
Towards Virtual 3D Asset Price Prediction Based on Machine Learning


Abstract
:1. Introduction
2. Theoretical Background
2.1. 3D Models and Virtual 3D Assets
2.2. Data Mining and Machine Learning
3. Related Studies
4. Methodology
5. Results
5.1. Data Preparation
5.2. Data Pre-Processing
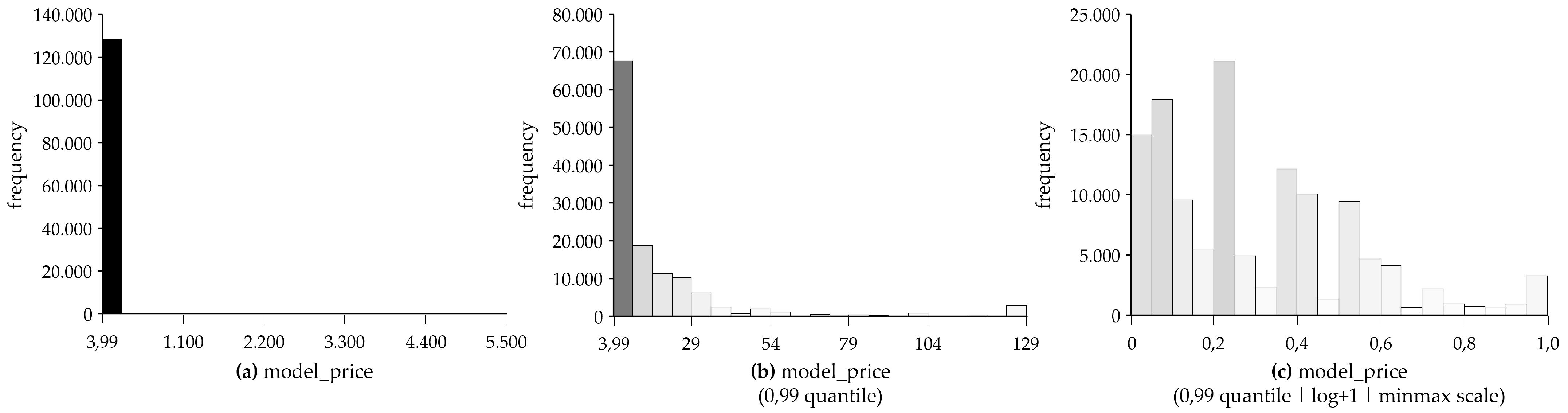
5.2.1. Univariate and Bivariate Data Analysis
5.2.2. Feature Selection
5.2.3. Feature Engineering

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Feature | Category | Encoding and Cut-Off Values |
|---|---|---|---|
| F1 | model_price | Currency | Cut-off Value: 129 |
| F9 | total_triangles_count | Geometry | Cut-off Value: 2.717.542 |
| F12 | materials_count | Appearance | Cut-off Value: 46 |
| C1 | pbr_type | Appearance | Encoding: none = 0, metalness = 1, specular = 3 |
| F13 | textures_count | Appearance | Cut-off Value: 57 |
| F14 | textures_mean_sizes | Appearance | Cut-off Value: 36.782,56 |
| C3 | vertex_color | Appearance | Encoding: true = 1, false = 0 |
| F15 | animations_count | Animation | Cut-off Value: 7 |
| C4 | rigged_geometry | Animation | Encoding: true = 1, false = 0 |
| C5 | scale_transformation | Configuration | Encoding: true = 1, false = 0 |
| C6 | file_format_score | Compatibility | Encoding: 1 format = 1, 2 formats = 2, …, 15 formats = 15 |
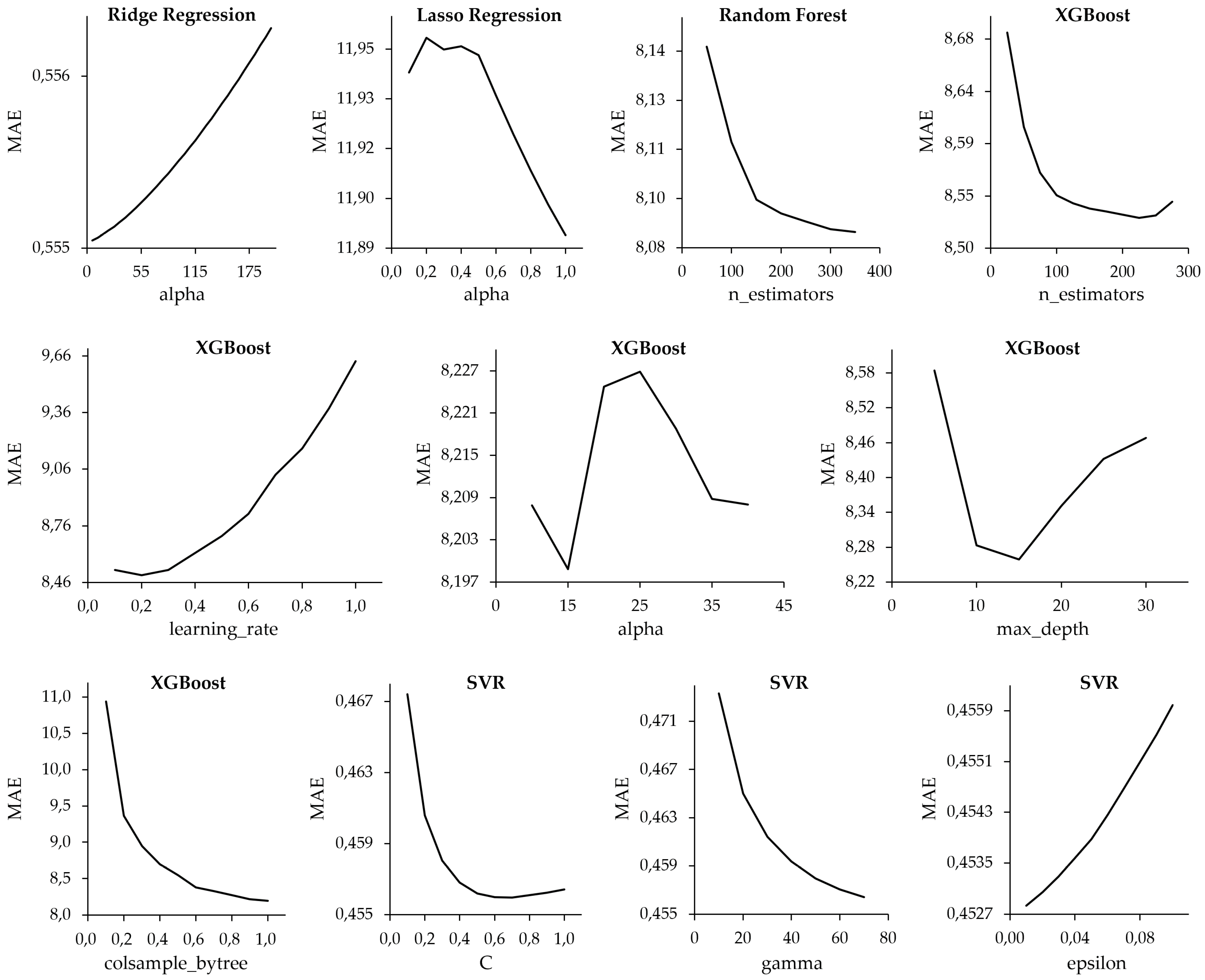
5.3. Model Training and Tuning
6. Evaluation and Demonstration
6.1. Model Performance
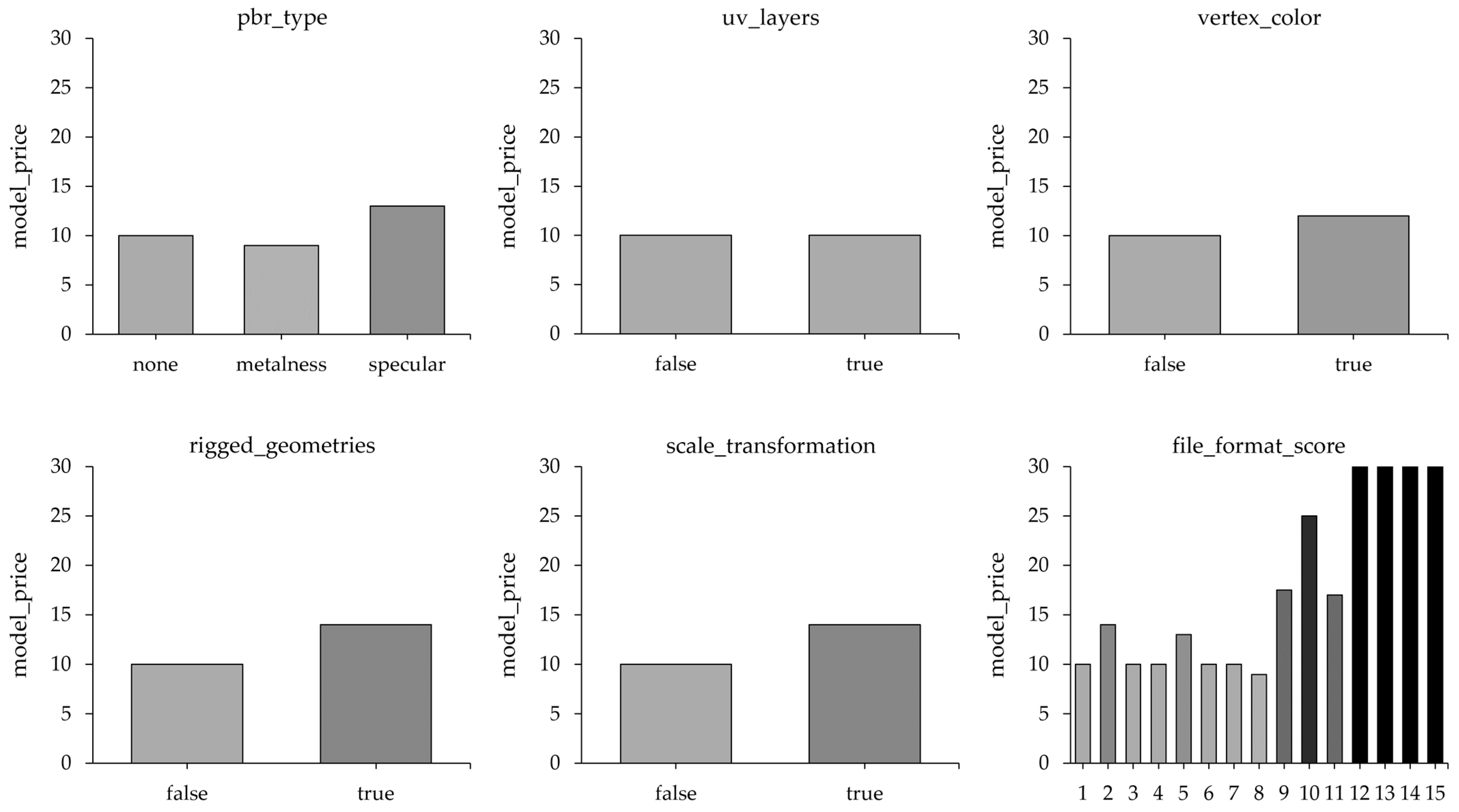
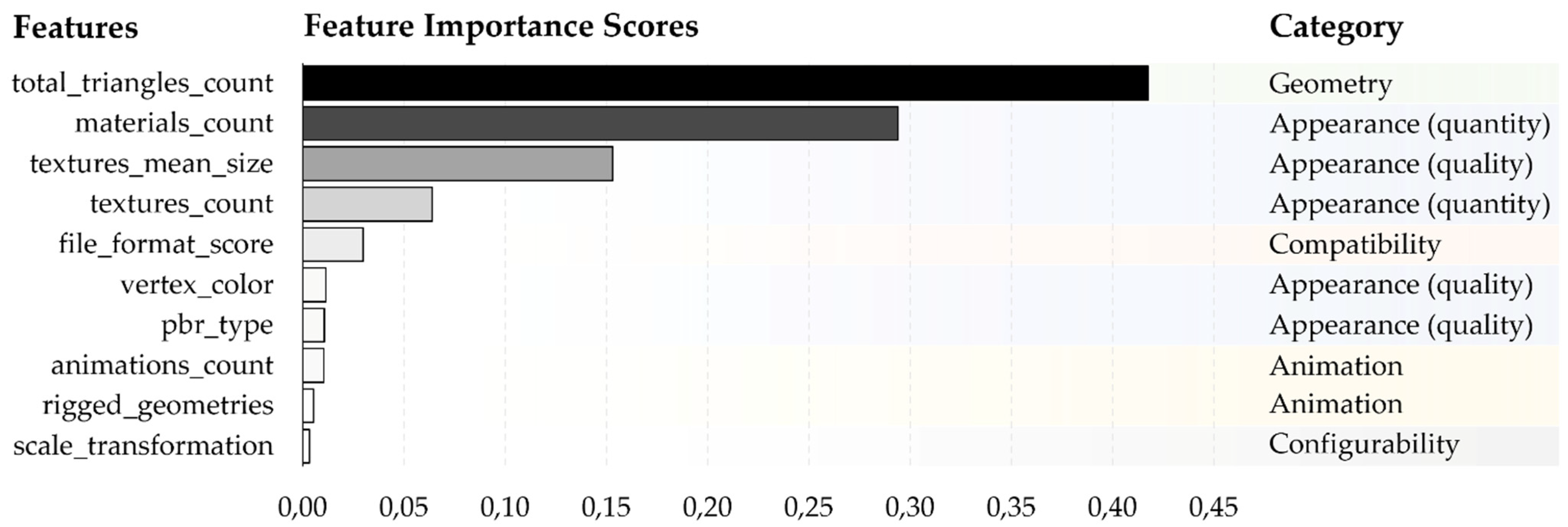
6.2. Feature Scoring and Discussion
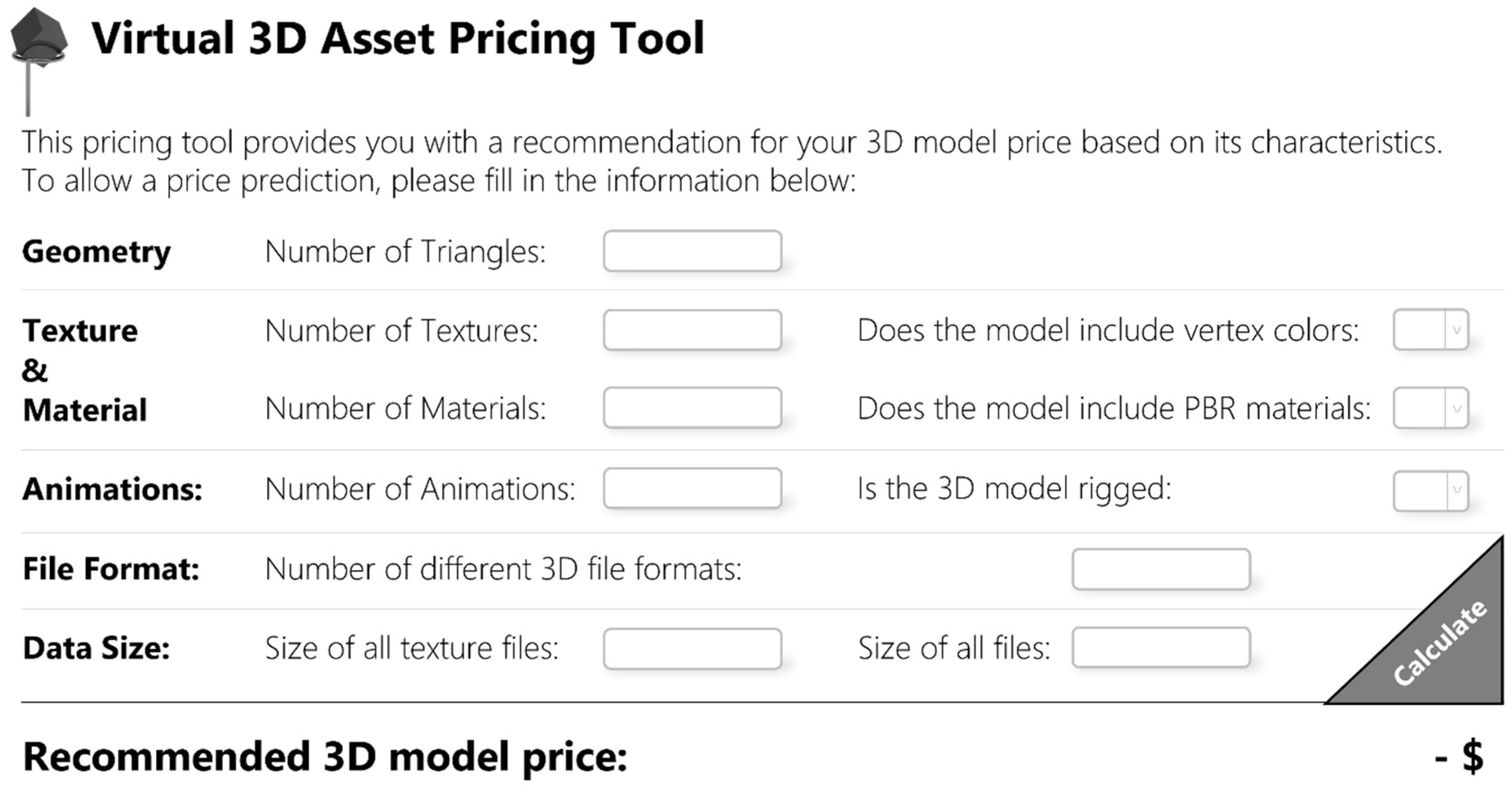
6.3. Price Prediction Tool
7. Conclusions and Implications
8. Limitations and Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| Publication | Application | Applied Machine Learning Models | Metrics |
|---|---|---|---|
| [82] | Accommodation | Logistic Regression, Decision Trees/Classification and Regression Tree, K -Nearest Neighbors, Random Forest | AUC-ROC |
| [49] | Accommodation | Linear Regression, Random Forest, XGBoost | MSE, MAE, R2 |
| [50] | Accommodation | Linear Regression, Gradient Boosting Machines, Support Vector Machines, Neural Networks, Classification and Regression Trees, Random Forest | MAE, R2 |
| [51] | Accommodation | Linear Regression, Support Vector Regression, Random Forest | (R)MSE, MAE, (a)R2 |
| [56] | Cryptocurrency | Logistic Regression, Random Forest, XGBoost, Quadratic Discriminant Analysis, Support Vector Machine, Long Short-Term Memory | Accuracy, Precision, Recall, F1-score |
| [57] | Cryptocurrency | Linear Regression, Random Forest, Support Vector Machines, Model Assembling | MAE, RMSE, Theil’s U2 |
| [59] | Energy | Gaussian Process Regression, Support Vector Machine, Tree Regression | MAE, RMSE, R2 |
| [52] | Stock Market | Linear Regression, Elastic Net (Lasso Regression, Ridge Regression), Principal Component Regression, Partial Least Squares, Random Forest, Gradient Boosted Regression Tree, Neural Network, Support Vector Machines | DM test (MSFE), R2 |
| [53] | Stock Market | Linear Regression, Principal Components Regression, Partial Least Squares, Elastic Net (Lasso Regression, Ridge Regression), Generalize Linear Model, Random Forest, Gradient Boosted Regression Tree, Neural Networks | DM test, R2 |
| [62] | Warehouse Rental | Linear Regression, Regression Tree, Random Forest, Gradient Boosting Regression Trees | correlation coefficient, RMSE |
Appendix B
| Model | Description |
|---|---|
