
Multi-Channel Fusion Decision-Making Online Detection Network for Surface Defects in Automotive Pipelines Based on Transfer Learning VGG16 Network


Abstract
:1. Introduction
1.1. The Significance and Development of Automotive Pipeline Surface Defect Detection
1.2. Current Status of Research and Problems Faced
1.3. Scope of Our Work and Contribution
2. Related Work
2.1. Levels of Fusion
2.2. Research on Multi-Channel Fusion in Deep Learning
2.2.1. Feature-Level Multi-Channel Fusion in Deep Learning
2.2.2. Decision-Level Multi-Channel Fusion in Deep Learning
2.2.3. Selection of Fusion Method for This Study
3. Rapid Quality Screening and Defect Extraction on Piping Surfaces
3.1. Problems Related to Rapid Pipe Surface Quality Screening
3.2. Improved ROI Detection Algorithm for Surface Defects
4. Surface Defect Detection Network Based on Transfer Learning VGG16 Multi-Channel Fusion Decision Making
4.1. Small-Sample Dataset Shift Problem
4.2. Multi-Channel Fusion Decision Network Based on Transfer Learning VGG16
4.2.1. Transfer Learning VGG16 Network
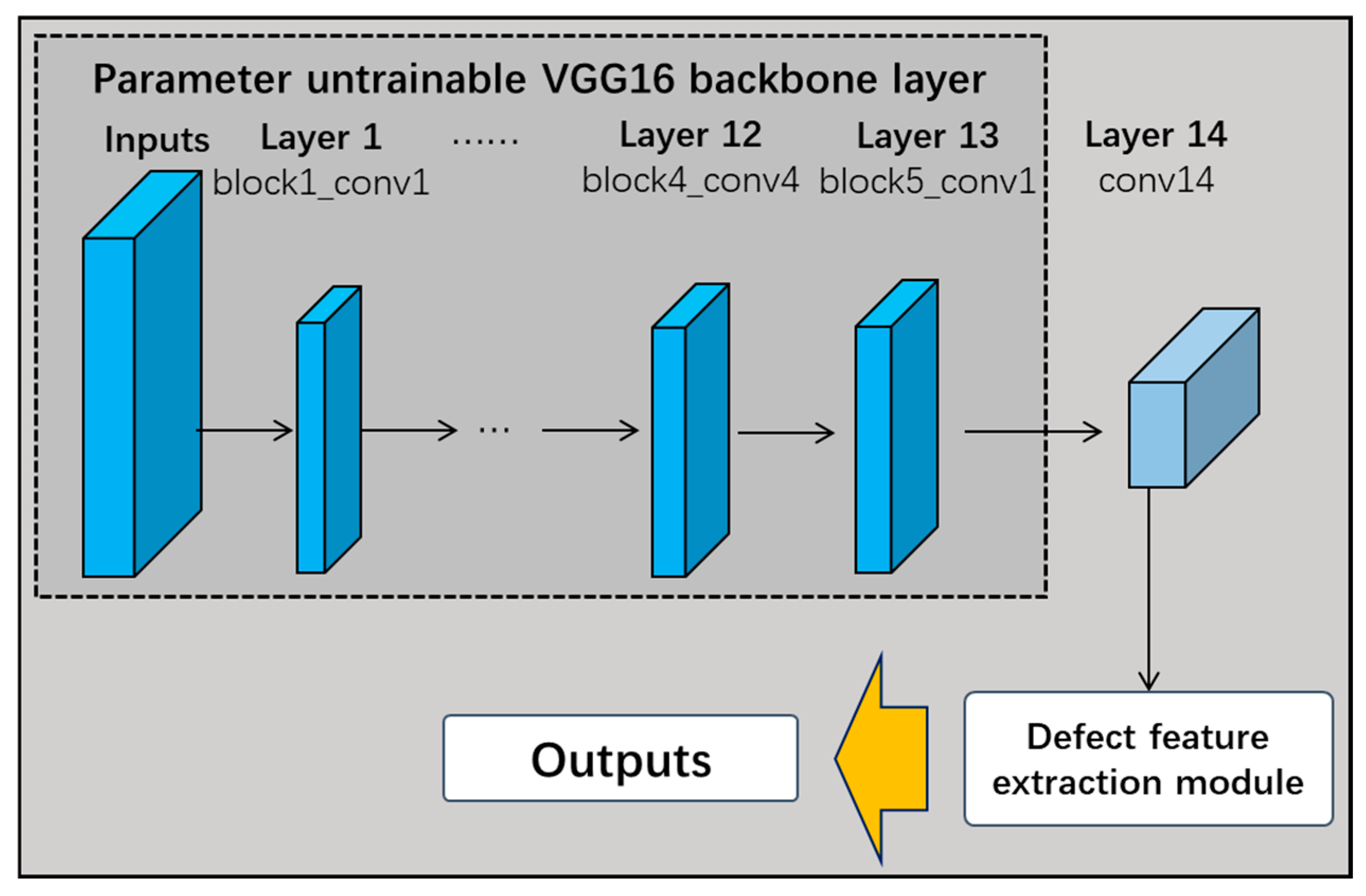
4.2.2. Defective Feature Extraction Layers
4.2.3. Multi-Channel Fusion Decision Network
5. Online Detection of Surface Defects on Automotive Piping
5.1. Experimental Environment, Data Preparation and Validation Process
5.1.1. Experimental Environments
5.1.2. Data Preparation
5.1.3. Experimental Verification Process
5.2. Transfer Learning VGG16 Online Detection Network
5.2.1. Transfer Learning VGG16 Network
5.2.2. Improved Transfer Learning VGG16 Network and Performance Comparison
5.3. Transfer Learning VGG16 Multi-Channel Fusion Decision-Making Online Detection Network
5.3.1. Multi-Channel Fusion Decision-Making for Online Detection Networks
5.3.2. Confusion Matrix for Fused Networks
- The fusion network can effectively improve the detection accuracy of the lightweight level network and meet the demand of real-time detection without significantly increasing the depth and structural improvement of the network;
- Fusion network combine multiple network branches, so it takes more time than its counterparts in terms of the inference time;
- A very deep network is not necessarily required for the online real-time defect classification task and the detection accuracy, speed, and complexity of the network need to be balanced.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Srinivasan, K.; Dastoor, P.H.; Radhakrishnaiah, P.; Jayaraman, S. FDAS: A Knowledge-based Framework for Analysis of Defects in Woven Textile Structures. J. Text. Inst. 1992, 83, 431–448. [Google Scholar] [CrossRef]
- Lu, Y. Design of PCB Board Inspection System Based on Machine Vision. Master’s Thesis, Zhejiang University of Technology, Hangzhou, China, 2021. [Google Scholar]
