Professionalization of Online Gaming? Theoretical and Empirical Analysis for a Monopoly-Holding Platform



{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Relevant Literature Focused on a Societal Approach: Two-Sided Markets and Salesforce Compensation
1.2. Research Objectives and Main Results
- RQ1. Which impact does the presence of uncertainty on the number of agents that join the monopoly-holding platform in both sides of the market have on equilibrium outcomes?
- RQ2. How does the asymmetric gap between indirect network effects influence the compensation plan developed by the principal and the managerial effort spent by the agent?
- RQ3. Can social welfare enhance with increasing membership in the online gaming industry? If so, under which market conditions?
2. Method
2.1. Demand Side
2.2. Supply Side
2.3. Managerial Compensation and Effort
2.4. Profit, Surpluses, Social Welfare, and Timing Structure
3. Analysis
3.1. Market Participation Stage
3.2. Managerial Effort Stage
3.3. Compensation Plan Stage
3.3.1. Market Environment Characterized by Indirect Network Effects
3.3.2. Comparison of Effectiveness and Risk with Markets Absent of Indirect Network Effects
3.3.3. Remaining Outcomes and the Role of Cross-Group Network Externalities on Profit
- (I)
- For each individual component:
- −
- is positively affected by both cross-group network externalities (i.e.,).
- −
- is positively influenced by the cross-group network externality on online gamers (i.e., ), while being either positively or negatively influenced by the cross-group network externality affecting viewers according to the following rule of inequalities
- (II)
- In aggregate terms:
- −
- Profit is unambiguously influenced by the cross-group network externality exerted on online gamers (i.e., ).
- −
- Profit can be either positively or negatively affected by the cross-group network externality exerted on viewers (i.e., holds).
3.4. Viewers Pricing Stage
4. Results
4.1. Subgame Perfect Nash Equilibrium
4.2. Impact of Cross-Group Network Externalities on the Viewer’s Price
- (I)
- For the cross-group network externality exerted by online gamers on viewers:otherwise holds.
- (II)
- For the cross-group network externality exerted by viewers on online gamers:otherwise holds, with
