Application of Entropy-Based Attribute Reduction and an Artificial Neural Network in Medicine: A Case Study of Estimating Medical Care Costs Associated with Myocardial Infarction


Abstract
:1. Introduction
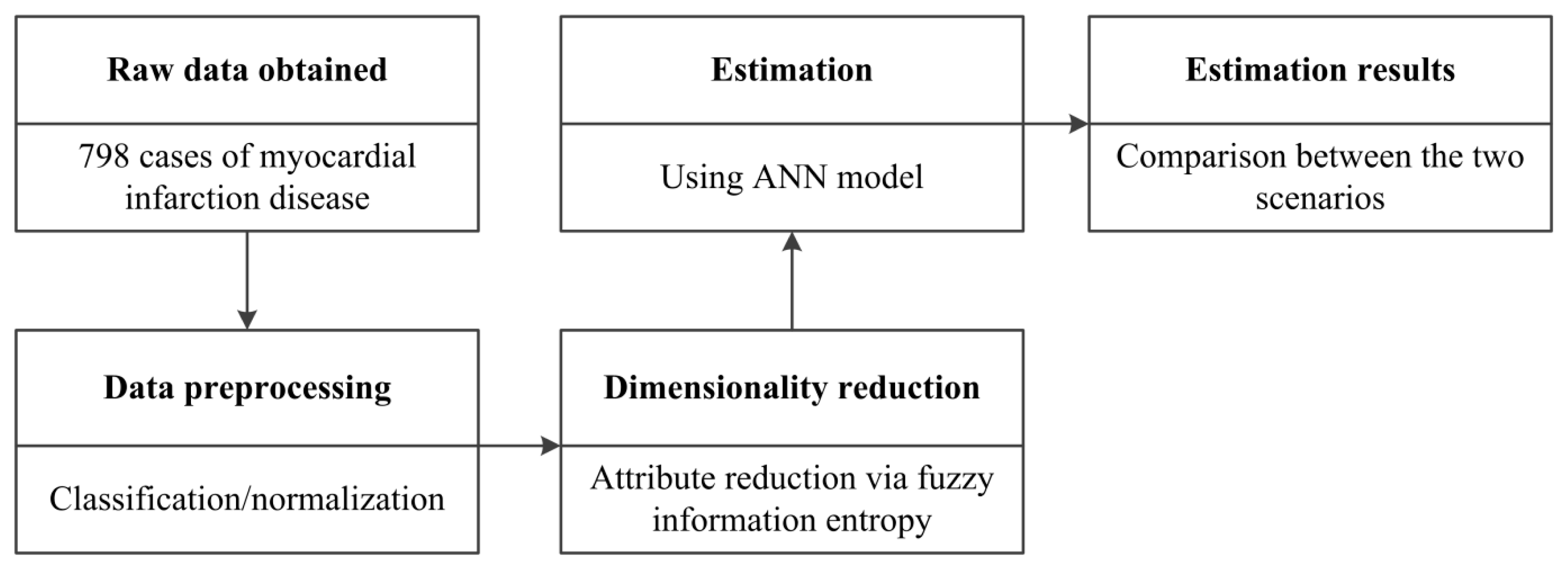
2. Materials and Methods
2.1. Raw Data
2.2. Fuzzy Information Entropy
2.2.1. Fuzzy Rough Set Model
- (1)
- Reflectivity: R(x, x) = 1;
- (2)
- Symmetry: R(x, y) = R(y, x);
- (3)
- Transitivity: miny(R(x, y), R(y, z)) ≤ R(x, z)
Definition 1
Definition 2
Definition 3
- (1)
- γB (D) = γc(D);
- (2)
- γB−b (D) < γB (D), for ∀b ∈ B
2.2.2. Entropy-Based Information Measure
Definition 4
Definition 5
Definition 6
Definition 7
2.3. Artificial Neural Network (ANN)
2.4. Model Selection and Comparison Methods
2.4.1. Akaike Information Criterion (AIC)
2.4.2. Evaluation of Performance
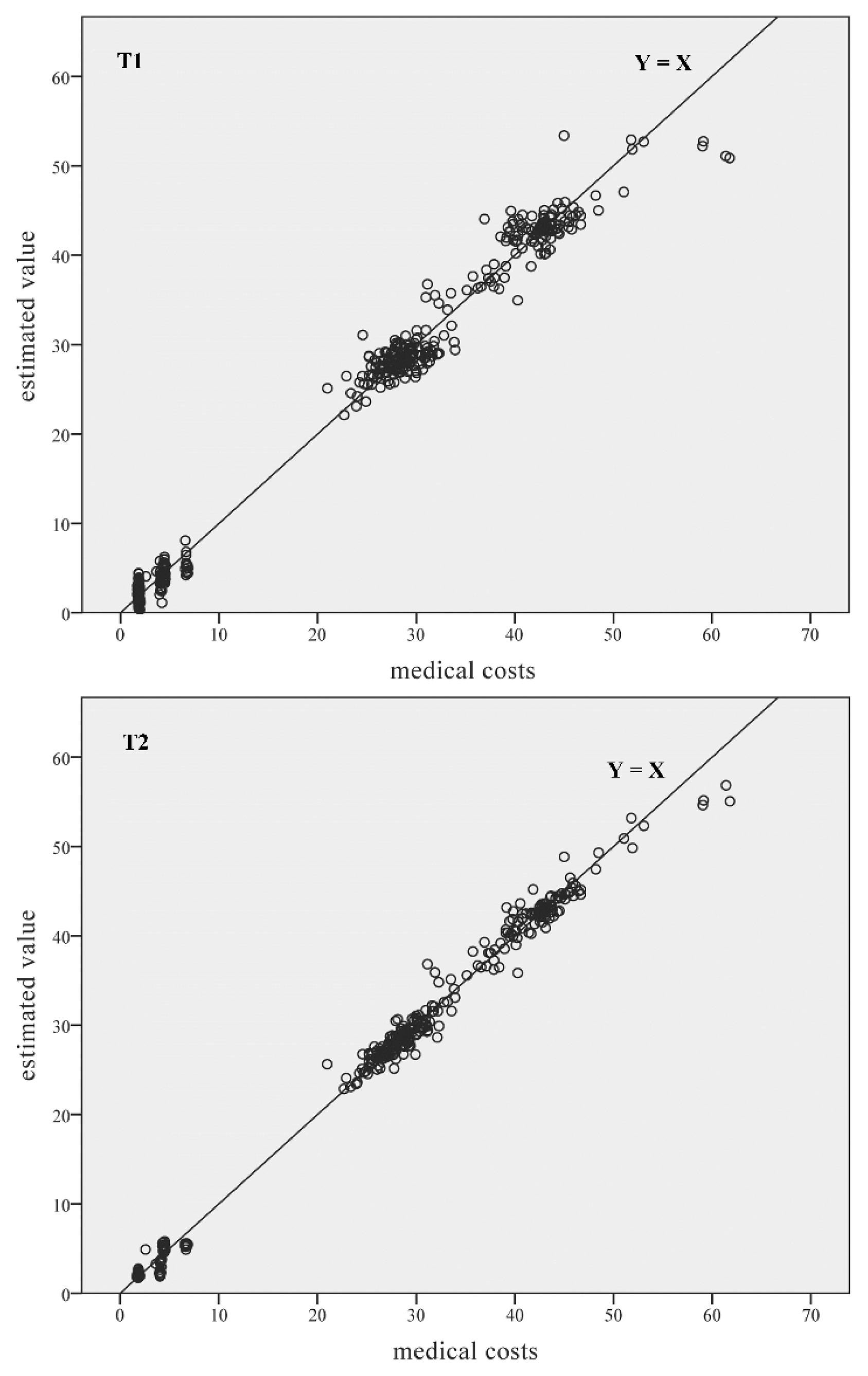
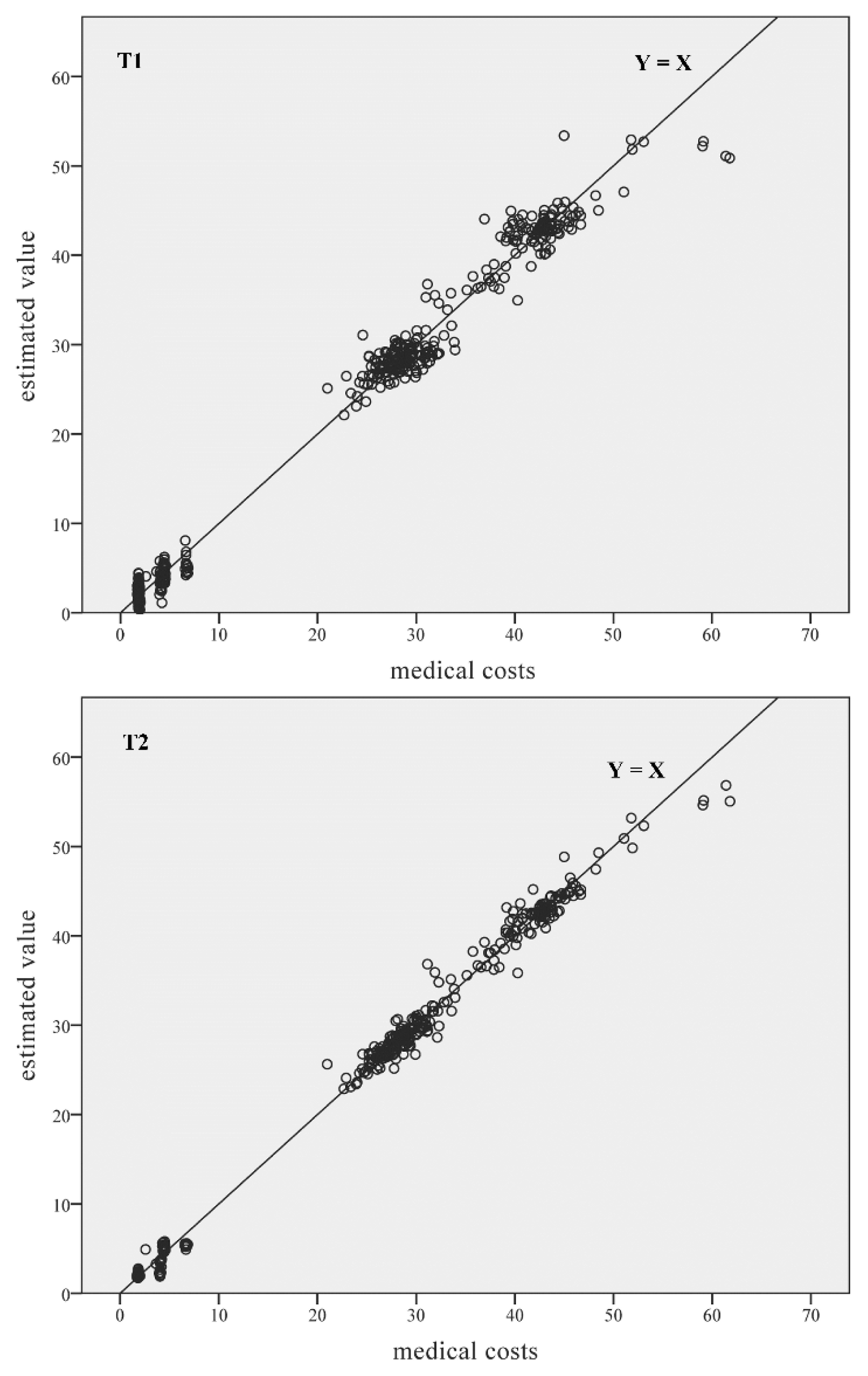
3. Experimental Results
3.1. Data Preprocessing
3.2. Dimension Reduction via Fuzzy Information Entropy
Definition 8
3.3. Estimation Using the Artificial Neural Network
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mark, D.B.; Hlatky, M.A.; Califf, R.M.; Naylor, C.D.; Lee, K.L.; Armstrong, P.W.; Barbash, G.; White, H.; Simoons, M.L.; Nelson, C.L.; et al. Cost effectiveness of thrombolytic therapy with tissue plasminogen activator as compared with streptokinase for acute myocardial infarction. New Engl. J. Med 1995, 332, 1418–1424. [Google Scholar]
- Frasure-Smith, N.; Lespérance, F.; Gravel, G.; Masson, A.; Juneau, M.; Talajic, M.; Bourassa, M.G. Depression and health-care costs during the first year following myocardial infarction. J. Psychosom. Res 2000, 48, 471–478. [Google Scholar]
