1. Introduction
In recent years, the rapid development of e-commerce has brought about an explosive growth in online product reviews. When consumers shop online, they pay special attention to the product evaluations from other consumers. In this context, online product reviews have gradually become an online reputation system for e-commerce enterprise. However, as the number of online reviews increases exponentially, the quality of online reviews has become increasingly uneven. It is increasingly difficult and time-consuming for consumers to find helpful review information and for e-commerce enterprises to manage this increasingly massive number of reviews. It is well-known that helpful online reviews form an important element for e-commerce communities, which are embedded with valuable information influencing consumer purchases [
1,
2]. Moreover, helpful product reviews are relevant to all stakeholders in the online review community, such as consumers, suppliers, retailers, and community platforms. Therefore, the ability to find helpful reviews and conduct causal analysis are common priorities both in industrial and academic fields. In order to more effectively extract valuable information from the vast number of online reviews, both industry and academia have made great efforts to improve the detection methods for helpful reviews. Although the existing statistical learning methods have a high detection rate for the detection of helpful reviews, they are still difficult to use to obtain reasonable explanations for the main causes and mechanisms underlying the occurrence of helpful reviews. Based on this context, we propose a feature contribution-driven analysis framework for review helpfulness. Our research thoroughly analyzes the formation mechanism of helpful reviews and proposes a corresponding detection method. On the one hand, the proposed method could alleviate the overload pressure caused by massive numbers of online reviews for consumers and enterprises. On the other hand, it provides a useful reference for the e-commerce online community to carry out the task of improving online review governance and optimizing the recommendation mechanism of online review information.
Toward the question of how to determine review helpfulness, a commonly used method for most e-commerce websites is to set up the ‘helpful votes’ function under each product review. Then, readers’ votes are accumulated and utilized to distinguish between helpful and unhelpful reviews. Since such a manual method requires not only a certain amount of time to accumulate ‘helpful votes’, but also to overcome the evaluation bias during the collection of ‘helpful votes’, a modeling method is often a preferred solution for this problem [
3,
4,
5].
Considerable relevant research regards “whether a review is helpful” as a classification problem, which requires extracting possible features from ‘labeled review’ as an input, and building a prediction model for an ‘unlabeled review’ combined with a classification algorithm. In the absence of a unified feature extraction standard that can be used to represent a review, researchers commonly extract as many different features as possible to improve the prediction performance to the maximum extent.
In this process, features that improve the performance of a prediction model are chosen as valuable features, which serve as the basis for interpreting which features affect review helpfulness. It is not hard to see such a ‘model-based interpretation’ is inadequate to some extent, since most commonly used models are ‘black-box’ models, which leaves some unsolved problems to be tackled.
First, when determining key features based on changes in model performance, there is a range of performance indicators to choose from, such as accuracy, recall, F1-measure, auc, and so on. Key features can also be determined using feature selection methods that come with some tree-based models, such as a Gini impurity decrease or counts of splits of features in trees. Obviously, if the key features incorporated into a model are inconsistent under different evaluation indicators, then the results of a review helpfulness interpretation are not convincing. However, this not-ideal outcome has occurred in most relevant and practical cases thus far, as the features selected by different evaluation indicators are inconsistent. Therefore, we need a more stable and consistent approach to discover the value of features in online product reviews.
Second, it is not clear how various input features should be combined to obtain the prediction result, so it is difficult to quantify the contribution of each feature in a model. Although some tree-based models automatically attribute results to feature importance, it is important to note that ‘feature importance’ is not the same as ‘feature contribution’. The former highlights which features affect model performance, while the latter not only highlights the affecting features, but also directly quantifies the contribution of each feature to the prediction result. In contrast to ‘feature importance’, ‘feature contribution’ provides a more intuitive explanation of why a review is helpful.
Third, in practice, various review features, such as many kinds of text or reviewer features, need to be extracted and put into a ‘black-box model’ to ensure an accurate prediction result is obtained. Inevitably, features interact with each other to influence prediction results. The existing traditional models require predefined feature interaction items and lack the ability to automatically capture any interaction between different features. Therefore, in the related research on review helpfulness prediction, only a few studies involve analyzing the influences of feature interaction items on prediction results.
In this paper, we turned to the recently proposed SHAP (Shapley) values method [
6,
7] and gradient boosting trees (GBT) models to fill in the research gaps outlined above. The SHAP values method is a feature attribution method which assigns to each feature a value for a particular prediction, which is helpful for interpreting the prediction result. The method notably provides a strict theoretical improvement from the classic Shapley Value estimation method [
8] by ensuring that there is feature consistency and model stability. On the other hand, GBT models such as gradient boosting decision trees (GBDT) [
9], eXtreme Gradient Boosting(XGBoost) [
10], or Light Gradient Boosting Machine(LightGBM) [
11] have been widely applied in various fields such as credit scoring [
12] and transportation modes identification [
13] in recent years. In addition to having a prediction accuracy advantage, GBT models also possess the benefits of capturing interactions among features without explicitly defining them. Therefore, by combining the SHAP values method with GBT models, it is possible to provide a detailed explanation of why a review is helpful.
We chose two different types of product reviews from Amazon.cn—on headsets and facial cleansers—as our experiment datasets. Based on the information quality theory, we first used a variety of text analysis techniques to extract three dimensions of text features, namely, readability, reliability, and relevancy. In addition, we added important features from reviewers and metadata to ensure feature diversity. Then, we constructed a set of GBT models and multiple sets of baseline ensemble models on the extracted features. Through multiple inter-group and intra-group comparative experiments, we chose the optimal model, XGBoost, as our experimental analysis model. Moreover, we verified the validity of the extracted features through detailed comparative experiments. Based on such comparative experiments, we presented the global contribution and joint feature contribution for a feature on these two kinds of datasets from a global and an individual view, respectively. The experiment results not only explained review helpfulness in detail on both the macro and micro levels, but also helped to comparatively analyze the differences between different product types for understanding review helpfulness.
The remainder of this research is organized as follows. Related work is presented in
Section 2.
Section 3 describes the research methodology in detail. Then,
Section 4 presents the experiment set-up and is followed by
Section 5, which presents the results of the experiments.
Section 6 discusses the results and findings of the research. Last,
Section 7 provides the conclusions, implications, and limitations of this research.
2. Literature Review
2.1. Review Feature Extraction
Heterogeneous features have often been examined by prior research, such as text-related features, reviewer-related features, or metadata features.
Text-related features are commonly extracted from different dimensions of review text with various text analysis techniques [
14], such as subjectivity [
15,
16], linguistics [
16,
17], readability [
16,
18], relevancy [
19], sentiment [
20,
21], as well as explained actions and reactions [
22]. Chen et al. [
15] consider implicit information hidden in the text and take several features into consideration, including a mixture of subjectivity and objectivity. Krishnamoorthy [
16] describes a novel method used to automatically extract linguistic features from review texts, and their research results show that linguistic features are better predictors of review helpfulness compared to review metadata, subjectivity, and readability for experiential goods. According to Hu et al. [
17], the number of words is a key predictor of helpfulness across three user-controllable filters. Akbarabadi et al. [
18] examine the effect of review title features on predicting the helpfulness of online reviews, but they imply that the title characteristics cannot be powerful determinants of online review helpfulness. Chen et al. [
19] treat a review as an information item and adopt an IQ framework for feature extraction, which adds evidence to the results that text relevancy facilitates decision-making. Many studies investigate the impacts of sentiment factors on the helpfulness of reviews. Both the findings of [
20,
21] show that sentiment or expressed emotional arousal in the text affects readers’ perceptions of review helpfulness. Different from the above studies which analyze review text directly, Moore [
22] focuses on what individuals explain in reviews, and reveals that actions explanations are more helpful than reactions explanations for utilitarian products.
Reviewer-related features often include the number of reviews posted by specific reviewers [
23], or social and reputation features [
24]. Zhang et al. [
23] consider both reviewer data and metadata are necessary supplements in building helpfulness prediction model, and thus extract the number of reviews posted by specific reviewers in the past and the grade of reviewers to represent reviewer features. Aghakhani et al. [
24] identify source credibility as theoretically important variables that affect electronic Word of Mouth(eWOM) adoption on Facebook.
Metadata features are the descriptions of a review itself, such as review rating [
17], or review published date [
16]. The findings of [
17] verify that review rating is a key predictor of review helpfulness. Krishnamoorthy [
16] also includes review metadata features in their model for helpfulness prediction.
2.2. Review Helpfulness Prediction Models
Prior studies mainly take advantage of machine learning methods to build review helpfulness prediction models, which treat review helpfulness prediction as a binary classification or a multivariate classification problem. On the basis of feature extraction and feature representation on an annotated review dataset, a specific feature selection method is used to identify the optimal feature set and obtain the optimal classification model. Traditional machine learning methods are widely used in building helpfulness prediction models, such as support vector machine(SVM) [
16,
19], support vector regression(SVR) [
23,
25], logistic regression(LR) [
26,
27], decision tree(DT) [
23,
28], and ensemble learning models such as random forest(RF) [
16,
29], bagging classifier [
28], or GBDT [
20]. Among them, tree ensemble models like random forest or ExtraTrees are considered to be more effective when compared to SVM or LR [
16,
29]. Recently, popular deep learning models have also been used to predict review helpfulness [
3].
In addition to machine learning methods, econometric regression methods are also employed by researchers. Relevant research mostly uses helpful voting information as dependent variable and text or reviewer features as independent variables to build an econometric model for review helpfulness assessment. By analyzing the statistically significant relationships between independent and dependent variables, the influences of review features on review helpfulness are obtained. Commonly used econometric models include multiple regression [
15,
30,
31], Tobit regression [
32], and negative binomial regression [
33].