| Multiple Linear Regression | Statistical approach for modelling the linear relationship between a dependent variable and one or more independent predictor variables for predicting the former. Ordinary Least Square (OLS): Estimates the parameters or coefficients of the predictor function from the input data, whereas the sign of each coefficient represents the direction of the linear relationship between target and predictor variables. In the case of multiple independent variables: multiple linear regression [83]. |
| Regularized Linear Regression | Regularization aims to simplify linear regression models through shrinking the coefficient estimates for certain predictor variables by adding a penalty. This adds a bias to the coefficients and results in a lower variance when predicting new data. Ridge Regression: Modified version of the OLS method, aiming to put bias into the estimation of the coefficients to minimize the variance of outcomes. Lasso Regression: Eliminates irrelevant features by imposing a constraint on the model parameters that cause regression coefficients for some variables to shrink towards zero. Given the technical issues regarding concerns on prediction accuracy and interpretation of the OLS, the lasso technique had been proposed to determine a small subset of predictors with the strongest influence from the group of all predictors used [84]. |
| Decision Tree Regression | Predictive ML models for continuous target variables and rule-based techniques that internalize the problem domain including the features of a dataset and their values in a tree-based structure. The features of a dataset are represented as nodes, whereas the observations are modelled as branches of the decision tree. At each node, a rule-based decision on certain feature values is made before the branch is split from the tree, most likely resulting in the best estimate for the target variable. The metric used to find the best partitioning for regression tasks is variance reduction. This decision process is repeated until a leaf node is reached that represents the value of the target variable [83,85]. Decision Tree Regression: Decision trees are easy to implement and—contrary to linear regression—do not pose any special assumption to the dataset; therefore, they do not generalize well, and thus, are prone to overfitting and noise in the dataset. |
| Random Forest Regression and Extreme Gradient Boosting Trees Regressor | Ensemble Learning: Ensemble learning is utilized to address issues in the decision tree regression. Essentially, multiple decision tree models are combined through bootstrap aggregation or bagging to create one robust ML model. Bagging: Multiple decision trees are trained, each using a random subset of the training dataset. Hence, the target value is not derived from a single decision tree, but rather an average of the predictions from the collection of trees. As a result, it decreases the variance in the overall model, making the ensembled model significantly more robust than the individual models [86]. Additionally, the handling of data becomes easier because the pre-processing of data is less relevant, including the management of missing values [87]. These decision trees are trained on random subsets of data and constitute a forest of decision trees; thus, these models are called random forest [88]. Random Forest Regression: One of the most popular ML models currently used: a supervised ML model which is basically derived from the decision tree model, the random forest model can perform classification and regression tasks [89]. Gradient boosting is a tree- and rule-based, supervised ensemble learning approach. It utilizes gradient descent to minimize a loss function and boosting to enhance the performance of weak instances of the model by retraining