Information-Theoretic Bounded Rationality and ε-Optimality

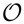{kind=link}
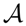{kind=link}
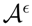{kind=link}
{kind=link}
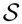{kind=link}
Abstract
:1. Introduction
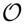 each of which can occur with a respective probability P(oj) where j = 1, …, N. We can imagine a lottery as a roulette wheel or a gamble where we obtain a prize oj with probability P(oj) that has a subjective utility U(oj) for the decision maker. The compound value of the lottery can then be determined by the expected utility E[U] = ∑j P(oj)U(oj), which is commonly used as the standard performance criterion in decision making. The concept of expected utility was first axiomatized by Neumann and Morgenstern [8]. In their axiomatic system, Neumann and Morgenstern [8] define a binary preference relation ≻ over the set of probability distributions ℘ defined over the set of outcomes
. If (and only if) this binary relation satisfies the axioms of completeness, transitivity, continuity and independence, then there exists a function U :
↦ ℝ, such that:
each of which can occur with a respective probability P(oj) where j = 1, …, N. We can imagine a lottery as a roulette wheel or a gamble where we obtain a prize oj with probability P(oj) that has a subjective utility U(oj) for the decision maker. The compound value of the lottery can then be determined by the expected utility E[U] = ∑j P(oj)U(oj), which is commonly used as the standard performance criterion in decision making. The concept of expected utility was first axiomatized by Neumann and Morgenstern [8]. In their axiomatic system, Neumann and Morgenstern [8] define a binary preference relation ≻ over the set of probability distributions ℘ defined over the set of outcomes
. If (and only if) this binary relation satisfies the axioms of completeness, transitivity, continuity and independence, then there exists a function U :
↦ ℝ, such that: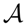 is an action that leads to consequence oj with probability P(oj|ai). The decision maker can assess the expected utility of each action as E[U|ai] = ∑j P(oj|ai)U(oj). Thus, the probabilistic model of the world defines a set of M different lotteries indexed by ai, where i = 1, …, M. The decision maker can compare the expected utilities of all the lotteries and choose the one with the highest expected utility, such that:
is an action that leads to consequence oj with probability P(oj|ai). The decision maker can assess the expected utility of each action as E[U|ai] = ∑j P(oj|ai)U(oj). Thus, the probabilistic model of the world defines a set of M different lotteries indexed by ai, where i = 1, …, M. The decision maker can compare the expected utilities of all the lotteries and choose the one with the highest expected utility, such that: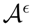 whose expected utility deviates at most by ε > 0 from the optimal expected utility of amax, such that:
whose expected utility deviates at most by ε > 0 from the optimal expected utility of amax, such that:2. Methods
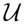 [0; 1] and T is the acceptance target value with T ≥ maxi V(ai). Otherwise, the sample is rejected. The efficiency of the sampling process depends on how many samples we will need on average from P0 to obtain one sample from P. This average number of samples from P0 needed for one sample of P is given by the mean of a geometric distribution:[0; 1] and
. From Equation (11), we know that the ratio Zβ(ai)/eβT can be interpreted as an acceptance probability; in this case, the acceptance probability of θ ~ P0(θ). Thus, in order to accept one sample from x, we need to accept
consecutive samples of θ, with acceptance criterion:[0; 1] and T as set above.
[0; 1] and T is the acceptance target value with T ≥ maxi V(ai). Otherwise, the sample is rejected. The efficiency of the sampling process depends on how many samples we will need on average from P0 to obtain one sample from P. This average number of samples from P0 needed for one sample of P is given by the mean of a geometric distribution:[0; 1] and
. From Equation (11), we know that the ratio Zβ(ai)/eβT can be interpreted as an acceptance probability; in this case, the acceptance probability of θ ~ P0(θ). Thus, in order to accept one sample from x, we need to accept
consecutive samples of θ, with acceptance criterion:[0; 1] and T as set above.3. Results
Theorem 1 (ε-Optimality).
Proof
Theorem 2 (ε-Optimality for rank utilities).
