


It’s Not Always about Wide and Deep Models: Click-Through Rate Prediction with a Customer Behavior-Embedding Representation



Abstract
1. Introduction
- Our results show that baseline elements such as pre-trained embeddings and a recurrent neural network such as an LSTM can predict customer click behavior better than modern CTR prediction models, without the need for large end-to-end models.
- In this respect, our approach results in reduced training time, making it more resource efficient.
- Furthermore, task-independent pre-training of embeddings based on customer clickstream data is sufficient to model customers and prevent overfitting.
2. Related Work
2.1. Approaching Click-Through Rate Prediction
2.2. Customer Representation
3. Use Case and Data Description
4. Experiments
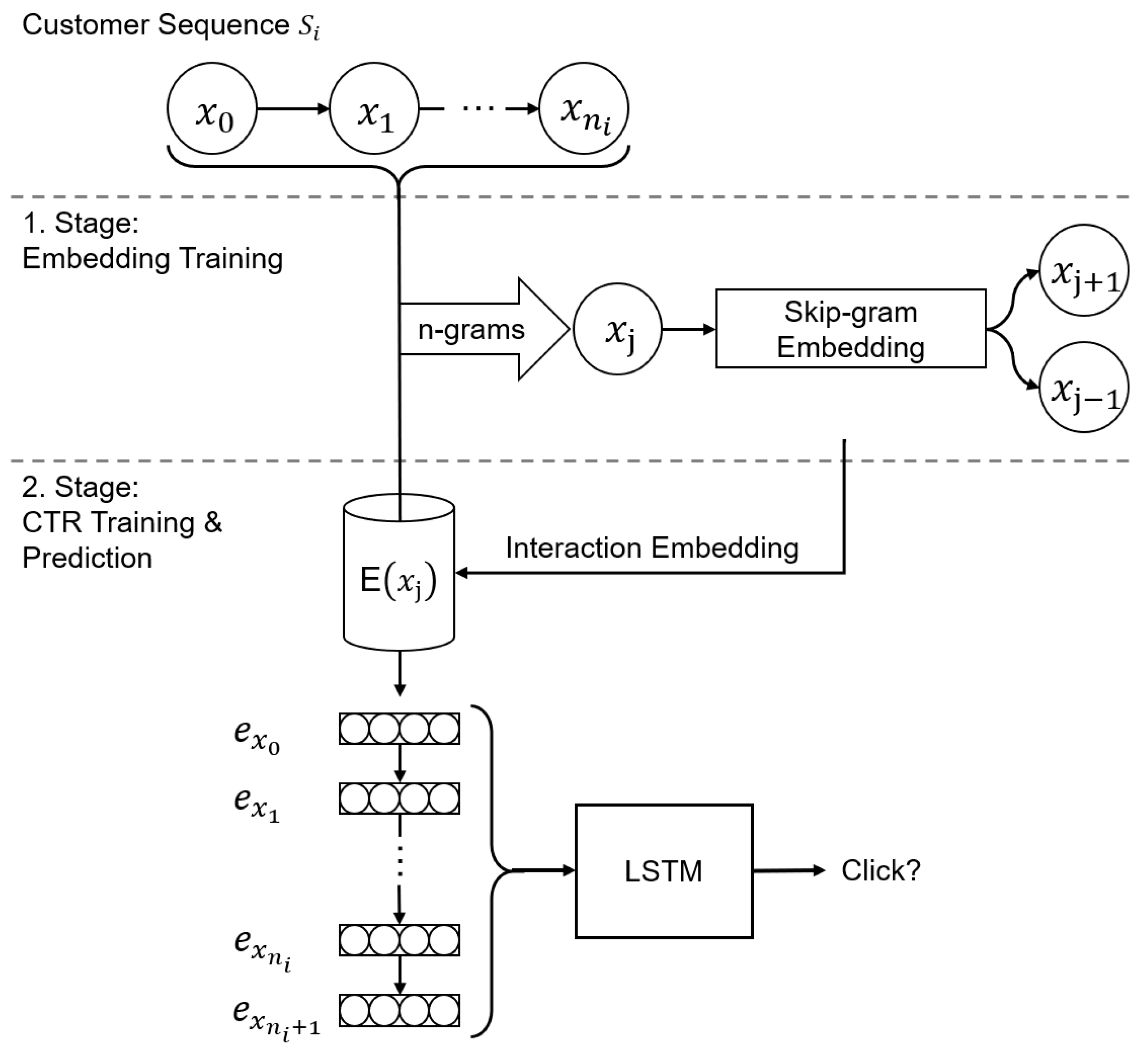
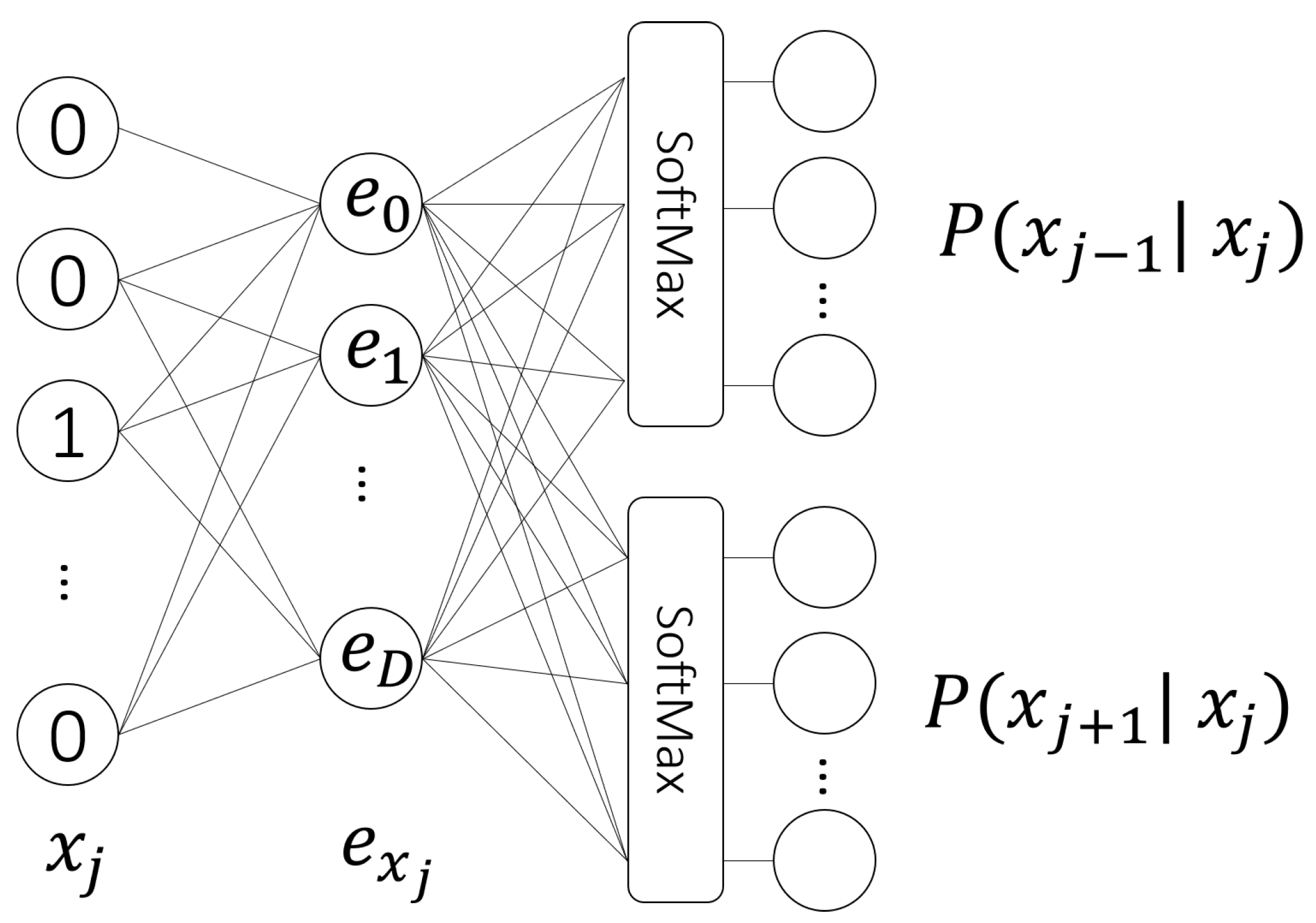
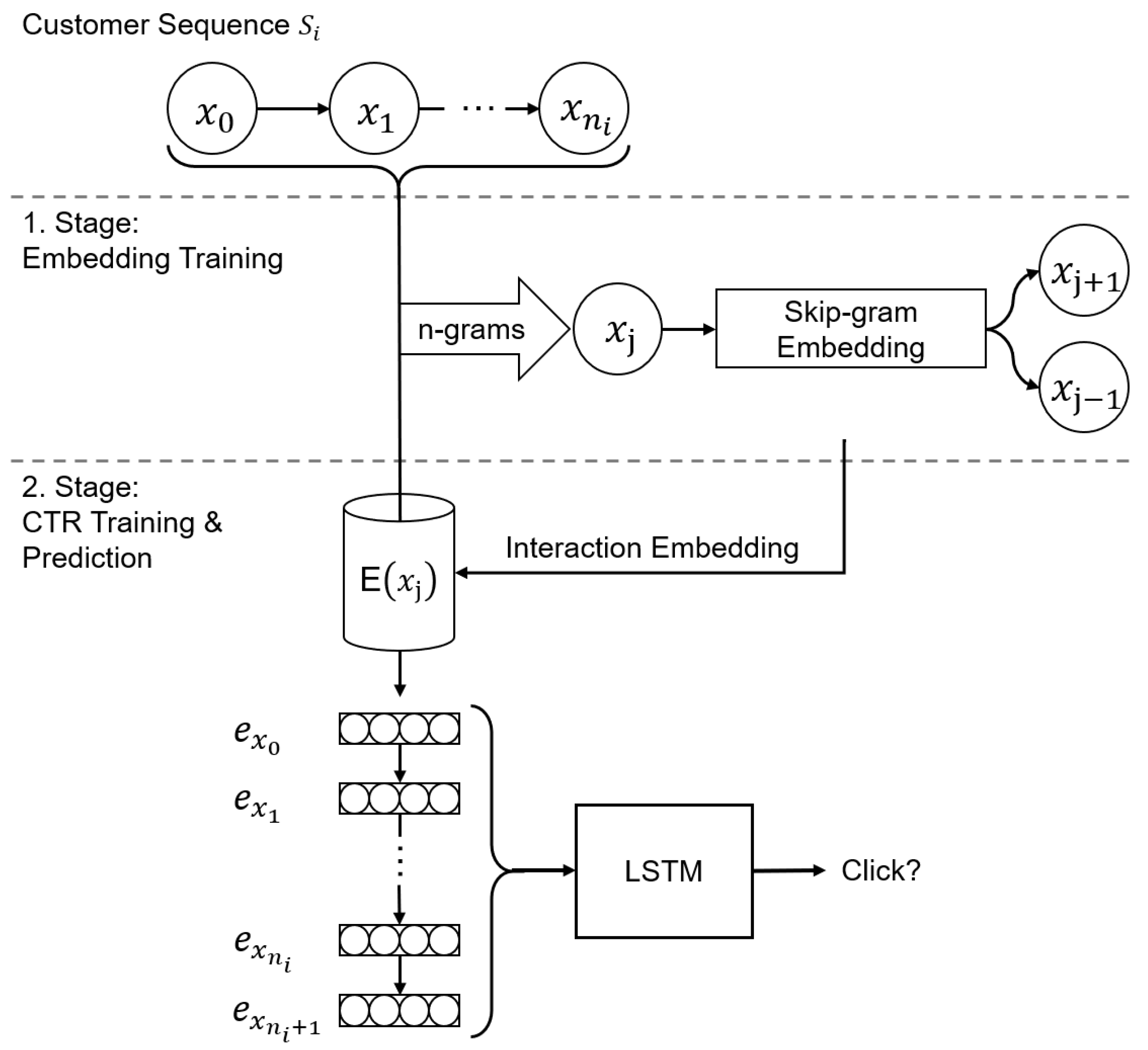
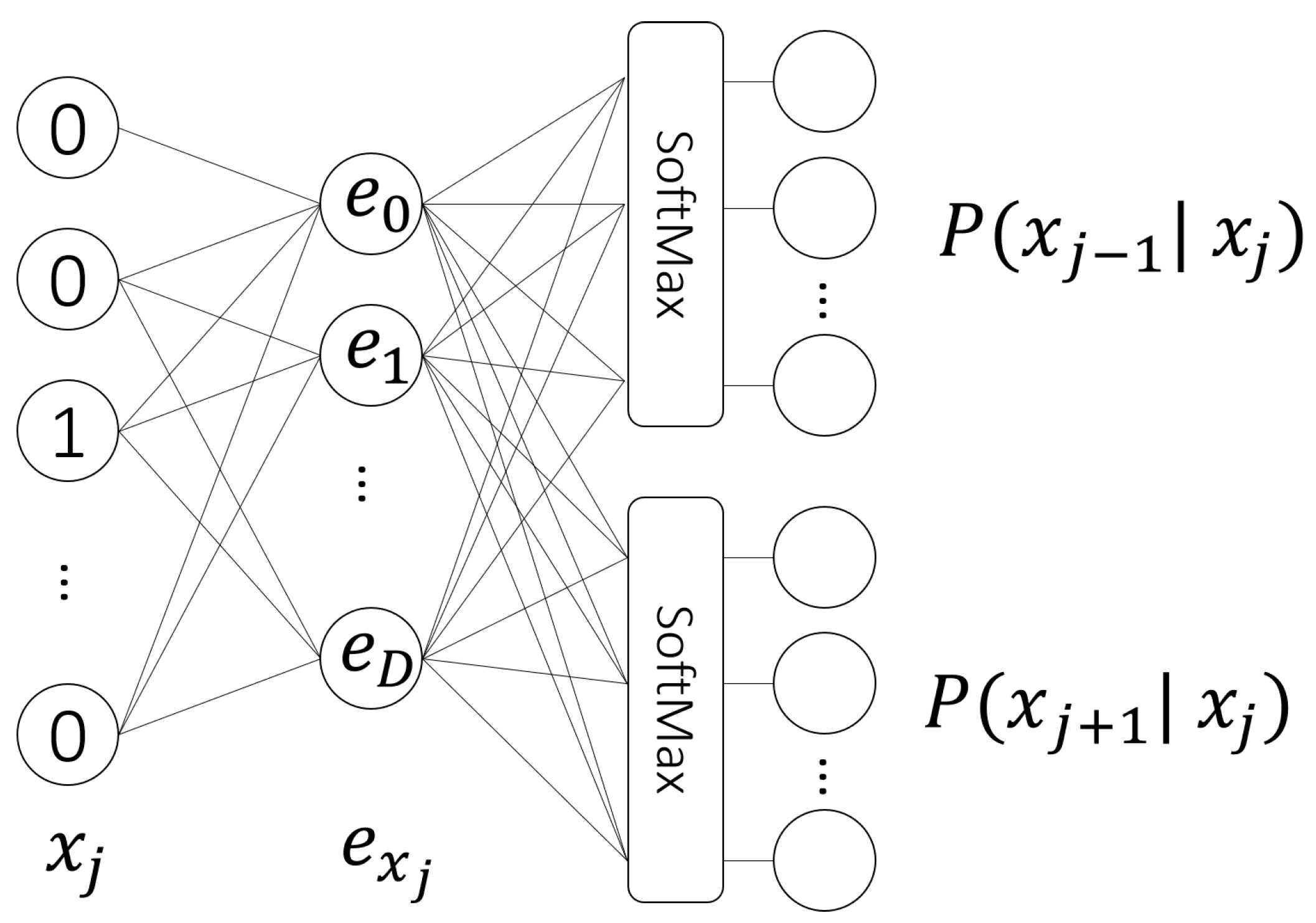
4.1. Approach Methodology
4.2. Baseline Approaches
- LSTM baseline: The LSTM baseline approach is similar to our approach, but is designed as an end-to-end model, lacking the embedding decoupling and thus the self-supervised pre-training of the customer behavior representation embedding.
- DIN: Zhou et al. [21] proposed the Deep Interest Network (DIN) for CTR-P with the idea that the model captures user interests in past user interactions. This is realized with an attention mechanism that refers to the target item.
- DIEN: Zhou et al. [10] proposed Deep Interest Evolution Network (DIEN) as the successor of DIN. It has a similar motivation to capture historical user interest but uses a different approach and model architecture. DIEN consists of three layers; (1) a Behavior Layer, (2) an Interest Extractor Layer, and (3) an Interest Evolving Layer. The Behavior Layer is the embedding layer that processes customers’ historical sequence. The second layer consists of gated recurrent units (GRU) [57]. The third layer consists of an attention mechanism and AUGRU, a GRU with an attentional update gate.
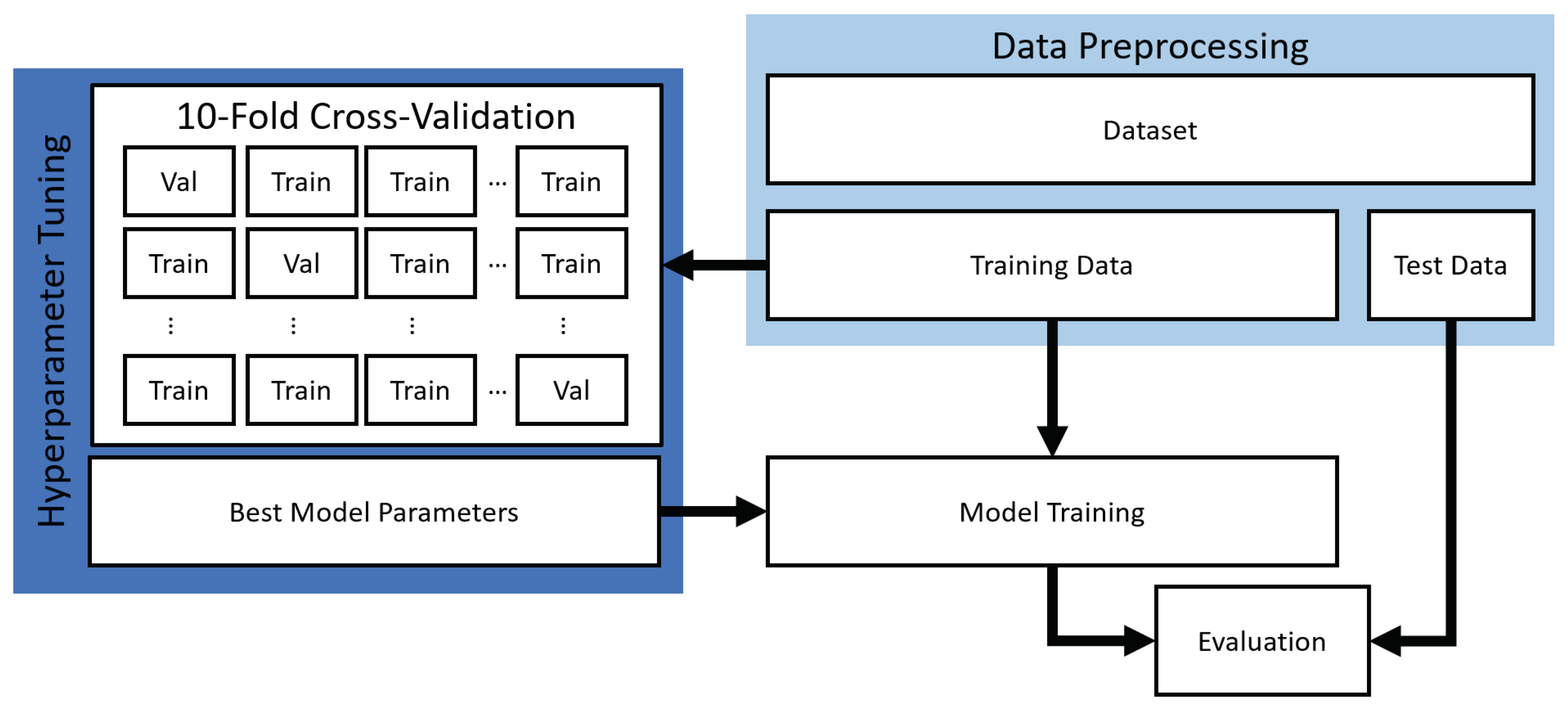
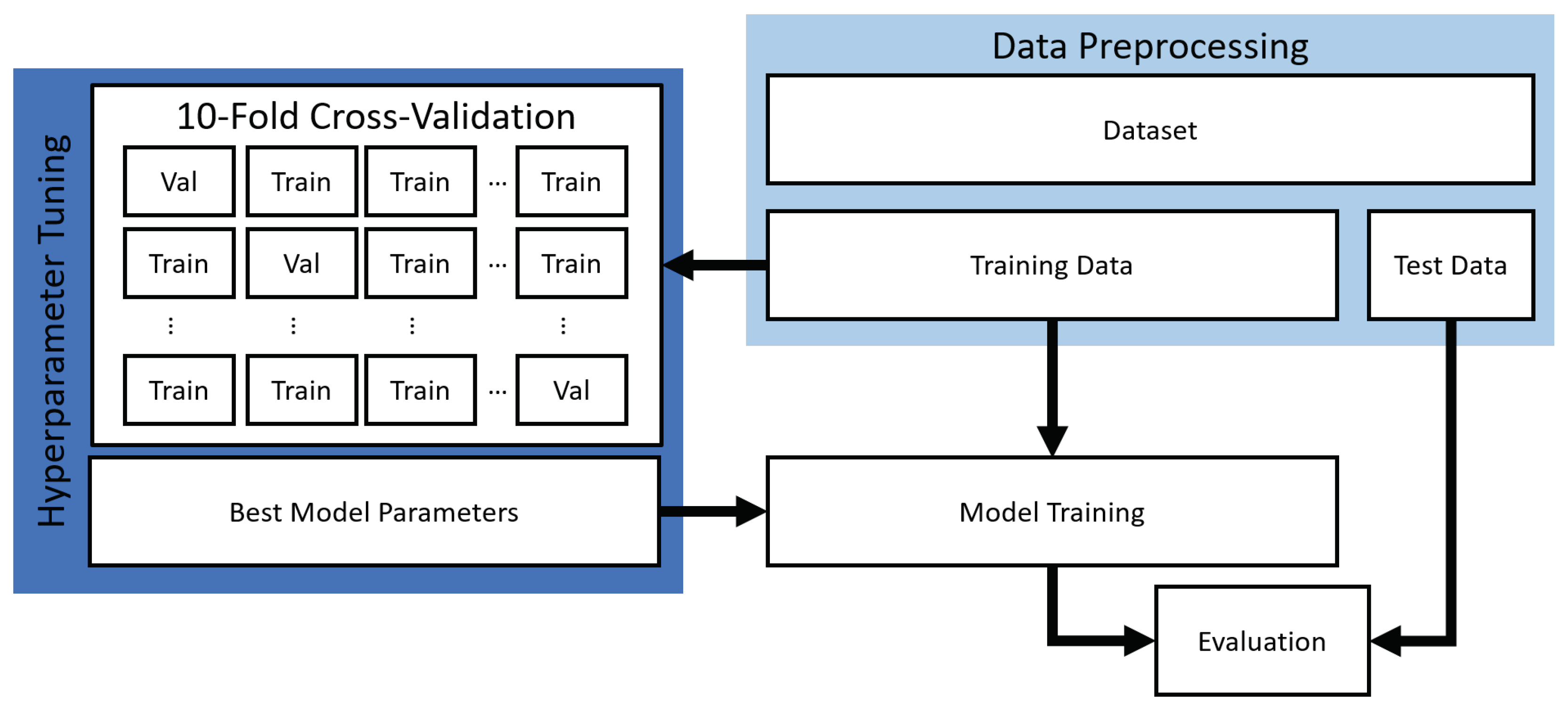
4.3. Data Preprocessing
4.4. Reproduction of the Experiments
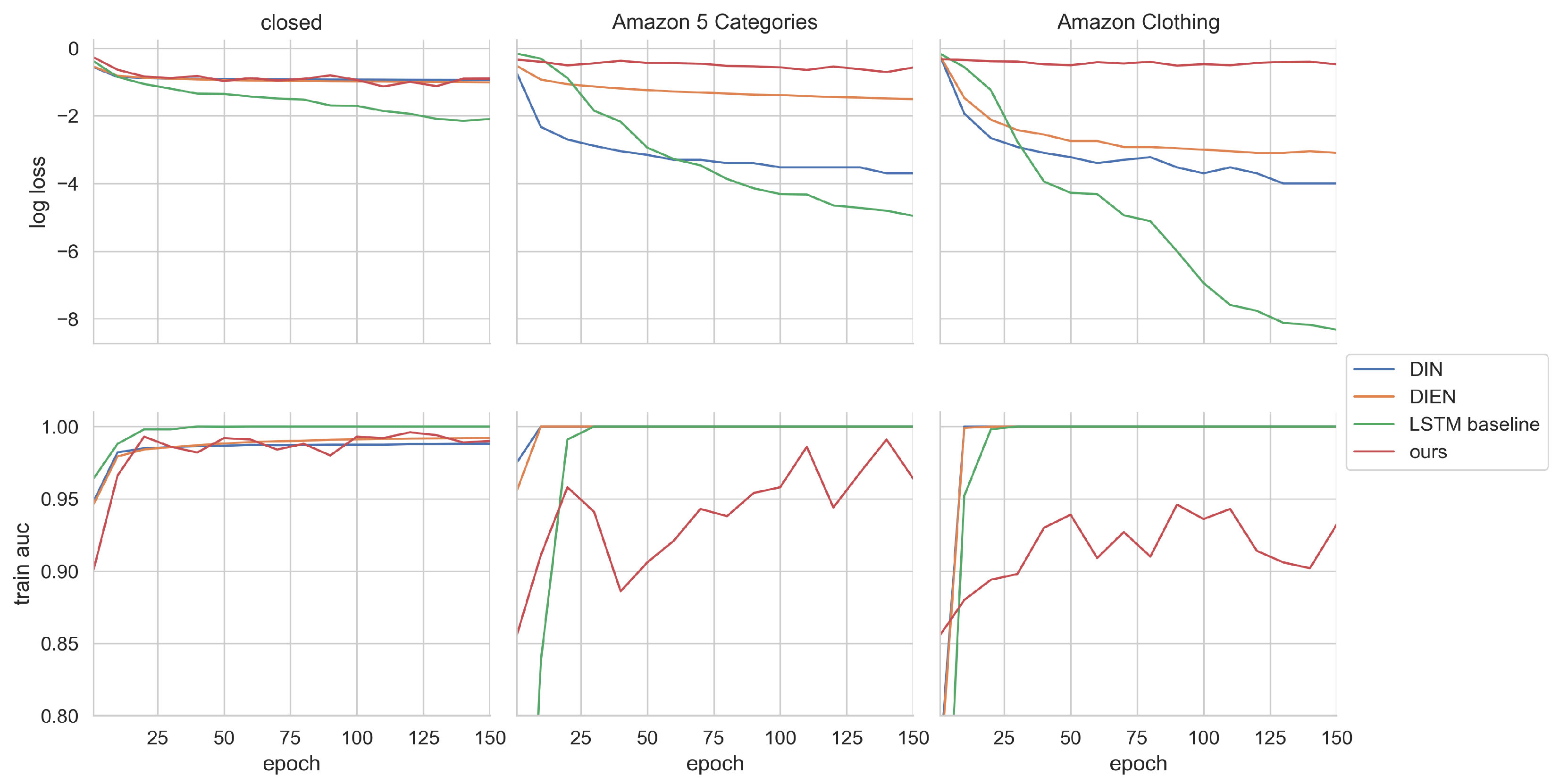
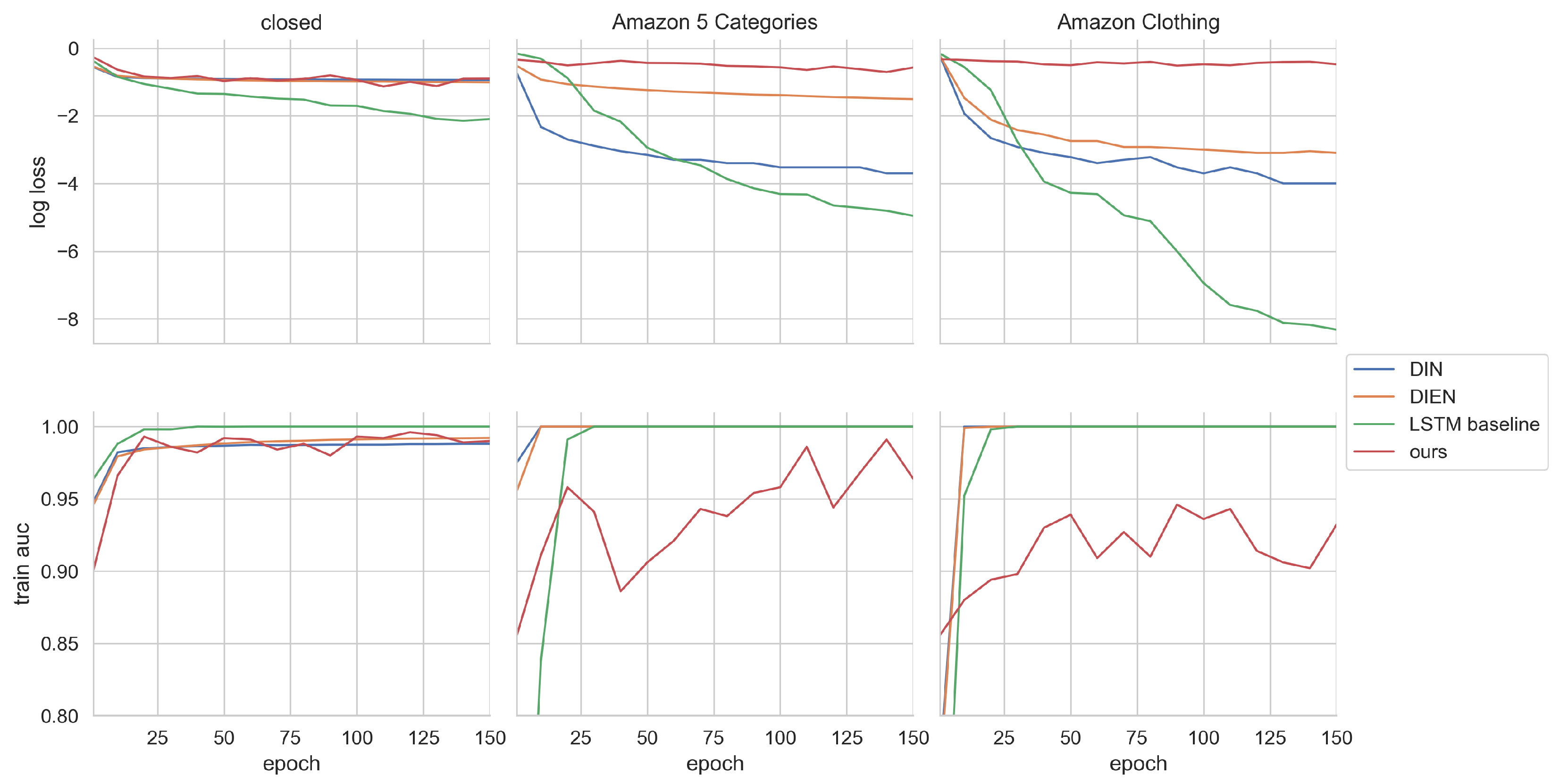
5. Results and Discussion