them [72,90]. Boosting is an iterative process, which ascribes higher weights to those instances of a model that have exhibited weak predictions, and thus, high error rates. It retrains so-called weak learners sequentially, and thus, learns from previous mistakes, instead of being trained on randomly selected subsets of the data. The error rates of these model instances are used to calculate the gradient, the partial derivatives of the loss function [90]. Extreme Gradient Boosting Trees Regressor (XGBoost): Scalable algorithm which supports parallel and distributed computing and enhances the performance of the model by identifying more accurate tree models. It computes and utilizes the second-order gradients (or second partial derivatives of the loss function), instead of using the standard loss function as an approximation for minimizing the error of the prediction model. Furthermore, the model applies regularization, which improves its overall generalization, and thus, efficiently prevents overfitting [72]. The chosen learning objective in this study was regression with squared loss. |
| Support Vector Regression | Kernel-based method based on the work of Cortes and Vapnik [91]: Input data vector is mapped into a high-dimensional feature space. The algorithm learns within this feature space, which is defined by a kernel function. In addition to the standard linear function, there are several kernel functions, such as the radial basis function (RBF) or polynomial function, which can be used for prediction tasks based on non-linear data. Utilizes Support Vector Machines (SVMs) for the regression task, and thus outputs a continuous value. SVMs are extended by the introduction of a tolerance parameter band, which prevents the model from overfitting, and a penalty parameter, which penalizes outliers that are outside of the confidence interval of the kernel function [92]. |
| Model | Description |
|---|---|
| MAE Mean Absolute Error | Average magnitude of variation between the predicted and the observed values. Using only absolute differences in the calculation, residuals with different signs do not cancel each other out. As this is a linear metric, all residuals are weighted equally while calculating the average; hence, the MAE is robust to outliers [93,94]. |
| MSE Mean Squared Error | The MAE calculates the average of the absolute differences between actual and predicted target values, whereas the MSE averages the squared residuals. Despite its popularity, the MSE overestimates the error of a model by squaring the differences between predicted and actually observed values. Therefore, any outliers are penalized significantly [94,95]. |
| RMSE Root-Mean Squared Error | The square-root of the MSE measures the average difference between the predicted and observed values of the target variable. The MSE lacks comparability with the predicted and actual target variable due to it representing the average of the squared residuals. The RMSE mitigates this issue by applying the square-root to the average of the squared residuals. It preserves the units of the target variable; thus, the RMSE allows for improved interpretability. Unlike the MAE and similar to the MSE, the RMSE is sensitive to outliers. Lower RMSE values indicate the better performance of a model [94]. |
