
Multimodal Low Resolution Face and Frontal Gait Recognition from Surveillance Video

Abstract
1. Introduction
2. Related Work
2.1. Low-Resolution Face Recognition
- (1)
- Mapping into unified feature space: In this approach, the HR gallery images and LR probe images are projected into a common space [16]. However, it is not straight forward to find the optimal inter-resolution (IR) space. Computation of two bidirectional transformations from both HR and LR to a unified feature space usually incorporates noise.
- (2)
- Super-resolution: Many researchers used up-scaling or interpolation techniques, such as cubic interpolation on the LR images. Conventional up-scaling techniques usually are not good for the images with relatively lower resolution. However, super-resolution [17,18] methods can be utilized to estimate HR versions of the LR ones to perform efficient matching.
- (3)
- Down-scaling: Down-sampling techniques [11] can be applied on the HR images followed by comparison with the LR image. However, these techniques are poor in performance for solving LR problem, primarily because the downsampling reduces the high-frequency information which is crucial for recognition.
2.2. Gait Recognition
- (1)
- Model-free approaches: In the model-free gait representation [23], the features are composed of a static component, i.e., size and shape of a person, and a dynamic component, which portrays the actual movement. Examples of static features are height, stride length, and silhouette bounding box. Whereas dynamic features can include frequency domain parameters like frequency and phase of the movements.
- (2)
- Model-based approaches: In the model-based gait representation approaches [13,24] we need to obtain a series of static or dynamic gait parameters via modeling or tracking the entire body or individual parts such as limbs, legs, and arms. Gait signatures formed using these model parameters are utilized to identify an individual.
2.3. Multimodal Face and Gait Recognition
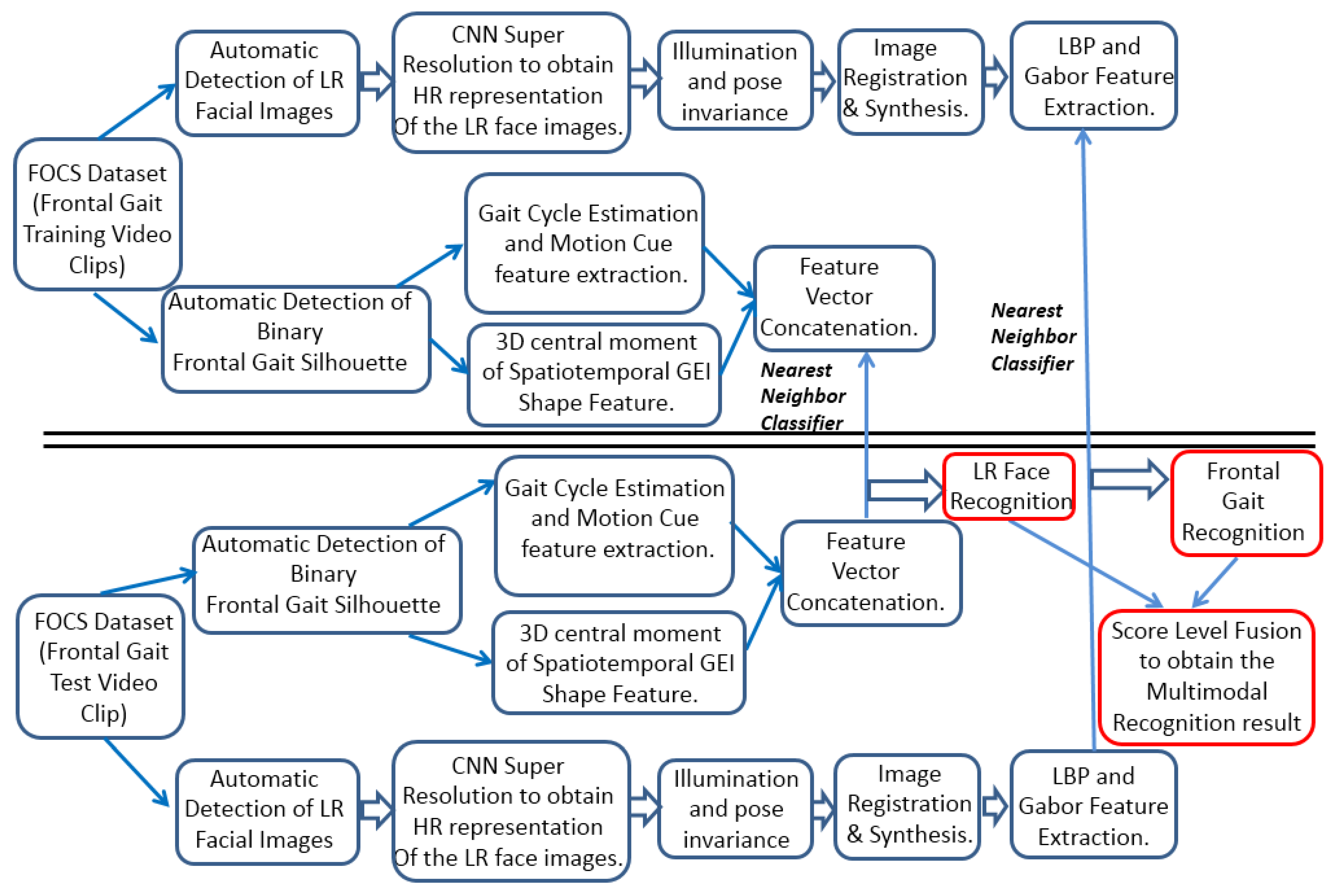