6. Summary and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; Volume 139, pp. 8821–8831. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & Deep Learning for Recommender Systems. In Proceedings of the DLRS 2016 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. In Proceedings of the CIKM ’19 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar] [CrossRef]
- Huang, G.; Chen, Q.; Deng, C. A New Click-Through Rates Prediction Model Based on Deep&Cross Network. Algorithms 2020, 13, 342. [Google Scholar] [CrossRef]
- Xia, Z.; Mao, S.; Bai, J.; Geng, X.; Yi, L. A Novel Integrated Network with LightGBM for Click-Through Rate Prediction. Res. Sq. 2021; preprint. [Google Scholar] [CrossRef]
- Li, X.; Wang, C.; Tan, J.; Zeng, X.; Ou, D.; Zheng, B. Adversarial Multimodal Representation Learning for Click-Through Rate Prediction. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 827–836. [Google Scholar] [CrossRef]
- Fan, Z.; Ou, D.; Gu, Y.; Fu, B.; Li, X.; Bao, W.; Dai, X.Y.; Zeng, X.; Zhuang, T.; Liu, Q. Modeling Users’ Contextualized Page-wise Feedback for Click-Through Rate Prediction in E-commerce Search. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Virtual, 21–25 February 2022; pp. 262–270. [Google Scholar] [CrossRef]
- Zhou, G.; Mou, N.; Fan, Y.; Pi, Q.; Bian, W.; Zhou, C.; Zhu, X.; Gai, K. Deep Interest Evolution Network for Click-Through Rate Prediction. Proc. AAAI Conf. Artif. Intell. 2019, 33, 5941–5948. [Google Scholar] [CrossRef]
- Ni, Y.; Ou, D.; Liu, S.; Li, X.; Ou, W.; Zeng, A.; Si, L. Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-Commerce Tasks. In Proceedings of the KDD ’18 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 596–605. [Google Scholar] [CrossRef]
- Carmel, D.; Haramaty, E.; Lazerson, A.; Lewin-Eytan, L. Multi-Objective Ranking Optimization for Product Search Using Stochastic Label Aggregation. In Proceedings of the WWW ’20 Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 373–383. [Google Scholar] [CrossRef]
- Li, F.; Chen, Z.; Wang, P.; Ren, Y.; Zhang, D.; Zhu, X. Graph Intention Network for Click-through Rate Prediction in Sponsored Search. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 961–964. [Google Scholar] [CrossRef]
- Pan, Z.; Chen, E.; Liu, Q.; Xu, T.; Ma, H.; Lin, H. Sparse Factorization Machines for Click-Through Rate Prediction. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 400–409. [Google Scholar] [CrossRef]