| R2 Coefficient of Determination | The coefficient of determination is a performance metric for regression models which represent the squared correlation between the predicted and observed target variable. In its essence, it describes the magnitude of variation in the target variable values, which is explained by the predicted values of the latter. In multiple regression models, R2 corresponds to the squared correlation between the observed outcome values and the predicted values of the target variable [96,97]. The R2 is a scale-free metric with values ranging to 1, whereas the performance of the underlying model is positively correlated to the value of R2. RMSE compares predicted and actual values; however, it does not necessarily provide insights regarding the independent performance of a model. Therefore, it is a more appropriate measure for comparing the errors between two models. Unlike RMSE, the R2 metric can be used to infer the predictive accuracy of a model in percent [98]. However, a weakness of the R2 is that the scores improve with a growing number of predictor variables, thus encouraging overfitting, whereas the model is not improving. A remedy for this issue is in its improvement, the adjusted R2 (aR2) [99]. |
| aR2 Adjusted Coefficient of Determination | The aR2 adjusts the R2 by increasing number of predictors on which the model is trained. Therefore, the score only increases if the additionally added predictor variable is useful. Otherwise, it decreases. The aR2 therefore includes the number of observations (n) and the number of predictor (p) variables used in a model [99]. |
Appendix C
References
- Pfouga, A.; Stjepandić, J. Leveraging 3D CAD Data in Product Life Cycle: Exchange—Visualization—Collaboration. In Transdisciplinary Lifecycle Analysis of Systems Curran; Wognum, R., Borsato, N., Stjepandić, M., Verhagen, J., Wim, J.C., Eds.; IOS Press BV: Amsterdam, NL, USA, 2015; pp. 575–584. [Google Scholar]
- Algharabat, R.; Abdallah Alalwan, A.; Rana, N.P.; Dwivedi, Y.K. Three dimensional product presentation quality antecedents and their consequences for online retailers: The moderating role of virtual product experience. J. Retail. Consum. Serv. 2017, 36, 203–217. [Google Scholar] [CrossRef] [Green Version]
- Hamari, J.; Keronen, L. Why do people buy virtual goods: A meta-analysis. Comput. Hum. Behav. 2017, 71, 59–69. [Google Scholar] [CrossRef] [Green Version]
- Mystakidis, S. Metaverse. Encyclopedia 2022, 2, 486–497. [Google Scholar] [CrossRef]
- Shen, B.; Tan, W.; Guo, J.; Zhao, L.; Qin, P. How to Promote User Purchase in Metaverse? A Systematic Literature Review on Consumer Behavior Research and Virtual Commerce Application Design. Appl. Sci. 2021, 11, 11087. [Google Scholar] [CrossRef]
- Korbel, J.J. Creating the Virtual: The Role of 3D Models in the Product Development Process for Physical and Virtual Consumer Goods. In Innovation through Information Systems; Ahlemann, F., Schütte, R., Stieglitz, S., Eds.; Springer International Publishing: Cham, Switzerland, 2021; Volume 46, pp. 492–507. [Google Scholar] [CrossRef]
- Unity Asset Store. Available online: https://assetstore.unity.com/ (accessed on 14 December 2021).
- MakerBot Thingiverse. Available online: https://www.thingiverse.com/ (accessed on 14 December 2021).
- CGTrader Marketplace: The World’s Preferred Source for 3D Content. Available online: https://www.cgtrader.com/ (accessed on 17 December 2021).
- TurboSquid: 3D Models for Professionals. Available online: https://www.turbosquid.com/ (accessed on 17 December 2021).
- About Sketchfab: The Leading Platform for 3D & AR on the Web. Available online: https://sketchfab.com/about (accessed on 17 December 2021).
- Dolonius, D.; Sintorn, E.; Assarsson, U. UV-free Texturing using Sparse Voxel DAGs. Comput. Graph. Forum 2020, 39, 121–132. [Google Scholar] [CrossRef]
- Unity Manual: Materials. Available online: https://docs.unity3d.com/Manual/Materials.html (accessed on 17 December 2021).
