Constraints of Compound Systems: Prerequisites for Thermodynamic Modeling Based on Shannon Entropy


Abstract
:1. Introduction
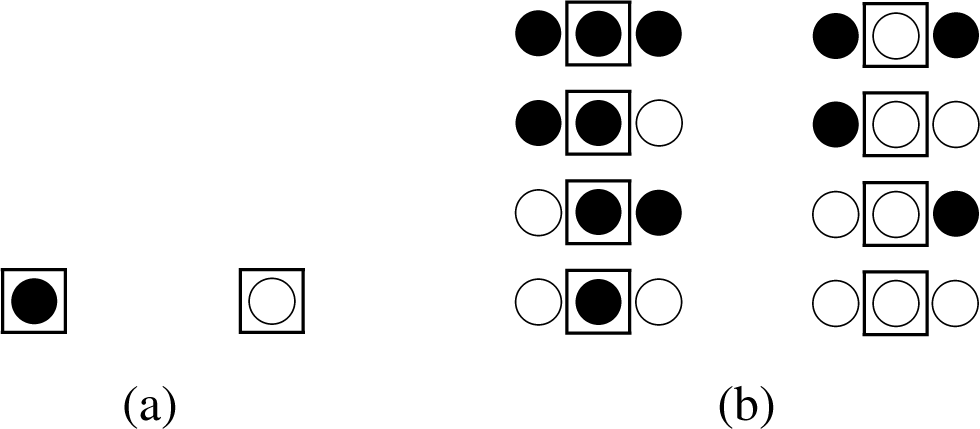
1.1. Compound Systems
1.2. The Bridge to Thermodynamic Entropy

{kind=link}
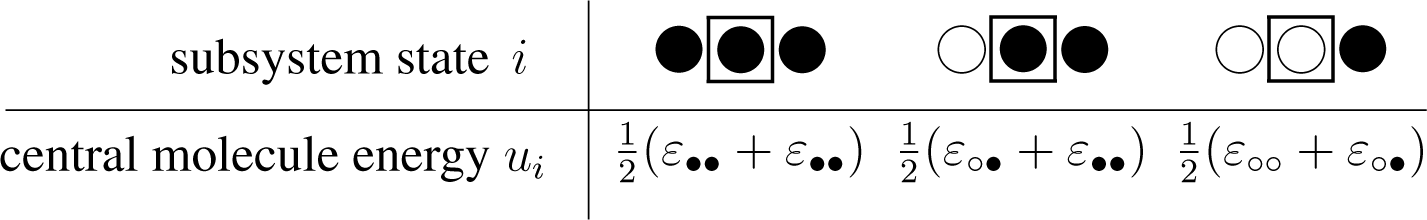{kind=link}
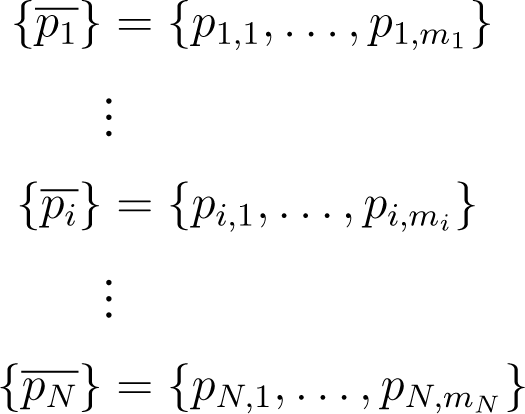{kind=link}
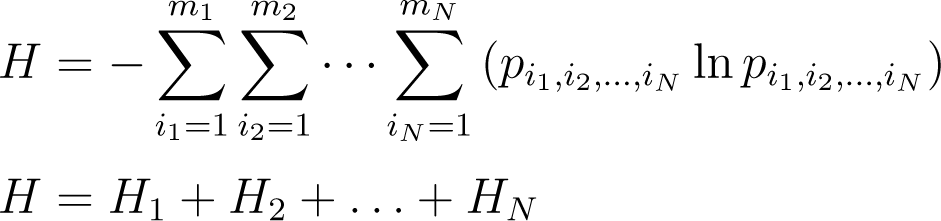{kind=link}
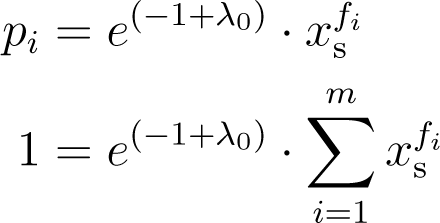{kind=link}
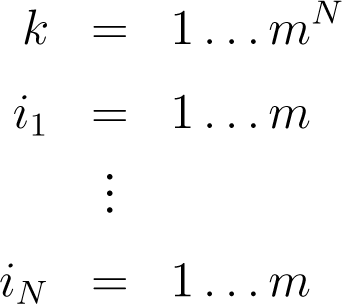{kind=link}
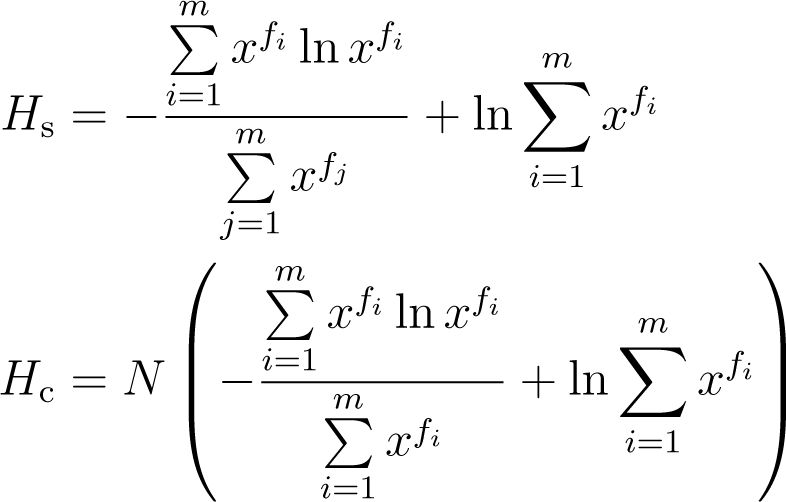{kind=link}
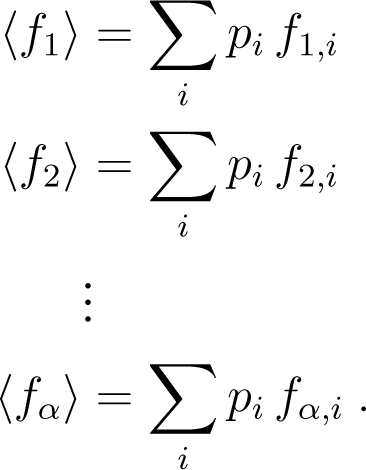{kind=link}
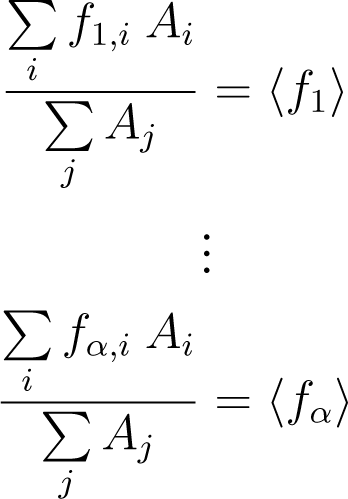{kind=link}
{kind=link}
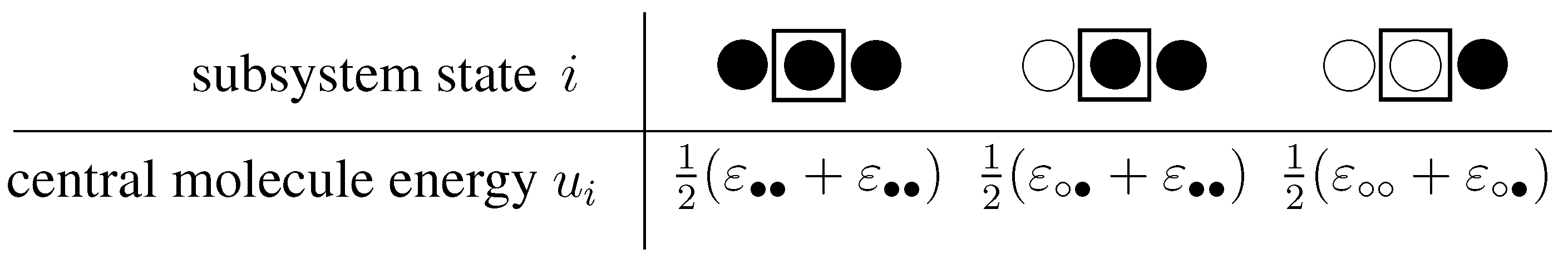{kind=link}
| Shannon entropy H | thermodynamic probability W |
|---|---|
| probability distribution: | occupation: |
| assumption | |
| equal subsystems, statistically independent | Stirling’s formula applied to N and to all |