- Ren, K.; Zhang, W.; Rong, Y.; Zhang, H.; Yu, Y.; Wang, J. User Response Learning for Directly Optimizing Campaign Performance in Display Advertising. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 679–688. [Google Scholar] [CrossRef]
- Kumar, V.; Venkatesan, R.; Reinartz, W. Performance Implications of Adopting a Customer-Focused Sales Campaign. J. Mark. 2008, 72, 50–68. [Google Scholar] [CrossRef]
- Chen, C.; Chen, H.; Zhao, K.; Zhou, J.; He, L.; Deng, H.; Xu, J.; Zheng, B.; Zhang, Y.; Xing, C. EXTR: Click-Through Rate Prediction with Externalities in E-Commerce Sponsored Search. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2732–2740. [Google Scholar] [CrossRef]
- Ge, T.; Zhao, L.; Zhou, G.; Chen, K.; Liu, S.; Yi, H.; Hu, Z.; Liu, B.; Sun, P.; Liu, H.; et al. Image Matters: Visually Modeling User Behaviors Using Advanced Model Server. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 2087–2095. [Google Scholar] [CrossRef]
- Gulhane, P.R.; Kumar, T.S.P. TensorFlow Based Website Click through Rate (CTR) Prediction Using Heat maps. In Proceedings of the 2018 International Conference on Recent Trends in Advance Computing (ICRTAC), Chennai, India, 10–11 September 2018; pp. 97–102. [Google Scholar] [CrossRef]
- Li, C.; Yi, K.; Fei, M.; Zhou, W.; Wu, X.; Chen, Y. Multiple-structure Attentional Network for Click-through Prediction in Recommendation System. In Proceedings of the 2021 IEEE International Conference on Recent Advances in Systems Science and Engineering (RASSE), Shanghai, China, 12–14 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan, Y.; Jin, J.; Li, H.; Gai, K. Deep Interest Network for Click-Through Rate Prediction. In Proceedings of the KDD ’18 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1059–1068. [Google Scholar] [CrossRef]
- Li, X.; Wang, C.; Tong, B.; Tan, J.; Zeng, X.; Zhuang, T. Deep Time-Aware Item Evolution Network for Click-Through Rate Prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 785–794. [Google Scholar] [CrossRef]
- Wang, F.; Zhao, L. A Hybrid Model for Commercial Brand Marketing Prediction Based on Multiple Features with Image Processing. Secur. Commun. Netw. 2022, 2022, 5455745. [Google Scholar] [CrossRef]
- Wong, C.M.; Feng, F.; Zhang, W.; Vong, C.M.; Chen, H.; Zhang, Y.; He, P.; Chen, H.; Zhao, K.; Chen, H. Improving Conversational Recommender System by Pretraining Billion-scale Knowledge Graph. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 2607–2612. [Google Scholar] [CrossRef]
