1. Introduction
In urban transportation planning, travel demand is frequently represented by multinomial or hierarchical logit discrete choice models, particularly for the selection of destinations, routes, and transportation modes. These models are also used in land use planning for modeling the real estate supply and activity location. Traditionally, both classes of choice models are deduced from the paradigm of the rational user who uses transportation services or real state units so as to maximize his or her utility as given by an assigned probability distribution. Estimation of the model parameters relies on classical statistical criteria, most commonly the method of maximum likelihood.
These models can also been deduced as the solution to certain constrained entropy maximization problems. The Lagrange multipliers of the constraints constitute alternative estimators of the population parameters to those generated by the known maximum likelihood approach, and in this work will be called maximum entropy estimators.
In [
1] it was shown that maximum likelihood estimators are identical to maximum entropy estimators in the case of multinomial logit models. Here, this equivalence will be investigated for the hierarchical logit model [
2].
The maximum entropy approach has been used primarily to formulate aggregate trip demand models, especially users’ single decisions. Particularly prominent are the spatial trip distribution formulations such as the doubly constrained gravitational model proposed by [
3] and its later modifications and extensions (see [
4,
5,
6,
7,
8,
9,
10]). Other important applications of maximum entropy are the combined models which integrate the different transportation decisions including trip generation, destination choice, mode choice and route choice. These models first appeared in the early 1980s and were followed over the next two decades by further important developments (e.g., [
1,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21]). In every maximum entropy application reported in the specialized literature, the demand model is the solution of an entropy maximization problem (or an equivalent formulation) with exogenous parameters in its objective function and a set of linear constraints. Applying the optimality conditions to these problems generates combined multinomial or hierarchical logit demand models, depending on the form of the objective function and its constraints. A microeconomic interpretation of the maximum entropy estimator of multinomial logit models and its equivalence to the maximum likelihood estimator is presented in [
22].
The endogenous and exogenous parameters of these models are estimated by applying certain statistical techniques used for calibrating econometric models, most notably the maximum likelihood method. This is a sensible strategy for a multinomial logit model given the equivalence of the two estimators noted above, but may not be the best option if the model is hierarchical logit.
To analyze the equivalence of the maximum likelihood and maximum entropy estimators in the context of a hierarchical logit model, we first carry out a theoretical analysis and then calculate both estimators based on Monte Carlo simulations. The estimators are then evaluated in terms of their bias with respect to known population parameters, their efficiency and consistency properties as well as certain general goodness-of-fit criteria such as mean square error. From the results obtained we determine the differences between the two approaches for various data scenarios.
Our conclusion is that the maximum entropy estimators provide a viable alternative for estimating hierarchical logit models; indeed, in the light of the simulations they appear to be superior to maximum likelihood estimates, especially with small sample sizes.
3. Simulation Analysis of ML and ME Estimators
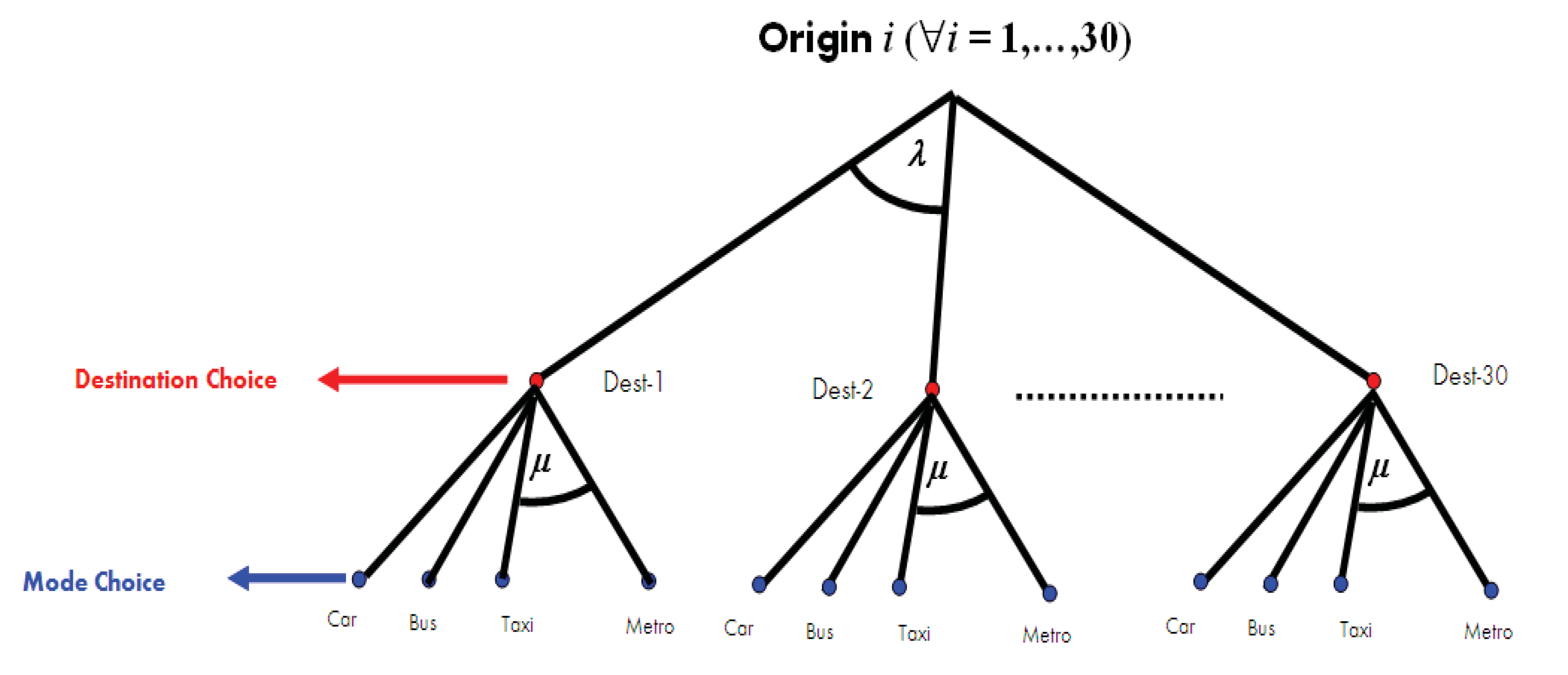
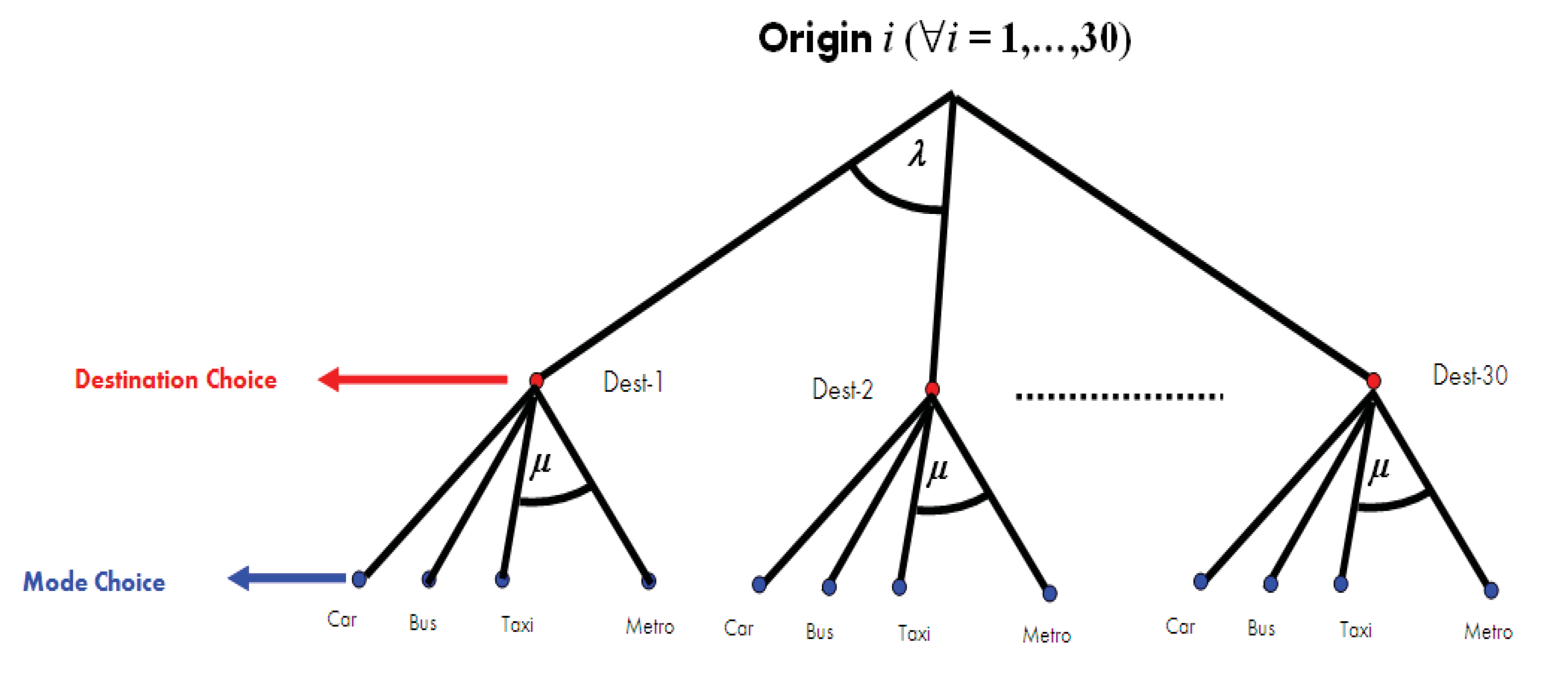
To compare the two parameter estimation approaches (ML and ME) we conducted a series of Monte Carlo simulations of a hierarchical model of combined destination choice and modal share using various sample sizes and values for the parameter
μ. Although this HL model is particular, it illustrates clearly the differences between both approaches. The simulated tree structure is depicted in
Figure 1.
Figure 1.
Simulated hierarchical tree structure.
Figure 1.
Simulated hierarchical tree structure.
We defined 30 origin and destination zones and four transportation modes (private car, bus, taxi and metro) available for trips between any origin and destination pair in either direction. For simplicity, we assumed that the parameter μ was the same for all destinations. The parameter was set at unity (). No specific attributes were assumed for the different groups.
The utility functions for the four modes are given below. In each case, the explanatory variables are travel time and travel cost and we include mode constants:
The explanatory variable parameters are generic, that is, the same for each mode. The values of these population parameters are set out in
Table 1.
Table 1.
Population parameter values in simulations.
Table 1.
Population parameter values in simulations.
| PARAMETER | VALUE (*) |
|---|
| 0.9 |
| 0 |
| 0.5 |
| 0.4 |
| −0.25 |
| −0.006 |
| SVT (**) | 41.47 |
| λ | 1 |
| ϕ = λ/μ = 1/μ | 0.5 (***) |
The values for the explanatory variables (time and cost) were extracted from a 2001 transportation survey for Greater Santiago of Chile [
23]. Their means and standard deviations for each transportation mode are given in
Table 2.
A total of 1,000 Monte Carlo simulations were conducted with each of five different sample sizes containing 500, 1,000, 5,000, 10,000 and 20,000 observations, respectively. We thus obtained 1,000 ML and ME estimators of the parameters for each sample size, from which the estimates of bias, variance and mean squared error were derived.
The likelihood and entropy maximization problems were solved numerically using Newton’s method. The convergence criterion in all simulations was 0.1%, meaning that the percentage difference between the estimates of each parameter obtained from two consecutive iterations of the method did not exceed 0.001.
Table 2.
Mean and standard deviation of explanatory variables by mode.
Table 2.
