A Novel Nonparametric Distance Estimator for Densities with Error Bounds




Abstract
:1. Introduction
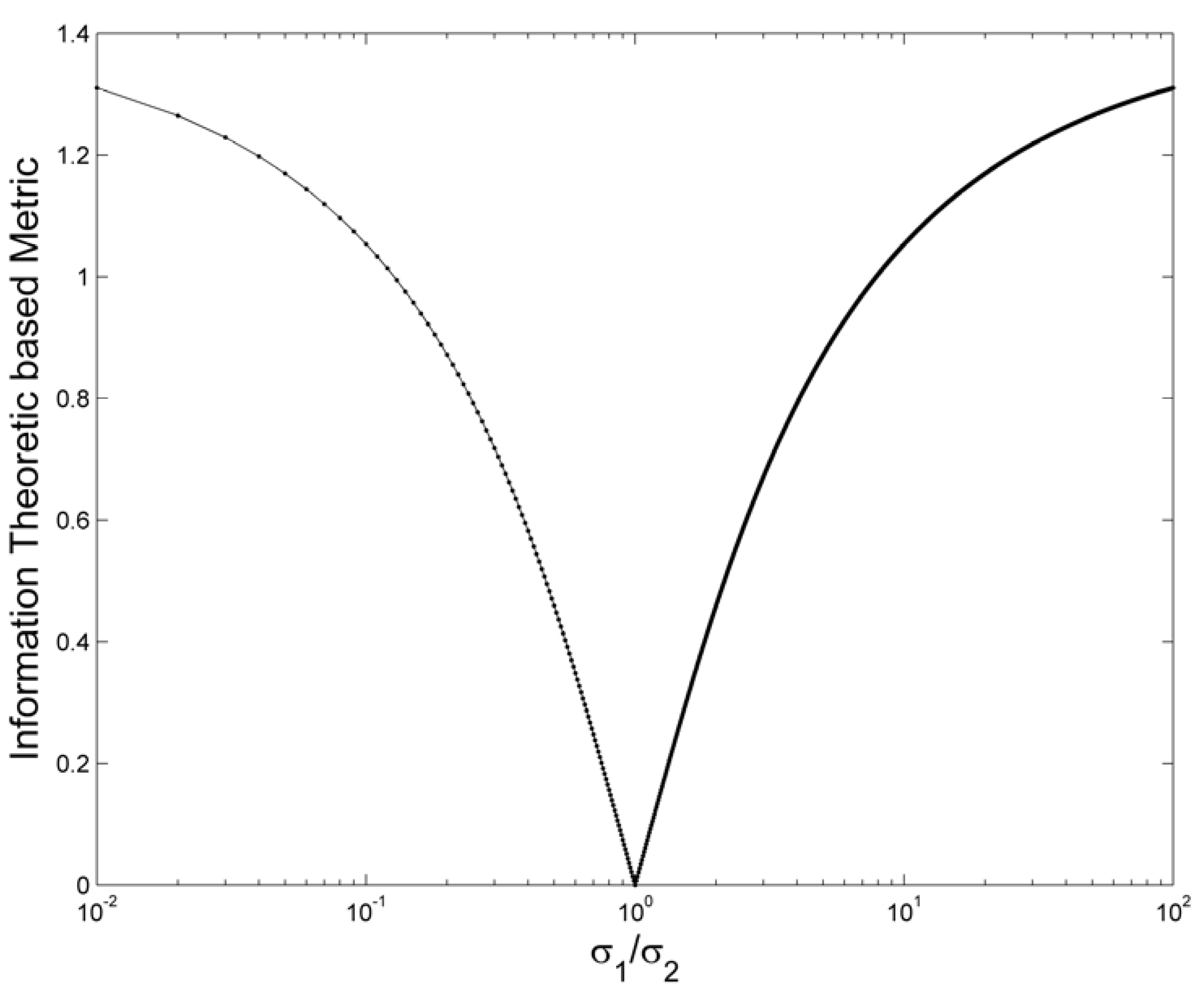
2. Theory Background
2.1. Square-Root Entropy
2.2. Nonparametric Hellinger’s Affinity Estimation
2.3. The Resampling Estimator
2.4. The Two Stage Resampling Estimator

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm 1—Two-stage resampling estimator |
