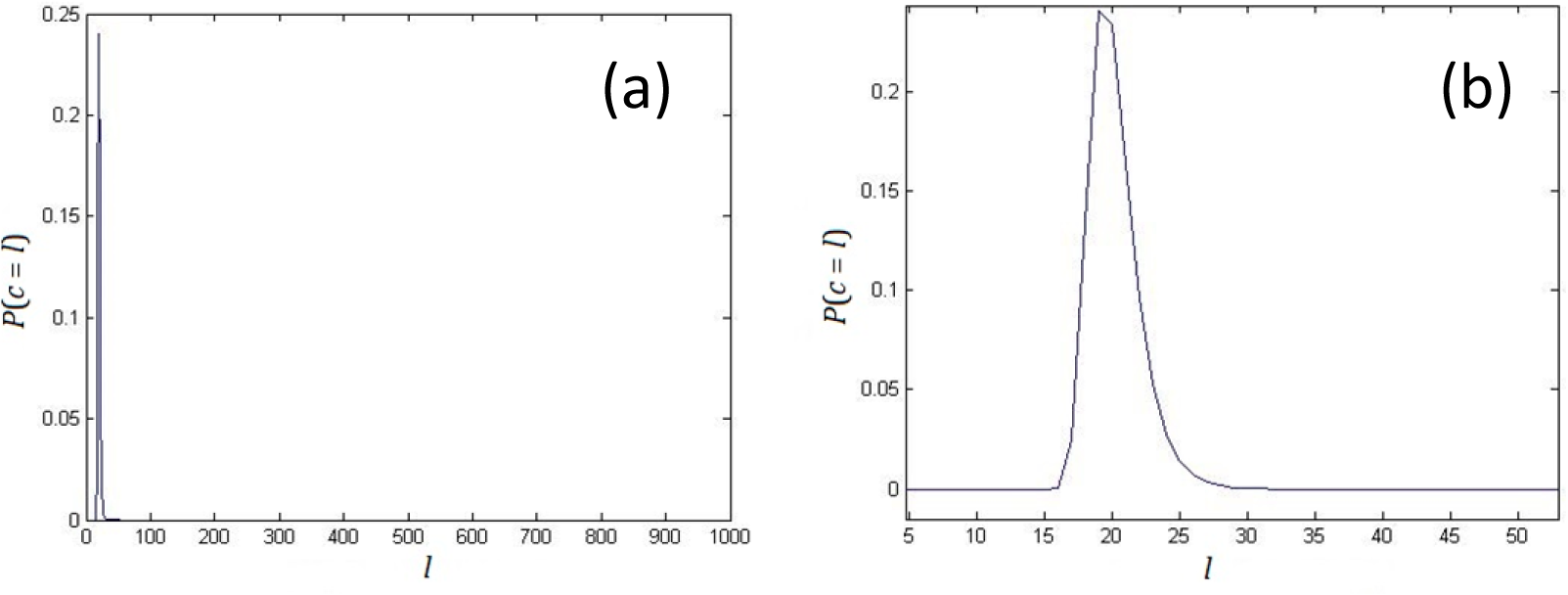
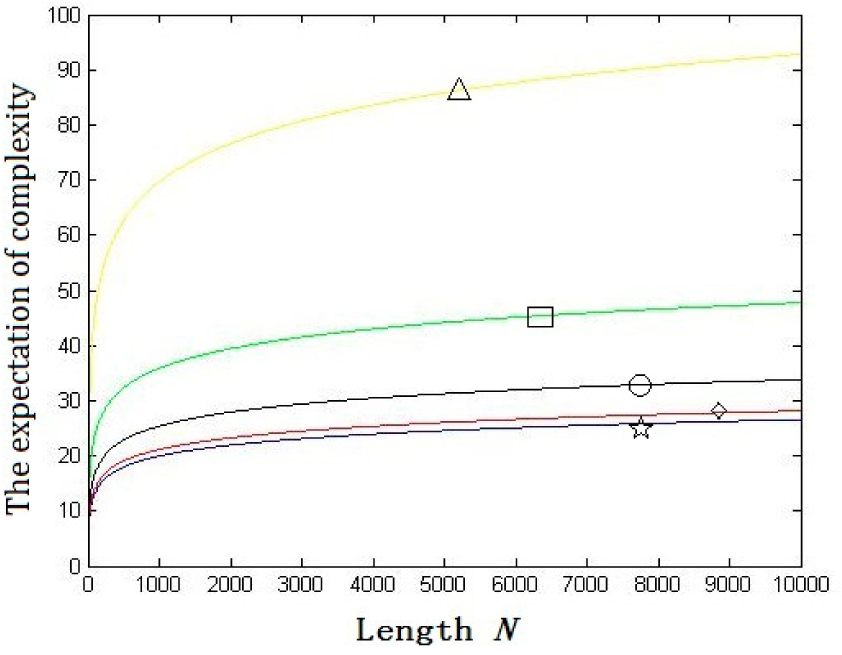
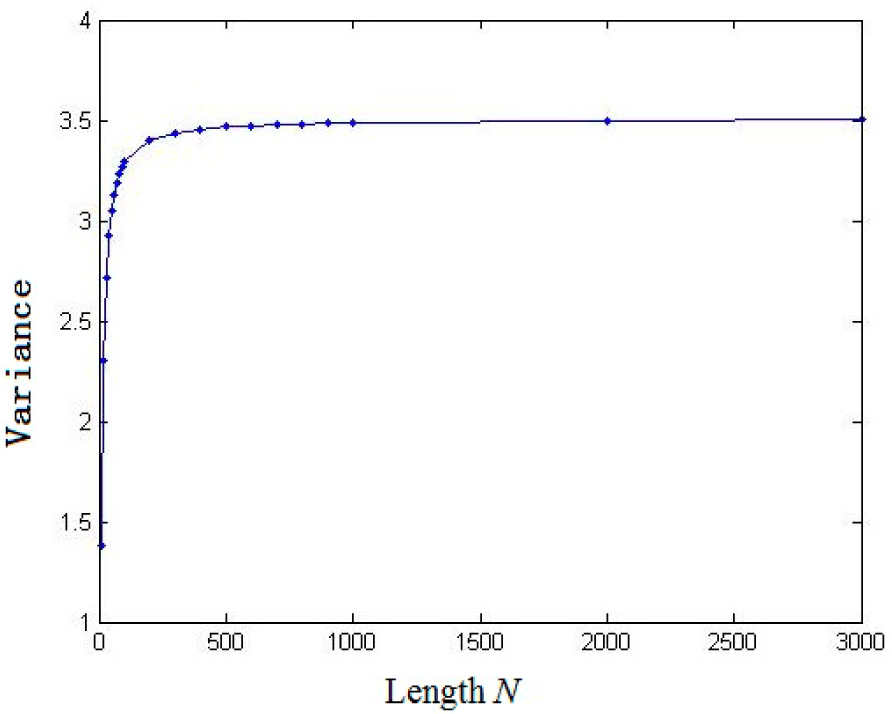