1.3. Additivity of Shannon Entropy: Its Significance for Thermodynamic Modeling
2. Probability Distributions with Maximum Entropy
2.1. Maximization of Unconstrained Systems
2.2. Constrained Maximization of a Single System
2.3. Constrained Maximization of a Cmpound System
2.4. Systems Underlying Several Constraints
3. Application to Thermodynamic Modeling of Fluid Phases
3.1. Ideal Gas
3.2. Condensed Phase Lattice Systems
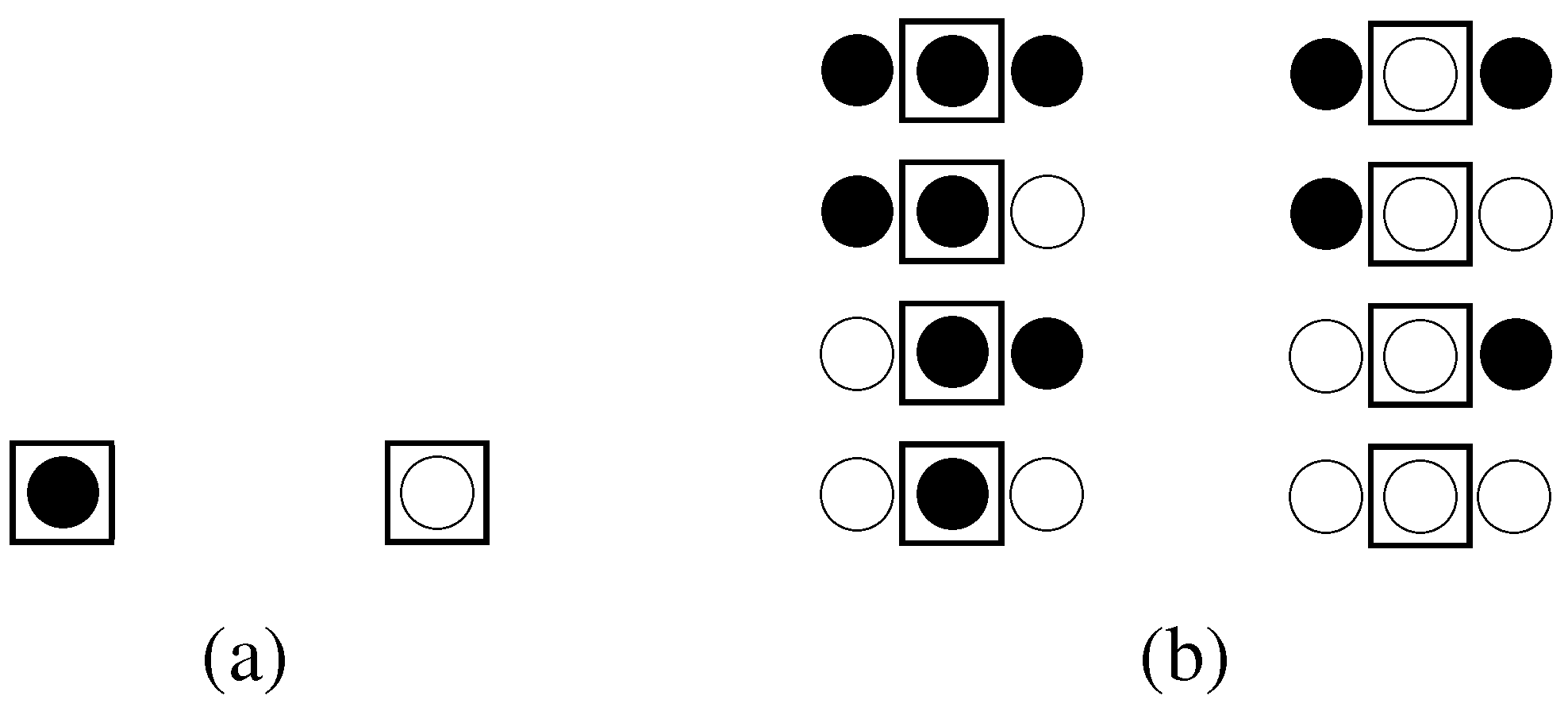
3.2.1. The concept of subsystems applied to a lattice system
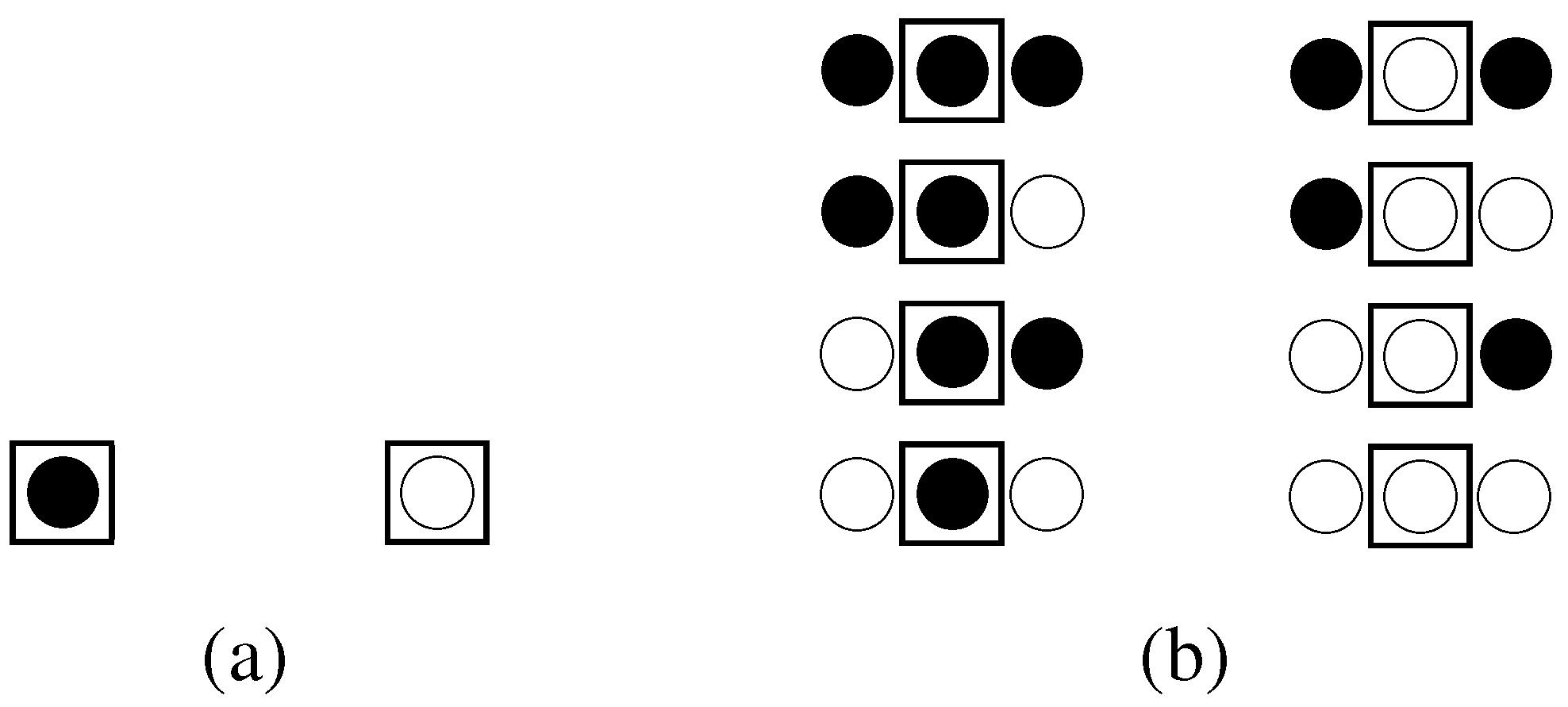
3.2.2. The unconstrained system
3.2.3. System considering constraints
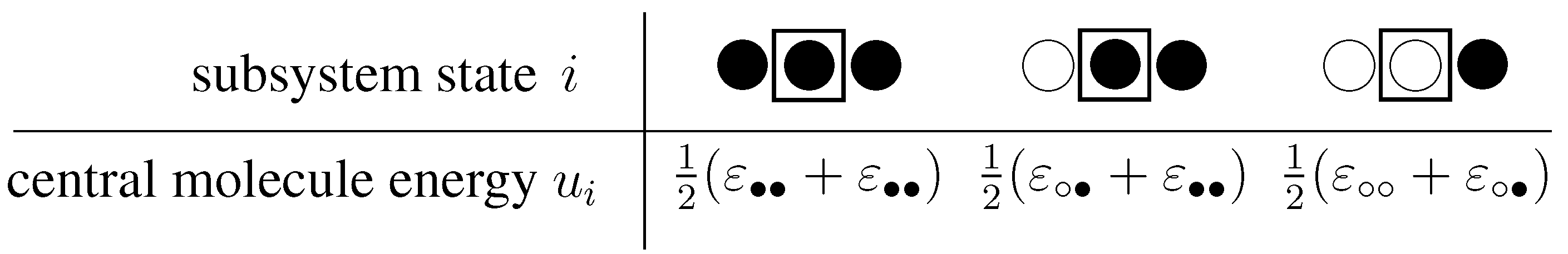
4. Conclusions
Supplementary Materials
Supplementary File 1Acknowledgments
Author Contributions
Conflicts of Interest
References