Proof
4. Adversarial Environments
with (expected) utility V(ai) = E[U|ai].4.1. Unknown Action Set
, and then, the environment chooses a subset
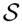 ∈ ℘(
)\{} of permissible actions, where ℘(
) denotes the powerset. All actions that are not part of the subset are eliminated. Finally, the action ai is randomly determined from the set of permissible actions with their renormalized probabilities. The problem is to find the betting probability P(ai) such that we maximize our expected return; however, the expectation has to be taken over the unknown subset
capriciously chosen by the opponent. This models a decision maker, who has to choose a generic hedging strategy by allocating resources to different alternatives, but where the rules of the game are only fully revealed after the choice is made. Formally, we want to choose the probability P(ai), such that the conditional expectation E[V(ai)|
] is as large as possible. Unsurprisingly, we cannot provide a deterministic optimal solution P(ai) = δ(ai −a*), since the environment could always eliminate a*. However, if we allow ourselves an arbitrarily small, non-zero performance loss ε > 0, then there is a way to assign probabilities P(ai), such that the conditional expectation is almost equal to the optimum, i.e., to the highest utility in the subset chosen by the opponent. This is precisely the result of the following theorem.
∈ ℘(
)\{} of permissible actions, where ℘(
) denotes the powerset. All actions that are not part of the subset are eliminated. Finally, the action ai is randomly determined from the set of permissible actions with their renormalized probabilities. The problem is to find the betting probability P(ai) such that we maximize our expected return; however, the expectation has to be taken over the unknown subset
capriciously chosen by the opponent. This models a decision maker, who has to choose a generic hedging strategy by allocating resources to different alternatives, but where the rules of the game are only fully revealed after the choice is made. Formally, we want to choose the probability P(ai), such that the conditional expectation E[V(ai)|
] is as large as possible. Unsurprisingly, we cannot provide a deterministic optimal solution P(ai) = δ(ai −a*), since the environment could always eliminate a*. However, if we allow ourselves an arbitrarily small, non-zero performance loss ε > 0, then there is a way to assign probabilities P(ai), such that the conditional expectation is almost equal to the optimum, i.e., to the highest utility in the subset chosen by the opponent. This is precisely the result of the following theorem.Theorem 3 (ε-Optimality in adversarial environments).
for any subset of possible actions selected by nature, such that:Proof
, such that:4.2. Unknown Utility
5. Discussion and Conclusion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gintis, H. A Framework for the Unification of the Behavioral Sciences. Behav. Brain Sci 2006, 30, 1–61. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 1st ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 1995. [Google Scholar]
- Kreps, D.M. Notes on the Theory of Choice; Westview Press: Boulder, CO, USA, 1988. [Google Scholar]
- Trommershauser, J.; Maloney, L.T.; Landy, M.S. Decision making, movement planning and statistical decision theory. Trends Cogn. Sci 2008, 12, 291–297. [Google Scholar]
- Braun, D.A.; Nagengast, A.J.; Wolpert, D. Risk-sensitivity in sensorimotor control. Front. Hum. Neurosci 2011, 5. [Google Scholar] [CrossRef]
- Wolpert, D.M.; Landy, M.S. Motor control is decision-making. Curr. Opin. Neurobiol 2012, 22, 996–1003. [Google Scholar]
- Fishburn, P. The Foundations of Expected Utility; D. Reidel Publishing: Dordrecht, The Netherlands, 1982. [Google Scholar]
- Neumann, J.V.; Morgenstern, O. Theory of Games and Economic Behavior; Princeton University Press: Princeton, NJ, USA, 1944. [Google Scholar]
- Simon, H.A. Rational choice and the structure of the environment. Psychol. Rev 1956, 63, 129–138. [Google Scholar]
- Simon, H. Theories of Bounded Rationality. In Decision and Organization; McGuire, C.B., Radner, R., Eds.; North Holland Pub. Co.: Amsterdam, The Netherlands, 1972; pp. 161–176. [Google Scholar]