Comparatively, the goal of machine learning methods is to extract as many feature items into a model as possible to improve the performance of prediction models. Therefore, machine learning methods bring more accurate prediction results. However, since traditional machine learning models are mostly black-box models, there are still some deficiencies for the identification and interpretation of key features in the models. As for econometric regression methods, the emphasis is to investigate the degree of consistency and the statistical hypothesis between the independent variables and the dependent variable; thus, the number of independent variables is very limited. Although econometric regression methods are more effective for explaining the helpfulness result and finding the key independent variables, the prediction accuracy for review helpfulness is not high due to the strict test hypotheses.
2.3. Interpretation of Review Helpfulness
The purpose of interpreting review helpfulness is to identify key features and to measure the extent to which these key features affect review helpfulness. Therefore, the key features need to be selected by ranking the importance of each extracted feature according to a specific feature engineering method. Existing studies have adopted many different methods to analyze and understand the importance of all kinds of review features on review helpfulness, such as the recursive feature elimination (RFE) method based on the performance comparison on helpfulness prediction models, the feature interpretation method based on the model itself like GBDT or RandForest, mutual information method, or principal component analysis (PCA).
Malik et al. [
34] make use of MSE, RMSE, and RRSE-based error metrics with 10-fold cross-validation to compare model performances and conduct feature selection, in which MSE metric is finally used to measure feature importance. Singh et al. [
20] use the GBDT model to predict review helpfulness, and they employ the feature importance metric from GBDT itself to identify key features. Zhang et al. [
23] apply recursive elimination of features to infer the most predictable features on review helpfulness based on model performance metrics such as MAE or RMSE, and ten features covering review text and metadata are finally chosen as predictors of review helpfulness. Liu et al. [
28] choose mutual information and principal component analysis to explore the utilization of all the features, and they present two different feature sets as the informative features on review helpfulness. In addition, Ghose et al. [
29] employ a random forest classifier and three broad categories of features named as reviewer-related features, review subjectivity features, and review readability features for review helpfulness estimation, revealing that using any of such three categories of features can result in a statistically equivalent performance as in the case of using all the available features.
The above studies indicate that the opinions on how to interpret review helpfulness are inconsistent. There are still great uncertainties in identifying affecting features in review helpfulness whether based on the model performance indicators or combined with specific feature engineering methods.
2.4. Research Gap
Although review helpfulness prediction is a hot research issue at present, at least one of the following areas still needs to be improved.
First, most studies extract features from different factors such as text, reviewer, or metadata to represent review helpfulness, but they lack supporting theory basis for explaining why these features are needed to be extracted, especially from the consumers’ perspective. In particular, since review text is important unstructured information, a more detailed analysis on how to determine the unified feature forms of the review text is needed. Based on the relevant research, information quality theory provides a good theoretical basis for feature extraction of online reviews. Therefore, it is necessary to reanalyze and redesign the feature forms of on reviews under the information quality theory basis.
Second, although traditional machine learning methods can obtain better performance for review helpfulness prediction, their ability of feature selection and feature interpretation are still weak. Common feature selection methods, such as Gini impurity, PCA, RFE, or MSE/RMS/RRSE based error metrics in different application fields, are not robust enough in relevant research. In particular, these methods fail to provide a consistent feature interpretation result, which leads to inconsistent conclusions about key features affecting review helpfulness. Therefore, improvements in predictive performance and interpretation ability of helpfulness prediction models need to be solved simultaneously.
Third, review helpfulness has not been well understood yet. Existing research mainly focuses on the identification of key features that influence review helpfulness, but seldom introduces the discussion of quantifying the contributions of the key features. In fact, feature contribution is more beneficial for us to identify key affecting features and understand how the key features influence review helpfulness from both the whole and individual view. Meanwhile, the interactions between key features have not been considered in detail in the helpfulness prediction models on reviews. Therefore, it is of great importance to develop an integrated feature interpretation framework on review helpfulness to solve such important questions.
3. Methodology
3.1. Basic Procedure of the Proposed Framework
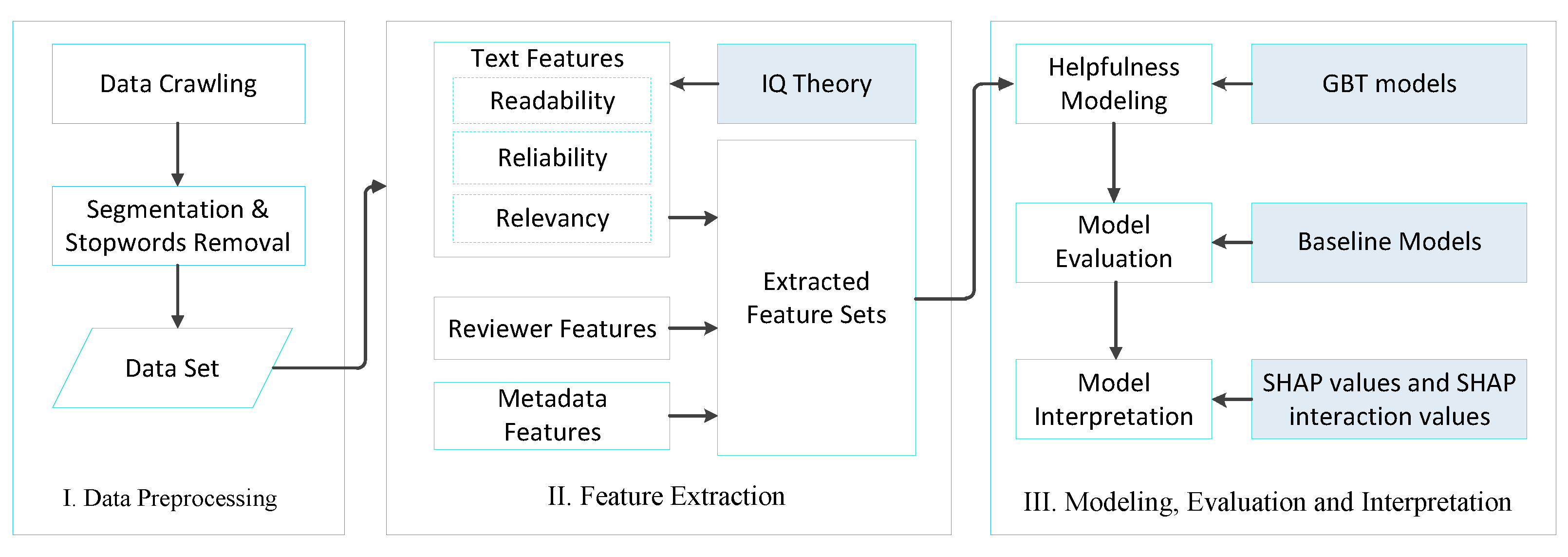
To conduct an integrated interpretation framework for review helpfulness, we subdivided the procedure into several major parts as shown in
Figure 1: (1) data preprocessing; (2) feature extraction; (3) review helpfulness modeling, evaluation, and interpretation.
3.2. Data Preprocessing
Product reviews and relevant data from Amazon.cn are crawled to construct the experimental data. At the data preprocessing stage, the main work includes sentence segmentation, word segmentation, and stopwords removal. It should be noted that Chinese product reviews include both Chinese and English punctuation marks. Thus, based on the sampling statistics of 15,370 Chinese review, the punctuation marks set of sub-sentences is determined, in which the Chinese punctuation marks include ‘, 。! ? ; …… () 『』《》【】’ and English punctuation marks include ‘,.!?;()~{}<>[]’. At the same time, we identified other meaningless punctuation marks in the reviews, such as ‘[“#$%&\’*+/:=@\\^_‘|、:“”·‘’=╯▽╰╮╭]’, which can be removed using the regular expression rules. Then, reviews are broken down into sub-sentences for word segmentation and stopwords removal.
3.3. Feature Extraction
This section begins by discussing the core dimensions of review text-related features. Then, it introduces the features extraction of context cues, including reviewer and metadata.
3.3.1. Text Features Based on Information Quality Theory
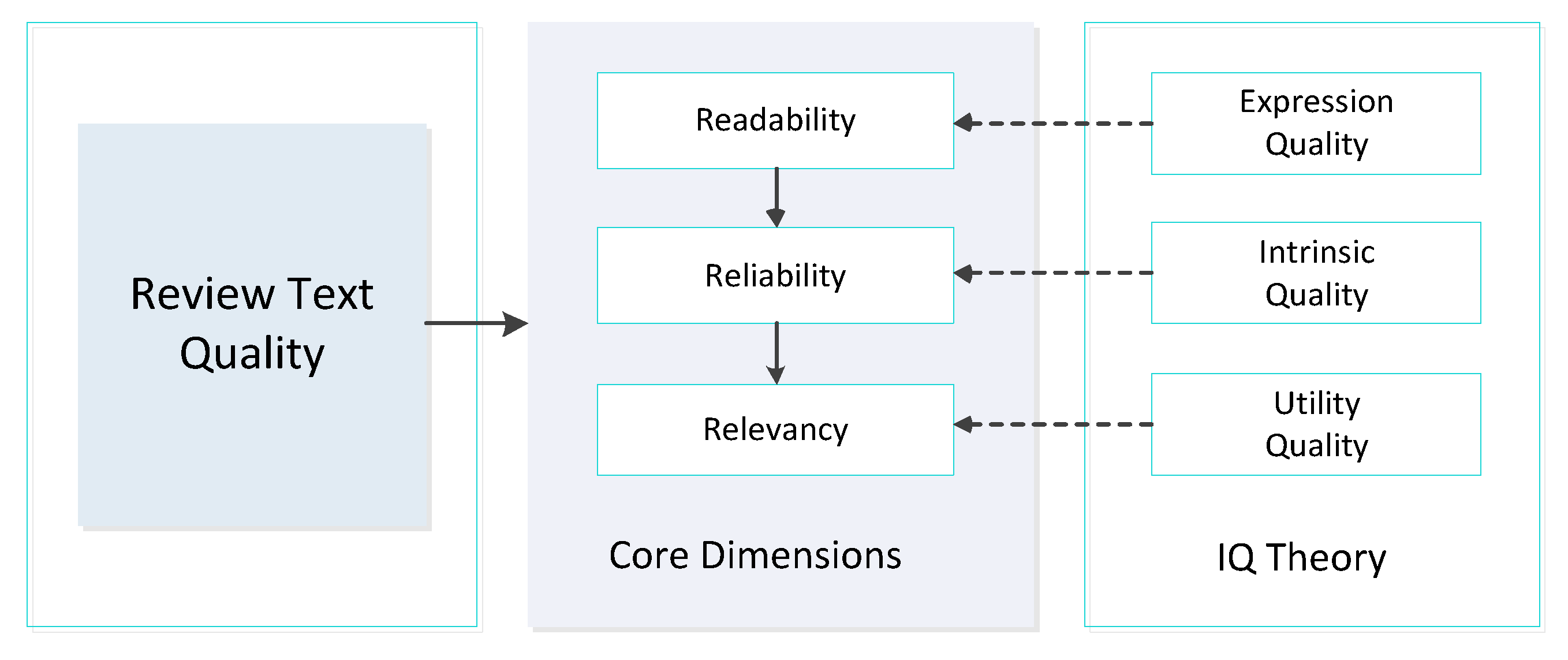
Based on the information quality (IQ) literature, information quality is user-oriented and multi-dimensional. In [
35], the hierarchy of information quality dimensions, namely accessibility, understandability, usefulness and believability, is established accordingly. This framework is based on a longitudinal process by which users acquire, understand, identify, and rely on reliable information to ensure that it is helpful for their decision-making.