- Chaikledkaew, U.; Pongchareonsuk, P.; Chaiyakunapruk, N.; Ongphiphadanakul, B. Factors affecting health-care costs and hospitalizations among diabetic patients in Thai Public hospitals. Value Health 2008, 11, 69–74. [Google Scholar]
- Wang, G.; Zhang, Z.; Ayala, C.; Dunet, D.; Fang, J. Costs of Hospitalizations with a Primary Diagnosis of Acute Myocardial Infarction Among Patients Aged 18–64 Years in the United States. In Ischemic Heart Disease, 1st ed; Gaze, D.C., Ed.; InTech: Rijeka, Croatia, 2013. [Google Scholar]
- Săftoiu, A.; Vilmann, P.; Gorunescu, F.; Janssen, J.; Hocke, M.; Larsen, M.; Iglesias-Garcia, J.; Arcidiacono, P.; Will, U.; Giovannini, M.; et al. Efficacy of an artificial neural network-based approach to endoscopic ultrasound elastography in diagnosis of focal pancreatic masses. Clin. Gastroenterol. Hepatol 2012, 10, 84–90. [Google Scholar]
- Hsieh, C.H.; Lu, R.H.; Lee, N.H.; Chiu, W.T.; Hsu, M.H.; Li, Y.C.J. Novel solutions for an old disease: Diagnosis of acute appendicitis with random forest, support vector machines, and artificial neural networks. Surgery 2011, 149, 87–93. [Google Scholar]
- Shi, H.Y.; Tsai, J.T.; Chen, Y.M.; Culbertson, R.; Chang, H.T.; Hou, M.F. Predicting two-year quality of life after breast cancer surgery using artificial neural network and linear regression models. Breast Cancer Res. Treat 2012, 135, 221–229. [Google Scholar]
- Uğuz, H. A biomedical system based on artificial neural network and principal component analysis for diagnosis of the heart valve diseases. J. Med. Syst 2012, 36, 61–72. [Google Scholar]
- Ansari, D.; Nilsson, J.; Andersson, R.; Regnér, S.; Tingstedt, B.; Andersson, B. Artificial neural networks predict survival from pancreatic cancer after radical surgery. Am. J. Surg 2013, 205, 1–7. [Google Scholar]
