Capacity Bounds and Mapping Design for Binary Symmetric Relay Channels

Abstract
1. Introduction
- denotes the binary Galois filed, i.e., .
- denotes the k-dimensional binary Galois filed, i.e., .
- denotes binary entropy function where .
- denotes the Hamming distance between the two binary sequences of length k.
- The operation * is defined as .
- We denote that the binary random variable Z has a Bernoulli distribution by where and .
- We denote the binary Kronecker delta function by , where and for .
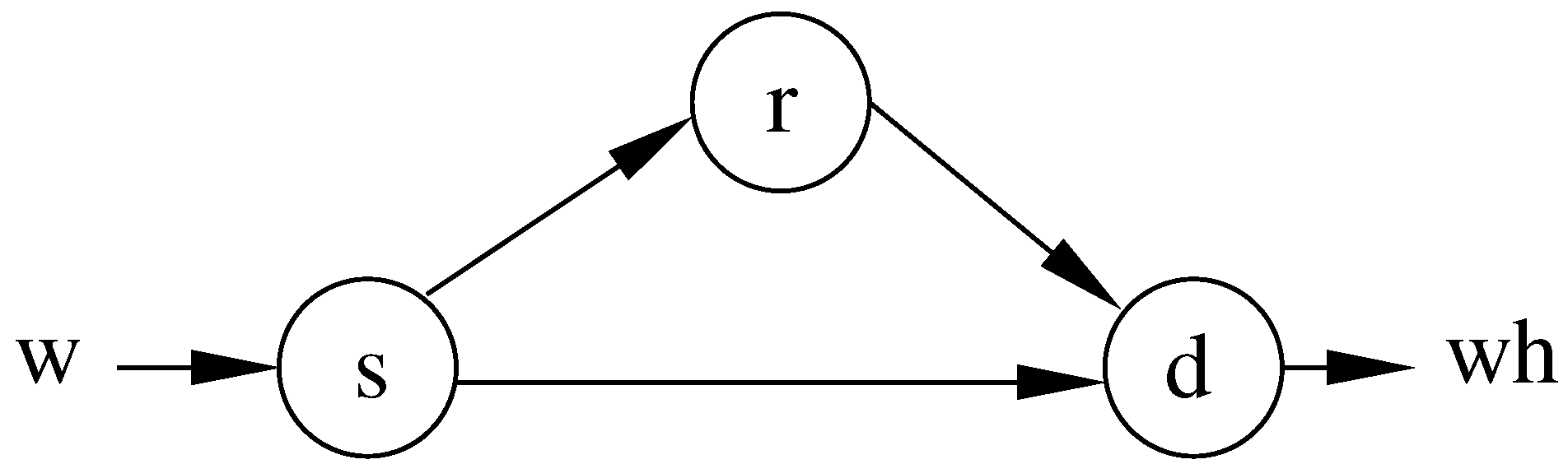
