1. Introduction
Predicting the stock market is an intricate challenge for investors, financial analysts, and researchers owing to its pivotal role in the global economy and its profound influence on individuals’ lives [
1,
2]. Consequently, researchers have made extensive endeavors to improve stock market prediction through the utilization of various theories and employing machine learning methods or statistical modeling relying on diverse data sources [
3]. The majority of previous studies have primarily relied on utilizing historical stock market data from platforms like Yahoo Finance. However, this approach poses significant limitations and shortcomings. It often fails to incorporate crucial hidden factors such as economic indicators, political events, investor sentiment, and market psychology [
4,
5]. As a result, this approach has exhibited considerable inaccuracy when attempting to forecast stock prices [
6]. Thus, it is crucial to consider a wider range of factors and integrate alternative data sources such as Facebook, Twitter, now known as X, and news to improve the performance of stock market predictions [
2].
Recently, the pervasive adoption of social media has facilitated the widespread dissemination of user experiences and feedback. This emerging trend has prompted researchers to investigate the utilization of social media as a valuable source for analyzing human sentiment concerning stock prices and capturing public opinions regarding specific companies or organizations. The incorporation of social media data into predictive models offers promising prospects for enhancing the accuracy and efficacy of stock market predictions [
7].
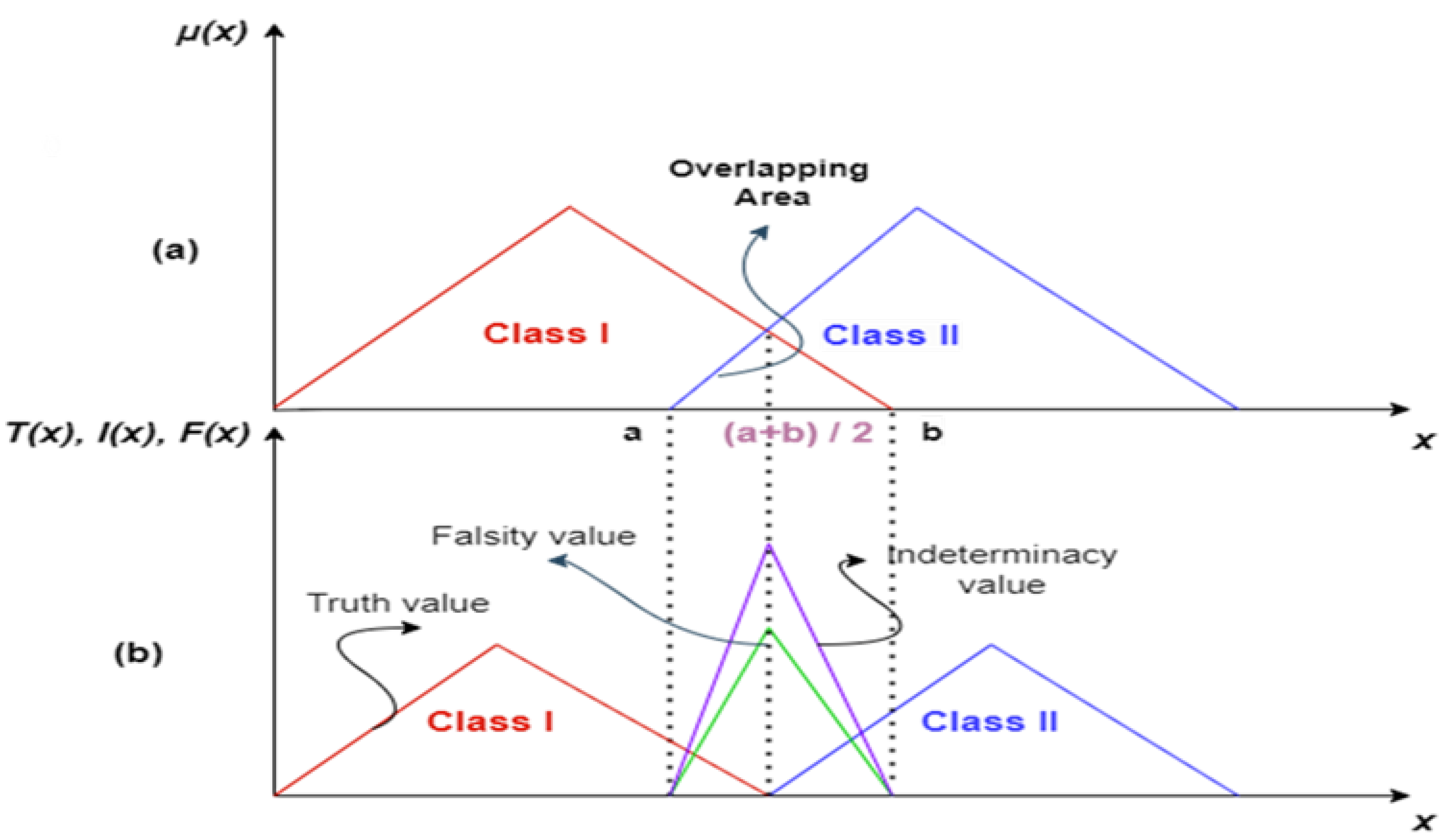
Several research studies have primarily concentrated on examining the influence of sentiment analysis (SA) on stock market forecasting. However, these studies often overlook the presence of uncertainty or indeterminate data, which can significantly impact the accuracy of SA results. Neglecting such uncertainties can consequently affect the reliability and effectiveness of stock market predictions [
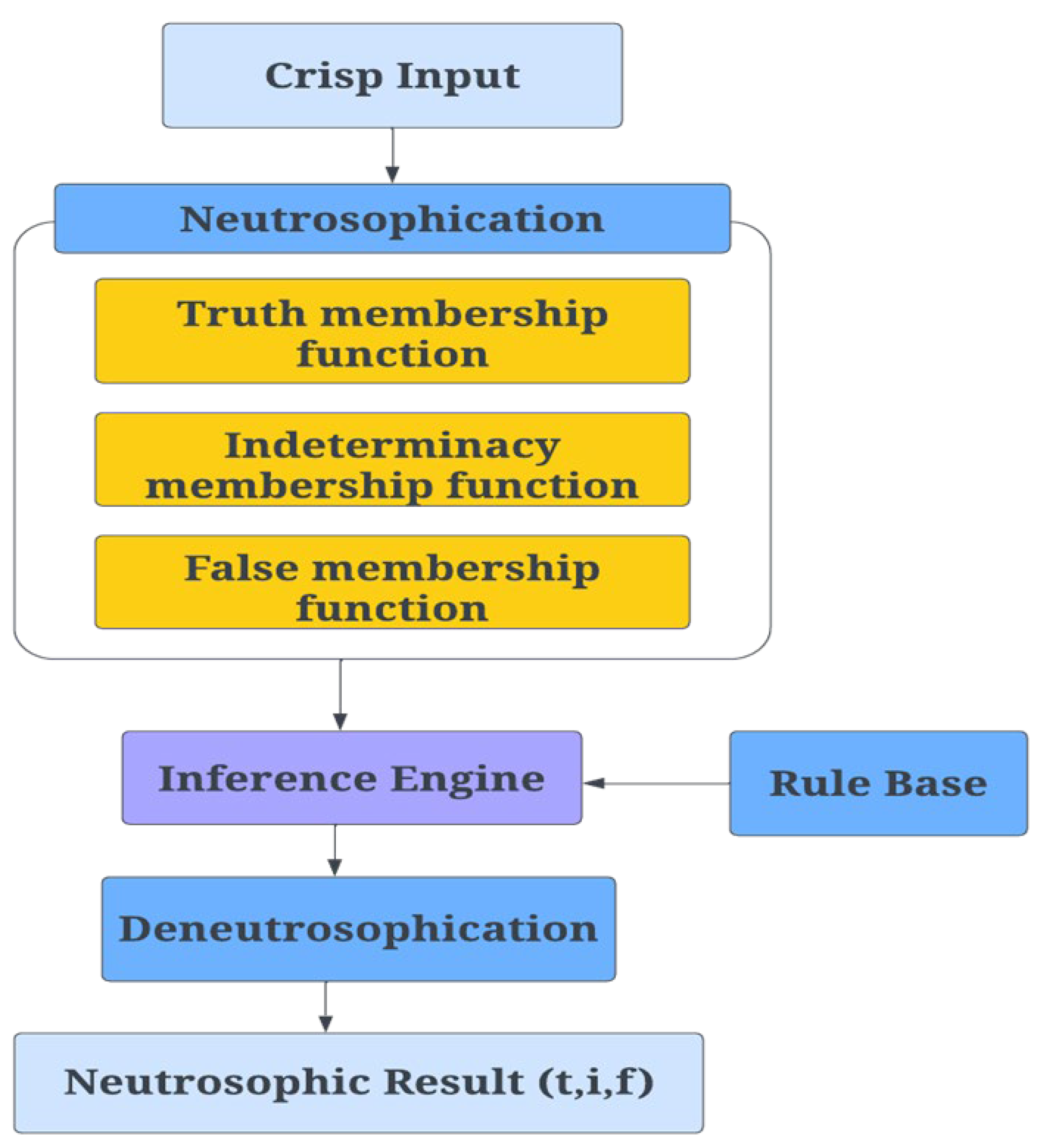
8]. The neutrosophic concept, representing a broader perspective of fuzzy logic [
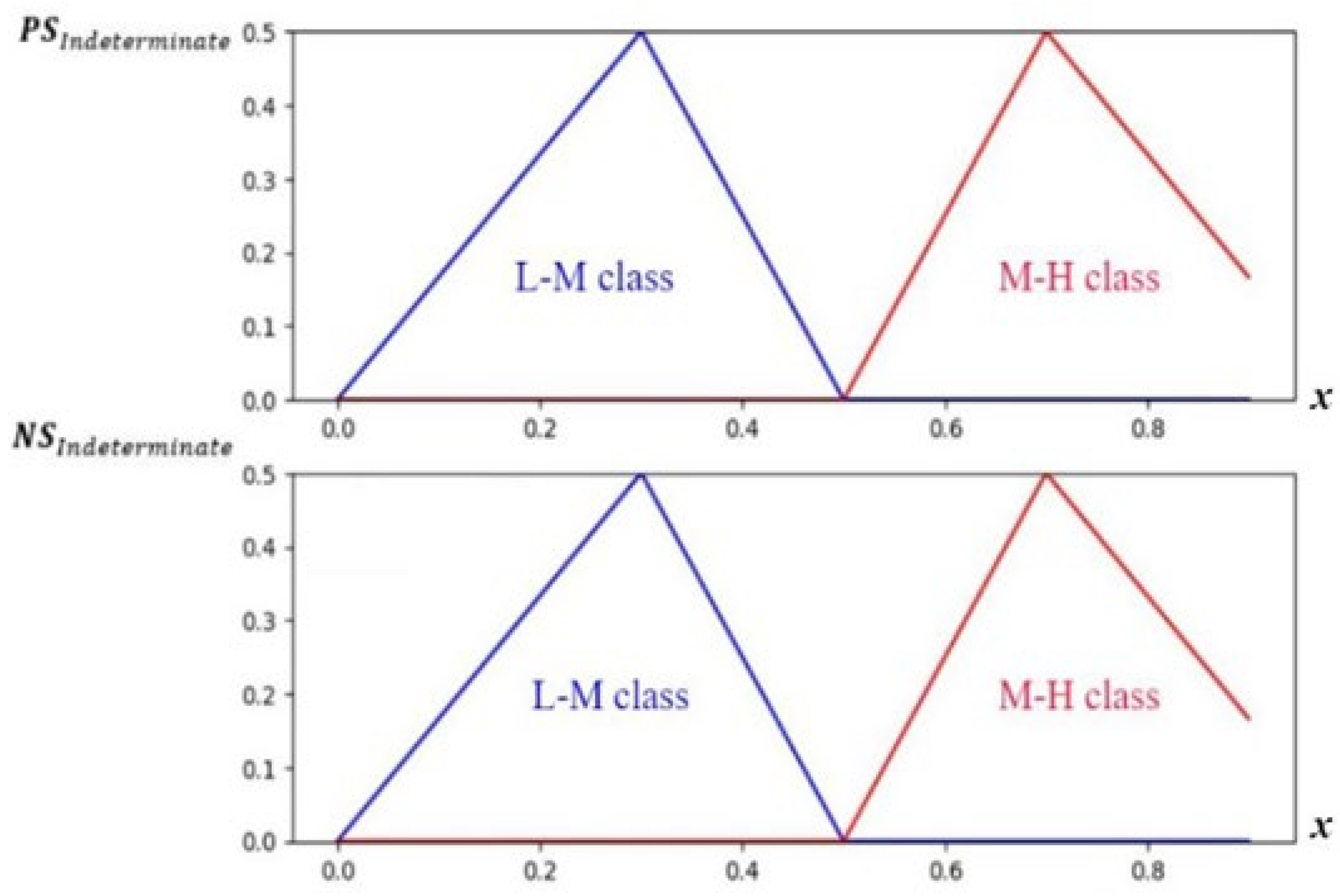
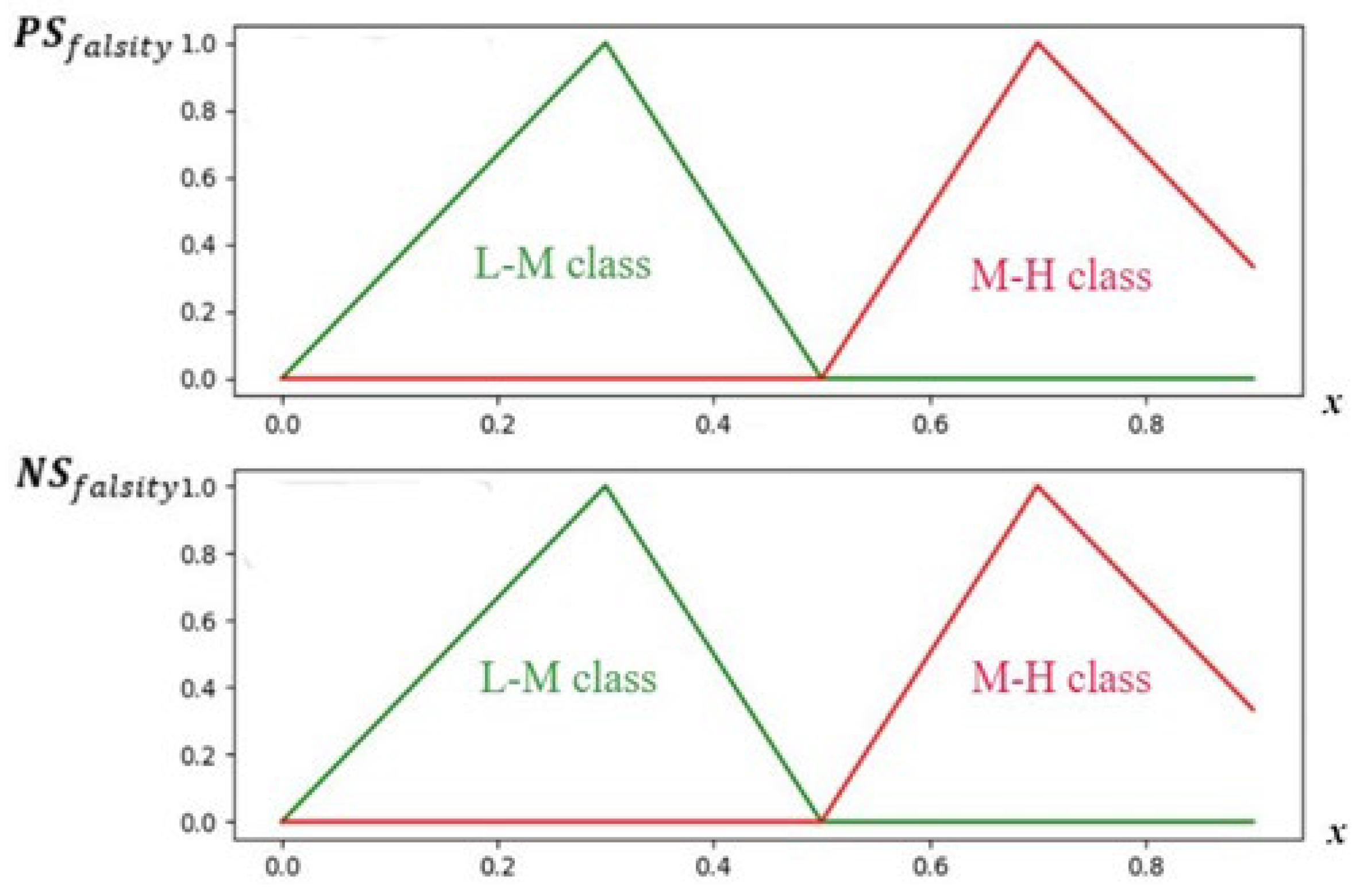
9], has been introduced to tackle uncertainty and indeterminacy. It revolves around three membership functions, namely truth, indeterminacy, and falsity. These functions play a crucial role in representing and analyzing ambiguous and uncertain information [
10,
11].
1.1. Problem Statement
The financial market is an extremely complex domain, with the primary objective of accurately predicting stock movements. This precision is of the utmost importance as it directly influences the confidence of investors in their critical decisions regarding buying, holding, or selling stocks amid the inherent risks in the market. Predicting stock price movements remains a challenge despite extensive research efforts in forecasting using historical data and social media data reflecting user opinions about stocks and companies. However, it often lacks challenges, especially regarding the uncertainty in social media data, particularly the use of ambiguous words and multiple meanings. The presence of uncertainty in the data results in an inaccurate classification of the tweets, consequently leading to an inaccurate predictive model.
