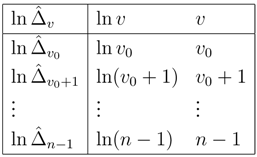1. Introduction
Let
be a finite or countable index set with cardinality
. Let
be a probability distribution on the alphabet
. Entropy, of the form
was introduced by Shannon in [
1] and is often referred to as Shannon’s entropy. Miller [
2] and Basharin [
3] were among the first to study nonparametric estimation of
H. Since then, the topic has been investigated from a variety of directions and perspectives. Many important references can be found in [
4] and [
5]. In this paper, we introduce a modification of an estimator of entropy, which was first defined by Zhang in [
6]. This modification aims to reduce the bias of the original estimator. Simulations suggest that, at least for the models considered, this estimator has very low bias compared with several other commonly used estimators. Throughout this paper, we use ln to denote the natural logarithm and we define, as is common,
. For any two functions
f and
g, taking values in
with
, we write
to mean
and
to mean
Assume that
P is unknown. Let
be an independent and identically distributed (
) sample of size
n from
according to
P. Let
be the observed sample frequencies of letters in the alphabet, and let
be the sample proportions. In this framework, we are interested in estimating
H. Perhaps the most intuitive nonparametric estimator of
H is given by
This is known as the plug-in estimator. When
is finite, the bias of
is given by
see Miller [
2] or, for a more formal treatment, Paninski [
5]. This leads to the so-called Miller–Madow estimator
where
is the number of distinct letters observed in the sample. Other estimators of
H include the jackknife estimator of Zahl [
7] and Strong, Koberle, de Ruyter van Steveninck, and Bialek [
8], and the NSB estimator of Nemenman, Shafee, and Bialek [
9] and Nemenman [