Information quality is an abstract concept in nature, so it is particularly important to choose the core dimensions that are generally considered to have a decisive influence on the quality of online reviews. Researchers [
36] point that the information quality framework can be used to objectively assess the quality of online reviews if metrics have been developed and the quality dimensions are operationalized relevant to the dataset and task. Thus, in accordance with the longitudinal process of the IQ framework, online consumers can perceive the quality of the review text in following three phases: starting to read reviews, judging the believability of content, and taking advantage of the reviews to make a purchase decision. According to each phase, we proposed a core measure dimension, namely readability, reliability, and relevancy, respectively, as shown in
Figure 2. Since accessibility has nothing to do with the online review community, we include only three core dimensions in our analysis. Derived from the IQ theory, readability measures the expression quality of review text, reliability measures the intrinsic quality of review text, and relevancy measures the utility quality of review text. Next, we detailed the feature extraction methods of each dimension.
Readability refers to the extent to which the review text is easy to understand. It can be operationalized as linguistic features or sentence structural features [
16,
20,
23]. Linguistic features are text features regarding words and sentences in reviews, which may influence readers’ reading time. After preprocessing, the total number of words (Nwords), sub-sentences (Nsents), adjectives (Nadj), adverbs (Nadv), verbs (Nverb) and average sub-sentences length (Averlen) are extracted in a review as linguistic features.
As simple linguistic features cannot reveal the relationships between words, we introduced the statistical language model to quantitatively analyze the collocation information of adjacent words in a sentence, so as to calculate a word’s probability of occurrence in a sentence. The calculated value can be used to estimate the uniqueness of a sentence’s expression. A bigram sentence language model is built as follows:
represents the occurrence probability of a given sentence X, and represents the word in the sentence X. If the corpus is large enough, Equation (1) can be estimated by the relative frequency of words according to the maximum likelihood estimation and Bernoulli’s Large number theorem.
In general, information entropy and perplexity are two metrics used to evaluate language models. The larger the entropy and perplexity, the more unique the sentence structure. For any given sentence
X, its entropy and perplexity values are calculated as follows:
Thus, we extracted the entropy and perplexity of all the sub-sentences in a review and respectively took their average values to evaluate the review’s words structure relationships.
Reliability refers to the extent to which the review text is to be trusted. Prior research has pointed that sentiment orientation (positive or negative) and writing style of the review text (subjective or objective) play important roles in determining the degree of review’s believability [
30,
37].
We followed a similar method as [
38] to judge the sentiment orientation of each sub-sentence, choosing NB classifiers and feature representations (unigram, bigram or trigram) at the word and phrase level. Three thousand reviews with either 1-star or 5-star ratings for each product category were selected to build the corpus. The trained model was then used to predict the sentiment orientation of each sub-sentence.
Suppose
r+ denotes the positive sub-sentences in a given review
R, and total(
r) denotes the sum of positive and negative sub-sentences, we obtained the overall sentiment orientation of
R, denoted as
PosSenti, by the proportion of the positive sub-sentences in all the sentimental sub-sentences, which can be expressed as the following:
The greater the PosSenti value of
R, the more positive
R is. Thus,
PosSenti represents the overall sentiment orientation of
R. Meanwhile, in order to measure the degree of mixing sentiment in
R, we introduced a variable, denoted as
DevPos. It is calculated as the deviation between the review
R’s
PosSenti and the average
PosSenti of all the reviews of the same product, which is expressed as the following:
Since the average PosSenti reflects the equilibrium value of the mixed distribution of positive and negative sentiments for all reviews of a product, the smaller the deviation from the average, the more balanced the mix of two kinds of sentiment orientations. Conversely, it means that the sentiment orientations of most sub-sentences in R are consistent.
We followed the same paradigm of studies in [
29,
39] to measure the objective degree of each sub-sentence. Three thousand product description sentences and 3000 product reviews were randomly selected to build the corpus. Then, we extracted n-grams (n = 8) features to train the classifier using a dynamic language model classifier, which was used to predict the objective probability of each sub-sentence. Assuming that the objective degree of a sub-sentence
r is
obj(
r), and the total number of sub-sentences in
R is
count(
r), we denoted the overall objective degree of review
R as
ObjDegree(
R), which can be expressed as the following:
Similar to a mixture of sentiments, a review is often a mixture of styles. Therefore, we took a similar approach to measure the mixed degree of a review’s style, denoted by
DevObj. It is calculated as the deviation between the review
R’s
ObjDegree and the average
ObjDegree of all the reviews belong to the same product, which is expressed as the following:
Relevancy refers to the extent to which a review is relevant to the product itself, and it is often operationalized as the quantity of consumer opinions toward a product’s attributes or features [
19,
30].
Online reviews usually include evaluations of multiple attributes of a product (such as appearance, price, effect, logistics, etc.) or multiple evaluations of one or two attributes (such as effect is good and satisfactory, etc.). The former represents the diversity of a review’s opinion, while the latter reflects the details of a review’s opinion. They both reflect the relevance of the review to the product and thus enable the measurement of the review’s relevancy. Therefore, we used the two indicators, namely frequency of attribute-opinion-pair (AttriFreq), and frequency of feature-opinion-pair (FeatureFreq), as a review’s relevancy features.
Motivated by the prior study on product feature and opinion extraction from online reviews [
40], we first identified the correct feature words and opinion words set of a product. Meanwhile, as some inexplicit feature words in a review cannot be extracted together, we followed the method of [
41] to identify and count them. After identifying the feature–opinion pair in a review, we calculated the semantic similarity of the feature words in a review’s feature–opinion pair using the Hownet (
http://www.keenage.com), which was used to determine whether any feature words belong to the same attribute, so as to count the total number of attribute–opinion pairs.
3.3.2. Reviewer Features
Studies have shown that reviewer-related features may influence the helpfulness of his or her reviews, such as the number of total reviews the reviewer has published [
29] or the reviewer’s expertise [
33]. Thus, based on the available data on Amazon.cn, we extracted the following three indicators to represent a reviewer’s reliability features: ranking (ReviewerRank), total helpful votes (TotalVotes), and average helpful rate of all reviews (AverHelpRate).
3.3.3. Metadata Features
Some metadata features, such as a review’s valence and timeliness, serve as context cues to infer a review’s quality or helpfulness. Thus, we extracted the review’s rating (Rating) and elapsed days from the date of review released to the date of our experiment (Timeliness) as the metadata features.
In summary, 19 features respectively belonging to text, reviewer, and metadata are finally extracted. The specific meaning and abbreviation for each feature are summarized in
Table 1.
3.4. Modeling, Evaluation, and Interpretation
Different from common ensemble techniques, such as random forest which relies on simple averaging of models in the ensemble, the core idea of gradient boosting techniques is to add new base-learners to the ensemble sequentially. In doing so, prediction performance of the ensemble model is improved through such additive base-learners by putting emphasis on the training data that are difficult to estimate. Despite the recent popularity of deep learning, boosting algorithms are more useful in the regime of limited training data, training time, and expertise for parameter tuning when compared to deep learning models. Thus, we employed the state-of-the-art gradient boosting trees models, namely GBDT, XGBoost, and LightGBM, for our modeling job.
3.4.1. Helpfulness Modeling
The original gradient boosting algorithm is proposed by Friedman [
9]. Given training data
X, m iteration steps, a base-learner function as
, and a specific loss function
, the model updating equation
and gradient descent step size
are formulated as follows:
A particular gradient boosting model can be designed with a diverse set of base-learners, which can be classified into three different distinct categories: linear models, smooth models, and decision tree-based models [
42]. Of which, decision tree-based ensembles are most frequently used in practice, such as the initial format, gradient boosting decision tree (GBDT), which demonstrates excellent performance in fitting the relationship between multiple heterogeneous input features and target variables. Moreover, tree-based ensembles can capture the influences of variables and their interactions without explicitly defining them in a computationally feasible way. The idea behind it is attributed to the structure of the DT, where each node is split at the most informative feature, and the space of input variables is partitioned into homogenous areas with an if-then rule. Such property makes the tree-based ensemble suitable for helpfulness prediction, thus enabling us to better understand our prediction model.