- Yazdchi, M.; Yazdi, M.; Mahyari, A.G. Steel surface defect detection using texture segmentation based on multifractal dimension. In Proceedings of the International Conference on Digital Image Processing (ICDIP), Bangkok, Thailand, 7–9 March 2009; pp. 346–350. [Google Scholar]
- Kwon, B.K.; Won, J.S.; Kang, D.J. Fast defect detection for various types of surfaces using random forest with VOV features. Int. J. Precis. Eng. Manuf. 2015, 16, 965–970. [Google Scholar] [CrossRef]
- Ding, R.; Dai, L.; Li, G.; Liu, H. TDD-net: A tiny defect detection network for printed circuit boards. CAAI Trans. Intell. Technol. 2019, 4, 110–116. [Google Scholar] [CrossRef]
- Tan, F.G.; Zhou, F.M.; Liu, L.S.; Li, J.X.; Luo, K.; Ma, Y.; Su, L.X.; Lin, H.L.; He, Z.G. Detection of wrong components in patch component based on transfer learning. Netw. Intell. 2020, 5, 1–9. [Google Scholar]
- Zhang, H.; Jiang, L.; Li, C. Cs-resnet: Cost-sensitive residual convolutional neural network for PCB cosmetic defect detection. Expert Syst. Appl. 2021, 185, 15673. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Z.; Yu, H.; Chen, X.; Li, D. S-OHEM: Stratified Online Hard Example Mining for Object Detection. In Proceedings of the Chinese Conference on Computer Vision, Tianjin, China, 11–14 October 2017; pp. 166–177. [Google Scholar]
- Wang, X.; Shrivastava, A.; Gupta, A. A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3039–3048. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Li, B.; Liu, Y.; Wang, X. Gradient Harmonized Single-stage Detector. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI), Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8577–8584. [Google Scholar]
- Wanyan, Y.; Yang, X.; Chen, C.; Xu, C. Active Exploration of Multimodal Complementarity for Few-Shot Action Recognition. In Proceedings of the 2023 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 21–26 July 2023; pp. 6492–6502. [Google Scholar]
- Hatano, M.; Hachiuma, R.; Fujii, R.; Saito, H. Multimodal Cross-Domain Few-Shot Learning for Egocentric Action Recognition. In Proceedings of the 18th European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Fu, Y.; Fu, Y.; Jiang, Y.G. Meta-FDMixup: Cross-Domain Few-Shot Learning Guided by Labeled Target Data. IEEE Trans. Image Process. 2022, 31, 7078–7090. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Liu, C.; Wang, J.; Ma, L.; Koniusz, P.; Torr, P.H.S.; Yang, L. Saliency-guided meta-hallucinator for few-shot learning. Sci. China Inf. Sci. 2024, 67, 202103. [Google Scholar] [CrossRef]
- Bucak, S.S.; Jin, R.; Jain, A.K. Multiple Kernel Learning for Visual Object Recognition: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1354–1369. [Google Scholar] [PubMed]
- Yu, Z. Methodologies for Cross-Domain Data Fusion: An Overview. IEEE Trans. Big Data 2015, 1, 16–34. [Google Scholar]