10]. These estimators (and others) have been shown to work well in numerical studies, although many of their theoretical properties (such as consistency and asymptotic normality) are not known.
Zhang [
6] proposed an estimator,
, of entropy, which is given in Equation (
4) below. When
is finite, the bias of
decays exponentially fast, and the estimator is asymptotically normal and efficient. See Zhang [
11] for details. This estimator is given by
where
In Zhang [
6] it is shown that
and that the bias of
is given by
Although
decays exponentially in
n when
is a finite set, it can still be annoyingly sizable for small
n. The objective of this paper is to put forth a good estimator
of
, and, in turn, a good estimator of
H by means of
. We deal with both the case when
is finite and the case when it is infinite.
2. Bias Adjustment
For a positive integer
v, let
be the difference between the bias of
based on an
sample of size
v and that of size
,
i.e.,
Clearly
. According to Zhang and Zhou [
12], for every
v with
,
, as given in Equation (
5), is the uniformly minimum variance unbiased estimator (
) of
. This implies that for every
v,
,
is a good estimator of
.
The methodology proposed in this paper is as follows: For all , we estimate with . We use to fit a parametric function such that is close to . We then extrapolate this function and take for . Our estimate of the bias is then .
It remains to choose a reasonable parametric form for
δ and to fit it. We consider these questions in two separate cases: (1) when
is finite, known or unknown, and (2) when
is countably infinite. The case when it is unknown whether
is finite or infinite is discussed in Remark 1 below.
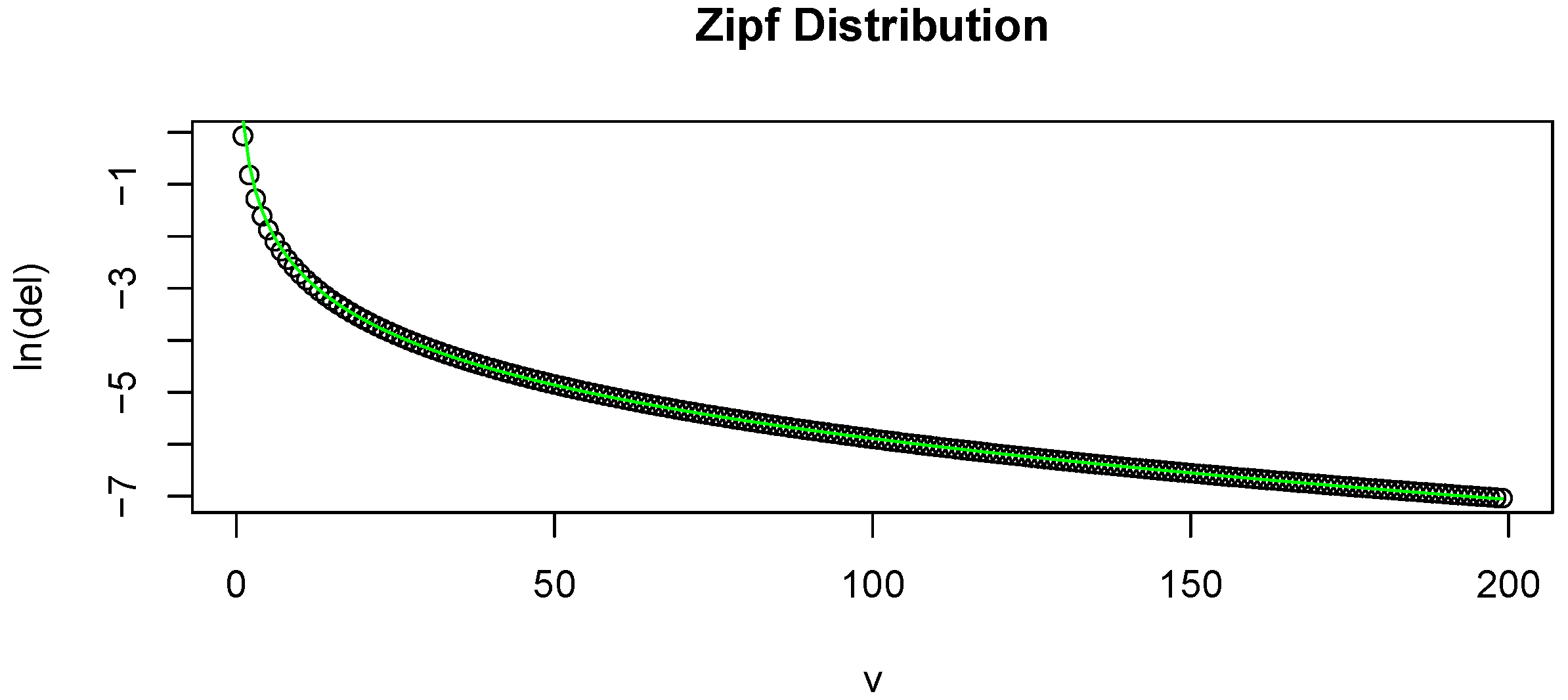
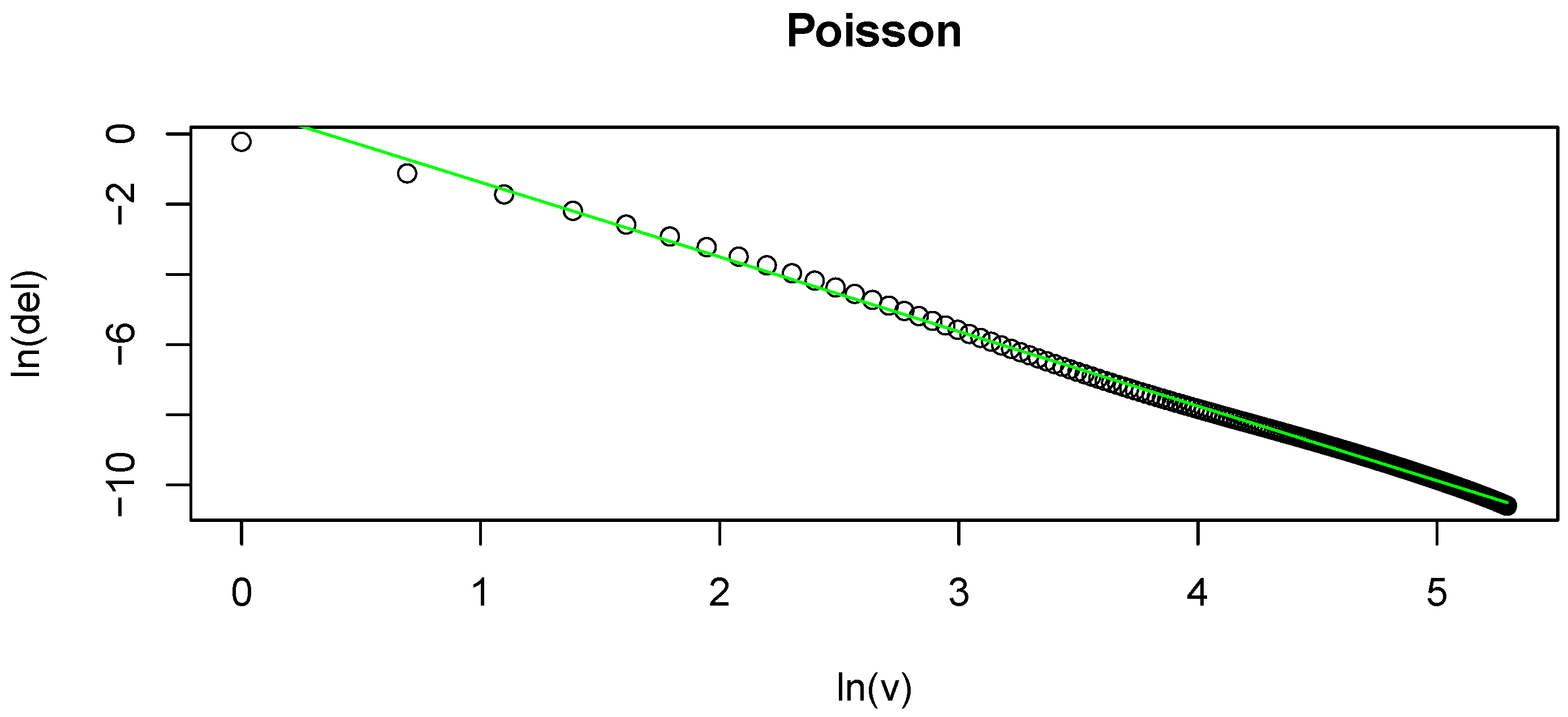
Figure 1 shows how well our chosen
fits
for typical examples.
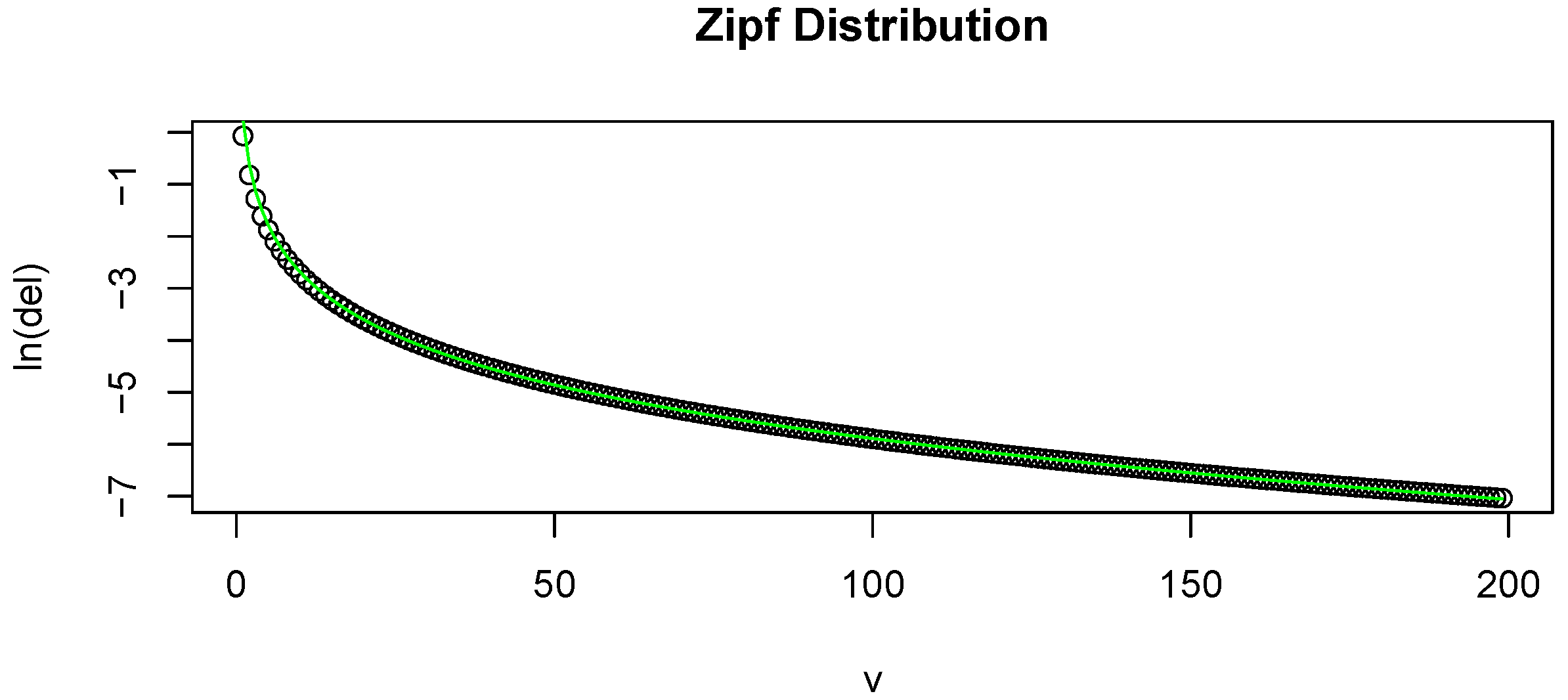