XGBoost was recently proposed by Chen and Guestrinis [
10]. Based on the original framework of gradient boosting [
9], it uses K additive trees to approximate the output
as the following:
Here,
is an independent Classification and Regression Tree (CART) at each of the
steps which maps the input variables
to
, and
is the space of functions containing all CARTs. Different from the original gradient boosting algorithm, XGBoost aims at minimizing the regularized objective function defined as below:
where
. The regularized objective function contains two parts: the training loss function
and the regularization term Ω. The training loss
measures the difference between the predicted value
and the true value
. The regularization term Ω measures the complexity of model, which helps to smooth the final learnt weight to avoid overfitting.
XGBoost also introduces two important techniques, namely shrinkage and column subsampling. Shrinkage technique scales the newly added weights at each step of boosting, thus helping to reduce the influence of each tree and overfitting as well. Column subsampling chooses only a random subset of input features in building a given tree, for speeding up the training process [
43].
Although a few effective optimizations have been adopted in XGBoost, the efficiency and scalability are still unsatisfactory in the case of high feature dimensions and large data size. To alleviate the problem, Ke et al. [
11] proposed a novel algorithm based on gradient boosting trees, namely LightGBM.
Conventional tree-based gradient boosting models need to scan all the data instances and then determine the split points by estimating the information gain, leading to computational complexities proportionally increasing to both the number of features and the number of instances. LightGBM utilizes two novel techniques, named as GOSS (Gradient-based One-side Sampling) and EFB (Exclusive Feature Bundling) methods, to reduce the number of data instances and the number of features, which help speed up the training process of boosting over 20 times as original GBDT algorithm while achieving almost the same accuracy. Notably, GOSS keeps all the instances with large gradients and performs random sampling on the instances with small gradients, since small gradients imply their training errors are small and are already well trained. To avoid changing the original data distribution by much, GOSS also introduces a constant multiplier to amplify the sampled data with small gradients when calculating the information gain. Additionally, EFB bundles those mutually exclusive features in the sparse feature space into a single feature by a greedy algorithm to reduce the number of features without hurting the accuracy of split point determination by much.
3.4.2. Model Evaluation
Two families of ensemble techniques, Bagging [
44,
45] and Adaboost [
46], are often combined with a given learning algorithm to improve their performance and robustness in applications. For performance comparisons, we introduced popular ensemble models as baseline ensemble models, including Bagging, Adaboost techniques with DT, LR, and SVM as base learners, respectively, namely Bagging-DT, Bagging-LR, Adaboost-DT, Adaboost-LR, and Bagging-SVM. Excellent ensembles such as RF [
47] and ExtraTrees [
48] are also included.
Three commonly used evaluation metrics are adopted in this research to measure the performance of the GBT models and baseline models, including Accuracy (ACC), F1-measure (F1) and AUC. Both datasets adopt a five-fold cross validation to calculate the average of such three metrics for model performance comparison.
After a classification task is completed, samples are divided into four parts: True Positives (TP), False Positives (FP), True Negatives (TN), and False Negatives (FN). The four parts of samples can be presented in the confusion matrix as shown in
Table 2.
ACC is the ratio of the number of the corrected samples to the total number of samples, which is defined as follows:
F1-measure, also known as F-score, is the weighted harmonic average of Precision and Recall and is often used to evaluate the quality of classification models. Precision, Recall, and F1-measure are defined as the following:
AUC (area under the curve) is a metric which computes the area under the receiver operating characteristic (ROC) curve. A ROC curve is a graphical plot which is created by plotting the TPR (TPR = ) vs. the FPR (FPR = 1 − TPR). It shows the performance of a binary classifier at various threshold settings. By computing the area under the roc curve, the curve information is summarized in one value. The larger the value, the better the classifier’s performance is.
3.4.3. Model Interpretation
Due to the specific structure of DT as base learner in the gradient boosting tree models, it is straightforward to obtain the valuable features through the trained model. Specifically, every node in a DT is a condition on a single feature designed to split the dataset. The measure based on which the locally optimal condition is chosen is either Gini impurity or information gain/entropy for classification task. Thus, according to this measure, feature importance can be ranked by the averaged impurity decrease from each feature over all the trees in the ensemble.
However, the ranking of feature importance found by the model is not enough to explain an individual prediction. For example, we have no idea about why the model makes a ‘helpful’ prediction for a review and how each feature contributes to the final outcome.
To gain insight into how individuals evaluate review helpfulness, we turned to the feature attribution methods, in which the explanatory model
is a linear function of the feature attribution values:
where
is the number of features,
is the feature attribution value of feature
i, and
represents feature
i being observed (
) or not (
). We regarded the feature attribution value as ‘feature contribution’.
Intuitively, the model can be used to interpret both a single prediction and the entire model based on the average feature attribution across all the observations. Thus, it is suitable to interpret our review helpfulness prediction model.
A thing to note is how to calculate the value of
in Equation (16). Lundberg et al. [
7] recently proposed SHAP values as a measure of feature attribution value based on a unification of ideas from game theory. Given a model
, and a set
containing non-zero indexes in
, the classic Shapley values attribute
to each feature can be formulated as follows:
where
is the set of all input features.
Due to the challenge of estimating
in the above equation with traditional Shapley values, Lundberg et al. [
7] introduced a tree SHAP value estimation algorithm (SHAP values) for GBT models. More details of tree SHAP algorithm can be referred to [
7]. As shown in [
7], the SHAP value method is the only consistent and locally accurate individualized feature attribution method when compared to Saabas method [
49]. It also shows consistent results in the global feature attribution across all data instances when compared to Gain and Split. Therefore, we used the Tree SHAP algorithm to explain the feature contribution to the individual review helpfulness and the helpfulness prediction model.
As some specific features are predictive in conjunction with the other features, measuring the interactions between features is a problem that cannot be ignored. Different from the contribution of an individual feature described in the previous section, the contribution of feature interactions is called joint feature contributions. Based on the Shapley interaction index [
7], which follows from similar axioms as SHAP values, the joint feature contribution value
between feature
i and
j can be obtained as follows:
when
, and
Since it is relatively easy to capture the pairwise relationship between joint features in GBT models, we further quantified the feature interactions by Equations (18) and (19), thus enabling the estimation of the joint contribution of interactive features on review helpfulness model.
4. Experiment Set-up
4.1. Dataset
We collected products reviews and related data of headsets and facial cleanser from Amazon.cn to build the experiment dataset. There were more than 50 reviews for each product correspondingly. The data collection period was from January 2016 to April 2016. Each review of the two datasets was then labelled as helpful or unhelpful based on the total number of helpful votes it received. To be specific, the reviews with five or more useful votes were labelled as helpful, while those that did not receive useful votes were labelled as unhelpful. To check the validity of the ‘helpfulness’ label, we randomly picked about 2500 reviews respectively from the helpful and unhelpful (to ensure balance) to build the annotation datasets for both categories of products. Two project team members were invited to annotate each review of the two annotation datasets without labels. Each member read the content of each review independently with visible information of the reviewer and metadata, and then they answered the question “whether the review is helpful for your purchase?”. By calculating the Kappa statistic, the annotation result of a member was compared with the result of its helpfulness label. The calculation results were 82.9% and 84.2%, respectively, indicating the reviews with ‘helpful vote’ selected in our annotation datasets were ideal for our experiment.
After preprocessing, the preliminary statistical results of some intuitive features among the two datasets are presented in
Table 3.
In total, there were 2406 helpful reviews and 2594 unhelpful reviews in the headset dataset, and 2515 helpful reviews and 2485 unhelpful reviews in the facial cleanser dataset. On average, facial cleanser reviews were more detailed than headset reviews with longer review words (43.5 vs. 31.2), more product features embedded in the reviews (3.6 vs. 2.8), and more information entropy (8.14 vs. 7.96). As for the perspective of review sentiment, headset reviews were more positive and objective than facial cleanser reviews, showing a higher degree of positive sentiments (0.64 vs. 0.55), a higher degree of objective sentiments (0.42 vs. 0.38), and a higher rating (4.25 vs. 4.13). It can also be observed that there were no significant differences between the two kinds of product reviews in terms of average sentence length, published date, and reviewer ranking.
4.2. Hyper-Parameter Tuning
Normally, machine learning algorithms have a few dozen hyper-parameters needing to be configured prior to model training. Hyper-parameter configurations have a significant impact on model performance, especially for GBDT, XGBoost, or LightGBM, which have a substantial number of hyper-parameters. Recently, the strategy of sequential model-based optimization (SMBO) [
50] has shown to be a better alternative to grid search for optimizing the hyper-parameters of machine learning algorithms [
12,
51]. The basis for hyper-parameters tuning is to optimize a mapping function over a configuration space, which specifies the hyper-parameter values to be explored for each hyper-parameter. We employed a SMBO method to tune the hyper-parameters for the baseline models and GBT models. A five-fold cross-validation accuracy was used to find the optimal hyper-parameter setting and the corresponding loss, and the total number of evaluations ‘n_calls’ or the number of iterations in bagging or Adaboost were all set to 100.
5. Experimental Results
5.1. Comparison of Performance for Review Helpfulness Prediction
On the basis of the five types of feature sets extracted from the two categories of datasets, the performances of the baseline models and GBT models were then compared by a five-fold cross-validation on the training set. All models were optimized with their corresponding optimal parameters. The results are summarized in
Table 4 and
Table 5.
From
Table 4 and
Table 5, the following consistent conclusions can be found.