- Simon, H. Models of Bounded Rationality; MIT Press: Cambridge, MA, USA, 1984. [Google Scholar]
- Aumann, R.J. Rationality and Bounded Rationality. Games Econ. Behav 1997, 21, 2–14. [Google Scholar]
- Rubinstein, A. Modeling bounded rationality; MIT Press: Cambridge, MA, USA,, 1998. [Google Scholar]
- Kahneman, D. Maps of Bounded Rationality: Psychology for Behavioral Economics. Am. Econ. Rev 2003, 93, 1449–1475. [Google Scholar]
- McKelvey, R.D.; Palfrey, T.R. Quantal Response Equilibria for Normal Form Games. Games Econ. Behav 1995, 10, 6–38. [Google Scholar]
- Mckelvey, R.; Palfrey, T.R. Quantal Response Equilibria for Extensive Form Games. Exp. Econ 1998, 1, 9–41. [Google Scholar]
- Wolpert, D.H. Information Theory—The Bridge Connecting Bounded Rational Game Theory and Statistical Physics. In Complex Engineered Systems; Braha, D., Minai, A.A., Bar-Yam, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 262–290. [Google Scholar]
- Spiegler, R. Bounded Rationality and Industrial Organization; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- Jones, B.D. Bounded Rationality Political Science: Lessons from Public Administration and Public Policy. J. Public Adm. Res. Theory 2003, 13, 395–412. [Google Scholar]
- Gigerenzer, G.; Selten, R. Bounded rationality: The adaptive toolbox; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Camerer, C. Behavioral Game Theory: Experiments in Strategic Interaction; Princeton University Press: Princeton, NJ, USA, 2003. [Google Scholar]
- Howes, A.; Lewis, R.; Vera, A. Rational adaptation under task and processing constraints: implications for testing theories of cognition and action. Psychol. Rev 2009, 116, 717–751. [Google Scholar]
- Janssen, C.P.; Brumby, D.P.; Dowell, J.; Chater, N.; Howes, A. Identifying Optimum Performance Trade-Offs Using a Cognitively Bounded Rational Analysis Model of Discretionary Task Interleaving. Top. Cogn. Sci 2011, 3, 123–139. [Google Scholar]
- Lewis, R.; Howes, A.; Singh, S. Computational rationality: Linking mechanism and behavior through bounded utility maximization. Top. Cogn. Sci 2014, in press. [Google Scholar]
- Lipman, B. Information Processing and Bounded Rationality: A Survey. Can. J. Econ 1995, 28, 42–67. [Google Scholar]
- Russell, S. Rationality and Intelligence. Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence, Montreal, Canada, 20–25 August 1995; Morgan Kaufmann: San Francisco, CA, USA, 1995; pp. 950–957. [Google Scholar]
- Russell, S.; Subramanian, D. Provably bounded-optimal agents. J. Artif. Intell. Res 1995, 3, 575–609. [Google Scholar]
- Glimcher, P.; Fehr, E.; Camerer, C.; Poldrack, R. Neuroeconomics: Decision Making and the Brain; Elsevier Science: Amsterdam, The Netherlands, 2008. [Google Scholar]
- Friston, K.; Schwartenbeck, P.; Fitzgerald, T.; Moutoussis, M.; Behrens, T.; Dolan, R.J. The anatomy of choice: Active inference and agency. Front. Hum. Neurosci 2013, 7. [Google Scholar] [CrossRef]
- Dixon, H. Some thoughts on economic theory and artificial intelligence. In Artificial Intelligence and Economic Analysis: Prospects and Problems; Moss, S., Rae, J., Eds.; Edward Elgar Publishing: Cheltenham, UK, 1992; pp. 131–154. [Google Scholar]
- Ortega, P.; Braun, D. A conversion between utility and information. Proceedings of the Third Conference on Artificial General Intelligence, Lugano, Switzerland, 5–8 March 2010; Atlantis Press: Paris, France, 2010; pp. 115–120. [Google Scholar]
- Ortega, P.A.; Braun, D.A. Information, utility and bounded rationality. In Artificial General Intelligence; Proceedings of the 4th International Conference on Artificial General Intelligence (AGI 2011), Mountain View, CA, USA, 3–6 August 2011, Schmidhuber, J., Thórisson, K.R., Looks, M., Eds.; Lecture Notes on Artificial Intelligence, Volume 6830; Springer: Berlin/Heidelberg, Germany, 2011; pp. 269–274. [Google Scholar]
- Braun, D.A.; Ortega, P.A.; Theodorou, E.; Schaal, S. Path integral control and bounded rationality. Proceedings of IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, Paris, France, 11–15 April 2011; pp. 202–209.