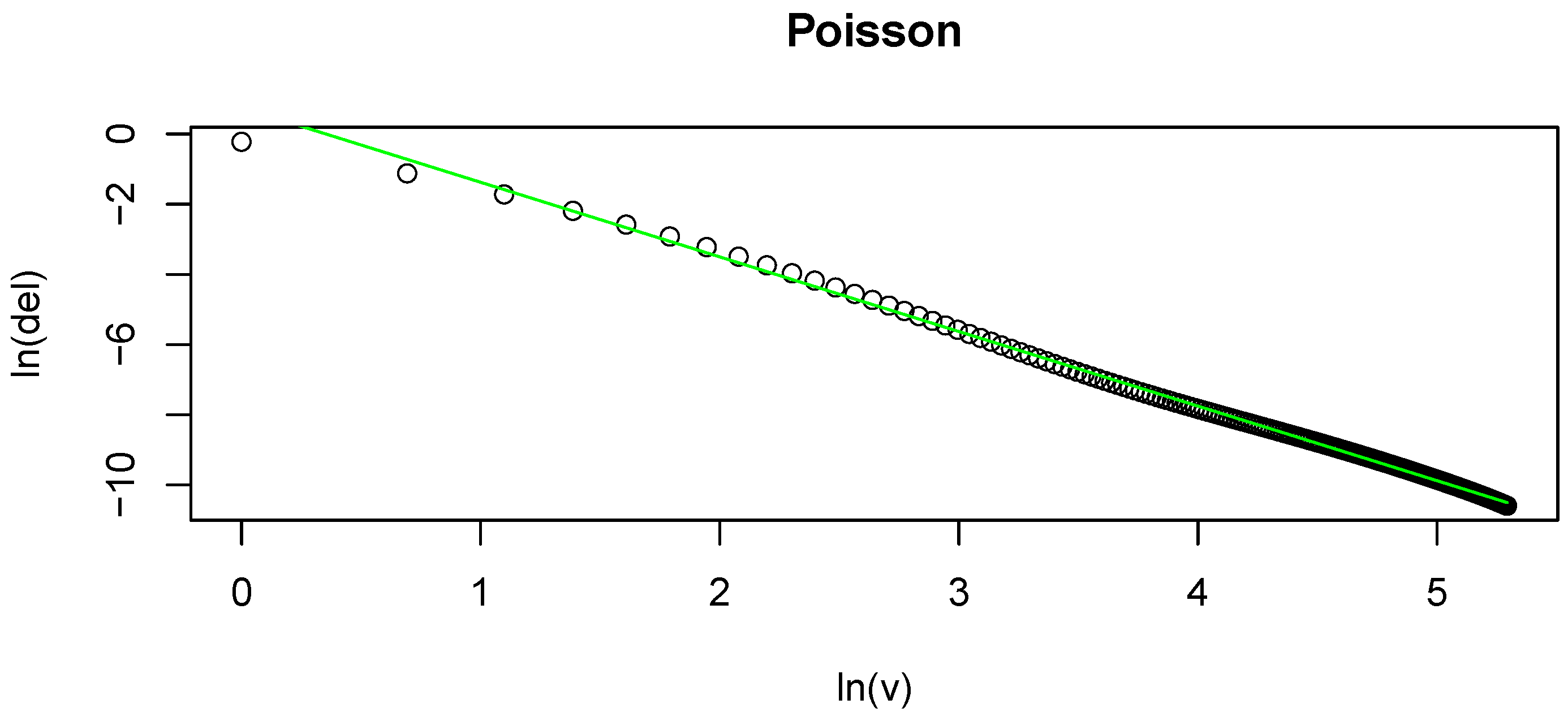
Figure 1.
(a) Plot of v on the x-axis and on the y-axis. This is based on a random sample of size 200 from a Zipf distribution. The overlaid line is the estimated ; (b) Plot of on the x-axis and on the y-axis. This is based on a random sample of size 200 from a Poisson distribution. The overlaid line is the estimated .
Figure 1.
(a) Plot of v on the x-axis and on the y-axis. This is based on a random sample of size 200 from a Zipf distribution. The overlaid line is the estimated ; (b) Plot of on the x-axis and on the y-axis. This is based on a random sample of size 200 from a Poisson distribution. The overlaid line is the estimated .
2.1. Case: is Finite
Assume that
is finite. If
then
as
v increases indefinitely. This suggests taking
where
and
. However, since, for small values of
v, other terms of the sum given in Equation (
7) may have a significant impact, we consider the slightly more general form
where
,
and
are parameters. These parameters are estimated by using least squares to fit
with data
Here
is a user-chosen positive integer. We can always take
, but we may wish to exclude the first several
since they may be atypical. We denote our estimate of
by
, and those of
α,
β, and
γ by
The bias adjusted
is given by
This summation may be approximated by the integral
or by truncating the sum at some very large integer
V. For the simulation results presented below, we take
and
.
Two finer modifications are made to
in Equation (
13) when the sample data present some undesirable features:
If the least squares fit based on Equation (
10) leads to
, the fitted results are abandoned, and instead the new model
is fit to the same data as in Equation (
11). The resulting estimates of the parameters are then
and a modified estimate of
H is given by
The switch from Equation (
10) to Equation (