|
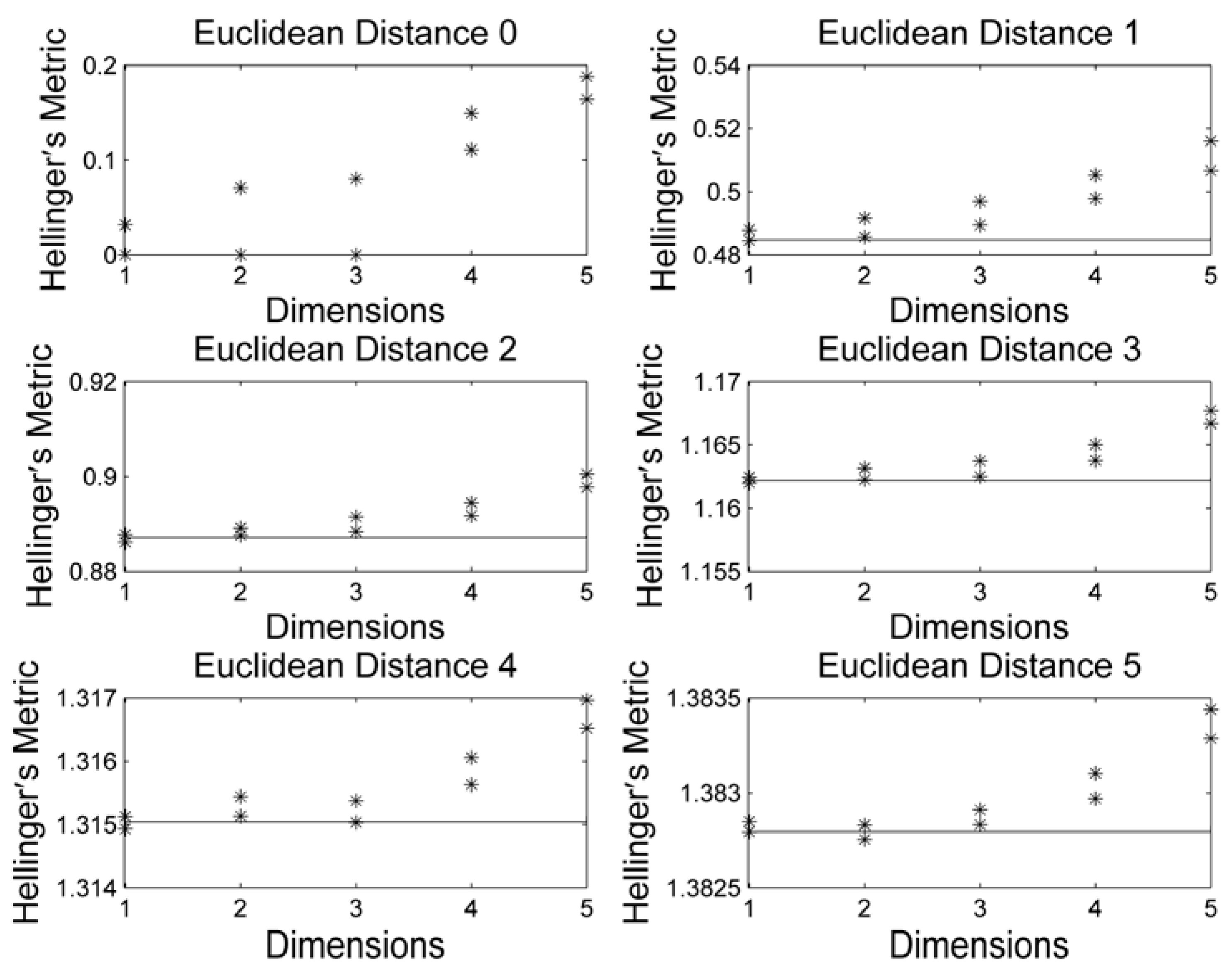
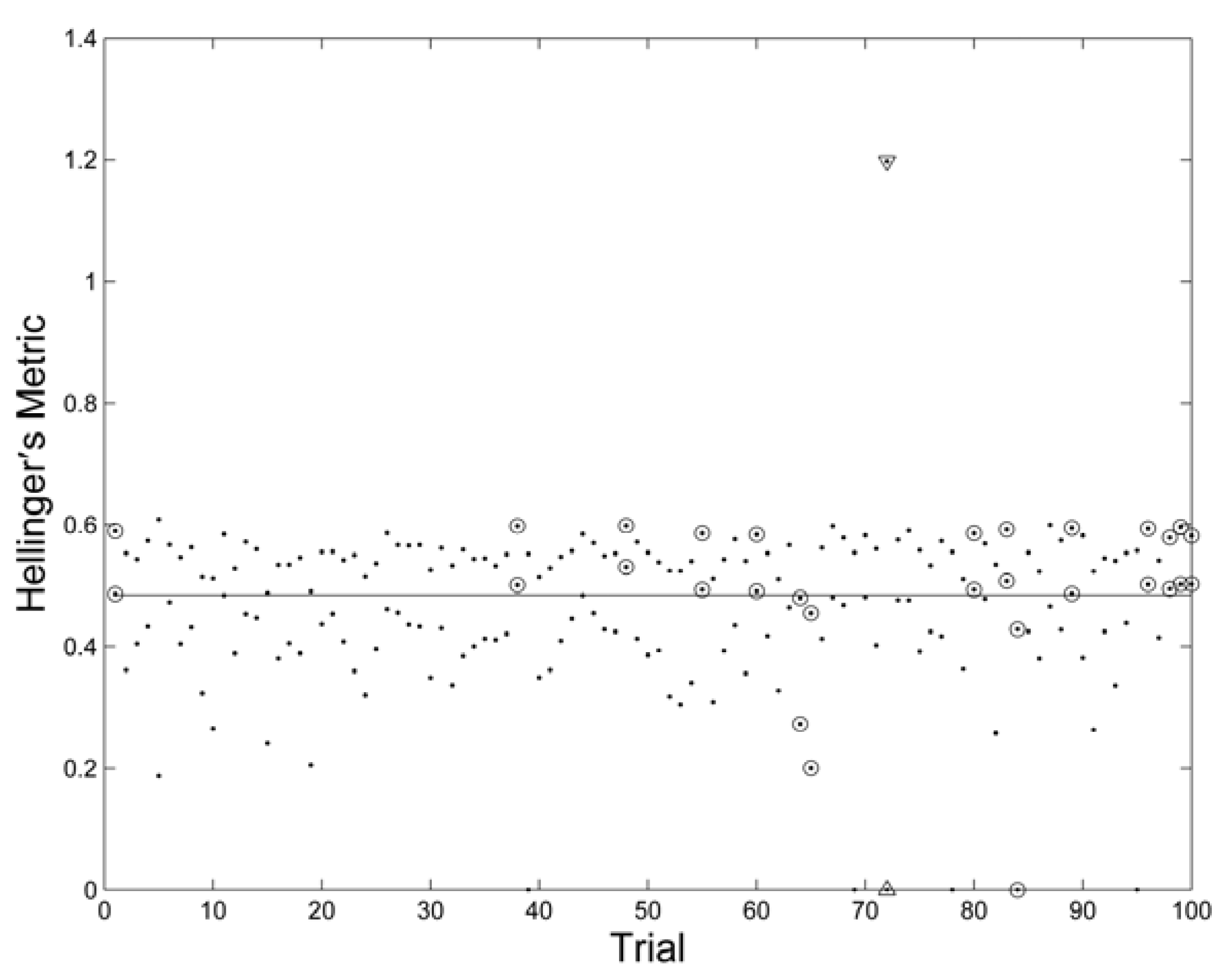
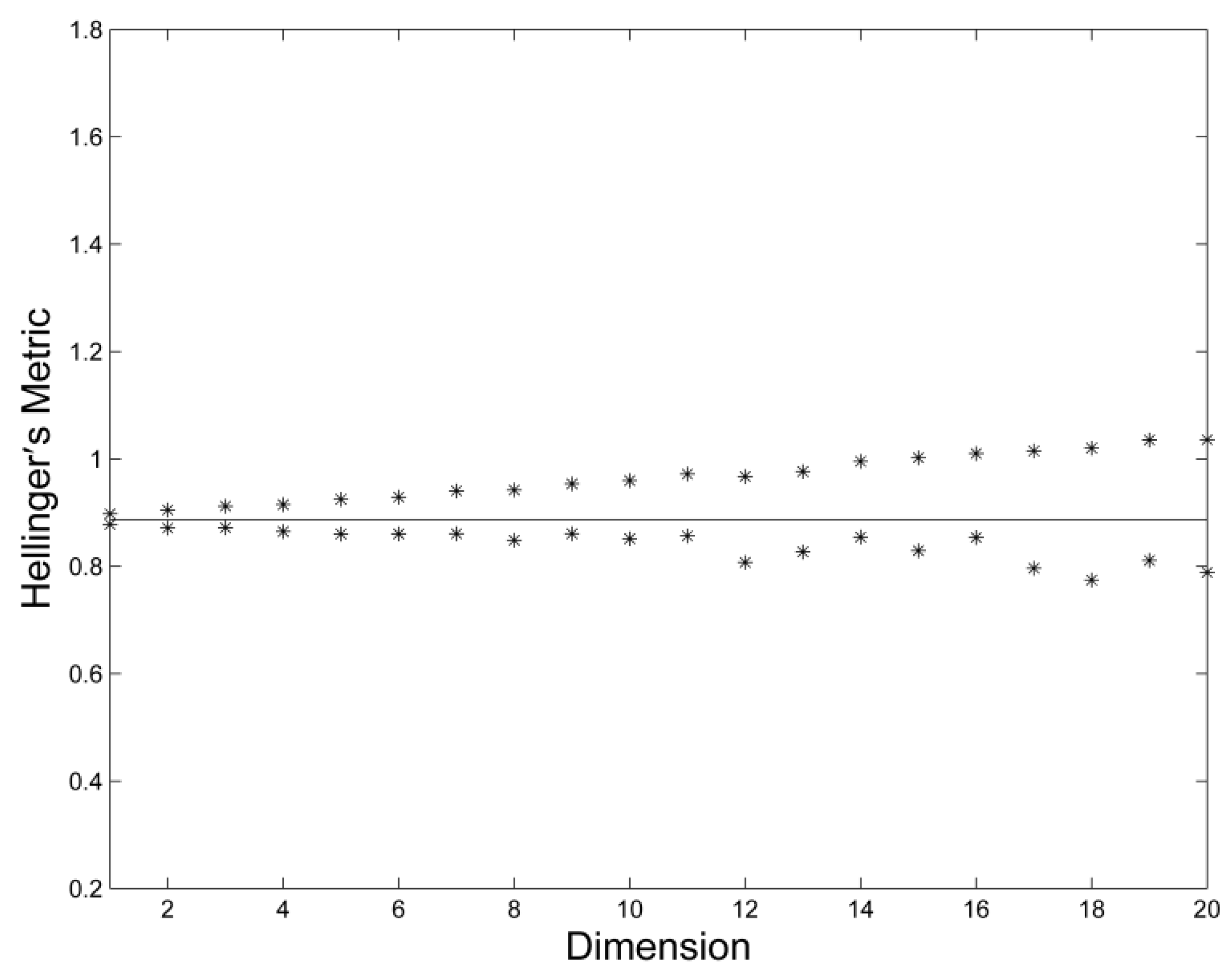
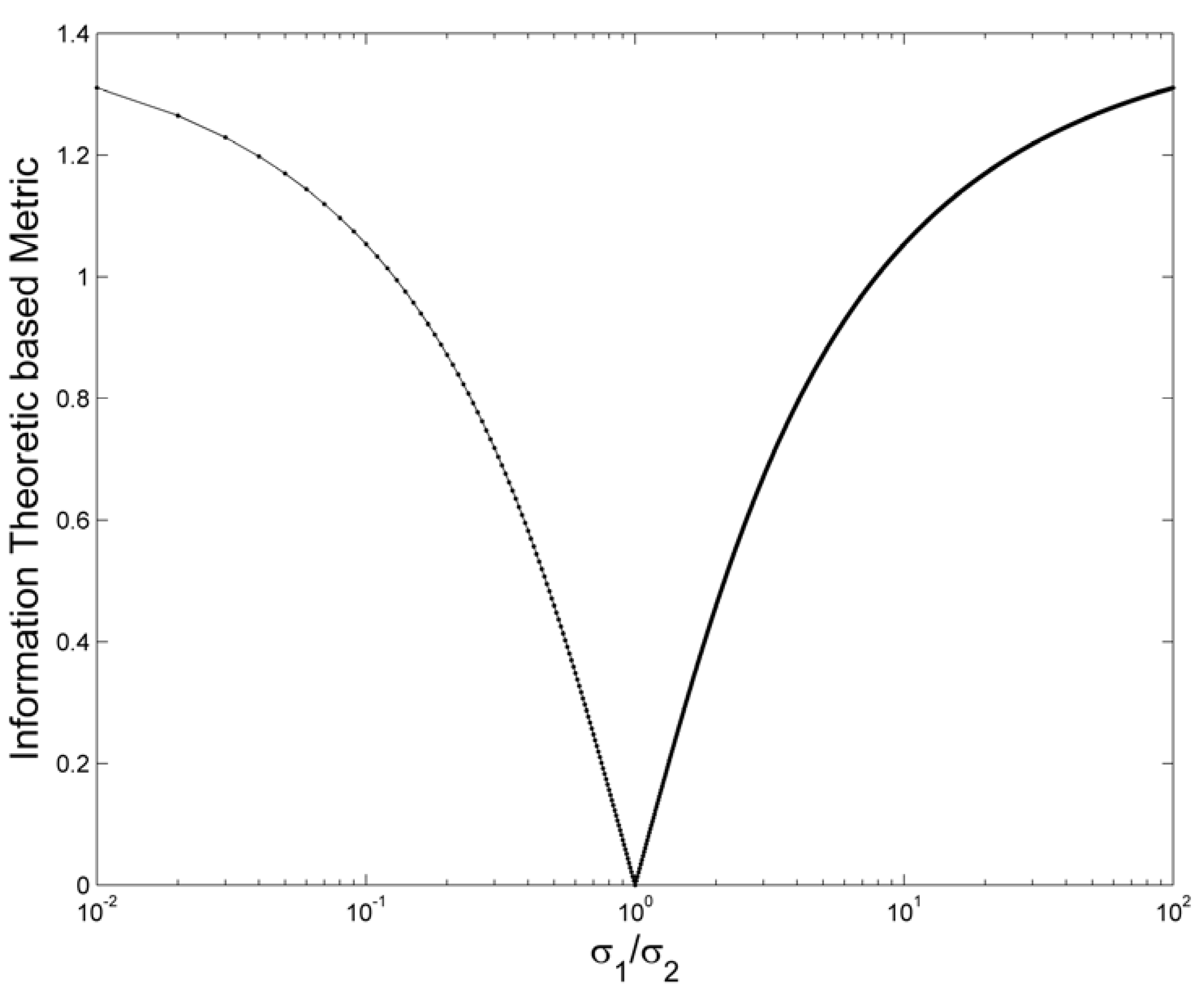
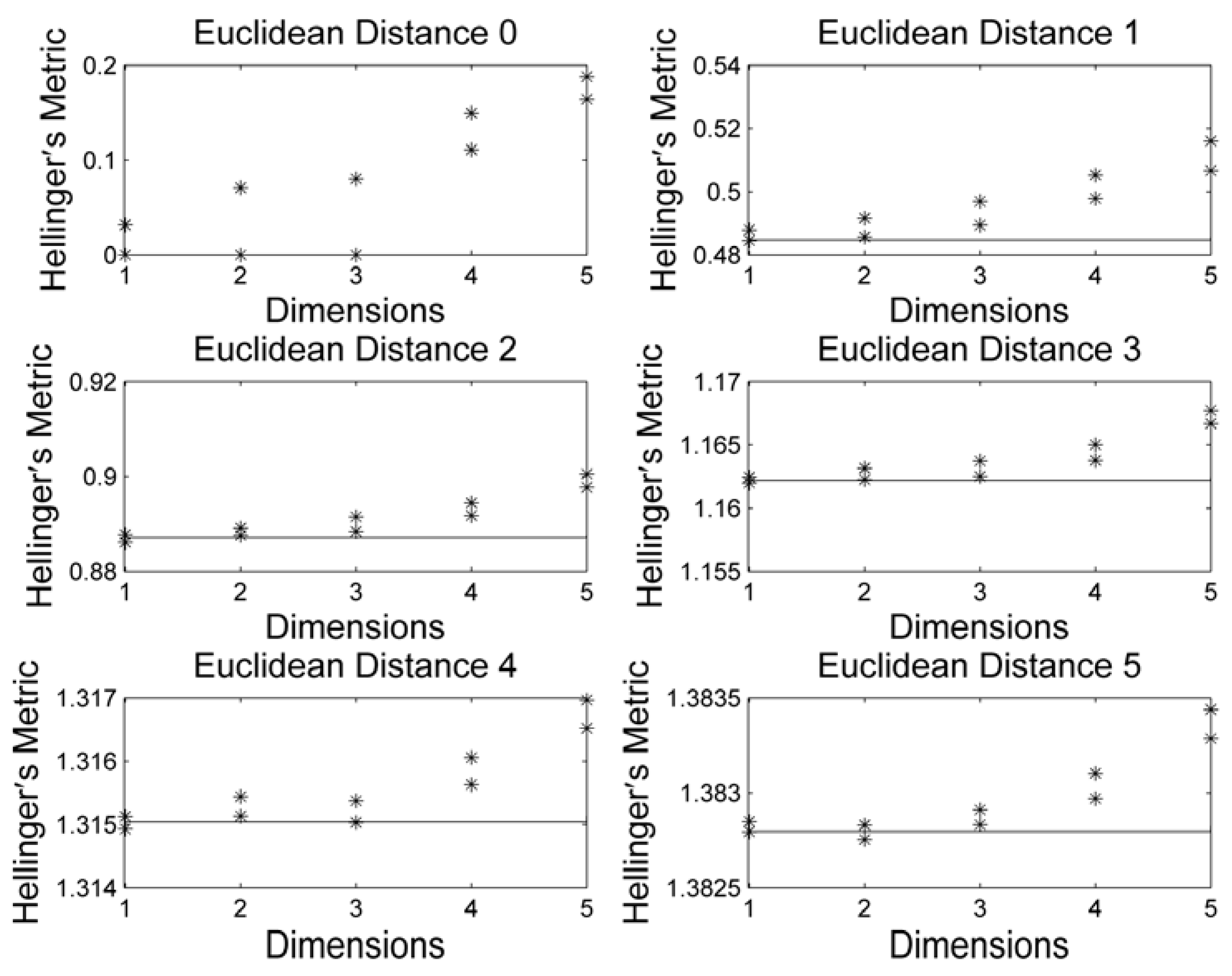
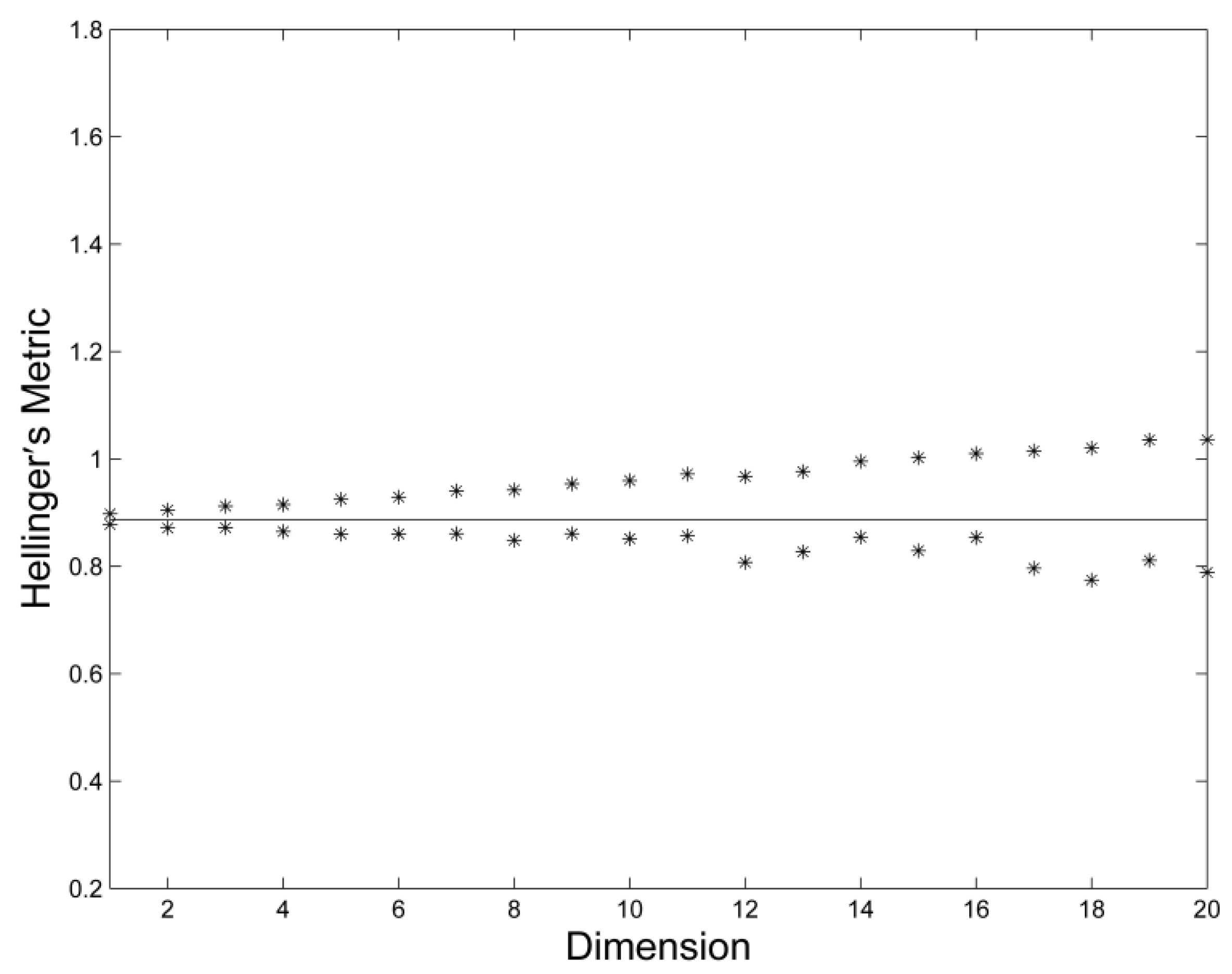
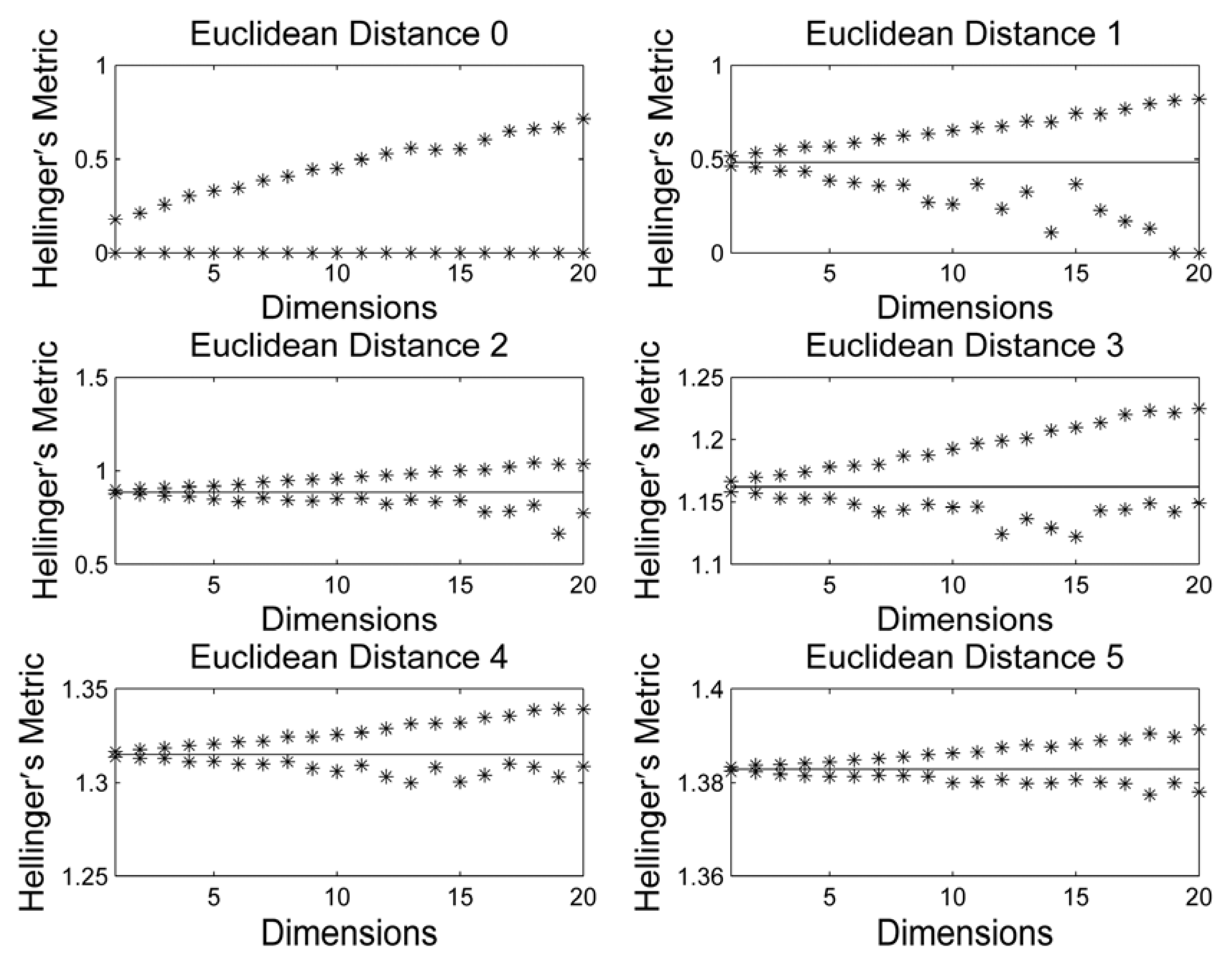
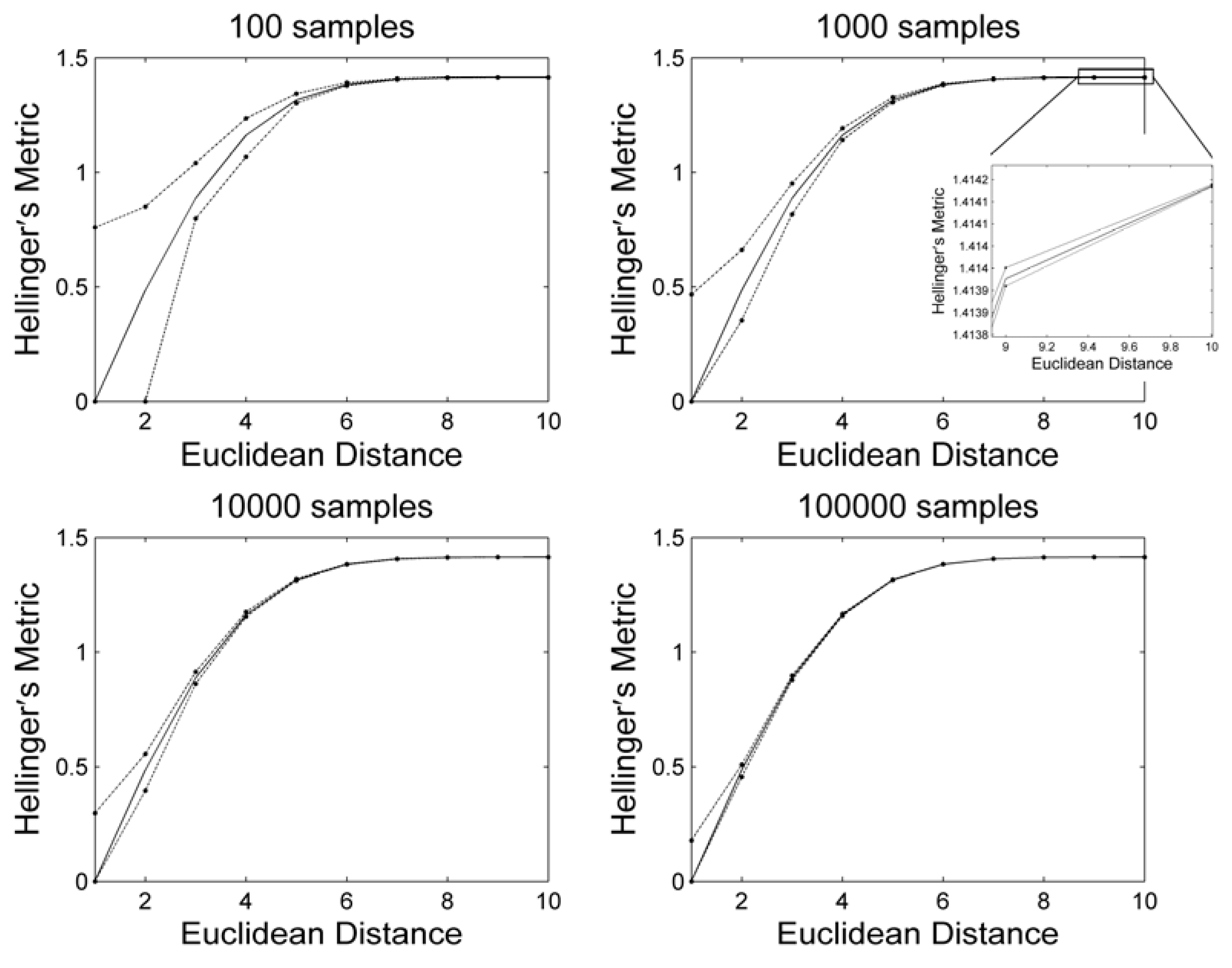
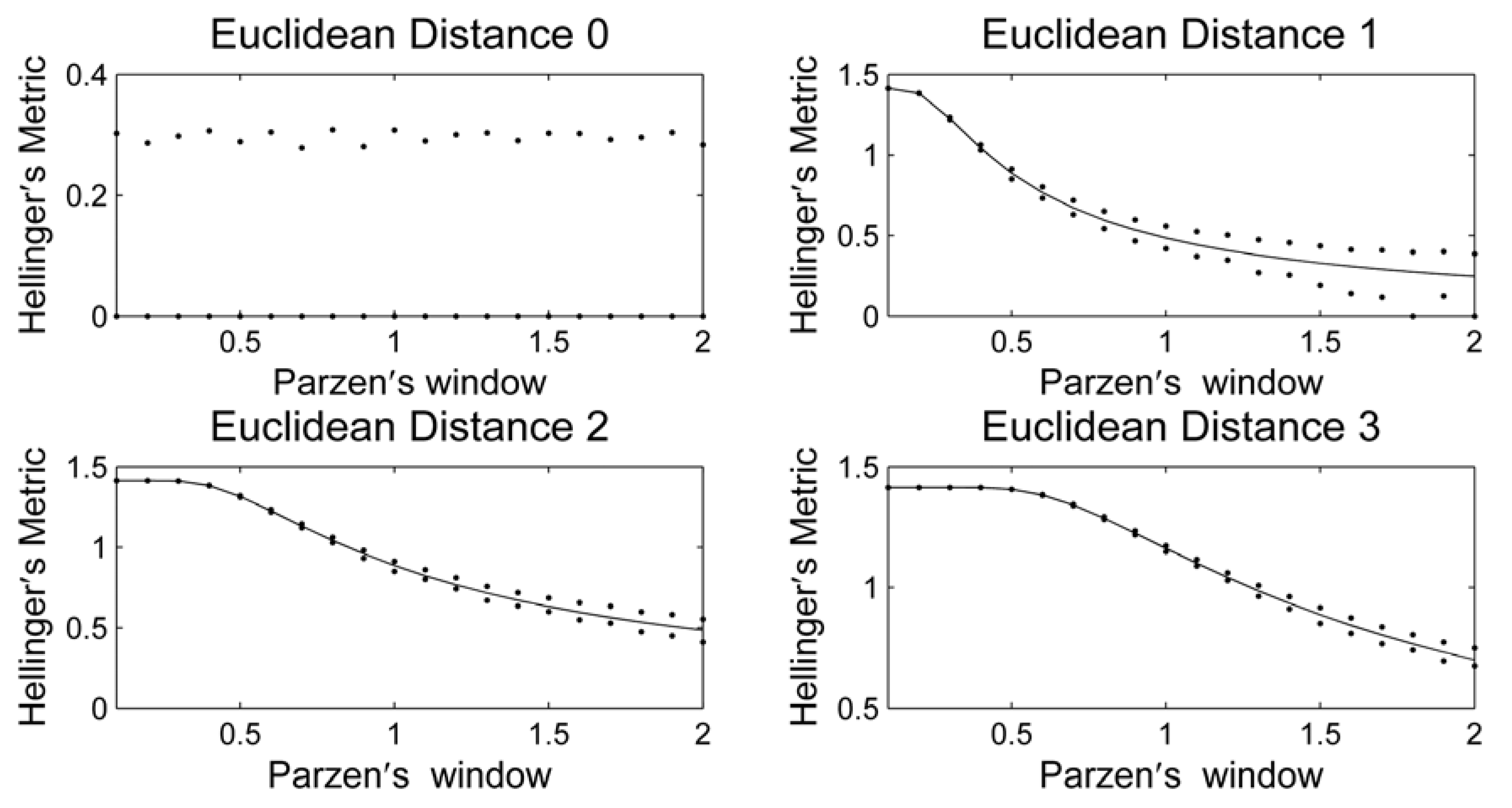