3. Materials and Methods
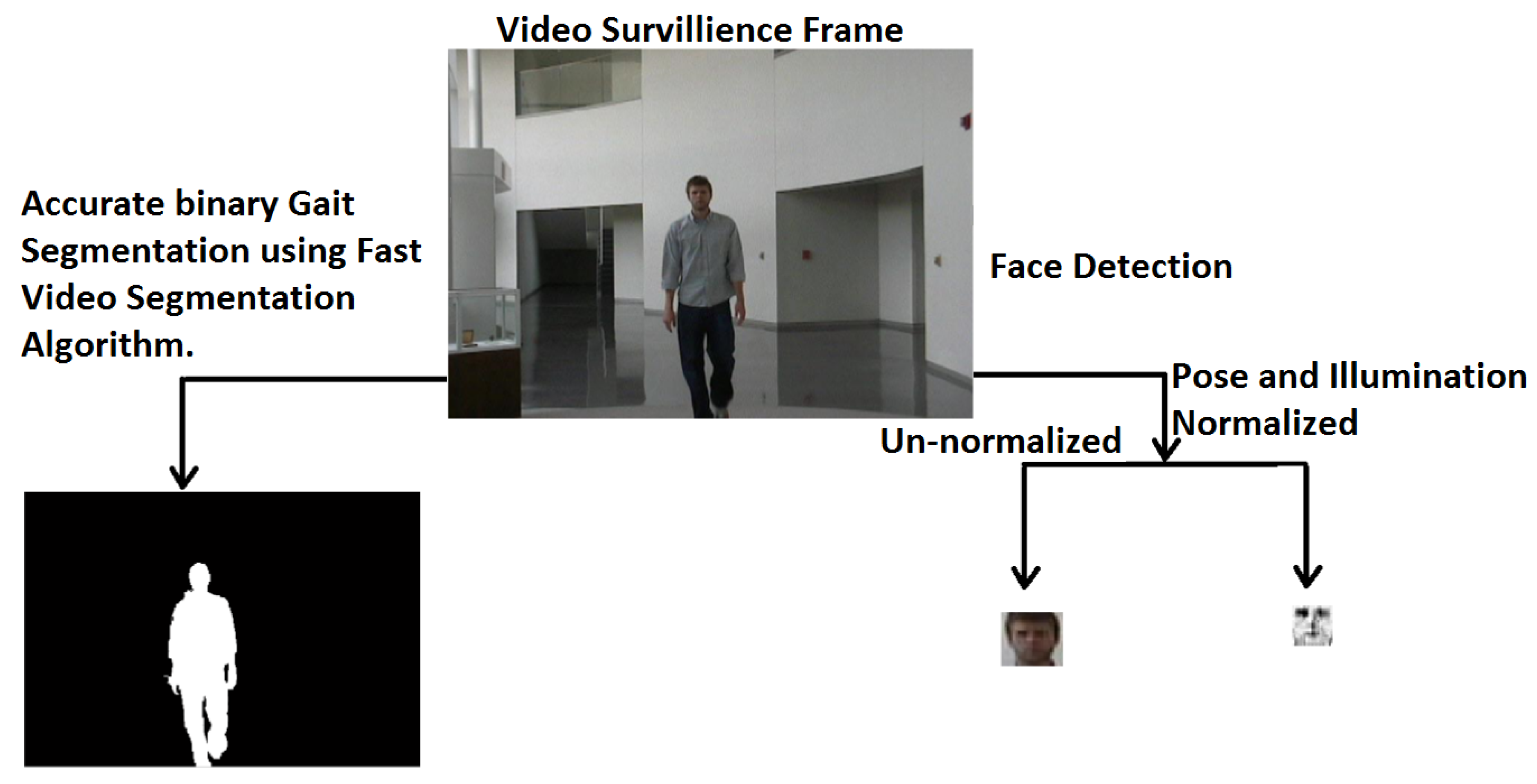
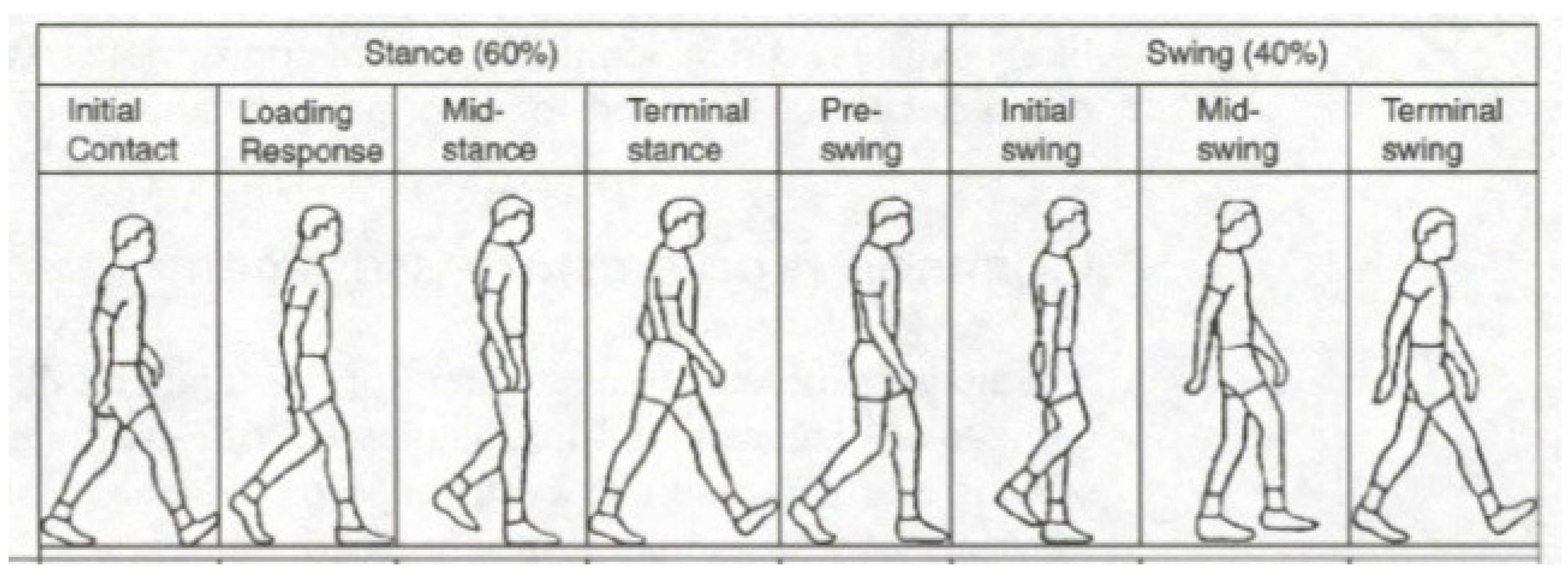
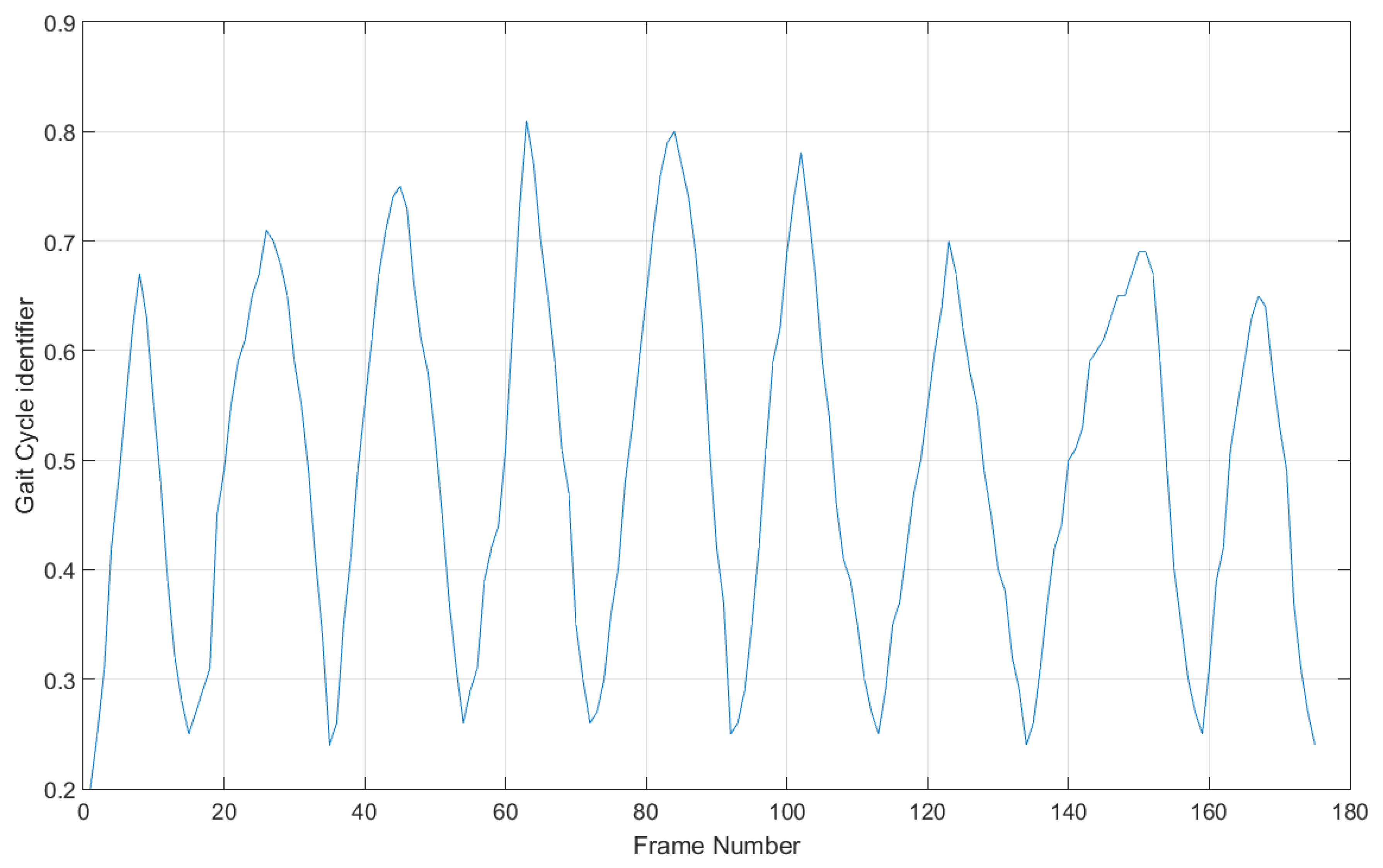
3.1. Gait Cycle Identification Using Frontal Gait
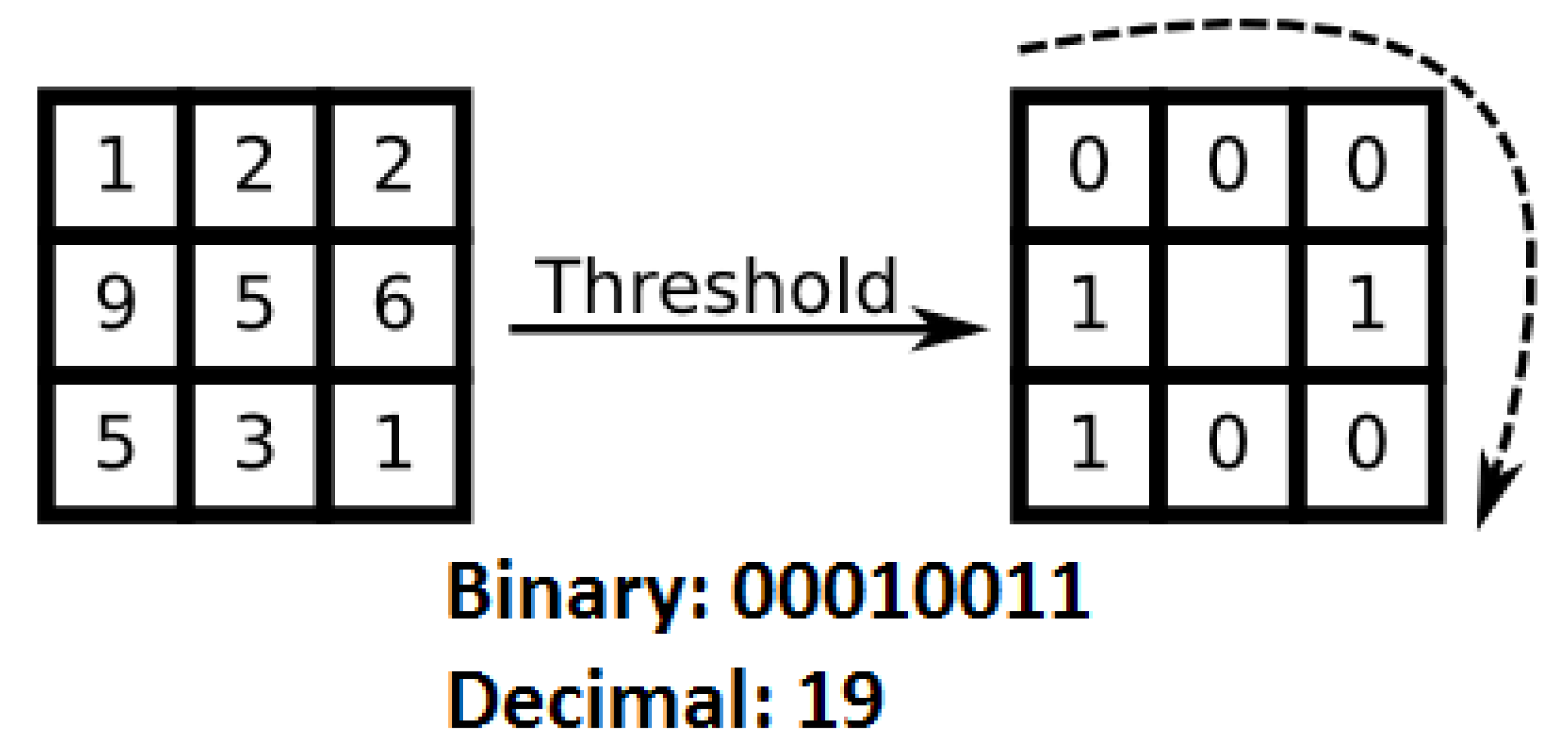
3.1.1. Gait Feature Representation
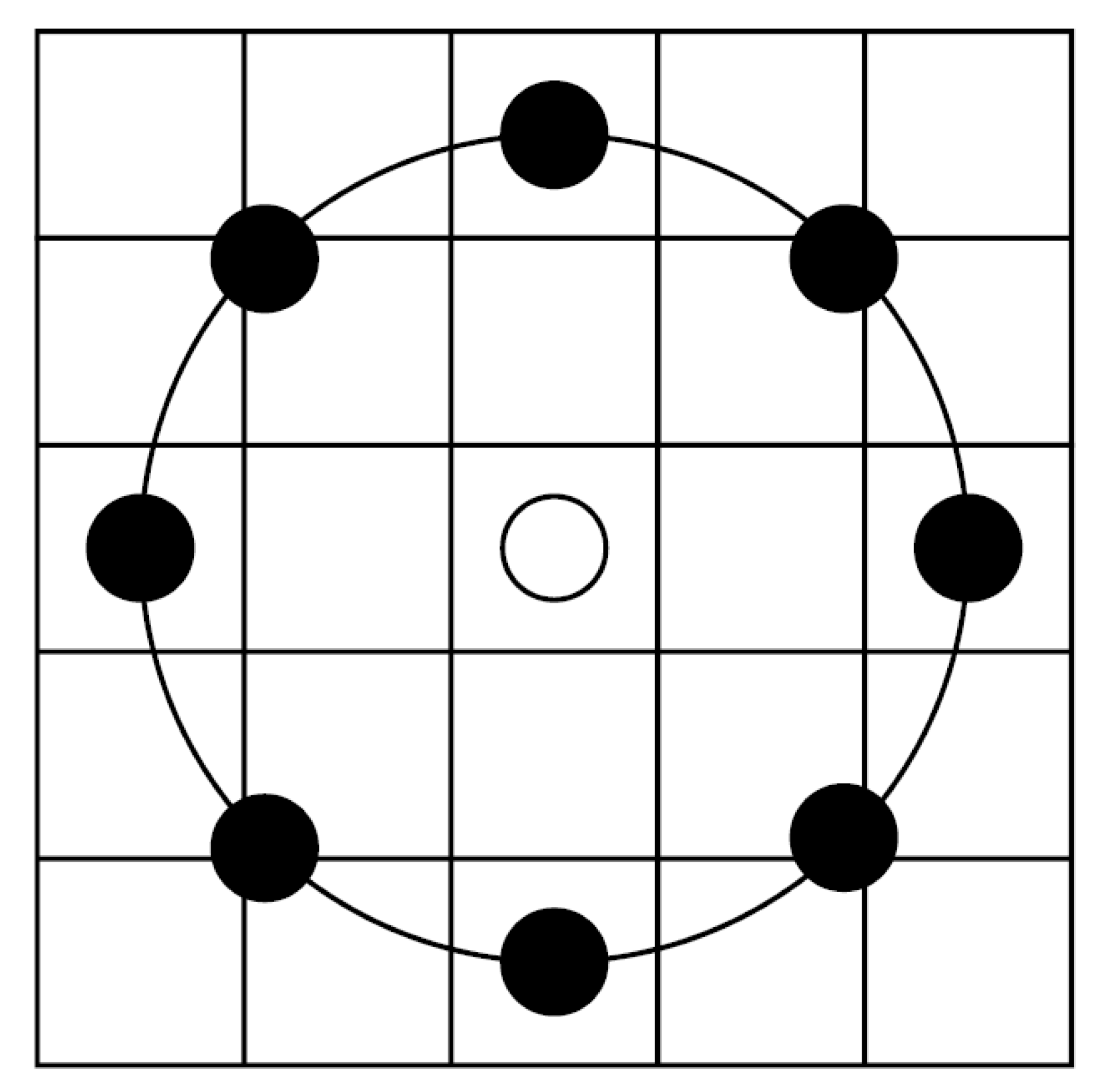
3.1.2. Three Dimensional Moments from the Spatio-Temporal Gait Energy Image
3.2. Low-Resolution Face Feature Representation
3.2.1. Super-Resolution
3.2.2. Illumination and Pose Invariance
3.2.3. Registration and Synthesizing Low-Resolution Face Images
3.2.4. Feature Extraction
4. Experimental Results
4.1. FOCS Dataset
4.2. Experimental Setup
4.2.1. Frontal Gait Recognition
4.2.2. Low-Resolution Face Recognition
| Algorithm 1 Low-Resolution Face Recognition |
1. Detect faces in the video surveillance frames. 2. Use a Super-resolution technique to obtain High-resolution from the Low-resolution detected face images. 3. Perform illumination and pose normalization. 4. Register the pre-processed and normalized face regions, followed by synthesizing them using Curvelet and Inverse Curvelet transformations. 5. Extract Local Binary Pattern (LBP) and Gabor features from the synthesized image. 6. Perform face recognition using the extracted features. |
- (1)
- LR face recognition without any super-resolution pre-processing technique.