14) is necessary because if
then
in Equation (
13) diverges. In this case, we recommend taking a relatively large value for
because small values of
v are more likely to require a polynomial part. For our simulations, we use
in this case.
When a sample has no letters with frequency 1, the model in Equation (
9) will not fit well. In this case we modify the sample by isolating one observation in a letter group with the least frequency and turn it into a singleton, e.g., a sample of the form
is replaced by
.
To show how well Equation (
9) fits
for a typical sample, we include an example of the fit in (a) of
Figure 1. Here we plot
v against
. The overlaid curve represents the fitted
. This is based on a simulation of a random sample of size 200 from a Zipf distribution. To give a snapshot of the performance of the proposed estimator, we conducted several numerical simulations, and compared the absolute value of the bias of the proposed estimator to that of several commonly used ones. The distributions that we performed the simulations on are:
(Triangular) , for , here ,
(Zipf) , for , here and .
The estimators that we compared the performance of our estimator to are: the plug-in estimator given in Equation (
2), the Miller–Madow estimator given in Equation (
3), and
given in Equation (
4).
For each distribution and each estimator, the bias was approximated as follows. We simulate
n observations from the given distribution and evaluate the estimator. We then subtract the estimated value from the true value
H. We repeat this 2000 times and average the errors. We then take the absolute value of the estimated bias. The procedure was slightly different for the estimator given in Equation (
4). Since, in this case, the bias has the explicit form given in Equation (
6), we approximate the bias by truncating this series at