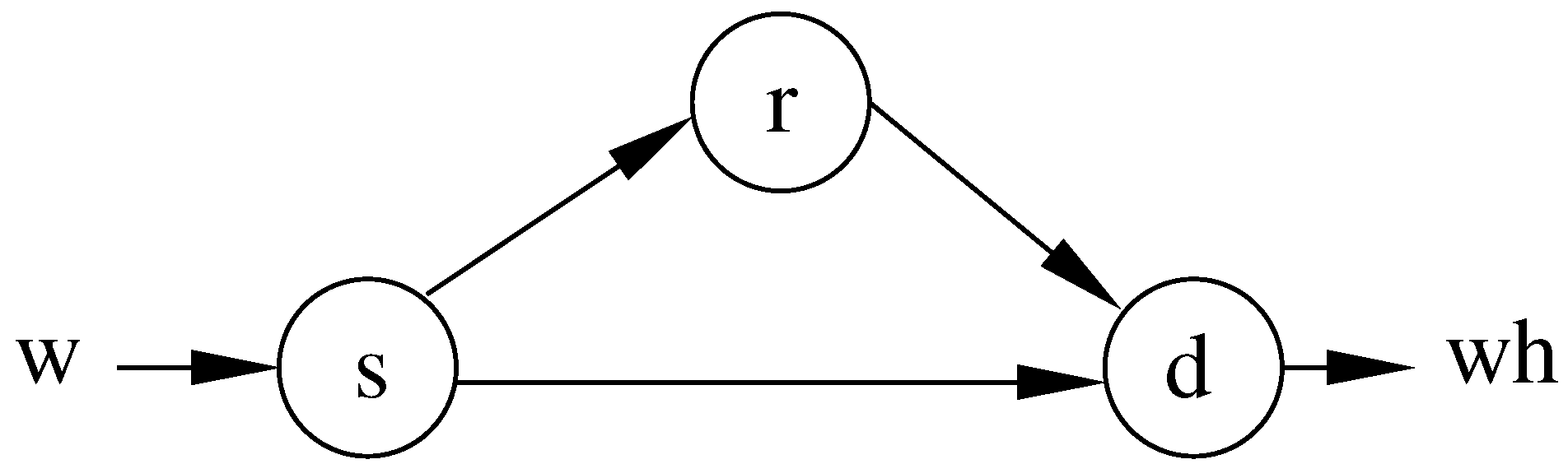
2. Binary Symmetric Relay Channel
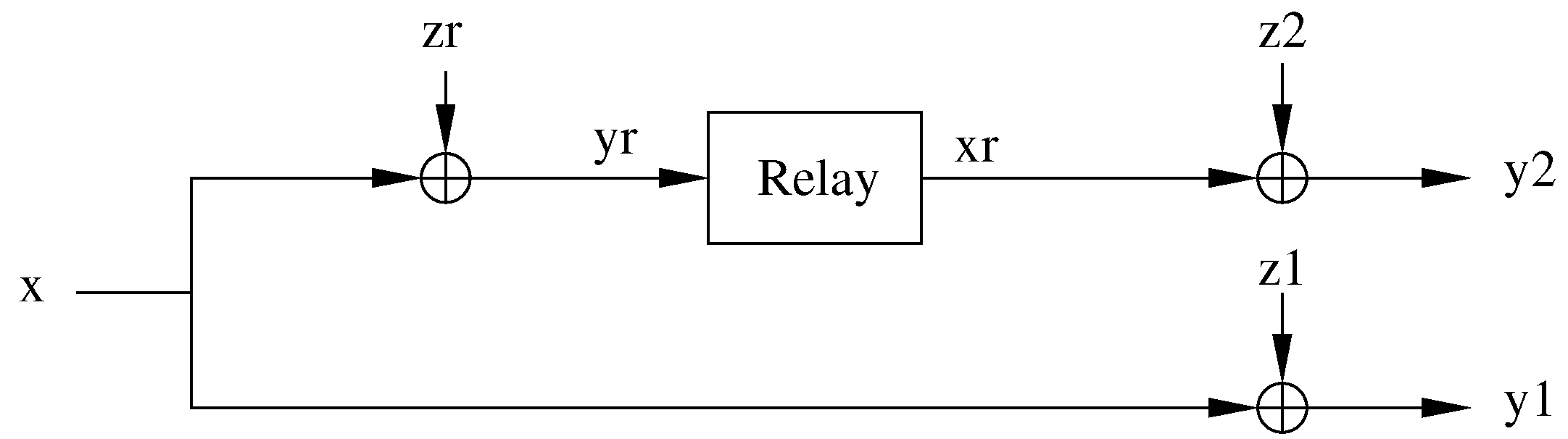
3. Capacity Bounds for the Orthogonal BSRC: Infinite Memory Relay Case
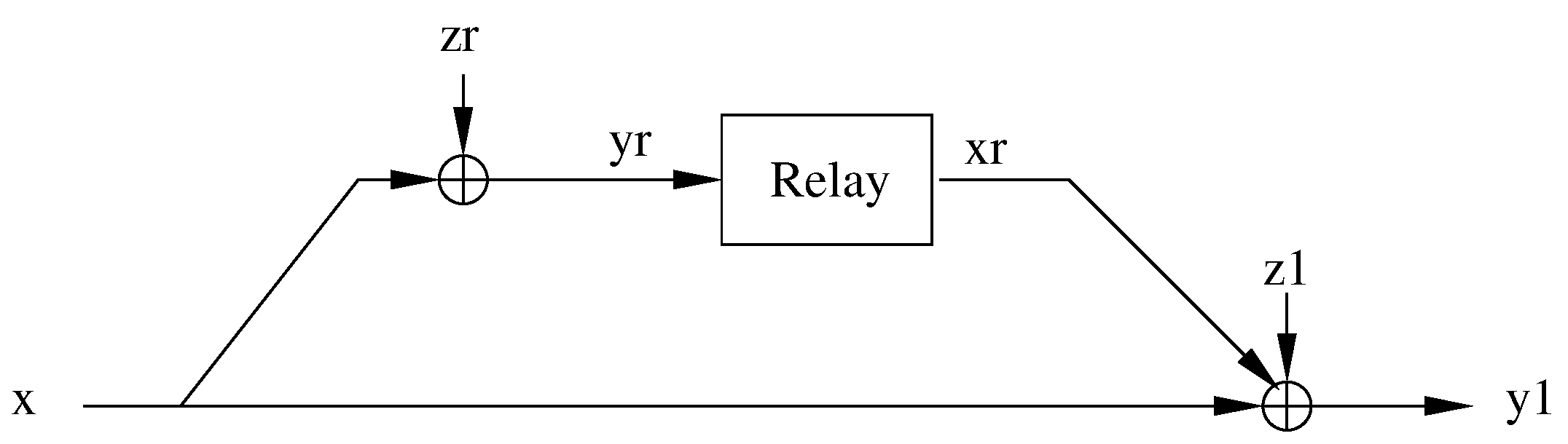
4. Capacity Bounds for the Orthogonal BSRC: Finite Memory Relay Case
4.1. Achievable Rate
4.2. Mapping Optimization for an Arbitrary k
4.3. Fourier Spectrum of the Optimized Mappings
| x3 | x2 | x1 | f | |
| + 1 | + 1 | + 1 | + 1 | |
| + 1 | + 1 | − 1 | + 1 | |
| + 1 | − 1 | + 1 | − 1 | |
| + 1 | − 1 | − 1 | − 1 | |
| − 1 | + 1 | + 1 | − 1 | |
| − 1 | + 1 | − 1 | + 1 | |