Mean and standard deviation of explanatory variables by mode.
| MODE | VARIABLE | MEAN (*) | STD DEV (*) |
|---|
| Car | Travel time | 16 | 11 |
| Cost | 2,031 | 138 |
| Taxi | Travel time | 17 | 11 |
| Cost | 2,279 | 148 |
| Bus | Travel time | 54 | 12 |
| Cost | 409 | 25 |
| Metro | Travel time | 45 | 7 |
| Cost | 833 | 73 |
3.1. Bias, Variance and Mean Squared Error (MSE)
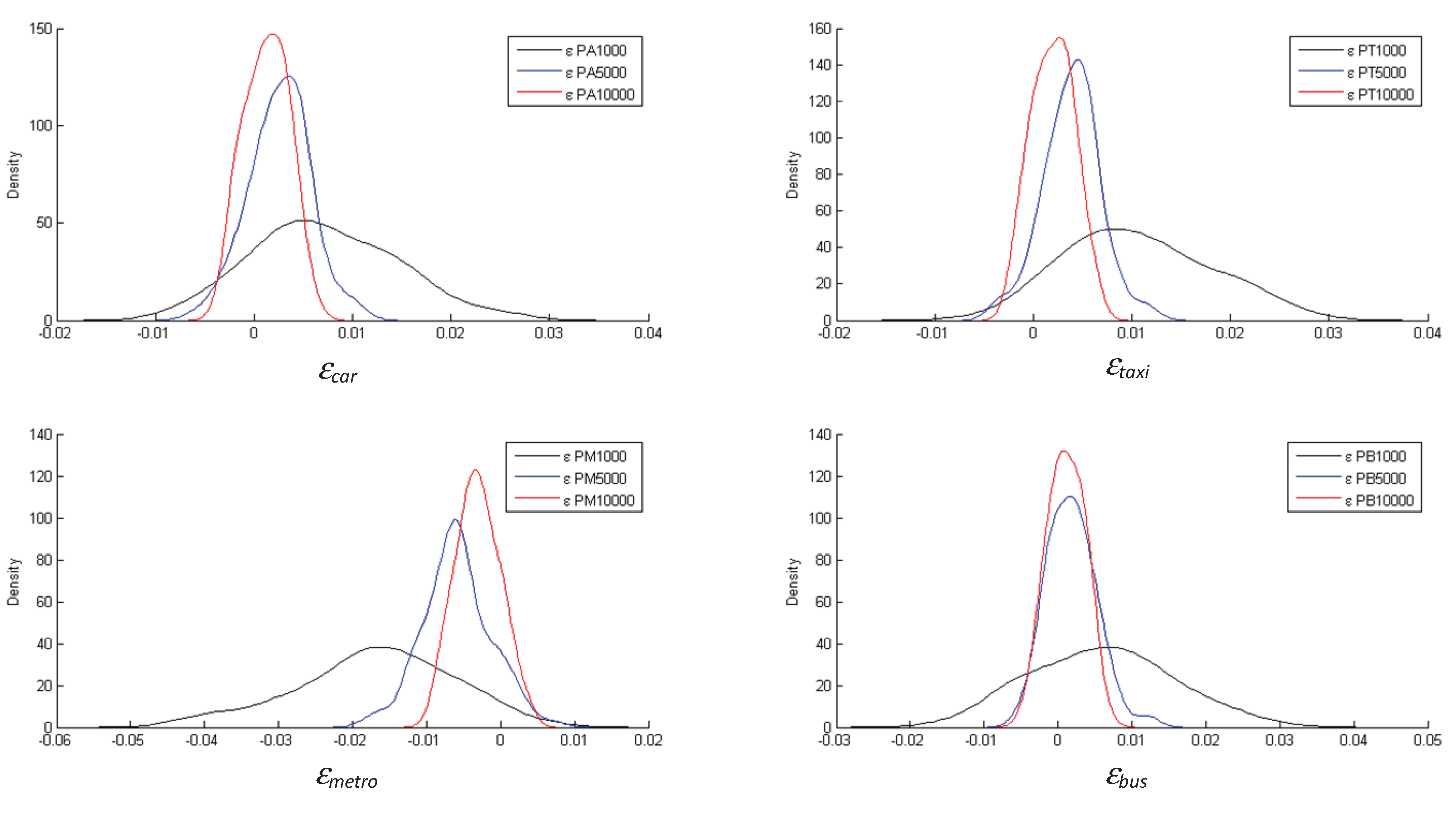
The 1,000 ML and ME estimators were used to construct histograms for simultaneously analyzing bias, variance and mean squared error. In
Figure 2 we compare histograms of the observed modal split and modeled modal split for the maximum likelihood estimator, for three sample size (1,000, 5,000 and 10,000); in maximum entropy estimator, both observed and modeled modal split are identical by construction [see Equation (19)]. Each variable a was defined, for each simulations and mode a (car, taxi, bus and metro) by the following expression:
. We observe that, just asymptotically, modeled modal split converges to observed modal split [see Equation (15)].
Figure 2.
Observed vs. modeled modal split using maximum likelihood estimation, for parameter value ϕ = 1/μ = 0.5.
Figure 2.
Observed vs. modeled modal split using maximum likelihood estimation, for parameter value ϕ = 1/μ = 0.5.
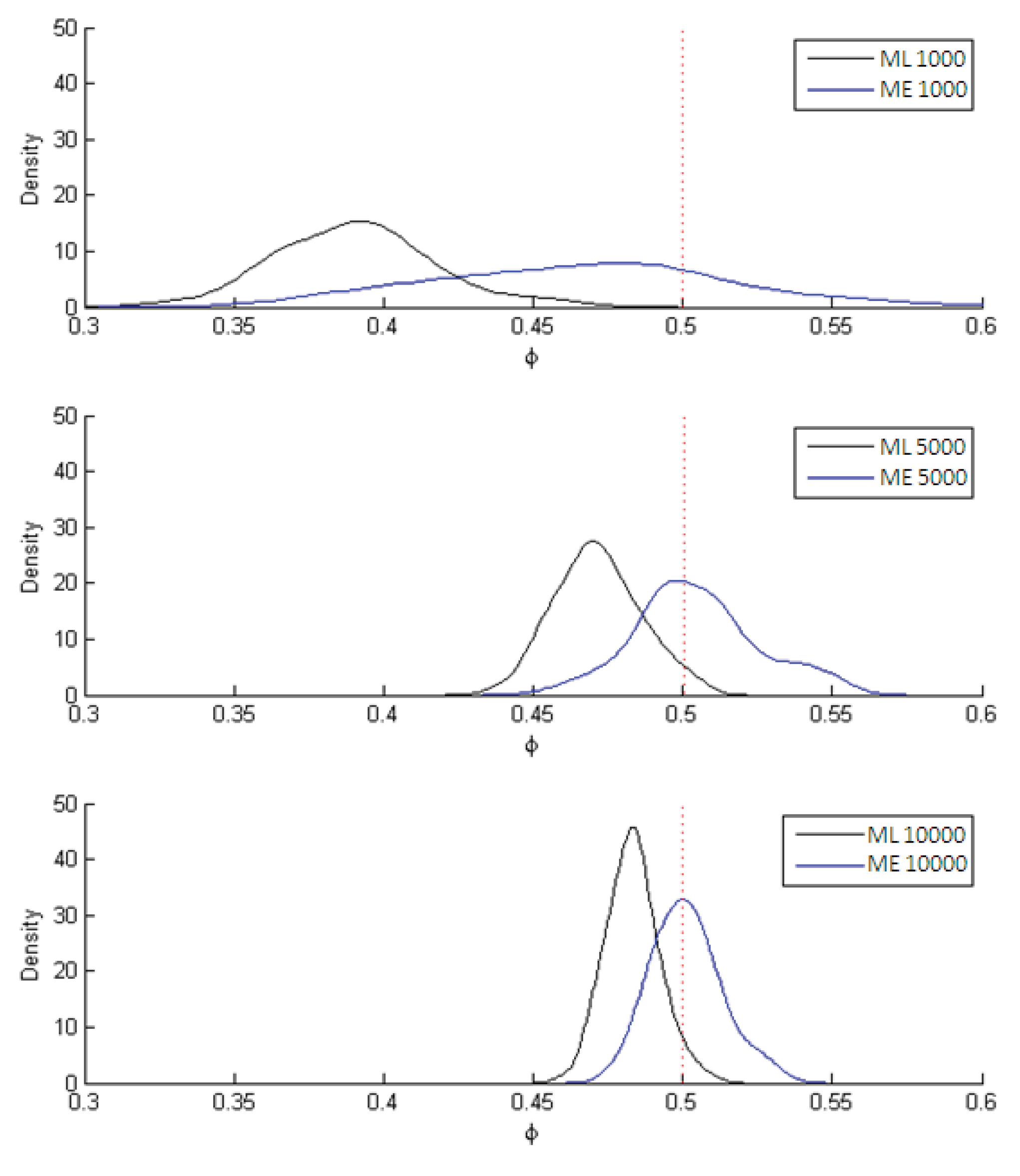
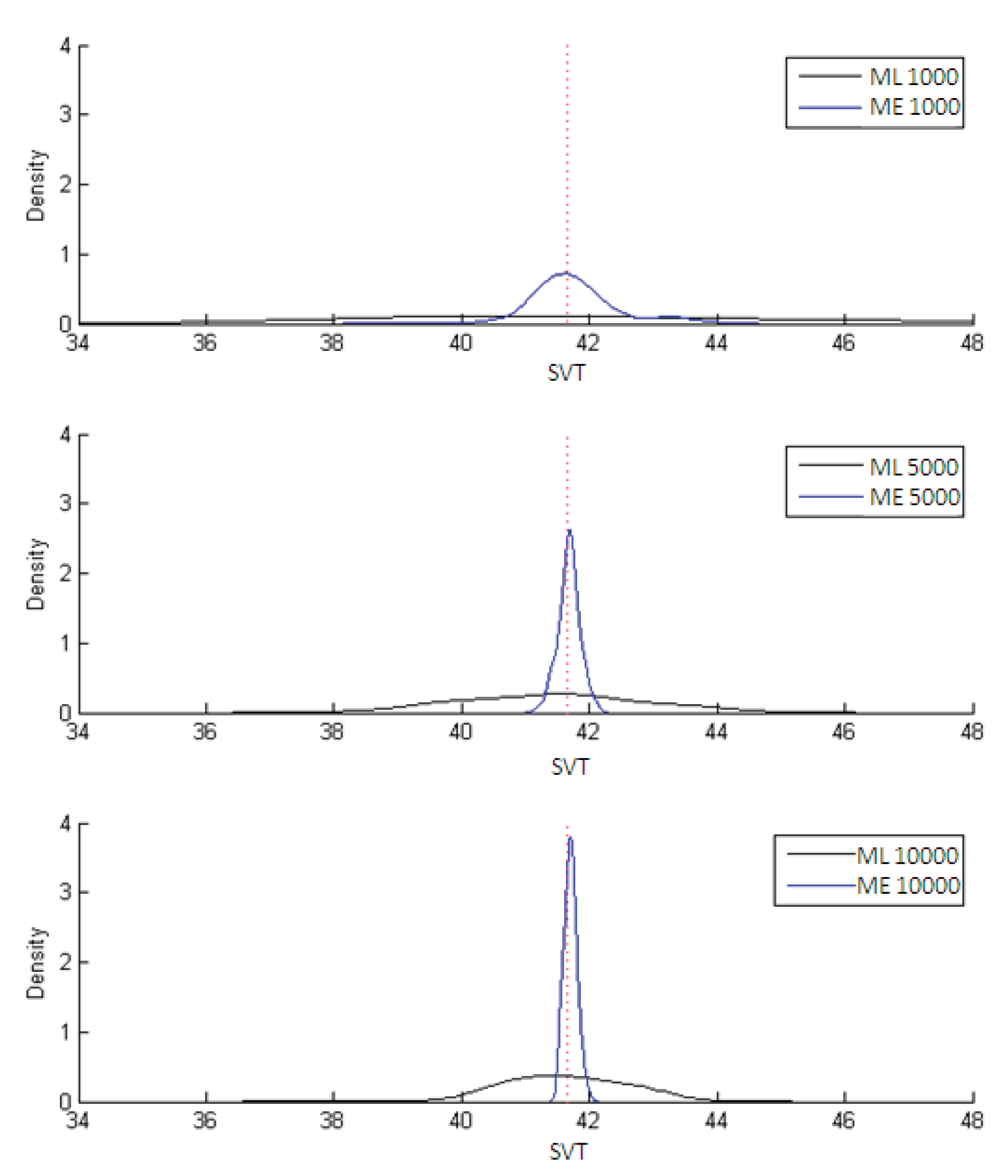
The estimates of the parameter
ϕ = 1/
μ are shown in
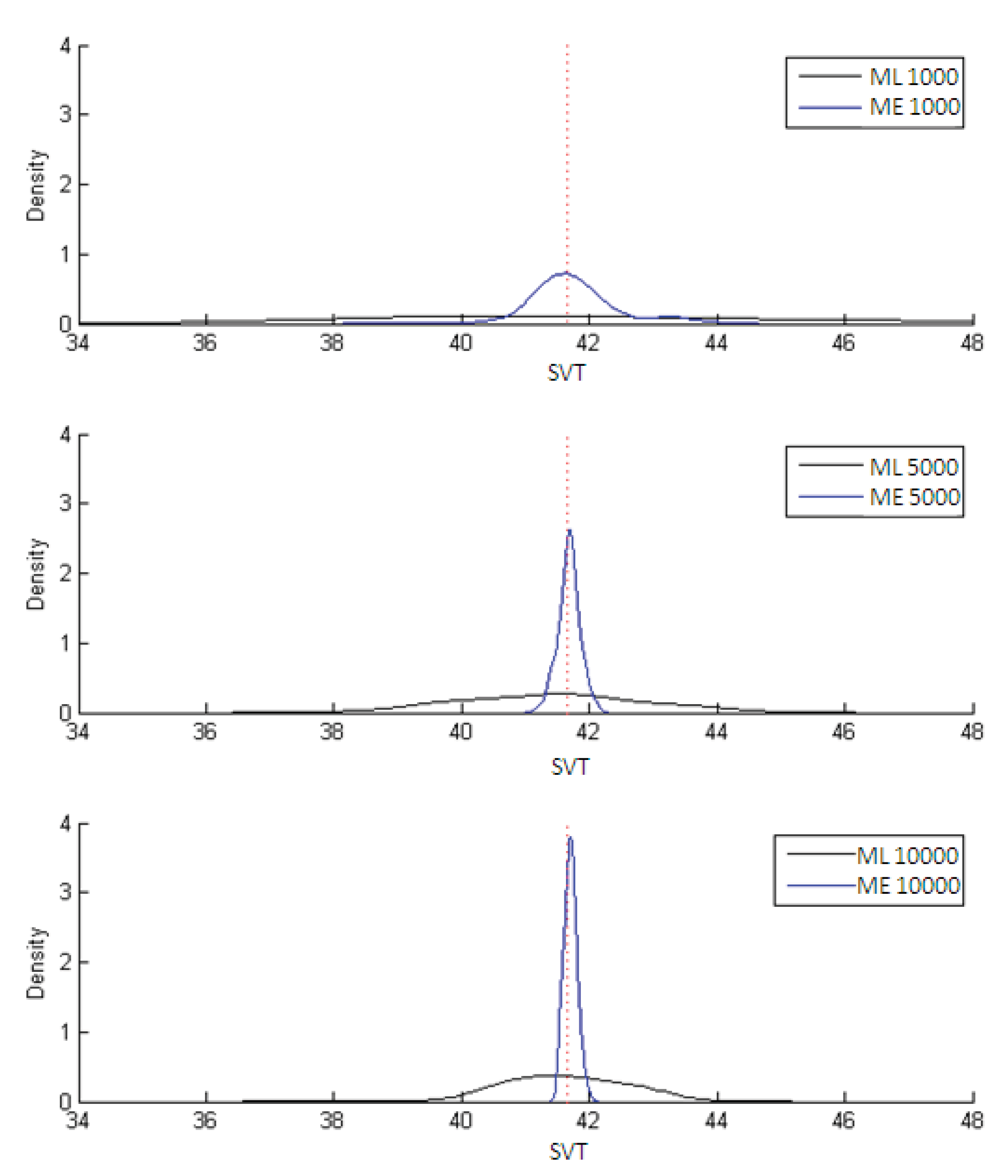
Figure 3 while the estimates of the subjective value of time (SVT) are displayed in
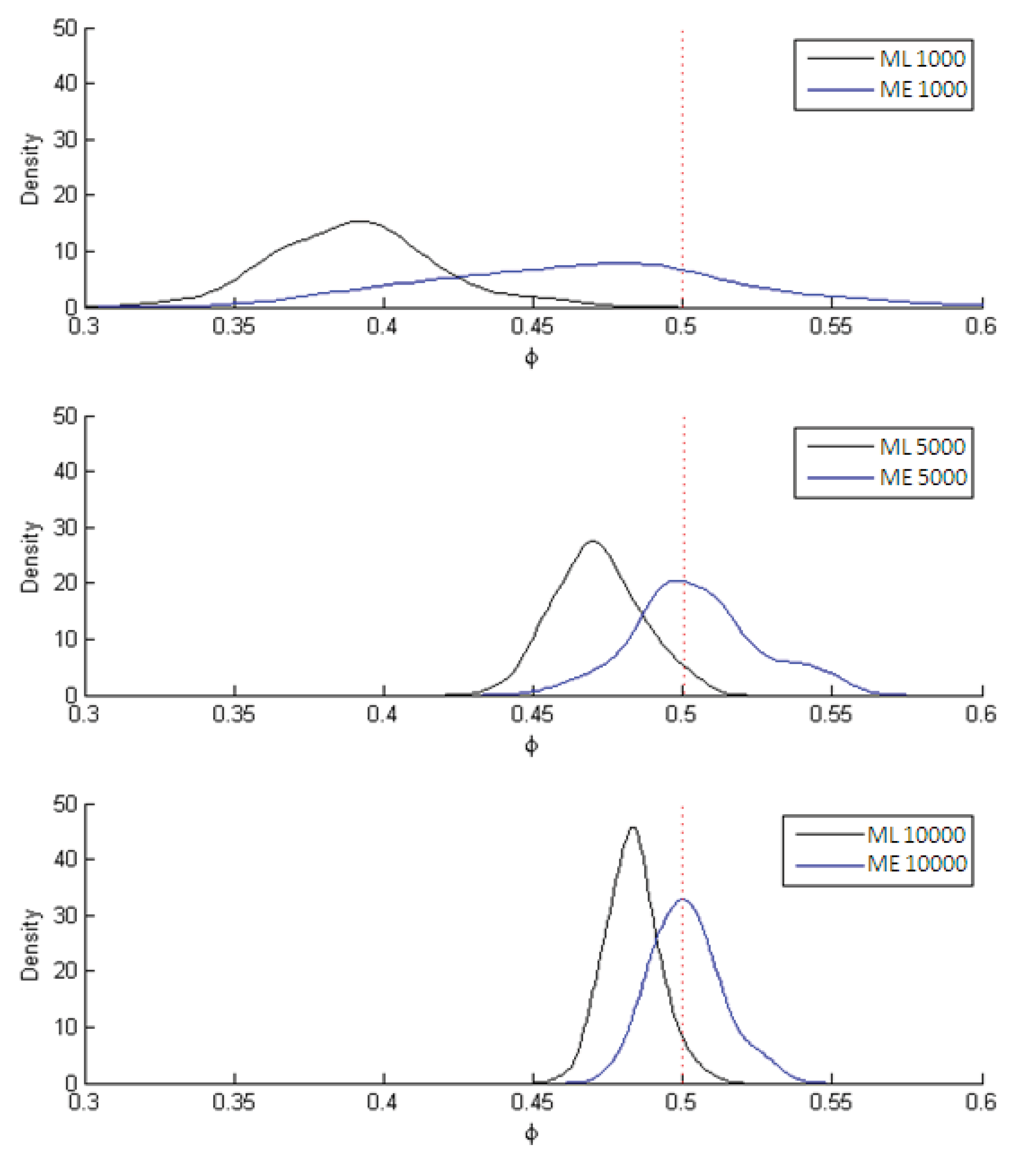
Figure 4. In both figures the dotted line marks the population parameter (used in the simulation) while the black curve traces out the ML estimates and the blue curve the ME estimates. The results in all cases are for 1,000; 5,000 and 10,000 observations, the three instances in which the differences between the two estimators most clearly stand out.
Figure 3.
Results of ML and ME estimators for parameter value ϕ = 1/μ = 0.5.
Figure 3.
Results of ML and ME estimators for parameter value ϕ = 1/μ = 0.5.