. The sample sizes considered in these simulations range from
to
. The plots of the estimated biases are graphed in
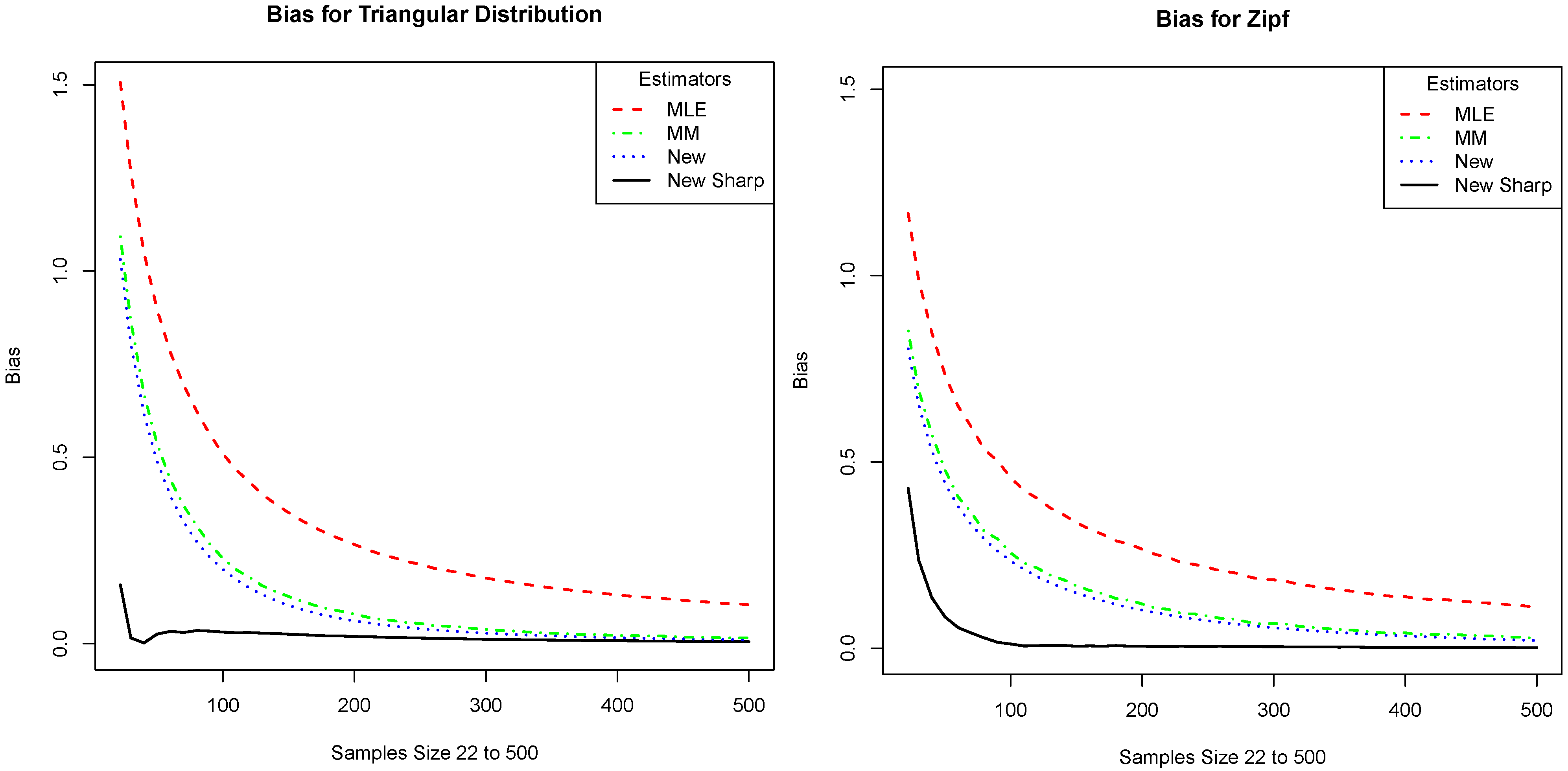
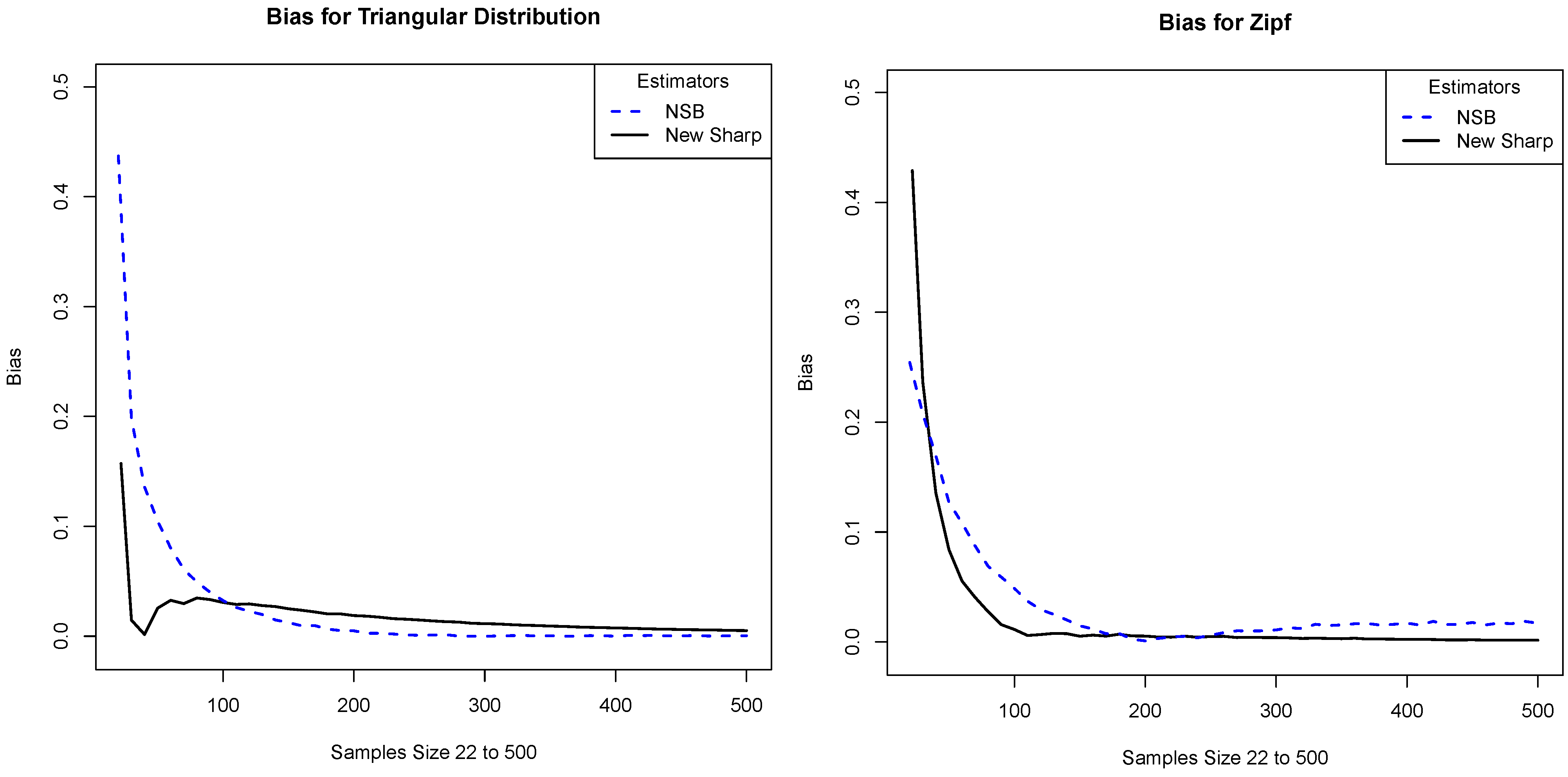
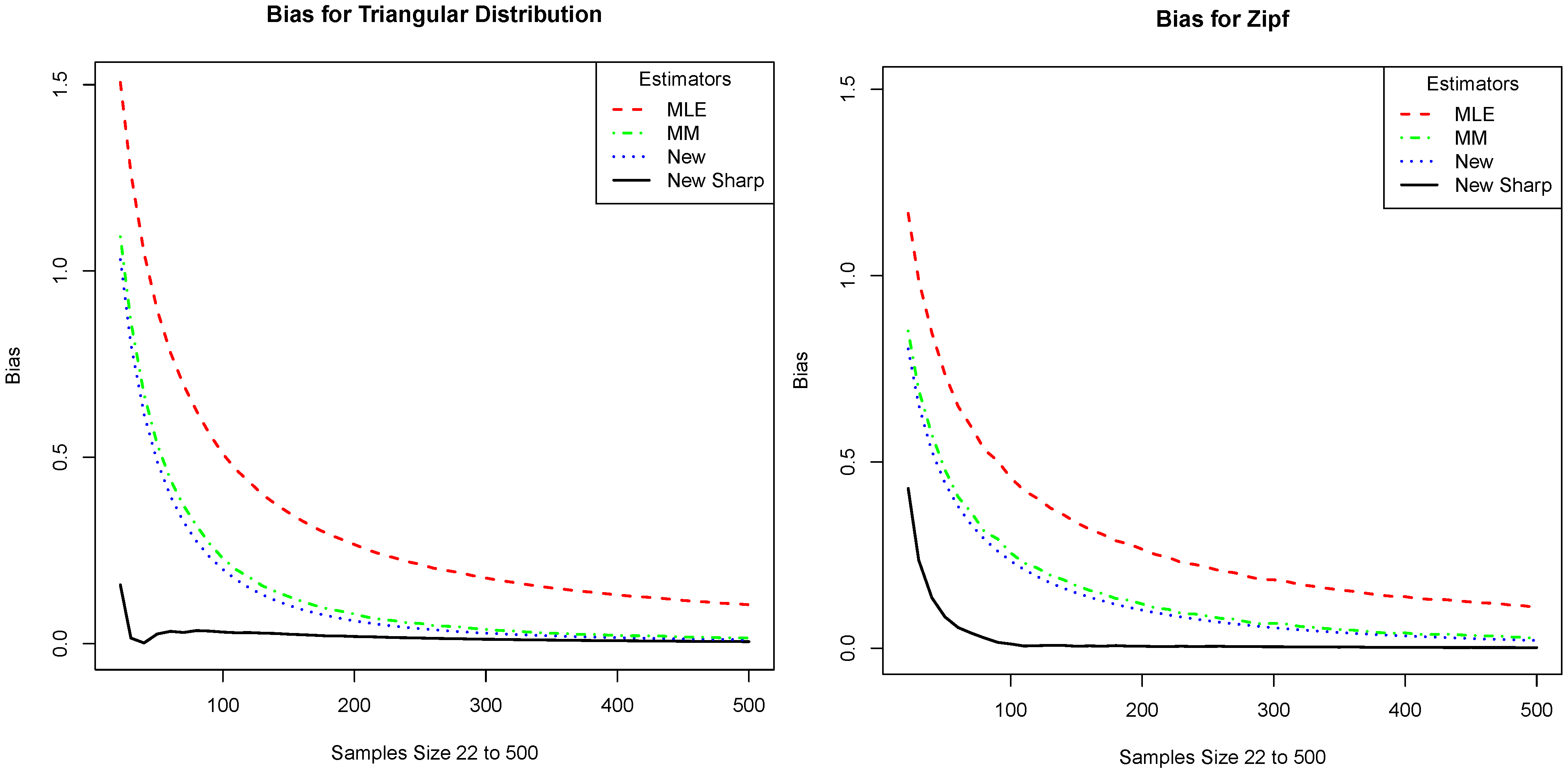
Figure 2; part (a) gives the plot for the triangular distribution and part (b) gives the plot for the Zipf distribution. Note that our proposed estimator has the lowest bias in all cases and that it is significantly lower for small samples.
Figure 2.
We compare the absolute value of the bias of our estimator (New Sharp) with that of the plug-in (MLE), the Miller–Madow (MM), and the one given in Equation (
4) (New). The
x-axis is the sample size and the
y-axis is the absolute value of the bias. The plots correspond to the distributions: (
a) Triangular distribution and (
b) Zipf distribution.
Figure 2.
We compare the absolute value of the bias of our estimator (New Sharp) with that of the plug-in (MLE), the Miller–Madow (MM), and the one given in Equation (
4) (New). The
x-axis is the sample size and the
y-axis is the absolute value of the bias. The plots correspond to the distributions: (
a) Triangular distribution and (
b) Zipf distribution.
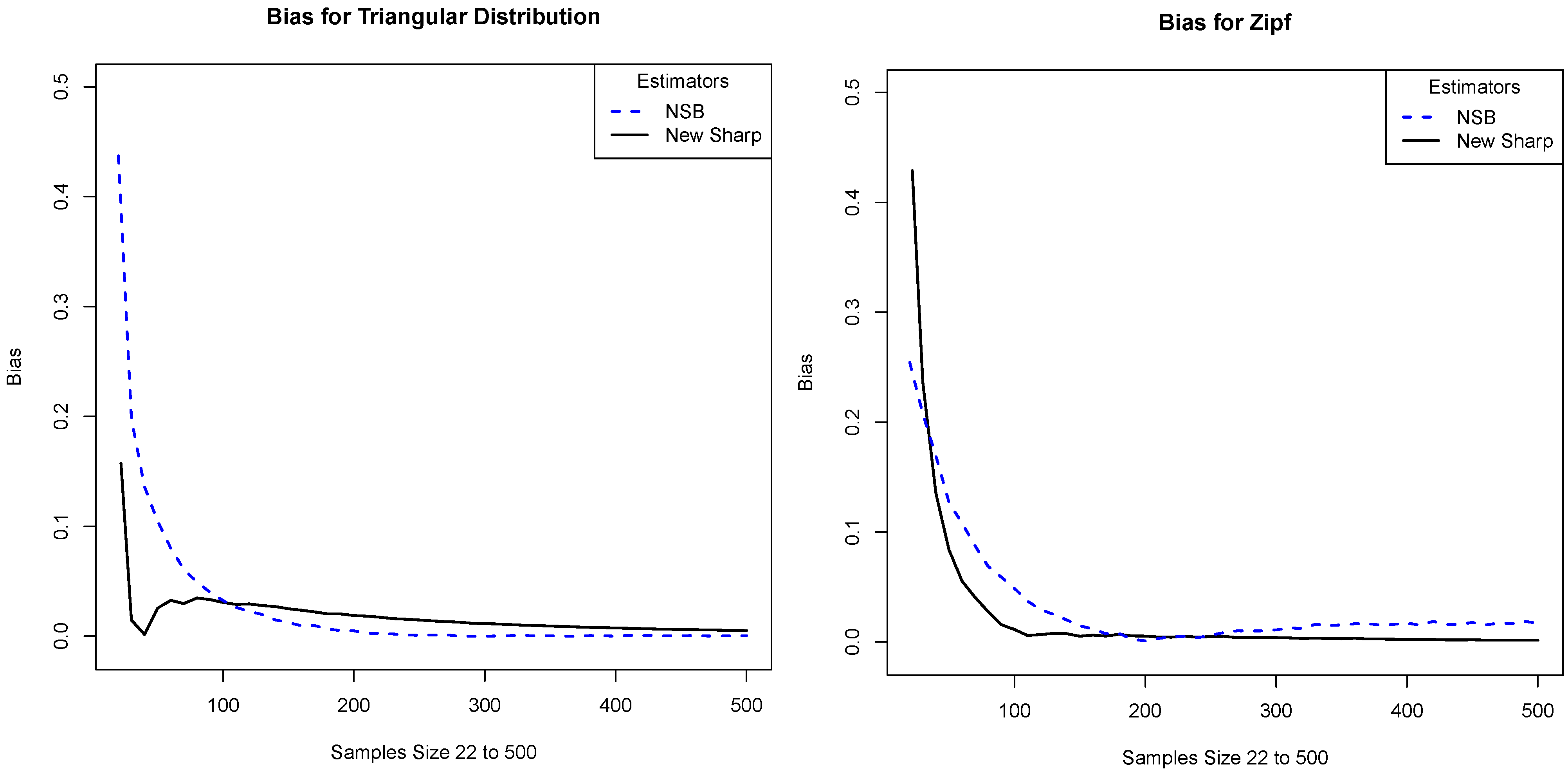
Another estimator of entropy is the NSB estimator of Nemenman, Shafee, and Bialek [
9] (see also Nemenman [
10] and the references therein). The authors of that paper provide code to do the estimation, which is available at
http://nsb-entropy.sourceforge.net/. We used version 1.13, which was updated on 20 July 2011. Unlike the estimators discussed above, this one requires knowledge of
, and, for this reason, we consider it separately. Plots comparing the bias of our estimator and that of NSB are given in
Figure 3. Note that our estimator is mostly comparable with NSB, although in certain regions it performs a bit better.
Figure 3.