- (2)
- LR face recognition using Bicubic Interploation super-resolution pre-processing technique.
- (3)
- LR face recognition using Sparse super-resolution [17] pre-processing technique.
4.3. Multimodal Recognition Accuracy
4.4. Parameter Selection for the CNN Super Resolution
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shakhnarovich, G.; Darrell, T. On probabilistic combination of face and gait cues for identification. In Proceedings of the Fifth IEEE International Conference on Automatic Face and Gesture Recognition, Washington, DC, USA, 21–21 May 2002; pp. 169–174. [Google Scholar]
- Kale, A.; Roychowdhury, A.K.; Chellappa, R. Fusion of gait and face for human identification. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’04), Montreal, QC, Canada, 17–21 May 2004; Volume 5, p. V–901–4. [Google Scholar]
- Wang, L.; Tan, T.; Hu, W.; Ning, H. Automatic gait recognition based on statistical shape analysis. IEEE Trans. Image Process. 2003, 12, 1120–1131. [Google Scholar] [CrossRef]
- Chen, S.; Gao, Y. An Invariant Appearance Model for Gait Recognition. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo, Beijing International Convention Center, Beijing, China, 2–5 July 2007; pp. 1375–1378. [Google Scholar]
- Bronstein, A.; Bronstein, M.; Kimmel, R. Three-Dimensional Face Recognition. Int. J. Comput. Vis. 2005, 64, 5–30. [Google Scholar] [CrossRef]
- Etemad, K.; Chellappa, R. Discriminant analysis for recognition of human face images. In Audio- and Video-Based Biometric Person Authentication; Lecture Notes in Computer Science; Springer: Berlin, Germany, 1997; pp. 125–142. [Google Scholar]
- Lu, C.; Tang, X. Surpassing Human-Level Face Verification Performance on LFW with GaussianFace. arXiv 2014, arXiv:1404.3840. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1701–1708. [Google Scholar]
- Turk, M.; Pentland, A. Eigenfaces for recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef]
- Wang, Z.; Miao, Z.; Jonathan Wu, Q.M.; Wan, Y.; Tang, Z. Low-resolution face recognition: A review. Vis. Comput. 2014, 30, 359–386. [Google Scholar] [CrossRef]
- Wilman, W.W.Z.; Yuen, P.C. Very low resolution face recognition problem. In Proceedings of the 2010 Fourth IEEE International Conference on Biometrics, Theory Applications and Systems (BTAS), Washington, DC, USA, 27–29 September 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Sarkar, S.; Phillips, P.J.; Liu, Z.; Vega, I.R.; Grother, P.; Bowyer, K.W. The humanID gait challenge problem: Data sets, performance, and analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 162–177. [Google Scholar] [CrossRef]
- Man, J.; Bhanu, B. Individual recognition using gait energy image. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 316–322. [Google Scholar]
- Kusakunniran, W.; Wu, Q.; Li, H.; Zhang, J. Multiple views gait recognition using View Transformation Model based on optimized Gait Energy Image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops (ICCV Workshops), Kyoto, Japan, 27 September–4 October 2009; pp. 1058–1064. [Google Scholar]
- Zheng, S.; Zhang, J.; Huang, K.; He, R.; Tan, T. Robust view transformation model for gait recognition. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2073–2076. [Google Scholar]
- Ren, C.X.; Dai, D.Q.; Yan, H. Coupled Kernel Embedding for Low-Resolution Face Image Recognition. IEEE Trans. Image Process. 2012, 21, 3770–3783. [Google Scholar] [PubMed]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image Super-Resolution Via Sparse Representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef]
- Shekhar, S.; Patel, V.M.; Chellappa, R. Synthesis-based recognition of low resolution faces. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–6. [Google Scholar]
- Yu, J.; Bhanu, B. Super-resolution Restoration of Facial Images in Video. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 4, pp. 342–345. [Google Scholar]
- Jia, K.; Gong, S. Generalized Face Super-Resolution. IEEE Trans. Image Process. 2008, 17, 873–886. [Google Scholar]
- Lee, T.K.M.; Belkhatir, M.; Sanei, S. A comprehensive review of past and present vision-based techniques for gait recognition. Multimed. Tools Appl. 2014, 72, 2833–2869. [Google Scholar] [CrossRef]
- Lee, L.; Grimson, W.E.L. Gait analysis for recognition and classification. In Proceedings of the Fifth IEEE International Conference on Automatic Face and Gesture Recognition, Washington, DC, USA, 21 May 2002; pp. 148–155. [Google Scholar]