4.3. Impact of the Asymmetric Gap between Indirect Network Effects on the Compensation Plan
- (I)
- In the absence of bilateral demand uncertainty:
- (II)
- Under the presence of uncertainty in the number of active viewers:
- (III)
- Under the presence of uncertainty in the number of active online gamers:
4.4. Managerial Reaction to the Asymmetric Gap between Indirect Network Effects
4.5. Market Shares, Cross-Group Network Externalities, and Membership Uncertainty
- (I)
- On the side of viewers:
- (II)
- On the side of online gamers:
5. Surplus Enjoyed by Each Side of the Market and Intermediation Profit
5.1. Theoretical Outcome
- (I)
- The impact of on ( and is ambiguous, but opposite (equivalent) in terms of sign to that holding for , respectively.
- (II)
- The impact of on and is strictly positive.
5.2. Empirical Validation
5.2.1. Data
5.2.2. Identification Strategy
5.2.3. Results
Principal Component Analysis
Least Absolute Shrinkage and Selection Operator
Continual Learning
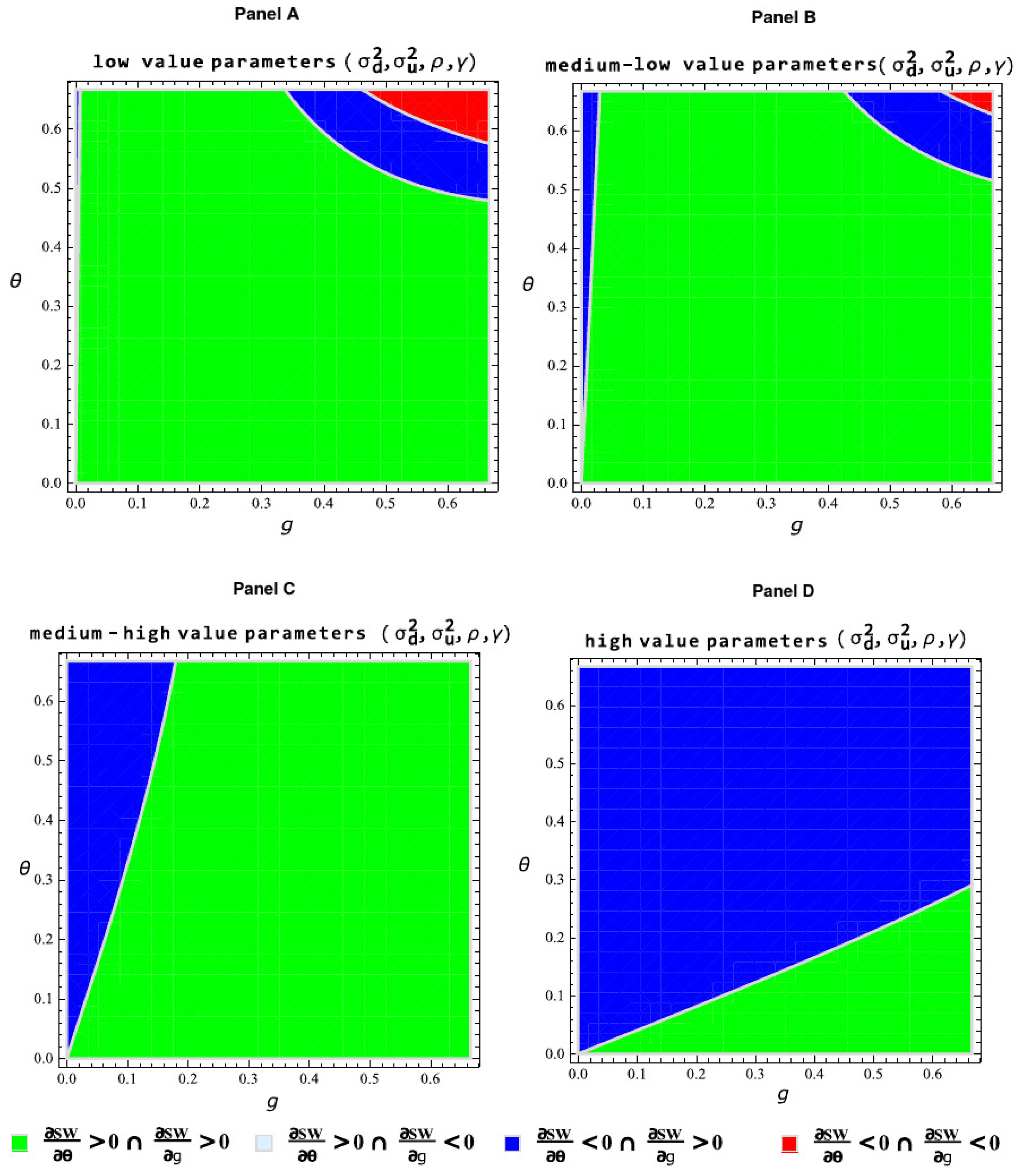
6. Cross-Group Network Externalities and Social Welfare
6.1. Impact
- −
- Social welfare unambiguously decreases for increasing and as long as both parameters are sufficiently strong. In other words, if the degree of attraction of members from a given side by members of the opposite side is already considerably high, then a higher intensity in both indirect network effects harms social welfare.
- −
- Social welfare can decrease (increase) for increasing ( as long as both parameters are neither excessively strong nor too weak.
- −
- The asymmetric case characterized by the rise (reduction) of social welfare for increasing ( never holds in equilibrium.
- −
- Social welfare enhances with increasing and as long as both parameters are sufficiently weak. In other words, if the degree of attraction of members from a given side by members of the opposite side is not excessively high, then a higher intensity in both indirect network effects improves social welfare.
6.2. Discussion
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Limelight. White Paper Report on the State of Online Gaming in 2019. Available online: https://www.limelight.com/resources/white-paper/state-of-online-gaming-2019/ (accessed on 28 June 2020).