We compare the absolute value of the bias of our estimator with that of the NSB estimator. The x-axis is the sample size and the y-axis is the absolute value of the bias. The plots correspond to the distributions: (a) Triangular distribution and (b) Zipf distribution.
Figure 3.
We compare the absolute value of the bias of our estimator with that of the NSB estimator. The x-axis is the sample size and the y-axis is the absolute value of the bias. The plots correspond to the distributions: (a) Triangular distribution and (b) Zipf distribution.
2.2. Case: is Countably Infinite
We now turn to the case when
is countably infinite. We need to find a reasonable parametric form for
. The following facts suggest an approach.
For any distribution on a countably infinite alphabet .
If for where , then .
These facts tell us that
decays slower than
. Moreover, the heavier the tail of the distribution, the slower the decay appears to be. Since, even for very heavy tailed distributions, we have polynomial decay, this suggests that the rate of decay is essentially
for some
. Thus, for all practical purposes, a reasonable model is
where
and
(we allow
to make the model more flexible). The model parameters are estimated by using least squares to fit
with the data in Equation (
11). We denote the estimate of
by
, and those of
α and
β by
The bias adjusted
is given by
where the summation may be approximated by the integral
or by truncating the sum at some very large integer
V. For the simulation results presented below, we take
and use the integral approximation to the sum.
As in the case when
is finite, we need to make adjustments in certain situations.
To show how well Equation (
16) fits
in a typical sample, we include an example of the fit in (b) of
Figure 1. Here we plot
against
. The overlaid curve represents the fitted
. This is based on a simulation of a random sample of size 200 from a Poisson distribution. As in the previous case, we evaluate the performance of the proposed estimator by conducting several numerical simulations. We estimated entropy for the following distributions:
(Power) , for , here and ,
(Geometric) , for , here ,
(Poisson) , for , where and .
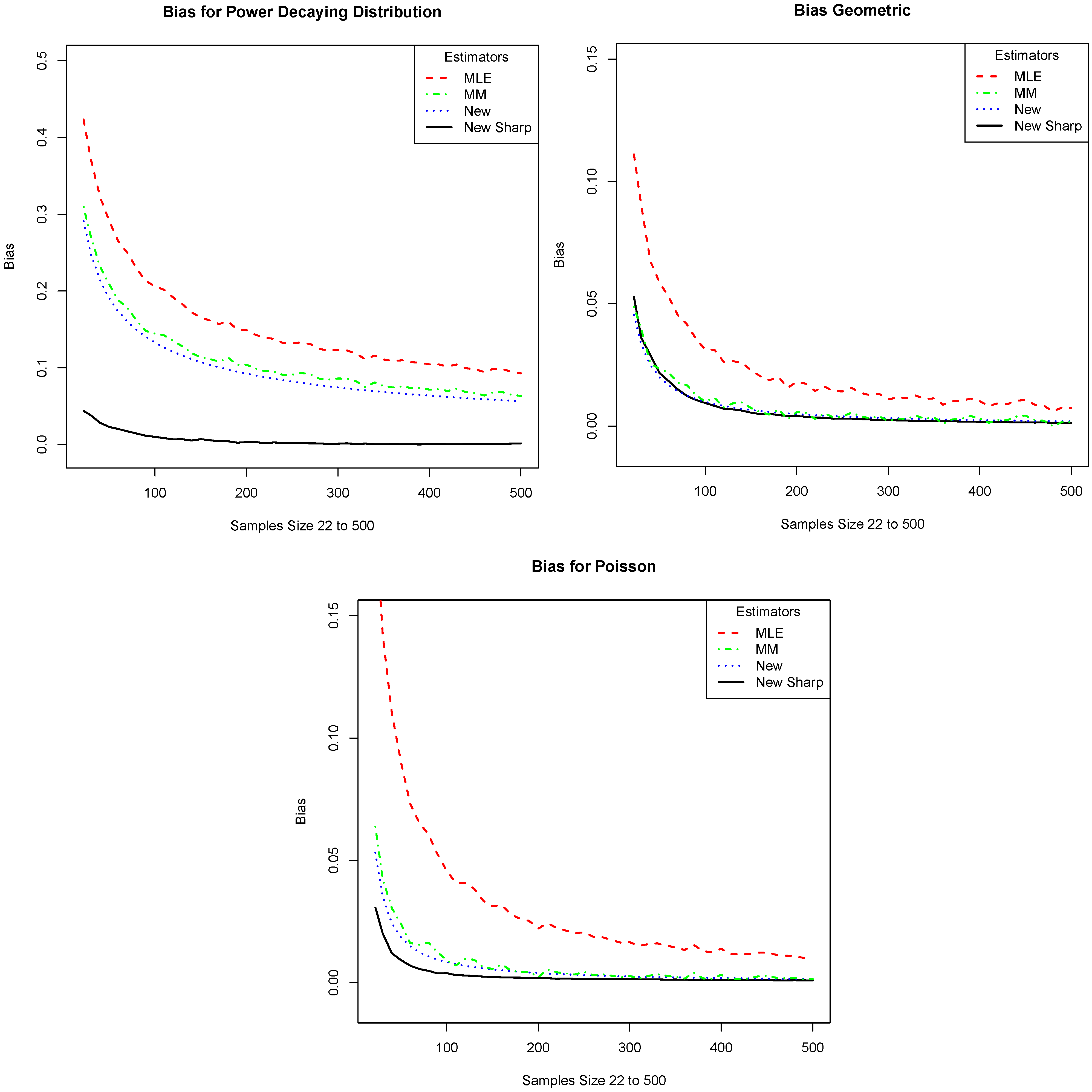
Again, we compare with the plug-in estimator, the Miller–Madow estimator, and
. Although the Miller–Madow estimator is motivated by the case where
is finite, it is often a good estimator in the infinite case as well. We approximate the bias, as in the previous case. The estimated biases for sample sizes ranging from
to
are graphed in
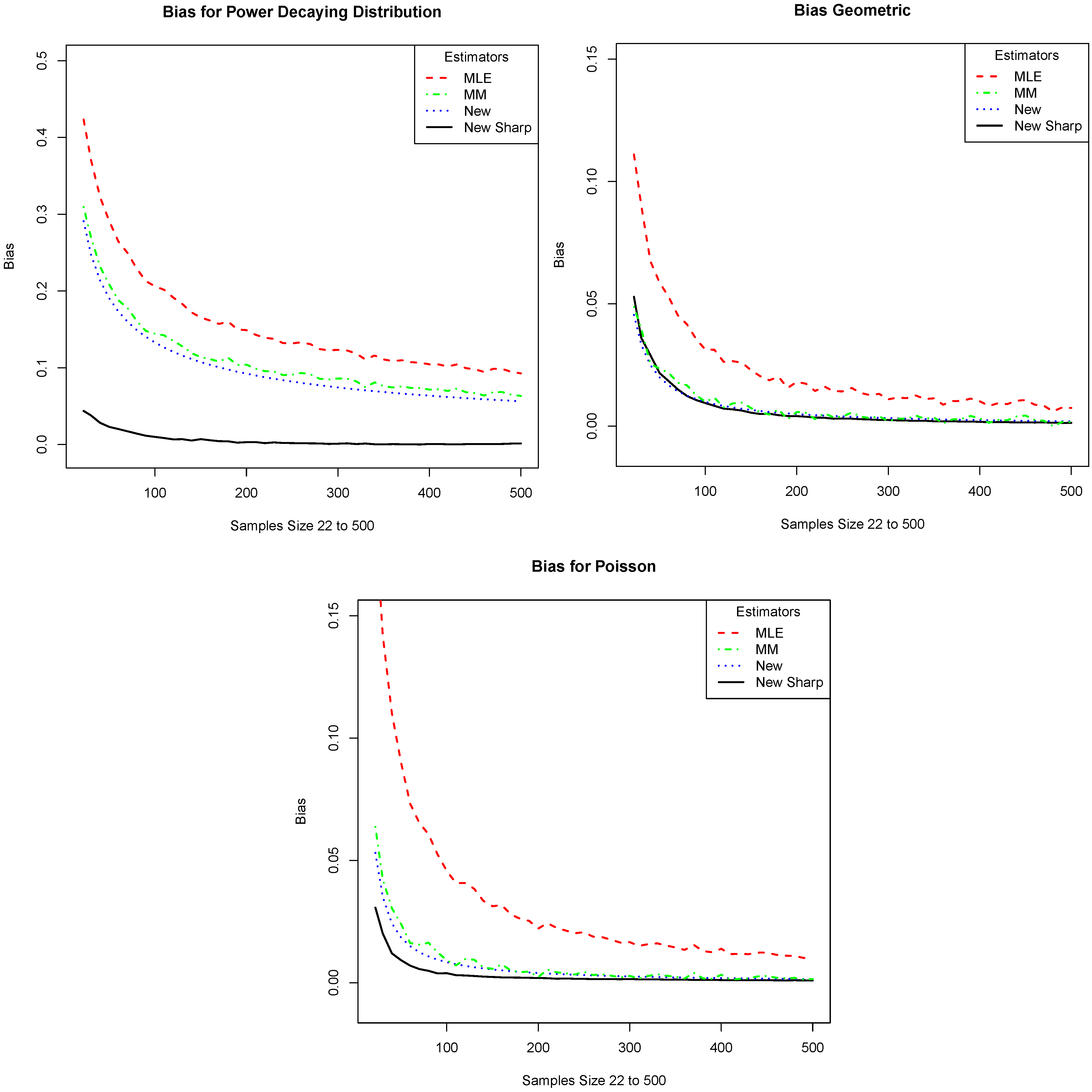
Figure 4. Parts (a), (b), and (c) of
Figure 4 correspond to the three distributions listed above. Note that the new estimator outperforms the other estimators. However, the improvement is not as drastic as in the case when
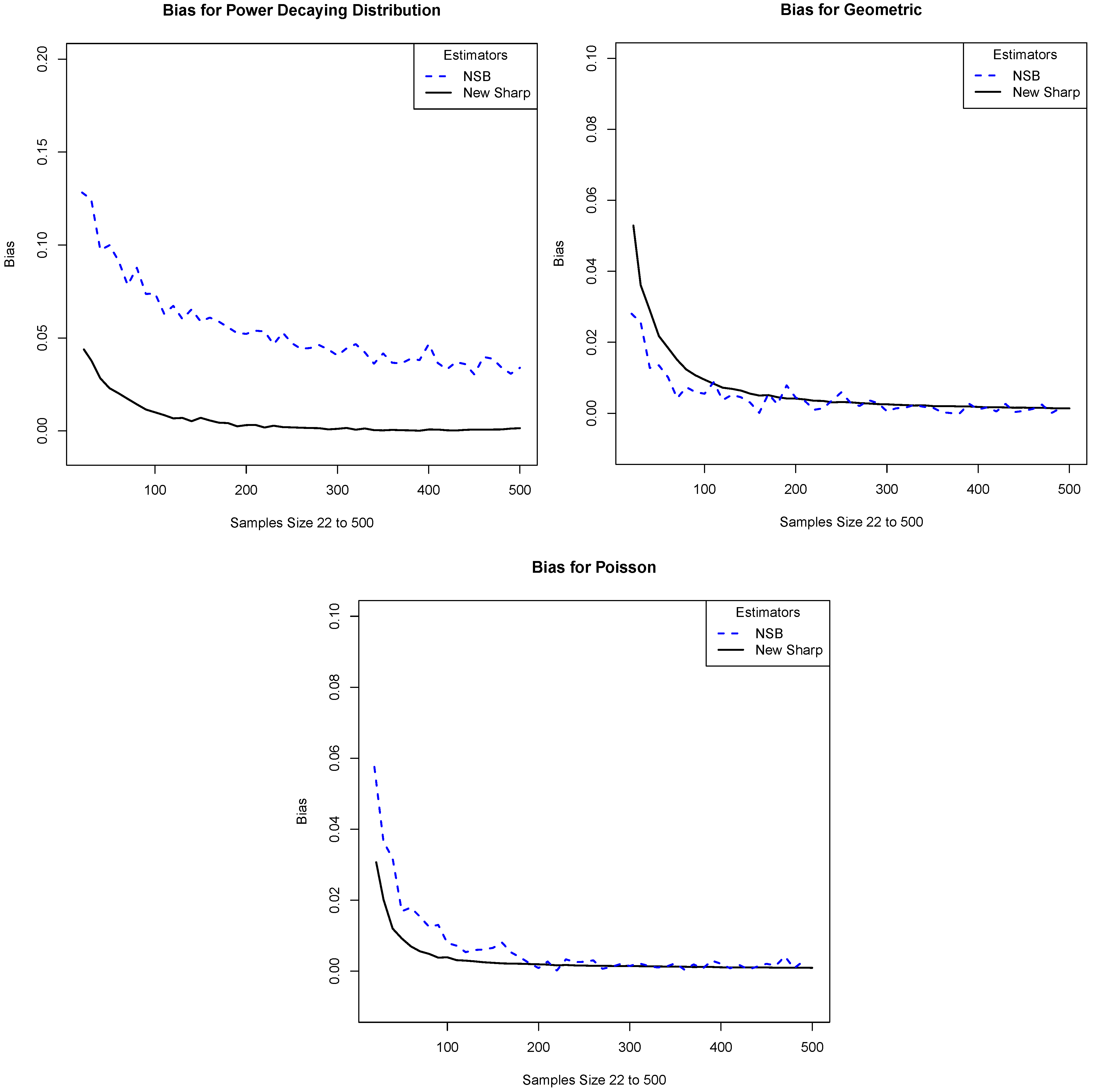
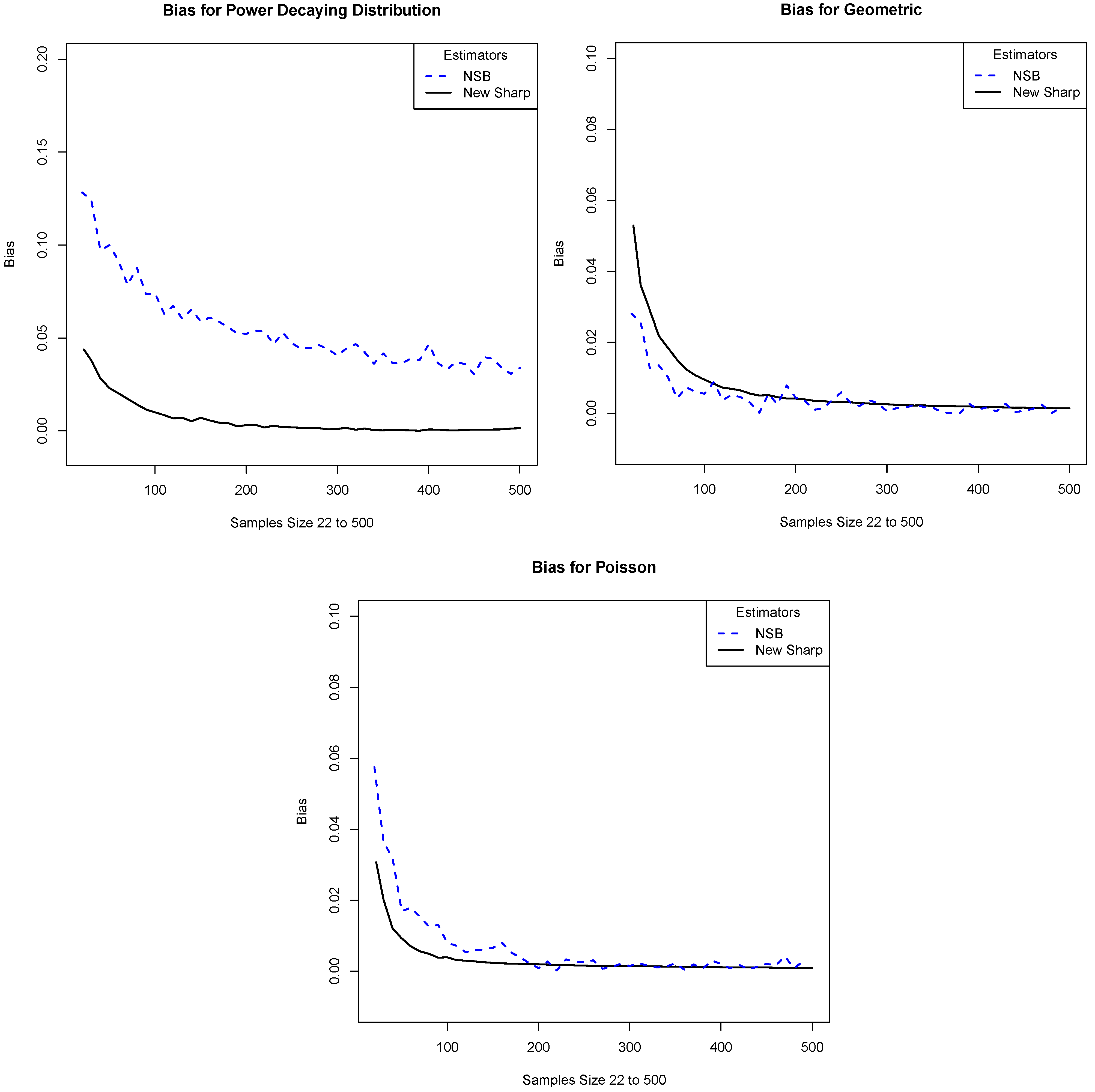
is finite. We also make separate comparisons with NSB. These are given in
Figure 5. Although NSB is designed for the case when
is known and finite, we can extend its use to the infinite case by telling the program that
is some large but finite value. In our simulations we take it to be