First, ordinary models such as DT or LR with some ensemble techniques performed better than their corresponding ordinary models. For example, Bagging-DT using the bagging technique on decision tree (DT) outperformed DT in terms of performance, with ACC, F1, and AUC increased by 1.56%, 2.02%, 0.0175, and 1.31%, 0.81%, and 0.0175, respectively, for the two types of datasets. Similarly, the performance of ordinary logistic regression (LR) can be improved greatly when ensembled as AdaBoost-LR with the ACC, F1, and AUC increased by 2.35%, 2.48%, 0.0432 and 4.64%, 2.72%, and 0.073, respectively, on the two types of datasets. The results imply the effectiveness of ensemble techniques. The results also indicate that the performances of SVM in the ordinary model and ensembles were worse than those of DT or LR.
Second, RF model performed excellently, and its result was the most consistent among all the baseline ensemble models on both types of datasets. Notably, for the headset dataset, RF performance was comparable to Bagging-DT, and for the facial cleanser dataset, RF was the best performing model of all the baseline models with 69.93% ACC, 70.62% F1, and 0.7674 AUC.
Third, by comparing the GBT models with the best benchmark ensemble model RF, it can be inferred that XGBoost model performed best in the GBT model group. In particular for the headset dataset, XGBoost had a strong advantage than RF with ACC and F1 increased by 1.48% and 0.67%, and for the facial cleanser dataset, XGBoost also demonstrated a weak advantage in the evaluation indicators, with ACC, F1, and AUC increased by 0.01%, 0.07%, and 0.01. As for GBDT, it was slightly ahead of RF on the headset dataset with ACC, F1, and AUC increased by 1%, 0.11%, and 0.009. Meanwhile, GBDT was comparable to RF on the facial cleanser dataset with ACC and AUC increased by 0.17% and 0.0068, but F1 decreased by −0.24%. Therefore, in terms of overall performance, GBDT still slightly outperformed RF in our experiment datasets. Compared to the results of LightGBM and RF, it can be found that LightGBM did not demonstrate significant performance advantages over RF. For the headset dataset, LightGBM only had the ACC increased by 0.68%, while for the facial cleanser dataset, LightGBM was slightly weaker than RF with ACC, F1, and AUC decreased by 0.94%, 0.78%, and 0.0017, respectively.
The performance comparison results reveal that GBT models achieved better prediction results for the review helpfulness prediction problem compared to ordinary and baseline ensemble models, especially as implemented in XGBoost. Therefore, XGBoost was adopted for the feature analysis and model interpretation of review helpfulness prediction in the following sections.
5.2. Analysis of Feature Validity
This section examines the validity of the feature sets generated in our research. As can be seen from
Table 1, five broad feature sets were extracted to represent reviews’ helpfulness: (1) text-readability features (TRD), (2) text-reliability features (TRL), (3) text-relevancy features (TRV), (4) reviewer features, and (5) metadata features. The first three are text-related features. To examine their validities, we first used each subset of the text-related features to build prediction models, and then we used all the text-related features (Text-ALL) to build models again. Moreover, we built the subsequent models by incrementally adding other sets of features. Meanwhile, we adopted a baseline feature set used in [
29] for comparison (Baseline). We evaluated each model in the same way as above, using five-fold cross validation and reporting the metrics of ACC, F1, and ROC. The evaluations of feature validity are presented in
Table 6.
The results reveal that our total feature sets were superior to the baseline feature set with ACC, F1, and ROC increased by 2.97%, 2.23%, 0.02 and 2.33%, 2.55%, and 0.04, respectively, across two kinds of datasets. Since the main differences between our feature sets and the baseline feature sets were text structural features and relevancy features, the results indicate these features were beneficial to improve the helpfulness of the model’s performance.
Another finding is that using any subset of text-related features resulted in a subtle difference in model performance, while using all available subsets of text-related features obtained optimal results. This seems to imply two possible explanations. One explanation is that the three feature sets representing readability, reliability, and relevancy contain some collinear features; thus, some features are interchangeable. This finding is also supported in [
29]. Another explanation is that there may be interactions between certain text-related features, which result in a slight improvement in model performance when adopting the total feature sets. Therefore, the next section discusses feature redundancy and the interactions between features.
5.3. Results of Feature Contribution on Helpfulness
5.3.1. Global Feature Contribution
To better interpret our optimal helpfulness model implemented in XGBoost, we applied the Tree SHAP method [
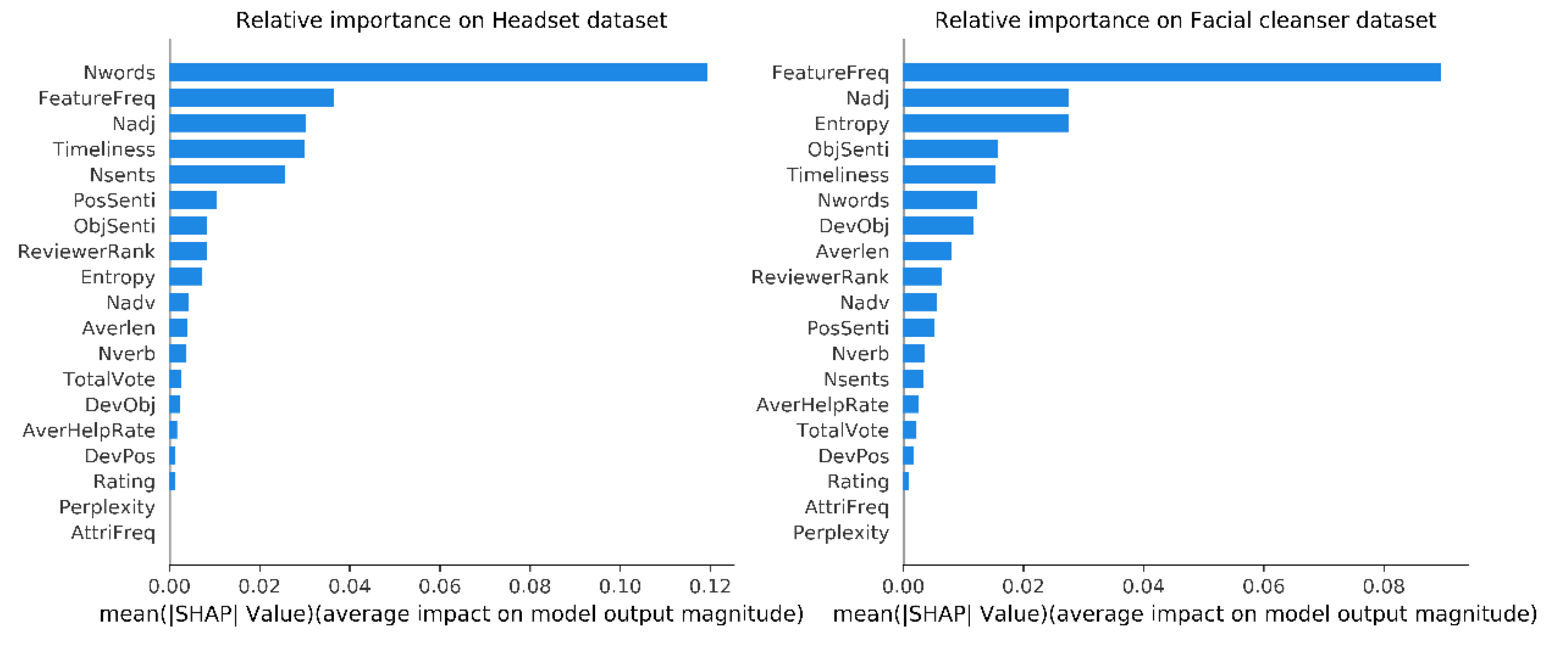
7], which has proven to be a powerful tool for confidently interpreting GBT models. Tree SHAP first measures the contribution each feature has on the model output (Tree SHAP values) for individuals in the training dataset. Then, the global feature contributions are ranked according to the mean (|Tree SHAP|) across all samples. The global feature contributions derived from the XGBoost helpfulness model are shown in
Figure 3.
In
Figure 3, the
x-axis is essentially the average magnitude change in model output when a feature is integrated out of the model. The features are ordered by the absolute sum value of their effect magnitudes on the model. It can be first inferred that feature contributions varied across different product categories, with some specific features contributing far more than other features. For example, for the headset dataset, Nwords dominated the other features, while for the facial cleanser dataset FeatureFreq stood out as the most import predictor. Both Nwords and FeatureFreq contributed significantly to the model outputs. The results reflect that, on the whole, headset consumers were more concerned with the content elaborateness, while facial cleanser consumers were more interested in the evaluation of some attributes of the product. Another finding is that in our extracted features, some contributed little or nothing to the model outputs, such as AttriFreq, Perplexity, Rating, and DevPos. Thus, it is necessary to re-evaluate the model performance to decide whether to exclude such low contribution or no contribution features. This issue will be discussed in the following section.