- Yao, S.; Tan, J.; Chen, X.; Yang, K.; Xiao, R.; Deng, H.; Wan, X. Learning a Product Relevance Model from Click-Through Data in E-Commerce. In Proceedings of the Web Conference 2021, Online, 19–23 April 2021; pp. 2890–2899. [Google Scholar] [CrossRef]
- Rosasco, L.; De Vito, E.; Caponnetto, A.; Piana, M.; Verri, A. Are loss functions all the same? Neural Comput. 2004, 16, 1063–1076. [Google Scholar] [CrossRef] [PubMed]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Sasaki, Y. The truth of the F-measure. Teach Tutor Mater 2007, 1, 1–5. [Google Scholar]
- Zeng, J.; Chen, Y.; Zhu, H.; Tian, F.; Miao, K.; Liu, Y.; Zheng, Q. User Sequential Behavior Classification for Click-Through Rate Prediction. In Proceedings of the Database Systems for Advanced Applications. DASFAA 2020 International Workshops: BDMS, SeCoP, BDQM, GDMA, and AIDE, Jeju, Republic of Korea, 24–27 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 267–280. [Google Scholar] [CrossRef]
- Wang, R.; Fu, B.; Fu, G.; Wang, M. Deep & Cross Network for Ad Click Predictions. In Proceedings of the ADKDD’17, Halifax, NS, Canada, 14 August 2017. [Google Scholar] [CrossRef]
- Sismeiro, C.; Bucklin, R.E. Modeling purchase behavior at an e-commerce web site: A task-completion approach. J. Mark. Res. 2004, 41, 306–323. [Google Scholar] [CrossRef]
- Romov, P.; Sokolov, E. RecSys Challenge 2015: Ensemble Learning with Categorical Features. In Proceedings of the RecSys ’15 Challenge: 2015 International ACM Recommender Systems Challenge, Vienna, Austria, 16–20 September 2015. [Google Scholar] [CrossRef]
- Li, Q.; Gu, M.; Zhou, K.; Sun, X. Multi-Classes Feature Engineering with Sliding Window for Purchase Prediction in Mobile Commerce. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 1048–1054. [Google Scholar] [CrossRef]
- Martínez, A.; Schmuck, C.; Pereverzyev, S.; Pirker, C.; Haltmeier, M. A machine learning framework for customer purchase prediction in the non-contractual setting. Eur. J. Oper. Res. 2020, 281, 588–596. [Google Scholar] [CrossRef]
- Esmeli, R.; Bader-El-Den, M.; Abdullahi, H. Towards early purchase intention prediction in online session based retailing systems. Electron. Mark. 2021, 31, 697–715. [Google Scholar] [CrossRef]
- Alves Gomes, M.; Meisen, T. A review on customer segmentation methods for personalized customer targeting in e-commerce use cases. Inf. Syst. e-Bus. Manag. 2023, 21, 527–570. [Google Scholar] [CrossRef]