- Kiros, R.; Salakhutdinov, R.; Zemel, R. Multimodal Neural Language Models. In Proceedings of the 31th International Conference on International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 2012–2025. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal Deep Learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Wang, C.; Dai, D.; Xia, S.; Liu, Y.; Wang, G. One-Stage Deep Edge Detection Based on Dense-Scale Feature Fusion and Pixel-Level Imbalance Learning. IEEE Trans. Artif. Intell. 2022, 5, 70–79. [Google Scholar] [CrossRef]
- Zhang, X.; He, L.; Chen, J.; Wang, B.; Wang, Y.; Zhou, Y. Multi-attention mechanism 3D object detection algorithm based on RGB and LiDAR fusion for intelligent driving. Sensors 2023, 23, 8732. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Hu, Y.; Lai, Q.; Wang, W.; Chen, J.; Liu, H.; Srivastava, G.; Bashir, A.K.; Hu, X. IIFDD: Intra and inter-modal fusion for depression detection with multi-modal information from Internet of Medical Things. Inf. Fusion 2024, 102, 102017. [Google Scholar] [CrossRef]
- Xiao, J. SVM and KNN ensemble learning for traffic incident detection. Phys. A Stat. Mech. Its Appl. 2017, 517, 29–35. [Google Scholar] [CrossRef]
- Zhang, Z.; Hao, Z.; Zeadally, S.; Zhang, J.; Han, B.; Chao, H.-C. Multiple Attributes Decision Fusion for Wireless Sensor Networks Based on Intuitionistic Fuzzy Set. IEEE Access 2017, 5, 12798–12809. [Google Scholar] [CrossRef]
- Chen, K. Research on Decision-Level Fusion Identification Method of Gearbox Faults Based on Multiple Deep Learning. Master’s Thesis, Chongqing Jiaotong University, Chongqing, China, 2023. [Google Scholar]
- Das, R.; Singh, T.D. Image-Text Multimodal Sentiment Analysis Framework of Assamese News Articles Using Late Fusion. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 1–30. [Google Scholar] [CrossRef]
- Yan, Y. Machine Vision Inspection and Quality Evaluation of Plate and Strip Steel; Science Press: Beijing, China, 2016. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Drozdzal, M.; Vorontsov, E.; Chartrand, G.; Kadoury, S.; Pal, C. The Importance of Skip Connections in Biomedical Image Segmentation. In Proceedings of the International Workshop on Deep Learning in Medical Image Analysis, Athens, Greece, 21 October 2016; pp. 179–187. [Google Scholar]
- Ma, W.; Wu, Y.; Cen, F. MDFN: Multi-Scale Deep Feature Learning Network for Object Detection. Pattern Recognit. 2020, 100, 107149–107169. [Google Scholar] [CrossRef]