5.3.2. Individual Feature Contribution
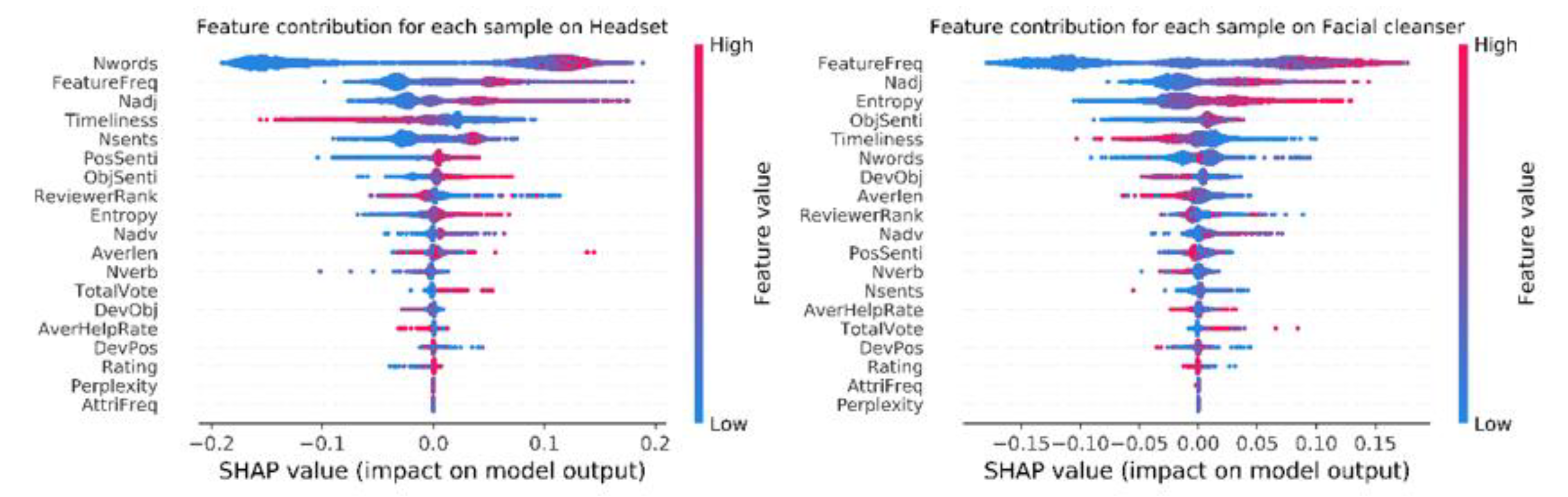
As Tree SHAP values are derived from an individualized model interpretation approach, an individualized interpretation for each sample can be obtained from the model.
Figure 4 presents some insights into how the contribution of an individual feature on the model output is affected by its value. The x position of the dot is the impact of the feature on the review helpfulness, and the color of the dot represents the value of that feature for the review.
Figure 4 reveals that there is a certain degree of linear relationship between the contributions of some features and their values. We can take the features that contributed the most to the two datasets respectively as examples. For the headset reviews, the more positive (PosSenti), the more objective (ObjSenti), and the more unique expression (Entropy) were easier to be understood as useful. This trend was only obvious in the Entropy feature of the facial cleanser dataset. In the opposite, the older (Timeliness) of the review, the less likely it was to be helpful for both kinds of reviews. For most of the remaining features, the relationships between their contributions and their value were non-linear, such as the number of words (Nwords) and frequency of features (FeatureFreq) in the headset dataset, or FeatureFreq and the number of adjectives (Nadj) in the facial cleanser dataset.
Another finding is that individual feature contributions varied across reviews, even with the same feature values, reflecting as a broad range of impacts on the model output in
Figure 4, such as some high-contribution features like Nwords, FeatureFreq, and Nadj in the headset dataset, or FeatureFreq, Nadj, and Entropy in the facial cleanser dataset. This may imply that other features may influence the impacts of these high-contribution features; thus, it is necessary to capture the joint contributions of these features from the model.
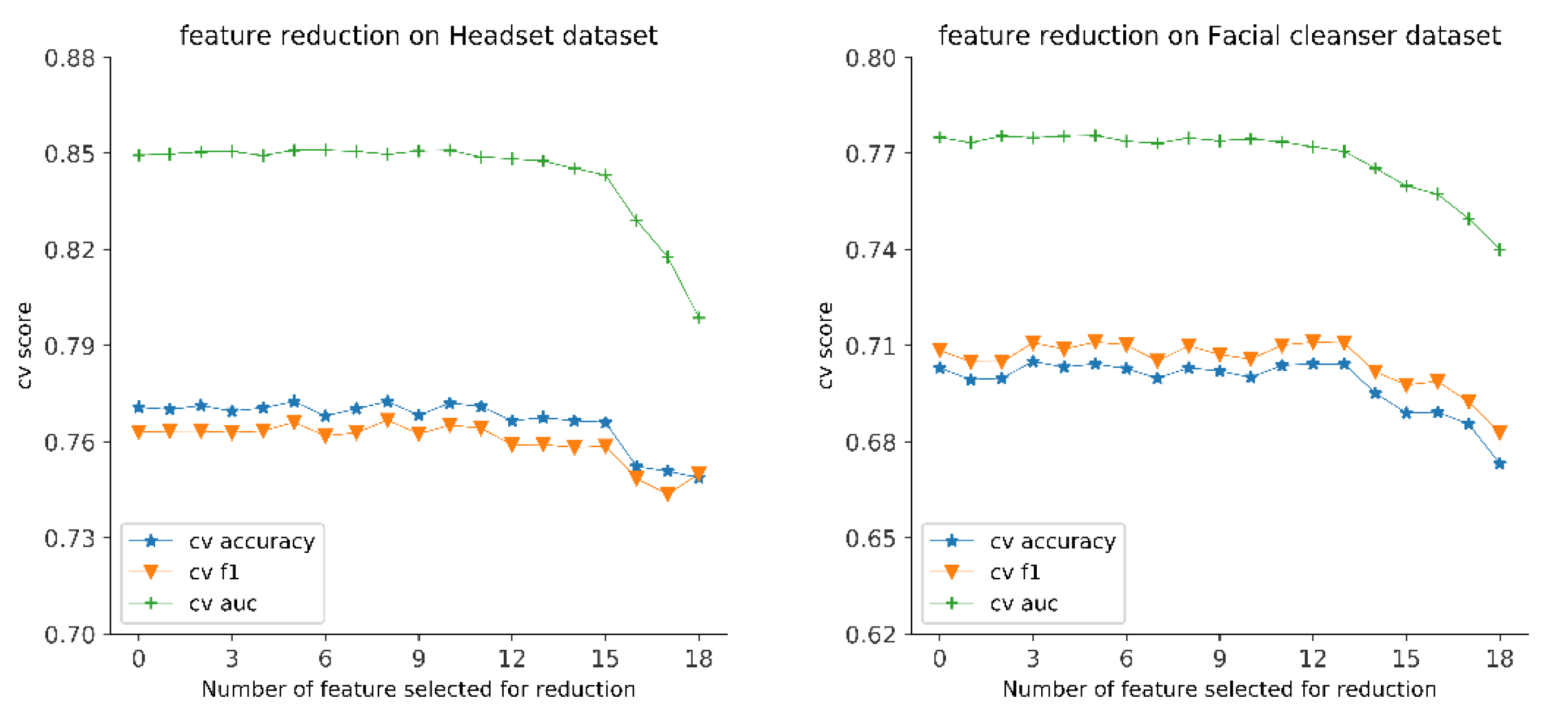
5.4. Feature Reduction Based on Global Contribution
The unimportant review features were determined according to the reverse order of the global feature contribution obtained in
Section 5.3.1. They were removed one by one from the XGBoost model, and at the same time the 5-fold cross validation(cv) ACC, F1, and AUC results were recalculated accordingly.
Figure 5 shows the performances of the model on the remaining features after removing features in turn on both types of datasets.
The first finding across two datasets is that eliminating a certain number of low-contribution features does not bring about obvious changes in model performances. For the headset dataset, it can be observed that until the top fifteen low-contribution features were selected to be removed, the model showed a downward trend on the indicators ACC, F1, and AUC. For the facial cleanser dataset, the corresponding number of features to be removed was thirteen. The findings imply that effective feature selection can be performed according to the global contribution of features. Another finding is that only a few features played decisive roles in assessing the helpfulness of reviews. Overall, the key features that affected the helpfulness of headset reviews were the following four features in turn: the number of words (Nwords), frequency of product features (FeatureFreq), the number of adjectives (Nadj), and elapsed days (Timeliness); the key features that influenced the helpfulness of facial cleanser reviews corresponded to the frequency of product features (FeatureFreq), the number of adjectives (Nadj), expression uniqueness (Entropy), objective sentiment degree (ObjSenti), the number of words (Nwords), and elapsed days (Timeliness).
5.5. Results of Joint Feature Contribution on Review Helpfulness
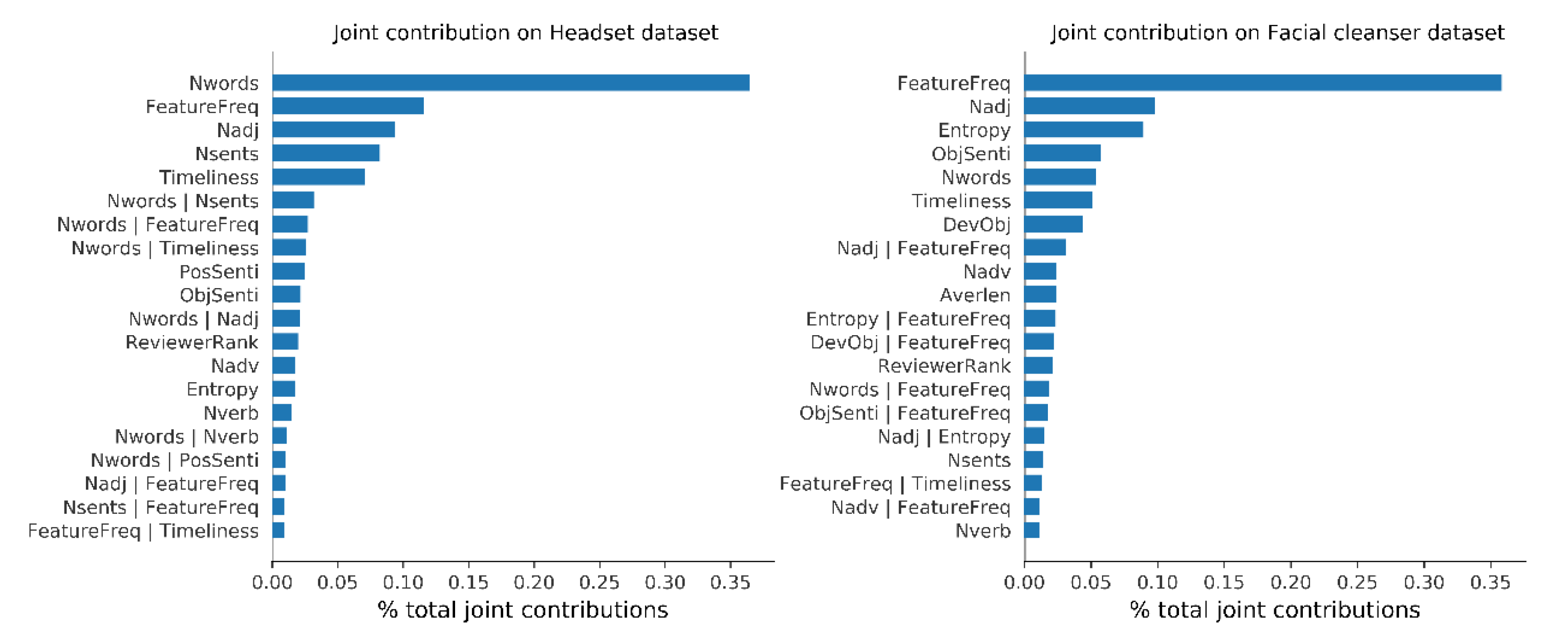
5.5.1. Global Joint Feature Contribution
The SHAP interaction values method was used to automatically capture the joint feature contributions embedded in the features, and then the contribution of each feature on the model output was decomposed into two-part effects: the main contribution of a feature itself and the joint contributions between the feature and other features.