Figure 4.
Results of ML and ME estimators for SVT = βTime/βCost.
Figure 4.
Results of ML and ME estimators for SVT = βTime/βCost.
As can be seen in
Figure 3, the ML estimate of
μ is relatively biased but consistent while the ME estimate is significantly less biased but also less efficient (
i.e., greater variance).
Figure 4 shows that both estimators of SVT are unbiased, although the ME estimator is clearly more efficient. This is confirmed in
Table 3, which summarizes the results on bias, variance and MSE for both ML and ME. Also clear from the table is that the ME estimators are less biased than the ML ones, though the variances of the latter are smaller. The MSE, however, is always lower for the ME estimators.
Table 3.
Summary of results for ML and ME estimators.
Table 3.
Summary of results for ML and ME estimators.
| METHOD | PARAMETER | SAMPLE SIZE | BIAS | VARIANCE | MSE (*) |
|---|
| ML | 1/μ | 500 | 0.16844 | 0.00096 | 0.02933 |
| 1/μ | 1,000 | 0.10912 | 0.00074 | 0.01265 |
| 1/μ | 5,000 | 0.03067 | 0.00016 | 0.00110 |
| 1/μ | 10,000 | 0.01655 | 0.00009 | 0.00036 |
| 1/μ | 20,000 | 0.00821 | 0.00004 | 0.00011 |
| VST | 500 | 2.57679 | 47.61970 | 54.25957 |
| VST | 1,000 | 0.68741 | 13.87630 | 14.34884 |
| VST | 5,000 | 0.16172 | 3.01595 | 3.04210 |
| VST | 10,000 | 0.12386 | 1.23927 | 1.25461 |
| VST | 20,000 | 0.11537 | 0.71021 | 0.72352 |
| ME | 1/μ | 500 | 0.12867 | 0.00384 | 0.02039 |
| 1/μ | 1,000 | 0.03050 | 0.00250 | 0.00343 |
| 1/μ | 5,000 | 0.00494 | 0.00047 | 0.00050 |
| 1/μ | 10,000 | 0.00182 | 0.00017 | 0.00017 |
| 1/μ | 20,000 | 0.00023 | 0.00006 | 0.00006 |
| VST | 500 | 1.70225 | 12.01048 | 14.90812 |
| VST | 1,000 | 0.35554 | 1.95599 | 2.08240 |
| VST | 5,000 | 0.19228 | 0.22072 | 0.25769 |
| VST | 10,000 | 0.08879 | 0.07469 | 0.08257 |
| VST | 20,000 | 0.03281 | 0.01565 | 0.01672 |
For parameter values ϕ = 1/μ = 0.2 and ϕ = 1/μ = 0.9, the bias, variance and MSE estimates with the same sample sizes are found in
Appendix B. In every case both bias and MSE are smaller for the ME estimator.