1.2. Motivation
The ability to accurately predict stock market movements has enormous benefits for investors and financial institutions. It can guide the investment decision-making process regarding buying or selling shares in response to price fluctuations. This can, in addition to reducing risk, promote financial stability and market efficiency. The stock market exhibits considerable volatility as it is influenced by various factors, including the impact of opinions and perceptions expressed on social media by users. However, one of the challenges of using social media is that data are sometimes uncertain and ambiguous. This motivates our research, which aims to improve stock movement prediction results by improving sentiment analysis results to tackle the challenge of data uncertainty in social media. This research will cover in detail how to detect data uncertainty and ambiguous opinions and how to resolve them using NL.
1.3. Contribution
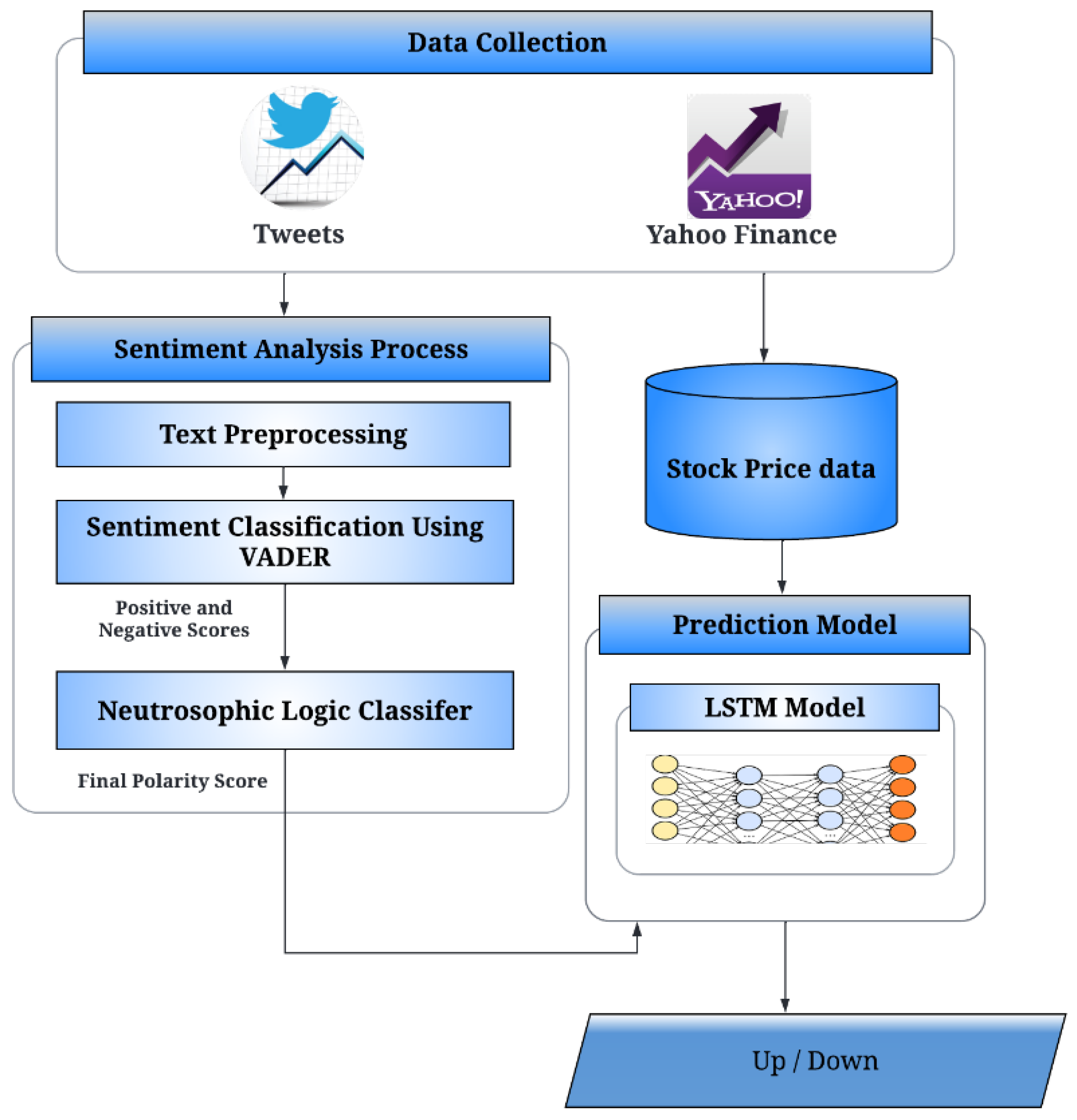
The objectives of this paper are to enhance the accuracy of stock market movement prediction by integrating SA of public opinion from Twitter, and historical stock market data. This enhancement will be achieved by improving the sentiment analysis results, specifically designed to handle the uncertain and ambiguous data gathered from Twitter, about various companies and people’s viewpoints regarding them. To address this challenge, we employ neutrosophic logic (NL) [
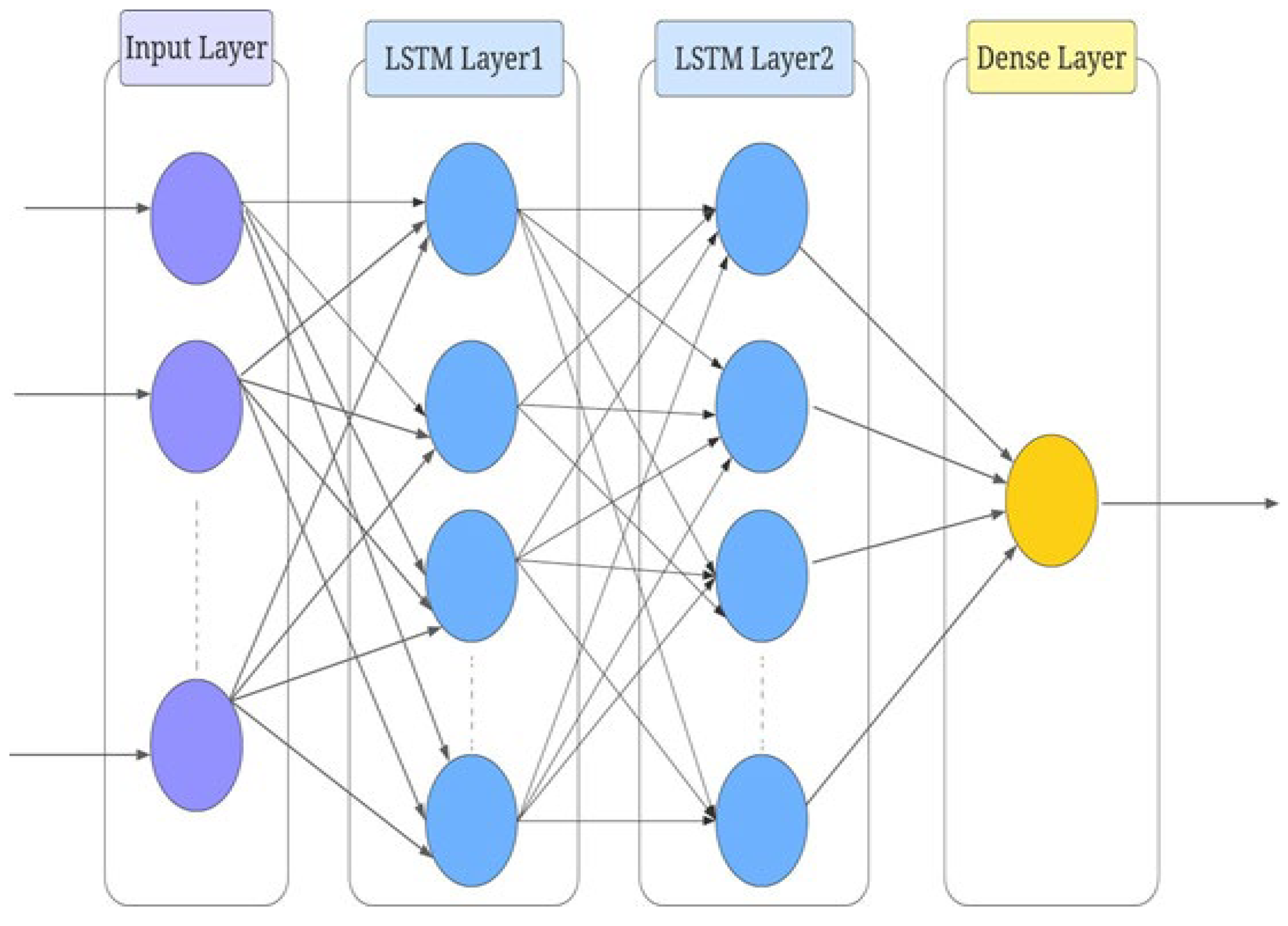
12]. Furthermore, the output of sentiment analysis, alongside historical stock market data collected from Yahoo Finance, is incorporated into a model known as long short-term memory (LSTM) with the utmost accuracy to forecast the stock market movement. LSTM was chosen due to its capability to retain information over extended periods and demonstrate efficiency as a predictive model [
13]. The core contributions of this paper are as follows:
Proposal of a sentiment classifier based on NL to handle the ambiguity and uncertainty present in the data collected from Twitter, particularly concerning individuals’ viewpoints regarding companies and stocks.
Proposal of an enhanced prediction model that integrates the outcomes of sentiment classification and historical stock market data through the utilization of the LSTM model.
The proposed model utilizes a benchmark dataset known as StockNet [
14] to evaluate the efficiency of our proposed model compared to the other models.
The results of this study yielded a predictive accuracy of 78.48% in anticipating fluctuations in stock prices when utilizing the StockNet dataset [
14]. Furthermore, this achievement surpassed the accuracy rate of prior studies that employed the same dataset.
The rest of this paper is structured as follows:
Section 2 describes the related works of stock market prediction and NL.
Section 3 focuses on the proposed model in detail.