| − 1 | − 1 | + 1 | + 1 | |
| − 1 | − 1 | − 1 | + 1 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
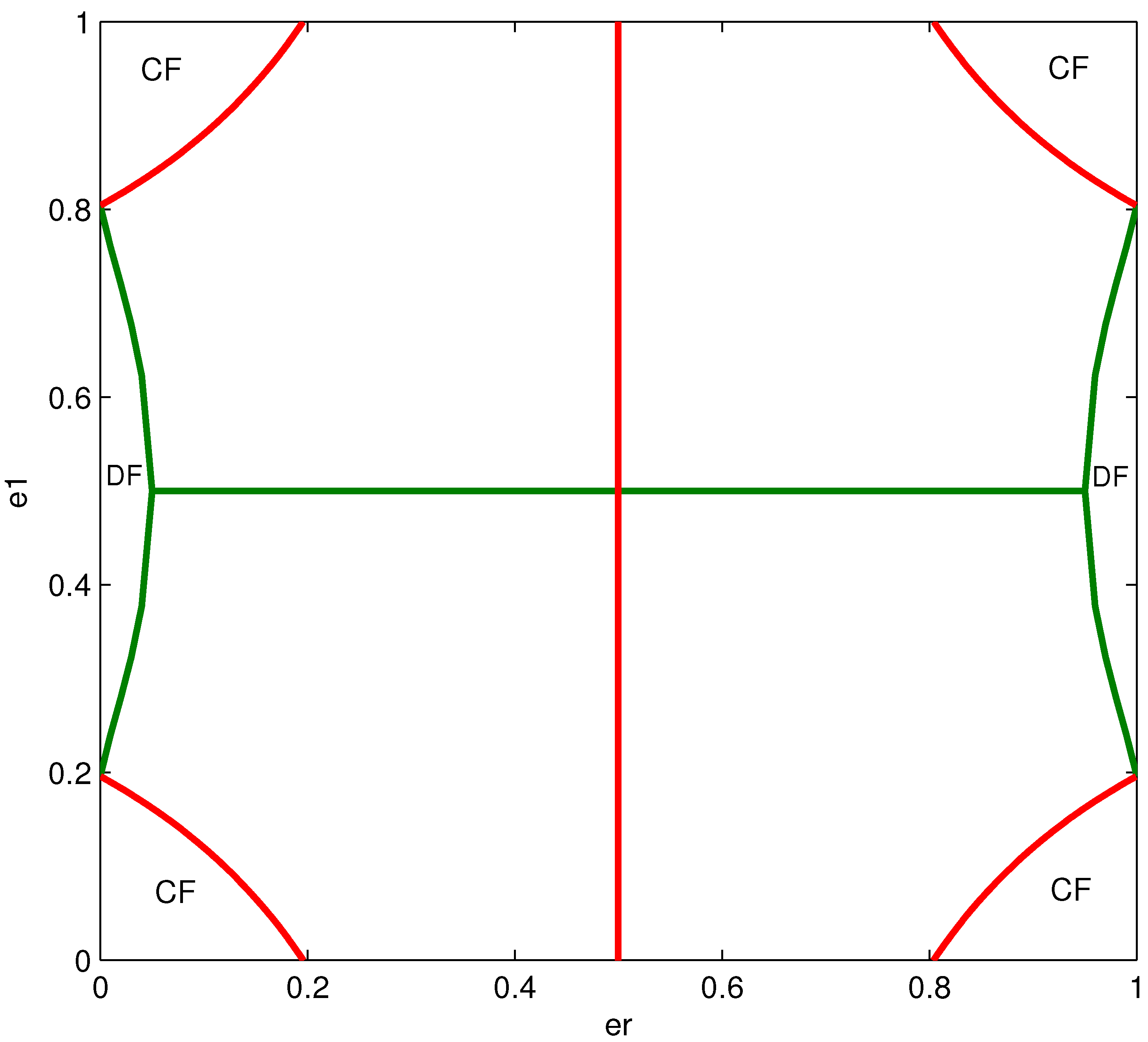
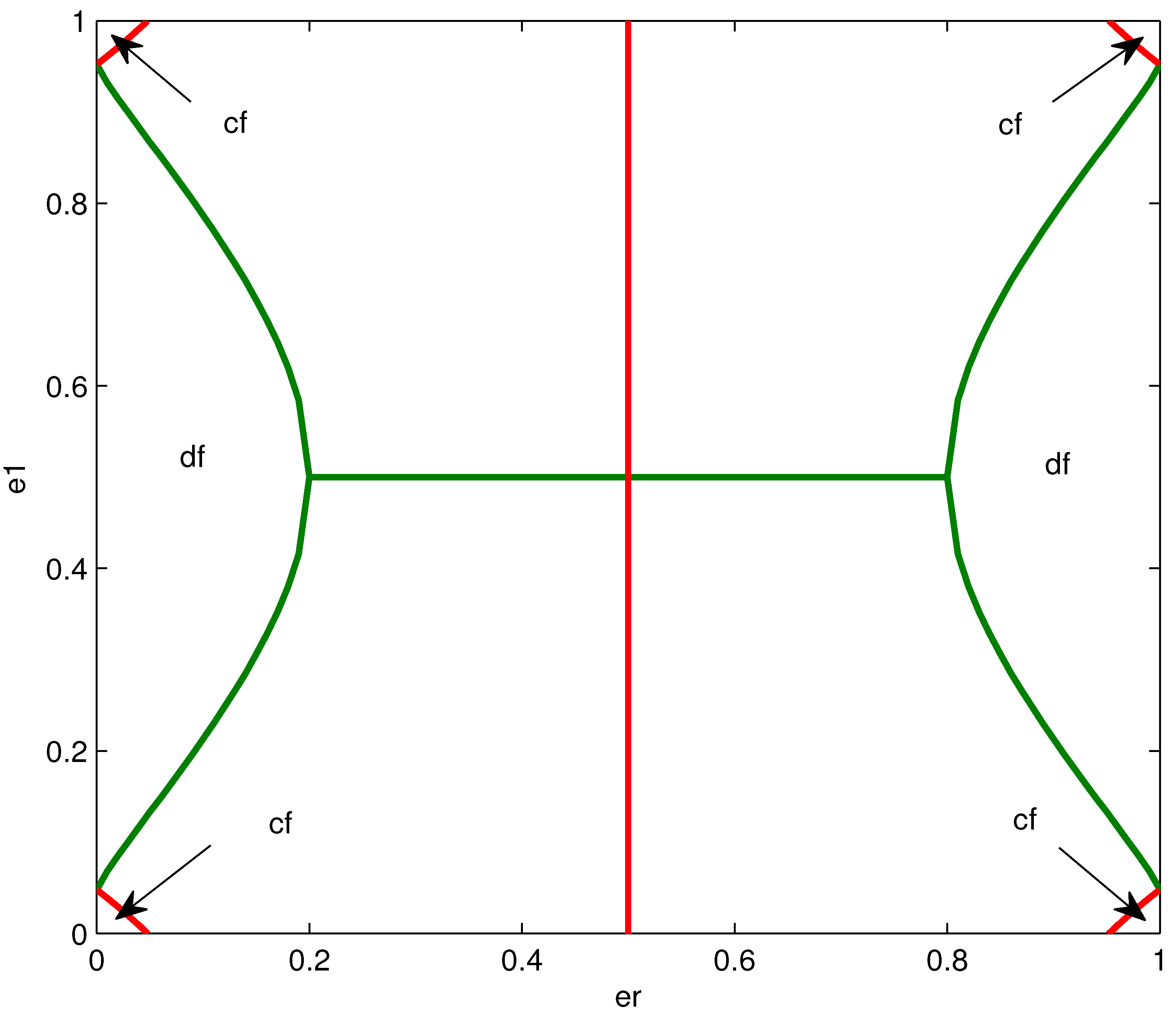
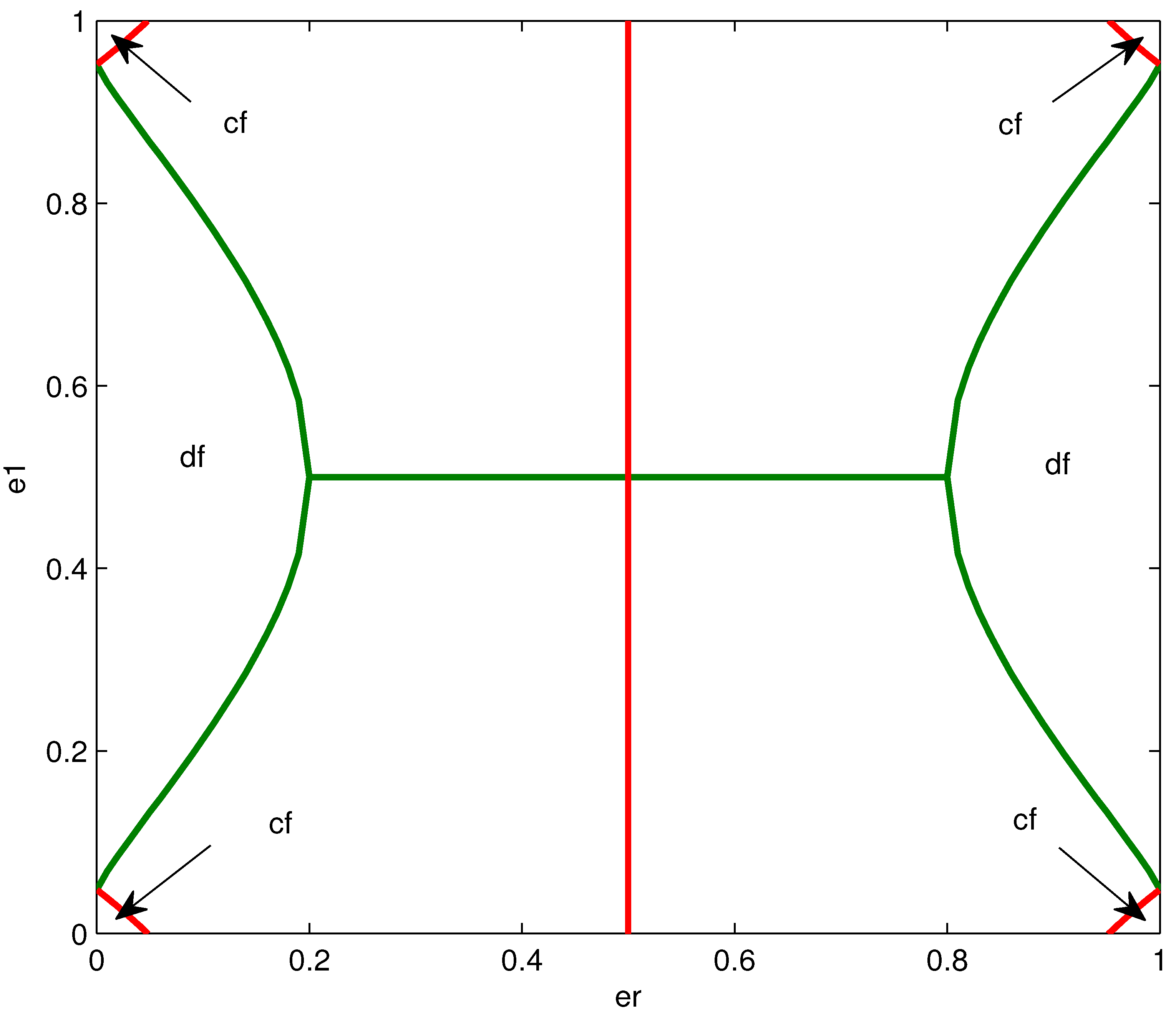
4.4. Effect of Channel Parameters on the Structure of the Optimized Mappings
| ρ | 0.1667 | 0.3611 | 0.4444 | 0.5556 | 0.6111 | 0.6389 |
| ρ | 0.1667 | 0.3333 | 0.5556 | 0.6389 | 0.6667 | 0.7500 |
| ρ | 0.8333 | 0.6667 | 0.6389 | 0.5833 | 0.4167 | 0.1667 |
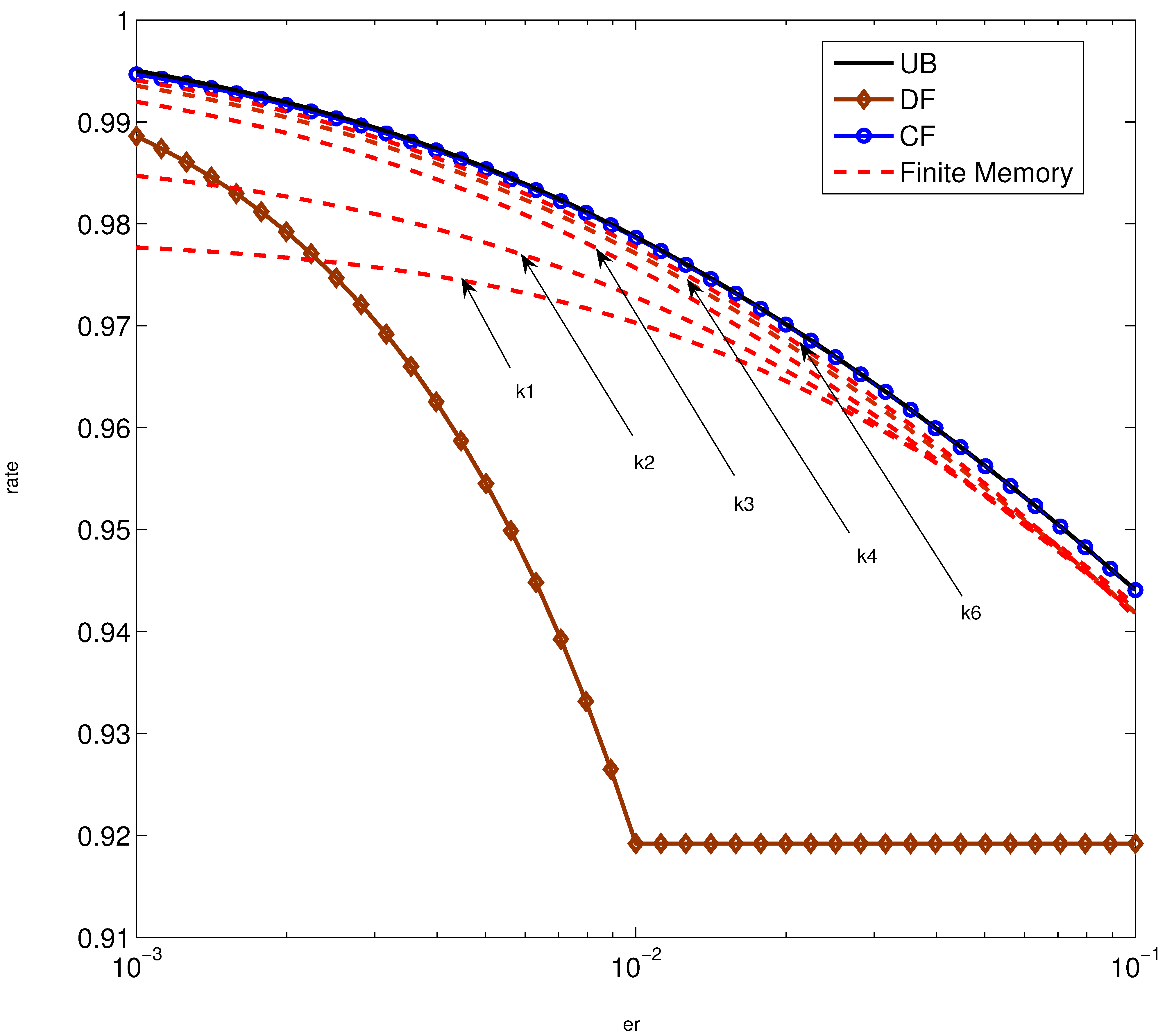
5. Numerical Examples