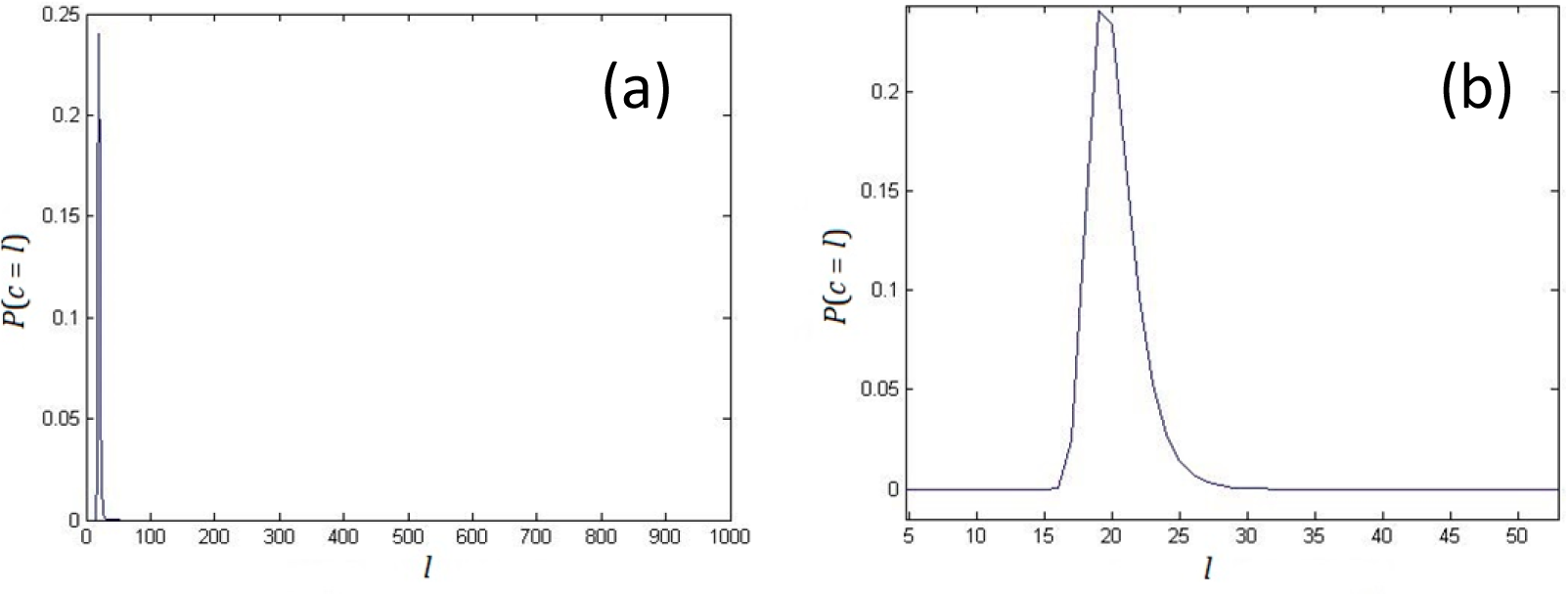
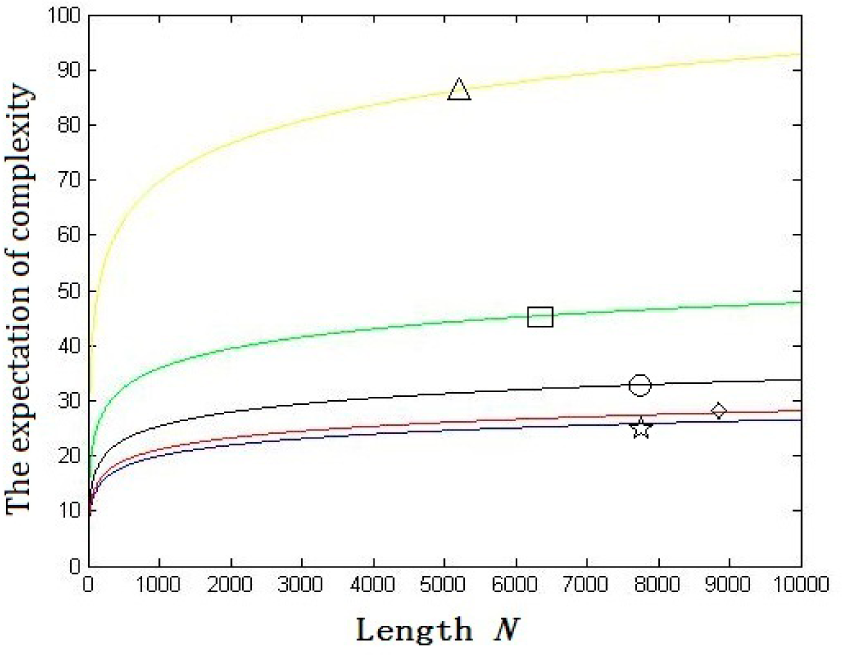
2. Nonlinear Complexity of Random Binary Sequences
- There exist a tuple with length l − 1, which occurs at least twice.