- Wang, L.; Tan, T.; Ning, H.; Hu, W. Silhouette analysis-based gait recognition for human identification. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1505–1518. [Google Scholar] [CrossRef]
- Davis, J.W.; Bobick, A.F. The representation and recognition of human movement using temporal templates. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 928–934. [Google Scholar]
- Goffredo, M.; Carter, J.N.; Nixon, M.S. Front-view Gait Recognition. In Proceedings of the 2nd IEEE International Conference on Biometrics: Theory, Applications and Systems, BTAS 2008, Washington, DC, USA, 29 September–1 October 2008; pp. 1–6. [Google Scholar]
- Lu, H.; Wang, J.; Plataniotis, K.N. Chapter A Review on Face and Gait Recognition: System, Data and Algorithms. In Advanced Signal Processing: Theory and Implementation for Sonar, Radar, and Non-Invasive Medical Diagnostic Systems, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2009; pp. 303–325. [Google Scholar]
- Zhou, X.; Bhanu, B. Feature Fusion of Face and Gait for Human Recognition at a Distance in Video. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 4, pp. 529–532. [Google Scholar]
- Xin, G.; Kate, S.-M.; Liang, W.; Ming, L.; Qiang, W. Context-aware fusion: A case study on fusion of gait and face for human identification in video. Pattern Recognit. 2010, 43, 3660–3673. [Google Scholar]
- Papazoglou, A.; Ferrari, V. Fast Object Segmentation in Unconstrained Video. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1777–1784. [Google Scholar]
- Brox, T.; Malik, J. Chapter Object Segmentation by Long Term Analysis of Point Trajectories. In Proceedings of the 11th European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 282–295. [Google Scholar]
- Sundaram, N.; Brox, T.; Keutzer, K. Dense Point Trajectories by GPU-Accelerated Large Displacement Optical Flow; Technical Report UCB/EECS-2010-104; EECS Department, University of California: Berkeley, CA, USA, 2010. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. GrabCut -Interactive Foreground Extraction using Iterated Graph Cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Lee, Y.J.; Kim, J.; Grauman, K. Key-segments for Video Object Segmentation. In ICCV ’11, Proceedings of the 2011 International Conference on Computer Vision; IEEE Computer Society: Washington, DC, USA, 2011; pp. 1995–2002. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 511–518. [Google Scholar]
- Phillips, P.; Moon, H.; Rizvi, S.; Rauss, P. The FERET evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1090–1104. [Google Scholar] [CrossRef]
- Murray, M.P.; Drought, A.B.; Kory, R.C. Walking Patterns of Normal Men. J. Bone Jt. Surg. 1964, 46, 335–360. [Google Scholar] [CrossRef]
- Perry, J.; Burnfield, J.M. Gait Analysis: Normal and Pathological Function; Slack Incorporated: West Deptford Township, NJ, USA, 2010. [Google Scholar]
- Little, J.J.; Boyd, J.E. Recognizing People by Their Gait: The Shape of Motion. Videre J. Comput. Vis. Res. 1998, 1, 1–32. [Google Scholar]
- Stephenson, J.L.; Serres, S.J.D.; Lamontagne, A. The effect of arm movements on the lower limb during gait after a stroke. Gait Posture 2010, 31, 109–115. [Google Scholar] [CrossRef] [PubMed]
- Jackson, K.M.; Joseph, J.; Wyard, S.J. The upper limbs during human walking. part 2: Function. Electromyogr. Clin. Neurophysiol. 1983, 23, 435–446. [Google Scholar] [PubMed]
- Lee, T.K.M.; Belkhatir, M.; Lee, P.A.; Sanei, S. Fronto-normal gait incorporating accurate practical looming compensation. In Proceedings of the 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Flusser, J.; Suk, T. Pattern recognition by affine moment invariants. Pattern Recognit. 1993, 26, 167–174. [Google Scholar] [CrossRef]
- Hu, M. Visual pattern recognition by moment invariants. IRE Trans. Inf. Theory 1962, 8, 179–187. [Google Scholar]
- Maity, S.; Abdel-Mottaleb, M. 3D Ear Segmentation and Classification Through Indexing. IEEE Trans. Inf. Forensics Secur. 2015, 10, 423–435. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Wang, H.; Li, S.Z.; Wang, Y.; Zhang, J. Self quotient image for face recognition. In ICIP ’04, Proceedings of the 2004 International Conference on Image Processing, Singapore, 24–27 October 2004; Volume 2, pp. 1397–1400.