- Hughes, A.M. Strategic Database Marketing: The Masterplan for Starting and Managing a Profitable, Customer-Based Marketing Program; Irwin Professional: Burr Ridge, IL, USA, 1994. [Google Scholar]
- Perišić, A.; Pahor, M. RFM-LIR Feature Framework for Churn Prediction in the Mobile Games Market. IEEE Trans. Games 2022, 14, 126–137. [Google Scholar] [CrossRef]
- Fridrich, M.; Dostál, P. User Churn Model in E-Commerce Retail. Sci. Pap. Univ. Pardubic. Ser. D Fac. Econ. Adm. 2022, 30. [Google Scholar] [CrossRef]
- Wu, J.; Shi, L.; Yang, L.; Niu, X.; Li, Y.; Cui, X.; Tsai, S.B.; Zhang, Y. User value identification based on improved RFM model and k-means++ algorithm for complex data analysis. Wirel. Commun. Mob. Comput. 2021, 2021, 9982484. [Google Scholar] [CrossRef]
- Fazlollahtabar, H. Intelligent marketing decision model based on customer behavior using integrated possibility theory and K-means algorithm. J. Intell. Manag. Decis. 2022, 1, 88–96. [Google Scholar] [CrossRef]
- Wang, L.; Sun, H. Influencing Factors of Second-Hand Platform Trading in C2C E-commerce. J. Intell. Manag. Decis. 2023, 2, 21–29. [Google Scholar] [CrossRef]
- Berger, P.; Kompan, M. User Modeling for Churn Prediction in E-Commerce. IEEE Intell. Syst. 2019, 34, 44–52. [Google Scholar] [CrossRef]
- Sheil, H.; Rana, O.; Reilly, R. Predicting purchasing intent: Automatic feature learning using recurrent neural networks. arXiv 2018, arXiv:1807.08207. [Google Scholar]
- Yang, B.; Liu, K.; Xu, X.; Xu, R.; Liu, H.; Xu, H. Learning Universal User Representations via Self-Supervised Lifelong Behaviors Modeling. In Proceedings of the ICLR 2022 Conference, Virtual, 25–29 April 2022. [Google Scholar]
- Wu, C.; Wu, F.; Qi, T.; Lian, J.; Huang, Y.; Xie, X. Ptum: Pre-training user model from unlabeled user behaviors via self-supervision. arXiv 2020, arXiv:2010.01494. [Google Scholar]
- Vasile, F.; Smirnova, E.; Conneau, A. Meta-Prod2Vec: Product Embeddings Using Side-Information for Recommendation. In Proceedings of the RecSys ’16: 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 225–232. [Google Scholar]
- Tercan, H.; Bitter, C.; Bodnar, T.; Meisen, P.; Meisen, T. Evaluating a Session-based Recommender System using Prod2vec in a Commercial Application. In Proceedings of the 23rd International Conference on Enterprise Information Systems, Virtual, 26–28 April 2021; SciTePress: Setúbal, Portugal, 2021; Volume 1, pp. 610–617. [Google Scholar] [CrossRef]