- All the tuples with length l do not occur more than once.
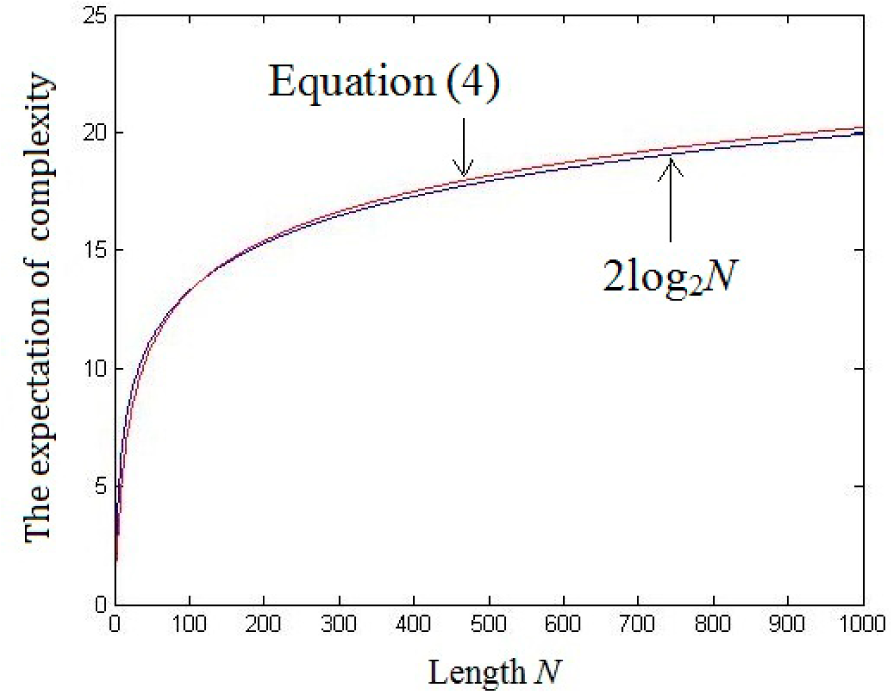
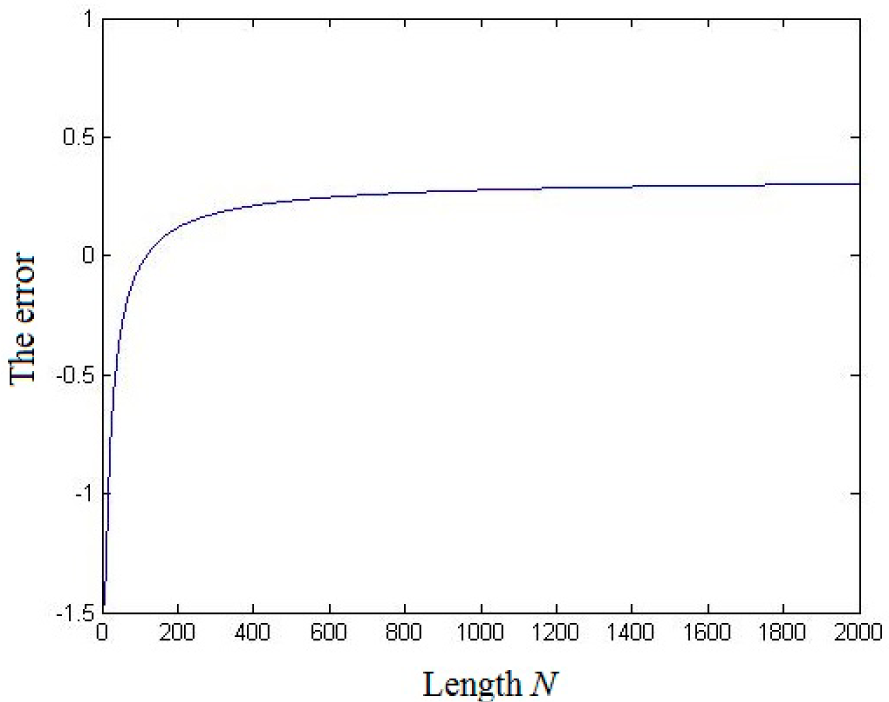
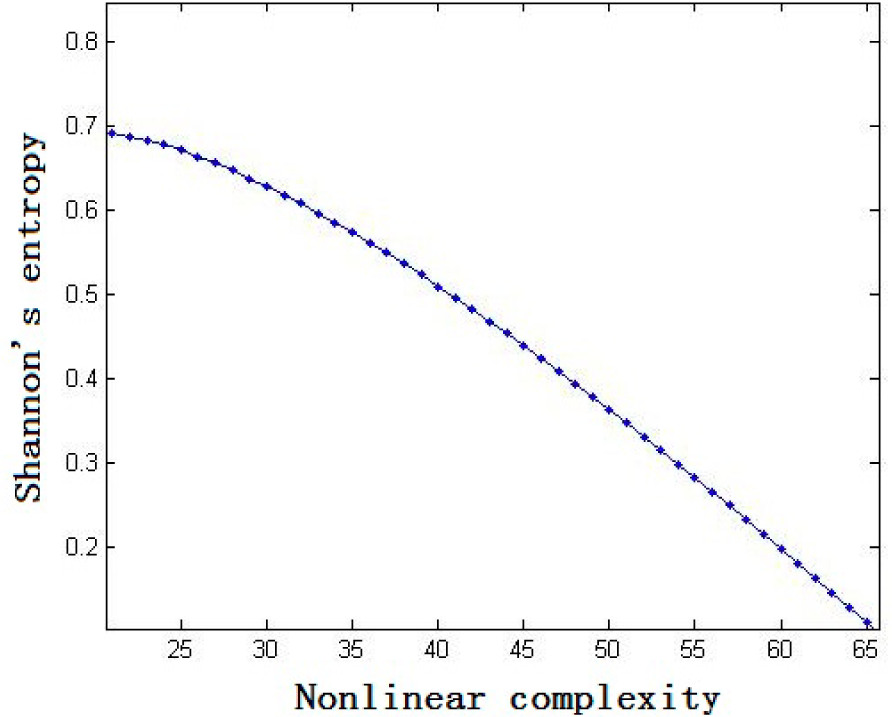
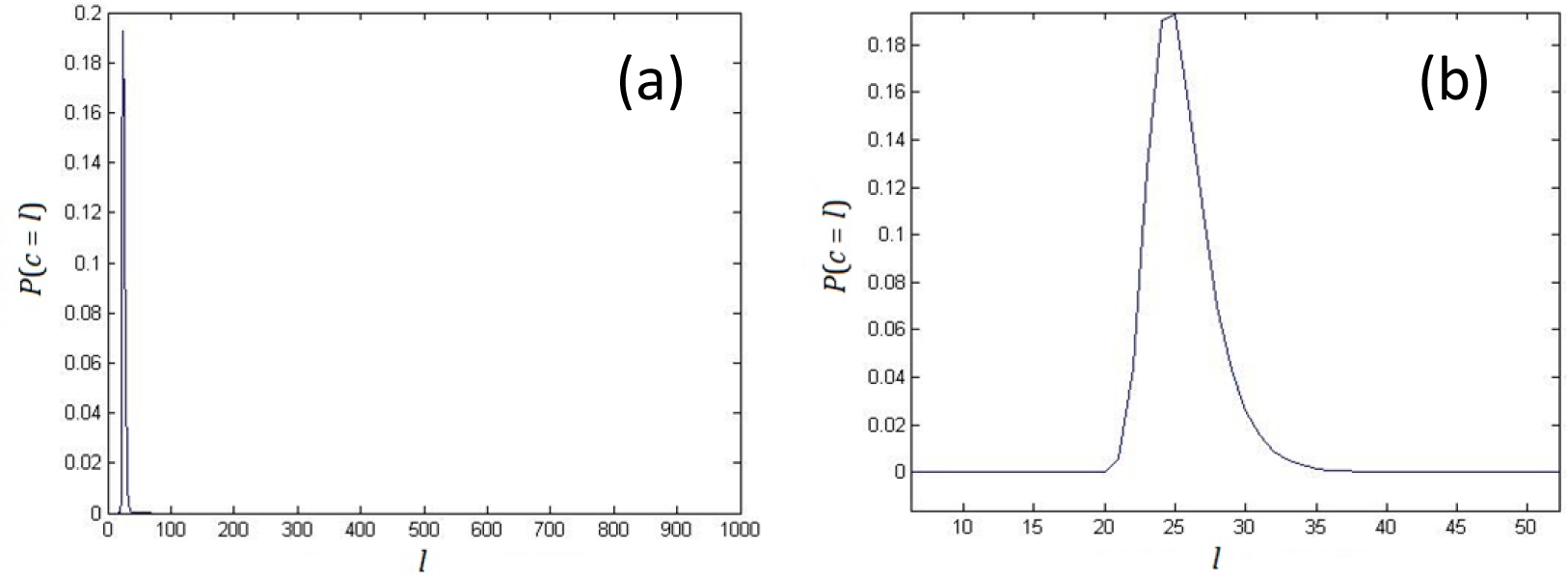
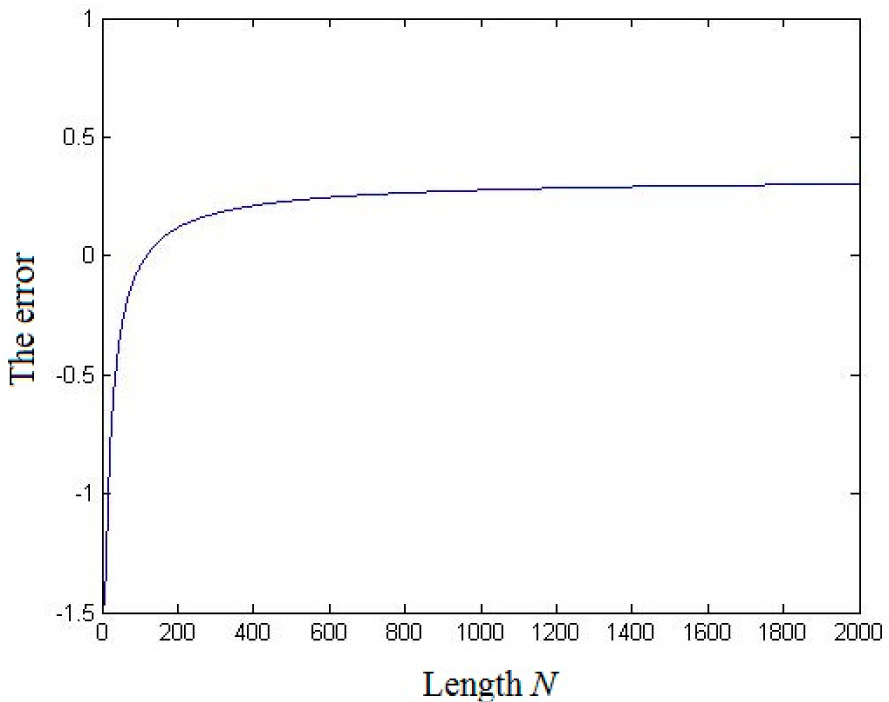
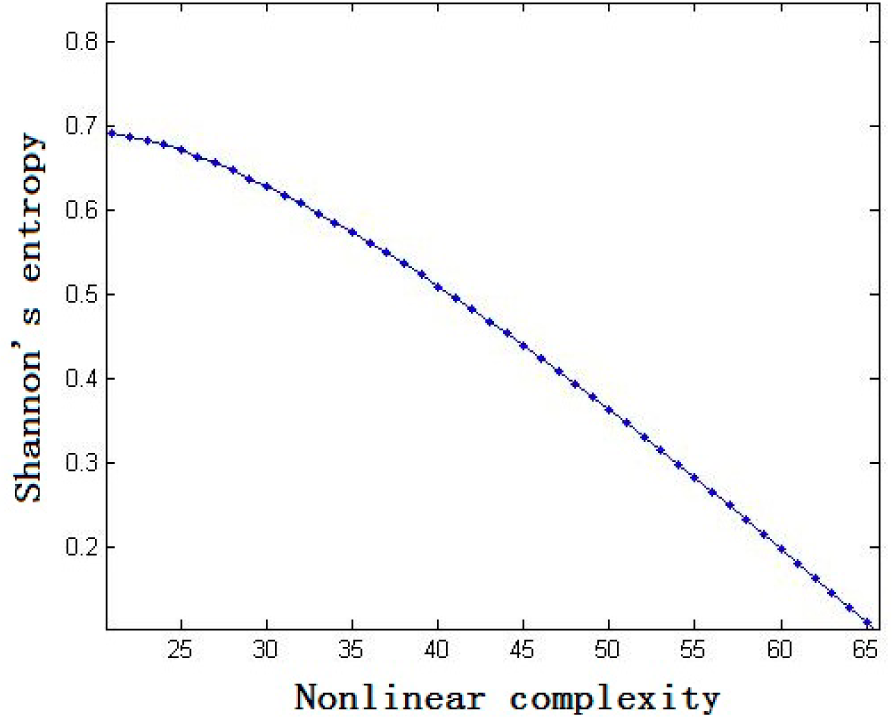
3. The Relationship between Nonlinear Complexity and Shannon’s Entropy
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kalouptsidis, N. Signal Processing Systems: Theory and Design; Wiley: New York, NY, USA, 1996. [Google Scholar]
- Golomb, S.W. Shift Register Sequences; Holden-Day: San Francisco, CA, USA, 1967. [Google Scholar]
- Wang, X.M.; Zhang, W.F.; Guo, W.; Zhang, J.S. Secure chaotic system with application to chaotic ciphers. Inf. Sci. 2013, 221, 555–570. [Google Scholar]