. We see that the performance of our estimator is roughly comparable with or somewhat better than that of NSB.
Remark 1. In practice, it may not be known, a priori, if is finite or infinite. In such situations, one does not know which of the two adjustments to use. One approach is as follows. Fit both models and denote their respective mean squared errors by and , then use the one that has the smaller .
Figure 4.
We compare the absolute value of the bias of our estimator (New Sharp) with that of the plug-in (MLE), the Miller–Madow (MM), and the one given in Equation (
4) (New). The
x-axis is the sample size and the
y-axis is the absolute value of the bias. The plots correspond to the distributions: (
a) Power; (
b) Geometric; and (
c) Poisson.
Figure 4.
We compare the absolute value of the bias of our estimator (New Sharp) with that of the plug-in (MLE), the Miller–Madow (MM), and the one given in Equation (
4) (New). The
x-axis is the sample size and the
y-axis is the absolute value of the bias. The plots correspond to the distributions: (
a) Power; (
b) Geometric; and (
c) Poisson.
Figure 5.
We compare the absolute value of the bias of our estimator with that of the NSB estimator. The x-axis is the sample size and the y-axis is the absolute value of the bias. The plots correspond to the distributions: (a) Power; (b) Geometric; and (c) Poisson.
Figure 5.
We compare the absolute value of the bias of our estimator with that of the NSB estimator. The x-axis is the sample size and the y-axis is the absolute value of the bias. The plots correspond to the distributions: (a) Power; (b) Geometric; and (c) Poisson.
3. Summary and Discussion
In Zhang [
6] an estimator of entropy was introduced, which, in the case of a finite alphabet, has exponentially decaying bias. In this paper we described a methodology for further reducing the bias of this estimator. Our approach is to note that when the alphabet is finite, the bias of this estimator decays exponentially fast, while in the case when the alphabet is infinite, the bias decays like a polynomial. We estimate the bias by fitting an appropriate function. Then we add this estimate of the bias to our estimated entropy. Simulation results suggest that, at least in the situations considered, the bias is drastically reduced for small sample sizes. Moreover, our estimator outperforms several standard estimators and is comparable with the well-known estimator NSB.
One situation where estimators of entropy run into difficulty is in the case where all n observations are singletons, that is when each observation is a different letter. There is not much that can be done in this case since the sample has very little information about the distribution (except that, in some sense, it is very “heavy tailed”). In this case, we can say that the sample size is very small, even if n is substantial.