- Alves Gomes, M.; Tercan, H.; Bodnar, T.; Meisen, P.; Meisen, T. A Filter is Better Than None: Improving Deep Learning-Based Product Recommendation Models by Using a User Preference Filter. In Proceedings of the 2021 IEEE 23rd Int Conf on High Performance Computing & Communications; 7th Int Conf on Data Science & Systems; 19th Int Conf on Smart City; 7th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Haikou, China, 20–22 December 2021; pp. 1278–1285. [Google Scholar] [CrossRef]
- Srilakshmi, M.; Chowdhury, G.; Sarkar, S. Two-stage system using item features for next-item recommendation. Intell. Syst. Appl. 2022, 14, 200070. [Google Scholar] [CrossRef]
- Alves Gomes, M.; Meyes, R.; Meisen, P.; Meisen, T. Will This Online Shopping Session Succeed? Predicting Customer’s Purchase Intention Using Embeddings. In Proceedings of the CIKM ’22: 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 2873–2882. [Google Scholar] [CrossRef]
- Alves Gomes, M.; Wönkhaus, M.; Meisen, P.; Meisen, T. TEE: Real-Time Purchase Prediction Using Time Extended Embeddings for Representing Customer Behavior. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 1404–1418. [Google Scholar] [CrossRef]
- Ni, J.; Li, J.; McAuley, J. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 188–197. [Google Scholar]
- Liu, H.; Lu, J.; Yang, H.; Zhao, X.; Xu, S.; Peng, H.; Zhang, Z.; Niu, W.; Zhu, X.; Bao, Y.; et al. Category-Specific CNN for Visual-aware CTR Prediction at JD.com. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July2020; pp. 2686–2696. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the NIPS’13: 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; pp. 103–111. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the NIPS’14: 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 2, pp. 3104–3112. [Google Scholar]
- Van Rossum, G.; Drake, F.L., Jr. Python Reference Manual; Centrum voor Wiskunde en Informatica: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the Python in Science Conference, Austin, TX, USA, 10–16 July 2023; pp. 56–61. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Shen, W. DeepCTR: Easy-to-Use, Modular and Extendible Package of Deep-Learning Based CTR Models. 