- Pai, H.-Y. Texture designs and workflows for physically based rendering using procedural texture generation. In Proceedings of the IEEE Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 3–6 October 2019. [Google Scholar]
- Pan, J.J.; Yang, X.; Xie, X.; Willis, P.; Zhang, J.J. Automatic rigging for animation characters with 3D silhouette. Comput. Anim. Virt. Worlds 2009, 20, 121–131. [Google Scholar] [CrossRef]
- Arshad, M.R.; Yoon, K.H.; Manaf, A.A.A.; Mohamed Ghazali, M.A. Physical Rigging Procedures Based on Character Type and Design in 3D Animation. Int. J. Recent Technol. Eng. 2019, 8, 4138–4147. [Google Scholar]
- 3D Systems: What Is an STL File? Available online: https://www.3dsystems.com/quickparts/learning-center/what-is-stl-file (accessed on 10 December 2021).
- Autodesk: FBX. Available online: https://www.autodesk.com/products/fbx/overview (accessed on 10 December 2021).
- Israel, J.H.; Wiese, E.; Mateescu, M.; Zöllner, C.; Stark, R. Investigating three-dimensional sketching for early conceptual design—Results from expert discussions and user studies. Comput. Graph. 2009, 33, 462–473. [Google Scholar] [CrossRef]
- Park, H.; Moon, H.-C. Design evaluation of information appliances using augmented reality-based tangible interaction. Comput. Ind. 2013, 64, 854–868. [Google Scholar] [CrossRef]
- Riar, M.; Xi, N.; Korbel, J.J.; Zarnekow, R.; Hamari, J. Using augmented reality for shopping: A framework for AR induced consumer behavior, literature review and future agenda. Internet Res. 2022. [Google Scholar] [CrossRef]
- Smink, A.R.; Frowijn, S.; van Reijmersdal, E.A.; van Noort, G.; Neijens, P.C. Try online before you buy: How does shopping with augmented reality affect brand responses and personal data disclosure. Electron. Commer. Res. Appl. 2019, 35, 100854. [Google Scholar] [CrossRef]
- Fairfield, J.A.T. Virtual Property. Boston Univ. Law Rev. 2005, 85, 1047–1102. [Google Scholar]
- Lehdonvirta, V.; Wilska, T.-A.; Johnson, M. Virtual Consumerism: Case Habbo Hotel. Inf. Commun. Soc. 2009, 12, 1059–1079. [Google Scholar] [CrossRef]
- Adroit Market Research: Global Virtual Goods Market. Available online: https://www.adroitmarketresearch.com/industry-reports/virtual-goods-market (accessed on 11 October 2021).
- Animesh, A.; Pinsonneault, A.; Yang, S.B.; Oh, W. An Odyssey into Virtual Worlds: Exploring the Impacts of Technological and Spatial Environments on Intention to Purchase Virtual Products. MIS Q. 2011, 35, 789–810. [Google Scholar] [CrossRef] [Green Version]
- Cheung, C.M.K.; Shen, X.-L.; Lee, Z.W.Y.; Chan, T.K.H. Promoting sales of online games through customer engagement. Electron. Commer. Res. Appl. 2015, 14, 241–250. [Google Scholar] [CrossRef] [Green Version]
- Cleghorn, J.; Griffiths, M. Why do gamers buy ‘virtual assets’?: An insight in to the psychology behind purchase behaviour. Digit. Educ. Rev. 2015, 27, 91–110. [Google Scholar]
- Jiang, Z.; Benbasat, I. Virtual Product Experience: Effects of Visual and Functional Control of Products on Perceived Diagnosticity and Flow in Electronic Shopping. J. Manag. Inf. Syst. 2004, 21, 111–147. [Google Scholar] [CrossRef]
- Ke, D.; Ba, S.; Stallaert, J.; Zhang, Z. An Empirical Analysis of Virtual Goods Permission Rights and Pricing Strategies. Decis. Sci. 2012, 43, 1039–1061. [Google Scholar] [CrossRef]
- Mäntymäki, M.; Salo, J. Why do teens spend real money in virtual worlds? A consumption values and developmental psychology perspective on virtual consumption. Int. J. Inf. Manag. 2015, 35, 124–134. [Google Scholar] [CrossRef]
- Zhu, D.H.; Chang, Y.P. Effects of interactions and product information on initial purchase intention in product placement in social games: The moderating role of product familiarity. J Electr. Commer. Res. 2015, 16, 22–33. [Google Scholar]
- CGTrader Analytics. Available online: https://www.cgtrader.com/profile/analytics/about (accessed on 17 December 2021).
- CGTrader: What Price Should I Choose for My Models? Available online: https://help.cgtrader.com/hc/en-us/articles/360015209858-What-price-should-I-choose-for-my-models (accessed on 6 September 2021).
- Sketchfab: Seller Guidelines. Available online: https://help.sketchfab.com/hc/en-us/articles/115004276366-Seller-Guidelines (accessed on 2 September 2021).
- TurboSquid: Product Pricing Guidelines. Available online: https://resources.turbosquid.com/turbosquid/pricing/product-pricing-guidelines/ (accessed on 9 September 2021).
- Chung, H.M.; Gray, P. Special Section: Data Mining. J. Manag. Inf. Syst. 1999, 16, 11–16. [Google Scholar] [CrossRef]
- Alasadi, S.A.; Bhaya, W.S. Review of Data Preprocessing Techniques in Data Mining. J. Eng. Appl. Sci. 2017, 12, 4102–4107. [Google Scholar]
- Ge, Z.; Song, Z.; Ding, S.X.; Huang, B. Data Mining and Analytics in the Process Industry: The Role of Machine Learning. IEEE Access 2017, 5, 20590–20616. [Google Scholar] [CrossRef]
- Mughal, M.J.H. Data mining: Web data mining techniques, tools and algorithms: An overview. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 208–215. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Ge, Z.; Song, Z.; Gao, F. Review and big data perspectives on robust data mining approaches for industrial process modeling with outliers and missing data. Annu. Rev. Control 2018, 46, 107–133. [Google Scholar] [CrossRef]
- Chu, X.; Ilyas, I.F.; Krishnan, S.; Wang, J. Data cleaning: Overview and emerging challenges. In Proceedings of the 2016 International Conference on Management of data, San Francisco, CA, USA, 26 June 2016. [Google Scholar]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Jovic, A.; Brkic, K.; Bogunovic, N. A review of feature selection methods with applications. In Proceedings of the 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015. [Google Scholar]
- Zheng, A.; Casari, A. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists; O’Reilly Media: Sebastopol, CA, USA, 2018. [Google Scholar]
- Nguyen, G.; Dlugolinsky, S.; Bobák, M.; Tran, V.; López García, Á.; Heredia, I.; Malík, P.; Hluchý, L. Machine Learning and Deep Learning frameworks and libraries for large-scale data mining: A survey. Artif. Intell. Rev. 2019, 52, 77–124. [Google Scholar] [CrossRef] [Green Version]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: New York, NY, USA, 2016; pp. 1–7. [Google Scholar]
- Islam, M.D.; Li, B.; Islam, K.S.; Ahasan, R.; Mia, M.R.; Haque, M.E. Airbnb rental price modeling based on Latent Dirichlet Allocation and MESF-XGBoost composite model. Mach. Learn. Appl. 2022, 7, 100208. [Google Scholar] [CrossRef]
- Razavi, R.; Israeli, A.A. Determinants of online hotel room prices: Comparing supply-side and demand-side decisions. Int. J. Contemp. Hosp. Manag. 2019, 31, 2149–2168. [Google Scholar] [CrossRef]