- Menezes, A.J.; van Oorschot, P.C.; Vanstone, S.A. Handbook of applied cryptography; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- Stojanovski, T.; Kocarev, L. Chaos-based random number generators-part I: Analysis [cryptography]. IEEE Trans. Circ. Syst. I 2001, 48, 281–288. [Google Scholar]
- Callegari, S.; Rovatti, R.; Setti, G. Embeddable ADC-based true random number generator for cryptographic applications exploiting nonlinear signal processing and chaos. IEEE Trans. Signal Process. 2005, 53, 793–805. [Google Scholar]
- Addabbo, T.; Alioto, M.; Fort, A.; Rocchi, S.; Vignoli, V. A feedback strategy to improve the entropy of a chaos-based random bit generator. IEEE Trans. Circ. Syst. I 2006, 53, 326–337. [Google Scholar]
- Nejati, H.; Beirami, A.; Ali, W.H. Discrete-time chaotic-map truly random number generators: Design, implementation and variability analysis of the zigzag map. Analog Integr. Circuits Signal Process. 2012, 73, 363–374. [Google Scholar]
- Beirami, A.; Nejati, H.; Ali, W.H. Zigzag map: A variability-aware discrete-time chaotic map truly random number generator. Electron. Lett. 2012, 48, 1537–1538. [Google Scholar]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Champaign, IL, USA, 1949. [Google Scholar]
- Kohda, T.; Tsuneda, A. Statistics of chaotic binary sequences. IEEE Trans. Inf. Theory 1997, 43, 104–112. [Google Scholar]
- Kodha, T.; Tsuneda, A.; Lawrance, A.J. Correlational properties of Chebyshev chaotic sequences. J. Time Ser. Anal. 2000, 21, 181–191. [Google Scholar]
- Visweswariah, K.; Kulkarni, S.R.; Verdu, S. Source codes as random number generators. IEEE Trans. Inf. Theory 1998, 44, 462–471. [Google Scholar]
- Beirami, A.; Nejati, H. A framework for investigating the performance of chaotic-map truly random number generators. IEEE Trans. Circ. Syst. II 2013, 60, 446–450. [Google Scholar]
- Beirami, A.; Nejati, H.; Callegari, S. Fundamental performance limits of chaotic-map random number generators. Proceedings of 52nd Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 1–3 October 2014; pp. 1126–1131.