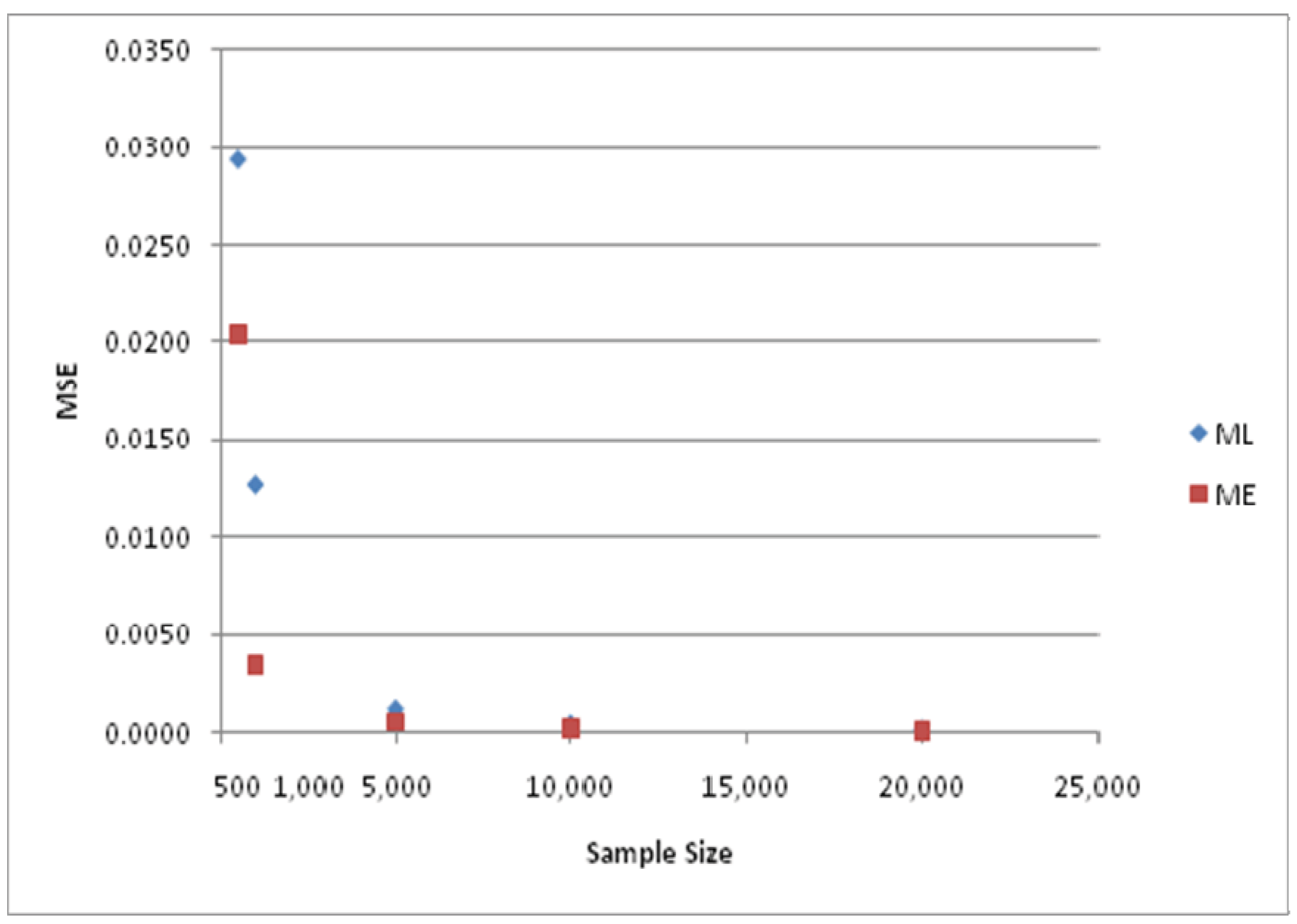
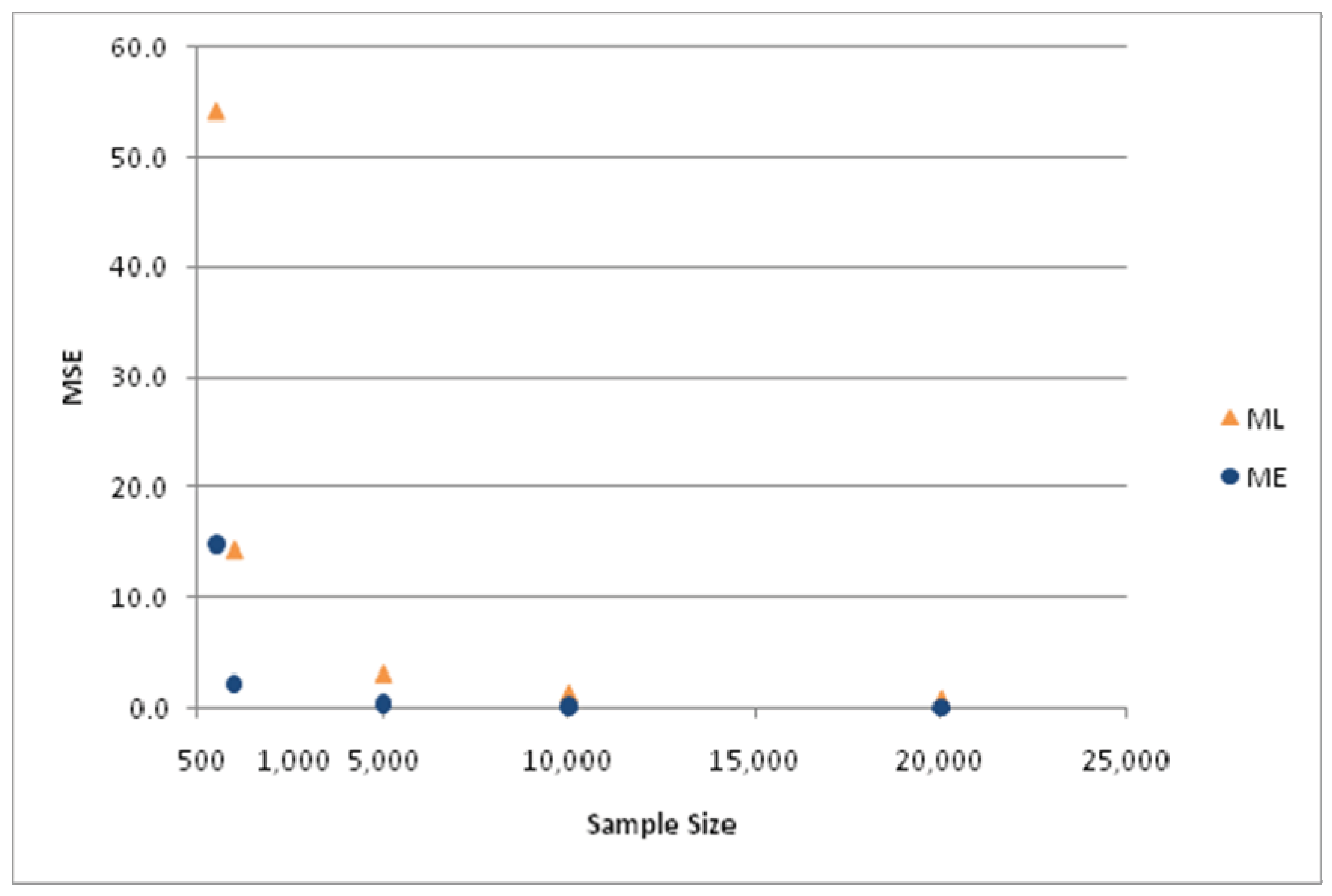
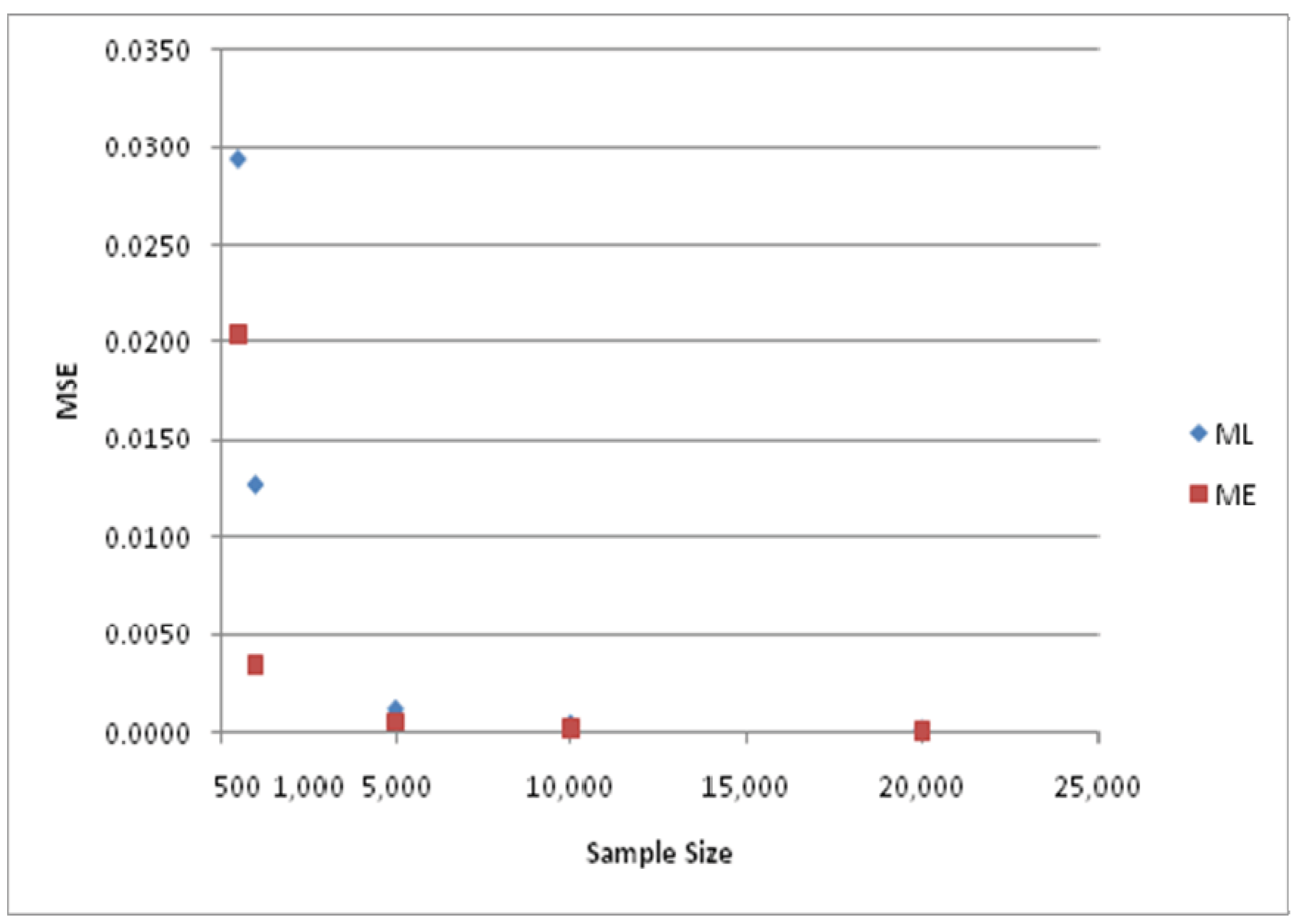
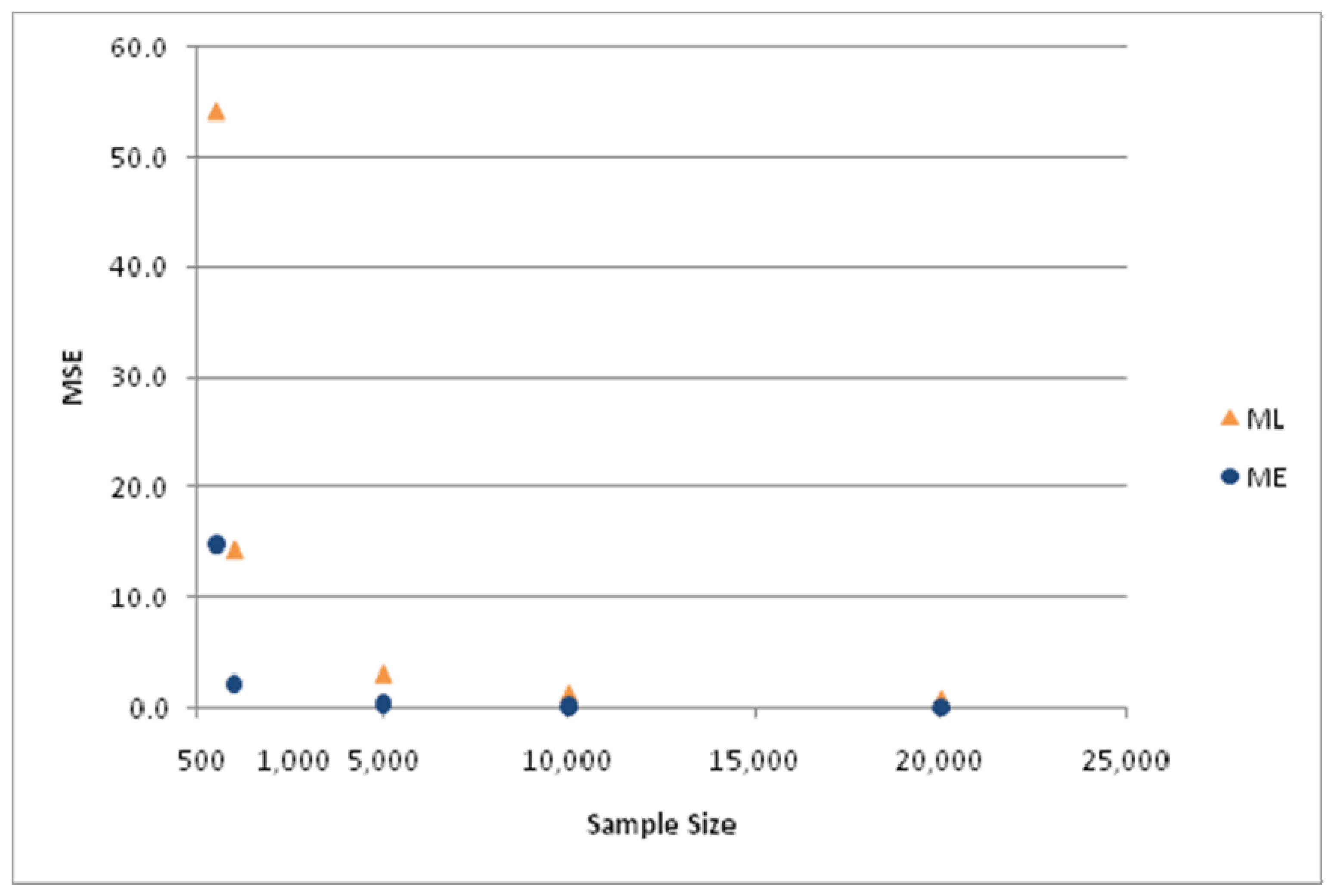
The differences in MSE for the two estimators are depicted in
Figure 5 and
Figure 6. The various results just presented lead to the conclusion that the ME estimator is systematically superior to the ML estimator in this hierarchical tree structure, particularly for small sample sizes.
The differences between both estimation approaches may respond to their abilities for reproducing the market modal shares of the calibration samples. It is well established that when the utility functions of a multinomial model contain a constant term by mode the modeled and observed modal shares are always the same [
24]. This is not the case for the hierarchical logit model when its parameters are estimated by ML. Under the ME approach, however, the problem constraints force the market modal shares to be reproduced.
Figure 5.
MSE of ML and ME estimators for parameter value ϕ = 1/μ = 0.5.
Figure 5.
MSE of ML and ME estimators for parameter value ϕ = 1/μ = 0.5.
Figure 6.
MSE of ML and ME estimators for SVT.
Figure 6.
MSE of ML and ME estimators for SVT.