- Chang, C.; Li, S. Study of price determinants of sharing economy-based accommodation services: Evidence from Airbnb.com. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 584–601. [Google Scholar] [CrossRef]
- Drobetz, W.; Otto, T. Empirical asset pricing via machine learning: Evidence from the European stock market. J. Asset Manag. 2021, 22, 507–538. [Google Scholar] [CrossRef]
- Gu, S.; Kelly, B.; Xiu, D. Empirical Asset Pricing via Machine Learning. Rev. Financ. Stud. 2020, 33, 2223–2273. [Google Scholar] [CrossRef] [Green Version]
- Bauer, J.; Jannach, D. Optimal pricing in e-commerce based on sparse and noisy data. Decis. Support Syst. 2018, 106, 53–63. [Google Scholar] [CrossRef]
- Greenstein-Messica, A.; Rokach, L. Machine learning and operation research based method for promotion optimization of products with no price elasticity history. Electron. Commer. Res. Appl. 2020, 40, 100914. [Google Scholar] [CrossRef]
- Chen, Z.; Li, C.; Sun, W. Bitcoin price prediction using machine learning: An approach to sample dimension engineering. J. Comput. Appl. Math. 2020, 365, 112395. [Google Scholar] [CrossRef]
- Sebastião, H.; Godinho, P. Forecasting and trading cryptocurrencies with machine learning under changing market conditions. Financ. Innov. 2021, 7, 3. [Google Scholar] [CrossRef]
- Wang, Q. Cryptocurrencies asset pricing via machine learning. Int. J. Data Sci. Anal. 2021, 12, 175–183. [Google Scholar] [CrossRef]
- Oviedo-Gómez, A.; Londoño-Hernández, S.M.; Manotas-Duque, D.F. Electricity Price Fundamentals in Hydrothermal Power Generation Markets using Machine Learning and Quantile Regression Analysis. Int. J. Energy Econ. Policy 2021, 11, 66–77. [Google Scholar] [CrossRef]
- Roozmand, O.; Nematbakhsh, M.A.; Baraani, A. An electronic marketplace based on reputation and learning. J. Theor. Appl. Electron. Commer. Res. 2007, 2, 1–17. [Google Scholar] [CrossRef]
- Kropp, L.A.; Korbel, J.J.; Theilig, M.-M.; Zarnekow, R. Dynamic Pricing of Product Clusters: A Multi-Agent Reinforcement Learning Approach. In Proceedings of the 27th European Conference on Information Systems (ECIS), Stockholm, Sweden, Uppsala, Sweden, 8–14 June 2019. [Google Scholar]
- Ma, Y.; Zhang, Z.; Ihler, A.; Pan, B. Estimating Warehouse Rental Price using Machine Learning Techniques. Int. J. Comput. Commun. Control 2018, 13, 235–250. [Google Scholar] [CrossRef] [Green Version]
- Hevner, A.R.; March, S.T.; Park, J.; Ram, S. Design Science in Information Systems Research. MIS Q. 2004, 28, 75–105. [Google Scholar] [CrossRef] [Green Version]
- Peffers, K.; Tuunanen, T.; Gengler, C.E.; Rossi, M.; Hui, W.; Virtanen, V.; Bragge, J. The design science research process: A model for producing and presenting information systems research. In Proceedings of the First International Conference on Design Science Research in Information Systems and Technology (DESRIST 2006), Claremont, CA, USA, 24–25 February 2006. [Google Scholar]
- Peffers, K.; Tuunanen, T.; Rothenberger, M.A.; Chatterjee, S. A Design Science Research Methodology for Information Systems Research. J. Manag. Inf. Syst. 2007, 24, 45–77. [Google Scholar] [CrossRef]
- Scrapy: An Open Source and Collaborative Framework for Extracting the Data You Need from Websites. Available online: https://scrapy.org/ (accessed on 13 June 2021).
- Pandas. Available online: https://pandas.pydata.org/ (accessed on 18 June 2021).
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M. seaborn: Statistical data visualization. J. Open Sour. Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Batista, G.E.A.P.A.; Monard, M.C. An analysis of four missing data treatment methods for supervised learning. Appl. Artif. Intell. 2003, 17, 519–533. [Google Scholar] [CrossRef]
- Pyle, D. Data Preparation for Data Mining; Morgan Kaufmann: San Francisco, CA, USA, 1999. [Google Scholar]
- Puth, M.-T.; Neuhäuser, M.; Ruxton, G.D. Effective use of Spearman’s and Kendall’s correlation coefficients for association between two measured traits. Anim. Behav. 2015, 102, 77–84. [Google Scholar] [CrossRef] [Green Version]
- De Winter, J.C.F.; Gosling, S.D.; Potter, J. Comparing the Pearson and Spearman correlation coefficients across distributions and sample sizes: A tutorial using simulations and empirical data. Psychol. Method. 2016, 21, 273–290. [Google Scholar] [CrossRef]
- Pandey, A.C.; Rajpoot, D.S.; Saraswat, M. Feature selection method based on hybrid data transformation and binary binomial cuckoo search. J. Ambient Intell. Hum. Comput. 2020, 11, 719–738. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Thaseen, I.S.; Kumar, C. Intrusion detection model using fusion of PCA and optimized SVM. In Proceedings of the International Conference on Contemporary Computing and Informatics (IC3I), Mysore, India, 27–29 November 2014. [Google Scholar]
- Cao, L.J.; Chua, K.S.; Chong, W.K.; Lee, H.P.; Gu, Q.M. A comparison of PCA, KPCA and ICA for dimensionality reduction in support vector machine. Neurocomputer 2003, 55, 321–336. [Google Scholar] [CrossRef]
- Flask: Web Development, One Drop at a Time. Available online: https://flask.palletsprojects.com (accessed on 15 July 2021).
- Afrianto, M.A.; Wasesa, M. Booking Prediction Models for Peer-to-peer Accommodation Listings using Logistics Regression, Decision Tree, K-Nearest Neighbor, and Random Forest Classifiers. J. Inf. Syst. Eng. Bus. Intell. 2020, 6, 123–132. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Feature Engineering and Selection: A Practical Approach for Predictive Models; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. Royal Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Lewis, R.J. An introduction to classification and regression tree (CART) analysis. In Proceedings of the Annual Meeting of the Society for Academic Emergency Medicine, San Francisco, CA, USA, 22–25 May 2000. [Google Scholar]
- Zhang, C.; Ma, Y. Ensemble Machine Learning: Methods and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Spedicato, G.A.; Dutang, C.; Petrini, L. Machine learning methods to perform pricing optimization: A comparison with standard GLMs. Variance 2018, 12, 69–89. [Google Scholar]
- Ali, J.; Khan, R.; Ahmad, N.; Maqsood, I. Random forests and decision trees. Int. J. Comput. Sci. Issues 2012, 9, 272–278. [Google Scholar]
- Mohd, T.; Masrom, S.; Johari, N. Machine learning housing price prediction in Petaling Jaya, Selangor, Malaysia. Int. J. Recent Technol. Eng. 2019, 8, 542–546. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Yaohao, P.; Albuquerque, P.H.M. Non-Linear Interactions and Exchange Rate Prediction: Empirical Evidence Using Support Vector Regression. Appl. Math. Financ. 2019, 26, 69–100. [Google Scholar] [CrossRef]
- Brassington, G. Mean absolute error and root mean square error: Which is the better metric for assessing model performance? In Proceedings of the EGU General Assembly Conference, Vienna, Austria, 23–28 April 2017.