This suggests a way to think about small sample sizes. Before discussing this, we describe a common approach to defining what a small sample size is. When is finite, a common heuristic is to say that a sample is small if its size n is less than , for some . While this may be useful in certain situations, it has several limitations. First, it assumes that is known and finite, and second there appears to be no good way to choose ϵ. Moreover, this ignores the fact that some letters may have very small probabilities and may not be very important for entropy estimation. To underscore this point, consider two models. The first has an alphabet of size K, while the second has a much larger alphabet size, say . However, assume that on K of its letters, the second model has almost the same probabilities as those of the first model, while the remaining letters have very tiny probabilities. The heuristic described above may call a sample of size n from the first population large while a sample of size n from the second population very small, even though, for the purposes of entropy estimation, the two samples may have approximately the same amount of information about their respective distributions.
What matters is not how big the sample is relative to , but how much information about the population the sample possesses. Thus, instead of starting with an external idea of what constitutes a small sample, we can “ask” the sample how much information it contains about the distribution. If it contains very little information about the sample then we can call it a “small sample.” When one has a small sample, in this sense, one should be very careful about using it for inference, and, in particular, for entropy estimation.
One way to quantify how much information a sample has is the sample’s coverage of the population, which is given by
. Thus, one can consider the sample large if
is large and small if
is small. Of course, to evaluate
one needs to know the underlying distribution. However, an estimator of
is given by Turing’s formula,
, where
is the number of singleton letters in the sample. Interested readers are referred to Good [
13], Robbins [
14], Esty [
15], Zhang and Zhang [
16], and Zhang [
17] for details.
Note that, for the situation described above, where each letter is a singleton, we have and . Thus, the sample has essentially no coverage of the distribution. Which values of T constitute a small sample and which constitute a large sample is an interesting question that we leave for another time.
We end this paper by discussing some future work. While our simulations suggest that the estimator introduced in this paper is quite useful, it is important to derive its theoretical properties. In a different direction, we note that, in practice, one often needs to compare one estimated entropy to another. An approach to doing this is to use the asymptotic normality of
or
(or a different estimator, if available) to set up a two sample
z-test. We recently conducted a series of studies on testing the equality of two entropies using this approach. We found two major difficulties that are not very surprisingly in retrospect:
The difference between biases due to different sample sizes causes a huge inflation of Type II error rate, even with reasonably large samples.
The bias in estimating the variance of an entropy estimator is also sizable and persistent.
Both of these issues are not well-studied in the current literature. We strongly believe that more research on this front should be encouraged.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}