- Ortega, P.A.; Braun, D.A. Thermodynamics as a theory of decision-making with information-processing costs. Proc. R. Soc. A 2013, 469. [Google Scholar] [CrossRef]
- Wolpert, D.; Harre, M.; Bertschinger, N.; Olbrich, E.; Jost, J. Hysteresis effects of changing parameters of noncooperative games. Phys. Rev. E 2012, 85, 036102. [Google Scholar]
- Luce, R. Individual choice behavior; Wiley: Oxford, UK, 1959. [Google Scholar]
- McFadden, D. Conditional logit analysis of qualitative choice behavior. In Frontiers in Econometrics; Zarembka, P., Ed.; Academic Press: New York, NY, USA, 1974; pp. 105–142. [Google Scholar]
- Meginnis, J. A new class of symmetric utility rules for gambles, subjective marginal probability functions, and a generalized Bayesian rule. In 1976 Proceedings of the American Statistical Association, Business and Economic Statistics Section; American Statistical Association: Washington, DC, USA, 1976; pp. 471–476. [Google Scholar]
- Fudenberg, D.; Kreps, D. Learning mixed equilibria. Games Econ. Behav 1993, 5, 320–367. [Google Scholar]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Luce, R. Utility of gains and losses: Measurement-theoretical and experimental approaches; Erlbaum: Mahwah, NJ, USA, 2000. [Google Scholar]
- Train, K. Discrete Choice Methods with Simulation, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Toussaint, M.; Harmeling, S.; Storkey, A. Probabilistic inference for solving (PO)MDPs; Technical Report; University of Edinburgh: Edinburgh, UK, 2006. [Google Scholar]
- Ortega, P.A.; Braun, D.A. A minimum relative entropy principle for learning and acting. J. Artif. Intell. Res 2010, 38, 475–511. [Google Scholar]
- Friston, K. The free-energy principle: A unified brain theory? Nat. Rev. Neurosci 2010, 11, 127–138. [Google Scholar]
- Tishby, N.; Polani, D. Information Theory of Decisions and Actions. In Perception-reason-action cycle: Models, algorithms and systems; Vassilis, H.T., Ed.; Springer: Berlin, Germany, 2011. [Google Scholar]
- Kappen, H.; Gómez, V.; Opper, M. Optimal control as a graphical model inference problem. Mach. Learn 2012, 1, 1–11. [Google Scholar]
- Vijayakumar, S.; Rawlik, K.; Toussaint, M. On Stochastic Optimal Control and Reinforcement Learning by Approximate Inference. Proceedings of Robotics: Science and Systems, Sydney, Australia, 9–13 July 2012; MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Ortega, P.A.; Braun, D.A. Free Energy and the Generalized Optimality Equations for Sequential Decision Making. Proceedings of the Tenth European Workshop on Reinforcement Learning, Edinburgh, Scotland, 30 June–1 July 2012.
- Ortega, P.A.; Braun, D.A. Generalized Thompson sampling for sequential decision-making and causal inference. Complex Adap. Syst. Model 2014, 5, 269–274. [Google Scholar]
- Ortega, P.A.; Braun, D.A.; Tishby, N. Monte Carlo Methods for Exact & Efficient Solution of the Generalized Optimality Equations. Proceedings of IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014.
- Auer, P.; Cesa-Bianchi, N.; Freund, Y.; Schapire, R.E. Gambling in a rigged casino: The adversarial multi-armed bandit problem. Proceedings of IEEE 36th Annual Symposium on Foundations of Computer Science, Milwaukee, WI, USA, 23–25 October 1995; pp. 322–331.
- Freund, Y.; Schapire, R.E. A Decision-theoretic Generalization of On-line Learning and an Application to Boosting. J. Comput. Syst. Sci 1997, 55, 119–139. [Google Scholar]
- Feynman, R.P. The Feynman Lectures on Computation; Addison-Wesley: Boston, MA, USA, 1996. [Google Scholar]
- Fudenberg, D.; Levine, D. The Theory of Learning in Games; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Noam, N.; Roughgarden, T.; Éva, T.; Vazirani, V. Algorithmic Game Theory; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Fudenberg, D.; Levine, D.K. Consistency and cautious fictitious play. J. Econ. Dyn. Control 1995, 19, 1065–1089. [Google Scholar]
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Braun, D.A.; Ortega, P.A. Information-Theoretic Bounded Rationality and ε-Optimality. Entropy 2014, 16, 4662-4676. https://doi.org/10.3390/e16084662
Braun DA, Ortega PA. Information-Theoretic Bounded Rationality and ε-Optimality. Entropy. 2014; 16(8):4662-4676. https://doi.org/10.3390/e16084662
Chicago/Turabian StyleBraun, Daniel A., and Pedro A. Ortega. 2014. "Information-Theoretic Bounded Rationality and ε-Optimality" Entropy 16, no. 8: 4662-4676. https://doi.org/10.3390/e16084662
APA StyleBraun, D. A., & Ortega, P. A. (2014). Information-Theoretic Bounded Rationality and ε-Optimality. Entropy, 16(8), 4662-4676. https://doi.org/10.3390/e16084662