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Bar-Lev, S.K.; Boukai, B.; Enis, P. On the mean squared error, the mean absolute error and the like. Commun. Stat. Theor. Method. 1999, 28, 1813–1822. [Google Scholar] [CrossRef]
- Huang, L.-S.; Chen, J. Analysis of variance, coefficient of determination and F-test for local polynomial regression. Ann. Stat. 2008, 36, 2085–2109. [Google Scholar] [CrossRef]
- Menard, S. Coefficients of Determination for Multiple Logistic Regression Analysis. Am. Stat. 2000, 54, 17–24. [Google Scholar]
- Botchkarev, A. Performance metrics (error measures) in machine learning regression, forecasting and prognostics Properties and typology. arXiv 2018, arXiv:1809.03006. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, A.K.; Srivastava, V.K.; Ullah, A. The coefficient of determination and its adjusted version in linear regression models. Econom. Rev. 1995, 14, 229–240. [Google Scholar] [CrossRef]

| Marketplace | Criteria | Pricing Guidelines |
|---|---|---|
| CGTrader [34] | Value for Buyers | “Consider the value your work brings to the buyer”. |
| Price Range | “Make sure you don’t underprice your model. Buyers might see it as a sign of poor quality”. | |
| Compatibility and Quality | “[…] make sure you provide a detailed description and preview images that showcase what distinguishes your model from the rest. That could be a large selection of file formats, high quality textures, optimization for games or VR/AR, etc.”. | |
| Sketchfab [35] | Value for Buyers | “Consider the value your work offers a potential customer”. |
| Price Range | “You can browse the store for similar models to guide your pricing decision”. “Be careful not to radically undercut the price of similar models on the store. This ultimately hurts all sellers by undermining the store economy”. “Low pricing can be interpreted by buyers as a sign of poor quality”. “Similarly, be aware that asking for significantly more than similar models from other contributors can lead to reduced sales”. | |
| Compatibility and Quality | “If you set a higher price than similar models from other sellers, use the model description to explain what distinguishes your model and adds to its value. For example, the inclusion of higher resolution textures or multiple file formats would be an added benefit”. | |
| Compatibility | “The more file formats you include, the more successful you will be”. “The ideal texture format for textures is PNG. Buyers will also appreciate the inclusion of Photoshop, Gimp, or similar editable layered files”. | |
| Quality | “A complete set of PBR textures (Albedo, Metallic, Roughness) and normal maps are desirable to buyers for contemporary game engines”. | |
| Animation | “Models with more animation states sell better”. “The success of animated models is often very rig dependent. Be sure to use our additional files feature to include rigged versions in popular software formats”. | |
| Turbosquid [36] | Price Range | “Setting your prices extremely low will not necessarily lead to better sales”. “Make sure you are pricing your models to achieve maximum sales and royalties. Look at comparable 3D models on the site to check their prices”. |
| Compatibility, Quality and Animation | “Realism” “File formats offered” “Texture/material/rigging settings” | |
| Complexity | “Complexity” “Poly count” |
| # | Process Step | Description |
|---|---|---|
| 1 | Problem identification and motivation | Three-dimensional models are widely used and gaining more significance through current technology trends; however, pricing determinants for virtual 3D assets are unknown and price predictions are therefore not feasible. |
| 2 | Objective of a solution | Identification of relevant price determinants and development of a price prediction model for virtual 3D assets. |
| 3 | Design and development | Dataset containing 135.384 3D model characteristics, univariate and bivariate analysis, feature engineering, and ML modelling. |
| 4 | Demonstration | Demonstration on the case of Sketchfab. |
| 5 | Evaluation | Evaluation of price determinants based on bivariate analysis, evaluation of ML models based on MAE, MSE, RMSE, R2, and aR2. |
| 6 | Communication | Front-end application for virtual 3D asset price prediction. |
| Feature | Data Type | Category | Description |
|---|---|---|---|
| model_price | float64 | Currency | Price of the 3D model in the Sketchfab store |
| 3d_model_size | float64 | Geometry | File size of the 3D model in Sketchfab format |
| face_count | float64 | Geometry | Number of faces in 3D model |
| lines | float64 | Geometry | Number of lines in 3D model |
| morph_geometries | float64 | Geometry | Number of morph geometries in 3D model |
| polygons_count | float64 | Geometry | Number of polygons in 3D model |
| points | float64 | Geometry | Number of points in 3D model |
| quads_count | float64 | Geometry | Number of quads in 3D model |
| total_triangles_count | float64 | Geometry | Number of total triangles in 3D model |
| triangles_count | float64 | Geometry | Number of triangles in 3D model |
| vertices_count | float64 | Geometry | Number of vertices in 3D model |
| materials_count | int64 | Appearance | Number of materials attached to the 3D model |
| pbr_type | String | Appearance | Physical based rendering characteristics (material) |
| textures_count | int64 | Appearance | Number of textures attached to the 3D model |
| total_texture_sizes | int64 | Appearance | File size of textures attached to 3D model |
| uv_layers | Boolean | Appearance | UV layers for texturing in 3D model |
| vertex_color | Boolean | Appearance | Vertex colors in 3D Model |
| animations_count | int64 | Animation | Number of animations attached to the 3D model |
| rigged_geometry | Boolean | Animation | Rig or “skeleton” of the 3D Model for animation |
| scale_transformation | Boolean | Configuration | Allows scale configuration of 3D model |