- Huang, J.R.; Fan, S.Z.; Abbod, M.F.; Jen, K.K.; Wu, J.F.; Shieh, J.S. Application of multivariate empirical mode decomposition and sample entropy in EEG signals via artificial neural networks for interpreting depth of anesthesia. Entropy 2013, 15, 3325–3339. [Google Scholar]
- Tu, J.V. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol 1996, 49, 1225–1231. [Google Scholar]
- Mantzaris, D.; Anastassopoulos, G.; Adamopoulos, A. Genetic algorithm pruning of probabilistic neural networks in medical disease estimation. Neural Netw 2011, 24, 831–835. [Google Scholar]
- Yeh, W.C.; Hsieh, T.J. Artificial bee colony algorithm-neural networks for S-system models of biochemical networks approximation. Neural Comput Appl 2012, 21, 365–375. [Google Scholar]
- Ömer Faruk, D. A hybrid neural network and ARIMA model for water quality time series prediction. Eng. Appl. Artif. Intell 2010, 23, 586–594. [Google Scholar]
- Azadeh, A.; Saberi, M.; Moghaddam, R.T.; Javanmardi, L. An integrated data envelopment analysis-artificial neural network-rough set algorithm for assessment of personnel efficiency. Expert Syst. Appl 2011, 38, 1364–1373. [Google Scholar]
- Dai, J.; Xu, Q. Attribute selection based on information gain ratio in fuzzy rough set theory with application to tumor classification. Appl. Soft Comput 2013, 13, 211–221. [Google Scholar]
- Mac Parthaláin, N.; Jensen, R. Unsupervised fuzzy-rough set-based dimensionality reduction. Inf. Sci 2013, 229, 106–121. [Google Scholar]
- Garcia, S.; Luengo, J.; Sáez, J.A.; López, V.; Herrera, F. A survey of discretization techniques: Taxonomy and empirical analysis in supervised learning. IEEE Trans. Knowl. Data Eng 2013, 25, 734–750. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D. Discretization techniques: A recent survey. GESTS Int. Trans. Comput. Sci. Eng 2006, 32, 47–58. [Google Scholar]