3. Results and Discussion
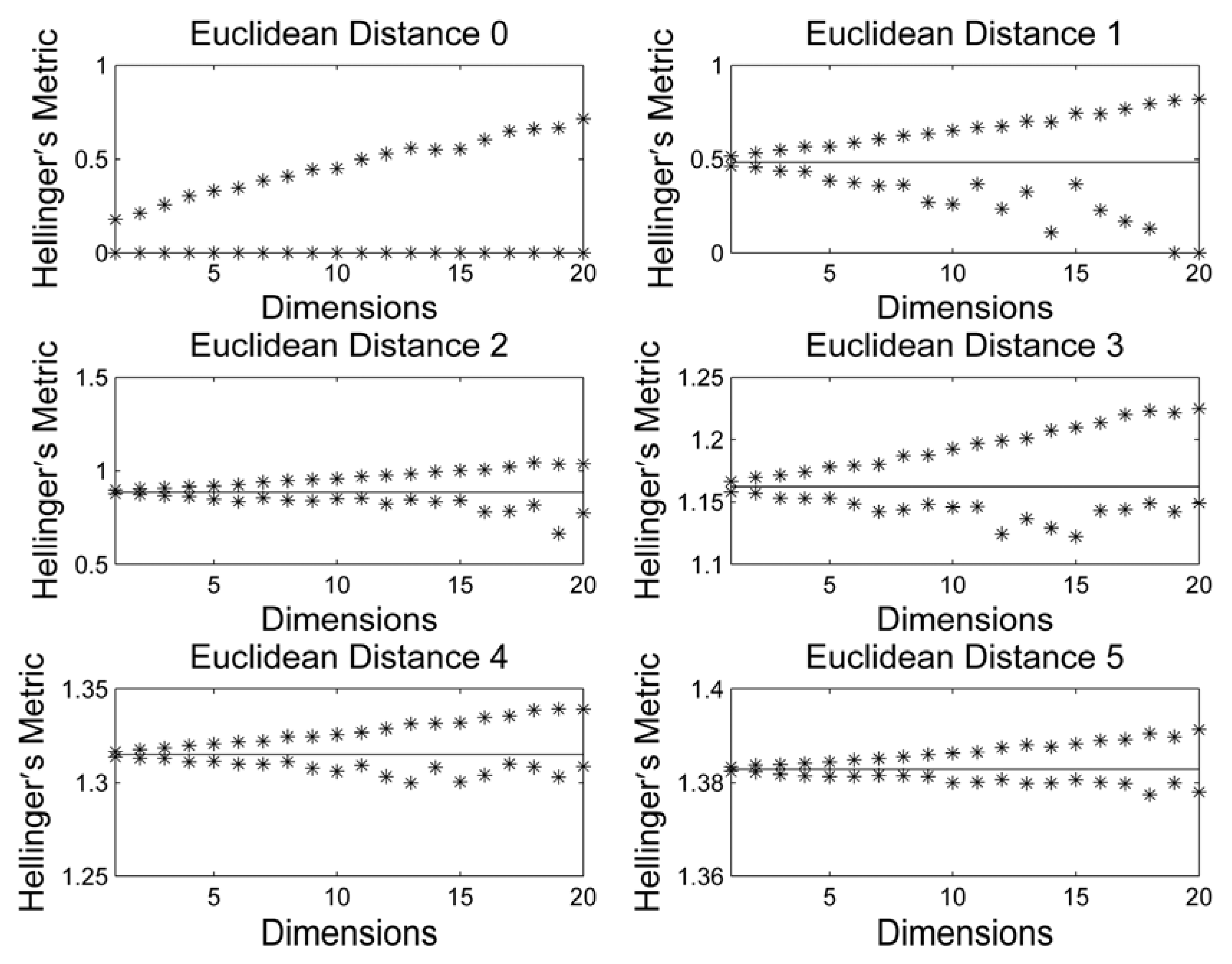
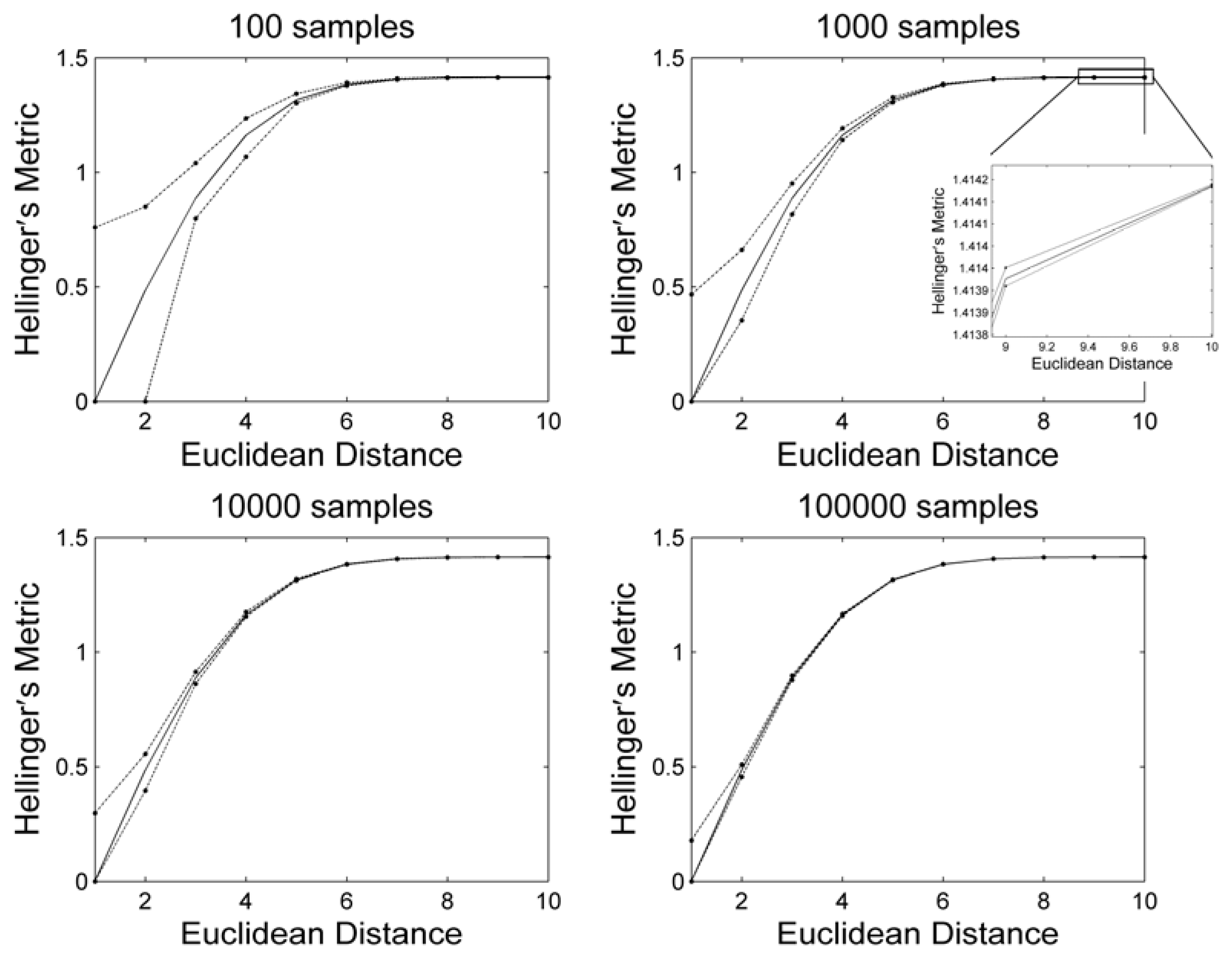
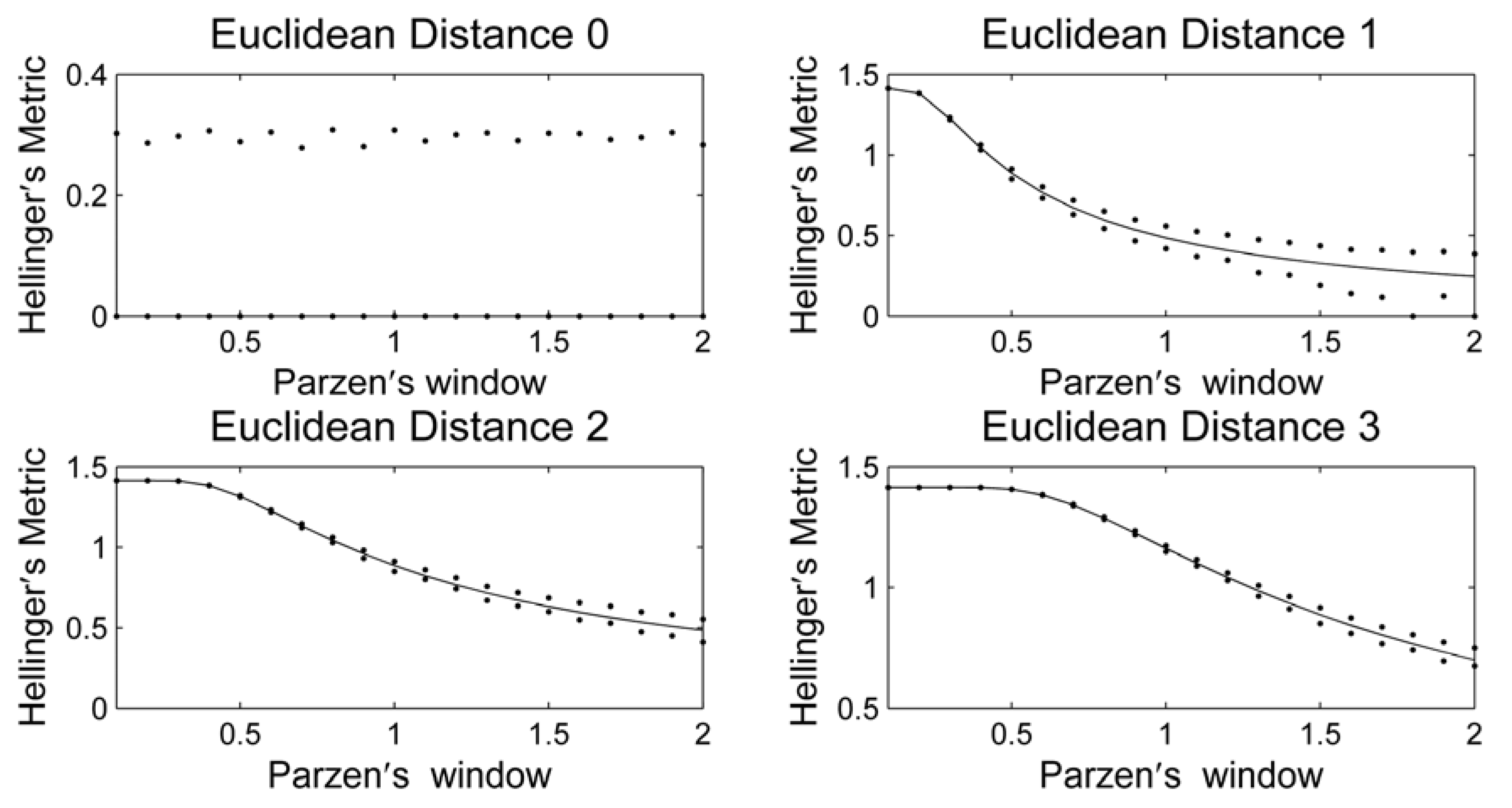
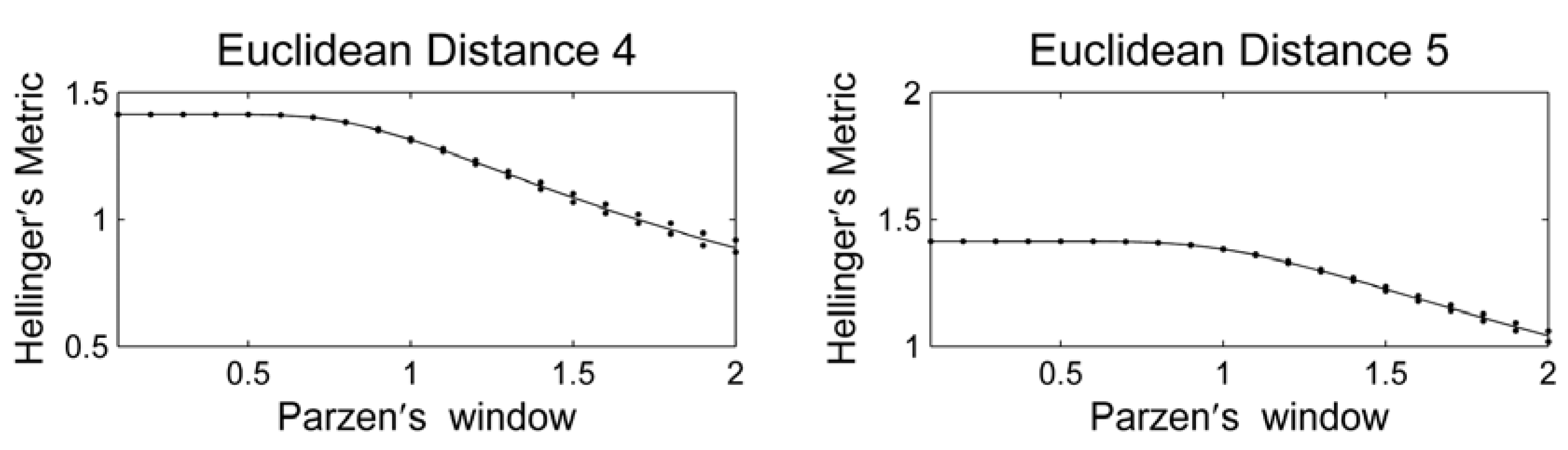
4. Conclusions
Acknowledgments
Conflict of Interest
References
- Hellinger, E. Neue Begründung der Theorie quadratischer Formen von unendlichvielen Veränderlichen. Crelle 1909, 210–271. [Google Scholar]