- Dohare, S.; Hernandez-Garcia, J.F.; Lan, Q.; Rahman, P.; Mahmood, A.R.; Sutton, R.S. Loss of plasticity in deep continual learning. Nature 2024, 632, 768–774. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Gao, L.; Li, X.; Yan, X. A semi-supervised convolutional neural network-based method for steel surface defect recognition. Robot. ComputIntegr. Manuf. 2020, 61, 101825. [Google Scholar] [CrossRef]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An End-to-end Steel Surface Defect Detection Approach via Fusing Multiple Hierarchical Features. IEEE Trans. Instrum. Meas. 2020, 69, 1493–1504. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 13024–13033. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 21–26 July 2023; pp. 7464–7475. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Methods | Fusion Level |
|---|---|---|
| 2011, [19] | Reconstructing feature representations by coupled deep auto coders | Feature-level |
| 2022, [20] | Encoder–decoder framework model | Feature-level |
| 2023, [21] | SimAM parameter-free attention mechanism | Feature-level |
| 2024, [22] | Intra-modal attention mechanism to fuse features | Feature-level |
| 2017, [23] | KNN + SVM | Decision-level |
| 2017, [24] | CSWBT-IFS | Decision-level |
| 2023, [25] | CNN + stacked denoising autoencoders | Decision-level |
| 2023, [26] | Computing a score for each sample, fusing the score with the decisions made by the classifier | Decision-level |
| Algorithm 1 Improved ROI detection algorithm |
| Input: Original images, template image |
| Output: Defect ROI |
| Step 1. Calculate Initial Values |
| //PROI can be set to a value or to 100% of the full image area. Set thresholds Pmax, Pmin, PROI. //Calculate the average value of the template image, template_average. template_average = average(template image) Step 2. original_images subtract from template_average //If template image is complex and not suitable for calculating average value, original images can be subtracted directly from the template image. for original_images in target_path do result = original_images − template_average result[(result < Pmin) | (result > Pmax)] = 0 return result Step 3. Find ROI //Find contours in the binary image Contours = cv2.findContours(binary) //Filter contours based on area rois = [cnt for cnt in contours if cv2.contourArea(cnt) > PROI] //Draw contours on the original image and save cv2.drawContours(original_image, rois) //Find the minimum bounding rectangle for all ROIs all_rois = concatenate(rois) cv2.boundingRect(all_rois) //Draw the minimum bounding rectangle cv2.rectangle(original_image) |
| Step 4. Output |
| Get Defect ROI |
| Models | Baseline VGG16 | Baseline VGG16 + RMAPM | Baseline VGG16 + RMSPP | Baseline VGG16 + RDCM | |
|---|---|---|---|---|---|
| Metrics | |||||
| Ablation Module | 14 CNN √ | 14 CNN √ | 14 CNN √ | 14 CNN √ | |
| RMAPM × | RMAPM √ | RMAPM × | RMAPM × | ||
| RMSPP × | RMSPP × | RMSPP √ | RMSPP × | ||
| RDCM × | RDCM × | RDCM × | RDCM √ | ||
| Accuracy | 0.9278 | 0.9405 | 0.9444 | 0.9532 | |