- Dubois, D.; Prade, H. Putting rough sets and fuzzy sets together. In Intelligent Decision Support, 1st ed; Slowiniski, R., Ed.; Kluwer Academic: Dordrecht, The Netherlands, 1992; pp. 203–232. [Google Scholar]
- Morsi, N.N.; Yakout, M.M. Axiomatics for fuzzy-rough sets. Fuzzy Sets Syst 1998, 100, 327–342. [Google Scholar]
- Jensen, R.; Shen, Q. Fuzzy-rough attribute reduction with application to web categorization. Fuzzy Sets Syst 2004, 141, 469–485. [Google Scholar]
- Jensen, R.; Shen, Q. Semantics-preserving dimensionality reduction: Rough and fuzzy-rough-based approaches. IEEE Trans. Knowl. Data Eng 2004, 16, 1457–1471. [Google Scholar]
- Hu, Q.; Yu, D.; Xie, Z. Information-preserving hybrid data reduction based on fuzzy-rough techniques. Pattern Recogn. Lett 2006, 27, 414–423. [Google Scholar]
- Tortum, A.; Yayla, N.; Çelik, C.; Gökdağ, M. The investigation of model selection criteria in artificial neural networks by the Taguchi method. Physica A 2007, 386, 446–468. [Google Scholar]
- Arifovic, J.; Gencay, R. Using genetic algorithms to select architecture of a feedforward artificial neural network. Physica A 2001, 289, 574–594. [Google Scholar]
- Hurvich, C.M.; Tsai, C.L. A corrected Akaike information criterion for vector autoregressive model selection. J. Time Ser. Anal 1993, 14, 271–279. [Google Scholar]
- May, R.; Dandy, G.; Maier, H. Review of input variable selection methods for artificial neural networks. In Artificial neural networks—Methodological advances and biomedical applications; Suzuki, K., Ed.; InTech: Rijeka, Croatia, 2011; pp. 19–44. [Google Scholar]
- Symonds, M.R.; Moussalli, A. A brief guide to model selection, multimodel inference and model averaging in behavioural ecology using Akaike’s information criterion. Behav. Ecol. Sociobiol 2011, 65, 13–21. [Google Scholar]


{kind=link}
{kind=link}
| Variables | Classification |
|---|---|