Section 4 illustrates the experimental results. The conclusion and future work are reported in
Section 5.
2. Related Work
Predicting stock price trends has consistently captivated the interest of researchers, prompting investigations using various methodologies. Past endeavors in this field can be classified into two approaches: the analytical approach and the sentiment analysis approach. Within the analytical approach, the focus is on gathering historical stock data from various financial sources like Yahoo Finance and Google Finance. Conversely, the sentiment analysis approach is centered around users’ reviews related to a specific stock or company, which are shared on diverse online platforms such as Facebook and Twitter [
15]. This section provides a comprehensive literature review that primarily focuses on previous studies adopting the sentiment analysis approach. Moreover, we examine the influence of different techniques employed to enhance the accuracy of stock market forecasting and elucidate the correlation between stock market prices and social media or financial news [
16]. In 2016, Pagolu et al. [
17] tried to determine a correlation between the stock prices of Microsoft and public sentiments in tweets about that company to forecast the stock price for the next day. Two different methods, namely Word2vec and N-gram, were employed to calculate the polarity of each tweet. The accuracy of the polarity classification was approximately 70%, and the correlation between stock prices and sentiment was approximately 71.82%. However, it is worth noting that their study was limited by a small dataset comprising only 3216 tweets used for training the model.
In 2018, Xu et al. [
14] suggested a deep generative approach, known as StockNet, for predicting stock market movement employing Twitter data and historical stock prices. This neural network architecture demonstrated a superior performance compared to prior works and incorporated recurrent, continuous latent variables to enhance the handling of randomness. However, the achieved accuracy was limited to approximately 58.23% due to the dataset’s limited size. Another significant study in this direction was performed in 2019, where Xu et al. [
18] suggested an attention-based LSTM approach that integrated tweets collected from StockTwits, historical data collected from Yahoo Finance, and technical indicators such as Average Directional Movement Index, Simple Moving Average, and Exponential Moving Average to enhance its effectiveness. The study primarily focused on comparing the performance of the attention-based LSTM approach with that of a traditional LSTM. The results of the model outperformed the traditional LSTM, achieving an accuracy rate of approximately 64%. However, it is important to note that this accuracy rate is still deemed insufficient due to the dataset’s limited size, and more stocks and technical indicators need to be collected.