- Shannon, C.E. A Mathematical Theory of Communication. Bell Sys. Techn. Journ. 1948, 27, 379–423,623–656. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information Theory and Statistical Mechanics. II. Phys. Rev. 1957, 108, 171–189. [Google Scholar] [CrossRef]
- Jaynes, E.T. Gibbs vs Boltzmann Entropies. Am. Journ. Phys. 1965, 33, 391–398. [Google Scholar] [CrossRef]
- Wehrl, A. General Properties of Entropy. Rev. Mod. Phys. 1978, 50, 221–260. [Google Scholar] [CrossRef]
- Guiasu, S.; Shenitzer, A. The Principle of Maximum Entropy. Math. Intell. 1985, 7, 42–48. [Google Scholar] [CrossRef]
- Ben-Naim, A. Entropy Demystified; World Scientific Publishing: Singapore, 2008. [Google Scholar]
- Ben-Naim, A. A Farewell to Entropy: Statistical Thermodynamics Based in Information; World Scientific Publishing: Singapore, 2008. [Google Scholar]
- Curado, E.; Tsallis, C. Generalized Statistical Mechanics: Connection with Thermodynamics. J. Phys. A 1991, 24, L69–L72. [Google Scholar] [CrossRef]
- Tsallis, C. Nonadditive Entropy: The Concept and its Use. Europ. Phys. Journ. A 2009, 40, 257–266. [Google Scholar] [CrossRef]
- Maczek, A. Statistical Thermodynamics; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Wilde, D.J.; Beightler, C.S. Foundations of Optimization; Prentice-Hall: Englewood Cliffs, NJ, USA, 1967. [Google Scholar]
- Fowler, R.H.; Kapitza, P.; Mott, N.F.; Bullard, E.C. Mixtures - The Theory of the Equilibrium Properties of Some Simple Classes of Mixtures, Solutions and Alloys; Oxford at the Clarendon Press, 1952. [Google Scholar]
- Abrams, D.S.; Prausnitz, J.M. Statistical Thermodynamics of Liquid Mixtures: A New Expression for the Excess Gibbs Energy of Partly or Completely Miscible Systems. AIChE J. 1975, 21, 116–128. [Google Scholar] [CrossRef]
- Bronneberg, R.; Pfennig, A. MOQUAC, a New Expression for the Excess Gibbs Energy based on Molecular Orientations. Fluid Phase Equilib. 2013, 338, 67–77. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Pfleger, M.; Wallek, T.; Pfennig, A. Constraints of Compound Systems: Prerequisites for Thermodynamic Modeling Based on Shannon Entropy. Entropy 2014, 16, 2990-3008. https://doi.org/10.3390/e16062990
Pfleger M, Wallek T, Pfennig A. Constraints of Compound Systems: Prerequisites for Thermodynamic Modeling Based on Shannon Entropy. Entropy. 2014; 16(6):2990-3008. https://doi.org/10.3390/e16062990
Chicago/Turabian StylePfleger, Martin, Thomas Wallek, and Andreas Pfennig. 2014. "Constraints of Compound Systems: Prerequisites for Thermodynamic Modeling Based on Shannon Entropy" Entropy 16, no. 6: 2990-3008. https://doi.org/10.3390/e16062990
APA StylePfleger, M., Wallek, T., & Pfennig, A. (2014). Constraints of Compound Systems: Prerequisites for Thermodynamic Modeling Based on Shannon Entropy. Entropy, 16(6), 2990-3008. https://doi.org/10.3390/e16062990