| Gender | Male; female |
| History of diabetes | No; Yes |
| Blood pressure | Hypotension; normal; hypertension |
| Smoker | No; Yes |
| Cholesterol | Normal; high |
| Physically active | No; Yes |
| Obesity | No; Yes |
| History of angina | No; Yes |
| History of MI | No; Yes |
| Prescribed nitroglycerin | No; Yes |
| Anti-clotting drugs | None; aspirin; heparin; warfarin |
| EKGa result | No ST elevation; ST elevation |
| CPKb blood result | Normal CPK; high CPK |
| Troponin T blood result | Normal troponin T; high troponin T |
| Clot-dissolving drugs | None; streptokinase; reteplase; alteplase |
| Hemorrhaging | No; Yes |
| Magnesium | No; Yes |
| Digitalis | No; Yes |
| Beta blockers | No; Yes |
| Surgical treatment | None; PTCAc; CABGd |
| Surgical complications | No surgery performed; No; Yes |
| Variables | Max | Min | Mean | Median | SD |
|---|---|---|---|---|---|
| Age in years | 87 | 45 | 61.75 | 61.00 | 8.835 |
| Medical visits (times) | 10 | 1 | 2.97 | 3.00 | 1.432 |
| Length of stay (day) | 11 | 1 | 3.54 | 4.00 | 2.656 |
| Medical treatment costs (103 CNY) | 61.80 | 1.71 | 19.92 | 25.77 | 17.164 |
| i | Reducti | H(D|Bi) | SIG(bi, Bi, D) |
|---|---|---|---|
| 1 | B1 = {Length of stay} | 1.4379 | 1.4379 |
| 2 | B2 = B1 ∪ {Surgical treatment} | 1.5734 | 0.1355 |
| 3 | B3 = B2 ∪ {Age in years} | 1.6572 | 0.0838 |
| 4 | B4 = B3 ∪ {Surgical complications} | 1.6682 | 0.011 |
| 5 | B5 = B4 ∪ {Time to hospital} | 1.6768 | 0.0086 |
| 6 | B6 = B5 ∪ {Clot-dissolving drugs} | 1.6786 | 0.0018 |
| 7 | B7 = B6 ∪ {Taking anti-clotting drugs} | 1.6813 | 0.0027 |
| 8 | B8 = B7 ∪ {Magnesium} | 1.6824 | 0.0011 |
| ANN architecture | |
|---|---|
| The number of layers | 3 |
| The number of neurons in the layers | Input: 24 (T1)/8 (T2) |
| Hidden: ≤10 | |
| Output: 1 | |