Figure 6 shows the ranking results of the main feature contribution and joint feature contribution with the proportion of feature contribution to the total contribution.
After stripping off the main feature contribution, more joint contributions measured from the headset dataset occurred between Nwords and Nsents, Nwords and FeatureFreq, Nwords and Timeliness, as well as Nwords and Nadj. It means the impact of the number of words in a review on review helpfulness was interactively affected by features such as the number of sentences, the feature frequency, elapsed days, and the number of adjectives. Therefore, it is concluded that for the headset buyers, the more acceptable reviews are usually those with a certain length, many sub-sentences, some opinions on the product features, and also published recently.
As for the facial cleanser dataset, more joint contributions occurred between FeatureFreq and Nadj, FeatureFreq and Entropy, FeatureFreq and Devobj, as well as FeatureFreq and Nwords. It means the impact of prominent features such as the number of product features in a review on review helpfulness is affected by features like the number of adjectives, expression uniqueness, objective sentiment deviation, and the number of words. It can also be inferred that the reviews that are more acceptable to facial cleanser buyers usually contain product feature opinions, unique expression structures, objective sentiment orientations different from the average level, and review text with a certain length. Moreover, according to the ranking results of main feature contribution, it can be found that the more prominent the main contribution of a feature is, the more likely it is to jointly contribute to other important features.
5.5.2. Individual Joint Feature Contribution
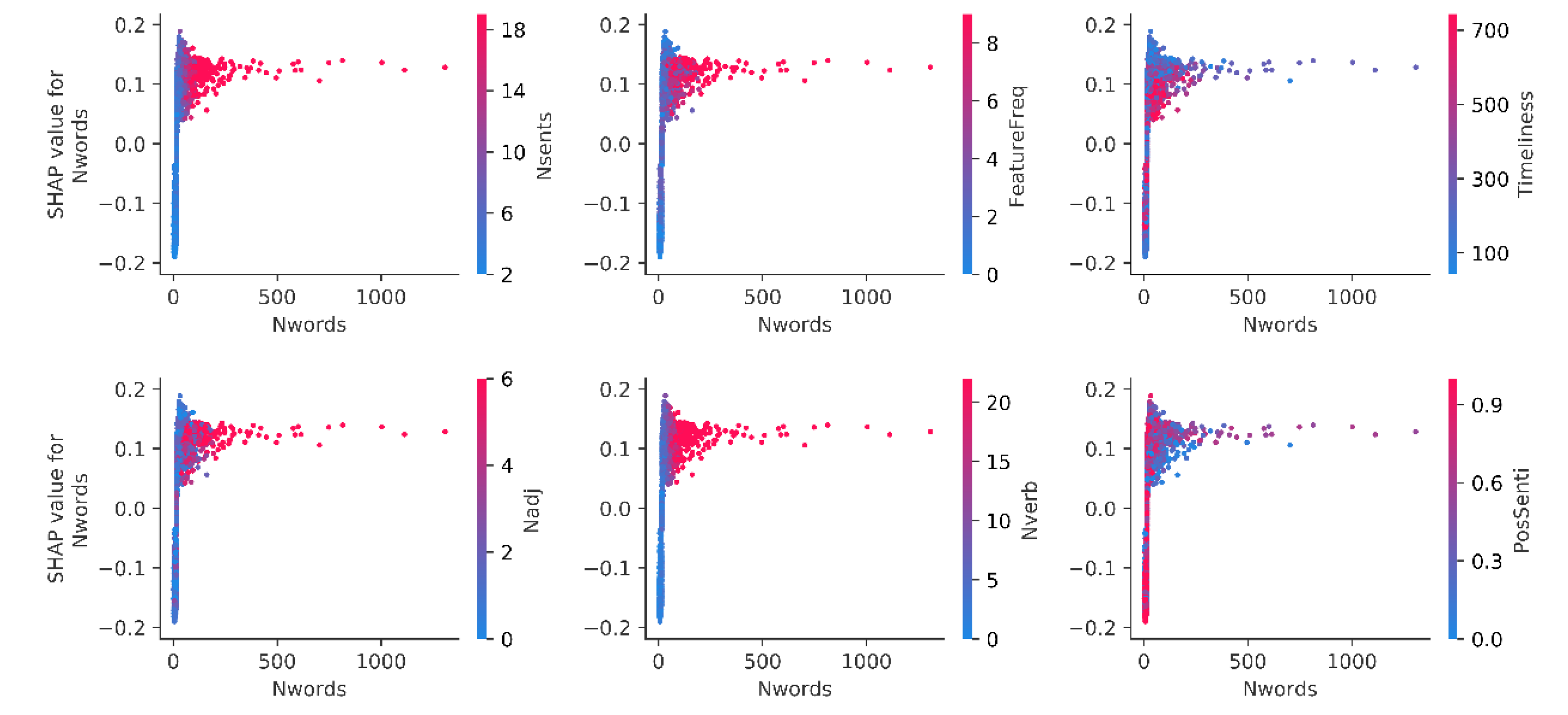
To observe how a prominent feature interacts with other features, we further mapped the value of the prominent feature against its SHAP value in the samples of the whole dataset and colored the value of several other features with strong interactions on the prominent feature.
Figure 7 demonstrates that for the headset dataset, even if most reviews’ lengths (Nwords) were less than 70, the extent to which length impacts the prediction differed, as shown by the obvious vertical dispersion of dots at a length less than 70. This means other features affect the contribution of Nwords. When the word length exceeded 70, the interaction effect was significantly reduced because the vertical dispersion of the dots was distinctly reduced. Based on the distribution of the red sample dots above the
Y-axis 0.0 and the value color of Nsents, FeatureFreq, Nadj, and Nverb on the sample dots, it can be concluded that the greater the number of sub-sentences, product feature frequency, adjectives, and adverbs there are, the more positively Nwords will contribute. Meanwhile, the dots color of Timeliness shows that Timeliness lowered the contribution of Nwords with a length above 70. This means that the earlier the review is published, the more likely it is to reduce the effect of Nwords on review helpfulness. By the dots color of PosSenti, it shows that PosSenti increased the contribution of Nwords with a length above 70. It means that the more positive the review, the more likely it is to increase the effect of Nwords on review helpfulness with a review length above 70.