- Massey, J.L. Shift register synthesis and BCH decoding. IEEE Trans. Inf. Theory 1969, 15, 122–127. [Google Scholar]
- Limniotis, K.; Kolokotronis, N.; Kalouptsidis, N. New results on the linear complexity of binary sequences. Proceedings of 2006 IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 2003–2007.
- Erdmann, D.; Murphy, S. An approximate distribution for the maximum order complexity. Des. Codes Cryptogr. 1997, 10, 325–339. [Google Scholar]
- Rizomiliotis, P.; Kalouptsidis, N. Results on the nonlinear span of binary sequences. IEEE Trans. Inf. Theory 2005, 51, 1555–1563. [Google Scholar]
- Lempel, A.; Ziv, J. On the complexity of finite sequences. IEEE Trans. Inf. Theory 1976, 22, 75–81. [Google Scholar]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar]
- Hamano, K.; Yamamoto, H. A differential equation method to derive the formulas of the T-complexity and the LZ-complexity. Proceedings of 2009 IEEE international conference on Symposium on Information Theory, Seoul, Korea, 28 June–3 July 2009; pp. 625–629.
- Jansen, C.J.A. The maximum order complexity of sequence ensembles. In Advances in Cryptology—Eurocrypt’91; Davies, D.W., Ed.; Springer: Berlin/Heidelberg, Germany, 1991; pp. 153–159. [Google Scholar]
- Niederreiter, H.; Xing, C.P. Sequences with high nonlinear complexity. IEEE Trans. Inf. Theory 2014, 60, 6696–6701. [Google Scholar]
- Limniotis, K.; Kolokotronis, N.; Kalouptsidis, N. On the nonlinear complexity and Lempel-Ziv complexity of finite length sequences. IEEE Trans. Inf. Theory 2007, 53, 4293–4302. [Google Scholar]
- Jansen, C.J.A.; Boekee, D.E. The shortest feedback shift register that can generate a given sequence. In Advances Cryptology—CRYPTO’89; Brassard, G., Ed.; Springer: Berlin/Heidelberg, Germany, 1990; pp. 90–99. [Google Scholar]
- Ebeling, W.; Steuer, R.; Titchener, M.R. Partition-based entropies of deterministic and stochastic maps. Stoch. Dyn. 2001, 1, 45–61. [Google Scholar]
- Liu, L.F.; Miao, S.X.; Hu, H.P.; Deng, Y.S. On the eigenvalue and Shannon’s entropy of finite length random sequences. Complexity 2014. [Google Scholar] [CrossRef]


© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Miao, S.; Liu, B. On Nonlinear Complexity and Shannon’s Entropy of Finite Length Random Sequences. Entropy 2015, 17, 1936-1945. https://doi.org/10.3390/e17041936
Liu L, Miao S, Liu B. On Nonlinear Complexity and Shannon’s Entropy of Finite Length Random Sequences. Entropy. 2015; 17(4):1936-1945. https://doi.org/10.3390/e17041936
Chicago/Turabian StyleLiu, Lingfeng, Suoxia Miao, and Bocheng Liu. 2015. "On Nonlinear Complexity and Shannon’s Entropy of Finite Length Random Sequences" Entropy 17, no. 4: 1936-1945. https://doi.org/10.3390/e17041936
APA StyleLiu, L., Miao, S., & Liu, B. (2015). On Nonlinear Complexity and Shannon’s Entropy of Finite Length Random Sequences. Entropy, 17(4), 1936-1945. https://doi.org/10.3390/e17041936