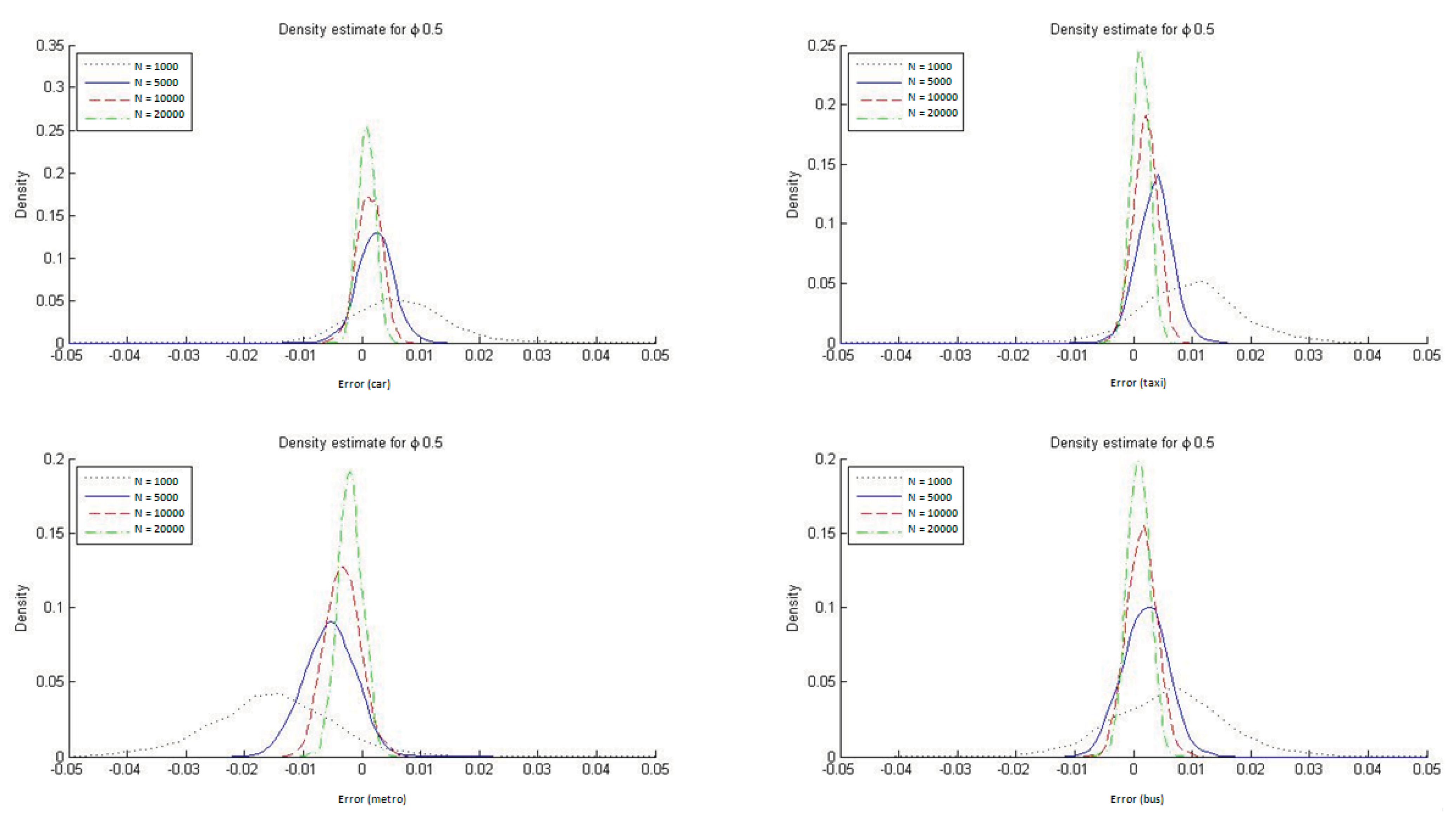
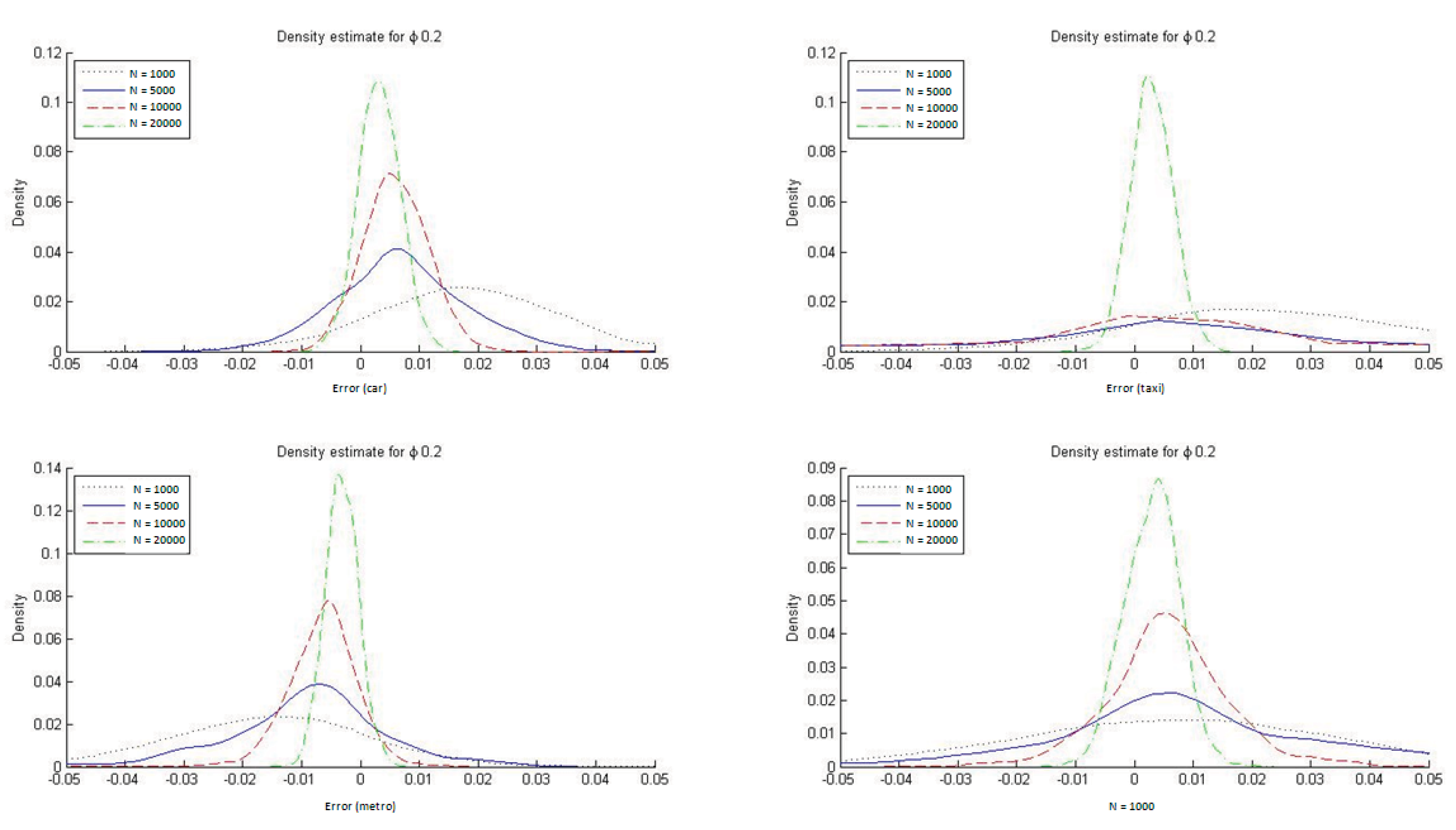
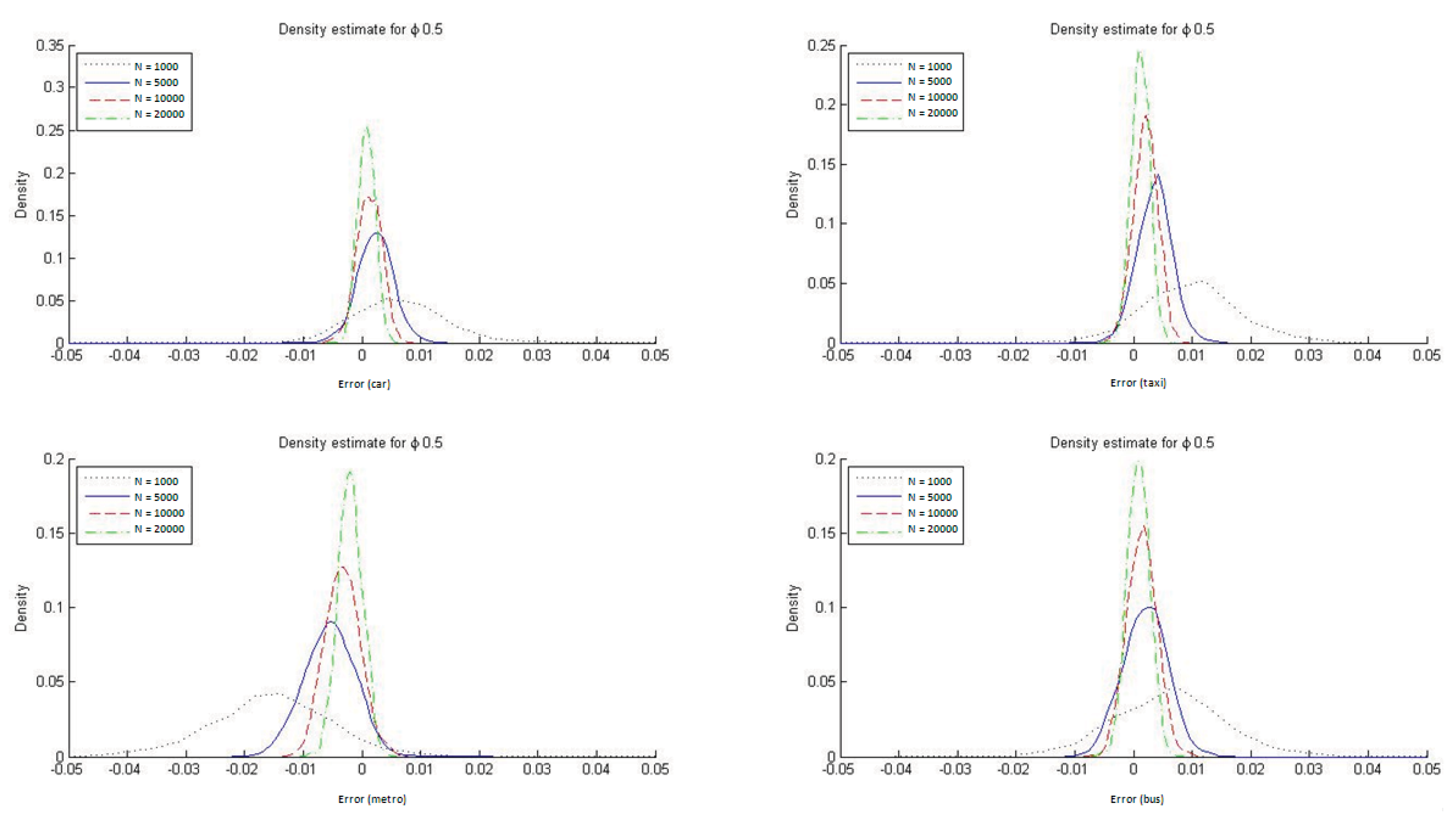
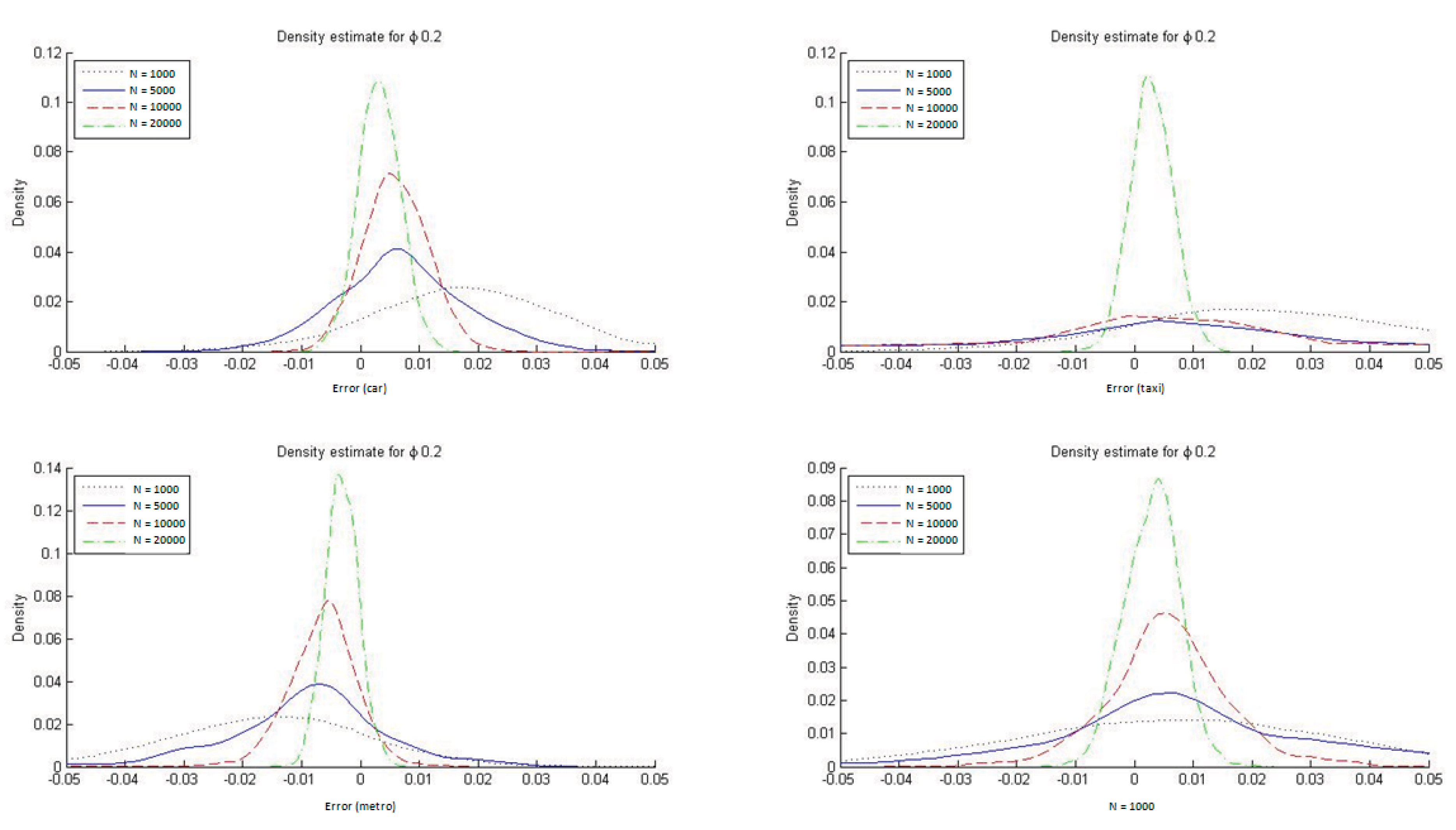
To determine the ability of the ML estimators to reproduce the market modal shares in HL models, we constructed histograms of DMS, defined as the difference between the modeled and observed modal shares (see
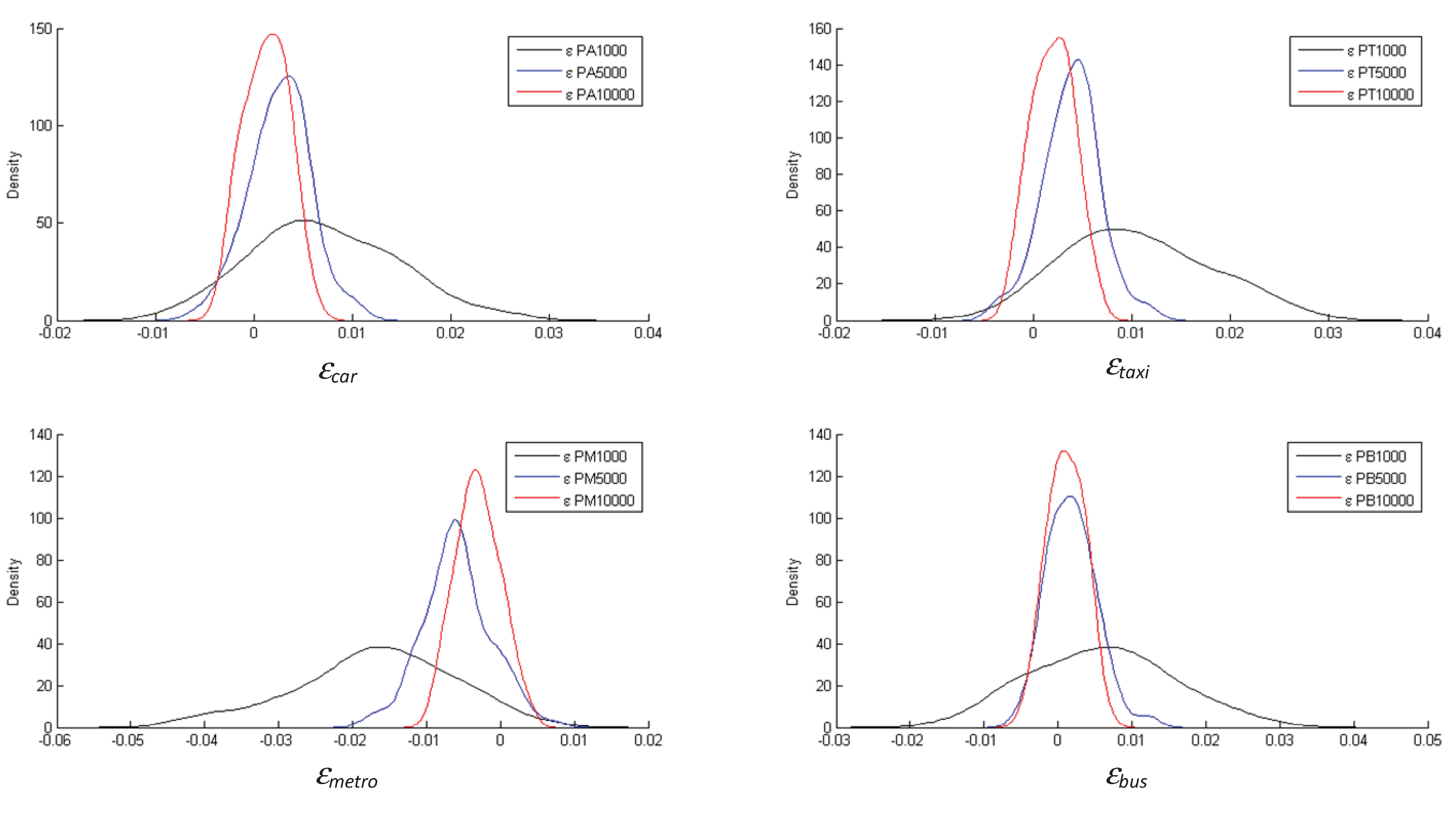
Figure 7). These differences were estimated for each of the four transportation modes. As is apparent from the figure, the ML estimators of the hierarchical logit model do not, on average, reproduce the sample modal shares, particularly in small samples.
It is also evident from
Figure 7 that with HL models the ML estimator reproduces the market modal shares only asymptotically whereas by construction the ME estimators always reproduce them. In
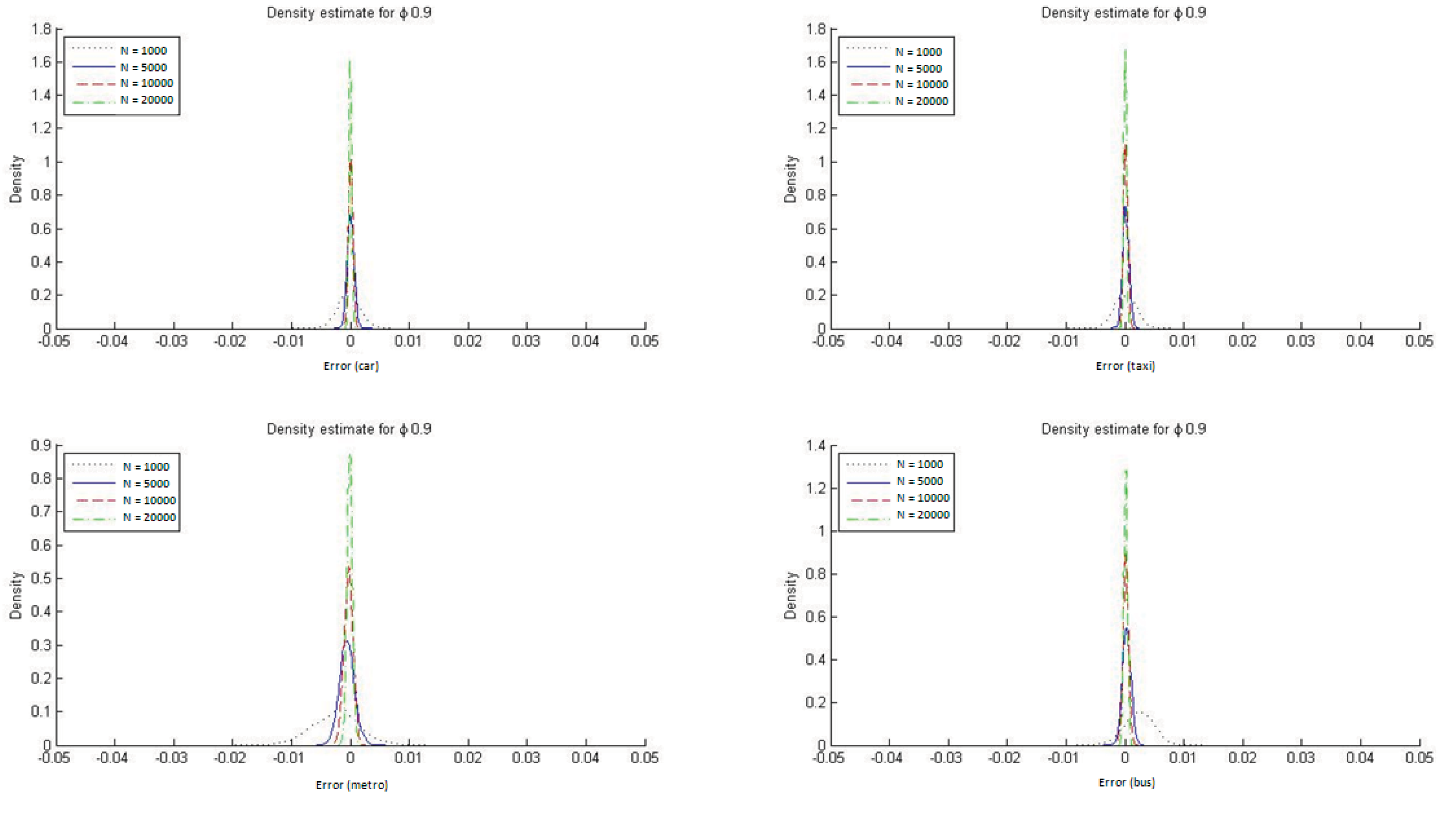
Appendix C we report the DMS distributions for the four transportation modes when ϕ = 1/μ = 0.2 and ϕ = 1/μ = 0.9. The conclusions are similar for the two cases, but with ϕ = 1/μ = 0.9 it is especially clear that the ML estimate for the HL model reproduces the modal shares must more accurately. This result is to be expected given that a value for the parameter ϕ closer to 1 implies that the HL model is more similar to an MNL one, which always reproduces the observed modal shares when estimated with ML.
Figure 7.
Distribution of DMS with ML estimation (ϕ = 1/μ = 0.5).
Figure 7.
Distribution of DMS with ML estimation (ϕ = 1/μ = 0.5).
3.2. Estimate of Consumer Surplus
Also of interest is the comparison of the ML and ME estimates of consumer surplus generated by our combined destination and mode choice model. This measure of the welfare perceived by the transportation system user is expressed by the expected maximum utility (EMU), which is written as follows:
This expression gives the consumer surplus of individual
i in group
g. The group refers to the origin-destination pair representing the trip taken, and since our model is an aggregate one, all individuals in a given group have the same utility function
for each mode alternative
a. This being the case, we have
EMUgi =
EMUg, and can therefore estimate the average EMU as:
where
tag is the number of individuals in group
g that takes alternative
a. We will use average EMU to make comparisons with the results generated by the simulations for various sample sizes (the sum of the
tag will therefore equal the size of the sample from which the parameters that give the EMU are estimated).