In 2020, Maqsood et al. [
19] applied three machine learning algorithms, namely linear regression, support vector regression, and deep learning, to forecast stock market trends for the four primary stocks from the US, Turkey, Pakistan, and Hong Kong and evaluate the efficacy of each model. Each model incorporated Twitter data related to eight significant events to augment the accuracy of stock market predictions. The authors concluded that not all events have a direct influence on stock market prediction. Nevertheless, noteworthy local events possess the potential to impact the effectiveness of prediction algorithms. One of the disadvantages is that it was determined that the sentiment analysis technique (i.e., SentiWordNet) employed in their study was overly simplistic to establish comprehensive conclusions regarding this statement. In the same year, Gupta et al. [
20] demonstrated the correlation between daily sentiments extracted from StockTwits and the corresponding daily movement of stock prices. Sentiment analysis was conducted using machine learning methods (SVM, naïve Bayes, and logistic regression) and feature extraction techniques (bigram, bag of words, trigram, LSA, and TF-IDF). The fusion of TF-IDF and logistic regression achieved the highest accuracy, ranging from 75% to 85%. However, one study drawback was that the authors focused only on positive and negative sentiments while disregarding neutral sentiments.
Sawhney et al. [
21] suggested a model, known as Multipronged Attention Network for Stock Forecasting (MAN-SF), which concurrently assimilates information from Twitter data, historical stock prices, and inter-stock relations for predicting stock market movement. The model leverages a graph neural network to discern relationships among different stocks, allowing it to acquire insights from correlations and interdependencies that impact stock movements. The authors employed the StockNet dataset and performed a comparative analysis of their model against others utilizing the same dataset. MAN-SF outperforms the strongest baselines, StockNet and Adversarial LSTM, demonstrating its superior performance in stock prediction with an accuracy of approximately 60.8%. Nevertheless, it is crucial to highlight that the accuracy rate was considered inadequate because of the dataset’s limitations.
In 2021, Heiden et al. [
13] tried to predict the stock price and investigated the impact of the news on it. They incorporated news sentiment as a feature in an LSTM prediction model, along with historical data. The authors obtained the news from the New York Times and employed a Valence Aware Dictionary and Sentiment Reasoner (VADER) for SA. The results indicated that including news sentiments improves the model’s performance. Furthermore, the model exhibits promising possibilities to predict stock prices for approximately 60 days into the future. One of the disadvantages of the study was the utilization of a limited dataset, potentially leading to less reliable and accurate results.
Ho et al. [
22] proposed a novel multi-channel collaborative network architecture for stock trend prediction. This architecture integrates social media sentiment features extracted from Twitter and candlestick chart features derived from the stock’s historical time series data to capture temporal patterns and price dynamics. The network employs two branches, each employing specific deep-learning techniques. A one-dimensional convolutional neural network is utilized for sentiment classification on the extracted social media features, while two-dimensional convolutional neural networks perform image classification on the transformed candlestick chart data. The experimental results indicate a superior performance when compared to single-network models that rely solely on either candlestick charts or sentiment data. Notably, the proposed model achieved a prediction accuracy of 75.38% for Apple stock.
Another study in this area was achieved in 2022, where Fazlija et al. [
23] demonstrated the use of financial market sentiment data extracted from news articles to predict fluctuations in the Standard & Poor’s 500 stock market returns using sentiment values. The authors discovered that employing the Bidirectional Encoder Representations from Transformers (BERT) model yielded the highest success rate in sentiment classification. Moreover, they devised a random forest classifier technique for forecasting future price movements of the stock market index. The findings of the study demonstrated the significance of incorporating sentiment scores derived from news articles in forecasting the movement of stock prices. A notable limitation of the study is the omission of news data from all companies included in the stock market index.
Cristescu et al. [
24] investigated the potential of SA to enhance the accuracy of the prediction of the stock market price using regression models. VADER was employed for SA based on news articles, and three types of regression models were implemented: cubic, quadratic, and linear regressions. The findings revealed that incorporating SA significantly improved the performance of the nonlinear regression model, evidenced by a superior fit compared to the linear model. Notably, the R-squared value was 0.005 for cubic regression and 0.001 for linear regression, indicating the superior performance of the cubic regression model.
Srijiranon et al. [
25] tried to improve the prediction of the stock market by introducing a hybrid model that integrates three techniques: Principal Component Analysis, Empirical Mode Decomposition (EMD), and LSTM employing the incorporation of historical stock market data and the news. They utilized the Financial Bidirectional Encoder Representations from Transformers (FinBERT) for the SA process. The results indicated that the hybrid model demonstrated a superior performance, and the incorporation of news sentiment analysis enhanced the LSTM model’s predictive capabilities.
Koukaras et al. [
26] emphasized the significance of SA in the enhancement of stock market prediction by employing StockTwits and Twitter data. The authors integrated SA with machine learning and utilized seven machine learning algorithms, including Logistic Regression, Support Vector Machine, Multilayer Perceptron, k-nearest neighbors, naïve Bayes, Decision Tree, and Random Forest. They performed VADER and TextBlob for SA. The findings revealed that optimal results were achieved when employing VADER incorporating the Support Vector Machine with an F-score of 76.3%.
In 2023, Costola et al. [
27] examined the correlation between the stock market and news regarding COVID-19 obtained from the New York Times, Reuters, and MarketWatch news platforms. To conduct SA, the authors employed a BERT model adapted for the financial market domain. The findings of this study revealed a positive relationship between the sentiment score and market returns. However, one limitation of the study is its exclusive focus on three news platforms, neglecting the inclusion of social networks as potential data sources. Nevertheless, none of the aforementioned approaches adequately capture the uncertainties and contradictions present in sentiment data. To tackle the issue of uncertainties in SA, the researchers attempted to leverage NL, aiming to enhance the efficiency of sentiment classification [
28,
29].