| file_format | String (Array) | Compatibility | 3D model file format |
| # | Numeric Feature | Mean | Std | Min | Max | 25% | 50% | 75% |
|---|---|---|---|---|---|---|---|---|
| F1 | model_price | 20,06 | 39,03 | 3,99 | 5.500,00 | 5,00 | 10,00 | 20,00 |
| F2 | 3d_model_size | 2.168,80 | 5.632,85 | 0,06 | 201.928,43 | 60,07 | 268,84 | 1.510,93 |
| F3 | face_count | 261.523,60 | 637.181,00 | 0,00 | 24.346.160,00 | 7.000,00 | 35.062,00 | 200.541,00 |
| F4 | lines | 78,68 | 4.024,83 | 0,00 | 565.115,00 | 0,00 | 0,00 | 0,00 |
| F5 | morph_geometries | 0,03 | 1,09 | 0,00 | 228,00 | 0,00 | 0,00 | 0,00 |
| F6 | polygons_count | 165,59 | 2.016,96 | 0,00 | 164.428,00 | 0,00 | 0,00 | 0,00 |
| F7 | points | 2.258,89 | 102.193,90 | 0,00 | 18.680.440,00 | 0,00 | 0,00 | 0,00 |
| F8 | quads_count | 59.432,71 | 225.627,90 | 0,00 | 9.387.565,00 | 0,00 | 873,00 | 16.585,00 |
| F9 | total_triangles_count | 261.523,20 | 637.183,70 | 0,00 | 24.346.160,00 | 7.000,00 | 35.056,00 | 200.541,00 |
| F10 | triangles_count | 141.452,10 | 464.422,70 | 0,00 | 24.346.160,00 | 116,00 | 3.384,00 | 50.000,00 |
| F11 | vertices_count | 142.457,40 | 357.146,80 | 0,00 | 12.529.260,00 | 3.805,00 | 18.804,00 | 108.254,00 |
| F12 | materials_count | 5,07 | 9,02 | 1,00 | 100,00 | 1,00 | 2,00 | 5,00 |
| F13 | textures_count | 6,48 | 11,97 | 0,00 | 443,00 | 1,00 | 4,00 | 6,00 |
| F14 | textures_mean_size | 3.898,17 | 7.611,02 | 0,00 | 203.399,44 | 168,90 | 1.292,63 | 4.262,19 |
| F15 | total_texture_sizes | 21.058,44 | 48.438,11 | 0,00 | 1.809.410,00 | 498,26 | 6.111,65 | 21.887,88 |
| F16 | animations_count | 0,34 | 3,80 | 0,00 | 312,00 | 0,00 | 0,00 | 0,00 |
| # | Categorical Feature | Values |
|---|---|---|
| C1 | pbr_type | none (84.099), metalness (42.506), specular (4.257) |
| C2 | uv_layers | true (121.518), false (9.344) |
| C3 | vertex_color | true (17.867), false (113.009) |
| C4 | rigged_geometry | true (8.096), false (122.766) |
| C5 | scale_transformation | true (5.862), false (125.000) |
| C6 | file_format_score | 1 file format (98.766), 2 file formats (19.649), 3 file formats (1.484), 4 file formats (3.452), 5 file formats (5.731), 6 file formats (1.307), 7 file formats (378), 8 file formats (26), 9 file formats (30), 10 file formats (22), 11 file formats (7), 12 file formats (3), 13 file formats (4), 14 file formats (2), and 15 file formats (1) |
| # | F1 | F2 | F3 | F6 | F8 | F9 | F10 | F11 | F12 | F13 | F14 | F15 | F16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | 1.00 | ||||||||||||
| F2 | 0.27 | 1.00 | |||||||||||
| F3 | 0.25 | 0.86 | 1.00 | ||||||||||
| F6 | 0.09 | 0.07 | 0.05 | 1.00 | |||||||||
| F8 | 0.12 | 0.21 | 0.26 | 0.40 | 1.00 | ||||||||
| F9 | 0.25 | 0.86 | 1.00 | 0.05 | 0.26 | 1.00 | |||||||
| F10 | 0.13 | 0.42 | 0.43 | −0.10 | −0.37 | 0.43 | 1.00 | ||||||
| F11 | 0.25 | 0.87 | 0.97 | 0.06 | 0.26 | 0.97 | 0.42 | 1.00 | |||||
| F12 | 0.17 | 0.21 | 0.21 | 0.28 | 0.28 | 0.21 | 0.04 | 0.22 | 1.00 | ||||
| F13 | 0.01 | −0.10 | −0.11 | 0.02 | 0.08 | −0.11 | −0.12 | −0.10 | 0.17 | 1.00 | |||
| F14 | −0.01 | −0.04 | −0.06 | −0.09 | −0.05 | −0.06 | −0.05 | −0.06 | −0.22 | 0.23 | 1.00 | ||
| F15 | 0.01 | −0.05 | −0.07 | −0.05 | 0.01 | −0.07 | −0.07 | −0.07 | −0.08 | 0.49 | 0.74 | 1.00 | |
| F16 | 0.07 | −0.04 | −0.08 | 0.04 | 0.04 | −0.08 | −0.04 | −0.08 | 0.05 | 0.04 | 0.02 | 0.03 | 1.00 |
| Model | Measure | MAE | MSE | RMSE | R2 | aR2 |
|---|---|---|---|---|---|---|
| Multiple Linear Regression | Mean | 10,640 | 444,019 | 21,069 | 0,146 | 0,144 |
| Min | 10,361 | 415,259 | 20,378 | 0,136 | 0,135 | |
| Max | 10,876 | 464,671 | 21,556 | 0,152 | 0,150 | |
| Ridge Regression | Mean | 10,640 | 443,999 | 21,068 | 0,146 | 0,144 |
| Min | 10,350 | 416,388 | 20,406 | 0,139 | 0,137 | |
| Max | 10,946 | 471,101 | 21,705 | 0,150 | 0,148 | |
| Lasso Regression | Mean | 11,892 | 375,045 | 19,363 | 0,278 | 0,276 |
| Min | 11,571 | 351,201 | 18,740 | 0,256 | 0,254 | |
| Max | 12,206 | 398,541 | 19,963 | 0,293 | 0,291 | |
| Decision Tree Regression | Mean | 10,010 | 347,412 | 18,637 | 0,331 | 0,331 |
| Min | 9,838 | 334,153 | 18,280 | 0,305 | 0,304 | |
| Max | 10,256 | 364,986 | 19,105 | 0,362 | 0,362 | |
| Random Forest Regression | Mean | 8,085 | 190,706 | 13,808 | 0,633 | 0,633 |
| Min | 8,012 | 182,984 | 13,527 | 0,627 | 0,627 | |
| Max | 8,222 | 197,737 | 14,062 | 0,637 | 0,637 | |
| Extreme Gradient Boosting Trees | Mean | 8,150 | 195,784 | 13,991 | 0,623 | 0,623 |
| Min | 8,128 | 190,339 | 13,796 | 0,615 | 0,615 | |
| Max | 8,215 | 203,181 | 14,254 | 0,630 | 0,630 | |
| Support Vector Regression | Mean | 7,467 | 202,967 | 14,247 | 0,610 | 0,603 |
| Min | 7,454 | 198,627 | 14,093 | 0,598 | 0,597 | |
| Max | 7,489 | 206,655 | 14,375 | 0,621 | 0,620 |
| Feature Set | MAE | MSE | RMSE | R2 | aR2 |
|---|---|---|---|---|---|
| Full Feature Set | 8,085 | 190,706 | 13,808 | 0,633 | 0,633 |
| Reduced Feature Set | 8,097 | 191,305 | 13,830 | 0,632 | 0,632 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Korbel, J.J.; Siddiq, U.H.; Zarnekow, R. Towards Virtual 3D Asset Price Prediction Based on Machine Learning. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 924-948. https://doi.org/10.3390/jtaer17030048
Korbel JJ, Siddiq UH, Zarnekow R. Towards Virtual 3D Asset Price Prediction Based on Machine Learning. Journal of Theoretical and Applied Electronic Commerce Research. 2022; 17(3):924-948. https://doi.org/10.3390/jtaer17030048
Chicago/Turabian StyleKorbel, Jakob J., Umar H. Siddiq, and Rüdiger Zarnekow. 2022. "Towards Virtual 3D Asset Price Prediction Based on Machine Learning" Journal of Theoretical and Applied Electronic Commerce Research 17, no. 3: 924-948. https://doi.org/10.3390/jtaer17030048
APA StyleKorbel, J. J., Siddiq, U. H., & Zarnekow, R. (2022). Towards Virtual 3D Asset Price Prediction Based on Machine Learning. Journal of Theoretical and Applied Electronic Commerce Research, 17(3), 924-948. https://doi.org/10.3390/jtaer17030048