- Gan, C. Understanding WeChat users’ liking behavior: An empirical study in China. Comp. Hum. Behav. 2017, 68, 30–39. [Google Scholar] [CrossRef]
- Sintas, J.L.; Belbeze, M.P.L.; Lamberti, G. Socially Patterned Strategic Complementarity between Offline Leisure Activities and Internet Practices among Young People. Leis. Sci. 2020, in press. [Google Scholar] [CrossRef]
- Analytis, P.P.; Wu, C.M.; Gelastopoulos, A. Make-or-Break: Chasing Risky Goals or Settling for Safe Rewards? Cogn. Sci. 2019, 43, e12743. [Google Scholar] [CrossRef]
- Cooper, K.B.; Schneider, H.S.; Waldman, M. Limited rationality and the strategic environment: Further theory and experimental evidence. Games Econ. Behav. 2017, 106, 188–208. [Google Scholar] [CrossRef]
- Markey, P.M.; Markey, C.N.; French, J.E. Violent video games and real-world violence: Rhetoric versus data. Psychol. Popul. Media Cult. 2015, 4, 277–295. [Google Scholar] [CrossRef]
- Bloomberg. China Just Became the 2017 Games Industry Capital of the World. Available online: https://www.bloomberg.com/news/articles/2017-06-01/china-just-became-the-games-industry-capital-of-the-world (accessed on 1 June 2020).
- World Health Organization. Gaming Disorder. Available online: https://www.who.int/news-room/q-a-detail/gaming-disorder (accessed on 10 July 2020).
- World Health Organization. ICD-11 for Mortality and Morbidity Statistics: 2019 Report. Available online: https://icd.who.int/browse11/l-m/en (accessed on 10 July 2020).
- Xiao, L.Y. People’s Republic of China Legal Update: The Notice on the Prevention of Online Gaming Addiction in Juveniles. Gaming Law Rev. 2020, 24, 51–53. [Google Scholar] [CrossRef]
- Kreps, D.M.; Wilson, R. Reputation and imperfect information. J. Econ. Theory 1982, 27, 253–279. [Google Scholar] [CrossRef]
- Rochet, J.C.; Tirole, J. Platform competition in two-sided markets. J. Eur. Econ. Assoc. 2003, 1, 990–1029. [Google Scholar] [CrossRef]
- Armstrong, M. Competition in two-sided markets. RAND J. Econ. 2006, 37, 668–691. [Google Scholar] [CrossRef]
- Thomes, T.P. In-house publishing and competition in the video game industry. Inf. Econ. Policy 2015, 32, 46–57. [Google Scholar] [CrossRef]
- Ribeiro, V.M. Apple’s disaster: Linking two-sided markets and strategic delegation. Manag Decis. Econ. 2018, 39, 32–45. [Google Scholar] [CrossRef]
- Coughlan, A.T.; Joseph, K. Sales force compensation: Research insights and research potential. In Handbook of Business-to-Business Marketing, 1st ed.; Lilien, G.L., Grewal, R., Eds.; Edward Elgar Publishing: Cheltenham, UK, 2012; Volume 26, pp. 473–495. [Google Scholar]
- Mehra, A.; Paul, J.; Kaurav, S. Determinants of mobile apps adoption among young adults: Theoretical extension and analysis. J. Mark. Commun. 2020, 1–29. [Google Scholar] [CrossRef]
- Kim, W.; Kankanhalli, A.; Lee, L. Investigating decision factors in mobile application purchase: A mixed-methods approach. Inf. Manag. 2016, 53, 727–739. [Google Scholar] [CrossRef]
- Hölmstrom, B. Moral hazard and observability. Bell J. Econ. 1979, 10, 74–91. [Google Scholar] [CrossRef]
- Basu, A.K.; Lal, R.; Srinivasan, V.; Staelin, R. Salesforce compensation plans: An agency theoretic perspective. Mark. Sci. 1985, 4, 267–291. [Google Scholar] [CrossRef]
- Albers, S. Optimization models for salesforce compensation. Eur. J. Oper. Res. 1996, 89, 1–17. [Google Scholar] [CrossRef]
- Roger, G.; Vasconcelos, L. Platform pricing structure and moral hazard. J. Econ. Manag. Strat. 2014, 23, 527–547. [Google Scholar] [CrossRef]
- Querbes, A. Banned from the sharing economy: An agent-based model of a peer-to-peer marketplace for consumer goods and services. J. Evol. Econ. 2018, 28, 633–665. [Google Scholar] [CrossRef]