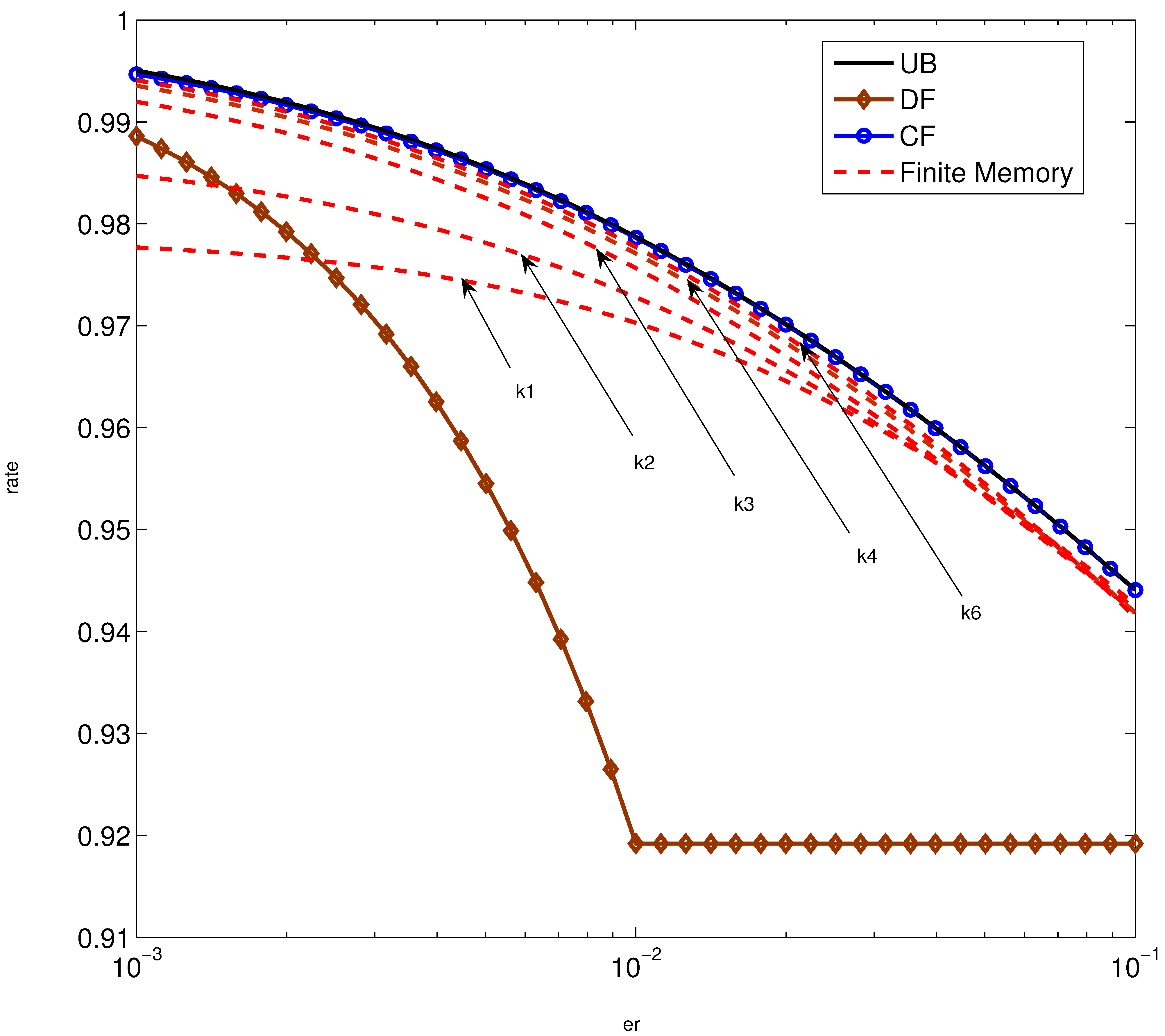
6. Summary and Concluding Remarks
Acknowledgements
Claims
Appendix
A. Proof of Proposition 1
B. Proof of Proposition 2
C. Proof of Proposition 3
D. Proof of Proposition 4
- Case 1:If we have and there exists such that . Thusis achievable where satisfies
- Case 2:If we have . Thusis achievable.
E. Proof of Proposition 5
F. Proof of Lemma 1
References
- van der Meulen, E.C. Three-terminal communication channels. Adv. Appl. Probab. 1971, 3, 120–154. [Google Scholar] [CrossRef]