Kandasamy et al. [
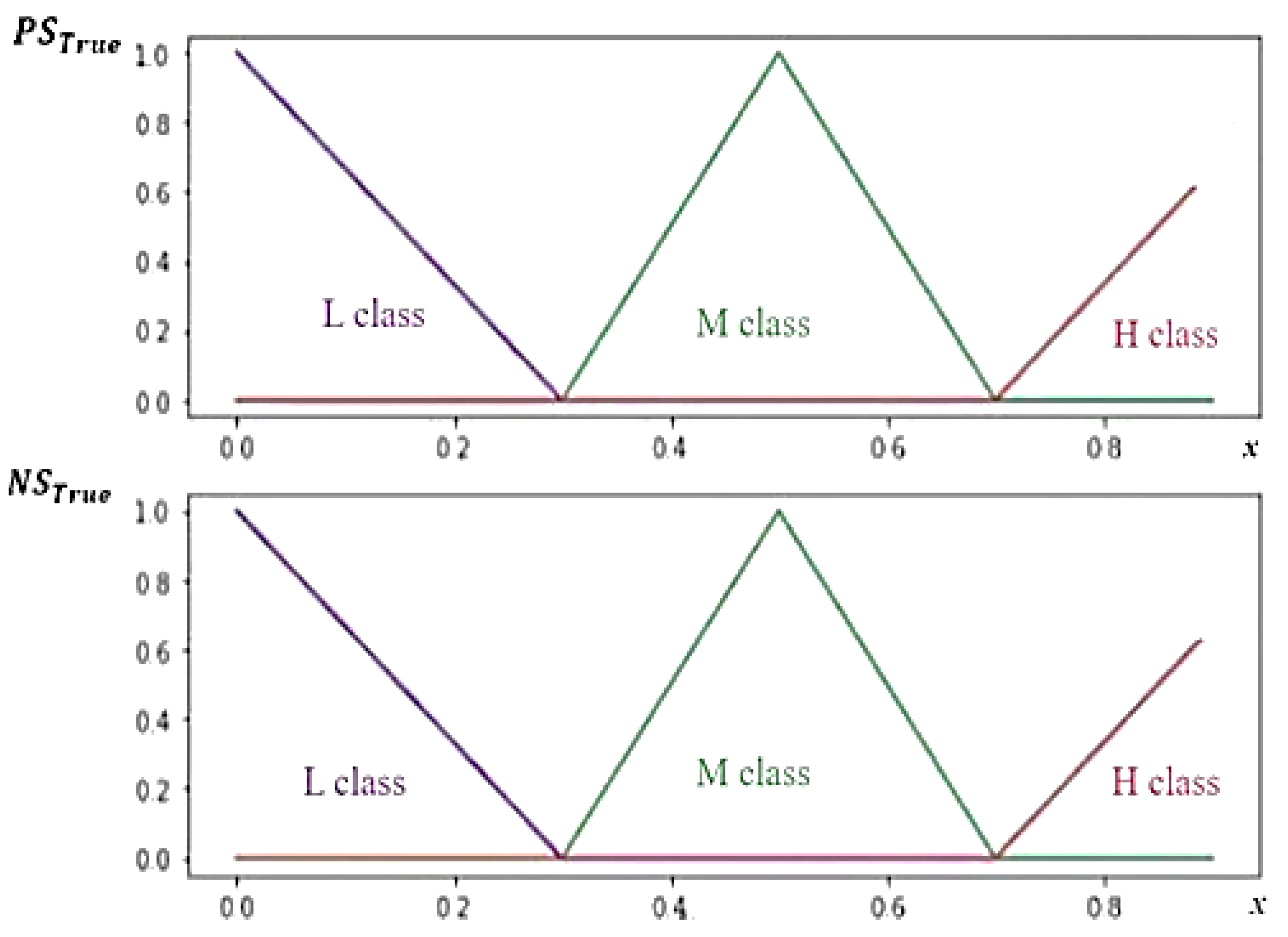
30] emphasized the presence of indeterminacy in the tweets based on the concept of neutrosophy. A dataset containing tweets related to the #MeToo movement was represented with positive, indeterminate, and negative memberships, forming a Set of Neutrosophic Values (SVNS) through the use of the VADER tool. Subsequently, the tweets were clustered and classified into positive, indeterminate, and negative classes. The K-means algorithm was employed to cluster the tuples into three major clusters, with the largest cluster representing the indeterminate tweets. To enhance the accuracy of predicting indeterminate polarity, the data were classified into eight distinct classes. The authors used training data to develop classifiers based on the Support Vector Machine (SVM), and k-nearest neighbor (k-NN) techniques. The study’s findings revealed that the k-NN demonstrated superior performance compared to SVM in effectively classifying the SVNS values.
Kandasamy et al. [
10] introduced a multi-refined neutrosophic set (MRNS), which refined the polarity result into seven classes (i.e., positive, indeterminate, negative, strong positive, indeterminate positive, indeterminate negative, and strong negative). The authors conducted a comparison between MRNS and two other approaches: one utilizing a single-valued neutrosophic set, and the other employing a triple-refined indeterminate neutrosophic set. The results demonstrated that MRNS outperformed the other approaches, providing a superior and more accurate result and effectively handling the inherent indeterminacy present in the data.
Reem et al. [
12] introduced an opinion-mining model tailored for social media to tackle the challenges associated with ambiguous opinion classification. The proposed model incorporates social network analysis utilizing the UCINET tool, which is used for analyzing social network data (the University of California at Irvine Network), neural networks to assess the influence levels of users, and a classifier to combine their influence with the polarity of their texts. The authors evaluate the model using three classifiers (i.e., type-1 fuzzy logic, type-2 fuzzy logic, and NL) to handle the uncertainty in the data. The results demonstrated that NL surpasses the other classifiers in accuracy when dealing with data uncertainty. This highlights the effectiveness of NL in enhancing the performance of opinion mining in the realm of social media.