- Saghafian, S.; Chao, X. The impact of operational decisions on the design of salesforce incentives. Nav. Res. Logist. 2014, 61, 320–340. [Google Scholar] [CrossRef]
- Dutta, A. Impact of Electronic Servicescape of Online Gaming on Customer Engagement. J. Electron. Commer. Organ. 2020, 18, 49–63. [Google Scholar] [CrossRef]
- Srauy, S. Professional norms and race in the North American video game industry. Games Cult. 2019, 14, 478–497. [Google Scholar] [CrossRef]
- Bhargava, H.K.; Rubel, O. Salesforce compensation design for two-sided market platforms. J. Mark. Res. 2019, 56, 666–678. [Google Scholar] [CrossRef]
- Hawi, N.S.; Samaha, M.; Griffiths, M.D. Internet gaming disorder in Lebanon: Relationships with age, sleep habits, and academic achievement. J. Behav. Addict. 2018, 7, 70–78. [Google Scholar] [CrossRef] [PubMed]
- Hawi, N.S.; Samaha, M.; Griffiths, M.D. The Digital Addiction Scale for Children: Development and Validation. Cyberpsychol. Behav. Soc. Netw. 2019, 22, 771–778. [Google Scholar] [CrossRef]
- Ko, C.H.; Lin, H.C.; Lin, P.C.; Yen, J.Y. Validity, functional impairment, and complications related to Internet gaming disorder in the DSM-5 and gaming disorder in the ICD-11. Aust. N. Z. J. Psychiatry 2020, 54, 707–718. [Google Scholar] [CrossRef]
- Morrison, J. Scroungers: Moral Panics and Media Myths, 1st ed.; Zed Books Ltd.: London, UK, 2019. [Google Scholar]
- Stehmann, J. Identifying research streams in online gambling and gaming literature: A bibliometric analysis. Comp. Hum. Behav. 2020, 107, 106219. [Google Scholar] [CrossRef]
- Wang, Q.; Ren, H.; Long, J.; Liu, Y.; Liu, T. Research progress and debates on gaming disorder. Gen. Psychiatry 2019, 32, e100071. [Google Scholar] [CrossRef]
- Goff, B.G.; Boles, J.S.; Bellenger, D.N.; Stojack, C. The influence of salesperson selling behaviors on customer satisfaction with products. J. Retail. 1997, 73, 171–183. [Google Scholar] [CrossRef]
- Misra, S.; Coughlan, A.T.; Narasimhan, C. Salesforce compensation: An analytical and empirical examination of the agency theoretic approach. Quant. Mark. Econ. 2005, 3, 5–39. [Google Scholar] [CrossRef]
- Katz, M.L.; Shapiro, C. Product compatibility choice in a market with technological progress. Oxf. Econ. Pap. 1986, 38, 146–165. [Google Scholar] [CrossRef]
- Twitch. Joining the Affiliate Program: Twitch Help Supporting Blog. Available online: https://help.twitch.tv/s/article/joining-the-affiliate-program?language=en_US (accessed on 10 June 2020).
- Pomponi, J.; Scardapane, S.; Lomonaco, V.; Uncini, A. Efficient continual learning in neural networks with embedding regularization. Neurocomputing 2020, 397, 139–148. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ribeiro, V.M.; Bao, L. Professionalization of Online Gaming? Theoretical and Empirical Analysis for a Monopoly-Holding Platform. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 682-708. https://doi.org/10.3390/jtaer16040040
Ribeiro VM, Bao L. Professionalization of Online Gaming? Theoretical and Empirical Analysis for a Monopoly-Holding Platform. Journal of Theoretical and Applied Electronic Commerce Research. 2021; 16(4):682-708. https://doi.org/10.3390/jtaer16040040
Chicago/Turabian StyleRibeiro, Vitor Miguel, and Lei Bao. 2021. "Professionalization of Online Gaming? Theoretical and Empirical Analysis for a Monopoly-Holding Platform" Journal of Theoretical and Applied Electronic Commerce Research 16, no. 4: 682-708. https://doi.org/10.3390/jtaer16040040
APA StyleRibeiro, V. M., & Bao, L. (2021). Professionalization of Online Gaming? Theoretical and Empirical Analysis for a Monopoly-Holding Platform. Journal of Theoretical and Applied Electronic Commerce Research, 16(4), 682-708. https://doi.org/10.3390/jtaer16040040