- Zhang, Z.; Ganesh, A.; Liang, X.; Ma, Y. TILT: Transform Invariant Low-Rank Textures. Int. J. Comput. Vis. 2012, 99, 1–24. [Google Scholar] [CrossRef]
- Boom, B.J.; Speeuwers, L.J.; Veldhuis, R.N.J. Subspace-Based Holistic Registration for Low-Resolution Facial Images. EURASIP J. Adv. Signal Process. 2010, 2010, 14. [Google Scholar] [CrossRef]
- Mitchell, H.B. Image Fusion: Theories, Techniques and Applications; Springer: Berlin, Germany, 2010. [Google Scholar]
- Xu, X.; Liu, W.Q.; Li, L. Low Resolution Face Recognition in Surveillance Systems. J. Comput. Commun. 2014, 2, 70–77. [Google Scholar]
- Candès, E.; Demanet, L.; Donoho, D.; Ying, L. Fast Discrete Curvelet Transforms. Multiscale Model. Simul. 2006, 5, 861–899. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face Description with Local Binary Patterns: Application to Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef]
- Liu, C.; Wechsler, H. Gabor feature based classification using the enhanced fisher linear discriminant model for face recognition. IEEE Trans. Image Process. 2002, 11, 467–476. [Google Scholar] [PubMed]
- Urolagin, S.; Prema, K.V.; Subba Reddy, N. Rotation invariant object recognition using Gabor filters. In Proceedings of the International Conference on Industrial and Information Systems, 2010s of the International Conference on Industrial and Information Systems, Mangalore, India, 29 July–1 August 2010; pp. 404–407. [Google Scholar]
- Yang, M.; Zhang, L. Gabor Feature Based Sparse Representation for Face Recognition with Gabor Occlusion Dictionary. In Proceedings of the European Conference on Computer Vision; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2010; Volume 6316, pp. 448–461. [Google Scholar]
- O’Toole, A.J.; Harms, J.; Snow, S.L.; Hurst, D.R.; Pappas, M.R.; Ayyad, J.H.; Abdi, H. A video database of moving faces and people. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 812–816. [Google Scholar] [CrossRef] [PubMed]
- Ross, A.A.; Nandakumar, K.; Jain, A.K. Handbook of Multibiometrics; Springer: Berlin, Germany, 2006. [Google Scholar]
- Hampel, F.R.; Ronchetti, E.M.; Rousseeuw, P.J.; Stahel, W.A. Robust Statistics: The Approach Based on Influence Functions (Wiley Series in Probability and Statistics); Wiley-Interscience, John Wiley and Sons Inc.: Hoboken, NJ, USA, 2005. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Vectors Used | Rank-1 Accuracy |
|---|---|
| 3D Moments | 88.62% (109 out of 123) |
| Average movement speed | 69.11% (85 out of 123) |
| 3D Moments and Average movement speed | 93.5% (115 out of 123) |
| Method | Rank-1 Frontal Gait Recognition Accuracy |
|---|---|
| Wang et al. [3] | 69.11% |
| Chen et al. [4] | 89.43% |
| Goffredo et al. [26] | 91.06% |
| This Work | 93.50% |
| Features Used | Super Resolution Technique | Rank-1 Accuracy |
|---|---|---|
| LBP | None | 72.36% (89 out of 123) |
| Gabor | None | 70.73% (87 out of 123) |
| LBP | Bicubic | 73.98% (91 out of 123) |
| Gabor | Bicubic | 71.54% (88 out of 123) |
| LBP | Sparse | 75.61% (93 out of 123) |
| Gabor | Sparse | 72.36% (89 out of 123) |
| LBP | SRCNN | 82.92% (102 out of 123) |
| Gabor | SRCNN | 79.67% (98 out of 123) |
| Fusion Rule | Rank-1 Accuracy |
|---|---|
| Sum Rule | 95.9% (118 out of 123) |
| Max Rule | 94.3% (116 out of 123) |
| Product Rule | 93.5% (115 out of 123) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maity, S.; Abdel-Mottaleb, M.; Asfour, S.S. Multimodal Low Resolution Face and Frontal Gait Recognition from Surveillance Video. Electronics 2021, 10, 1013. https://doi.org/10.3390/electronics10091013
Maity S, Abdel-Mottaleb M, Asfour SS. Multimodal Low Resolution Face and Frontal Gait Recognition from Surveillance Video. Electronics. 2021; 10(9):1013. https://doi.org/10.3390/electronics10091013
Chicago/Turabian StyleMaity, Sayan, Mohamed Abdel-Mottaleb, and Shihab S. Asfour. 2021. "Multimodal Low Resolution Face and Frontal Gait Recognition from Surveillance Video" Electronics 10, no. 9: 1013. https://doi.org/10.3390/electronics10091013
APA StyleMaity, S., Abdel-Mottaleb, M., & Asfour, S. S. (2021). Multimodal Low Resolution Face and Frontal Gait Recognition from Surveillance Video. Electronics, 10(9), 1013. https://doi.org/10.3390/electronics10091013