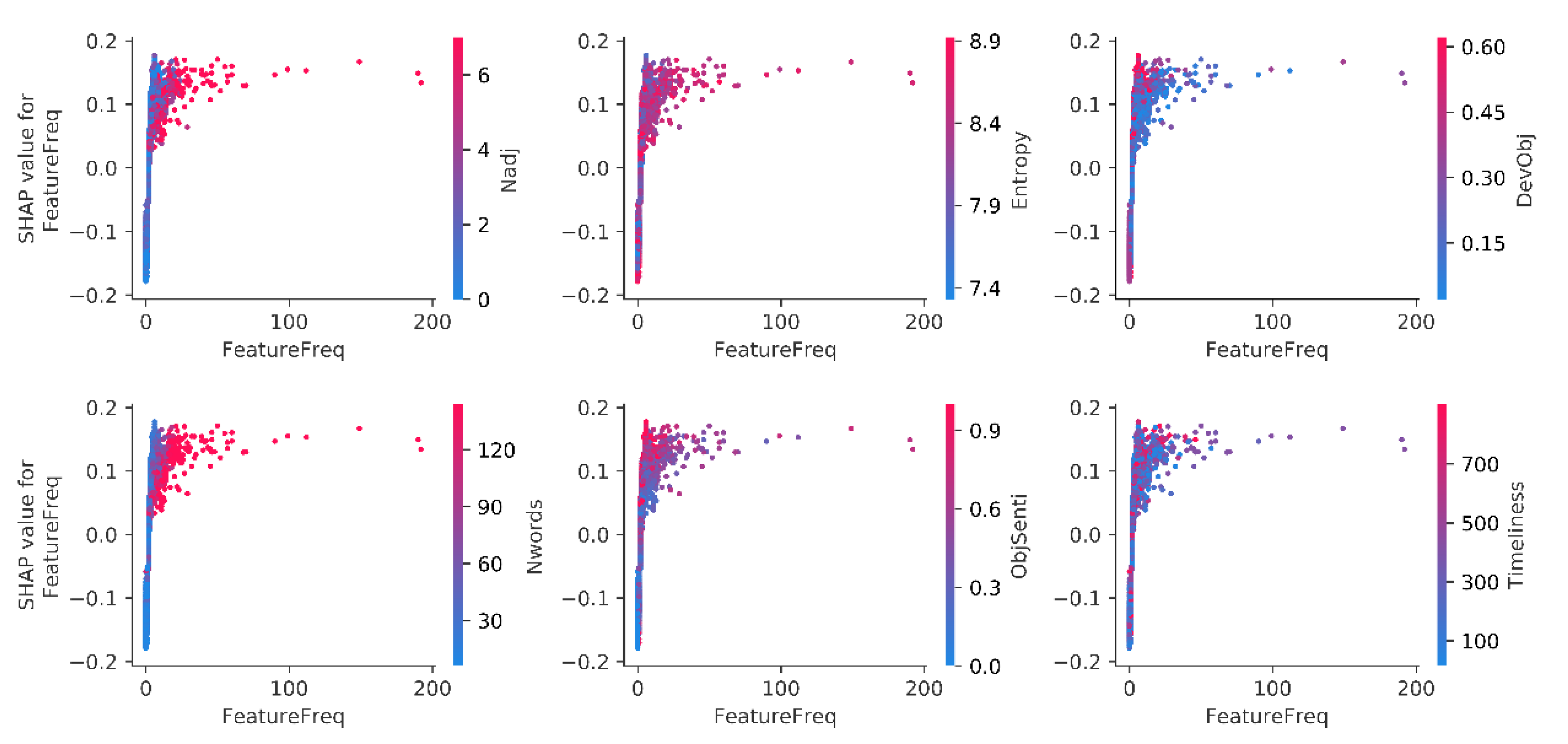
As for the facial cleanser dataset, similar findings can be found from the obvious dispersion change trend of dots on the FeatureFreq in
Figure 8. As the frequency of product feature contained in a review increased, the interaction effect acts on FeatureFreq decreased significantly. According to the dispersion of the red sample dots above the
Y-axis 0.0 and the value color of Nadj, Nwords, Entropy, and ObjSenti on the sample dots, it can be inferred that the greater the number of adjectives (Nadj) and words (Nwords), the more unique expression (Entropy), and the more objective (ObjSenti) in sentence expression, the more positive impacts on FeatureFreq’s contribution will produce. By the dots color of DevObj, it moderately shows that a greater objective sentiment deviation increased FeatureFreq’s contribution. It means that the greater the difference between the objective sentiment of the review and the average level, the more likely it is to increase the effect of FeatureFreq on review helpfulness. By the dots color of Timeliness, it shows most dots with positive contributions (greater than 0.0 on the
y-axis) had a small Timeliness value. This finding is consistent with headset dataset, which implies that the more recent the review date, the more likely FeatureFreq is to increase review helpfulness.
6. Further Discussion
To begin with, the above research results indicate that text-related review features and published time mainly affect review helpfulness. However, for different product types, the specific text-related features that play influential roles are different. From the experimental results, the features that contribute the most to the helpfulness of headset reviews are the following four features in order: the number of words (Nwords), product feature frequency (FeatureFreq), the number of adjectives (Nadj), and the elapsed days from review published date to experiment date (Timeliness). It can be inferred that when consumers purchase headset products, the reviews they want to refer to generally include more detailed product descriptions, especially the feature opinions on certain aspects of the headset, and are published recently. In contrast, the features that contribute the most to the helpfulness of facial cleanser reviews are the following features in order: product feature frequency (FeatureFreq), the number of adjectives (Nadj), information entropy(Entropy), objective sentiment degree (ObjSenti), the number of words (Nwords), and the elapsed days from review published date to experiment date (Timeliness). This indicates when consumers purchase facial cleanser, they not only pay attention to the opinions, product details, or date of the reviews, but they also pay attention to the objectivity and expression uniqueness of the reviews, and they may prefer more objective and personalized reviews.
Additionally, the experimental results also show that both the interactions between text-related features and between text-related feature and review date indeed affect review helpfulness. The more the features have impacts on the review helpfulness, the greater the interactions with other features. The results of this study show that the number of words is the most important feature affecting the helpfulness of headset reviews, and it has the most obvious interactions with features like the number of sentences, the number of product features, the number of adjectives, and review published date. A similar finding is also found in the facial cleanser dataset, where the feature frequency has the greatest impact on review helpfulness, and also has the greatest interactions with the number of adjectives, information entropy of the review, objectivity of the review, and the review length.
Finally, from the experiment results, it can be found that the influences of most features on review helpfulness show non-linear and dynamic trends, which can be seen from the feature contributions and interactive feature contributions of individual reviews. Notably, with the increase in feature value, the effect of interactions between features on review helpfulness decreases gradually.
Similar to the research related to online review helpfulness mentioned in the literature review, this paper also verifies the main influence of text-related features and timeliness of reviews on review helpfulness, such as review length, product features frequency, sentiment degree, and writing style. However, the experiment results contain more differences. First of all, this study extracts the syntactic structure (expression uniqueness) feature of text, namely entropy, and verifies that expression uniqueness plays an important role, which expands the extraction scope and form of review text features. This suggests that it is not only necessary to examine the character or word features of review text, but it also necessary to consider the structure and collocation between characters or words. Secondly, this study not only identifies the important features impacting review helpfulness, but it also further quantifies the feature importance, that is, the contribution of each feature, and analyzes the impact of each feature on review helpfulness in detail. Finally, based on the investigation of important features, this study adds to the investigation of interactions between features. By analyzing the contributions of global joint features and individual joint features, the degree and trend of feature interactions are analyzed in detail.
7. Conclusions
In this paper, we have answered the question of why a review is helpful from both the macro and micro levels by measuring the feature contribution with SHAP values and SHAP interaction values. Combined with the optimal GBT model implemented in XGBoost to help modeling review helpfulness, we identified features that influence review helpfulness, quantified those feature contributions, and automatically captured the interaction effects between them. Through experimental analysis on two types of datasets, this paper reveals the main feature contribution and joint feature contribution of headset reviews and facial cleanser reviews. The results of the comparative analysis and visual analysis on multiple groups of experiments explain the formation mechanism of helpful reviews for the two kinds of products. Some meaningful conclusions can be drawn from our experiment. (1) Both datasets indicate that a few features contribute the most, while most features contribute less or have no contribution. Specifically, for the headset dataset, Nwords (review length) dominated the other features; while for facial cleanser dataset, FeatureFreq (feature opinion frequency in a review) stood out as the most import predictor. (2) There are indeed interactions between features. We found prominent features are easier to interact with other features. (3) By visualizing the relationships between feature values and feature contributions, we found there are linear relationships between features’ contributions and their values in a few features, and most of them are nonlinear relationships. Meanwhile, by visualizing the relationship between feature values and joint feature contributions, we found the interactions between features gradually decreased with the increase of feature values.
Different from prior research which mainly focuses on explaining feature importance based on helpfulness of the model performance, this study provides a more stable, comprehensive, and detailed analysis of review helpfulness on the basis of feature contribution. Combined with the SHAP value method and XGBoost model, this study first introduces a stable calculation method for quantifying feature contributions and avoids the inconsistency problem of feature analysis caused by multiple evaluation indicators in the previous studies. Moreover, unlike the previous studies mostly focusing on examining the direct impacts of multiple features on review helpfulness, this study supplements the interactions between features, captures, and quantifies the degree of joint contribution through SHAP value method and XGBoost model. In doing so, this study reveals the influence of feature value on review helpfulness from the micro level for the first time by visualizing the relationships among feature value, feature contribution, and feature joint contribution for an individual review. Notably, this kind of influence is nonlinear in most cases, and the interaction relationship is dynamic and complex.
In the e-commerce context, enterprises are faced with many uncertainties in managing user-generated content. Based on a feature contribution-driven analysis framework on review helpfulness, this study provides some specific implications to eliminate these uncertainties, especially for IT managers, professionals, as well as academics. First, for the IT managers, the establishment of an effective and accurate online reputation management system is the most concerned issue. The review evaluation method based on feature contribution analysis proposed in this study is conducive to more accurate identification of helpful reviews, so as to establish an effective management way of online reviews based on reviews’ helpfulness evaluation results. This will further help promote the value of online reviews and enabling the role of IT technology in economic performance. Second, for the professionals, they are not only concerned with the helpfulness results of online reviews, they are more concerned with what factors contribute to the evaluation results. This study analyzes and measures feature contributions and joint feature contributions on review helpfulness by analyzing readability, reliability, relevance, and metadata. In doing so, professionals could analyze the reasons for the formation of review values from the factors of multiple dimensions of reviews, so as to develop corresponding review management strategies. It will be of benefit to guide reviewers to publish useful reviews and identify reviews that are helpful to consumers. Meanwhile, professionals can further explore the valuable information in the helpful reviews to guide relevant business work, such as to conduct innovative design of new products or to implement marketing communication decisions based on helpful reviews. Third, it is always an area of focus for academics to interpret the helpfulness model. This study introduces Shapley Additive exPlanations method into the XGBoost model, so as to decompose the contribution of each feature from the helpfulness evaluation results. To our knowledge, this is the first time that an external explanatory tool has been used to explain the influence of review features on review helpfulness in relevant studies. This has a special implication for researchers to combine external interpretation tools with evaluation model to uncover the black-box nature of the traditional helpful evaluation model and improve its explanatory ability.
Limited by experimental conditions, this study only includes the reviews from two typical product types. At the same time, due to the uncertainty of online review quality, the quantitative measure model of review helpfulness and the interactions in the model need to be further improved. The feature representations of review helpfulness could also be further explored and designed.
Future research could be conducted from the following aspects. First, collect as much review data as possible, cover as much product data as possible, and verify the robustness of the experiment conclusions. Second, explore as many feature forms of review helpfulness as possible, either from review text or others, to enhance the performance of prediction model. Last, only two levels of review helpfulness (either helpful or unhelpful) are considered in this research; thus, multiple levels of review helpfulness can be further analyzed in the future.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}