2017. Available online: https://github.com/shenweichen/deepctr (accessed on 17 March 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. In Proceedings of the ECML PKDD Workshop: Languages for Data Mining and Machine Learning, Prague, Czech Republic, 23–27 September 2013; pp. 108–122. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Shi, Y.; Yang, Y. HFF: Hybrid Feature Fusion Model for Click-Through Rate Prediction. In Proceedings of the Cognitive Computing—ICCC 2020: 4th International Conference, Held as Part of the Services Conference Federation, SCF 2020, Honolulu, HI, USA, 18–20 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–14. [Google Scholar] [CrossRef]
- European-Parliament. Regulation (EU) 2016/679 of the European Parliament and of the Council; Official Journal of the European Union: Luxembourg, 2016. [Google Scholar]
- Burri, M.; Schär, R. The reform of the EU data protection framework: Outlining key changes and assessing their fitness for a data-driven economy. J. Inf. Policy 2016, 6, 479–511. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Approach | Dataset | Score | ||
|---|---|---|---|---|---|---|
| AUC | F1 | Logloss | ||||
| Fan et al. [9] | 2022 | RACP | Avito | 0.794 | ||
| Taobao (closed) | 0.7623 | |||||
| C. Li et al. [20] | 2021 | Mul-AN | Criteo | 0.8 | 0.483 | |
| MovieLens-100k | 0.847 | 0.395 | ||||
| X. Li et al. [8] | 2020 | MARN | Amazon Review Electro | 0.803 | ||
| Amazon Review Clothing | 0.791 | |||||
| Taobao (closed) | 0.749 | |||||
| X. Lie et al. [22] | 2020 | TIEN | Amazon Review Beauty | 0.8701 | 0.784 | 0.4479 |
| Amazon Review Clothing | 0.7962 | 0.698 | 0.5476 | |||
| Amazon Review Grocery | 0.8252 | 0.7524 | 0.5019 | |||
| Amazon Review Phones | 0.839 | 0.7427 | 0.4949 | |||
| Amazon Review Sports | 0.8266 | 0.7543 | 0.5101 | |||
| Zeng et al. [29] | 2020 | USRF | RetailRocket datasets | 0.8888 | 0.8001 | |
| Amazon Review Digital Music | 0.7086 | 0.6709 | ||||
| MovieLense-1M | 0.9921 | 0.8445 | ||||
| Zhou et al. [10] | 2019 | DIEN | Amazon Review Electro | 0.7792 | ||
| Amazon Review Books | 0.8453 | |||||
| Taobao | 0.6541 | |||||
| Zhou et al. [21] | 2018 | DIN | Amazon Review Electro | 0.8871 | ||
| MovieLense-20M | 0.7348 | |||||
| Alibaba (closed) | ||||||
| Wang et al. [30] | 2017 | DCN | Criteo | 0.4419 | ||
| Notation | Description |
|---|---|
| Set of all customers C, customer interactions X, and sequences S | |
| A customer and interaction , | |
| is a ascended time-ordered customer behavior sequence with sequence length | |