- Cover, T.M.; El Gamal, A. Capacity theorems for the relay channel. IEEE Trans. Inform. Theory 1979, 25, 572–584. [Google Scholar] [CrossRef]
- Høst-Madsen, A.; Zhang, J. Capacity bounds and power allocation for wireless relay channels. IEEE Trans. Inform. Theory 2006, 51, 2020–2040. [Google Scholar] [CrossRef]
- El Gamal, A.; Mohseni, M.; Zahedi, S. Bounds on capacity and minimum energy-per-bit for AWGN relay channels. IEEE Trans. Inform. Theory 2006, 52, 1545–1561. [Google Scholar] [CrossRef]
- Kramer, G.; Gastpar, M.; Gupta, P. Cooperative strategies and capacity theorems for relay networks. IEEE Trans. Inform. Theory 2005, 51, 3037–3063. [Google Scholar] [CrossRef]
- Dabora, R.; Servetto, S.D. On the role of estimate-and-forward with time sharing in cooperative communication. IEEE Trans. Inform. Theory 2008, 541, 4409–4431. [Google Scholar] [CrossRef]
- Laneman, J.N.; Wornell, G.W.; Tse, D.N.C. Cooperative diversity in wireless networks: Efficient protocols and outage behavior. IEEE Trans. Inform. Theory 2004, 50, 3062–3080. [Google Scholar] [CrossRef]
- Sendonaris, A.; Erkip, E.; Aazhang, B. User cooperation diversity-Part I: System description. IEEE Trans. Commun. 2003, 51, 1927–1938. [Google Scholar] [CrossRef]
- Sendonaris, A.; Erkip, E.; Aazhang, B. User cooperation diversity-Part II: Implementation aspects and performance analysis. IEEE Trans. Commun. 2003, 51, 1939–1948. [Google Scholar] [CrossRef]
- Aleksic, M.; Razaghi, P.; Yu, W. Capacity of a class of modulo-sum relay channels. IEEE Trans. Inform. Theory 2009, 55, 921–930. [Google Scholar] [CrossRef]
- Kim, Y.H. Coding Techniques for Primitive Relay Channels. In Proceedings of the Forty-Fifth Annual Allerton Conference, Allerton House, UIUC, IL, USA, 26–28 September 2007.