| The initial weights and bias | The Nguyen–Widow method |
| Activation functions | Hidden: Hyperbolic tangent |
| Output: Identity | |
| ANN parameters | |
| Learning algorithm | Back-propagation |
| Optimization algorithm | Gradient descent |
| Initial learning rate | 0.4 |
| Momentum | 0.9 |
| Stopping criteria | |
| Maximum training time | 10 min |
| Maximum training epochs | 1000 |
| Minimum relative change in training error | 0.0001 |
| Scenario | H.U. | k | N | RSS | AICC/n | RMSE | MAPE |
|---|---|---|---|---|---|---|---|
| T1 | 9 | 235 | 496 | 1,593.81 | 2.97 | 1.79 | 17.46% |
| T2 | 8 | 81 | 496 | 586.42 | 0.56 | 1.09 | 6.57% |
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Du, Q.; Nie, K.; Wang, Z. Application of Entropy-Based Attribute Reduction and an Artificial Neural Network in Medicine: A Case Study of Estimating Medical Care Costs Associated with Myocardial Infarction. Entropy 2014, 16, 4788-4800. https://doi.org/10.3390/e16094788
Du Q, Nie K, Wang Z. Application of Entropy-Based Attribute Reduction and an Artificial Neural Network in Medicine: A Case Study of Estimating Medical Care Costs Associated with Myocardial Infarction. Entropy. 2014; 16(9):4788-4800. https://doi.org/10.3390/e16094788
Chicago/Turabian StyleDu, Qingyun, Ke Nie, and Zhensheng Wang. 2014. "Application of Entropy-Based Attribute Reduction and an Artificial Neural Network in Medicine: A Case Study of Estimating Medical Care Costs Associated with Myocardial Infarction" Entropy 16, no. 9: 4788-4800. https://doi.org/10.3390/e16094788
APA StyleDu, Q., Nie, K., & Wang, Z. (2014). Application of Entropy-Based Attribute Reduction and an Artificial Neural Network in Medicine: A Case Study of Estimating Medical Care Costs Associated with Myocardial Infarction. Entropy, 16(9), 4788-4800. https://doi.org/10.3390/e16094788