| A interaction of has a context with context window size | |
| D-dimensional embedding representation of interaction | |
| Embedding function E that uses the trained embedding and maps |
| Amazon Clothing | Amazon 5 Categories | Closed | |
|---|---|---|---|
| #interactions | 10,714,172 | 25,862,230 | 53,825,295 |
| #users | 1,164,752 | 2,547,663 | 574,890 |
| #sequences | 1,164,752 | 2,547,663 | 6,195,916 |
| #unique interactions | 372,593 | 801,890 | 66,891 |
| #train samples | 970,717 | 2,127,165 | 119,905 |
| ⌀train sequence length | 8.6689 | 9.5863 | 12.6557 |
| #test samples | 171,406 | 376,606 | 21,160 |
| ⌀test sequence length | 7.5048 | 7.8988 | 11.6173 |
| #n-grams | 7,452,387 | 18,742,161 | 3,849,627 |
| Amazon Clothing | Amazon 5 Categories | Closed | ||||
|---|---|---|---|---|---|---|
| Approach | AUC | F1 | AUC | F1 | AUC | F1 |
| LSTM baseline | 0.7651 | 0.7071 | 0.7712 | 0.7106 | 0.9731 | 0.9387 |
| DIN | 0.7885 | 0.7221 | 0.7948 | 0.725 | 0.9626 | 0.9329 |
| DIEN | 0.7796 | 0.7280 | 0.7759 | 0.7246 | 0.9510 | 0.9251 |
| ours | 0.8851 | 0.7962 | 0.8896 | 0.7996 | 0.9810 | 0.9450 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alves Gomes, M.; Meyes, R.; Meisen, P.; Meisen, T. It’s Not Always about Wide and Deep Models: Click-Through Rate Prediction with a Customer Behavior-Embedding Representation. J. Theor. Appl. Electron. Commer. Res. 2024, 19, 135-151. https://doi.org/10.3390/jtaer19010008
Alves Gomes M, Meyes R, Meisen P, Meisen T. It’s Not Always about Wide and Deep Models: Click-Through Rate Prediction with a Customer Behavior-Embedding Representation. Journal of Theoretical and Applied Electronic Commerce Research. 2024; 19(1):135-151. https://doi.org/10.3390/jtaer19010008
Chicago/Turabian StyleAlves Gomes, Miguel, Richard Meyes, Philipp Meisen, and Tobias Meisen. 2024. "It’s Not Always about Wide and Deep Models: Click-Through Rate Prediction with a Customer Behavior-Embedding Representation" Journal of Theoretical and Applied Electronic Commerce Research 19, no. 1: 135-151. https://doi.org/10.3390/jtaer19010008
APA StyleAlves Gomes, M., Meyes, R., Meisen, P., & Meisen, T. (2024). It’s Not Always about Wide and Deep Models: Click-Through Rate Prediction with a Customer Behavior-Embedding Representation. Journal of Theoretical and Applied Electronic Commerce Research, 19(1), 135-151. https://doi.org/10.3390/jtaer19010008