| Recall | 0.9278 | 0.9405 | 0.9444 | 0.9532 | |
| F1 | 0.9294 | 0.9420 | 0.9457 | 0.9535 | |
| PDent | 0.6707 | 0.6623 | 0.6711 | 0.7209 | |
| PCrack | 0.9498 | 0.9472 | 0.9503 | 0.9564 | |
| PEdge damage | 0.9227 | 0.9303 | 0.9495 | 0.9118 | |
| PCrease | 0.9788 | 0.9876 | 0.9757 | 0.9759 | |
| PBreak | 0.8879 | 0.9337 | 0.9581 | 0.9793 | |
| Branch | Branch1 | Branch2 | Branch3 | Branch4 | Fusion Layer | |
|---|---|---|---|---|---|---|
| Models | RMAPM + VGG16 | RMSPPM + VGG16 | RDCM + VGG16 | Baseline VGG16 | Fusion Model | |
| Metrics | ||||||
| Accuracy | 0.94047 | 0.9444 | 0.95317 | 0.9278 | 0.9778 | |
| Recall | 0.9405 | 0.9444 | 0.9532 | 0.9278 | 0.9782 | |
| F1 | 0.942 | 0.9457 | 0.9535 | 0.9294 | 0.9779 | |
| PDent | 0.6623 | 0.6711 | 0.7209 | 0.6707 | 0.8906 | |
| PCrack | 0.9472 | 0.9503 | 0.9564 | 0.9498 | 0.9866 | |
| PEdge damage | 0.9303 | 0.9495 | 0.9118 | 0.9227 | 0.9505 | |
| PCrease | 0.9876 | 0.9757 | 0.9759 | 0.9788 | 0.9940 | |
| PBreak | 0.9337 | 0.9581 | 0.9793 | 0.8879 | 0.9799 | |
| Type | Algorithm | Accuracy | Top1@mAP0.5 | Time per Image | Memory Size of Weights |
|---|---|---|---|---|---|
| Traditional Algorithms | KNN | 83.45% | - | 0.0020 s 500.0 FPS | - |
| Gradient Boosting | 86.32% | - | 0.0032 s 312.5 FPS | - | |
| Deep-Learning Algorithms | PLCNN [32], 2020 | 94.71% | 94.13% | 0.0053 s 188.7 FPS | 58.0 MB |
| ResNet50 + MFN [33], 2020 | 96.46% | 95.64% | 0.0069 s 144.9 FPS | 62.1 MB | |
| YOLOX-m [34], 2021 | 98.03% | 97.51% | 0.0075 s 133.3 FPS | 186.8 MB | |
| Scaled-YOLOv4-CSP [35], 2021 | 98.42% | 98.12% | 0.0053 s 188.7 FPS | 213.5 MB | |
| YOLOv7-E6 [36], 2023 | 99.13% | 98.76% | 0.0046 s 217.4 FPS | 192.1 MB | |
| Ours’ | 97.78% | 96.03% | 0.0065 s 153.8 FPS | 56.2 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, J.; Tian, Y.; Wan, X. Multi-Channel Fusion Decision-Making Online Detection Network for Surface Defects in Automotive Pipelines Based on Transfer Learning VGG16 Network. Sensors 2024, 24, 7914. https://doi.org/10.3390/s24247914
Song J, Tian Y, Wan X. Multi-Channel Fusion Decision-Making Online Detection Network for Surface Defects in Automotive Pipelines Based on Transfer Learning VGG16 Network. Sensors. 2024; 24(24):7914. https://doi.org/10.3390/s24247914
Chicago/Turabian StyleSong, Jian, Yingzhong Tian, and Xiang Wan. 2024. "Multi-Channel Fusion Decision-Making Online Detection Network for Surface Defects in Automotive Pipelines Based on Transfer Learning VGG16 Network" Sensors 24, no. 24: 7914. https://doi.org/10.3390/s24247914
APA StyleSong, J., Tian, Y., & Wan, X. (2024). Multi-Channel Fusion Decision-Making Online Detection Network for Surface Defects in Automotive Pipelines Based on Transfer Learning VGG16 Network. Sensors, 24(24), 7914. https://doi.org/10.3390/s24247914