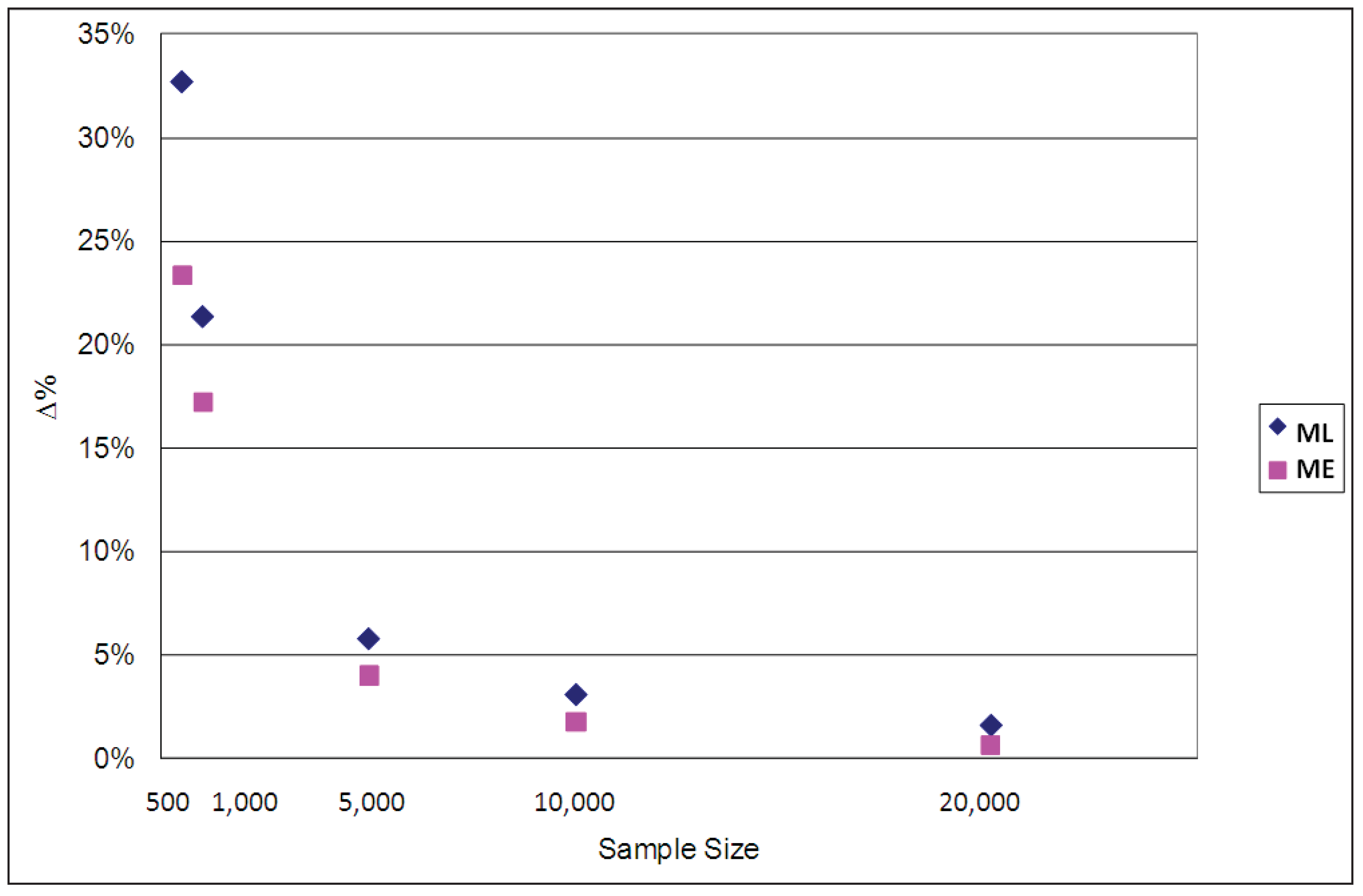
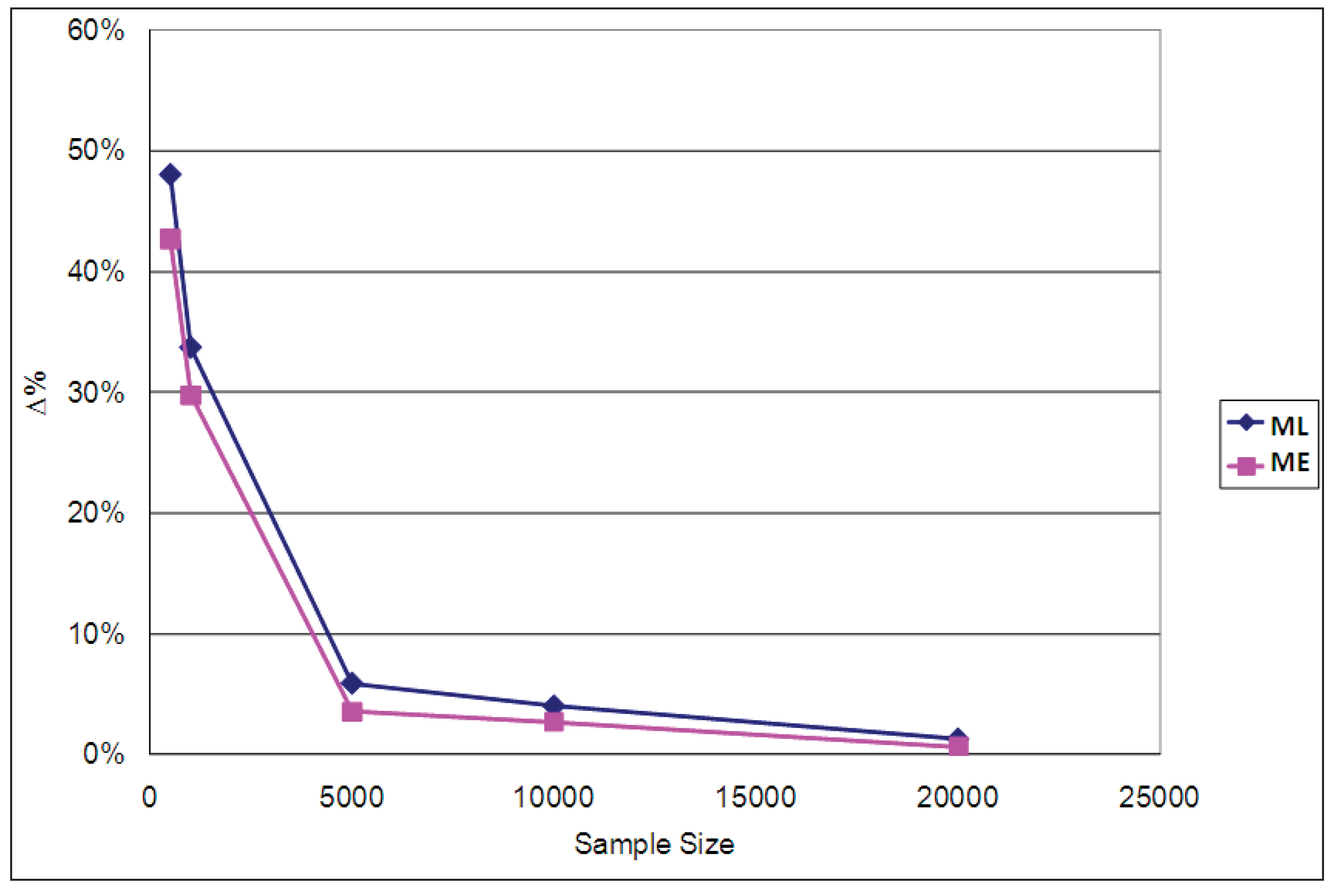
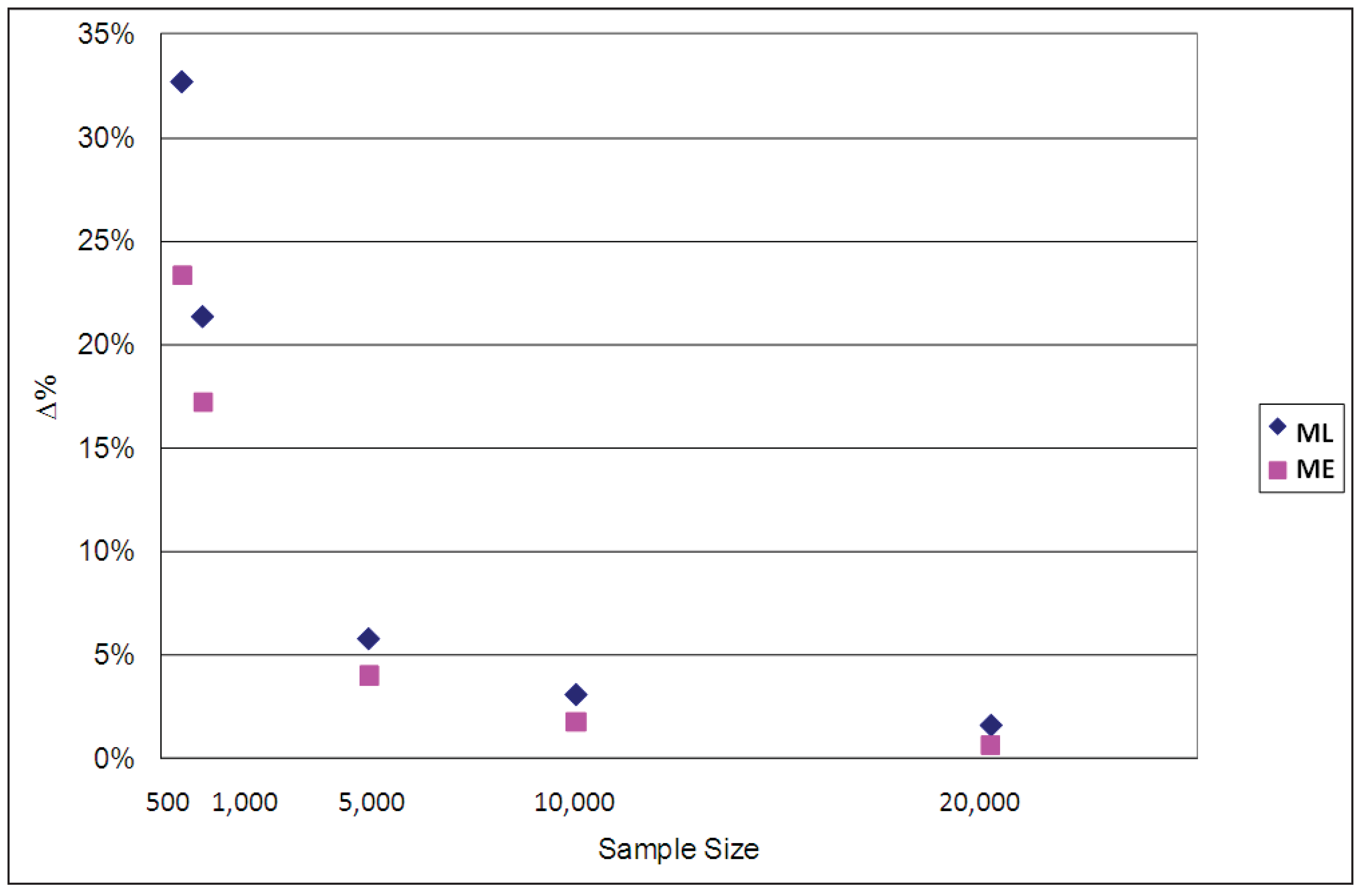
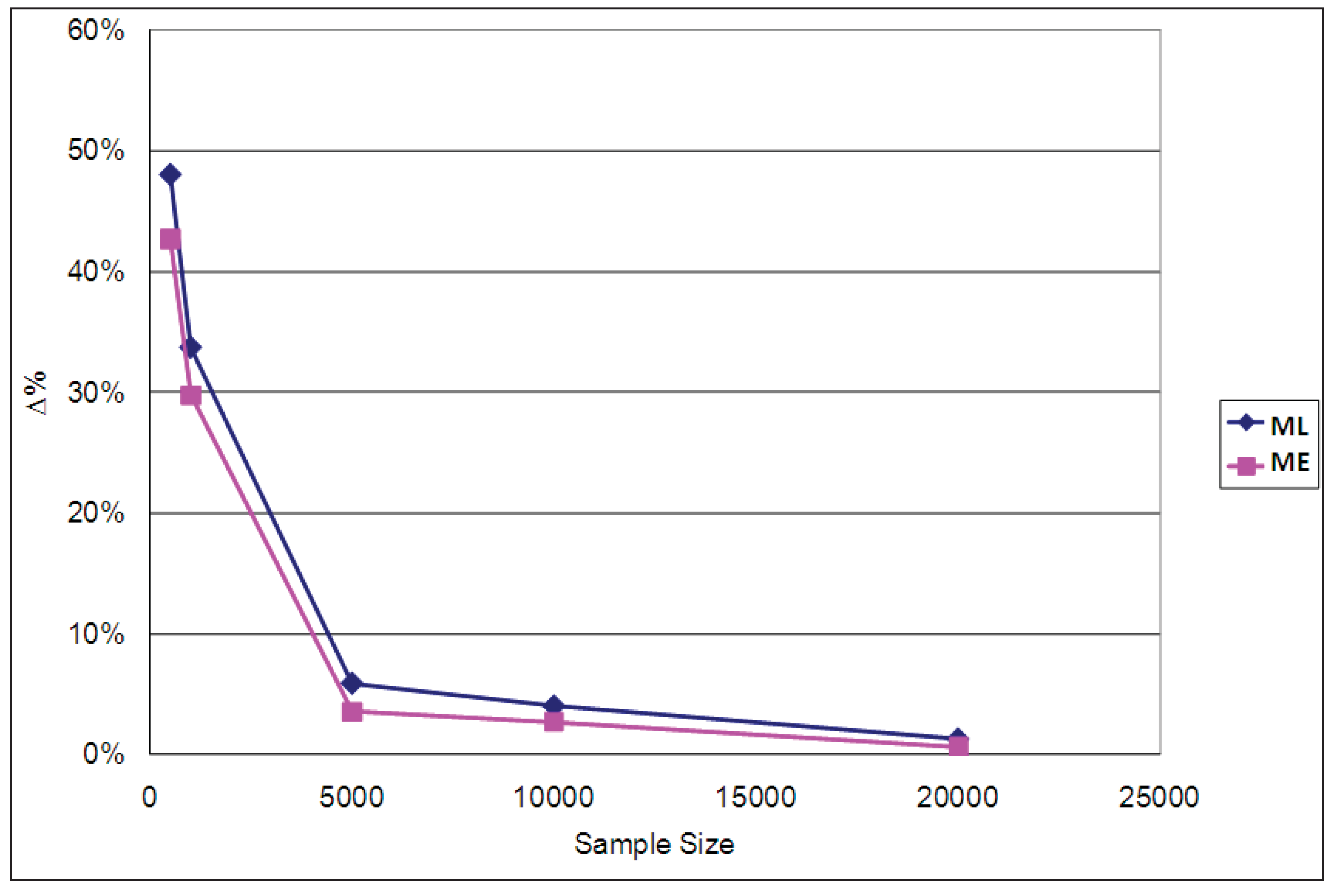
The average EMU values estimated for each case using the ML and ME estimators are compared with the population parameters used for the simulations in
Table 4. The percentage differences between the estimated and population parameter values are graphed in
Figure 8. It is clear from both the table and the figure that the EMU estimates produced by the ML parameters are more biased than those of the ME parameters, especially when sample sizes are small, though they both converge asymptotically to the true values when the sample size increases. The corresponding results for ϕ = 1/μ = 0.2 and ϕ = 1/μ = 0.9 are reported in
Appendix D, confirming that for all three cases (ϕ = 0.2, ϕ = 0.5 and ϕ = 0.9) the ME estimator of average EMU is less biased than the ML one.