- Lau, A.P.T.; Cui, S. Joint power minimization in wireless relay channels. IEEE Trans. Wirel. Commun. 2007, 6, 2820–2824. [Google Scholar]
- Karystinos, G.N.; Liavas, A.P. Outage Capacity of a Cooperative Scheme with Binary Input and a Simple Relay. In Proceedings of the IEEE ICASSP 2008-International Conference Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March– 4 April 2008.
- Sagar, Y.; Kwon, H.M.; Ding, Y. Capacity of Modulo-Sum Simple Relay Network. In Proceedings International Zurich Seminar on Communications, Zurich, Switzerland, 3–5 March 2010.
- El Gamal, A.; Aref, M. The capacity of the semi-deterministic relay channel. IEEE Trans. Inform. Theory 1982, 28, 536. [Google Scholar] [CrossRef]
- Khormuji, M.N.; Larsson, E.G. Rate-optimized constellation rearrangement for the relay channel. IEEE Commun. Lett. 2008, 12, 618–620. [Google Scholar] [CrossRef]
- Khormuji, M.N.; Skoglund, M. Piecewise linear relaying: Low complexity parametric relaying. In Proceedings of the IEEE SPAWC, Perugia, Italy, 21–24 June 2009.
- Khormuji, M.N.; Skoglund, M. On instantaneous relaying. IEEE Trans. Inform. Theory 2010, 56, 3378–3394. [Google Scholar] [CrossRef]
- Zaidi, A.; Khormuji, M.N.; Yao, S.; Skoglund, M. Rate-maximizing Mappings for Memoryless Relaying. In Proceedings of the IEEE ISIT, Seoul, Korea, 28 June–3 July, 2009.
- Skoglund, M. On channel-constrained vector quantization and index assignment for discrete memoryless channels. IEEE Trans Inform. Theory 1999, 45, 2615–2622. [Google Scholar] [CrossRef]
- Mehes, A.; Zeger, K. Performance of quantizers on noisy channels using structured families of codes. IEEE Trans. Inform. Theory 2000, 46, 2468–2476. [Google Scholar]
- Rudin, W. Fourier Analysis on Groups; John Wiley And Sons Ltd: Hoboken, NJ, USA, 1990. [Google Scholar]
- Khormuji, M.N.; Skoglund, M. On the Capacity of the Binary Symmetric Relay Channel with a Finite Memory Relay. In Proceedings of the IEEE ITW, Cairo, Egypt, 6–8 January 2010.
- Liavas, A. Outage Capacity of a Cooperative Scheme with Binary Input and a Simple Relay. Year-1 Work-Package-1 report of European Commission FET Project FP6-033533-COOPCOM, November 2007. [Google Scholar]
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Khormuji, M.N.; Skoglund, M. Capacity Bounds and Mapping Design for Binary Symmetric Relay Channels. Entropy 2012, 14, 2589-2610. https://doi.org/10.3390/e14122589
Khormuji MN, Skoglund M. Capacity Bounds and Mapping Design for Binary Symmetric Relay Channels. Entropy. 2012; 14(12):2589-2610. https://doi.org/10.3390/e14122589
Chicago/Turabian StyleKhormuji, Majid Nasiri, and Mikael Skoglund. 2012. "Capacity Bounds and Mapping Design for Binary Symmetric Relay Channels" Entropy 14, no. 12: 2589-2610. https://doi.org/10.3390/e14122589
APA StyleKhormuji, M. N., & Skoglund, M. (2012). Capacity Bounds and Mapping Design for Binary Symmetric Relay Channels. Entropy, 14(12), 2589-2610. https://doi.org/10.3390/e14122589