5. Conclusions and Future Work
In this paper, we introduced a stock market movement prediction model that fuses social media data with historical stock price data. Due to the importance of stock market prediction in recent years and the significant influence of social media on it, the problem of data uncertainty and ambiguity in social media decreases the accuracy of SA results, thereby reducing the accuracy of the stock market forecasting model that utilizes SA. Previous studies did not address this problem. Therefore, the main purpose of our work is to enhance the performance of stock movement prediction by improving the SA results of the tweets through the utilization of NL integrated with a lexicon-based approach capable of handling ambiguous, incomplete, and uncertain data collected from Twitter, particularly in relation to individuals’ perspectives on corporations and stocks and companies. Our proposed model demonstrated its advantage by utilizing the StockNet dataset benchmark and comparing it to models that use this dataset. The proposed model feeds the integrated SA scores with historical stock market data into an LSTM model to foresee the stock movement. Notably, our model distinguishes itself as the first to employ NL in the SA process to predict stock market movement. The findings highlight the importance of incorporating social media data into stock market prediction models because it showed superiority in accuracy and MCC score in comparison to the model without the integration of SA. The proposed model outperformed other models that utilized the same dataset by utilizing NL in the SA process to make the results more compatible with human sentiment and using the integration of historical stock market data with SA results as input factors to our prediction model using LSTM, which resulted in a relatively high accuracy, of around 78.48%, and an MCC score of 0.587. Our investigation into the impact of the NL model in SA on prediction performance revealed that it outperformed the model that utilized TextBlob in the SA. Furthermore, we conducted an examination of the efficiency of employing LSTM in our prediction model, finding that it outperforms models using naïve Bayes, neural networks, and Support Vector Machine. In our model, we also measured the performance of our model based on financial metrics by calculating the return and Sharpe ratio to help investors in trading decisions. We compared our model with baselines and the buy-and-hold strategy. The results showed the superiority of our model in return and Sharpe ratio scores, indicating strong potential for generating excess return and managing risk. In the future, we aim to consider the effect of the variety of user profiles, in terms of whether they are experts, investors, qualified, influencers, or students, on the SA results and seek to use other social media platforms’ data, such as Facebook, LinkedIn, and StockTwits. Additionally, we intend to detect and filter out spam tweets and posts to enhance the sentiment classification performance. Moreover, we aim to utilize a larger benchmark dataset in comparison to our dataset.







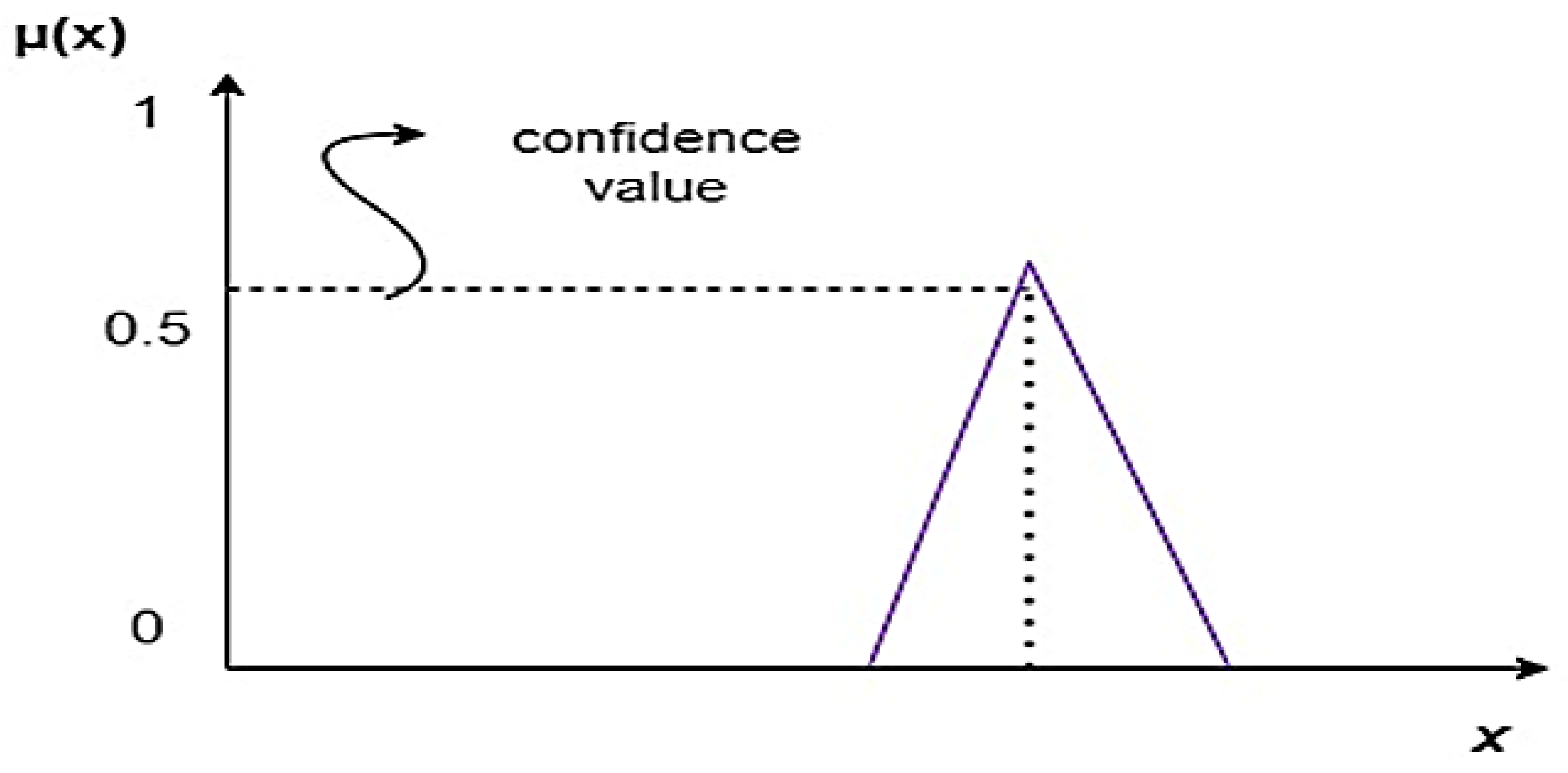

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}