- Ali, S.M.; Silvey, S.D. A general class of coefficients of divergence of one distribution from another. J. R. Stat. Soc. Series B. 1966, 28, 131–142. [Google Scholar]
- Ullah, A. Entropy, divergence and distance measures with econometric applications. J. Stat. Plan Inferace 1996, 49, 137–162. [Google Scholar] [CrossRef]
- Principe, J.C. Information Theoretic Learning Renyi's Entropy and Kernel Perspectives; Springer: New York, NY, USA, 2010. [Google Scholar]
- Pardo, L. Statistical Inference Based on Divergence Measures; Chapman and Hall/CRC: Boca Raton, FL, USA, 2005; p. 483. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Bregman, L.M. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. USSR Comput. Math. Math. Phys. 1967, 7, 200–217. [Google Scholar] [CrossRef]
- Jeffreys, H. Fisher and inverse probability. Int. Stat. Rev. 1974, 42, 1–3. [Google Scholar] [CrossRef]
- Rao, C.R.; Nayak, T.K. Cross entropy, dissimilarity measures, and characterizations of quadratic entropy. IEEE Trans. Inf. Theory 1985, 31, 589–593. [Google Scholar] [CrossRef]
- Lin, J.H. Divergence measures based on the Shannon Entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef]
- Menéndez, M.L.; Morales, D.; Pardo, L.; Salicrú, M. (h, Φ)-entropy differential metric. Appl. Math. 1997, 42, 81–98. [Google Scholar] [CrossRef]
- Seth, S.; Principe, J.C. Compressed signal reconstruction using the correntropy induced metric. In Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31–April 4, 2008; pp. 3845–3848.