Table 4.
Average EMU.
| SAMPLE SIZE | SIMULATION | ML | Δ% ML (*) | ME | Δ% ME (*) |
|---|
| 500 | 7.0574 | 4.7481 | 32.7% | 5.4107 | 23.3% |
| 1,000 | 7.0601 | 5.5514 | 21.4% | 5.8450 | 17.2% |
| 5,000 | 7.0918 | 6.6807 | 5.8% | 6.8073 | 4.0% |
| 10,000 | 7.0755 | 6.8564 | 3.1% | 6.9500 | 1.8% |
| 20,000 | 7.0679 | 6.9539 | 1.6% | 7.0223 | 0.6% |
Figure 8.
Percentage differences between population and estimated average EMU (ϕ = 1/μ = 0.5).
Figure 8.
Percentage differences between population and estimated average EMU (ϕ = 1/μ = 0.5).
3.3. Out-of-Sample Prediction
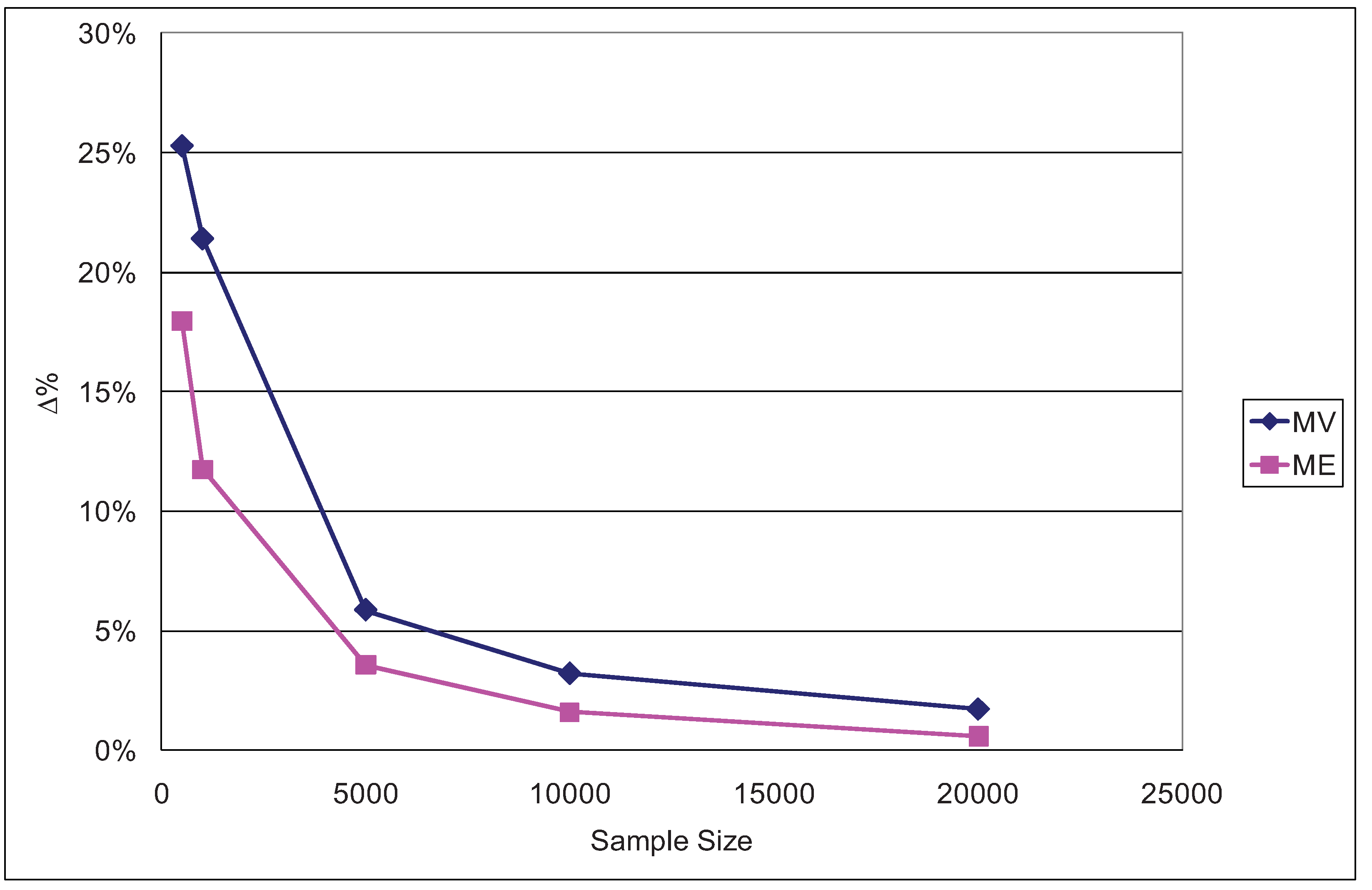
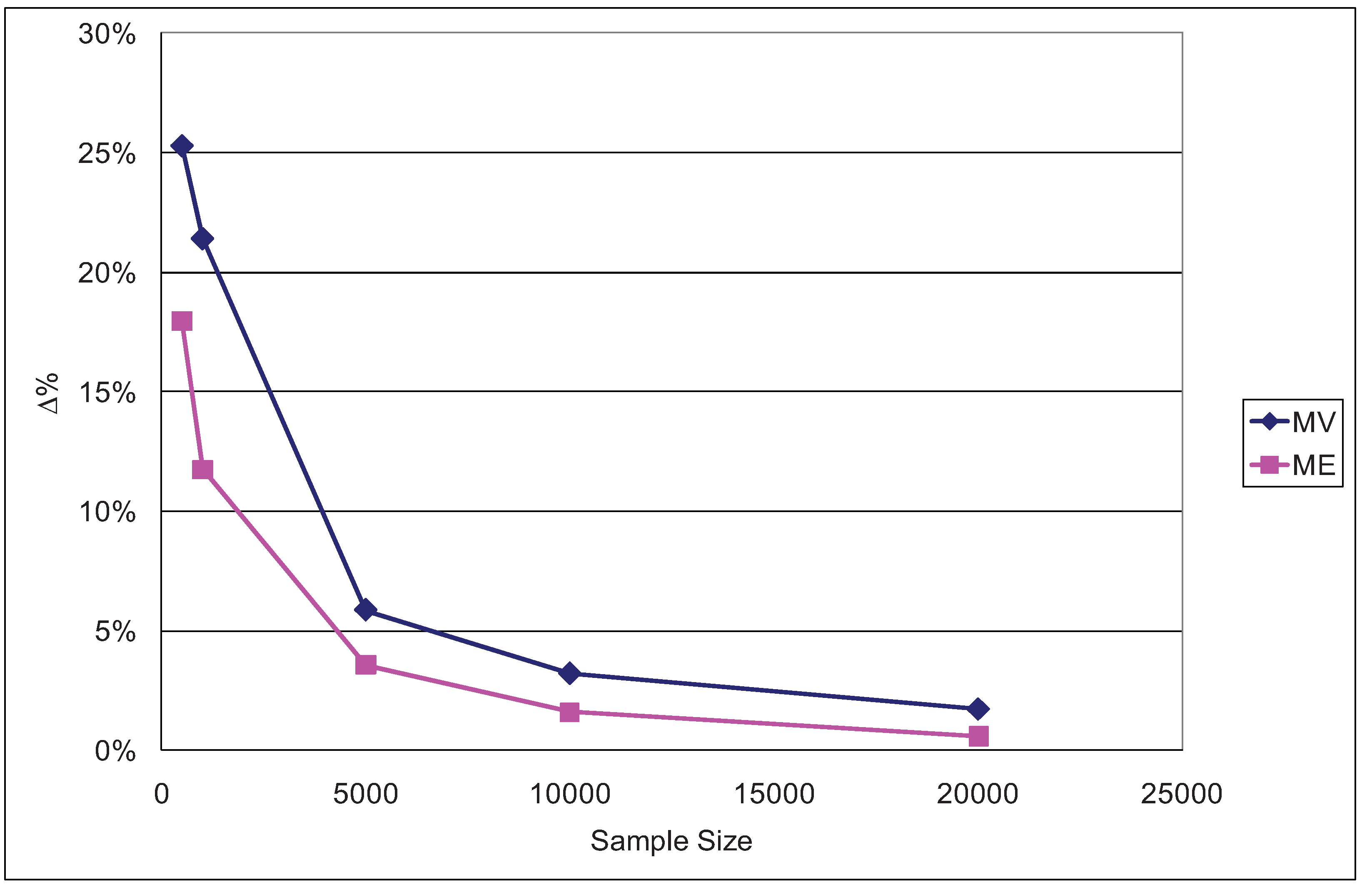
To study the behavior of the ML and ME estimators of consumer surplus we varied the travel times of the four transportation modes and estimated the resulting changes in average EMU as given by (13). The travel time variations consisted in reducing this factor by 10% for all four modes. The results obtained are shown for various sample sizes in
Figure 9.
Figure 9.
Percentage differences in ΔEMU for a 10% reduction in travel time (ϕ = 1/μ = 0.5).
Figure 9.
Percentage differences in ΔEMU for a 10% reduction in travel time (ϕ = 1/μ = 0.5).
In every case it can be observed that the ML overestimates EMU to a greater extent than does ME. The overestimation effect is particularly significant for the small samples (500 and 1,000 data items), which is consistent with
Figure 9. The corresponding results for ϕ = 1/μ = 0.2 and ϕ = 1/μ = 0.9 are reported in
Appendix E, confirming that for all three cases (ϕ = 0.2, ϕ = 0.5 and ϕ = 0.9) the ME overestimate of ΔEMU is smaller than the ML one.
4. Conclusions
In the context of aggregate transportation demand forecasting and land use planning, entropy maximization problems are often formulated, mainly because their solutions are the well-known multinomial logit and hierarchical logit models. The parameters of these models are normally estimated using the maximum likelihood method, but they can also be estimated by solving the entropy maximization problems directly. These latter estimators are referred to here as maximum entropy estimators. It has long been known (see [
1,
22]) that both estimation methods lead to the same results if the model is multinomial logit.
This work extended the analysis to the case of aggregate hierarchical logit models. We began by formulating a general problem of maximizing the hierarchical entropy and deducing that its solution is a hierarchical logit model. We then observed that the maximum entropy estimators were different from the maximum likelihood ones, especially in that the latter do not reproduce either the average values of the explanatory variables or the observed market modal shares (of the calibration sample) whereas the maximum entropy estimators do reproduce them by construction.
The two estimators were then subjected to various empirical analyses. The population parameters of a relatively general travel demand hierarchical model were estimated using Monte Carlo simulations with samples of various sizes. The results obtained showed that the maximum entropy estimator is superior to the maximum likelihood estimator, especially for smaller sample sizes. More specifically, the maximum entropy estimator exhibited less bias and a smaller mean square error. The reduced bias in turn results in underestimations of consumer surplus with maximum likelihood.
Though similar analyses of other hierarchical structures are required, we may conclude on the basis of the results presented here that the maximum entropy approach is a better alternative for estimating hierarchical logit aggregate models than the maximum likelihood approach, particularly with small or medium-size samples such as those typically used in actual transportation planning processes.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}