- Topsoe, F. Some inequalities for information divergence and Related measures of discrimination. IEEE Trans. Inf. Theory 2000, 46, 1602–1609. [Google Scholar] [CrossRef]
- Liese, F.; Vajda, I. On divergences and informations in statistics and information theory. IEEE Trans. Inf. Theory 2006, 52, 4394–4412. [Google Scholar] [CrossRef]
- Cubedo, M.; Oller, J.M. Hypothesis testing: A model selection approach. J. Stat. Plan. Inference 2002, 108, 3–21. [Google Scholar] [CrossRef]
- Puga, A.T. Non-parametric Hellinger’s Metric. In Proceedings of CMNE/CILANCE 2007, Porto, Portugal, 13–15 June 2007.
- Hartley, R.V.L. Transmission of information. Bell Syst. Tech. J. 1928, 7, 535–563. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Rényi, A. On Measures of Entropy and Information, Fourth Berkeley Symposium on Math. Statist. and Prob; University of California: Berkeley: CA, USA, 1961; Volume 1, pp. 547–561. [Google Scholar]
- Nonextensive Entropy: Interdisciplinary Applications; Gell-Mann, M.; Tsallis, C. (Eds.) Oxford University Press: New York, NY, USA, 2004.
- Wolf, C. Two-state paramagnetism induced by Tsallis and Renyi statistics. Int. J. .Theor. Phys. 1998, 37, 2433–2438. [Google Scholar] [CrossRef]
- Gokcay, E.; Principe, J.C. Information theoretic clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 158–171. [Google Scholar] [CrossRef]
- Ramshaw, J.D. Thermodynamic stability conditions for the Tsallis and Renyi entropies. Phys. Lett. A 1995, 198, 119–121. [Google Scholar] [CrossRef]
- Gibbs, A.L.; Su, F.E. On choosing and bounding probability metrics. Int. Stat. Rev. 2002, 70, 419–435. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Scott, D.W. Multivariate Density Estimation: Theory, Practice, and Visualization; Wiley: New York, NY, USA, 1992. [Google Scholar]
- Devroye, L. Non-Uniform Random Variate Generation; Springer-Verlag: New York, NY, USA, 1986. [Google Scholar]
- Preda, V.C. The student distribution and the principle of maximum-entropy. Ann. Inst. Stat. Math. 1982, 34, 335–338. [Google Scholar] [CrossRef]
- Kapur, J.N. Maximum-Entropy Models in Science and Engineering; Wiley: New York, NY, USA, 1989. [Google Scholar]
- The Probable Error of a Mean. Available online: http://www.jstor.org/discover/10.2307/2331554? uid=2&uid=4&sid=21102107492741/ (accessed on 28 April 2013).
- Leonenko, N.; Pronzato, L.; Savani, V. A class of Renyi information estimators for multidimensional densities. Ann. Stat. 2008, 36, 2153–2182. [Google Scholar] [CrossRef]
- Li, S.; Mnatsakanov, R.M.; Andrew, M.E. k-nearest neighbor based consistent entropy estimation for hyperspherical distributions. Entropy 2011, 13, 650–667. [Google Scholar] [CrossRef]
- Penrose, M.D.; Yukich, J.E. Laws of large numbers and nearest neighbor distances. In Advances in Directional and Linear Statistics; Wells, M.T., SenGupta, A., Eds.; Physica-Verlag: Heidelberg, Germany, 2011; pp. 189–199. [Google Scholar]
- Misra, N.; Singh, H.; Hnizdo, V. Nearest neighbor estimates of entropy for multivariate circular distributions. Entropy 2010, 12, 1125–1144. [Google Scholar] [CrossRef]
- Mnatsakanov, R.; Misra, N.; Li, S.; Harner, E. k-Nearest neighbor estimators of entropy. Math. Method. Stat. 2008, 17, 261–277. [Google Scholar] [CrossRef]
- Wang, Q.; Kulkarni, S.R.; Verdu, S. Divergence estimation for multidimensional densities via k-nearest-neighbor distances. IEEE Trans. Inf. Theory 2009, 55, 2392–2405. [Google Scholar] [CrossRef]
- Hall, P.; Park, B.U.; Samworth, R.J. Choice of neighbor order in nearest-neighbor classification. Ann. Stat. 2008, 36, 2135–2152. [Google Scholar] [CrossRef]
- Nigsch, F.; Bender, A.; van Buuren, B.; Tissen, J.; Nigsch, E.; Mitchell, J.B.O. Melting point prediction employing k-nearest neighbor algorithms and genetic parameter optimization. J. Chem. Inf. Model. 2006, 46, 2412–2422. [Google Scholar] [CrossRef] [PubMed]
- Beyer, K.; Goldstein, J.; Ramakrishnan, R.; Shaft, U. When Is “Nearest Neighbor” Meaningful? In Proceedings of 7the International Conference on Database Theory, Jerusalem, Israel, 12 January 1999; pp. 217–235.
- Vemuri, B.C.; Liu, M.; Amari, S.I.; Nielsen, F. Total bregman divergence and its applications to DTI analysis. IEEE Trans. Med. Imag. 2011, 30, 475–483. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Vemuri, B.; Amari, S. I.; Nielsen, F. Shape retrieval using hierarchical total bregman soft clustering. IEEE T. Pattern Anal. 2012, 34, 2407–2419. [Google Scholar]
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Carvalho, A.R.F.; Tavares, J.M.R.S.; Principe, J.C. A Novel Nonparametric Distance Estimator for Densities with Error Bounds. Entropy 2013, 15, 1609-1623. https://doi.org/10.3390/e15051609
Carvalho ARF, Tavares JMRS, Principe JC. A Novel Nonparametric Distance Estimator for Densities with Error Bounds. Entropy. 2013; 15(5):1609-1623. https://doi.org/10.3390/e15051609
Chicago/Turabian StyleCarvalho, Alexandre R.F., João Manuel R. S. Tavares, and Jose C. Principe. 2013. "A Novel Nonparametric Distance Estimator for Densities with Error Bounds" Entropy 15, no. 5: 1609-1623. https://doi.org/10.3390/e15051609
APA StyleCarvalho, A. R. F., Tavares, J. M. R. S., & Principe, J. C. (2013). A Novel Nonparametric Distance Estimator for Densities with Error Bounds. Entropy, 15(5), 1609-1623. https://doi.org/10.3390/e15051609